

온라인 부동산 거래 사이트인 Zillow 스크래핑은 시장 분석, 주택 산업 동향, 경쟁사 개요를 아우르는 부동산 시장에 대한 귀중한 통찰력을 제공합니다. Zillow를 스크래핑하면 부동산 가격, 위치, 특징, 역사적 추세에 대한 포괄적인 정보를 수집할 수 있어 시장 분석 수행, 주택 산업 동향 파악, 경쟁사 전략 평가, 투자 목표에 부합하는 데이터 기반 의사 결정을 내리는 데 도움이 됩니다.
이 튜토리얼에서는 Beautiful Soup을 사용해 Zillow를 스크래핑하는 방법을 배웁니다. 유용한 데이터 수집 방법 외에도 Zillow가 사용하는 반스크래핑 기술과 Bright Data가 이를 해결하는 방법을 알아볼 수 있습니다.
스크래핑 과정 없이 바로 데이터를 얻고 싶으신가요? 저희 Zillow 데이터셋을 확인해 보세요.
Zillow 스크래핑
파이썬을 처음 접하는 분이든 이미 숙련된 분이든, 이 튜토리얼은 Beautiful Soup이나 Requests 같은 무료 라이브러리를 사용해 웹 스크레이퍼를 구축하는 데 도움을 드립니다. 지금 시작해 보세요!
필수 조건
시작하기 전에 웹 스크래핑과 HTML에 대한 기본적인 이해가 필요합니다. 또한 다음을 수행해야 합니다:
- 공식 문서
- Playwright
pip3 install beautifulsoup4
pip3 install requests
pip3 install pandas
pip3 install playwright
Zillow 웹사이트 구조 이해
Zillow 스크래핑을 시작하기 전에 사이트 구조를 이해하는 것이 중요합니다. Zillow 홈페이지에는 주택, 아파트 및 다양한 부동산을 검색할 수 있는 편리한 검색창이 있습니다. 검색을 시작하면 결과 페이지에 부동산 목록이 표시되며, 여기에는 가격, 주소 및 기타 관련 세부 정보가 포함됩니다. 이 검색 결과는 가격, 침실 수, 욕실 수 등의 매개변수에 따라 정렬할 수 있다는 점을 언급할 가치가 있습니다.
초기 표시된 결과 외에 더 많은 검색 결과를 원한다면 페이지 하단에 위치한 페이지네이션 버튼을 활용할 수 있습니다. 각 페이지에는 일반적으로 40개의 목록이 포함되어 있어 추가 부동산에 접근할 수 있습니다. 페이지 좌측에 위치한 필터를 활용하면 선호도와 요구 사항에 따라 검색 범위를 좁힐 수 있습니다.
웹사이트의 HTML 구조를 이해하려면 다음 단계를 따르세요:
- Zillow 웹사이트 방문: www.zillow.com
- 검색창에 도시명 또는 우편번호를 입력하고 엔터 키를 누릅니다.
- 부동산 카드에서 마우스 오른쪽 버튼을 클릭하고 ‘검사’를 선택하여 브라우저 개발자 도구를 엽니다.
- 스크래핑하려는 데이터가 포함된 태그와 속성을 식별하기 위해 HTML 구조를 분석하세요.
핵심 데이터 포인트 식별
Zillow에서 정보를 효과적으로 수집하려면 스크래핑하려는 정확한 콘텐츠를 식별해야 합니다. 이 가이드는 다음과 같은 주요 데이터 포인트를 포함한 부동산 정보 추출 방법을 보여줍니다:
- 주소: 부동산의 위치(도로 주소, 도시, 주 포함).
- 가격: 부동산의 매물 가격으로, 현재 시장 가치를 파악하는 데 도움이 됩니다.
- Zestimate: Zillow가 추정하는 부동산의 시장 가치입니다. Zestimate는 다양한 요소를 고려하여 시장 동향과 유사 부동산 데이터를 기반으로 한 대략적인 평가액을 제공합니다.
- 침실: 부동산의 침실 수.
- 욕실: 부동산 내 욕실 수.
- 평수: 부동산의 총 면적을 평(약 1평 = 0.093㎡) 단위로 표시한 것.
- 연식: 부동산이 건축된 연도입니다.
- 유형: 주택, 아파트, 콘도 등 해당 부동산의 유형을 나타냅니다.
Zillow는 다양한 정보를 제공하여 여러분이 쉽게 여러 매물을 평가하고 비교하며, 특정 지역의 가격 동향을 고려하고, 부동산 상태를 평가하며, 추가 편의 시설을 확인할 수 있도록 합니다. 또한 과거 및 현재 시장 데이터를 분석함으로써 트렌드를 파악하고 부동산 구매, 판매 또는 투자에 관한 전략적 결정을 내릴 수 있습니다.
스크레이퍼 구축
스크래핑할 대상을 확인했으니 이제 스크래퍼를 구축할 차례입니다. 여기서는 Requests 라이브러리를 사용해 Zillow에 HTTP 요청을 보내고, Beautiful Soup으로 HTML을 파싱하며, Python으로 데이터를 추출합니다.
데이터 추출
첫 번째 단계는 원하는 데이터를 추출하는 것입니다. scraper.py라는 새 파일을 생성하고 다음 코드를 추가하세요:
import requests
from bs4 import BeautifulSoup
url = 'https://www.zillow.com/homes/for_sale/San-Francisco_rb/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
listings = []
for listing in soup.find_all('div', {'class': 'property-card-data'}):
result = {}
result['address'] = listing.find('address', {'data-test': 'property-card-addr'}).get_text().strip()
result['price'] = listing.find('span', {'data-test': 'property-card-price'}).get_text().strip()
details_list = listing.find('ul', {'class': 'dmDolk'})
details = details_list.find_all('li') if details_list else []
result['bedrooms'] = details[0].get_text().strip() if len(details) > 0 else ''
result['bathrooms'] = details[1].get_text().strip() if len(details) > 1 else ''
result['sqft'] = details[2].get_text().strip() if len(details) > 2 else ''
type_div = listing.find('div', {'class': 'gxlfal'})
result['type'] = type_div.get_text().split("-")[1].strip() if type_div else ''
listings.append(result)
print(listings)
이 코드는 Zillow 검색 결과 페이지에 HTTP GET 요청을 수행한 후 Beautiful Soup을 사용하여 HTML을 파싱합니다. 각 부동산의 데이터 포인트를 추출한 후 모든 부동산을 출력합니다.
스크레이퍼 실행
스크레이퍼를 실행하려면 Zillow 검색 결과 페이지의 URL을 제공해야 합니다. URL은 다음과 같은 형식이어야 합니다: https://www.zillow.com/homes/for_sale/{city-or-zip}_rb/, 여기서 {city-or-zip}은 스크레이핑하려는 도시 이름이나 우편번호로 대체됩니다.
예를 들어, 샌프란시스코에서 판매 중인 주택 정보를 수집하려면 https://www.zillow.com/homes/for_sale/San-Francisco_rb/ 웹 주소를 사용합니다.
웹사이트 URL을 입력한 후에는 프로그램을 실행하여 스크래핑을 시작할 차례입니다. scraper.py 파일의 변경 사항을 저장한 후 셸 또는 터미널에서 다음 명령어를 실행하세요:
python3 scraper.py
…출력 결과…
[{'address': '19 Tehama St SUITE 3, San Francisco, CA 94105', 'price': '$1,025,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '956 sqft', 'type': 'Condo for sale'}, {'address': '267A Chattanooga St, San Francisco, CA 94114', 'price': '$1,740,000', 'bedrooms': '2 bds', 'bathrooms': '3 ba', 'sqft': '2,114 sqft', 'type': 'Condo for sale'}, {'address': '998 Union St, San Francisco, CA 94133', 'price': '$1,650,000', 'bedrooms': '2 bds', 'bathrooms': '1 ba', 'sqft': '1,181 sqft', 'type': 'Condo for sale'}, {'address': '37-39 Mirabel Ave, San Francisco, CA 94110', 'price': '$2,395,000', 'bedrooms': '7 bds', 'bathrooms': '6 ba', 'sqft': '2,300 sqft', 'type': 'Multi'}, {'address': '304 Yale St, San Francisco, CA 94134', 'price': '$1,399,900', 'bedrooms': '3 bds', 'bathrooms': '4 ba', 'sqft': '1,764 sqft', 'type': 'New construction'}, {'address': '173 Coleridge St, San Francisco, CA 94110', 'price': '$745,000', 'bedrooms': '2 bds', 'bathrooms': '2 ba', 'sqft': '905 sqft', 'type': 'Condo for sale'}, {'address': '289 Sadowa St, San Francisco, CA 94112', 'price': '$698,000', 'bedrooms': '4 bds', 'bathrooms': '2 ba', 'sqft': '1,535 sqft', 'type': 'House for sale'}, {'address': '1739 19th Ave, San Francisco, CA 94122', 'price': '$475,791', 'bedrooms': '2 bds', 'bathrooms': '2 ba', 'sqft': '1,780 sqft', 'type': '타운하우스 매물'}, {'address': '1725 Quesada Ave, San Francisco, CA 94124', 'price': '$600,000', 'bedrooms': '3 bds', 'bathrooms': '2 ba', 'sqft': '1,011 sqft', 'type': 'Condo for sale'}]
웹 스크래핑은 웹사이트의
robots.txt파일과 서비스 약관을 준수해야 하며, 과도한 스크래핑은 IP 차단으로 이어질 수 있음을 유의하십시오.
데이터 저장하기
데이터를 추출했으니 이제 JSON 또는 CSV 파일로 저장해야 합니다. 데이터를 파일로 저장하면 수집한 내용을 기반으로 처리하고 분석을 생성할 수 있습니다.
데이터를 저장하려면 먼저 scraper.py 파일 상단에 pandas 및 json 라이브러리를 임포트하세요:
import pandas as pd
import json
그런 다음 파일 끝에 다음 코드를 추가하세요:
#Json 파일에 데이터 쓰기
with open('listings.json', 'w') as f:
json.dump(listings, f)
print('Data written to Json file')
#csv 파일에 데이터 쓰기
df = pd.DataFrame(listings)
df.to_csv('listings.csv', index=False)
print('Data written to CSV file')
이 코드는 json.dump()를 사용하여 사전 목록인 listings 데이터를 listings.json이라는 JSON 파일에 기록합니다. 그런 다음 listings 데이터로 pandas DataFrame을 생성하고 to_csv() 메서드를 사용하여 listings.csv라는 CSV 파일에 기록합니다. 코드는 데이터가 JSON 및 CSV 파일에 모두 성공적으로 기록되었음을 나타내는 메시지를 출력합니다.
다음으로 셸 또는 터미널에서 코드를 실행하세요:
python3 scraper.py
…출력…
[{'address': '19 Tehama St SUITE 3, San Francisco, CA 94105', 'price': '$1,025,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '956 sqft', 'type': 'Condo for sale'}, {'address': '267A Chattanooga St, San Francisco, CA 94114', 'price': '$1,740,000', 'bedrooms': '2 bds', 'bathrooms': '3 ba', 'sqft': '2,114 sqft', 'type': 'Condo for sale'}, {'address': '998 Union St, San Francisco, CA 94133', 'price': '$1,650,000', 'bedrooms': '2 bds', 'bathrooms': '1 ba', 'sqft': '1,181 sqft', 'type': 'Condo for sale'}, {'address': '37-39 Mirabel Ave, San Francisco, CA 94110', 'price': '$2,395,000', 'bedrooms': '7 bds', 'bathrooms': '6 ba', 'sqft': '2,300 sqft', 'type': 'Multi'}, {'address': '304 Yale St, San Francisco, CA 94134', 'price': '$1,399,900', 'bedrooms': '3 bds', 'bathrooms': '4 ba', 'sqft': '1,764 sqft', 'type': 'New construction'}, {'address': '173 Coleridge St, San Francisco, CA 94110', 'price': '$745,000', 'bedrooms': '2 bds', 'bathrooms': '2 ba', 'sqft': '905 sqft', 'type': 'Condo for sale'}, {'address': '289 Sadowa St, San Francisco, CA 94112', 'price': '$698,000', 'bedrooms': '4 bds', 'bathrooms': '2 ba', 'sqft': '1,535 sqft', 'type': 'House for sale'}, {'address': '1739 19th Ave, San Francisco, CA 94122', 'price': '$475,791', 'bedrooms': '2 bds', 'bathrooms': '2 ba', 'sqft': '1,780 sqft', 'type': '타운하우스 매물'}, {'address': '1725 Quesada Ave, San Francisco, CA 94124', 'price': '$600,000', 'bedrooms': '3 bds', 'bathrooms': '2 ba', 'sqft': '1,011 sqft', 'type': '매물 콘도'}]
Json 파일에 데이터 기록 완료
CSV 파일에 데이터 기록 완료
작동한다면 프로젝트 디렉토리에 두 개의 새 파일이 생성된 것을 확인할 수 있습니다: listings.csv 파일과 listings.json 파일입니다. 이 두 파일은 각각 GitHub 저장소의 listings.csv 및 listings.json 파일과 유사한 내용을 가져야 합니다 .
코드를 여러 번 실행해 보면 높은 실패율(약 50%)을 확인할 수 있습니다. 이는 Zillow가 자동 스크래핑을 감지할 때 실제 콘텐츠 대신 CAPTCHA 페이지를 반환하기 때문입니다. Zillow와 같은 웹사이트를 스크래핑할 때 더 나은 성공률을 달성하려면 다양한 IP 간 전환이 가능하고 CAPTCHA를 우회할 수 있는 도구를 사용해야 합니다.
Zillow가 사용하는 스크래핑 방지 기술
무단 데이터 수집을 막기 위해 Zillow는 웹사이트에서 자동 데이터 복사(스크래핑)를 차단하는 다양한 방법을 사용합니다. 여기에는 CAPTCHA 사용, IP 주소 차단, 허니팟 트랩 설치 등이 포함됩니다.
CAPTCHA는 사용자가 사람인지 컴퓨터 프로그램인지 판별하는 테스트입니다. 일반적으로 사람은 쉽게 풀 수 있지만 프로그램은 어렵게 만들어 데이터 스크래핑을 늦추거나 차단할 수 있습니다.
Zillow가 스크래핑을 차단하는 또 다른 방법은 IP 주소 차단입니다. IP 주소는 컴퓨터의 집 주소와 같습니다. 데이터 스크래핑 시 흔히 발생하는 과도한 요청을 하는 컴퓨터의 IP 주소를 차단하여 추가 요청을 막을 수 있습니다. 차단 기간은 상황의 심각성에 따라 단기 또는 장기일 수 있습니다.
Zillow는 허니팟 트랩도 사용합니다. 이 트랩은 인간이 아닌 프로그램만 인식할 수 있는 데이터 조각이나 링크입니다. 프로그램이 허니팟 트랩과 상호작용하면 Zillow는 이를 봇으로 인식하고 차단할 수 있습니다.
이러한 모든 방법들로 인해 Zillow에서 데이터를 스크래핑하는 것은 어렵습니다. 시간이 많이 소요되고, 어려우며, 때로는 불가능할 수도 있습니다. Zillow에서 데이터를 스크래핑하려는 사람은 이러한 방법들을 알 뿐만 아니라 데이터 스크래핑과 관련된 법적, 도덕적 문제도 이해해야 합니다. Zillow가 이러한 방법들의 사용 방식을 변경할 수 있으며, 이를 공개하지 않을 수도 있다는 점을 기억하십시오.
더 나은 대안: Bright Data를 이용한 Zillow 스크래핑
Bright Data는자사의 스크래핑 브라우저를 통해 Zillow가 사용하는 반스크래핑 기술을 우회함으로써 Zillow 데이터 수집에 대한 더 나은 대안을 제공합니다. 스크래핑 브라우저는 Bright Data 네트워크에서 Puppeteer 스크립트를 실행할 수 있게 하여 수백만 개의 IP 주소에 접근할 수 있게 하며, Zillow의 반스크래핑 기술에 의한 탐지를 방지합니다.
Bright Data의 스크래핑 브라우저를 사용한 Zillow 스크래핑
Bright Data의 스크래핑 브라우저를 사용하여 Zillow를 스크래핑하려면 다음 단계를 따르세요:
1. Bright Data 계정 생성
아직 Bright Data 계정이 없다면 Bright Data 웹사이트를 방문하여 ‘무료 체험 시작’을 클릭하고 안내에 따라 진행하세요.
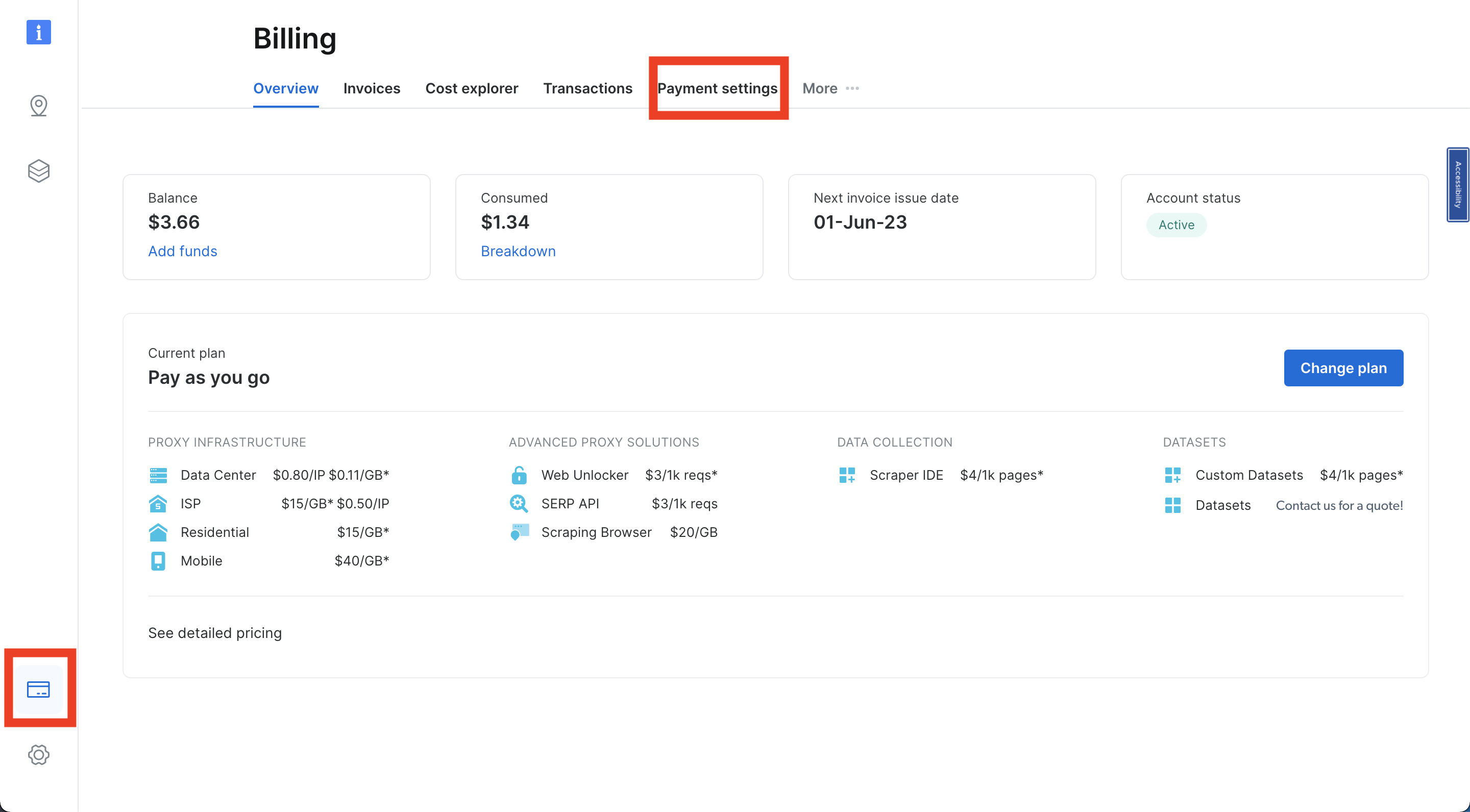
Bright Data 계정에 로그인한 후, 탐색 모음 좌측 하단의 신용카드 아이콘을 클릭하여 ‘결제’로 이동하세요. 선호하는 옵션에 따라 결제 수단을 추가하세요. 그렇지 않으면 계정을 활성화할 수 없습니다:
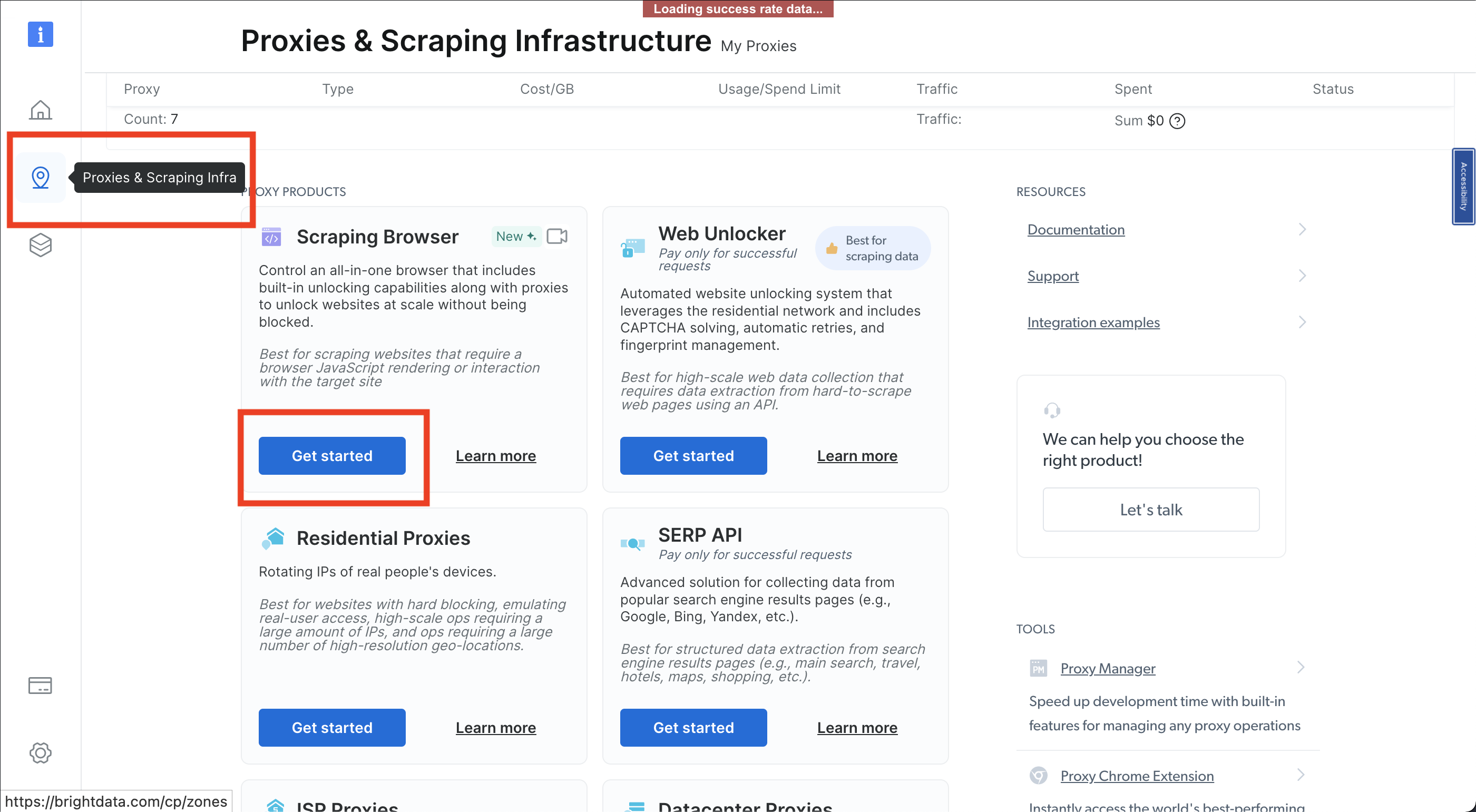
다음으로 핀 아이콘을 클릭하면 ‘프록시 및 스크래핑 인프라’ 페이지가 열립니다. 여기서 ‘스크래핑 브라우저’ > ‘시작하기’를 선택하세요:
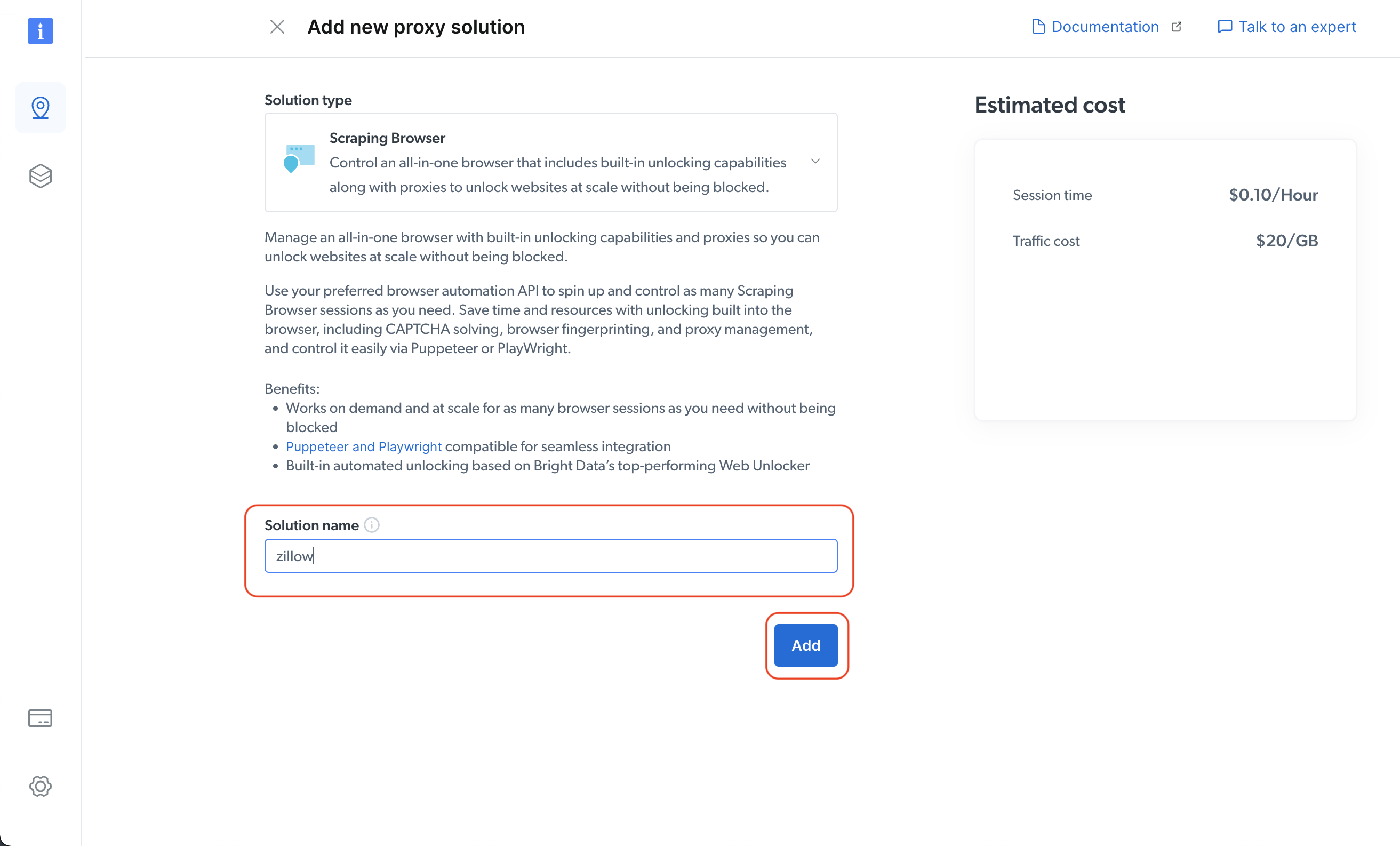
솔루션 이름을 지정한 후 ‘추가’ 버튼을 클릭하세요:
그런 다음 ‘액세스 매개변수’를 클릭하고 사용자 이름, 호스트, 비밀번호를 기록해 두세요. 튜토리얼 후반부에 필요할 것입니다:
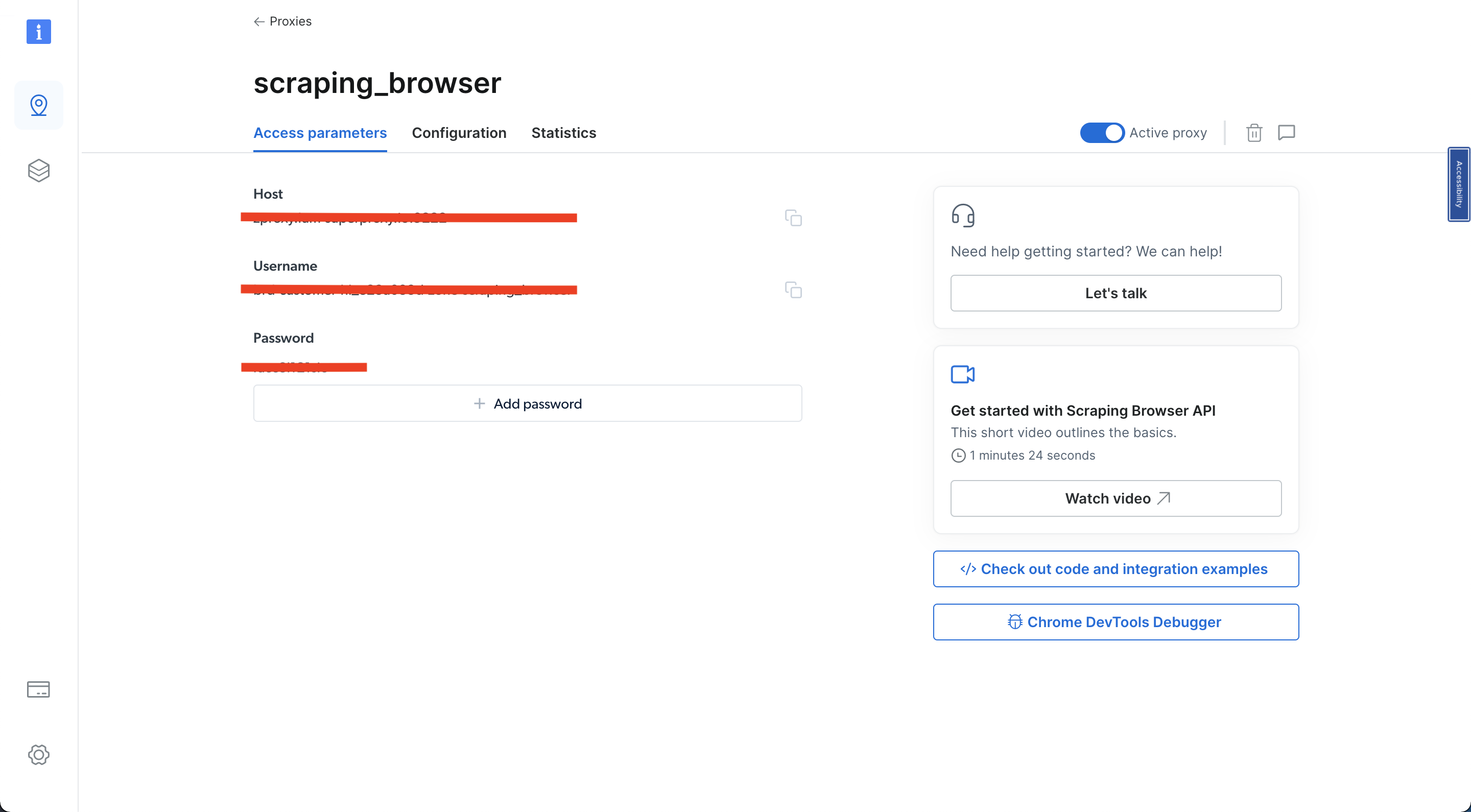
이전 단계를 완료하면 진행할 준비가 된 것입니다.
2. 스크레이퍼 작성
scraper-brightdata. py라는 새 파일을 생성하고 다음 코드를 추가하세요:
import asyncio
from playwright.async_api import async_playwright
import json
import pandas as pd
username='YOUR_BRIGHTDATA_USERNAME'
password='YOUR_BRIGHTDATA_PASSWORD'
auth=f'{username}:{password}'
host = 'YOUR_BRIGHTDATA_HOST'
browser_url = f'wss://{auth}@{host}'
async def main():
async with async_playwright() as pw:
print('원격 브라우저에 연결 중...')
browser = await pw.chromium.connect_over_cdp(browser_url)
print('연결됨. 새 페이지 열기 중...')
page = await browser.new_page()
print('Zillow로 이동 중...')
await page.goto('https://www.zillow.com/homes/for_sale/San-Francisco_rb/', timeout=3600000)
print('데이터 스크래핑 중...')
listings = []
properties = await page.query_selector_all('div.property-card-data')
for property in properties:
result = {}
address = await property.query_selector('address[data-test="property-card-addr"]')
result['address'] = await address.inner_text() if address else ''
price = await property.query_selector('span[data-test="property-card-price"]')
result['price'] = await price.inner_text() if price else ''
details = await property.query_selector_all('ul.dmDolk > li')
result['bedrooms'] = await details[0].inner_text() if len(details) >= 1 else ''
result['bathrooms'] = await details[1].inner_text() if len(details) >= 2 else ''
result['sqft'] = await details[2].inner_text() if len(details) >= 3 else ''
type_div = await property.query_selector('div.gxlfal')
result['type'] = (await type_div.inner_text()).split("-")[1].strip() if type_div else ''
listings.append(result)
await browser.close()
return listings
# 비동기 함수 실행
listings = asyncio.run(main())
# 리스팅 출력
for listing in listings:
print(listing)
# Json 파일로 데이터 기록
with open('listings-brightdata.json', 'w') as f:
json.dump(listings, f)
print('Data written to Json file')
# CSV에 데이터 기록
df = pd.DataFrame(listings)
df.to_csv('listings-brightdata.csv', index=False)
print('CSV 파일에 데이터 기록 완료')
YOUR_BRIGHTDATA_USERNAME, YOUR_BRIGHTDATA_PASSWORD, YOUR_BRIGHTDATA_HOST를 실제 Bright Data 계정 자격 증명 정보로 반드시 교체하십시오.
3. 스크레이퍼 실행
scraper-brightdata.py 파일을 저장한 후 셸 또는 터미널에서 코드를 실행하세요:
python3 scraper-brightdata.py
…출력…
원격 브라우저에 연결 중...
연결됨. 새 페이지 열기 중...
Zillow로 이동 중...
데이터 스크래핑 중...
{'address': '1438 Green St UNIT 2B, San Francisco, CA 94109', 'price': '$995,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '974 sqft', 'type': 'Condo for sale'}
{'address': '815 Tennessee St UNIT 504, San Francisco, CA 94107', 'price': '$1,195,000', 'bedrooms': '2 bds', 'bathrooms': '2 ba', 'sqft': '-- sqft', 'type': ''}
{'주소': '455 27번가, 샌프란시스코, CA 94121', '가격': '$1,375,000', '침실': '2개', '욕실': '1개', '평수': '1,040 평방피트', '유형': '매매 주택'}
{'address': '19 Tehama St SUITE 3, San Francisco, CA 94105', 'price': '$1,025,000', 'bedrooms': '1 bd', 'bathrooms': '1 ba', 'sqft': '956 sqft', 'type': '매매 중인 콘도'}
{'address': '267A 채터누가 스트리트, 샌프란시스코, CA 94114', 'price': '$1,740,000', 'bedrooms': '2 침실', 'bathrooms': '3 욕실', 'sqft': '2,114 평방피트', 'type': '매물 콘도'}
{'주소': '998 유니언 스트리트, 샌프란시스코, CA 94133', '가격': '$1,650,000', '침실': '2개', '욕실': '1개', '평수': '1,181 평방피트', '유형': '매매 중인 콘도'}
{'address': '37-39 미라벨 애비뉴, 샌프란시스코, CA 94110', 'price': '$2,395,000', 'bedrooms': '7개 침실', 'bathrooms': '6개 욕실', 'sqft': '2,300 평방피트', 'type': '다세대 주택'}
{'address': '304 Yale St, San Francisco, CA 94134', 'price': '$1,399,900', 'bedrooms': '3개 침실', 'bathrooms': '4개 욕실', 'sqft': '1,764 평방피트', 'type': '신축 건물'}
{'address': '173 Coleridge St, San Francisco, CA 94110', 'price': '$745,000', 'bedrooms': '2 bds', 'bathrooms': '2 ba', 'sqft': '905 sqft', 'type': 'Condo for sale'}
Json 파일에 기록된 데이터
CSV 파일에 기록된 데이터
이 코드는 Bright Data 스크래핑 브라우저에 연결하여 Zillow 검색 결과 페이지로 이동한 후 데이터를 추출합니다. 다음으로 코드는 결과를 출력한 후, json.dump()를 사용하여 목록 데이터 (사전 목록)를 listings-brightdata.json이라는 JSON 파일에 기록합니다. 그런 다음 listings 데이터에서 팬더스 데이터프레임을 생성하고 to_csv() 메서드를 사용하여 listings-brightdata.csv라는 CSV 파일에 기록합니다. 코드는 데이터가 JSON 및 CSV 파일에 모두 성공적으로 기록되었음을 나타내는 메시지를 출력합니다.
정상적으로 작동하면 listings-brightdata.csv 파일과 listings-brightdata.json 파일 두 개가 생성됩니다. 이 파일들은 listings-brightdata.json 및 listings-brightdata.csv와 유사한 형태여야 합니다.
이 코드를 여러 번 실행해 보았는데 파일에 데이터가 저장되지 않았다면, Zillow에서 IP가 차단되었거나 스크래핑이 완료되기 전에 브라우저가 닫혔기 때문입니다. 스크래핑이 완료되기 전에 브라우저가 종료된 경우, 타임아웃 값을 더 크게 변경해야 합니다. 이전 코드에서는 await page.goto('https://www.zillow.com/homes/for_sale/San-Francisco_rb/', timeout=3600000)와 관련이 있습니다.
IP가 Zillow에 의해 차단된 경우, 다행히 Bright Data는 여러 지역에 대한 액세스를 제공하므로 지역을 변경해야 합니다.
다른 지역 간 전환 방법은 다음과 같습니다: 핀 아이콘을 클릭하여 ‘프록시 및 스크래핑 인프라’로 이동한 후, ‘스크래핑 브라우저’를 선택하고 ‘액세스 매개변수’를 클릭하세요. 다음으로 ‘ </> 코드 및 통합 예제 확인’을 클릭합니다:
언어로 Python을 선택하면 오른쪽 탐색 메뉴에 ‘국가’ 드롭다운 목록이 나타납니다. 원하는 국가를 선택하면 해당 지역이 동시에 업데이트됩니다. Python 샘플 코드에서 auth 변수가 변경되는 것을 확인할 수 있습니다. 해당 지역과 관련된 사용자를 auth 변수에서 가져와야 합니다. 주로 : 앞의 값입니다 . auth 변수는 사용자 이름과 비밀번호를 다음과 같은 구문으로 저장하기 때문입니다. username:password:
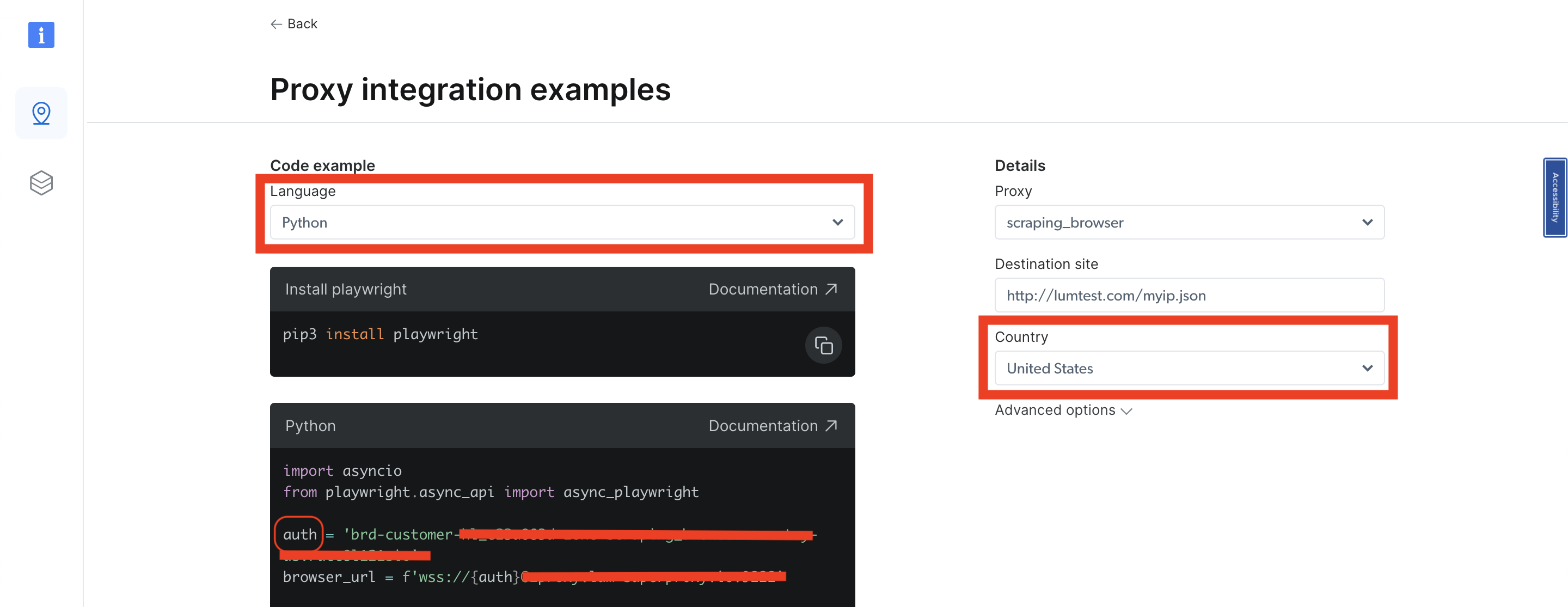
국가를 변경할 때마다 해당 국가/지역에 대한 다른 사용자를 얻게 됩니다. 획득한 사용자 이름과 선택한 국가를 기반으로 사용자를 가져와 코드에 넣고 다시 실행하세요.
결론
이 튜토리얼에서는 Beautiful Soup을 사용해 Zillow를 스크래핑하는 방법을 배웠습니다. 또한 Zillow가 어떤
스크래핑 방지 기술이 적용되는지, 그리고 이를 우회하는 방법을 배웠습니다. 이러한 문제를 해결하기 위해 Bright Data 스크래핑 브라우저가 소개되었으며, 이를 통해 Zillow의 스크래핑 방지 메커니즘을 극복하고 원활하게 원하는 데이터를 추출할 수 있습니다.
스크래핑 브라우저 외에도 Bright Data의 Zillow 스크레이퍼 API는 안티 스크래핑 조치를 우회하여 포괄적인 Zillow 데이터에 원활하게 접근할 수 있도록 해줍니다.
참고: 본 가이드는 작성 당시 당사 팀에 의해 철저히 테스트되었으나, 웹사이트가 코드와 구조를 자주 업데이트함에 따라 일부 단계가 예상대로 작동하지 않을 수 있습니다.





