이 가이드에서는 다음을 확인할 수 있습니다:
- PHP에서 HTML 파싱이 유용한 이유
- 본문 목표를 시작하기 위한 필수 조건
- 를 사용한 PHP HTML 파싱 방법
DomHTMLDocument- 간단한 HTML DOM 파서
- Symfony의
DomCrawler
- 세 가지 접근법의 비교표
자, 시작해 보겠습니다!
PHP에서 HTML을 파싱하는 이유는?
PHP에서 HTML 파싱은 HTML 콘텐츠를 DOM(문서 객체 모델) 구조로 변환하는 작업을 의미합니다. DOM 형식으로 변환된 후에는 HTML 콘텐츠를 쉽게 탐색하고 조작할 수 있습니다.
특히 PHP에서 HTML을 파싱하는 주요 이유는 다음과 같습니다:
- 데이터 추출: HTML 요소에서 텍스트나 속성과 같은 특정 콘텐츠를 웹 페이지에서 수집합니다.
- 자동화: HTML 콘텐츠에서 콘텐츠 스크래핑, 보고, 데이터 집계와 같은 작업을 자동화합니다.
- 서버 측 HTML 콘텐츠 처리: 애플리케이션에 표시하기 전에 서버에서 웹 콘텐츠를 조작, 정리 또는 포맷하기 위해 HTML을 파싱합니다.
필수 조건
코딩을 시작하기 전에 컴퓨터에PHP 8.4 이상이설치되어 있는지 확인하세요. 다음 명령어를 실행하여 확인할 수 있습니다:
php -v
출력 결과는 다음과 유사해야 합니다:
PHP 8.4.3 (cli) (built: Jan 19 2026 14:20:58) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.4.3, Copyright (c) Zend Technologies
with Zend OPcache v8.4.3, Copyright (c), by Zend Technologies
다음으로, 의존성 관리를 쉽게 하기 위해 Composer 프로젝트를 초기화해야 합니다. 시스템에 Composer가 설치되어 있지 않다면,다운로드하여 설치 지침을 따르세요.
먼저 PHP HTML 프로젝트용 새 폴더를 생성합니다:
mkdir php-html-parser
터미널에서 해당 폴더로 이동한 후 composer init 명령어로 Composer 프로젝트를 초기화하세요:
composer init
이 과정에서 몇 가지 질문이 표시됩니다. 기본값으로도 충분하지만, 원한다면 PHP HTML 파싱 프로젝트에 더 구체적인 세부 정보를 추가해도 됩니다.
다음으로 선호하는 IDE에서 프로젝트 폴더를 엽니다. PHP 개발에는Visual Studio Code(PHP 확장 기능 포함)또는IntelliJ WebStorm이적합합니다.
이제 프로젝트 폴더에 빈 index.php 파일을 추가하세요. 프로젝트 구조는 다음과 같아야 합니다:
php-html-parser/
├── vendor/
├── composer.json
└── index.php
index.php 파일을 열고 프로젝트를 초기화하기 위해 다음 코드를 추가하세요:
<?php
require_once __DIR__ . "/vendor/autoload.php";
// 스크래핑 로직...
이 파일에는 곧 PHP로 HTML을 파싱하는 로직이 포함될 것입니다.
이제 다음 명령어로 스크립트를 실행할 수 있습니다:
php index.php
훌륭합니다! 이제 PHP로 HTML을 파싱할 준비가 모두 완료되었습니다. 여기서부터 필요한 HTML 검색 및 파싱 로직을 스크립트에 추가하기 시작할 수 있습니다.
PHP에서 HTML 가져오기
PHP에서 HTML을 파싱하기 전에 파싱할 HTML이 필요합니다. 이 섹션에서는 PHP에서 HTML 콘텐츠에 접근하는 두 가지 다른 방법을 살펴보겠습니다.
CURL 사용
PHP는 HTTP 요청을 수행하는 데 널리 사용되는 HTTP 클라이언트인cURL을 기본적으로 지원합니다.cURL 확장을 활성화하거나Linux에서 다음 명령어로 설치하세요:
sudo apt-get install php8.4-curl
cURL을 사용하여 온라인 서버에HTTP GET 요청을보내고 서버가 반환한 HTML 문서를 가져올 수 있습니다.
다음은 간단한 GET 요청을 수행하고 HTML 콘텐츠를 가져오는 예제 스크립트입니다:
// cURL 세션 초기화
$ch = curl_init();
// GET 요청을 보낼 URL 설정
curl_setopt($ch, CURLOPT_URL, "https://www.scrapethissite.com/pages/forms/?per_page=100");
// 응답을 출력하지 않고 반환하도록 설정
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// cURL 요청 실행 및 결과 $response에 저장
$html = curl_exec($ch);
// cURL 세션 종료
curl_close($ch);
// HTML 응답 출력
echo $html;
위 코드 조각을 index.php 에 추가하고 실행하세요. 다음과 같은 HTML 코드가 생성됩니다:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>하키 팀: 양식, 검색 및 페이지네이션 | Scrape This Site | 웹 스크래핑 학습을 위한 공개 샌드박스</title>
<link rel="icon" type="image/png" href="/static/images/scraper-icon.png" />
<!-- 간결함을 위해 생략... -->
</html>
PHP에서 cURL GET 요청에 대한 가이드에서 자세히 알아보세요.
파일에서 가져오기
HTML 콘텐츠를 가져오는 또 다른 방법은 전용 파일에 저장하는 것입니다. 이를 수행하려면:
- 브라우저에서 원하는 페이지를 방문하세요
- 페이지에서 마우스 오른쪽 버튼을 클릭하세요
- “페이지 소스 보기” 옵션을 선택하세요
- 복사한 HTML을 파일로 붙여넣기
또는 직접 HTML 로직을 파일로 작성할 수도 있습니다.
이 예시에서는 파일 이름을index.html로 가정합니다. 이 파일에는 cURL을 사용하여 이전에 가져온Scrape This Site의“하키 팀” 페이지 HTML이 포함되어 있습니다:
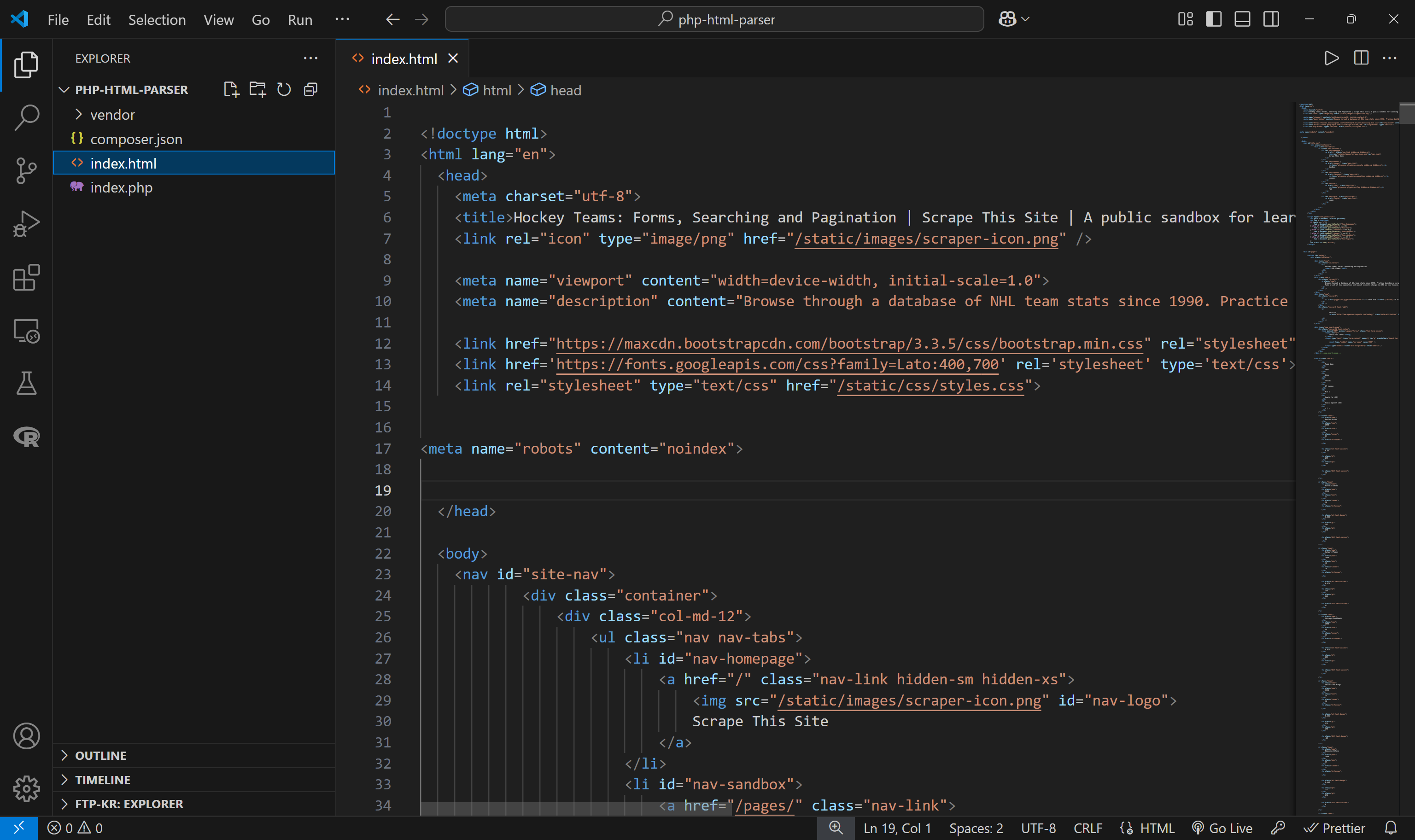
PHP에서 HTML 파싱: 3가지 접근법
이 섹션에서는 PHP에서 HTML을 파싱하기 위해 세 가지 다른 라이브러리를 사용하는 방법을 배웁니다:
- 순수 PHP에서
DomHTMLDocument사용하기 - Simple HTML DOM Parser 라이브러리 사용
- Symfony의
DomCrawler컴포넌트 사용
세 가지 경우 모두 cURL을 통해 가져온 HTML 문자열 또는 로컬 index.html 파일에서 읽은 HTML 콘텐츠를 파싱하는 방법을 살펴봅니다.
그런 다음 각 PHP HTML 파싱 라이브러리가 제공하는 메서드를 사용하여 페이지에서 모든 하키 팀 항목을 선택하고 해당 데이터 추출하는 방법을 배웁니다:
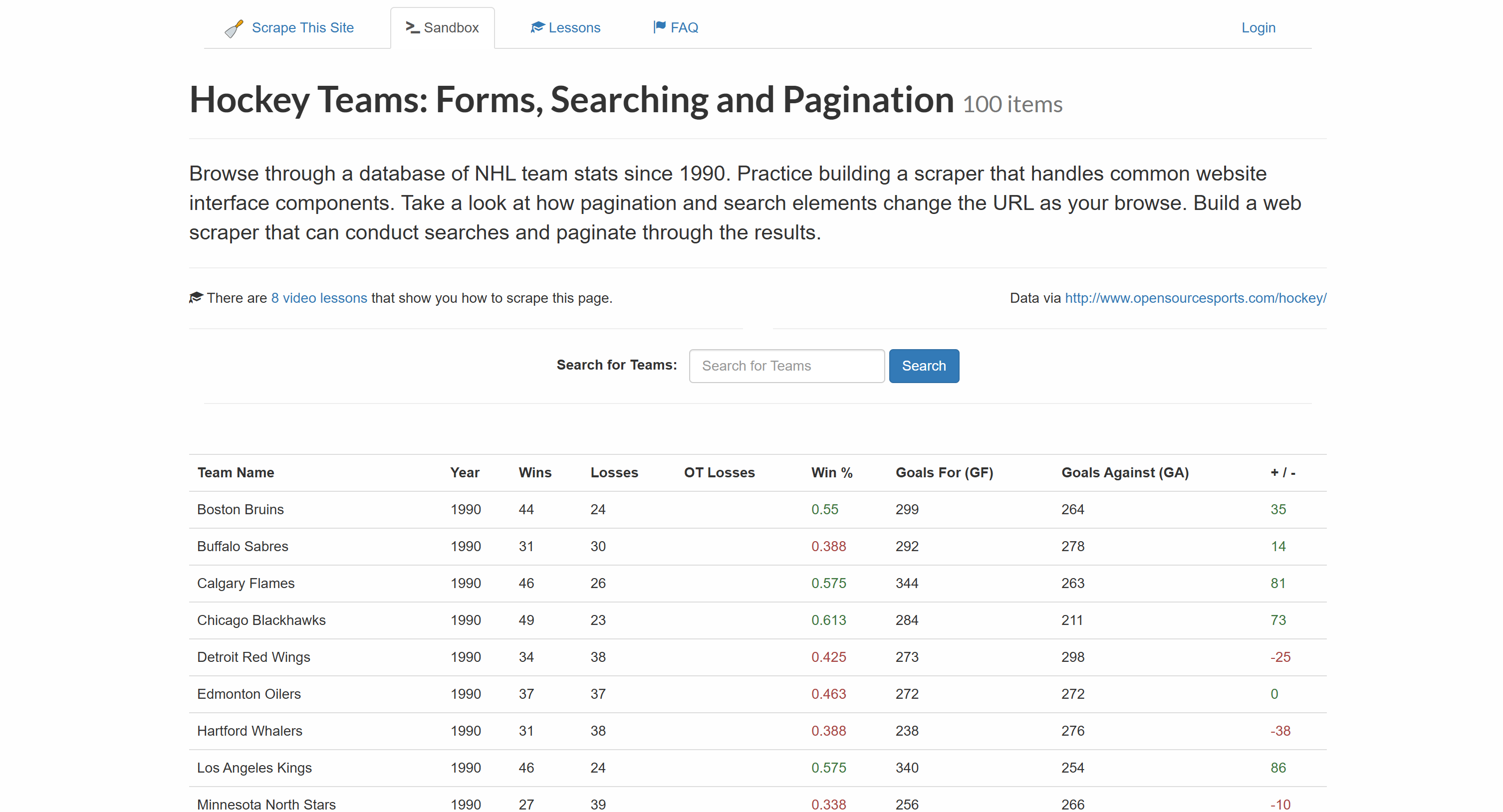
최종 결과는 다음과 같은 세부 정보를 포함하는 스크랩된 하키 팀 항목 목록이 될 것입니다:
- 팀 이름
- 연도
- 승
- 패배
- 승률
- 득점 (GF)
- 실점 (GA)
- 득실차
HTML 테이블에서 다음과 같은 구조로 데이터를 추출할 수 있습니다:
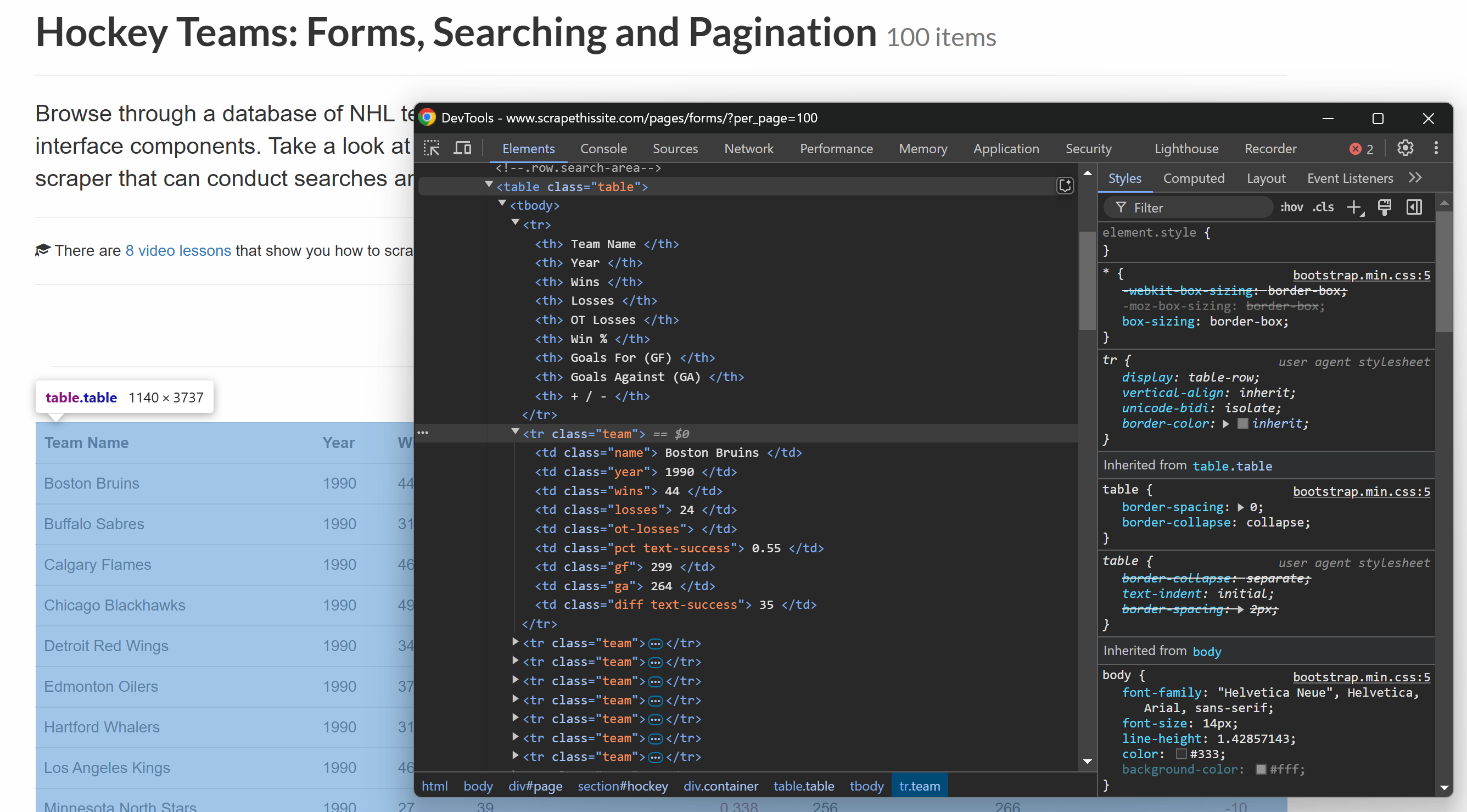
보시다시피 테이블 행의 각 열은 특정 클래스를 가지고 있습니다. CSS 선택자로 해당 클래스를 사용하여 요소를 선택한 후, 텍스트에 접근하여 내용을 추출할 수 있습니다.
HTML 파싱은 웹 스크래핑 스크립트의 한 단계에 불과하다는 점을 명심하세요. 더 깊이 알아보려면PHP를 사용한 웹 스크래핑 튜토리얼을 읽어보세요.
이제 PHP에서 HTML 파싱을 위한 세 가지 다른 접근법을 살펴보겠습니다.
접근법 #1: DomHTMLDocument 사용
PHP 8.4 이상에는 내장된DomHTMLDocument클래스가 제공됩니다. 이 클래스는 HTML 문서를 나타내며 HTML 콘텐츠를 파싱하고 DOM 트리를 탐색할 수 있게 합니다. PHP에서 HTML 파싱에 사용하는 방법을 확인해 보세요!
1단계: 설치 및 설정
DomHTMLDocument는표준 PHP 라이브러리(SPL)의 일부입니다. 사용하려면DOM 확장기능을 활성화하거나 다음 Linux 명령어로 설치해야 합니다:
sudo apt-get install php-dom
추가 작업은 필요하지 않습니다. 이제 PHP에서 HTML 파싱을 위해 DomHTMLDocument를 사용할 준비가 되었습니다.
2단계: HTML 파싱
HTML 문자열은 다음과 같이 파싱할 수 있습니다:
$dom = DOMHTMLDocument::createFromString($html);
동등하게 index.html 파일을 다음과 같이 파싱할 수 있습니다:
$dom = DOMHTMLDocument::createFromFile("./index.html");
$dom은데이터 파싱에 필요한 메서드를 제공하는DomHTMLDocument객체입니다.
3단계: 데이터 파싱
다음과 같은 접근 방식으로 DOMHTMLDocument를 사용하여 모든 하키 팀 항목을 선택할 수 있습니다:
// 페이지의 각 행 선택
$table = $dom->getElementsByTagName("table")->item(0);
$rows = $table->getElementsByTagName("tr");
// 각 행 반복 및 데이터 추출
foreach ($rows as $row) {
$cells = $row->getElementsByTagName("td");
// 각 열에서 데이터 추출
$team = trim($cells->item(0)->textContent);
$year = trim($cells->item(1)->textContent);
$wins = trim($cells->item(2)->textContent);
$losses = trim($cells->item(3)->textContent);
$win_pct = trim($cells->item(5)->textContent);
$goals_for = trim($cells->item(6)->textContent);
$goals_against = trim($cells->item(7)->textContent);
$goal_diff = trim($cells->item(8)->textContent);
// 스크랩된 팀 데이터를 위한 배열 생성
$team_data = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"win_pct" => $win_pct,
"goals_for" => $goals_for,
"goals_against" => $goals_against,
"goal_diff" => $goal_diff
];
// 추출된 팀 데이터 출력
print_r($team_data);
print ("n");
}
DOMHTMLDocument는 고급 쿼리 메서드를 제공하지 않습니다. 따라서 getElementsByTagName() 같은 메서드와 수동 반복 처리에 의존해야 합니다.
사용된 메서드 설명:
getElementsByTagName(): 문서 내에서 지정된 태그(예:<table>,<tr>,<td>)의 모든 요소를 검색합니다.item():getElementsByTagName()이 반환한 요소 목록에서 개별 요소를 반환합니다.textContent: 이 속성은 요소의 원시 텍스트 콘텐츠를 제공하여 가시적인 데이터(팀명, 연도 등)를 추출할 수 있게 합니다.
더 깔끔한 데이터를 위해 텍스트 콘텐츠 앞뒤의 여분의 공백을 제거하기 위해trim()도 사용했습니다.
index.php에 추가하면 위 코드 조각은 다음과 같은 결과를 생성합니다:
Array
(
[team] => Boston Bruins
[year] => 1990
[wins] => 44
[losses] => 24
[win_pct] => 0.55
[goals_for] => 299
[goals_against] => 264
[goal_diff] => 35)
// 생략...
Array
(
[team] => Detroit Red Wings
[year] => 1994
[wins] => 33
[losses] => 11
[승률] => 0.688
[득점] => 180
[실점] => 117
[득실차] => 63
)
접근법 #2: Simple HTML DOM Parser 사용
Simple HTML DOM Parser는HTML 콘텐츠를 쉽게 파싱하고 조작할 수 있게 해주는 경량 PHP 라이브러리입니다. 이 라이브러리는 활발히 유지보수되고 있으며 GitHub에서 880개 이상의 스타를 보유하고 있습니다.
단계 #1: 설치 및 설정
다음 명령어로 Composer를 통해 Simple HTML Dom Parser를 설치할 수 있습니다:
composer require voku/simple_html_dom
또는 simple_html_dom.php 파일을 직접 다운로드하여 프로젝트에 포함시킬 수도 있습니다.
그런 다음 index.php 에서 다음 코드 줄로 임포트하세요:
use vokuhelperHtmlDomParser;
2단계: HTML 파싱
HTML 문자열을 파싱하려면 file_get_html() 메서드를 사용하세요:
$dom = HtmlDomParser::str_get_html($html);
index.html을 파싱하려면 대신 file_get_html()을 작성하세요:
$dom = HtmlDomParser::file_get_html($str);
이렇게 하면 HTML 콘텐츠가 $dom 객체에 로드되어 DOM을 쉽게 탐색할 수 있습니다.
3단계: 데이터 파싱
Simple HTML DOM Parser를 사용하여 HTML에서 하키 팀 데이터를 추출합니다:
// 테이블 내 모든 행 찾기
$rows = $dom->findMulti("table tr.team");
// 각 행을 순회하며 데이터 추출
foreach ($rows as $row) {
// CSS 선택자로 데이터 추출
$team_element = $row->findOne(".name");
$team = trim($team_element->plaintext);
$year_element = $row->findOne(".year");
$year = trim($year_element->plaintext);
$wins_element = $row->findOne(".wins");
$wins = trim($wins_element->plaintext);
$losses_element = $row->findOne(".losses");
$losses = trim($losses_element->plaintext);
$win_pct_element = $row->findOne(".pct");
$win_pct = trim($win_pct_element->plaintext);
$goals_for_element = $row->findOne(".gf");
$goals_for = trim($goals_for_element->plaintext);
$goals_against_element = $row->findOne(".ga");
$goals_against = trim(string: $goals_against_element->plaintext);
$goal_diff_element = $row->findOne(".diff");
$goal_diff = trim(string: $goal_diff_element->plaintext);
// 추출된 팀 데이터로 배열 생성
$team_data = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"승률" => $win_pct,
"득점" => $goals_for,
"실점" => $goals_against,
"골 차" => $goal_diff
];
// 스크랩한 팀 데이터 출력
print_r($team_data);
print("n");
}
위에서 사용된 간단한 HTML DOM 파서 기능은 다음과 같습니다:
findMulti(): 지정된 CSS 선택자로 식별되는 모든 요소를 선택합니다.findOne(): 지정된 CSS 선택자와 일치하는 첫 번째 요소를 찾습니다.plaintext: HTML 요소 내부의 원시 텍스트 콘텐츠를 가져오는 속성입니다.
이번에는 보다 완벽하고 견고한 로직을 가진 CSS 선택자를 사용했습니다. 그럼에도 결과는 초기 HTML 파싱 PHP 접근법과 동일할 것입니다.
접근법 #3: Symfony의 DomCrawler 컴포넌트 사용
Symfony의DomCrawler컴포넌트는HTML 문서를 파싱하고 그로부터 데이터를 추출하는 쉬운 방법을 제공합니다.
참고: 이 컴포넌트는Symfony 프레임워크의일부이지만, 이 섹션에서 수행할 것처럼 독립적으로도 사용할 수 있습니다.
1단계: 설치 및 설정
다음 Composer 명령어로 Symfony의 DomCrawler 컴포넌트를 설치하세요:
composer require symfony/dom-crawler
그런 다음 index.php 파일에 다음을 임포트하세요:
use SymfonyComponentDomCrawlerCrawler;
단계 #2: HTML 파싱
HTML 문자열을 파싱하려면html()메서드로Crawler인스턴스를 생성하세요:
$crawler = new Crawler($html);
파일을 파싱하려면 file_get_contents() 를 사용하고 Crawler 인스턴스를 생성하세요:
$crawler = new Crawler(file_get_contents("./index.html"));
위의 코드는 HTML 콘텐츠를 $crawler 객체에 로드하며, 이 객체는 데이터를 탐색하고 추출하기 위한 편리한 메서드를 제공합니다.
단계 #3: 데이터 파싱
DomCrawler 컴포넌트를 사용하여 하키 팀 데이터를 추출합니다:
// 테이블 내 모든 행 선택
$rows = $crawler->filter("table tr.team");
// 각 행을 순회하며 데이터 추출
$rows->each(function ($row, $i) {
// CSS 선택자로 데이터 추출
$team_element = $row->filter(".name");
$team = trim($team_element->text());
$year_element = $row->filter(".year");
$year = trim($year_element->text());
$wins_element = $row->filter(".wins");
$wins = trim($wins_element->text());
$losses_element = $row->filter(".losses");
$losses = trim($losses_element->text());
$win_pct_element = $row->filter(".pct");
$win_pct = trim($win_pct_element->text());
$goals_for_element = $row->filter(".gf");
$goals_for = trim($goals_for_element->text());
$goals_against_element = $row->filter(".ga");
$goals_against = trim($goals_against_element->text());
$goal_diff_element = $row->filter(".diff");
$goal_diff = trim($goal_diff_element->text());
// 추출된 팀 데이터로 배열 생성
$team_data = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"승률" => $win_pct,
"득점" => $goals_for,
"실점" => $goals_against,
"골 차" => $goal_diff
];
// 스크랩한 팀 데이터 출력
print_r($team_data);
print ("n");
});
사용된 DomCrawler 메서드:
each(): 선택된 요소 목록을 반복 처리합니다.filter(): CSS 선택자에 기반하여 요소를 선택합니다.text(): 선택된 요소의 텍스트 콘텐츠를 추출합니다.
훌륭합니다! 이제 여러분은 PHP HTML 파싱의 달인이 되었습니다.
PHP에서 HTML 파싱: 비교표
아래 요약표에서 PHP에서 HTML을 파싱하는 세 가지 접근법을 비교해 볼 수 있습니다:
| DOMHTMLDocument | 간단한 HTML DOM 파서 | Symfony의 DomCrawler | |
|---|---|---|---|
| 유형 | 네이티브 PHP 컴포넌트 | 외부 라이브러리 | 심포니 컴포넌트 |
| GitHub 스타 | — | 880개 이상 | 4,000+ |
| XPath 지원 | ❌ | ✔️ | ✔️ |
| CSS 선택기 지원 | ❌ | ✔️ | ✔️ |
| 학습 곡선 | 낮음 | 낮음에서 중간 | 중간 |
| 사용 편의성 | 중간 | 높음 | 높음 |
| API | 기본 | 풍부한 | 리치 |
결론
이 글에서는 PHP에서 HTML 파싱을 위한 세 가지 접근법, 즉 기본 내장 확장 기능부터 타사 라이브러리에 이르기까지를 살펴보았습니다.
이 모든 솔루션이 작동하지만, 대상 웹 페이지가 렌더링에 JavaScript를 사용할 수 있다는 점을 명심하세요. 이 경우 위에서 소개한 것과 같은 단순한 HTML 파싱 접근법은 작동하지 않습니다. 대신Scraping Browser와 같은 고급 HTML 파싱 기능을 갖춘 완전한 스크래핑 브라우저가 필요합니다.
HTML 파싱을 건너뛰고 즉시 데이터를 얻고 싶으신가요? 수백 개의 웹사이트를 아우르는즉시 사용 가능한 데이터 세트를확인해 보세요!
무료 체험으로 데이터 및 스크래핑 솔루션을 테스트해 보려면 지금 바로 Bright Data 무료 계정을 생성하세요!