
이 가이드에서는 LLM 멘션 추적을 위한 범용 LLM 스크레이퍼의 사용법과 아키텍처를 살펴보겠습니다. 본 프로젝트는 다음 스크레이퍼들을 단일 통합 인터페이스로 결합할 예정입니다:
이 가이드를 다 읽으면 다음을 수행할 수 있게 됩니다.
- Bright Data 웹 스크래핑 API를 사용하여 스크래퍼를 실행합니다.
- 스크레이퍼 준비 상태를 확인하고 결과를 다운로드합니다.
- Bright Data의 출력 형식을 사용하여 손쉽게 정규화할 수 있습니다.
- 연구 및 검증을 위해 여러 LLM에서 프롬프트를 동시에 비교합니다.
프로젝트를 바로 시작하고 싶으신가요? GitHub에서 확인해 보세요.
범용 LLM 스크레이퍼를 구축하는 이유
연구 행동이 변화했습니다. 사용자들은 이제 AI 챗봇에 질문을 하고 생성된 답변을 신뢰하며, 다시 검색을 계속하는 경우는 거의 없습니다. 이는 SEO 및 시장 정보 운영을 극적으로 변화시킵니다: 챗봇 출력에 브랜드가 언급되지 않으면 잠재 고객이 여러분을 발견하지 못할 수도 있습니다.
기업은 이제 검색 결과뿐만 아니라 모델 출력에도 노출되어야 합니다. Bright Data의 사전 구축된 LLM 스크레이퍼는 시장에서 가장 인기 있는 모델들의 정규화된 출력을 제공합니다. 이러한 API를 단일 인터페이스로 통합함으로써 팀은 모든 주요 LLM의 추천 결과를 비교할 수 있습니다.
다음 프롬프트를 고려해 보세요: 최고의 주거용 프록시 제공업체는 어디인가요?
각 LLM을 수동으로 쿼리하고 결과를 읽는 데는 한 시간 이상 소요될 수 있습니다. 통합된 결과를 통해 프롬프트를 여러 LLM에 동시에 전달하고 정규식을 사용하여 응답에 귀사가 등장하는지 즉시 판단할 수 있습니다.
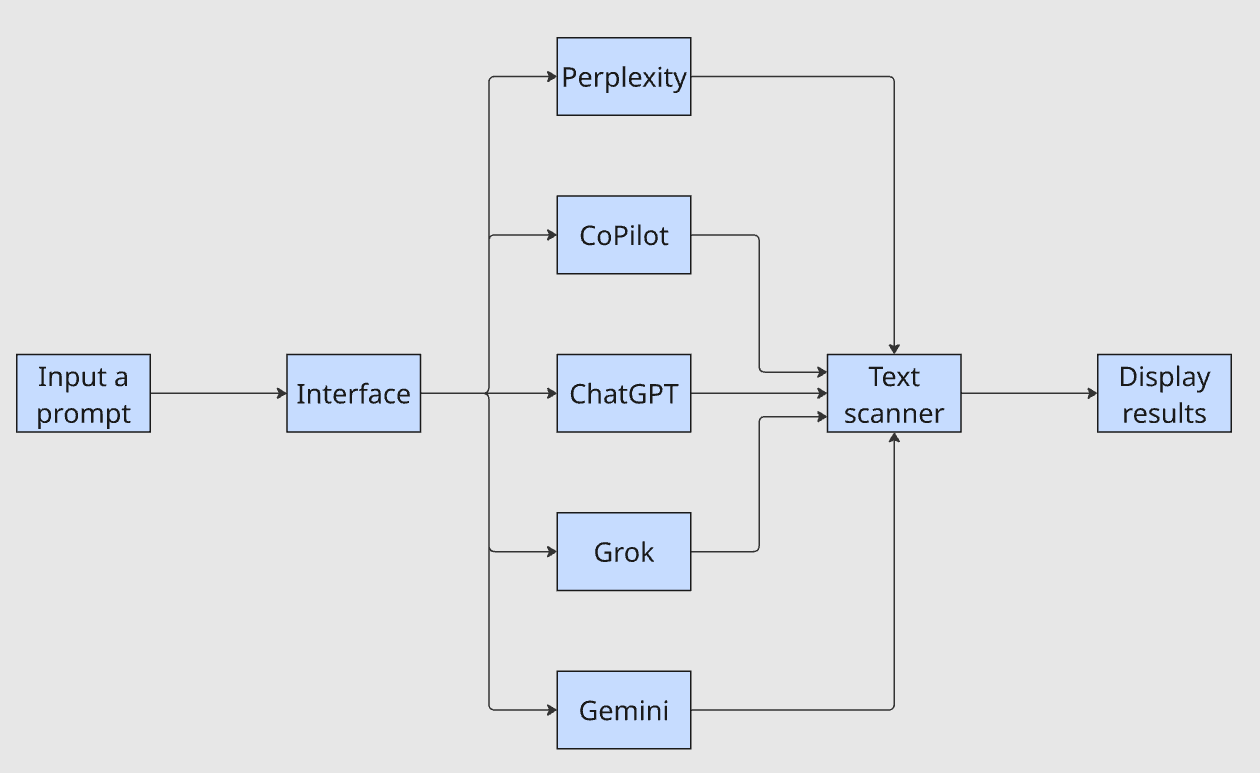
이 인터페이스는 단일 프롬프트를 받아 각 LLM에 전달하고, 출력을 텍스트 스캐너를 통해 처리하여 결과를 표시합니다. '우리 회사가 결과에 포함되었는가? ‘라는 질문에 대한 답변 시간이 1시간에서 몇 분으로 단축됩니다.
실제 소프트웨어 구축
이제 실제 소프트웨어를 구축해야 합니다. 기본 프로젝트 뼈대를 생성한 후 진행하면서 코드를 채워 넣을 것입니다. 이 섹션에는 전체 코드베이스가 포함되어 있지 않습니다. 이는 개념적 설명이며, 줄별 단계별 안내가 아닙니다.
시작하기
새 프로젝트 폴더를 생성하는 것으로 시작합니다.
mkdir universal-llm-scraper
cd universal-llm-scraper의존성 충돌을 방지하기 위해 가상 환경을 생성합니다.
python -m venv .venv이제 가상 환경을 활성화해야 합니다. Linux 또는 macOS에서는 첫 번째 명령어로 활성화할 수 있습니다. Windows에서는 두 번째 명령어를 사용하세요.
Linux/macOS
source .venv/bin/activateWindows
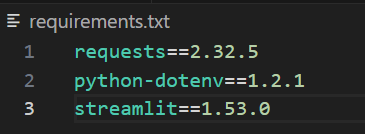
..venvScriptsActivate.ps1마지막으로 requirements.txt 파일을 생성하고 아래에 표시된 종속성을 추가하세요. 버전 번호는 조정 가능합니다. 다만 빌드 시 잘 작동했던 버전들이므로 재현성을 위해 고정했습니다.
requests==2.32.5
python-dotenv==1.2.1
streamlit==1.53.0완료 시 파일은 아래 이미지와 같을 것입니다.
이러한 종속성을 설치하려면 아래 pip 명령을 실행하세요.
pip install -r requirements.txt객체로서의 AI 모델
다음으로, 우리의 모든 AI 모델이 객체로 기능한다는 점을 이해해야 합니다. 각 모델은 다음과 같은 속성을 가집니다.
name: 모델에 대한 사람이 읽을 수 있는 레이블입니다.dataset_id: 스크레이퍼의 고유 식별자입니다.url: AI 모델에 접근하기 위해 사용하는 실제 URL입니다.
아래 클래스에서는 동일한 모델 객체를 생성합니다. 이 클래스에는 메서드나 로직이 필요하지 않습니다. 컴퓨터 과학에 익숙하다면 구식 구조체(struct)와 유사합니다.
class AIModel:
def __init__(self, name: str, dataset_id: str, url: str):
self.name = name
self.dataset_id = dataset_id
self.url = url 모델 리트리버 작성
다음으로 모델 리트리버를 작성해야 합니다. 이 클래스는 더 많은 중책을 맡습니다. 모델 리트리버는 Bright Data와 나머지 코드 사이의 통합 오케스트레이션 계층을 제공합니다. Bright Data API 키를 사용하여 API에 인증합니다. 또한 다양한 메서드( get_model_response(), trigger_prompt_collection(), collect_snapshot(), write_model_output()) 를 제공합니다 . 진행하면서 이 메서드들을 채워 넣을 것입니다.
class AIModelRetriever:
def __init__(self, api_token: str):
self.api_token = api_token
def get_model_response(self, model: AIModel, prompt: str):
pass
def trigger_prompt_collection(self, model: AIModel, prompt: str, country: str = ""):
pass
def collect_snapshot(self, model: AIModel, snapshot_id: str):
pass
def write_model_output(self, model: AIModel, llm_response: dict):
passget_model_response()
이 메서드는 주로 오케스트레이션에 사용됩니다. trigger_prompt_collection()을 사용하여 스크레이퍼를 시작하고 그 snapshot_id를 반환합니다. 그런 다음 collect_snapshot()을 사용하여 API를 폴링하고 응답이 준비되면 반환합니다. 마지막으로 write_model_output()을 사용하여 응답을 파일에 기록합니다.
def get_model_response(self, model: AIModel, prompt: str):
snapshot_id = self.trigger_prompt_collection(model, prompt)
if not snapshot_id:
raise RuntimeError(f"{model.name}: 스냅샷 트리거 실패. 잠시 기다린 후 다시 시도해 주세요.")
llm_response = self.collect_snapshot(model, snapshot_id)
if not llm_response:
raise RuntimeError(f"{model.name}에 대한 {snapshot_id} 스냅샷 수집 실패. 잠시 기다린 후 다시 시도해 주세요.")
self.write_model_output(model, llm_response)trigger_prompt_collection()
컬렉션을 트리거하기 위해 API 토큰을 HTTP 헤더에 전달합니다. 이후 API에 POST 요청을 시도합니다. HTTP 실패가 예측 불가능할 수 있으므로 최대 세 번까지 재시도합니다. 응답이 정상일 경우 snapshot_id를 반환합니다. 오류 발생 시 재시도 횟수가 소진될 때까지 계속 시도합니다. 재시도 횟수를 초과하면 함수를 종료합니다.
def trigger_prompt_collection(self, model: AIModel, prompt: str, country: str = ""):
headers = {
"Authorization": f"Bearer {self.api_token}",
"Content-Type": "application/json",
}
data = json.dumps(
{"input":
[
{
"url": model.url,
"prompt": prompt,
"country":country,
}
],
})
tries = 3
while tries > 0:
response = None
try:
response = requests.post(
f"https://api.brightdata.com/datasets/v3/scrape?dataset_id={model.dataset_id}¬ify=false&include_errors=true",
headers=headers,
data=data,
timeout=POST_TIMEOUT
)
response.raise_for_status()
payload = response.json()
snapshot_id = payload["snapshot_id"]
return snapshot_id
except (ValueError, KeyError, TypeError, requests.RequestException) as e:
print(f"{model.name} 스냅샷 트리거 실패: {e}")
tries -= 1
if response is not None and response.status_code >= 400:
print(f"Status: {response.status_code}")
print(response.text)
print("retries exceeded")
returncollect_snapshot()
스냅샷 ID를 획득한 후, 매분마다 준비 상태를 확인합니다. 수집이 진행 중일 경우 API는 상태 코드 202를 반환합니다. 스냅샷이 준비되면 200을 반환합니다. 다른 상태 코드를 수신하면 에러를 발생시키고 재시도 로직으로 진입합니다. 재시도 횟수를 초과하면 메서드를 종료합니다.
def collect_snapshot(self, model: AIModel, snapshot_id: str):
url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}"
ready = False
llm_response = None
print(f"{model.name} 스냅샷 {snapshot_id} 대기 중")
max_errors = 3
while not ready and max_errors > 0:
headers = {"Authorization": f"Bearer {self.api_token}"}
try:
response = requests.get(url, headers=headers, timeout=GET_TIMEOUT)
except requests.RequestException as e:
max_errors -= 1
print(f"{model.name}: 폴링 오류 ({e})")
continue
if response.status_code == 200:
print(f"{model.name} 스냅샷 {snapshot_id} 준비 완료!")
ready = True
llm_response = response.json()
return llm_response
elif response.status_code == 202:
sleep(60)
else:
max_errors-=1
print("서버 통신 오류")
print(f"최대 오류 횟수 초과, 스냅샷 {snapshot_id} 수집 실패")
returnwrite_model_output()
이 함수는 매우 간단합니다. 모델 출력을 저장하는 용도로만 사용합니다. os.makedirs(OUTPUT_FOLDER, exist_ok=True) 는 outputs 폴더가 존재하는지 확인하기 위해 사용됩니다. 그런 다음 파일을 outputs 폴더에 작성하고 model.name을 사용하여 파일 이름을 지정합니다.
def write_model_output(self, model: AIModel, llm_response: dict):
os.makedirs(OUTPUT_FOLDER, exist_ok=True)
path = os.path.join(OUTPUT_FOLDER, f"{model.name}-output.json")
with open(path, "w", encoding="utf-8") as file:
json.dump(llm_response, file, indent=4, ensure_ascii=False)
print(f"{model.name} 보고서를 {path}에 생성 완료") 메인 파일 작성
이제 메인 파일을 작성하겠습니다. UI를 로드하지 않고 백엔드 프로세스를 실행하는 데 사용할 수 있습니다. run_one()은 단일 모델에서 프로세스를 실행할 수 있게 합니다. main() 내부에서는 ThreadPoolExecutor() 를 사용하여 이 함수를 여러 스레드에서 동시에 실행합니다. 한 번에 하나의 컬렉션을 처리하는 대신, 스레드당 하나의 컬렉션을 처리하여 결과를 획기적으로 가속화할 수 있습니다.
import os
from concurrent.futures import ThreadPoolExecutor, as_completed
from dotenv import load_dotenv
from ai_models import chatgpt, perplexity, gemini, grok, copilot, AIModelRetriever
MAX_WORKERS = 5
def run_one(model, retriever, prompt):
retriever.get_model_response(model, prompt)
return model.name
def main():
load_dotenv()
api_token = os.environ["BRIGHTDATA_API_TOKEN"]
prompt = "왜 하늘은 파란색인가요?"
models = [chatgpt, perplexity, gemini, grok, copilot]
retriever = AIModelRetriever(api_token=api_token)
실패 횟수 = 0
ThreadPoolExecutor(최대 작업자 수=min(최대 작업자 수, 모델 목록의 길이)) as pool:
미래 작업 = {pool.submit(run_one, m, retriever, prompt): m for m in 모델 목록}
미래 작업이 완료된 것들 중:
모델 = 미래 작업 목록[해당 미래 작업]
시도:
name = fut.result()
print(f"{name}: 완료")
except Exception as e:
failures += 1
print(f"{model.name}: 실패 ({e})")
if failures == len(models):
raise SystemExit(1)
if __name__ == "__main__":
main()아래 명령어로 메인 파일을 실행할 수 있습니다.
python main.pyStreamlit UI
Streamlit UI는 개념적으로 메인 파일과 매우 유사합니다. 각 컬렉션을 실행하기 위해 여전히 다중 스레드를 사용합니다. write_output() 및 sanitize_filename() 함수는 파일명을 정리하기 위해 사용됩니다. 터미널에 출력하는 대신, Streamlit을 사용하여 변수를 생성해 로컬 브라우저 내에서 앱을 실행하고 표시합니다.
UI 작성
import os
import json
import re
from concurrent.futures import ThreadPoolExecutor, as_completed
from pathlib import Path
import streamlit as st
from dotenv import load_dotenv
from ai_models import chatgpt, perplexity, gemini, grok, copilot, AIModelRetriever
OUTPUT_DIR = Path("output")
MAX_WORKERS = 5
def sanitize_filename(name: str) -> str:
return re.sub(r"[^A-Za-z0-9._-]+", "_", name).strip("_")
def write_output(model_name: str, payload: dict) -> Path:
OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
path = OUTPUT_DIR / f"{sanitize_filename(model_name)}-output.json"
path.write_text(json.dumps(payload, indent=4, ensure_ascii=False), encoding="utf-8")
return path
def main():
st.set_page_config(page_title="유니버설 LLM 스크레이퍼", layout="wide")
st.title("유니버설 LLM 스크레이퍼")
load_dotenv()
api_token = os.getenv("BRIGHTDATA_API_TOKEN")
if not api_token:
st.error("BRIGHTDATA_API_TOKEN이 누락되었습니다. 프로젝트 루트 디렉터리의 .env 파일에 추가하세요.")
st.stop()
models = [chatgpt, perplexity, gemini, grok, copilot]
model_names = [m.name for m in models]
model_by_name = {m.name: m for m in models}
with st.sidebar:
st.header("실행 설정")
prompt = st.text_area("프롬프트", value="최고의 주거용 프록시 제공업체는 어디인가요?", height=120)
target_phrase = st.text_input("추적할 대상 문구", value="Bright Data")
selected = st.multiselect("모델 선택", options=model_names, default=model_names)
country = st.text_input("국가 (선택 사항)", value="")
save_to_disk = st.checkbox("결과를 출력에 저장?", value=True)
redact_terms = st.text_area("숨길 브랜드 용어 (한 줄에 하나씩)", value="")
redact_mode = st.selectbox("숨김 모드", ["마스크", "제거"], index=0)
run_clicked = st.button("스크래핑 실행", type="primary", use_container_width=True)
if "results" not in st.session_state:
st.session_state.results = {} # model_name -> payload
if "errors" not in st.session_state:
st.session_state.errors = {} # 모델명 -> 오류 문자열
if "paths" not in st.session_state:
st.session_state.paths = {} # 모델명 -> 저장된 경로
def apply_redaction(text: str) -> str:
terms = [t.strip() for t in redact_terms.splitlines() if t.strip()]
if not terms:
return text
pattern = re.compile(r"(" + "|".join(map(re.escape, terms)) + r")", flags=re.IGNORECASE)
if redact_mode == "Mask":
return pattern.sub("███", text)
return pattern.sub("", text)
def extract_answer_text(payload: dict) -> str | None:
if not isinstance(payload, dict):
return None
if isinstance(payload.get("answer_text"), str):
return payload["answer_text"]
if "data" in payload and isinstance(payload["data"], list) and payload["data"]:
first = payload["data"][0]
if isinstance(first, dict) and isinstance(first.get("answer_text"), str):
return first["answer_text"]
return None
def mentions_target(payload: dict) -> bool:
if not target_phrase:
return False
answer = extract_answer_text(payload)
if isinstance(answer, str):
return target_phrase.lower() in answer.lower()
# Fallback: if we can't find answer_text, just search the serialized payload
try:
blob = json.dumps(payload, ensure_ascii=False)
return target_phrase.lower() in blob.lower()
except Exception:
return False
# 레이아웃: 상태 + 결과
status_col, results_col = st.columns([1, 2], gap="large")
with status_col:
st.subheader("상태")
if run_clicked:
st.session_state.results = {}
st.session_state.errors = {}
st.session_state.paths = {}
if not selected:
st.warning("모델을 하나 이상 선택하세요.")
st.stop()
retriever = AIModelRetriever(api_token=api_token)
status_boxes = {name: st.empty() for name in selected}
progress = st.progress(0)
done = 0
total = len(selected)
def run_one(model_name: str):
model = model_by_name[model_name]
페이로드 = 리트리버.런(모델, 프롬프트, 국가=국가)
리턴 모델_이름, 페이로드
위드 스레드풀익제큐터(최대_작업자=min(최대_작업자, 총_수)) as 풀:
퓨처스 = [풀.서브미트(런_원, 이름) for 이름 in 선택된_모델]
for fut in as_completed(futures):
try:
model_name, payload = fut.result()
st.session_state.results[model_name] = payload
status_boxes[model_name].success(f"{model_name}: 완료")
if save_to_disk:
path = write_output(model_name, payload)
st.session_state.paths[model_name] = str(path)
except Exception as e:
err = str(e)
st.session_state.errors[f"job-{done+1}"] = err
st.error(err)
done += 1
progress.progress(done / total)
st.success("실행 완료.")
# 저장된 파일 표시 (있는 경우)
if st.session_state.paths:
st.caption("저장된 파일")
for k, v in st.session_state.paths.items():
st.write(f"- {k}: {v}")
if st.session_state.errors:
st.caption("오류")
for k, v in st.session_state.errors.items():
st.write(f"- {k}: {v}")
with results_col:
st.subheader("결과")
if not st.session_state.results:
st.info("결과 수집을 위해 '스크래핑 실행'을 클릭하세요.")
st.stop()
tabs = st.tabs(list(st.session_state.results.keys()))
for tab, model_name in zip(tabs, st.session_state.results.keys()):
payload = st.session_state.results[model_name]
with tab:
answer_text = extract_answer_text(payload)
mentioned = mentions_target(payload)
st.markdown(f"**언급된 대상 문구:** {'✅' if mentioned else '❌'}")
if answer_text and isinstance(answer_text, str):
st.markdown("### 답변")
st.text_area(
label="",
value=apply_redaction(answer_text),
height=260
)
else:
st.markdown("### 원본 JSON")
st.json(payload)
if __name__ == "__main__":
main()네, app.py는 메인 파일보다 길지만 main.py와의 주요 차이점은 몇 가지뿐입니다.
- 상태 관리: Streamlit을 사용해 결과, 오류, 파일 경로를
st.session_state에저장합니다. 이를 통해 UI 내에서 해당 정보를 불러와 표시할 수 있습니다. - 오케스트레이션: 프롬프트와 모델 컬렉션을 하드코딩하지 않고 UI 내에서 수집 및 트리거합니다.
- 텍스트 검사: 답변 텍스트를 검사하여 목표 문구가 포함되었는지 확인합니다. 목표 문구가 있으면 ✅을 표시하고, 없으면 ❌을 표시합니다.
UI 사용법
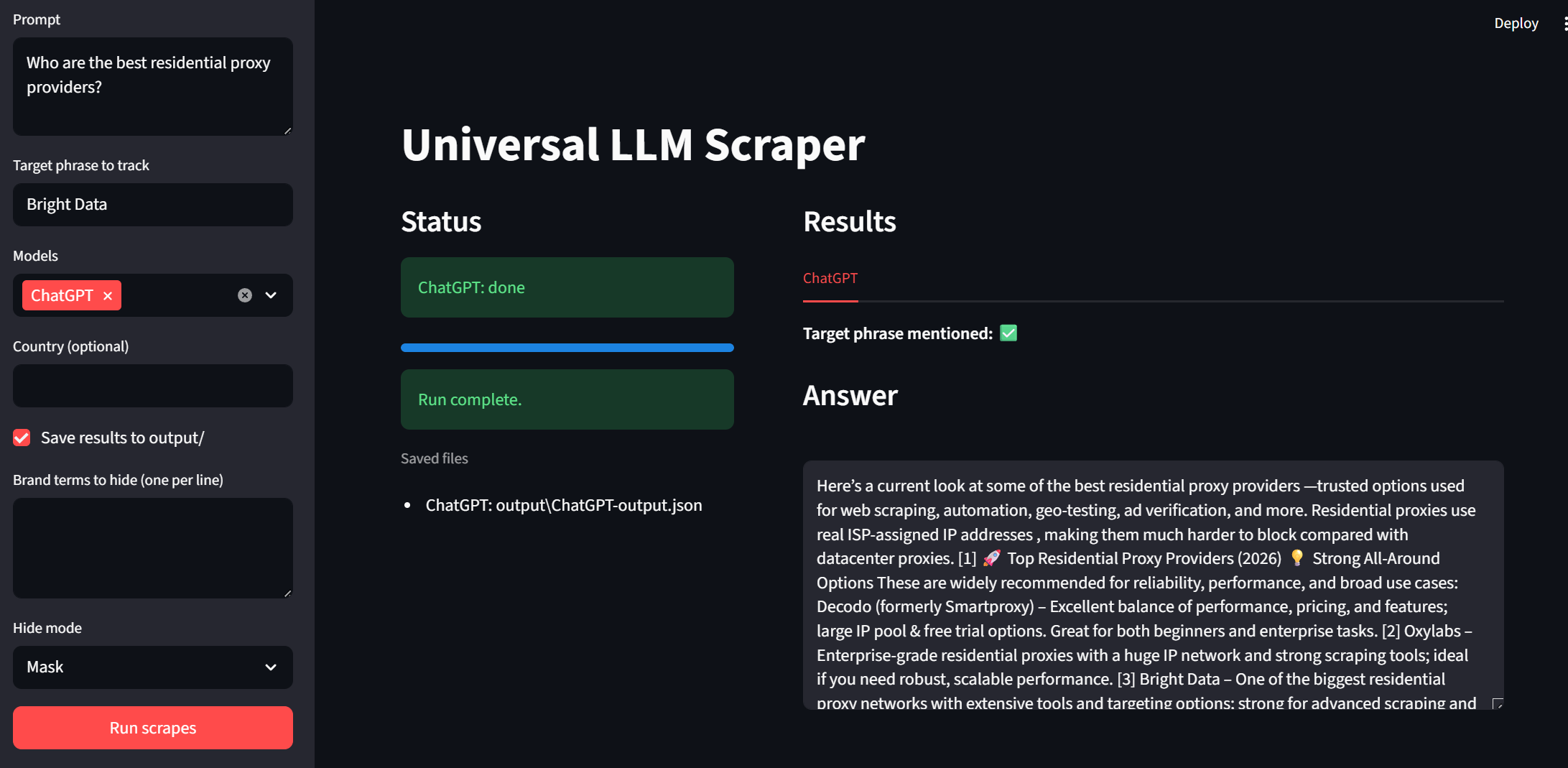
이제 UI를 테스트해 볼 차례입니다. 아래 스니펫으로 앱을 실행할 수 있습니다.
streamlit run app.py사이드바를 살펴보세요. 프롬프트와 대상 문구를 입력할 수 있습니다. 모델은 이제 드롭다운을 통해 선택 가능합니다. “국가”와 “출력 저장”은 사용자 측에서 선택적으로 조정할 수 있는 옵션입니다. 프로그램을 실행하려면 하단의 “스크랩 실행” 버튼을 클릭하기만 하면 됩니다.
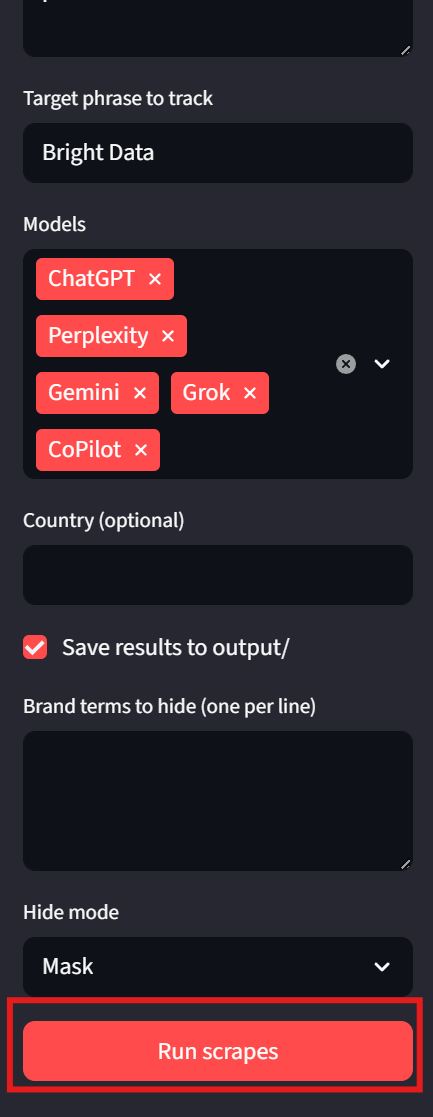
결과
각 모델은 결과 내 별도의 탭으로 표시됩니다. 이를 통해 결과를 빠르게 검토할 수 있습니다. 아래 이미지에서 Bright Data는 각 모델 출력에 대해 녹색 체크 표시를 받았습니다. 예시:
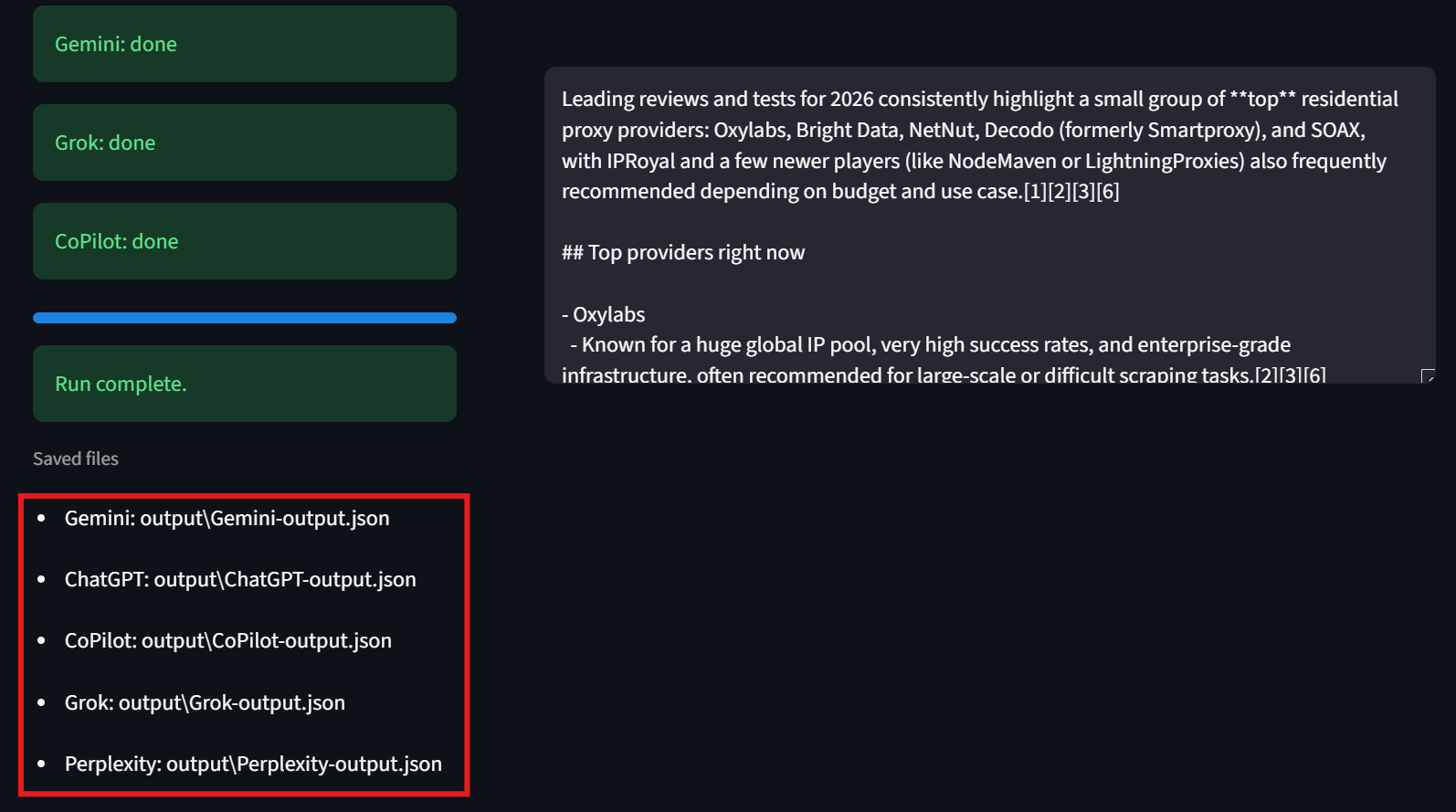
사용자는 인터페이스 좌측 하단도 확인해야 합니다. 여기에는 각 결과 파일의 경로가 표시되어 원본 결과를 손쉽게 확인할 수 있습니다.
다음 단계로 나아가기
먼저 Supabase 계정이 필요합니다. supabase.com으로 이동하여 안내를 따라 계정을 생성하세요. Supabase는 다양한 요금제를 제공하여 필요에 맞게 선택할 수 있습니다. 본 프로젝트에는 무료 요금제로 충분합니다. 다만 데이터베이스 규모가 커지면 업그레이드가 필요할 수 있습니다.
API 키가 필요합니다. 계정 및 프로젝트 설정을 완료한 후 사이드바의 ‘프로젝트 설정’을 클릭하세요. ‘API 키’ 탭으로 이동하여 API 키를 확인합니다.
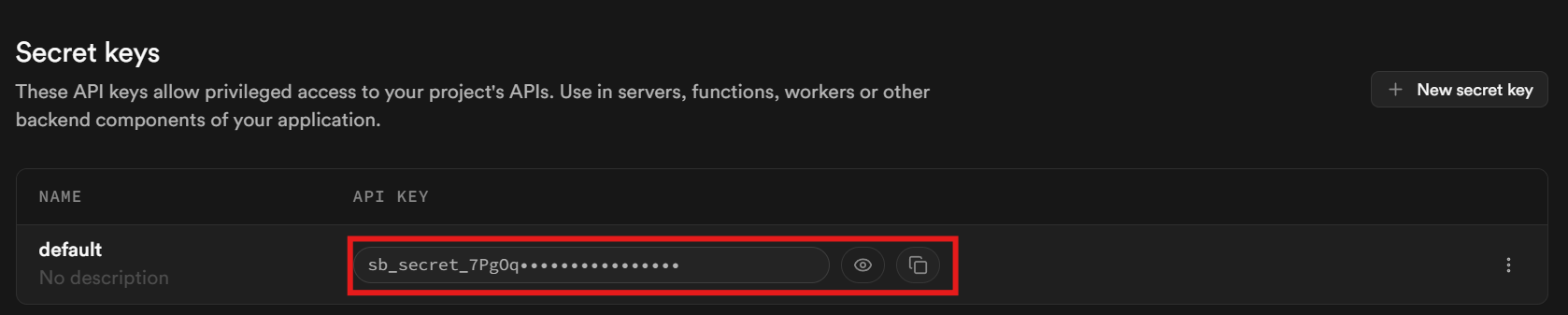
페이지 하단으로 스크롤하세요. 키는 “비밀 키(Secret keys)” 섹션에 위치합니다.
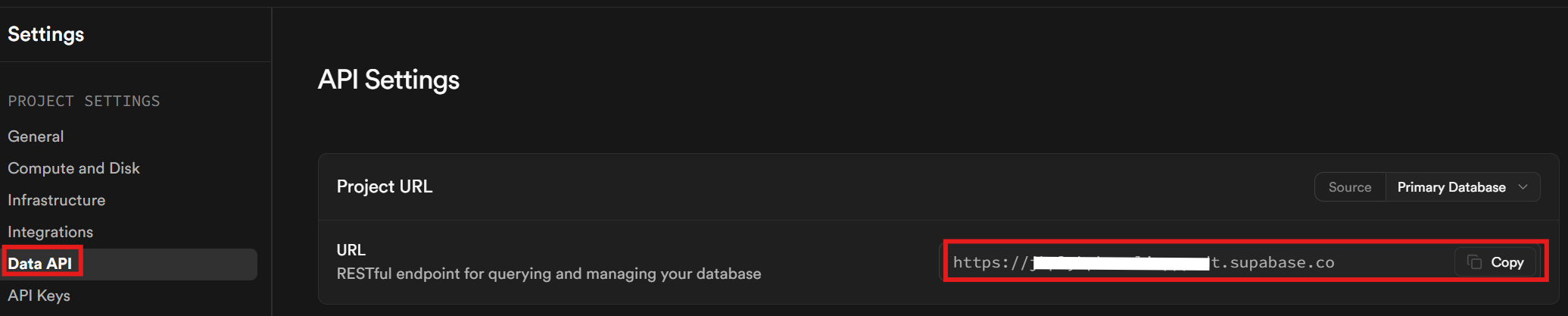
마지막으로 데이터 API 탭에서 Supabase URL을 확인하세요. 이 URL은 데이터베이스와 통신할 때 사용합니다.
키를 확보한 후에는 환경 파일과 요구 사항 파일을 업데이트해야 합니다. 새 환경 파일은 다음과 같아야 합니다.
BRIGHTDATA_API_TOKEN=<your-bright-data-api-key>
SUPABASE_URL=<your-supabase-project-url>
SUPABASE_API_TOKEN=<your-supabase-api-key>요구 사항 파일은 이제 다음과 같습니다.
requests==2.32.5
python-dotenv==1.2.1
streamlit==1.53.0
supabase==2.27.2테이블 생성
이제 데이터베이스 내에 테이블을 생성해야 합니다. 사이드바를 사용하여 SQL 편집기를 엽니다.
LLM 실행
다음 SQL 코드를 스크립트에 붙여넣고 실행하세요. 이렇게 하면 llm_runs라는 테이블이 생성됩니다. 컬렉션을 실행할 때마다 결과를 여기에 저장할 것입니다.
create table public.llm_runs (
id bigint generated by default as identity primary key,
created_at_ts bigint not null, -- unix seconds
model_name text not null,
prompt text not null,
country text null,
target_phrase text null,
mentioned boolean not null default false,
payload jsonb not null
);
create index if not exists llm_runs_created_at_ts_idx
on public.llm_runs (created_at_ts);
create index if not exists llm_runs_model_idx
on public.llm_runs (model_name);
create index if not exists llm_runs_target_idx
on public.llm_runs (target_phrase);프롬프트
프롬프트 저장 기능도 필요합니다. 아래 코드는 프롬프트 테이블을 생성합니다.
create table public.prompts (
id bigint generated by default as identity primary key,
created_at_ts bigint not null,
prompt text not null,
is_active boolean not null default true
);
create index if not exists prompts_created_at_ts_idx
on public.prompts (created_at_ts desc);
create index if not exists prompts_active_idx
on public.prompts (is_active);스케줄
마지막으로 예약된 작업을 저장할 테이블이 필요합니다.
create table public.schedules (
id bigint generated by default as identity primary key,
name text not null,
is_enabled boolean not null default true,
next_run_ts bigint not null,
last_run_ts bigint null,
models jsonb not null default '[]'::jsonb,
country text null,
target_phrase text null,
only_active_prompts boolean not null default true,
locked_until_ts bigint null,
lock_owner text null,
repeat_every_seconds bigint not null default 86400
);
create index if not exists schedules_due_idx
on public.schedules (is_enabled, next_run_ts);
create index if not exists schedules_lock_idx
on public.schedules (locked_until_ts);업데이트된 아키텍처
최종 코드베이스는 이제 튜토리얼에 담기에는 너무 커졌습니다. 모든 파일을 여기에 나열하기보다는 데이터베이스 연결, 헤드리스 러너 및 Streamlit UI의 핵심 포인트 몇 가지를 살펴보겠습니다.
데이터베이스 상호작용
다양한 데이터베이스 헬퍼가 있지만, 모든 작업은 주로 데이터베이스 내 읽기 및 생성 작업을 중심으로 이루어집니다. 아래 코드는 전체 데이터베이스에 연결할 수 있게 해줍니다.
def get_db() -> Client:
url = os.getenv("SUPABASE_URL")
key = os.getenv("SUPABASE_API_TOKEN") # .env 파일과 일관성 유지
if not url or not key:
raise RuntimeError("환경 변수에 SUPABASE_URL 또는 SUPABASE_API_TOKEN이 누락되었습니다.")
return create_client(url, key)데이터베이스와 실제로 상호작용하려면 get_db() 위에 추가 메서드를 호출합니다. 다음 스니펫에서 get_db()는 데이터베이스를 가져옵니다. 그런 다음 db.table("llm_runs").insert(row).execute() 를 사용하여 llm_runs 테이블에 새 행을 삽입합니다. 프롬프트 및 스케줄링 헬퍼도 동일한 기본 논리를 따릅니다.
def save_run(
*,
model_name: str,
prompt: str,
country: str,
target_phrase: str,
mentioned: bool,
payload: dict,)
-> dict:
db = get_db()
row = {
"created_at_ts": int(time.time()),
"model_name": model_name,
"prompt": prompt,
"country": country or None,
"target_phrase": target_phrase or None,
"mentioned": bool(mentioned),
"payload": payload, # JSONB
}
res = db.table("llm_runs").insert(row).execute()
if not getattr(res, "data", None):
row["payload"] = {"ERROR": "실행 실패"}
res = db.table("llm_runs").insert(row).execute()
raise RuntimeError(f"삽입 실패: {res}")
return res.data[0]헤드리스 러너
프로젝트 범위가 확장되면서 Streamlit UI 생성 후 main.py를 headless_runner.py로 이름 변경했습니다. 이제 하나의 메인 프로그램이 아닌 두 개의 스크립트가 동시에 실행됩니다.
persist_run() 은 API로부터 빈 페이로드를 확인합니다. 페이로드가 비어 있으면 False를 반환하고 삽입 실패에 대한 메시지를 터미널에 출력합니다. 페이로드에 정보가 포함되어 있으면 save_run()을 사용하여 결과를 데이터베이스에 삽입합니다.
def persist_run(*, model_name: str, prompt: str, payload, target_phrase: str, country: str = "") -> bool:
if payload is None:
print(f"{model_name}: skipping DB insert (payload is None).")
return False
# 빈 리스트/딕셔너리를 "저장하지 않음"으로 처리하려면 다음을 유지하세요:
if payload == {} or payload == []:
print(f"{model_name}: DB 삽입 건너뜀 (빈 페이로드). type={type(payload).__name__}")
return False
try:
json.dumps(payload, ensure_ascii=False)
except TypeError as e:
print(f"{model_name}: 페이로드가 JSON 직렬화 불가능합니다 ({e}). 문자열로 변환 중.")
payload = {"raw": json.dumps(payload, default=str, ensure_ascii=False)}
mentioned = mentions_target(payload if isinstance(payload, dict) else {"data": payload}, target_phrase)
try:
save_run(
model_name=model_name,
prompt=prompt,
country=country,
target_phrase=target_phrase,
mentioned=mentioned,
payload=payload,
)
except Exception as db_err:
print(f"{model_name}: DB 삽입 실패: {db_err}")
return mentioned다음으로 넘어가기 전에, 헤드리스 러너의 또 다른 주요 구성 요소를 살펴볼 필요가 있습니다. 다양한 선택적 환경 변수를 사용하여 구성을 조정할 수 있습니다. 실제 프로그램 실행은 간단한 while 루프 내에서 유지됩니다. 실행 루프 내부에서는 스케줄에 새로운 작업이 있는지 지속적으로 확인합니다. 예약된 작업이 실행 시점이 되면 run_schedule_once()를 호출하여 실행을 시작합니다.
# DB 변경 없이 조정 가능
tick_every_seconds = int(os.getenv("SCHED_TICK_SECONDS", "15")) # 깨어나는 주기(초)
lock_seconds = int(os.getenv("SCHED_LOCK_SECONDS", "1800")) # 작업 실행 중 잠금 지속 시간
drain_all_due = os.getenv("SCHED_DRAIN_ALL_DUE", "1") == "1" # 매 틱마다 모든 예정 작업 실행
save_to_disk = os.getenv("SCHED_SAVE_TO_DISK", "0") == "1"
while True:
now_ts = int(time.time())
ran_any = False
# 예약된 작업 하나를 클레임하여 실행하거나, 모든 예정된 작업을 처리
while True:
try:
due = claim_due_schedule(now_ts=now_ts, lock_owner=lock_owner, lock_seconds=lock_seconds)
except Exception as e:
print(f"예정된 작업 클레임 실패: {e}")
due = None
if not due:
break
ran_any = True
try:
run_schedule_once(
schedule_row=due,
retriever=retriever,
available_models=available_models,
model_by_name=model_by_name,
save_to_disk=save_to_disk,
)
except Exception as e:
# 실행 중 오류 발생 시 스케줄 진행 중단
# 잠금 만료 후 스케줄 재개
print(f"스케줄 실행 오류: {e}")
if not drain_all_due:
break
# 다음 요청을 위한 시간 업데이트
now_ts = int(time.time())
if not ran_any:
# 선택 사항: 로그 출력 줄이기
print(f"[{int(time.time())}] 예정된 스케줄 없음.")
time.sleep(tick_every_seconds)헤드리스 러너를 시작하려면 새 터미널을 열고 python headless_runner.py를 실행하세요.
Streamlit 애플리케이션
우리 Streamlit 애플리케이션이 크게 확장되었습니다. 여전히 streamlit run app.py로 실행할 수 있습니다 . 이제 다섯 개의 별도 탭이 있습니다. 원래의 “Run Scrapes” 페이지는 여전히 대시보드에 즉시 표시됩니다.
“프롬프트(Prompts)” 탭에서는 사용자가 새 프롬프트를 생성하고 필요 시 저장하여 나중에 사용할 수 있습니다. 이 페이지 하단에서는 대량 실행을 구성하고 수행할 수 있습니다.
“History” 탭을 사용하면 상세 실행 내역을 확인할 수 있습니다. 이 페이지 하단에서는 원한다면 원시 JSON 페이로드를 검사할 수도 있습니다.
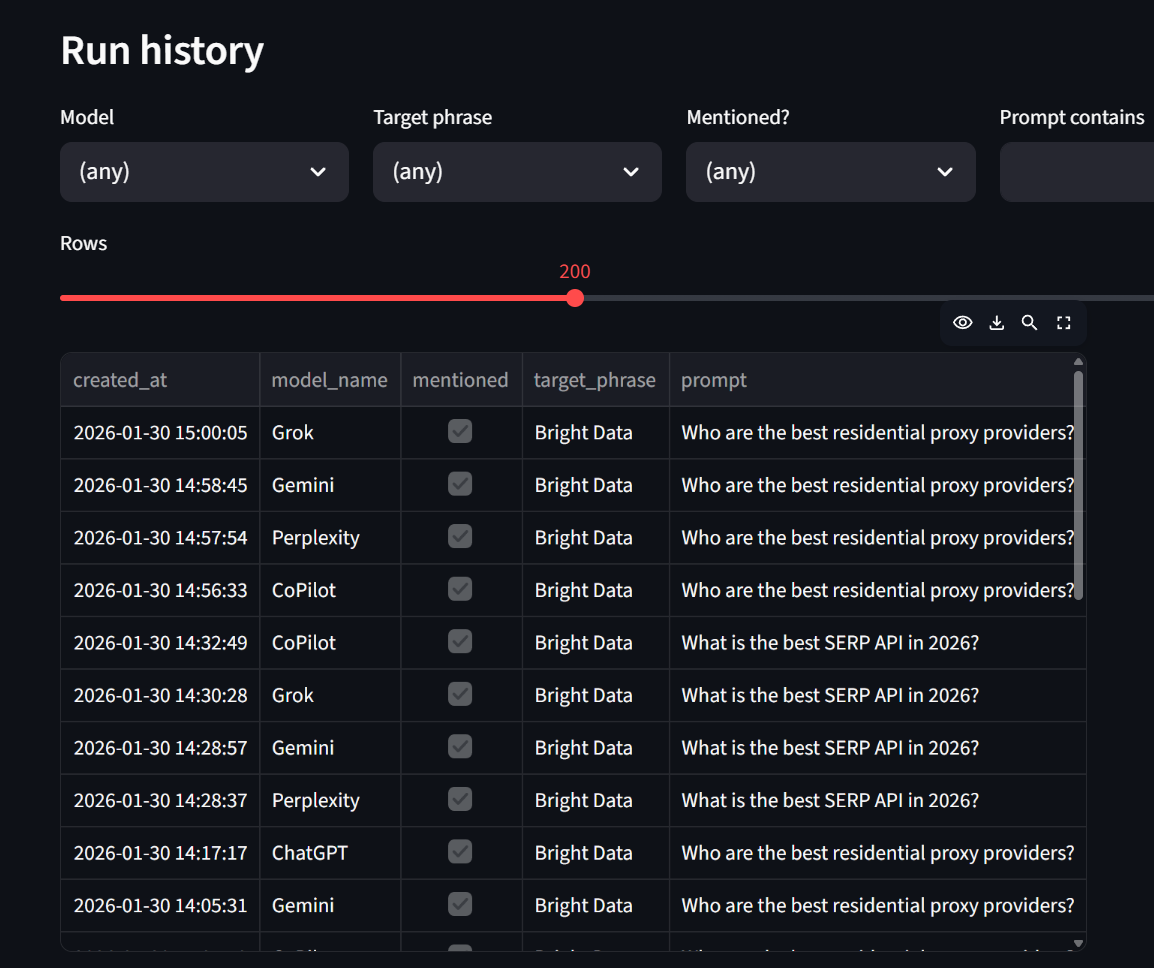
보고서 탭에서는 모델별로 분류된 언급률을 확인할 수 있습니다. 보시다시피, 여기 모든 모델에서 Bright Data가 100% 언급되었습니다.
마지막으로 스케줄러 탭이 있습니다. 사용자는 스케줄을 생성하거나 삭제할 수 있습니다. 기다리기 싫다면 “지금 실행” 버튼을 사용할 수도 있으며, 헤드리스 러너가 다음 실행 주기에 이를 처리합니다.
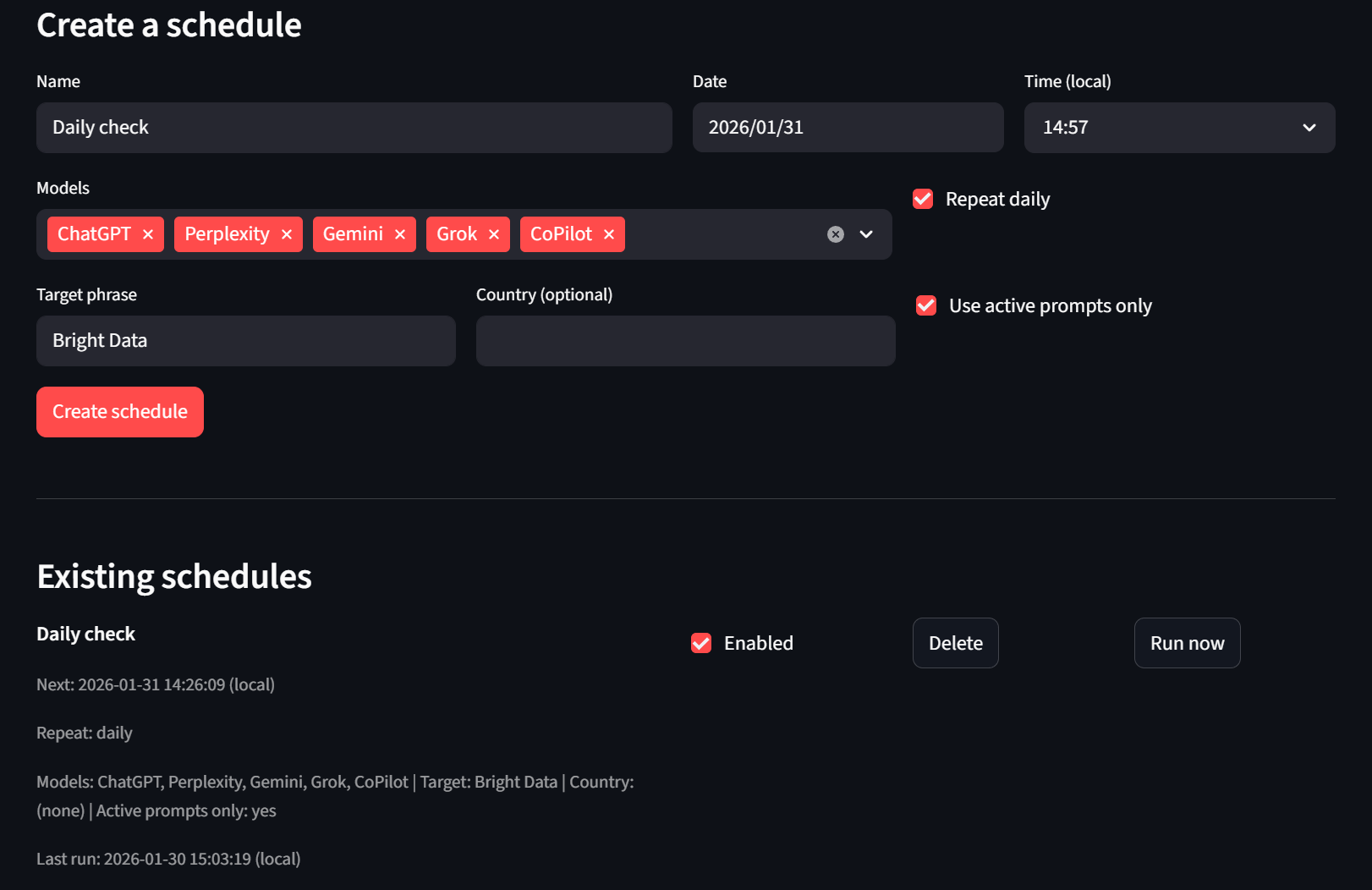
결론
본문 초반에 프로토타입을 구축하셨다면, 이러한 도구를 다음 단계로 발전시키는 데 필요한 개념을 이미 이해하고 계실 것입니다.
이 가이드에서 소개한 아키텍처는 다음을 지원할 수 있습니다:
- 지속적 메모리 및 기록 추적: AI 모델이 귀사 브랜드를 언급하는 방식의 추세를 파악하고, 순위 변동을 추적하며, 신흥 경쟁사를 식별하기 위해 결과를 시간별로 저장합니다.
- 매일 모니터링되는 수백 개의 프롬프트: 수천 개의 키워드 변형, 제품 카테고리, 경쟁사 비교에 걸쳐 예약된 수집을 자동화합니다.
- 자동화된 보고 및 분석: 모든 주요 LLM(대규모 언어 모델)에 걸쳐 브랜드 언급률, 감성 분석, 인용 빈도 및 경쟁적 포지셔닝을 보여주는 보고서 생성.
- 경보 시스템: 추천 목록에서 브랜드가 제외되거나 경쟁사가 가시성을 확보할 때 알림을 발동합니다.
- 다중 지역 모니터링: 지역별 AI 응답 차이를 추적하여 현지화된 마케팅 전략 수립에 활용합니다.
대규모로 브랜드 평판을 관리하는 기업 팀에게 “우리 회사가 AI에 의해 추천되고 있는가?”라는 질문에 모든 주요 모델, 모든 관련 쿼리, 매일 매일 답변할 수 있는 능력은 더 이상 선택 사항이 아닙니다. 이는 필수적인 인프라입니다.
Bright Data의 웹 스크레이퍼 API는 이러한 수준의 모니터링을 가능하게 하는 표준화되고 신뢰할 수 있는 데이터 피드를 제공합니다. ChatGPT, Perplexity, Gemini, Grok 또는 Microsoft Copilot을 추적하든, 통합된 스키마는 통합 과정의 마찰을 제거하여 팀이 데이터 정리 대신 인사이트에 집중할 수 있게 합니다.
자신만의 AI 가시성 모니터링 시스템을 구축할 준비가 되셨나요? 무료 체험을 시작하고 Bright Data가 차세대 SEO 전략을 어떻게 강화하는지 확인해 보세요.






