신뢰할 수 있는 웹 데이터 추출 솔루션 구축은 올바른 인프라에서 시작됩니다. 이 가이드에서는 공개 웹페이지 URL과 자연어 프롬프트를 입력받는 단일 페이지 애플리케이션을 생성합니다. 이후 스크래핑, 파싱을 거쳐 깨끗하고 구조화된 JSON을 반환하여 추출 프로세스를 완전히 자동화합니다.
이 스택은 Bright Data의 봇 방지 스크래핑 인프라, Supabase의 안전한 백엔드, Lovable의 신속한 개발 도구를 하나의 원활한 워크플로로 결합합니다.
구축할 내용
사용자 입력부터 구조화된 JSON 출력 및 저장까지 구축할 전체 데이터 파이프라인은 다음과 같습니다:
사용자 입력
↓
인증
↓
데이터베이스 로깅
↓
엣지 함수
↓
Bright Data 웹 언락커 (반봇 보호 우회)
↓
원시 HTML
↓
턴다운 (HTML → 마크다운)
↓
정제된 구조화된 텍스트
↓
Google Gemini AI (자연어 처리)
↓
구조화된 JSON
↓
데이터베이스 저장
↓
프론트엔드 표시
↓
사용자 내보내기완성된 앱의 모습은 다음과 같습니다:
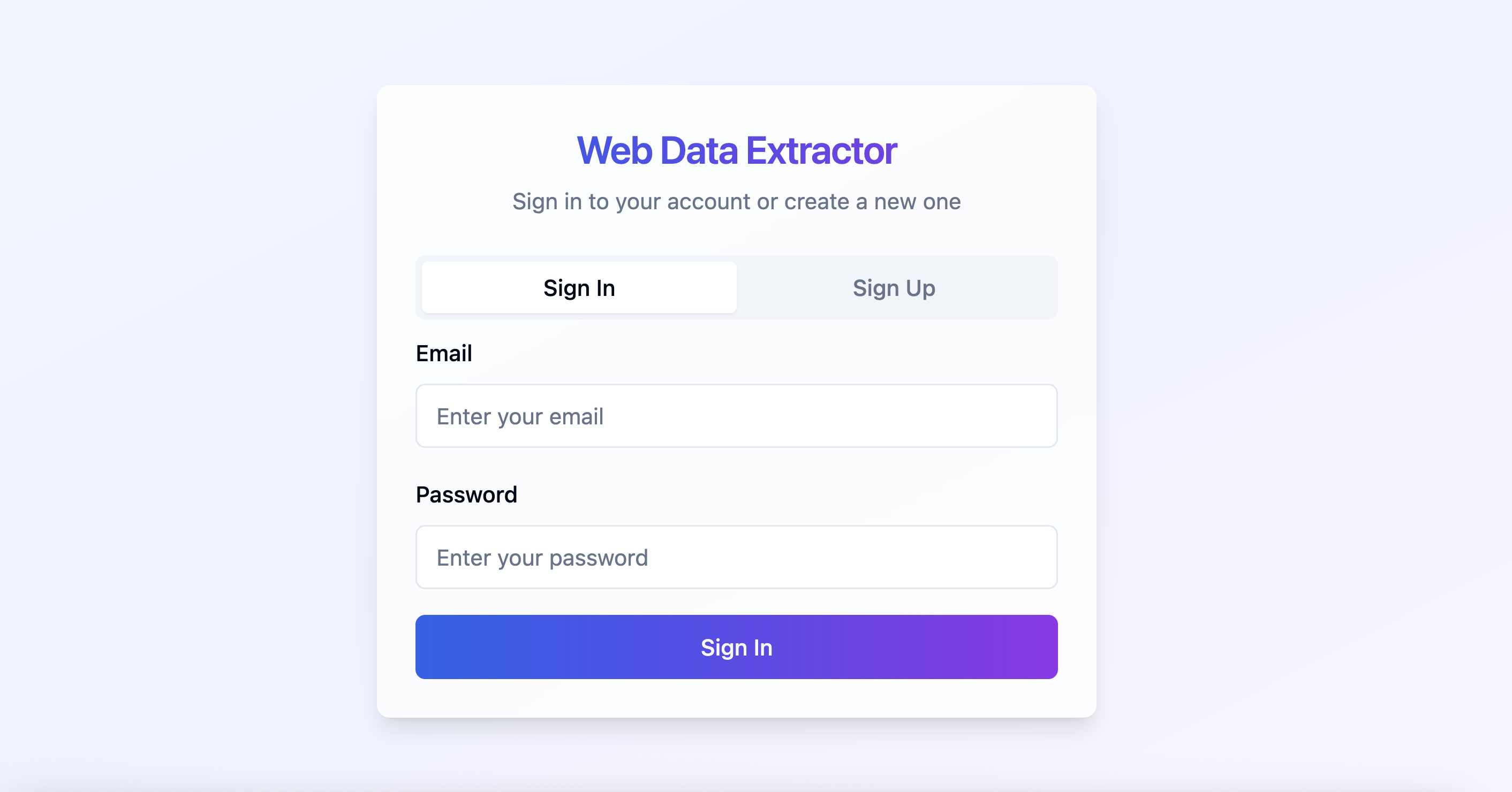
사용자 인증: Supabase 기반 인증 화면을 통해 안전하게 가입하거나 로그인할 수 있습니다.
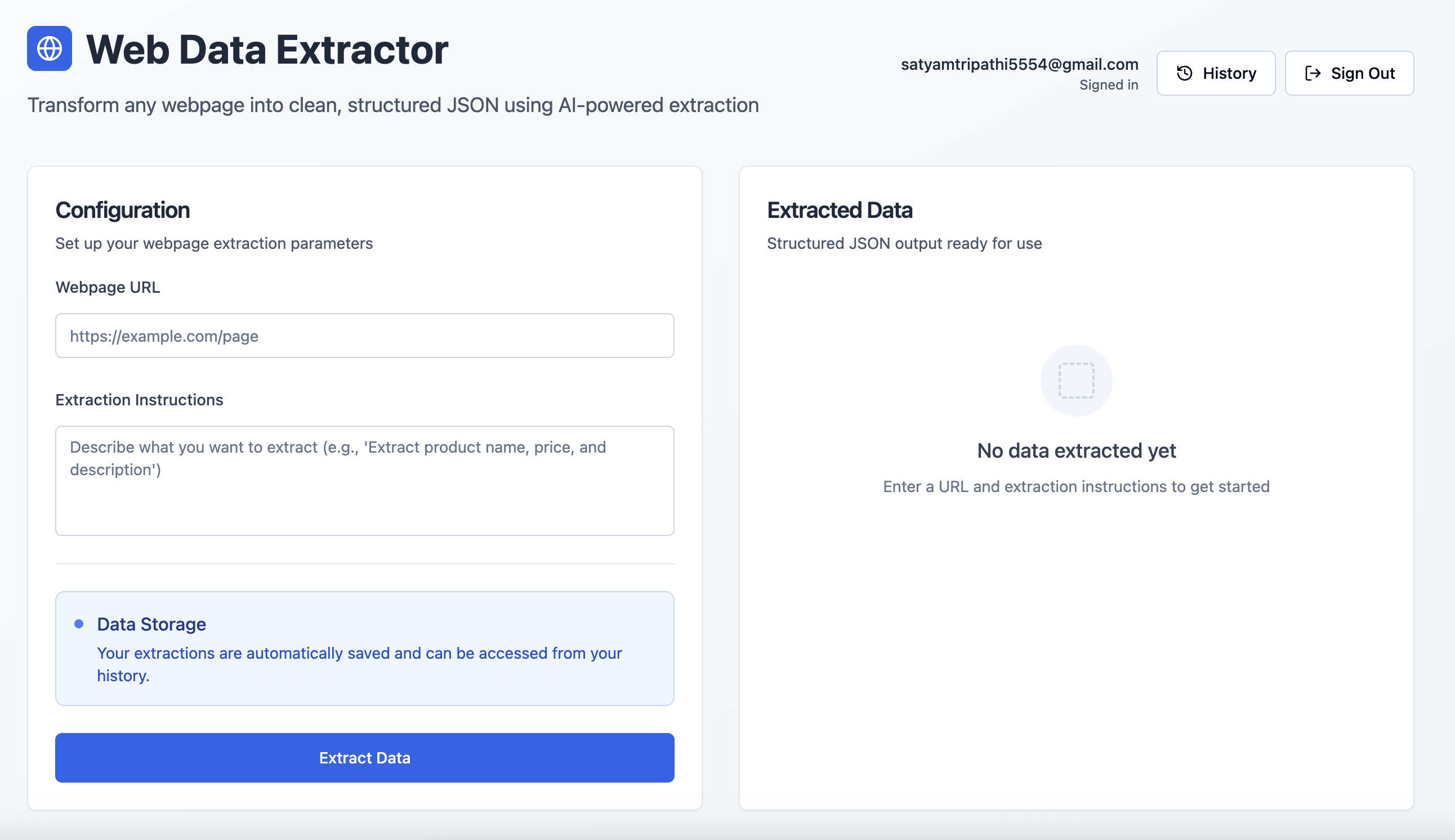
데이터 추출 인터페이스: 로그인 후 사용자는 웹페이지 URL과 자연어 프롬프트를 입력하여 구조화된 데이터를 검색할 수 있습니다.
기술 스택 개요
각 구성 요소가 제공하는 전략적 이점과 함께 스택을 분석해 보겠습니다.
- Bright Data: 웹 스크래핑은 종종 차단, CAPTCHA, 고급 봇 탐지 등에 부딪힙니다. Bright Data는 이러한 문제를 해결하기 위해 특별히 설계되었습니다. 다음과 같은 기능을 제공합니다:
- 자동 프록시 로테이션
- CAPTCHA 해결 및 봇 방지
- 일관된 접근을 위한 글로벌 인프라
- 동적 콘텐츠를 위한 자바스크립트 렌더링
- 자동화된 속도 제한 처리
이 가이드에서는 Bright Data의 Web Unlocker를 사용합니다. 이 도구는 가장 보호가 강화된 페이지에서도 전체 HTML을 안정적으로 가져오는 전용 도구입니다.
- Supabase:Supabase는 다음과 같은 기능을 갖춘 현대적인 앱을 위한 안전한 백엔드 기반을 제공합니다.
- 내장된 인증 및 세션 처리
- 실시간 지원을 제공하는 PostgreSQL 데이터베이스
- 서버리스 로직을 위한 Edge Functions
- 안전한 키 저장 및 접근 제어
- Lovable: Lovable은 AI 기반 도구와 네이티브 Supabase 통합으로 개발을 간소화합니다. 다음을 제공합니다:
- AI 기반 코드 생성
- 프론트엔드/백엔드 스캐폴딩의 원활한 통합
- 기본 제공되는 React + Tailwind UI
- 생산 환경에 바로 적용 가능한 앱을 위한 빠른 프로토타이핑
- Google Gemini AI:Gemini는 자연어 프롬프트를 사용하여 원시 HTML을 구조화된 JSON으로 변환합니다. 지원 기능:
- 정확한 콘텐츠 이해 및 파싱
- 전체 페이지 컨텍스트를 위한 대용량 입력 지원
- 확장 가능하고 비용 효율적인 데이터 추출
사전 요구사항 및 설정
개발을 시작하기 전에 다음 항목에 대한 접근 권한이 있는지 확인하십시오:
- Bright Data 계정
- brightdata.com에서 가입하세요
- 웹 언락커(Web Unlocker) 영역 생성
- 계정 설정에서API 키를 발급받으세요
- Google AI Studio 계정
- Google AI Studio 방문
- 새 API 키 생성
- Supabase 프로젝트
- supabase.com에서 가입하기
- 새 조직 생성 후 새 프로젝트 설정
- 프로젝트 대시보드에서 Edge Functions → Secrets → Add New Secret 으로 이동합니다 .
BRIGHT_DATA_API_KEY및GEMINI_API_KEY와같은 시크릿을 각각의 값과 함께 추가합니다 .
- 러블리블 계정
- lovable.dev에 등록하세요
- 프로필 → 설정 → 통합으로 이동하세요
- Supabase 항목에서 ‘Supabase 연결’을 클릭하세요
- API 접근 권한을 승인하고 방금 생성한 Supabase 조직에 연결하세요
Lovable 프롬프트로 단계별 애플리케이션 구축
프론트엔드부터 백엔드, 데이터베이스, 지능형 파싱에 이르기까지 웹 데이터 추출 앱을 개발하기 위한 체계적인 프롬프트 기반 흐름은 다음과 같습니다.
1단계 – 프론트엔드 설정
깔끔하고 직관적인 사용자 인터페이스 디자인으로 시작하세요.
React와 Tailwind CSS를 사용하여 현대적인 웹 데이터 추출 앱을 구축하세요. UI에는 다음이 포함되어야 합니다:
- 카드 스타일 레이아웃의 그라데이션 배경
- 웹페이지 URL 입력 필드
- 추출 프롬프트용 텍스트 영역 (예: "제품 제목, 가격, 평점 추출")
- 구조화된 JSON 출력을 렌더링할 표시 영역
- 호버 효과와 적절한 간격을 적용한 반응형 스타일링2단계 – Supabase 연결 및 인증 추가
Supabase 프로젝트 연결 방법:
- Lovable 오른쪽 상단의 Supabase 아이콘 클릭
- ‘Supabase 연결’ 선택
- 사전에 생성한 조직 및 프로젝트 선택
Lovable이 자동으로 Supabase 프로젝트를 통합합니다. 연결 후 아래 안내에 따라 인증을 활성화하세요:
완벽한 Supabase 인증 설정:
- 이메일/비밀번호 기반 가입 및 로그인 양식
- 세션 관리 및 자동 지속성
- 인증되지 않은 사용자에 대한 경로 보호
- 로그아웃 기능
- 가입 시 사용자 프로필 생성
- 모든 인증 관련 오류 처리Lovable이 필요한 SQL 스키마와 트리거를 생성합니다. 검토 후 승인하여 인증 흐름을 완료하세요.
3단계 – Supabase 데이터베이스 스키마 정의
추출 활동을 기록하고 저장하기 위한 필수 테이블 설정:
추출 및 결과를 저장할 Supabase 테이블 생성:
- extractions: URL, 프롬프트, user_id, 상태, 처리 시간, 오류 메시지 저장
- extraction_results: 파싱된 JSON 출력 저장
RLS 정책 적용으로 각 사용자가 자신의 데이터만 접근 가능하도록 보장단계 #4 – Supabase Edge 함수 생성
이 함수는 핵심 스크래핑, 변환 및 추출 로직을 처리합니다:
'extract-web-data'라는 Edge Function 생성:
- Bright Data의 Web Unlocker로 대상 페이지 가져오기
- Turndown으로 원시 HTML을 Markdown으로 변환
- Markdown과 프롬프트를 Google Gemini AI(gemini-2.0-flash-001)로 전송
- 정리된 구조화된 JSON 반환
- CORS, 오류, 응답 형식 처리
- 에지 함수 시크릿으로 GEMINI_API_KEY 및 BRIGHT_DATA_API_KEY 필요
아래는 Bright Data로 HTML 가져오기, Turndown으로 마크다운 변환, Gemini로 AI 기반 추출을 처리하는 참조 구현입니다:
import { GoogleGenerativeAI } from '@google/generative-ai';
import TurndownService from 'turndown';
interface BrightDataConfig {
apiKey: string;
zone: string;
}
// 상수
const GEMINI_MODEL = 'gemini-2.0-flash-001';
const WEB_UNLOCKER_ZONE = 'YOUR_WEB_UNLOCKER_ZONE';
export class WebContentExtractor {
private geminiClient: GoogleGenerativeAI;
private modelName: string;
private htmlToMarkdownConverter: TurndownService;
private brightDataConfig: BrightDataConfig;
constructor() {
const geminiApiKey: string = 'GEMINI_API_KEY';
const brightDataApiKey: string = 'BRIGHT_DATA_API_KEY';
try {
this.geminiClient = new GoogleGenerativeAI(geminiApiKey);
this.modelName = GEMINI_MODEL;
this.htmlToMarkdownConverter = new TurndownService();
this.brightDataConfig = {
apiKey: brightDataApiKey,
zone: WEB_UNLOCKER_ZONE
};
} catch (error) {
console.error('WebContentExtractor 초기화 실패:', error);
throw error;
}
}
/**
* Bright Data Web Unlocker 서비스를 사용하여 웹페이지 콘텐츠 가져오기
*/
async fetchContentViaBrightData(targetUrl: string): Promise<string | null> {
try {
// 대상 URL에 Web Unlocker 매개변수 추가
const urlSeparator: string = targetUrl.includes('?') ? '&' : '?';
const requestUrl: string = `${targetUrl}${urlSeparator}product=unlocker&method=api`;
const apiResponse = await fetch('https://api.brightdata.com/request', {
method: 'POST',
headers: {
'Authorization': `Bearer ${this.brightDataConfig.apiKey}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
zone: this.brightDataConfig.zone,
url: requestUrl,
format: 'raw'
})
});
if (!apiResponse.ok) {
throw new Error(`웹 언락커 요청 실패: 상태 코드 ${apiResponse.status}`);
}
const htmlContent: string = await apiResponse.text();
return htmlContent && htmlContent.length > 0 ? htmlContent : null;
} catch (error) {
console.error('웹페이지 콘텐츠 가져오기 실패:', error);
return null;
}
}
/**
* AI 처리를 위해 HTML을 깔끔한 마크다운 형식으로 변환합니다
*/
async convertToMarkdown(htmlContent: string): Promise<string | null> {
try {
const markdownContent: string = this.htmlToMarkdownConverter.turndown(htmlContent);
return markdownContent;
} catch (error) {
console.error('HTML을 마크다운으로 변환하는 데 실패했습니다:', error);
return null;
}
}
/**
* Gemini AI를 사용하여 마크다운 콘텐츠에서 특정 정보를 추출합니다
* 일관되고 사실적인 응답을 위해 낮은 온도(low temperature)를 사용합니다
*/
async extractInformationWithAI(markdownContent: string, userQuery: string): Promise<string | null> {
try {
const aiPrompt: string = this.buildAIPrompt(userQuery, markdownContent);
const aiModel = this.geminiClient.getGenerativeModel({ model: this.modelName });
const aiResult = await aiModel.generateContent({
contents: [{ role: 'user', parts: [{ text: aiPrompt }] }],
generationConfig: {
maxOutputTokens: 2048,
temperature: 0.1,
}
});
const response = await aiResult.response;
return response.text();
} catch (error) {
console.error('AI로 정보 추출 실패:', error);
return null;
}
}
private buildAIPrompt(userQuery: string, markdownContent: string): string {
return `당신은 데이터 추출 보조입니다. 아래는 웹페이지에서 추출한 마크다운 형식의 콘텐츠입니다.
이 내용을 분석하여 사용자가 요청한 정보를 추출해 주세요.
사용자 요청: ${userQuery}
마크다운 콘텐츠:
${markdownContent}
사용자 요청에 기반하여 명확하고 구조화된 응답을 제공해 주세요. 요청된 정보가 콘텐츠에 존재하지 않을 경우, 이를 명확히 표시해 주세요.`;
}
/**
* 주요 추출 워크플로우: 웹페이지 가져오기 → 마크다운 변환 → AI로 추출
*/
async extractDataFromUrl(websiteUrl: string, extractionQuery: string): Promise<string | null> {
try {
const htmlContent: string | null = await this.fetchContentViaBrightData(websiteUrl);
if (!htmlContent) {
console.error('URL에서 HTML 콘텐츠를 가져올 수 없습니다');
return null;
}
const markdownContent: string | null = await this.convertToMarkdown(htmlContent);
if (!markdownContent) {
console.error('HTML을 마크다운으로 변환할 수 없습니다');
return null;
}
const 추출된정보: string | null = await this.AI를사용한정보추출(마크다운콘텐츠, 추출쿼리);
return 추출된정보;
} catch (오류) {
console.error('extractDataFromUrl에서 오류 발생:', 오류);
return null;
}
}
}
/**
* WebContentExtractor 사용 예시
*/
async function runExtraction(): Promise<void> {
const TARGET_WEBSITE_URL: string = 'https://example.com';
const DATA_EXTRACTION_QUERY: string = 'Extract the product title, all available prices, ...';
try {
const contentExtractor = new WebContentExtractor();
const extractionResult: string | null = await contentExtractor.extractDataFromUrl(TARGET_WEBSITE_URL, DATA_EXTRACTION_QUERY);
if (extractionResult) {
console.log(extractionResult);
} else {
console.log('지정된 URL에서 데이터 추출 실패');
}
} catch (error) {
console.error(`애플리케이션 오류: ${error}`);
}
}
// 애플리케이션 실행
runExtraction().catch(console.error);Gemini AI로 전송하기 전에 원시 HTML을 Markdown으로 변환하면 몇 가지 주요 이점이 있습니다. 불필요한 HTML 노이즈를 제거하고, 더 깔끔하고 구조화된 입력을 제공하여 AI 성능을 향상시키며, 토큰 사용량을 줄여 더 빠르고 비용 효율적인 처리가 가능합니다.
중요 고려 사항: Lovable은 자연어로 앱을 구축하는 데 탁월하지만, Bright Data나 Gemini 같은 외부 도구를 적절히 통합하는 방법을 항상 인지하지 못할 수 있습니다. 정확한 구현을 보장하려면 프롬프트에 작동하는 샘플 코드를 포함하세요. 예를 들어, 위 프롬프트의 fetchContentViaBrightData 메서드는 Bright Data의 Web Unlocker를 활용한 간단한 사용 사례를 보여줍니다.
Bright Data는 Web Unlocker, SERP API, Scraper API 등 여러 API를 제공하며, 각각 고유한 엔드포인트, 인증 방식 및 매개변수를 가집니다. Bright Data 대시보드에서 제품 또는 영역을 설정할 때, 개요 탭은 구성에 맞춰 언어별(Node.js, Python, cURL) 코드 스니펫을 제공합니다. 해당 스니펫을 그대로 사용하거나 Edge Function 로직에 맞게 수정하세요.
단계 #5 – 프론트엔드를 Edge Function에 연결하기
Edge Function이 준비되면 React 앱에 통합하세요:
프론트엔드를 Edge Function에 연결하세요:
- 양식 제출 시 Edge Function 호출
- 데이터베이스에 요청 기록
- 응답 후 상태 업데이트(처리 중/완료/실패)
- 처리 시간, 상태 아이콘, 토스트 알림 표시
- 로딩 상태와 함께 추출된 JSON 표시단계 #6 – 추출 기록 추가
사용자가 이전 요청을 검토할 수 있는 방법을 제공합니다:
다음 기능을 가진 기록 보기 생성:
- 로그인한 사용자의 모든 추출 기록 목록 표시
- URL, 프롬프트, 상태, 소요 시간, 날짜 표시
- 보기 및 삭제 옵션 포함
- 행 확장 시 추출 결과 표시
- 상태 아이콘 사용 (완료, 실패, 처리 중)
- 긴 텍스트/URL을 반응형 레이아웃으로 우아하게 처리7단계 – UI 마무리 및 최종 개선
유용한 UI 터치로 경험을 개선하세요:
인터페이스 개선:
- "새 추출"과 "기록" 간 전환 토글 추가
- 구문 강조 및 복사 버튼이 포함된 JsonDisplay 컴포넌트 생성
- 긴 프롬프트 및 URL에 대한 반응성 문제 수정
- 로딩 스핀너, 빈 상태, 대체 메시지 추가
- 페이지 하단에 기능 카드 또는 팁 포함결론
이 통합은 현대적 웹 자동화의 장점을 결합합니다: Supabase의 안전한 사용자 흐름, Bright Data의 안정적인 스크래핑, Gemini의 유연한 AI 기반 파싱 – 이 모든 것이 Lovable의 직관적인 채팅 기반 빌더를 통해 코딩 없이도 높은 생산성을 제공하는 워크플로우로 구현됩니다.
직접 구축해 보시겠습니까? brightdata.com에서 시작하여 인프라 고민 없이 모든 사이트에 확장 가능한 접근을 제공하는 Bright Data의 데이터 수집 솔루션을 살펴보세요.