

이 가이드에서는 다음을 배우게 됩니다:
curl_cffi의정의 및 제공 기능- TLS 지문 기반 봇 탐지를 최소화하는 방법
- 웹 스크래핑을 위해 Python과 함께 사용하는 방법
- 고급 사용법 및 메서드
- 유사한 HTTP 클라이언트와의 비교
자, 시작해 보겠습니다!
curl_cffi란 무엇인가?
curl_cffi는 CFFI를 통해 curl-impersonate 포크에 대한 Python 바인딩을 제공하는 라이브러리입니다. 즉, 브라우저 TLS/JA3/HTTP2 지문을 모방할 수 있는 HTTP 클라이언트입니다. 이로 인해 TLS 지문을 기반으로 한 안티봇 차단을 우회하는 데 탁월한 솔루션이 됩니다.
⚙️ 주요 기능
- JA3/TLS 및 HTTP2 지문 위장 지원 (최신 브라우저 및 사용자 정의 지문 포함)
requests및httpx보다 훨씬 빠르며,aiohttp와 동등한 성능requestsAPI를 모방- 비동기 HTTP 요청을 위한
asyncio지원 - 각 요청마다 프록시 로테이션 지원
- HTTP/2.0 지원
웹소켓지원
작동 방식
curl_cffi는 실제 브라우저와 일치하는 TLS 지문을 생성하는 라이브러리인 cURL Impersonate를 기반으로 구축되었습니다.
HTTPS 요청을 보낼 때 TLS 핸드셰이크가 발생하여 고유한 TLS 지문이 생성됩니다. HTTP 클라이언트는 브라우저와 다르기 때문에 지문이 자동화를 노출시켜 봇 방지 방어를 유발할 수 있습니다.
cURL Impersonate는 실제 브라우저 TLS 지문과 일치하도록 cURL을 수정합니다:
- TLS 라이브러리 조정: cURL의 라이브러리 대신 브라우저가 사용하는 TLS 연결 라이브러리를 활용합니다.
- 구성 변경: TLS 확장 및 SSL 옵션을 조정하여 브라우저를 모방합니다.
- HTTP/2 맞춤 설정: 브라우저 핸드셰이크 설정을 일치시킵니다.
- 비기본 cURL 플래그: 정확성을 위해
--ciphers,--curves및 사용자 정의 헤더 설정.
이를 통해 요청이 브라우저처럼 보이게 하여 봇 탐지를 우회하는 데 도움이 됩니다. 자세한 내용은 cURL Impersonate 가이드를 참조하십시오.
웹 스크래핑을 위한 curl_cffi 사용 방법: 단계별 가이드
목표가 Walmart의 “키보드” 페이지를 스크래핑하는 경우:
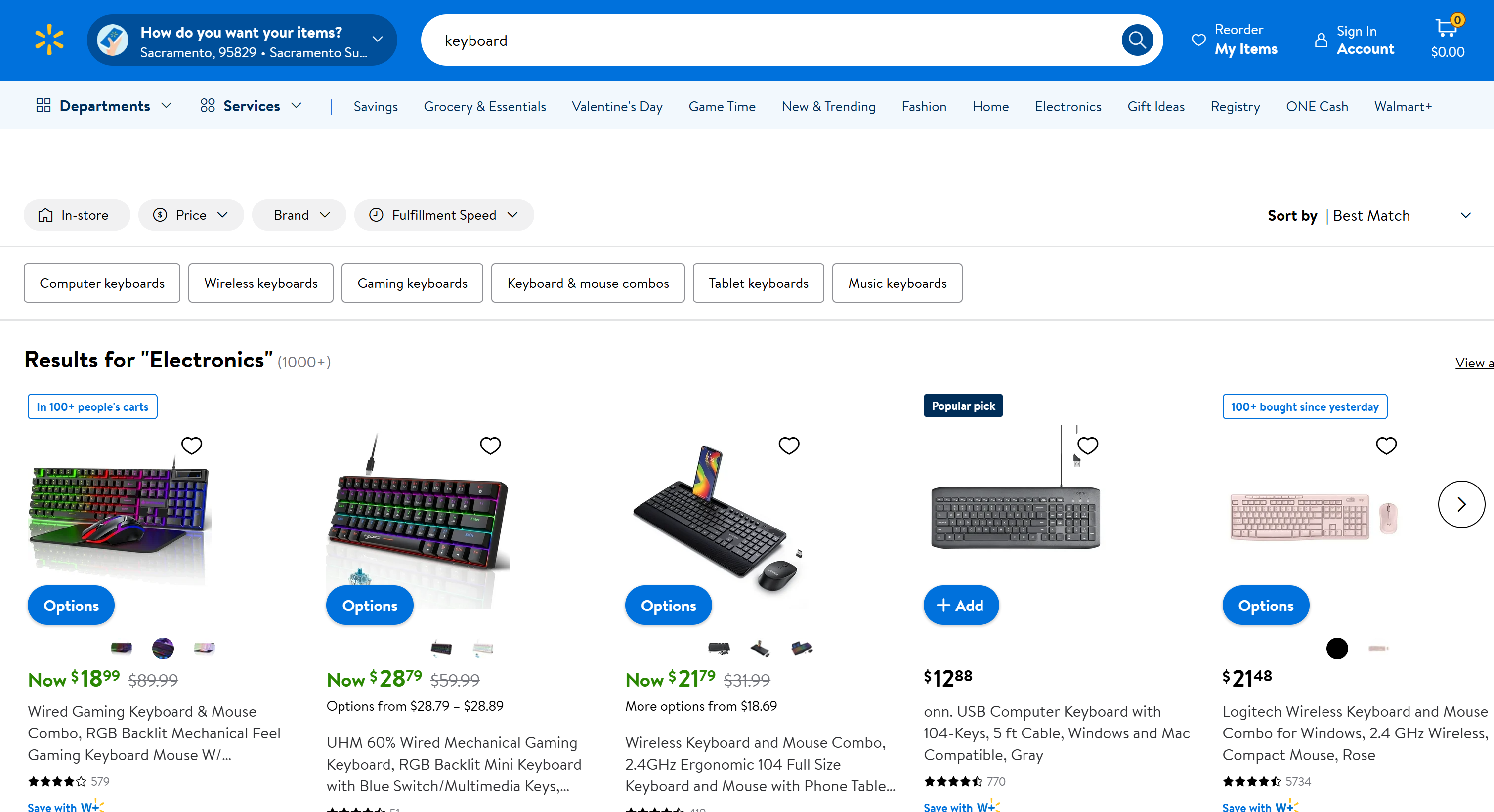
어떤 HTTP 클라이언트로도 이 페이지에 접근하면 다음과 같은 오류 페이지를 받게 됩니다:
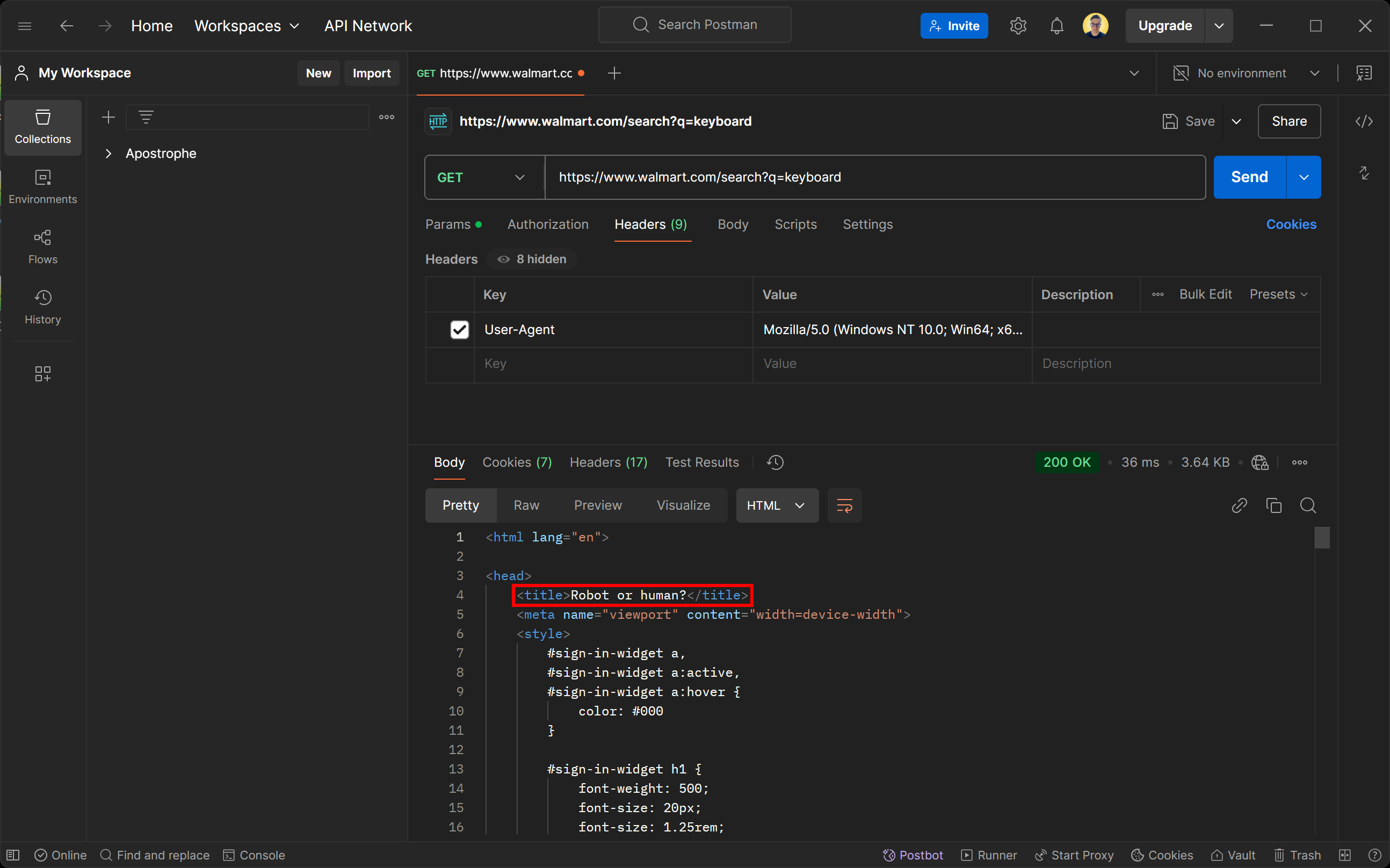
200 OK 응답 상태에 속지 마십시오. 월마트 서버가 반환한 페이지는 실제로 봇 탐지 페이지입니다. CAPTCHA 챌린지를 통해 사용자가 인간인지 확인하도록 특별히 요청합니다.
사용자 에이전트를 실제 브라우저처럼 설정해도 어떻게 이런 일이 가능할까요? 그 답은 TLS 지문 인식입니다!
이제 curl_cffi를 활용해 봇 방지 조치를 우회하고 손쉽게 웹 스크래핑을 수행하는 방법을 살펴보겠습니다.
1단계: 프로젝트 설정
먼저, 컴퓨터에 Python 3 이상이 설치되어 있는지 확인하세요. 설치되어 있지 않다면 공식 사이트에서 다운로드하여 설치 지침을 따르세요.
그런 다음 다음 명령어로 curl_cffi 스크래핑 프로젝트용 디렉터리를 생성하세요:
mkdir curl-cfii-scraper
해당 디렉터리로 이동하여 가상 환경을 설정하세요:
cd curl-cfii-scraper
python -m venv env
선호하는 Python IDE로 프로젝트 폴더를 엽니다. Python 확장 프로그램이 설치된 Visual Studio Code 나 PyCharm Community Edition을 사용할 수 있습니다.
이제 프로젝트 폴더 안에 scraper.py 파일을 생성하세요. 처음에는 비어 있지만 곧 스크래핑 로직을 추가하게 될 것입니다.
IDE 터미널에서 가상 환경을 활성화하세요. Linux 또는 macOS에서는 다음 명령어를 사용합니다:
./env/bin/activate
Windows에서는 다음과 같이 실행하세요:
env/Scripts/activate
완벽합니다! 이제 모든 준비가 완료되었습니다.
2단계: curl_cffi 설치
활성화된 가상 환경에서 curl-cffi pip 패키지를 통해 HTTP 클라이언트를 설치하세요:
pip install curl-cffi
이 라이브러리는 백그라운드에서 Windows, macOS, Linux용 curl 임페르소네이션 바이너리를 자동으로 다운로드합니다.
3단계: 대상 페이지에 연결하기
curl_cffi에서 requests를 임포트합니다:
from curl_cffi import requests
이 객체는 Python Requests 라이브러리와 유사한 고급 API를 제공합니다.
이를 사용하여 다음과 같이 대상 페이지에 GET HTTP 요청을 수행할 수 있습니다:
response = requests.get("https://www.walmart.com/search?q=keyboard", impersonate="chrome")
impersonate="chrome" 인수는 curl_cffi가 HTTP 요청을 최신 버전 Chrome에서 온 것처럼 보이도록 지시합니다. 결과적으로 Walmart는 자동화된 요청을 일반 브라우저 요청으로 처리하여 봇 방지 페이지 대신 표준 웹 페이지를 반환합니다.
대상 페이지의 HTML 콘텐츠는 다음과 같이 접근할 수 있습니다:
html = response.text
html을 출력하면 다음과 같이 표시됩니다:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charSet="utf-8"/>
<meta property="fb:app_id" content="105223049547814"/>
<meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=1, interactive-widget=resizes-content"/>
<link rel="dns-prefetch" href="https://tap.walmart.com "/>
<link rel="preload" fetchpriority="high" crossorigin="anonymous" href="https://i5.walmartimages.com/dfw/63fd9f59-a78c/fcfae9b6-2f69-4f89-beed-f0eeb4237946/v1/BogleWeb_subset-Bold.woff2" as="font" type="font/woff2"/>
<link rel="preload" fetchpriority="high" crossorigin="anonymous" href="https://i5.walmartimages.com/dfw/63fd9f59-a78c/fcfae9b6-2f69-4f89-beed-f0eeb4237946/v1/BogleWeb_subset-Regular.woff2" as="font" type="font/woff2"/>
<link rel="preconnect" href="https://beacon.walmart.com"/>
<link rel="preconnect" href="https://b.wal.co"/>
<title>전자제품 - Walmart.com</title>
<!-- 간결함을 위해 생략 ... -->
좋습니다! 이것이 일반 월마트 “키보드” 제품 페이지의 HTML입니다.
4단계: 데이터 스크래핑 로직 추가
curl_cffi는 단순히 페이지의 HTML을 가져오는 데 도움을 주는 HTTP 클라이언트입니다. 웹 스크래핑을 수행하려면 BeautifulSoup과 같은 HTML 파싱 라이브러리도 필요합니다. 자세한 안내는 BeautifulSoup 웹 스크래핑 가이드를 참조하세요.
활성화된 가상 환경에서 BeautifulSoup을 설치하세요:
pip install beautifulsoup4
scraper.py에서 임포트합니다:
from bs4 import BeautifulSoup
그런 다음 페이지의 HTML을 파싱하는 데 사용하세요:
soup = BeautifulSoup(response.text, "html.parser")
"html.parser" 는 BeautifulSoup이 HTML 문자열을 파싱하는 데 사용하는 Python 표준 라이브러리의 기본 HTML 파서입니다. 이제 soup에는 페이지에서 HTML 요소를 선택하고 데이터를 추출하는 데 필요한 모든 메서드가 포함됩니다.
이 예제에서는 데이터 파싱이 핵심이 아니므로 페이지 제목만 스크래핑합니다. find() 메서드를 사용해 CSS 선택자로 제목을 선택한 후 text 속성으로 텍스트에 접근할 수 있습니다:
title_element = soup.find("title")
title = title_element.text
고급 스크래핑 로직에 대해서는 Walmart 스크래핑 방법 가이드를 참조하세요.
마지막으로 페이지 제목을 출력합니다:
print(title)
훌륭합니다! 기본적인 웹 스크래핑 로직을 구현하셨습니다.
5단계: 모든 것을 통합하기
다음은 최종 curl_cffi 웹 스크래핑 스크립트입니다:
from curl_cffi import requests
from bs4 import BeautifulSoup
# "keyboard"로 월마트 검색 페이지에 GET 요청 전송
response = requests.get("https://www.walmart.com/search?q=keyboard", impersonate="chrome")
# 페이지에서 HTML 추출
html = response.text
# BeautifulSoup으로 응답 콘텐츠 파싱
soup = BeautifulSoup(response.text, "html.parser")
# CSS 선택자로 title 태그 찾기 및 출력
title_element = soup.find("title")
# 해당 태그에서 데이터 추출
title = title_element.text
# 더 복잡한 스크래핑 로직...
# 스크래핑된 데이터 출력
print(title)
다음 명령어로 실행:
python3 scraper.py
또는 Windows에서는 동일하게:
python scraper.py
결과는 다음과 같습니다:
Electronics - Walmart.com
impersonate="chrome" 인수를 제거하면 대신 다음과 같은 결과가 출력됩니다:
로봇인가, 인간인가?
이는 브라우저 사칭이 스크래핑 방지 조치를 회피하는 데 얼마나 중요한 역할을 하는지 보여줍니다.
미션 완료!
curl_cffi: 고급 사용법
라이브러리의 작동 방식을 이해하셨다면, 이제 좀 더 고급 시나리오를 탐구할 준비가 되셨습니다.
브라우저 사칭 선택
curl_cffi는 여러 브라우저의 사칭을 지원합니다. 각 브라우저는 고유한 레이블과 연결되어 있으며, 아래와 같이 impersonate 인자로 전달할 수 있습니다:
response = requests.get("<YOUR_URL>", impersonate="<BROWSER_LABEL>")
지원되는 브라우저의 레이블은 다음과 같습니다:
chrome99,chrome100,chrome101,chrome104,chrome107,chrome110,chrome116,chrome119,chrome120,chrome123,chrome124,chrome131chrome99_android,chrome131_androidedge99,edge101safari15_3,safari15_5,safari17_0,safari17_2_ios,safari18_0,safari18_0_ios
참고:
- 최신 브라우저 버전을 항상 모방하려면
chrome,safari및safari_ios를사용하면 됩니다. - 현재 Firefox는 지원되지 않습니다. WebKit 기반 브라우저만 지원됩니다.
- 브라우저 버전은 지문이 변경될 때만 추가됩니다.
chrome122와같이 버전이 생략된 경우에도 이전 버전의 헤더를 사용하여 해당 버전을 모방할 수 있습니다. - 비(非) 브라우저 대상의 경우,
ja3,akamai및 유사한 인수를 사용하여 사용자 정의 TLS 지문을 지정하십시오. 자세한 내용은 사칭에 관한 문서를 참조하십시오.
세션 관리
requests 라이브러리와 마찬가지로 curl-cfii도 세션을 지원합니다. 세션 객체를 사용하면 쿠키, 헤더 또는 기타 세션별 데이터와 같은 특정 매개 변수를 여러 요청에 걸쳐 유지할 수 있습니다.
cURL Impersonate 라이브러리의 Python 바인딩을 사용하여 세션을 정의하는 방법은 다음과 같습니다:
# 새 세션 생성
session = requests.Session()
# 이 엔드포인트는 서버에 쿠키를 설정합니다
session.get("https://httpbin.io/cookies/set/userId/5", impersonate="chrome")
# 세션 쿠키가 저장되었는지 확인하기 위해 출력
print(session.cookies)
위 스크립트의 출력 결과는 다음과 같습니다:
<Cookies[<Cookie userId=5 for httpbin.org />]>
결과는 서버에서 정의한 쿠키 저장 등 요청 간 상태를 유지하는 세션의 기능을 입증합니다.
프록시 통합
requests 라이브러리와 마찬가지로 curl_cffi도 proxies 객체를 통해 프록시 통합을 지원합니다:
# 프록시 URL 정의
proxy = "YOUR_PROXY_URL"
# HTTP 및 HTTPS용 프록시 사전 생성
proxies = {"http": proxy, "https": proxy}
# 프록시 및 브라우저 임프레션 사용 요청 수행
response = requests.get("<YOUR_URL>", impersonate="chrome", proxies=proxies)
기본 API가 requests와 매우 유사하므로, Requests에서 프록시를 사용하는 방법에 대한 가이드를 참조하세요.
비동기 API
curl_cffi는 AsyncSession 객체를 통해 asyncio를 이용한 비동기 요청을 지원합니다:
from curl_cffi.requests import AsyncSession
import asyncio
# 비동기 코드를 실행할 비동기 함수 정의
async def fetch_data():
async with AsyncSession() as session:
# 비동기 GET 요청 수행
response = await session.get("https://httpbin.org/anything", impersonate="chrome")
# 응답 텍스트 출력
print(response.text)
# 비동기 함수 실행
asyncio.run(fetch_data())
AsyncSession을 사용하면 여러 비동기 요청을 효율적으로 처리하기 쉬워지며, 이는 웹 스크래핑 속도를 높이는 데 매우 중요합니다.
WebSockets 연결
curl_cffi는 WebSocket 클래스를 통해 웹소켓도 지원합니다:
from curl_cffi.requests import WebSocket
# 수신 메시지를 처리할 콜백 함수 정의
def on_message(ws, message):
print(message)
# 콜백 함수와 함께 WebSocket 연결 초기화
ws = WebSocket(on_message=on_message)
# 샘플 WebSocket 서버에 연결하고 메시지 수신 대기
ws.run_forever("wss://api.gemini.com/v1/marketdata/BTCUSD")
이는 웹소켓을 사용하여 데이터를 동적으로 채우는 사이트나 API에서 실시간 데이터를 스크래핑하는 데 특히 유용합니다. 금융 시장 데이터, 실시간 스포츠 점수, 실시간 채팅을 제공하는 사이트 등이 그 예입니다.
렌더링된 페이지를 스크래핑하는 대신, 효율적인 데이터 수집을 위해 웹소켓 채널을 직접 타겟팅할 수 있습니다.
참고: AsyncWebSocket 클래스를 사용하면 비동기적으로 WebSocket을활용할 수 있습니다.
웹 스크래핑을 위한 curl_cffi vs Requests vs AIOHTTP vs HTTPX 비교
다음은 웹 스크래핑을 위한 curl_cffi와 다른 인기 있는 Python HTTP 클라이언트를 비교한 요약표입니다:
| 기능 | curl_cffi | Requests | AIOHTTP | HTTPX |
|---|---|---|---|---|
| 동기 API | ✔️ | ✔️ | ❌ | ✔️ |
| 비동기 API | ✔️ | ❌ | ✔️ | ✔️ |
**WebSocket**지원 |
✔️ | ❌ | ✔️ | ❌ |
| 연결 풀링 | ✔️ | ✔️ | ✔️ | ✔️ |
| HTTP/2 지원 | ✔️ | ❌ | ❌ | ✔️ |
**사용자 에이전트** 사용자 정의 |
✔️ | ✔️ | ✔️ | ✔️ |
| TLS 지문 스푸핑 | ✔️ | ❌ | ❌ | ❌ |
| 속도 | 높음 | 중간 | 높음 | 중간 |
| 재시도 메커니즘 | ❌ | HTTP 어댑터를통해 사용 가능 |
타사 라이브러리에서만 사용 가능 | 내장 전송 계층을통해 사용 가능 |
| 프록시 통합 | ✔️ | ✔️ | ✔️ | ✔️ |
| 쿠키 처리 | ✔️ | ✔️ | ✔️ | ✔️ |
웹 스크래핑을 위한curl_cffi 대안
curl_cffi는 웹 스크래핑에 수동적인 접근 방식을 취하며, 대부분의 코드를 직접 작성해야 합니다. 단순한 정적 웹사이트에는 적합하지만, 동적 또는 보안 수준이 높은 사이트를 대상으로 할 때는 문제가 발생하기 쉽습니다.
Bright Data는 웹 스크래핑을 위한 다양한 curl_cffi 대안을 제공합니다:
- 스크래핑 브라우저 API: Puppeteer, Selenium, Playwright와 통합된 완전 관리형 클라우드 브라우저 인스턴스입니다. 이 브라우저들은 내장된 CAPTCHA 해결 기능과 자동 프록시 로테이션을 제공하여, 실제 사용자와 동일하게 웹사이트와 상호작용하면서 안티봇 방어 체계를 우회합니다.
- 웹 스크레이퍼 API: 100개 이상의 인기 도메인에서 최신 구조화된 데이터를 가져오기 위한 사전 구성된 엔드포인트입니다. 이 API는 윤리적이고 규정을 준수하며, HTTPX 또는 기타 HTTP 클라이언트를 사용한 간편한 데이터 추출을 지원합니다.
- 노코드 스크레이퍼: 코딩 없이 직관적으로 데이터 수집을 제공하는 온디맨드 서비스입니다. 인프라, 프록시, 스크래핑 방어 장벽을 다루지 않고도 제어성, 확장성, 유연성을 제공합니다.
- 데이터셋: 다양한 웹사이트의 사전 구축된 데이터셋에 접근하거나 요구 사항에 맞게 데이터 수집을 맞춤 설정하세요.
이러한 솔루션은 강력한 확장성과 규정 준수 기능을 갖춘 데이터 추출 도구를 제공하여 수동 작업을 줄여 스크래핑을 간소화합니다.
결론
이 글에서는 웹 스크래핑을 위한 curl_cffi 라이브러리 사용법을 알아보았습니다. 그 목적, 주요 기능 및 장점을 살펴보았습니다. 이 HTTP 클라이언트는 실제 브라우저를 모방하는 요청을 생성하는 빠르고 신뢰할 수 있는 옵션으로 탁월합니다.
그러나 자동화된 HTTP 요청은 공개 IP 주소를 노출시켜 신원과 위치를 드러낼 수 있으며, 이는 개인정보 보호 위험을 초래합니다. 보안과 익명성을 보호하기 위한 가장 효과적인 해결책 중 하나는 프록시 서버를 사용하여 IP 주소를 숨기는 것입니다.
Bright Data는 포춘 500대 기업 및 20,000명 이상의 고객에게 서비스를 제공하는 세계 최고의 프록시 서버를 운영합니다. 다양한 프록시 유형을 제공합니다:
- 데이터센터 프록시 – 77만 개 이상의 데이터센터 IP.
- 주거용 프록시 – 195개국 이상에 걸쳐 7,200만 개 이상의 주거용 IP.
- ISP 프록시 – 70만 개 이상의 ISP IP 주소.
Bright Data 무료 계정을 지금 생성하여 당사의 프록시 및 스크래핑 솔루션을 테스트해 보세요!






