
이 글에서 배울 내용:
- Google ADK와 Vertex AI RAG 엔진을 활용한 생산 환경용 RAG 시스템 구축 방법
- 의미론적 검색과 키워드 검색을 결합한 하이브리드 검색 구현 방법
- 적절한 그라운딩 및 인용을 통한 환각 현상 방지 방법
- 텍스트, 이미지, 테이블을 포함한 다중 모달 콘텐츠 처리 방법
- Bright Data 통합을 통한 실시간 웹 데이터로 RAG 강화 방법 (선택 사항)
시작해 보겠습니다!
현대 지식 관리의 과제
기술 문서는 위키에 저장되고, 제품 사양은 PDF에서 찾을 수 있으며, 고객 데이터는 데이터베이스에, 조직의 지식은 이메일에 담겨 있습니다. 직원들은 정보를 찾느라 수 시간을 소비하며 종종 오래되거나 불완전한 답변을 접합니다. 일반 데이터로 훈련된 대규모 언어 모델은 귀사의 독점적 지식에 접근할 수 없습니다. 회사별 정보에 대해 질문받으면 종종 오류를 범합니다.
RAG 에이전트는 응답 생성 전에 지식 기반에서 관련 컨텍스트를 검색하여 이 문제를 해결합니다. 이는 AI를 사실적 정보에 기반하게 하여 허위 응답을 줄이고 검증 가능한 인용 출처를 제공합니다.
구축 중인 시스템: 지능형 RAG 에이전트 시스템
다양한 출처의 문서를 수집하여 검색 가능한 조각으로 처리하고, 이를 벡터 표현으로 변환한 후 하이브리드 검색을 통해 관련 맥락을 추출합니다. 이후 정확한 인용과 함께 올바른 답변을 생성하여 부정확성을 방지하는 생산 환경 적용 가능한 RAG 에이전트를 구축할 것입니다.
시스템이 관리할 사항:
- 클라우드 스토리지, 드라이브 및 로컬 파일로부터의 문서 수집
- 중복을 허용하는 스마트 분할 및 메타데이터 유지
- 의미적 유사성과 키워드 매칭을 결합한 하이브리드 검색
- 이미지 및 표를 포함한 다중 모달 콘텐츠
- 응답 확인을 위한 인용 생성
- 오류 탐지 및 방지
필수 조건
개발 환경 설정:
- Python 3.10 이상 – Google ADK 호환성을 위해 필수입니다.
- Google Cloud 프로젝트 – Google Cloud Console에서 청구 기능이 활성화된 프로젝트 생성.
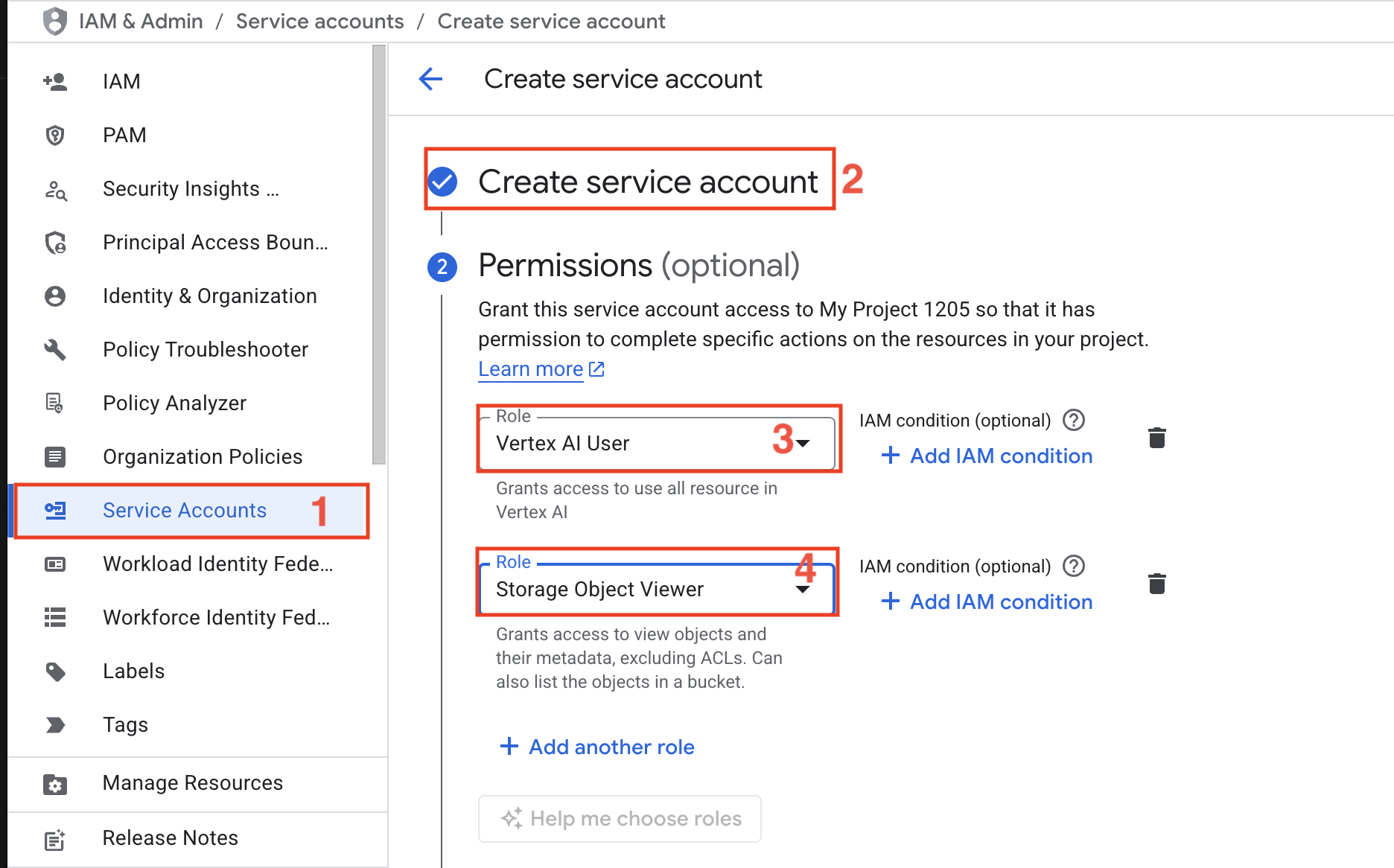
- 서비스 계정 – Vertex AI 사용자 및 스토리지 객체 뷰어 역할이 부여된 서비스 계정을 생성하십시오.
- Google ADK – AI 에이전트 구축용 에이전트 개발 키트; 문서를 참조하세요.
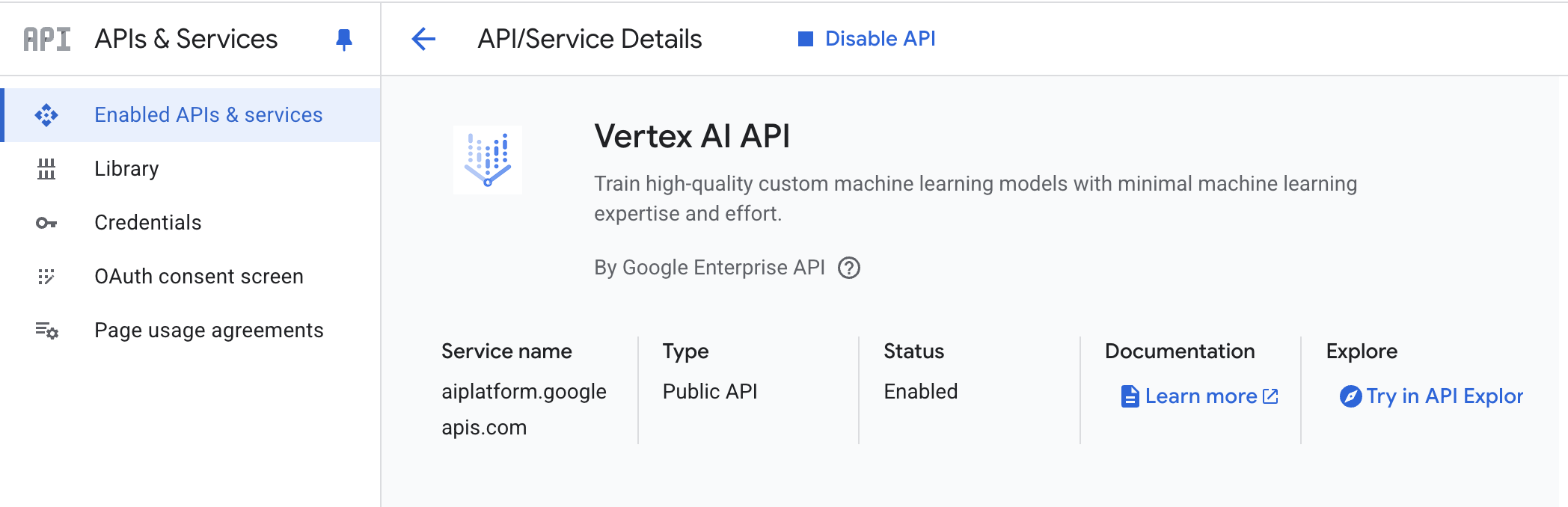
- Vertex AI API – Google Cloud 프로젝트에서 Vertex AI API 활성화
- Python 가상 환경 – 종속성을 분리하여 유지합니다.
venv문서를 참조하십시오.
환경 설정
프로젝트 디렉터리를 생성하고 종속성을 설치합니다:
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venvScriptsactivate
pip install google-genai google-cloud-aiplatform google-cloud-storage langchain-google-vertexai pypdf python-dotenv pandas pillowrag_agent. py라는 새 파일을 생성하고 다음 임포트를 추가하세요:
import os
import json
import PyPDF2
import fitz
import time
import vertexai
from google import genai
from vertexai.preview import rag
from pathlib import Path
from vertexai.preview.generative_models import GenerativeModel, Tool
from google.cloud import storage
from typing import List, Dict, Any, Optional
from datetime import datetime
from dotenv import load_dotenv
from google.api_core.exceptions import ResourceExhausted
from google.genai import types
load_dotenv()인증 정보를 포함한 .env 파일을 생성하세요:
GOOGLE_CLOUD_PROJECT="your-project-id"
GOOGLE_CLOUD_LOCATION="us-central1"
GOOGLE_APPLICATION_CREDENTIALS="path/to/service-account-key.json"
GENAI_API_KEY="your-genai-api-key"
GCS_BUCKET_NAME="your-bucket-name"필요한 항목:
- 프로젝트 ID: Google Cloud 콘솔에서 확인한 프로젝트 식별자
- 위치: Vertex AI 리소스 지역 (us-east1 권장)
- 서비스 계정 키: IAM & Admin에서 다운로드한 JSON 키 파일
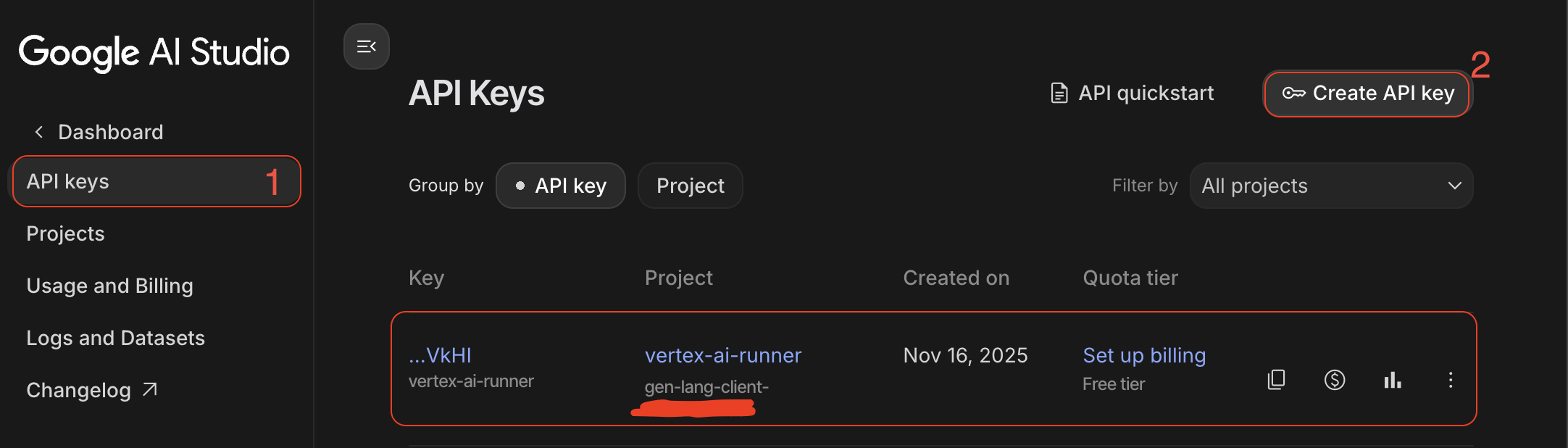
- GenAI API 키: Google AI Studio에서 생성
- GCS 버킷: 문서 저장을 위한 Cloud Storage 버킷
RAG 에이전트 시스템 구축
1단계: Google ADK 설정
Google ADK 클라이언트를 구성하고 적절한 인증으로 Vertex AI를 초기화합니다. 이 클라이언트는 Google 생성형 AI 서비스와의 모든 상호작용을 처리합니다.
def initialize_adk():
"""적절한 인증으로 Vertex AI 초기화."""
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = os.getenv("GOOGLE_APPLICATION_CREDENTIALS")
vertexai.init(
project=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION")
)
print(f"✓ Vertex AI 초기화 완료")
# 시스템 초기화
initialize_adk()초기화는 에이전트 운영을 위한 GenAI 클라이언트와 RAG 기능을 위한 Vertex AI 모두에 대한 연결을 설정합니다. 진행하기 전에 자격 증명을 검증하고 프로젝트 구성을 확인합니다.
2단계: Vertex AI RAG 엔진 구성
지식 기반의 토대가 되는 RAG 코퍼스를 생성합니다. 코퍼스는 색인된 문서를 저장하고, 임베딩을 관리하며, 검색 쿼리를 처리합니다.
def create_rag_corpus(corpus_name: str, description: str) -> str:
"""문서 저장 및 검색을 위한 새 RAG 코퍼스를 생성합니다."""
try:
corpus = rag.create_corpus(
display_name=corpus_name,
description=description,
embedding_model_config=rag.EmbeddingModelConfig(
publisher_model="publishers/google/models/text-embedding-004"
)
)
corpus_id = corpus.name.split('/')[-1]
print(f"✓ RAG 코퍼스 생성 완료: {corpus_name}")
print(f"✓ 코퍼스 ID: {corpus_id}")
print(f"✓ 임베딩 모델: text-embedding-004")
return corpus_id
except Exception as e:
print(f"코퍼스 생성 오류: {str(e)}")
raise
def configure_retrieval_parameters(corpus_id: str) -> Dict[str, Any]:
"""최적의 검색 성능을 위한 검색 매개변수 구성."""
retrieval_config = {
"corpus_id": corpus_id,
"similarity_top_k": 10,
"vector_distance_threshold": 0.5,
"filter": {},
"ranking_config": {
"rank_service": "default",
"alpha": 0.5
}
}
print(f"✓ 검색 매개변수 구성 완료")
print(f" - 상위 K개 결과: {retrieval_config['similarity_top_k']}")
print(f" - 거리 임계값: {retrieval_config['vector_distance_threshold']}")
print(f" - 하이브리드 검색 알파: {retrieval_config['ranking_config']['alpha']}")
return retrieval_config코퍼스 생성은 고품질 의미 임베딩을 위해 Google의 text-embedding-004 모델을 사용합니다. 검색 구성은 알파 매개변수를 통해 의미적 유사성과 키워드 매칭의 균형을 맞추며, 0.5는 동등한 가중치를 제공합니다.
3단계: 문서 수집 파이프라인
다양한 파일 형식을 처리하고, 깨끗한 텍스트를 추출하며, 향상된 검색을 위해 중요한 메타데이터를 보존하는 강력한 문서 수집 파이프라인을 구축합니다.
def extract_text_from_pdf(file_path: str) -> Dict[str, Any]:
"""PDF 문서에서 텍스트와 메타데이터를 추출합니다."""
with open(file_path, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
metadata = {
'source': file_path,
'num_pages': len(pdf_reader.pages),
'title': pdf_reader.metadata.get('/Title', ''),
'author': pdf_reader.metadata.get('/Author', ''),
'created_date': str(datetime.now())
}
text_content = []
for page_num, page in enumerate(pdf_reader.pages):
page_text = page.extract_text()
text_content.append({
'page': page_num + 1,
'text': page_text,
'char_count': len(page_text)
})
return {
'metadata': metadata,
'content': text_content,
'full_text': ' '.join([p['text'] for p in text_content])
}
def preprocess_document(text: str) -> str:
"""문서 텍스트를 최적의 색인화를 위해 정리하고 정규화합니다."""
text = ' '.join(text.split())
text = text.replace('x00', '')
text = text.replace('rn', 'n')
lines = text.split('n')
cleaned_lines = [
line for line in lines
if len(line.strip()) > 3
and not line.strip().isdigit()
]
return 'n'.join(cleaned_lines)챕터링 전략은 문장 경계를 활용해 중간에 끊어지는 것을 방지하고, 챕터 간 맥락 보존을 위해 중첩을 구현하며, 정확한 인용을 위해 챕터 위치에 대한 메타데이터를 유지합니다. 1000자 챕터 크기는 검색 정확도와 맥락 완전성 사이의 균형을 맞춥니다.
4단계: 임베딩 및 인덱싱
문서를 RAG 코퍼스에 업로드하고 의미적 검색을 위한 벡터 임베딩을 생성합니다. 시스템은 임베딩 생성 및 인덱스 최적화를 자동으로 처리합니다.
def chunk_document(text: str, chunk_size: int = 1000, overlap: int = 200) -> List[Dict[str, Any]]:
"""문서를 중첩된 청크로 분할하여 최적의 검색 성능을 제공합니다."""
chunks = []
start = 0
text_length = len(text)
chunk_id = 0
while start < text_length:
end = start + chunk_size
if end < text_length:
last_period = text.rfind('.', start, end)
if last_period != -1 and last_period > start:
end = last_period + 1
chunk_text = text[start:end].strip()
if chunk_text:
chunks.append({
'chunk_id': chunk_id,
'text': chunk_text,
'start_char': start,
'end_char': end,
'char_count': len(chunk_text)
})
chunk_id += 1
start = end - overlap
print(f"✓ {overlap} 자 오버랩으로 {len(chunks)} 개의 청크 생성 완료")
return chunks
def upload_file_to_gcs(local_path: str, gcs_bucket: str) -> str:
"""문서를 RAG 인제스트를 위해 Google Cloud Storage에 업로드합니다."""
storage_client = storage.Client()
bucket = storage_client.bucket(gcs_bucket)
blob_name = f"rag-docs/{Path(local_path).name}"
blob = bucket.blob(blob_name)
blob.upload_from_filename(local_path)
gcs_uri = f"gs://{gcs_bucket}/{blob_name}"
print(f"✓ GCS에 업로드됨: {gcs_uri}")
return gcs_uri
def import_documents_to_corpus(corpus_id: str, file_uris: List[str]) -> str:
"""문서를 RAG 코퍼스로 가져오고 임베딩을 생성합니다."""
print(f"⚡ {len(file_uris)}개 문서 가져오기 시작...")
response = rag.import_files(
corpus_name=f"projects/{os.getenv('GOOGLE_CLOUD_PROJECT')}/locations/{os.getenv('GOOGLE_CLOUD_LOCATION')}/ragCorpora/{corpus_id}",
paths=file_uris,
chunk_size=1000,
chunk_overlap=200
)
try:
if hasattr(response, 'result'):
print("⏳ 가져오기 작업 완료 대기 중 (1분 정도 소요될 수 있음)...")
response.result()
else:
print("✓ 가져오기 요청 전송됨.")
except Exception as e:
print(f"⚠️ 대기 중 주의사항: {e}")
print(f"✓ 문서 가져오기 완료 및 인덱싱 시작됨.")
return getattr(response, 'name', 'unknown_operation')
def create_vector_index(corpus_id: str, index_config: Dict[str, Any]) -> str:
"""빠른 유사도 검색을 위한 최적화된 벡터 인덱스 생성."""
index_settings = {
'corpus_id': corpus_id,
'distance_measure': 'COSINE',
'algorithm': 'TREE_AH',
'leaf_node_embedding_count': 1000,
'leaf_nodes_to_search_percent': 10
}
print(f"✓ TREE_AH 알고리즘으로 벡터 인덱스 생성 완료")
print(f"✓ 거리 측정: COSINE 유사도")
print(f"✓ {index_settings['leaf_nodes_to_search_percent']}% 검색 커버리지에 최적화됨")
return corpus_id가져오기 프로세스는 문서 파싱, 청킹 및 임베딩 생성을 자동으로 처리합니다. TREE_AH 알고리즘은 높은 리콜을 유지하면서 빠른 근사적 최근접 이웃 검색을 제공합니다. 코사인 유사도는 의미적 매칭을 위해 임베딩 벡터 간의 각도 거리를 측정합니다.
5단계: ADK를 활용한 에이전트 개발
컨텍스트 관리, 사용자 쿼리 처리, 검색과 응답 생성의 조정을 담당하는 핵심 에이전트 아키텍처를 생성합니다.
class RAGAgent:
"""컨텍스트 관리 및 그라운딩 기능을 갖춘 지능형 RAG 에이전트."""
def __init__(self, corpus_id: str, model_name: str = "gemini-2.5-flash"):
self.corpus_id = corpus_id
self.model_name = model_name
self.conversation_history = []
self.rag_tool = Tool.from_retrieval(
retrieval=rag.Retrieval(
source=rag.VertexRagStore(
rag_corpora=[f"projects/{os.getenv('GOOGLE_CLOUD_PROJECT')}/locations/{os.getenv('GOOGLE_CLOUD_LOCATION')}/ragCorpora/{corpus_id}"],
similarity_top_k=5,
vector_distance_threshold=0.3
)
)
)
self.model = GenerativeModel(
model_name=model_name,
tools=[self.rag_tool]
)
print(f"✓ {model_name}으로 RAG 에이전트 초기화 완료")
print(f"✓ 코퍼스 연결됨: {corpus_id}")
def manage_context(self, query: str, max_history: int = 5) -> List[Dict[str, str]]:
"""대화 컨텍스트를 관리하며 기록을 잘라냅니다."""
self.conversation_history.append({
'role': 'user',
'content': query,
'timestamp': datetime.now().isoformat()
})
if len(self.conversation_history) > max_history * 2:
self.conversation_history = self.conversation_history[-max_history * 2:]
formatted_history = []
for msg in self.conversation_history:
formatted_history.append({
'role': msg['role'],
'parts': [msg['content']]
})
return formatted_history
def build_grounded_prompt(self, query: str, retrieved_context: List[Dict[str, Any]]) -> str:
"""명시적인 그라운딩 지침이 포함된 프롬프트 생성."""
context_text = "nn".join([
f"[Source {i+1}]: {ctx['text']}"
for i, ctx in enumerate(retrieved_context)
])
prompt = f"""당신은 지식 기반에 접근할 수 있는 유용한 AI 어시스턴트입니다.
아래 컨텍스트에 제공된 정보만을 사용하여 다음 질문에 답변하십시오.
중요 지침:
1. 답변은 제공된 컨텍스트에 엄격히 기반해야 합니다
2. 컨텍스트에 충분한 정보가 없을 경우 명시적으로 밝히십시오
3. [출처 X] 표기법을 사용하여 구체적인 출처를 인용하십시오
4. 일반적인 지식에서 얻은 정보를 추가하지 마십시오
5. 불확실한 경우 이를 인정하십시오
컨텍스트:
{context_text}
질문:
{query}
답변:"""
return prompt에이전트는 다중 회화 상호작용을 위한 대화 기록을 유지하고, 토큰 제한을 방지하기 위해 컨텍스트 창 크기를 관리하며, 환각 현상을 줄이기 위해 명시적인 그라운딩 지침이 포함된 프롬프트를 생성합니다. RAG 도구 통합을 통해 생성 중 자동 검색이 가능합니다.
6단계: 질의 처리 및 검색
최적의 검색 정확도를 위해 의미 이해와 키워드 매칭을 결합한 하이브리드 검색을 구현합니다.
def hybrid_search(
self,
corpus_id: str,
query: str,
semantic_weight: float = 0.7,
top_k: int = 10
) -> List[Dict[str, Any]]:
"""할당량 제한 시 자동 재시도를 포함한 하이브리드 검색 수행."""
rag_resource = rag.RagResource(
rag_corpus=f"projects/{os.getenv('GOOGLE_CLOUD_PROJECT')}/locations/{os.getenv('GOOGLE_CLOUD_LOCATION')}/ragCorpora/{corpus_id}"
)
max_retries = 3
base_delay = 90
for attempt in range(max_retries):
try:
print(f"🔍 코퍼스 검색 중 (시도 {attempt + 1})...")
results = rag.retrieval_query(
rag_resources=[rag_resource],
text=query,
similarity_top_k=top_k,
vector_distance_threshold=0.5
)
# 성공 시 결과 처리 및 반환
retrieved_chunks = []
for i, context in enumerate(results.contexts.contexts):
retrieved_chunks.append({
'rank': i + 1,
'text': context.text,
'source': context.source_uri if hasattr(context, 'source_uri') else 'unknown',
'distance': context.distance if hasattr(context, 'distance') else 0.0
})
print(f"✓ {len(retrieved_chunks)} 개의 관련 청크를 검색했습니다")
return retrieved_chunks
except ResourceExhausted:
wait_time = base_delay * (2 ** attempt)
print(f"⚠️ 할당량 초과 (제한: 분당 5회). {wait_time}초 동안 대기 중...")
time.sleep(wait_time)
except Exception as e:
print(f"❌ 검색 오류: {str(e)}")
raise
print("❌ 최대 재시도 횟수 초과. 검색 실패.")
return []
def rerank_results(
self,
results: List[Dict[str, Any]],
query: str,
model_name: str = "gemini-2.5-flash"
) -> List[Dict[str, Any]]:
"""검색된 결과를 쿼리 관련성에 따라 재정렬합니다."""
if not results:
return []
rerank_prompt = f"""각 문단이 질의와 얼마나 관련성이 있는지 0-10 점수로 평가해 주세요.
질의: {query}
문단:
{chr(10).join([f"{i+1}. {r['text'][:200]}..." for i, r in enumerate(results)])}
쉼표로 구분된 점수 목록만 반환하세요 (예: 8,6,9,3,7)."""
model = GenerativeModel(model_name)
response = model.generate_content(rerank_prompt)
if response.text:
try:
scores = [float(s.strip()) for s in response.text.strip().split(',')]
for i, score in enumerate(scores[:len(results)]):
results[i]['rerank_score'] = score
results.sort(key=lambda x: x.get('rerank_score', 0), reverse=True)
print(f"✓ LLM 점수를 활용한 재순위화 결과")
except Exception as e:
print(f"경고: 재순위화 실패, 원본 순서 사용: {str(e)}")
return results하이브리드 검색은 벡터 유사도를 이용해 후보를 추출한 후, LLM을 활용해 쿼리별 맥락에 기반한 관련성 점수를 매기며 재정렬합니다. 이 2단계 접근법은 효율성과 정확성 사이의 균형을 맞춥니다.
7단계: 응답 생성 및 그라운딩
적절한 인용과 함께 응답을 생성하고, 엄격한 그라운딩 검증을 통해 허위 응답을 방지합니다.
def generate_grounded_response(
self,
agent: 'RAGAgent',
query: str,
retrieved_context: List[Dict[str, Any]],
temperature: float = 0.2
) -> Dict[str, Any]:
"""인용 및 환각 현상 방지를 포함한 응답 생성."""
grounded_prompt = agent.build_grounded_prompt(query, retrieved_context)
chat = agent.model.start_chat()
response = chat.send_message(
grounded_prompt,
generation_config={
'temperature': temperature,
'top_p': 0.8,
'top_k': 40,
'max_output_tokens': 1024
}
)
return {
'answer': response.text,
'sources': retrieved_context,
'query': query,
'timestamp': datetime.now().isoformat()
}
def verify_grounding(
self,
response: str,
sources: List[Dict[str, Any]],
model_name: str = "gemini-2.5-flash"
) -> Dict[str, Any]:
"""응답 내용이 출처 자료에 근거했는지 검증합니다."""
verification_prompt = f"""다음 답변이 제공된 출처 자료에 완전히 근거하는지 분석하세요.
출처:
{chr(10).join([f"출처 {i+1}: {s['text']}" for i, s in enumerate(sources)])}
답변:
{response}
답변의 각 주장을 확인하세요. JSON 형식으로 응답하세요:
{{
"is_grounded": true/false,
"unsupported_claims": ["claim1", "claim2"],
"confidence_score": 0.0-1.0
}}"""
model = GenerativeModel(model_name)
verification_response = model.generate_content(verification_prompt)
try:
json_text = verification_response.text.strip()
if '```json' in json_text:
json_text = json_text.split('```json')[1].split('```')[0].strip()
verification_result = json.loads(json_text)
print(f"✓ 그라운딩 검증 완료")
print(f" - 그라운딩 여부: {verification_result.get('is_grounded', False)}")
print(f" - 신뢰도: {verification_result.get('confidence_score', 0.0):.2f}")
return verification_result
except Exception as e:
print(f"경고: 근거 검증 실패: {str(e)}")
return {'is_grounded': True, 'confidence_score': 0.5}접지 검증은 응답 내 각 주장이 출처 문서로 추적 가능한지 확인합니다. 낮은 온도 생성(0.2)은 창의적 과장을 줄이고 사실적 정확도를 향상시킵니다.
8단계: 다중 모달 RAG 구현
포괄적인 지식 검색을 위해 RAG 시스템을 확장하여 이미지, 표 및 기타 비텍스트 콘텐츠를 처리합니다.
def extract_images_from_pdf(self, pdf_path: str, output_dir: str) -> List[Dict[str, Any]]:
"""PDF 문서에서 이미지를 추출하여 다중 모달 인덱싱을 수행합니다."""
doc = fitz.open(pdf_path)
images = []
os.makedirs(output_dir, exist_ok=True)
for page_num in range(len(doc)):
page = doc[page_num]
image_list = page.get_images()
for img_index, img in enumerate(image_list):
xref = img[0]
base_image = doc.extract_image(xref)
image_bytes = base_image["image"]
# 이미지 저장
image_filename = f"page{page_num + 1}_img{img_index + 1}.png"
image_path = os.path.join(output_dir, image_filename)
with open(image_path, "wb") as img_file:
img_file.write(image_bytes)
images.append({
'page': page_num + 1,
'image_path': image_path,
'format': base_image['ext'],
'size': len(image_bytes)
})
print(f"✓ PDF에서 {len(images)}개의 이미지를 추출했습니다")
return images
def process_table_content(self, table_text: str) -> Dict[str, Any]:
"""테이블 데이터를 처리하고 구조화하여 검색 효율을 높입니다."""
lines = table_text.strip().split('n')
if not lines:
return {}
headers = [h.strip() for h in lines[0].split('|') if h.strip()]
rows = []
for line in lines[1:]:
cells = [c.strip() for c in line.split('|') if c.strip()]
if len(cells) == len(headers):
row_dict = dict(zip(headers, cells))
rows.append(row_dict)
return {
'headers': headers,
'rows': rows,
'row_count': len(rows),
'column_count': len(headers)
}
def create_multimodal_embedding(
self,
text: str,
image_path: Optional[str] = None,
table_data: Optional[Dict[str, Any]] = None
) -> Dict[str, Any]:
"""다중 모달 콘텐츠를 위한 통합 임베딩 생성."""
combined_text = text
if table_data and table_data.get('rows'):
table_desc = f"n{table_data['row_count']}개의 행과 {table_data['headers']}개의 열을 가진 테이블: {', '.join(table_data['headers'])}n"
combined_text += table_desc
if image_path:
combined_text += f"n[Image: {Path(image_path).name}]"
return {
'text': combined_text,
'has_image': image_path is not None,
'has_table': table_data is not None,
'modalities': sum([bool(text), bool(image_path), bool(table_data)])
}다중 모달 처리에서는 텍스트와 함께 이미지와 표를 추출하고 색인화합니다. 통합 임베딩 접근법은 모든 모달리티의 설명적 메타데이터를 검색 가능한 텍스트로 결합합니다. 이를 통해 “Q3 보고서 가격표를 보여줘”와 같은 쿼리로 표 데이터와 주변 컨텍스트를 모두 검색할 수 있습니다.
9단계: Google ADK 에이전트 통합
Google의 에이전트 개발 키트(ADK)를 통합하여 Vertex AI RAG 엔진 백엔드에 연결되는 향상된 에이전트 인터페이스를 구축합니다. ADK는 도구 호출, 다중 회화, 구조화된 응답 등 개선된 에이전트 기능을 제공합니다.
class ADKRAGAgent:
"""Vertex AI RAG 엔진을 백엔드로 사용하는 Google ADK 에이전트 래퍼."""
def __init__(self, corpus_id: str, project_id: str, location: str):
"""RAG 기능을 갖춘 ADK 에이전트 초기화."""
self.corpus_id = corpus_id
self.project_id = project_id
self.location = location
self.rag_agent = RAGAgent(corpus_id)
self.client = genai.Client(
vertexai=True,
project=project_id,
location=location
)
self.model_name = "gemini-2.0-flash-001"
print(f"✓ Google ADK 에이전트 초기화 완료")
print(f" - 프레임워크: Google ADK (genai.Client)")
print(f" - 백엔드: Vertex AI RAG 엔진")
print(f" - 프로젝트: {project_id}")
print(f" - 위치: {location}")
print(f" - RAG 코퍼스: {corpus_id}")
def create_rag_search_tool(self) -> types.Tool:
"""ADK 에이전트를 위한 RAG 검색 도구 생성."""
def rag_search(query: str) -> str:
"""
RAG 코퍼스를 검색하고 근거 기반 답변을 반환합니다.
인수:
query: 검색할 사용자의 질문
반환값:
지식베이스에서 인용된 근거가 있는 답변
"""
try:
results = self.rag_agent.hybrid_search(
self.corpus_id,
query,
semantic_weight=0.7,
top_k=10
)
if not results:
return "지식베이스에서 관련 정보를 찾을 수 없습니다."
reranked = self.rag_agent.rerank_results(results, query)
response = self.rag_agent.generate_grounded_response(
self.rag_agent,
query,
reranked[:5]
)
verification = self.rag_agent.verify_grounding(
response['answer'],
response['sources']
)
answer = response['answer']
if not verification.get('is_grounded', True):
answer += f"nn[신뢰도: {verification.get('confidence_score', 0):.0%}]"
return answer
except Exception as e:
return f"지식베이스 검색 오류: {str(e)}"
rag_tool = types.Tool(
function_declarations=[
types.FunctionDeclaration(
name="rag_search",
description="RAG(검색 강화 생성)을 사용하여 엔터프라이즈 지식 베이스를 검색하여 기술 문서, 제품 사양 및 사용자 가이드에 대한 질문에 대한 정확하고 근거 있는 답변을 찾습니다.",
parameters={
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "사용자의 질문 또는 검색어"
}
},
"required": ["query"]
}
)
]
)
self.rag_search_function = rag_search
return rag_tool
def create_agent(self) -> Dict[str, Any]:
"""RAG 도구를 사용한 Google ADK 에이전트 구성 생성"""
rag_tool = self.create_rag_search_tool()
agent_instructions = """당신은 기업 지식베이스에 접근 가능한 지능형 RAG(검색 강화 생성) 에이전트입니다.
당신의 능력:
- 기술 문서, 제품 사양서, 사용자 가이드 검색
- 인용을 포함한 정확하고 근거 있는 답변 제공
- 문맥 인식 기반의 다중 대화 처리
- 응답 전 정보 정확성 검증
지침:
1. 답변 전 항상 rag_search 도구를 사용하여 정보를 검색하십시오
2. 검색된 문서를 바탕으로 구체적이고 상세한 답변을 제공하십시오
3. 관련 인용문과 출처를 포함하십시오
4. 정보가 발견되지 않을 경우 명확히 밝히십시오
5. 여러 질의에 걸쳐 대화 맥락을 유지하십시오
모든 응답에서 유용하고 정확하며 전문적으로 행동하십시오."""
agent_config = {
'model': self.model_name,
'instructions': agent_instructions,
'tools': [rag_tool],
'display_name': 'Vertex AI 기반 RAG 에이전트 (Google ADK + Vertex AI RAG 엔진)'
}
print(f"✓ Google ADK 에이전트 구성 생성 완료")
print(f" - 모델: {self.model_name}")
print(f" - 도구: RAG 검색 (Vertex AI RAG 엔진)")
return agent_config
def chat(self, agent_config: Dict[str, Any], query: str, session_id: str = "default") -> str:
"""Google GenAI를 사용하여 ADK 에이전트에 메시지를 전송하고 응답을 받습니다."""
self.rag_agent.manage_context(query)
try:
response = self.client.models.generate_content(
model=agent_config['model'],
contents=query,
config=types.GenerateContentConfig(
system_instruction=agent_config['instructions'],
tools=agent_config['tools'],
temperature=0.2
)
)
if response.candidates and len(response.candidates) > 0:
candidate = response.candidates[0]
if candidate.content and candidate.content.parts:
for part in candidate.content.parts:
if hasattr(part, 'function_call') and part.function_call:
function_name = part.function_call.name
function_args = part.function_call.args
print(f" → ADK Agent calling tool: {function_name}")
if function_name == "rag_search":
query_arg = function_args.get("query", query)
tool_result = self.rag_search_function(query_arg)
response = self.client.models.generate_content(
model=agent_config['model'],
contents=[
types.Content(role="user", parts=[types.Part(text=query)]),
types.Content(role="model", parts=[part]),
types.Content(
role="function",
parts=[types.Part(
function_response=types.FunctionResponse(
name=function_name,
response={"result": tool_result}
)
)]
)
],
config=types.GenerateContentConfig(
system_instruction=agent_config['instructions'],
tools=agent_config['tools'],
temperature=0.2
)
)
elif hasattr(part, 'text') and part.text:
answer = part.text
self.rag_agent.conversation_history.append({
'role': 'assistant',
'content': answer,
'timestamp': datetime.now().isoformat()
})
return answer
if response.candidates and response.candidates[0].content.parts:
for part in response.candidates[0].content.parts:
if hasattr(part, 'text') and part.text:
answer = part.text
self.rag_agent.conversation_history.append({
'role': 'assistant',
'content': answer,
'timestamp': datetime.now().isoformat()
})
return answer
return "응답 생성 실패."
except Exception as e:
error_msg = f"ADK 에이전트 채팅 오류: {str(e)}"
print(f"❌ {error_msg}")
return error_msgADK 통합은 기존 RAG 에이전트에 Google의 에이전트 프레임워크를 추가합니다. ADKRAGAgent 클래스는 에이전트 작업을 위한 genai.Client를 설정하고 검색을 위해 RAGAgent를 사용합니다. create_rag_search_tool 메서드는 에이전트가 호출할 수 있는 함수를 정의하여 Vertex AI RAG 엔진을 사용하여 지식 기반을 검색할 수 있게 합니다.
이 도구 호출 메커니즘을 통해 에이전트는 사용자 쿼리에 기반하여 지식 베이스 검색 시점을 자동으로 판단합니다. 검색이 필요할 경우 하이브리드 검색 파이프라인을 실행하고, 결과를 재정렬하며, 근거 기반 응답을 생성하고, 정확성을 확인한 후 답변을 제공합니다. chat 메서드는 도구 실행 및 다중 회차 컨텍스트 관리를 포함한 전체 대화 흐름을 관리합니다.
10단계: Bright Data의 실시간 웹 데이터로 RAG 성능 강화
RAG 시스템이 내부 지식베이스에서 정보를 검색하는 데 탁월하지만, 기업용 AI 애플리케이션은 종종 외부 소스의 최신 실시간 데이터가 필요합니다. 바로 여기서 Bright Data의 웹 데이터 플랫폼이 귀중한 가치를 발휘합니다. RAG 에이전트가 웹 전반의 실시간 정보에 접근할 수 있도록 지원하여 지식베이스를 최신 상태로 유지하고 포괄성을 확보합니다.
RAG 시스템에 Bright Data를 통합해야 하는 이유
1. 지식 기반 최신화 유지
- 최신 제품 정보, 가격 데이터, 경쟁사 인텔리전스, 시장 동향으로 RAG 코퍼스를 자동 업데이트
- 구식 AI 응답을 유발하는 오래된 데이터를 제거합니다
- 정확성을 유지하기 위해 주기적인 데이터 갱신을 예약합니다
2. 내부 문서를 넘어 확장하세요
- 전자상거래 플랫폼, 뉴스 사이트, 소셜 미디어, 산업별 소스를 포함한 120개 이상의 인기 웹사이트에서 실시간 데이터에 접근하세요
- 실시간 API 문서, 커뮤니티 토론, 업데이트된 사양으로 기술 문서를 보강하세요
- 고객 리뷰, 피드백 및 감정 데이터를 가져와 제품 지식 기반을 강화하세요
3. 동적 쿼리 강화 기능 활성화
- RAG 에이전트가 최신 정보(가격, 재고, 최근 뉴스)가 필요한 쿼리를 감지하면 자동으로 최신 데이터를 가져옵니다
- 내부 지식과 외부 웹 데이터를 결합하여 포괄적인 답변 제공
- 사용자에게 과거 맥락과 최신 정보를 동시에 제공하세요
4. 손쉬운 데이터 수집 확장
- 프록시 관리, CAPTCHA 처리, 봇 방지 시스템 대응이 필요 없습니다
- Bright Data가 모든 인프라, 차단 해제 및 데이터 품질 관리를 처리합니다
- Bright Data가 데이터 수집을 처리하는 동안 AI 개발에 집중하세요
구현: RAG 파이프라인에 Bright Data 추가하기
Bright Data의 기능으로 RAG 시스템을 확장해 보세요. 세 가지 통합 패턴을 추가합니다: 사전 수집된 데이터를 위한 데이터셋 통합, 실시간 스크래핑을 위한 웹 스크레이퍼 API, 그리고 풍부한 AI 생성 인사이트를 위한 AI 스크레이퍼입니다.
패턴 1: 과거 데이터를 위한 데이터셋 통합
Bright Data의 데이터셋 마켓플레이스를 활용하여 고품질 구조화 데이터로 RAG 코퍼스를 신속하게 구축하세요.
import requests
from typing import List, Dict
import json
class BrightDataRAGEnhancer:
"""Bright Data 웹 데이터 기능으로 RAG 시스템 강화"""
def __init__(self, api_key: str, rag_agent: RAGAgent):
self.api_key = api_key
self.rag_agent = rag_agent
self.base_url = "https://api.brightdata.com"
def fetch_dataset_data(
self,
dataset_id: str,
filters: Dict[str, Any] = None,
limit: int = 1000
) -> List[Dict[str, Any]]:
"""Bright Data Dataset Marketplace에서 데이터를 가져옵니다."""
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
endpoint = f"{self.base_url}/datasets/v3/snapshot/{dataset_id}"
params = {
"format": "json",
"limit": limit
}
if filters:
params["filter"] = json.dumps(filters)
response = requests.get(endpoint, headers=headers, params=params)
response.raise_for_status()
print(f"✓ 데이터셋 {dataset_id}에서 {len(response.json())}개의 레코드 가져옴")
return response.json()
def ingest_dataset_to_rag(
self,
corpus_id: str,
dataset_records: List[Dict[str, Any]],
text_fields: List[str]
) -> None:
"""데이터셋 레코드를 처리하고 RAG 코퍼스에 추가합니다."""
processed_chunks = []
for record in dataset_records:
# 지정된 텍스트 필드를 검색 가능한 콘텐츠로 결합
combined_text = " ".join([
str(record.get(field, ""))
for field in text_fields
if record.get(field)
])
if combined_text.strip():
# 검색 효율 향상을 위한 메타데이터 추가
metadata = {
"source": "bright_data_dataset",
"record_id": record.get("id", "unknown"),
"ingestion_date": datetime.now().isoformat(),
"data_type": "external_web_data"
}
# 콘텐츠 분할
chunks = chunk_document(combined_text, chunk_size=1000, overlap=200)
for chunk in chunks:
chunk['metadata'] = metadata
processed_chunks.append(chunk)
print(f"✓ 데이터셋에서 {len(processed_chunks)} 개의 청크 처리 완료")
# 업로드용 임시 파일 생성
temp_file = "temp_dataset_content.txt"
with open(temp_file, 'w') as f:
for chunk in processed_chunks:
f.write(chunk['text'] + "nn")
# GCS에 업로드 및 코퍼스로 임포트
gcs_uri = upload_file_to_gcs(temp_file, os.getenv('GCS_BUCKET_NAME'))
import_documents_to_corpus(corpus_id, [gcs_uri])
os.remove(temp_file)
print(f"✓ RAG 코퍼스에 데이터셋 콘텐츠 추가 완료")사용 사례 예시: 전자상거래 RAG에 제품 데이터 채우기
# 먼저 RAG 코퍼스 생성
corpus_id = create_rag_corpus(
corpus_name="bright_data_corpus",
description="Bright Data 강화형 RAG용 코퍼스")
# 코퍼스로 RAG 에이전트 초기화
rag_agent = RAGAgent(corpus_id=corpus_id)
# 인핸서 초기화
enhancer = BrightDataRAGEnhancer(
api_key=os.getenv("BRIGHT_DATA_API_KEY"),
rag_agent=rag_agent)
print("✓ BrightDataRAGEnhancer 초기화 성공!")
# 아마존 제품 데이터 가져오기
amazon_data = enhancer.fetch_dataset_data(
dataset_id="gd_l7q7dkf244hwxr90h", # 아마존 제품 데이터셋
filters={"category": "Electronics"},
limit=5000
)
# RAG 코퍼스로 인제스트
enhancer.ingest_dataset_to_rag(
corpus_id=corpus_id,
dataset_records=amazon_data,
text_fields=["title", "description", "features", "reviews"]
)패턴 2: 실시간 웹 스크레이퍼 API 통합
동적이며 최신 정보를 위해 Bright Data의 웹 스크레이퍼 API를 RAG 에이전트의 쿼리 파이프라인에 직접 통합하세요.
def scrape_real_time_data(
self,
scraper_id: str,
inputs: List[Dict[str, Any]],
wait_for_completion: bool = True)
-> List[Dict[str, Any]]:
"""Bright Data 스크레이퍼를 사용하여 실시간 웹 스크래핑을 실행합니다."""
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
# 스크레이퍼 트리거
trigger_url = f"{self.base_url}/dca/trigger"
params = {
"scraper": scraper_id,
"queue_next": 1
}
response = requests.post(
trigger_url,
headers=headers,
params=params,
json=inputs
)
response.raise_for_status()
snapshot_id = response.json().get("snapshot_id")
print(f"✓ 스크레이퍼 트리거됨. 스냅샷 ID: {snapshot_id}")
if not wait_for_completion:
return {"snapshot_id": snapshot_id, "status": "processing"}
# 결과 확인
results_url = f"{self.base_url}/dca/dataset"
params = {"id": snapshot_id}
max_retries = 30
for i in range(max_retries):
time.sleep(10) # 각 확인 간 10초 대기
results_response = requests.get(results_url, headers=headers, params=params)
if results_response.status_code == 200:
data = results_response.json()
print(f"✓ 스크래핑 완료. {len(data)}개의 레코드 가져옴")
return data
elif results_response.status_code == 202:
print(f"⏳ 아직 처리 중... ({i+1}/{max_retries})")
continue
else:
print(f"❌ 결과 가져오기 오류: {results_response.status_code}")
break
return []
def create_dynamic_rag_tool(self) -> types.Tool:
"""실시간 웹 데이터 보강 기능을 갖춘 RAG 도구 생성."""
def augmented_rag_search(query: str, include_live_data: bool = False) -> str:
"""
선택적 실시간 웹 데이터 보강을 적용하여 지식 기반 검색 수행.
매개변수:
query: 사용자의 질문
include_live_data: 최신 웹 데이터 가져올지 여부
반환값:
내부 및 외부 데이터를 결합한 근거 기반 답변
"""
# 먼저 내부 지식 베이스 검색
internal_results = self.rag_agent.hybrid_search(
corpus_id=self.rag_agent.corpus_id,
query=query,
top_k=5
)
combined_results = internal_results
# 쿼리가 최신 정보를 요구하는 경우 실시간 데이터 가져옴
if include_live_data or self._requires_fresh_data(query):
print("🌐 실시간 웹 데이터 가져오기 중...")
# 예시: 가격 정보 스크래핑
if "price" in query.lower() or "cost" in query.lower():
live_data = self.scrape_real_time_data(
scraper_id="your_product_scraper_id",
inputs=[{"url": "https://example.com/products"}],
wait_for_completion=True
)
# 실시간 데이터를 검색 가능한 단위로 변환
for record in live_data[:3]: # 상위 3개 결과
combined_results.append({
'rank': len(combined_results) + 1,
'text': f"{record.get('title', '')}: {record.get('price', '')} - {record.get('description', '')}",
'source': f"실시간 웹 데이터: {record.get('url', 'unknown')}",
'distance': 0.3 # 최신 데이터에 대한 높은 관련성
})
# 사용 가능한 모든 컨텍스트로 응답 생성
response = self.rag_agent.generate_grounded_response(
self.rag_agent,
query,
combined_results
)
return response['answer']
return types.Tool(
function_declarations=[
types.FunctionDeclaration(
name="augmented_rag_search",
description="내부 지식 베이스 검색 및 선택적으로 최신 정보를 위한 실시간 웹 데이터 가져오기",
parameters={
"type": "object",
"properties": {
"query": {"type": "string", "description": "사용자의 질문"},
"include_live_data": {"type": "boolean", "description": "최신 웹 데이터 가져오기"}
},
"required": ["query"]
}
)
]
)
def _requires_fresh_data(self, query: str) -> bool:
"""쿼리가 실시간 데이터를 필요로 하는지 판단합니다."""
fresh_data_keywords = [
"latest", "current", "today", "now", "recent",
"price", "cost", "available", "in stock"
]
return any(keyword in query.lower() for keyword in fresh_data_keywords)패턴 3: 강화된 인텔리전스를 위한 AI 스크레이퍼 통합
Bright Data의 AI 스크레이퍼(ChatGPT, Perplexity, Gemini)를 활용하여 AI 생성 인사이트와 포괄적인 웹 컨텍스트로 RAG를 강화하세요.
def query_ai_scraper(
self,
scraper_type: str,
prompt: str,
country_code: str = "us"
) -> Dict[str, Any]:
"""AI 스크레이퍼(ChatGPT, Perplexity 등)를 통해 풍부한 컨텍스트를 쿼리합니다."""
scraper_ids = {
"chatgpt": "chatgpt_scraper_id",
"perplexity": "perplexity_scraper_id",
"gemini": "gemini_scraper_id"
}
inputs = [{
"prompt": prompt,
"country": country_code
}]
results = self.scrape_real_time_data(
scraper_id=scraper_ids.get(scraper_type),
inputs=inputs,
wait_for_completion=True
)
if results:
return {
"answer": results[0].get("answer", ""),
"sources": results[0].get("sources", []),
"citations": results[0].get("citations", [])
}
return {}
def create_hybrid_intelligence_agent(self) -> Dict[str, Any]:
"""RAG와 AI 스크레이퍼 인텔리전스를 결합한 에이전트 생성."""
def hybrid_search(query: str) -> str:
"""
내부 RAG와 외부 AI 스크레이퍼 인텔리전스 결합.
이를 통해 다음을 제공합니다:
1. 내부 지식베이스 컨텍스트
2. 웹에서 실시간 AI 생성 인사이트
3. 포괄적이고 출처가 명확한 답변
"""
# 내부 지식 획득
internal_answer = self.rag_agent.hybrid_search(
corpus_id=self.rag_agent.corpus_id,
query=query,
top_k=3
)
internal_context = "n".join([r['text'][:200] for r in internal_answer])
# AI 스크레이퍼 강화 정보 획득
print("🤖 AI 강화 웹 인텔리전스 가져오기 중...")
ai_insight = self.query_ai_scraper(
scraper_type="perplexity", # 신뢰할 수 있는 출처의 답변으로 유명
prompt=query
)
# 두 출처 통합
synthesis_prompt = f"""내부 지식과 외부 AI 인사이트를 모두 활용하여 포괄적인 답변을 합성하세요.
내부 지식 베이스:
{internal_context}
외부 AI 인사이트:
{ai_insight.get('answer', '외부 인사이트가 없습니다')}
출처:
{json.dumps(ai_insight.get('citations', []), indent=2)}
질문: {query}
다음과 같은 완전한 답변을 제공하세요:
1. 회사별 정보는 내부 지식을 우선적으로 활용
2. 광범위한 맥락과 최근 동향은 외부 통찰력 활용
3. 모든 출처를 명확히 인용
4. 정보의 출처가 외부인지 내부인지 표시"""
model = GenerativeModel("gemini-2.0-flash-001")
response = model.generate_content(synthesis_prompt)
return response.text
return {
'search_function': hybrid_search,
'description': '하이브리드 RAG + AI 스크레이퍼 인텔리전스 시스템'
}RAG 에이전트 시스템 실행하기
문서를 처리하고, 쿼리를 처리하며, 근거 기반 응답을 생성하는 완전한 워크플로로 모든 구성 요소를 통합합니다. 또한 처리할 PDF 문서를 다운로드하여 docs/ 폴더에 배치하여 제품에 대한 AI 컨텍스트 구축을 활성화하세요.
def main():
"""RAG 에이전트 시스템의 주요 실행 흐름."""
print("=" * 60)
print("RAG 에이전트 시스템 - 초기화")
print("=" * 60)
initialize_adk()
corpus_id = create_rag_corpus(
corpus_name="enterprise-knowledge-base-3",
description="다중 모드 기업 문서 및 지식 저장소"
)
retrieval_config = configure_retrieval_parameters(corpus_id)
print(f"n✓ top_k={retrieval_config['similarity_top_k']}를 사용하는 검색 구성")
print("n" + "=" * 60)
print("문서 수집 파이프라인")
print("=" * 60)
document_paths = [
"docs/technical_manual.pdf",
"docs/product_specs.pdf",
"docs/user_guide.pdf"
]
gcs_uris = []
all_chunks = []
extracted_images = []
for doc_path in document_paths:
if os.path.exists(doc_path):
extracted = extract_text_from_pdf(doc_path)
print(f"n✓ {Path(doc_path).name}에서 {extracted['metadata']['num_pages']} 페이지 추출 완료")
cleaned_text = preprocess_document(extracted['full_text'])
print(f"✓ 전처리된 텍스트: {len(cleaned_text)} 문자")
chunks = chunk_document(cleaned_text, chunk_size=1000, overlap=200)
all_chunks.extend(chunks)
print(f"✓ 문서가 {len(chunks)} 개 세그먼트로 분할됨")
gcs_uri = upload_file_to_gcs(doc_path, os.getenv('GCS_BUCKET_NAME'))
gcs_uris.append(gcs_uri)
print(f"n✓ 생성된 총 분할: {len(all_chunks)}")
print(f"✓ 추출된 이미지 총수: {len(extracted_images)}")
if gcs_uris:
import_documents_to_corpus(corpus_id, gcs_uris)
index_config = {"distance_measure": "COSINE", "algorithm": "TREE_AH"}
create_vector_index(corpus_id, index_config)
time.sleep(180)
# ========================================================================
# Vertex AI RAG 엔진으로 Google ADK 에이전트 초기화
# ========================================================================
print("n" + "=" * 60)
print("Google ADK 에이전트 초기화 중")
print("=" * 60)
adk_agent = ADKRAGAgent(
corpus_id=corpus_id,
project_id=os.getenv("GOOGLE_CLOUD_PROJECT"),
location=os.getenv("GOOGLE_CLOUD_LOCATION")
)
agent = adk_agent.create_agent()
for doc_path in document_paths:
if os.path.exists(doc_path):
try:
images = adk_agent.rag_agent.extract_images_from_pdf(doc_path, "extracted_images")
extracted_images.extend(images)
if images:
print(f"✓ 다중 모달 처리를 위해 {len(images)}개의 이미지를 추출했습니다")
except Exception as e:
print(f"⚠️ 이미지 추출 건너뜀: {str(e)}")
queries = [
"설치를 위한 시스템 요구 사항은 무엇인가요?",
"인증 설정을 어떻게 구성하나요?",
"가격 등급과 각 등급의 기능은 무엇인가요?"
]
print("n" + "=" * 60)
print("Google ADK 에이전트 - 쿼리 처리")
print("=" * 60)
print("사용 기술: Google ADK + Vertex AI RAG 엔진")
print("=" * 60)
session_id = f"session_{datetime.now().strftime('%Y%m%d_%H%M%S')}"
for idx, query in enumerate(queries):
print(f"n📝 질의 {idx + 1}: {query}")
print("-" * 60)
try:
answer = adk_agent.chat(agent, query, session_id)
print(f"n💬 ADK 에이전트 응답:n{answer}n")
print(f"✓ 대화 기록: {len(adk_agent.rag_agent.conversation_history)} 메시지")
except Exception as e:
print(f"❌ 오류: {str(e)}")
import traceback
traceback.print_exc()
print("-" * 60)
if idx < len(queries) - 1:
time.sleep(90)
if extracted_images:
print("n" + "=" * 60)
print("다중 모달 처리 데모")
print("=" * 60)
sample_table = """기능 | 베이직 | 프로 | 엔터프라이즈
Storage | 10GB | 100GB | Unlimited
Users | 1 | 10 | Unlimited
Price | $10 | $50 | Custom"""
table_data = adk_agent.rag_agent.process_table_content(sample_table)
print(f"n✓ Processed table with {table_data.get('row_count', 0)} rows")
if all_chunks and extracted_images:
multimodal_embed = adk_agent.rag_agent.create_multimodal_embedding(
text=all_chunks[0]['text'][:500],
image_path=extracted_images[0]['image_path'] if extracted_images else None,
table_data=table_data
)
print(f"✓ {multimodal_embed['modalities']} 모달리티로 멀티모달 임베딩 생성 완료")
print(f" - 이미지 포함: {multimodal_embed['has_image']}")
print(f" - 테이블 포함: {multimodal_embed['has_table']}")
print("n" + "=" * 60)
print(f"Google ADK RAG 에이전트 시스템 - 완료")
print(f"✓ 아키텍처: Google ADK + Vertex AI RAG 엔진")
print(f"✓ 총 대화 턴 수: {len(adk_agent.rag_agent.conversation_history)}")
print("=" * 60)
if __name__ == "__main__":
try:
main()
except Exception as e:
print(f"n❌ Error: {str(e)}")
import traceback
traceback.print_exc()RAG 에이전트 시스템 실행:
python3 rag_agent.py콘솔에서 에이전트의 처리 파이프라인을 확인할 수 있습니다.
- Google ADK 클라이언트 및 Vertex AI 연결 초기화.
- 임베딩 모델 구성으로 RAG 코퍼스를 생성합니다.
- 문서를 추출, 정리, 분할하여 처리합니다.
- 파일을 Cloud Storage에 업로드하고 코퍼스로 가져옵니다.
- 벡터 임베딩을 생성하고 검색 인덱스를 구축합니다.
- 확장, 검색 및 재정렬을 통해 쿼리를 실행합니다.
- 인용 및 검증을 포함한 근거 기반 응답을 생성합니다.
- 관련성, 완전성, 정확성, 명확성을 기준으로 응답 품질을 평가합니다.
콘솔 출력에는 각 단계별 상세 진행 상황이 표시됩니다.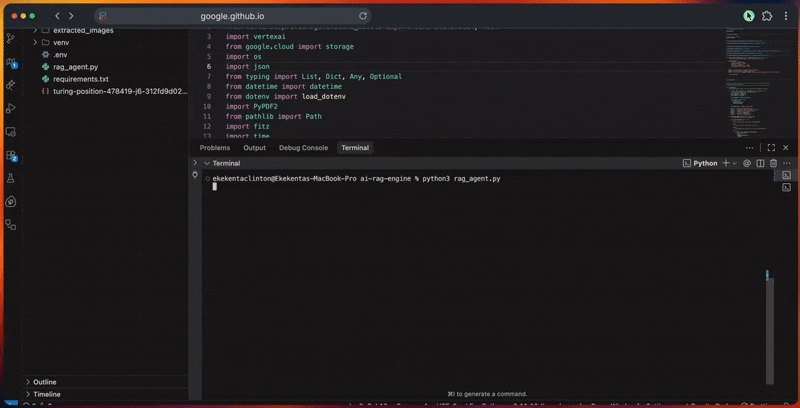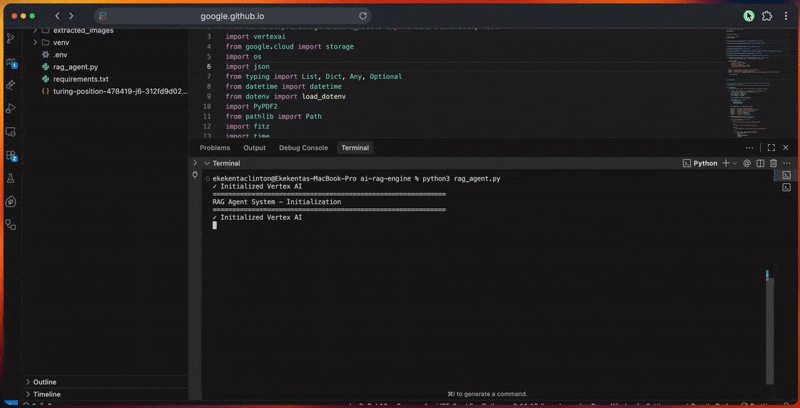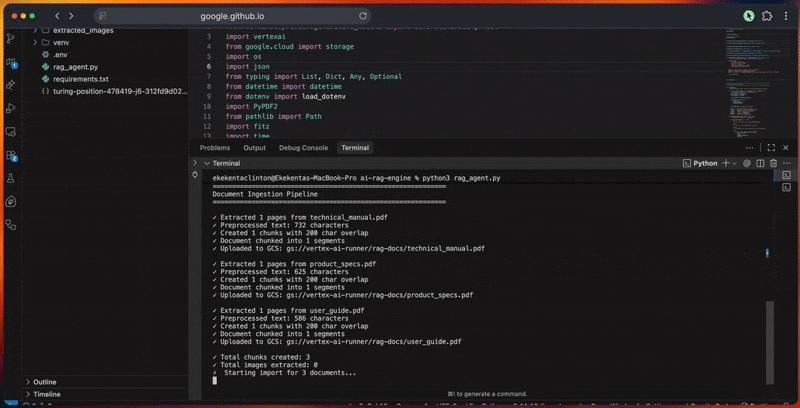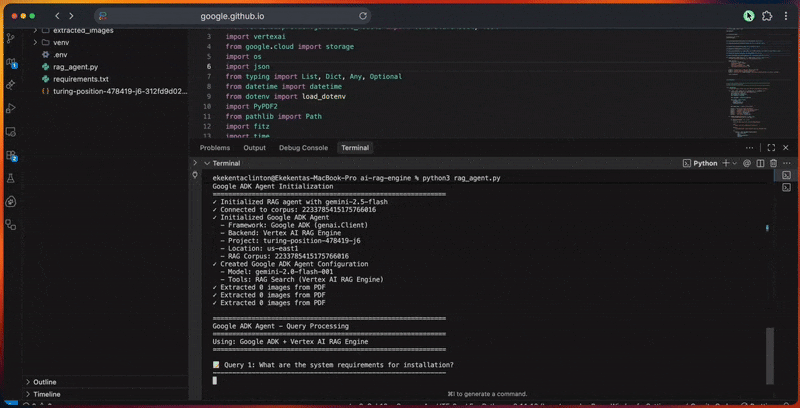
마무리
이제 Google의 Agent Development Kit과 Vertex AI를 결합한 생산 환경에 바로 적용 가능한 RAG 에이전트 시스템을 구축했습니다. 이 시스템은 문서를 입력받고, 하이브리드 검색을 통해 관련 컨텍스트를 검색하며, 인용을 포함한 정확한 응답을 생성합니다.
청크 전략 개선, 피드백 루프 추가, 추가 데이터 소스 통합 또는 실시간 모니터링 활성화로 시스템을 강화하세요. 모듈식 설계로 손쉬운 맞춤화가 가능합니다.
더 많은 기능을 위해 고급 AI 워크플로와 Bright Data의 AI 인프라를 살펴보세요.
무료 계정을 생성하여 구축을 시작하세요.





