


Discover API (베타)
AI 에이전트는 채팅 인터페이스에서 핵심 비즈니스 워크플로우를 실행하는 자율 시스템으로 진화하고 있습니다. 신뢰를 얻으려면 표면적인 링크 목록이 아닌, 실제 웹에서 더 넓고 깊이 검증 가능한 증거가 필요합니다.
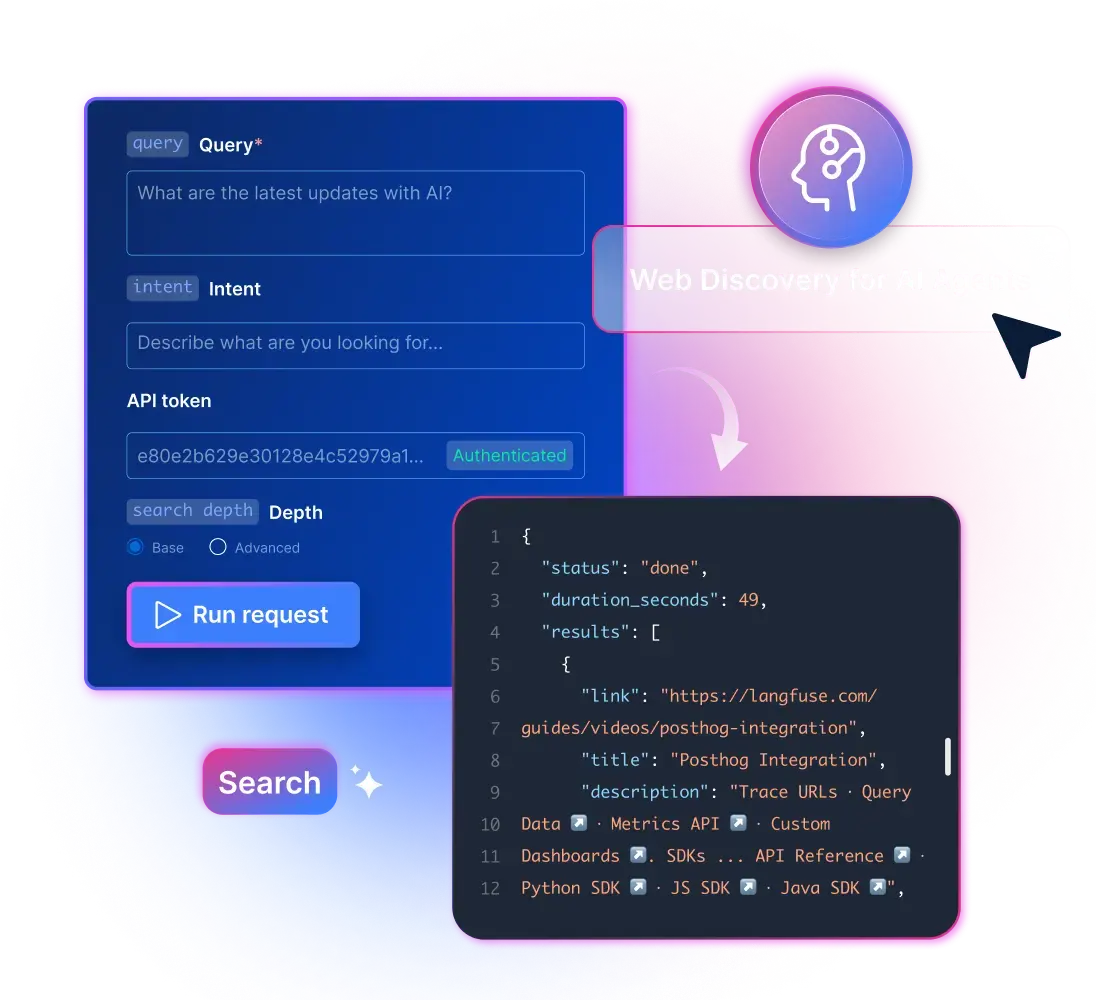
에서 항상 실시간으로 웹 콘텐츠를 가져옵니다.
요청당 최대 1000개 결과
의도 순위로 노출됨- 병렬 에이전트
워크로드를 위해 구축됨
사람이 하는 것처럼 웹사이트를 탐색하세요
SEO에 유리한 출처가 아닌, 작업에 부합하는 출처를 우선시하십시오.
수동 페이지네이션 로직 없이 최대 1000개 결과 가져오기
캐시되거나 색인된 경로로 인한 위험 감소
검증 및 RAG를 위한 선택적 정리된 마크다운 원본 텍스트
고처리량, 병렬 에이전트 워크로드를 위해 구축됨
에이전트가 Discover를 사용하는 이유검색 엔진은 인간을 위한 것입니다. 검색 API는 속도와 상위 링크에 최적화되어 있습니다. Discover는 최신성, 높은 회수율, 검증 가능한 컨텍스트가 필요한 시장 인식 워크플로우를 위해 구축되었습니다.
SEO에 유리한 출처가 아닌, 작업에 부합하는 출처를 우선시하십시오.
수동 페이지네이션 로직 없이 최대 1000개 결과 가져오기
캐시되거나 색인된 경로로 인한 위험 감소

검증 및 RAG를 위한 선택적 정리된 마크다운 원본 텍스트

고처리량, 병렬 에이전트 워크로드를 위해 구축됨

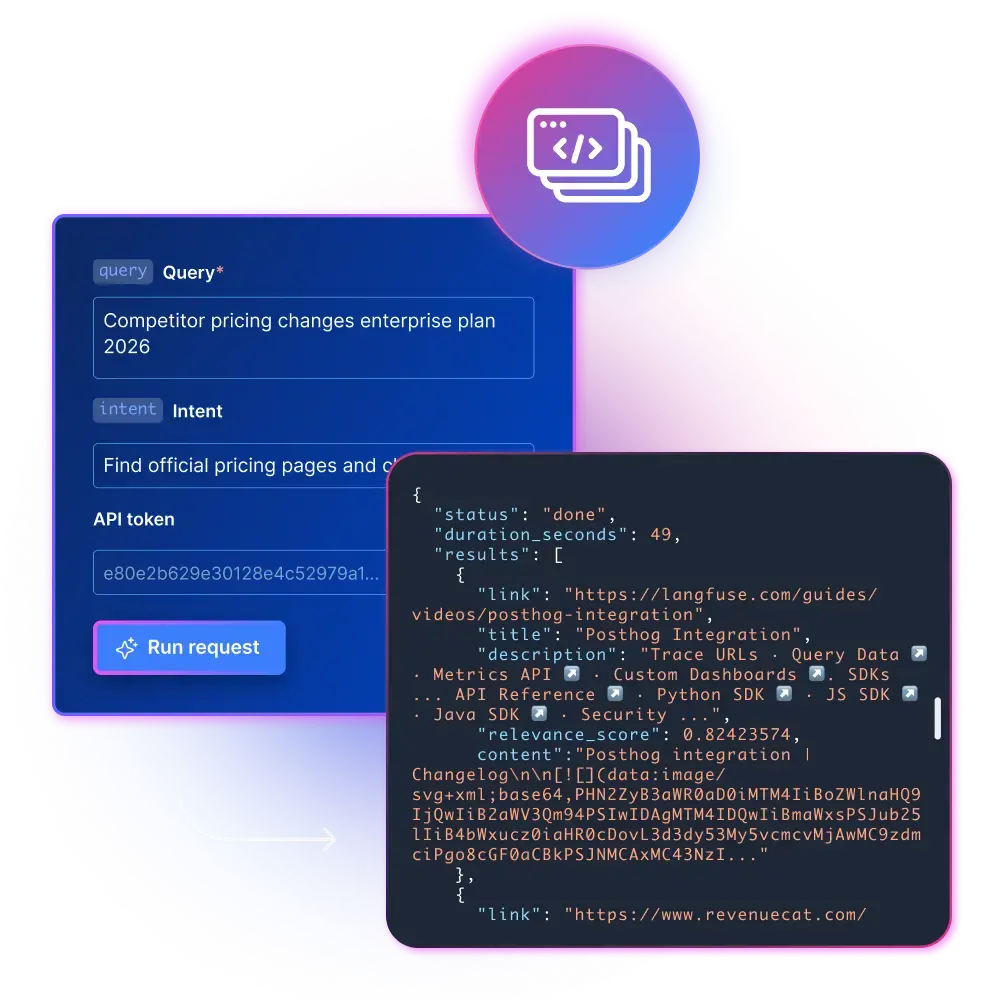
`POST https://api.brightdata.com/discover`
```bash
curl "https://api.brightdata.com/discover"
-H "Authorization: Bearer "
-H "Content-Type: application/json"
-d '{
"query": "경쟁사 가격 변경 사항 엔터프라이즈 플랜 2026",
"num_results": 50,
"intent": "공식 가격 페이지 및 변경 사항 찾기",
"content": true,
"format": "markdown"
}'
require('request-promise')({
url: 'https://geo.brdtest.com/mygeo.json',
proxy: 'http://brd-customer-[your customerID]-zone-residential:"[your password]"@brd.superproxy.io:33335',
})
.then(function(data){ console.log(data); },
function(err){ console.error(err); });
import requests
url = "https://api.brightdata.com/datasets/snapshots/{id}/download"
headers = {"Authorization": "Bearer "}
response = requests.get(url, headers=headers)
print(response.json())
using System;
using System.Net;
class Example
{
static void Main()
{
// '[your customerID]' 및 '[your password]'를 실제 자격 증명으로 대체하십시오
var client = new WebClient();
client.Proxy = new WebProxy("brd.superproxy.io:33335");
client.Proxy.Credentials = new NetworkCredential("brd-customer-[your customerID]-zone-residential", "[your password]");
Console.WriteLine(client.DownloadString("https://geo.brdtest.com/mygeo.json"));
}
}
Quickstart
시장 인텔리전스를 위해 구축됨

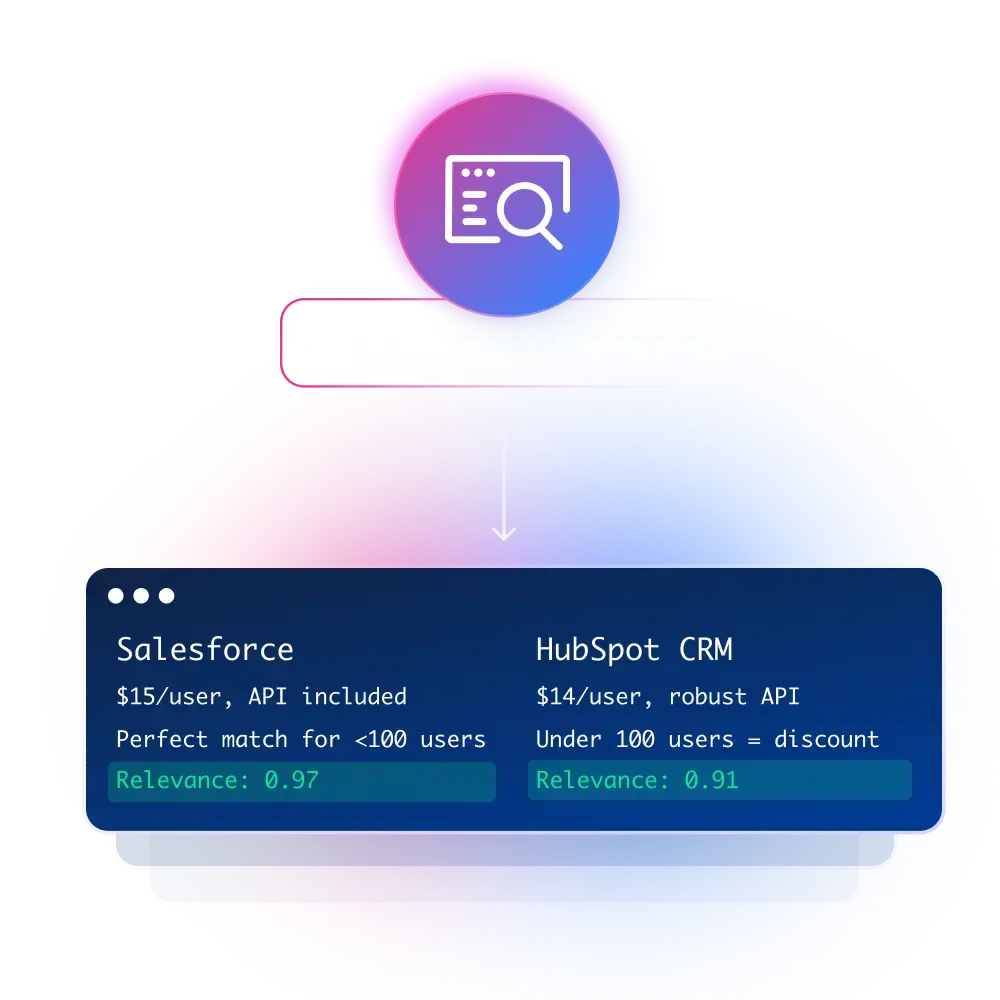
경쟁 정보
가격, 출시, 포지셔닝 변경 사항을 추적하십시오

위험 모니터링
사건, 정책 변경 및 신호를 감지하십시오

실사
여러 독립적인 출처를 통해 주장을 검증하십시오.

보강
검증된 실시간 웹 데이터로 CRM을 채우십시오

수직 검색 엔진
단일 도메인에 대한 의도 기반 검색 구축

대체 데이터
웹 전반에 걸친 롱테일 신호를 포착하십시오
Bright Data 데이터셋과 연동되도록 설계됨
실시간 탐색과 최신 증거 수집에는 Discover를 사용하십시오. 대규모 데이터의 기준 설정 및 신속한 검색에는 Bright Data Datasets를 활용하십시오. 반복적인 대규모 데이터 요구 시, 동일한 개체를 계속 재탐색하는 것보다 Datasets가 비용 효율적이며, 에이전트가 실시간 탐색을 수행하기 전에 더 강력한 출발점을 제공합니다.
FAQ
Discover는 캐시되거나 색인되나요?
디스커버는 항상 실시간으로 운영됩니다. 각 요청은 쿼리 시점에 실제 웹을 대상으로 실행됩니다.
의도(intent)는 무엇을 하나요?
의도는 에이전트가 달성하려는 목표를 알려주어 작업에 대한 결과를 순위화합니다.
include_content는 언제 사용해야 하나요?
원본 텍스트와의 검증 또는 RAG 근거가 필요한 경우 include_content=true를 사용하십시오.
Discover와 Datasets 중 무엇을 사용해야 하나요?
데이터셋을 기본 커버리지에 활용하십시오. 디스커버를 실시간 발견 및 최신 증거 수집에 사용하십시오. 대부분의 팀은 두 가지를 모두 사용합니다.
역사적 연구나 모니터링을 할 수 있나요?
웹 아카이브 API를 사용하여 과거 데이터 보완 및 장기적 모니터링을 수행하십시오.
1000개 이상의 결과가 필요한 경우에는 어떻게 되나요?
여러 Discover 호출을 연결하거나 대량 수집을 위해 데이터셋을 사용한 후, Discover를 통해 최신 상태를 유지하십시오.