Google Images는 웹에서 스크래핑하기 가장 어려운 사이트 중 하나입니다. 스크래퍼를 명시적으로 차단하지는 않지만, 데이터를 얻으려면 정말 고생해야 합니다… 정말 원해야만 가능하죠!
동적 CSS 선택자부터 Base64 인코딩까지, Google Images 스크래핑은 일반 HTML 스크래핑보다 퍼즐을 푸는 것과 훨씬 더 유사합니다.
필수 조건
Google Images를 스크래핑하려면 Python과 Selenium에 대한 기본적인 이해가 필요합니다. Selenium이 설치되어 있는지 확인해야 합니다. 필요하다면 Python과 Selenium을 활용한 웹 스크래핑에 대해 더 알아보시길 권장합니다.
먼저 ChromeDriver와 Chrome이 설치되어 있는지 확인하세요. 최신 버전은 여기에서 다운로드할 수 있습니다.
ChromeDriver를 다운로드할 때는 사용 중인 Chrome 버전과 일치하는 버전을 선택해야 합니다.
다음 명령어로 Chrome 버전을 확인할 수 있습니다.
google-chrome --version
출력 결과는 아래와 유사해야 합니다.
Google Chrome 131.0.6778.139
이들 준비가 완료되면 pip를 사용하여 Selenium을 설치할 수 있습니다.
pip install selenium
스크래핑 대상
코드를 무턱대고 시작할 수는 없습니다. 스크래핑 대상과 추출 방법을 명확히 파악해야 합니다. 앞서 언급했듯이 Google 이미지 스크래핑은 퍼즐을 푸는 것과 같습니다.
구글 이미지 중 하나를 살펴보겠습니다. 이 이미지는 실제로 g-img라는 사용자 정의 HTML 태그에 포함되어 있습니다. 우리는 이 g-img 요소들을 모두 찾아야 합니다.
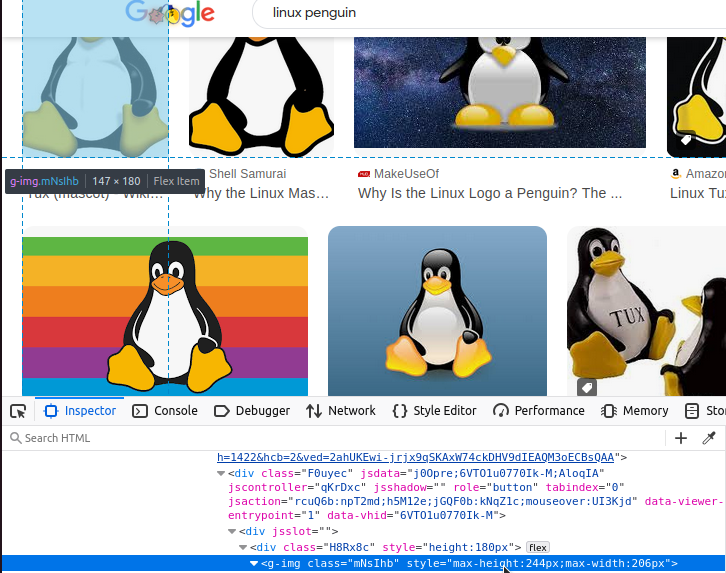
모든 g-img 태그를 찾은 후에는 해당 img 요소를 추출해야 합니다. 아래에서 그 예시를 확인할 수 있습니다.
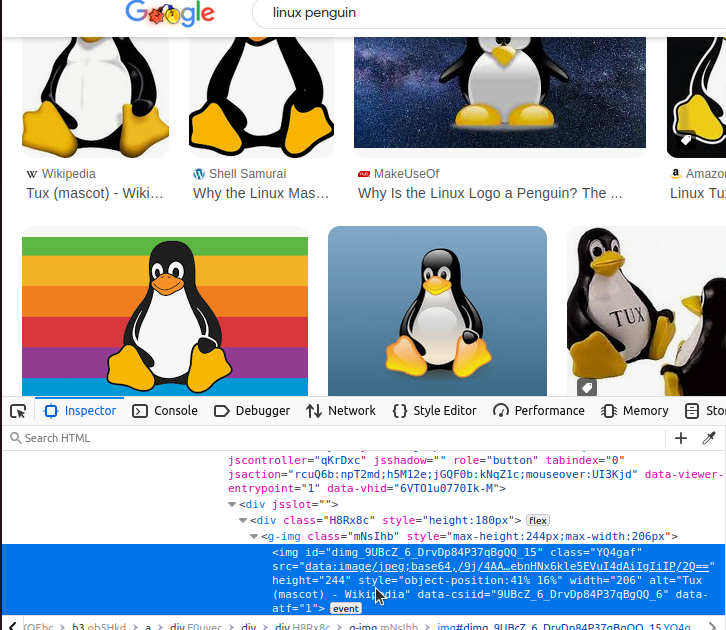
img 태그를 자세히 살펴보셨다면 매우 이상한 점을 눈치채셨을 겁니다. src 속성이 무작위로 보이는 기호들의 기괴한 문자열이기 때문입니다.
data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD/2wCEAAkGBxAREBUQExAVFhUVFxISEBYXEhISFRAXFRUWFhgWGBUYHSggGBolGxUVITIhJikrLi4uGCAzODMtQygtLysBCgoKDg0OGhAQGzcmHyU1Li8tLzc1LS0tMzAvLSsrLTAwMS0tLS0rLS8tLjAvLy83LS0xLy0tNy0vLS0tLS0yLf/AABEIAPQAzgMBIgACEQEDEQH/xAAcAAEAAgIDAQAAAAAAAAAAAAAABgcFCAEDBAL/xABHEAABAwICBwQFCQUHBAMAAAABAAIDBBEFIQYHEjFBUWETInGRIzJCgaEIFFJicoKSscEzQ6Ky0RUkZJPC4fBjc7PxJTSj/8QAGwEBAAMBAQEBAAAAAAAAAAAAAAEEBQYCAwf/xAAvEQEAAgEDAwICCgMBAAAAAAAAAQIDBAUREiExE0Gh0SIjMjNCUWGBkbFSceEk/9oADAMBAAIRAxEAPwC8UREBERAREQEREBEVI69NYDml2FUzyDYfPXtNjZwuIQeoILrcw36QQZfTvXRT0rnU9ExtRKMnSE+gjPIFpvIR0sM95zCp7GtYmLVRJkrpWjOzIndgwA8LR2uPG5UWRSO2epkedp73OPNzi4+ZXsoserIf2VXPHy2J5GfkVjkQWVo5rpxSnIE5ZVR8Q8COQDkJGD4uDld2hWntDijfQv2ZQLvgfZsrQMiQAbObuzF94vbctbsEwRs0ZPFY2aKejmbLG9zHsO0x7SWuaRxBCgbmIoBqo1hNxSExS2bVxAGQDITNyHatHDMgEcCRzCn6AiIgIiICIiAiIgIiICIiAiIgIiIMXpRjDaKjnq3W9FG54BNtp1rMb73Fo9603qql8sj5ZHFz3uc+Rx3uc4lzifEkrY/5QdcY8IEY/fTxRu+y0Pl/ONq1rQERFIIiIJTguKtgi35rG4ji3bXuFiwxxF7Ej8l8IMjgGMTUVVHVQmz4nBw5OG5zT9UgkHoVuBo/jEVbSxVcR7krA8C4JadzmG2W01wLT1BWlyv75OONF9NUUTj+xe2WL7Mtw5o6Bzb/AH1AuNERAREQEREBERAREQEREBERAREQVB8pJ39yphzncfKN39VSej+j09Y4iMANbbae69h0Ft56K6vlJj+6Uv8A3n/+NeXQinpMMwNmJ1QLw7vRxtteRz3ENB5nLwAbfPcgrTGNEamiaZCGyxW9IACC0c7cLcwclFngXy3cFs9oZpXQYreGShbDKWGRsb2xyNlZexLJABci4uCAc+OdqF1j6PigxOemYD2e0HwD6kgD2tHO1y37qCNsYXENAJJIAAzJJyACn2jugDHgOqHuufYYQA3oXWNz4W9679R2j8dViLzMy7YYi8NNx33Oa0EjlYu+CtPWJp9S4MY6eGlZJM8bewNmNkTLkBziASSSDYDkSSMrhAsR1WFsZmoZXdo0bQikLS2W3sh1hYnrcdQqtxGxeTsbDrkSMsRsOGRyO7Pgtj9C9OosQkFLUUwp5pGudAWPDo6gNF3bLrAhwGeyb5DfwVT67tHjSYiJMtmoZ2gIyu5p2XXHA22fO6CvVaHyd6gtxV7L5PppRbqHxuH5HzVXqxNQjrY0zrFOP4b/AKKRs6iIoBERAREQEREBERAREQEREBERBUPykW/3GmP+II84n/0UVx5r59DqN7RcQVHpvqtD6iJpPvewfeUx+Ue3/wCMgPKqYPOGf+iiOpTSmJsU+F1LC+KQPkaC0vaQ4BskbhwByIvlcnO5F4taKxzPhMRMzxCLarsSkbidEwH1Z/wsexzX+7Zc5THWHo5XYriT6mCNkUbGtgjfJJsumDC4mTZaCWglxsDY2AWewPRqipnSGCEt2y7Nztt7Wn2A/eB/wk71JYVzGr360W6cEdvzlepo+I5uhervBMSwytY+ZscsTwYZnRybTo2uIIcWuAJAcBuByJUL16QyNxuZzvVeyB8PIs7Jrcum216vCOlZtdoGN2yLF2yNojlfesVpPoxS4gwMnYSW3Eb2u2Xx337J3W6EEdFOHf5rMetXt+cfL3+DxbSx+FRur+eokxOgiY5x2KmJzQPZbtNMv3dhrrjldTz5Sc7TUUkYPebHM4jo5zQP5HeSmmhGiOH4W50sbJHzOBaJZHNeWNO8MDQ0NvbfYnrZUnrRr6qfE5ZKiJ0Rs1sLHFp2YhfZs5tw652iSCRckcFvafWYNR93bn+/4Vr47V8wiasDUS62Nw9WTj/83H9FX6m2peXZxykN8iZmnrtQSAfGytPDatERQCIiAiIgIiICIiAiIgIiICIiCt9f8G1gznW9SaF/hcln+tV7q6oWx0zX2G1L33niRchovyA/Mq0ddse1gVV0+buHuqIr/C6o3Vk6okmfCyQgMidM1pzFw9jbeB29yo7hgvnwzWk/9ffT5K0vzZcNKshTi5UZw/HGjuyMc1wyNml4v7s/gstDjMI3F58Ipf1bZcPkw5K24mGra0THZINwXRPK1jS5zgAMySbALES4+45Mhdfm8ho8bC5PwWNmL5HB0rtojNrQLMZ4N59Tcr1fH1ee0PFaS9VRikr3gsOxGObRtSdTf1R03/kqs1v1QfUQj22xnaP1S87Iv4h3mrMZG53qj38Aqw1sYNJDURzlxc2VmyPqOYc2+BDgfe7kt/aNFkrljLavERHb9VfVZadHRWeZQRZXRTEhS11NUk2EU0T3/YDhtj8N1ltCo4JduCRoJdm08V59KtG/mvfabsJt4Lpmc29BXKheqHSIV2FQuJvJCPm017k7UYGy4k79phYb8yeSmigEREBERAREQEREBERAREQEReDHcYgoqd9TO/ZjjF3HiTwa0cXE5AIILr9xZkOEugJ79TJHGwXF7RvbK53gNho++FWmoqgc+pqphuZA2M+MkjXD4ROUY010oqcYre1LXWJEVJC3vdm0mzWgD1nuNrniTyAA2J1b6GjDcPbA6xmkPa1Lhu2yLBgPJosOpueKCM43hDnHtYsnDeN21/usQ2vmZk5r/eCrDxGhLTcDJY8s6fBZ+p27Fnt1T2lZxam1I48ovBPM/wBWM+JFh8Vl6LDHHN5v0G5ZyloXP4LOUWFtbmVGn2zBhnq45n9TJqr3jjxDH4fhFxmLBYbWLoV89w+WOMXlZ6anHEvYD3B9ppc3xcDwU7a2y5WgrNJqOqdE8SNNiMwsvjukslVG2MtAAzPUqR67NF/mOJOlY20NVtTx8mvv6Vn4iHcgJAOCr9ehP9TGlow/EBHI60FTsxSkmwY6/o5D4Elp4WeTwW0S0eWyepPToV1MKOd/95gaACTc1EQsA+/FzcgfceJtAs5ERAREQEREBERAREQEREHTWVUcMbpZHhjGNL3ucbBrQLkkrVrWjp7JitRZpLaWIn5vHu2juMrxxceA9kZcSTI9eOnpqpjhsDj2ELvTuBynlb7OW9jD5uF+DSqmAQXT8n/Q4Pc7FZm3DCY6QHcXbny+71R12uQV7LE6KYcylooKZm6KNjD1cB3nHqXXPvWWUD4liDhYheP+y2XvZe4my+GyZoEUIbuC7EXBcOaDlF8GVvMLrfVMHFBBNeWCipwp8gF5KYiobz2R3ZB4bLi77gWsS3Jqo21DXwvzZKx8Thza9pafgVp1UQOje6Nws5jnMcORabH4hTA617MIxOalnjqYXlskTg9juvEHmCLgjiCQvGikbc6v9NIMVphKyzZWWbUxXziceI5sNjY+I3ghShaaaLaQz4fVMqoHWc3JzbnZlYfWjeOLTb3EAjMBba6LY/DiFJHVwnuvGbT60bhk5juoPnkRkQoGWREQEREBERAREQFDtbGkxw7DJJWOtLIRBTni17wbu6bLQ5w6gc1MVQPyj8W26qmowTaON0z88i6V2y0EcwIz+NBT8UZcbAXK92j9BJPVwwxt2nukaAOGRuSTyABJ6Bc1TOxjDPbeNp5+i3g33/l4q7NQmhojpziUze/NdtOCPViBzdY/ScPJoPFBZdDBJvuQFlGMtxuvpFA4cF008fE+5d6IC+HRAr7RB5JcPaeJXgnwt4zabrNIgjrHuYcxZVRrp0EbsnFqVlrm9bG0ZAn9+B1PrW4na+kVek9O14sQseaMWdE9odG8OY9pF2va4WLSOIIJCkaewBju647J4O4Hx5eK4qaV8Zs4eB4HqCs1pxo47D8QmpMy1rtqEn2o395hvxNjY9WleWmuxuxILxH3mO/tN/UKRiFZ2onS40lb8zkd6GqIa25yjn3MPTa9Q8zsclXeI0ZieWndvaeBB3ELzMeWkOBIIIIINiCNxB4FBvAij+gOP/2hh0FUbbbmbM1srSM7r8uALgSOhCkCgEREBERAREQcOcALk2AzJ5LUvSPFxiGK1FaT6Lbc5u/9lGNlmR3EtaMuZV6a7dJ/mWGuia601VeCPmGW9K/3NOzfgXtWt0g7OnA4ym5+yy2XmR5IPdo3hUmJ4jFT5gzSd8j93GM3kfZY028AtvaWnZFG2JjQ1jGtZG0ZBrWgBoA5AAKkPk4YJd9TXuHqhtNEerrPk99hH+Iq9EkERFA4Llyul57wXcgIiICIiAuCLrlEFM/KHwhtqWuAFw51NIbZkEGSPPoWy/iVS1lcx0eytiddFF2uCVOWcfZSt6bEjdo/hLlqupgZk+mpL+1CdnrsHNv6j3LDLL4FmydvNgPkf91iCpF3fJuxuzqmgcd9qqIdRaOTP/K8irzWpeqnFfmuMUr72a+TsH8iJh2Yv0DnNPuW2igEREBERAXBK5UA126Quo8Ke1htJUOFM0je1rgTI78LS3xcEFG61NKv7SxF8jXXhi9DTcixpN3/AHnXN+WyOCj2LO/ZjlG34ucV5IIi9waOKymk1EYnRA8Ym+Yc4H9PNSNktTeGfN8GphazpQ6of17RxLT+DYHuU1XhwOkENLBCBYRxRRjpsMa39F7l5BERB0O9cLvXT7a7kBERAREQEREEf1gx7WE1w/w1QfwxuP6LUBbg6futhVcf8LUjzicP1WnymBmcDyinf9VjR7yT+iwyy7z2dG1vGRxefAd0flf3rEKR9wTOY5r2mzmkOaeRabg+YW7FFUCWNko3Pa148HAEfmtJFuJoG8nCqEnf81pb/wCUxQM6iIgIiICp/wCUlA40dLJ7LZnMPi+MkfyOVwKJ6cVEbwylLWvO0yV1wDsbJuwjk6+fu6r4anUVwY5yW9nvHjm9orDWCPRyv2O1bSzbO8ERuv47O+3Wy7p3uqaexzkhubcS0+sLcxYHzWwjGCyg+n+inaA1lMNmdgu8NH7do4EfTHA8d3K2LpN+jJk6MteInxPz+a5l0XTXms8r3CKktVutwEtosQeBubBUE5dGSnh0f581dq6BQEREHQD313rot313oCIiAiIgIiwOPY/2EjYWgFxbtuJuQ0EkDLiTY+XVfLPmphpN7+IeqUm88Q8OtepEeC1jucXZ/wCY9sf+paq0tJtDac8MbzOZPQDitl9ML4hQyUsr9hjtlz3Mb3gI3B+4m29oWsL3X8BkOgXy0muxarn0/bz24esmK2P7TL1vZTEWl2Q0BrRa4sBYZ3XWzAZnC8Za/wAHWPkVilksCqZGSAtdYceSuPm8E8LmOLXNLSN4IstzdHKE09HT053xQwxHxZG1p/Ja46P4f/aWJQNsOzhfHJUvO4Rh4Jb1LrW+PBbPNcCLg3BzBGYK8Res2msT3jzCeJ45coiL0h0VtZHCwySODWjj+gHErAHTOG+UMpHOzBf+JebTtxLoWcO+4jmRsgeQJ81iooQBuXO7nu2TBlnHj9mhp9LS9OqzL1emeVo4DtcC8gAe5u/zCjtOHve6WQkucbuJ4/8AOS93ZDkvprQFharcc2oji8rmPDTH9mHIXzI24X2ioPspLWZo183m+cxt9HKe+AMo3/0dv8b8ws5qv1sPoQ2krC6SmFmxvzdJSjgLb3xjlvA3XsAp/jeGMqIXwvF2vBH/AK6/0WvWMYa+mmfA/e05G1g4cHDxC7XZtd6+L07far8YZGrw9FuqPEtzKOqjmjbLE9r2PAcx7SHNcDxBC7lqfoBrAqsKk7pMlO43lgc47J+sw+w/qMjxBsLbN6M6Q02IUzaqnftMdkQcnxuG9j28HC48bgi4IK2VRky3O6+kRQCIiAiIg65JQ3eoHpZIHVzSOMTPg+RSjFnFQzGf/ss+wP5nLO3WP/NP7LOk+8h94iCYXN+k1zfMWWtUsZa4tcLFpLXDiCDYhbNTsu1QHSTQqCoeZM2PPrObazurmneeossXaNZTBNov4ld1WGckRNfZUK76GmllkbFE0ue82a1u8/7deCndNq2G136gkcmxhp8y4/kp9ozo7T0gtFGAT6zjm93i48OgyWvqN3w46/Q7z8FTHo72n6XaDQnRltBS7BIMr7PneOJG5oP0W3PvJPGysDQ6pc5kkZN9hwI6B98vMOPvWEAyWQ0YnEczmHLtALfabew8ifJYm3am062L3nvbmJ/fx8eFvUY49GYiPCWIiLsGSienbbGB3WRvmGn9CsXEclltYB9FF/3f9Dv9lhqX1QuL32vGpmf9f02NHP1UO5ERYq0IiIOCFXmtXRvtYvnUbe/H69hm5m8+W/z5qxF1zRhwIIyORVjSam2nyxkr7PnlxxesxLV9WVqEx2SDFG0oJMdU17Xt4B8bHSMf491zfvdFzWap6qeolFI+HZB2hG97mPa08R3bFoOW+4y6XsDVZqpfh0/z2qkY+YNc2FkdyyLaFnPLiAS7ZJFgLC533y/QsOauWkXp4lh3rNZ4laiIi9vIiIgIiIMTi7VXc2KxVFU7snbQi9C5w9UvaS52yeIG0BfmCsBrc1oNkLqKhku3Ns9Q05O4FkR5c38eGWZxurNlqdvUvP8AER+izt1njTys6SPrFnNbcLyzUy9cO5fdlxkTw12OjpF7YorLssuUm0yC65WX/MdF2IoQzeC47tWimNnbmv3B/Q8nfms+q/nAsu/CNKexJjlJcy3cO9zTyvxFr+Fl0u3btM8Y838/P5qGfSfip/D602qhJURwA/swXP8AtPtYeIAv95eaJtgsBHXF8z5Hes5znHpc7vdu9yzMdUCsPcsts2abrmCnRSIelF8NkBX1dZz7OUXC5QFwuUQYrEZZIXNniNnxm45EcWkcQdynej+PQVkYdG4bYAMse0C+I8iN9rg2PFQvExdpVU6ZCSIiohkfHJGe69j3MeA7I2c0gjOy6TY9TNZ9OfEqOsxRMdTZ9FrPgmunFoAGyujqG/8AUZsvAtuD47eZBUrpflAN/eYaR1ZUg/wmMfmuq4Za7UVK1PygIx+zw5x+1UBtvcGG6jONa8MTmBbCyGnB3FrTLIPvP7v8KDYDHMcpaKIzVM7ImDcXHNxtezWjN7ugBK191ka2Zq8OpaYOhpjdrze0tQOIdb1WH6I38TnYV7imJz1MhlnmfK8+095ebb7C+4Z7hkvIgK49B4NmKNvJrb+Nrn4qn4WbTg3mQPM2V2aMEZLH3m31cQu6KPpTKaw7l9rriOS+7rkWk5XBK+XyALH1dcBxUxWZS9z5gF55a5o4qOVuL9V78G0crauztnsoz7cgIuObWb3fAdVcw6LJlniIfO+StPMuK7FhbepLodo24g1FSz1haONwzAJB2nDgchYeKzGBaJU1KQ+xkkH7x9iQfqt3N/Pqs+uh0W11xT1X7z+TPzarqjiqI43oOyWR0sMnZucS5zS3aYSd5GYLbnx8FG63Ryvgz7LtGjjGdv8Ahyd8FaSKzn23Bl7zHE/o+dNTkoppuJFp2XXBG8EEEeIK9UeKjmrTq6GKUWkiY8cnMa63msDW6C0Ml9lj4yeMbyP4XXaPJZeXYv8AGVquuj3hFI8SB4r1x1bTxX1XaupRnBVA8myNLf423/lUexDCsQpM5IHFo9tnpGW5nZzaPEBZ2bZ8tO/D711VLe6TB4XDngKJ0uOg8V6H4uLb1nTpbxPh94tDIYlUCxVcaVh8rXRxsc97rBrWNL3HMbmjMrOYrjAsc1OdU+jkkYdXzNLXSt2IGnItjJDi8jhtENt0H1lu7VpLReLSqarLHTwo6h1cYzMLsw+YfbDYfhIWrJxanscIzpWt8aiD/S4raRF1DKauSanMbAypmHoKiDPzcF459VmNs30Dz9mSB/8AK8ra9EGm1ZoriMN+0oKlgG8mnlDfxWssOVvCvBiWC0tSLT00Mo/6kTJLeG0MkGmdCfSx/bZ/MFa2A1lrKxMW1O4PMdpkT4HXvtQyEC4+o/aaB0ACqrGMPnw+pdTygggkxutZsrL917eYPwNxwWbuOGclYWtLfplYVPiAtvXY6v6qCUuL5b16XYt1XN20dolpxkqklViXVYhjpqmUQwtL3u3AcBxJPADmV4sNhqK2YQQN2nH1jubGPpPd7I/PcLq59FdGoaGLYb3pHWM0hFnSHkOTRwH5m5Wlott6p5t4V8+piscR5Y3RfQeGmtLNaWbfci7Iz9Rp3n6xz5WUtRF0NMdaRxWGZa02nmRERe3kREQEREBERBH8a0Moaolz4th53yRns3E8zbJx+0Cqb0ioBT1HYse4tva7iCd/QAfBEVLV46cc8d1jDaeeOVi6GaCUIayqe10r/WaJCHMYRxDAACftXtwU/RFapWKxxEPjaZme4iIvbyIiICIiAvBjOC01ZH2VRC2Ru8XGbTuu1wzaeoIREFO6faF01B3oXy55hrnNcG9B3b28SV1avdFYK93pnyADOzHNaHW4G7SfIhcoqk46+rxw+8Wno5XPhGEU9JH2UETY27zbe483OObj1JK9yIrcRw+AiIgIiIP/2Q==
이 문자열의 시작 부분이 모든 것의 열쇠를 쥐고 있습니다: data:image/jpeg;base64,. jpeg는 이것이 JPEG 파일임을 알려줍니다. base64는 Base64로 인코딩되었음을 알려줍니다. 이 문자열을 디코딩하면 실제로 이미지의 바이너리를 얻게 됩니다. 이미지의 바이너리가 웹 페이지 내에 포함되어 있기 때문에 실제 출처를 추적할 수는 없습니다. 하지만 이 바이너리를 파일로 저장하여 이미지를 재구성할 수는 있습니다.
파이썬으로 Google 이미지 스크래핑하기
이제 원하는 바를 알았으니, 실제로 스크레이퍼 코딩을 시작할 때입니다. 다음 몇 섹션에서 스크레이퍼를 구성하고 코드가 정확히 무엇을 하는지 살펴보겠습니다.
시작하기
새로운 Python 파일을 생성하세요. 기본적인 임포트와 구조부터 시작하겠습니다.
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import base64
from pathlib import Path
options = webdriver.ChromeOptions()
"""
실제 스크래핑 로직은 여기에 작성됩니다
"""
if __name__ == "__main__":
scrape_images("linux penguin", 100)
- Selenium에서
webdriver와By를임포트합니다.webdriver는브라우저를 제어하는 데 사용됩니다.By는페이지에서 항목을 찾는 데 사용됩니다. - 스크레이퍼를 일정 시간 동안 일시 중지시키기 위해
sleep을사용합니다. 예를 들어 스크레이퍼가 1초 동안 대기하도록 하려면sleep(1)을사용합니다. - 예상하셨겠지만,
base64는이미지 바이너리를 디코딩하는 데 사용됩니다. Path는결과물이 담긴 폴더에 이미지를 작성하는 데 사용됩니다.options = webdriver.ChromeOptions()는 Selenium에 사용자 정의 설정을 적용할 수 있게 합니다. 주로 Selenium을 헤드리스 모드로 실행하기 위한 것입니다. 헤드리스 모드는 실제 브라우저를 머신에 렌더링하지 않고 스크레이퍼를 실행할 수 있게 하여 소중한 리소스를 절약합니다.
Google 이미지 스크래핑
다음으로 스크래핑 함수를 작성하겠습니다. 아래 코드는 전체 스크래퍼를 포함합니다. scrape_images() 함수에 특히 주의하세요.
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
import base64
from pathlib import Path
options = webdriver.ChromeOptions()
def scrape_images(keyword, batch_size, headless=True):
if headless:
options.add_argument("--headless")
formatted_keyword = keyword.replace(" ", "+")
folder_name = keyword.replace(" ", "-")
output_folder = Path(f"results-{folder_name}")
output_folder.mkdir(parents=True, exist_ok=True)
result_count = 0
driver = webdriver.Chrome(options=options)
driver.get(f"https://www.google.com/search?q={formatted_keyword}")
sleep(1)
list_items = driver.find_elements(By.CSS_SELECTOR, "div[role='listitem']")
list_items[1].click()
while result_count < batch_size:
driver.execute_script("window.scrollBy(0, 300);")
sleep(1)
img_tags = driver.find_elements(By.CSS_SELECTOR, "g-img > img")
for img_tag in img_tags:
src = img_tag.get_attribute("src")
if not src or not src.startswith("data:image/"):
continue
base64_binary = src.split("base64,")[-1]
mime_type = src.split(";")[0].split(":")[1]
file_extension = mime_type.split("/")[-1]
if file_extension == "gif":
continue
alt_text = img_tag.get_attribute("alt") or "image"
filename = f"{alt_text}-{result_count}.{file_extension}"
image_binary = base64.b64decode(base64_binary)
output_path = output_folder.joinpath(filename)
with open(output_path, "wb") as file:
file.write(image_binary)
result_count+=1
print(f"저장됨: {filename}")
driver.quit()
if __name__ == "__main__":
scrape_images("linux penguin", 100)
- 기본적으로
headless를True로설정합니다. 사용자가False로설정하면 화면에 보이는 실제 브라우저가 실행됩니다. 디버깅에 유용합니다. - 실제
키워드에서 공백을 제거하여formatted_keyword와folder_name을 생성합니다. 이를 통해 파일을 문제없이 저장할 수 있습니다. webdriver.Chrome(options=options)로 브라우저를 실행합니다.driver.get(f"https://www.google.com/search?q={formatted_keyword}")는해당 키워드의Google 검색 결과 페이지로 이동합니다.- 이제 이미지 탭을 클릭해야 합니다. role이
listitem인모든div요소를 찾아 이 작업을 수행합니다.list_items[1].click()은 두 번째 항목인 이미지 탭을 클릭합니다. - 원하는 모든 이미지를 찾을 때까지 스크래핑 코드를 반복 실행하기 위해
while루프를 사용합니다. driver.execute_script("window.scrollBy(0, 300);")는 자바스크립트를 실행하여 페이지를 300픽셀 아래로 스크롤합니다. 스크롤 후에는 콘텐츠가 로드되는 동안 1초 동안sleep()을 실행합니다.driver.find_elements(By.CSS_SELECTOR, "g-img > img")는g-img안에 중첩된 모든img태그를 찾기 위해 사용됩니다.- 다음으로 찾은
img항목들을 반복 처리합니다. img태그가data:image/로시작하지 않으면continue를사용하여 건너뜁니다. 그렇지 않으면src속성을 추출합니다.- 기본적인 문자열 분할을 통해 인코딩된 바이너리와 파일 확장자(JPEG, PNG 등)를 추출합니다. 확장자가 GIF인 경우 건너뜁니다. 어떤 이유에서인지 GIF는 파일에 기록하면 표시되지 않습니다.
base64.b64decode(base64_binary)는 이미지를 실제 기계가 읽을 수 있는 바이너리로 디코딩합니다.
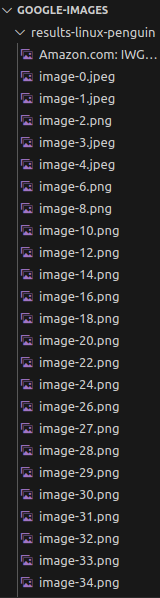
코드를 실행하면 프로젝트 폴더 내에 새 폴더가 생성됩니다. 이 폴더에는 이미지가 가득 차 있을 것입니다.
Bright Data 사용 고려
저희 SERP API는 Google 이미지를 자동으로 파싱하므로 직접 처리할 필요가 없습니다. 이미지 메타데이터까지 찾아내므로 실제 파일명을 가진 이미지를 얻을 수 있습니다. 물론 API는 완전한 확장성을 갖추어 방대한 요청량을 처리할 수 있습니다.
먼저 SERP API에 가입하세요.
준비가 되면 영역 생성을 완료하세요.
Access Details에서 자격 증명을 확인할 수 있습니다.
아래 코드를 Python 파일에 복사하여 붙여넣으세요. proxy_auth 내 자격 증명을 본인의 것으로 교체하면 준비 완료입니다.
import requests
import base64
from pathlib import Path
import json
proxy = "brd.superproxy.io:33335"
proxy_auth = "brd-customer-<your-customer-id>-zone-<your-zone-name>:<your-zone-password>"
proxy_url = f"http://{proxy_auth}@{proxy}"
def scrape_images(keyword):
formatted_keyword = keyword.replace(" ", "+")
folder_name = keyword.replace(" ", "-")
output_folder = Path(f"serp-results-{folder_name}")
output_folder.mkdir(parents=True, exist_ok=True)
url = f"https://www.google.com/search?q={formatted_keyword}&tbm=isch&brd_json=1"
response = requests.get(
url,
proxies={"http": proxy_url, "https": proxy_url},
verify=False
)
images = response.json()["images"]
result_count = 0
for image in images:
image_binary = base64.b64decode(image["source_logo"].split("base64,")[-1])
title = image["title"].replace(" ", "-").replace("/", "").strip(".")
file_extension = image["source_logo"].split(";")[0].split(":")[1].split("/")[-1]
if file_extension == "gif":
continue
filename = f"{title}.{file_extension}"
with open(output_folder.joinpath(filename), "wb") as file:
file.write(image_binary)
print(f"저장됨: {filename}")
if __name__ == "__main__":
scrape_images("linux penguin")
코드를 실행하면 다시 여러 이미지가 생성되지만, 이번에는 모두 이름이 지정됩니다.
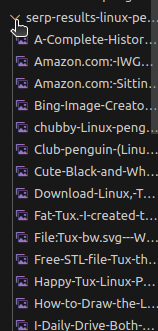
결론
결론적으로, Google에서 이미지를 스크래핑하는 것은 퍼즐 조각이 모두 없는 상태에서 퍼즐을 풀려는 것과 비슷합니다. 저희 Google Images API는 메타데이터를 찾아내어 Selenium의 필요성을 없애줍니다!
다른 출처에서 이미지를 스크래핑해야 한다면, 저희는 인스타그램 이미지 API, 셔터스톡 스크래퍼 및 다양한 구조화된 데이터셋도 제공합니다. 지금 가입하여 무료 체험을 포함한 여러분의 필요에 딱 맞는 완벽한 제품을 찾아보세요!