

오늘 가이드에서는 Scrapy Spider를 작성하고 AWS Lambda에 배포하는 방법을 다룹니다. 코드 자체는 상당히 직관적입니다. Lambda 같은 클라우드 서비스를 다룰 때는 고려해야 할 요소가 많습니다. 이러한 요소들을 효과적으로 관리하고 문제가 발생했을 때 대처하는 방법을 보여드리겠습니다.
필수 조건
이 작업을 수행하려면 다음이 필요합니다:
- 여기
- Scrapy를 이용한 스크래핑 기본 지식
서버리스란 무엇인가?
서버리스 아키텍처는 컴퓨팅의 미래로 주목받고 있습니다. 서버리스 애플리케이션의 실제 실행 시간당 비용은 더 비쌀 수 있지만, 서버 운영 비용을 이미 지불하고 있지 않다면 Lambda가 합리적인 선택입니다.
스크레이퍼 실행에 1분이 소요되고 하루에 한 번 실행한다고 가정해 보겠습니다. 기존 서버를 사용하면 24시간 가동되는 한 달 치 비용을 지불해야 하지만, 실제 사용 시간은 30분에 불과합니다. Lambda와 같은 서비스를 이용하면 실제 사용한 만큼만 비용을 지불하면 됩니다.
장점
- 청구: 사용한 만큼만 지불합니다.
- 확장성: Lambda는 자동으로 확장되므로 신경 쓸 필요가 없습니다.
- 서버 관리: 서버 관리에 시간을 할애할 필요가 없습니다. 모든 것이 자동으로 처리됩니다.
단점
- 지연 시간: 함수가 유휴 상태였던 경우 시작 및 실행에 더 오랜 시간이 소요됩니다.
- 실행 시간: Lambda 함수는 기본 타임아웃 3초, 최대 15분으로 실행됩니다. 기존 서버는 훨씬 유연합니다.
- 이식성: OS 호환성에 의존할 뿐만 아니라 공급업체의 정책에 좌우됩니다. Lambda 함수를 복사하여 Azure나 Google Cloud에서 바로 실행할 수 없습니다.
Bright Data는 이러한 제한이 없는 솔루션을 제공합니다. 다음에서 살펴보겠습니다.
서버리스 함수: 최고의 대안
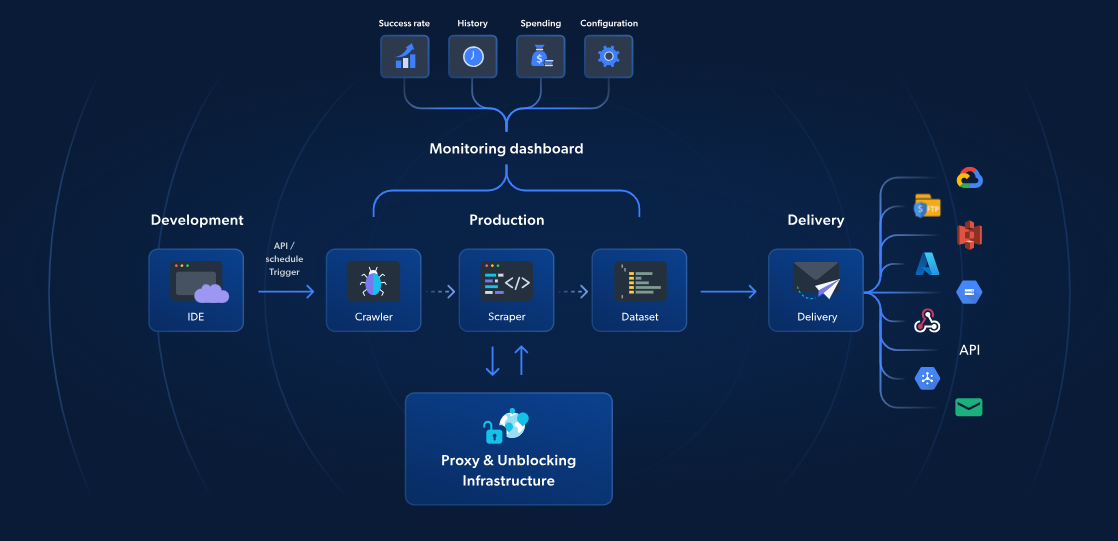
AWS Lambda와 Scrapy가 서버리스 웹 스크래핑을 제공하지만, Bright Data의 서버리스 함수는 더 빠르고 안정적인 스크래핑을 위한 전용 솔루션을 제공합니다. 70개 이상의 사전 구축된 JavaScript 템플릿, 통합 클라우드 기반 IDE, AI 기반 차단 해제 솔루션을 통해 CAPTCHA 우회, 손쉬운 확장, 인프라 관리 번거로움 없이 데이터 추출에 집중할 수 있습니다.
AWS 및 Scrapy 방식과 달리 Bright Data 솔루션은 프록시 관리, 자동 확장, S3 또는 Google Cloud 같은 스토리지 플랫폼과의 직접 연동을 포함합니다. 페이지 로드 1,000회당 단 2.7달러부터 시작하는 서버리스 함수는 고급 웹 스크래핑을 더 간단하고 빠르며 비용 효율적으로 만듭니다.
이제 Scrapy와 AWS 가이드를 계속 진행해 보겠습니다.
시작하기
서비스 설정
AWS 계정을 생성한 후에는 S3 버킷이 필요합니다. ‘모든 서비스’ 페이지로 이동하여 아래로 스크롤하세요.
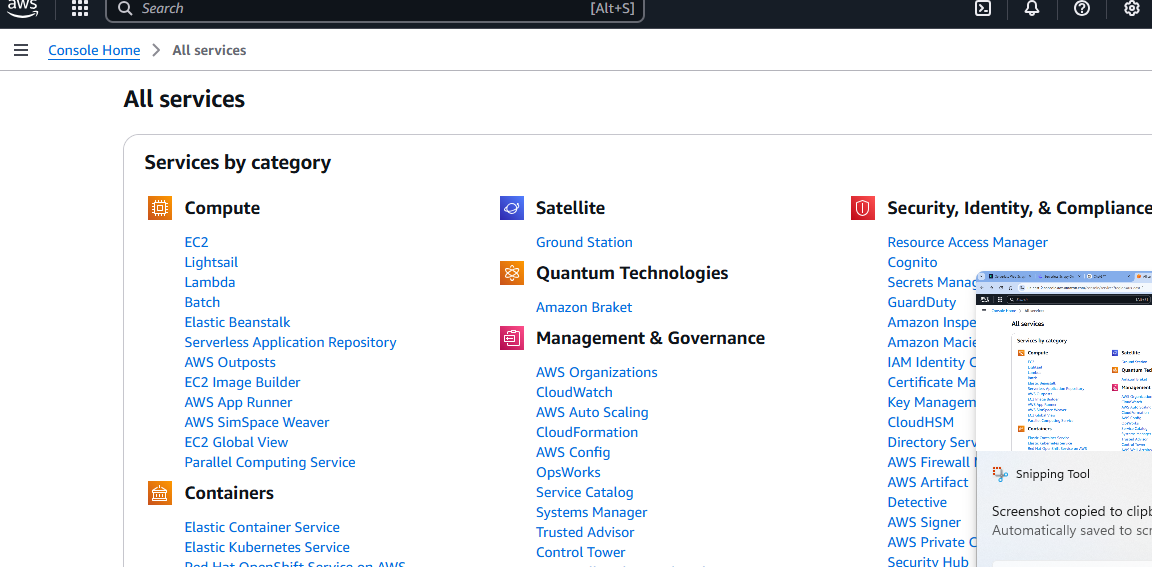
저장소( Storage) 섹션이 보일 것입니다. 이 섹션의 첫 번째 옵션인 S3를 클릭하세요.
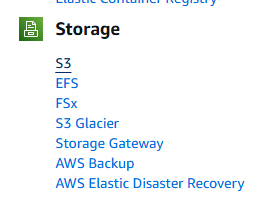
다음으로 ‘버킷 생성’ 버튼을 클릭하세요.
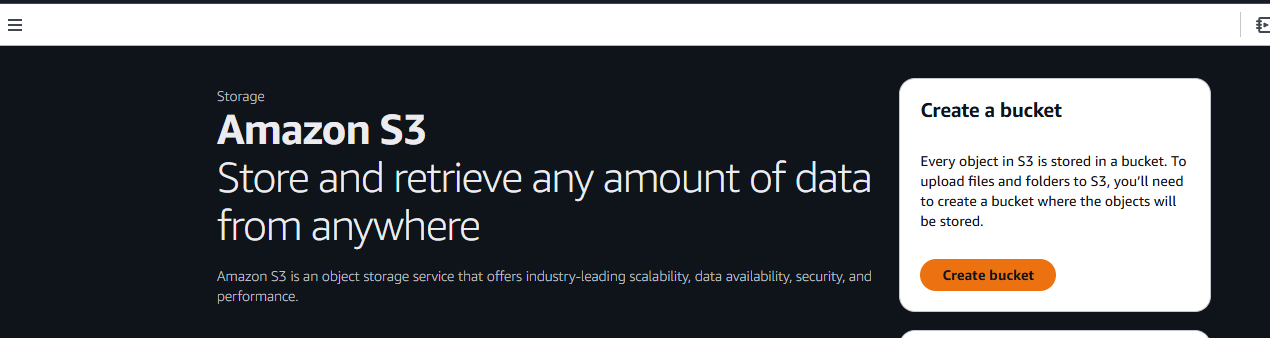
이제 버킷 이름을 지정하고 설정을 선택해야 합니다. 기본값 그대로 진행하겠습니다.
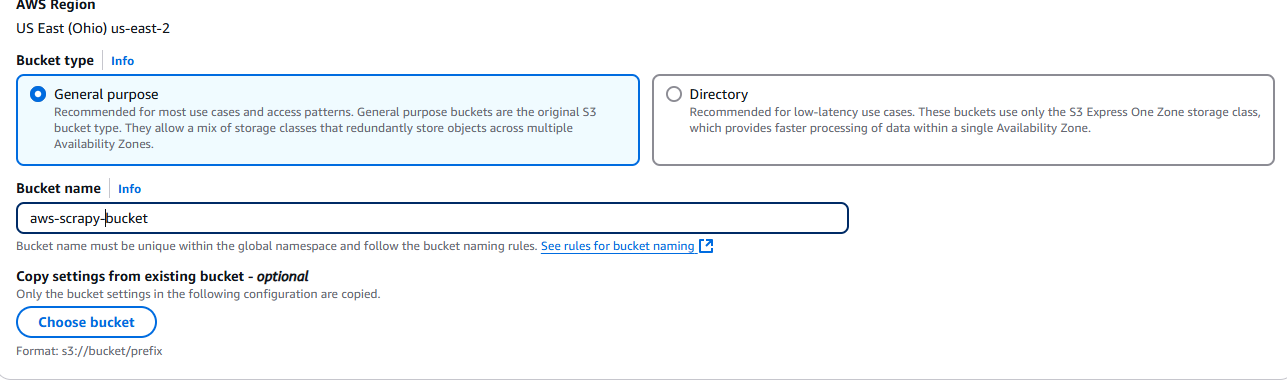
설정이 완료되면 페이지 오른쪽 하단에 있는 ‘버킷 생성’ 버튼을 클릭하세요.

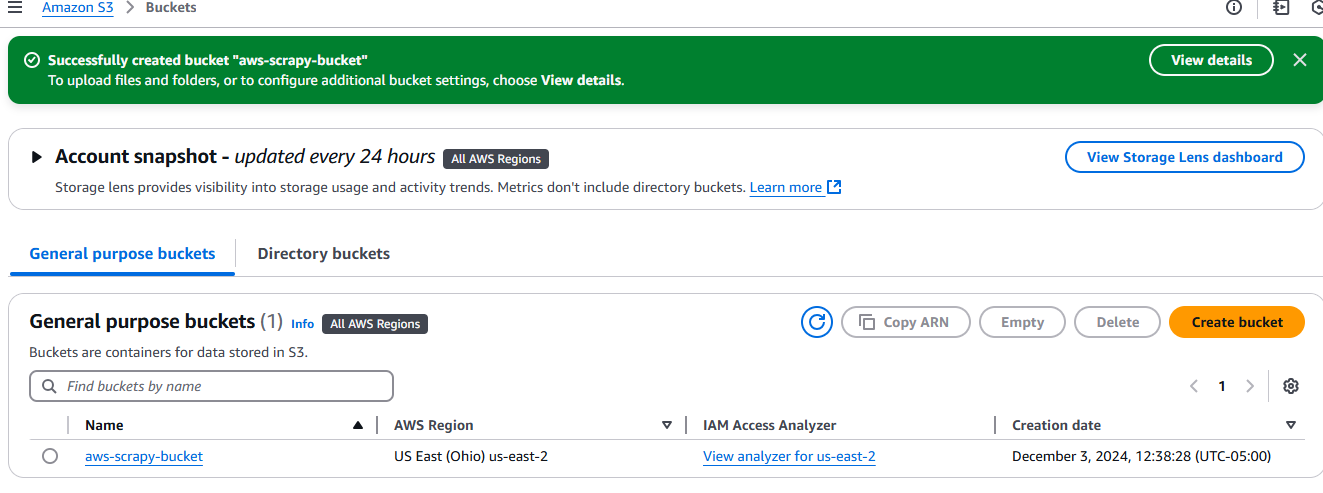
생성하면 Amazon S3의 ‘버킷’ 탭에 버킷이 표시됩니다.
프로젝트 설정
새 프로젝트 폴더를 생성합니다.
mkdir scrapy_aws
새 폴더로 이동하여 가상 환경을 만듭니다.
cd scrapy_aws
python3 -m venv venv
환경을 활성화합니다.
source venv/bin/activate
Scrapy 설치.
pip install scrapy
스크래핑 대상
동적 웹사이트, 봇 방지 조치 또는 대규모 스크래핑의 경우 Bright Data의 Scraping Browser를 사용하세요. 작업을 자동화하고 CAPTCHA를 우회하며 원활하게 확장할 수 있습니다.
대상 사이트로 books.toscrape를 사용하겠습니다. 웹 스크래핑에 전적으로 집중한 교육용 사이트입니다. 아래 이미지를 보면 각 책은 product_pod 클래스명을 가진 문서입니다. 페이지에서 이 모든 요소를 추출하고자 합니다.
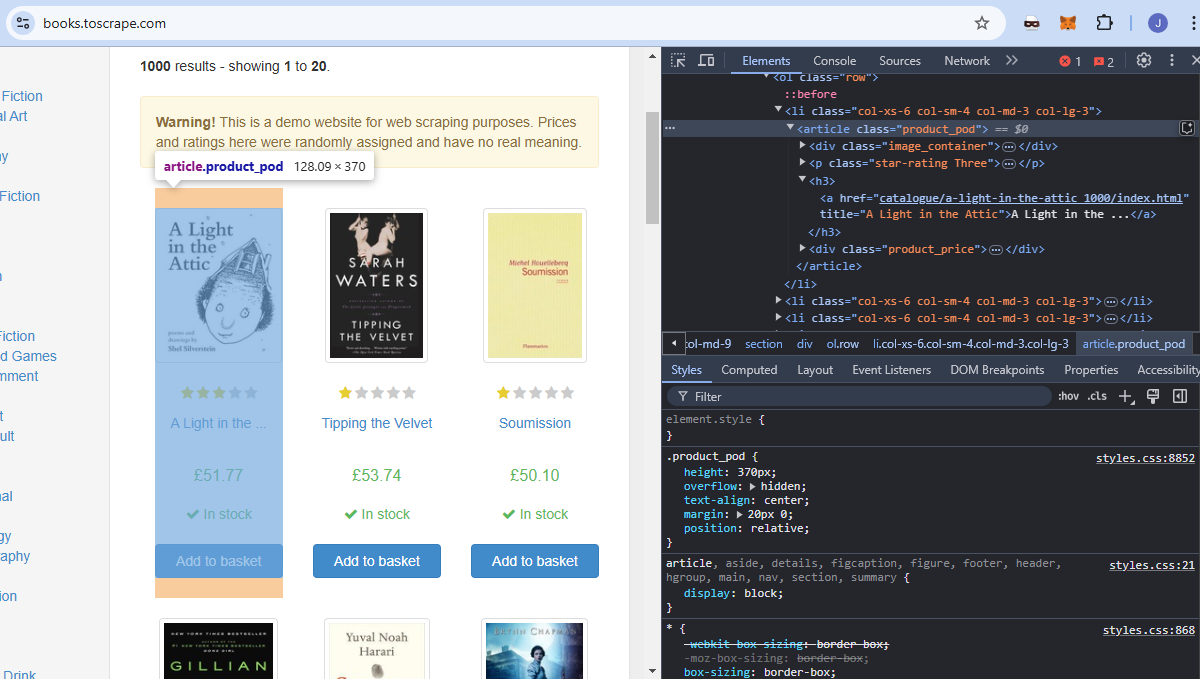
각 도서의 제목은 h3 요소 안에 중첩된 a 요소 내에 포함되어 있습니다.

각 가격은 div 안에 중첩된 p에 포함되어 있습니다. 이 p는 price_color 클래스명을 가집니다.
코드 작성
이제 스크레이퍼를 작성하고 로컬에서 테스트해 보겠습니다. 새 Python 파일을 열고 다음 코드를 붙여넣으세요. 저희는 aws_spider.py라는 이름으로 저장했습니다.
import scrapy
class BookSpider(scrapy.Spider):
name = "books"
allowed_domains = ["books.toscrape.com"]
start_urls = ["https://books.toscrape.com"]
def parse(self, response):
for card in response.css("article"):
yield {
"title": card.css("h3 > a::text").get(),
"price": card.css("div > p::text").get(),
}
next_page = response.css("li.next > a::attr(href)").get()
if next_page:
yield scrapy.Request(response.urljoin(next_page))
다음 명령어로 스파이더를 테스트할 수 있습니다. 책과 가격 정보가 담긴 JSON 파일이 출력되어야 합니다.
python -m scrapy runspider aws_spider.py -o books.json
이제 핸들러가 필요합니다. 핸들러의 역할은 간단합니다. 스파이더를 실행하는 것입니다. 여기서는 기본적으로 동일한 두 개의 핸들러를 만들 것입니다. 주요 차이점은 하나는 로컬에서 실행하고 다른 하나는 Lambda에서 실행한다는 점입니다.
다음은 로컬 핸들러로, lambda_function_local.py라고 명명했습니다.
import subprocess
def handler(event, context):
# 로컬 테스트용 출력 파일 경로
output_file = "books.json"
# Scrapy 스파이더를 -o 플래그와 함께 실행하여 출력을 books.json에 저장
subprocess.run(["python", "-m", "scrapy", "runspider", "aws_spider.py", "-o", output_file])
# 성공 메시지 반환
return {
'statusCode': '200',
'body': f"스크래핑 완료! 출력 파일 {output_file}에 저장됨",
}
# 로컬 테스트용 블록 추가
if __name__ == "__main__":
# AWS Lambda 호출 이벤트 및 컨텍스트 시뮬레이션
fake_event = {}
fake_context = {}
# 핸들러 호출 및 결과 출력
result = handler(fake_event, fake_context)
print(result)
books.json 파일을 삭제하세요. 다음 명령어로 로컬 핸들러를 테스트할 수 있습니다. 모든 것이 정상적으로 작동하면 프로젝트 폴더에 새로운 books.json 파일이 생성됩니다. bucket_name을 자신의 버킷 이름으로 변경하는 것을 잊지 마세요.
python lambda_function_local.py
이제 Lambda에 사용할 핸들러를 살펴보겠습니다. 매우 유사하지만, 데이터를 S3 버킷에 저장하기 위한 약간의 수정 사항이 있습니다.
import subprocess
import boto3
def handler(event, context):
# 로컬 및 S3 출력 파일 경로 정의
local_output_file = "/tmp/books.json" # Lambda 실행 시 /tmp에 위치해야 함
bucket_name = "aws-scrapy-bucket"
s3_key = "scrapy-output/books.json" # S3 버킷 내 경로
# Scrapy 스파이더 실행 및 로컬에 출력 저장
subprocess.run(["python3", "-m", "scrapy", "runspider", "aws_spider.py", "-o", local_output_file])
# 파일을 S3에 업로드
s3 = boto3.client("s3")
s3.upload_file(local_output_file, bucket_name, s3_key)
return {
'statusCode': 200,
'body': f"스크래핑 완료! 출력물이 s3://{bucket_name}/{s3_key}에 업로드되었습니다"
}
- 먼저 데이터를 임시 파일(
local_output_file = "/tmp/books.json")에 저장합니다. 이렇게 하면 데이터가 손실되는 것을 방지할 수 있습니다. s3.upload_file(local_output_file, bucket_name, s3_key)로 버킷에 업로드합니다.
AWS Lambda에 배포하기
이제 AWS Lambda에 배포해야 합니다.
패키지 폴더를 만듭니다.
mkdir package
의존성 패키지를 package 폴더로 복사합니다.
cp -r venv/lib/python3.*/site-packages/* package/
파일을 복사합니다. 이전에 테스트한 로컬 핸들러가 아닌, Lambda용으로 만든 핸들러를 복사했는지 확인하세요.
cp lambda_function.py aws_spider.py package/
패키지 폴더를 zip 파일로 압축합니다.
zip -r lambda_function.zip package/
ZIP 파일을 생성한 후 AWS Lambda로 이동하여 ‘함수 생성’을 선택합니다 . 요청 시 런타임(Python) 및 아키텍처와 같은 기본 정보를 입력하세요.
S3 버킷에 대한 접근 권한을 부여하도록 설정하세요.
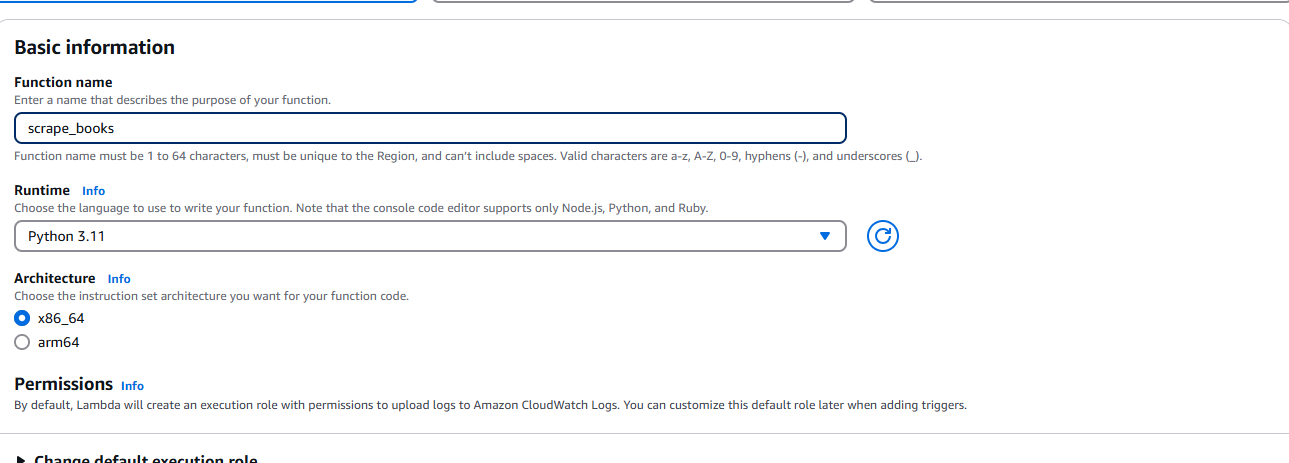
함수 생성 후 소스 탭 우측 상단의 ‘업로드’ 드롭다운을 선택하세요.

.zip 파일을 선택하고 생성한 ZIP 파일을 업로드합니다.
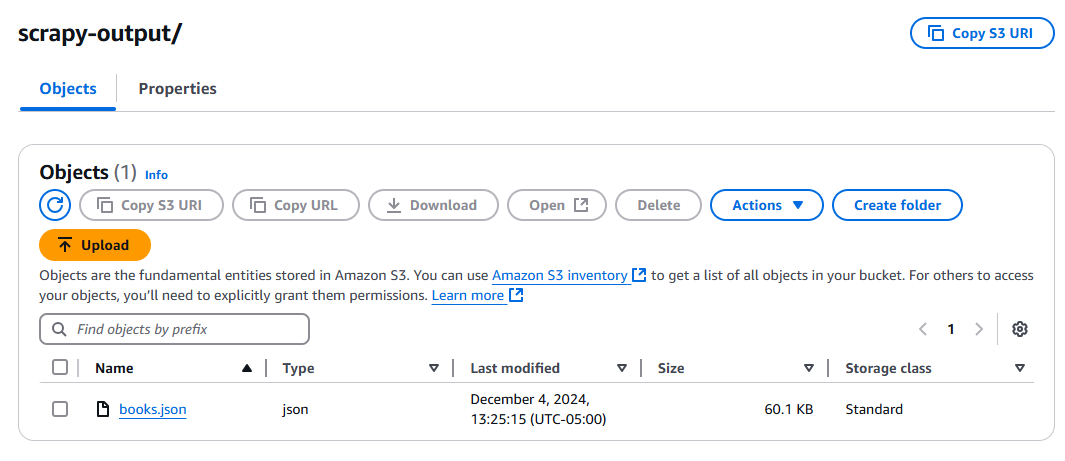
테스트 버튼을 클릭하고 함수가 실행될 때까지 기다립니다. 실행 후 S3 버킷을 확인하면 books.json이라는 새 파일이 생성되어 있을 것입니다.
문제 해결 팁
Scrapy를 찾을 수 없음
Scrapy를 찾을 수 없다는 오류가 발생할 수 있습니다. 이 경우 subprocess.run()의 명령어 배열에 다음을 추가해야 합니다.

일반적인 종속성 문제
Python 버전이 동일한지 확인해야 합니다. 로컬에 설치된 Python을 확인하세요.
python --version
이 명령어가 Lambda 함수와 다른 버전을 출력하면, Lambda 구성을 일치하도록 변경하십시오.
핸들러 문제

핸들러는 lambda_function.py에 작성한 함수와 일치해야 합니다. 위에서 볼 수 있듯이 lambda_function.handler가 있습니다. lambda_function은 Python 파일의 이름을 나타냅니다. handler는 함수의 이름입니다.
S3에 쓰기 불가
출력 저장 시 권한 문제가 발생할 수 있습니다. 이 경우 Lambda 인스턴스에 해당 권한을 추가해야 합니다.
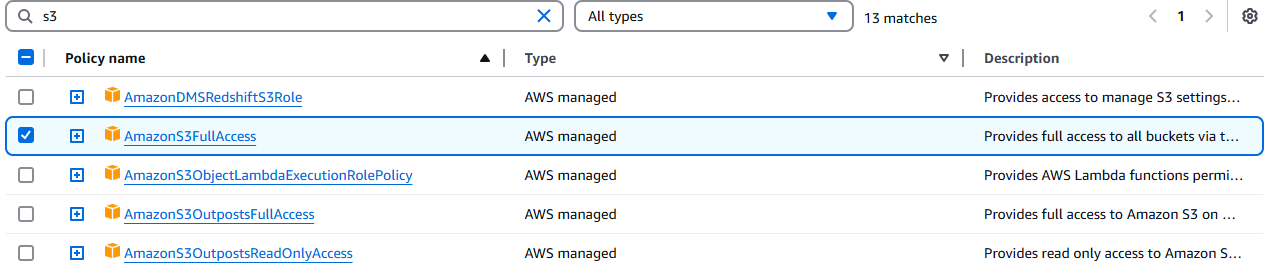
IAM 콘솔로 이동하여 해당 Lambda 함수를 검색합니다. 해당 함수를 클릭한 후 ‘권한 추가’ 드롭다운을 클릭합니다.
정책 연결을 클릭합니다.
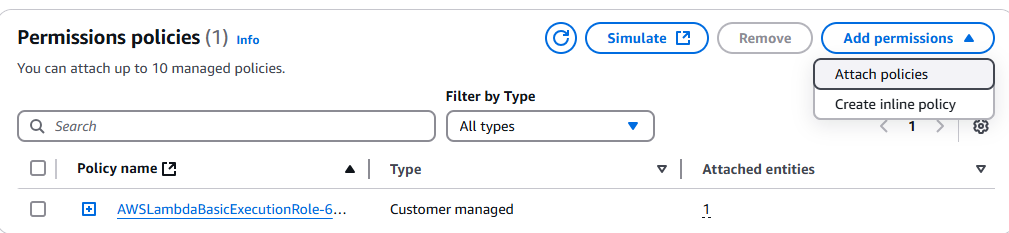
AmazonS3FullAccess를 선택합니다.
마무리
완료했습니다! 이제 AWS 콘솔이라는 UI 악몽 속에서도 당당히 맞설 수 있을 것입니다. Scrapy로 크롤러를 작성하는 방법을 알게 되었고, Amazon Linux와의 바이너리 호환성을 보장하기 위해 Linux 또는 WSL로 환경을 패키징하는 방법도 알게 되었습니다.
수동 스크래핑이 부담스럽다면, 저희 웹 스크레이퍼 API와 즉시 사용 가능한 데이터셋을 확인해 보세요. 지금 가입하여 무료 체험을 시작하세요!






