

Cloud Run, Firestore, BigQuery, Workflows 및 Cloud Scheduler를 사용하여 Google Cloud에서 서버리스 스크래핑 파이프라인을 구축하는 단계별 가이드.
이 글에서 배울 내용:
- 웹 스크래핑 파이프라인에 서버리스 아키텍처가 효과적인 이유.
- 필요한 Google Cloud 인프라를 처음부터 설정하는 방법.
- Cloud Run에 비공개 스크레이퍼 서비스와 공개 API 서비스를 배포하는 방법.
- Cloud Workflows로 스크래핑 실행을 조정하고 Cloud Scheduler로 자동화하는 방법.
- Firestore와 BigQuery를 사용하여 스크래핑된 데이터를 저장하고 쿼리하는 방법.
- 전체 파이프라인이 종단 간 작동하는지 확인하는 방법.
자, 시작해 보겠습니다!
서버리스 스크래핑 파이프라인을 구축해야 하는 이유
대부분의 스크래핑 튜토리얼은 스크립트 단계에서 멈춥니다. HTML을 가져오고, 몇 가지 필드를 파싱하는 정도가 전부죠. 하지만 실제 환경에서 스크래퍼를 운영하려면 더 어려운 질문들에 답해야 합니다: 데이터는 어디로 가나요? 일정대로 실행하려면 어떻게 해야 하나요? 나중에 결과를 쿼리하려면 어떻게 해야 하나요? 스크래퍼가 실행되지 않을 때 비용을 낮게 유지하려면 어떻게 해야 하나요?
바로 여기서 서버리스가 빛을 발합니다. Google Cloud Run은 서비스가 요청을 처리할 때만 요금을 부과합니다. 관리할 서버도, 밤새 가동되어 비용을 소모하는 유휴 컴퓨팅도 없습니다. 여기에 작업 추적을 위한 Firestore, 분석을 위한 BigQuery, 오케스트레이션을 위한 Cloud Workflows를 결합하면, 유휴 시에는 제로로 확장되고 필요 시 즉시 가동되는 데이터 파이프라인 아키텍처를 구축할 수 있습니다.
이 가이드를 마치면 다음과 같은 것을 갖게 됩니다:
- 실제 스크래핑을 수행하는 Cloud Run 기반의 비공개
스크래퍼 서비스 - 데이터를 노출하는 Cloud Run 기반 공개
API 서비스. - 작업 상태와 결과를 추적하는 Firestore 컬렉션.
- 분석을 위해 쿼리할 수 있는 BigQuery 테이블.
- 전체 스크래핑 실행을 조정하는 Cloud Workflow.
- 크론 스케줄에 따라 이를 트리거하는 Cloud Scheduler 작업.
아키텍처 이해하기
명령어를 실행하기 전에 모든 구성 요소가 어떻게 연결되는지 살펴보는 것이 도움이 됩니다. 처음 구축할 때 적절한 아키텍처를 파악하는 데 상당한 시간을 투자했으니, 함께 살펴보겠습니다.
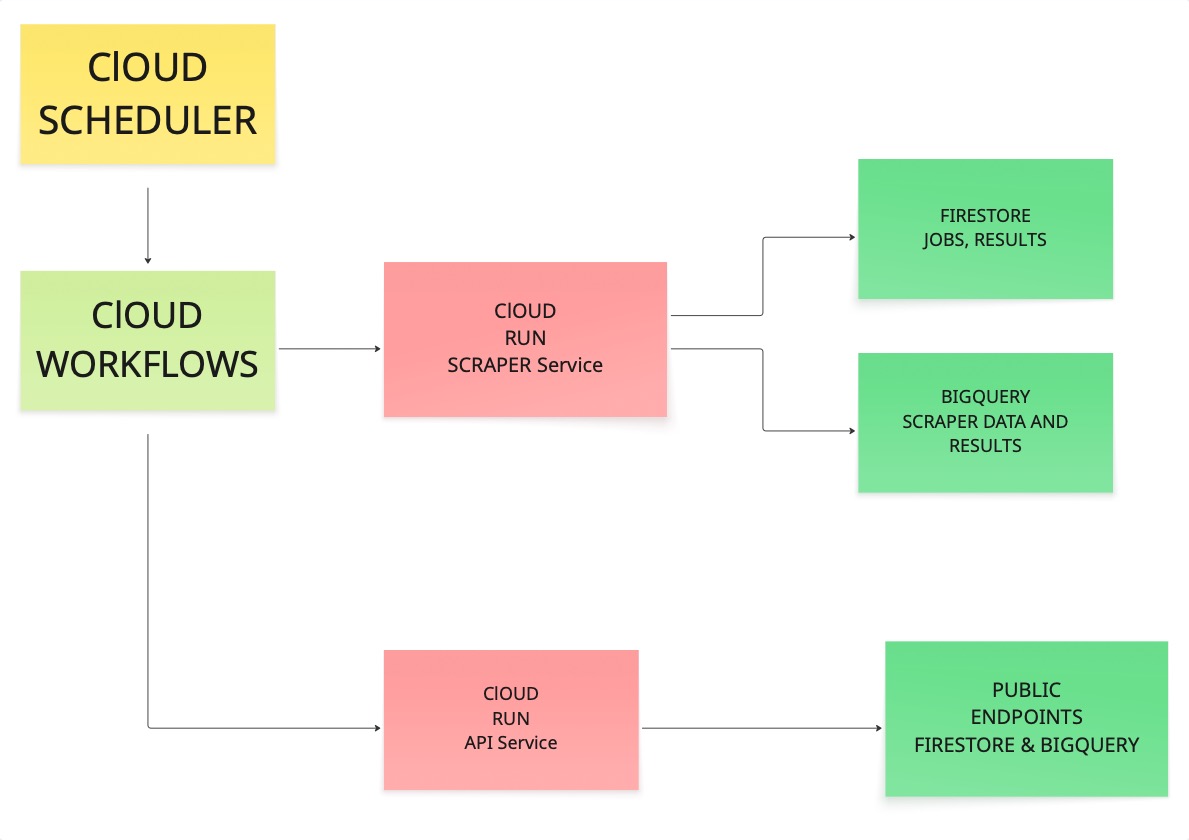
스케줄러가 워크플로를 트리거합니다. 워크플로가 스크레이퍼를 호출합니다. 스크레이퍼는 URL을 방문하여 콘텐츠를 추출하고 결과를 Firestore와 BigQuery에 모두 기록합니다. 그런 다음 API 서비스가 해당 저장소에서 데이터를 읽고 공개 엔드포인트를 통해 데이터를 노출합니다.
이 연결 고리 각각이 제대로 작동한다면, 실제 운영 환경에서 신뢰할 수 있는 시스템을 구축한 것입니다.
필수 준비 사항
시작하기 전에 다음 사항을 확인하세요:
- Google 계정
- 결제 기능이 활성화된 GCP 프로젝트(비용은 최소한이지만 결제가 활성화되어야 함).
- Node.js 18 이상.
- 컴퓨터에 설치된
gcloudCLI.
간단한 정상 작동 확인을 실행하세요:
node --version
npm --version
gcloud --version세 가지 모두 버전 번호가 출력되면 준비 완료입니다.
Google Cloud 프로젝트 설정
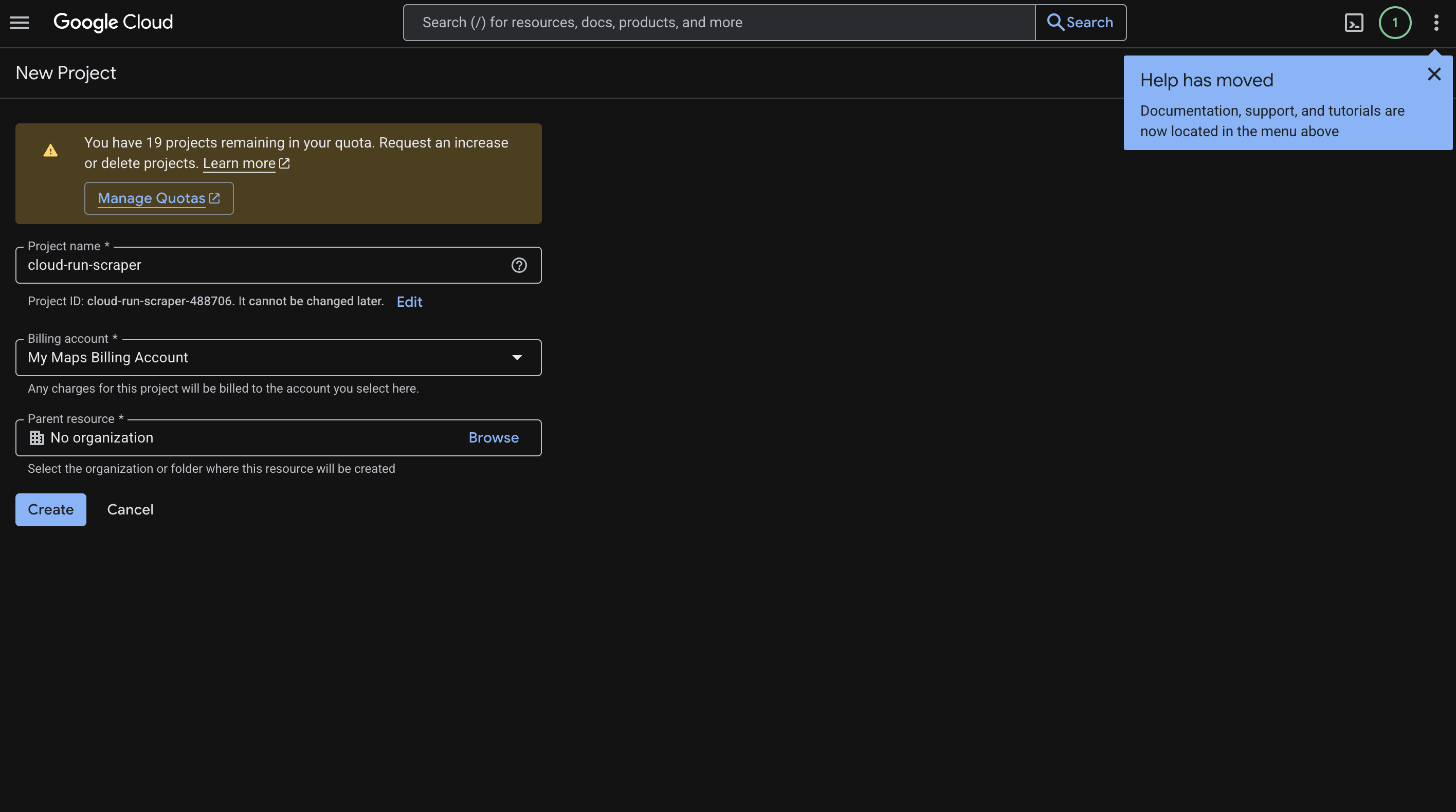
Cloud Console로 이동하여 새 프로젝트를 생성하세요. 저희는 cloud-run-scraper라고 명명했지만, 사용 사례에 맞게 원하는 이름으로 지정하시면 됩니다.
다음과 같이 진행하세요:
- 프로젝트 이름을 입력하세요.
- ‘생성’을 클릭하세요.
- 생성된 프로젝트 ID (예:
cloud-run-scraper-123456)를 복사하세요. 이 ID는 가이드 전체에서 필요합니다. - 청구로 이동하여 프로젝트에 결제 계정을 연결하세요.
해당 화면은 다음과 같습니다:
셸 구성
프로젝트 ID를 여기저기 복사 붙여넣기하지 않도록 몇 가지 환경 변수를 미리 설정하는 것이 좋습니다. 이렇게 하면 명령어가 깔끔하고 재사용 가능해집니다:
export PROJECT_ID="YOUR_PROJECT_ID"
export REGION="us-central1"
export REPO_NAME="cloud-run-scraper-repo"
export BQ_DATASET="scraper_data"
export BQ_TABLE="scraped_results"그런 다음 gcloud를 프로젝트에 연결하세요:
gcloud config set project "$PROJECT_ID"
gcloud config set run/region "$REGION"인증합니다(브라우저가 열립니다):
gcloud auth login
gcloud auth application-default login필수 API 활성화
Google Cloud 사용 시 자주 발생하는 문제 중 하나는 필요한 API를 명시적으로 활성화하기 전까지는 아무것도 작동하지 않는다는 점입니다. 마치 회로 차단기를 켜는 것과 같습니다. 다음 명령어를 한 번 실행하면 완료됩니다:
gcloud services enable
run.googleapis.com
cloudbuild.googleapis.com
workflows.googleapis.com
artifactregistry.googleapis.com
cloudscheduler.googleapis.com
bigquery.googleapis.com
firestore.googleapis.com
secretmanager.googleapis.com다음 명령어로 모든 서비스가 활성화되었는지 확인할 수 있습니다:
gcloud services list --enabled | rg "run.googleapis.com|cloudbuild.googleapis.com|workflows.googleapis.com|artifactregistry.googleapis.com|cloudscheduler.googleapis.com|bigquery.googleapis.com|firestore.googleapis.com"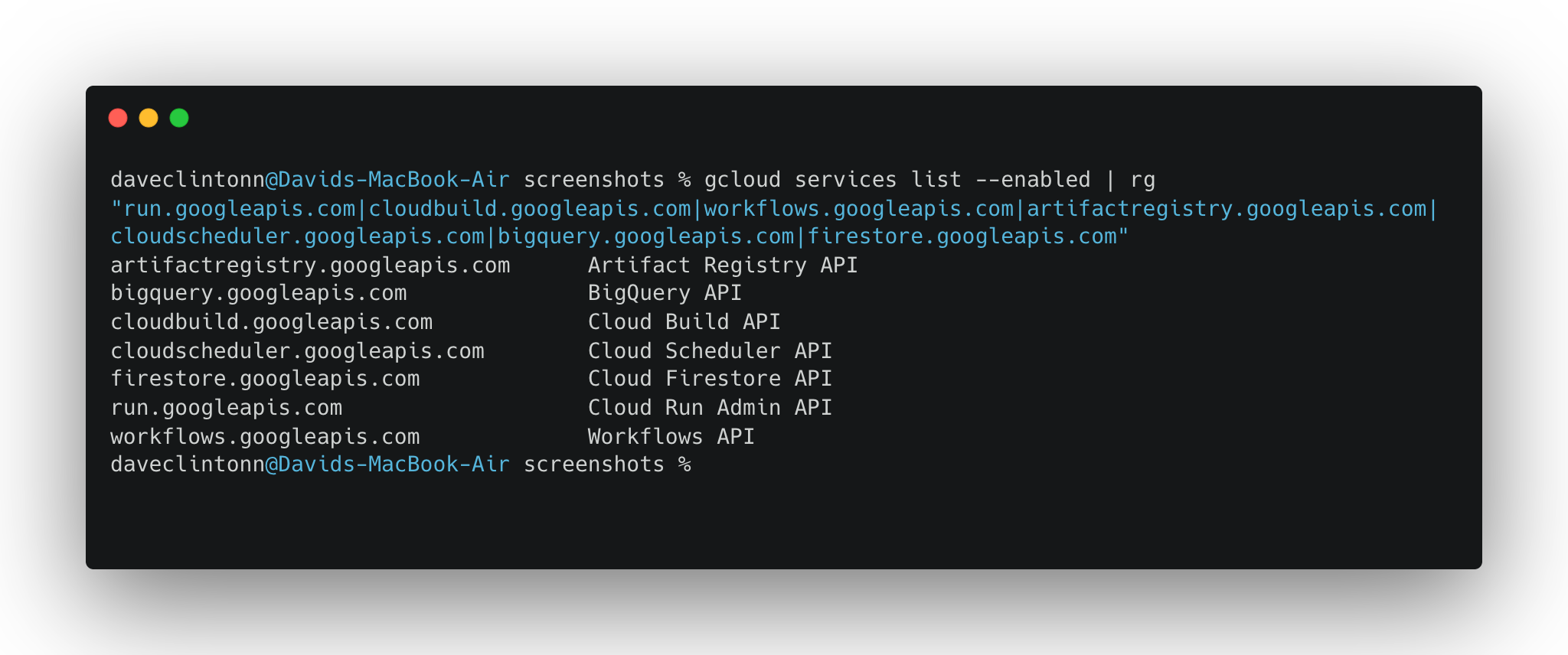
Firestore 설정
작업 추적 데이터를 저장하고 결과를 스크래핑하려면 네이티브 모드의 Firestore가 필요합니다:
gcloud firestore databases create --location="$REGION" --type=firestore-native이 프로젝트에 이미 Firestore가 설정되어 있다면 이 단계를 건너뛸 수 있습니다. 데이터베이스가 이미 존재한다는 오류가 발생합니다.
아티팩트 레지스트리 생성
Artifact Registry는 Docker 이미지가 저장되는 곳입니다. GCP의 사설 컨테이너 레지스트리로 생각하시면 됩니다:
gcloud artifacts repositories create "$REPO_NAME"
--repository-format=docker
--location="$REGION"
--description="cloud-run-scraper용 Docker 이미지"그런 다음 Docker가 레지스트리와 인증하는 방법을 알려줍니다:
gcloud auth configure-docker "$REGION-docker.pkg.dev"BigQuery 설정
이제 스크랩된 데이터가 저장될 BigQuery 데이터셋과 테이블을 생성합니다. 이 구조가 전체 파이프라인의 핵심 가치입니다. 체계적인 ETL 파이프라인 흐름을 통해 모든 스크랩 데이터를 대상으로 SQL 쿼리를 실행하여 트렌드를 분석하고, 소스별로 필터링하거나 대시보드를 구축할 수 있습니다.
데이터셋 생성:
bq --location="$REGION" mk -d "$PROJECT_ID:$BQ_DATASET"그런 다음 스크레이퍼가 사용하는 스키마로 테이블 생성:
bq mk --table
"$PROJECT_ID:$BQ_DATASET.$BQ_TABLE"
url:STRING,title:STRING,content:STRING,scraped_at:TIMESTAMP,job_id:STRING,source:STRING,metadata:STRING작동 여부를 빠르게 확인합니다:
bq show "$PROJECT_ID:$BQ_DATASET.$BQ_TABLE"IAM 권한 설정
이 부분은 가장 흥미롭지는 않지만 매우 중요합니다. Cloud Run 서비스는 Firestore, BigQuery 및 서로 간 통신 권한이 필요합니다. 이러한 IAM 바인딩이 없으면 명확한 설명 없이 신비로운 403 오류가 발생합니다.
먼저 컴퓨트 서비스 계정을 확인하세요:
PROJECT_NUMBER=$(gcloud projects describe "$PROJECT_ID" --format="value(projectNumber)")
COMPUTE_SA="${PROJECT_NUMBER}[email protected]"
echo "$COMPUTE_SA"그런 다음 필요한 역할을 부여하세요:
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/datastore.user"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/bigquery.dataEditor"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/bigquery.jobUser"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/run.invoker"
gcloud projects add-iam-policy-binding "$PROJECT_ID"
--member="serviceAccount:${COMPUTE_SA}"
--role="roles/workflows.invoker"총 다섯 개의 역할 바인딩입니다. 각 바인딩은 서비스 계정이 특정 작업을 수행할 수 있도록 허용합니다: Firestore 읽기/쓰기, BigQuery에 삽입, Cloud Run 서비스 호출, 워크플로 트리거.
의존성 설치
저장소 루트 디렉터리에서 두 서비스의 종속성을 설치합니다:
npm --prefix scraper-service install
npm --prefix api-service install스크레이퍼 서비스 배포
이 서비스는 전체 파이프라인의 핵심 역할을 담당합니다. URL을 방문하여 콘텐츠를 추출하고 결과를 Firestore와 BigQuery에 기록하는 서비스입니다. 스크레이퍼에서 더 복잡한 봇 방지 시나리오를 처리하려면 Bright Data의 Scraping Browser와 같은 도구를 활용하여 대규모 클라우드 기반 브라우저 자동화를 구현해 볼 가치가 있습니다.
이 서비스를 비공개 서비스로 배포합니다. --no-allow-unauthenticated 플래그에 유의하세요. 워크플로우에서 오는 요청처럼 인증된 요청만 호출할 수 있습니다:
gcloud run deploy scraper-service
--source ./scraper-service
--region "$REGION"
--memory 2Gi
--cpu 2
--timeout 300
--no-allow-unauthenticated
--set-env-vars NODE_ENV=production배포 완료 후 URL을 가져옵니다:
SCRAPER_URL=$(gcloud run services describe scraper-service --region "$REGION" --format='value(status.url)')
echo "$SCRAPER_URL"해당 URL을 저장하세요. 워크플로 구성에 필요합니다.
API 서비스 배포
API 서비스는 파이프라인의 공개적인 측면입니다. Firestore와 BigQuery에서 데이터를 읽고, 스크랩된 데이터에 접근할 수 있도록 엔드포인트를 노출합니다:
gcloud run deploy api-service
--source ./api-service
--region "$REGION"
--memory 512Mi
--cpu 1
--timeout 60
--allow-unauthenticated
--set-env-vars NODE_ENV=productionURL 확인:
API_URL=$(gcloud run services describe api-service --region "$REGION" --format='value(status.url)')
echo "$API_URL"배포된 서비스 테스트
이제 재미있는 부분이 시작됩니다: 실제 운영 중인 서비스를 호출하여 모든 것이 제대로 작동하는지 확인하는 것입니다. IP 차단이나 속도 제한과 같은 일반적인 웹 스크래핑 문제들은 서버리스 환경에서도 스크래퍼에 영향을 미칠 수 있으므로, 처음부터 이에 대한 전략을 마련해 두는 것이 좋습니다.
API 서비스에 대해 다음을 시도해 보세요:
curl -s "$API_URL/"
curl -s "$API_URL/jobs?limit=10"
curl -s "$API_URL/analytics/summary"스크래퍼의 경우 비공개 서비스이므로 인증 토큰을 전달해야 합니다:
curl -s -X POST
-H "Authorization: Bearer $(gcloud auth print-identity-token)"
-H "Content-Type: application/json"
-d '{"url":"http://books.toscrape.com"}'
"$SCRAPER_URL/scrape"페이지의 특정 요소를 대상으로 지정하려면 사용자 정의 CSS 선택기도 전달할 수 있습니다:
curl -s -X POST
-H "Authorization: Bearer $(gcloud auth print-identity-token)"
-H "Content-Type: application/json"
-d '{"url":"http://books.toscrape.com","selectors":{"title":"h1, h2","content":"p, article"}}'
"$SCRAPER_URL/scrape"워크플로 설정
워크플로는 스크레이퍼를 일정과 연결하는 역할을 합니다. 이는 Cloud Workflows가 목록의 각 URL에 대해 스크레이퍼를 호출하도록 지시하는 YAML 파일입니다.
workflows/scrape-pipeline.yaml 파일을 열고 scraper_url을 스크레이퍼 배포 단계에서 얻은 URL로 설정하세요.
그런 다음 배포합니다:
gcloud workflows deploy scrape-pipeline
--location "$REGION"
--source workflows/scrape-pipeline.yaml
--service-account "$COMPUTE_SA"스케줄러 작업 생성
이제 파이프라인이 완전히 자동화됩니다. UTC 기준 매일 오전 6시에 워크플로를 실행하는 cron 작업을 설정합니다:
gcloud scheduler jobs create http scrape-pipeline-daily
--location "$REGION"
--schedule "0 6 * * *"
--uri "https://workflowexecutions.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}/workflows/scrape-pipeline/executions"
--http-method POST
--oauth-service-account-email "$COMPUTE_SA"
--oauth-token-scope "https://www.googleapis.com/auth/cloud-platform"
--message-body '{"argument":"{"urls":["http://books.toscrape.com","http://quotes.toscrape.com"]}"}'작업이 이미 존재하고 업데이트만 원하는 경우:
gcloud scheduler jobs update http scrape-pipeline-daily
--location "$REGION"
--schedule "0 6 * * *"
--uri "https://workflowexecutions.googleapis.com/v1/projects/${PROJECT_ID}/locations/${REGION}/workflows/scrape-pipeline/executions"
--http-method POST
--oauth-service-account-email "$COMPUTE_SA"
--oauth-token-scope "https://www.googleapis.com/auth/cloud-platform"
--message-body '{"argument":"{"urls":["http://books.toscrape.com","http://quotes.toscrape.com"]}"}'첫 번째 전체 테스트 실행
스케줄러를 기다리지 마십시오. 워크플로를 수동으로 트리거하고 전체 파이프라인이 실행되는 것을 확인하세요:
gcloud workflows run scrape-pipeline
--location "$REGION"
--data '{"urls":["http://books.toscrape.com","http://quotes.toscrape.com"]}'실행 상태는 다음 명령어로 모니터링할 수 있습니다:
gcloud workflows executions list scrape-pipeline --location "$REGION"1~2분 정도 기다리세요. 실행 상태가 SUCCEEDED로 표시되면 데이터가 Firestore와 BigQuery로 전송되기 시작합니다.
데이터 확인
이제 데이터가 실제로 필요한 위치에 도착했는지 확인해 보겠습니다.
BigQuery에서 행 수 확인:
bq query --use_legacy_sql=false "SELECT COUNT(*) AS total_rows FROM `${PROJECT_ID}.${BQ_DATASET}.${BQ_TABLE}`"최신 스크랩 결과를 확인하세요:
bq query --use_legacy_sql=false "SELECT source, url, scraped_at, job_id FROM `${PROJECT_ID}.${BQ_DATASET}.${BQ_TABLE}` ORDER BY scraped_at DESC LIMIT 10"콘솔에서 Firestore를 확인하세요. jobs 와 results라는 두 컬렉션이 표시되어야 합니다.
그런 다음 API를 호출하여 모든 데이터를 읽을 수 있는지 확인하세요:
curl -s "$API_URL/jobs?limit=1"응답에서 jobId 를 추출하여 더 깊이 살펴보세요:
curl -s "$API_URL/jobs/YOUR_JOB_ID"
curl -s "$API_URL/results/YOUR_JOB_ID"모든 요청에서 데이터가 반환되면 파이프라인이 종단 간 정상 작동 중입니다.
Cloud Build를 활용한 CI/CD
이 저장소에는 두 서비스를 한 번에 빌드하고 배포하는 cloudbuild.yaml 파일이 포함되어 있습니다. 변경 사항을 배포하려면 다음을 실행하세요:
gcloud builds submit --config cloudbuild.yaml .이 단일 명령어로 두 Docker 이미지를 빌드하고 Artifact Registry에 푸시한 후 두 Cloud Run 서비스를 배포합니다. 단일 파이프라인을 넘어 확장하려는 경우, 다양한 솔루션이 이와 같은 클라우드 기반 설정을 어떻게 보완할 수 있는지 알아보려면 최고의 웹 스크래핑 도구 개요를 확인하세요.
최종 체크리스트
완료로 선언하기 전에 다음 검증 단계를 수행하세요:
gcloud run services list --region us-central1명령어 실행 시 두 서비스가 모두 표시되어야 합니다.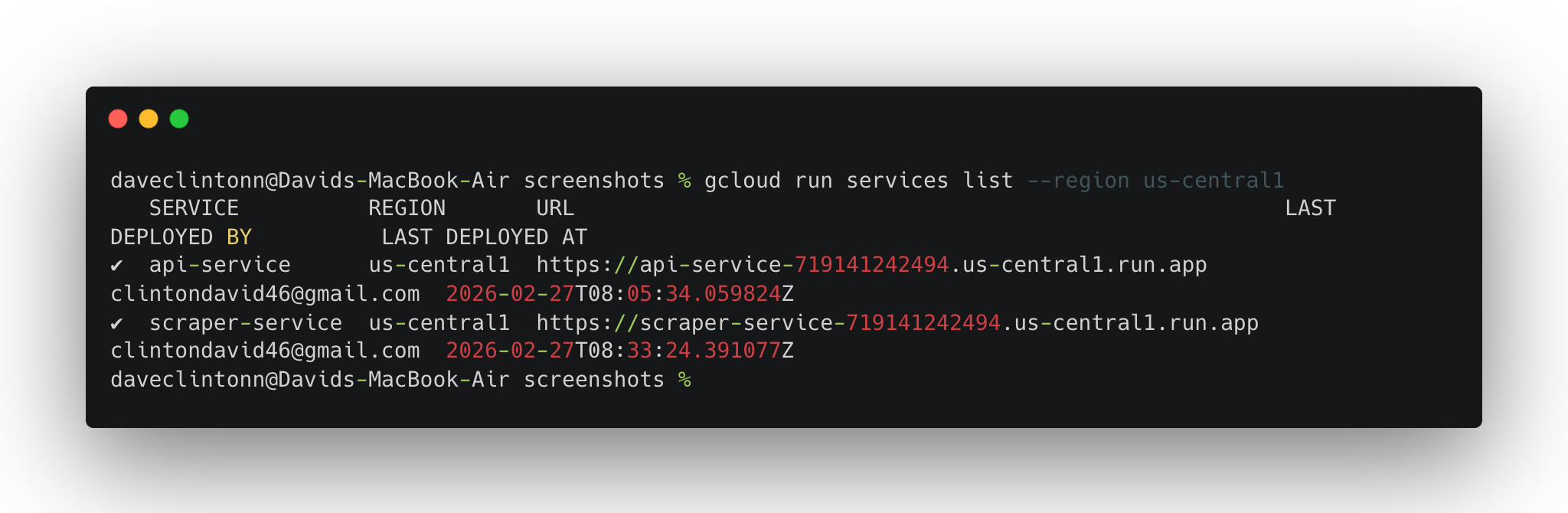
gcloud workflows describe scrape-pipeline --location us-central1을실행하면 워크플로 세부 정보가 반환됩니다.
gcloud scheduler jobs list --location us-central1을실행하면 스케줄러 작업이 표시되어야 합니다.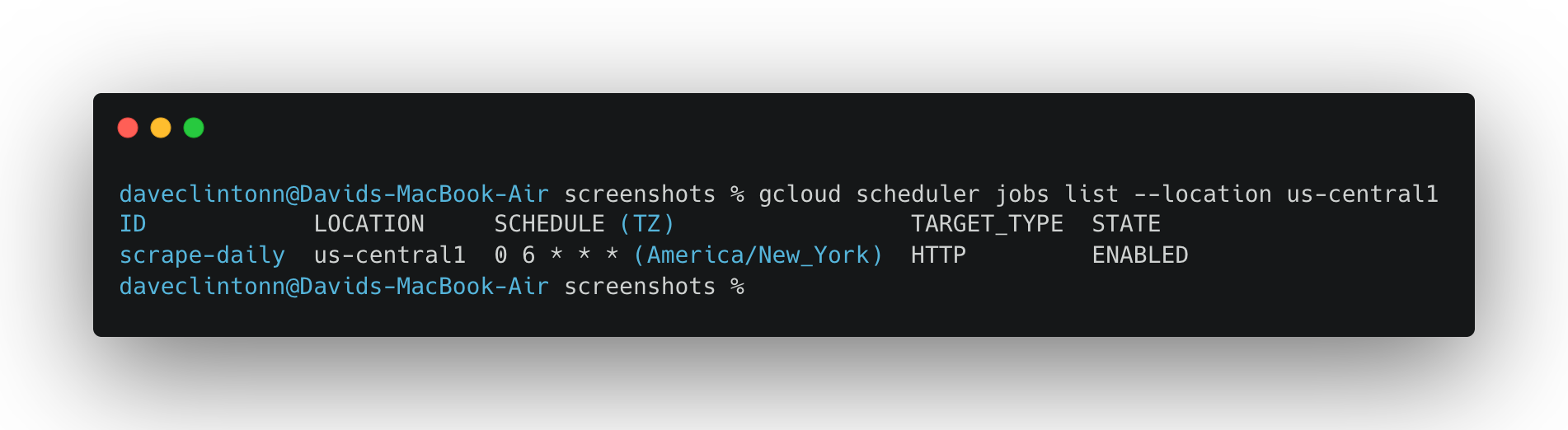
- Firestore에는
작업및결과컬렉션이 있어야 합니다. - BigQuery 테이블에는 행이 있어야 합니다.
- API
/jobs엔드포인트는 실제 레코드를 반환해야 합니다.
여섯 가지 모두 확인되면 더 이상 데모를 실행하는 것이 아닙니다. 실제 파이프라인이 일정대로 스크래핑하고, 두 곳에 데이터를 저장하며, 공개 API를 통해 제공하는 상태입니다.
결론
이 가이드에서는 Google Cloud에서 완전한 서버리스 웹 스크래핑 파이프라인 구축 과정을 살펴보았습니다. 인프라 설정, 두 개의 Cloud Run 서비스 배포, Cloud Workflows를 통한 스크래핑 작업 조정, Cloud Scheduler를 통한 모든 작업 자동화 등을 다루었습니다.
자체 인프라 유지보다 관리형 접근을 선호한다면, Bright Data의 사전 수집 데이터셋이나 Scraper Studio를 활용해 어떤 웹사이트든 즉시 사용 가능한 데이터 파이프라인으로 전환할 수 있습니다. Scrapy와 AWS를 활용한 서버리스 스크래핑 가이드를 참고하면 다른 클라우드 제공업체에서 유사한 아키텍처가 어떻게 구현되는지 확인할 수 있습니다. 프로젝트를 복제하고 대상 URL을 교체하기만 하면 스크래핑 파이프라인을 즉시 가동할 수 있습니다.





