
이 가이드에서는 다음을 다룹니다:
- Jsoup란 무엇인가?
- 필수 조건
- Jsoup을 사용한 웹 스크레이퍼 구축 방법
- 결론
Jsoup이란 무엇인가?
Jsoup은 Java HTML 파서입니다. 즉, Jsoup은 모든 HTML 문서를 파싱할 수 있게 해주는 Java 라이브러리입니다. Jsoup을 사용하면 로컬 HTML 파일을 파싱하거나 URL에서 원격 HTML 문서를 다운로드할 수 있습니다.
Jsoup는 또한 DOM을 다루기 위한 다양한 메서드를 제공합니다. 구체적으로 CSS 선택자와 Jquery와 유사한 메서드를 사용하여 HTML 요소를 선택하고 그로부터 데이터를 추출할 수 있습니다. 이로 인해 Jsoup는 초보자부터 전문가까지 모두에게 효과적인 웹 스크래핑 Java 라이브러리입니다.
Jsoup이 자바에서 웹 스크래핑을 수행하는 유일한 라이브러리는 아닙니다. HtmlUnit 역시 널리 쓰이는 자바 웹 스크래핑 라이브러리입니다. 자바 웹 스크래핑에 관한 저희 HtmlUnit 가이드를 참고하세요.
필수 조건
첫 코드 라인을 작성하기 전에 아래 필수 조건을 충족해야 합니다:
- Java >= 8: 8 이상 버전의 Java라면 모두 사용 가능합니다. LTS(장기 지원) 버전의 Java를 다운로드하여 설치하는 것이 권장됩니다. 특히, 본 튜토리얼은 Java 17을 기준으로 합니다. 작성 시점 기준, Java 17은 최신 LTS 버전입니다.
- Maven 또는 Gradle: 선호하는 Java 빌드 자동화 도구를 선택할 수 있습니다. 특히, 종속성 관리 기능을 위해 Maven 또는 Gradle이 필요합니다.
- 자바를 지원하는 고급 IDE: Maven 또는 Gradle과 함께 자바를 지원하는 어떤 IDE도 괜찮습니다. 이 튜토리얼은 아마도 가장 우수한 자바 IDE인 IntelliJ IDEA를 기준으로 합니다.
필요한 모든 사전 조건을 충족시키기 위해 위 링크를 따라 필요한 모든 것을 다운로드하고 설치하세요. 순서대로 Java, Maven 또는 Gradle, 그리고 Java용 IDE를 설정하세요. 일반적인 문제와 이슈를 피하기 위해 공식 설치 가이드를 따르세요.
이제 모든 필수 조건을 충족하는지 확인해 보겠습니다.
Java가 올바르게 설정되었는지 확인하기
터미널을 엽니다. 아래 명령어로 Java 설치 및 Java 경로 설정이 올바른지 확인할 수 있습니다:
java -version이 명령어는 다음과 유사한 결과를 출력해야 합니다:
java version "17.0.5" 2022-10-18 LTS
Java(TM) SE Runtime Environment (build 17.0.5+9-LTS-191)
Java HotSpot(TM) 64-Bit Server VM (build 17.0.5+9-LTS-191, mixed mode, sharing)Maven 또는 Gradle이 설치되었는지 확인하십시오
Maven을 선택한 경우 터미널에서 다음 명령을 실행하세요:
mvn -v다음과 같이 설정된 Maven 버전에 대한 정보가 표시되어야 합니다:
Apache Maven 3.8.6 (84538c9988a25aec085021c365c560670ad80f63)
Maven home: C:Mavenapache-maven-3.8.6
Java 버전: 17.0.5, 공급업체: Oracle Corporation, 런타임: C:Program FilesJavajdk-17.0.5
기본 로케일: en_US, 플랫폼 인코딩: Cp1252
OS 이름: "windows 11", 버전: "10.0", 아키텍처: "amd64", 제품군: "windows"Gradle을 선택한 경우 터미널에서 다음 명령을 실행하세요:
gradle -v마찬가지로, 설치한 Gradle 버전에 대한 정보가 아래와 같이 출력됩니다:
------------------------------------------------------------
Gradle 7.5.1
------------------------------------------------------------
빌드 시간: 2022-08-05 21:17:56 UTC
리비전: d1daa0cbf1a0103000b71484e1dbfe096e095918
Kotlin: 1.6.21
Groovy: 3.0.10
Ant: Apache Ant(TM) version 1.10.11 compiled on July 10 2021
JVM: 17.0.5 (Oracle Corporation 17.0.5+9-LTS-191)
OS: Windows 11 10.0 amd64좋습니다! 이제 자바에서 Jsoup을 사용한 웹 스크래핑 방법을 배울 준비가 되었습니다!
Jsoup을 사용한 웹 스크레이퍼 구축 방법
여기서는 Jsoup을 사용한 웹 스크래핑 스크립트 구축 방법을 배울 것입니다. 이 스크립트는 웹사이트에서 데이터를 자동으로 추출할 수 있습니다. 구체적으로 대상 웹사이트는 ‘추출할 인용문(Quotes to Scrape)’입니다. 이 프로젝트가 생소하다면, 이는 웹 스크래핑을 위한 샌드박스에 불과합니다.
Quotes to Scrape의 모습은 다음과 같습니다:
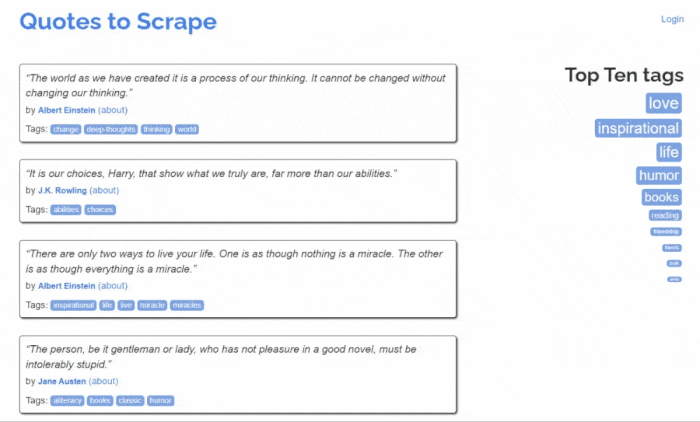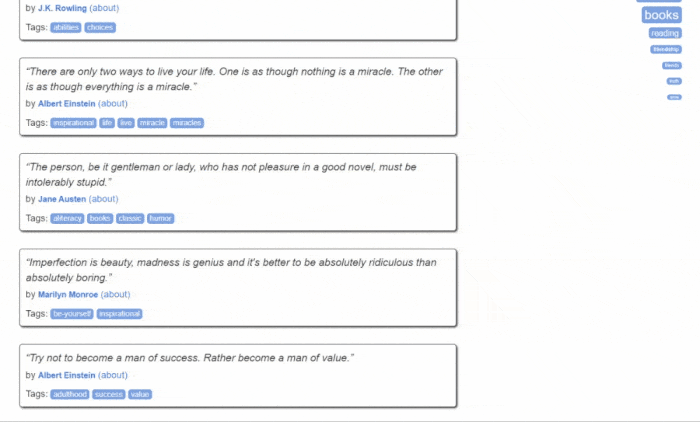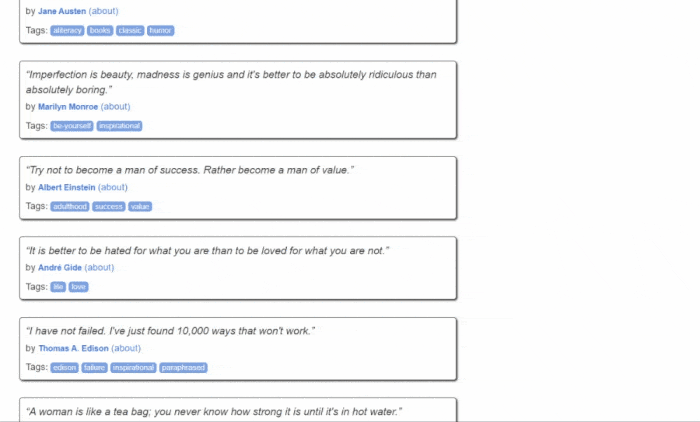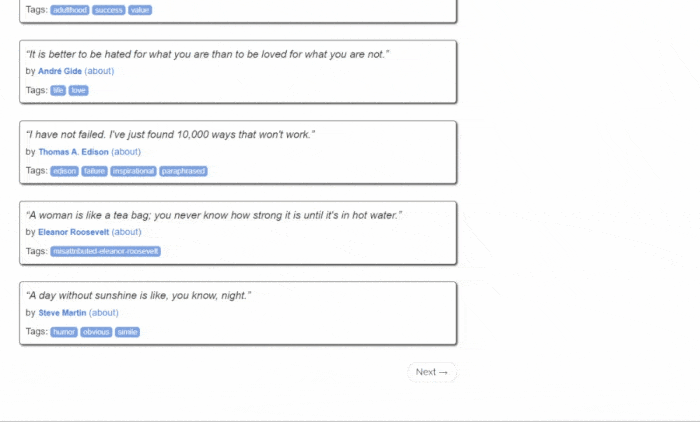
보시다시피 대상 웹사이트는 단순히 페이지별로 나열된 명언 목록을 포함하고 있습니다. Jsoup 웹 스크레이퍼의 목표는 각 페이지를 순회하며 모든 명언을 추출하고, 이 데이터를 CSV 형식으로 반환하는 것입니다.
이제 단계별 Jsoup 튜토리얼을 따라 간단한 웹 스크레이퍼를 구축하는 방법을 배워보세요!
1단계: Java 프로젝트 설정
여기서는 IntelliJ IDEA 2022.2.3에서 Java 프로젝트를 초기화하는 방법을 보여드리겠습니다. 다른 IDE를 사용해도 무방합니다. IntelliJ IDEA에서는 몇 번의 클릭만으로 Java 프로젝트를 설정할 수 있습니다. IntelliJ IDEA를 실행하고 로딩이 완료될 때까지 기다리세요. 그런 다음 상단 메뉴에서 파일 > 새로 만들기 > 프로젝트... 옵션을 선택하세요.
이제 새 프로젝트 팝업에서 다음과 같이 Java 프로젝트를 초기화하세요:
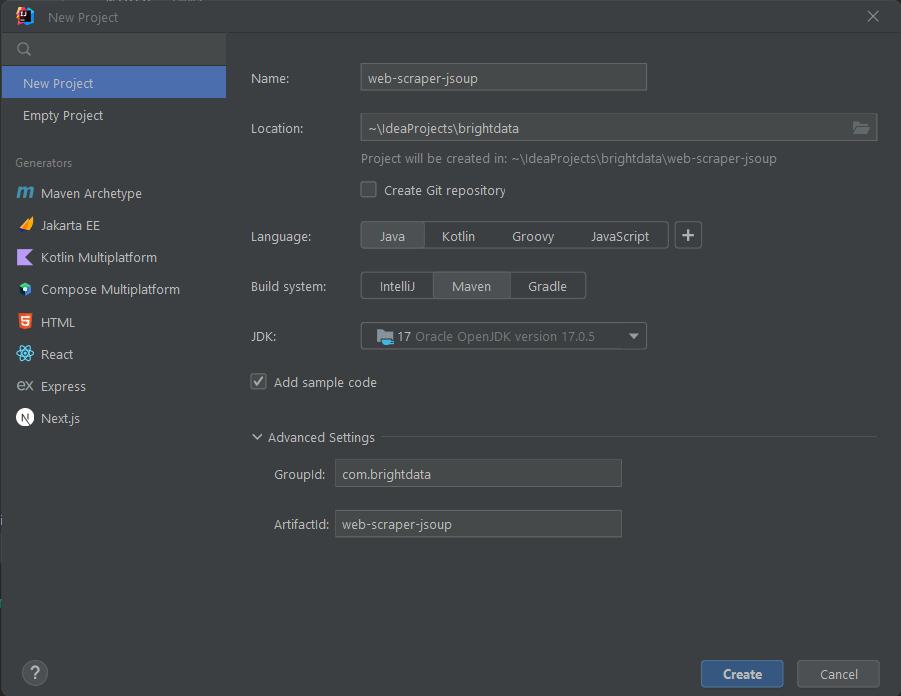
프로젝트 이름과 위치를 지정하고, 프로그래밍 언어로 Java를 선택한 후 설치한 빌드 도구에 따라 Maven 또는 Gradle 중 하나를 선택하세요. 생성 버튼을 클릭하고 IntelliJ IDEA가 Java 프로젝트를 초기화할 때까지 기다리세요. 이제 다음과 같은 빈 Java 프로젝트가 표시되어야 합니다:
이제 Jsoup을 설치하고 웹에서 데이터를 스크래핑할 시간입니다!
2단계: Jsoup 설치
Maven 사용자인 경우 pom.xml 파일의 dependencies 태그 안에 아래 줄을 추가하세요:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>이제 Maven pom.xml 파일은 다음과 같아야 합니다:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.brightdata</groupId>
<artifactId>web-scraper-jsoup</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.3</version>
</dependency>
</dependencies>
</project>또는 Gradle 사용자인 경우, build.gradle 파일의 dependencies 객체에 다음 줄을 추가하세요:
implementation "org.jsoup:jsoup:1.15.3"이제 프로젝트의 종속성에 jsoup을 추가했습니다. 이제 설치할 차례입니다. IntelliJ IDEA에서는 아래의 Gradle/Maven 재로드 버튼을 클릭하세요:
이렇게 하면 jsoup 종속성이 설치됩니다. 설치 과정이 완료될 때까지 기다리세요. 이제 모든 Jsoup 기능을 사용할 수 있습니다. Main.java 파일 상단에 다음 import 문장을 추가하여 Jsoup이 올바르게 설치되었는지 확인할 수 있습니다:
import org.jsoup.*;IntelliJ IDEA에서 오류가 발생하지 않으면, 이제 Java 웹 스크래핑 스크립트에서 Jsoup을 사용할 수 있음을 의미합니다.
이제 Jsoup으로 웹 스크레이퍼를 코딩해 보겠습니다!
3단계: 대상 웹 페이지에 연결하기
Jsoup을 사용하면 단 한 줄의 코드로 대상 웹사이트에 연결할 수 있습니다:
// HTTP GET 요청으로 대상 웹사이트 다운로드
Document doc = Jsoup.connect("https://quotes.toscrape.com/").get();Jsoup의 connect() 메서드를 통해 웹사이트에 연결할 수 있습니다. 내부적으로는 Jsoup가 매개변수로 지정된 URL에 HTTP GET 요청을 수행하고, 대상 서버가 반환한 HTML 문서를 가져와 doc Jsoup Document 객체에 저장합니다.
connect()가 실패하면 Jsoup이 IOException을 발생시킨다는 점을 명심하세요. 여러 이유로 발생할 수 있습니다. 그러나 많은 웹사이트가 유효한 User-Agent 헤더가 포함되지 않은 요청을 차단한다는 점을 인지해야 합니다. 익숙하지 않다면, User-Agent 헤더는 요청이 발생한 애플리케이션과 OS 버전을 식별하는 문자열 값입니다. 웹 스크래핑을 위한User-Agent에 대해 자세히 알아보세요.
Jsoup 에서 User-Agent 헤더는 다음과 같이 지정할 수 있습니다:
Document doc = Jsoup
.connect("https://quotes.toscrape.com/")
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();특히, Jsoup의 userAgent() 메서드를 사용하면 User-Agent 헤더를 설정할 수 있습니다. 다른 HTTP 헤더 값은 header() 메서드를 통해 설정해야 합니다.
이제 Main.java 클래스는 다음과 같이 보일 것입니다:
package com.brightdata;
import org.jsoup.*;
import org.jsoup.nodes.*;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
// HTTP GET 요청으로 대상 웹사이트 다운로드
Document doc = Jsoup
.connect("https://quotes.toscrape.com/")
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
}
}대상 웹사이트를 분석하여 데이터를 추출하는 방법을 알아봅시다.
4단계: HTML 페이지 검사
HTML 문서에서 데이터를 추출하려면 먼저 웹 페이지의 HTML 코드를 분석해야 합니다. 먼저 스크래핑하려는 데이터가 포함된 HTML 요소를 식별해야 합니다. 그런 다음 이러한 HTML 요소를 선택할 방법을 찾아야 합니다.
이 모든 작업은 브라우저의 개발자 도구를 통해 수행할 수 있습니다. Google Chrome이나 크로미움 기반 브라우저에서 관심 있는 데이터를 표시하는 HTML 요소를 마우스 오른쪽 버튼으로 클릭하세요. 그런 다음 ‘검사’를 선택합니다.
이제 다음과 같은 화면이 표시됩니다:
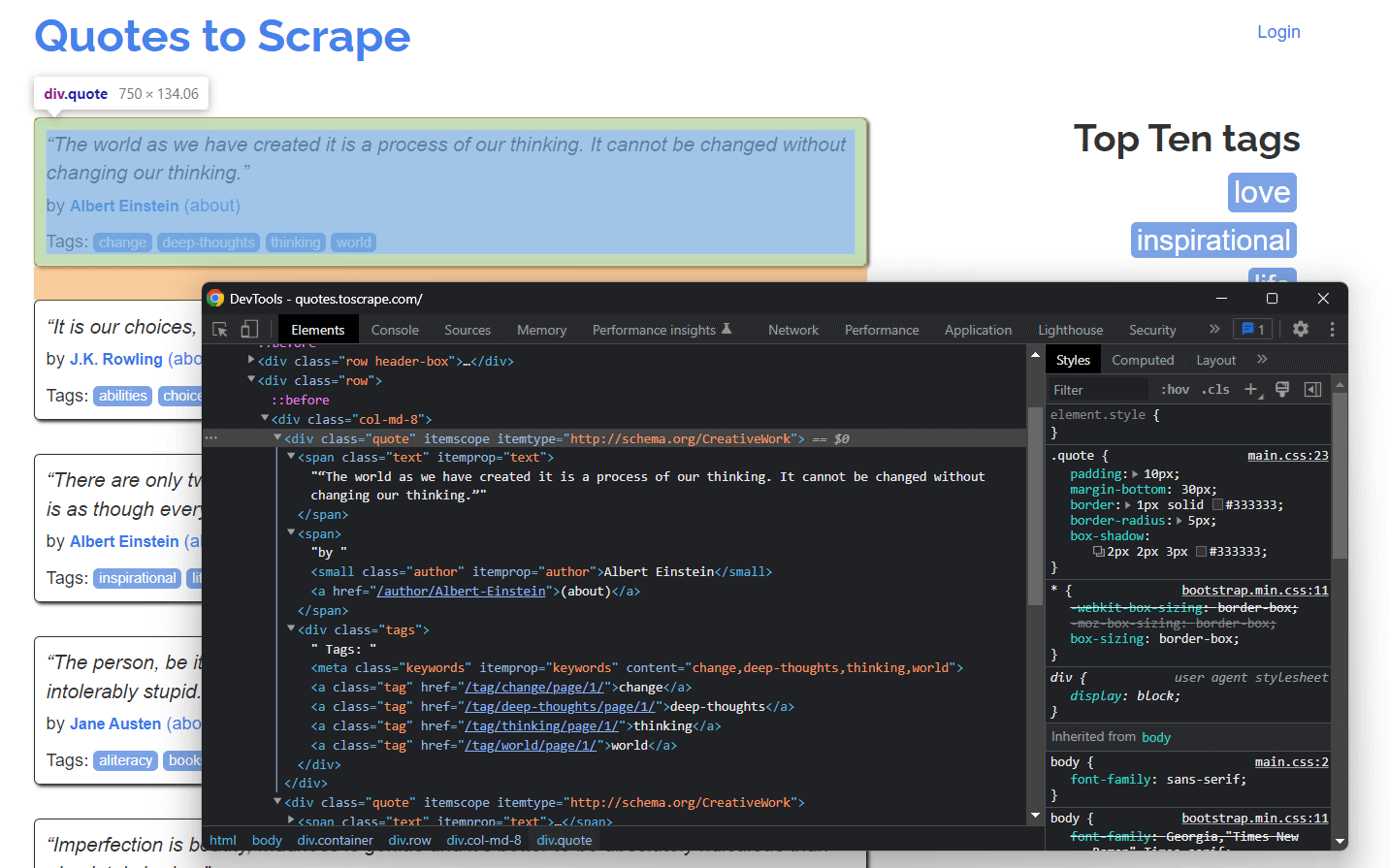
HTML 코드를 살펴보면 각 인용문이 <div> HTML로 감싸져 있음을 확인할 수 있습니다. 구체적으로 이 <div> 요소는 다음을 포함합니다:
- 인용문 텍스트를 포함하는
<span>HTML 요소 - 저자의 이름을 포함하는
<small>HTML 요소 - 인용문과 관련된 태그를 포함하는
<a>HTML 요소 목록을 가진<div>요소
이제 이 HTML 요소들에 적용된 CSS 클래스를 살펴보세요. 이를 통해 DOM에서 해당 HTML 요소들을 추출하는 데 필요한 CSS 선택자를 정의할 수 있습니다. 구체적으로, 아래 .quote에 CSS 선택자를 적용하면 인용문과 관련된 모든 데이터를 가져올 수 있습니다:
.text.author.tags .tag
이제 Jsoup에서 이를 수행하는 방법을 알아봅시다.
5단계: Jsoup으로 HTML 요소 선택하기
Jsoup Document 클래스는 DOM에서 HTML 요소를 선택하는 여러 방법을 제공합니다. 가장 중요한 방법들을 살펴보겠습니다.
Jsoup은 태그를 기반으로 HTML 요소를 추출할 수 있습니다:
// 모든 <div> HTML 요소 선택
Elements divs = doc.getElementsByTag("div");이는 DOM에 포함된 <div> HTML 요소 목록을 반환합니다.
마찬가지로 클래스로 HTML 요소를 선택할 수 있습니다:
// ".quote" HTML 요소 가져오기
Elements quotes = doc.getElementsByClass("quote");id 속성을 기반으로 단일 HTML 요소를 가져오려면 다음을 사용할 수 있습니다:
// "#quote-1" HTML 요소 가져오기
Element div = doc.getElementById("quote-1");속성을 기준으로 HTML 요소를 선택할 수도 있습니다:
// "value" 속성을 가진 모든 HTML 요소 선택
Elements htmlElements = doc.getElementsByAttribute("value");또는 특정 텍스트를 포함하는 요소를 선택할 수도 있습니다:
// "for" 단어를 포함하는 모든 HTML 요소 선택
Elements htmlElements = doc.getElementsContainingText("for");이것들은 몇 가지 예시일 뿐입니다. Jsoup는 웹 페이지에서 HTML 요소를 선택하는 20가지 이상의 다양한 방법을 제공합니다. 모두 확인해 보세요.
앞서 배운 바와 같이 CSS 선택자는 HTML 요소를 선택하는 효과적인 방법입니다. Jsoup에서는 select() 메서드를 통해 CSS 선택자를 적용하여 요소를 가져올 수 있습니다:
// 모든 quote HTML 요소 선택
Elements quoteElements = doc.getElementsByClass(".quote");Elements는 ArrayList를 상속하므로, 이를 반복하여 모든 Jsoup 요소를 얻을 수 있습니다. 모든 HTML 선택 메서드는 단일 요소에도 적용할 수 있다는 점에 유의하세요. 이렇게 하면 선택 논리가 선택된 HTML 요소의 자식 요소들로 제한됩니다.
따라서 아래와 같이 각 .quote 요소에 대해 원하는 HTML 요소를 선택할 수 있습니다:
for (Element quoteElement: quoteElements) {
Element text = quoteElement.select(".text").first();
Element author = quoteElement.select(".author").first();
Elements tags = quoteElement.select(".tag");
}이제 이러한 HTML 요소에서 데이터를 추출하는 방법을 알아보겠습니다.
6단계: Jsoup을 사용한 웹 페이지 데이터 추출
먼저, 스크랩한 데이터를 저장할 Java 클래스가 필요합니다. 메인 패키지에 Quote.java 파일을 생성하고 다음과 같이 초기화하세요:
package com.brightdata;
package com.brightdata;
public class Quote {
private String text;
private String author;
private String tags;
public String getText() {
return text;
}
public void setText(String text) {
this.text = text;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getTags() {
return tags;
}
public void setTags(String tags) {
this.tags = tags;
}
}이제 이전 섹션 마지막에 제시된 코드 조각을 확장해 보겠습니다. 선택된 HTML 요소에서 원하는 데이터를 추출하여 다음과 같이 Quote 객체에 저장합니다:
// 스크랩된 데이터를 담을 Quote 데이터 객체 목록 초기화
// List<Quote> quotes = new ArrayList<>();
// 제품 HTML 요소 목록 가져오기
// 모든 quote HTML 요소 선택
// Elements quoteElements = doc.select(".quote");
// HTML 인용문 목록 quoteElements 반복
for (Element quoteElement : quoteElements) {
// 인용문 데이터 객체 초기화
Quote quote = new Quote();
// 인용문 텍스트 추출 및 특수 문자 제거
String text = quoteElement.select(".text").first().text()
.replace("“", "")
.replace("”", "");
String author = quoteElement.select(".author").first().text();
// 태그 목록 초기화
List<String> tags = new ArrayList<>();
// 태그 목록 반복
for (Element tag : quoteElement.select(".tag")) {
// 태그 문자열을 태그 목록에 추가
tags.add(tag.text());
}
// 수집한 데이터를 Quote 객체에 저장
quote.setText(text);
quote.setAuthor(author);
quote.setTags(String.join(", ", tags)); // 태그를 "A, B, ..., Z" 형식의 문자열로 병합
// 스크랩된 인용문 목록에 Quote 객체 추가
quotes.add(quote);
}각 명언은 하나 이상의 태그를 가질 수 있으므로, 모든 태그를 Java 리스트에 저장할 수 있습니다. 그런 다음 String.join() 메서드를 사용하여 문자열 리스트를 단일 문자열로 줄일 수 있습니다. 마지막으로 이 문자열을 quote 객체에 저장할 수 있습니다.
for 루프가 끝날 때쯤이면 quotes에는 대상 웹사이트 홈페이지에서 추출한 모든 인용문 데이터가 저장될 것입니다. 하지만 대상 웹사이트는 수많은 페이지로 구성되어 있죠!
Jsoup을 사용해 전체 웹사이트를 크롤링하는 방법을 알아봅시다.
7단계: Jsoup로 웹사이트 전체 크롤링하기
Quotes to Scrape 홈페이지의 ‘다음 →’ 버튼을 자세히 살펴보세요. 브라우저 개발자 도구로 이 HTML 요소를 검사합니다. 버튼을 마우스 오른쪽 버튼으로 클릭하고 ‘검사’를 선택하세요.
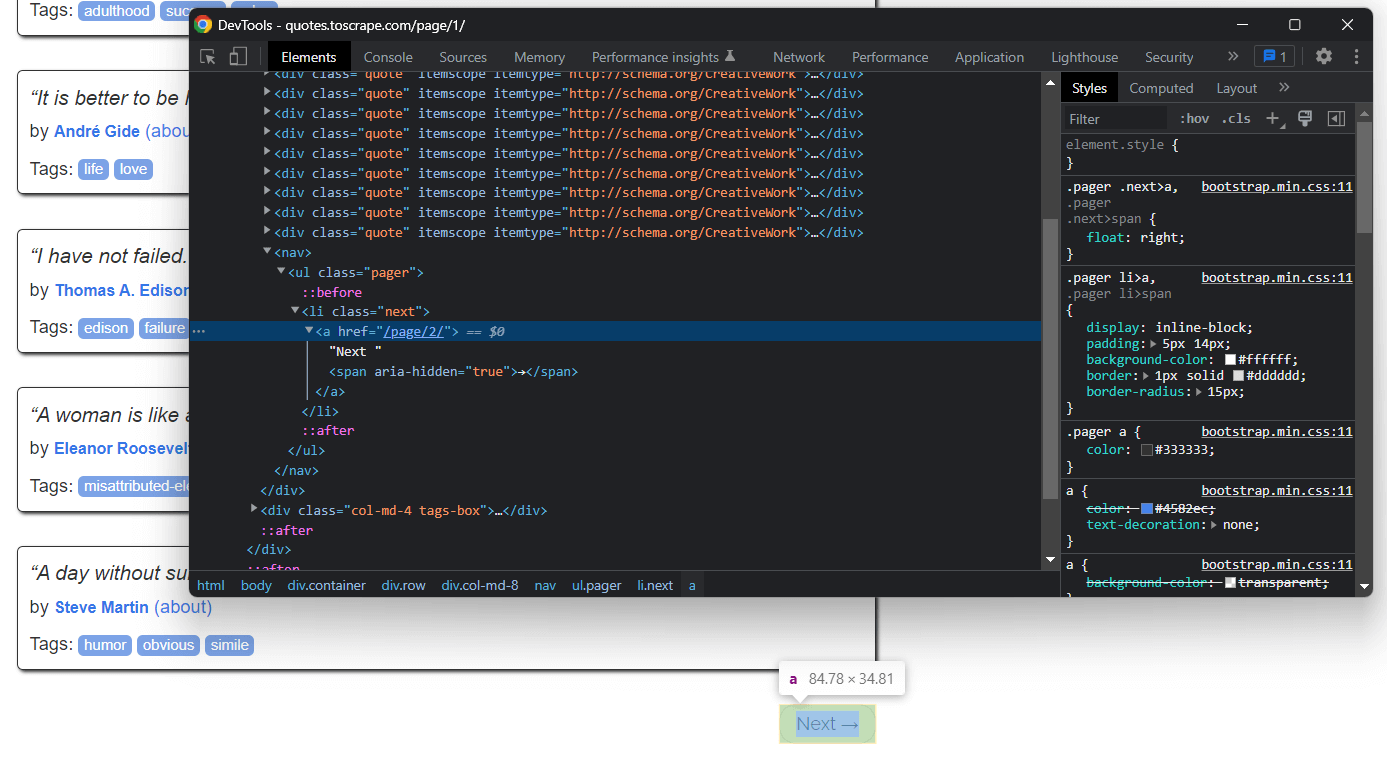
여기서 “다음 →” 버튼이 <li> HTML 요소임을 알 수 있습니다. 이 요소 안에는 다음 페이지로의 상대 URL을 저장한 <a> HTML 요소가 포함되어 있습니다. 대상 웹사이트의 마지막 페이지를 제외한 모든 페이지에서 “다음 →” 버튼을 찾을 수 있다는 점에 유의하세요. 대부분의 페이지가 있는 웹사이트는 이러한 방식을 따릅니다.
해당 <a> HTML 요소에 저장된 링크를 추출하면 스크래핑할 다음 페이지를 얻을 수 있습니다. 따라서 웹사이트 전체를 스크래핑하려면 아래 논리를 따르세요:
.nextHTML 요소 검색- 존재할 경우, 그
<a>자식 요소에 포함된 상대 URL을 추출하고 2번 단계로 진행합니다. - 존재하지 않으면 해당 페이지가 마지막 페이지이므로 여기서 작업을 종료할 수 있습니다.
- 존재할 경우, 그
- 추출한
<a>HTML 요소의 상대 URL을 웹사이트의 기본 URL과 연결합니다 - 완성된 URL을 사용하여 새 페이지에 접속합니다.
- 새 페이지에서 데이터를 스크래핑합니다.
- 1번으로 이동합니다.
이것이 웹 크롤링의 핵심입니다. Jsoup을 사용해 페이지가 나누어진 웹사이트를 다음과 같이 크롤링할 수 있습니다:
// 대상 웹사이트 홈페이지의 URL
String baseUrl = "https://quotes.toscrape.com";
// 스크랩된 데이터를 담을 Quote 데이터 객체 목록 초기화
// List<Quote> quotes = new ArrayList<>();
// 홈페이지 가져오기...
// "다음 →" HTML 요소 찾기
Elements nextElements = doc.select(".next");
// 스크랩할 다음 페이지가 존재하는 경우
while (!nextElements.isEmpty()) {
// "다음 →" HTML 요소 가져오기
Element nextElement = nextElements.first();
// 다음 페이지의 상대 URL 추출
String relativeUrl = nextElement.getElementsByTag("a").first().attr("href");
// 다음 페이지의 완전한 URL 생성
String completeUrl = baseUrl + relativeUrl;
// 다음 페이지에 연결
doc = Jsoup
.connect(completeUrl)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
// 스크래핑 로직...
// 새 페이지에서 "다음 →" HTML 요소 찾기
nextElements = doc.select(".next");
}보시다시피, 위에서 설명한 크롤링 로직은 간단한 while 루프로 구현할 수 있습니다. 코드 몇 줄이면 충분합니다. 구체적으로는 do ... while 방식을 따라야 합니다.
축하합니다! 이제 사이트 전체를 크롤링할 수 있게 되었습니다. 남은 것은 스크랩한 데이터를 더 유용한 형식으로 변환하는 방법을 배우는 것뿐입니다.
8단계: 스크랩한 데이터를 CSV로 내보내기
스크랩한 데이터를 다음과 같이 CSV 파일로 변환할 수 있습니다:
// 출력 CSV 파일 초기화
File csvFile = new File("output.csv");
// 쓰기 프로세스 종료 시 사용되지 않은 리소스 해제를 처리하기 위해 try-with-resources 사용
try (PrintWriter printWriter = new PrintWriter(csvFile)) {
// 모든 인용문 반복
for (Quote quote : quotes) {
// 인용문 데이터를 문자열 목록으로 변환
List<String> row = new ArrayList<>();
// CSV 파일 일관성 유지를 위해 각 필드를 따옴표로 감싸기
row.add(""" + quote.getText() + """);
row.add(""" +quote.getAuthor() + """);
row.add(""" +quote.getTags() + """);
// CSV 행 출력
printWriter.println(String.join(",", row));
}
}이 코드 조각은 인용문을 CSV 형식으로 변환하여 output.csv 파일에 저장합니다. 보시다시피, 이를 구현하기 위해 추가 의존성을 필요로 하지 않습니다. File을 사용하여 CSV 파일을 초기화하기만 하면 됩니다. 그런 다음 PrintWriter를 사용하여 각 인용문을 output.csv 파일에 CSV 형식의 행으로 출력함으로써 데이터를 채울 수 있습니다.
PrintWriter는 더 이상 필요하지 않을 때 항상 닫아야 합니다. 구체적으로, 위의 try-with-resources는 try 문이 끝날 때 PrintWriter 인스턴스가 닫히도록 보장합니다.
웹사이트 탐색에서 시작하여 이제 모든 데이터를 스크래핑하여 CSV 파일에 저장할 수 있습니다. 이제 완성된 Jsoup 웹 스크래퍼를 살펴볼 차례입니다.
모든 것을 통합하기
다음은 Java로 작성된 완전한 Jsoup 웹 스크래핑 스크립트입니다:
package com.brightdata;
import org.jsoup.*;
import org.jsoup.nodes.*;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
import java.io.PrintWriter;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// 대상 웹사이트 홈페이지의 URL
String baseUrl = "https://quotes.toscrape.com";
// 스크랩된 데이터를 담을 Quote 데이터 객체 목록 초기화
// List<Quote> quotes = new ArrayList<>();
// HTTP GET 요청으로 대상 웹사이트 다운로드
Document doc = Jsoup
.connect(baseUrl)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
// "다음 →" HTML 요소 찾기
Elements nextElements = doc.select(".next");
// 스크래핑할 다음 페이지가 있는 경우
while (!nextElements.isEmpty()) {
// "다음 →" HTML 요소 가져오기
Element nextElement = nextElements.first();
// 다음 페이지의 상대 URL 추출
String relativeUrl = nextElement.getElementsByTag("a").first().attr("href");
// 다음 페이지의 완전한 URL 생성
String completeUrl = baseUrl + relativeUrl;
// 다음 페이지 연결
doc = Jsoup
.connect(completeUrl)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
.get();
// 제품 HTML 요소 목록 가져오기
// 모든 인용문 HTML 요소 선택
Elements quoteElements = doc.select(".quote");
// HTML 인용문 목록(quoteElements) 반복 처리
for (Element quoteElement : quoteElements) {
// 인용문 데이터 객체 초기화
Quote quote = new Quote();
// 인용문의 텍스트 추출 및 특수 문자 제거
String text = quoteElement.select(".text").first().text();
String author = quoteElement.select(".author").first().text();
// 태그 목록 초기화
List<String> tags = new ArrayList<>();
// 태그 목록 반복
for (Element tag : quoteElement.select(".tag")) {
// 태그 문자열을 태그 목록에 추가
tags.add(tag.text());
}
// 수집한 데이터를 Quote 객체에 저장
quote.setText(text);
quote.setAuthor(author);
quote.setTags(String.join(", ", tags)); // 태그를 "A; B; ...; Z" 형식의 문자열로 병합
// 스크랩된 인용문 목록에 Quote 객체 추가
quotes.add(quote);
}
// 새 페이지에서 "Next →" HTML 요소 찾기
nextElements = doc.select(".next");
}
// 출력 CSV 파일 초기화
File csvFile = new File("output.csv");
// 쓰기 프로세스 종료 시 사용되지 않은 리소스 해제를 처리하기 위해 try-with-resources 사용
try (PrintWriter printWriter = new PrintWriter(csvFile, StandardCharsets.UTF_8)) {
// BOM 처리
printWriter.write('ufeff');
// 모든 인용문 반복
for (Quote quote : quotes) {
// 인용문 데이터를 문자열 목록으로 변환
List<String> row = new ArrayList<>();
// CSV 파일 일관성 유지를 위해 각 필드를 따옴표로 감싸기
row.add(""" + quote.getText() + """);
row.add(""" +quote.getAuthor() + """);
row.add(""" +quote.getTags() + """);
// CSV 행 출력
printWriter.println(String.join(",", row));
}
}
}
}여기서 볼 수 있듯이, 100줄 미만의 코드로 자바에서 웹 스크래퍼를 구현할 수 있습니다. Jsoup 덕분에 웹사이트에 연결하고 전체를 크롤링하며 모든 데이터를 자동으로 추출할 수 있습니다. 그런 다음 스크래핑된 데이터를 CSV 파일에 기록할 수 있습니다. 이것이 바로 이 Jsoup 웹 스크래퍼의 핵심입니다.
IntelliJ IDEA에서 아래 버튼을 클릭하여 웹 스크래핑 Jsoup 스크립트를 실행하세요:

IntelliJ IDEA가 Main.java 파일을 컴파일하고 Main 클래스를 실행합니다. 스크래핑 프로세스가 완료되면 프로젝트 루트 디렉터리에 output.csv 파일이 생성됩니다. 파일을 열면 다음과 같은 데이터가 포함되어 있을 것입니다:
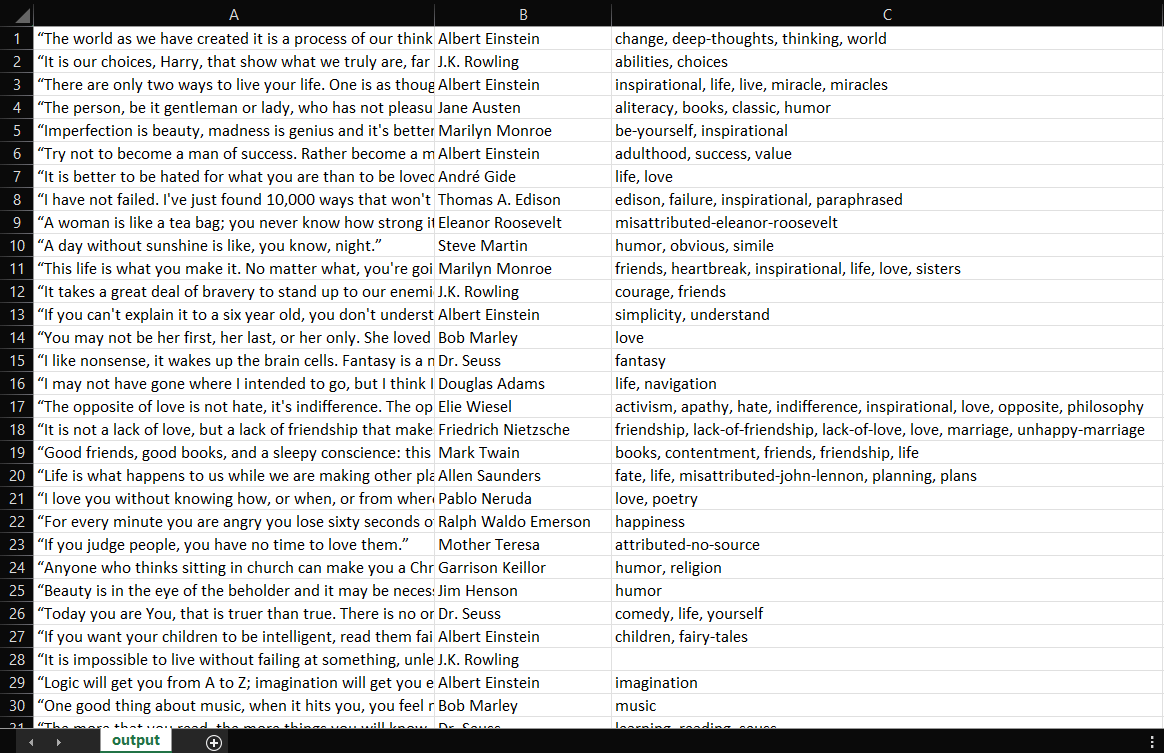
잘하셨습니다! 이제 ‘스크래핑할 명언’의 100개 명언 전체가 담긴 CSV 파일을 얻으셨습니다! 이는 Jsoup으로 웹 스크래퍼를 구축하는 방법을 배웠음을 의미합니다!
결론
이 튜토리얼에서는 웹 스크레이퍼 구축을 시작하는 데 필요한 사항, Jsoup의 개념, 그리고 이를 활용해 웹에서 데이터를 추출하는 방법을 배웠습니다. 구체적으로 실제 사례를 통해 Jsoup을 사용해 웹 스크레이핑 애플리케이션을 구축하는 과정을 살펴보았습니다. 배운 바와 같이, Java에서 Jsoup을 이용한 웹 스크레이핑은 몇 줄의 코드만으로 가능합니다.
하지만 웹 스크래핑이 그렇게 쉬운 작업은 아닙니다. 여러 가지 도전 과제가 존재하기 때문입니다. 반봇(anti-bot) 및 반스크래핑(anti-scraping) 기술이 그 어느 때보다 보편화되었다는 점을 잊지 마세요. Bright Data가 제공하는 강력하고 완벽한 기능을 갖춘 웹 스크래핑 도구만 있으면 됩니다. 스크래핑 자체를 다루고 싶지 않으신가요? 저희 데이터셋을 살펴보세요.
차단되는 것을 피하는 방법에 대해 더 알고 싶다면, Bright Data에서 제공하는 다양한 프록시 서비스 중 사용 사례에 맞는 프록시를 채택할 수 있습니다. 프로젝트에 완벽한 솔루션을 찾으려면 저희에게 문의하세요.




