

TL;DR: 이 튜토리얼은 C++로 웹사이트에서 데이터를 추출하는 방법과 스크래핑에 가장 효율적인 언어 중 하나인 이유를 보여줍니다.
이 가이드에서는 다음을 다룹니다:
- C++은 웹 스크래핑에 적합한 언어인가요?
- 최고의 C++ 웹 스크래핑 라이브러리
- C++로 웹 스크레이퍼 구축 방법
C++은 웹 스크래핑에 적합한 언어인가요?
C++은 정적 타입 프로그래밍 언어로, 고성능 애플리케이션 개발에 널리 사용됩니다. 이는 속도, 효율성, 메모리 관리 능력으로 잘 알려져 있기 때문입니다. C++은 웹 스크래핑을 포함한 다양한 애플리케이션에서 유용하게 활용되는 다목적 언어입니다.
C++은 컴파일 언어로서 Python과 같은 인터프리터 언어보다 본질적으로 빠릅니다. 이로 인해 빠른 스크레이퍼 구축에 탁월한 선택입니다. 그러나 C++은 웹 개발을 위해 설계된 것이 아니며 웹 스크래핑용 라이브러리가 많지 않습니다. 일부 타사 패키지가 존재하지만, Python, Ruby 또는 Java만큼 옵션이 다양하지는 않습니다.
요약하자면, C++로 웹 스크래핑을 수행하는 것은 가능하고 효율적이지만 다른 언어에 비해 저수준 프로그래밍이 더 많이 필요합니다. 이 과정을 더 쉽게 만들어 줄 도구가 무엇인지 알아봅시다!
최고의 C++ 웹 스크래핑 라이브러리
다음은 C++용 인기 웹 스크래핑 라이브러리입니다:
- CPR: Python Requests 프로젝트에서 영감을 받은 현대적인 C++ HTTP 클라이언트 라이브러리입니다. libcurl을 래핑하여 이해하기 쉬운 인터페이스, 내장 인증 기능, 비동기 호출 지원을 제공합니다 .
- libxml2: Gnome용으로 개발된 강력하고 완벽한 기능의 XML 및 HTML 문서 파싱 라이브러리입니다. XPath 선택자를 통한 DOM 조작을 지원합니다.
- Lexbor: CSS 선택자를 지원하는 완전히 C로 작성된 빠르고 가벼운 HTML 파싱 라이브러리입니다. Linux에서만 사용할 수 있습니다.
수년간 C++에서 가장 널리 사용된 HTML 파서는 Gumbo였습니다. 그러나 2016년 이후 유지보수가 중단되었으며, 공식 README에서도 사용을 권장하지 않습니다.
필수 조건
코딩을 시작하기 전에 다음을 준비해야 합니다:
아래 가이드를 따라 운영 체제에 맞는 필수 조건을 충족하는 방법을 확인하세요.
macOS에서 C++ 설정하기
macOS에서 가장 널리 사용되는 C, C++ 및 Objective-C 컴파일러는 Clang입니다. 많은 Mac에는 Clang이 미리 설치되어 있다는 점을 유의하세요. 이를 확인하려면 터미널을 열고 아래 명령어를 실행하세요:
clang --version
명령을 찾을 수 없음: clang 오류가 발생하면 Clang이 설치되지 않았거나 올바르게 구성되지 않았음을 의미합니다. 이 경우 Xcode 명령줄 도구를 통해 설치할 수 있습니다:
xcode-select --install
설치에는 시간이 다소 소요될 수 있으니 기다려 주세요.
vcpkg를 설정하려면 먼저 macOS 개발자 도구가 필요합니다. 다음 명령어로 Mac에 추가하세요:
xcode-select --install
그런 다음 vcpkg를 전역으로 설치해야 합니다. /dev 폴더를 생성하고 터미널에서 해당 폴더로 이동한 후 다음 명령어를 실행하세요:
git clone https://github.com/microsoft/vcpkg
이제 해당 디렉토리에 소스 코드가 포함됩니다. 패키지 관리자를 빌드하려면 다음 명령어를 실행하세요:
./vcpkg/bootstrap-vcpkg.sh
이 명령어를 실행하려면 관리자 권한이 필요할 수 있습니다.
마지막으로, 이 가이드에 따라 /dev/vcpkg를 $PATH 에 추가하세요.
CMake를 설치하려면 공식 사이트에서 설치 프로그램을 다운로드하고 실행한 후 설치 마법사를 따르십시오.
Windows에서 C++ 설정하기
MSYS2에서 MinGW-x64 설치 프로그램을 다운로드하고 실행한 다음 지침을 따르세요. 이 패키지는 GCC, Mingw-w64 및 기타 유용한 C++ 도구와 라이브러리의 최신 네이티브 빌드를 제공합니다.
설치 과정이 끝난 후 열린 MSYS2 터미널에서 Mingw-w64 툴체인을 설치하려면 아래 명령어를 실행하세요:
pacman -S --needed base-devel mingw-w64-x86_64-toolchain
프로세스가 완료될 때까지 기다린 후, 여기 설명된 대로 MinGW를 PATH 환경 변수에 추가하세요.
다음으로 vcpkg를 전역적으로 설치해야 합니다. C:/dev 폴더를 생성하고, PowerShell에서 해당 폴더를 열어 다음 명령을 실행하세요:
git clone https://github.com/microsoft/vcpkg
vcpkg 하위 폴더에 포함된 패키지 관리자의 소스 코드를 빌드하려면 다음 명령을 실행하세요:
./vcpkg/bootstrap-vcpkg.bat
이제 이전과 동일하게 C:/dev/vcpkg를 PATH 에 추가하세요.
이제 CMake만 설치하면 됩니다. 설치 프로그램을 다운로드하고 더블클릭한 후, 설치 과정에서 아래 옵션을 선택했는지 확인하세요.
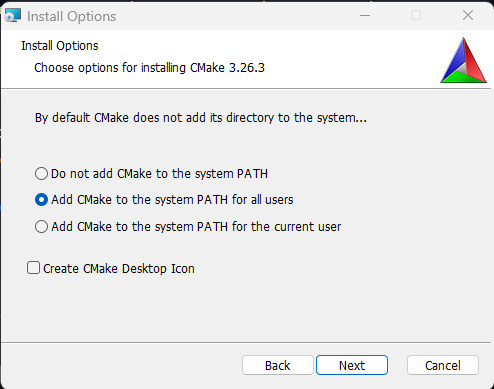
리눅스에서 C++ 설정하기
Debian 기반 배포판에서는 개발에 필요한 GCC( GNU 컴파일러 컬렉션), CMake 및 기타 유용한 패키지를 다음과 같이 설치하십시오:
sudo apt install build-essential cmake
시간이 다소 걸릴 수 있으니 기다려 주세요.
다음으로 vcpkg를 전역 설치해야 합니다. /dev 디렉터리를 생성하고 터미널에서 해당 디렉터리로 이동한 후 다음 명령어를 입력하세요:
git clone https://github.com/microsoft/vcpkg
이제 vcpkg 하위 디렉터리에 패키지 관리자의 소스 코드가 포함됩니다. 다음 명령어로 도구를 빌드하세요:
./vcpkg/bootstrap-vcpkg.sh
이 명령어는 관리자 권한이 필요할 수 있습니다.
그런 다음 이 가이드에 따라 /dev/vcpkg를 $PATH 환경 변수에 추가하세요.
완벽합니다! 이제 C++ 웹 스크래핑을 시작하는 데 필요한 모든 것이 준비되었습니다!
C++로 웹 스크레이퍼 구축하기
이 장에서는 C++ 웹 스파이더를 코딩하는 방법을 배웁니다. 대상 사이트는 Bright Data 홈페이지이며, 스크립트는 다음을 처리합니다:
- 웹페이지에 연결하기
- DOM에서 관심 있는 HTML 요소 선택
- 해당 요소에서 데이터 추출
- 스크래핑된 데이터를 CSV로 내보내기
현재 방문자가 대상 페이지를 탐색할 때 보이는 화면은 다음과 같습니다:
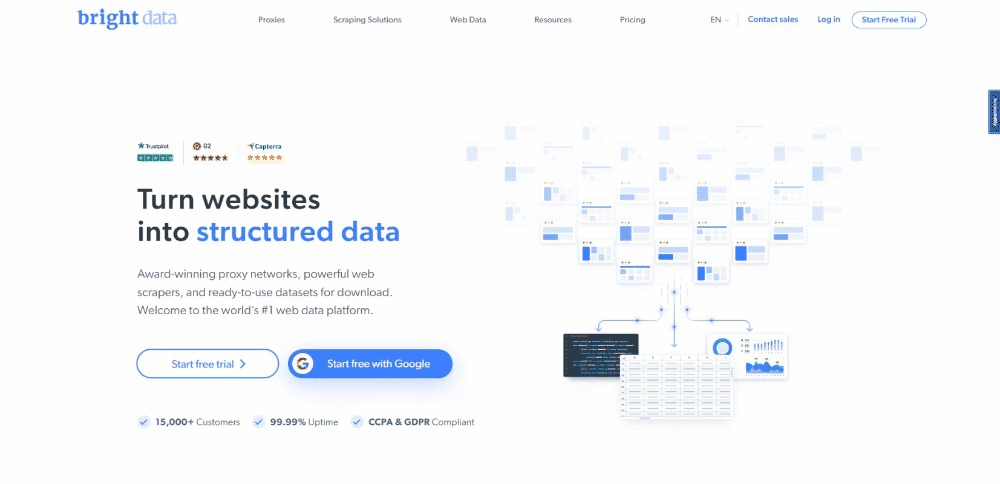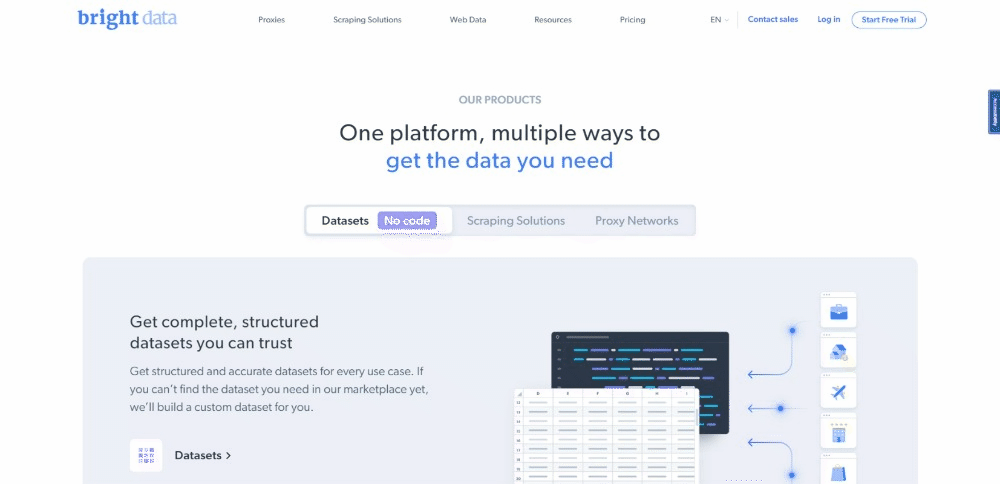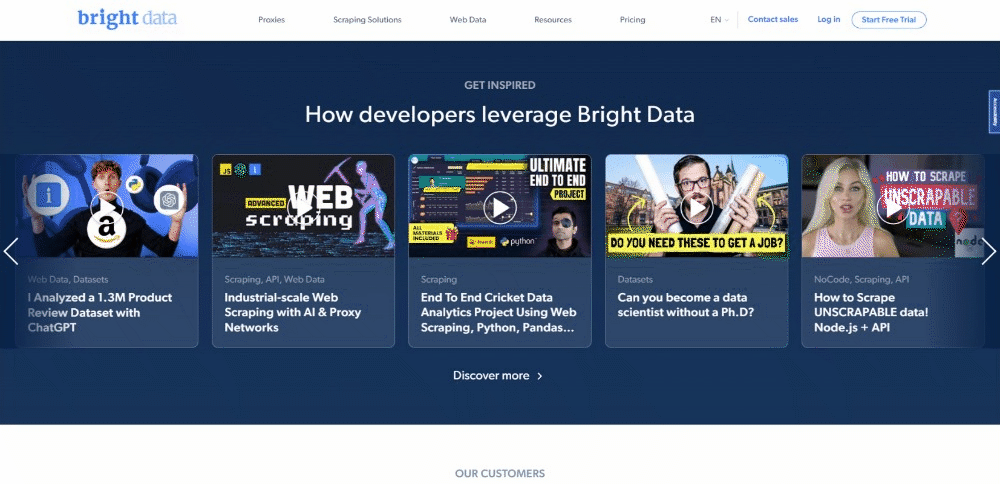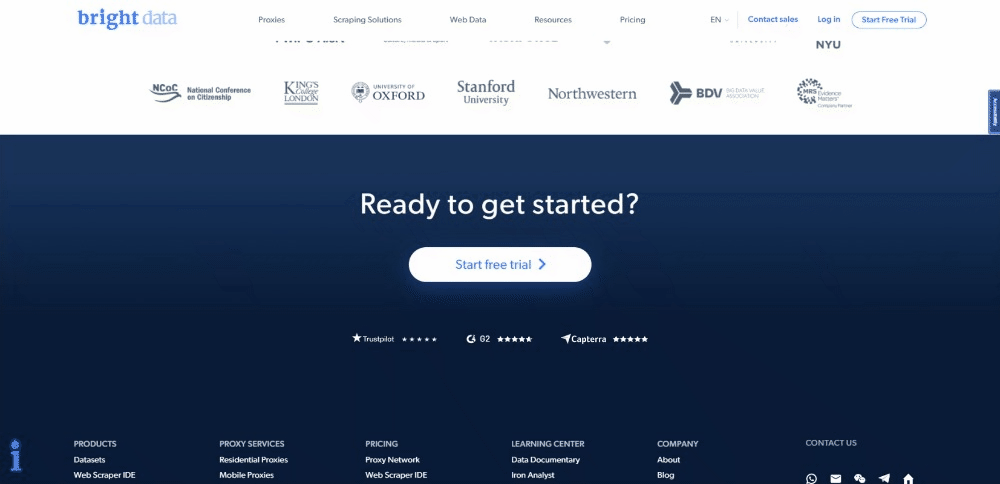
BrightData 홈페이지는 자주 변경됩니다. 따라서 이 글을 읽을 때쯤에는 이미 변경되었을 수 있습니다.
이 페이지에서 추출할 만한 흥미로운 데이터는 다음과 같은 카드에 포함된 업계 정보입니다:
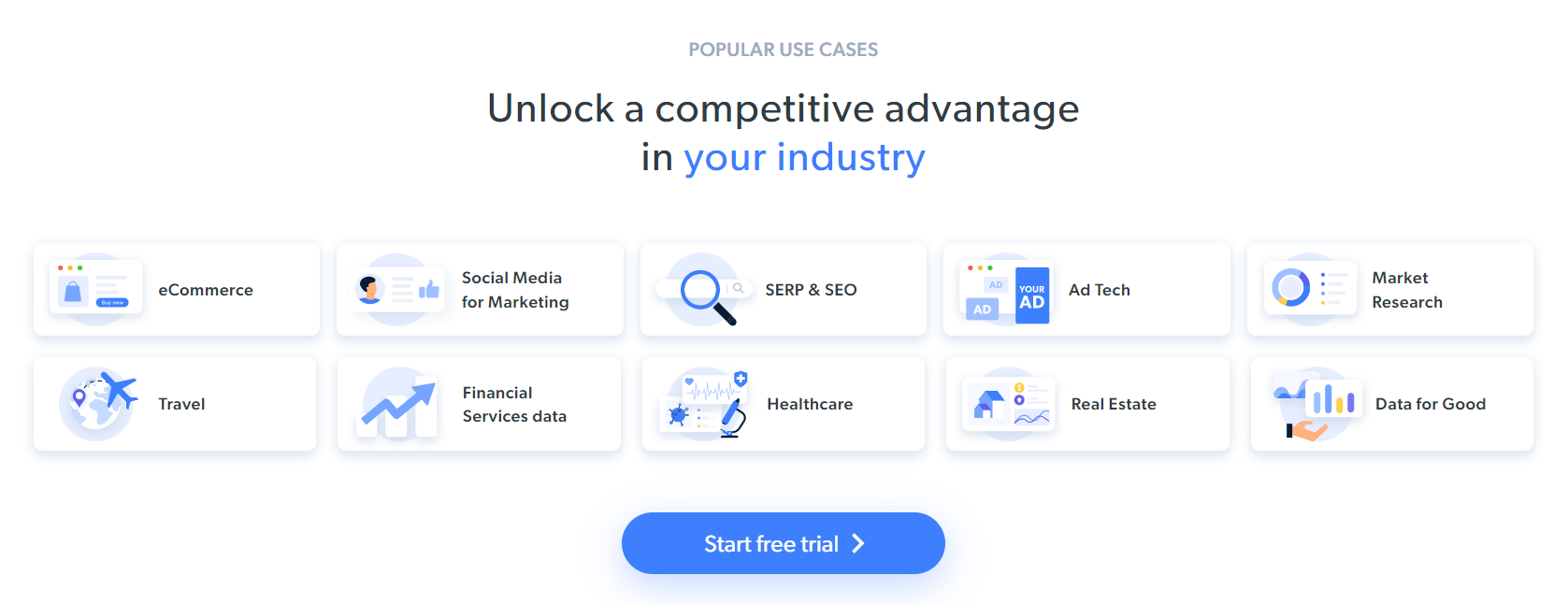
이 단계별 튜토리얼의 스크래핑 목표가 정의되었습니다. C++로 웹 스크래핑을 수행하는 방법을 살펴보겠습니다!
1단계: C++ 스크래핑 프로젝트 초기화
먼저 C++ 프로젝트를 저장할 폴더가 필요합니다. 터미널을 열고 다음 명령어로 프로젝트 디렉터리를 생성하세요:
mkdir c++-web-scraper
이 디렉터리에 스크래핑 스크립트를 저장합니다.
C++로 소프트웨어를 빌드할 때는 Visual Studio IDE를 선택하는 것이 좋습니다. 구체적으로, vcpkg를 패키지 관리자로 사용하여 C++ 개발을 위한 Visual Studio Code (VS Code) 설정 방법을 살펴보겠습니다. 유사한 절차를 다른 C++ IDE에도 적용할 수 있습니다.
VS Code는 C++에 대한 기본 지원을 제공하지 않으므로 먼저 C/C++ 플러그인을 추가해야 합니다. Visual Studio Code를 실행하고 왼쪽 바의 “확장 프로그램” 아이콘을 클릭한 후 상단 검색창에 “C++”을 입력하세요.
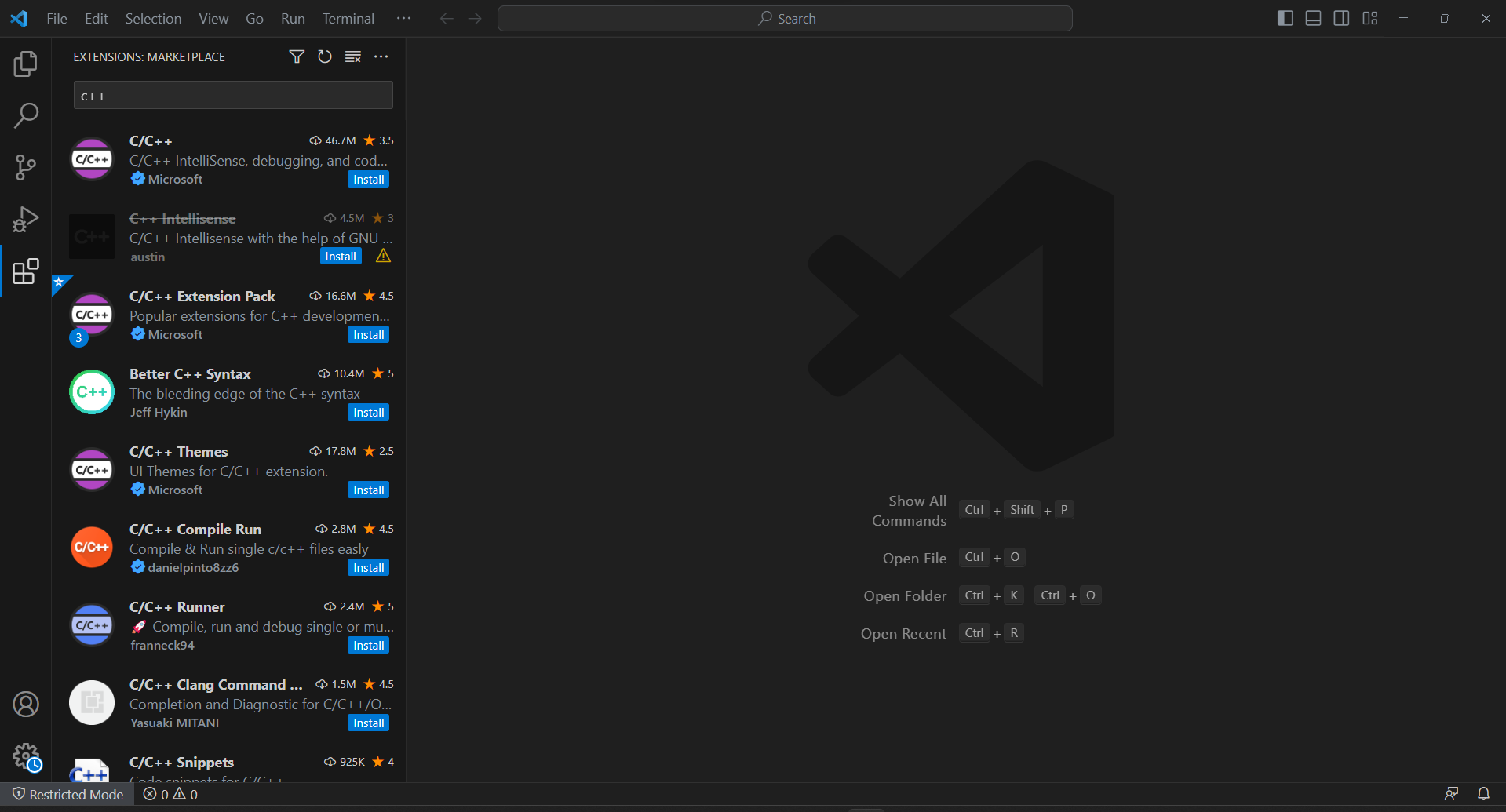
첫 번째 항목의 “설치” 버튼을 클릭하여 VS Code에 C++ 개발 기능을 추가합니다. 확장 프로그램이 설정될 때까지 기다린 후 "``파일``" > "``폴더 열기...``"로 c++-web-scraper 폴더를 엽니다.
“탐색기”섹션에서 마우스 오른쪽 버튼을 클릭하고 “새 파일…”을 선택한 후 다음과 같이 scraper.cpp 파일을 생성하세요:
#include <iostream>
int main()
{
std::cout << "Hello World" << std::endl;
}
이제 C++ 프로젝트가 생성되었습니다!
2단계: 스크래핑 라이브러리 설치
C++의 복잡한 구문과 제한된 웹 기능은 웹 스크레이퍼 구축 시 장애물이 될 수 있습니다. 작업을 간소화하려면 웹 스크레이핑용 C++ 라이브러리를 활용하세요. 앞서 언급했듯이 선택지가 매우 제한적입니다. 따라서 가장 널리 사용되는 cpr과 libxml2를 선택하세요.
Windows에서는 vcpkg를 통해 다음과 같이 설치할 수 있습니다:
vcpkg install cpr libxml2 --triplet=x64-windows
macOS에서는 triplet 옵션을 x64-osx로, Linux에서는 x64-linux로 변경하세요.
Visual Studio Code 터미널에서 프로젝트 루트 디렉터리에서 다음 명령어도 실행해야 합니다:
vcpkg integrate install
이를 통해 vcpkg 패키지를 프로젝트에 링크할 수 있습니다.
VS Code를 재시작하면 이제 설치된 라이브러리를 #include로 임포트할 수 있습니다. 따라서 scraper.cpp 파일 상단에 다음 세 줄을 추가하세요:
#include "cpr/cpr.h"
#include "libxml/HTMLparser.h"
#include "libxml/xpath.h"
IDE에서 오류가 발생하지 않는지 확인하세요.
3단계: C++ 프로젝트 초기화 완료
C++ 스크래핑 스크립트를 빌드하고 프로젝트 초기화 과정을 완료하려면 VS Code에 CMake Tools 확장 프로그램을 추가해야 합니다:
프로젝트에 .vscode 폴더가 없다면 생성하세요. VS Code는 현재 프로젝트 관련 설정을 이 폴더에서 찾습니다.
.vscode 폴더 내에 settings.json 파일을 다음과 같이 생성하여 CMake Tools가 vcpkg를 툴체인으로 사용하도록 구성하세요:
{
"cmake.configureSettings": {
"CMAKE_TOOLCHAIN_FILE": "c:/dev/vcpkg/scripts/buildsystems/vcpkg.cmake"
}
}
macOS 및 Linux에서는 vcpkg 설치 경로에 따라 CMAKE_TOOLCHAIN_FILE 필드를 수정하세요. 위 설치 가이드를 따랐다면 경로는 /dev/vcpkg/scripts/buildsystems/vcpkg.cmake여야 합니다.
VS Code 메인 검색창에 “>cmake”를 입력하고 “CMake: Configure” 옵션을 선택하세요:
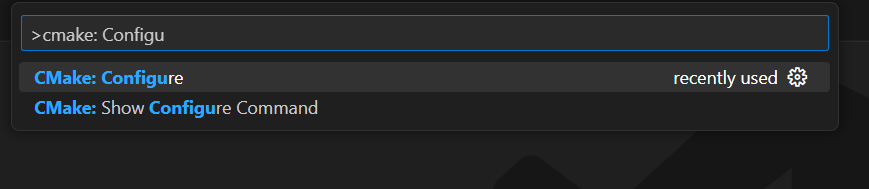
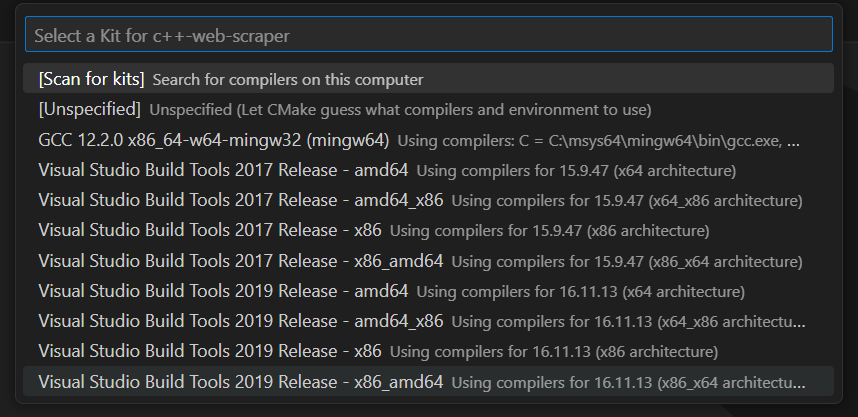
이를 통해 대상 컴파일 플랫폼을 선택할 수 있습니다. Windows에서는 “Visual Studio Build Tools 2019 Release – x86_amd64″를 선택하세요:
프로젝트 루트 폴더에 CMakeLists.txt 파일을 추가하여 CMake를 설정합니다:
cmake_minimum_required(VERSION 3.0.0)
project(main VERSION 0.1.0)
INCLUDE_DIRECTORIES(
C:/dev/vcpkg/installed/x86-windows/include)
LINK_DIRECTORIES(
C:/dev/vcpkg/installed/x86-windows/lib)
add_executable(main scraper.cpp)
target_compile_features(main PRIVATE cxx_std_20)
find_package(cpr CONFIG REQUIRED)
target_link_libraries(main PRIVATE cpr::cpr)
find_package(LibXml2 REQUIRED)
target_link_libraries(main PRIVATE LibXml2::LibXml2)
이 설정은 앞서 설치한 두 패키지를 포함합니다. vcpkg 설치 폴더에 따라 INCLUDE_DIRECTORIES와 LINK_DIRECTORIES를 반드시 업데이트하세요.
Visual Studio Code에서 C++ 프로그램을 실행하려면 런치 구성 파일이 필요합니다. .vscode 폴더에서 launch.json을 아래와 같이 초기화하세요:
{
"configurations": [
{
"name": "C++ 실행 (Windows)",
"type": "cppvsdbg",
"request": "launch",
"program": "${workspaceFolder}/build/Debug/main.exe",
"args": [],
"stopAtEntry": false,
"cwd": "${workspaceFolder}",
"environment": []
}
]
}
실행 또는 디버깅 명령을 실행할 때 VS Code는 이제 CMake가 생성한 프로그램 경로에서 파일을 실행합니다. macOS 및 Linux에서는 .exe 파일이 아니라는 점에 유의하십시오.
설정이 완료되었습니다!
앱을 디버깅하거나 빌드할 때마다 상단 입력 필드에 “>cmake: Build”를 입력하고 “CMake: Build” 옵션을 선택하세요.
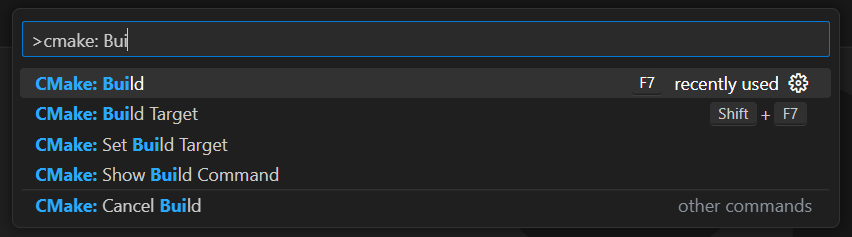
빌드 프로세스가 완료될 때까지 기다린 후 “실행 및 디버깅” 섹션에서 또는 F5 키를 눌러 컴파일된 프로그램을 실행하세요. VSC 디버그 콘솔에서 애플리케이션 결과를 확인할 수 있습니다.
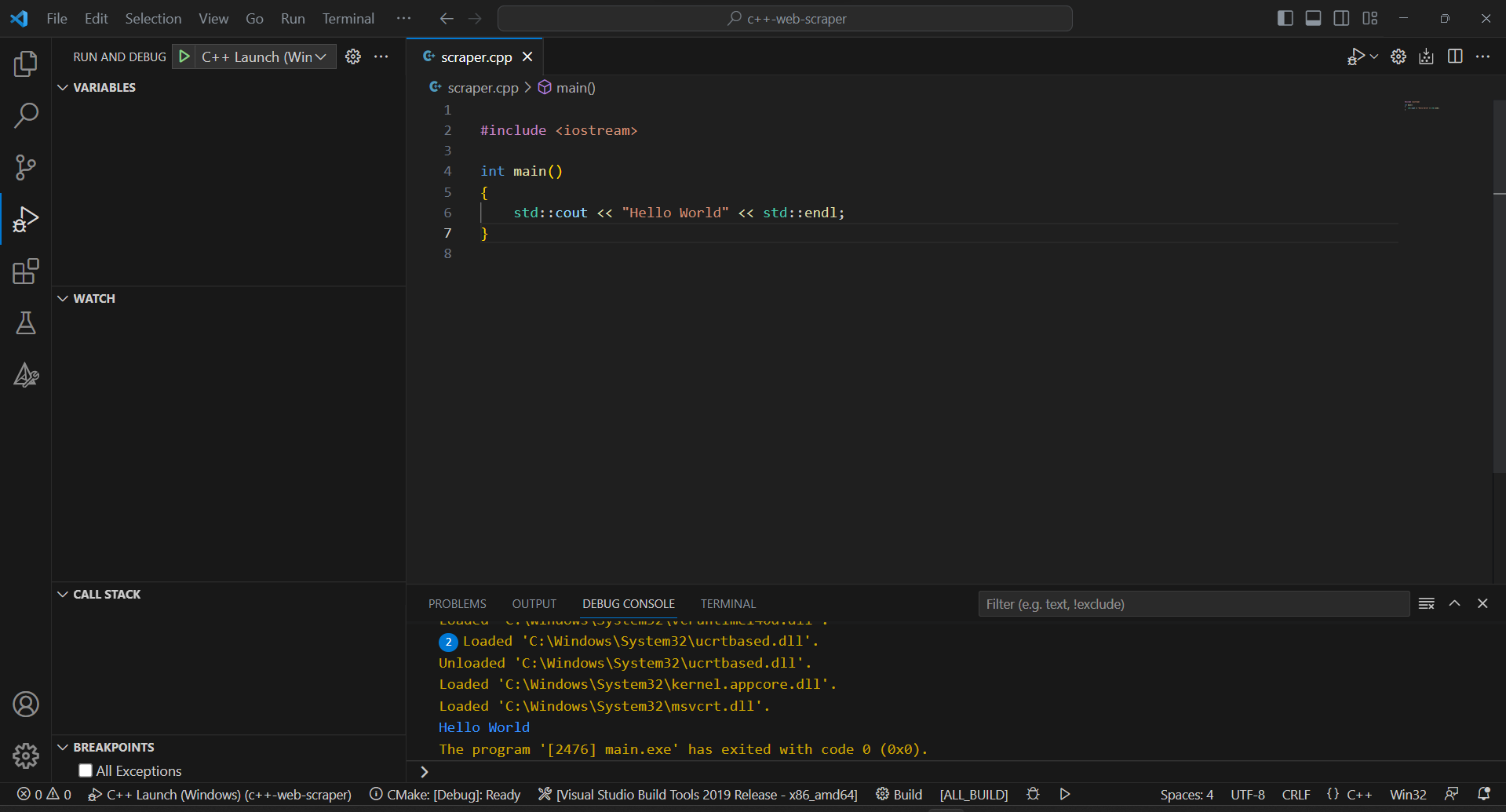
좋습니다! 이제 C++로 데이터를 스크래핑할 시간입니다!
4단계: CPR로 대상 페이지 다운로드
페이지에서 데이터를 추출하려면 먼저 HTTP GET 요청을 통해 해당 페이지의 HTML 문서를 가져와야 합니다.
CPR을 사용하여 대상 페이지를 다운로드합니다:
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/"});
배경에서 Get() 메서드는 매개변수로 전달된 URL에 대한 GET 요청을 수행합니다. response.text에는 서버가 반환한 HTML 코드의 문자열 표현이 포함됩니다.
자동화된 HTTP 요청은 반봇 기술을 작동시킬 수 있습니다. 이러한 기술은 요청을 차단하여 스크립트가 대상 사이트에 접근하지 못하게 할 수 있습니다. 특히 가장 기본적인 스크래핑 방지 솔루션은 유효한 User-Agent HTTP 헤더가 없는 들어오는 요청을 차단합니다.웹 스크래핑용User-Agent 가이드에서 자세히 알아보세요.
다른 HTTP 클라이언트와 마찬가지로 CPR은 User-Agent에 자리 표시자 값을 사용합니다. 이는 인기 브라우저에서 사용하는 에이전트와 매우 다르기 때문에, 봇 방지 시스템이 쉽게 감지할 수 있습니다. 이러한 이유로 차단되는 것을 방지하려면 CPR에서 유효한 User-Agent를 다음과 같이 설정할 수 있습니다:
cpr::Header headers = {{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}};
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/121.21.21.da/31/3das/32/1"}, headers);
해당 Get() 을 통해 수행된 HTTP 요청은 이제 Google Chrome 113에서 온 것으로 표시됩니다.
scraper.cpp의 현재 내용은 다음과 같습니다:
#include <iostream>
#include "cpr/cpr.h"
#include "libxml/HTMLparser.h"
#include "libxml/xpath.h"
int main()
{
// GET 요청용 사용자 에이전트 정의
cpr::Header headers = {{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}};
// 대상 페이지를 가져오기 위한 HTTP 요청 수행
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/"}, headers);
// 스크래핑 로직...
}
5단계: libxml2로 HTML 콘텐츠 파싱
서버에서 반환된 HTML 문서를 쉽게 탐색할 수 있도록 하려면 먼저 파싱해야 합니다.
이를 위해 C 문자열 표현을 libxml2의 htmlReadMemory() 함수에 전달합니다:
htmlDocPtr doc = htmlReadMemory(response.text.c_str(), response.text.length(), nullptr, nullptr, HTML_PARSE_NOWARNING | HTML_PARSE_NOERROR);
이제 doc 변수는 libxml2가 제공하는 DOM 탐색 API를 노출합니다. 구체적으로 XPath 선택자를 통해 페이지의 HTML 요소를 가져올 수 있습니다. 작성 시점 기준, libxml2는 CSS 선택자를 지원하지 않습니다.
6단계: 원하는 HTML 요소를 가져오기 위한 XPath 선택자 정의
관심 있는 HTML 노드에 대한 효과적인 XPath 선택 전략을 정의하려면 대상 페이지의 DOM을 분석해야 합니다. 브라우저에서 Bright Data 홈페이지를 열고, 산업 카드 중 하나를 마우스 오른쪽 버튼으로 클릭한 후 “검사”를 선택하세요. 그러면 개발자 도구(DevTools) 섹션이 열립니다:
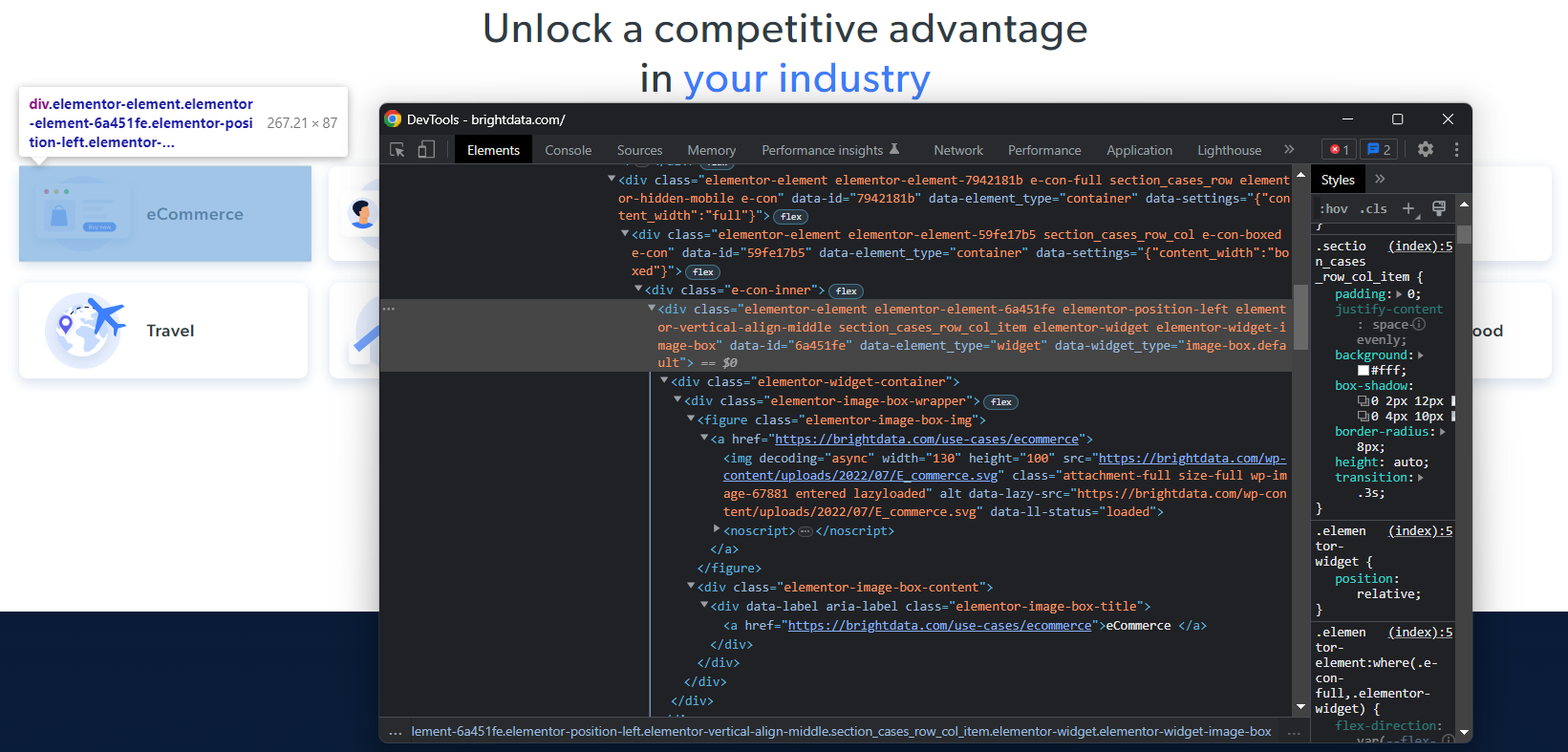
HTML 코드를 살펴보면 각 산업 카드가 다음을 포함하는 <div> 요소임을 알 수 있습니다:
- 해당 업계를 나타내는 이미지를 포함하는
<img>와 업계 페이지 URL을 포함하는<a>를 가진<figure>요소. <a>태그에 업종명을 저장하는<div>HTML 요소.
각 카드에 대해 C++ 스크레이퍼의 목표는 다음을 추출하는 것입니다:
- 산업 이미지 URL
- 산업 페이지 URL
- 산업명
적절한 XPath 선택자를 정의하려면 관심 요소의 DOM 구조에 주목하세요. 아래 XPath 선택자로 모든 산업 카드를 가져올 수 있음을 알 수 있습니다:
//div[contains(@class, 'section_cases_row_col_item')]
의문이 있다면 브라우저 콘솔에서 $x()로 XPath 명령어를 테스트하세요:
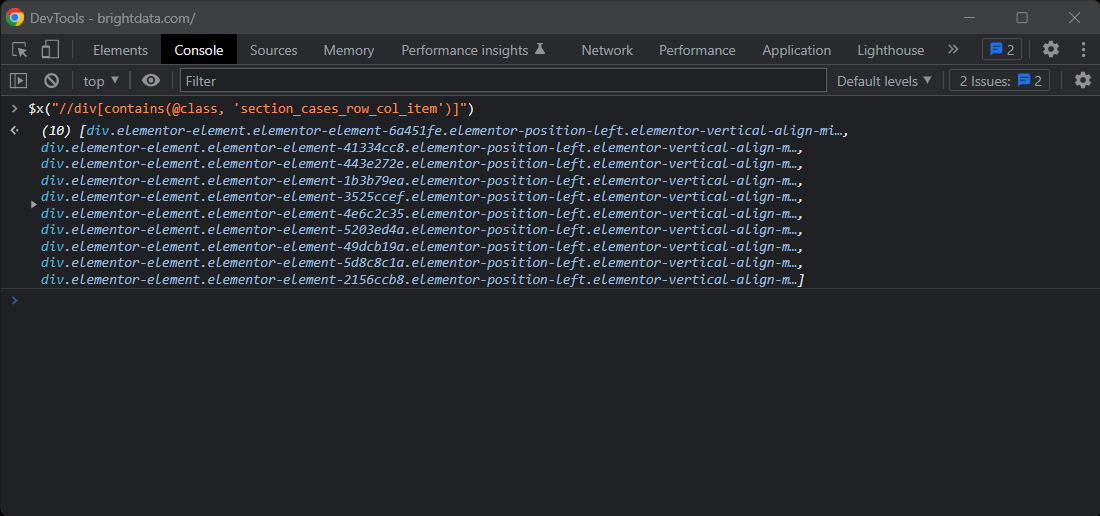
특정 카드를 대상으로 원하는 노드를 가져오려면 다음을 사용하세요:
.//figure/a/img.//figure/a.//div[contains(@class, 'elementor-image-box-title')]/a
7단계: libxml2를 사용하여 웹페이지에서 데이터 추출
이제 libxml2를 사용하여 이전에 정의한 XPath 선택자를 적용하고 대상 HTML 웹 페이지에서 원하는 데이터를 가져올 수 있습니다.
먼저, 추출된 데이터를 저장할 데이터 구조체가 필요합니다:
struct IndustryCard
{
std::string image;
std::string url;
std::string name;
};
C++에서 struct는 여러 데이터 속성을 동일한 이름으로 메모리 블록에 묶어 저장할 수 있게 합니다.
그런 다음 main() 함수에서 IndustryCard배열을 초기화합니다:
std::vector<IndustryCard> industry_cards;
이 배열은 모든 스크래핑 데이터 객체를 저장합니다.
다음 C++ 웹 스크래핑 로직으로 이 벡터를 채웁니다:
// 검색된 모든 데이터를 저장할 배열 정의
std::vector<IndustryCard> industry_cards;
// libxml2 컨텍스트를 현재 문서로 설정
xmlXPathContextPtr context = xmlXPathNewContext(doc);
// XPath 선택자로 모든 industry card HTML 요소 선택
xmlXPathObjectPtr industry_card_html_elements = xmlXPathEvalExpression((xmlChar *)"//div[contains(@class, 'section_cases_row_col_item')]", context);
// 산업 카드 요소 목록 반복
for (int i = 0; i < industry_card_html_elements->nodesetval->nodeNr; ++i)
{
// 루프의 현재 요소 가져오기
xmlNodePtr industry_card_html_element = industry_card_html_elements->nodesetval->nodeTab[i];
// libxml2 컨텍스트를 현재 요소에 설정
// XPath 선택자를 자식 요소로 제한하기 위함
xmlXPathSetContextNode(industry_card_html_element, context);
xmlNodePtr image_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a/img", context)->nodesetval->nodeTab[0];
std::string image = std::string(reinterpret_cast<char *>(xmlGetProp(image_html_element, (xmlChar *)"data-lazy-src")));
xmlNodePtr url_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a", context)->nodesetval->nodeTab[0];
std::string url = std::string(reinterpret_cast<char *>(xmlGetProp(url_html_element, (xmlChar *)"href")));
xmlNodePtr name_html_element = xmlXPathEvalExpression((xmlChar *)".//div[contains(@class, 'elementor-image-box-title')]/a", context)->nodesetval->nodeTab[0];
std::string name = std::string(reinterpret_cast<char *>(xmlNodeGetContent(name_html_element)));
// 수집된 데이터로 IndustryCard 구조체 인스턴스 생성
IndustryCard industry_card = {image, url, name};
// 스크랩된 데이터 객체를 벡터에 추가
industry_cards.push_back(industry_card);
}
// libxml2가 할당한 리소스 해제
xmlXPathFreeObject(industry_card_html_elements);
xmlXPathFreeContext(context);
xmlFreeDoc(doc);
위의 코드 조각은 xmlXPathEvalExpression()으로 정의한 XPath 선택자를 적용하여 산업 카드를 선택합니다. 그런 다음 카드를 반복 처리하며 각 카드에서 관심 있는 자식 요소를 추출하는 유사한 방식을 구현합니다. 다음으로 산업 이미지 URL, 페이지 URL 및 이름을 추출합니다. 마지막으로 libxml2가 할당한 리소스를 해제합니다.
보시다시피, libxml2를 사용한 C++ 웹 스크래핑은 그리 복잡하지 않습니다. xmlGetProp() 과 xmlNodeGetContent() 덕분에 각각 HTML 속성의 값과 노드의 내용을 얻을 수 있습니다.
이제 C++에서의 데이터 스크래핑 방식을 이해했으니, 한 단계 더 나아가 업계 페이지도 스크래핑할 수 있는 도구를 갖췄습니다. 여기서 발견한 링크를 따라가며 새로운 스크래핑 로직을 설계하기만 하면 됩니다. 이것이 바로 웹 크롤링과 웹 스크래핑의 핵심입니다!
대단합니다! 목표를 달성하셨군요. 하지만 튜토리얼은 아직 끝나지 않았습니다.
7단계: 스크랩한 데이터를 CSV로 내보내기
for() 루프가 끝날 때쯤이면 industry_cards는 스크래핑된 데이터를 구조체 인스턴스에 저장하게 됩니다. 예상하셨겠지만, 이는 다른 팀에 데이터를 제공하기에 최적의 형식이 아닙니다. 따라서 수집한 데이터를 CSV로 변환해야 하는 이유가 여기에 있습니다.
C++ 내장 함수를 사용해 벡터를 CSV 파일로 내보내는 방법은 다음과 같습니다:
// CSV 출력 파일 초기화
std::ofstream csv_file("output.csv");
// CSV 헤더 작성
csv_file << "url,image,name" << std::endl;
// CSV 출력 파일 채우기
for (IndustryCard industry_card : industry_cards)
{
// 각 산업 카드 레코드를 CSV 레코드로 변환
csv_file << industry_card.url << "," << industry_card.image << "," << industry_card.name << std::endl;
}
// 파일 리소스 해제
csv_file.close();
위 코드는 output.csv 파일을 생성하고 헤더 레코드로 초기화합니다. 그런 다음 industry_cards 배열을 반복하며 각 요소를 CSV 형식의 문자열로 변환하여 출력 파일에 추가합니다.
스크래핑 C++ 스크립트를 빌드하고 실행하면 프로젝트 루트 디렉터리에 다음과 같은 output.csv 파일이 생성됩니다:
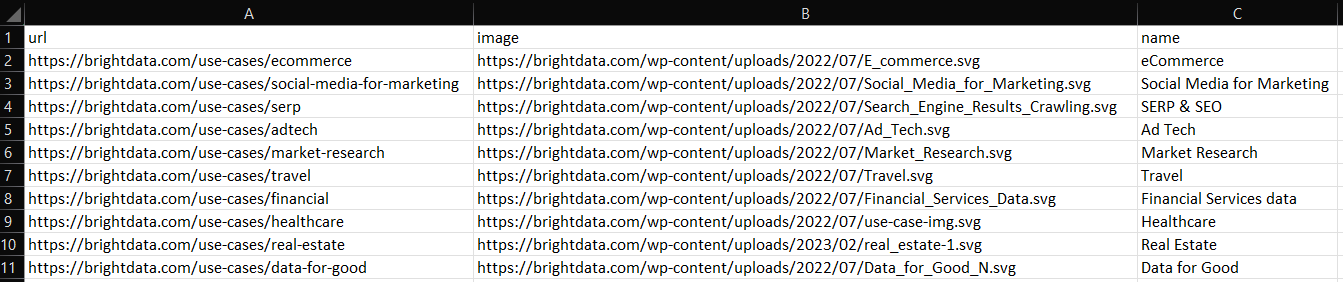
잘하셨습니다! 이제 C++에서 스크래핑한 데이터를 CSV로 내보내는 방법을 알게 되었습니다!
8단계: 모든 것을 통합하기
전체 C++ 스크래퍼 코드는 다음과 같습니다:
// scraper.cpp
#include <iostream>
#include "cpr/cpr.h"
#include "libxml/HTMLparser.h"
#include "libxml/xpath.h"
#include <vector>
// 스크랩된 데이터를 저장할 구조체 정의
struct IndustryCard
{
std::string image;
std::string url;
std::string name;
};
int main()
{
// GET 요청용 사용자 에이전트 정의
cpr::Header headers = {{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36"}};
// 대상 페이지를 가져오기 위한 HTTP GET 요청 수행
cpr::Response response = cpr::Get(cpr::Url{"https://brightdata.com/"}, headers);
// 서버에서 반환된 HTML 문서 파싱
htmlDocPtr doc = htmlReadMemory(response.text.c_str(), response.text.length(), nullptr, nullptr, HTML_PARSE_NOWARNING | HTML_PARSE_NOERROR);
// 검색된 모든 데이터를 저장할 배열 정의
std::vector<IndustryCard> industry_cards;
// libxml2 컨텍스트를 현재 문서로 설정
xmlXPathContextPtr context = xmlXPathNewContext(doc);
// XPath 선택자로 모든 산업 카드 HTML 요소 선택
xmlXPathObjectPtr industry_card_html_elements = xmlXPathEvalExpression((xmlChar *)"//div[contains(@class, 'section_cases_row_col_item')]", context);
// 산업 카드 요소 목록 반복
for (int i = 0; i < industry_card_html_elements->nodesetval->nodeNr; ++i)
{
// 루프의 현재 요소 가져오기
xmlNodePtr industry_card_html_element = industry_card_html_elements->nodesetval->nodeTab[i];
// libxml2 컨텍스트를 현재 요소로 설정
// XPath 선택자를 자식 노드로 제한
xmlXPathSetContextNode(industry_card_html_element, context);
xmlNodePtr image_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a/img", context)->nodesetval->nodeTab[0];
std::string image = std::string(reinterpret_cast<char *>(xmlGetProp(image_html_element, (xmlChar *)"data-lazy-src")));
xmlNodePtr url_html_element = xmlXPathEvalExpression((xmlChar *)".//figure/a", context)->nodesetval->nodeTab[0];
std::string url = std::string(reinterpret_cast<char *>(xmlGetProp(url_html_element, (xmlChar *)"href")));
xmlNodePtr name_html_element = xmlXPathEvalExpression((xmlChar *)".//div[contains(@class, 'elementor-image-box-title')]/a", context)->nodesetval->nodeTab[0];
std::string name = std::string(reinterpret_cast<char *>(xmlNodeGetContent(name_html_element)));
// 수집된 데이터로 IndustryCard 구조체 인스턴스 생성
IndustryCard industry_card = {image, url, name};
// 스크랩된 데이터 객체를 벡터에 추가
industry_cards.push_back(industry_card);
}
// libxml2가 할당한 리소스 해제
xmlXPathFreeObject(industry_card_html_elements);
xmlXPathFreeContext(context);
xmlFreeDoc(doc);
// CSV 출력 파일 초기화
std::ofstream csv_file("output.csv");
// CSV 헤더 작성
csv_file << "url,image,name" << std::endl;
// CSV 출력 파일 채우기
for (IndustryCard industry_card : industry_cards)
{
// 각 산업 카드 레코드를 CSV 레코드로 변환
csv_file << industry_card.url << "," << industry_card.image << "," << industry_card.name << std::endl;
}
// 파일 리소스 해제
csv_file.close();
return 0;
}
자, 이제 완성되었습니다! 약 80줄의 코드로 C++ 데이터 추출 스크립트를 만들 수 있습니다!
결론
이 튜토리얼에서는 C++이 웹 스크래핑에 효율적인 언어인 이유를 배웠습니다. 다른 언어만큼 많은 스크래핑 라이브러리가 존재하지는 않지만, 몇 가지가 존재합니다. 그리고 여기서 가장 인기 있는 라이브러리가 무엇인지 확인할 기회가 있었습니다. 다음으로, CPR과 libxml2를 사용하여 실제 대상에서 데이터를 수집할 수 있는 C++ 스파이더를 구축하는 방법을 살펴보았습니다.
그러나 웹 스크래핑에는 많은 어려움이 따릅니다. 실제로 점점 더 많은 사이트들이 데이터를 보호하기 위해 봇 방지 및 스크래핑 방지 기술을 도입하고 있습니다. 이러한 도구들은 스크래핑 C++ 스크립트가 수행하는 자동화된 요청을 감지하고 차단할 수 있습니다. 다행히도 데이터 수집 요구를 위한 자동화된 솔루션이 많이 존재합니다. 귀하의 사용 사례에 가장 적합한 솔루션이 무엇인지 알아보려면 저희에게 문의하세요.
웹 스크래핑 자체는 다루고 싶지 않지만 웹 데이터에는 관심이 있으신가요? 당사의 즉시 사용 가능한 데이터셋을 살펴보세요.





