

이 글을 마치면 다음을 이해하게 될 것입니다:
- Bright Data Google AI Mode Scraper API 서비스 활용 방법
- Skyvern을 활용한 작업 자동화
- Bright Data API 서비스를 Skyvern과 연동하여 웹 작업 자동화하기
- 자동화와 데이터 피드를 결합하여 전자상거래 어시스턴트 구축하기.
- 장바구니 상품 정보를 자동으로 가져오는 방법
자, 시작해 보세요!
Bright Data API 서비스 활용
브라우저 자동화의 핵심은 CAPTCHA, IP 차단, 동적 웹 로딩과 같은 문제를 우회하는 능력입니다. 바로 여기서 Bright Data가 필수적입니다.
120개 이상의 웹 도메인을 지원하는 Bright Data의 웹 스크레이퍼를 사용하면 브라우저 자동화가 더욱 효율적이고 안정적으로 이루어집니다. IP 차단, CAPTCHA, 쿠키 및 기타 형태의 봇 탐지와 같은 일반적인 스크레이핑 문제를 관리합니다.
시작하려면 무료 체험판에 가입하고 스크래핑하려는 도메인의 API 키와 dataset_id를 획득하세요. 이 정보만 있으면 바로 시작할 수 있습니다.
BBC 뉴스와 같은 모든 도메인에서 최신 데이터를 가져오는 단계는 다음과 같습니다:
- 아직 계정이 없다면 Bright Data 계정을 생성하세요. 무료 체험판이 제공됩니다.
- 웹 스크레이퍼 페이지로 이동하세요. 웹 스크레이퍼 라이브러리에서 사용 가능한 스크레이퍼 템플릿을 살펴보세요.
- BBC 뉴스와 같은 대상 도메인을 검색하여 선택하세요.
- BBC 뉴스 스크레이퍼 목록에서 ‘BBC 뉴스 — URL로 수집’을 선택하세요. 이 스크레이퍼는 도메인에 로그인하지 않고도 데이터를 가져올 수 있게 해줍니다.
- 스크레이퍼 API 옵션을 선택하세요. 노코드 스크레이퍼는 코드 없이 데이터셋을 가져오는 데 도움이 됩니다.
- API 요청 빌더를 클릭한 후
API 키,BBC 데이터셋 URL,dataset_id를복사하세요. API 키와dataset_id는워크플로우에서 자동화 기능을 활성화하는 데 필요합니다. 이를 통해 프로그래밍 시 Bright Data 기능을 직접 이용할 수 있습니다.
Skyvern이란?
Skyvern은 웹 브라우저 내 작업을 자동화하기 위해 인공 지능을 활용하는 AI 브라우저 자동화 도구입니다. 머신 러닝, 자연어 처리, 컴퓨터 비전을 결합하여 복잡한 브라우저 작업을 처리합니다.
Skyvern은 Selenium이나 Playwright 같은 기존 자동화 도구와 다음과 같은 점에서 차별화됩니다:
- UI 변경에 대한 적응성: 자가 복구 기능을 통해 Skyvern은 스크립트 중단 없이 UI 변경에 동적으로 적응합니다.
- 워크플로 복잡성: 단일 프롬프트를 통해 AI 추론을 활용한 다단계 워크플로를 처리할 수 있습니다.
- 시각적 인식: 컴퓨터 비전을 활용하여 UI 요소를 시각적으로 이해하고 상호작용합니다.
이러한 기능을 통해 Skyvern을 사용하여 예약 사이트에 로그인하거나, 양식을 작성하거나, 쇼핑 카트에 상품을 추가할 수 있습니다. Bright Data의 웹 스크래핑 기능과 통합하면 Skyvern은 다양한 웹 자동화 요구 사항을 해결할 수 있는 강력한 프레임워크를 제공할 수 있습니다.
자동화 워크플로
예를 들어, 온라인 스토어에서 차량 부품을 구매하려는 경우, 사용 가능한 옵션을 비교하고 자동으로 장바구니에 추가할 수 있습니다. 워크플로는 다음과 같습니다:
- Bright Data AI Mode Scraper API가 지정된 제조업체의 부품 번호 등 제품 설명 및 세부 정보를 가져옵니다.
- 사용자는 결과를 검토하고 선택합니다. Bright Data는 빠르고 안정적인 웹 데이터 검색을 제공합니다.
- Skyvern은 Bright Data에서 가져온 세부 정보를 사용하여 finditparts.com에 접속합니다. 그런 다음 사이트를 탐색하고 선택한 제품을 장바구니에 추가한 후 장바구니 세부 정보와 장바구니 URL을 출력합니다.
- 결제 및 지불 단계로 바로 진행하세요.
필수 조건
- Python 프로그래밍에 대한 기본 지식. Python은 여기에서 다운로드하세요.
- 활성화된 Bright Data 계정. 여기에서 가입하고 환영 이메일을 통해 API 키를 확인하세요.
- JSON 및 REST API에 대한 기본 지식
프로젝트 설정
1단계: Bright Data 설정
사용 사례에 Bright Data의 강력한 API 서비스를 활용하는 방법에 설명된 것과 동일한 단계를 따라 Bright Data API 키, 데이터 세트 ID 및 Google AI 모드 URL을 검색하십시오.
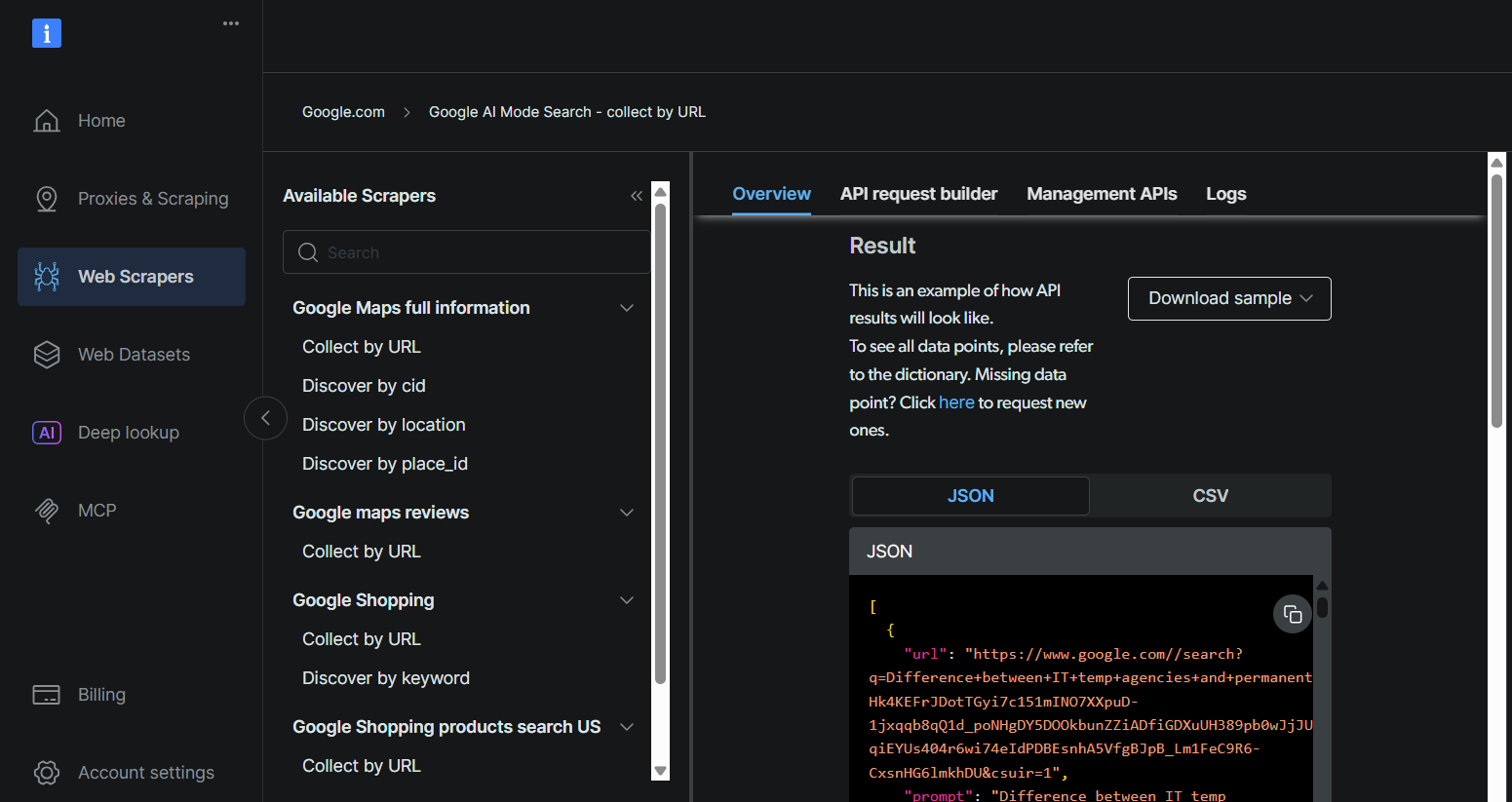
2단계: Skyvern Cloud 가입
- https://app.skyvern.com/로 이동하여 가입하면 5달러의 무료 크레딧을 받을 수 있습니다.
- Skyvern 에이전트에게 작업을 실행해 달라고 요청하여 작동 방식을 확인하세요. 예: Hacker News 홈페이지로 이동하여 상위 3개 게시물을 가져옵니다.
- 작업 진행 상황을 추적하려면 기록을 확인하세요. 완료 상태는 작업이 성공적으로 끝났음을 나타냅니다.
- 완료되면 기록에서 해당 작업을 클릭하여 출력 결과, 매개변수 및 작업에 대한 추가 세부 정보를 확인하세요.
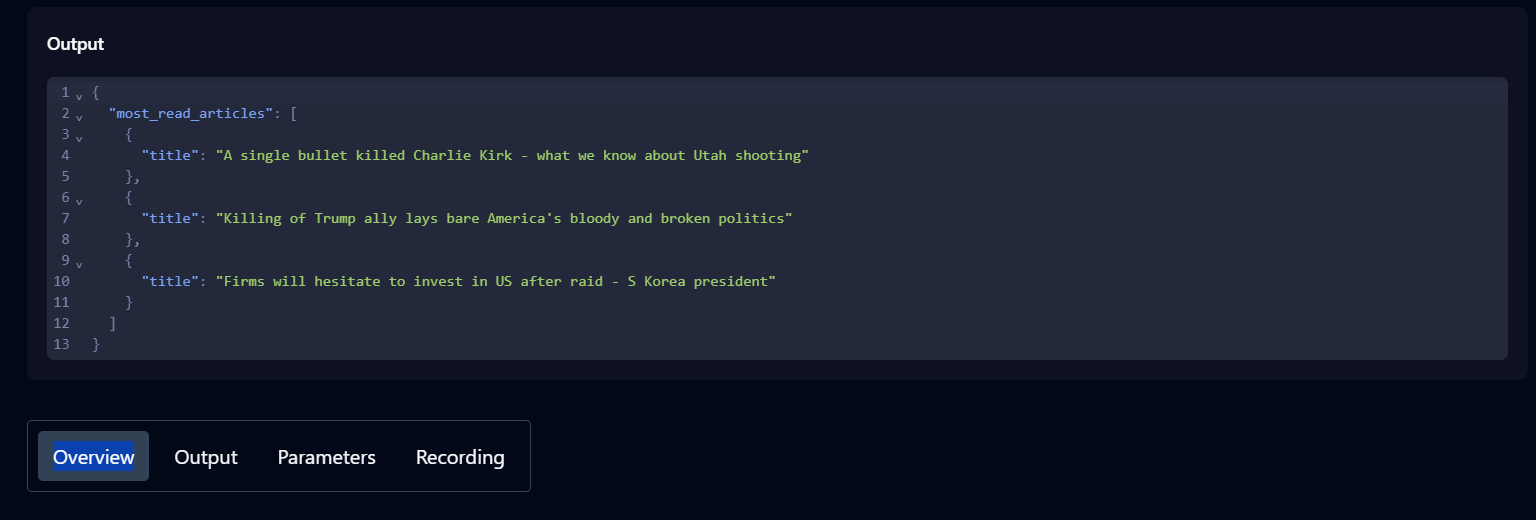
이제 Skyvern 설정이 완료되었으므로 코드 스크립트 작성을 시작할 수 있습니다.
3단계: 컴퓨터에 Skyvern 설치하기
3.1 가상 환경 생성
원하는 프로젝트 폴더에서 Python으로 가상 환경을 생성하세요:
python -m venv .venv
환경을 활성화합니다.
.venvScriptsactivate
3.2 모든 기기에 Skyvern 설치하기
pip install skyvern
설치 문제가 발생하면 Windows에서 Ubuntu 터미널을 사용할 수 있습니다. Ubuntu 터미널 설정 방법은 이 게시물을 참조하세요.
터미널 실행 후 원하는 디렉토리로 이동하여 다음 명령을 실행하세요:
pip install uv가상 환경 생성:
uv venv venv다음 명령어로 Skyvern을 설치하세요:
uv pip install skyvern3.3 Skyvern 빠른 시작
설치가 완료되면 다음 명령어를 실행하세요:
skyvern quickstart- ‘Skyvern을 로컬에서 실행하시겠습니까, 아니면 클라우드에서 실행하시겠습니까?’라는 메시지가 표시되면 ‘cloud’를 입력하세요.
- ‘Skyvern baseURL을 입력하세요’라는 메시지가 표시되면 Enter 키를 누릅니다.
- MCP 프롬프트를 제외한 모든 설치 프롬프트에서는 ‘n’을 입력하세요. MCP 프롬프트에서는 ‘y’를 입력해야 합니다.
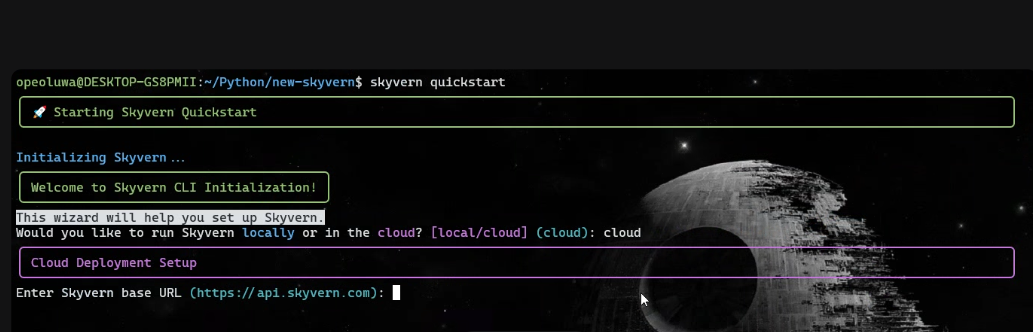
설정 후 다음 명령을 실행하세요:
skyvern initapp.py라는 Python 스크립트를 생성하세요.
4단계: Bright Data로 제품 정보 조회
4.1 app.py에서 다음 코드를 사용하여 Bright Data로 부품 번호 조회:
import asyncio
import requests
import time
import json
def trigger_scraping_job(api_key, data):
"""
URL, 프롬프트, 국가를 포함한 딕셔너리 목록으로 Bright Data 데이터셋 작업을 트리거합니다.
성공 시 snapshot_id를 반환합니다.
"""
endpoint = "https://api.brightdata.com/datasets/v3/trigger"
params = {
"dataset_id": "gd_mcswdt6z2elth3zqr2", # 귀하의 데이터셋 ID
"include_errors": "true",
}
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
response = requests.post(endpoint, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json().get("snapshot_id")
print(f"요청 성공! 스냅샷 ID: {snapshot_id}")
return snapshot_id
else:
print(f"요청 실패! 상태: {response.status_code}")
print(response.text)
return None
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
"""
Bright Data 스냅샷 엔드포인트를 데이터가 준비될 때까지 폴링합니다.
JSON 응답을 출력 파일에 저장합니다.
"""
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"ID: {snapshot_id} 스냅샷 폴링 중...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("스냅샷 준비 완료. 다운로드 중...")
snapshot_data = response.json()
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"스냅샷이 {output_file}에 저장되었습니다")
return
elif response.status_code == 202:
print(f"스냅샷이 아직 준비되지 않았습니다. {polling_timeout} 초 후에 재시도 중...")
time.sleep(polling_timeout)
else:
print(f"요청 실패! 상태: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "YOUR_BRIGHT_DATA_API_KEY" # 귀하의 API 키
# curl JSON 데이터 구조와 정확히 일치
data = [
{
"url": "https://google.com/aimode",
"prompt": "finditparts.com에서 SKF 제조사의 휠 씰 부품 번호를 찾아주세요",
"country": ""
}
]
snapshot_id = trigger_scraping_job(BRIGHT_DATA_API_KEY, data)
if snapshot_id:
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "product.json")프롬프트는 다음과 같습니다: ‘finditparts.com에서 제조사가 SKF인 휠 씰의 부품 번호를 찾으세요.’
이 작업은 SKF 제조사의 제품 설명과 부품 번호가 포함된 product.json 파일을 생성합니다.
{
"url": "https://www.finditparts.com/products/16775486/skf-45093xt?srcid=CHL01SCL010-Npla-Dmdt-Gusa-Svbr-Mmuu-K16775486-L22",
"title": "www.finditparts.com",
"description": "SKF 45093XT 휠 씰 | FinditParts",
"icon": "https://encrypted-tbn0.gstatic.com/faviconV2?url=https://www.finditparts.com&client=AIM&size=128&type=FAVICON&fallback_opts=TYPE,SIZE,URL",
"domain": "https://www.finditparts.com",
"cited": true
},
{
"url": "https://www.finditparts.com/products/193780/cr-slash-skf-14115?srcid=CHL01SCL010-Npla-Dmdt-Gusa-Svbr-Mmuu-K193780-L1464",
"title": "www.finditparts.com",
"description": "SKF 14115 휠 씰 | FinditParts",
"icon": "https://encrypted-tbn0.gstatic.com/faviconV2?url=https://www.finditparts.com&client=AIM&size=128&type=FAVICON&fallback_opts=TYPE,SIZE,URL",
"domain": "https://www.finditparts.com",
"cited": true
},
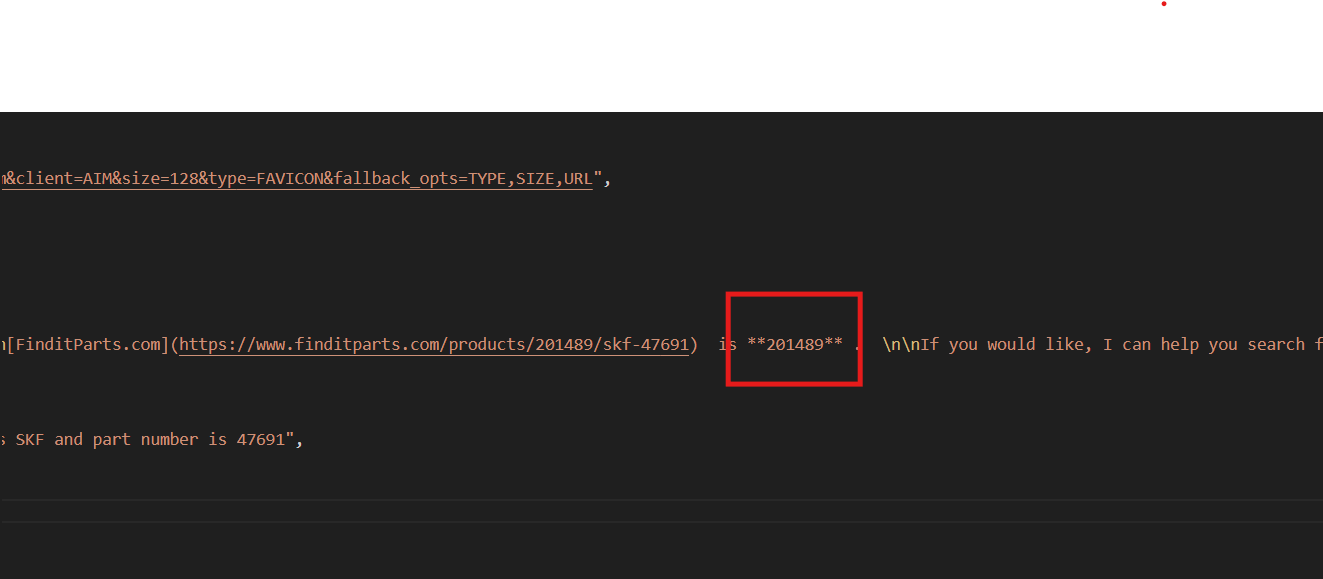
{다음으로, 원하는 부품 번호(설명란에 위치)를 선택하고 다음 프롬프트로 Bright Data 코드를 재실행하세요: ‘부품 번호 47691인 SKF 휠 씰의 제품 ID를 찾으세요’
# curl JSON 데이터 구조를 정확히 일치시킵니다
data = [
{
"url": "https://google.com/aimode",
"prompt": "SKF 휠 씰(부품 번호 47691)의 제품 ID를 찾으세요",
"country": ""
}
]Skyvern은 finditparts.com (자동차 부품 전자상거래 웹사이트)에서 장바구니에 세부 정보를 추가하기 위해 제품 ID가 필요합니다.
이 프로세스는 원하는 제품 ID가 포함된 product.json 파일을 생성합니다.
5단계: Skyvern에 작업 요청하기
먼저 https://app.skyvern.com/tasks/create/finditparts로 이동하세요. 이 URL은 Skyvern에서 작업을 생성하는 단축키입니다.
기본 콘텐츠(Base Content) 섹션 아래의 고급 설정 ( Advanced Settings)을 클릭하고, 사용 사례에 맞게 제품 ID와 프롬프트를 업데이트하세요.
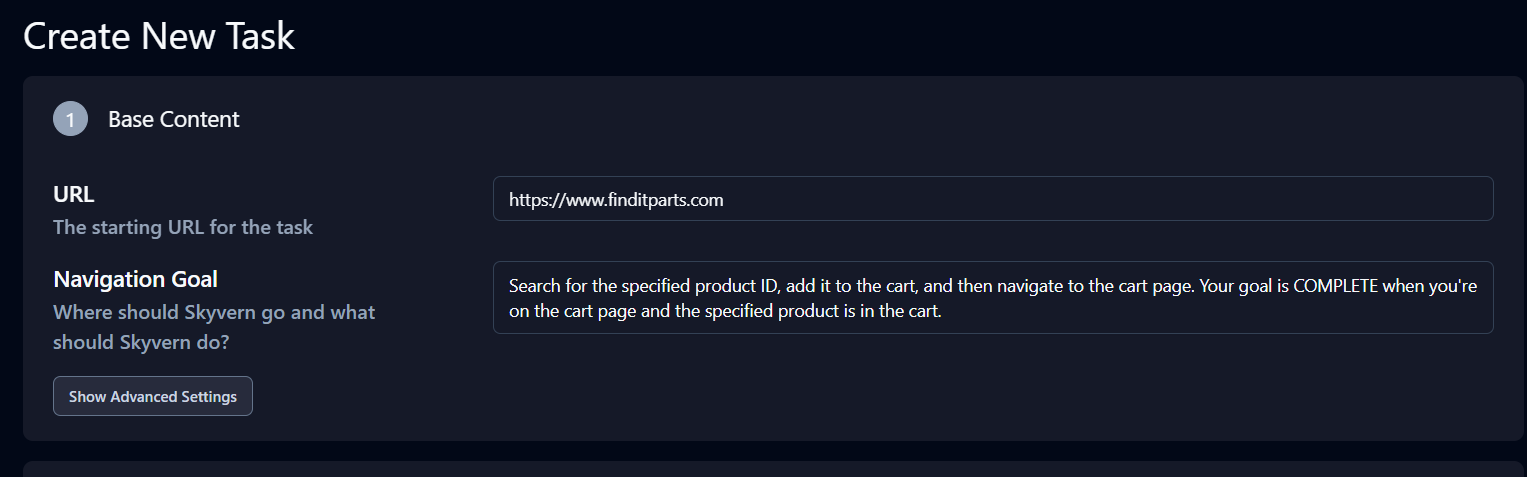
프롬프트는 다음과 같습니다: ‘지정된 제품 ID를 검색하여 장바구니에 추가한 후 장바구니 페이지로 이동하세요. 장바구니 페이지에 도달하고 지정된 제품이 장바구니에 있을 때 목표가 완료됩니다.’
고급 설정 아래의 추출 섹션도 중요합니다. 데이터 추출 목표를 다음과 같이 수정하세요: ‘장바구니 페이지 URL과 장바구니 페이지의 모든 제품 수량 정보를 추출합니다.’
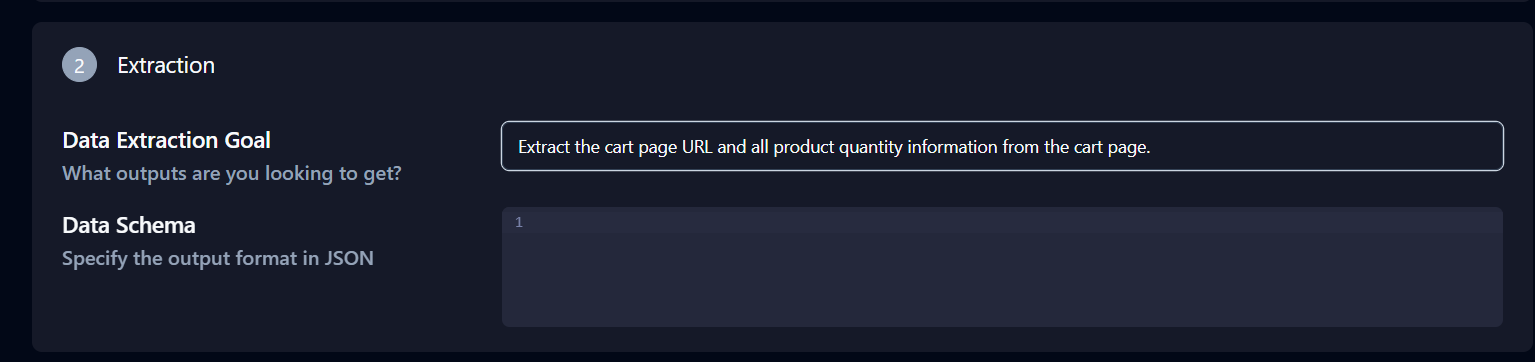
페이지 하단의 ‘API 명령어 복사’를 클릭하고 터미널에 붙여넣은 후 Enter 키를 누르세요.
그러면 터미널에 task_id가 생성되고 Skyvern Cloud에 작업 인스턴스가 생성됩니다. 작업 상태는 ‘기록’에서 대기 중, 실행 중, 완료 중인지 확인할 수 있습니다.
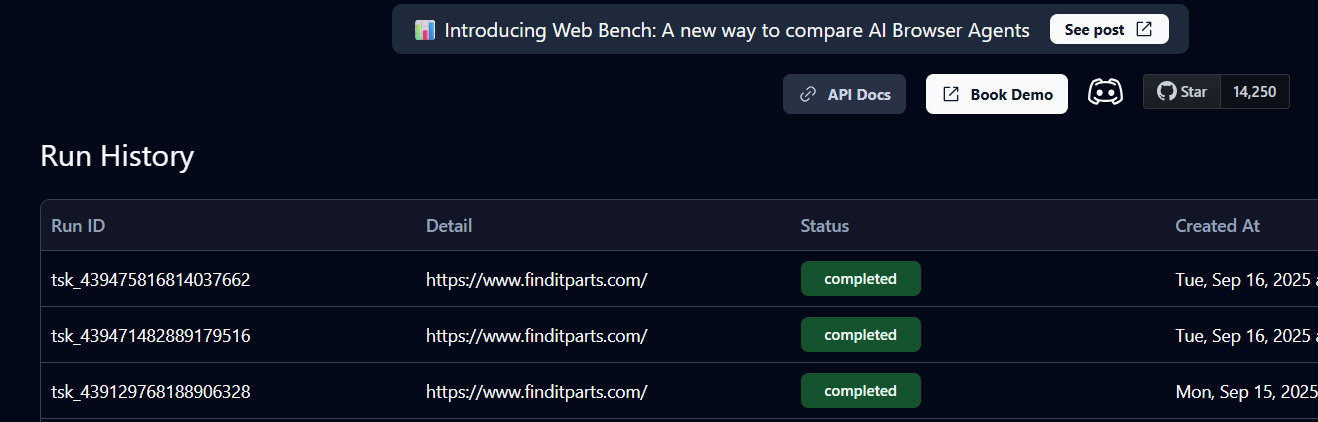
상태가 완료됨 ( Completed) 이면 작업이 끝난 것입니다. 이제 Skyvern에서 반환한 장바구니 세부 정보와 상품 URL을 확인할 수 있습니다.
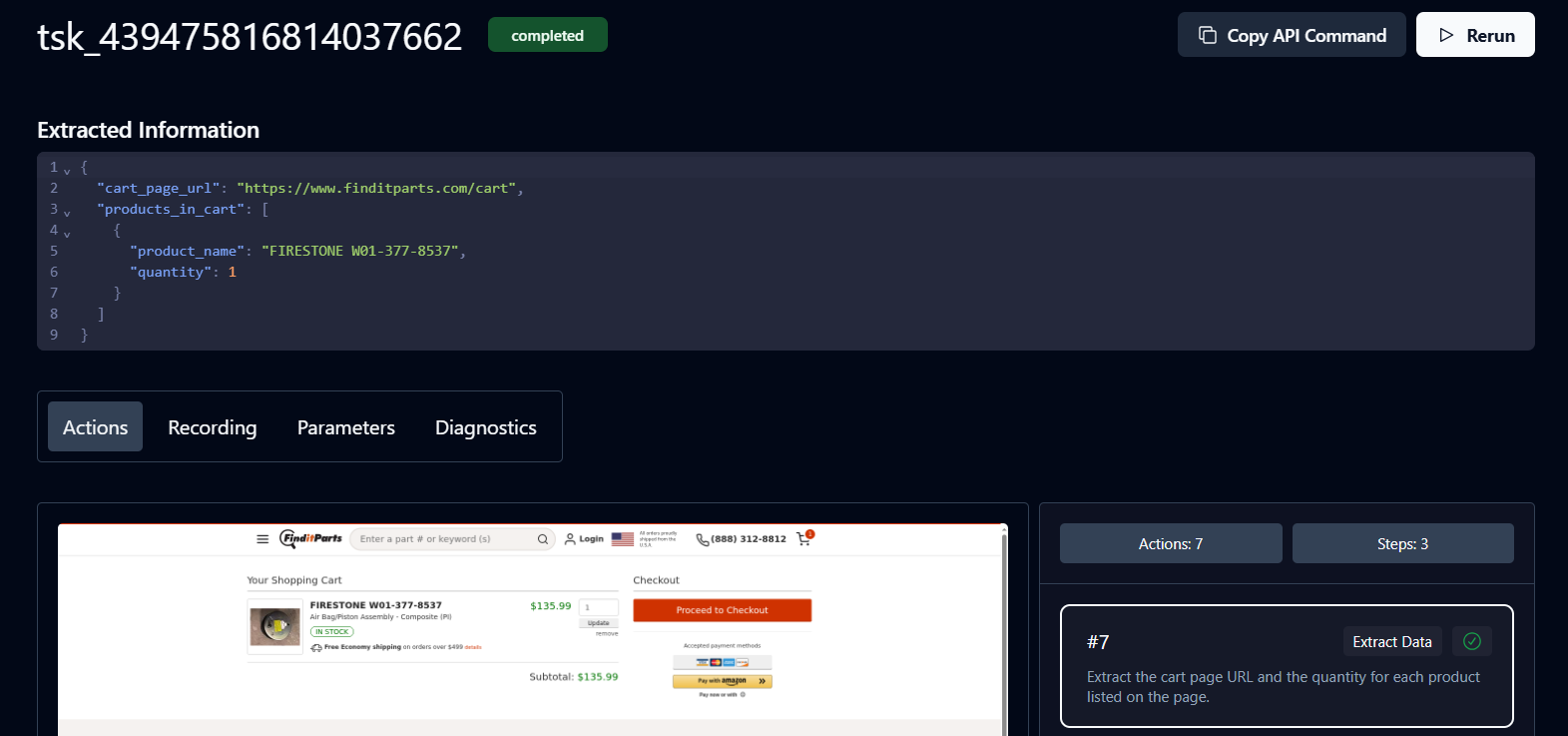
축하합니다. 워크플로가 완료되었습니다. URL을 클릭하여 결제를 진행하세요.
Bright Data는 온라인에서 제품을 수동으로 검색할 필요 없이 옵션을 직접 기기로 가져옵니다. 이를 통해 최적의 제품을 선택하고 Skyvern으로 구매 프로세스를 자동화할 수 있습니다.
다음 단계
워크플로를 확장하여 여러 제품을 장바구니에 추가한 후 결제를 진행하거나, 전체 제품에 대한 자연어 처리(NLP) 요약문을 생성할 수 있습니다. 또한 워크플로를 클라우드에 배포하여 지속적으로 모니터링할 수 있습니다. 마지막으로 Google 캘린더와 연동하여 할인 정보를 추적할 수 있습니다.
결론
이 튜토리얼에서는 Bright Data의 Scraper API와 Skyvern을 결합하여 온라인에서 제품을 찾고 구매하는 과정을 자동화하는 방법을 배웠습니다. Scraper API 외에도 Bright Data는 AI 에이전트에 활용할 수 있는 다양한 도구를 제공합니다. 예를 들어 전자상거래, 소셜 미디어 등에 맞춤화된 즉시 사용 가능한 데이터셋, 고급 다단계 자동화를 위한 Web MCP 서버, 40개 이상의 전문 도구 접근 권한 등이 있습니다. 이러한 제품들을 함께 활용하면 웹 데이터를 효율적으로 수집, 분석, 실행하는 AI 기반 워크플로우를 쉽게 구축할 수 있습니다.
지금 바로 Bright Data의 전체 제품군을 탐색하여 AI 자동화 프로젝트를 강화하세요.






