

이 튜토리얼에서는 다음을 다룹니다:
- GitHub 저장소를 스크래핑하는 이유는 무엇인가요?
- GitHub 스크래핑 라이브러리 및 도구
- Beautiful Soup을 활용한 GitHub 저장소 스크래퍼 구축
GitHub 저장소를 스크래핑하는 이유는 무엇인가요?
GitHub 저장소를 스크래핑하는 데는 여러 이유가 있습니다. 가장 대표적인 이유는 다음과 같습니다:
- 기술 동향 파악: 저장소의 스타 수와 릴리스를추적함으로써 프로그래밍 언어, 프레임워크, 라이브러리의 최신 트렌드를 파악할 수 있습니다. GitHub 스크레이퍼를 사용하면 어떤 기술이 인기를 얻고 있는지 분석하여 성장세를 모니터링하고 새롭게 부상하는 트렌드를 식별할 수 있습니다. 이 데이터는 기술 도입, 기술 개발, 자원 배분과 관련된 의사 결정에 지침이 될 수 있습니다.
- 풍부한 프로그래밍 지식 기반 확보: GitHub는 오픈소스 프로젝트, 코드 샘플, 솔루션의 보고입니다. 이는 플랫폼에서 방대한 프로그래밍 지식과 모범 사례를 수집할 수 있음을 의미합니다. 이는 교육 목적, 코딩 기술 향상, 다양한 기술 구현 방식 이해에 유용합니다.
- 협업 개발에 대한 통찰력 확보: 저장소는 풀 리퀘스트, 이슈, 토론을 통해 개발자들이 어떻게 협업하는지에 대한 통찰력을 제공합니다. 이 데이터를 수집함으로써 협업 패턴을 연구하여 팀워크 전략 수립, 프로젝트 관리 개선, 소프트웨어 개발 프로세스 완성에 도움을 받을 수 있습니다.
GitHub는 git 저장소를 호스팅하는 유일한 클라우드 기반 플랫폼이 아니며, 많은 대안이 존재합니다. 그러나 다음과 같은 이유로 데이터 스크래핑에 있어 여전히 선호되는 선택지입니다:
- 대규모 사용자 기반
- 높은 사용자 활동성
- 확립된 평판
특히 GitHub 데이터는 기술 동향 모니터링, 라이브러리 및 프레임워크 발견, 소프트웨어 개발 프로세스 개선에 유용합니다. 이 정보는 IT 업계에서 경쟁 우위를 유지하는 데 핵심적인 역할을 합니다.
GitHub 스크래핑 라이브러리 및 도구
파이썬은 직관적인 구문, 개발자 친화적인 특성, 방대한 라이브러리 덕분에 웹 스크래핑에 탁월한 언어로 널리 인정받고 있습니다. GitHub 스크래핑에 파이썬이 권장되는 이유는 다음과 같습니다. 파이썬으로 웹 스크래핑을 수행하는 방법에 대한 심층 가이드에서 자세히 알아보세요.
다음 단계는 다양한 옵션 중에서 가장 적합한 스크래핑 라이브러리를 선택하는 것입니다. 정보에 기반한 결정을 내리려면 먼저 브라우저에서 플랫폼을 탐색해야 합니다. 개발자 도구(DevTools)를 열고 GitHub의 저장소 페이지에서 수행되는 AJAX 호출을 살펴보세요. 대부분은 무시해도 된다는 것을 알게 될 것입니다. 실제로 대부분의 페이지 데이터는 서버가 반환하는 HTML 문서에 내장되어 있습니다.
이는 서버에 HTTP 요청을 보내는 라이브러리와 HTML 파서만으로도 작업에 충분함을 의미합니다. 따라서 다음을 선택해야 합니다:
- Requests: Python 생태계에서 가장 널리 사용되는 HTTP 클라이언트 라이브러리입니다. HTTP 요청 전송 및 해당 응답 처리를 간소화합니다.
- Beautiful Soup: 포괄적인 HTML 및 XML 파싱 라이브러리입니다. 웹 스크래핑을 위한 강력한 DOM 탐색 및 데이터 추출 API를 제공합니다.
Requests와 Beautiful Soup 덕분에 파이썬으로 GitHub 스크래핑을 효과적으로 수행할 수 있습니다. 이제 이를 달성하는 방법의 세부 사항으로 들어가 보겠습니다!
Beautiful Soup으로 GitHub 저장소 스크레이퍼 구축하기
이 단계별 튜토리얼을 따라 Python으로 GitHub를 스크래핑하는 방법을 배워보세요. 코딩과 스크래핑 과정을 모두 건너뛰고 싶으신가요? 대신 GitHub 데이터셋을 구매하세요.
1단계: Python 프로젝트 설정
시작하기 전에 아래 필수 조건을 충족하는지 확인하세요:
- 컴퓨터에 설치된 Python 3+: 설치 프로그램을 다운로드하고 실행한 후 안내를 따르세요.
- 원하는 Python IDE: Python 확장 프로그램이 설치된 Visual Studio Code와 PyCharm Community Edition이 권장되는 두 가지 IDE입니다.
이제 Python 프로젝트 설정에 필요한 모든 준비가 완료되었습니다!
터미널에서 다음 명령어를 실행하여 github-scraper 폴더를 생성하고 Python 가상 환경으로 초기화하세요:
mkdir github-scraper
cd github-scraper
python -m venv envWindows에서는 아래 명령어로 환경을 활성화하세요:
envScriptsactivate.ps1Linux 또는 macOS에서는 다음을 실행하세요:
./env/bin/activate그런 다음 프로젝트 폴더에 아래 줄이 포함된 scraper.py 파일을 추가하세요:
print('Hello, World!')현재 GitHub 스크레이퍼는 “Hello, World!”만 출력하지만, 곧 공개 저장소에서 데이터를 추출하는 로직이 포함될 예정입니다.
스크립트는 다음과 같이 실행할 수 있습니다:
python scraper.py모든 것이 계획대로 진행되었다면 터미널에 다음과 같은 메시지가 출력됩니다:
Hello, World!작동하는 것을 확인했으니, 선호하는 Python IDE에서 프로젝트 폴더를 열어보세요.
훌륭합니다! 이제 Python 코드를 작성할 준비를 하세요.
2단계: 스크래핑 라이브러리 설치
앞서 언급했듯이, Beautiful Soup과 Requests는 GitHub에서 웹 스크래핑을 수행하는 데 도움이 됩니다. 활성화된 가상 환경에서 다음 명령어를 실행하여 프로젝트의 종속성에 추가하세요:
pip install beautifulsoup4 requestsscraper.py 파일을 비운 후 다음 줄로 두 패키지를 임포트하세요:
import requests
from bs4 importBeautifulSoup
# 스크래핑 로직...Python IDE에서 오류가 발생하지 않는지 확인하세요. 사용되지 않은 임포트 때문에 경고가 표시될 수 있습니다. GitHub에서 저장소 데이터를 추출하기 위해 이 스크래핑 라이브러리를 곧 사용할 예정이므로 무시하세요!
3단계: 대상 페이지 다운로드
데이터를 추출할 GitHub 저장소를 선택하세요. 본 가이드에서는 luminati-proxy 저장소를 스크래핑하는 방법을 보여드립니다. 스크래핑 로직은 동일하므로 다른 저장소도 사용 가능합니다.
브라우저에서 대상 페이지의 모습은 다음과 같습니다:

대상 페이지의 URL을 변수에 저장하세요:
url = 'https://github.com/luminati-io/luminati-proxy'그런 다음 requests.get()으로 페이지를 다운로드합니다 :
page = requests.get(url)백그라운드에서 requests는 해당 URL로 HTTP GET 요청을 수행하고 서버가 생성한 응답을 page 변수에 저장합니다. 주목해야 할 부분은 text 속성입니다. 여기에는 대상 웹페이지와 연관된 HTML 문서가 포함됩니다. 간단한 print 명령어로 이를 확인하세요:
print(page.text)스크레이퍼를 실행하면 터미널에 다음과 같은 내용이 표시됩니다:
<!DOCTYPE html>
<html lang="en" data-color-mode="dark" data-light-theme="light" data-dark-theme="dark" data-a11y-animated-images="system" data-a11y-link-underlines="false">
<head>
<meta charset="utf-8">
<link rel="dns-prefetch" href="https://github.githubassets.com">
<link rel="dns-prefetch" href="https://avatars.githubusercontent.com">
<link rel="dns-prefetch" href="https://github-cloud.s3.amazonaws.com">
<link rel="dns-prefetch" href="https://user-images.githubusercontent.com/">
<link rel="preconnect" href="https://github.githubassets.com" crossorigin>
<link rel="preconnect" href="https://avatars.githubusercontent.com">
<!-- 간결함을 위해 생략... -->
좋아요! 이제 이 코드를 파싱하는 방법을 배워보겠습니다4단계: HTML 문서 파싱하기
위에서 가져온 HTML 문서를 파싱하려면 Beautiful Soup에 전달하세요:
soup = BeautifulSoup(page.text, 'html.parser')BeautifulSoup() 생성자는 두 개의 인자를 받습니다:
- HTML 콘텐츠를 포함하는 문자열: 여기서는
page.text변수에 저장됨. - Beautiful Soup이 사용할 파서: “
html.parser“는 Python 내장 HTML 파서의 이름입니다.
BeautifulSoup() 은 HTML을 파싱하여 탐색 가능한 트리 구조를 반환합니다. 구체적으로 soup 변수는 DOM 트리에서 요소를 선택하는 효과적인 메서드를 제공합니다. 예를 들어:
find(): 매개변수로 전달된 선택기 전략과 일치하는 첫 번째 HTML 요소를 반환합니다.find_all(): 입력된 선택기 전략과 일치하는 HTML 요소들의 목록을 반환합니다.select_one(): 매개변수로 전달된 CSS 선택자와 일치하는 첫 번째 HTML 요소를 반환합니다.select(): 입력된 CSS 선택자와 일치하는 HTML 요소 목록을 반환합니다.
이러한 메서드는 트리 내 단일 노드에서도 호출할 수 있습니다. 또한 Beautiful Soup 노드 객체는 다음과 같은 메서드도 제공합니다:
find_next_sibling(): 지정된 CSS 선택자와 일치하는 요소 형제 노드 중 첫 번째 HTML 노드를 반환합니다.find_next_siblings(): 매개변수로 전달된 CSS 선택자와 일치하는 요소 형제 요소 내의 모든 HTML 노드를 반환합니다.
이러한 함수들 덕분에 GitHub 스크래핑을 시작할 준비가 되었습니다. 어떻게 하는지 살펴보겠습니다!
5단계: 대상 페이지 파악하기
코딩에 착수하기 전에 완료해야 할 또 다른 중요한 단계가 있습니다. 사이트에서 데이터를 스크래핑한다는 것은 관심 있는 HTML 요소를 선택하고 그로부터 데이터를 추출하는 것입니다. 효과적인 선택 전략을 정의하는 것이 항상 쉬운 것은 아니며, 대상 웹페이지의 구조를 분석하는 데 시간을 투자해야 합니다.
따라서 브라우저에서 GitHub 대상 페이지를 열고 익숙해지세요. 마우스 오른쪽 버튼을 클릭하고 “검사”를 선택하여 개발자 도구(DevTools)를 엽니다:
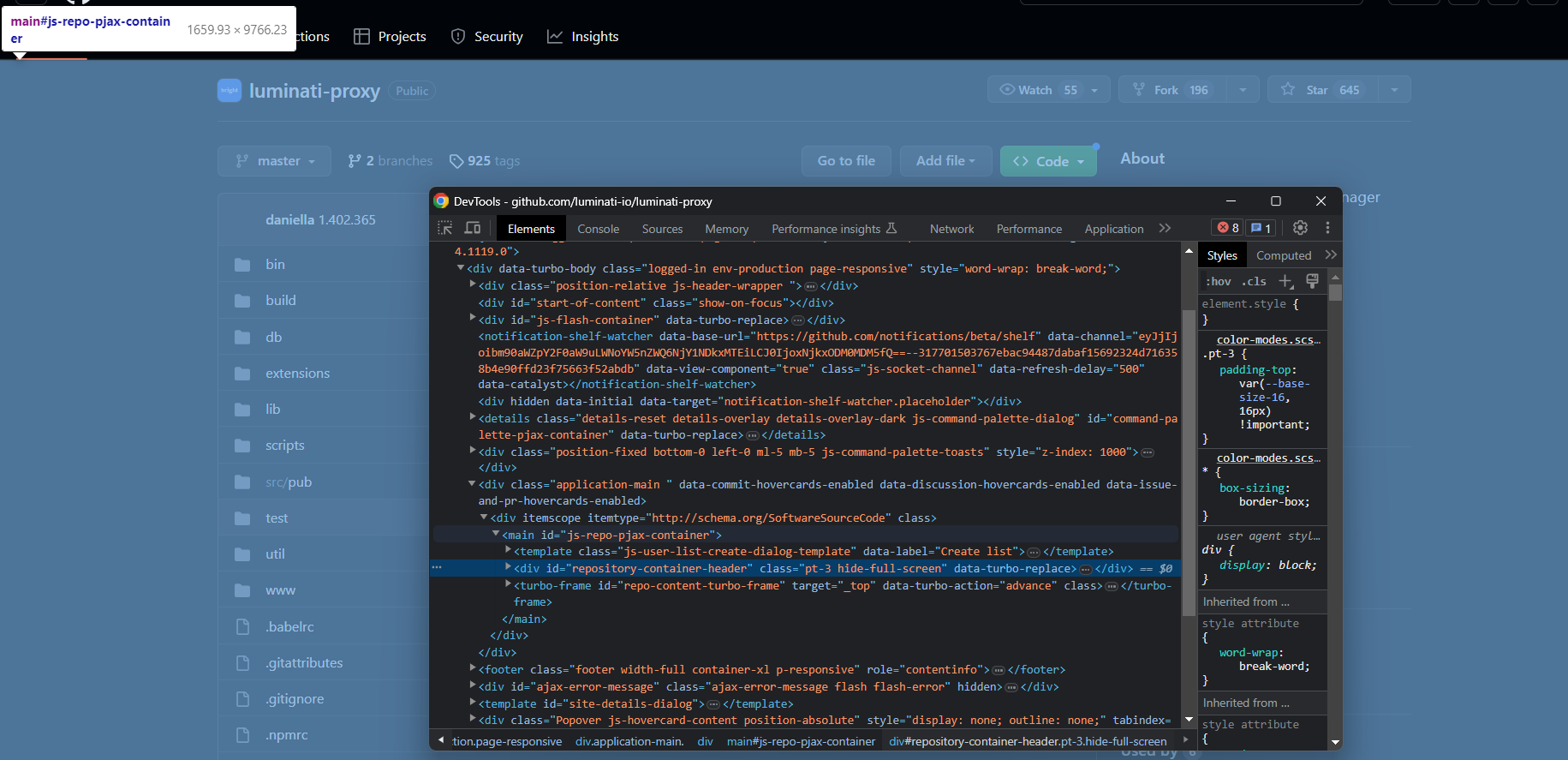
HTML 코드를 살펴보면, 사이트가 많은 요소에 고유한 클래스나 속성을 부여하지 않았음을 알 수 있습니다. 따라서 원하는 요소에 접근하기가 일반적으로 어렵고, 까다로운 방식으로 형제 요소를 거쳐야 할 수도 있습니다.
하지만 걱정하지 마세요. GitHub에 효과적인 선택기 전략을 세우는 것이 쉽지는 않지만 불가능하지도 않습니다. 스크래핑할 준비가 될 때까지 개발자 도구에서 페이지를 계속 검사하세요!
6단계: 저장소 데이터 추출
목표는 GitHub 저장소에서 유용한 데이터(예: 스타, 설명, 마지막 커밋 등)를 추출하는 것입니다. 따라서 이 데이터를 추적하기 위해 Python 사전(dictionary)을 초기화해야 합니다. 코드에 다음을 추가하세요:
repo = {}먼저 name 요소를 살펴보세요:

특징적인 itemprop="name" 속성이 있음을 확인하세요. 이를 선택하고 텍스트 내용을 추출합니다:
name_html_element = soup.select_one('[itemprop="name"]')name = name_html_element.text.strip()Beautiful Soup 노드가 주어지면 get_text() 메서드를 사용하여 텍스트 콘텐츠에 접근합니다.
디버거에서 name_html_element.text를 확인하면 다음과 같이 표시됩니다:
nluminati-proxynGitHub 텍스트 필드에는 공백과 줄바꿈이 포함되는 경향이 있습니다. Python의 strip() 함수를 사용해 이를 제거하세요.
리포지토리 이름 바로 아래에는 브랜치 선택기가 있습니다:
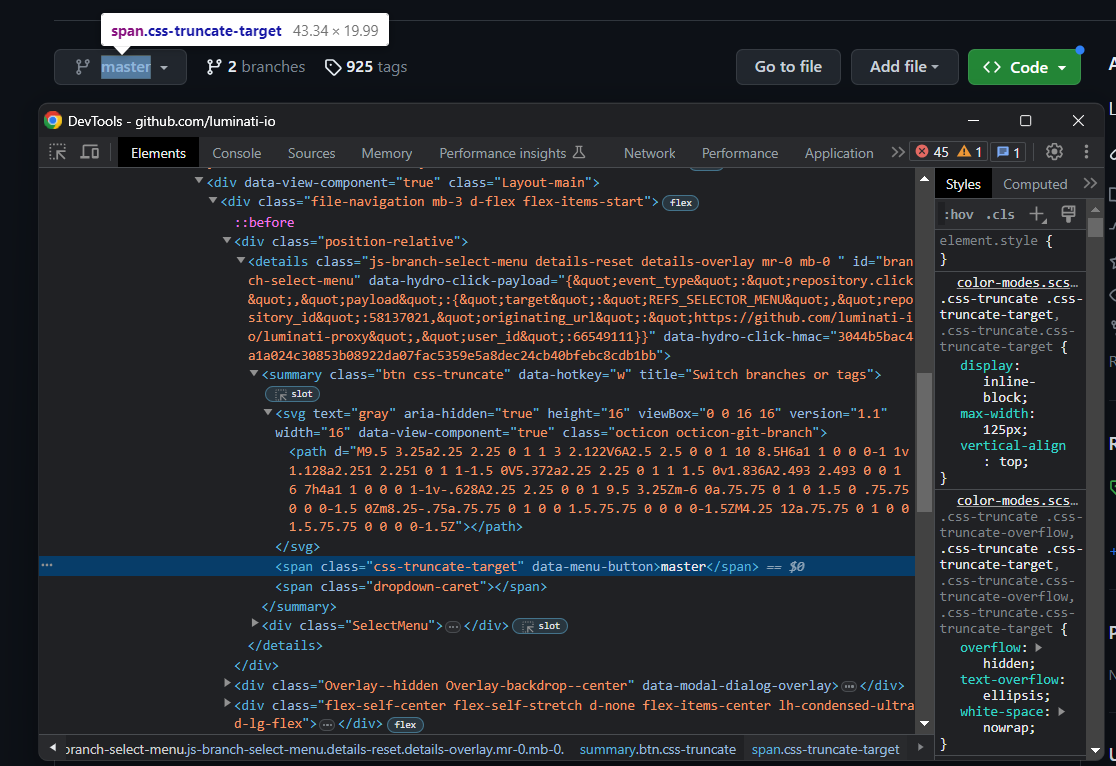
메인 브랜치 이름을 저장하는 HTML 요소를 직접 선택하는 쉬운 방법은 없습니다. 대신 .octicon-git-branch 노드를 선택한 후, 그 자식 요소들 중에서 목표 span을 찾아야 합니다:
git_branch_icon_html_element = soup.select_one('.octicon-git-branch')
main_branch_html_element = git_branch_icon_html_element.find_next_sibling('span')
main_branch = main_branch_html_element.get_text().strip()
아이콘의 형제 요소를 통해 관심 요소에 접근하는 이 패턴은 GitHub에서 매우 효과적입니다. 이 섹션에서 여러 번 사용되는 것을 보게 될 것입니다.
이제 브랜치 헤더에 집중해 보세요:
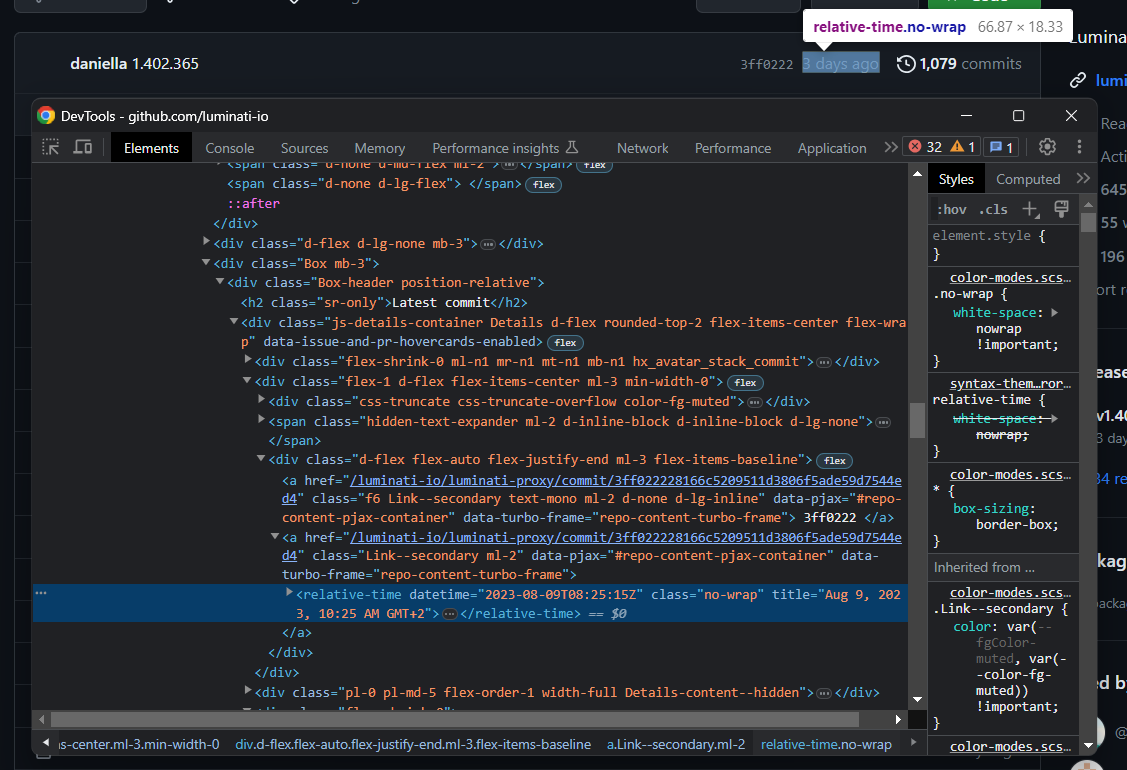
최신 커밋 시간을 추출하려면:
relative_time_html_element = boxheader_html_element.select_one('relative-time')
latest_commit = relative_time_html_element['datetime']주어진 노드에 대해, Python 사전처럼 HTML 속성에 접근할 수 있습니다.
이 섹션의 또 다른 중요한 정보는 커밋 수입니다:
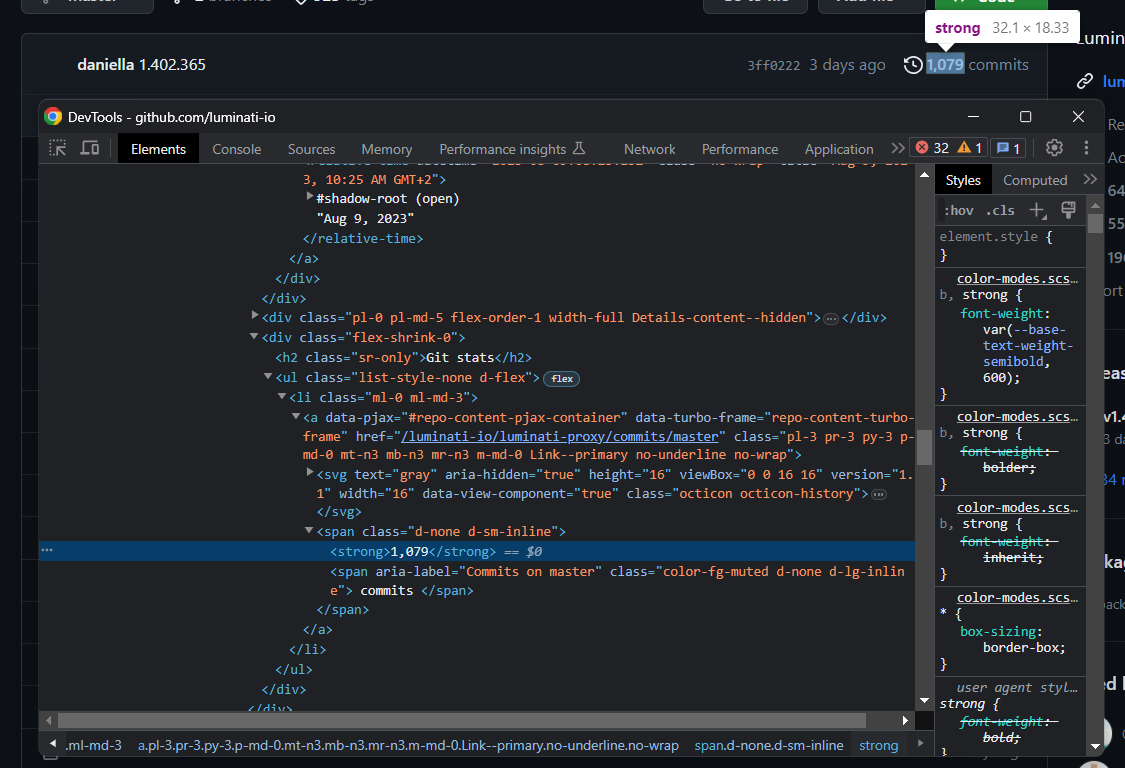
앞서 설명한 아이콘 패턴으로 수집합니다:
history_icon_html_element = boxheader_html_element.select_one('.octicon-history')
commits_span_html_element = history_icon_html_element.find_next_sibling('span')
commits_html_element = commits_span_html_element.select_one('strong')
commits = commits_html_element.get_text().strip().replace(',', '')find_next_sibling()은 최상위 형제 요소에만 접근할 수 있다는 점에 유의하세요. 그 자식 요소 중 하나를 선택하려면 먼저 형제 요소를 가져온 다음 위에서 수행한 것처럼 select_one()을호출해야 합니다.
GitHub에서는 천 단위 이상의 숫자에 쉼표(,)가 포함되므로, Python의 replace() 메서드로 이를 제거합니다.
다음으로 오른쪽의 정보 상자에 주목하세요:
다음과 같이 선택합니다:
bordergrid_html_element = soup.select_one('.BorderGrid')설명 요소를 검사합니다:
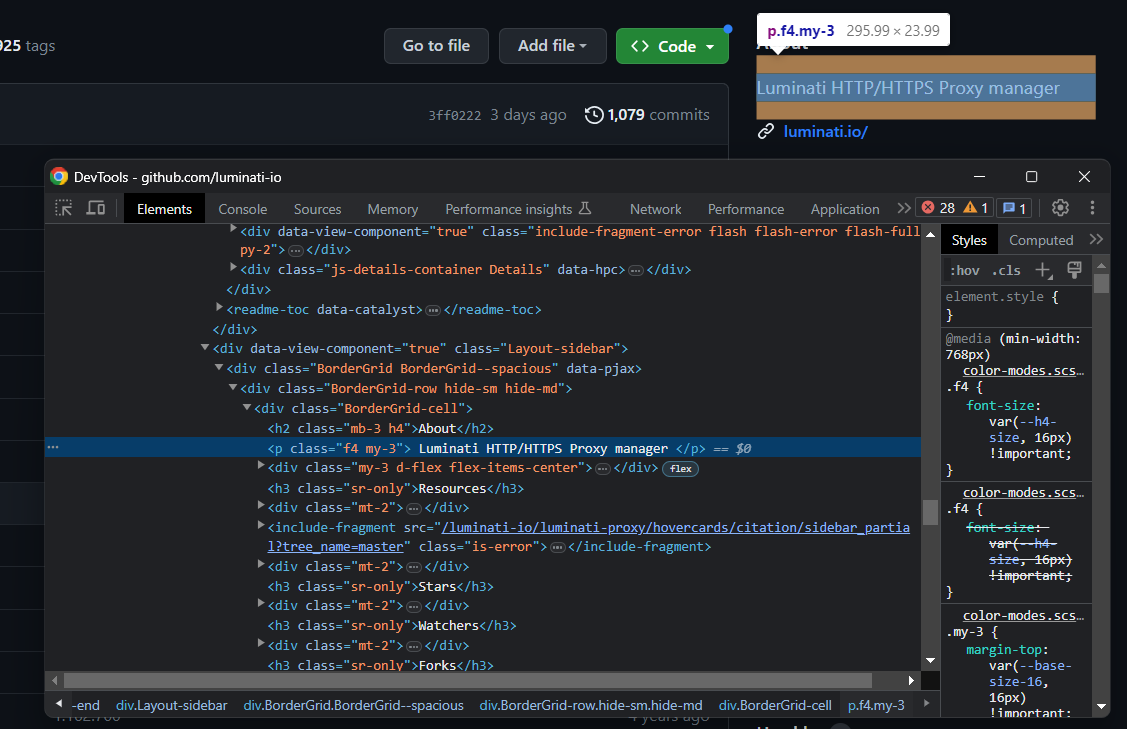
다시 한번, 형제 요소를 통해 선택할 수 있습니다:
about_html_element = bordergrid_html_element.select_one('h2')
description_html_element = about_html_element.find_next_sibling('p')
description = description_html_element.get_text().strip()그런 다음 아이콘 패턴을 적용하여 저장소의 별표, 관심, 포크를 가져옵니다.
아이콘에 초점을 맞춘 후 해당 텍스트 형제 요소에 집중합니다:
star_icon_html_element = bordergrid_html_element.select_one('.octicon-star')
stars_html_element = star_icon_html_element.find_next_sibling('strong')
stars = stars_html_element.get_text().strip().replace(',', '')
eye_icon_html_element = bordergrid_html_element.select_one('.octicon-eye')
watchers_html_element = eye_icon_html_element.find_next_sibling('strong')
watchers = watchers_html_element.get_text().strip().replace(',', '')
fork_icon_html_element = bordergrid_html_element.select_one('.octicon-repo-forked')
forks_html_element = fork_icon_html_element.find_next_sibling('strong')
forks = forks_html_element.get_text().strip().replace(',', '')
잘하셨습니다! 방금 GitHub 저장소를 스크래핑했습니다.
7단계: README 스크래핑
추출해야 할 또 다른 필수 정보는 README.md 파일입니다. 이 파일은 GitHub 저장소를 설명하고 코드 사용법을 안내하는 선택적 텍스트 파일입니다.
README.md 파일을 클릭한 후 “Raw” 버튼을 누르면 아래 URL로 이동합니다:
https://raw.githubusercontent.com/luminati-io/luminati-proxy/master/README.md
따라서 GitHub 저장소의 README 파일 URL은 아래 형식을 따르는 것으로 추론할 수 있습니다:
https://raw.githubusercontent.com/<repo_id>/<repo_main_branch>/README.md
<repo_main_branch> 정보가 main_branch 변수에 저장되어 있으므로, Python f-string을 사용하여 이 URL을 프로그래밍 방식으로 생성할 수 있습니다:
readme_url = f'https://raw.githubusercontent.com/luminati-io/luminati-proxy/{main_branch}/README.md'
그런 다음 requests를 사용하여 README의 원시 마크다운 콘텐츠를 가져옵니다:
readme_url = f'https://raw.githubusercontent.com/luminati-io/luminati-proxy/{main_branch}/README.md'
readme_page = requests.get(readme_url)
readme = None
# README.md 파일이 존재할 경우
if readme_page.status_code != 404:
readme = readme_page.text
리포지토리에 README 파일이 없을 때 GitHub 404 페이지 콘텐츠가 저장되지 않도록 404 확인을 수행합니다.
8단계: 스크랩한 데이터 저장
스크랩한 데이터 변수를 저장소 사전( repo dictionary)에 추가하는 것을 잊지 마세요:
repo['name'] = name
repo['latest_commit'] = latest_commit
repo['commits'] = commits
repo['main_branch'] = main_branch
repo['description'] = description
repo['stars'] = stars
repo['watchers'] = watchers
repo['forks'] = forks
repo['readme'] = readme
print(repo) 를 사용하여 데이터 추출 과정이 원하는 대로 작동하는지 확인하세요. Python GitHub 스크레이퍼를 실행하면 다음과 같은 결과가 출력됩니다:
{'name': 'luminati-proxy', 'latest_commit': '2023-08-09T08:25:15Z', 'commits': '1079', 'main_branch': 'master', 'description': 'Luminati HTTP/HTTPS 프록시 관리자', 'stars': '645', 'watchers': '55', 'forks': '196', 'readme': '# 프록시 관리자 (간결함을 위해 생략...)'}
훌륭합니다! GitHub 스크래핑 방법을 아시네요!
9단계: 스크랩한 데이터를 JSON으로 내보내기
수집한 데이터를 공유, 읽기, 분석하기 쉽게 만드는 것이 마지막 단계입니다. 이를 달성하는 가장 좋은 방법은 JSON과 같은 사람이 읽을 수 있는 형식으로 데이터를 내보내는 것입니다:
import json
# ...
with open('repo.json', 'w') as file:
json.dump(repo, file, indent=4)
파이썬 표준 라이브러리에서 json을 임포트하고, open()으로 repo.json 파일을 초기화한 후 json.dump() 를 사용해 데이터를 채웁니다. 파이썬에서 JSON을 파싱하는 방법에 대해 자세히 알아보려면 가이드를 참고하세요.
완벽합니다! 이제 전체 GitHub Python 스크레이퍼를 살펴볼 시간입니다.
10단계: 모든 것을 합치기
완성된 scraper.py 파일은 다음과 같습니다:
import requests
from bs4 import BeautifulSoup
import json
# 스크래핑 대상 저장소 URL
url = 'https://github.com/luminati-io/luminati-proxy'
# 대상 페이지 다운로드
page = requests.get(url)
# 서버에서 반환된 HTML 문서 파싱
soup = BeautifulSoup(page.text, 'html.parser')
# 스크랩된 데이터를 담을 객체 초기화
repo = {}
# 저장소 스크랩 로직
name_html_element = soup.select_one('[itemprop="name"]')
name = name_html_element.get_text().strip()
git_branch_icon_html_element = soup.select_one('.octicon-git-branch')
main_branch_html_element = git_branch_icon_html_element.find_next_sibling('span')
main_branch = main_branch_html_element.get_text().strip()
# 저장소 히스토리 데이터 추출
boxheader_html_element = soup.select_one('.Box .Box-header')
relative_time_html_element = boxheader_html_element.select_one('relative-time')
latest_commit = relative_time_html_element['datetime']
history_icon_html_element = boxheader_html_element.select_one('.octicon-history')
commits_span_html_element = history_icon_html_element.find_next_sibling('span')
commits_html_element = commits_span_html_element.select_one('strong')
commits = commits_html_element.get_text().strip().replace(',', '')
# 오른쪽 박스의 저장소 세부 정보 스크래핑
bordergrid_html_element = soup.select_one('.BorderGrid')
about_html_element = bordergrid_html_element.select_one('h2')
description_html_element = about_html_element.find_next_sibling('p')
description = description_html_element.get_text().strip()
star_icon_html_element = bordergrid_html_element.select_one('.octicon-star')
stars_html_element = star_icon_html_element.find_next_sibling('strong')
stars = stars_html_element.get_text().strip().replace(',', '')
eye_icon_html_element = bordergrid_html_element.select_one('.octicon-eye')
watchers_html_element = eye_icon_html_element.find_next_sibling('strong')
watchers = watchers_html_element.get_text().strip().replace(',', '')
fork_icon_html_element = bordergrid_html_element.select_one('.octicon-repo-forked')
forks_html_element = fork_icon_html_element.find_next_sibling('strong')
forks = forks_html_element.get_text().strip().replace(',', '')
# README.md용 URL 생성 및 다운로드
readme_url = f'https://raw.githubusercontent.com/luminati-io/luminati-proxy/{main_branch}/README.md'
readme_page = requests.get(readme_url)
readme = None
# README.md 파일이 존재할 경우
if readme_page.status_code != 404:
readme = readme_page.text
# 스크랩한 데이터 저장
repo['name'] = name
repo['latest_commit'] = latest_commit
repo['commits'] = commits
repo['main_branch'] = main_branch
repo['description'] = description
repo['stars'] = stars
repo['watchers'] = watchers
repo['forks'] = forks
repo['readme'] = readme
# 스크랩한 데이터를 repo.json 출력 파일로 내보내기
with open('repo.json', 'w') as file:
json.dump(repo, file, indent=4)
100줄 미만의 코드로 리포지토리 데이터를 수집하는 웹 크롤러를 구축할 수 있습니다.
다음 명령어로 스크립트를 실행하세요:
python scraper.py
스크래핑 프로세스가 완료될 때까지 기다리면 프로젝트 루트 폴더에 repo.json 파일이 생성됩니다. 파일을 열면 다음과 같은 내용을 확인할 수 있습니다:
{
"name": "luminati-proxy",
"latest_commit": "2023-08-09T08:25:15Z",
"commits": "1079",
"main_branch": "master",
"description": "Luminati HTTP/HTTPS 프록시 관리자",
"stars": "645",
"watchers": "55",
"forks": "196",
"readme": "# 프록시 관리자n[](https://david-dm.org/luminati-io/luminati-proxy)n[](https://david-dm..."
}
축하합니다! 웹페이지에 포함된 원시 데이터에서 시작하여 이제 JSON 파일에 반구조화된 데이터를 갖게 되었습니다. 방금 Python으로 GitHub 저장소 스크레이퍼를 구축하는 방법을 배웠습니다!
결론
이 단계별 가이드를 통해 GitHub 저장소 스크래퍼를 구축해야 하는 이유를 이해하셨습니다. 구체적으로, 가이드된 튜토리얼을 통해 GitHub를 스크래핑하는 방법을 배웠습니다. 여기서 보셨듯이, 이는 몇 줄의 코드만으로 가능합니다.
동시에 점점 더 많은 사이트가 스크래핑 방지 기술을 도입하고 있습니다. 이러한 기술은 IP 차단 및 속도 제한을 통해 요청을 식별하고 차단하여 스크래퍼가 사이트에 접근하는 것을 막습니다. 이를 피하는 가장 좋은 방법은 프록시를 사용하는 것입니다. Bright Data의 방대한 최상급 프록시 서비스와 전용 GitHub 프록시를 살펴보세요.
Bright Data는 웹 스크래핑에 최적화된 프록시를 운영하며, 포춘 500대 기업을 포함한 20,000여 고객사에 서비스를 제공합니다. 글로벌 프록시 네트워크는 다음과 같습니다:
- 데이터센터 프록시 – 77만 개 이상의 데이터센터 IP.
- 주거용 프록시 – 195개국 이상에 걸쳐 7,200만 개 이상의 주거용 IP.
- ISP 프록시 – 70만 개 이상의 ISP IP 주소.
종합적으로 Bright Data는 시장에서 가장 크고 신뢰할 수 있는 스크래핑 전용 프록시 네트워크 중 하나입니다. 영업 담당자와 상담하여 Bright Data 제품 중 귀사의 요구사항에 가장 적합한 솔루션을 확인해 보십시오.
참고: 본 가이드는 작성 당시 당사 팀에 의해 철저히 테스트되었으나, 웹사이트가 코드와 구조를 자주 업데이트함에 따라 일부 단계가 예상대로 작동하지 않을 수 있습니다.





