이 포괄적인 가이드에서는 다음을 다룹니다:
- 최고의 C# 웹 스크래핑 라이브러리
- 필수 조건
- C#으로 정적 콘텐츠 웹사이트 스크래핑하기
- C#으로 동적 콘텐츠 웹사이트 스크래핑하기
- 스크래핑된 데이터 활용 방법
- 프록시를 통한 데이터 프라이버시
- 결론
최고의 C# 웹 스크래핑 라이브러리
적절한 도구를 활용하면웹 스크래핑이 훨씬 쉬워집니다. C#용 최고의 NuGet 스크래핑 라이브러리를 살펴보겠습니다:
HtmlAgilityPack: 가장 인기 있는 C# 스크래퍼 라이브러리입니다.HtmlAgilityPack은웹 페이지 다운로드, HTML 콘텐츠 파싱, HTML 요소 선택 및 데이터 스크래핑 기능을 제공합니다.HttpClient: 가장 널리 사용되는 C# HTTP 클라이언트입니다.HttpClient는HTTP 요청을 쉽고 비동기적으로 수행할 수 있게 해주므로 웹 크롤링에 특히 유용합니다.Selenium WebDriver는여러 프로그래밍 언어를 지원하며 웹 애플리케이션용 자동화 테스트를 작성할 수 있게 해주는 라이브러리입니다. 웹 스크래핑 목적으로도 사용할 수 있습니다.Puppeteer Sharp는Puppeteer의 C# 포팅 버전입니다. Puppeteer Sharp는 헤드리스 브라우저 기능을 제공하며 동적 콘텐츠 페이지의 스크래핑을 가능하게 합니다.
이 튜토리얼에서는 HtmlAgilityPack과 Selenium을 사용하여 C#으로 웹 스크래핑을 수행하는 방법을 살펴보겠습니다.
C#을 이용한 웹 스크래핑의 필수 조건
C# 웹 스크레이퍼의 첫 코드를 작성하기 전에 몇 가지 필수 조건을 충족해야 합니다:
- Visual Studio: 무료 Visual Studio 2022 Community 에디션으로도 충분합니다.
- .NET 6+: 6 이상 LTS 버전이면 됩니다.
이 중 하나라도 충족되지 않는 경우, 위 링크를 클릭하여 도구를 다운로드하고 설치 마법사를 따라 설정하세요.
이제 Visual Studio에서 C# 웹 스크래핑 프로젝트를 생성할 준비가 되었습니다.
Visual Studio에서 프로젝트 설정하기
Visual Studio를 열고 “새 프로젝트 만들기” 옵션을 클릭합니다.
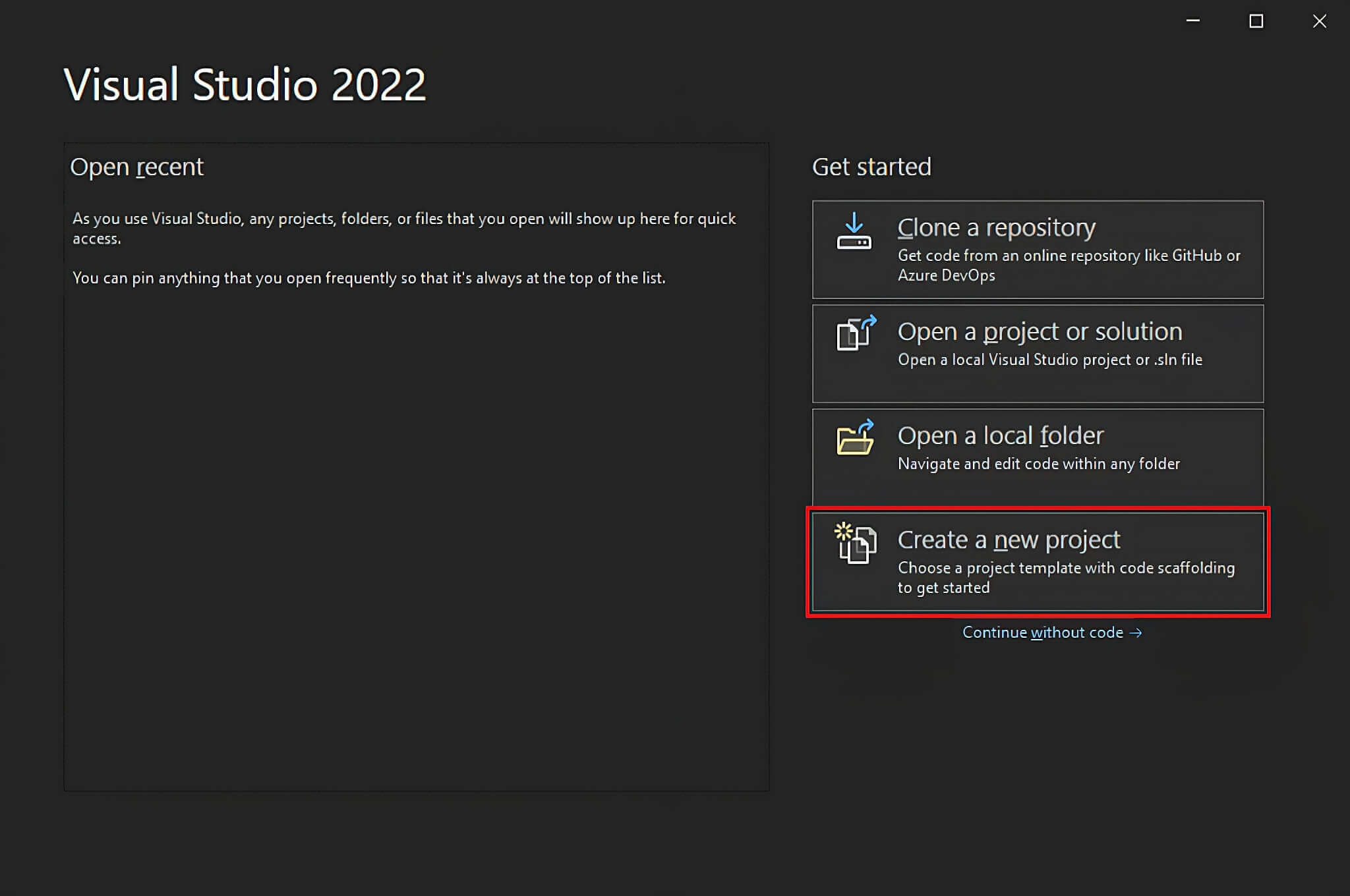
“새 프로젝트 만들기” 창에서 드롭다운 목록에서 “C#” 옵션을 선택합니다. 프로그래밍 언어를 지정한 후 “콘솔 앱” 템플릿을 선택하고 “다음”을 클릭합니다.
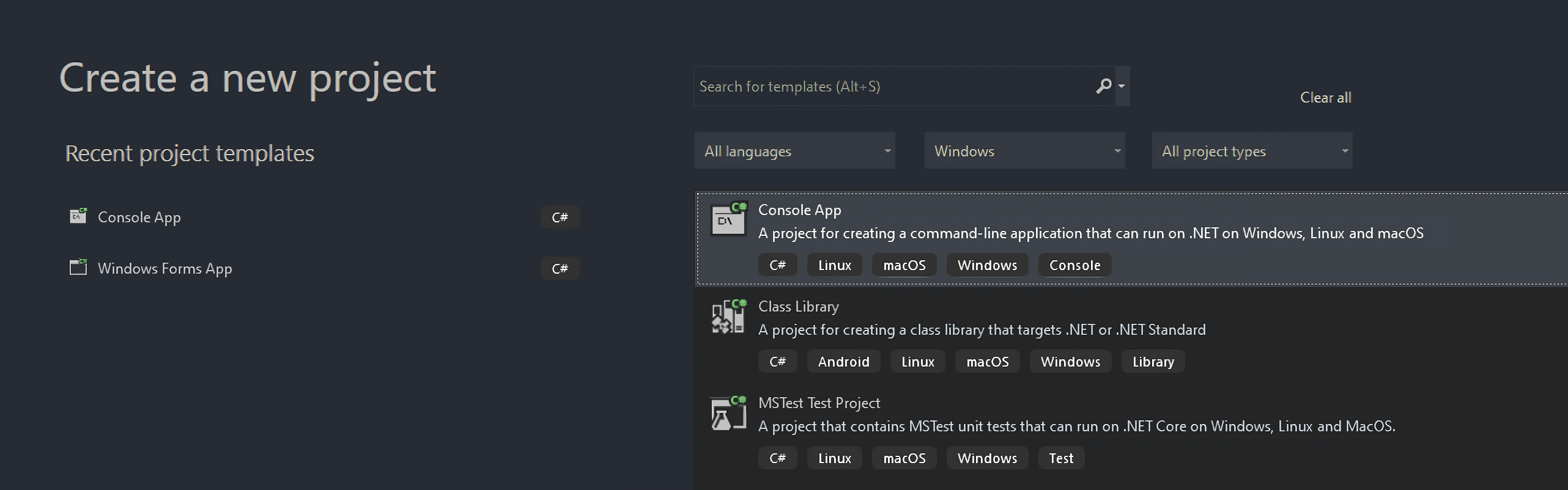
그런 다음 프로젝트 이름을 StaticWebScraping으로 지정하고 “선택”을 클릭한 후 .NET 버전을 선택합니다. .NET 6.0을 설치했다면 Visual Studio가 자동으로 선택해 줄 것입니다.
“Create” 버튼을 클릭하여 C# 웹 스크래핑 프로젝트를 초기화합니다. Visual Studio가 App.cs 파일이 포함된 StaticWebScraping 폴더를 생성합니다. 이 파일에는 C#으로 작성된 웹 스크래핑 로직이 저장됩니다:
namespace WebScraping {
public class Program {
public static void Main() {
// 스크래핑 로직...
}
}
}
이제 C#으로 웹 스크레이퍼를 구축하는 방법을 알아볼 시간입니다!
C#으로 정적 콘텐츠 웹사이트 스크래핑하기
정적 콘텐츠 웹사이트에서는 웹 페이지의 내용이 서버가 반환하는 HTML 문서에 이미 저장되어 있습니다. 즉, 정적 콘텐츠 웹 페이지는 데이터를 가져오기 위해 XHR 요청을 수행하거나 렌더링을 위해 JavaScript가 필요하지 않습니다.
정적 웹사이트 스크래핑은 상당히 간단합니다. 다음만 수행하면 됩니다:
- 웹 스크래핑 C# 라이브러리 설치
- 대상 웹 페이지를 다운로드하고 HTML 문서를 파싱합니다
- 웹 스크래핑 라이브러리를 사용하여 관심 있는 HTML 요소를 선택
- 추출된 데이터 처리
이제위키피디아의“스폰지밥 스퀘어팬츠 에피소드 목록” 페이지에 이 모든 단계를 적용해 보겠습니다:
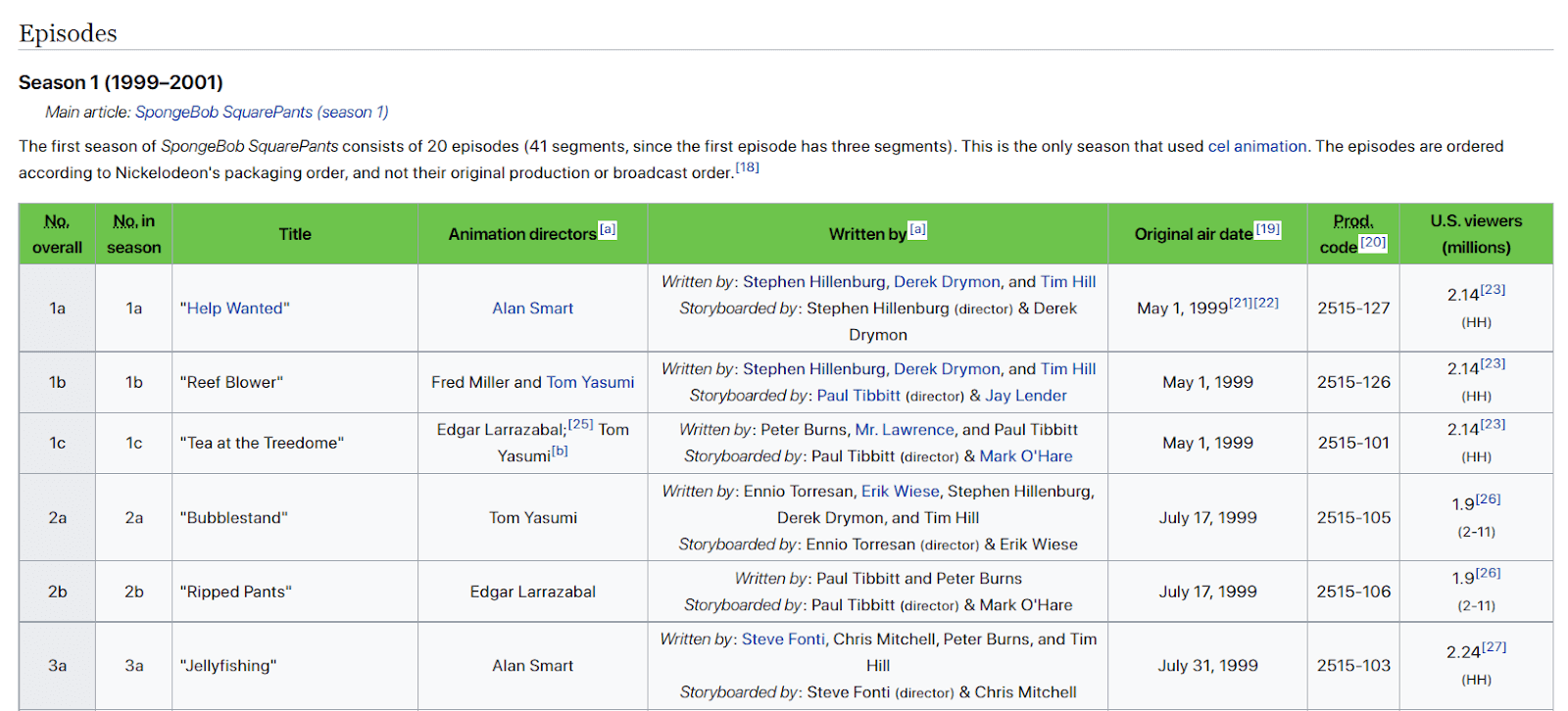
이제 구축할 C# 웹 스크레이퍼의 목표는 해당 정적 콘텐츠 위키백과 페이지에서 모든 에피소드 데이터를 자동으로 추출하는 것입니다.
시작해 보겠습니다!
1단계: HtmlAgilityPack 설치
HtmlAgilityPack은 HTML 문서를 파싱하고, DOM에서 요소를 선택하며, 해당 요소에서 데이터를 추출할 수 있게 해주는 오픈소스 C# 라이브러리입니다. 기본적으로 HtmlAgilityPack은 정적 콘텐츠 웹사이트를 스크래핑하는 데 필요한 모든 기능을 제공합니다.
설치하려면 “솔루션 탐색기”에서 프로젝트 이름 아래의 “의존성” 옵션을 마우스 오른쪽 버튼으로 클릭하세요. 그런 다음 “NuGet 패키지 관리”를 선택하세요. NuGet 패키지 관리자 창에서 “HtmlAgilityPack”을 검색하고 화면 오른쪽 섹션의 “설치” 버튼을 클릭하세요.
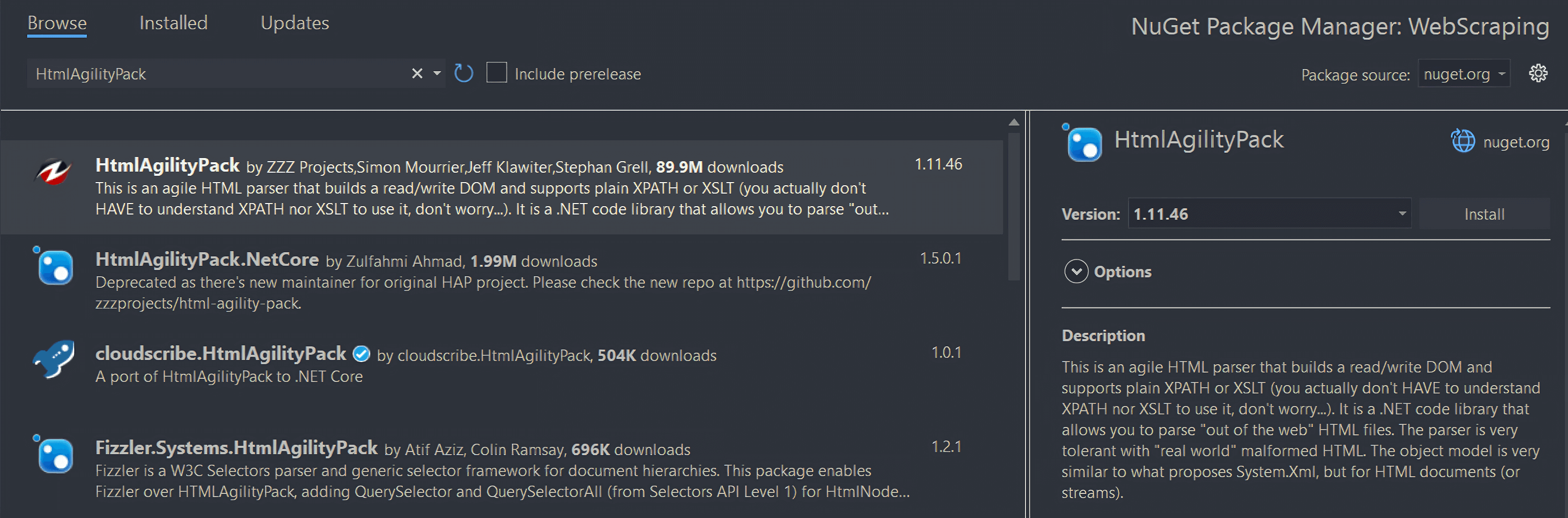
프로젝트 변경에 동의하는지 묻는 팝업 창이 나타납니다. “확인”을 클릭하여 HtmlAgilityPack을 설치하세요. 이제 정적 웹사이트에서 C#으로 웹 스크래핑을 수행할 준비가 되었습니다.
이제 App.cs 파일 상단에 다음 줄을 추가하여 HtmlAgilityPack을 임포트하세요:
using HtmlAgilityPack;2단계: HTML 웹 페이지 로드
HtmlAgilityPack을 사용하여 대상 웹 페이지에 다음과 같이 연결할 수 있습니다:
// 대상 위키백과 페이지의 URL
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
var web = new HtmlWeb();
// 대상 페이지 다운로드
// 및 HTML 콘텐츠 파싱
var document = web.Load(url);
HtmlWeb 클래스의 인스턴스는 Load() 메서드를 통해 웹 페이지를 로드할 수 있게 합니다. 이 메서드는 내부적으로 HTTP GET 요청을 수행하여 매개변수로 전달된 URL과 연관된 HTML 문서를 가져옵니다. 그런 다음 Load() 는 페이지에서 HTML 요소를 선택하는 데 사용할 수 있는 HtmlAgilityPack HtmlDocument 인스턴스를 반환합니다.
3단계: HTML 요소 선택
XPath 선택자를 사용하여 웹 페이지에서 HTML 요소를 선택할 수 있습니다. 구체적으로 XPath는 하나 이상의 특정 DOM 요소를 선택할 수 있게 합니다. HTML 요소와 관련된 XPath 선택자를 얻으려면 해당 요소를 마우스 오른쪽 버튼으로 클릭하고 브라우저의 검사 도구를 엽니다. 관심 있는 DOM 요소가 선택되었는지 확인한 후, 해당 DOM 요소를 마우스 오른쪽 버튼으로 클릭하고 “XPath 복사”를 선택합니다.
C# 웹 스크레이퍼의 목표는 각 에피소드와 연관된 데이터를 추출하는 것입니다. 따라서 위에서 설명한 절차를 <tr> 에피소드 요소에 적용하여 XPath 선택자를 추출하세요.
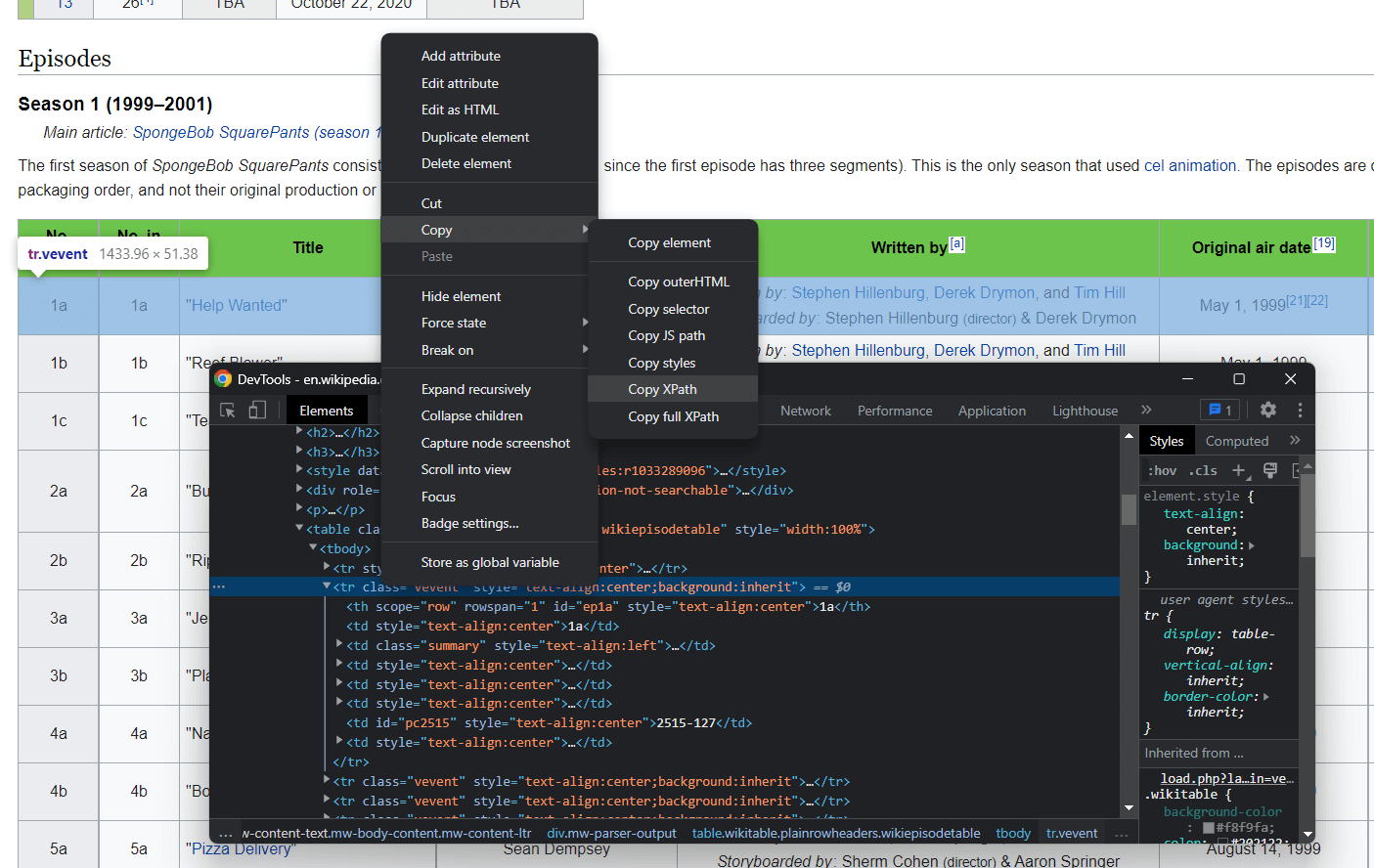
다음과 같은 결과가 반환됩니다:
//*[@id="mw-content-text"]/div[1]/table[2]/tbody/tr[2]
모든 <tr> 요소를 선택해야 한다는 점을 명심하세요. 따라서 행 선택 요소와 연관된 인덱스를 변경해야 합니다. 구체적으로, 테이블의 첫 번째 행은 테이블 헤더만 포함하므로 스크래핑하지 않아야 합니다. XPath에서 인덱스는 1부터 시작하므로, position()>1 XPath 구문을 추가하여 페이지의 첫 번째 에피소드 테이블에 있는 모든 <tr> 요소를 선택할 수 있습니다.
또한 모든 시즌 테이블의 데이터를 스크래핑해야 합니다. 위키백과 페이지에서 에피소드 데이터를 포함하는 테이블은 HTML 문서에 포함된 두 번째부터 열다섯 번째 HTML 테이블입니다. 따라서 최종 XPath 문자열은 다음과 같습니다:
//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]
이제 HtmlAgilityPack에서 제공하는 SelectNodes() 를 사용하여 다음과 같이 관심 있는 HTML 요소를 선택할 수 있습니다:
var nodes = document.DocumentNode.SelectNodes("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]");SelectNodes() 메서드는 HtmlNode 인스턴스에서만 호출할 수 있다는 점에 유의하세요. 따라서 DocumentNode 속성을 사용하여 HTML 문서의 루트 HTML 노드를 가져와야 합니다.
또한 XPath 선택기는 웹 페이지에서 HTML 요소를 선택하는 여러 방법 중 하나일 뿐이라는 점을 잊지 마십시오. CSS 선택기도 널리 사용되는 또 다른 옵션입니다.
4단계: HTML 요소에서 데이터 추출
먼저, 스크랩된 데이터를 저장할 사용자 정의 클래스가 필요합니다. WebScraping 폴더에 Episode.cs 파일을 생성하고 다음과 같이 초기화하세요:
namespace StaticWebScraping {
public class Episode {
public string OverallNumber { get; set; }
public string Title { get; set; }
public string Directors { get; set; }
public string WrittenBy { get; set; }
public string Released { get; set; }
}
}
보시다시피, 이 클래스에는 에피소드에 대해 스크래핑할 가장 중요한 정보를 모두 저장하기 위한 네 가지 속성이 있습니다. OverallNumber가 문자열인 이유는 스폰지밥의 에피소드 번호에는 항상 문자가 포함되기 때문입니다.
이제 App.cs 파일에 다음과 같이 웹 스크래핑 C# 로직을 구현할 수 있습니다:
using HtmlAgilityPack;
using System;
using System.Collections.Generic;
namespace StaticWebScraping {
public class Program {
public static void Main() {
// 대상 위키백과 페이지의 URL
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
var web = new HtmlWeb();
// 대상 페이지 다운로드
// 및 HTML 콘텐츠 파싱
var document = web.Load(url);
// 관심 있는 HTML 노드 선택
var nodes = document.DocumentNode.SelectNodes("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]");
// 스크랩된 데이터를 저장할 객체 목록 초기화
List<Episode> episodes = new List<Episode>();
// 노드 반복 처리
// 및 데이터 추출
foreach (var node in nodes) {
// 스크랩된 데이터 목록에
// 새로운 Episode 인스턴스 추가
episodes.Add(new Episode() {
전체수 = HtmlEntity.DeEntitize(node.SelectSingleNode("th[1]").InnerText),
제목 = HtmlEntity.DeEntitize(node.SelectSingleNode("td[2]").InnerText),
감독 = HtmlEntity.DeEntitize(node.SelectSingleNode("td[3]").InnerText),
WrittenBy = HtmlEntity.DeEntitize(node.SelectSingleNode("td[4]").InnerText),
Released = HtmlEntity.DeEntitize(node.SelectSingleNode("td[5]").InnerText)
});
}
// 스크랩한 데이터를 CSV로 변환...
// 이 데이터를 DB에 저장...
// 이 데이터로 API 호출...
}
}
}
이 C# 웹 스크레이퍼는 선택된 HTML 노드를 순회하며, 각 노드에 대해 Episode 클래스의 인스턴스를 생성하고 episodes 목록에 저장합니다. 관심 대상 HTML 노드는 테이블의 행임을 유의하십시오. 따라서 SelectSingleNode() 메서드로 요소를 선택한 후, InnerText 속성을 사용하여 스크랩할 데이터를 추출해야 합니다. 특수 HTML 문자를 자연스러운 표현으로 대체하기 위해 HtmlEntity.DeEntitize() 정적 함수를 사용하는 점에 주목하십시오.
5단계: 스크랩된 데이터를 CSV로 내보내기
이제 C#으로 웹 스크래핑을 수행하는 방법을 배웠으므로, 추출한 데이터로 원하는 작업을 수행할 수 있습니다. 가장 일반적인 시나리오 중 하나는 추출한 데이터를 CSV와 같은 사람이 읽을 수 있는 형식으로 변환하는 것입니다. 이렇게 하면 팀의 누구든지 추출한 데이터를 Excel에서 직접 탐색할 수 있습니다.
이제 C#으로 스크랩한 데이터를 CSV로 내보내는 방법을 알아봅시다.
작업의 편의를 위해 라이브러리를 사용해 보겠습니다. CSVHelper는 CSV 파일 읽기 및 쓰기를 위한 빠르고 사용하기 쉬운 강력한 .NET 라이브러리입니다. CSVHelper 종속성을 추가하려면 Visual Studio의 “NuGet 패키지 관리” 섹션을 열고 “CSVHelper”를 검색한 후 설치하세요.
CSVHelper를 사용해 스크랩한 데이터를 아래와 같이 CSV로 변환할 수 있습니다:
using CsvHelper;
using System.IO;
using System.Text;
using System.Globalization;
// 스크래핑 로직…
// CSV 파일 초기화
using (var writer = new StreamWriter("output.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
// CSV 파일 채우기
csv.WriteRecords(episodes);
}
using 키워드가 익숙하지 않다면, 이는 해당 범위 내에서 사용된 객체들이 범위 종료 시 자동으로 해제되도록 정의합니다. 즉, using은 파일 리소스 처리에 매우 유용합니다. 이후 CSVHelper의 WriteRecords() 함수가 스크래핑된 데이터를 자동으로 CSV 형식으로 변환하여 output.csv 파일에 기록합니다.
C# 웹 스크레이퍼 실행이 완료되면 프로젝트 루트 폴더에 output.csv 파일이 생성됩니다. 이 파일을 Excel에서 열면 다음과 같은 데이터를 확인할 수 있습니다:
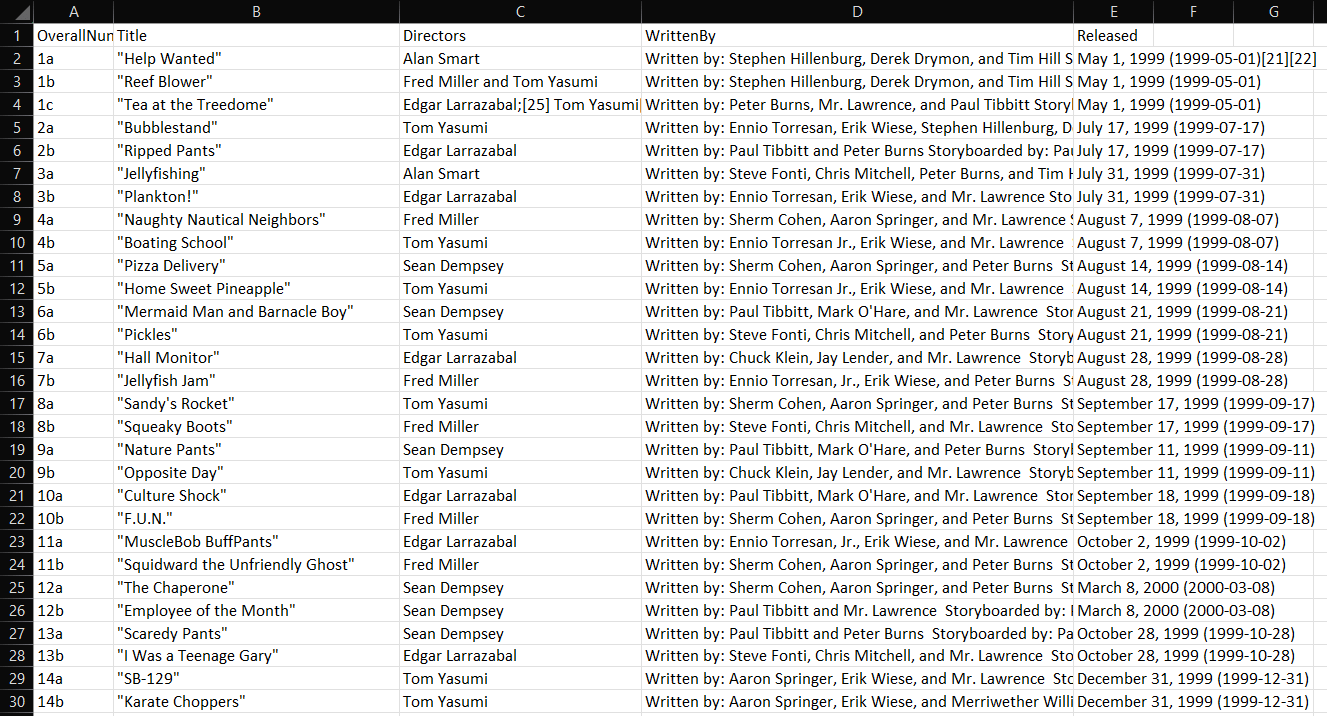
자, 이제 C#으로 정적 콘텐츠 웹사이트에서 웹 스크래핑을 수행하는 방법을 배웠습니다!
C#으로 동적 콘텐츠 웹사이트 스크래핑하기
동적 콘텐츠 웹사이트는 AJAX 기술을 통해 자바스크립트로 데이터를 동적으로 가져옵니다. 동적 콘텐츠 페이지와 연결된 HTML 문서는 기본적으로 비어 있을 수 있습니다. 동시에 렌더링 시점에 데이터를 동적으로 가져오고 렌더링하는 역할을 하는 자바스크립트 스크립트를 포함합니다. 이는 해당 페이지에서 데이터를 추출하려면 브라우저가 페이지를 렌더링해야 함을 의미합니다. 브라우저만이 자바스크립트를 실행할 수 있기 때문입니다.
동적 웹사이트 스크래핑은 까다로울 수 있으며 정적 웹사이트 스크래핑보다 확실히 더 어렵습니다. 구체적으로, 이러한 웹사이트를 스크래핑하려면 헤드리스 브라우저가 필요합니다. 이 기술에 익숙하지 않다면, 헤드리스 브라우저는 GUI가 없는 브라우저입니다. 달리 말하면, C#으로 동적 콘텐츠 웹사이트를 스크래핑하려면 Selenium과 같은 헤드리스 브라우저 기능을 제공하는 라이브러리가 필요합니다.
문서 시작 부분에 제시된 단락을 따라 새 C# 프로젝트를 설정하세요. 이번에는 프로젝트 이름을 DynamicWebScraping으로 지정합니다.
1단계: Selenium 설치
Selenium은 여러 프로그래밍 언어를 지원하는 자동화 테스트용 오픈소스 프레임워크입니다. Selenium은 헤드리스 브라우저 기능을 제공하며 웹 브라우저에 특정 작업을 수행하도록 지시할 수 있게 합니다.
프로젝트 종속성에 Selenium을 추가하려면 다시 “NuGet 패키지 관리” 섹션으로 이동하여 “Selenium.WebDriver”를 검색한 후 설치하세요.
App.cs 파일 상단에 다음 두 줄을 추가하여 Selenium을 임포트하세요:
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
2단계: 대상 웹사이트에 연결하기
Selenium은 대상 웹사이트를 브라우저에서 직접 열기 때문에 HTTP GET 요청을 수동으로 수행할 필요가 없습니다. Selenium Web Driver를 다음과 같이 사용하기만 하면 됩니다:
// 대상 위키백과 페이지의 URL
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
// 헤드리스 모드로 Chrome 웹 드라이버 초기화
var chromeOptions = new ChromeOptions();
chromeOptions.AddArguments("headless");
var driver = new ChromeDriver();
// 대상 웹 페이지 연결
driver.Navigate().GoToUrl(url);
여기서 Chrome 웹 드라이버 인스턴스를 생성했습니다. 다른 브라우저를 사용하는 경우 적절한 브라우저 드라이버를 사용하여 코드를 수정하세요. 그런 다음 드라이버 변수의 Navigate() 메서드를 통해 GoToUrl() 메서드를 호출하여 대상 웹 페이지에 연결할 수 있습니다. 구체적으로 이 함수는 URL 매개변수를 받아 헤드리스 브라우저에서 해당 URL과 연결된 웹 페이지를 방문합니다.
3단계: HTML 요소에서 데이터 추출
앞서 본 것과 마찬가지로, 관심 있는 HTML 요소를 선택하려면 다음 XPath 선택자를 사용할 수 있습니다:
//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]
Selenium에서 XPath 선택자를 사용하는 방법:
var nodes = driver.FindElements(By.XPath("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]"));
구체적으로 Selenium의 By.XPath() 메서드는 XPath 문자열을 적용하여 페이지 DOM에서 HTML 요소를 선택할 수 있게 합니다.
이제 DynamicWebScraping 네임스페이스 아래에 이전과 같이 Episode.cs 클래스를 이미 정의했다고 가정합니다. 이제 아래와 같이 Selenium을 사용하여 C# 웹 스크레이퍼를 구축할 수 있습니다:
using System;
using System.Collections.Generic;
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
namespace DynamicWebScraping {
public class Program {
public static void Main() {
// 대상 위키피디아 페이지의 URL
string url = "https://en.wikipedia.org/wiki/List_of_SpongeBob_SquarePants_episodes";
// 헤드리스 모드로 Chrome 웹 드라이버 초기화
var chromeOptions = new ChromeOptions();
chromeOptions.AddArguments("headless");
var driver = new ChromeDriver();
// 대상 웹 페이지 연결
driver.Navigate().GoToUrl(url);
// 관심 있는 HTML 노드 선택
var nodes = driver.FindElements(By.XPath("//*[@id='mw-content-text']/div[1]/table[position()>1 and position()<15]/tbody/tr[position()>1]"));
// 스크랩된 데이터를 저장할 객체 목록 초기화
List<Episode> episodes = new();
// 노드 반복 처리 및 데이터 추출
foreach (var node in nodes) {
// 스크랩된 데이터 목록에 새로운 Episode 인스턴스 추가
episodes.Add(new Episode() {
OverallNumber = node.FindElement(By.XPath("th[1]")).Text,
Title = node.FindElement(By.XPath("td[2]")).Text,
Directors = node.FindElement(By.XPath("td[3]")).Text,
WrittenBy = node.FindElement(By.XPath("td[4]")).Text,
Released = node.FindElement(By.XPath("td[5]")).Text
});
}
// 스크랩한 데이터를 CSV로 변환...
// 이 데이터를 DB에 저장...
// 이 데이터로 API 호출...
}
}
}
보시다시피, 웹 스크래핑 로직은 HtmlAgilityPack을 사용했을 때와 크게 다르지 않습니다. 구체적으로, Selenium의 FindElements() 및 FindElement() 메서드를 통해 이전과 동일한 스크래핑 목표를 달성할 수 있습니다. 진정한 차이는 Selenium이 이러한 모든 작업을 브라우저 내에서 수행한다는 점입니다.
동적 콘텐츠 웹사이트에서는 데이터가 가져와지고 렌더링될 때까지 기다려야 할 수 있습니다. WebDriverWait를 사용하면 이를 달성할 수 있습니다.
축하합니다! 이제 동적 콘텐츠 웹사이트에서 C# 웹 스크래핑을 수행하는 방법을 배웠습니다. 남은 것은 스크래핑된 데이터를 어떻게 활용할지 배우는 일뿐입니다.
스크래핑된 데이터 활용 방법
- 데이터베이스에 저장하여 필요할 때마다 쿼리하세요.
- JSON으로 변환하여 API 호출에 활용하세요.
- CSV와 같이 사람이 읽을 수 있는 형식으로 변환하여 Excel로 엽니다.
이것들은 단지 몇 가지 예시일 뿐입니다. 중요한 것은 스크래핑된 데이터를 코드에 확보한 후 원하는 대로 활용할 수 있다는 점입니다. 일반적으로 스크래핑된 데이터는 마케팅, 데이터 분석 또는 영업 팀을 위해 더 유용한 형식으로 변환됩니다.
그러나 웹 스크래핑에는 여러 가지 어려움이 따릅니다!
프록시를 통한 데이터 프라이버시
IP 노출, 차단 방지, 신원 보호를 원한다면 웹 스크래핑 프록시 사용을 고려하세요. 프록시 서버는 애플리케이션과 대상 웹사이트 서버 사이의 게이트웨이 역할을 하여 결과적으로 IP를 숨깁니다.
결과적으로 프록시 서비스를 통해 IP 차단을 극복하고, 익명으로 데이터를 수집하며, 모든 국가의 콘텐츠에 접근할 수 있습니다. 다양한 프록시 유형이 존재하며 각각 다른 사용 사례와 목적을 가집니다. 적합한 프록시 제공업체를 선택하는 것이 중요합니다.
이제 웹 프록시가 웹 스크래핑 프로세스에 가져다주는 이점을 살펴보겠습니다.
IP 차단 회피
웹 스크래핑 애플리케이션이 인터넷상의 웹사이트에 접근할 때, 요청이 발신된 IP 주소는 공개됩니다. 이는 웹사이트가 이를 추적하여 과도한 요청을 하는 사용자를 차단할 수 있음을 의미합니다. 이것이 바로 봇 탐지의 핵심입니다. 웹 프록시를 사용하면 대상 서버는 사용자의 IP가 아닌 회전 프록시의 IP를 확인합니다. 따라서 프록시를 통해 IP 차단을 쉽게 우회할 수 있습니다.
회전 IP 주소
프리미엄 프록시는 일반적으로 회전 IP 기능을 제공합니다. 이는 프록시 서버에 접속할 때마다 대규모 IP 풀에서 새로운 IP 주소를 할당받는다는 의미입니다. 이는 스크래핑 방지 시스템이 사용자를 추적하는 것을 피하는 데 매우 효과적입니다.
지역별 스크래핑
많은 웹사이트는 요청이 발생하는 위치에 따라 정보를 변경합니다. 또한 일부는 특정 지역에서만 이용 가능합니다. 이러한 웹사이트를 스크래핑하여 전 세계 시장 조사를 수행하는 것은 문제가 될 수 있습니다. 다행히 익명 프록시를 사용하면 출구 IP 주소의 위치를 선택할 수 있습니다. 이는 국제화된 웹사이트에서 제품에 대한 가치 있는 정보를 수집하는 훌륭한 방법입니다.
결론
여기서 C#을 사용한 웹 스크레이퍼 구축 방법을 배웠습니다. 보셨듯이, 이는 많은 코드 라인을 필요로 하지 않습니다. 동시에, 대상 웹 페이지가 변경되면 스크레이퍼도 그에 맞게 업데이트해야 합니다. 일부 웹사이트는 매일 구조를 변경하기도 합니다. Bright Data는 기업의 웹 스크레이핑 요구를 지원하기 위한 다양한 제품을 제공합니다. 귀사의 요구에 가장 적합한 제품이 무엇인지 알아보려면 영업 담당자와 상담하십시오.