여러 플랫폼에 흩어진 고객 리뷰는 기업에 분석 난제를 안깁니다. 수동 리뷰 모니터링은 시간이 많이 소요되며 핵심 인사이트를 놓치는 경우가 많습니다. 본 가이드는 다양한 출처의 리뷰를 자동으로 수집, 분석, 분류하는 AI 에이전트 구축 방법을 안내합니다.
배울 내용:
- CrewAI와 Bright Data의 Web MCP를 활용한 리뷰 인텔리전스 시스템 구축 방법
- 고객 피드백에 대한 측면 기반 감정 분석 수행 방법
- 주제별 리뷰 분류 및 실행 가능한 인사이트 생성 방법
GitHub에서 최종 프로젝트를 확인해 보세요!
CrewAI란 무엇인가요?
CrewAI는 협업형 AI 에이전트 팀 구축을 위한 오픈소스 프레임워크입니다. 복잡한 워크플로우를 실행하기 위해 에이전트의 역할, 목표, 도구를 정의합니다. 각 에이전트는 특정 작업을 처리하면서 공동 목표를 향해 협력합니다.
CrewAI는 다음과 같이 구성됩니다:
- 에이전트: 정의된 책임과 도구를 가진 LLM 기반 작업자
- 작업(Task): 명확한 출력 요구사항을 가진 특정 업무
- 도구: 데이터 추출과 같은 특수 작업을 위해 에이전트가 사용하는 기능
- 크루(Crew): 함께 작업하는 에이전트 집합
MCP란 무엇인가요?
MCP(Model Context Protocol)는 통합 인터페이스를 통해 AI 에이전트를 외부 도구 및 데이터 소스와 연결하는 JSON-RPC 2.0 표준입니다.
Bright Data의 웹 MCP 서버는 1억 5천만 개 이상의 회전하는 주거용 IP를 통한 봇 방지 기능, 동적 콘텐츠를 위한 자바스크립트 렌더링, 스크랩된 데이터의 깔끔한 JSON 출력, 다양한 플랫폼을 위한 50개 이상의 기성 도구를 통해 웹 스크래핑 기능에 대한 직접적인 접근을 제공합니다.
구축 중인 시스템: 다중 소스 리뷰 인텔리전스 에이전트
G2, Capterra, Trustpilot, TrustRadius 등 여러 플랫폼에서 특정 기업에 대한 리뷰를 자동으로 스크래핑하고 각 플랫폼의 평점과 주요 리뷰를 가져온 다음, 측면 기반 감정 분석을 수행하고 피드백을 주제(지원, 가격, 사용 편의성)별로 분류하며 각 카테고리의 감정 점수를 매기고 실행 가능한 비즈니스 인사이트를 생성하는 CrewAI 시스템을 만들 것입니다.
필수 사항
개발 환경 설정:
- Python 3.11 이상
- 웹 MCP 서버용 Node.js 및 npm
- Bright Data 계정 – 가입 후 API 토큰 생성(무료 체험 크레딧 제공).
- Nebius API 키 – Nebius AI Studio에서 키 생성( + Get API Key 클릭). 무료로 사용 가능하며 결제 프로필이 필요하지 않습니다.
- Python 가상 환경 – 종속성을 분리하여 관리합니다.
venv문서를 참조하세요.
환경 설정
프로젝트 디렉터리를 생성하고 종속성을 설치하세요:
python -m venv venv
# macOS/Linux: source venv/bin/activate
# Windows: venv\Scripts\activate
pip install "crewai-tools[mcp]" crewai mcp python-dotenv pandas textblob
review_intelligence. py라는 새 파일을 생성하고 다음 임포트를 추가하세요:
from crewai import Agent, Task, Crew, Process
from crewai_tools import MCPServerAdapter
from mcp import StdioServerParameters
from crewai.llm import LLM
import os
import json
import pandas as pd
from datetime import datetime
from dotenv import load_dotenv
from textblob import TextBlob
load_dotenv()
Bright Data 웹 MCP 구성
인증 정보를 포함한 .env 파일을 생성하세요:
BRIGHT_DATA_API_TOKEN="your_api_token_here"
WEB_UNLOCKER_ZONE="your_web_unlocker_zone"
BROWSER_ZONE="your_browser_zone"
NEBIUS_API_KEY="your_nebius_api_key"
필요한 것:
- API 토큰: Bright Data 대시보드에서 새 API 토큰 생성
- 웹 언락커 영역: 부동산 사이트용 새 웹 언락커 영역 생성
- 브라우저 API 영역: 자바스크립트 중심 부동산 사이트용 새 브라우저 API 영역 생성
- Nebius API 키: 필수 조건에서 이미 생성됨
review_intelligence.py에서 LLM 및 웹 MCP 서버 구성:
llm = LLM(
model="nebius/Qwen/Qwen3-30B-A3B",
api_key=os.getenv("NEBIUS_API_KEY"))
server_params = StdioServerParameters(
command="npx",
args=["@brightdata/mcp"],
env={
"API_TOKEN": os.getenv("BRIGHT_DATA_API_TOKEN"),
"WEB_UNLOCKER_ZONE": os.getenv("WEB_UNLOCKER_ZONE"),
"BROWSER_ZONE": os.getenv("BROWSER_ZONE"),
},
)
에이전트 및 작업 정의
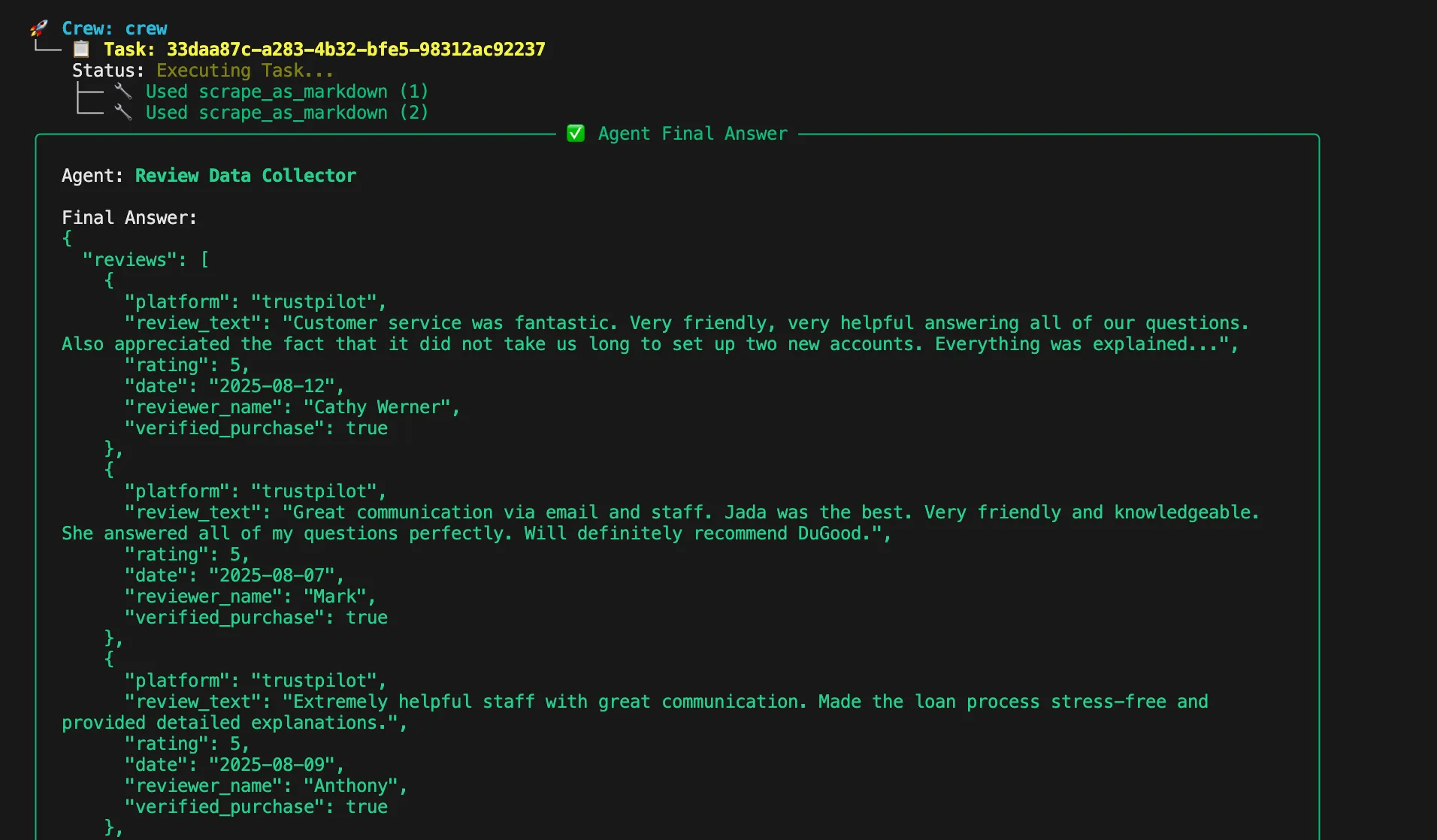
리뷰 분석의 다양한 측면을 위한 특수 에이전트를 정의합니다. 리뷰 스크레이퍼 에이전트는 여러 플랫폼에서 고객 리뷰를 추출하고, 리뷰 텍스트, 평점, 날짜, 플랫폼 출처가 포함된 정제되고 구조화된 JSON 데이터를 반환합니다. 이 에이전트는 웹 스크래핑에 대한 전문 지식을 갖추고 있으며, 리뷰 플랫폼 구조에 대한 깊은 이해와 봇 방지 조치 우회 능력을 보유하고 있습니다.
def build_review_scraper_agent(mcp_tools):
return Agent(
role="리뷰 데이터 수집기",
goal=(
"여러 플랫폼에서 고객 리뷰를 추출하고, 리뷰 텍스트, 평점, 날짜, 플랫폼 출처가 포함된 깔끔하고 구조화된 JSON 데이터를 반환합니다."
),
backstory=(
"리뷰 플랫폼 구조에 대한 깊은 지식을 갖춘 웹 스크래핑 전문가입니다. "
"반봇(anti-bot) 조치를 우회하고 아마존, 옐프, 구글 리뷰 등 다양한 플랫폼에서 완전한 리뷰 데이터셋을 추출하는 데 능숙합니다."
),
tools=mcp_tools,
llm=llm,
max_iter=3,
verbose=True,
)
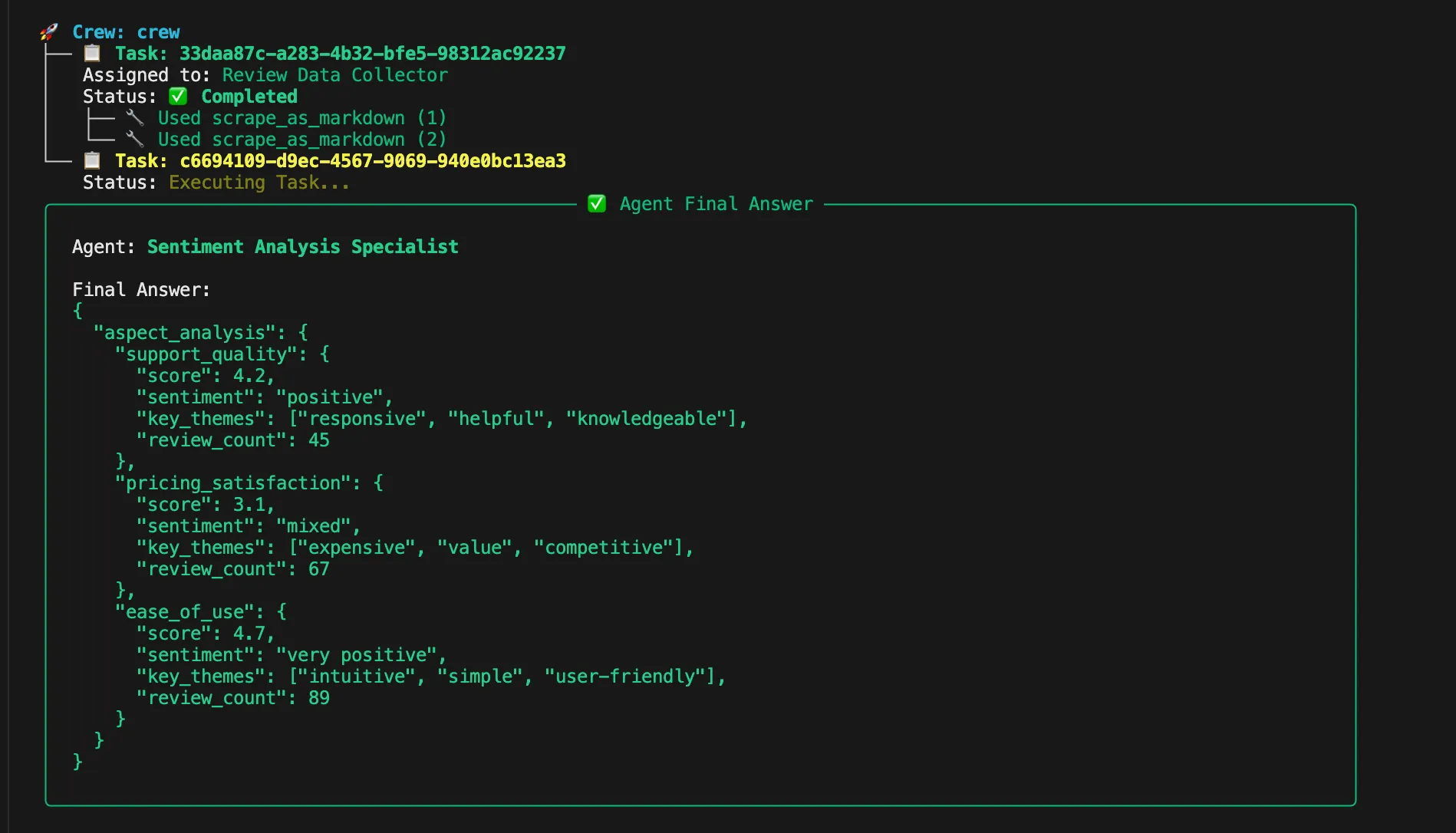
감정 분석 에이전트는 지원 품질, 가격 만족도, 사용 편의성이라는 세 가지 핵심 측면에 걸쳐 리뷰 감정을 분석합니다. 각 범주에 대해 수치 점수와 상세한 근거를 제공합니다. 이 에이전트는 자연어 처리 및 고객 감정 분석을 전문으로 하며, 감정 지표와 측면별 피드백 패턴 식별에 탁월합니다.
def build_sentiment_analyzer_agent():
return Agent(
role="감정 분석 전문가",
goal=(
"세 가지 핵심 측면(지원 품질, 가격 만족도, 사용 편의성)에 대한 리뷰 감정을 분석합니다. 각 범주에 대해 수치 점수와 상세한 근거를 제공합니다."
),
backstory=(
"자연어 처리 및 고객 감정 분석을 전문으로 하는 데이터 과학자. 고객 리뷰 내 감정 지표, 맥락적 단서, 측면별 피드백 패턴 식별에 탁월한 역량을 보유."
),
llm=llm,
max_iter=2,
verbose=True,
)
인사이트 생성 에이전트는 감정 분석 결과를 실행 가능한 비즈니스 인사이트로 전환합니다. 트렌드를 식별하고, 핵심 문제를 강조하며, 개선을 위한 구체적인 권장 사항을 제공합니다. 이 에이전트는 고객 경험 최적화 및 피드백 데이터를 구체적인 비즈니스 행동으로 전환하는 기술과 함께 전략적 분석 전문성을 제공합니다.
def build_insights_generator_agent():
return Agent(
role="비즈니스 인텔리전스 애널리스트",
goal=(
"감정 분석 결과를 실행 가능한 비즈니스 인사이트로 전환합니다. "
"추세를 파악하고, 핵심 문제를 강조하며, 구체적인 "
"개선 권장 사항을 제공합니다."
),
backstory=(
"고객 경험 최적화 분야의 전문성을 갖춘 전략적 분석가입니다. "
"고객 피드백 데이터를 구체적인 비즈니스 실행 방안과 "
"우선순위 프레임워크로 전환하는 데 능숙합니다."
),
llm=llm,
max_iter=2,
verbose=True,
)
크루 구성 및 실행
분석 파이프라인의 각 단계에 대한 작업을 생성합니다. 스크래핑 작업은 지정된 제품 페이지에서 리뷰를 수집하고 플랫폼 정보, 리뷰 텍스트, 평점, 날짜, 검증 상태가 포함된 구조화된 JSON을 출력합니다.
def build_scraping_task(agent, product_urls):
return Task(
description=f"다음 제품 페이지에서 리뷰 수집: {product_urls}",
expected_output="""{
"reviews": [
{
"platform": "amazon",
"review_text": "훌륭한 제품, 빠른 배송...",
"rating": 5,
"date": "2024-01-15",
"reviewer_name": "John D.",
"verified_purchase": true
}
],
"total_reviews": 150,
"platforms_scraped": ["amazon", "yelp"]
}""",
agent=agent,
)
감정 분석 작업은 리뷰를 처리하여 지원, 가격, 사용 편의성 측면을 분석합니다. 각 범주에 대한 수치 점수, 감정 분류, 주요 주제 및 리뷰 수를 반환합니다.
def build_sentiment_analysis_task(agent):
return Task(
description="지원, 가격, 사용 편의성 측면에 대한 감정을 분석합니다",
expected_output="""{
"aspect_analysis": {
"support_quality": {
"score": 4.2,
"sentiment": "positive",
"key_themes": ["responsive", "helpful", "knowledgeable"],
"review_count": 45
},
"pricing_satisfaction": {
"score": 3.1,
"sentiment": "혼합",
"key_themes": ["비싼", "가치", "경쟁력 있는"],
"review_count": 67
},
"사용 편의성": {
"점수": 4.7,
"감정": "매우 긍정적",
"주요 주제": ["직관적", "간단함", "사용자 친화적"],
"리뷰 수": 89
}
}
}""",
agent=agent,
)
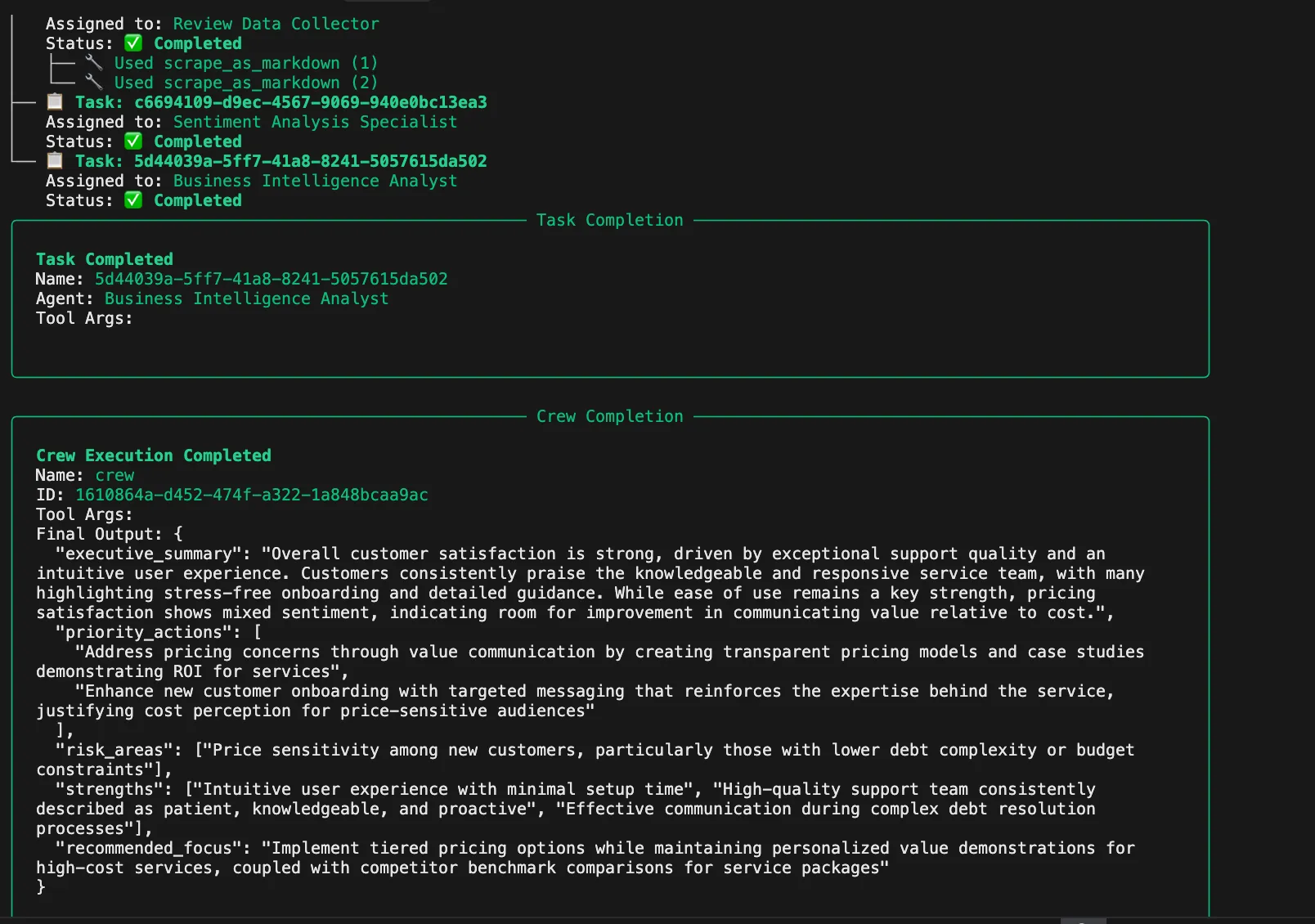
인사이트 작업은 감성 분석 결과를 바탕으로 실행 가능한 비즈니스 인텔리전스를 생성합니다. 경영진 요약, 우선순위 조치, 위험 영역, 강점 식별 및 전략적 권장 사항을 제공합니다.
def build_insights_task(agent):
return Task(
description="감정 분석을 통해 실행 가능한 비즈니스 인사이트 생성",
expected_output="""{
"executive_summary": "전반적인 고객 만족도는 매우 높습니다...",
"priority_actions": [
"가치 전달을 통한 가격 관련 우려 사항 해결",
"탁월한 사용 편의성 기준 유지"
],
"risk_areas": ["신규 고객의 가격 민감도"],
"strengths": ["직관적인 사용자 경험", "우수한 지원 팀"],
"recommended_focus": "가격 전략 최적화"
}""",
agent=agent,
)
측면 기반 감정 분석
리뷰에 언급된 특정 측면을 식별하고 관심 영역별 감정 점수를 계산하는 감정 분석 기능을 추가합니다.
def analyze_aspect_sentiment(reviews, aspect_keywords):
"""리뷰에 언급된 특정 측면에 대한 감정을 분석합니다."""
aspect_reviews = []
for review in reviews:
text = review.get('review_text', '').lower()
if any(keyword in text for keyword in aspect_keywords):
blob = TextBlob(review['review_text'])
sentiment_score = blob.sentiment.polarity
aspect_reviews.append({
'text': review['review_text'],
'sentiment_score': sentiment_score,
'rating': review.get('rating', 0),
'platform': review.get('platform', '')
})
return aspect_reviews
리뷰를 주제(지원, 가격, 사용 편의성)로 분류하기
분류 함수는 키워드 매칭을 기반으로 리뷰를 지원, 가격, 사용 편의성 주제로 분류합니다. 지원 키워드에는 고객 서비스 및 지원 관련 용어가 포함됩니다. 가격 키워드는 비용, 가치, 경제성 언급을 다룹니다.
def categorize_by_aspects(reviews):
"""리뷰를 지원, 가격, 사용 편의성 주제로 분류합니다."""
support_keywords = ['support', 'help', 'service', 'customer', 'response', 'assistance']
pricing_keywords = ['가격', '비용', '비싼', '싼', '가치', '돈', '부담 없는']
usability_keywords = ['쉬운', '어려운', '직관적인', '복잡한', '사용자 친화적인', '인터페이스']
분류된 = {
'지원': 리뷰에 대한 감정 분석(리뷰, 지원_키워드),
'가격': 리뷰에 대한 감정 분석(리뷰, 가격_키워드),
'사용 편의성': 리뷰에 대한 감정 분석(리뷰, 사용성_키워드)
}
분류된 반환
주제별 감정 점수 매기기
감정 분석을 수치 등급과 의미 있는 범주로 변환하는 점수화 로직 구현.
def calculate_aspect_scores(categorized_reviews):
"""각 측면 범주에 대한 수치 점수를 계산합니다."""
scores = {}
for aspect, reviews in categorized_reviews.items():
if not reviews:
scores[aspect] = {'score': 0, 'count': 0, 'sentiment': 'neutral'}
continue
# 평균 감정 점수 계산
sentiment_scores = [r['sentiment_score'] for r in reviews]
avg_sentiment = sum(sentiment_scores) / len(sentiment_scores)
# 1-5 점수로 변환
normalized_score = ((avg_sentiment + 1) / 2) * 5
# 감정 범주 결정
if avg_sentiment > 0.3:
sentiment_category = 'positive'
elif avg_sentiment < -0.3:
sentiment_category = 'negative'
else:
sentiment_category = 'neutral'
scores[aspect] = {
'score': round(normalized_score, 1),
'count': len(reviews),
'sentiment': sentiment_category,
'raw_sentiment': round(avg_sentiment, 2)
}
return scores
최종 인사이트 보고서 생성
모든 에이전트와 작업을 순차적으로 조정하여 워크플로 실행을 완료합니다. 주 함수는 스크래핑, 감정 분석, 인사이트 생성을 위한 특수화된 에이전트를 생성합니다. 이 에이전트들을 순차적 작업 처리가 가능한 크루로 구성합니다.
def analyze_reviews(product_urls):
"""리뷰 인텔리전스 워크플로우를 조정하는 메인 함수."""
with MCPServerAdapter(server_params) as mcp_tools:
# 에이전트 생성
scraper_agent = build_review_scraper_agent(mcp_tools)
sentiment_agent = build_sentiment_analyzer_agent()
insights_agent = build_insights_generator_agent()
# 작업 생성
scraping_task = build_scraping_task(scraper_agent, product_urls)
sentiment_task = build_sentiment_analysis_task(sentiment_agent)
insights_task = build_insights_task(insights_agent)
# 크루 조립
crew = Crew(
agents=[scraper_agent, sentiment_agent, insights_agent],
tasks=[scraping_task, sentiment_task, insights_task],
process=Process.sequential,
verbose=True
)
return crew.kickoff()
if __name__ == "__main__":
product_urls = [
"<https://www.amazon.com/product-example-1>",
"<https://www.yelp.com/biz/business-example>"
]
try:
result = analyze_reviews(product_urls)
print("리뷰 인텔리전스 분석 완료!")
print(json.dumps(result, indent=2))
except Exception as e:
print(f"분석 실패: {str(e)}")
분석 실행:
python review_intelligence.py
각 에이전트가 작업을 계획하고 실행하는 과정에서 에이전트의 사고 과정을 콘솔에서 확인할 수 있습니다. 시스템은 다음과 같은 방식으로 작동합니다:
- * 여러 플랫폼에서 포괄적인 리뷰 데이터 추출
- 경쟁 격차 및 시장 포지셔닝 분석
- 감정 패턴 처리 및 리뷰 품질 점수화
- 기능 언급 및 가격 정보 식별
- 전략적 권고사항 및 위험 경보 제공
결론
CrewAI와 Bright Data의 강력한 웹 데이터 플랫폼으로 리뷰 인텔리전스를 자동화하면 더 깊은 고객 인사이트를 확보하고, 경쟁 분석을 간소화하며, 더 스마트한 비즈니스 결정을 내릴 수 있습니다. Bright Data의 제품과 업계 최고의 봇 방지 웹 스크래핑 솔루션을 통해 모든 산업 분야의 리뷰 수집 및 감성 분석을 확장할 수 있습니다. 최신 전략과 업데이트를 확인하려면 Bright Data 블로그를 탐색하거나 상세한 웹 스크래핑 가이드에서 자세히 알아보시고, 지금 바로 고객 피드백의 가치를 극대화하세요.