

대부분의 웹 스크래핑 데이터는 아마존, 유튜브와 같은 동적 웹사이트에서 비롯됩니다. 이러한 웹사이트는 사용자 입력에 기반한 상호작용적이고 반응형 사용자 경험을 제공합니다. 예를 들어, 유튜브 계정에 접속하면 표시되는 동영상 콘텐츠는 사용자의 입력에 맞춰 조정됩니다. 결과적으로, 사용자 상호작용으로 인해 데이터가 지속적으로 변경되기 때문에 동적 사이트의 웹 스크래핑은 더 어려울 수 있습니다.
동적 사이트에서 데이터를 스크래핑하려면 사용자의 웹사이트 상호작용을 시뮬레이션하고, 자바스크립트로 생성된 특정 콘텐츠를 탐색 및 선택하며, 비동기 자바스크립트 및 XML(AJAX) 요청을 처리하는 고급 기술을 사용해야 합니다.
이 가이드에서는 Selenium이라는 오픈 소스 Python 라이브러리를 사용하여 동적 웹사이트에서 데이터를 스크래핑하는 방법을 배웁니다.
Selenium을 사용한 동적 웹사이트에서 데이터 스크래핑하기
동적 사이트에서 데이터 스크래핑을 시작하기 전에 사용할 Python 패키지인 Selenium을 이해해야 합니다.
Selenium이란?
Selenium은 오픈 소스 Python 패키지이자 자동화 테스트 프레임워크로, 동적 웹사이트에서 다양한 작업이나 태스크를 실행할 수 있게 해줍니다. 이러한 태스크에는 대화 상자 열기/닫기, YouTube에서 특정 쿼리 검색, 양식 작성 등이 포함되며, 모두 선호하는 웹 브라우저에서 수행됩니다.
파이썬과 함께 셀레늄을 활용하면, 셀레늄 파이썬 패키지를 사용해 몇 줄의 파이썬 코드만 작성함으로써 웹 브라우저를 제어하고 동적 웹사이트에서 데이터를 자동으로 추출할 수 있습니다.
이제 셀레늄의 작동 방식을 알았으니 시작해 보겠습니다.
새로운 Python 프로젝트 생성
가장 먼저 해야 할 일은 새로운 Python 프로젝트를 생성하는 것입니다. 수집된 모든 데이터와 소스 코드 파일을 저장할 data_scraping_project라는 디렉터리를 만드세요. 이 디렉터리에는 두 개의 하위 디렉터리가 포함됩니다:
scripts: 동적 웹사이트에서 데이터를 추출하고 수집하는 모든 Python 스크립트를 포함합니다.data 디렉터리는동적 웹사이트에서 추출된 모든 데이터를 저장할 곳입니다.
파이썬 패키지 설치
data_scraping_project 디렉터리를 생성한 후, 동적 웹사이트에서 데이터를 스크래핑, 수집 및 저장하는 데 도움이 되는 다음 Python 패키지를 설치해야 합니다:
- 셀레니움(Selenium)
- Webdriver Manager는 다양한 브라우저용 바이너리 드라이버를 관리합니다. Webdriver는 사이트와 상호작용하기 위한 다양한 명령을 실행할 수 있는 API 세트를 제공하여 콘텐츠를 파싱, 로드 및 변경하기 쉽게 합니다.
- pandas는 동적 웹사이트에서 스크랩한 데이터를 간단한 CSV 파일로 저장합니다.
터미널에서 다음 pip 명령을 실행하여 Selenium Python 패키지를 설치할 수 있습니다:
pip install selenium
셀레늄은 바이너리 드라이버를 사용하여 선택한 웹 브라우저를 제어합니다. 이 Python 패키지는 Chrome, Chromium, Brave, Firefox, IE, Edge, Opera 등 지원되는 웹 브라우저용 바이너리 드라이버를 제공합니다.
터미널에서 다음 pip 명령어를 실행하여 webdriver-manager를 설치하세요:
pip install webdriver-manager
pandas를 설치하려면 다음 pip 명령어를 실행하세요:
pip install pandas
스크래핑할 대상
이 글에서는 Programming with Mosh라는 YouTube 채널과 Hacker News를 스크래핑할 예정입니다:
Programming with Mosh YouTube 채널에서 다음 정보를 스크래핑합니다:
- 동영상 제목.
- 동영상 링크 또는 URL.
- 이미지의 링크 또는 URL.
- 해당 동영상의 조회수.
- 동영상 게시 시간.
- 특정 YouTube 동영상 URL의 댓글.
그리고 Hacker News에서는 다음 데이터를 수집합니다:
- 기사 제목.
- 기사의 링크.

스크랩할 내용을 알았으니, 이제 새로운 Python 스크립트를 생성해 보겠습니다(예: data_scraping_project/scripts/youtube_videos_list.py).
Python 패키지 임포트
먼저 데이터를 스크래핑하고 수집하여 CSV 파일로 저장하는 데 사용할 Python 패키지를 임포트해야 합니다:
# 라이브러리 임포트
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import pandas as pd
Webdriver 인스턴스화
Webdriver를 인스턴스화하려면 Selenium이 사용할 브라우저(이 경우 Chrome)를 선택한 후 바이너리 드라이버를 설치해야 합니다.
Chrome에는 웹 페이지의 HTML 코드를 표시하고 스크래핑 및 데이터 수집을 위한 HTML 요소를 식별하는 개발자 도구가 있습니다. HTML 코드를 표시하려면 Chrome 웹 브라우저에서 웹 페이지를 마우스 오른쪽 버튼으로 클릭하고 ‘요소 검사’를 선택해야 합니다.
Chrome용 바이너리 드라이버를 설치하려면 다음 코드를 실행하세요:
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
Chrome용 바이너리 드라이버가 컴퓨터에 설치되며 Webdriver가 자동으로 인스턴스화됩니다.
Selenium으로 데이터 스크래핑하기
Selenium으로 데이터를 스크래핑하려면 YouTube URL을 간단한 Python 변수(예: url)로 정의해야 합니다. 이 링크에서 특정 YouTube URL의 댓글을 제외한 앞서 언급된 모든 데이터를 수집합니다:
# URL 정의
url = "https://www.youtube.com/@programmingwithmosh/videos"
# 웹 페이지 로드
driver.get(url)
# 웹 페이지 로드 최대 시간(초) 설정
driver.implicitly_wait(10)
Selenium은 Chrome 브라우저에서 YouTube 링크를 자동으로 로드합니다. 또한 웹 페이지가 완전히 로드되도록(모든 HTML 요소 포함) 시간 프레임(예: 10초)을 지정합니다. 이는 JavaScript로 렌더링된 데이터를 스크래핑하는 데 도움이 됩니다.
ID와 태그를 사용한 데이터 스크래핑
Selenium의 장점 중 하나는 ID와 태그를 포함한 웹 페이지의 다양한 요소를 활용해 데이터를 추출할 수 있다는 점입니다.
예를 들어, ID 요소(예: post-title)나 태그(예: h1 및 p)를 사용하여 데이터를 스크래핑할 수 있습니다:
<h1 id ="post-title">Python을 사용한 데이터 스크래핑 소개</h1>
<p>Selenium Python 패키지를 사용해 동적 웹사이트에서 데이터를 수집할 수 있습니다</p>
또는 YouTube 링크에서 데이터를 스크래핑하려면 웹 페이지에 표시된 ID를 사용해야 합니다. 웹 브라우저에서 YouTube URL을 열고, 마우스 오른쪽 버튼을 클릭한 후 ‘검사’를 선택하여 ID를 확인하세요. 그런 다음 마우스로 페이지를 탐색하여 채널에 표시된 동영상 목록을 포함하는 ID를 찾아보세요:
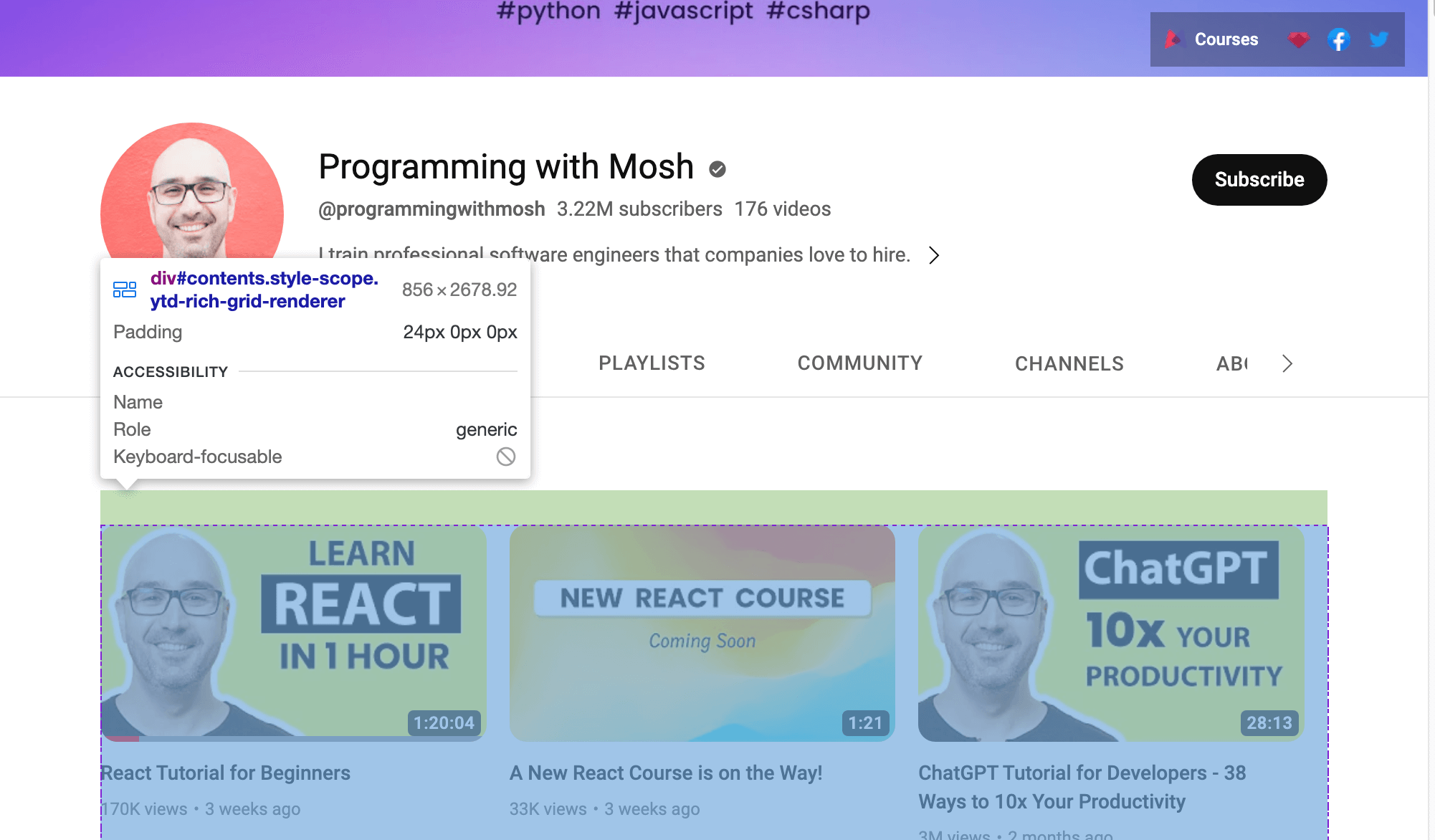
웹드라이버를 사용해 식별된 ID 내 데이터를 스크래핑하세요. ID 속성으로 HTML 요소를 찾으려면 find_element() 셀레니움 메서드를 호출하고 첫 번째 인자로 By.ID, 두 번째 인자로 ID를 전달하세요.
각 동영상의 제목과 링크를 수집하려면 video-title-link ID 속성을 사용해야 합니다. 이 ID 속성을 가진 여러 HTML 요소를 수집할 예정이므로 find_elements() 메서드를 사용해야 합니다:
# contents ID 내 데이터 수집
contents = driver.find_element(By.ID, "contents")
#1 video-title-link ID로 모든 동영상 제목 링크 획득
video_elements = contents.find_elements(By.ID, "video-title-link")
#2 각 유튜브 동영상 제목 및 링크 수집
titles = []
links = []
for video in video_elements:
#3 동영상 제목 추출
video_title = video.get_attribute("title")
#4 동영상 제목 추가
titles.append(video_title)
#5 동영상 링크 추출
video_link = video.get_attribute("href")
#6 동영상 링크 추가
links.append(video_link)(video_link)
이 코드는 다음과 같은 작업을 수행합니다:
콘텐츠객체의 ID 속성에 해당하는 데이터를 수집합니다.- WebElement
contents객체에서 ID 속성이video-title-link인모든 HTML 요소를 수집합니다. - 제목과 링크를 추가하기 위해 두 개의 리스트를 생성합니다.
get_attribute()메서드를 사용하여 동영상 제목을 추출하고제목을전달합니다.- 동영상 제목을 titles 목록에 추가합니다.
get_atribute()메서드를 사용하여 동영상 링크를 추출하고href를인자로 전달합니다.- 링크 목록에 동영상 링크를 추가합니다.
이 시점에서 모든 동영상 제목과 링크는 두 개의 Python 목록( 제목 과 링크)에 포함됩니다.
다음으로, 동영상을 시청하기 위해 YouTube 동영상 링크를 클릭하기 전에 웹 페이지에 있는 이미지의 링크를 스크래핑해야 합니다. 이 이미지 링크를 스크래핑하려면 find_elements() Selenium 메서드를 호출하여 모든 HTML 요소를 찾고, 첫 번째 인자로 By.TAG_NAME을, 두 번째 인자로 태그 이름을 전달해야 합니다:
#1 태그별로 모든 이미지 요소 가져오기
img_elements = contents.find_elements(By.TAG_NAME, "img")
#2 각 유튜브 동영상에 대한 img 링크 및 링크 수집
img_links = []
for img in img_elements:
#3 img 링크 추출
img_link = img.get_attribute("src")
if img_link:
#4 img 링크 추가
img_links.append(img_link)
이 코드는 contents라는 WebElement 객체에서 img 태그 이름을 가진 모든 HTML 요소를 수집합니다. 또한 이미지 링크를 추가할 리스트를 생성하고, get_attribute() 메서드를 사용하여 src를 인자로 전달해 추출합니다. 마지막으로 이미지 링크를 img_links 리스트에 추가합니다.
YouTube URL의 웹 페이지에서 각 동영상에 대해 조회 수와 게시 시간을 확인할 수 있습니다. 이 데이터를 추출하려면 ID가 metadata-line인 모든 HTML 요소를 수집한 후 span 태그 이름이 있는 HTML 요소에서 데이터를 수집해야 합니다:
#1 스크래핑할 특정 ID를 가진 요소 찾기
meta_data_elements = contents.find_elements(By.ID, 'metadata-line')
#2 span 태그에서 데이터 수집
meta_data = []
for element in meta_data_elements:
#3 span HTML 요소 수집
span_tags = element.find_elements(By.TAG_NAME, 'span')
#4 스팬 데이터 수집
span_data = []
for span in span_tags:
#5 각 스팬 HTML 요소의 데이터 추출
span_data.append(span.text)
#6 스팬 데이터를 리스트에 추가
meta_data.append(span_data)
# 스크랩된 데이터 출력
print(meta_data)
이 코드 블록은 WebElement 콘텐츠 객체에서 ID 속성이 metadata-line인 모든 HTML 요소를 수집하고, 조회수 및 게시 시간을 포함하는 span 태그의 데이터를 추가할 리스트를 생성합니다.
또한 meta_data_elements라는 WebElement 객체에서 span 태그명을 가진 모든 HTML 요소를 수집하여 이 span 데이터로 리스트를 생성합니다. 그런 다음 span HTML 요소에서 텍스트 데이터를 추출하여 span_data 리스트에 추가합니다. 마지막으로 span_data 리스트의 데이터를 meta_data에 추가합니다.
스팬 HTML 요소에서 추출된 데이터는 다음과 같습니다:

다음으로, 두 개의 Python 리스트를 생성하여 조회수 및 게시 시간을 별도로 저장해야 합니다:
#1 리스트의 리스트를 반복하며 각 하위 리스트의 첫 번째와 두 번째 항목을 수집
views_list = []
published_list = []
for sublist in meta_data:
#2 조회수 데이터를 views_list에 추가
views_list.append(sublist[0])
#3 게시 시간을 published_list에 추가
published_list.append(sublist[1])
여기서 meta_data에서 데이터를 추출하는 두 개의 Python 리스트를 생성하고, 각 하위 리스트의 조회수(views)를 views_list에, 게시 시간(published_time)을 published_list에 추가합니다.
지금까지 동영상 제목, 동영상 페이지 URL, 이미지 URL, 조회수, 동영상 게시 시간을 스크래핑했습니다. 이 데이터는 pandas Python 패키지를 사용하여 pandas DataFrame에 저장할 수 있습니다. 다음 코드를 사용하여 제목, 링크, img_links, views_list, published_list 목록의 데이터를 pandas DataFrame에 저장하세요:
# pandas 데이터프레임에 저장
data = pd.DataFrame(
list(zip(titles, links, img_links, views_list, published_list)),
columns=['Title', 'Link', 'Img_Link', 'Views', 'Published'])
# 상위 10개 행 표시
data.head(10)
# 데이터를 csv 파일로 내보내기
data.to_csv("../data/youtube_data.csv",index=False)
driver.quit()
스크랩된 데이터는 pandas DataFrame에서 다음과 같이 표시됩니다:
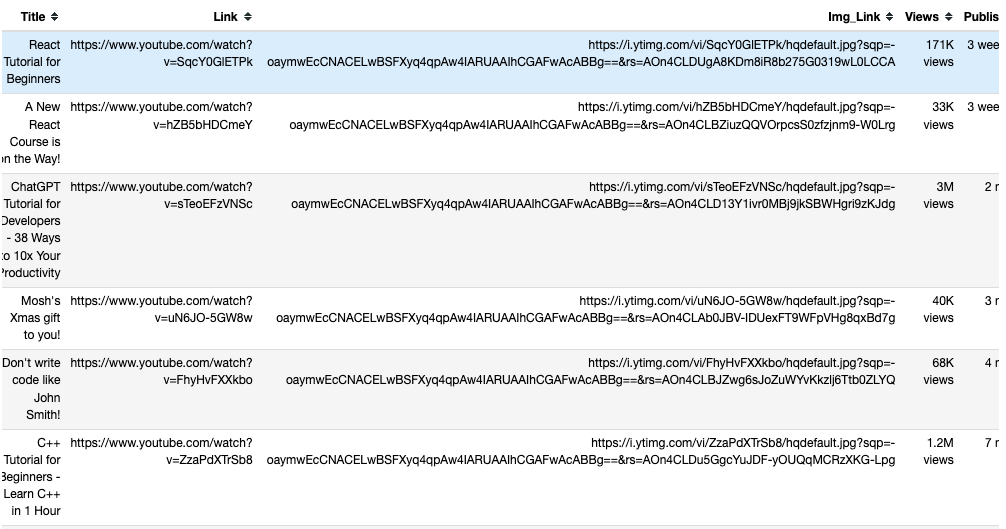
저장된 데이터는 to_csv()를 사용하여 pandas에서 youtube_data.csv 라는 CSV 파일로 내보내집니다.
이제 youtube_videos_list.py를 실행하여 모든 것이 정상적으로 작동하는지 확인할 수 있습니다.
CSS 선택자를 사용한 데이터 스크래핑
Selenium은 웹 페이지의 CSS 선택자를 사용하여 HTML 요소의 특정 패턴을 기반으로 데이터를 추출할 수도 있습니다. CSS 선택자는 ID, 태그 이름, 클래스 또는 기타 속성에 따라 특정 요소를 대상으로 적용됩니다.
예를 들어, 여기 HTML 페이지에는 여러 div 요소가 있으며 그중 하나는 "inline-code" 클래스 이름을 가집니다:
<html>
<body>
<p>Hello World!</p>
<div>Learn Data Scraping</div>
<div class="inline-code"> data scraping with Python code</div>
<div>Saving</div>
</body>
</html>
CSS 선택자를 사용하면 웹 페이지에서 태그 이름이 div이고 클래스 이름이 “inline-code”인 HTML 요소를 찾을 수 있습니다. 동일한 접근 방식을 적용하여 YouTube 동영상 댓글 섹션에서 댓글을 추출할 수 있습니다.
이제 CSS 선택자를 사용하여 이 YouTube 동영상에 게시된 댓글을 수집해 보겠습니다.
YouTube 댓글 섹션은 다음 태그와 클래스 이름으로 접근 가능합니다:
<ytd-comment-thread-renderer class="style-scope ytd-item-section-renderer">...</tyd-comment-thread-renderer>
새로운 스크립트를 생성해 보겠습니다(예: data_scraping_project/scripts/youtube_video_
comments.py)를 생성합니다. 이전과 마찬가지로 필요한 모든 패키지를 임포트하고, Chrome 웹 브라우저를 자동으로 시작하고 YouTube 동영상 URL로 이동한 후 CSS 선택기를 사용하여 댓글을 스크래핑하는 다음 코드를 추가합니다:
#1 크롬 드라이버 인스턴스화
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
#2 URL 정의
url = "https://www.youtube.com/watch?v=hZB5bHDCmeY"
#3 웹페이지 로드
driver.get(url)
#4 CSS 선택자 정의
comment_section = 'ytd-comment-thread-renderer.ytd-item-section-renderer’
#5 지정된 조건에 맞는 요소 발견될 때까지 대기
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, comment_section))
)
except:
driver.quit()
#6. CSS 선택자 내 HTML 요소 수집
comment_blocks = driver.find_elements(By.CSS_SELECTOR,comment_section)
이 코드는 Chrome 드라이버를 인스턴스화하고 스크래핑할 YouTube 동영상 링크를 정의합니다. 그런 다음 브라우저에 웹 페이지를 로드하고 CSS 선택자에 맞는 HTML 요소가 준비될 때까지 10초간 대기합니다.
다음으로 ytd-comment-thread-renderer.ytd-item-section-renderer라는 CSS 선택자를 사용하여 모든 댓글 HTML 요소를 수집하고, 모든 댓글 요소를 comment_blocks WebElement 객체에 저장합니다.
그런 다음 comment_blocks WebElement 객체의 각 댓글에서 ID author-text를 사용하여 작성자 이름을, ID content-text를 사용하여 댓글 텍스트를 추출할 수 있습니다:
#1 작성자 및 댓글의 id 속성 지정
author_id = 'author-text'
comment_id = 'content-text'
#2 목록 내 각 댓글 및 작성자의 텍스트 값 추출
comments = []
authors = []
for comment_element in comment_blocks:
#3 각 댓글의 작성자 수집
author = comment_element.find_element(By.ID, author_id)
#4 작성자 이름 추가
authors.append(author.text)
#5 댓글 수집
comment = comment_element.find_element(By.ID, comment_id)
#6 댓글 텍스트 추가
comments.append(comment.text)
#7 팬더스 데이터프레임에 저장
comments_df = pd.DataFrame(list(zip(authors, comments)), columns=['작성자', '댓글'])
#8 CSV 파일로 데이터 내보내기
comments_df.to_csv("../data/youtube_comments_data.csv",index=False)
driver.quit()
이 코드는 작성자와 댓글의 ID를 지정합니다. 그런 다음 작성자 이름과 댓글 텍스트를 추가하기 위해 두 개의 Python 리스트를 생성합니다. WebElement 객체에서 지정된 ID 속성을 가진 각 HTML 요소를 수집하여 Python 리스트에 데이터를 추가합니다.
마지막으로 스크랩한 데이터를 pandas DataFrame에 저장하고 youtube_comments_data.csv라는 CSV 파일로 내보냅니다.
pandas DataFrame에서 처음 10개의 행에 해당하는 작성자와 댓글은 다음과 같습니다:

클래스 이름을 사용한 데이터 스크래핑
CSS 선택자로 데이터를 스크래핑하는 것 외에도 특정 클래스 이름을 기반으로 데이터를 추출할 수 있습니다. Selenium을 사용하여 클래스 이름 속성으로 HTML 요소를 찾으려면 find_element() 메서드를 호출하고 첫 번째 인자로 By.CLASS_NAME을 전달하며, 두 번째 인자로 클래스 이름을 찾아야 합니다.
이 섹션에서는 클래스 이름을 사용하여 Hacker News에 게시된 기사의 제목과 링크를 수집합니다. 해당 웹 페이지에서 각 기사의 제목과 링크를 포함하는 HTML 요소는 웹 페이지 코드에서 볼 수 있듯이 titleline 클래스 이름을 가집니다:
<span class="titleline"><a href="https://mullvad.net/en/browser">The Mullvad Browser</a><span class="sitestr"> (<a href="from?site=mullvad.net"><span class="sitestr">mullvad.net</span></a>)</span></span></td></tr><tr><td colspan="2"></td><td class="subtext"><span class="subline">
<span class="score" id="score_35421034">302 points</span> by <a href="user?id=Foxboron" class="hnuser">Foxboron</a> <span class="age" title="2023-04-03T10:11:50"><a href="item?id=35421034">2시간 전</a></span> <span id="unv_35421034"></span> | <a href="hide?id=35421034&auth=60e6bdf9e482441408eb9ca98f92b13ee2fac24d&goto=news" class="clicky">숨기기</a> | <a href="item?id=35421034">119개 댓글</a> </span>
새로운 Python 스크립트(예: data_scraping_project/scripts/hacker_news.py)를 생성하고, 필요한 모든 패키지를 임포트한 후, Hacker News 페이지에 게시된 각 기사의 제목과 링크를 스크래핑하기 위해 다음 Python 코드를 추가하세요:
#1 URL 정의
hacker_news_url = 'https://news.ycombinator.com/'
#2 Chrome 드라이버 인스턴스화
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
#3 웹 페이지 로드
driver.get(hacker_news_url)
#4 지정된 조건에 맞는 요소가 발견될 때까지 대기
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, 'titleline'))
)
except:
driver.quit()
#5 목록 내 각 제목과 링크의 텍스트 값 추출
titles= []
links = []
#6 웹 페이지의 모든 기사 찾기
story_elements = driver.find_elements(By.CLASS_NAME, 'titleline')
#7 각 기사의 제목과 링크 추출
for story_element in story_elements:
#8 제목을 제목 목록에 추가
titles.append(story_element.text)
#9 기사 URL 추출
link = story_element.find_element(By.TAG_NAME, "a")
#10 링크를 링크 목록에 추가
links.append(link.get_attribute("href"))
driver.quit()
이 코드는 웹 페이지의 URL을 정의하고, 자동으로 Chrome 웹 브라우저를 시작하며, Hacker News의 URL을 탐색합니다. CLASS NAME과 일치하는 HTML 요소가 준비될 때까지 10초 동안 대기합니다.
그런 다음 각 기사의 제목과 링크를 추가하기 위해 두 개의 Python 리스트를 생성합니다. 또한 WebElement 드라이버 객체에서 titleline 클래스 이름을 가진 각 HTML 요소를 수집하고 story_elements WebElement 객체에 표현된 각 기사의 제목과 링크를 추출합니다.
마지막으로 코드는 기사 제목을 titles 리스트에 추가하고 story_element 객체에서 a 태그명을 가진 HTML 요소를 수집합니다. get_attribute() 메서드를 사용하여 링크를 추출하고 links 리스트에 링크를 추가합니다.
다음으로, 수집한 데이터를 내보내려면 pandas의 to_csv() 메서드를 사용해야 합니다. 제목과 링크를 모두 hacker_news_data.csv CSV 파일로 내보내고 다음 디렉터리에 데이터를 저장합니다:
# pandas 데이터프레임에 저장
hacker_news = pd.DataFrame(list(zip(titles, links)),columns=['Title', 'Link'])
# 데이터를 csv 파일로 내보내기
hacker_news.to_csv("../data/hacker_news_data.csv",index=False)
첫 다섯 행의 제목과 링크가 pandas DataFrame에 표시되는 방식은 다음과 같습니다:
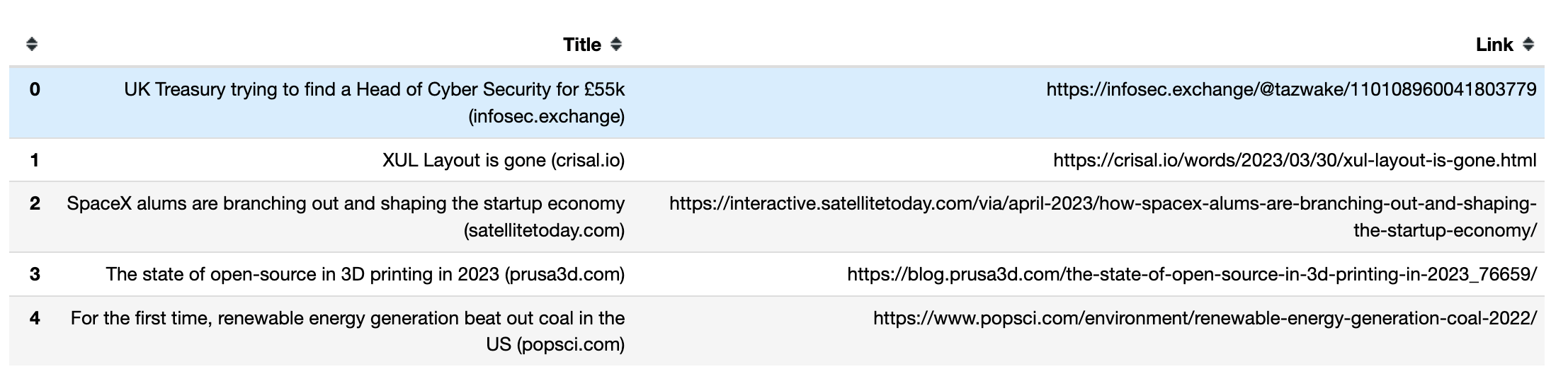
무한 스크롤 처리 방법
일부 동적 웹 페이지는 페이지 하단까지 스크롤할 때 추가 콘텐츠를 로드합니다. 하단까지 이동하지 않으면 Selenium은 화면에 보이는 데이터만 스크래핑할 수 있습니다.
더 많은 데이터를 스크래핑하려면 Selenium이 페이지 하단까지 스크롤하고, 새 콘텐츠가 로드될 때까지 기다린 후 원하는 데이터를 자동으로 추출하도록 지시해야 합니다. 예를 들어, 다음 Python 스크립트는 Python 도서의 첫 40개 결과를 스크롤하며 링크를 추출합니다:
#1 패키지 임포트
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
#2 Chrome 웹드라이버 인스턴스화
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
#3 웹페이지로 이동
driver.get("https://example.com/results?search_query=python+books")
#4 링크를 저장할 리스트 생성
books_list = []
#5 현재 웹페이지의 높이 가져오기
last_height = driver.execute_script("return document.body.scrollHeight")
#6 목표 개수 설정
books_count = 40
#7 웹 페이지 계속 아래로 스크롤
while books_count > len(books_list):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
#8 페이지 로드 완료 대기
time.sleep(5)
#9 페이지의 새 높이 계산
new_height = driver.execute_script("return document.body.scrollHeight")
#10 페이지 하단에 도달했는지 확인
if new_height == last_height:
break
last_height = new_height
#11 데이터 추출
links = driver.find_elements(By.TAG_NAME, "a")
for link in links:
#12 추출된 데이터 추가
books_list.append(link.get_attribute("href"))
#13 웹 드라이버 종료
driver.quit()
이 코드는 사용될 Python 패키지를 임포트하고 Chrome을 인스턴스화하여 실행합니다. 이후 웹 페이지로 이동하여 각 검색 결과의 링크를 추가할 Python 리스트를 생성합니다.
현재 페이지의 높이를 return document.body.scrollHeight 스크립트를 실행하여 얻고, 수집할 링크 수를 설정합니다. 그런 다음 book_count 변수의 값이 book_list의 길이보다 클 때까지 계속 스크롤을 내리고, 페이지 로딩을 위해 5초를 대기합니다.
return document.body.scrollHeight 스크립트를 실행하여 웹 페이지의 새 높이를 계산하고 페이지 하단에 도달했는지 확인합니다. 도달한 경우 루프가 종료되고, 그렇지 않으면 last_height를 업데이트한 후 계속 스크롤합니다. 마지막으로 WebElement 객체에서 태그 이름이 'a'인 HTML 요소를 수집하고 링크를 추출하여 links 목록에 추가합니다. 링크 수집 후 WebDriver를 종료합니다.
참고: 페이지가 무한 스크롤인 경우 스크립트가 종료되려면 스크랩할 항목의 총 개수를 설정해야 합니다. 설정하지 않으면 코드가 계속 실행됩니다.
Bright Data를 활용한 웹 스크래핑
Selenium과 같은 오픈 소스 스크레이퍼로 데이터를 수집하는 것도 가능하지만, 일반적으로 지원이 부족합니다. 또한 이 과정은 복잡하고 시간이 많이 소요될 수 있습니다. 강력하고 신뢰할 수 있는 웹 스크래핑 솔루션을 찾고 있다면 Bright Data를 고려해 보세요.
Bright Data는 세계 최고의 프록시 서버를 운영하며, 포춘 500대 기업 수십 곳과 20,000명 이상의 고객에게 서비스를 제공합니다. 광범위한 프록시 네트워크에는 다음이 포함됩니다:
데이터센터 프록시 – 77만 개 이상의 데이터센터 IP.
주거용 프록시 – 195개국 이상의 주거용 기기에서 제공되는 7,200만 개 이상의 IP.
ISP 프록시 – 70만 개 이상의 ISP IP 주소.
모바일 프록시 – 700만 개 이상의 모바일 IP.
종합적으로, 이는 시장에서 가장 크고 신뢰할 수 있는 스크래핑 전용 프록시 네트워크 중 하나입니다. 그러나 Bright Data는 단순한 프록시 제공업체를 넘어섭니다. 스크래핑 브라우저 (Puppeteer, Selenium, Playwright), 웹 스크래퍼 IDE, SERP API를 포함한 최고 수준의 웹 스크래핑 서비스도 제공합니다.
스크래핑 자체는 원하지 않지만 웹 데이터에 관심이 있다면, 즉시 사용 가능한 데이터 세트를 활용할 수 있습니다.




