

이 튜토리얼에서는 다음 내용을 배웁니다:
- Bright Data의 전송 인프라로부터 데이터를 수신하도록 Snowflake를 설정하는 방법.
- Goodreads Books 데이터셋이 Snowflake 내부 스테이지로 직접 전송되도록 구성하기.
- 스냅샷을 트리거하고 쿼리 가능한 테이블에 로드한 후, 600만 개 이상의 도서 레코드에 대해 SQL을 실행하기.
시작해 봅시다!
Snowflake 수집 워크플로 소개
개략적으로, 파이프라인은 세 단계로 구성되며 각 단계는 별도의 섹션에서 다룹니다:
- Snowflake 설정: Bright Data가 인증할 데이터베이스, 스테이지, 역할, 서비스 사용자를 생성합니다. SQL 작업이 가장 많은 부분이지만, 각 명령은 전체가 제공되며 순서대로 실행됩니다.
- Bright Data 구성: 마켓플레이스에서 데이터셋을 선택하고, Snowflake 환경에 연결한 후, 스냅샷을 트리거합니다. Bright Data는 파일을 내부 스테이지로 직접 푸시합니다.
- 로드 및 쿼리: 단일
COPY INTO명령으로 스테이지된 파일을 구조화된 테이블로 이동합니다. 이후는 표준 SQL입니다.
출력 결과는 구조화된 웹 데이터로 채워진 완전히 쿼리 가능한 Snowflake 테이블이며, 사용 사례에 따라 원하는 일정으로 새로 고침됩니다. CSV 내보내기나 맞춤형 ETL 글루 코드는 필요하지 않습니다.
각 단계와 구현 방법에 대해 자세히 알아보세요!
1. Snowflake 설정
Bright Data는 Snowflake 계정에 직접 인증하여 파일을 전송합니다. 이를 위해 전용 내부 스테이지(들어오는 파일의 랜딩 존), 해당 스테이지에 대한 쓰기 권한이 있는 서비스 역할, 그리고 그 역할에 할당된 서비스 사용자가 필요합니다.
이 목적을 위해 전용 객체를 사용하면 수집이 분석 워크로드와 분리되고, 나중에 자격 증명을 감사, 취소 또는 교체하기가 더 쉬워집니다.
2. Bright Data 데이터셋 구성 및 스냅샷 전송
Bright Data의 데이터셋 마켓플레이스에는 Amazon, LinkedIn, Crunchbase, Glassdoor, 호텔 리스팅, 부동산, 채용 공고 등을 포함하는 사전 구축된 검증 데이터셋이 있습니다. 각 데이터셋에는 전체 필드 참조가 포함되어 있어 첫 번째 바이트가 도착하기 전에 Snowflake 스키마를 설계할 수 있습니다.
Snowflake 직접 전송은 데이터셋 제품에서 사용 가능합니다. 웹 스크래퍼 API를 사용하는 경우에는 S3 버킷으로 파일을 전송하고 외부 스테이지에서 로드하세요.
Snowflake를 전송 대상으로 구성하면 Bright Data가 전송을 처리합니다. 생성한 서비스 사용자로 인증하고, 파일을 내부 스테이지에 스테이지하며, 제어판에 전송 내역을 기록합니다. 요청 시, 일정에 따라, 또는 마켓플레이스 데이터셋 API를 통해 스냅샷을 트리거할 수 있습니다.
3. 로드 및 쿼리
스테이지에 파일이 있으면, 단일 COPY INTO 명령으로 테이블에 로드합니다. 이후에는 특별한 구문이나 새로운 도구 없이 표준 SQL로 쿼리합니다.
Bright Data를 수신하도록 Snowflake 설정하기
Snowflake 측을 준비하여 파이프라인 구축을 시작해 봅시다. 이 섹션의 모든 명령은 Snowsight의 SQL 워크시트 내부 또는 SnowSQL을 통해 실행됩니다. 데이터베이스, 역할, 사용자를 생성하는 데 필요한 권한이 있는지 확인하려면 먼저 다음을 실행하세요:
USE ROLE ACCOUNTADMIN;사전 요구사항
이 섹션을 따라 진행하려면 다음이 필요합니다:
ACCOUNTADMIN또는SYSADMIN권한이 있는 Snowflake 계정.- Snowflake UI(Snowsight)에 대한 기본 지식.
1단계: 데이터베이스 및 스키마 생성
Snowflake에서 데이터베이스는 모든 데이터 객체의 최상위 컨테이너입니다. 스키마는 데이터베이스 내부에 위치하며 관련 테이블, 스테이지 및 기타 객체를 그룹화합니다. Bright Data 전용 데이터베이스와 스키마를 생성하면 해당 객체가 기존 데이터와 분리되고 권한 관리가 더 쉬워집니다.
CREATE DATABASE IF NOT EXISTS bright_data_db;
CREATE SCHEMA IF NOT EXISTS bright_data_db.web_data;원하는 경우 기존 데이터베이스를 사용할 수 있습니다. 이후 명령에서 bright_data_db가 나타나는 곳마다 해당 이름으로 대체하세요.
2단계: 전용 웨어하우스 생성
Snowflake에서 웨어하우스는 COPY INTO를 포함한 SQL 문을 실행하는 컴퓨팅 클러스터입니다. 스토리지와 분리되어 있어 활성 실행 중에만 컴퓨팅 비용을 지불합니다. Bright Data 수집 전용 웨어하우스를 사용하면 해당 컴퓨팅 비용을 명확히 파악할 수 있고, 수집 워크로드가 분석 쿼리와 리소스 경쟁을 하지 않습니다.
CREATE WAREHOUSE IF NOT EXISTS bright_data_wh
WAREHOUSE_SIZE = 'XSMALL'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE;AUTO_SUSPEND = 60은 비활성 60초 후 웨어하우스를 종료하여 전송 사이에 유휴 상태로 실행되지 않도록 합니다. AUTO_RESUME = TRUE는 다음 COPY INTO가 실행될 때 자동으로 재시작합니다. XSmall은 대부분의 Bright Data 전송을 충분히 처리합니다. 볼륨이 증가하면 크기를 조정하세요.
3단계: 내부 명명된 스테이지 생성
Snowflake에서 스테이지는 파일이 테이블에 로드되기 전에 위치하는 명명된 위치입니다. 내부 명명된 스테이지는 Snowflake 자체 내부에 있습니다. S3 버킷이나 외부 클라우드 스토리지가 필요하지 않습니다.
이 스테이지는 Bright Data와 테이블 사이의 브릿지 역할을 합니다. Bright Data는 데이터를 테이블에 행 단위로 직접 로드하는 대신, 구조화된 파일(Parquet 또는 JSON)을 먼저 스테이지에 저장합니다. 그런 다음 Snowflake는 COPY INTO를 통해 해당 파일을 대량으로 읽어들이는데, 이는 행 단위 삽입보다 훨씬 빠르고 비용 효율적입니다. 또한 체크포인트를 제공합니다: 스테이지의 파일을 검사하고, 올바른지 확인한 후, 로드를 트리거할 시점을 선택할 수 있습니다.
CREATE STAGE IF NOT EXISTS bright_data_db.web_data.bright_data_stage
COMMENT = 'Landing zone for Bright Data dataset deliveries';4단계: 역할 생성 및 적절한 권한 부여
Snowflake에서 역할은 사용자에게 할당할 수 있는 권한 모음입니다. 사용자에게 직접 권한을 부여하는 대신, 역할에 권한을 부여하고 그 역할을 사용자에게 할당합니다. 이렇게 하면 사용자 계정 자체를 건드리지 않고도 나중에 액세스를 취소하거나 수정하기 쉽습니다.
이 역할은 Bright Data에게 필요한 정확한 액세스 권한만 부여하고 그 이상은 부여하지 않습니다.
CREATE ROLE IF NOT EXISTS bright_data_loader;
-- Allow the role to use the database and schema
GRANT USAGE ON DATABASE bright_data_db TO ROLE bright_data_loader;
GRANT USAGE ON SCHEMA bright_data_db.web_data TO ROLE bright_data_loader;
-- Allow the role to use and operate the warehouse
GRANT USAGE ON WAREHOUSE bright_data_wh TO ROLE bright_data_loader;
GRANT OPERATE ON WAREHOUSE bright_data_wh TO ROLE bright_data_loader;
-- Allow the role to write files into the stage
-- READ must be granted alongside WRITE; Snowflake requires it for COPY INTO ... FROM @stage
GRANT READ ON STAGE bright_data_db.web_data.bright_data_stage
TO ROLE bright_data_loader;
GRANT WRITE ON STAGE bright_data_db.web_data.bright_data_stage
TO ROLE bright_data_loader;각 부여 작업의 내용과 필요한 이유는 다음과 같습니다:
- 데이터베이스 및 스키마에 대한 USAGE: 역할이 내부 객체를 보고 탐색할 수 있도록 합니다. 이 권한이 없으면 역할이 스테이지에 직접 권한을 가지고 있어도 Snowflake는 “객체가 존재하지 않음” 오류를 반환합니다.
- 웨어하우스에 대한 USAGE: 역할이 웨어하우스에 대해 SQL 문을 실행할 수 있도록 합니다. 이것이
COPY INTO가 실제로 실행될 수 있게 하는 권한입니다. - 웨어하우스에 대한 OPERATE: 웨어하우스가 일시 중단된 경우 역할이 재개할 수 있도록 합니다. 이 권한이 없으면 Bright Data가 로드를 트리거할 때 자동 일시 중단된 웨어하우스가 재시작되지 않습니다.
- 스테이지에 대한 READ:
COPY INTO가 스테이지에서 파일을 읽어 테이블로 로드하는 데 필요합니다. - 스테이지에 대한 WRITE: Bright Data가 스테이지에 파일을 저장하는 데 필요합니다.
5단계: Bright Data 서비스 사용자 생성
서비스 사용자는 사람이 아닌 시스템이나 애플리케이션을 위해 생성된 Snowflake 계정입니다. 전용 서비스 사용자를 사용하면 Bright Data의 액세스가 모든 사람 사용자 계정과 분리되며, 다른 사람에게 영향을 주지 않고 자격 증명을 교체하거나 취소할 수 있습니다.
CREATE USER IF NOT EXISTS brightdata_svc
PASSWORD = 'YourStrongPasswordHere'
LOGIN_NAME = 'brightdata_svc'
DEFAULT_ROLE = bright_data_loader
DEFAULT_WAREHOUSE = bright_data_wh
DEFAULT_NAMESPACE = bright_data_db.web_data
MUST_CHANGE_PASSWORD = FALSE
DISABLED = FALSE
COMMENT = 'Service user for Bright Data dataset delivery';
GRANT ROLE bright_data_loader TO USER brightdata_svc;MUST_CHANGE_PASSWORD = FALSE는 첫 번째 로그인 시 비밀번호 재설정을 요청하지 않도록 하여 자동화된 연결이 중단되는 것을 방지합니다. DEFAULT_ROLE, DEFAULT_WAREHOUSE, DEFAULT_NAMESPACE는 세션이 어떻게 시작되든 서비스 사용자가 항상 올바른 컨텍스트로 연결되도록 합니다. 마지막 줄은 이 사용자에게 bright_data_loader 역할을 할당하여 4단계에서 정의된 정확한 권한을 부여합니다.
사용자 이름과 비밀번호를 안전하게 보관하세요. 다음 섹션에서 Bright Data 제어판에 붙여넣어야 합니다.
6단계: Bright Data의 IP 허용 목록 추가 (네트워크 정책을 사용하는 경우)
Snowflake 계정에 네트워크 정책이 적용되어 있는 경우, Bright Data의 전송 서버를 허용 목록에 추가해야 합니다. 아래 IP는 작성 시점에 현재 유효한 것들입니다. 정적 IP는 변경될 수 있으므로 적용하기 전에 Bright Data 지원팀이나 문서에서 최신 범위를 확인하세요:
ALTER NETWORK POLICY your_policy_name
SET ALLOWED_IP_LIST = (
-- paste your existing allowed IPs here,
'35.169.71.210',
'34.233.211.38',
'44.194.183.74',
'54.243.177.151'
);계정에 활성화된 네트워크 정책이 없는 경우 이 단계를 건너뛰세요.
7단계: 대상 테이블 생성
이 튜토리얼은 예시로 Goodreads 도서 데이터를 사용합니다. 아래 스키마는 Bright Data의 Goodreads Books 데이터셋이 JSON으로 전송하는 필드 이름에 직접 매핑됩니다:
CREATE TABLE IF NOT EXISTS bright_data_db.web_data.goodreads_books (
id VARCHAR, -- Goodreads book ID
name VARCHAR, -- book title
url VARCHAR,
author VARIANT, -- array: [{name, num_books, num_followers}]
star_rating FLOAT, -- average rating 1-5
num_ratings INT, -- total number of ratings
num_reviews VARCHAR, -- total reviews (may be formatted, e.g. "1,234")
summary VARCHAR, -- book description/blurb
genres VARIANT, -- array of genre strings
first_published VARCHAR, -- publication date as text
about_author VARIANT, -- object: {name, num_books, num_followers}
community_reviews VARIANT -- object: {5_stars, 4_stars, ...} with counts and percentages
);VARIANT는 Snowflake의 반정형 타입입니다. 배열과 중첩 객체를 그대로 저장하고 점 표기법과 괄호 구문(author[0]:name, community_reviews['5_stars']:reviews_num)을 사용하여 쿼리할 수 있습니다. 이렇게 하면 로드 시점에 복잡한 중첩 필드를 평탄화할 필요가 없습니다. 필요한 하위 필드를 파악한 후 뷰나 LATERAL FLATTEN으로 나중에 처리할 수 있습니다.
이해할 가치가 있는 몇 가지 필드 결정 사항:
- VARIANT로서의
author: 각 책에는 여러 저자가 있을 수 있습니다. 필드는 객체 배열로 도착합니다. VARIANT로 저장하면 별도의 조인 테이블 없이 모든 저자 데이터가 보존됩니다. - VARIANT로서의
genres: 장르도 배열입니다. 한 책이 여러 장르에 속할 수 있습니다. 장르별로 쿼리해야 할 때LATERAL FLATTEN(INPUT => genres)로 평탄화하세요. - VARCHAR로서의
num_reviews: Bright Data의 데이터 사전은 이 필드를 숫자가 아닌 텍스트로 표시하며, 형식화된 값으로 도착할 수 있습니다(예:1234대신"1,234"). 집계가 필요한 경우 쿼리 시점에TO_NUMBER(REPLACE(num_reviews, ',', ''))로 형변환하세요. - VARIANT로서의
community_reviews: 각 별점 수준별 평가 분포를 포함하며, 각각 개수와 백분율이 있습니다. VARIANT로 저장하고 필요에 따라 특정 별점 수준을 쿼리하세요.
참고: 마켓플레이스에서 다른 데이터셋(LinkedIn 기업, 채용 공고, Amazon 제품 등)을 선택하는 경우, 해당 필드 목록에 맞게 스키마를 조정하세요. Bright Data는 제어판의 데이터셋 페이지에서 모든 데이터셋에 대한 전체 필드 참조를 제공합니다.
훌륭합니다! 이제 Snowflake 환경이 Bright Data로부터 데이터를 수신할 준비가 되었습니다.
Snowflake로 전송하도록 Bright Data 구성하기
Snowflake 측이 준비되었으니, Bright Data가 데이터를 푸시하도록 구성해 봅시다.
사전 요구사항
이 섹션을 따라 진행하려면 다음이 필요합니다:
- 활성 구독 또는 체험판이 있는 Bright Data 계정.
- 이전 섹션의 Snowflake 연결 세부 정보: 계정 식별자, 사용자 이름, 비밀번호, 데이터베이스, 스키마, 스테이지, 웨어하우스 이름.
1단계: 데이터셋 선택
Bright Data 계정에 로그인하고 웹 데이터셋 > 데이터셋 마켓플레이스로 이동합니다. Goodreads를 검색하고 결과에서 Goodreads Books 데이터셋을 선택합니다.
데이터셋 페이지에서 왼쪽 패널의 필드 목록을 검토합니다. 모든 필드가 7단계에서 생성한 테이블의 열에 직접 매핑되는 것을 확인할 수 있습니다. 이는 첫 번째 행이 도착하기 전에 스키마가 올바른지 확인해 줍니다.
2단계: Snowflake를 전송 대상으로 구성
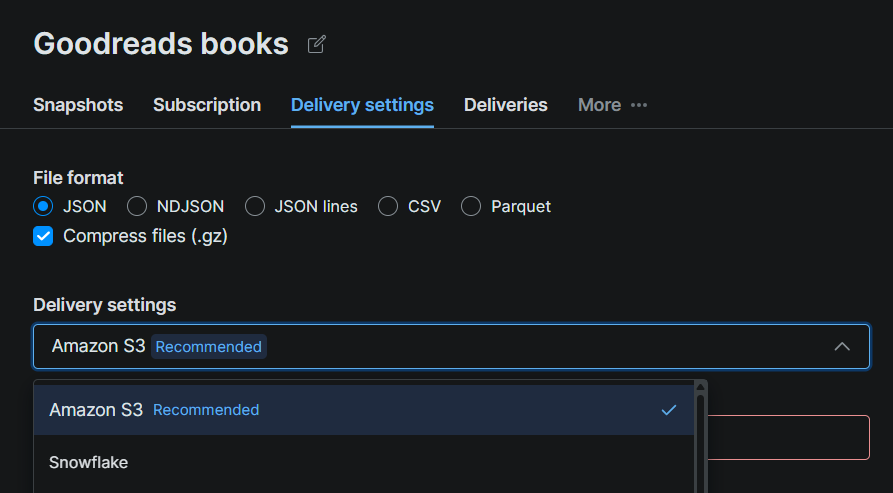
데이터셋 페이지에서 전송 설정 탭을 클릭하고 대상으로 Snowflake를 선택합니다. Snowflake 설정의 세부 정보로 연결 양식을 작성합니다:
| 필드 | 값 |
|---|---|
| 계정 식별자 | Snowflake 계정 URL (예: xy12345.us-east-1) |
| 데이터베이스 | bright_data_db |
| 스키마 | web_data |
| 스테이지 | bright_data_stage |
| 웨어하우스 | bright_data_wh |
| 역할 | bright_data_loader |
| 사용자 | brightdata_svc |
| 비밀번호 | 5단계에서 설정한 비밀번호 |
연결 양식 아래의 세 필드는 선택 사항이며, 이 튜토리얼에서는 기본값으로 두어도 됩니다:
- 데이터셋 파일 이름: Bright Data가 스테이지하는 파일의 사용자 정의 접두사. 기본 이름 지정을 사용하려면 비워 두세요.
- 배치 크기 (레코드 수): Bright Data가 각 스테이지된 파일에 패킹하는 레코드 수. 기본값은 대부분의 워크로드에 적합합니다.
- 배치를 하나의 파일로 그룹화 (.tar): 스테이지하기 전에 모든 배치를 단일 아카이브로 결합합니다. 파이프라인이 전송당 단일 파일을 특별히 필요로 하지 않는 한 체크 해제로 두세요.
Snowflake 테스트를 클릭합니다. 녹색 확인 표시는 Bright Data가 인증하고 스테이지에 쓸 수 있음을 의미합니다. 테스트가 통과되면 저장을 클릭합니다.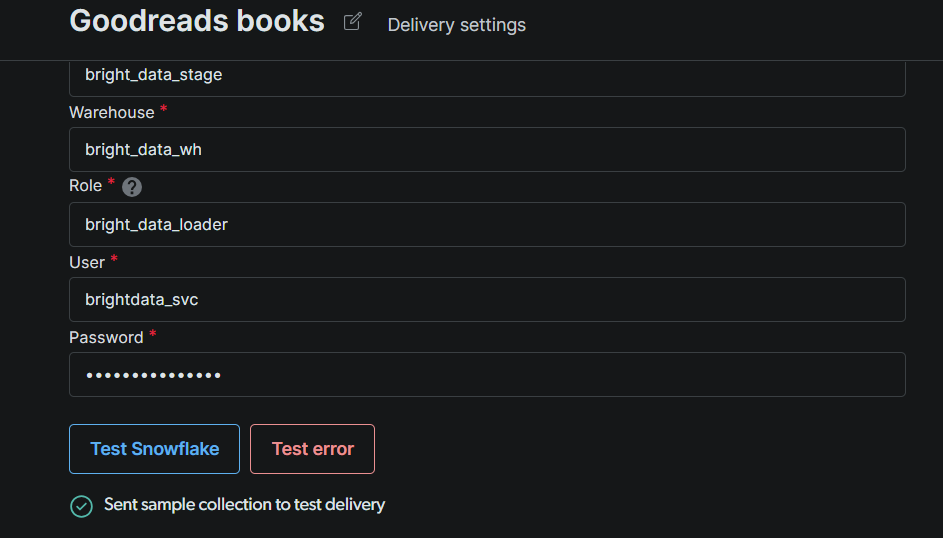
참고: 테스트가 실패하면 순서대로 세 가지를 확인하세요: (1) 계정 식별자 형식 (Snowflake는 orgname-accountname 또는 레거시 accountid.region.cloud 형식을 기대합니다); (2) 서비스 사용자가 역할 할당을 포함하여 4단계의 모든 부여 권한을 갖고 있는지; (3) 계정에 네트워크 정책이 활성화된 경우 Bright Data의 IP가 허용 목록에 있는지.
3단계: 스냅샷 요청
데이터셋 페이지에서 전송 탭을 클릭합니다. 그런 다음 오른쪽 상단 모서리의 전송 추가 +를 클릭합니다. 이렇게 하면 대상(Snowflake)을 선택하고, 전송할 스냅샷이나 날짜 범위를 선택하고, 확인하는 전송 구성 패널이 열립니다.
제출되면 전송이 스냅샷 ID, 상태, 대상, 파일 이름, 파일 유형 열이 있는 테이블에 나타납니다. Bright Data가 파일을 스테이지로 푸시하는 것을 완료하면 상태가 대기 중에서 완료로 변경됩니다.
프로그래밍 방식으로 전송을 트리거하려면, 마켓플레이스 데이터셋 API는 두 단계 흐름을 사용합니다: 먼저 필터 API를 호출하여 필터링된 스냅샷을 생성한 다음, 스냅샷 전송을 호출하여 Snowflake 스테이지로 푸시합니다.
1단계: 필터링된 스냅샷 생성:
curl --request POST
--url "https://api.brightdata.com/datasets/filter"
--header "Authorization: Bearer YOUR_API_TOKEN"
--header "Content-Type: application/json"
--data '{
"dataset_id": "YOUR_DATASET_ID",
"filter": {
"operator": "and",
"filters": [
{"name": "star_rating", "operator": ">", "value": "4"},
{"name": "num_ratings", "operator": ">", "value": "1000"}
]
}
}'응답에는 snapshot_id가 포함됩니다. 다음 호출에 전달하세요.
2단계: Snowflake 스테이지로 스냅샷 전송:
curl --request POST
--url "https://api.brightdata.com/datasets/snapshots/YOUR_SNAPSHOT_ID/deliver"
--header "Authorization: Bearer YOUR_API_TOKEN"
--header "Content-Type: application/json"
--data '{
"destination": "snowflake"
}'Bright Data는 기본적으로 데이터셋에 구성된 형식을 사용합니다. 명시적으로 지정하려면 요청 본문에 "format": "parquet" 또는 "format": "ndjson"을 추가하세요. 스테이지에 도착하는 형식이 COPY INTO의 FILE_FORMAT에 전달하는 형식입니다.
전송 상태를 확인하려면 GET /datasets/snapshots/YOUR_SNAPSHOT_ID를 폴링하거나, 제어판의 전송 탭에서 모니터링하세요. 상태 열에 완료가 표시되면 파일이 스테이지에 있고 로드할 준비가 된 것입니다. 훌륭합니다!
전송이 완료되면 제어판의 스냅샷 페이지 링크가 포함된 이메일도 받게 됩니다. 거기서 처음 30개의 레코드를 미리 보고, 총 레코드 수를 확인하고, 비용 요약 보고서를 다운로드할 수 있습니다. 1,000개 레코드당 $2.50의 가격으로, 보고서는 도착한 레코드 수와 비용을 정확히 보여줍니다. 훌륭합니다!
Snowflake에 데이터 로드하기
Bright Data의 작업은 파일이 내부 스테이지에 도착하면 끝납니다. 파일을 테이블에 로드하는 것은 사용자의 책임이며, SQL 명령 하나로 처리됩니다. 이 분리는 이해할 가치가 있습니다: 로드 실행 시점, 적용되는 오류 처리, 테이블 새로 고침 빈도를 사용자가 제어한다는 의미입니다.
사전 요구사항
이 섹션을 따라 진행하려면 다음이 필요합니다:
- 위의 Snowflake 설정 및 Bright Data 구성 섹션을 완료했을 것.
- 스냅샷 전송이 완료되었음을 확인했을 것 (이메일 또는 Bright Data 제어판의 스냅샷 페이지를 통해).
1단계: 스테이지에 파일이 도착했는지 확인
다른 작업 전에 먼저 이것을 실행하세요:
LIST @bright_data_db.web_data.bright_data_stage;크기와 타임스탬프와 함께 하나 이상의 파일이 나열되어야 합니다. 스테이지가 비어 있으면 스냅샷 전송이 아직 완료되지 않은 것입니다. Bright Data 제어판의 스냅샷 페이지에서 상태를 확인하세요.
결과에서 파일 확장자를 확인하세요. Bright Data가 전송에 사용하는 형식에 따라 다음 단계의 COPY INTO에 전달하는 FILE_FORMAT이 결정됩니다. UI로 트리거된 스냅샷의 경우, 전송 구성 시 별도로 지정하지 않으면 Bright Data는 일반적으로 NDJSON으로 전송합니다. deliver-snapshot 엔드포인트를 사용하는 API로 트리거된 스냅샷의 경우, 형식은 요청 본문에 전달한 것입니다. .parquet 파일이 보이면 TYPE = 'PARQUET'을 사용하세요. .json 또는 .ndjson 파일이 보이면 TYPE = 'JSON'을 사용하세요.
2단계: 파일을 테이블에 로드
Parquet 파일의 경우:
COPY INTO bright_data_db.web_data.goodreads_books
FROM @bright_data_db.web_data.bright_data_stage
FILE_FORMAT = (TYPE = 'PARQUET')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE
ON_ERROR = 'CONTINUE';JSON 또는 NDJSON 파일의 경우:
COPY INTO bright_data_db.web_data.goodreads_books (
id, name, url, author, star_rating, num_ratings,
num_reviews, summary, genres, first_published,
about_author, community_reviews
)
FROM (
SELECT
$1:id::VARCHAR,
$1:name::VARCHAR,
$1:url::VARCHAR,
$1:author::VARIANT,
$1:star_rating::FLOAT,
$1:num_ratings::INT,
$1:num_reviews::VARCHAR,
$1:summary::VARCHAR,
$1:genres::VARIANT,
$1:first_published::VARCHAR,
$1:about_author::VARIANT,
$1:community_reviews::VARIANT
FROM @bright_data_db.web_data.bright_data_stage
)
FILE_FORMAT = (TYPE = 'JSON' STRIP_OUTER_ARRAY = TRUE)
ON_ERROR = 'CONTINUE';MATCH_BY_COLUMN_NAME(Parquet 전용)은 순서에 관계없이 열 이름을 자동으로 매핑합니다. ON_ERROR = CONTINUE는 전체 로드를 중단하는 대신 잘못된 형식의 행을 건너뜁니다.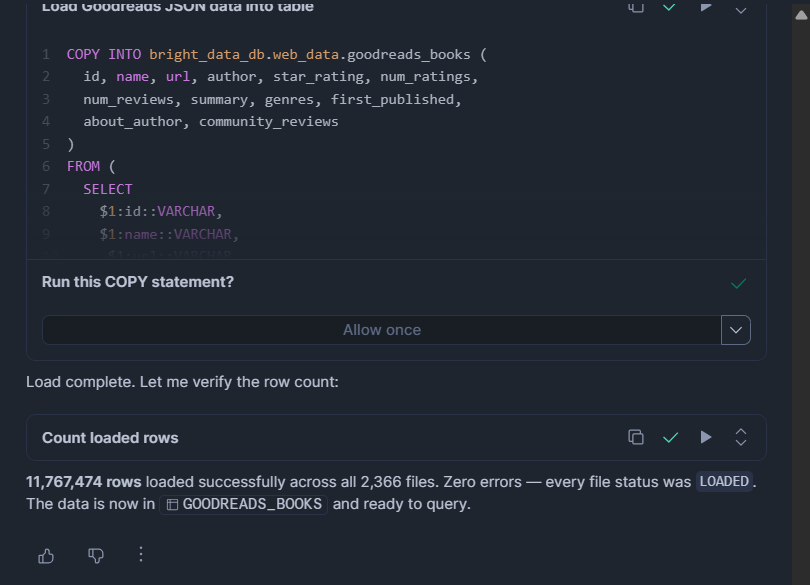
3단계: 로드 확인
-- Count the loaded rows
SELECT COUNT(*) FROM bright_data_db.web_data.goodreads_books;
-- Check for skipped rows or errors in the last hour
SELECT *
FROM TABLE(BRIGHT_DATA_DB.INFORMATION_SCHEMA.COPY_HISTORY(
TABLE_NAME => 'BRIGHT_DATA_DB.WEB_DATA.GOODREADS_BOOKS',
START_TIME => DATEADD(HOURS, -1, CURRENT_TIMESTAMP())
));COPY_HISTORY는 로드된 행, 건너뛴 행, 처리된 파일 이름, 그리고 실패한 행에 대한 정확한 오류 메시지를 보여줍니다. 특히 처음 로드할 때는 매번 로드 후 이것을 검토하세요.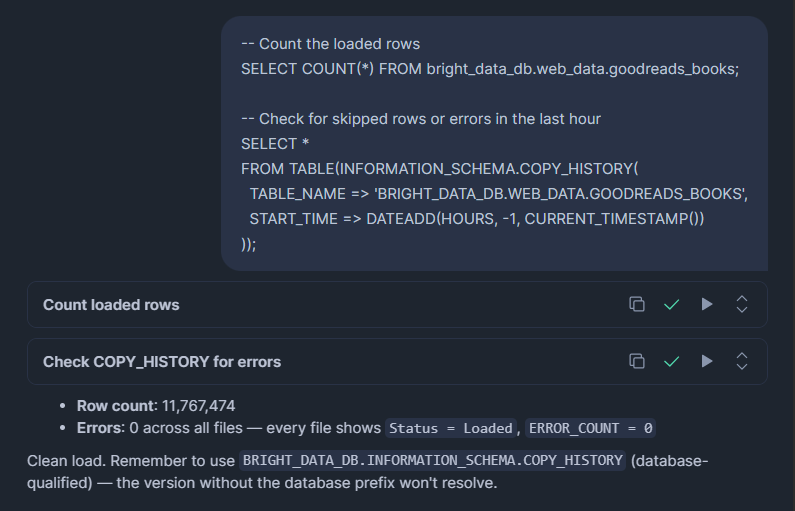
데이터 쿼리하기
Snowflake에 Goodreads 도서 데이터가 있으면, 수백만 개의 도서 제목에 걸쳐 독서 트렌드, 저자 성과, 장르 인기도를 대규모로 이해하는 것이 가치 있습니다. 아래 쿼리는 이러한 사용 사례를 직접 반영합니다.
원시 데이터 검사
분석 쿼리를 작성하기 전에 데이터가 예상대로 보이는지 확인하세요:
SELECT id, name, url, star_rating, num_ratings, first_published
FROM bright_data_db.web_data.goodreads_books
LIMIT 10;결과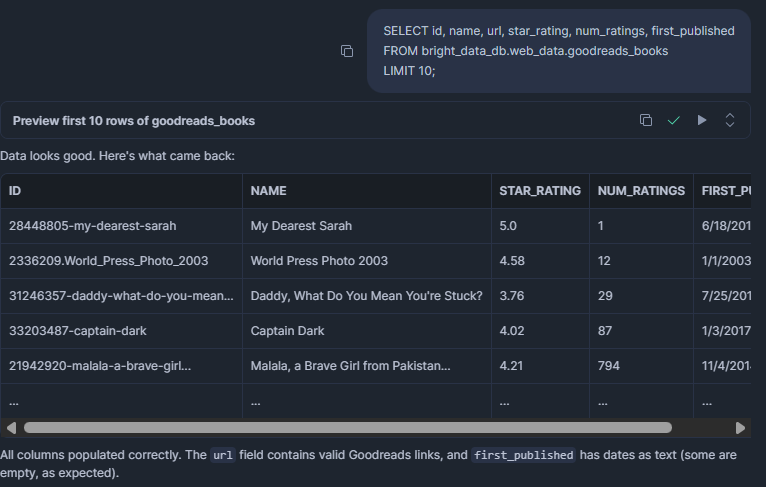
독자 검증이 가장 강한 책은?
높은 star_rating만으로는 충분하지 않습니다. 12명으로부터 4.8점을 받은 책은 거의 아무것도 알려주지 않습니다. 이 쿼리는 높은 평점과 많은 독자를 모두 갖춘 책을 보여주는데, 이것이 책의 진정한 지속력을 나타내는 조합입니다.
SELECT
name,
author[0]:name::VARCHAR AS primary_author,
star_rating,
num_ratings,
first_published
FROM bright_data_db.web_data.goodreads_books
WHERE num_ratings > 10000
AND star_rating >= 4.5
ORDER BY num_ratings DESC
LIMIT 20;결과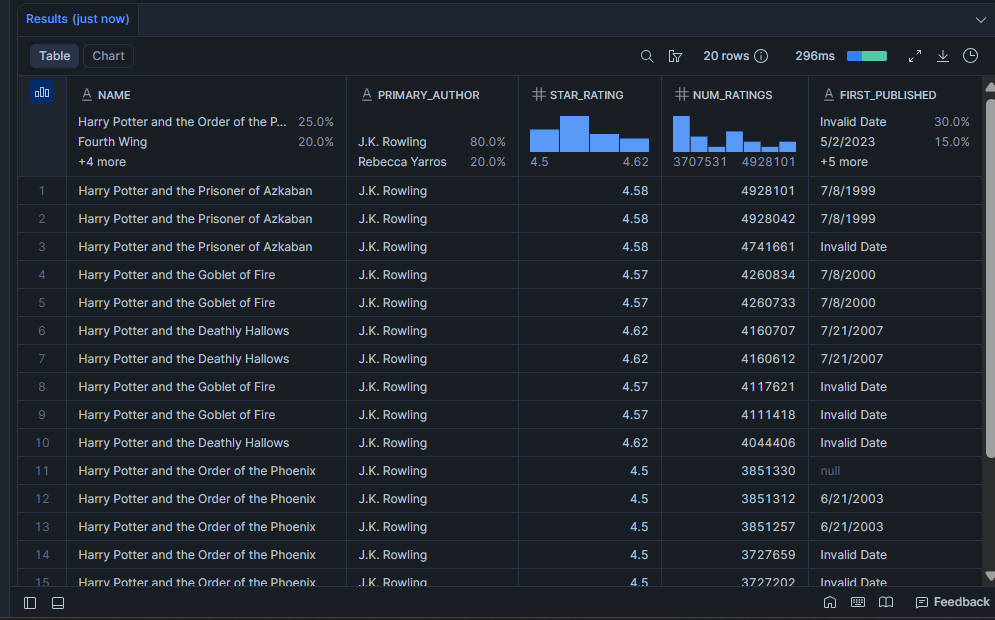
가장 많은 도서와 가장 높은 평균 평점을 가진 장르는?
독자 수요가 집중된 곳을 이해하는 데 유용합니다. 도서 수는 많지만 평균 평점이 낮은 장르는 저품질 항목으로 넘쳐날 수 있으며, 이는 출판사나 추천 엔진에게 기회가 될 수 있습니다.
SELECT
g.value::VARCHAR AS genre,
COUNT(*) AS book_count,
ROUND(AVG(star_rating), 2) AS avg_rating,
SUM(num_ratings) AS total_ratings
FROM bright_data_db.web_data.goodreads_books,
LATERAL FLATTEN(INPUT => genres) g
WHERE g.value IS NOT NULL
GROUP BY genre
ORDER BY total_ratings DESC
LIMIT 15;결과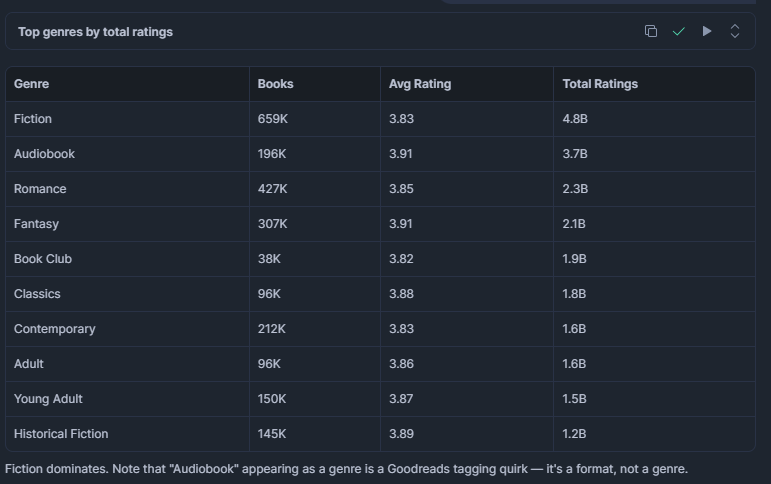
데이터셋에서 팔로워가 가장 많은 저자는?
저자 팔로워 수는 플랫폼 청중의 대리 지표입니다. 평균 도서 평점과 함께 보면 팔로워가 가장 많은 저자가 가장 존경받는지, 아니면 팔로워 수와 품질이 다른지 알 수 있습니다.
about_author는 각 도서 레코드의 평면 객체로, 배열 인덱싱 없이 간단하게 쿼리할 수 있습니다. 이것은 특정 도서 페이지에 설명된 저자를 반영하므로, 크레딧된 저자 배열인 author와 약간 다를 수 있습니다.
SELECT
about_author:name::VARCHAR AS author_name,
about_author:num_books::INT AS books_published,
about_author:num_followers::VARCHAR AS followers,
ROUND(AVG(star_rating), 2) AS avg_book_rating,
SUM(num_ratings) AS total_ratings_received
FROM bright_data_db.web_data.goodreads_books
WHERE about_author:name IS NOT NULL
GROUP BY author_name, books_published, followers
ORDER BY followers DESC NULLS LAST
LIMIT 20;결과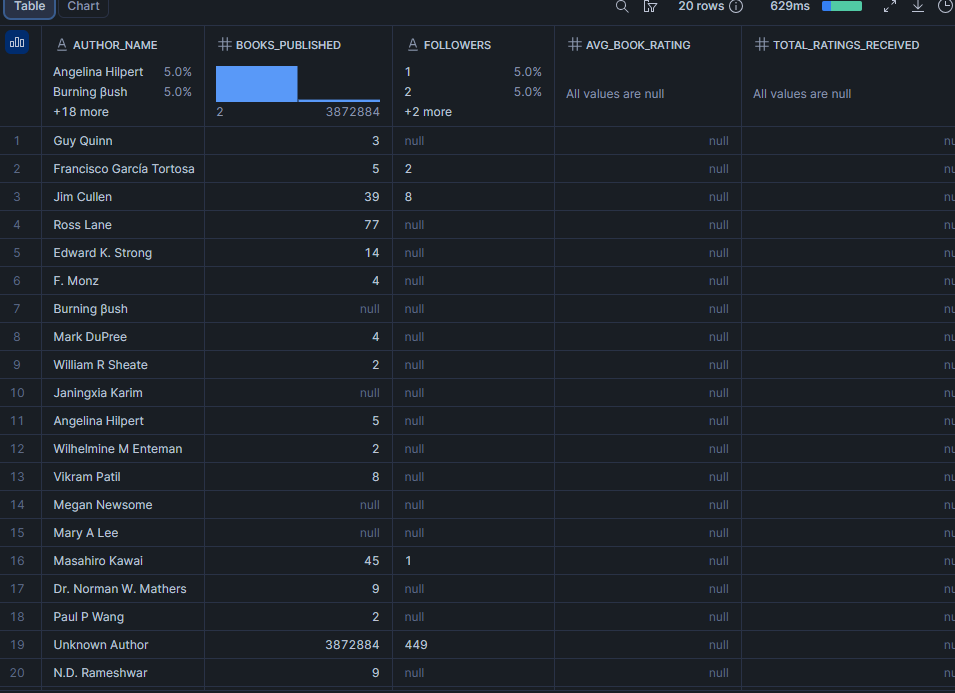
참고: 소스 필드가 VARCHAR이기 때문에 followers는 텍스트로 정렬됩니다(예: "12.3k"와 같은 형식화된 값이 포함될 수 있음). 데이터셋이 정수를 전송하는 경우, TO_NUMBER(followers)로 형변환하고 숫자로 정렬하세요.
책이 얼마나 양극화되어 있나요? 커뮤니티 리뷰에서 별점 분포 추출
평균 평점이 높지만 1점 리뷰 비율이 큰 책은 보편적으로 사랑받기보다 논란이 있을 수 있습니다. 이 쿼리는 특정 책의 평점 분포를 가져옵니다.
SELECT
name,
star_rating,
num_reviews,
community_reviews['5_stars']:reviews_num::INT AS five_star_count,
community_reviews['4_stars']:reviews_num::INT AS four_star_count,
community_reviews['3_stars']:reviews_num::INT AS three_star_count,
community_reviews['2_stars']:reviews_num::INT AS two_star_count,
community_reviews['1_stars']:reviews_num::INT AS one_star_count,
community_reviews['1_stars']:reviews_percentage::FLOAT AS one_star_pct
FROM bright_data_db.web_data.goodreads_books
WHERE id = 'YOUR_BOOK_ID'; -- substitute the Goodreads book IDnum_reviews는 별점 분포와 함께 총 작성된 리뷰 수를 제공하며, 긴 서면 의견을 끌어들이는 책과 조용한 별점 평가를 수집하는 책을 구별하는 데 유용합니다.
짜잔! 이제 Bright Data에서 구조화된 웹 데이터를 가져와 Snowflake에서 쿼리 가능하게 만드는 작동하는 파이프라인이 완성되었습니다.
새로 고침 자동화
프로덕션 사용을 위해서는 매번 수동으로 COPY INTO를 실행하는 대신 새 스냅샷이 자동으로 로드되기를 원할 것입니다. 옵션 A부터 시작하세요. 전송 완료 후 몇 초 이내에 테이블이 업데이트되어야 하는 경우에만 옵션 B로 이동하세요.
옵션 A: 일정 기반 수집을 위한 Snowflake Task
Snowflake Task는 cron 일정으로 COPY INTO를 실행하며 추가 인프라가 필요하지 않습니다. Task가 실행될 때 파일이 스테이지에 준비되도록 Bright Data에서 일치하는 전송 일정을 설정하세요.
CREATE TASK IF NOT EXISTS bright_data_db.web_data.load_goodreads_task
WAREHOUSE = bright_data_wh
SCHEDULE = 'USING CRON 0 6 * * * UTC'
AS
COPY INTO bright_data_db.web_data.goodreads_books
FROM @bright_data_db.web_data.bright_data_stage
FILE_FORMAT = (TYPE = 'PARQUET')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE
ON_ERROR = 'CONTINUE';
ALTER TASK bright_data_db.web_data.load_goodreads_task RESUME;프로 팁: 첫 번째 자동 실행 시, Task가 실행된 후 COPY_HISTORY를 확인하여 일정 타이밍이 Bright Data가 전송을 완료하는 시점과 일치하는지 확인하세요. 전송이 완료되기 전에 실행되는 Task는 빈 스테이지를 발견하고 0개의 행을 로드합니다.
옵션 B: 낮은 지연 이벤트 기반 수집을 위한 Snowpipe REST API
Snowpipe는 insertFiles REST 엔드포인트를 통해 프로그래밍 방식으로 트리거되어 파일이 도착하는 즉시 스테이지에서 로드합니다. 사용 사례가 거의 실시간 최신성을 필요로 하는 경우에만 사용하세요. 옵션 A에 비해 상당한 설정 복잡성이 추가됩니다.
설정은 두 부분으로 구성됩니다. 먼저 파이프를 생성합니다:
CREATE PIPE IF NOT EXISTS bright_data_db.web_data.goodreads_pipe
AS
COPY INTO bright_data_db.web_data.goodreads_books
FROM @bright_data_db.web_data.bright_data_stage
FILE_FORMAT = (TYPE = 'PARQUET')
MATCH_BY_COLUMN_NAME = CASE_INSENSITIVE;AUTO_INGEST = TRUE가 없는 것에 주목하세요. 내부 명명된 스테이지의 경우, 클라우드 메시징을 통한 자동 수집은 AWS 호스팅 Snowflake 계정에서만 사용 가능하며 현재 미리 보기 기능입니다. REST API 방식은 모든 클라우드 플랫폼에서 작동합니다.
두 번째로, 스냅샷이 준비될 때 스테이지된 파일을 나열하고 Snowpipe에 제출하도록 웹훅 핸들러를 연결합니다:
import snowflake.connector
from snowflake.ingest import SimpleIngestManager, StagedFile
SNOWFLAKE_ACCOUNT = "your-account-identifier"
SNOWFLAKE_USER = "brightdata_svc"
SNOWFLAKE_PASSWORD = "YourStrongPasswordHere"
PIPE_NAME = "bright_data_db.web_data.goodreads_pipe"
STAGE_NAME = "bright_data_db.web_data.bright_data_stage"
def handle_brightdata_webhook(snapshot_id: str):
# Step 1: list files that arrived in the stage
conn = snowflake.connector.connect(
account=SNOWFLAKE_ACCOUNT,
user=SNOWFLAKE_USER,
password=SNOWFLAKE_PASSWORD,
)
cursor = conn.cursor()
cursor.execute(f"LIST @{STAGE_NAME}")
staged_files = [StagedFile(row[0], None) for row in cursor.fetchall()]
cursor.close()
conn.close()
if not staged_files:
print(f"No files found in stage for snapshot {snapshot_id}")
return
# Step 2: tell Snowpipe to load them
ingest_manager = SimpleIngestManager(
account=SNOWFLAKE_ACCOUNT,
host=f"{SNOWFLAKE_ACCOUNT}.snowflakecomputing.com",
user=SNOWFLAKE_USER,
pipe=PIPE_NAME,
private_key=open("rsa_key.p8", "rb").read(), # Snowpipe REST requires key-pair auth
)
response = ingest_manager.ingest_files(staged_files)
print(f"Snowpipe response: {response}")참고: Snowpipe REST API는 비밀번호 인증이 아닌 키 쌍 인증이 필요합니다. RSA 키 쌍을 생성하고, Snowflake에서 brightdata_svc에 공개 키를 할당한 후(ALTER USER brightdata_svc SET RSA_PUBLIC_KEY='...'), 위에 개인 키 파일 경로를 전달하세요. pip install snowflake-ingest로 SDK를 설치하세요.
결론
이 글에서는 Bright Data에서 Snowflake로의 완전한 웹 데이터 수집 파이프라인을 구축하는 방법을 배웠습니다. 워크플로는 다음과 같습니다:
- Bright Data가 직접 인증하는 전용 데이터베이스, 스테이지, 역할, 서비스 사용자로 Snowflake를 준비합니다.
- 중간 스토리지 없이 Snowflake를 전송 대상으로 하는 Bright Data 데이터셋을 구성합니다.
- 제어판의 전송 탭 또는 데이터셋 API를 통해 스냅샷을 트리거하고, 파일이 스테이지에 도착할 때까지 전송 상태를 모니터링합니다.
- 단일
COPY INTO명령으로 스테이지된 파일을 구조화된 Snowflake 테이블에 로드하고 표준 SQL로 데이터를 쿼리합니다.
동일한 설정이 Bright Data 마켓플레이스의 모든 데이터셋에 적용됩니다: Amazon 제품, LinkedIn 기업, 채용 공고, 호텔 리스팅, Crunchbase 레코드 등. 각각은 동일한 전송 패턴을 따르며, 테이블 스키마만 변경됩니다.
오늘 무료 Bright Data 계정을 만들고 Snowflake 환경에 실시간 웹 데이터를 가져오기 시작하세요!





