

AI 모델 훈련은 의사 결정을 위해 데이터의 패턴을 인식하도록 가르치는 과정입니다. 파인 튜닝은 OpenAI의 GPT-4와 같은 대규모 데이터셋으로 훈련된 모델을, 훈련 과정을 지속하여 더 작고 특정 작업에 특화된 데이터셋에 적응시키는 전략입니다.
다음 섹션에서는 OpenAI 파인 튜닝을 활용한 맞춤형 AI 모델 훈련 과정을 심층적으로 살펴보고, 파인 튜닝 프로세스의 각 단계를 안내합니다.
AI와 모델 훈련 이해
인공지능(AI)은 학습, 문제 해결, 의사 결정 등 일반적으로 인간과 유사한 지능이 필요한 작업을 수행할 수 있는 시스템 개발을 의미합니다. AI 모델의 핵심은 입력 데이터를 기반으로 예측을 수행하는 알고리즘 집합입니다. AI의 하위 분야인 머신 러닝(ML)은 기계가 데이터로부터 학습하고 자율적으로 성능을 향상시킬 수 있게 합니다.
AI 모델은 고양이와 개를 구분하는 아이처럼 특징을 관찰하고, 추측하며, 오류를 수정하고, 재시도하는 방식으로 학습합니다. 모델 훈련이라 불리는 이 과정은 모델이 입력 데이터를 처리하고 패턴을 분석·처리한 후 이 지식을 활용해 예측을 수행하는 것을 포함합니다. 모델의 성능은 출력값을 기대 결과와 비교하여 평가되며, 성능 향상을 위해 조정됩니다. 충분한 훈련을 거치면 모델 내 알고리즘 집합은 주어진 상황에 대한 정확한 수학적 예측기를 구현하여 입력 데이터의 다양한 변형을 처리할 수 있게 됩니다.
모델을 처음부터 훈련시키는 것은 사전 지식 없이 데이터의 패턴을 학습하도록 모델을 가르치는 것을 의미합니다. 이는 대량의 데이터와 계산 자원이 필요하며, 제한된 데이터로는 모델 성능이 저조할 수 있습니다.
반면, 파인 튜닝은 대규모 데이터셋으로부터 일반적인 패턴을 학습한 사전 훈련된 모델을 기반으로 시작합니다. 이후 모델은 더 작고 특정된 데이터셋으로 추가 훈련되어, 기존에 학습한 지식을 새로운 작업에 적용할 수 있게 합니다. 이는 종종 더 적은 데이터와 계산 자원으로 더 나은 성능을 이끌어냅니다. 파인 튜닝은 작업 특화 데이터셋이 상대적으로 작을 때 특히 유용합니다.
파인 튜닝 준비
기존 모델을 선별된 데이터셋으로 추가 훈련하는 파인 튜닝은 AI 모델을 처음부터 구축하고 훈련하는 것보다 매력적인 선택처럼 보일 수 있습니다. 그러나 파인 튜닝 과정의 성공은 몇 가지 핵심 요소에 달려 있습니다.
적합한 모델 선택
파인 튜닝을 위한 기본 모델을 선택할 때는 다음 사항을 고려하십시오:
작업 정렬: 문제 범위와 기대되는 모델 기능을 명확히 정의하는 것이 중요합니다. 파인 튜닝 과정에서 원본 작업과 대상 작업 간의 불일치는 성능 저하로 이어질 수 있으므로, 유사한 작업에서 뛰어난 성능을 보이는 모델을 선택하세요. 예를 들어, 텍스트 생성 작업에는 GPT-3가 적합할 수 있는 반면, 텍스트 분류 작업에는 BERT 또는 RoBERTa가 더 나을 수 있습니다.
모델 규모와 복잡성: 성능과 효율성 사이에서 필요한 균형을 유지하세요. 대규모 모델은 복잡한 패턴을 더 잘 포착하지만 더 많은 자원을 필요로 합니다.
평가 지표: 작업과 관련된 평가 지표를 선택하세요. 예를 들어 분류 작업에는 정확도가 중요할 수 있으며, 언어 생성 작업에는 BLEU 또는 ROUGE가 유용할 수 있습니다.
커뮤니티 및 자원: 문제 해결 및 구현을 위한 대규모 커뮤니티와 풍부한 자원을 갖춘 모델을 선택하세요. 해당 작업에 대한 명확한 미세 조정 가이드라인이 있는 모델을 우선시하고, 사전 훈련된 모델 체크포인트는 신뢰할 수 있는 출처에서 구하세요.
데이터 수집 및 준비
미세 조정 시 데이터의 품질과 다양성은 모델 성능에 상당한 영향을 미칠 수 있습니다. 주요 고려 사항은 다음과 같습니다:
필요한 데이터 유형: 데이터 유형은 특정 작업과 모델이 사전 훈련된 데이터에 따라 달라집니다. NLP 작업의 경우 일반적으로 책, 기사, 소셜 미디어 게시물 또는 음성 대본과 같은 출처의 텍스트 데이터가 필요합니다. 웹 스크래핑, 설문조사 또는 소셜 미디어 플랫폼의 API와 같은 방법을 사용하여 데이터를 수집하세요. 예를 들어, 방대하고 다양하며 최신 데이터가 필요한 경우 AI를 활용한 웹 스크래핑이 특히 유용할 수 있습니다.
데이터 정리 및 주석 부착: 데이터 정리는 불필요한 데이터 제거, 누락되거나 불일치하는 데이터 처리, 정규화 등을 포함합니다. 주석 부착은 모델이 학습할 수 있도록 데이터에 레이블을 부여하는 작업입니다. Bright Data와 같은 자동화 도구를 활용하면 이러한 과정을 간소화하고 효율성을 높일 수 있습니다.
다양하고 대표적인 데이터셋 통합: 모델 미세 조정 시 다양하고 대표적인 데이터셋은 모델이 다양한 관점에서 학습하도록 하여 더 일반화되고 신뢰할 수 있는 예측을 가능하게 합니다. 예를 들어 영화 리뷰를 위한 감정 분석 모델을 미세 조정하는 경우, 데이터셋은 실제 세계의 클래스 분포를 반영하여 다양한 영화, 장르, 감정을 포함한 리뷰를 포함해야 합니다.
훈련 환경 설정
선택한 AI 모델과 프레임워크에 필요한 하드웨어 및 소프트웨어를 확보하십시오. 예를 들어, 대규모 언어 모델(LLM)은 일반적으로 GPU로 제공되는 상당한 연산 능력이 필요합니다.
TensorFlow나 PyTorch 같은 프레임워크는 AI 모델 훈련에 흔히 사용됩니다. 훈련 워크플로에 원활하게 통합하려면 관련 라이브러리 및 도구와 추가 종속성을 설치하는 것이 필수적입니다. 예를 들어 OpenAI에서 개발한 특정 모델을 튜닝하려면 OpenAI API 같은 도구가 필요할 수 있습니다.
미세 조정 과정
미세 조정의 기본을 이해했으니, 이제 자연어 처리 분야의 적용 사례를 살펴보겠습니다.
OpenAI API를 사용하여 사전 훈련된 모델을 미세 조정하겠습니다. 현재 gpt-3.5-turbo-0125(권장), gpt-3.5-turbo-1106, gpt-3.5-turbo-0613, babbage-002, davinci-002 및 실험적인 gpt-4-0613과 같은 모델에 대해 미세 조정이 가능합니다. GPT-4 미세 조정은 실험 단계에 있으며, 자격을 갖춘 사용자는 미세 조정 UI에서 액세스를 요청할 수 있습니다.
1. 데이터셋 준비
연구에 따르면 GPT-3.5는 분석적 추론 능력이 부족한 것으로 나타났습니다. 따라서 2022년 공개된 로스쿨 입학 시험(LSAT)의 분석적 추론 문제 데이터셋을 활용해 gpt-3.5-turbo 모델의 분석적 추론 능력을 향상시키기 위한 파인 튜닝을 시도해 보겠습니다. 공개된 데이터셋은 여기에서 확인할 수 있습니다.
미세 조정 모델의 품질은 미세 조정에 사용된 데이터에 직접적으로 좌우됩니다. 데이터셋의 각 예시는 OpenAI의 Chat Completions API에 따라 형식화된 대화 형태여야 하며, 각 메시지에 역할(role), 내용(content), 선택적 이름(name)이 포함된 메시지 목록으로 구성되어 JSONL 파일로 저장되어야 합니다.
gpt-3.5-turbo미세 조정을 위한 필수 대화 채팅 형식은 다음과 같습니다:
{"messages": [{"role": "system", "content": ""}, {"role": "user", "content": ""}, {"role": "assistant", "content": ""}]}
이 형식에서 "messages" 는 시스템, 사용자, 어시스턴트라는 세 가지 "역할" 간의 대화를 구성하는 메시지 목록입니다. "system" 역할의 "content" 는 미세 조정된 시스템의 동작을 지정해야 합니다.
아래는 본 가이드에서 사용할 AR-LSAT 데이터셋에서 가져온 형식화된 예시입니다:

데이터셋 생성 시 주요 고려 사항은 다음과 같습니다:
- OpenAI 가격 페이지
- 토큰 계산 노트북
- 파이썬 스크립트
2. API 키 생성 및 OpenAI 라이브러리 설치
OpenAI 모델을 미세 조정하려면 충분한 크레딧 잔액이 있는 OpenAI 개발자 계정이 필수입니다.
API 키 생성 및 OpenAI 라이브러리 설치를 위해 다음 단계를 따르세요:
1. OpenAI 공식 웹사이트에서 가입하세요.
2. 미세 조정을 활성화하려면 ‘설정’ 메뉴의 ‘결제’ 탭에서 크레딧 잔액을 충전하세요.
3. 좌측 상단 사용자 프로필 아이콘을 클릭하고 “API 키”를 선택하여 키 생성 페이지로 이동합니다.
4. 이름을 입력하여 새 비밀 키를 생성합니다.

5. 파인 튜닝을 위해 Python OpenAI 라이브러리를 설치하세요.
pip install openai
6. os 라이브러리를 사용하여 토큰을 환경 변수로 설정하고 API 통신을 구축하세요.
import os
from openai import OpenAI
# OPENAI_API_KEY 환경 변수 설정
os.environ['OPENAI_API_KEY'] = '4단계에서 생성한 키'
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'])
3. 훈련 및 검증 파일업로드
데이터 검증 후, 파인 튜닝 작업을 위해 Files API를 사용하여 파일을 업로드합니다.
training_file_id = client.files.create(
file=open(training_file_name, "rb"),
purpose="fine-tune")
validation_file_id = client.files.create(
file=open(validation_file_name, "rb"),
purpose="fine-tune"
)
print(f"훈련 파일 ID: {training_file_id}")
print(f"검증 파일 ID: {validation_file_id}")
훈련 및 검증 데이터에 대한 고유 식별자가 성공적으로 실행되면 표시됩니다.

4. 파인 튜닝 작업생성
파일 업로드 후 UI 또는 프로그래밍 방식으로 파인 튜닝 작업을 생성합니다.
OpenAI SDK를 사용하여 미세 조정 작업을 시작하는 방법은 다음과 같습니다:
response = client.fine_tuning.jobs.create(
training_file=training_file_id.id,
validation_file=validation_file_id.id,
model="gpt-3.5-turbo",
hyperparameters={
"n_epochs": 10,
"batch_size": 3,
"learning_rate_multiplier": 0.3
})
job_id = response.id
status = response.status
print(f'Fine-tunning model with jobID: {job_id}.')
print(f"훈련 응답: {response}")
print(f"훈련 상태: {status}")
model: 미세 조정할 모델의 이름 (gpt-3.5-turbo,babbage-002,davinci-002또는 기존 미세 조정 모델).training_file및validation_file: 파일 업로드 시 반환된 파일 ID.n_epochs,batch_size및learning_rate_multiplier: 사용자 정의할 수 있는 하이퍼파라미터입니다.
추가적인 미세 조정 매개 변수를 설정하려면 미세 조정에 대한 API 사양을 참조하십시오.
위의 코드는 jobID(`ftjob-0EVPunnseZ6Xnd0oGcnWBZA7`)에 대해 다음과 같은 정보를 생성합니다.

파인 튜닝 작업은 완료까지 시간이 소요될 수 있습니다. 다른 작업 뒤에 대기열에 배치될 수 있으며, 모델 및 데이터셋 크기에 따라 훈련 기간은 몇 분에서 몇 시간까지 다양할 수 있습니다.
훈련이 완료되면 파인 튜닝 작업을 시작한 사용자에게 이메일 확인서가 발송됩니다.
다음과 같은 파인 튜닝 UI를 통해 작업 상태를 모니터링할 수 있습니다:
5. 미세 조정된 모델 분석
OpenAI는 훈련 중 다음 지표를 계산합니다:
- 훈련 손실
- 훈련 토큰 정확도
- 검증 손실
- 검증 토큰 정확도
검증 손실과 검증 토큰 정확도는 두 가지 방식으로 계산됩니다: 각 단계에서 소규모 데이터 배치에 대해, 그리고 각 에포크 종료 시 전체 검증 세트에 대해 계산됩니다. 전체 검증 손실과 전체 검증 토큰 정확도는 모델 성능 추적에 가장 정확한 지표이며, 원활한 훈련을 보장하기 위한 정상성 검사(손실은 감소해야 하며, 토큰 정확도는 증가해야 함) 역할을 합니다.
파인 튜닝 작업이 진행 중일 때 다음 경로를 통해 이러한 지표를 확인할 수 있습니다.
1. UI:

2. API:
import os
from openai import OpenAI
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'],)
jobid = ‘모니터링할 작업 ID’
print(f"파인 튜닝 작업 {jobid} 이벤트 스트리밍 중")
# signal.signal(signal.SIGINT, signal_handler)
events = client.fine_tuning.jobs.list_events(fine_tuning_job_id=jobid)
try:
for event in events:
print(
f'{event.data}'
)
except Exception:
print("스트림 중단됨 (클라이언트 연결 끊김).")
위의 코드는 미세 조정 작업에 대한 스트리밍 이벤트를 출력합니다. 여기에는 단계 번호, 훈련 손실, 검증 손실, 총 단계 수, 훈련 및 검증에 대한 평균 토큰 정확도가 포함됩니다:
파인 튜닝 작업에 대한 스트리밍 이벤트: ftjob-0EVPunnseZ6Xnd0oGcnWBZA7
{'step': 67, 'train_loss': 0.30375099182128906, 'valid_loss': 0.49169286092122394, 'total_steps': 67, 'train_mean_token_accuracy': 0.8333333134651184, 'valid_mean_token_accuracy': 0.8888888888888888}
6. 성능 향상을 위한 매개변수 및 데이터셋 조정
파인 튜닝 작업 결과가 기대만큼 좋지 않다면, 성능 향상을 위해 다음 방법을 고려하십시오:
1. 훈련 데이터셋 조정:
- 훈련 데이터셋을 개선하려면 모델의 취약점을 보완하는 예시를 추가하고, 데이터의 응답 분포가 예상 분포와 일치하는지 확인하세요.
- 모델이 재현하는 데이터 문제를 확인하고, 응답에 필요한 모든 정보가 예시에 포함되었는지 확인하는 것도 중요합니다.
- 여러 사람이 생성한 데이터 간 일관성을 유지하고, 모든 훈련 예제의 형식을 추론 시 예상되는 형식과 일치하도록 표준화하십시오.
- 일반적으로 양질의 데이터는 대량의 저품질 데이터보다 효과적입니다.
2. 하이퍼파라미터 조정:
- OpenAI에서는 에포크, 학습률 배율, 배치 크기라는 세 가지 하이퍼파라미터를 지정할 수 있습니다.
- 데이터 세트 크기에 따라 내장 함수가 선택한 기본값으로 시작한 다음, 필요한 경우 조정하십시오.
- 모델이 훈련 데이터를 예상대로 따르지 않으면 에포크 수를 늘리십시오.
- 모델의 다양성이 예상보다 낮아지면 에포크 수를 1~2개 줄이세요.
- 모델이 수렴하지 않는 것처럼 보이면 학습률 배율을 증가시킵니다.
7. 체크포인트 모델 사용
현재 OpenAI는 파인 튜닝 작업의 마지막 세 에포크에 대한 체크포인트에 대한 액세스를 제공합니다. 이러한 체크포인트는 추론 및 추가 파인 튜닝에 사용할 수 있는 완전한 모델입니다.
이 체크포인트에 접근하려면 작업이 성공할 때까지 기다린 후, 퀄리티 작업 ID로 체크포인트 엔드포인트를 쿼리하세요. 각 체크포인트 객체에는 모델 체크포인트 이름이 포함된 fine_tuned_model_checkpoint 필드가 채워집니다. 퀄리티 UI를 통해서도 체크포인트 모델 이름을 확인할 수 있습니다.
openai.chat.completions.create() 함수를 사용하여 프롬프트와 모델 이름으로 쿼리를 실행해 체크포인트 모델 결과를 검증할 수 있습니다:
completion = client.chat.completions.create(
model="ft:gpt-3.5-turbo-0125:personal::9PWZuZo5",
messages=[
{"role": "system", "content": "지침: 본문과 해당 본문에 대한 질문이 제시됩니다. 네 가지 선택지 중 유일하게 정답인 옵션을 선택해야 합니다. 첫 번째 선택지가 정답이면 'A'를, 두 번째 선택지가 정답이면 'B'를, 세 번째 선택지가 정답이면 'C'를, 네 번째 선택지가 정답이면 'D'를, 다섯 번째 선택지가 정답이면 'E'를 생성하세요. 질문과 선택지를 꼼꼼히 읽고 네 개의 답안 라벨 중 정답을 선택하세요. 본문을 충분히 읽어 본문의 내용을 정확히 이해했는지 확인하세요"},
{"role": "user", "content": "본문: 학교 신문을 위해 다섯 명의 학생—장(Jiang), 크레이머(Kramer), 로페즈(Lopez), 메그레지안(Megregian), 오닐(O'Neill)—이 각각 정확히 세 편의 연극 중 하나 이상을 리뷰합니다: 선셋, 타메를레인, 언덕울림 중 정확히 세 편의 연극을 각각 한 편 이상 리뷰하지만, 다른 연극은 리뷰하지 않습니다. 다음 조건이 반드시 적용됩니다: 크레이머와 로페즈는 메그레지안보다 리뷰하는 연극 수가 적어야 합니다. 로페즈와 메그레지안은 장이 리뷰하는 연극을 리뷰하지 않습니다. 크레이머와 오닐은 둘 다 타메를레인을 리뷰합니다. 정확히 두 명의 학생이 서로 정확히 동일한 연극 하나 또는 여러 편을 리뷰한다.질문: 다음 중 '일몰'만을 리뷰하는 학생들의 정확하고 완전한 목록은 무엇인가?nA. 로페즈nB. 오닐nC. 장, 로페즈nD. 크레이머, 오닐nE. 로페즈, 메그레지안n답변:"}
])
print(completion.choices[0].message)
답변 사전에서 검색된 결과는 다음과 같습니다:

아래와 같이 OpenAI 플레이그라운드에서 미세 조정된 모델을 다른 모델과 비교할 수도 있습니다:
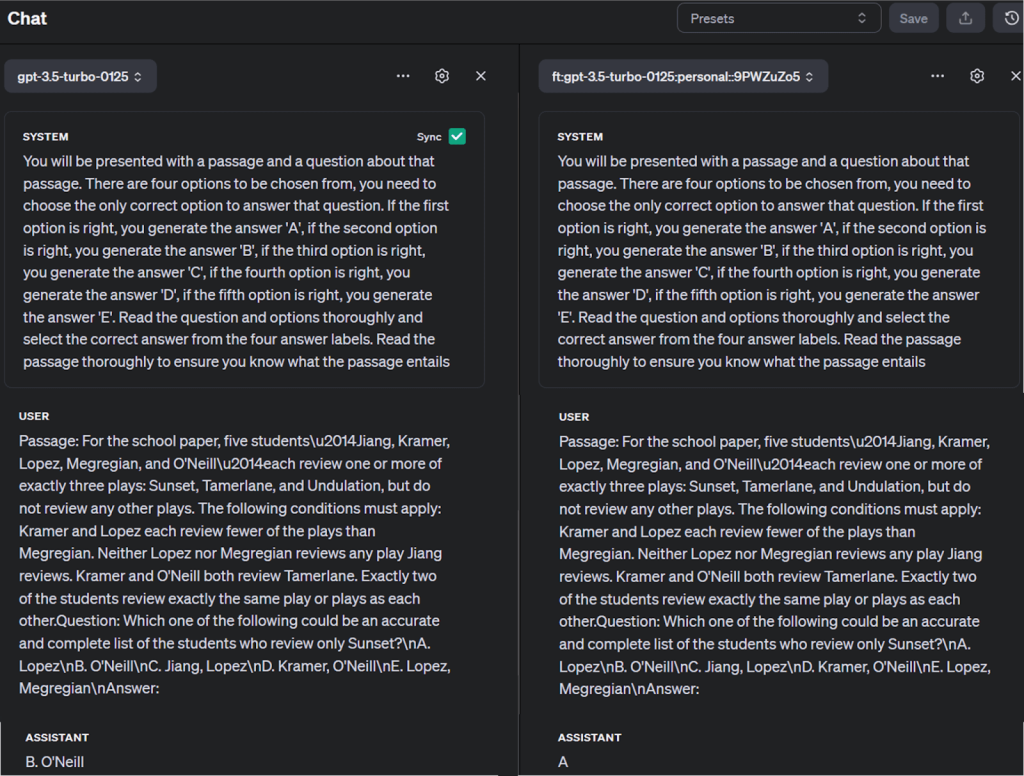
팁과 모범 사례
성공적인 미세 조정을 위해 다음 팁을 고려하세요:
데이터 품질: 과적합(훈련 데이터에서는 성능이 좋지만 미확인 데이터에서는 성능이 저하되는 현상)을 방지하기 위해 작업별 데이터가 깨끗하고 다양하며 대표성을 갖도록 하십시오.
하이퍼파라미터 선택: 수렴 속도 저하나 성능 저하를 방지하기 위해 적절한 하이퍼파라미터를 선택하세요. 이는 복잡하고 시간이 많이 소요될 수 있지만 효과적인 훈련에 매우 중요합니다.
자원 관리: 대규모 모델의 파인 튜닝에는 상당한 컴퓨팅 자원과 시간이 소요된다는 점을 인지하십시오.
함정 피하기
과적합과 과소적합: 모델의 복잡성과 훈련량을 균형 있게 조정하여 과적합(높은 분산)과 과소적합(높은 편향)을 피하세요.
재앙적 망각: 튜닝 과정에서 모델이 이전에 학습한 일반 지식을 망각할 수 있습니다. 다양한 작업에 대한 모델 성능을 정기적으로 평가하여 이를 완화하세요.
도메인 이동 민감도: 미세 조정 데이터가 사전 훈련 데이터와 크게 다를 경우 도메인 이동 문제가 발생할 수 있습니다. 도메인 적응 기법을 사용하여 이 간극을 해소하십시오.
모델 저장 및 재사용
훈련 후 모델 상태를 저장하여 나중에 재사용하세요. 여기에는 모델 매개변수와 사용된 최적화기의 상태가 포함됩니다. 이를 통해 동일한 상태에서 훈련을 재개할 수 있습니다.
윤리적 고려 사항
편향 증폭: 사전 훈련된 모델은 편향을 상속할 수 있으며, 이는 튜닝 과정에서 증폭될 수 있습니다. 편향되지 않은 예측이 필요한 경우, 편향 및 공정성 테스트를 거친 사전 훈련 모델을 선택하십시오.
의도하지 않은 출력: 미세 조정된 모델은 그럴듯하지만 잘못된 출력을 생성할 수 있습니다. 이를 처리하기 위해 강력한 후처리 및 검증 메커니즘을 구현하십시오.
모델 드리프트: 환경이나 데이터 분포의 변화로 인해 모델 성능이 시간이 지남에 따라 저하될 수 있습니다. 모델 성능을 정기적으로 모니터링하고 필요 시 재미세 조정하십시오.
고급 기법 및 심화 학습
LLM 미세 조정의 고급 기법으로는 성능 유지와 함께 계산 및 재정적 비용을 절감하는 Low Ranking Adaptation(LoRA) 및 Quantized LoRA(QLoRA)가 있습니다. 매개변수 효율적 미세 조정(PEFT)은 최소한의 학습 가능 매개변수로 모델을 효율적으로 조정합니다. DeepSpeed와 ZeRO는 대규모 훈련을 위한 메모리 사용을 최적화합니다. 이러한 기법들은 과적합, 재앙적 망각, 도메인 이동 민감도 등의 문제를 해결하여 LLM 미세 조정의 효율성과 효과성을 향상시킵니다.
미세 조정 외에도 전이 학습(transfer learning)과 강화 학습(reinforcement learning)과 같은 고급 훈련 기법이 존재합니다. 전이 학습은 한 문제에서 습득한 지식을 관련 문제에 적용하는 반면, 강화 학습은 에이전트가 환경 내에서 행동을 취해 보상을 극대화하는 결정을 학습하는 기계 학습의 한 유형입니다.
AI 모델 훈련에 대해 더 깊이 탐구하고자 하는 분들에게 아래 자료가 도움이 될 수 있습니다:
- Attention is all you need (Ashish Vaswani 외)
- 이안 굿펠로, 요슈아 벵지오, 에런 쿠르빌의 저서 “딥 러닝”
- Daniel Jurafsky와 James H. Martin의 저서 “Speech and Language Processing”
- LLM 훈련의 다양한 방법
- LLM 기법 마스터하기: Hugging Face의 NLP 과정 훈련
- 허깅 페이스의 NLP 과정
결론
AI 모델 훈련은 상당량의 고품질 데이터가 필요한 과정입니다. 문제 정의, 모델 선택, 반복적 개선이 필수적이지만, 진정한 차별점은 사용된 데이터의 품질과 양입니다. 웹 스크레이퍼를 구축하고 유지하는 대신, Bright Data 플랫폼에서 제공하는 사전 구축 또는 맞춤형 데이터셋을 활용하여 데이터 수집을 간소화할 수 있습니다.
데이터셋 마켓플레이스를 통해 인기 웹사이트의 검증된 기성 데이터셋에 접근하거나, 자동화 플랫폼을 활용해 특정 요구사항에 맞는 맞춤형 데이터셋을 생성할 수 있습니다. 이를 통해 정확하고 규정을 준수하는 데이터로 모델 훈련에 효율적으로 집중함으로써 다양한 산업 분야에서 더 빠르고 신뢰할 수 있는 결과를 얻을 수 있습니다.
Bright Data의 데이터셋 솔루션을 살펴보고, 원활한 데이터 수집을 위해 워크플로에 쉽게 통합하세요.
지금 가입하여 무료 데이터셋 샘플을 포함한 Bright Data의 스크래핑 인프라 무료 체험을 시작하세요.





