

프록시를 이용한 IP 로테이션은 웹 스크래핑, 특히 제한을 가할 수 있는 현대 웹사이트를 다룰 때 필수적입니다. 차단되거나 속도 제한을 받는 것을 피하려면 여러 IP 주소로 요청을 분산시키는 것이 중요합니다. IP 주소를 순환시키면 웹사이트가 스크래핑 활동을 추적하고 제한하기가 더 어려워집니다. 이는 웹 스크래핑 프로세스의 효율성과 신뢰성을 향상시켜 데이터를 더 효과적으로 추출할 수 있게 합니다. 웹 스크래핑 시 프록시 사용과 IP 주소 로테이션을 통해 IP 기반 차단 및 제재를 피하고, 속도 제한을 극복하며, 지역 제한 콘텐츠에 접근할 수 있습니다.
이 글에서는 웹 스크래핑 워크플로우에 프록시를 구현하여 사용되는 IP 주소를 회전시키는 방법을 설명합니다. 효과적인 프록시를 구할 수 있는 곳, IP 회전을 위한 팁, 대상 웹사이트에 의해 차단되는 것을 피하는 방법을 알아보게 됩니다.
Python을 활용한 IP 로테이션
Python을 사용한 일반적인 스크래핑 프로세스는 Requests나 Scrapy 같은 Python 라이브러리를 활용해 웹사이트에 접근하고 콘텐츠를 파싱합니다. 이후 추출하고자 하는 정보를 위해 웹사이트 콘텐츠를 필터링할 수 있습니다. 다음은 전형적인 스크래핑 프로세스의 예시입니다:
import requests
url = 'http://example.com'
# 요청 생성
response = requests.get(url)
print(response.text)
이 프로세스는 필요한 정보를 얻는 데 유용하며, 단일 사용 사례나 데이터를 한 번만 추출해야 하는 경우에 적합합니다. 그러나 시스템 IP를 사용하여 요청을 수행하므로, 웹사이트가 시간 경과에 따라 접근을 제한하는 반복적 또는 지속적인 요청 시 문제가 발생할 수 있습니다.
예시 스크래핑 과정의 결과는 다음과 같습니다:
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans",
…
웹 스크래핑이나 요청을 위한 대부분의 파이썬 라이브러리(Requests나 Scrapy 등)는 요청 시 사용되는 IP 주소를 변경할 수 있는 기능을 제공합니다. 그러나 이를 활용하려면 유효한 IP 주소 목록이나 공급원이 필요합니다. 이러한 공급원은 Bright Data 프록시와 같이 무료 또는 상업적일 수 있습니다.
상업적 옵션은 유효성을 보장하며, 스크래핑 과정에서 중단 없이 운영할 수 있도록 프록시를 관리하고 순환시키는 유용한 도구를 제공합니다. 예를 들어 Bright Data는 사용 사례, 확장성, 요청한 데이터에 대한 차단되지 않은 접근 보장 수준에 따라 가격대가 다른 여러 범주의 프록시를 보유하고 있습니다:
무료 프록시를 사용하면 스크래핑 과정 전반에 걸쳐 순환할 수 있는 유효한 프록시 목록을 Python으로 생성할 수 있습니다:
proxies = ["103.155.217.1:41317", "47.91.56.120:8080", "103.141.143.102:41516", "167.114.96.13:9300", "103.83.232.122:80"]
이것으로 여러 요청을 수행할 때 목록에서 다른 IP 주소를 선택하는 회전 메커니즘만 있으면 됩니다. Python에서는 다음과 같은 함수와 유사하게 구현할 수 있습니다:
import random
import requests
def scraping_request(url):
ip = random.randrange(0, len(proxies))
ips = {"http": proxies[ip], "https": proxies[ip]}
response = requests.get(url, proxies=ips)
print(f"현재 사용 중인 프록시: {ips['https']}")
return response.text
이 코드는 호출될 때마다 목록에서 무작위 프록시를 선택합니다. 선택된 프록시는 스크래핑 요청에 사용됩니다.
잘못된 프록시를 처리하는 오류 처리 케이스를 포함하면 전체 스크래핑 코드는 다음과 같이 보일 것입니다:
import random
import requests
proxies = ["103.155.217.1:41317", "47.91.56.120:8080", "103.141.143.102:41516", "167.114.96.13:9300", "103.83.232.122:80"]
def scraping_request(url):
ip = random.choice(proxies)
try:
response = requests.get(url, proxies={"http": ip, "https": ip})
if response.status_code == 200:
print(f"현재 사용 중인 프록시: {ip}")
ip = random.randrange(0, len(proxies))
ips = {"http": proxies[ip], "https": proxies[ip]}
response = requests.get(url, proxies=ips)
try:
if response.status_code == 200:
print(f"현재 사용 중인 프록시: {ips['https']}")
print(response.text)
elif response.status_code == 403:
print("클라이언트 접근 금지")
elif response.status_code == 429:
print("Too many requests")
except Exception as e:
print(f"An unexpected error occurred: {e}")
scraping_request("http://example.com")
이 회전하는 프록시 목록을 사용하여 Scrapy와 같은 다른 스크래핑 프레임워크로도 요청을 수행할 수 있습니다.
Scrapy를 이용한 스크래핑
Scrapy를 사용하려면 웹 크롤링을 성공적으로 수행하기 전에 라이브러리를 설치하고 필요한 프로젝트 아티팩트를 생성해야 합니다.
파이썬 환경에서 pip 패키지 관리자를 사용하여 Scrapy를 설치할 수 있습니다:
pip install Scrapy
설치 후 다음 명령어로 현재 디렉터리에 템플릿 파일을 포함한 Scrapy 프로젝트를 생성할 수 있습니다:
scrapy startproject sampleproject
cd sampleproject
scrapy genspider samplebot example.com
이 명령어들은 IP 로테이션 메커니즘을 추가하여 완성할 수 있는 기본 코드 파일도 생성합니다.
sampleproject/spiders/samplebot.py 파일을 열고 다음 코드로 업데이트하세요:
import scrapy
import random
proxies = ["103.155.217.1:41317", "47.91.56.120:8080", "103.141.143.102:41516", "167.114.96.13:9300", "103.83.232.122:80"]
ip = random.randrange(0, len(proxies))
class SampleSpider(scrapy.Spider):
name = "samplebot"
allowed_domains = ["example.com"]
start_urls = ["https://example.com"]
def start_requests(self):
for url in self.start_urls:
proxy = random.choice(proxies)
yield scrapy.Request(url, meta={"proxy": f"http://{proxy}"})
request = scrapy.Request(
"http://www.example.com/index.html",
meta={"proxy": f"http://{ip}"}
)
def parse(self, response):
# 요청에 사용된 프록시 기록
proxy_used = response.meta.get("proxy")
self.logger.info(f"사용된 프록시: {proxy_used}")
print(response.text)
이 스크래핑 스크립트를 실행하려면 프로젝트 디렉토리 최상위에서 다음 명령어를 실행하세요:
scrapy crawl samplebot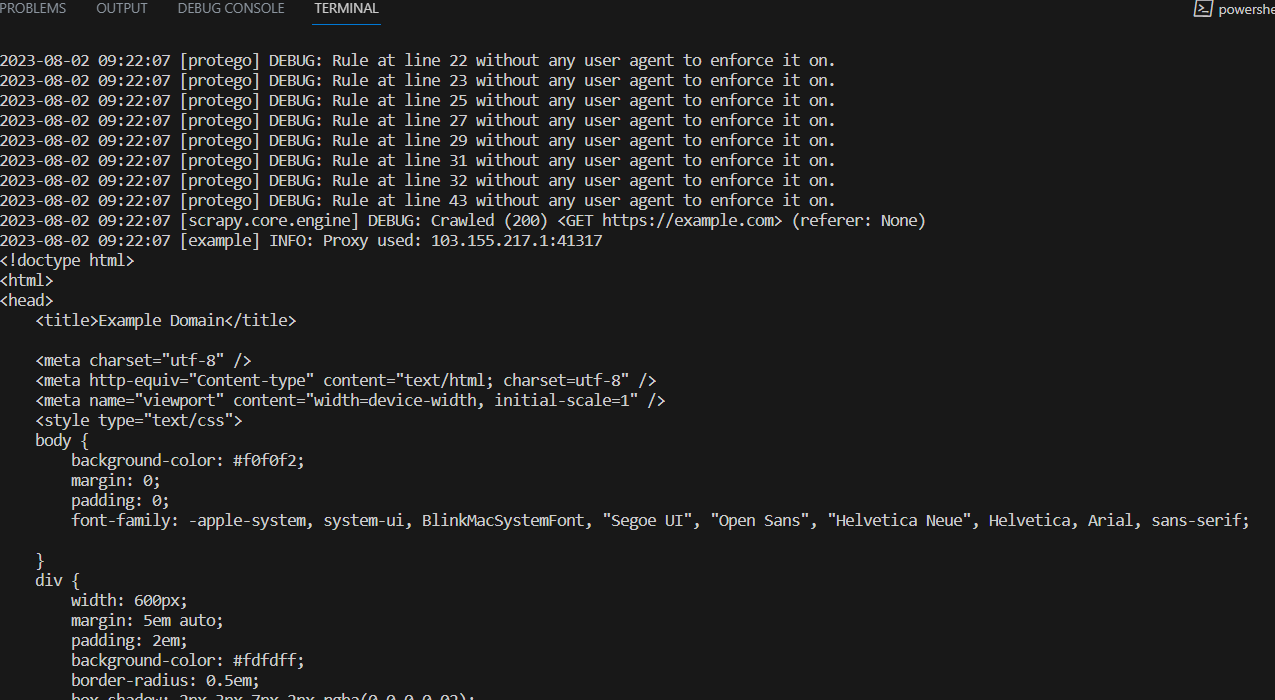
IP 로테이션 팁
웹 스크래핑은 웹사이트와 스크래퍼 간의 경쟁 형태로 진화했습니다. 스크래퍼는 필요한 데이터를 얻기 위해 새로운 방법과 기술을 고안하고, 웹사이트는 접근을 차단하는 새로운 방법을 찾습니다.
IP 로테이션은 웹사이트가 설정한 제한을 우회하기 위한 기술입니다. IP 로테이션의 효과를 극대화하고 대상 웹사이트에 차단될 가능성을 최소화하려면 다음 팁을 고려하세요:
- 크고 다양한 프록시 풀 확보: IP 로테이션을 사용할 때는 상당한 수의 프록시와 다양한 IP 주소로 구성된 대규모 프록시 풀이 필요합니다. 이러한 다양성은 적절한 로테이션을 달성하고 프록시 과다 사용으로 인한 속도 제한 및 차단 위험을 줄여줍니다. 서로 다른 IP 범위와 위치를 가진 여러 프록시 공급자를 사용하는 것을 고려하세요. 또한, 자연스러운 사용자 행동을 더 잘 모방하기 위해 서로 다른 프록시로 요청하는 시점과 간격을 다양하게 하는 것도 고려하세요.
- 강력한 오류 처리 메커니즘 구축: 웹 스크래핑 과정에서 일시적인 연결 문제, 차단된 프록시, 대상 웹사이트 변경 등으로 다양한 오류가 발생할 수 있습니다. 스크립트에 오류 처리 기능을 구현하면 연결 오류, 타임아웃, HTTP 상태 오류 등 일반적인 예외를 포착하고 처리하여 스크래핑 프로세스의 원활한 실행을 보장할 수 있습니다. 단시간 내에 오류가 다수 발생할 경우 스크래핑 프로세스를 일시 중지하는 서킷 브레이커 설정을 고려하십시오.
- 사용 전 프록시 테스트: 스크래핑 스크립트를 실제 환경에 배포하기 전에 프록시 풀의 일부를 사용하여 다양한 시나리오에서 IP 로테이션 기능과 오류 처리 메커니즘을 테스트하세요. 샘플 웹사이트를 활용해 실제 환경을 시뮬레이션하고 스크립트가 이러한 상황을 처리할 수 있는지 확인하세요.
- 프록시 성능 및 효율성 모니터링: 응답 시간 지연이나 빈번한 실패 등 문제를 감지하기 위해 프록시 성능을 정기적으로 모니터링하세요. 각 프록시의 성공률을 추적하여 비효율적인 프록시를 식별해야 합니다. Bright Data와 같은 프록시 제공업체는 프록시의 상태와 성능을 확인하는 도구를 제공합니다. 프록시 성능을 모니터링하면 더 안정적인 프록시로 신속하게 전환하고 성능이 저조한 프록시를 로테이션 풀에서 제거할 수 있습니다.
웹 스크래핑은 반복적인 과정이며, 웹사이트는 구조와 응답 패턴을 변경하거나 스크래핑 방지를 위한 새로운 조치를 시행할 수 있습니다. 스크래핑 프로세스를 정기적으로 모니터링하고 변화에 적응하여 스크래핑 작업의 효과를 유지하세요.
결론
이 글에서는 IP 로테이션과 파이썬을 활용한 스크래핑 프로세스 구현 방법을 살펴보았습니다. 또한 파이썬 스크래핑 프로세스의 효율성을 유지하기 위한 실용적인 팁도 알아보았습니다.
Bright Data는 웹 스크래핑 솔루션을 위한 원스톱 플랫폼입니다. 고품질의 윤리적 프록시, 웹 스크래핑 브라우저, 스크래핑 봇 개발 및 프로세스를 위한 IDE, 즉시 사용 가능한 데이터셋, 스크래핑 중 프록시 회전 및 관리를 위한 여러 도구를 제공합니다.





