웹 스크래핑은 종종 봇 방지 메커니즘 우회, Puppeteer 같은 브라우저 자동화 도구로 동적 콘텐츠 로드, IP 차단 회피를 위한 프록시 로테이션, CAPTCHA 해결을 요구합니다. 이러한 전략에도 불구하고 확장성과 안정적인 세션 유지가 여전히 어렵습니다.
본 글은 기존 프록시 기반 스크래핑에서 Bright Data Scraping Browser로의 전환 방법을 안내합니다. 프록시 관리 및 확장 자동화를 통해 개발 비용과 유지보수를 줄이는 방법을 알아보세요. 구성, 성능, 확장성, 복잡성 측면에서 두 방식을 비교합니다.
참고: 본 문서의 예시는 교육 목적으로만 제공됩니다. 데이터 스크래핑 전에는 반드시 대상 웹사이트의 서비스 약관을 확인하고 관련 법규를 준수하십시오.
필수 조건
튜토리얼을 시작하기 전에 다음 필수 조건을 충족하는지 확인하십시오:
- Node.js
- Visual Studio Code
- 스크래핑 브라우저를 사용하기 위한무료 Bright Data 계정
코드를 저장할 새 Node.js 프로젝트 폴더를 생성하세요.
그런 다음 터미널 또는 셸을 열고 다음 명령어를 사용하여 새 디렉터리를 생성하세요:
mkdir scraping-tutorialrncd scraping-tutorial
새로운 Node.js 프로젝트 초기화:
npm init -y
-y 플래그는 모든 질문에 자동으로 '예'라고 답하여 기본 설정으로 package.json 파일을 생성합니다.
프록시 기반 웹 스크래핑
일반적인 프록시 기반 접근 방식에서는 Puppeteer와 같은 브라우저 자동화 도구를 사용하여 대상 도메인과 상호작용하고, 동적 콘텐츠를 로드하며, 데이터를 추출합니다. 이 과정에서 IP 차단 방지 및 익명성 유지를 위해 프록시를 통합합니다.
Puppeteer를 사용하여 프록시를 통해 전자상거래 웹사이트의 데이터를 스크래핑하는 웹 스크래핑 스크립트를 빠르게 생성해 보겠습니다.
Puppeteer를 사용한 웹 스크래핑 스크립트 생성
먼저 Puppeteer를 설치합니다:
npm install puppeteer
그런 다음 scraping-tutorial 폴더에 proxy-scraper.js라는 파일(원하는 이름으로 지정 가능)을 생성하고 다음 코드를 추가합니다:
const puppeteer = require(u0022puppeteeru0022);rnrn(async () =u003e {rn // Launch a headless browserrn const browser = await puppeteer.launch({rn headless: true,rn });rn const page = await browser.newPage();rnrn const baseUrl = u0022https://books.toscrape.com/catalogue/page-u0022;rn const books = [];rnrn for (let i = 1; i u003c= 5; i++) { // Loop through the first 5 pagesrn const url = `${baseUrl}${i}.html`;rnrn console.log(`Navigating to: ${url}`);rnrn // Navigate to the pagern await page.goto(url, { waitUntil: u0022networkidle0u0022 });rnrn // Extract book data from the current pagern const pageBooks = await page.evaluate(() =u003e {rn let books = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u003e {rn let title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn let price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn books.push({ title, price });rn });rn return books;rn });rnrn books.push(...pageBooks); // Append books from this page to the main listrn }rnrn console.log(books); // Print the collected datarnrn await browser.close();rn})();rn
이 스크립트는 Puppeteer를 사용하여 Books to Scrape 웹사이트의 첫 5개 페이지에서 도서 제목과 가격을 스크래핑합니다. 헤드리스 브라우저를 실행하고 새 페이지를 열며 각 카탈로그 페이지를 순차적으로 탐색합니다.
각 페이지에서 스크립트는 page.evaluate() 내의 DOM 선택자를 사용하여 책 제목과 가격을 추출하고 데이터를 배열에 저장합니다. 모든 페이지 처리가 완료되면 데이터가 콘솔에 출력되고 브라우저가 닫힙니다. 이 접근 방식은 페이지가 나누어진 웹사이트에서 데이터를 효율적으로 추출합니다.
다음 명령어로 코드를 테스트하고 실행하세요:
node proxy-scraper.js출력 결과는 다음과 같아야 합니다:
Navigating to: https://books.toscrape.com/catalogue/page-1.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-2.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-3.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-4.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-5.htmlrn[rn { title: 'A Light in the Attic', price: '£51.77' },rn { title: 'Tipping the Velvet', price: '£53.74' },rn { title: 'Soumission', price: '£50.10' },rn { title: 'Sharp Objects', price: '£47.82' },rn { title: 'Sapiens: A Brief History of Humankind', price: '£54.23' },rn { title: 'The Requiem Red', price: '£22.65' },rn…output omitted…rn {rn title: 'In the Country We Love: My Family Divided',rn price: '£22.00'rn }rn]
프록시 설정
프록시는 요청을 분산하고 추적을 불가능하게 하기 위해 스크래핑 구성에 흔히 사용됩니다. 일반적인 방법은 프록시 풀을 유지하고 동적으로 순환시키는 것입니다.
프록시를 배열에 넣거나 별도 파일에 저장할 수 있습니다:
const proxies = [rn u0022proxy1.example.com:portu0022, rn u0022proxy2.example.com:portu0022rn // Add more proxies herern];
프록시 순환 로직 활용
브라우저를 실행할 때마다 프록시 배열을 순환하는 로직으로 코드를 개선해 보겠습니다. proxy-scraper.js를 업데이트하여 다음 코드를 포함시키세요:
const puppeteer = require(u0022puppeteeru0022);rnrnconst proxies = [rn u0022proxy1.example.com:portu0022, rn u0022proxy2.example.com:portu0022rn // Add more proxies herern];rnrn(async () =u003e {rn // Choose a random proxyrn const randomProxy =rn proxies[Math.floor(Math.random() * proxies.length)];rnrn // Launch Puppeteer with proxyrn const browser = await puppeteer.launch({rn headless: true,rn args: [rn `u002du002dproxy-server=http=${randomProxy}`,rn u0022u002du002dno-sandboxu0022,rn u0022u002du002ddisable-setuid-sandboxu0022,rn u0022u002du002dignore-certificate-errorsu0022,rn ],rn });rnrn const page = await browser.newPage();rnrn const baseUrl = u0022https://books.toscrape.com/catalogue/page-u0022;rn const books = [];rnrn for (let i = 1; i u003c= 5; i++) {rn // Loop through the first 5 pagesrn const url = `${baseUrl}${i}.html`;rnrn console.log(`Navigating to: ${url}`);rnrn // Navigate to the pagern await page.goto(url, { waitUntil: u0022networkidle0u0022 });rnrn // Extract book data from the current pagern const pageBooks = await page.evaluate(() =u003e {rn let books = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u003e {rn let title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn let price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn books.push({ title, price });rn });rn return books;rn });rnrn books.push(...pageBooks); // Append books from this page to the main listrn }rnrn console.log(`Using proxy: ${randomProxy}`);rn console.log(books); // Print the collected datarnrn await browser.close();rn})();rn
참고: 프록시 교체를 수동으로 수행하는 대신 luminati-proxy 같은 라이브러리를 사용해 프로세스를 자동화할 수 있습니다.
이 코드에서는 프록시 목록에서 무작위로 프록시를 선택하고 --proxy-server=${randomProxy} 옵션을 사용하여 Puppeteer에 적용합니다. 탐지를 피하기 위해 무작위 사용자 에이전트 문자열도 할당됩니다. 그런 다음 스크래핑 로직이 반복되고 제품 데이터 스크래핑에 사용된 프록시가 기록됩니다.
코드를 다시 실행하면 이전과 유사한 출력이 표시되지만, 사용된 프록시가 추가됩니다:
Navigating to: https://books.toscrape.com/catalogue/page-1.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-2.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-3.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-4.htmlrnNavigating to: https://books.toscrape.com/catalogue/page-5.htmlrnUsing proxy: 115.147.63.59:8081rn…output omitted…
프록시 기반 스크래핑의 문제점
프록시 기반 접근 방식은 많은 사용 사례에서 효과적이지만 다음과 같은 문제점에 직면할 수 있습니다:
- 잦은 차단: 사이트의 강력한 봇 탐지 시스템으로 인해 프록시가 차단될 수 있습니다.
- 성능 오버헤드: 프록시 회전 및 요청 재시도는 데이터 수집 파이프라인 속도를 저하시킵니다.
- 복잡한 확장성: 최적의 성능과 가용성을 위해 대규모 프록시 풀을 관리하고 회전시키는 것은 복잡합니다. 로드 밸런싱, 프록시 과다 사용 방지, 쿨다운 기간 설정, 실시간 장애 처리가 필요합니다. 동시 요청이 증가할수록 시스템은 탐지를 회피하면서 블랙리스트에 오른 IP나 성능이 저하된 IP를 지속적으로 모니터링하고 교체해야 하므로 어려움이 가중됩니다.
- 브라우저 유지 관리: 브라우저 유지 관리는 기술적으로 까다롭고 리소스 집약적일 수 있습니다. 실제 사용자 행동을 모방하고 고급 봇 방지 제어 기능을 회피하기 위해 브라우저의 지문(쿠키, 헤더 및 기타 식별 속성)을 지속적으로 업데이트하고 처리해야 합니다.
- 클라우드 브라우저 오버헤드: 클라우드 기반 브라우저는 증가된 리소스 요구사항과 복잡한 인프라 제어에 따른 추가 운영 오버헤드를 발생시켜 운영 비용을 상승시킵니다. 일관된 성능을 위한 브라우저 인스턴스 확장은 프로세스를 더욱 복잡하게 만듭니다.
Bright Data 스크래핑 브라우저를 활용한 동적 스크래핑
이러한 문제를 해결하기 위해 Bright Data 스크래핑 브라우저와 같은 단일 API 솔루션을 활용할 수 있습니다. 이는 운영을 간소화하고 수동 프록시 회전 및 복잡한 브라우저 설정의 필요성을 제거하며, 데이터 수집 성공률을 높이는 경우가 많습니다.
Bright Data 계정 설정
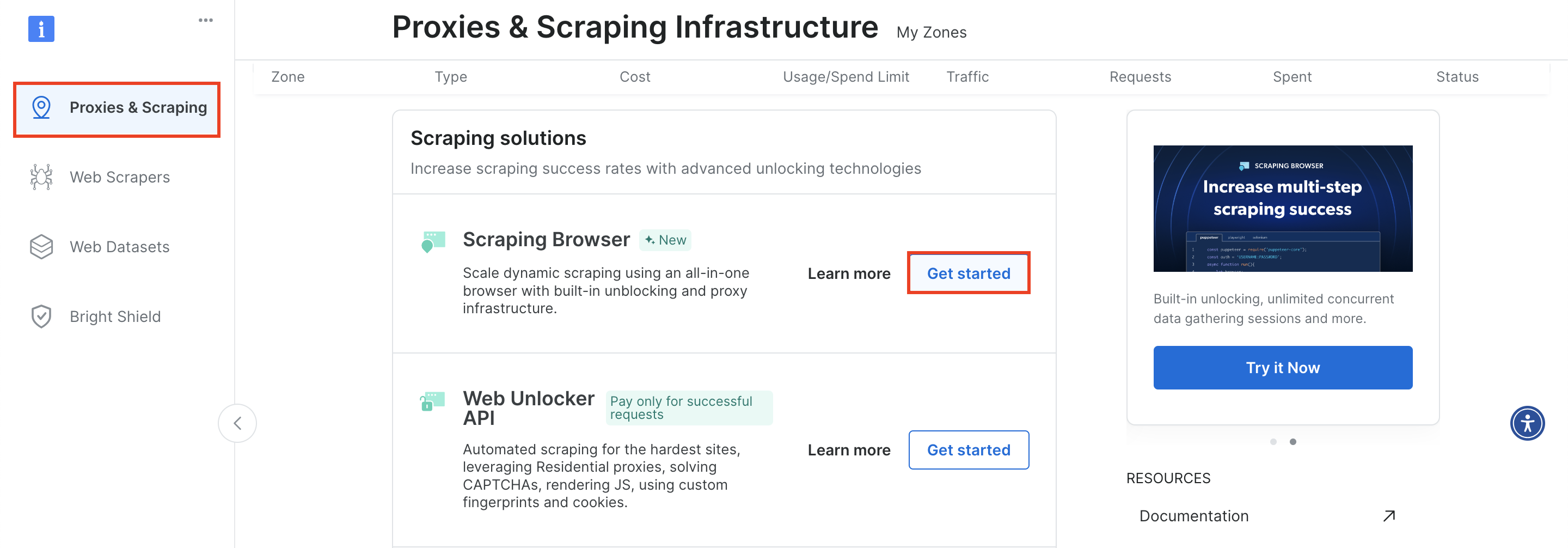
시작하려면 Bright Data 계정에 로그인한 후 ‘프록시 및 스크래핑’으로 이동하여 아래로 스크롤해 ‘스크래핑 브라우저’를 찾은 다음 ‘시작하기’를 클릭하세요:
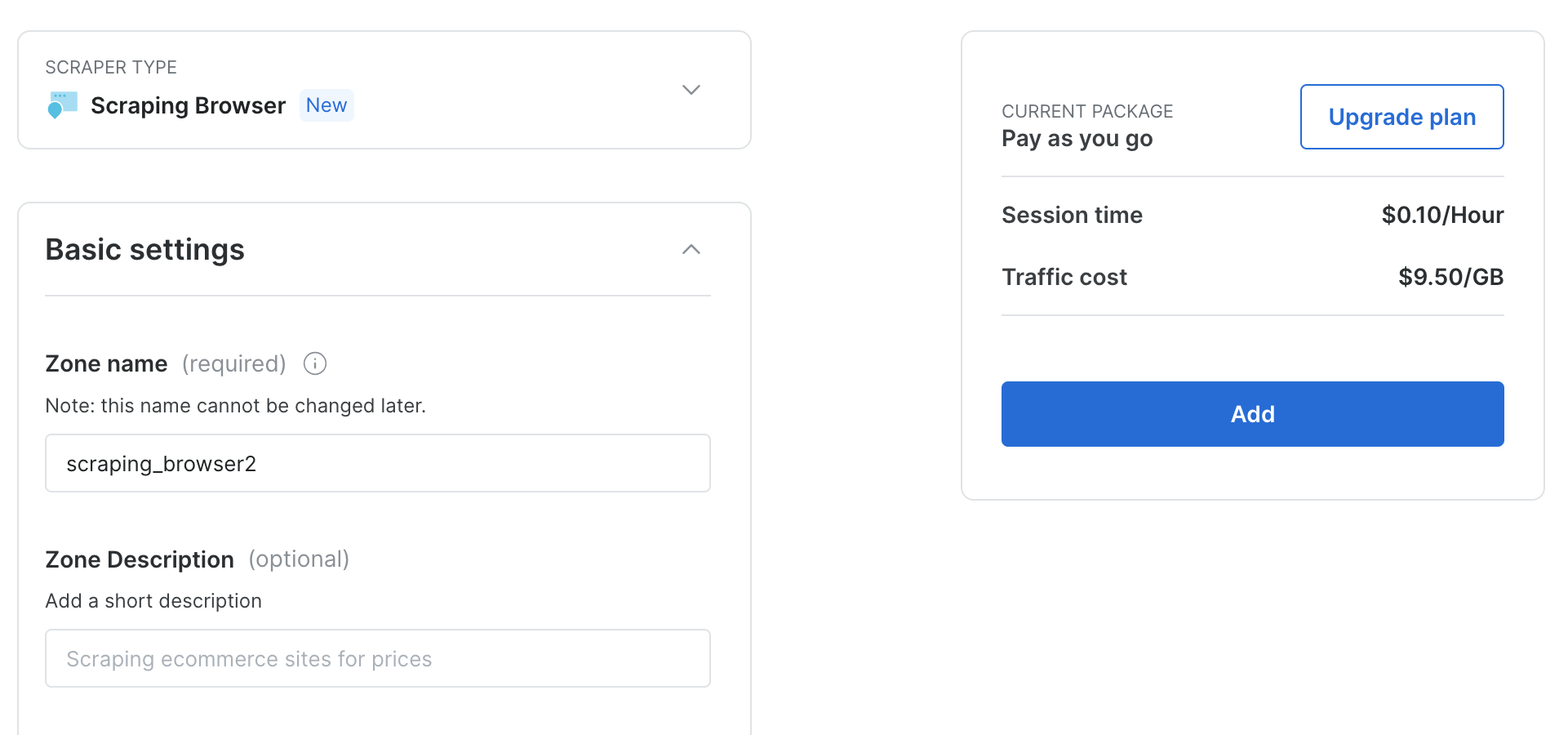
기본 설정을 유지한 상태에서 ‘추가’를 클릭하여 새로운 스크래핑 브라우저 인스턴스를 생성하세요:
스크래핑 브라우저 인스턴스 생성 후 곧 필요할 펭펭티어(Puppeteer) URL을 메모해 두세요:
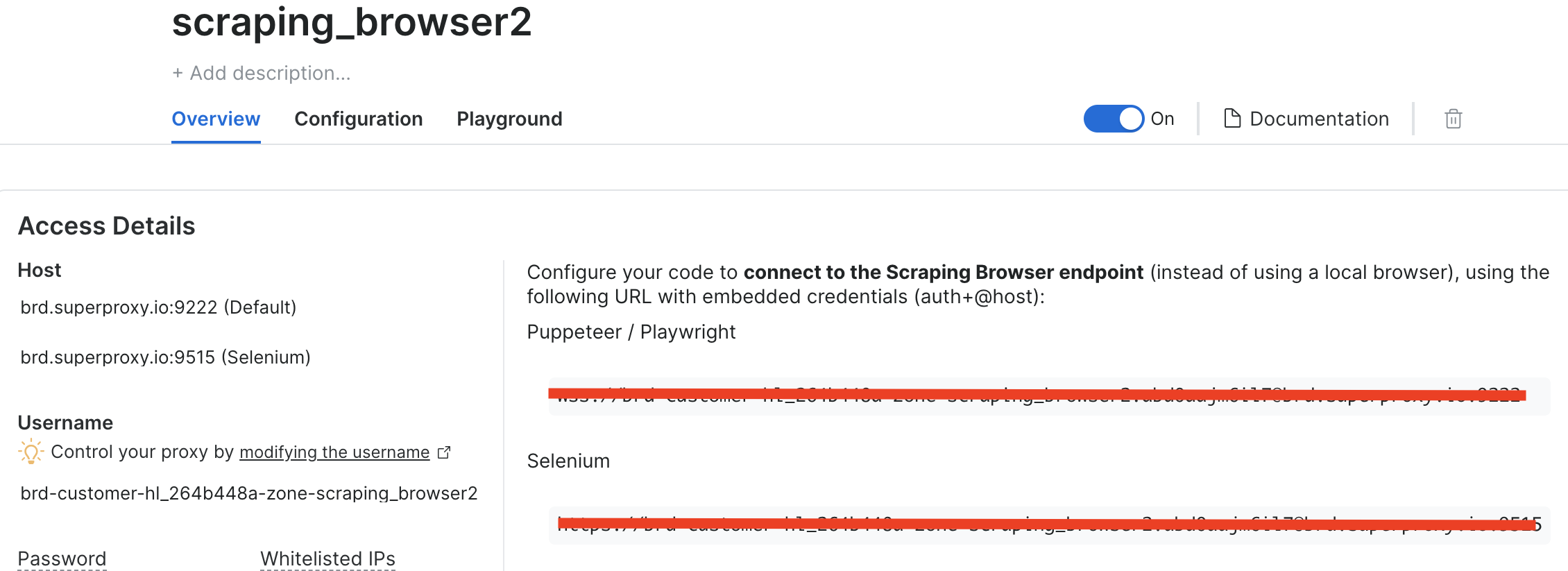
Bright Data 스크래핑 브라우저 사용을 위한 코드 조정
이제 코드를 조정하여 회전 프록시 대신 Bright Data 스크래핑 브라우저 엔드포인트에 직접 연결하도록 하겠습니다.
brightdata-scraper.js라는 새 파일을 생성하고 다음 코드를 추가하세요:
const puppeteer = require(u0022puppeteeru0022);rnrn(async () =u003e {rn // Choose a random proxyrn const SBR_WS_ENDPOINT = u0022YOUR_BRIGHT_DATA_WS_ENDPOINTu0022rnrn // Launch Puppeteer with proxyrn const browser = await puppeteer.connect({rn browserWSEndpoint: SBR_WS_ENDPOINT,rn });rnrn const page = await browser.newPage();rnrn const baseUrl = u0022https://books.toscrape.com/catalogue/page-u0022;rn const books = [];rnrn for (let i = 1; i u003c= 5; i++) {rn // Loop through the first 5 pagesrn const url = `${baseUrl}${i}.html`;rnrn console.log(`Navigating to: ${url}`);rnrn // Navigate to the pagern await page.goto(url, { waitUntil: u0022networkidle0u0022 });rnrn // Extract book data from the current pagern const pageBooks = await page.evaluate(() =u003e {rn let books = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u003e {rn let title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn let price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn books.push({ title, price });rn });rn return books;rn });rnrn books.push(...pageBooks); // Append books from this page to the main listrn }rnrn console.log(books); // Print the collected datarnrn await browser.close();rn})();
YOUR_BRIGHT_DATA_WS_ENDPOINT를 이전 단계에서 확인한 URL로 반드시 교체하세요.
이 코드는 이전 코드와 유사하지만, 프록시 목록을 관리하며 서로 다른 프록시 사이를 전환하는 대신 Bright Data 엔드포인트에 직접 연결합니다.
다음 코드를 실행하세요:
node brightdata-scraper.js
출력 결과는 이전과 동일하지만, 이제 프록시를 수동으로 회전하거나 사용자 에이전트를 구성할 필요가 없습니다. Bright Data Scraping Browser가 프록시 회전부터 CAPTCHA 우회까지 모든 작업을 처리하여 중단 없는 데이터 스크래핑을 보장합니다.
코드를 익스프레스 엔드포인트로 전환하기
Bright Data 스크래핑 브라우저를 더 큰 애플리케이션에 통합하려면 Express 엔드포인트로 노출하는 것을 고려하세요.
먼저 Express를 설치하세요:
npm install express
server.js 파일을 생성하고 다음 코드를 추가하세요:
const express = require(u0022expressu0022);rnconst puppeteer = require(u0022puppeteeru0022);rnrnconst app = express();rnconst PORT = 3000;rnrn// Needed to parse JSON bodies:rnapp.use(express.json());rnrn// Your Bright Data Scraping Browser WebSocket endpointrnconst SBR_WS_ENDPOINT =rn u0022wss://brd-customer-hl_264b448a-zone-scraping_browser2:[email protected]:9222u0022;rnrn/**rn POST /scraperrn Body example:rn {rn u0022baseUrlu0022: u0022https://books.toscrape.com/catalogue/page-u0022rn }rn*/rnapp.post(u0022/scrapeu0022, async (req, res) =u003e {rn const { baseUrl } = req.body;rnrn if (!baseUrl) {rn return res.status(400).json({rn success: false,rn error: 'Missing u0022baseUrlu0022 in request body.',rn });rn }rnrn try {rn // Connect to the existing Bright Data (Luminati) Scraping Browserrn const browser = await puppeteer.connect({rn browserWSEndpoint: SBR_WS_ENDPOINT,rn });rnrn const page = await browser.newPage();rn const books = [];rnrn // Example scraping 5 pages of the base URLrn for (let i = 1; i u003c= 5; i++) {rn const url = `${baseUrl}${i}.html`;rn console.log(`Navigating to: ${url}`);rnrn await page.goto(url, { waitUntil: u0022networkidle0u0022 });rnrn const pageBooks = await page.evaluate(() =u003e {rn const data = [];rn document.querySelectorAll(u0022.product_podu0022).forEach((item) =u003e {rn const title = item.querySelector(u0022h3 au0022)?.getAttribute(u0022titleu0022) || u0022u0022;rn const price = item.querySelector(u0022.price_coloru0022)?.innerText || u0022u0022;rn data.push({ title, price });rn });rn return data;rn });rnrn books.push(...pageBooks);rn }rnrn // Close the browser connectionrn await browser.close();rnrn // Return JSON with the scraped datarn return res.json({rn success: true,rn books,rn });rn } catch (error) {rn console.error(u0022Scraping error:u0022, error);rn return res.status(500).json({rn success: false,rn error: error.message,rn });rn }rn});rnrn// Start the Express serverrnapp.listen(PORT, () =u003e {rn console.log(`Server is listening on http://localhost:${PORT}`);rn});
이 코드에서는 Express 앱을 초기화하고, JSON 페이로드를 수락하며, POST /scrape 경로를 정의합니다. 클라이언트는 baseUrl을 포함한 JSON 본문을 전송하며, 이는 대상 URL과 함께 Bright Data 스크래핑 브라우저 엔드포인트로 전달됩니다.
새 Express 서버 실행:
node server.js
엔드포인트 테스트를 위해 Postman (또는 원하는 REST 클라이언트)을 사용하거나 터미널/셸에서 다음과 같이 curl을 사용할 수 있습니다:
curl -X POST http://localhost/scrape rn-H 'Content-Type: application/json' rn-d '{u0022baseUrlu0022: u0022https://books.toscrape.com/catalogue/page-u0022}'rn
출력 결과는 다음과 같아야 합니다:
{rn u0022successu0022: true,rn u0022booksu0022: [rn {rn u0022titleu0022: u0022A Light in the Atticu0022,rn u0022priceu0022: u0022£51.77u0022rn },rn {rn u0022titleu0022: u0022Tipping the Velvetu0022,rn u0022priceu0022: u0022£53.74u0022rn },rn {rn u0022titleu0022: u0022Soumissionu0022,rn u0022priceu0022: u0022£50.10u0022rn },rn {rn u0022titleu0022: u0022Sharp Objectsu0022,rn u0022priceu0022: u0022£47.82u0022rn },rn {rn u0022titleu0022: u0022Sapiens: A Brief History of Humankindu0022,rn u0022priceu0022: u0022£54.23u0022rn },rn {rn u0022titleu0022: u0022The Requiem Redu0022,rn u0022priceu0022: u0022£22.65u0022rn },rn {rn u0022titleu0022: u0022The Dirty Little Secrets of Getting Your Dream Jobu0022,rn u0022priceu0022: u0022£33.34u0022rn },rn {rn u0022titleu0022: u0022The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhullu0022,rn u0022priceu0022: u0022£17.93u0022rn },rn rn ... output omitted...rn rn {rn u0022titleu0022: u0022Judo: Seven Steps to Black Belt (an Introductory Guide for Beginners)u0022,rn u0022priceu0022: u0022£53.90u0022rn },rn {rn u0022titleu0022: u0022Joinu0022,rn u0022priceu0022: u0022£35.67u0022rn },rn {rn u0022titleu0022: u0022In the Country We Love: My Family Dividedu0022,rn u0022priceu0022: u0022£22.00u0022rn }rn ]rn}
다음은 수동 설정(로테이션 프록시)과 Bright Data Scraping Browser 방식의 차이점을 보여주는 다이어그램입니다:
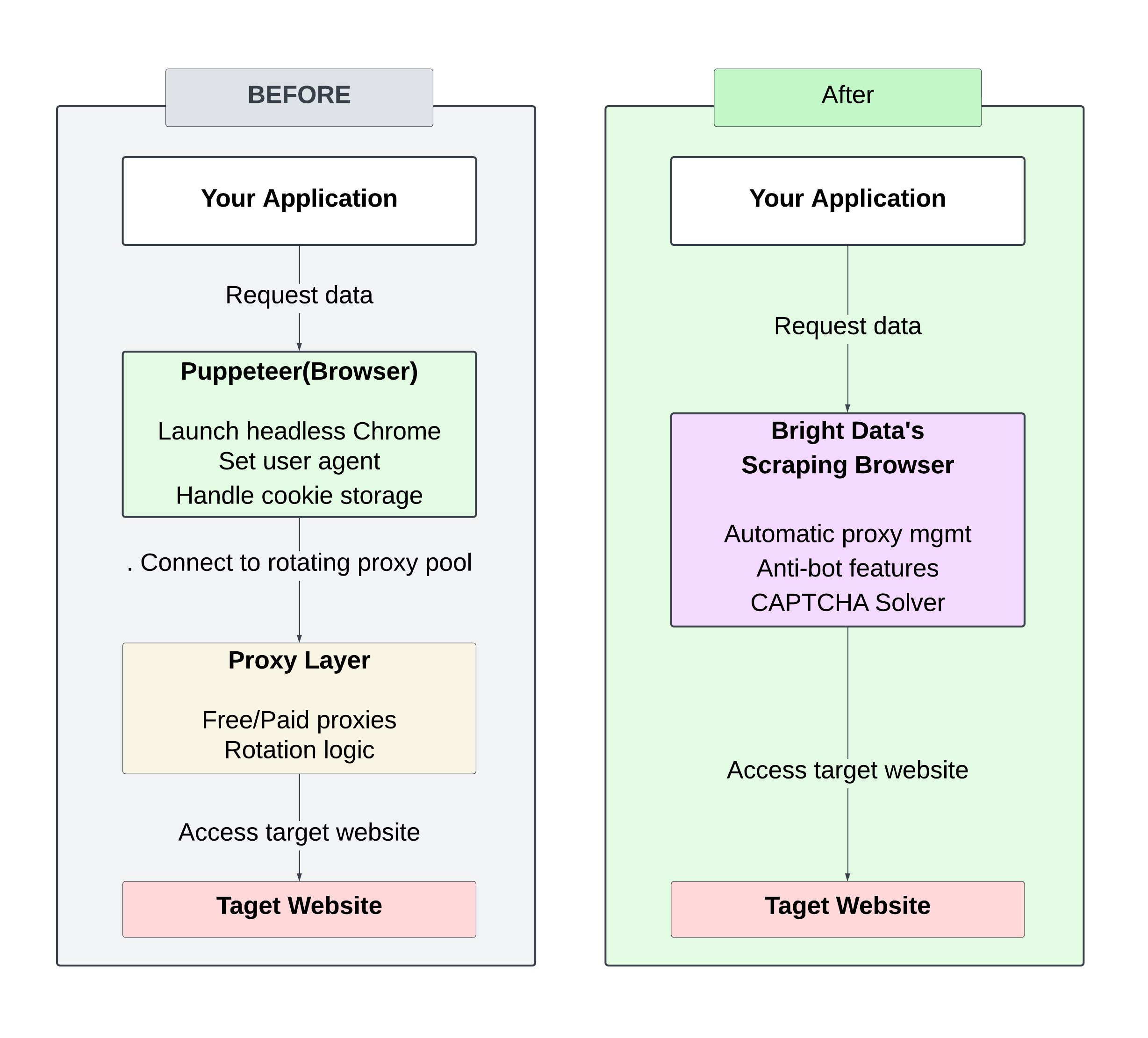
수동으로 프록시를 회전 관리하려면 지속적인 주의와 조정이 필요하며, 이로 인해 차단이 빈번하고 확장성이 제한됩니다.
Bright Data Scraping Browser를 사용하면 프록시나 헤더 관리가 필요 없어 프로세스가 간소화되며, 최적화된 인프라를 통해 더 빠른 응답 시간을 제공합니다. 통합된 안티봇 전략은 성공률을 높여 차단되거나 플래그가 지정될 가능성을 줄여줍니다.
이 튜토리얼의 모든 코드는 이 GitHub 저장소에서 확인할 수 있습니다.
ROI 계산
수동 프록시 기반 스크래핑 설정에서 Bright Data Scraping Browser로 전환하면 개발 시간과 비용을 크게 절감할 수 있습니다.
기존 설정
뉴스 웹사이트를 매일 스크래핑하려면 다음이 필요합니다:
- 초기 개발: 약 50시간 (시간당 100달러 기준 5,000달러)
- 지속적 유지 관리: 코드 업데이트, 인프라, 확장 및 프록시 관리를 위해 월 약 10시간(1,000달러)
- 프록시/IP 비용: 월 약 250달러(IP 요구 사항에 따라 다름)
총 예상 월간 비용: 약 1,250달러
Bright Data 스크래핑 브라우저 설정
- 개발 시간: 5~10시간 (1,000달러)
- 유지 관리: 월 약 2~4시간(200달러)
- 프록시 또는 인프라 관리 불필요
- Bright Data 서비스 비용:
- 트래픽 사용량: GB당 8.40 USD (예: 월 30GB = 252 USD)
월간 총 예상 비용: 약 450달러
프록시 관리를 자동화하고 Bright Data 스크래핑 브라우저를 확장하면 초기 개발 비용과 지속적인 유지 관리 비용을 모두 줄여 대규모 데이터 스크래핑을 보다 효율적이고 비용 효율적으로 수행할 수 있습니다.
결론
기존 프록시 기반 웹 스크래핑 구성에서 Bright Data 스크래핑 브라우저로 전환하면 프록시 회전 및 수동 봇 방지 처리의 번거로움을 없앨 수 있습니다.
HTML 가져오기 외에도 Bright Data는 데이터 추출을 간소화하는 추가 도구를 제공합니다:
이러한 솔루션은 스크래핑 프로세스를 간소화하고 작업량을 줄이며 확장성을 향상시킬 수 있습니다.