

이 가이드에서 여러분은 다음을 발견하게 될 것입니다:
- 리서치 에이전트의 정의와 기존 방식의 한계
- 신뢰할 수 있는 데이터 수집을 위한 Bright Data 설정 방법
- Streamlit UI로 로컬 AI 기반 리서치 에이전트 구축 방법
- 구조화된 인사이트를 위해 Bright Data API를 로컬 모델과 통합하는 방법
이제 여러분만의 지능형 리서치 어시스턴트 구축을 시작해 보세요. 또한 Bright Data의 AI 기반 검색 엔진인 Deep Lookup을 확인해 보시길 권합니다. Deep Lookup을 사용하면 웹을 데이터베이스처럼 검색할 수 있습니다.
산업적 문제점
- 연구자들은 너무 많은 출처에서 쏟아지는 정보에 직면하여 수동 검토가 불가능한 상황에 처합니다.
- 기존의 연구는 느리고 수동적인 검색, 추출 및 종합을 수반합니다.
- 결과는 종종 불완전하고, 연결성이 떨어지며, 체계적으로 정리되지 않습니다.
- 간단한 스크래핑 도구는 신뢰성이나 맥락 없이 원시 데이터만 제공합니다.
해결책: 리서치 에이전트
딥 리서치 에이전트는 수집부터 보고까지 연구를 자동화하는 AI 시스템입니다. 맥락을 처리하고, 작업을 관리하며, 체계적인 통찰력을 제공합니다.
주요 구성 요소:
- 플래너 에이전트: 연구를 작업 단위로 분할
- 리서치 서브 에이전트: 검색 수행 및 데이터 추출
- 작성 에이전트: 체계적인 보고서 작성
- 컨디션 에이전트: 품질을 확인하고 필요 시 심층 연구를 트리거
이 가이드는 Bright Data의 API, Streamlit UI, 그리고 프라이버시와 통제를 위한 로컬 LLM을 사용하여 로컬 연구 시스템을 구축하는 방법을 보여줍니다.
필수 사항
- API 키가 있는 Bright Data 계정.
- Python 3.10 이상
- 의존성:
requestsfaiss또는chromadbpython-dotenvstreamlitollama(로컬 모델용)
Bright Data 구성
Bright Data 계정 생성
- Bright Data에 가입하기
- API 자격 증명 섹션으로 이동
- API 토큰 생성
환경 변수를 사용하여 API 자격 증명을 안전하게 저장하세요. 자격 증명을 저장할 .env 파일을 생성하여 민감한 정보를 코드와 분리하세요.
BRIGHT_DATA_API_KEY="your_bright_data_api_token_here"환경 설정
# 가상 환경 생성
python -m venv venv
source venv/bin/activate
# 종속성 설치
pip install requests openai chromadb python-dotenv streamlit구현
1단계: 연구
이것이 우리의 연구 과제가 될 것입니다.
query = "의료 분야 AI 활용 사례"2단계: 데이터 수집
이 단계에서는 Bright Data의 데이터 수집 API를 사용하여 웹에서 프로그래밍 방식으로 데이터를 가져오는 방법을 보여줍니다. 코드는 연구 쿼리를 전송하고 관련 데이터를 검색하면서 API 자격 증명을 안전하게 처리합니다.
import requests, os
from dotenv import load_dotenv
load_dotenv()
url = "https://api.brightdata.com/dca/trigger"
payload = {"query": query, "limit": 20}
headers = {"Authorization": f"Bearer {os.getenv('BRIGHT_DATA_API_KEY')}"}
res = requests.post(url, json=payload, headers=headers)
print(res.json())3단계: 처리 및 임베딩
이 단계에서는 가져온 연구 데이터를 처리하여 의미적 검색 및 유사도 매칭을 가능하게 하는 벡터 데이터베이스인 ChromaDB에 저장합니다. 이를 통해 의료 AI 활용 사례나 기타 연구 주제에 대한 질의가 가능한 검색 가능한 지식 기반을 구축합니다.
import chromadb
from chromadb.config import Settings
# ChromaDB 초기화
client = chromadb.PersistentClient(path="./research_db")
collection = client.get_or_create_collection("research_data")
# 연구 결과 저장
def store_research_data(results):
documents = []
metadatas = []
ids = []
for i, item in enumerate(results):
documents.append(item.get('content', ''))
metadatas.append({
'source': item.get('source', ''),
'query': query,
'timestamp': item.get('timestamp', '')
})
ids.append(f"doc_{i}")
collection.add(
documents=documents,
metadatas=metadatas,
ids=ids
)4단계: 로컬 모델 요약
이 단계에서는 Ollama를 통해 로컬에서 실행되는 대규모 언어 모델(LLM)을 활용하여 연구 콘텐츠의 간결한 요약본을 생성하는 방법을 보여줍니다. 이 접근 방식은 데이터 처리를 비공개로 유지하고 오프라인 요약 기능을 가능하게 합니다.
import subprocess
import json
def summarize_with_ollama(content, model="llama2"):
"""로컬 Ollama 모델을 사용하여 연구 내용 요약"""
try:
result = subprocess.run(
['ollama', 'run', model, f"이 연구 내용을 요약하세요: {content[:2000]}"],
capture_output=True,
text=True,
timeout=120
)
return result.stdout.strip()
except Exception as e:
return f"요약 실패: {str(e)}"
# 사용 예시
research_data = res.json().get('results', [])
for item in research_data:
summary = summarize_with_ollama(item.get('content', ''))
print(f"요약: {summary}")ollama run llama2 "의료 분야에서 AI 활용 사례 요약하기"Streamlit UI
마지막으로 Bright Data의 데이터 수집과 Ollama를 통한 로컬 AI 요약 기능을 결합한 완전한 웹 UI를 생성합니다. 이 인터페이스를 통해 사용자는 직관적인 대시보드를 통해 연구 매개변수를 구성하고, 데이터 수집을 실행하며, AI 요약본을 생성할 수 있습니다.
app.py 생성
import streamlit as st
import requests, os
from dotenv import load_dotenv
import subprocess
import json
load_dotenv()
st.set_page_config(page_title="Deep Research Agent", page_icon="🔎")
st.title("🔎 Bright Data를 활용한 로컬 심층 연구 에이전트")
# 사이드바 구성
with st.sidebar:
st.header("Configuration")
api_key = st.text_input(
"Bright Data API Key",
type="password",
value=os.getenv('BRIGHT_DATA_API_KEY', '')
)
model_choice = st.selectbox(
"Ollama 모델",
["llama2", "mistral", "codellama"]
)
research_depth = st.slider("연구 깊이", 5, 50, 20)
# 메인 연구 인터페이스
query = st.text_input("연구 주제 입력:", "의료 분야 AI 활용 사례")
col1, col2 = st.columns(2)
with col1:
if st.button("🚀 연구 실행", type="primary"):
if not api_key:
st.error("Bright Data API 키를 입력해 주세요")
elif query:
st.error("연구 주제를 입력해 주세요")
else:
with st.spinner("연구 데이터 수집 중..."):
# Bright Data에서 데이터 가져오기
url = "https://api.brightdata.com/dca/trigger"
payload = {"query": query, "limit": research_depth}
headers = {"Authorization": f"Bearer {api_key}"}
res = requests.post(url, json=payload, headers=headers)
if res.status_code == 200:
st.success(f"{len(res.json().get('results', []))}개의 소스를 성공적으로 수집했습니다!")
st.session_state.research_data = res.json()
# 결과 표시
for i, item in enumerate(res.json().get('results', [])):
with st.expander(f"출처 {i+1}: {item.get('title', '제목 없음')}"):
st.write(item.get('content', '내용 없음'))
else:
st.error(f"데이터 가져오기 실패: {res.status_code}")
with col2:
if st.button("🤖 Ollama로 요약하기"):
if 'research_data' in st.session_state:
with st.spinner("AI 요약 생성 중..."):
for i, item in enumerate(st.session_state.research_data.get('results', [])):
content = item.get('content', '')[:1500] # 콘텐츠 길이 제한
try:
result = subprocess.run(
['ollama', 'run', model_choice, f"이 콘텐츠 요약: {content}"],
capture_output=True,
text=True,
timeout=60
)
summary = result.stdout.strip()
with st.expander(f"AI 요약 {i+1}"):
st.write(summary)
except Exception as e:
st.error(f"원본 {i+1} 요약 실패: {str(e)}")
else:
st.warning("데이터 수집을 위해 먼저 연구를 실행해 주세요")
# 원시 데이터가 있으면 표시
if 'research_data' in st.session_state:
with st.expander("View Raw Research Data"):
st.json(st.session_state.research_data)애플리케이션 실행:
streamlit run app.py애플리케이션을 실행하고 포트 8501을 방문하면 다음과 같은 UI가 표시됩니다:
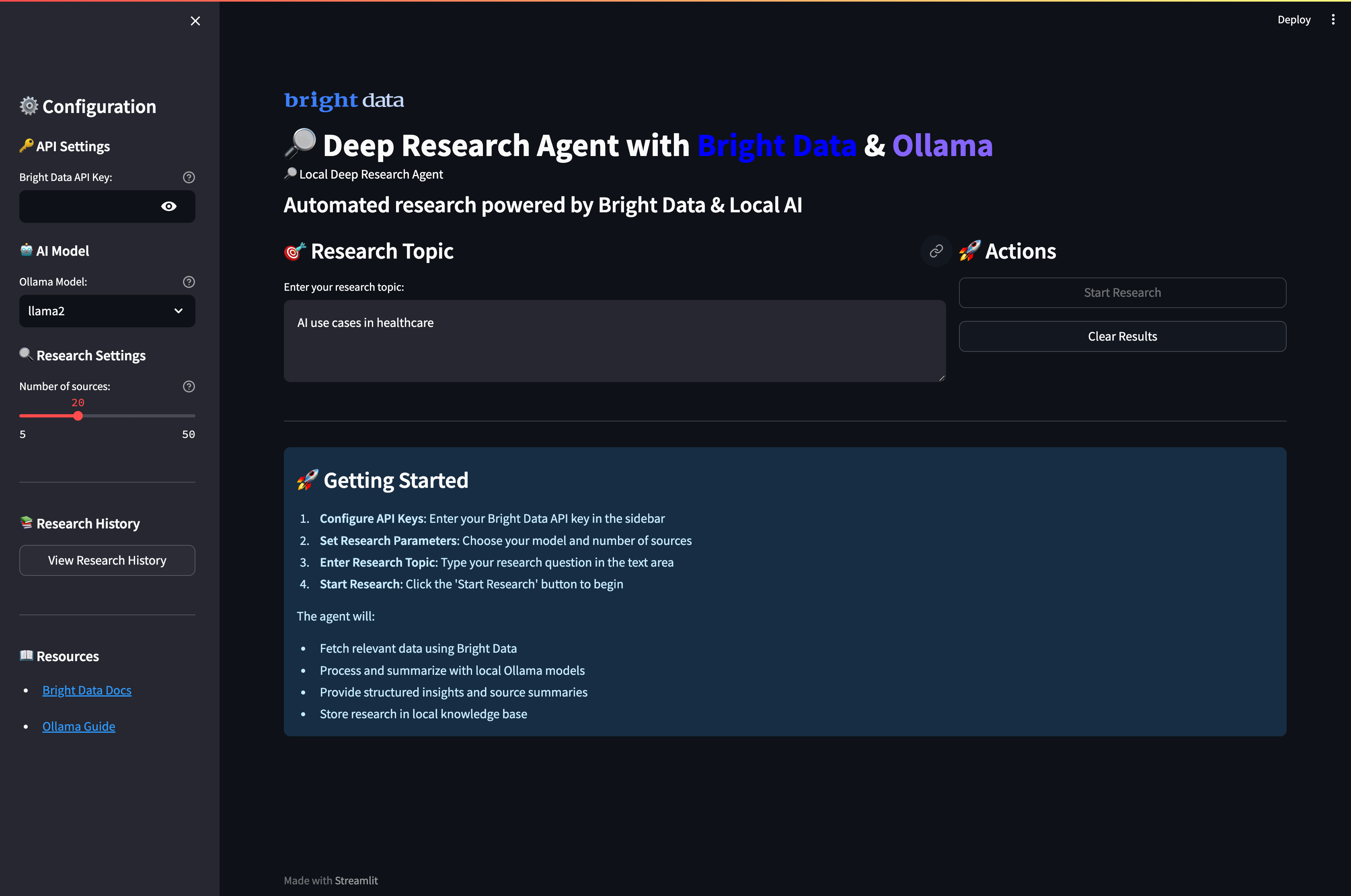
딥 리서치 에이전트 실행하기
AI 기반 분석으로 포괄적인 연구를 시작하려면 애플리케이션을 실행하세요. 터미널을 열고 프로젝트 디렉터리로 이동합니다.
streamlit run app.py시스템의 지능형 다중 에이전트 워크플로가 연구 요청을 처리하는 과정을 확인할 수 있습니다:
- 데이터 수집 단계: 에이전트가 Bright Data의 안정적인 API를 활용해 다양한 웹 소스에서 포괄적인 연구 데이터를 수집하며, 관련성과 신뢰도를 자동으로 필터링합니다.
- 콘텐츠 처리: 각 소스는 지능형 분석을 거쳐 시스템이 핵심 정보를 추출하고 주요 주제를 식별하며 의미 이해를 통해 콘텐츠 품질을 평가합니다.
- AI 요약: 로컬 Ollama 모델이 수집된 데이터를 처리하여 핵심 통찰력을 보존하고 모든 소스 간 문맥 정확성을 유지하면서 간결한 요약본을 생성합니다.
- 지식 종합: 시스템은 여러 소스의 정보를 동시에 분석하여 반복되는 패턴을 식별하고, 관련 개념을 연결하며, 새롭게 부상하는 트렌드를 탐지합니다.
- 구조화된 보고: 마지막으로 에이전트는 모든 결과를 체계적으로 정리하고 명확한 인용과 전문적인 서식을 적용하여 핵심 발견 사항과 통찰력을 강조하는 포괄적인 연구 보고서로 작성합니다.
향상된 연구 파이프라인
고급 연구 기능을 위해 구현을 확장하십시오.
이 향상된 파이프라인은 단순 요약 beyond을 넘어 수집된 연구 데이터로부터 구조화된 분석, 핵심 통찰력 및 실행 가능한 결과를 제공하는 완전한 연구 워크플로우를 생성합니다. 파이프라인은 정보 수집을 위한 Bright Data와 지능형 분석을 위한 로컬 Ollama 모델을 통합합니다.
# advanced_research.py
def comprehensive_research_pipeline(query, api_key, model="llama2"):
"""데이터 수집 및 AI 분석을 포함한 완전한 연구 파이프라인"""
# 1단계: Bright Data에서 데이터 가져오기
url = "https://api.brightdata.com/dca/trigger"
payload = {"query": query, "limit": 20}
headers = {"Authorization": f"Bearer {api_key}"}
response = requests.post(url, json=payload, headers=headers)
if response.status_code != 200:
return {"error": "데이터 수집 실패"}
research_data = response.json()
# 2단계: Ollama로 처리 및 분석
insights = []
for item in research_data.get('results', []):
content = item.get('content', '')
# 각 출처별 인사이트 생성
analysis_prompt = f"""
이 콘텐츠를 분석하고 주요 인사이트를 제공하세요:
{content[:2000]}
중점 사항:
- 주요 포인트 및 발견 사항
- 핵심 데이터 및 통계
- 잠재적 적용 분야
- 언급된 한계점
"""
try:
result = subprocess.run(
['ollama', 'run', model, analysis_prompt],
capture_output=True,
text=True,
timeout=90
)
insights.append({
'source': item.get('source', ''),
'analysis': result.stdout.strip(),
'title': item.get('title', '')
})
except Exception as e:
insights.append({
'source': item.get('source', ''),
'analysis': f"분석 실패: {str(e)}",
'title': item.get('title', '')
})
return {
'research_data': research_data,
'ai_insights': insights,
'query': query
}결론
이 로컬 딥 리서치 에이전트는 Bright Data의 신뢰할 수 있는 웹 데이터 수집과 Ollama를 활용한 로컬 AI 처리를 결합한 자동화된 리서치 시스템 구축 방법을 보여줍니다. 구현은 다음을 제공합니다:
- 프라이버시 우선 접근 방식: 모든 AI 처리는 Ollama를 통해 로컬에서 수행됩니다
- 신뢰할 수 있는 데이터 수집: Bright Data가 고품질의 구조화된 웹 데이터를 보장합니다
- 사용자 친화적 인터페이스: Streamlit UI로 복잡한 연구 접근성 향상
- 맞춤형 워크플로: 다양한 연구 분야 및 요구사항에 유연하게 적용 가능
이 시스템은 데이터 수집, 처리, 분석을 자동화하여 수시간 걸리던 수동 연구를 몇 분 만에 자동화된 인사이트 생성으로 전환함으로써 주요 산업 과제를 해결합니다.
연구 역량을 더욱 강화하려면 산업별 데이터를 위한 Bright Data의 데이터셋 솔루션을 살펴보고, 세계 최대 규모의 웹 데이터베이스 쿼리 및 검색을 위해 Deep Lookup 사용을 고려해 보십시오.
나만의 연구 에이전트를 구축할 준비가 되셨나요? 신뢰할 수 있는 웹 데이터 수집을 시작하고 연구 워크플로우를 혁신하기 위해 무료 Bright Data 계정을 생성하세요.






