

이 튜토리얼에서는 다음을 배웁니다:
- 사이트에서 이미지를 스크래핑하는 것이 유용한 이유
- Selenium을 사용한 Python으로 웹사이트 이미지 스크래핑 방법
시작해 보겠습니다!
사이트에서 이미지를 스크래핑하는 이유는?
웹 스크래핑은 단순히 텍스트 데이터를 추출하는 것이 아닙니다. 이미지 같은 멀티미디어 파일을 포함한 모든 유형의 데이터를 대상으로 할 수 있습니다. 특히 웹사이트에서 이미지를 스크래핑하는 것은 다음과 같은 여러 상황에서 유용합니다.
- 머신러닝 및 AI 모델 훈련용 이미지 수집: 온라인에서 다운로드한 이미지를 활용해 모델을 훈련시켜 정확도와 효율성을 높입니다.
- 경쟁사가 시각적 커뮤니케이션을 어떻게 접근하는지 연구하기: 마케팅 팀이 경쟁사가 주요 메시지를 전달하기 위해 사용하는 이미지에 접근할 수 있도록 하여 트렌드와 전략을 이해합니다.
- 온라인 제공처에서 시각적으로 매력적인 이미지를 자동으로 수집: 고품질 이미지를 활용하여 사이트 및 소셜 미디어 플랫폼에서 높은 참여도를 달성하고, 관객의 관심을 끌고 유지합니다.
Python 이미지 스크래핑: 단계별 가이드
웹페이지에서 이미지를 스크래핑하려면 다음 작업을 수행해야 합니다:
- 대상 사이트에 연결
- 페이지에서 관심 있는 모든 이미지 HTML 노드 선택
- 각 노드에서 이미지 URL 추출
- 해당 URL과 연결된 이미지 파일 다운로드
이 작업에 적합한 대상 사이트로는 인터넷에서 가장 인기 있는 이미지 제공처 중 하나인 Unsplash가 있습니다. 무료 이미지 검색어 “wallpaper”의 대시보드는 다음과 같습니다:
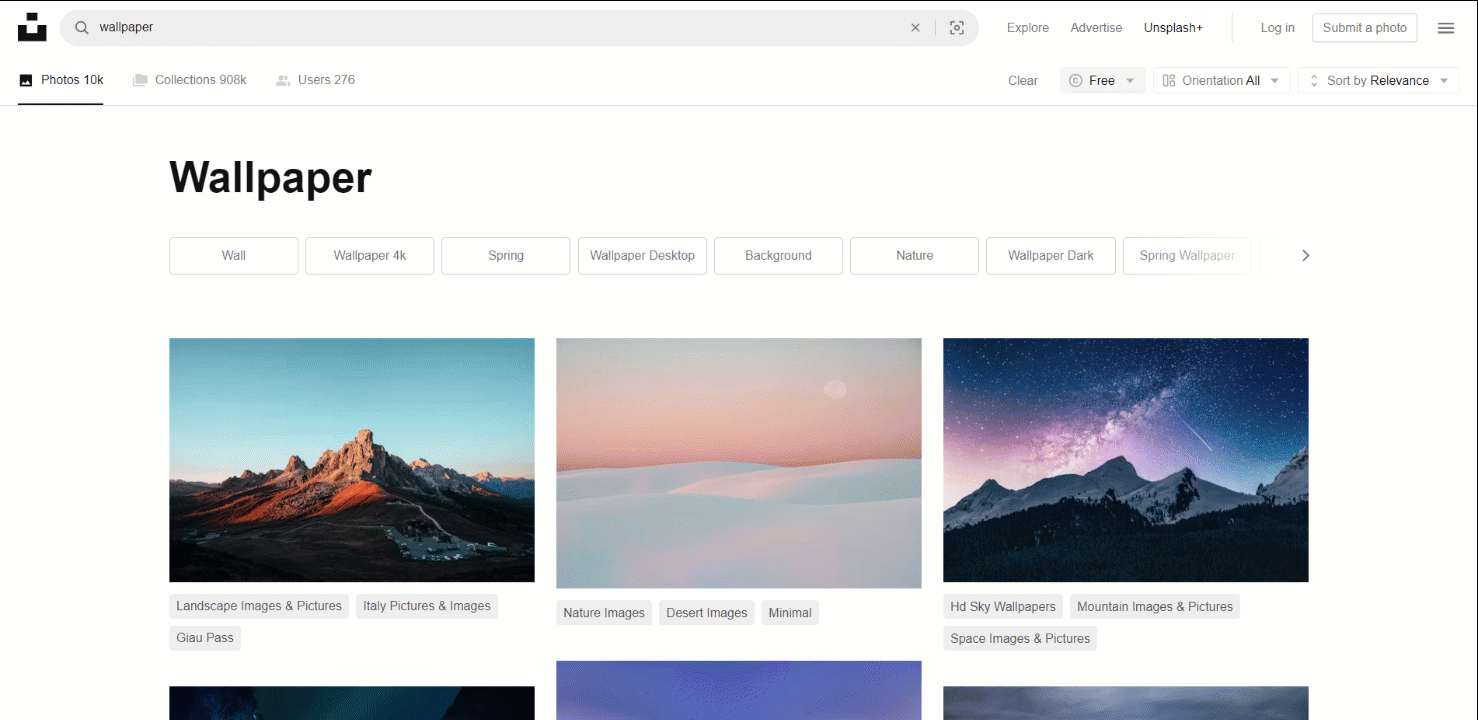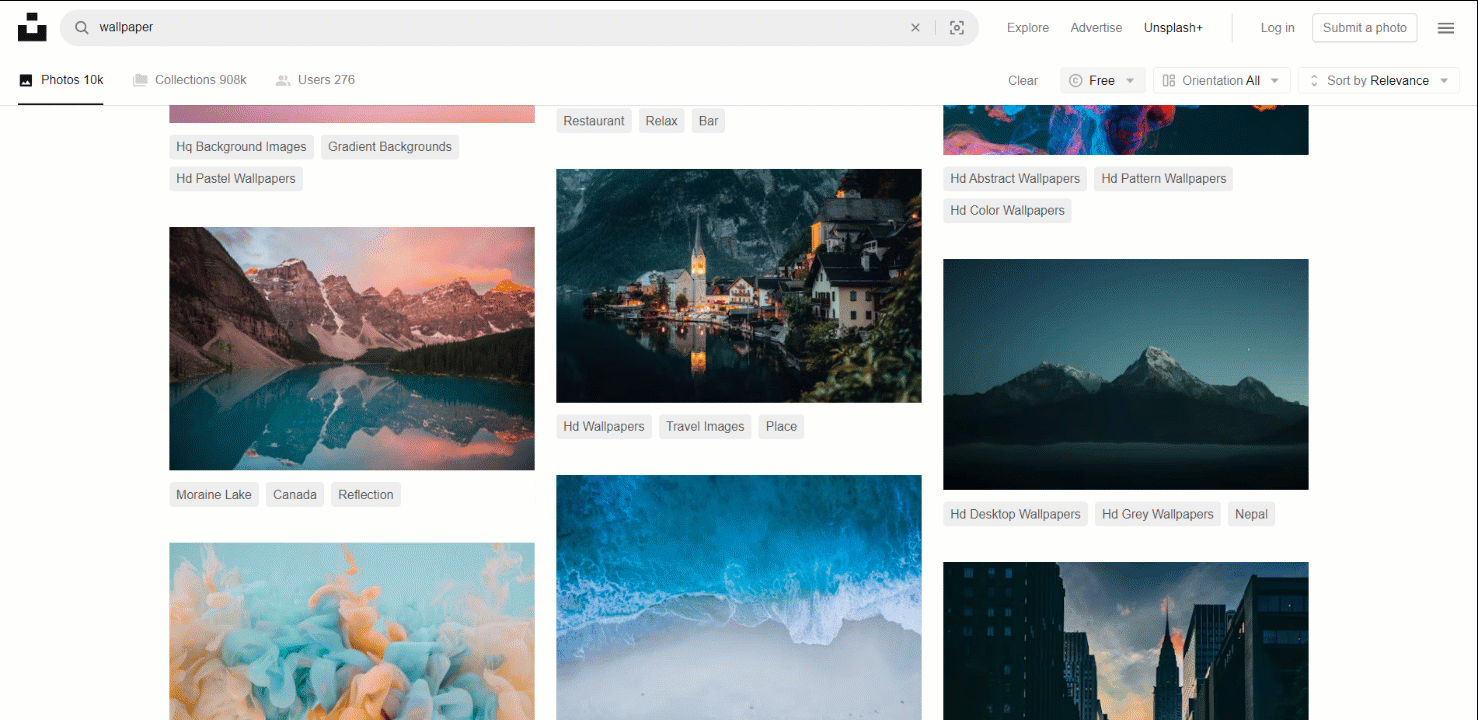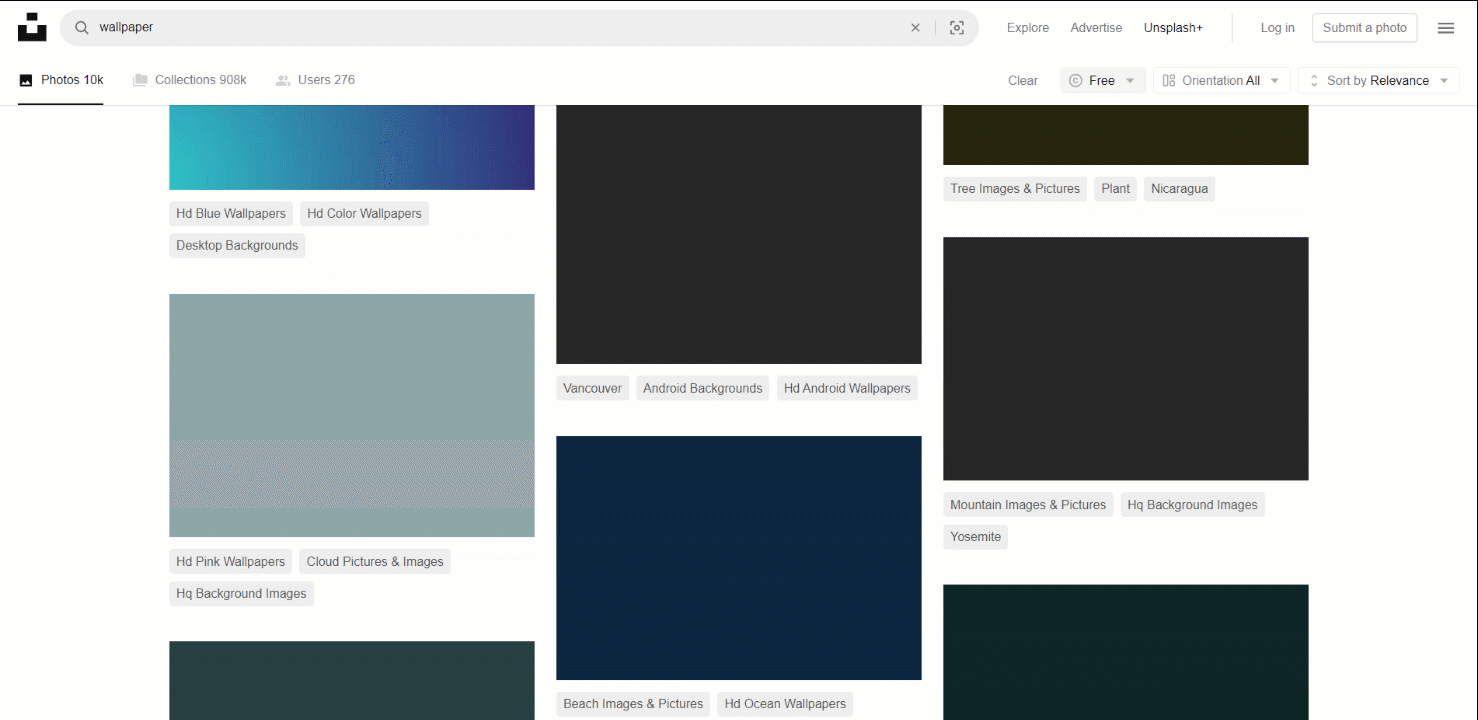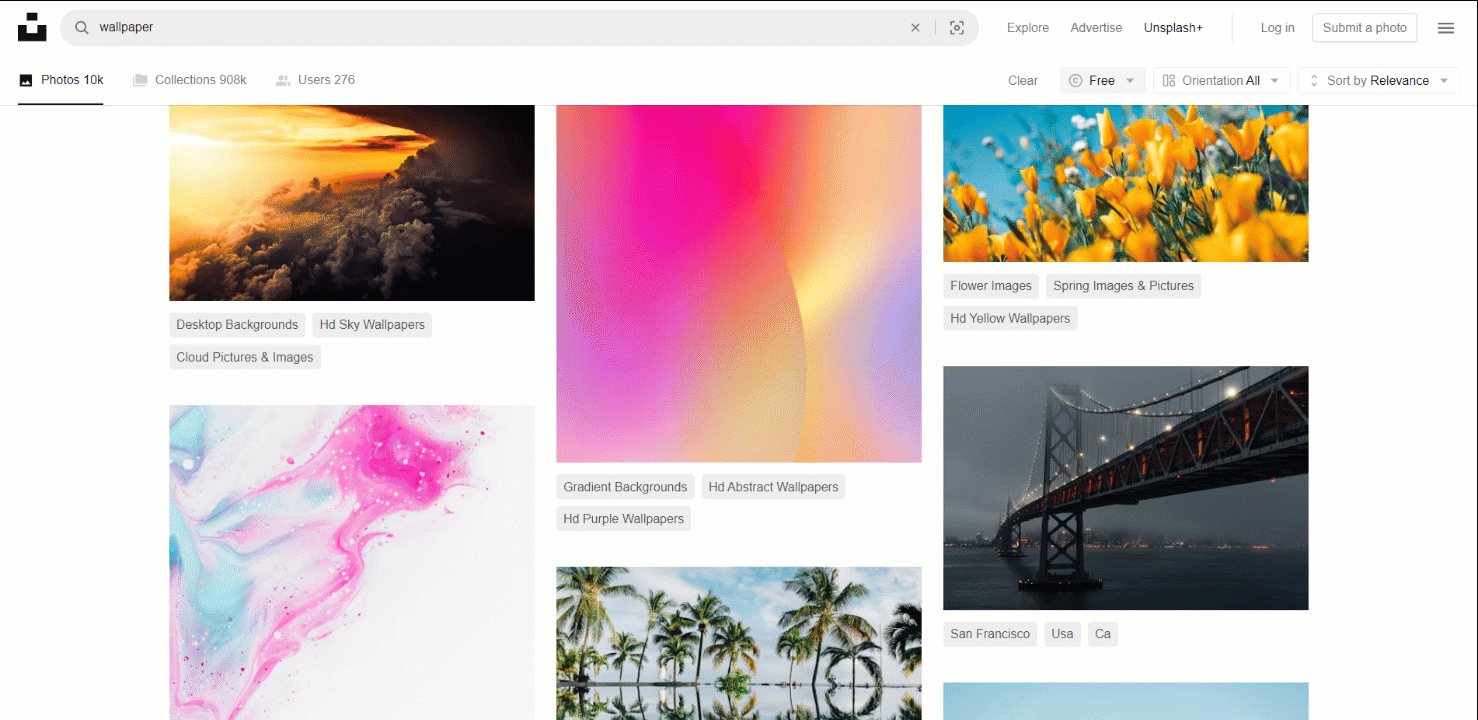
보시다시피, 사용자가 아래로 스크롤할 때마다 페이지가 새로운 이미지를 로드합니다. 즉, 스크래핑을 위해서는 브라우저 자동화 도구가 필요한 인터랙티브 사이트입니다.
해당 페이지의 URL은 다음과 같습니다:
https://unsplash.com/s/photos/wallpaper?license=free이제 파이썬으로 해당 사이트에서 이미지를 스크래핑하는 방법을 알아볼 시간입니다!
1단계: 시작하기
이 튜토리얼을 따라하려면 컴퓨터에 Python 3이 설치되어 있는지 확인하세요. 설치되어 있지 않다면 설치 프로그램을 다운로드하고 더블클릭한 후 안내에 따라 설치하세요.
아래 명령어로 Python 이미지 스크래핑 프로젝트를 초기화하세요:
mkdir image-scraper
cd image-scraper
python -m venv env이렇게 하면 image-scraper 폴더가 생성되고 그 안에 Python 가상 환경이 추가됩니다.
선택한 Python IDE에서 프로젝트 폴더를 엽니다. PyCharm Community Edition 이나 Python 확장 프로그램이 설치된 Visual Studio Code를 사용하면 됩니다.
프로젝트 폴더에 scraper.py 파일을 생성하고 다음과 같이 초기화하세요:
print('Hello, World!')현재 이 파일은 “Hello, World!”를 출력하는 간단한 스크립트이지만, 곧 이미지 스크래핑 로직이 포함될 것입니다.
IDE의 실행 버튼을 누르거나 아래 명령어를 실행하여 스크립트가 작동하는지 확인하세요:
python scraper.py터미널에 다음과 같은 메시지가 표시되어야 합니다:
Hello, World!훌륭합니다! 이제 Python 프로젝트가 준비되었습니다. 다음 단계에서 웹사이트에서 이미지를 스크래핑하는 데 필요한 로직을 구현하세요.
2단계: Selenium 설치
Selenium은 정적 및 동적 콘텐츠가 혼재된 사이트도 처리할 수 있어 이미지 스크래핑에 탁월한 라이브러리입니다. 브라우저 자동화 도구로서 JavaScript 실행이 필요한 페이지도 렌더링할 수 있습니다. Selenium 웹 스크래핑 가이드에서 자세히 알아보세요.
BeautifullSoup 같은 HTML 파서와 비교하면 Selenium은 더 많은 사이트를 대상으로 하고 더 다양한 사용 사례를 처리할 수 있습니다. 예를 들어, 사용자 상호작용에 의존하여 새 이미지를 로드하는 이미지 제공업체에서도 작동합니다. 바로 이 가이드의 대상 사이트인 Unsplash가 그런 경우입니다.
셀레늄 설치 전, Python 가상 환경을 활성화해야 합니다. Windows에서는 다음 명령어로 수행하세요:
envScriptsactivatemacOS 및 Linux에서는 대신 다음을 실행하세요:
source env/bin/activate활성화된 환경 터미널에서 다음 pip 명령어로 Selenium WebDriver 패키지를 설치하세요:
pip install selenium설치 과정은 시간이 다소 소요될 수 있으니 기다려 주세요.
완벽합니다! 이제 Python으로 이미지를 스크래핑하는 데 필요한 모든 준비가 완료되었습니다.
3단계: 대상 사이트에 연결하기
다음 줄을 scraper.py에 추가하여 Selenium과 Chrome 인스턴스 제어에 필요한 클래스를 임포트하세요.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options이제 다음 코드로 헤드리스 Chrome WebDriver 인스턴스를 초기화할 수 있습니다:
# Chrome을 헤드리스 모드로 실행
options = Options()
options.add_argument("--headless") # 개발 중에는 주석 처리
# 지정된 옵션으로 Chrome WebDriver 인스턴스 초기화
driver = webdriver.Chrome(
service=ChromeService(),
options=options
)Selenium이 GUI가 있는 Chrome 창을 실행하도록 하려면 --headless 옵션을 주석 처리하세요. 이렇게 하면 스크립트가 페이지에서 수행하는 작업을 실시간으로 확인할 수 있어 디버깅에 유용합니다. 실제 운영 환경에서는 리소스를 절약하기 위해 --headless 옵션을 활성화한 상태로 유지하세요.
스크립트 끝에 다음 줄을 추가하여 브라우저 창을 반드시 닫으십시오:
# 브라우저를 닫고 자원을 해제합니다
driver.quit() 일부 페이지는 사용자의 기기 화면 크기에 따라 이미지를 다르게 표시합니다. 반응형 콘텐츠 관련 문제를 방지하려면 다음 명령어로 Chrome 창을 최대화하세요:
driver.maximize_window()이제 get() 메서드를 사용하여 Selenium을 통해 Chrome이 대상 페이지에 연결하도록 지시할 수 있습니다:
url = "https://unsplash.com/s/photos/wallpaper?license=free"
driver.get(url)모든 것을 합치면 다음과 같습니다:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
# Chrome을 헤드리스 모드로 실행하기 위해
options = Options()
options.add_argument("--headless")
# 지정된 옵션으로 Chrome WebDriver 인스턴스 초기화
driver = webdriver.Chrome(
service=ChromeService(),
options=options
)
# 반응형 콘텐츠 관련 문제 방지
driver.maximize_window()
# 대상 페이지 URL
url = "https://unsplash.com/s/photos/wallpaper?license=free"
# 제어되는 브라우저에서 대상 페이지 방문
driver.get(url)
# 브라우저 종료 및 리소스 해제
driver.quit()헤더 모드에서 이미지 스크래핑 스크립트를 실행합니다. Chrome을 종료하기 전, 해당 페이지의 일부 섹션이 잠시 표시됩니다:
“Chrome is being controlled by automated test software” 메시지는 Selenium이 Chrome 창을 의도한 대로 제어 중임을 의미합니다.
훌륭합니다! 페이지의 HTML 코드를 살펴보고 이미지 추출 방법을 알아보세요.
단계 #4: 대상 사이트 검사
Python 이미지 스크래핑 로직을 파고들기 전에, 반드시 대상 페이지의 HTML 소스 코드를 검사해야 합니다. 이렇게 해야만 효과적인 노드 선택 로직을 정의하는 방법을 이해하고 원하는 데이터를 추출하는 방법을 파악할 수 있습니다.
따라서 브라우저에서 대상 사이트를 방문한 후 이미지를 마우스 오른쪽 버튼으로 클릭하고 “검사” 옵션을 선택하여 개발자 도구를 엽니다:
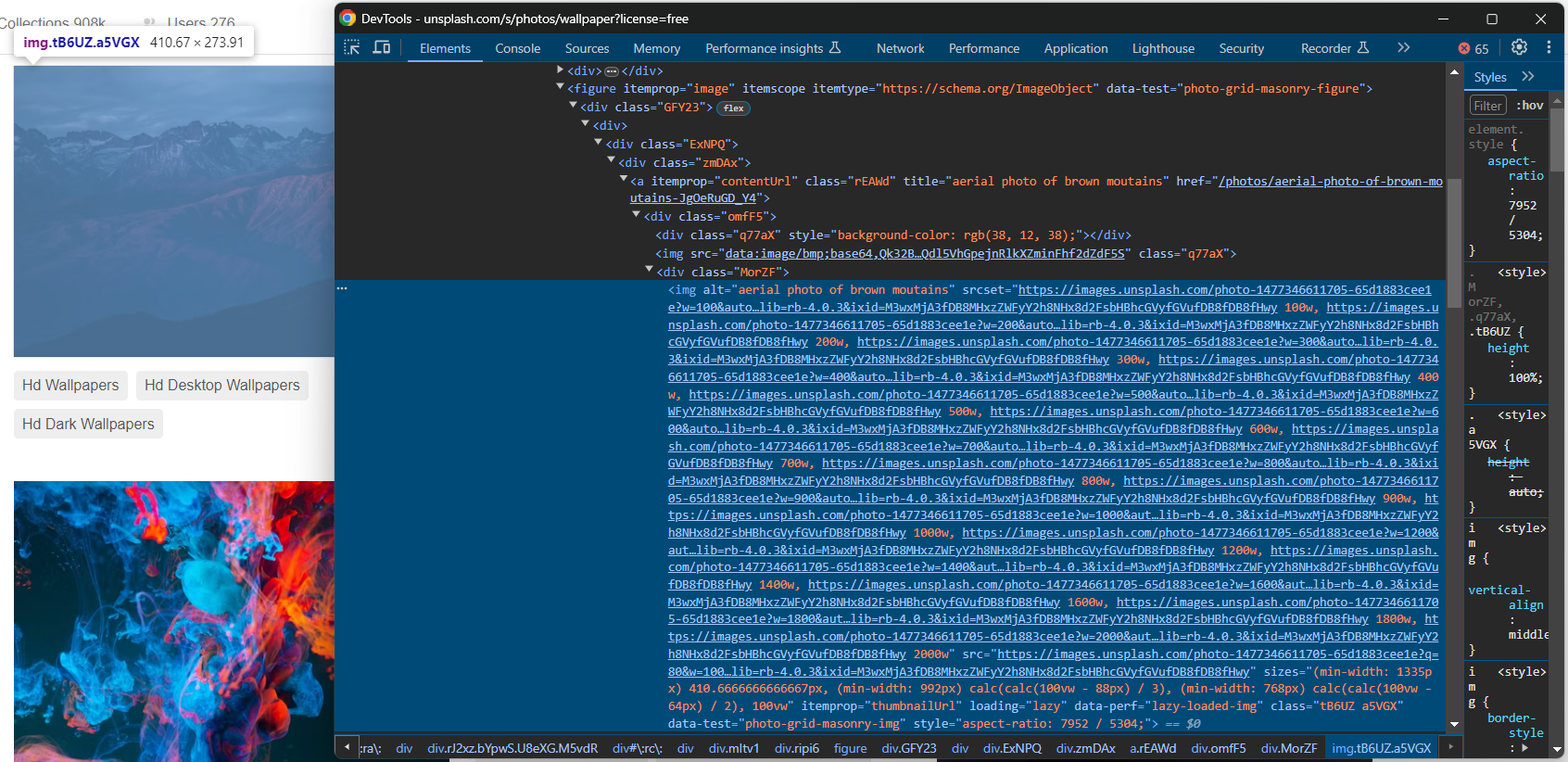
여기서 몇 가지 흥미로운 사실을 확인할 수 있습니다.
첫째, 이미지는 <img> HTML 요소 안에 포함되어 있습니다. 이는 관심 있는 이미지 노드를 선택하기 위한 CSS 선택자가 다음과 같음을 의미합니다:
[data-test="photo-grid-masonry-img"]둘째, 이미지 요소에는 기존 src 속성과 srcset 속성이 모두 존재합니다. 후자 속성에 익숙하지 않다면, srcset은 반응형 브레이크포인트에 따라 브라우저가 적절한 이미지를 선택하도록 돕는 힌트와 함께 여러 소스 이미지를 지정합니다.
구체적으로 srcset 속성의 값은 다음과 같은 형식을 가집니다:
<이미지_소스_1_URL> <이미지_소스_1_크기>, <이미지_소스_1_URL> <이미지_소스_2_크기>, ...여기서:
<image_source_1_url>,<image_source_2_url>등은 서로 다른 크기의 이미지 URL입니다.<image_source_1_size>,<image_source_2_size>등은 각 이미지 소스의 크기입니다. 허용되는 값은 픽셀 너비(예:200w) 또는 픽셀 비율(예:1.5x)입니다.
이미지에 두 속성이 모두 있는 이 시나리오는 현대적인 반응형 사이트에서 꽤 흔합니다. src 속성의 이미지 URL을 직접 타겟팅하는 것은 최선의 접근법이 아닙니다. srcset에는 더 높은 품질의 이미지 URL이 포함될 수 있기 때문입니다.
위의 HTML에서 볼 수 있듯이 모든 이미지 URL은 절대 경로입니다. 따라서 사이트 기본 URL을 추가할 필요가 없습니다.
다음 단계에서는 Selenium을 사용하여 Python으로 올바른 이미지를 추출하는 방법을 배울 것입니다.
단계 #5: 모든 이미지 URL 가져오기
findElements() 메서드를 사용하여 페이지에서 원하는 모든 HTML 이미지 노드를 선택합니다:
image_html_nodes = driver.find_elements(By.CSS_SELECTOR, "[data-test="photo-grid-masonry-img"]") 이 명령이 작동하려면 다음 임포트가 필요합니다:
from selenium.webdriver.common.by import By다음으로, 이미지 요소에서 추출된 URL을 담을 리스트를 초기화합니다:
image_urls = []image_html_nodes의 노드를 반복하며 src 속성의 URL 또는 srcset 속성이 존재할 경우 가장 큰 이미지의 URL을 수집하고 image_urls에 추가합니다:
for image_html_node in image_html_nodes:
try:
# 기본 동작으로 "src" 속성의 URL 사용
image_url = image_html_node.get_attribute("src")
# srcset 속성이 존재할 경우,
# srcset 값에서 가장 큰 이미지 URL 추출
srcset = image_html_node.get_attribute("srcset")
if srcset is not None:
# srcset 값의 마지막 요소 가져오기
srcset_last_element = srcset.split(", ")[-1]
# 값의 첫 번째 요소(이미지 URL)를 가져옴
image_url = srcset_last_element.split(" ")[0]
# 이미지 URL을 리스트에 추가
image_urls.append(image_url)
except StaleElementReferenceException as e:
continueUnsplash는 상당히 동적인 사이트이므로 이 루프를 실행할 때쯤이면 일부 이미지가 페이지에 더 이상 존재하지 않을 수 있습니다. 이러한 오류를 방지하려면 StaleElementReferenceException을 처리하세요.
다시 한번, 다음 임포트 문 추가를 잊지 마세요:
from selenium.common.exceptions import StaleElementReferenceException이제 스크랩한 이미지 URL을 다음과 같이 출력할 수 있습니다:
print(image_urls)현재 scraper.py 파일은 다음과 같아야 합니다:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.common.exceptions import StaleElementReferenceException
# Chrome을 헤드리스 모드로 실행하기 위해
options = Options()
options.add_argument("--headless")
# 지정된 옵션으로 Chrome WebDriver 인스턴스 초기화
driver = webdriver.Chrome(
service=ChromeService(),
options=options)
# 반응형 콘텐츠 관련 문제 방지
driver.maximize_window()
# 대상 페이지 URL
url = "https://unsplash.com/s/photos/wallpaper?license=free"
# 제어되는 브라우저에서 대상 페이지 방문
driver.get(url)
# 페이지에서 이미지 노드 선택
image_html_nodes = driver.find_elements(By.CSS_SELECTOR, "[data-test="photo-grid-masonry-img"]")
# 스크랩된 이미지 URL 저장 위치
image_urls = []
# 각 이미지에서 URL 추출
for image_html_node in image_html_nodes:
try:
# 기본 동작으로 "src" 속성의 URL 사용
image_url = image_html_node.get_attribute("src")
# "srcset" 속성에서 가장 큰 이미지 URL 추출
# 이 속성이 존재할 경우
srcset = image_html_node.get_attribute("srcset")
if srcset is not None:
# "srcset" 값의 마지막 요소 가져오기
srcset_last_element = srcset.split(", ")[-1]
# 값의 첫 번째 요소(이미지 URL) 가져오기
image_url = srcset_last_element.split(" ")[0]
# 이미지 URL을 리스트에 추가
image_urls.append(image_url)
except StaleElementReferenceException as e:
continue
# 스크랩한 데이터를 터미널에 출력
print(image_urls)
# 브라우저를 닫고 리소스를 해제
driver.quit()스크립트를 실행하여 이미지를 스크랩하면 다음과 유사한 출력을 얻을 수 있습니다:
[
'https://images.unsplash.com/photo-1707343843598-39755549ac9a?w=2000&auto=format&fit=crop&q=60&ixlib=rb-4.0.3&ixid=M3wxMjA3fDF8MHxzZWFyY2h8MXx8d2FsbHBhcGVyfGVufDB8fDB8fHwy',
# 생략...
'https://images.unsplash.com/photo-1507090960745-b32f65d3113a?w=2000&auto=format&fit=crop&q=60&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxzZWFyY2h8MjB8fHdhbGxwYXBlcnxlbnwwfHwwfHx8Mg%3D%3D'
]자, 시작해 보겠습니다! 위 배열에는 가져올 이미지의 URL이 포함되어 있습니다. 이제 파이썬으로 이미지를 다운로드하는 방법만 살펴보면 됩니다.
6단계: 이미지 다운로드
파이썬에서 이미지를 다운로드하는 가장 쉬운 방법은 표준 라이브러리의 url.request 패키지에서 urlretrieve() 메서드를 사용하는 것입니다. 이 함수는 URL로 지정된 네트워크 객체를 로컬 파일로 복사합니다.
scraper.py 파일 상단에 다음 줄을 추가하여 url.request를 임포트하세요:
import urllib.request프로젝트 폴더 내에 images 디렉터리를 생성하세요:
mkdir images스크립트가 이미지 파일을 작성할 위치입니다.
이제 스크랩된 이미지 URL 목록을 반복 처리합니다. 각 이미지에 대해 증분 파일 이름을 생성하고 urlretrieve()로 이미지를 다운로드합니다:
image_name_counter = 1
# 각 이미지를 다운로드하여
# "/images" 로컬 폴더에 추가
for image_url in image_urls:
print(f"{image_name_counter}번 이미지 다운로드 중 ...")
file_name = f"./images/{image_name_counter}.jpg"
# 이미지 다운로드
urllib.request.urlretrieve(image_url, file_name)
print(f"이미지 {file_name}에 성공적으로 다운로드됨n")
# 이미지 카운터 증가
image_name_counter += 1이것이 파이썬으로 이미지를 다운로드하는 데 필요한 모든 것입니다. print() 문은 필수적이지 않지만 스크립트가 무엇을 하는지 이해하는 데 유용합니다.
와! 방금 웹사이트에서 이미지를 스크래핑하는 Python 방법을 배웠습니다. 이제 이미지 스크래핑 Python 스크립트의 전체 코드를 살펴볼 시간입니다.
7단계: 모든 것을 합치기
다음은 최종 scraper.py 코드입니다:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.common.exceptions import StaleElementReferenceException
import urllib.request
# Chrome을 헤드리스 모드로 실행하기 위해
options = Options()
options.add_argument("--headless")
# 지정된 옵션으로 Chrome WebDriver 인스턴스 초기화
driver = webdriver.Chrome(
service=ChromeService(),
options=options)
# 반응형 콘텐츠 관련 문제 방지
driver.maximize_window()
# 대상 페이지의 URL
url = "https://unsplash.com/s/photos/wallpaper?license=free"
# 제어되는 브라우저에서 대상 페이지 방문
driver.get(url)
# 페이지에서 이미지 노드 선택
image_html_nodes = driver.find_elements(By.CSS_SELECTOR, "[data-test="photo-grid-masonry-img"]")
# 추출된 이미지 URL 저장 위치
image_urls = []
# 각 이미지에서 URL 추출
for image_html_node in image_html_nodes:
try:
# 기본 동작으로 "src" 속성의 URL 사용
image_url = image_html_node.get_attribute("src")
# "srcset" 속성이 존재할 경우,
# 가장 큰 이미지의 URL 추출
srcset = image_html_node.get_attribute("srcset")
if srcset is not None:
# "srcset" 값의 마지막 요소 가져오기
srcset_last_element = srcset.split(", ")[-1]
# 값의 첫 번째 요소(이미지 URL)를 가져옴
# image_url = srcset_last_element.split(" ")[0]
# 이미지 URL을 목록에 추가
image_urls.append(image_url)
except StaleElementReferenceException as e:
continue
# 디스크에 저장된 이미지 추적
image_name_counter = 1
# 각 이미지 다운로드 및
# "/images" 로컬 폴더에 추가
for image_url in image_urls:
print(f"{image_name_counter}번 이미지 다운로드 중 ...")
file_name = f"./images/{image_name_counter}.jpg"
# 이미지 다운로드
urllib.request.urlretrieve(image_url, file_name)
print(f"이미지 {file_name}에 성공적으로 다운로드됨n")
# 이미지 카운터 증가
image_name_counter += 1
# 브라우저 종료 및 리소스 해제
driver.quit()훌륭합니다! 100줄 미만의 코드로 사이트에서 이미지를 자동 다운로드하는 Python 스크립트를 만들 수 있습니다.
다음 명령어로 실행하세요:
python scraper.py이 Python 이미지 스크래핑 스크립트는 다음과 같은 문자열을 기록합니다:
이미지 번호 1 다운로드 중...
이미지 "./images/1.jpg"에 성공적으로 다운로드됨
# 간결함을 위해 생략...
이미지 번호 20 다운로드 중...
이미지 "./images/20.jpg"에 성공적으로 다운로드됨/images 폴더를 살펴보면 스크립트가 자동으로 다운로드한 이미지를 확인할 수 있습니다:
이 이미지는 앞서 본 Unsplash 페이지 스크린샷의 이미지와 다릅니다. 사이트가 지속적으로 업데이트된 콘텐츠를 제공하기 때문입니다.
자, 이제 완료되었습니다!
8단계: 다음 단계
목표는 달성했지만, Python 스크립트를 개선할 수 있는 몇 가지 방법이 있습니다. 가장 중요한 것은 다음과 같습니다:
- 이미지 URL을 CSV로 내보내거나 데이터베이스에 저장하기: 이렇게 하면 나중에 이미지를 다시 다운로드하거나 사용할 수 있습니다.
- 이미
/images폴더에 있는 이미지 다운로드 생략: 이미 다운로드된 이미지를 건너뛰어 네트워크 자원을 절약합니다. - 메타데이터 정보도 스크래핑하기: 태그와 작성자 정보를 가져오면 다운로드한 이미지에 대한 완전한 정보를 얻는 데 유용할 수 있습니다. Python 웹 스크래핑 가이드에서 방법을 알아보세요.
- 더 많은 이미지 스크래핑: 무한 스크롤 동작을 시뮬레이션하여 추가 이미지를 불러오고 모두 다운로드합니다.
결론
이 가이드에서는 웹사이트에서 이미지를 스크래핑하는 것이 유용한 이유와 Python으로 이를 수행하는 방법을 배웠습니다. 특히 사이트에서 이미지를 자동으로 다운로드할 수 있는 Python 이미지 스크래핑 스크립트를 구축하는 단계별 튜토리얼을 살펴보았습니다. 여기서 입증된 바와 같이, 이는 복잡하지 않으며 몇 줄의 코드만으로 가능합니다.
동시에, 반봇 시스템을 간과해서는 안 됩니다. 셀레니움은 훌륭한 도구이지만, 이러한 첨단 기술에는 무력합니다. 이들은 여러분의 스크립트를 봇으로 감지하고 사이트의 이미지에 접근하는 것을 막을 수 있습니다.
이를 방지하려면 자바스크립트를 렌더링하고 지문 인식, CAPTCHA, 스크래핑 방지 기능을 처리할 수 있는 도구가 필요합니다. 바로 브라이트 데이터의 스크래핑 브라우저가 그 역할을 합니다!
스크래핑 솔루션에 대해 저희 데이터 전문가와 상담해 보세요.
참고: 본 가이드는 작성 당시 당사 팀이 철저히 테스트했으나, 웹사이트가 코드와 구조를 자주 업데이트함에 따라 일부 단계가 예상대로 작동하지 않을 수 있습니다.
FAQ
웹사이트에서 이미지를 스크래핑하는 것은 합법적인가요?
웹사이트에서 이미지를 스크래핑하는 행위 자체는 불법이 아닙니다. 동시에 공개된 이미지만 다운로드하고, 스크래핑 시robots.txt 파일을 준수하며, 사이트의 이용 약관을 따르는 것이 중요합니다. 많은 사람들이 웹 스크래핑이 불법이라고 생각하지만 이는 오해입니다. 웹 스크래핑에 관한 오해에 대한 저희 글을 통해 자세히 알아보세요.
Python으로 이미지를 다운로드하는 데 가장 적합한 라이브러리는 무엇인가요?
정적 콘텐츠 사이트에서는 requests 같은 HTTP 클라이언트와 beautifulsoup4 같은 HTML 파서만으로도 충분합니다. 동적 콘텐츠 사이트나 상호작용이 많은 페이지에서는 Selenium이나 Playwright 같은 브라우저 자동화 도구가 필요합니다. 웹 스크래핑에 가장 적합한 헤드리스 브라우저 도구 목록을 확인해 보세요.
urllib.request에서 “HTTP Error 403: Forbidden”을 해결하는 방법은 무엇인가요?
HTTP 403 오류는 대상 사이트가 urllib.request로 수행된 요청을 자동화된 스크립트에서 온 것으로 인식하기 때문에 발생합니다. 이 문제를 효과적으로 피하는 방법은 User-Agent 헤더를 실제 환경의 값으로 설정하는 것입니다. urlretrieve() 메서드를 사용할 때 다음과 같이 설정할 수 있습니다:
opener = urllib.request.build_opener()
user_agent_string = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
opener.addheaders = [("User-Agent", user_agent_header)]
urllib.request.install_opener(opener)
# urllib.request.urlretrieve(...)




