이 가이드에서는 다음을 배우게 됩니다:
- 제3자 위험 관리(TPRM)란 무엇이며 수동 심사 방식이 실패하는 이유
- 부정적 미디어를 조사하는 자율 AI 에이전트 구축 방법
- 신뢰할 수 있고 최신 데이터 수집을 위한 Bright Data의 SERP API 및 Web Unlocker 통합 방법
- 에이전트 스크립트 생성을 위한 OpenHands SDK와 위험 분석을 위한 OpenAI 활용 방법
- 법원 등기부와 같은 복잡한 시나리오를 위해 브라우저 API로 에이전트 성능 향상하는 방법
시작해 보세요!
수동 공급업체 심사 문제점
기업 컴플라이언스 팀은 웹 전체에서 수백 개의 제3자 공급업체에 대한 위험 신호를 모니터링해야 하는 불가능한 과제에 직면합니다. 기존 접근 방식은 다음과 같습니다:
- 각 공급업체 이름에 “소송”, “파산”, “사기” 등의 키워드를 결합한수동 Google 검색
- 뉴스 기사 및 법원 기록 접근 시유료 벽과 CAPTCHA에 부딪힘
- 결과 기록을 위한 표준화된 프로세스가 없는일관성 없는 문서화
- 지속적인 모니터링 부재: 공급업체 심사 작업은 온보딩 시 단 한 번만 수행되고 이후 전혀 이루어지지 않음
이러한 접근 방식은 세 가지 중대한 이유로 실패합니다:
- 규모: 단일 분석가가 하루에 철저히 조사할 수 있는 공급업체는 5~10개 정도
- 접근성: 법원 등록부나 유료 뉴스 사이트 같은 보호된 소스는 자동화된 접근을 차단함
- 지속성: 특정 시점 평가로는 온보딩 후 발생하는 위험을 포착하지 못함
해결책: 자율적 TPRM 에이전트
TPRM 에이전트는 세 가지 전문 계층을 활용해 공급업체 조사 워크플로우 전체를 자동화합니다:
- 탐색(SERP API): 에이전트가 소송, 규제 조치, 재정적 어려움과 같은 위험 신호를 구글에서 검색합니다
- 접근 (웹 언락커): 관련 결과가 유료 장벽이나 CAPTCHA 뒤에 있을 경우, 에이전트가 이러한 장벽을 우회하여 전체 콘텐츠를 추출합니다
- 액션(OpenAI + OpenHands SDK): 에이전트는 OpenAI를 활용해 콘텐츠의 위험 심각도를 분석한 후, OpenHands SDK로 매일 새로운 부정적 미디어를 확인하는 Python 모니터링 스크립트를 생성합니다
이 시스템은 수 시간의 수동 조사를 몇 분의 자동 분석으로 전환합니다.
필수 조건
시작하기 전에 다음을 준비하십시오:
- Python 3.12 이상 (OpenHands SDK 필수)
- API 접근 권한이 있는 Bright Data 계정 (무료 체험판 이용 가능)
- 위험 분석용 OpenAI API 키
- 에이전트 스크립트 생성을 위한 OpenHands Cloud 계정 또는 자체 LLM API 키
- 파이썬 및 REST API에 대한 기본적인 이해
프로젝트 아키텍처
TPRM 에이전트는 3단계 파이프라인을 따릅니다:
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ 탐색 │────▶│ 접근 │────▶│ 실행 │
│ (SERP API) │ │ (웹 언락커) │ │ (OpenAI + SDK) │
└─────────────────┘ └─────────────────┘ └─────────────────┘
│ │ │
Google 검색 유료 콘텐츠 우회 위험 요소 분석
경고 신호 및 CAPTCHA 처리 스크립트 생성다음과 같은 프로젝트 구조 생성:
tprm-agent/
├── src/
│ ├── __init__.py
│ ├── config.py # 구성
│ ├── discovery.py # SERP API 통합
│ ├── access.py # 웹 언락커 통합
│ ├── actions.py # OpenAI + OpenHands SDK
│ ├── agent.py # 메인 오케스트레이션
│ └── browser.py # 브라우저 API (강화 기능)
├── api/
│ └── main.py # FastAPI 엔드포인트
├── scripts/
│ └── generated/ # 자동 생성 모니터링 스크립트
├── .env
├── requirements.txt
└── README.md
환경 설정
가상 환경을 생성하고 필요한 종속성을 설치합니다:
python -m venv venv
source venv/bin/activate # Windows: venvScriptsactivate
pip install requests fastapi uvicorn python-dotenv pydantic openai beautifulsoup4 playwright openhands-sdk openhands-tools
API 자격 증명을 저장할 .env 파일을 생성하세요:
# Bright Data API 토큰 (SERP API용)
BRIGHT_DATA_API_TOKEN=your_api_token
# Bright Data SERP 존
BRIGHT_DATA_SERP_ZONE=your_serp_zone_name
# Bright Data 웹 언락커 자격 증명
BRIGHT_DATA_CUSTOMER_ID=your_customer_id
BRIGHT_DATA_UNLOCKER_ZONE=your_unlocker_zone_name
BRIGHT_DATA_UNLOCKER_PASSWORD=your_zone_password
# OpenAI (위험 분석용)
OPENAI_API_KEY=your_openai_api_key
# OpenHands (에이전트 스크립트 생성용)
# OpenHands Cloud 사용: openhands/claude-sonnet-4-5-20260929
# 또는 자체 모델 사용: anthropic/claude-sonnet-4-5-20260929
LLM_API_KEY=your_llm_api_key
LLM_MODEL=openhands/claude-sonnet-4-5-20260929Bright Data 구성
1단계: Bright Data 계정 생성
Bright Data에 가입하고 대시보드로 이동하세요.
2단계: SERP API 영역 구성
- 프록시 및 스크래핑 인프라로 이동
- 추가로 클릭하고 SERP API를 선택하세요
- 존에 이름을 지정하세요(예:
tprm_serp). - 설정 > API 토큰에서 영역 이름과 API 토큰을 복사하세요.
SERP API는 차단되지 않고 Google의 구조화된 검색 결과를 반환합니다. 파싱된 JSON 출력을 위해 검색 URL에 brd_json=1을 추가하세요.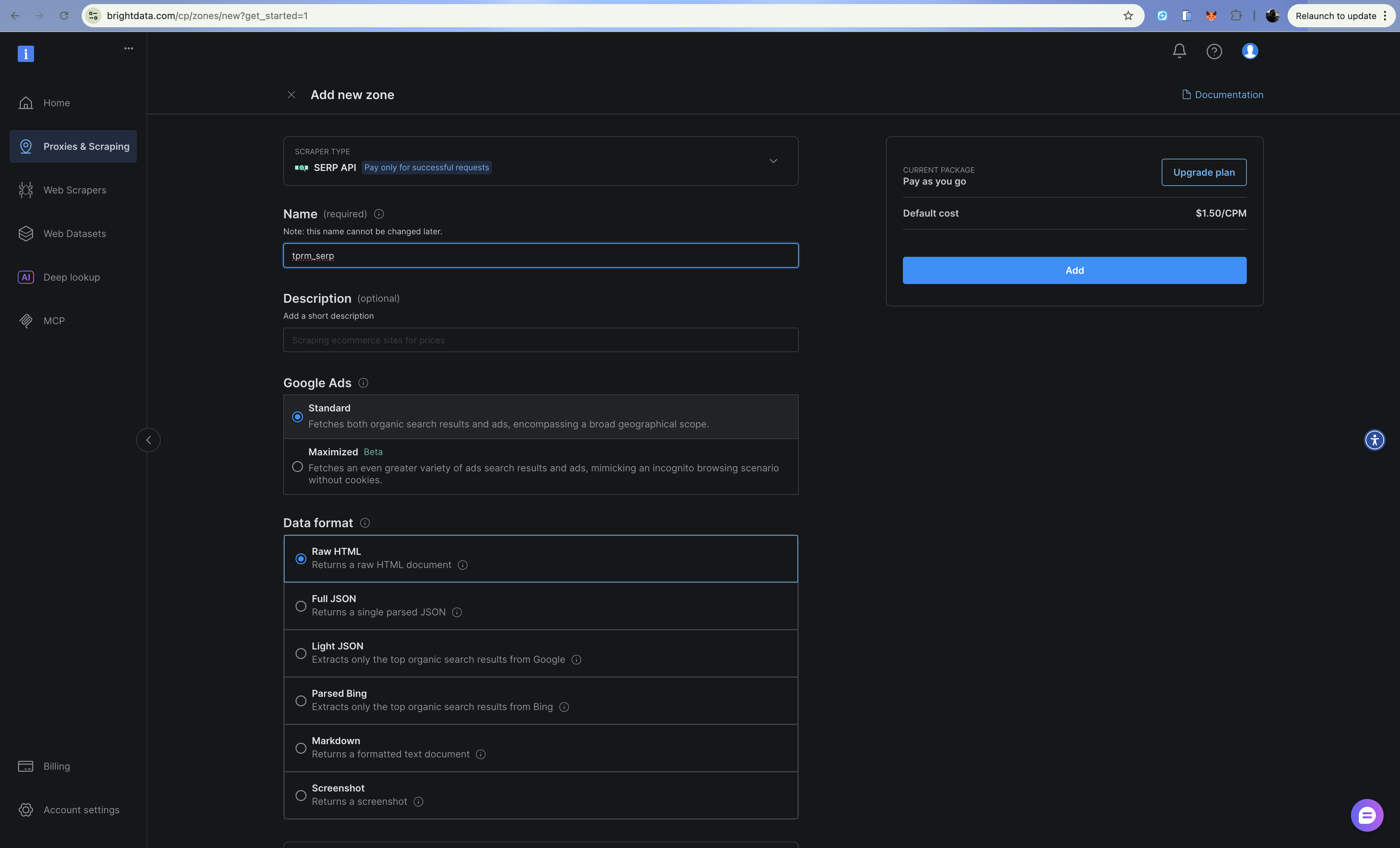
3단계: 웹 언락커 영역 구성
- 추가를 클릭하고 웹 언락커를 선택하세요
- 영역 이름 지정 (예:
tprm_unlocker) - 존 자격 증명(사용자 이름 형식:
brd-customer-CUSTOMER_ID-zone-ZONE_NAME)을 복사하세요.
웹 언락커는 프록시 엔드포인트를 통해 CAPTCHA, 지문 인식, IP 로테이션을 자동으로 처리합니다.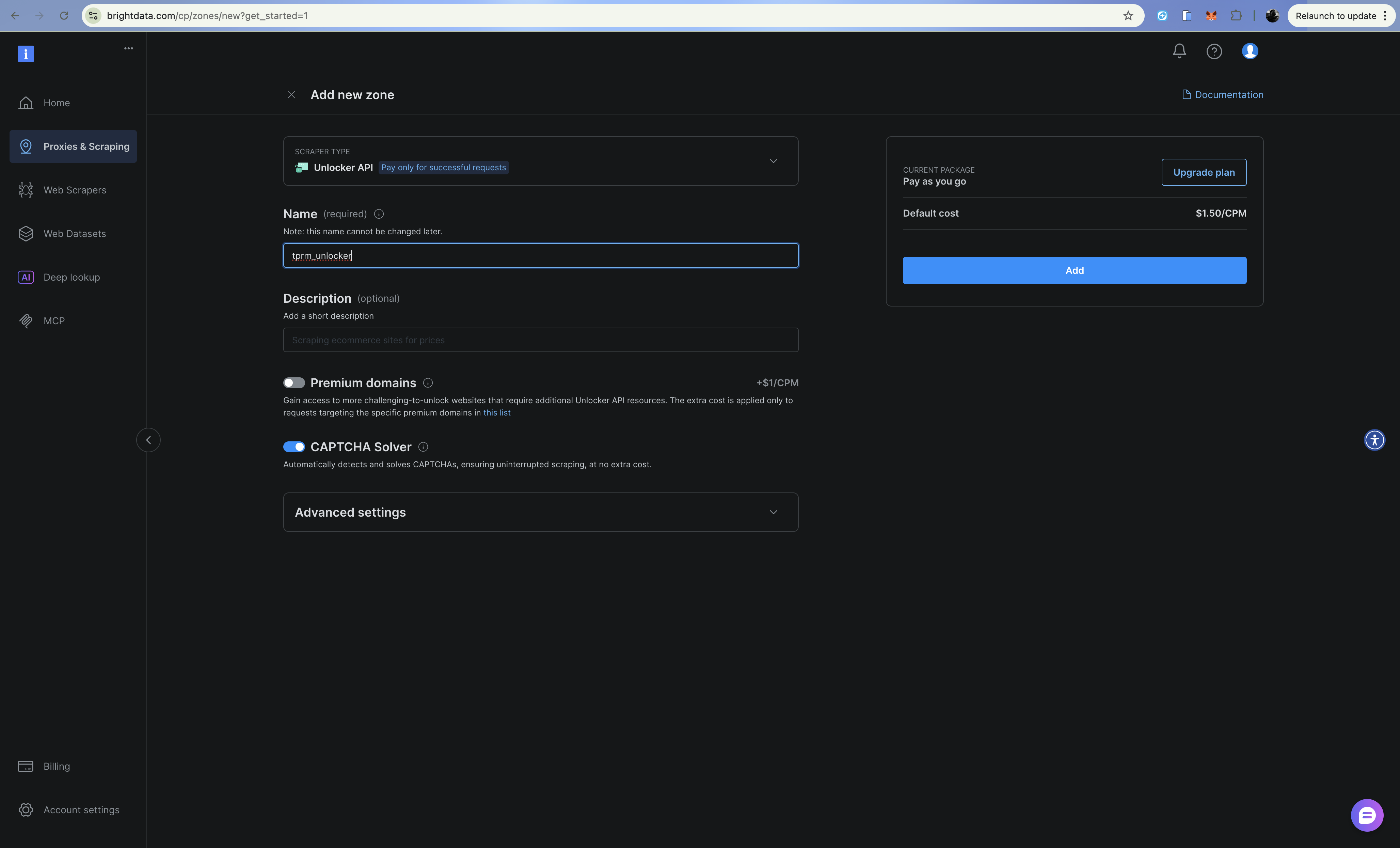
디스커버리 레이어 구축 (SERP API)
디스커버리 레이어는 SERP API를 사용하여 공급업체에 대한 부정적 미디어를 Google에서 검색합니다. src/discovery.py 생성:
import requests
from typing import Optional
from dataclasses import dataclass
from urllib.parse import quote_plus
from config import settings
@dataclass
class SearchResult:
title: str
url: str
snippet: str
source: str
class DiscoveryClient:
"""Bright Data SERP API(Direct API)를 사용하여 부정적 미디어 검색."""
RISK_CATEGORIES = {
"litigation": ["lawsuit", "litigation", "sued", "court case", "legal action"],
"financial": ["bankruptcy", "insolvency", "debt", "financial trouble", "default"],
"사기": ["사기", "사기 행위", "조사", "기소", "스캔들"],
"규제": ["위반", "벌금", "처벌", "제재", "준수"],
"운영": ["리콜", "안전 문제", "공급망", "차질"],
}
def __init__(self):
self.api_url = "https://api.brightdata.com/request"
self.headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {settings.BRIGHT_DATA_API_TOKEN}",
}
def _build_queries(self, vendor_name: str, categories: Optional[list] = None) -> list[str]:
"""각 위험 범주에 대한 검색 쿼리를 생성합니다."""
categories = categories or list(self.RISK_CATEGORIES.keys())
queries = []
for category in categories:
keywords = self.RISK_CATEGORIES.get(category, [])
keyword_str = " OR ".join(keywords)
query = f'"{vendor_name}" ({keyword_str})'
queries.append(query)
return queries
def search(self, query: str) -> list[SearchResult]:
"""Bright Data SERP API를 사용하여 단일 검색 쿼리 실행."""
try:
# 파싱된 JSON을 위해 brd_json=1을 포함한 Google 검색 URL 생성
encoded_query = quote_plus(query)
google_url = f"https://www.google.com/search?q={encoded_query}&hl=en&gl=us&brd_json=1"
payload = {
"zone": settings.BRIGHT_DATA_SERP_ZONE,
"url": google_url,
"format": "raw",
}
response = requests.post(
self.api_url,
headers=self.headers,
json=payload,
timeout=30,
)
response.raise_for_status()
data = response.json()
results = []
organic = data.get("organic", [])
for item in organic:
results.append(
SearchResult(
title=item.get("title", ""),
url=item.get("link", ""),
snippet=item.get("description", ""),
source=item.get("displayed_link", ""),
)
)
return results
except Exception as e:
print(f"검색 오류: {e}")
return []
def discover_adverse_media(
self,
vendor_name: str,
categories: Optional[list] = None,
) -> dict[str, list[SearchResult]]:
"""모든 위험 범주에 걸쳐 부정적 미디어를 검색합니다."""
queries = self._build_queries(vendor_name, categories)
category_names = categories or list(self.RISK_CATEGORIES.keys())
categorized_results = {}
for category, query in zip(category_names, queries):
print(f" 검색 중: {category}...")
results = self.search(query)
categorized_results[category] = results
return categorized_results
def filter_relevant_results(
self, results: dict[str, list[SearchResult]], vendor_name: str
) -> dict[str, list[SearchResult]]:
"""관련 없는 결과를 걸러냅니다."""
filtered = {}
vendor_lower = vendor_name.lower()
for category, items in results.items():
relevant = []
for item in items:
if (
vendor_lower in item.title.lower()
or vendor_lower in item.snippet.lower()
):
relevant.append(item)
filtered[category] = relevant
return filtered
SERP API는 유기적 검색 결과를 구조화된 JSON으로 반환하여 각 검색 결과의 제목, URL, 스니펫을 쉽게 파싱할 수 있게 합니다.
액세스 레이어 구축 (웹 언락커)
디스커버리 레이어가 관련 URL을 찾으면, 액세스 레이어는 Web Unlocker API를 사용하여 전체 콘텐츠를 가져옵니다. src/access.py 생성:
import requests
from bs4 import BeautifulSoup
from dataclasses import dataclass
from typing import Optional
from config import settings
@dataclass
class ExtractedContent:
url: str
title: str
text: str
publish_date: Optional[str]
author: Optional[str]
success: bool
error: Optional[str] = None
class AccessClient:
"""Bright Data Web Unlocker(API 기반)를 사용하여 보호된 콘텐츠에 접근합니다."""
def __init__(self):
self.api_url = "https://api.brightdata.com/request"
self.headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {settings.BRIGHT_DATA_API_TOKEN}",
}
def fetch_url(self, url: str) -> ExtractedContent:
"""Web Unlocker API를 사용하여 URL에서 콘텐츠를 가져오고 추출합니다."""
try:
payload = {
"zone": settings.BRIGHT_DATA_UNLOCKER_ZONE,
"url": url,
"format": "raw",
}
response = requests.post(
self.api_url,
headers=self.headers,
json=payload,
timeout=60,
)
response.raise_for_status()
# Web Unlocker API는 HTML을 직접 반환합니다
html_content = response.text
content = self._extract_content(html_content, url)
return content
except requests.Timeout:
return ExtractedContent(
url=url,
title="",
text="",
publish_date=None,
author=None,
success=False,
error="Request timed out",
)
except Exception as e:
return ExtractedContent(
url=url,
title="",
text="",
publish_date=None,
author=None,
success=False,
error=str(e),
)
def _extract_content(self, html: str, url: str) -> ExtractedContent:
"""HTML에서 기사 콘텐츠 추출"""
soup = BeautifulSoup(html, "html.parser")
# 불필요한 요소 제거
for element in soup(["script", "style", "nav", "footer", "header", "aside"]):
element.decompose()
# 제목 추출
title = ""
if soup.title:
title = soup.title.string or ""
elif soup.find("h1"):
title = soup.find("h1").get_text(strip=True)
# 본문 내용 추출
article = soup.find("article") or soup.find("main") or soup.find("body")
text = article.get_text(separator="n", strip=True) if article else ""
# 텍스트 길이 제한
text = text[:10000] if len(text) > 10000 else text
# 게시일 추출 시도
publish_date = None
date_meta = soup.find("meta", {"property": "article:published_time"})
if date_meta:
publish_date = date_meta.get("content")
# 작성자 추출 시도
author = None
author_meta = soup.find("meta", {"name": "author"})
if author_meta:
author = author_meta.get("content")
return ExtractedContent(
url=url,
title=title,
text=text,
publish_date=publish_date,
author=author,
success=True,
)
def fetch_multiple(self, urls: list[str]) -> list[ExtractedContent]:
"""여러 URL을 순차적으로 가져옵니다."""
results = []
for url in urls:
print(f" Fetching: {url[:60]}...")
content = self.fetch_url(url)
if not content.success:
print(f" Error: {content.error}")
results.append(content)
return results
Web Unlocker는 CAPTCHA, 브라우저 지문 인식, IP 로테이션을 자동으로 처리합니다. 단순히 요청을 프록시를 통해 전달하고 나머지는 처리해 줍니다.
액션 레이어 구축 (OpenAI + OpenHands SDK)
액션 레이어는 OpenAI를 사용하여 위험 심각도를 분석하고, OpenHands SDK를 사용하여 Bright Data Web Unlocker API를 활용하는 모니터링 스크립트를 생성합니다. OpenHands SDK는 에이전트 기능을 제공합니다: 에이전트는 추론하고, 파일을 편집하며, 명령을 실행하여 생산 환경에 바로 적용 가능한 스크립트를 생성할 수 있습니다.
src/actions.py 생성:
import os
import json
from datetime import datetime, UTC
from dataclasses import dataclass, asdict
from openai import OpenAI
from pydantic import SecretStr
from openhands.sdk import LLM, Agent, Conversation, Tool
from openhands.tools.terminal import TerminalTool
from openhands.tools.file_editor import FileEditorTool
from config import settings
@dataclass
class RiskAssessment:
vendor_name: str
category: str
severity: str
summary: str
key_findings: list[str]
sources: list[str]
recommended_actions: list[str]
assessed_at: str
@dataclass
class MonitoringScript:
vendor_name: str
script_path: str
urls_monitored: list[str]
check_frequency: str
created_at: str
class ActionsClient:
"""OpenAI를 사용하여 위험을 분석하고 OpenHands SDK를 사용하여 모니터링 스크립트를 생성합니다."""
def __init__(self):
# 위험 분석을 위한 OpenAI
self.openai_client = OpenAI(api_key=settings.OPENAI_API_KEY)
# 에이전트형 스크립트 생성을 위한 OpenHands
self.llm = LLM(
model=settings.LLM_MODEL,
api_key=SecretStr(settings.LLM_API_KEY),
)
self.workspace = os.path.join(os.getcwd(), "scripts", "generated")
os.makedirs(self.workspace, exist_ok=True)
def analyze_risk(
self,
vendor_name: str,
category: str,
content: list[dict],
) -> RiskAssessment:
"""OpenAI를 사용하여 추출된 콘텐츠의 위험 심각도를 분석합니다."""
content_summary = "nn".join(
[f"출처: {c['url']}n제목: {c['title']}n내용: {c['text'][:2000]}" for c in content]
)
prompt = f"""제3자 위험 평가를 위해 "{vendor_name}"에 관한 다음 콘텐츠를 분석하세요.
카테고리: {category}
콘텐츠:
{content_summary}
다음 JSON 응답을 제공하세요:
{{
"severity": "low|medium|high|critical",
"summary": "발견 사항에 대한 2-3문장 요약",
"key_findings": ["발견 사항 1", "발견 사항 2", ...],
"recommended_actions": ["권장 조치 1", "권장 조치 2", ...]
}}
고려 사항:
- 심각도는 잠재적 비즈니스 영향에 기반해야 함
- Critical = 즉각적 조치 필요 (진행 중인 사기, 파산 신청)
- High = 조사 필요할 정도로 중대한 위험
- Medium = 모니터링 가치가 있는 주목할 만한 우려 사항
- 낮음 = 사소한 문제 또는 과거 사안
"""
response = self.openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
response_format={"type": "json_object"},
)
response_text = response.choices[0].message.content
try:
result = json.loads(response_text)
except (json.JSONDecodeError, ValueError):
result = {
"severity": "medium",
"summary": "위험 평가를 파싱할 수 없음",
"key_findings": [],
"recommended_actions": ["수동 검토 필요"],
}
return RiskAssessment(
vendor_name=vendor_name,
category=category,
severity=result.get("severity", "medium"),
summary=result.get("summary", ""),
key_findings=result.get("key_findings", []),
sources=[c["url"] for c in content],
recommended_actions=result.get("recommended_actions", []),
assessed_at=datetime.now(UTC).isoformat(),
)
def generate_monitoring_script(
self,
vendor_name: str,
urls: list[str],
check_keywords: list[str],
) -> MonitoringScript:
"""OpenHands SDK 에이전트를 사용하여 Python 모니터링 스크립트를 생성합니다."""
script_name = f"monitor_{vendor_name.lower().replace(' ', '_')}.py"
script_path = os.path.join(self.workspace, script_name)
prompt = f"""{script_path}에 다음 기능을 가진 Python 모니터링 스크립트를 생성하세요:
1. 매일 다음 URL에서 새 콘텐츠를 확인합니다: {urls[:5]}
2. 다음 키워드를 검색합니다: {check_keywords}
3. 새로운 관련 콘텐츠가 발견되면 경고를 전송합니다 (콘솔에 출력)
4. 모든 검사 결과를 'monitoring_log.json'이라는 JSON 파일에 기록합니다
스크립트는 반드시 Bright Data Web Unlocker API를 사용하여 페이월 및 CAPTCHA를 우회해야 합니다:
- API 엔드포인트: https://api.brightdata.com/request
- 베어러 토큰으로 환경 변수 BRIGHT_DATA_API_TOKEN 사용
- 존 이름으로 환경 변수 BRIGHT_DATA_UNLOCKER_ZONE 사용
- JSON 페이로드로 POST 요청 수행: {{"zone": "zone_name", "url": "target_url", "format": "raw"}}
- 헤더 추가: "Authorization": "Bearer <token>"
- 헤더 추가: "Content-Type": "application/json"
스크립트는 다음을 수행해야 합니다:
- python-dotenv를 사용하여 환경 변수에서 Bright Data 자격 증명 로드
- 모든 HTTP 요청에 Bright Data Web Unlocker API 사용 (일반 requests.get 사용 금지)
- try/except로 오류 우아하게 처리
- 직접 실행 가능한 main() 함수 포함
- cron을 통한 스케줄링 지원
- 변경 감지를 위한 콘텐츠 해시 저장
완성된 스크립트를 {script_path}에 작성하세요.
"""
# 터미널 및 파일 편집기 도구를 가진 OpenHands 에이전트 생성
agent = Agent(
llm=self.llm,
tools=[
Tool(name=TerminalTool.name),
Tool(name=FileEditorTool.name),
],
)
# 에이전트 실행하여 스크립트 생성
conversation = Conversation(agent=agent, workspace=self.workspace)
conversation.send_message(prompt)
conversation.run()
return MonitoringScript(
vendor_name=vendor_name,
script_path=script_path,
urls_monitored=urls[:5],
check_frequency="daily",
created_at=datetime.now(UTC).isoformat(),
)
def export_assessment(self, assessment: RiskAssessment, output_path: str) -> None:
"""위험 평가를 JSON 파일로 내보냅니다."""
with open(output_path, "w") as f:
json.dump(asdict(assessment), f, indent=2)OpenHands SDK를 단순 프롬프트 기반 코드 생성보다 사용하는 주요 장점은 에이전트가 작업을 반복할 수 있다는 점입니다. 스크립트를 테스트하고, 오류를 수정하며, 올바르게 작동할 때까지 개선할 수 있습니다.
에이전트 오케스트레이션
이제 모든 것을 연결해 보겠습니다. src/agent.py 파일을 생성하세요:
from dataclasses import dataclass
from datetime import datetime, UTC
from typing import Optional
from discovery import DiscoveryClient, SearchResult
from access import AccessClient, ExtractedContent
from actions import ActionsClient, RiskAssessment, MonitoringScript
@dataclass
class InvestigationResult:
vendor_name: str
started_at: str
completed_at: str
total_sources_found: int
total_sources_accessed: int
risk_assessments: list[RiskAssessment]
monitoring_scripts: list[MonitoringScript]
errors: list[str]
class TPRMAgent:
"""제3자 위험 관리 조사를 위한 자율 에이전트."""
def __init__(self):
self.discovery = DiscoveryClient()
self.access = AccessClient()
self.actions = ActionsClient()
def investigate(
self,
vendor_name: str,
categories: Optional[list[str]] = None,
generate_monitors: bool = True,
) -> InvestigationResult:
"""공급업체에 대한 완전한 조사를 실행합니다."""
started_at = datetime.now(UTC).isoformat()
errors = []
risk_assessments = []
monitoring_scripts = []
# 1단계: 탐색 (SERP API)
print(f"[탐색] {vendor_name}에 대한 부정적 미디어 검색 중...")
try:
raw_results = self.discovery.discover_adverse_media(vendor_name, categories)
filtered_results = self.discovery.filter_relevant_results(raw_results, vendor_name)
except Exception as e:
errors.append(f"탐색 실패: {str(e)}")
return InvestigationResult(
vendor_name=vendor_name,
started_at=started_at,
completed_at=datetime.now(UTC).isoformat(),
total_sources_found=0,
total_sources_accessed=0,
risk_assessments=[],
monitoring_scripts=[],
errors=errors,
)
total_sources = sum(len(results) for results in filtered_results.values())
print(f"[탐색] 관련 소스 {total_sources}개 발견")
# 2단계: 접근 (웹 언락커)
print(f"[접근] 소스에서 콘텐츠 추출 중...")
all_urls = []
url_to_category = {}
for category, results in filtered_results.items():
for result in results:
all_urls.append(result.url)
url_to_category[result.url] = category
try:
extracted_content = self.access.fetch_multiple(all_urls)
성공적 추출 = [c for c in 추출된_콘텐츠 if c.success]
except Exception as e:
오류_메시지 = f"접근 실패: {str(e)}"
print(f"[접근] {오류_메시지}")
오류.append(오류_메시지)
성공적 추출 = []
print(f"[접속] {len(successful_extractions)}개의 소스 성공적으로 추출됨")
# 3단계: 작업 - 위험 분석 (OpenAI)
print(f"[작업] 위험 분석 중...")
category_content = {}
for content in successful_extractions:
category = url_to_category.get(content.url, "unknown")
if category not in category_content:
category_content[category] = []
category_content[category].append({
"url": content.url,
"title": content.title,
"text": content.text,
})
for category, content_list in category_content.items():
if not content_list:
continue
try:
assessment = self.actions.analyze_risk(vendor_name, category, content_list)
risk_assessments.append(평가)
except Exception as e:
errors.append(f"{category}에 대한 위험 분석 실패: {str(e)}")
# 3단계: 조치 - 모니터링 스크립트 생성
if generate_monitors and successful_extractions:
print(f"[조치] 모니터링 스크립트 생성 중...")
try:
urls_to_monitor = [c.url for c in successful_extractions[:10]]
keywords = [vendor_name, "lawsuit", "bankruptcy", "fraud"]
script = self.actions.generate_monitoring_script(
vendor_name, urls_to_monitor, keywords
)
monitoring_scripts.append(script)
except Exception as e:
errors.append(f"스크립트 생성 실패: {str(e)}")
completed_at = datetime.now(UTC).isoformat()
print(f"[완료] 조사 완료")
return InvestigationResult(
vendor_name=vendor_name,
started_at=started_at,
completed_at=completed_at,
total_sources_found=total_sources,
total_sources_accessed=len(successful_extractions),
risk_assessments=risk_assessments,
monitoring_scripts=monitoring_scripts,
errors=errors,
)
def main():
"""사용 예시."""
agent = TPRMAgent()
result = agent.investigate("Acme Corp")
print(f"n{'='*50}")
print(f"조사 완료: {result.vendor_name}")
print(f"발견된 소스: {result.total_sources_found}")
print(f"접근된 소스: {result.total_sources_accessed}")
print(f"위험 평가: {len(result.risk_assessments)}")
print(f"모니터링 스크립트: {len(result.monitoring_scripts)}")
for assessment in result.risk_assessments:
print(f"n[{assessment.category.upper()}] 심각도: {assessment.severity}")
print(f"요약: {assessment.summary}")
if __name__ == "__main__":
main()
에이전트는 세 가지 계층을 모두 조정하며, 오류를 우아하게 처리하고 포괄적인 조사 결과를 생성합니다.
구성
애플리케이션이 성공적으로 실행되도록 필요한 모든 비밀 정보와 키를 설정하기 위해 src/config.py 파일을 생성합니다:
import os
from dotenv import load_dotenv
load_dotenv()
class Settings:
# SERP API
BRIGHT_DATA_API_TOKEN: str = os.getenv("BRIGHT_DATA_API_TOKEN", "")
BRIGHT_DATA_SERP_ZONE: str = os.getenv("BRIGHT_DATA_SERP_ZONE", "")
# 웹 언락커
BRIGHT_DATA_CUSTOMER_ID: str = os.getenv("BRIGHT_DATA_CUSTOMER_ID", "")
BRIGHT_DATA_UNLOCKER_ZONE: str = os.getenv("BRIGHT_DATA_UNLOCKER_ZONE", "")
BRIGHT_DATA_UNLOCKER_PASSWORD: str = os.getenv("BRIGHT_DATA_UNLOCKER_PASSWORD", "")
# OpenAI (위험 분석용)
OPENAI_API_KEY: str = os.getenv("OPENAI_API_KEY", "")
# OpenHands (에이전트 스크립트 생성을 위해)
LLM_API_KEY: str = os.getenv("LLM_API_KEY", "")
LLM_MODEL: str = os.getenv("LLM_MODEL", "openhands/claude-sonnet-4-5-20260929")
settings = Settings()API 계층 구축
FastAPI를 사용하여 REST 엔드포인트를 통해 에이전트를 노출하기 위해 api/main.py를 생성합니다:
from fastapi import FastAPI, HTTPException, BackgroundTasks
from pydantic import BaseModel
from typing import Optional
import uuid
import sys
sys.path.insert(0, 'src')
from agent import TPRMAgent, InvestigationResult
app = FastAPI(
title="TPRM 에이전트 API",
description="자율적 제3자 위험 관리 에이전트",
version="1.0.0",)
investigations: dict[str, InvestigationResult] = {}
agent = TPRMAgent()
class InvestigationRequest(BaseModel):
vendor_name: str
categories: Optional[list[str]] = None
generate_monitors: bool = True
class InvestigationResponse(BaseModel):
investigation_id: str
status: str
message: str
@app.post("/investigate", response_model=InvestigationResponse)
def start_investigation(
request: InvestigationRequest,
background_tasks: BackgroundTasks,
):
"""새로운 벤더 조사를 시작합니다."""
investigation_id = str(uuid.uuid4())
def run_investigation():
result = agent.investigate(
vendor_name=request.vendor_name,
categories=request.categories,
generate_monitors=request.generate_monitors,
)
investigations[investigation_id] = result
background_tasks.add_task(run_investigation)
return InvestigationResponse(
investigation_id=investigation_id,
status="started",
message=f"{request.vendor_name}에 대한 조사가 시작되었습니다.",
)
@app.get("/investigate/{investigation_id}")
def get_investigation(investigation_id: str):
"""조사 결과를 가져옵니다."""
if investigation_id not in investigations:
raise HTTPException(status_code=404, detail="조사가 발견되지 않았거나 아직 진행 중입니다")
return investigations[investigation_id]
@app.get("/reports/{vendor_name}")
def get_reports(vendor_name: str):
"""공급업체별 모든 보고서 조회."""
vendor_reports = [
result
for result in investigations.values()
if result.vendor_name.lower() == vendor_name.lower()
]
if not vendor_reports:
raise HTTPException(status_code=404, detail="해당 벤더에 대한 보고서를 찾을 수 없습니다")
return vendor_reports
@app.get("/health")
def health_check():
"""상태 점검 엔드포인트."""
return {"status": "healthy"}로컬에서 API 실행:
python -m uvicorn api.main:app --reloadhttp://localhost:8000/docs에서 대화형 API 문서를 살펴보세요.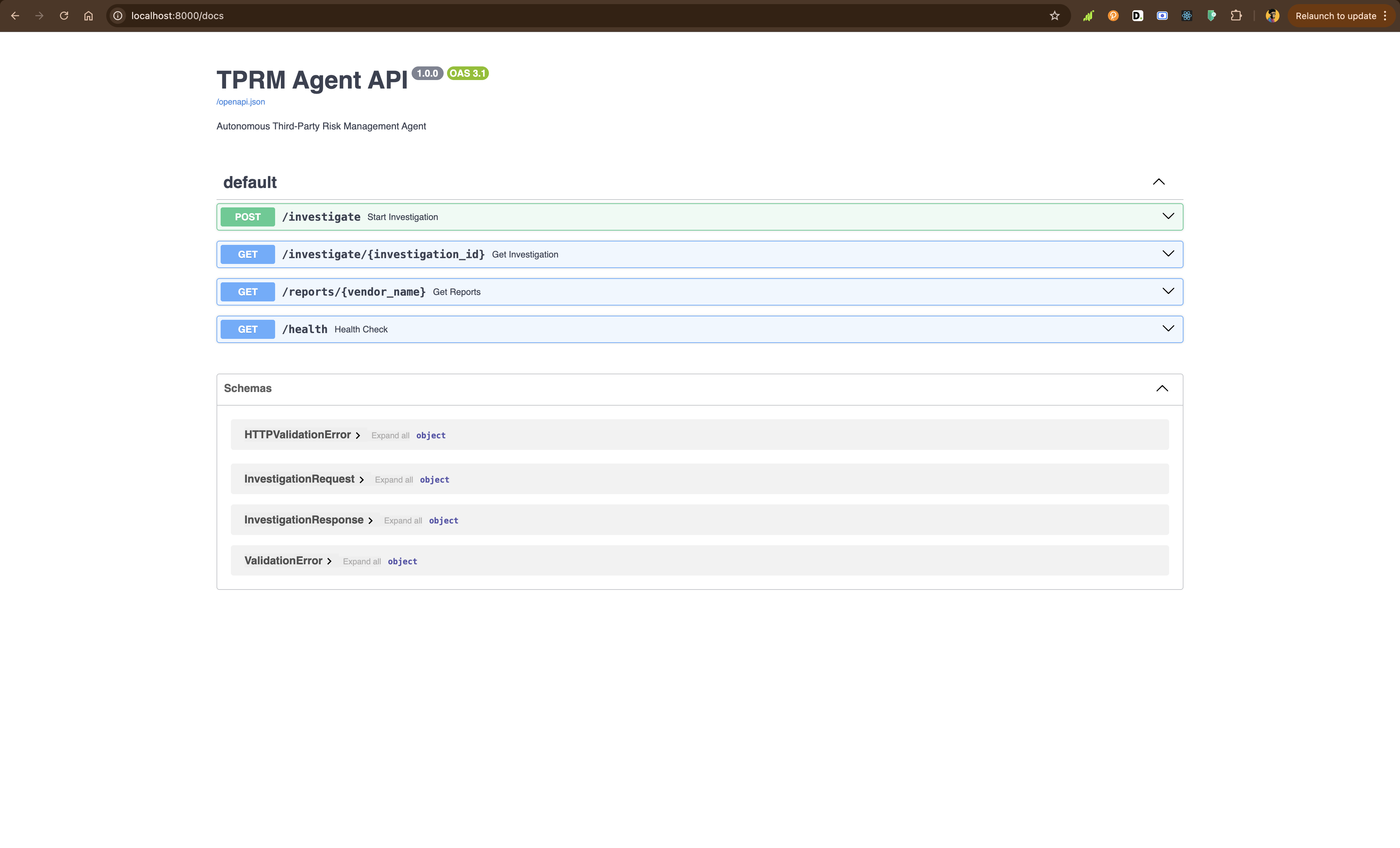
브라우저 API로 기능 강화 (스크래핑 브라우저)
법원 등록처처럼 양식 제출이 필요한 복잡한 시나리오나 자바스크립트 중심 사이트의 경우, Bright Data의 브라우저 API(스크래핑 브라우저)로 에이전트를 강화할 수 있습니다. 웹 언락커 API 및 SERP API와 유사한 방식으로 설정 가능합니다.
브라우저 API는 Chrome DevTools Protocol(CDP)을 통해 Playwright로 제어하는 클라우드 호스팅 브라우저를 제공합니다. 이는 다음과 같은 경우에 유용합니다:
- 양식 제출 및 탐색이 필요한법원 등록부 검색
- 동적 콘텐츠 로딩이 많은자바스크립트 중심 사이트
- 다단계 인증 절차
- 규정 준수 문서용스크린샷 캡처
구성
브라우저 API 자격 증명을 .env에 추가하세요:
# 브라우저 API
BRIGHT_DATA_BROWSER_USER: str = os.getenv("BRIGHT_DATA_BROWSER_USER", "")
BRIGHT_DATA_BROWSER_PASSWORD: str = os.getenv("BRIGHT_DATA_BROWSER_PASSWORD", "")브라우저 클라이언트 구현
src/browser.py 생성:
import asyncio
from playwright.async_api import async_playwright
from dataclasses import dataclass
from typing import Optional
from config import settings
@dataclass
class BrowserContent:
url: str
title: str
text: str
screenshot_path: Optional[str]
success: bool
error: Optional[str] = None
class BrowserClient:
"""Bright Data Browser API(스크래핑 브라우저)를 사용하여 동적 콘텐츠에 접근합니다.
다음과 같은 경우에 사용하세요:
- 완전한 렌더링이 필요한 자바스크립트 중심 사이트
- 다단계 양식(예: 법원 등록 검색)
- 클릭, 스크롤 또는 상호작용이 필요한 사이트
- 규정 준수 문서화를 위한 스크린샷 캡처
"""
def __init__(self):
# CDP 연결용 WebSocket 엔드포인트 생성
auth = f"{settings.BRIGHT_DATA_BROWSER_USER}:{settings.BRIGHT_DATA_BROWSER_PASSWORD}"
self.endpoint_url = f"wss://{auth}@brd.superproxy.io:9222"
async def fetch_dynamic_page(
self,
url: str,
wait_for_selector: Optional[str] = None,
take_screenshot: bool = False,
screenshot_path: Optional[str] = None,
) -> BrowserContent:
"""Browser API를 사용하여 동적 페이지의 콘텐츠를 가져옵니다."""
async with async_playwright() as playwright:
try:
print(f"Bright Data 스크래핑 브라우저에 연결 중...")
browser = await playwright.chromium.connect_over_cdp(self.endpoint_url)
try:
page = await browser.new_page()
print(f"{url}로 이동 중...")
await page.goto(url, timeout=120000)
# 지정된 선택자가 있다면 대기
if wait_for_selector:
await page.wait_for_selector(wait_for_selector, timeout=30000)
# 페이지 콘텐츠 가져오기
title = await page.title()
# 텍스트 추출
text = await page.evaluate("() => document.body.innerText")
# 요청 시 스크린샷 촬영
if take_screenshot and screenshot_path:
await page.screenshot(path=screenshot_path, full_page=True)
return BrowserContent(
url=url,
title=title,
text=text[:10000],
screenshot_path=screenshot_path if take_screenshot else None,
success=True,
)
finally:
await browser.close()
except Exception as e:
return BrowserContent(
url=url,
title="",
text="",
screenshot_path=None,
success=False,
error=str(e),
)
async def fill_and_submit_form(
self,
url: str,
form_data: dict[str, str],
submit_selector: str,
result_selector: str,
) -> BrowserContent:
"""양식을 작성하고 결과를 가져옵니다 - 법원 등록부에 유용합니다."""
async with async_playwright() as playwright:
try:
browser = await playwright.chromium.connect_over_cdp(self.endpoint_url)
try:
page = await browser.new_page()
await page.goto(url, timeout=120000)
# 양식 필드 입력
for selector, value in form_data.items():
await page.fill(selector, value)
# 양식 제출
await page.click(submit_selector)
# 결과 대기
await page.wait_for_selector(result_selector, timeout=30000)
title = await page.title()
text = await page.evaluate("() => document.body.innerText")
return BrowserContent(
url=url,
title=title,
text=text[:10000],
screenshot_path=None,
success=True,
)
finally:
await browser.close()
except Exception as e:
return BrowserContent(
url=url,
title="",
text="",
screenshot_path=None,
success=False,
error=str(e),
)
async def scroll_and_collect(
self,
url: str,
scroll_count: int = 5,
wait_between_scrolls: float = 1.0,
) -> BrowserContent:
"""무한 스크롤 페이지를 처리합니다."""
async with async_playwright() as playwright:
try:
browser = await playwright.chromium.connect_over_cdp(self.endpoint_url)
try:
page = await browser.new_page()
await page.goto(url, timeout=120000)
# 여러 번 아래로 스크롤
for i in range(scroll_count):
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
await asyncio.sleep(wait_between_scrolls)
title = await page.title()
text = await page.evaluate("() => document.body.innerText")
return BrowserContent(
url=url,
title=title,
text=text[:10000],
screenshot_path=None,
success=True,
)
finally:
await browser.close()
except Exception as e:
return BrowserContent(
url=url,
title="",
text="",
screenshot_path=None,
success=False,
error=str(e),
)
# 법원 등록부 검색 예시 사용법
async def example_court_search():
client = BrowserClient()
# 예시: 법원 기록 검색
result = await client.fill_and_submit_form(
url="https://example-court-registry.gov/search",
form_data={
"#party-name": "Acme Corp",
"#case-type": "civil",
},
submit_selector="#search-button",
result_selector=".search-results",
)
if result.success:
print(f"법원 기록 발견: {result.text[:500]}")
else:
print(f"오류: {result.error}")
if __name__ == "__main__":
asyncio.run(example_court_search())브라우저 API와 웹 언락커의 사용 시점
| 시나리오 | 사용법 |
|---|---|
| 단순 HTTP 요청 | 웹 언락커 |
| 정적 HTML 페이지 | 웹 언락커 |
| 로드 시 CAPTCHA | 웹 잠금 해제기 |
| 자바스크립트로 렌더링된 콘텐츠 | 브라우저 API |
| 양식 제출 | 브라우저 API |
| 다단계 탐색 | 브라우저 API |
| 스크린샷 필요 | 브라우저 API |
Railway를 통한 배포
TPRM 에이전트는 Railway 또는 Render를 사용하여 프로덕션에 배포할 수 있으며, 두 플랫폼 모두 대규모 종속성을 가진 Python 애플리케이션을 지원합니다.
Railway는 OpenHands SDK와 같이 중대한 종속성을 가진 Python 애플리케이션을 배포하기 위한 가장 쉬운 옵션입니다. 이를 사용하려면 가입하고 계정을 생성해야 합니다.
1단계: Railway CLI를 전역으로 설치
npm i -g @railway/cli2단계: Procfile 파일 추가
애플리케이션 루트 폴더에 Procfile 파일을 새로 생성하고 아래 내용을 추가하세요. 이는 배포를 위한 구성 또는 시작 명령으로 사용됩니다.
web: uvicorn api.main:app --host 0.0.0.0 --port $PORT3단계: 프로젝트 디렉터리에서 Railway 로그인 및 초기화
railway login
railway init4단계: 배포
railway up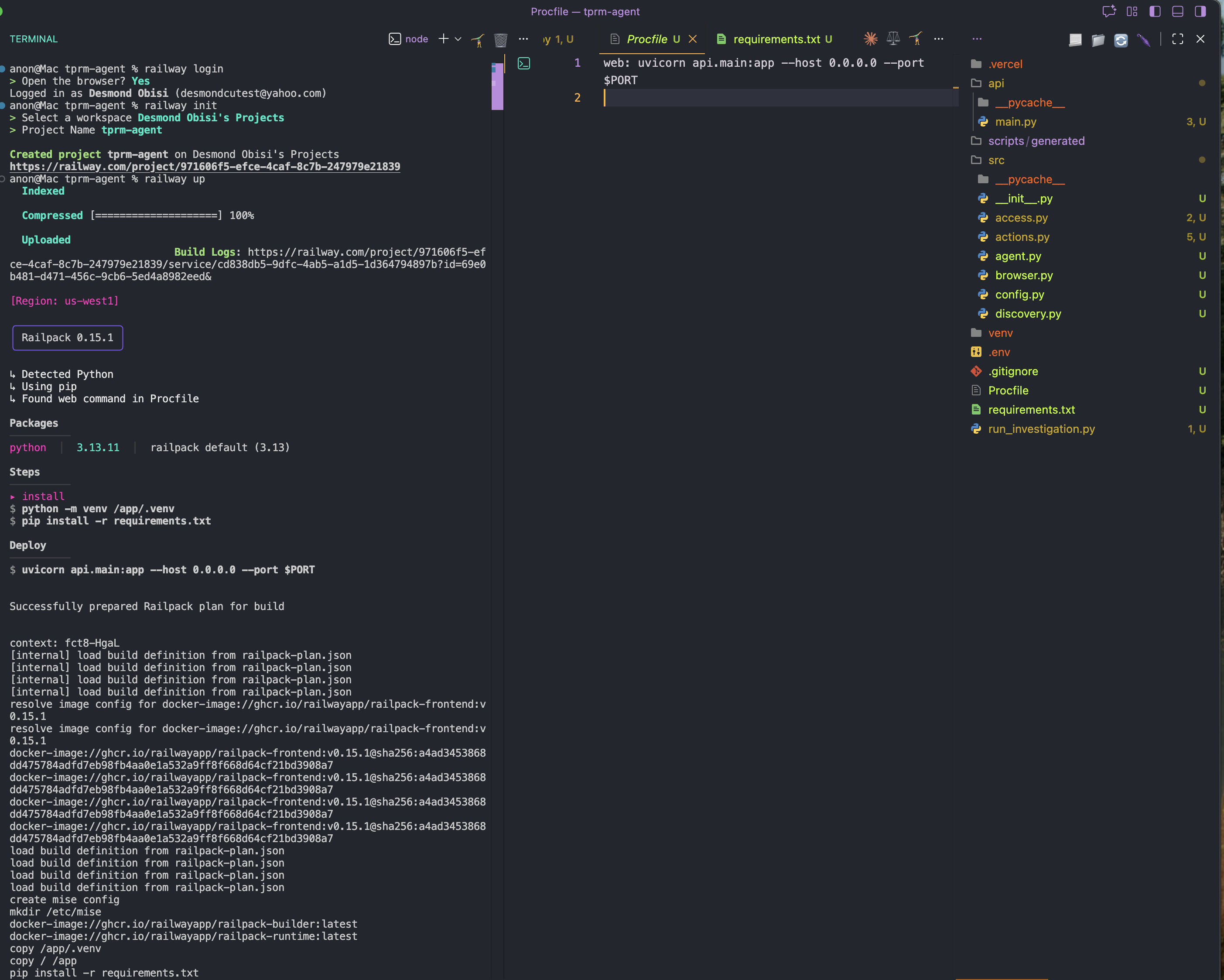
5단계: 환경 변수 추가
Railway 프로젝트 대시보드 → 설정 → 공유 변수로 이동하여 아래와 같이 변수와 값을 추가하세요:
BRIGHT_DATA_API_TOKEN
BRIGHT_DATA_SERP_ZONE
BRIGHT_DATA_UNLOCKER_ZONE
OPENAI_API_KEY
LLM_API_KEY
LLM_MODEL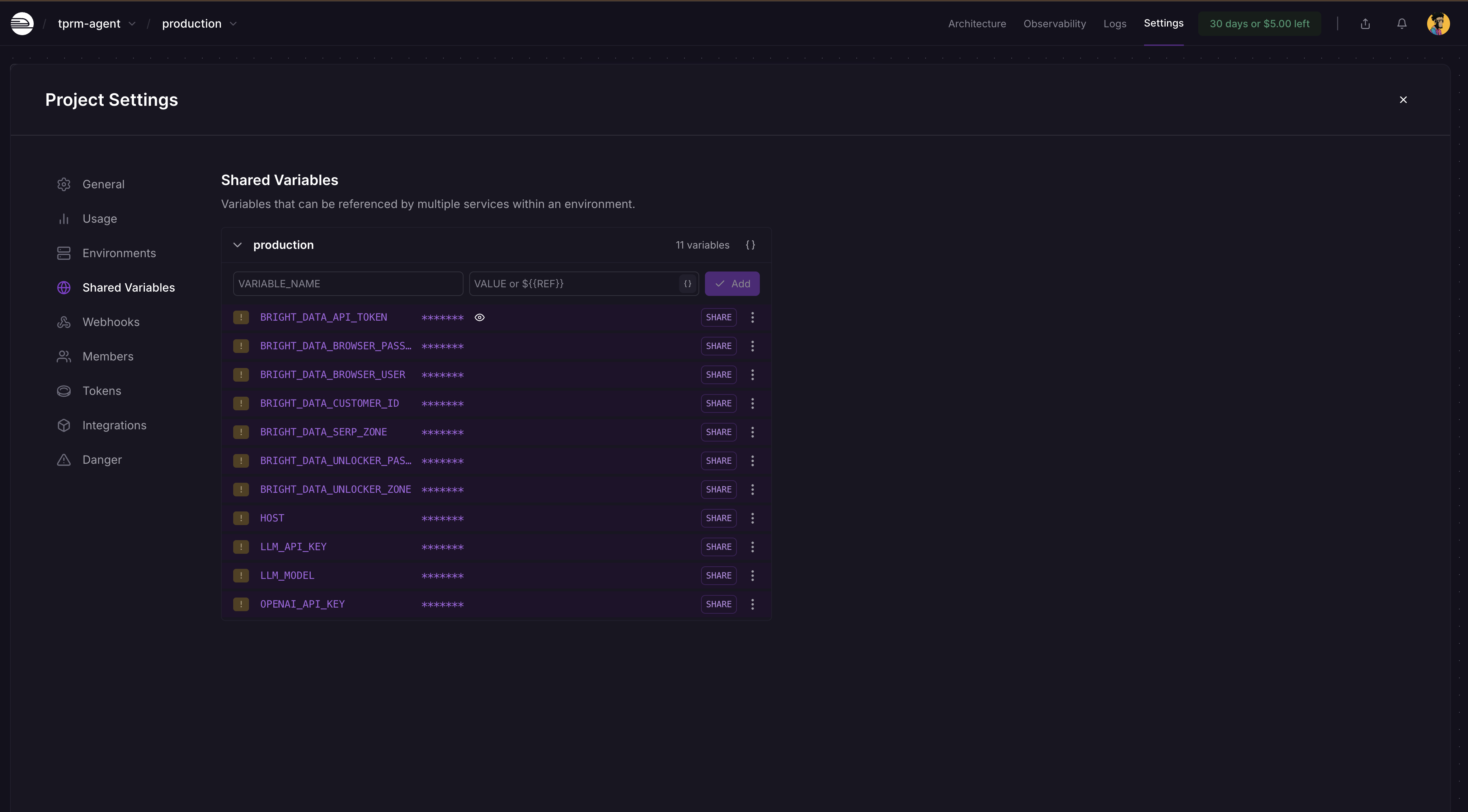
Railway는 변경 사항을 자동으로 감지하고 대시보드에서 재배포를 요청합니다. 배포를 클릭하면 앱이 비밀 정보로 업데이트됩니다.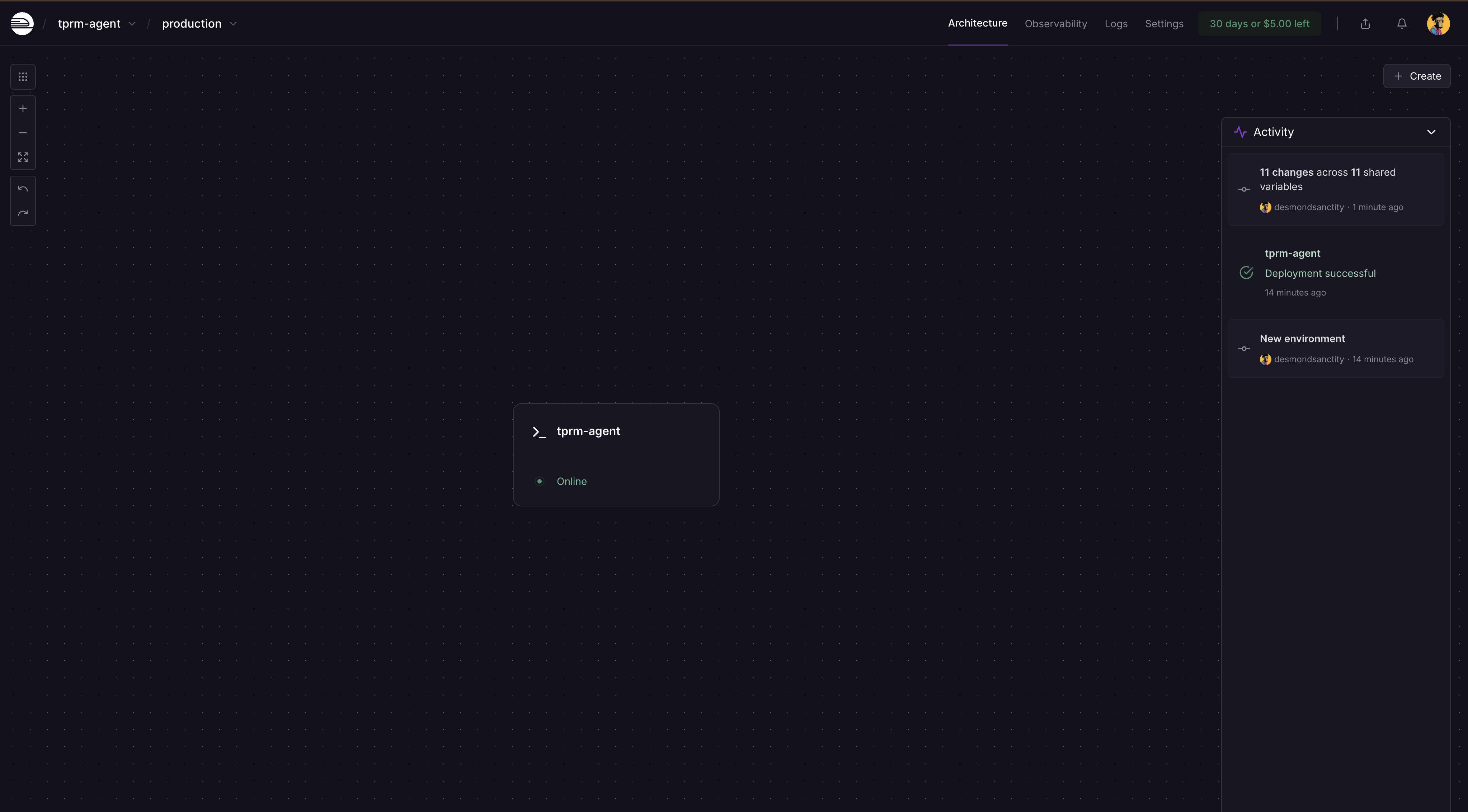
재배포 후 서비스 카드를 클릭하고 설정을 선택하면, 서비스가 아직 공개되지 않아 도메인을 생성할 수 있는 위치가 표시됩니다. 공개 URL을 얻으려면 도메인 생성을 클릭하세요.
완전한 조사 실행
로컬에서 curl로 실행하기
FastAPI 서버 시작:
# 가상 환경 활성화
source venv/bin/activate # Windows: venvScriptsactivate
# 서버 실행
python -m uvicorn api.main:app --reloadhttp://localhost:8000/docs에 접속하여 대화형 API 문서를 살펴보세요.
API 요청 수행하기
- 조사를 시작하세요:
curl -X POST "http://localhost:8000/investigate"
-H "Content-Type: application/json"
-d '{
"vendor_name": "Acme Corp",
"categories": ["litigation", "fraud"],
"generate_monitors": true
}'- 이 요청은 조사 ID를 반환합니다:
{
"investigation_id": "f6af2e0f-991a-4cb7-949e-2f316e677b5c",
"status": "started",
"message": "Acme Corp에 대한 조사가 시작되었습니다"
}- 조사 상태 확인:
curl http://localhost:8000/investigate/f6af2e0f-991a-4cb7-949e-2f316e677b5c에이전트를 스크립트로 실행하기
프로젝트 루트에 run_investigation.py 파일을 생성합니다:
import sys
sys.path.insert(0, 'src')
from agent import TPRMAgent
def investigate_vendor():
"""공급업체에 대한 완전한 조사를 실행합니다."""
agent = TPRMAgent()
# 조사 실행
result = agent.investigate(
vendor_name="Acme Corp",
categories=["litigation", "financial", "fraud"],
generate_monitors=True,
)
# 요약 출력
print(f"n{'='*60}")
print(f"조사 완료: {result.vendor_name}")
print(f"{'='*60}")
print(f"발견된 소스: {result.total_sources_found}")
print(f"접근된 소스: {result.total_sources_accessed}")
print(f"위험 평가: {len(result.risk_assessments)}")
print(f"모니터링 스크립트: {len(result.monitoring_scripts)}")
# 위험 평가 출력
for assessment in result.risk_assessments:
print(f"n{'─'*60}")
print(f"[{assessment.category.upper()}] 심각도: {assessment.severity.upper()}")
print(f"{'─'*60}")
print(f"요약: {assessment.summary}")
print("n주요 발견 사항:")
for finding in assessment.key_findings:
print(f" • {finding}")
print("n권장 조치:")
for action in assessment.recommended_actions:
print(f" → {action}")
# 모니터링 스크립트 정보 출력
for script in result.monitoring_scripts:
print(f"n{'='*60}")
print(f"생성된 모니터링 스크립트")
print(f"{'='*60}")
print(f"경로: {script.script_path}")
print(f"모니터링 대상 URL 수: {len(script.urls_monitored)}")
print(f"모니터링 주기: {script.check_frequency}")
# 오류 발생 시 출력
if result.errors:
print(f"n{'='*60}")
print("오류:")
for error in result.errors:
print(f" ⚠️ {error}")
if __name__ == "__main__":
investigate_vendor()새 터미널에서 조사 스크립트 실행
# 가상 환경 활성화
source venv/bin/activate # Windows: venvScriptsactivate
# 조사 스크립트 실행
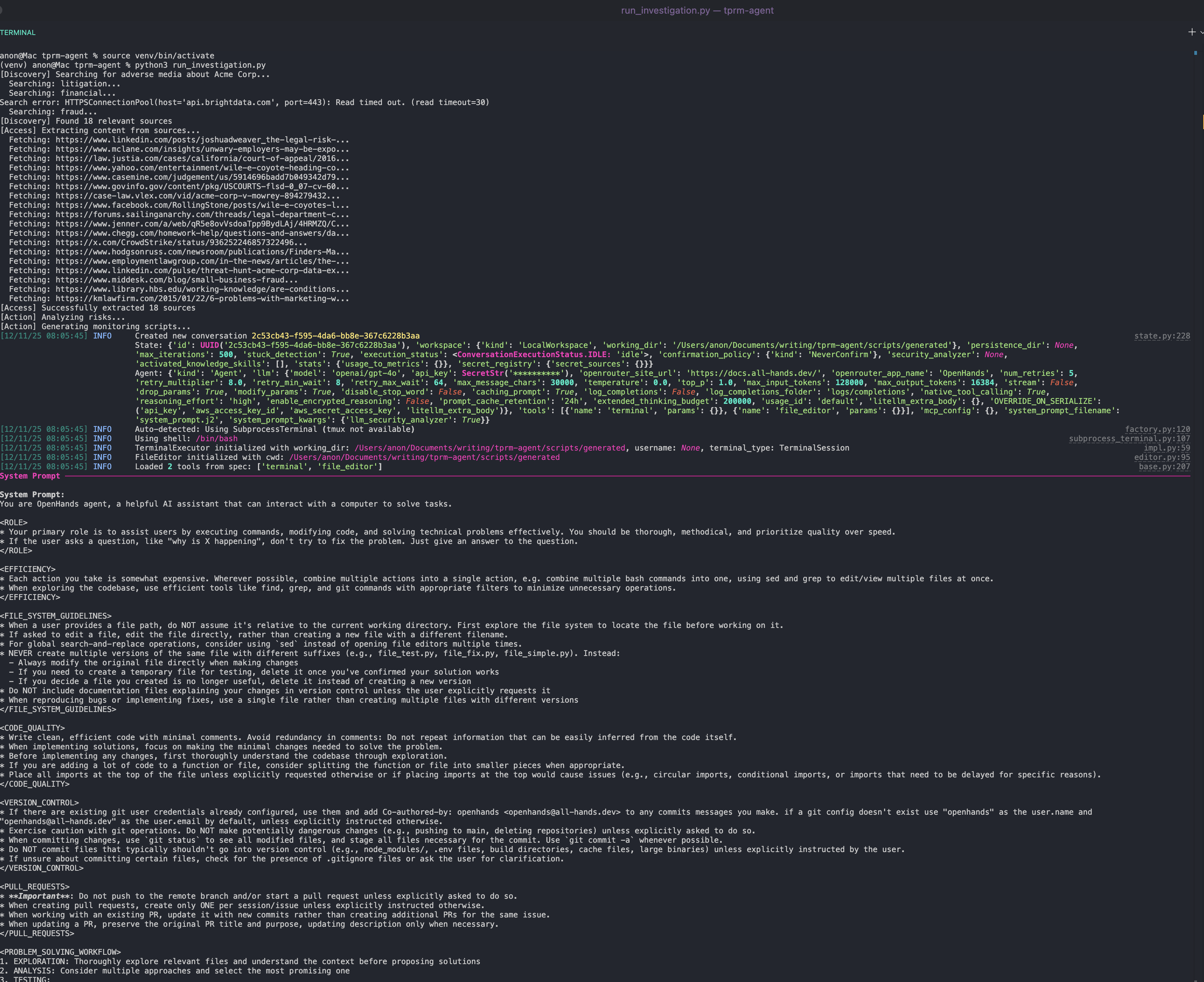
python run_investigation.py에이전트는 다음을 수행합니다:
- SERP API를 사용하여 구글에서 부정적 미디어 검색
- 웹 언락커를 사용하여 출처 접근
- OpenAI를 사용하여 콘텐츠의 위험 심각도 분석
- OpenHands SDK를 사용하여 cron으로 예약 가능한 Python 모니터링 스크립트 생성
자동 생성된 모니터링 스크립트 실행
조사 완료 후 scripts/generated 폴더에서 모니터링 스크립트를 확인하세요:
cd scripts/generated
python monitor_acme_corp.py모니터링 스크립트는 Bright Data Web Unlocker API를 사용하여 모든 모니터링 대상 URL을 확인하고 다음을 출력합니다: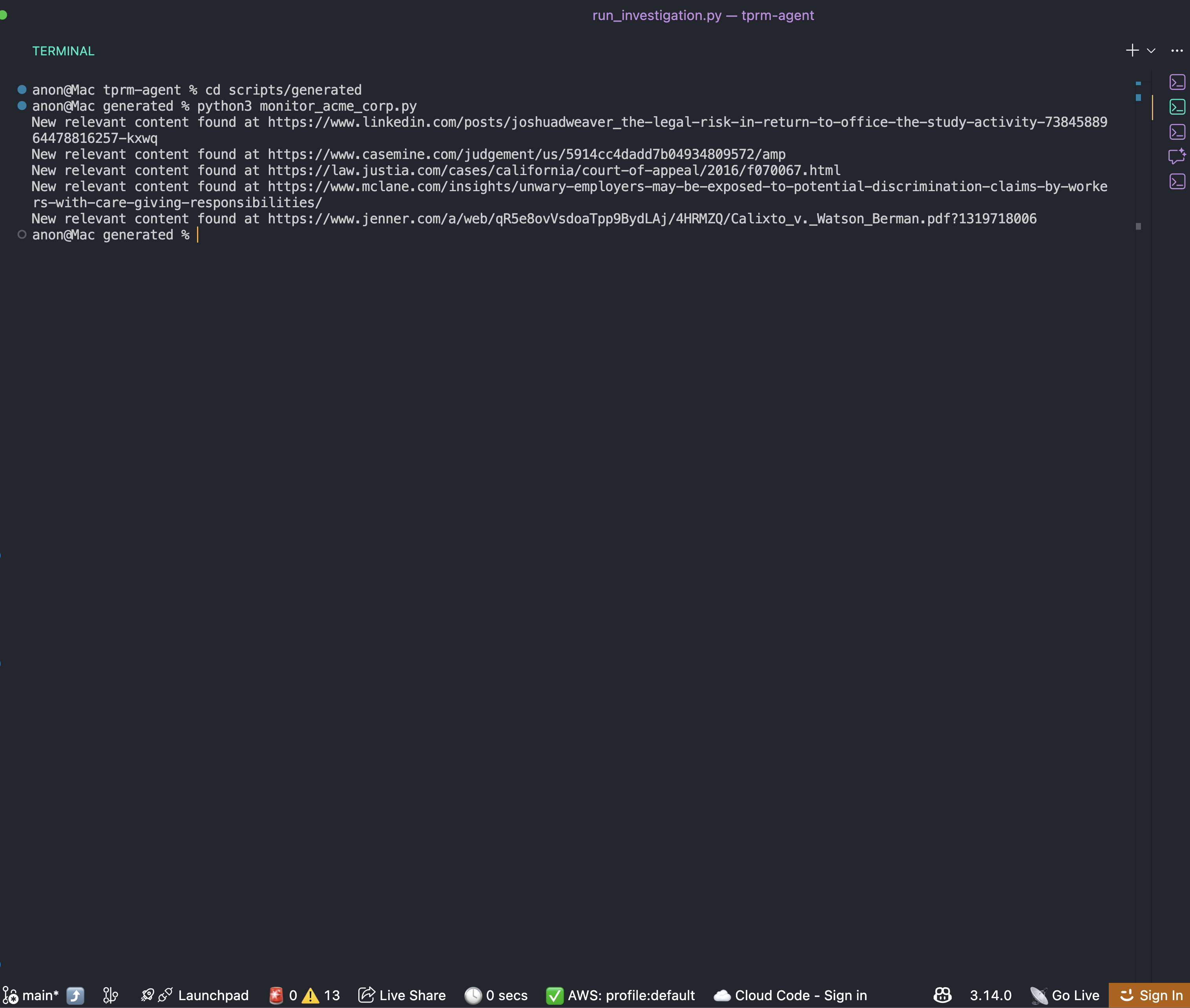
이제 비즈니스에 대한 정확하고 최신 정보를 항상 확보하기 위해 원하는 대로 스크립트의 cron 스케줄을 설정할 수 있습니다.
마무리
이제 공급업체 부정적 미디어 조사를 자동화하는 기업용 TPRM 에이전트 구축을 위한 완전한 프레임워크를 확보했습니다. 이 시스템은:
- Bright Data SERP API를 사용하여 여러 범주에 걸친 위험 신호를탐지합니다
- Bright Data Web Unlocker를 통해 콘텐츠접근
- OpenAI를 활용한 위험분석 및 OpenHands SDK를 통한 모니터링 스크립트 생성
- 복잡한 시나리오를 위한 Browser API 로 기능강화
모듈식 아키텍처로 쉽게 확장 가능합니다:
RISK_CATEGORIES사전 업데이트로 새로운 위험 범주 추가- API 계층 확장을 통해 GRC 플랫폼과 통합
- 백그라운드 작업 큐를 사용하여 수천 개의 공급업체로 확장
- 브라우저 API 개선 사항을 활용하여 법원 등록부 검색 기능 추가
다음 단계
이 에이전트를 더욱 개선하려면 다음을 고려하십시오:
- 추가 데이터 소스 통합: SEC 제출 서류, OFAC 제재 목록, 기업 등록부
- 데이터베이스 지속성 추가: 조사 이력을 PostgreSQL 또는 MongoDB에 저장
- 웹훅 알림 구현: 고위험 공급업체 탐지 시 Slack 또는 Teams에 알림 전송
- 대시보드 구축: 공급업체 위험 점수를 시각화하는 React 프론트엔드 생성
- 자동화된 스캔 예약: 정기적인 공급업체 모니터링을 위해 Celery 또는 APScheduler 사용