

웹 스크래핑은 웹 페이지에서 데이터를 추출하는 과정입니다. 데이터는 다양한 형태를 취할 수 있으므로, 텍스트 스크래핑이라는 용어는 특히 텍스트 데이터 수집을 지칭할 때 사용됩니다.
성공적인 비즈니스 의사결정을 위해서는 방대한 양의 관련 데이터 확보가 필수적입니다. 경쟁사 웹사이트에서 정보를 스크래핑하면 그들의 비즈니스 로직을 파악할 수 있어 경쟁 우위를 점하는 데 도움이 됩니다. 이 튜토리얼에서는 Python으로 텍스트 스크래퍼를 구현하는 방법을 배워 웹 데이터를 쉽게 추출하고 활용할 수 있게 됩니다.
필수 조건
이 튜토리얼을 시작하기 전에 다음 준비 사항이 필요합니다:
- pip
- 가상 환경
파이썬으로 웹 스크래핑을 시작하는 데 도움이 되는 추가 정보를 원하시면 이 글을 참고하세요.
웹사이트 구조 이해
스크래핑을 시작하기 전에, 대상 웹사이트의 구조를 분석해야 합니다. 웹사이트는 콘텐츠의 구성과 표시 방식을 정의하는 마크업 언어인 HTML을 사용하여 구축됩니다.
헤드라인, 단락, 링크 등 각 콘텐츠는 HTML 태그로 둘러싸여 있습니다. 이러한 태그를 통해 스크래핑할 데이터의 위치를 파악할 수 있습니다. 예를 들어, 이 예제에서는 모의 웹사이트인 ‘Quotes to Scrape’에서 명언을 스크래핑합니다. 이 웹사이트의 구조를 확인하려면 브라우저에서 웹사이트를 열고, 페이지에서 마우스 오른쪽 버튼을 클릭한 후 ‘검사’ 또는 ‘요소 검사’를 선택하여 개발자 도구를 실행해야 합니다. 그러면 페이지의 HTML 코드가 표시됩니다:
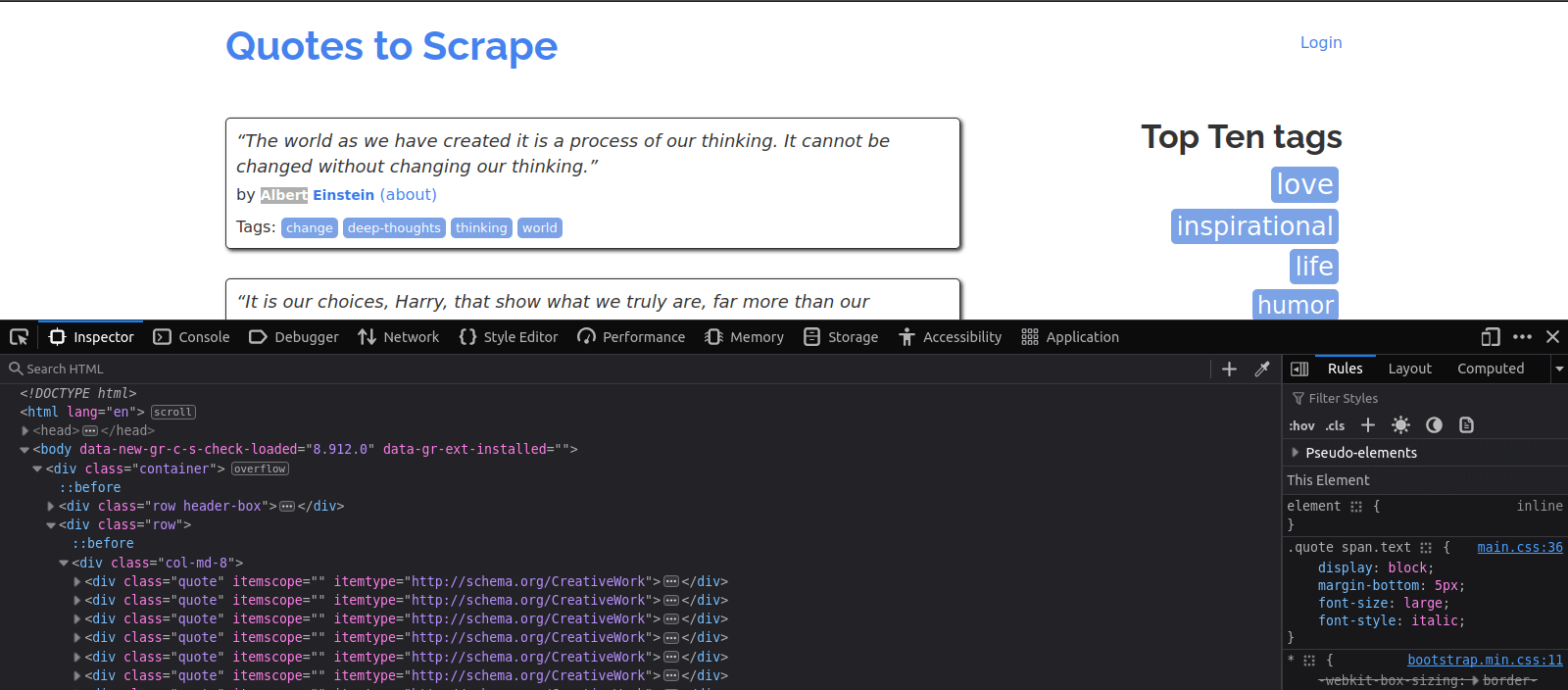
시간을 내어 구조를 익히세요. <div>, <span>, <p>, <a> 와 같은 태그를 찾아보세요. 이러한 태그에는 추출하고자 하는 텍스트나 링크가 포함되어 있는 경우가 많습니다. 또한 태그에는 일반적으로 class 속성이 포함되어 있음을 유의하세요. 이 속성은 HTML 요소에 특정 클래스를 정의하여 CSS로 스타일을 지정하거나 JavaScript로 선택할 수 있게 하는 역할을 합니다.
참고:
클래스속성은 텍스트 스크래핑에서 특히 유용합니다. 동일한 스타일이나 구조를 공유하는 페이지의 특정 요소를 타겟팅하는 데 도움이 되어 필요한 정확한 데이터를 추출하기 쉽게 만듭니다.
여기서 각 인용문은 class= "quote" 속성을 가진 div 요소에 포함되어 있습니다. 각 인용문의 텍스트와 저자에 관심이 있다면, 텍스트는 class= "text” 속성을 가진 div 안에, 저자는 class=” author” 속성을 가진 small 요소 안에 포함되어 있습니다:
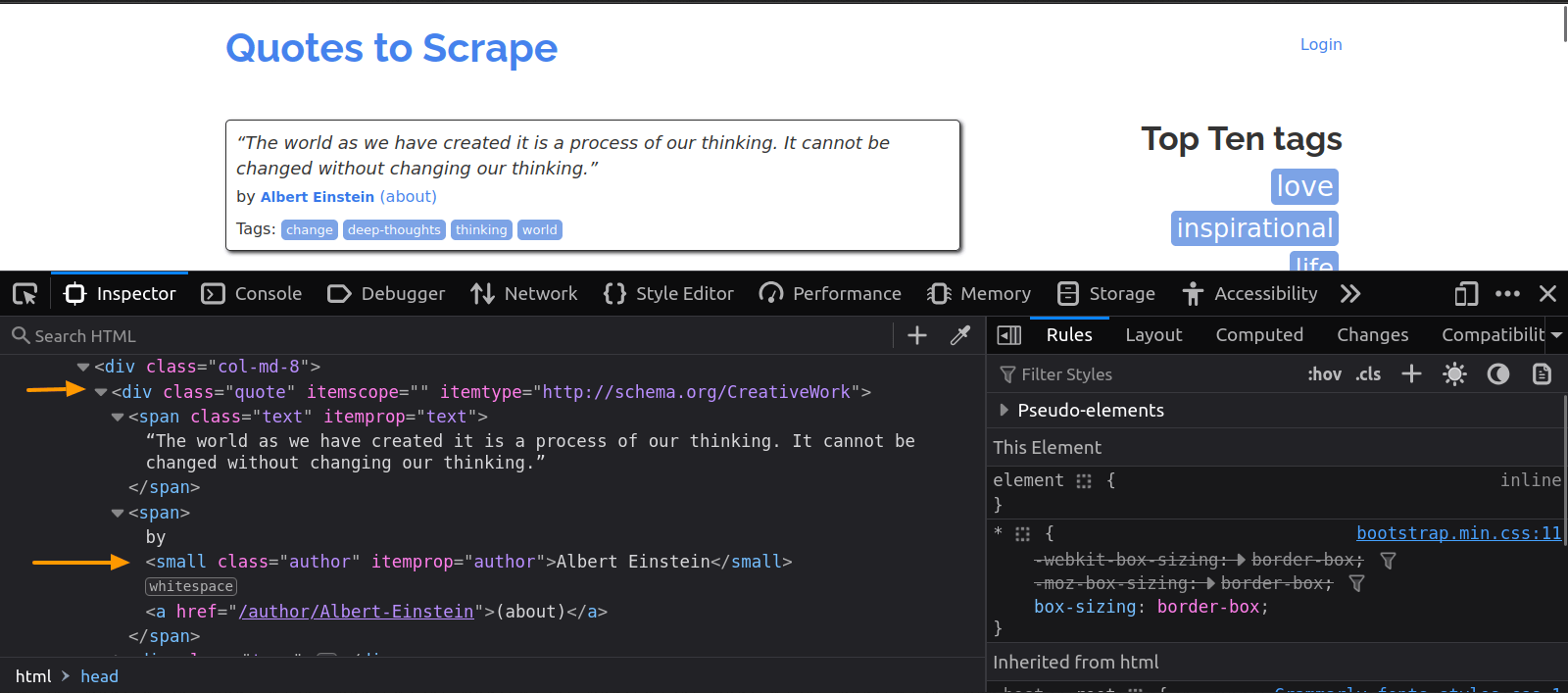
HTML 작동 방식에 익숙하지 않다면, HTML 웹 스크래핑 관련 글을 참고하여 자세히 알아보세요.
웹사이트 텍스트 스크래핑
웹사이트 구조를 파악한 후, 다음 단계는 Quotes to Scrape 사이트를 스크래핑할 코드를 작성하는 것입니다.
이 작업에는 사용 편의성과 requests, BeautifulSoup 같은 강력한 라이브러리 덕분에 파이썬이 널리 사용됩니다. requests 라이브러리를 사용해 페이지의 HTML 콘텐츠를 가져옵니다. 분석이나 추출 전에 원시 데이터를 가져와야 하므로 이 과정이 필수적입니다. HTML 콘텐츠를 확보한 후에는 BeautifulSoup을 활용해 더 관리하기 쉬운 구조로 분해할 수 있습니다.
시작하려면 텍스트 스크래핑 스크립트용 Python 파일( text-scraper.py)을 생성하세요. 그런 다음 BeautifulSoup과 requests를 임포트합니다:
import requests
from bs4 import BeautifulSoup
스크래핑할 웹사이트의 URL을 지정하고 GET 요청을 전송합니다:
# 명언 사이트의 URL
url = 'https://quotes.toscrape.com/'
# URL로 GET 요청 전송
response = requests.get(url)
GET 요청을 보낸 후 전체 페이지의 HTML을 받게 됩니다. 필요한 데이터(이 경우 각 명언의 텍스트와 저자)만 추출하려면 이를 파싱해야 합니다. 이를 위해 먼저 HTML을 파싱할 BeautifulSoup 객체를 생성해야 합니다:
soup = BeautifulSoup(response.text, 'html.parser')
인용문을 포함하는 모든 div 요소(즉, quote 클래스)를 찾습니다:
quotes = soup.find_all('div', class_='quote')
인용문을 저장할 리스트 생성:
data = []
각 인용문에서 텍스트와 저자를 추출하여 data 리스트에 저장합니다:
for quote in quotes:
text = quote.find('span', class_='text').text.strip()
author = quote.find('small', class_='author').text.strip()
data.append({
'Text': text,
'Author': author
})
스크립트는 다음과 같아야 합니다:
import requests
from bs4 import BeautifulSoup
# 명언 사이트 URL
url = 'http://quotes.toscrape.com/'
# URL로 GET 요청 전송
response = requests.get(url)
# HTML을 파싱할 BeautifulSoup 객체 생성
soup = BeautifulSoup(response.text, 'html.parser')
# 모든 명언 컨테이너 찾기
quotes = soup.find_all('div', class_='quote')
# 각 명언에서 데이터 추출
data = []
for quote in quotes:
text = quote.find('span', class_='text').text.strip()
author = quote.find('small', class_='author').text.strip()
data.append({
'Text': text,
'Author': author
})
print(data)
이제 터미널에서 스크립트를 실행할 차례입니다:
# Linux 및 macOS용
python3 text-scraper.py
# Windows용
python text-scraper.py
추출된 인용문 목록이 출력됩니다:
[{'Author': 'Albert Einstein',
'Text': '"우리가 창조한 세상은 우리의 사고 과정이다. 우리의 사고를 바꾸지 않고서는 '
'세상을 바꿀 수 없다."'},
{'Author': 'J.K. Rowling',
'Text': '"해리, 우리의 진정한 모습을 드러내는 것은 우리의 능력보다 훨씬 더 '
'우리의 선택이다."'},
{'Author': 'Albert Einstein',
'Text': '"인생을 사는 방법은 단 두 가지뿐이다. 하나는 아무것도 '
'기적이 아닌 것처럼 사는 것이고 다른 하나는 모든 것이 기적인 것처럼 사는 것이다."'},
{'Author': 'Jane Austen',
'Text': '"신사든 숙녀든, 좋은 소설에서 즐거움을 느끼지 못하는 사람은 참을 수 없을 만큼 어리석은 사람이다."'},
{'Author': 'Marilyn Monroe',
'Text': ""불완전함이 아름다움이고, 광기가 천재성이다. 차라리 '
'완전히 우스꽝스러운 사람이 되는 게 완전히 지루한 사람보다 낫다.''},
{'Author': 'Albert Einstein',
'Text': '"성공한 사람이 되려 하지 마라. 차라리 가치 있는 사람이 되라."'},
{'Author': 'André Gide',
'Text': '"'당신이 아닌 모습으로 사랑받는 것보다, 있는 그대로 미움받는 것이 낫다.'"},
{'Author': 'Thomas A. Edison',
'Text': ""나는 실패한 것이 아니다. 단지 10,000가지 안 되는 방법을 발견했을 뿐이다.""},
{'Author': 'Eleanor Roosevelt',
'Text': '"여자는 티백과 같습니다. 뜨거운 물에 담기기 전까지는 그 강도를 알 수 없지요."'},
{'Author': 'Steve Martin',
'Text': '"햇빛 없는 날은, 말하자면, 밤과 같습니다."'}]
이 텍스트 스크래핑은 상당히 간단해 보였지만, 웹 스크래핑 중에는 IP 차단, 웹사이트가 너무 많은 요청을 감지할 경우, 또는 자동화된 접근을 방지하기 위한 CAPTCHA와 같은 문제를 겪을 수 있습니다. 이러한 문제를 극복하기 위해 프록시를 사용할 수 있습니다.
익명 스크래핑을 위한 프록시 사용
프록시는 IP 주소를 순환시키고 요청이 서로 다른 위치에서 오는 것처럼 보이게 하여 IP 차단과 CAPTCHA를 회피하고 우회하는 데 도움이 됩니다. 프록시를 사용하려면 모든 요청을 프록시 서버를 통해 라우팅하도록 request.get() 메서드를 구성해야 합니다.
이 시나리오에서는 195개 이상의 국가에서 1억 5천만 개 이상의 IP 주소에 접근할 수 있는Bright Data 로테이팅 프록시를 사용합니다. 시작하려면 오른쪽 상단의‘무료 체험 시작’을선택하고 등록 양식을 작성한 후‘계정 생성’을 클릭하여 무료 Bright Data 계정을 만드세요:
기본 주거용 프록시 생성
Bright Data 계정 생성 후 로그인하여 ‘프록시 및 스크래핑 ‘ 섹션으로 이동합니다. ‘프록시 네트워크 ‘ 섹션에서 ‘레지던셜 프록시’를 찾아 ‘시작하기’를 클릭하세요:
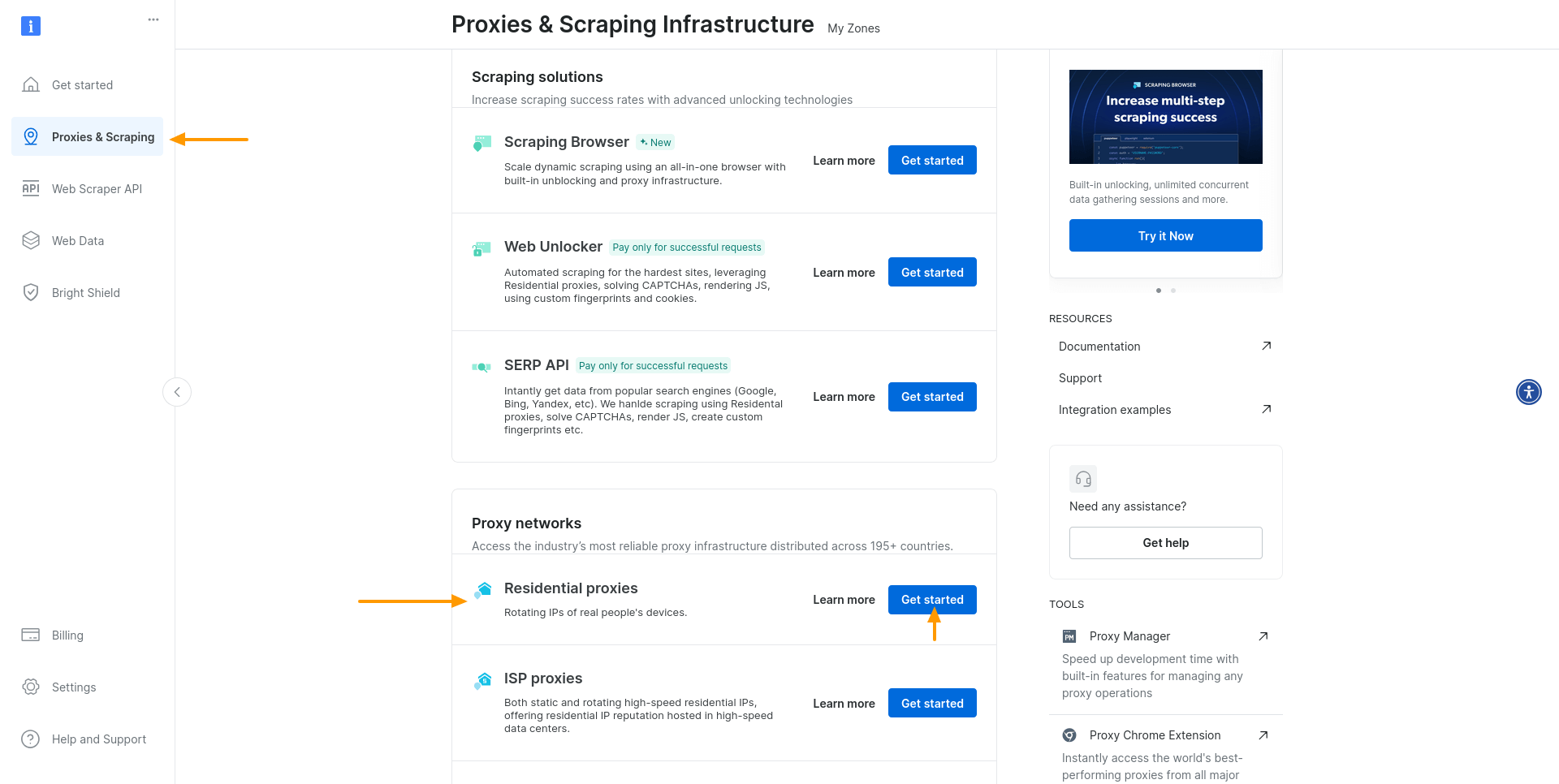
주거용 프록시를 위한 새 영역 추가를 요청받습니다. 기본값을 유지하고 영역 이름을 지정한 후 ‘추가’를 클릭하세요:
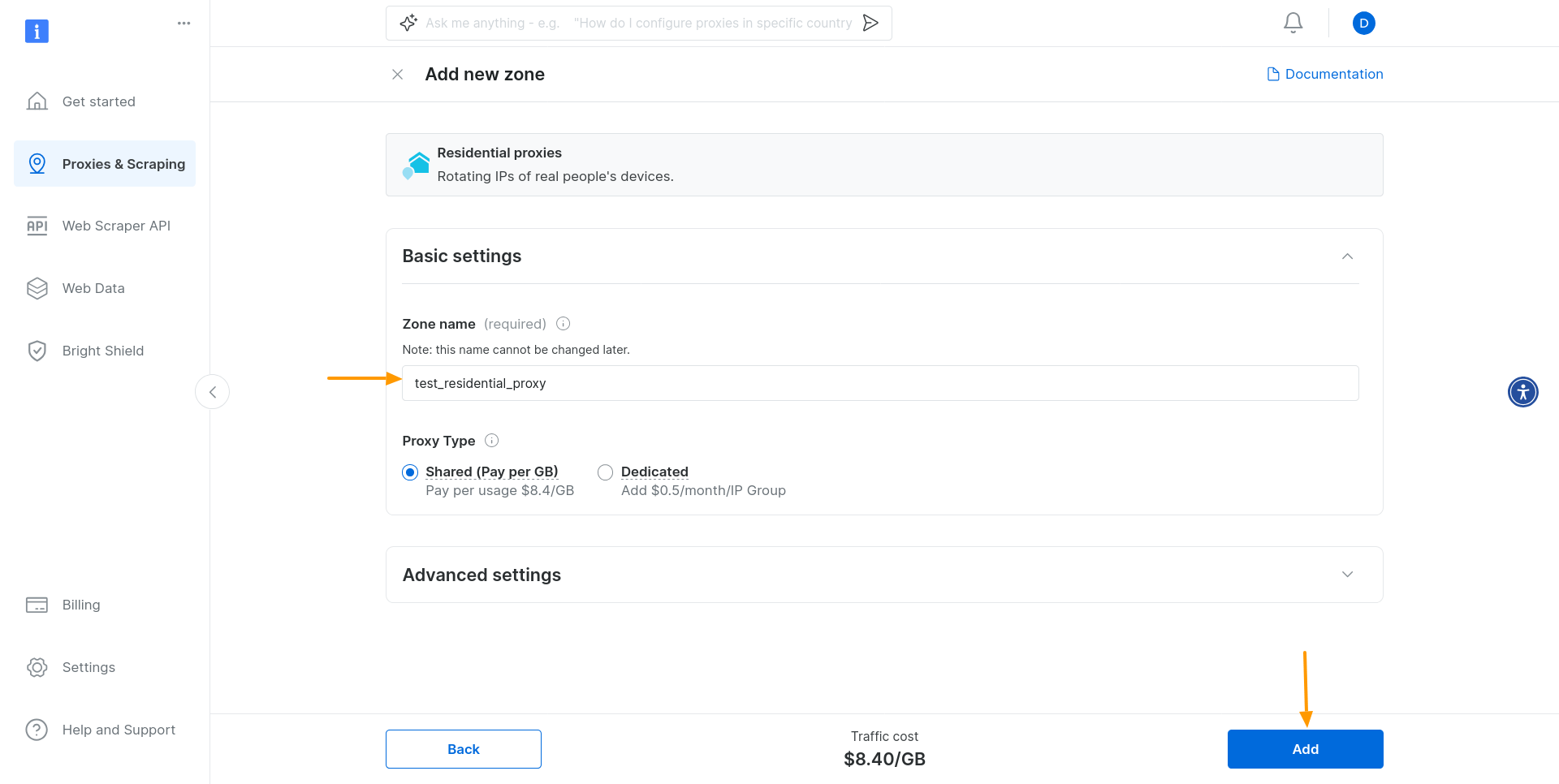
이렇게 하면 새로운 주거용 프록시 존 생성이 완료됩니다!
프록시를 사용하려면 인증 정보(사용자 이름, 비밀번호, 호스트)가 필요합니다. 인증 정보를 찾으려면 다시 ‘프록시 및 스크래핑’ 섹션으로 이동하여 방금 생성한 프록시 영역을 선택하세요:
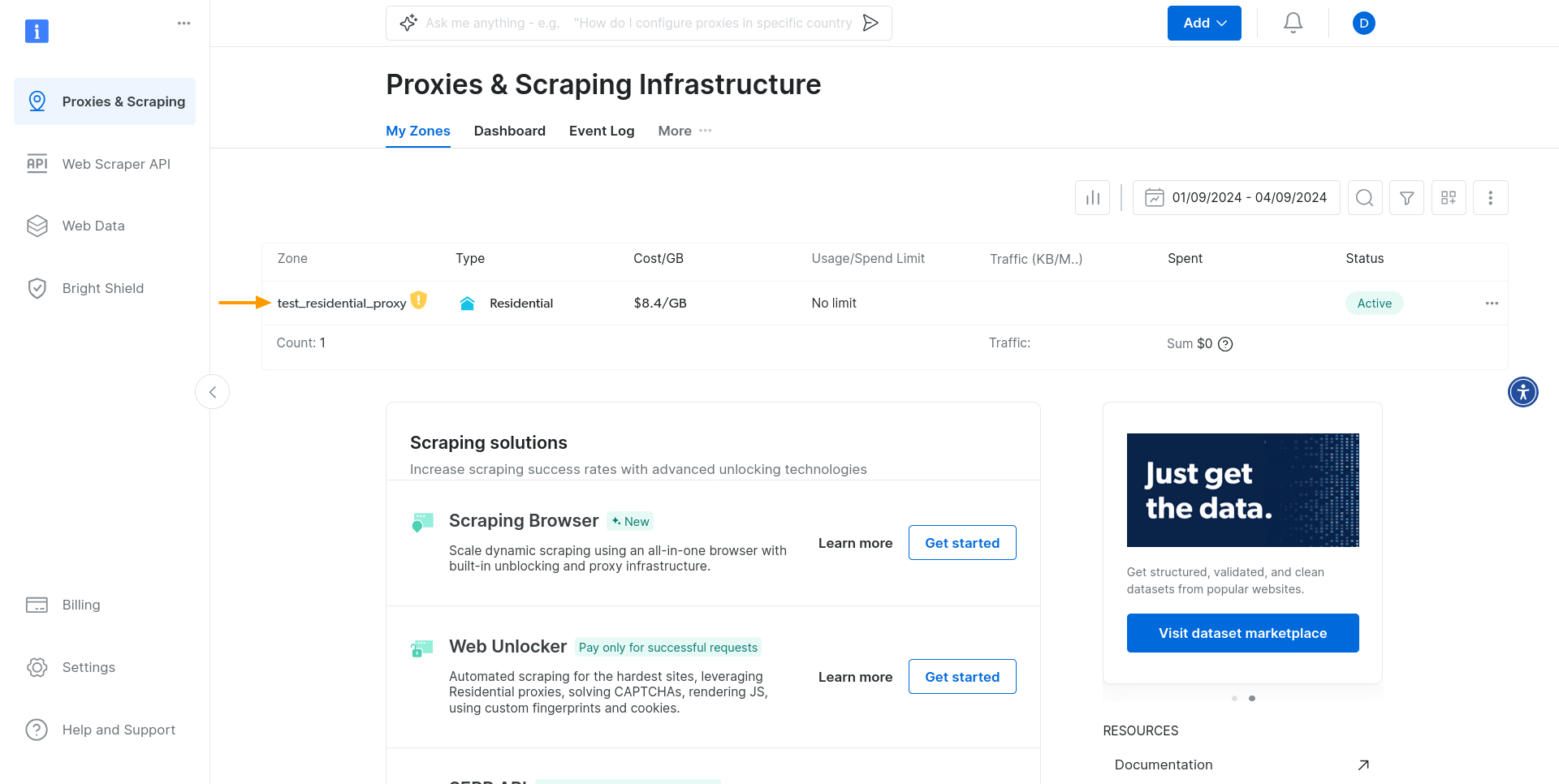
프록시 영역을 클릭하면 영역 제어판이 표시됩니다. ‘인증’ 섹션에서 자격 증명을 확인할 수 있습니다:
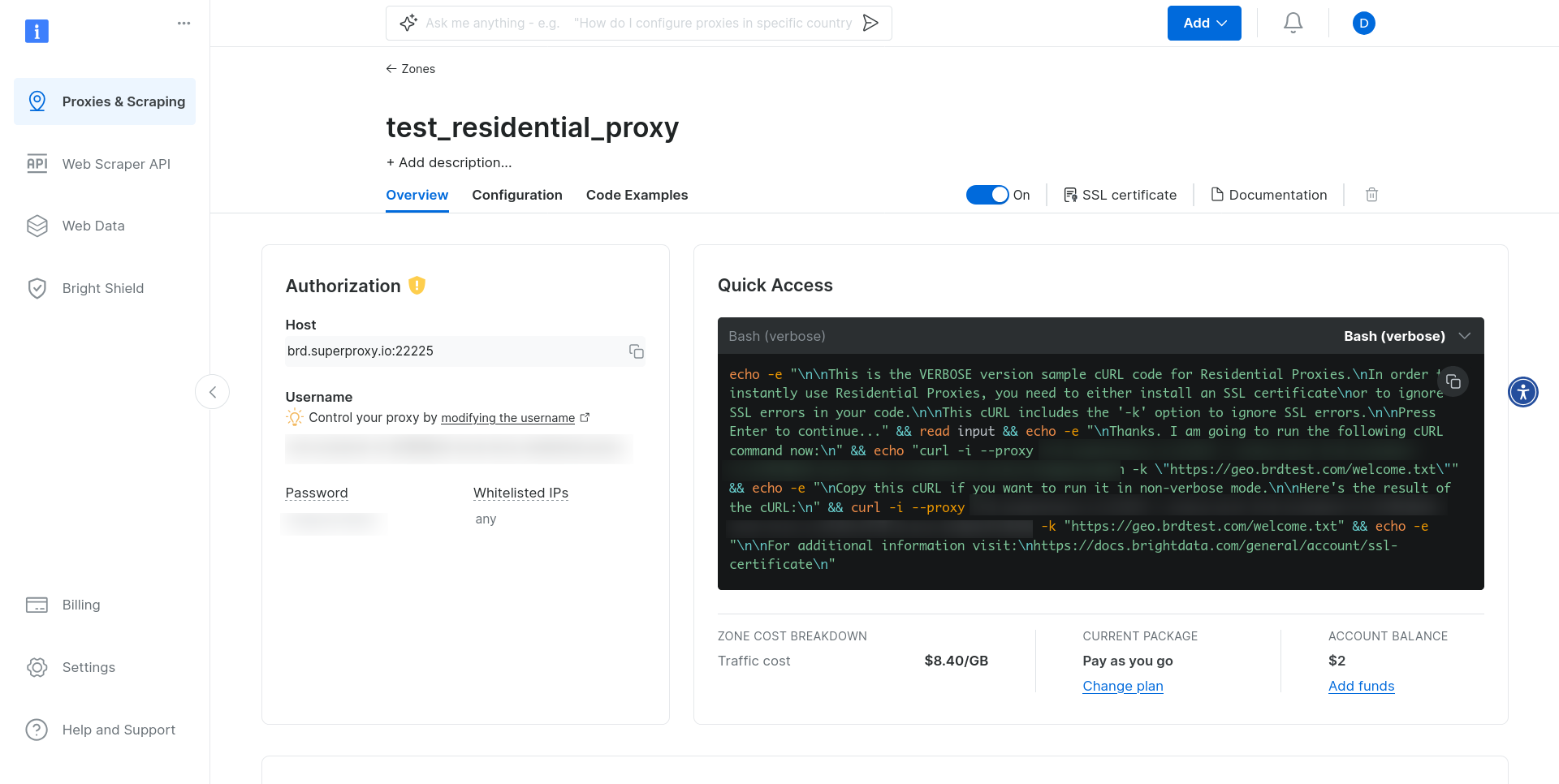
스크래핑 스크립트 업데이트
프록시 인증 정보를 확보했으니 이제 프록시를 구성할 차례입니다. 먼저 인증 정보를 변수로 저장하세요:
host = 'brd.superproxy.io'
port = 22225
username = 'brd-customer-<customer_id>-zone-<zone_name>'
password = '<zone_password>'
그런 다음 저장된 자격 증명으로 프록시 URL을 구성하세요:
proxy_url = f'http://{username}:{password}@{host}:{port}'
HTTP 및 HTTPS 요청 모두에 대한 프록시 구성을 생성합니다:
proxies = {
'http': proxy_url,
'https': proxy_url
}
기존 requests.get() 호출에 프록시 구성을 추가합니다:
response = requests.get(url, proxies=proxies)
이 시점에서 스크립트는 다음과 같아야 합니다:
import requests
from bs4 import BeautifulSoup
# BrightData 인증 정보
host = 'brd.superproxy.io'
port = 22225
username = 'brd-customer-<customer_id>-zone-<zone_name>'
password = '<zone_password>'
# 프록시 URL 생성
proxy_url = f'http://{username}:{password}@{host}:{port}'
# 프록시 구성 생성
proxies = {
'http': proxy_url,
'https': proxy_url
}
# 인용문 웹사이트 URL
url = 'http://quotes.toscrape.com/'
# 지정된 프록시를 통해 URL로 GET 요청 전송
response = requests.get(url, proxies=proxies)
# HTML 파싱을 위한 BeautifulSoup 객체 생성
soup = BeautifulSoup(response.text, 'html.parser')
# 모든 명언 컨테이너 찾기
quotes = soup.find_all('div', class_='quote')
# 각 인용문에서 데이터 추출
data = []
for quote in quotes:
text = quote.find('span', class_='text').text.strip()
author = quote.find('small', class_='author').text.strip()
data.append({
'Text': text,
'Author': author
})
print(data)
스크립트 실행 및 테스트
이 스크립트를 실행하면 프록시 없이 실행한 스크립트와 동일한 결과를 얻을 수 있습니다. 차이점은 스크래핑하는 웹사이트가 이제 요청을 다른 곳에서 보내는 것으로 인식하므로 실제 위치는 비공개로 유지된다는 점입니다. 이를 설명하기 위해 새로운 간단한 스크립트를 작성해 보겠습니다.
필요한 라이브러리를 임포트하고 스크립트에서 url을 "http://lumtest.com/myip.json" 로 설정합니다:
import requests
from bs4 import BeautifulSoup
url = "http://lumtest.com/myip.json"
프록시 설정 없이 해당 URL로 GET 요청을 보내고 응답에 대해 BeautifulSoup 객체를 생성합니다:
# URL로 GET 요청 전송
response = requests.get(url)
# HTML 파싱을 위한 BeautifulSoup 객체 생성
soup = BeautifulSoup(response.text, 'html.parser')
마지막으로 soup 객체를 출력합니다:
print(soup)
이 스크립트를 실행하면 응답으로 IP 주소와 위치 정보가 반환됩니다.
비교를 위해, Bright Data 프록시를 사용하도록 GET 요청을 구성하고 나머지는 동일하게 유지합니다:
# BrightData 인증 정보
host = 'brd.superproxy.io'
port = 22225
username = 'brd-customer-hl_459f8bd4-zone-test_residential_proxy'
password = '8sdgouh1dq5h'
proxy_url = f'http://{username}:{password}@{host}:{port}'
proxies = {
'http': proxy_url,
'https': proxy_url
}
# URL로 GET 요청 전송
response = requests.get(url, proxies=proxies)
업데이트된 스크립트를 실행하면 응답으로 다른 IP 주소가 표시되는 것을 확인할 수 있습니다. 이는 실제 IP가 아닌 설정한 프록시의 IP 주소입니다. 기본적으로 프록시 서버 중 하나 뒤에 자신의 IP 주소를 숨기고 있는 것입니다.
데이터 저장
웹사이트에서 데이터를 성공적으로 스크래핑한 후, 다음 단계는 쉽게 접근하고 분석할 수 있는 구조화된 형식으로 저장하는 것입니다. CSV는 데이터 분석 도구와 프로그래밍 언어에서 널리 지원되므로 이 용도로 인기가 높습니다.
스크랩한 데이터를 CSV 파일로 저장하려면, 데이터를 CSV 형식으로 변환하는 메서드를 제공하는 pandas 라이브러리를 (스크래핑 스크립트 상단에) 먼저 임포트하세요:
import pandas as pd
그런 다음 수집한 스크래핑 데이터를 pandas DataFrame 객체로 생성합니다:
df = pd.DataFrame(data)
마지막으로 DataFrame을 CSV 파일로 변환하고 이름을 지정합니다(예: quotes.csv):
df.to_csv('quotes.csv', index=False)
이러한 변경 사항을 적용한 후 스크립트를 실행하세요. 그러면 스크랩한 데이터가 CSV 파일에 저장됩니다.
이 간단한 예시에서는 인용문으로 할 수 있는 작업이 많지 않습니다. 그러나 수집한 데이터에 따라 다양한 분석 방법을 통해 통찰력을 도출할 수 있습니다.
pandas의 describe() 함수를 사용해 기술통계를 탐색하는 것부터 시작할 수 있습니다. 이 함수는 평균, 중앙값, 표준편차 등 수치 데이터의 빠른 개요를 제공합니다. Matplotlib 또는 seaborn을 사용하여 데이터를 시각화하면 히스토그램, 산점도 또는 막대 차트를 생성하여 패턴이나 추세를 시각적으로 식별하는 데 도움이 됩니다. 텍스트 데이터의 경우 단어 빈도 분석이나 감정 분석과 같은 자연어 처리 기법을 사용하여 리뷰나 댓글의 공통 주제나 전반적인 감정을 이해하는 것을 고려해 보세요.
더 깊은 통찰력을 얻으려면 데이터 세트 내 서로 다른 변수 간의 상관관계를 찾아보세요. 예를 들어, 책 평점과 리뷰 길이 간의 관계를 조사하거나, 평점이 장르나 작가별로 어떻게 달라지는지 분석할 수 있습니다. pandas groupby() 함수를 사용하여 데이터를 집계하고 범주별 지표를 비교하세요.
데이터의 맥락과 해결하려는 질문을 고려하는 것을 잊지 마십시오. 예를 들어, 책 리뷰를 분석하는 경우 높은 평점에 가장 크게 기여하는 요인을 조사하거나 시간 경과에 따른 인기 장르의 추세를 파악할 수 있습니다. 항상 분석 결과를 비판적으로 검토하고 데이터 수집 과정에서 발생할 수 있는 잠재적 편향을 고려하십시오.
결론
이 튜토리얼에서는 Python으로 텍스트 스크래핑하는 방법을 배우고, 프록시 사용의 이점을 탐색하며, Bright Data의 회전 프록시가 IP 차단 회피와 익명성 유지에 어떻게 도움이 되는지 알아보았습니다.
자체 스크래핑 솔루션을 개발하는 것은 보람 있을 수 있지만, 코드 유지 관리, CAPTCHA 처리, 웹사이트 정책 준수 유지와 같은 어려움이 따르는 경우가 많습니다. 바로 여기서 Bright Data 스크래핑 API가 도움이 될 수 있습니다. 자동 CAPTCHA 해결, IP 로테이션, 강력한 데이터 파싱과 같은 기능을 통해 Bright Data는 스크래핑 과정을 단순화하여 인프라 관리보다 데이터 분석에 집중할 수 있게 합니다.
Bright Data 무료 체험판에 가입하여 웹 스크래핑 프로젝트를 어떻게 향상시킬 수 있는지 확인해 보세요. 비즈니스 요구에 맞는 안정적이고 확장 가능하며 효율적인 데이터 수집 솔루션을 제공합니다.






