

벡터 데이터베이스는 머신러닝 모델이 생성한 고차원 데이터 임베딩을 저장하고 색인화할 수 있습니다. 이는 현대 AI의 핵심 요소로, 문맥 정보 저장 및 의미 있는 시맨틱 검색을 지원합니다.
검색 강화 생성(RAG)과 자주 연관되지만, 그 응용 범위는 이를 훨씬 뛰어넘습니다. 구체적으로 의미론적 검색, 추천 시스템, 이상 탐지 등 다양한 애플리케이션을 구동합니다.
이 가이드를 따라 벡터 데이터베이스의 정의, 작동 방식, 완전한 예시를 통한 활용법, 그리고 미래 전망을 이해해 보세요!
벡터 데이터베이스란 무엇인가?
벡터 데이터베이스는 벡터 데이터를 저장하기 위해 설계된 저장 시스템입니다. 여기서 벡터란 텍스트, 이미지, 오디오와 같은 비정형 데이터를 표현하는 수치 임베딩을 의미하며, 일반적으로 머신러닝 모델에 의해 생성됩니다.
기존 데이터베이스와 달리 벡터 데이터베이스는 고차원 데이터를 고밀도 수치 벡터로 저장하고 N차원 공간에서 인덱싱하여 유사도 기반 검색을 최적화합니다.
AI/ML에서 벡터 데이터베이스의 중요성 증가
대부분의 경우 기존 SQL 데이터베이스는 AI 및 머신러닝 작업에 적합하지 않습니다. 그 이유는 구조화된 데이터만 저장하고 정확한 일치 쿼리나 제한된 유사성 검색만 지원하기 때문입니다. 따라서 비정형 콘텐츠 처리나 데이터 포인트 간 의미적 관계 파악에 어려움을 겪습니다.
현재 AI 애플리케이션은 데이터의 문맥적 이해를 요구합니다. 이는 임베딩을 통해 달성될 수 있는데, 관계형 데이터베이스는 임베딩 저장이나 쿼리에 최적화되어 있지 않습니다. 벡터 데이터베이스는 의미와 문맥을 반영하는 유사도 기반 검색을 지원함으로써 이러한 한계를 해결하고, 데이터의 의미적 이해를 가능하게 합니다.
이 기술의 가장 일반적인 시나리오는 검색 강화 생성(RAG)이지만, 다른 가능한 사용 사례는 다음과 같습니다:
- 의미적 검색 엔진
- 추천 시스템
- 시계열 데이터의 이상 탐지
- 컴퓨터 비전 분야의 이미지 분류 및 검색
- 자연어 처리(NLP) 애플리케이션
벡터 데이터베이스의 작동 방식
벡터 데이터베이스는 데이터를 고차원 공간에 존재하는 벡터 임베딩으로 관리합니다. 각 차원은 데이터의 특징을 나타내며, 이는 머신러닝 모델이 해석한 원본 데이터의 특정 특성(임베딩으로 표현됨)에 해당합니다. 임베딩의 차원이 높을수록 표현이 더 상세해져 데이터 구조에 대한 풍부한 이해가 가능해집니다.
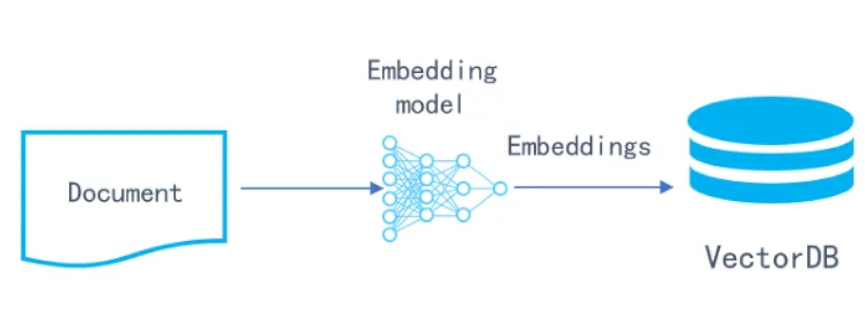
벡터 데이터베이스는 의미적으로 유사한 데이터를 찾기 위해 다음과 같은 유사도 측정법을 사용합니다:
- 코사인 유사도: 두 벡터 사이의 각도 코사인을 측정하여 방향 유사성을 평가합니다. 텍스트 데이터에 흔히 사용됩니다.
- 유클리드 거리: 두 벡터 사이의 직선 거리를 측정하며, 방향과 크기가 모두 중요한 공간 데이터에 유용합니다.
- 내적 유사도: 대응하는 벡터 성분들의 곱을 계산하며, 내적 값이 클수록 유사도가 높음을 나타냅니다. 추천 시스템 및 순위 지정 작업에 유용합니다.
SQL 및 NoSQL 데이터베이스가 데이터 쿼리 속도를 높이기 위해 인덱스를 사용하는 것처럼, 벡터 데이터베이스는 다음과 같은 고급 인덱싱 기법을 활용할 수 있습니다:
- 근사적 최근접 이웃(ANN): 가장 가까운 벡터를 근사화하여 유사도 검색을 가속화하며, 정확한 검색에 비해 계산 비용을 절감합니다.
- 계층적 탐색 가능 소규모 세계(HNSW): 벡터를 그래프 구조로 표현하여 대규모 고차원 공간에서 더 빠른 탐색을 가능하게 합니다.
또한, 벡터 데이터를 더 작고 관리하기 쉬운 그룹으로 구성하기 위해 파티셔닝 및 클러스터링 기법을 적용할 수 있습니다. 이러한 방법은 저장 효율성과 검색 성능을 모두 향상시킵니다.
주요 벡터 데이터베이스 옵션
벡터 데이터베이스의 개념과 AI 데이터 인프라 작동 방식을 이해하셨다면, 이제 가장 널리 사용되는 벡터 데이터베이스 옵션을 살펴볼 준비가 되셨습니다. 다음 측면을 기준으로 각 옵션을 분석해 보겠습니다:
- 아키텍처
- 성능 특성
- 통합 기능
- 가격 모델
- 주요 활용 사례
어떤 벡터 데이터베이스가 두드러지는지 알고 싶다면 아래 요약표를 확인해 보세요:
| 데이터베이스 이름 | 오픈 소스/상용 | 호스팅 옵션 | 최적 용도 | 특이한 측면 | 통합 복잡성 |
|---|---|---|---|---|---|
| 파인콘 | 상업용 | 완전 관리형 서버리스 클라우드 | 시맨틱 검색, Q&A, 챗봇 | 병렬 읽기/쓰기, 원활한 OpenAI/Vercel 통합, 장기 기억 지원 | 낮음 – 다양한 언어용 SDK, 플러그 앤 플레이 통합 |
| Weaviate | 오픈 소스 및 상용 | 자체 호스팅, 서버리스 클라우드, 관리형 엔터프라이즈 클라우드 | 미디어/텍스트 검색, 분류, 얼굴 인식 | HNSW + 플랫 벡터 인덱싱, 역방향 인덱스, 풍부한 생태계 통합 | 중간 – 광범위한 통합 표면, 약간의 학습 곡선 |
| Milvus | 오픈 소스 및 상용 | 자체 호스팅, Zilliz Cloud | RAG, 추천, 미디어 검색, 이상 탐지 | 데이터 샤딩, 스트리밍 수집, 다중 모드 데이터 인덱싱 | 중간 – 다양한 SDK, 주요 AI/LLM 프레임워크와 호환 |
| Chroma | 오픈 소스 및 상용 | 자체 호스팅, Chroma Cloud | 경량 애플리케이션, CV 검색, AI 챗봇 | 인메모리 모드, Swagger를 통한 REST API, 풍부한 임베딩 통합 | 낮음 – 사용 편의성을 위해 구축된 Python 및 TypeScript SDK |
| Qdrant | 오픈 소스 및 상용 | 자체 호스팅, 관리형 클라우드, 하이브리드 클라우드, 프라이빗 클라우드 | RAG, 고급 검색, 분석, AI 에이전트 | 모듈식 페이로드/벡터 인덱싱, HNSW, 세분화된 업데이트 | 중간 – 광범위한 API/클라이언트 지원, 확장성 및 모듈식 |
선택한 벡터 데이터베이스 옵션을 살펴볼 시간입니다!
파인콘
- 아키텍처: 완전 관리형, 서버리스
- 성능 특성:
- 고성능 ANN 검색
- 엔터프라이즈급 확장성
- 병렬화된 읽기 및 쓰기
- 통합 기능:
- REST API
- 다양한 SDK (Python, Node.js, Java, Go, .NET, Rust)
- OpenAI, Vercel, AWS, LangChain 등과의 네이티브 통합
- 가격 모델:
- 스타터: 시험 사용 및 소규모 애플리케이션용 (무료)
- 스탠다드: 모든 규모의 프로덕션 애플리케이션용 (월 $25부터)
- 엔터프라이즈: 미션 크리티컬 프로덕션 애플리케이션용 (월 $500부터)
- 주요 활용 사례:
- 시맨틱 검색
- 장기 기억을 활용한 생성형 질문 답변
- 챗봇
Weaviate
- 아키텍처: 모듈식, 클라우드 네이티브
- 성능 특성:
- HNSW 인덱싱
- 플랫 벡터 인덱스
- 전통적인 역방향 인덱스
- 통합 기능:
- Python, Java 및 Go 클라이언트 라이브러리
- AWS 및 Google과 같은 클라우드 하이퍼스케일러
- Modal, Replicate와 같은 컴퓨팅 인프라
- Airbyte, Databricks, Firecrawl, IBM 등 데이터 플랫폼
- CrewAI, LangChain, LlamaIndex, Semantic Kernel과 같은 LLM 및 에이전트 프레임워크
- DeepEval, LangWatch 등 운영 도구
- 가격 모델:
- 오픈소스 특성상 자체 호스팅 시 무료
- 서버리스 클라우드: 서버리스 SaaS 배포용 (월 25달러부터)
- 엔터프라이즈 클라우드: 전용 인스턴스에서 모든 것이 관리됨 (AI 단위당 $2.64부터)
- 주요 활용 사례:
- 책/영화 추천 시스템
- 팟캐스트/비디오 캡션/텍스트 검색
- 얼굴 인식
- 오디오 장르 분류
Milvus
- 아키텍처: 수평적 확장성을 위한 스토리지 및 컴퓨팅 분리형 공유 스토리지 아키텍처
- 성능 특성:
- ANN 기반 벡터 인덱스
- 데이터 샤딩에 대한 네이티브 지원
- 스트리밍 데이터 수집
VARCHAR,INT,FLOAT및DOUBLE데이터 유형을 위한 확장 가능한 역색인
- 통합 기능:
- Python, Java, Go 및 Node.js SDK
- LlamaIndex, LangChain, Hugging Face, Haystack, OpenAI 에이전트, VoyageAI, Kafka 등 다양한 플랫폼 지원
- 가격 정책:
- 오픈소스 특성으로 무료 (자체 호스팅)
- Zilliz Cloud에서 서버리스 또는 전용 데이터베이스 서버 사용 시 무료부터 월 $99까지
- 주요 활용 사례:
- 검색 강화 생성(Retrieval Augmented Generation)
- 추천 시스템
- 미디어 및 의미적 검색
- 이상 및 사기 탐지
Chroma

- 아키텍처: 소규모 애플리케이션용 단일 노드 서버 또는 대규모 애플리케이션용 클라우드 분산
- 성능 특성:
- 인메모리 단순 로컬 스토리지
- 클라우드 기반 완전 관리형 호스팅 서비스
- 통합 기능:
- Python 및 TypeScript SDK
- Swagger로 문서화된 REST API
- OpenAI, Google Gemini, Cohere, Baseten, Hugging Face, Instructor, Hugging Face Embedding Server, Jina AI, Roboflow, Ollama Embeddings
- AWS, Azure, Google Cloud와 같은 클라우드 제공업체
- 가격 모델:
- 오픈소스 특성으로 무료 (자체 호스팅)
- Chroma Cloud: 빠르고 확장 가능하며 서버리스 벡터, 풀텍스트 및 메타데이터 검색을 위한
- Starter: 신속한 시작 및 운영 ($0/월 + 사용량 기반 비용)
- 팀: 생산 환경 사용 사례 확장 ($250/월 + 사용량 기반 비용)
- 엔터프라이즈: 보안, 확장성, 지원 및 신뢰성을 최우선으로 하는 조직용 (맞춤형 가격)
- 주요 활용 사례:
- 추천 시스템
- 컴퓨터 비전에서의 이미지 검색
- AI 기반 챗봇
Qdrant
- 아키텍처: 대규모 및 멀티 테넌시 애플리케이션을 위한 로컬 자체 호스팅 또는 분산 클라우드 배포
- 성능 특성:
- HNSW 인덱싱
- 벡터와 페이로드를 독립적으로 인덱싱할 수 있는 구성 가능한 모듈형 인덱싱
- ANN 검색
- 벡터 업데이트 및 삭제에 최적화된 기능
- 통합 기능:
- REST API, gRPC API
- Python, JavaScript/Typescript, Rust, Go, .NET, Java 클라이언트 라이브러리
- 가격 모델:
- 오픈 소스 특성 덕분에 무료(자체 호스팅)
- Qdrant Cloud: 기업용 관리형 솔루션
- 관리형 클라우드: 배포 및 유지 관리 없이 프로덕션 솔루션 확장 (GB당 $0부터 시작)
- 하이브리드 클라우드: 모든 클라우드 공급자, 온프레미스 인프라 또는 에지 위치에서 자체 클러스터를 가져와 관리형 클라우드에 연결 (시간당 $0.014부터)
- 프라이빗 클라우드: 최대 제어권 및 데이터 주권을 위해 Qdrant를 온프레미스에 완전히 배포 (맞춤형 가격)
- 주요 활용 사례:
- RAG
- 추천 시스템
- 고급 검색
- 데이터 분석 및 이상 탐지
- AI 에이전트
브라이트 데이터로 벡터 데이터베이스 강화
벡터 임베딩의 품질에 영향을 미치는 두 가지 핵심 요소는 다음과 같습니다:
- 임베딩 생성에 사용되는 머신러닝 모델.
- 해당 모델에 입력되는 데이터의 품질.
이는 벡터 데이터베이스 파이프라인의 성능이 공급되는 데이터의 품질에 좌우됨을 보여줍니다. 저품질, 불완전하거나 노이즈가 많은 데이터로 임베딩을 생성하면 최고의 머신러닝 모델과 벡터 데이터베이스조차도 열악한 결과를 내놓을 수밖에 없습니다.
이제 깨끗하고 풍부하며 포괄적인 데이터 수집이 왜 중요한지 이해하셨을 것입니다. 바로 여기에 Bright Data가 필요한 이유입니다!
Bright Data는 윤리적이고 효율적으로 대규모 고품질 웹 데이터를 수집할 수 있도록 지원하는 선도적인 웹 스크래핑 및 데이터 수집 플랫폼입니다. 이 플랫폼의 데이터 수집 솔루션은 수백 개의 도메인에서 구조화된 실시간 데이터를 추출할 수 있습니다. 또한 이러한 솔루션은 사용자 정의 스크래핑 스크립트의 성능을 향상시키기 위해 직접 워크플로에 통합될 수 있습니다.
이 데이터 소싱 방식의 핵심 장점은 Bright Data가 모든 것을 처리한다는 점입니다. 인프라 관리, IP 로테이션 처리, 봇 방지 기능 우회, HTML 데이터 파싱, 완전한 규정 준수 보장까지 모두 담당합니다.
이러한 웹 스크래핑 도구는 웹 페이지에서 직접 신선하고 구조화된 데이터에 접근할 수 있도록 지원합니다. 웹이 가장 방대한 데이터 소스임을 고려할 때, 이를 활용하는 것은 풍부한 컨텍스트를 지닌 벡터 임베딩을 생성하는 데 이상적입니다. 이러한 임베딩은 다음과 같은 다양한 AI 및 검색 애플리케이션에 활용될 수 있습니다:
- 전자상거래 추천을 위한 제품 정보
- 의미론적 및 컨텍스트 검색을 위한 뉴스 기사
- 트렌드 탐지 및 분석을 위한 소셜 미디어 콘텐츠
- 위치 기반 경험을 위한 비즈니스 목록
원시 데이터에서 벡터 임베딩으로: 변환 과정
원시 데이터를 벡터 임베딩으로 변환하는 과정은 두 단계로 이루어집니다:
- 데이터 전처리
- 임베딩 생성
각 단계의 작동 방식과 내용을 더 잘 이해하기 위해 이를 세분화해 보겠습니다.
1단계. 데이터 전처리
원시 데이터는 잡음이 많거나 중복되거나 구조화되지 않은 경우가 많습니다. 원시 데이터를 임베딩으로 변환하는 첫 번째 단계는 데이터를 정리하고 정규화하는 것입니다. 이 과정은 임베딩 생성을 위해 머신러닝 모델에 입력하기 전에 입력 데이터의 품질과 일관성을 높여줍니다.
예를 들어, 머신 러닝에 웹 데이터를 활용할 때 일반적인 전처리 단계는 다음과 같습니다:
- 원시 HTML을 파싱하여 구조화된 콘텐츠 추출
- 공백 제거 및 데이터 형식 표준화(예: 가격, 날짜, 통화 기호).
- 소문자로 변환, 구두점 제거, 특수 HTML 문자 처리 등을 통한 텍스트 정규화.
- 중복 정보를 피하기 위한 콘텐츠 중복 제거.
2단계. 임베딩 생성
데이터가 정리되고 전처리되면 ML 임베딩 모델을 통과시킬 수 있습니다. 그러면 데이터가 고밀도 수치 벡터로 변환됩니다.
임베딩 모델 선택은 입력 데이터 유형과 원하는 출력 품질에 따라 달라집니다. 다음은 몇 가지 대표적인 방법입니다:
- OpenAI 임베딩 모델: 우수한 의미 이해력을 바탕으로 고품질의 범용 벡터를 생성합니다.
- Sentence Transformers: 최첨단 문장, 텍스트, 이미지 임베딩을 위한 오픈소스 Python 프레임워크입니다. 로컬에서 실행되며 다양한 사전 훈련 모델을 지원합니다.
- 도메인 특화 임베딩 모델: 재무 보고서, 법률 문서, 생의학 텍스트 등 틈새 데이터셋에 대해 미세 조정되어 특정 시나리오에서 높은 성능을 달성합니다.
예를 들어, OpenAI 임베딩 모델을 사용하여 임베딩을 생성하는 방법은 다음과 같습니다.
# 요구사항: pip install openai
from openai import OpenAI
client = OpenAI() # "OPENAI_API_KEY" 환경 변수에서 OpenAI 키 읽기
# 샘플 입력 데이터 (사용자 입력 데이터로 대체)
input_data = """
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
"""
# OpenAI 임베딩 모델을 사용하여 임베딩 생성
response = client.embeddings.create(
model="text-embedding-3-large",
input=input_data)
# 임베딩 가져와 출력
embedding = response.data[0].embedding
print(embedding)출력은 다음과 같은 3072차원 벡터가 됩니다:
[
-0.005813355557620525,
# 다른 3070개 요소...,
-0.006388738751411438
]마찬가지로, sentence-transformers를 사용하여 임베딩을 생성하는 방법은 다음과 같습니다:
# 요구 사항: pip install sentence_transformers
from sentence_transformers import SentenceTransformer
# 샘플 입력 데이터 (사용자 입력 데이터로 대체)
input_data = """
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
"""
# 사전 훈련된 Sentence Transformer 모델 로드
model = SentenceTransformer("all-MiniLM-L6-v2")
# 임베딩 생성
embedding = model.encode(input_data)
# 결과 임베딩 출력
print(embedding)이번에는 출력이 더 짧은 384차원 벡터가 될 것입니다:
[
-0.034803513,
# 다른 381개 요소...,
-0.046595078
]임베딩 품질과 계산 효율성 사이에는 상충 관계가 있음을 유의하십시오. OpenAI에서 제공하는 것과 같은 대규모 모델은 풍부하고 정밀한 임베딩을 생성하지만 시간이 다소 소요될 수 있으며, 프리미엄 AI 모델에 대한 네트워크 호출이 필요할 수도 있습니다. 반면 SentenceTransformers와 같은 로컬 모델은 무료이며 훨씬 빠르지만 의미적 미묘함을 희생할 수 있습니다.
적절한 임베딩 전략 선택은 성능 요구사항과 달성하고자 하는 의미적 정확도 수준에 따라 달라집니다.
실용적 통합: 단계별 가이드
아래 단계를 따라 웹 페이지의 원시 데이터에서 Python 스크립트를 통한 효과적인 의미 검색까지 진행하는 방법을 배워보세요.
이 튜토리얼 섹션에서는 다음 과정을 안내합니다:
- Bright Data의 웹 스크레이퍼 API를 사용하여 BBC에서 뉴스 기사를 가져옵니다.
- 스크래핑된 데이터를 전처리하고 임베딩 생성을 위해 준비하기.
- SentenceTransformers를 사용하여 텍스트 임베딩 생성.
- Milvus 설정하기.
- 처리된 텍스트와 임베딩으로 벡터 데이터베이스 채우기.
- 검색 쿼리를 기반으로 의미적으로 관련성 있는 뉴스 기사를 검색합니다.
자, 시작해 보겠습니다!
필수 조건
시작하기 전에 다음 사항을 확인하세요:
- 로컬에 설치된 Python 3+
- 로컬에 Docker 설치
- Bright Data 계정
아직 설치하지 않았다면, 컴퓨터에 Python과 Docker를 설치하고 무료 Bright Data 계정을 생성하세요.
1단계: Bright Data의 웹 스크레이퍼 API를 사용한 데이터 수집
의 뉴스 기사를 스크래핑하는 것은 항상 쉬운 일이 아닙니다. 많은 뉴스 포털이 스크래핑 방지 및 봇 방지 조치로 페이지를 보호하기 때문입니다. 이러한 보호 기능을 안정적으로 우회하고 BBC에서 최신 데이터를 가져오기 위해 Bright Data의 웹 스크레이퍼 API를 사용할 것입니다.
이 API는 BBC를 포함한 120개 이상의 인기 웹사이트에서 구조화된 데이터를 수집하기 위한 전용 엔드포인트를 제공합니다. 스크래핑 프로세스는 다음과 같이 작동합니다:
- 사용자는 특정 도메인의 지정된 URL에 대한 스크래핑 작업을 트리거하기 위해 해당 엔드포인트로 POST 요청을 보냅니다.
- Bright Data는 클라우드에서 스크래핑 작업을 수행합니다.
- 스크래핑된 데이터(JSON, CSV 또는 기타 형식)가 준비될 때까지 주기적으로 다른 엔드포인트를 폴링합니다.
파이썬 코드를 살펴보기 전에 Requests 라이브러리를 설치하세요:
pip install requests다음으로 Bright Data 문서를 참고하여 웹 스크레이퍼 API에 익숙해지세요. 또한 API 키를 발급받으십시오.
이제 아래 코드를 사용하여 BBC 뉴스에서 데이터를 가져옵니다:
import requests
import json
import time
def trigger_bbc_news_articles_scraping(api_key, urls):
# 웹 스크레이퍼 API 작업을 트리거할 엔드포인트
url = "https://api.brightdata.com/datasets/v3/trigger"
params = {
"dataset_id": "gd_ly5lkfzd1h8c85feyh", # BBC 웹 스크레이퍼 ID
"include_errors": "true",
}
# API 호출을 위해 입력 데이터를 원하는 형식으로 변환
data = [{"url": url} for url in urls]
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"요청 성공! 응답: {snapshot_id}")
return response.json()["snapshot_id"]
else:
print(f"요청 실패! 오류: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"ID: {snapshot_id} 스냅샷 폴링 중...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("스냅샷 준비 완료. 다운로드 중...")
snapshot_data = response.json()
# 스냅샷을 출력 JSON 파일에 기록
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"스냅샷이 {output_file}에 저장되었습니다")
return
elif response.status_code == 202:
print(F"스냅샷이 아직 준비되지 않았습니다. {polling_timeout} 초 후에 재시도 중...")
time.sleep(polling_timeout)
else:
print(f"요청 실패! 오류: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Bright Data의 웹 스크레이퍼 API 키로 교체하세요
# 데이터를 가져올 BBC 기사 URL
urls = [
"https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo",
"https://www.bbc.com/sport/formula1/articles/cgenqvv9309o",
"https://www.bbc.com/sport/formula1/articles/c78jng0q2dxo",
"https://www.bbc.com/sport/formula1/articles/cdrgdm4ye53o",
"https://www.bbc.com/sport/formula1/articles/czed4jk7eeeo",
"https://www.bbc.com/sport/football/articles/c807p94r41do",
"https://www.bbc.com/sport/football/articles/crgglxwge10o",
"https://www.bbc.com/sport/tennis/articles/cy700xne614o",
"https://www.bbc.com/sport/tennis/articles/c787dk9923ro",
"https://www.bbc.com/sport/golf/articles/ce3vjjq4dqzo"
]
snapshot_id = trigger_bbc_news_articles_scraping(BRIGHT_DATA_API_KEY, urls)
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "news-data.json")참고: 선택한 입력 URL은 모두 BBC 스포츠 기사를 참조합니다. 위 스크립트를 실행하면 다음과 같은 출력이 표시됩니다:
요청 성공! 응답: s_m9in0ojm4tu1v8h78
ID: s_m9in0ojm4tu1v8h78에 대한 스냅샷 폴링 중...
스냅샷이 아직 준비되지 않았습니다. 20초 후에 재시도 중...
# ...
스냅샷이 아직 준비되지 않았습니다. 20초 후에 재시도 중...
스냅샷 준비 완료. 다운로드 중...
스냅샷이 news-data.json에 저장되었습니다보시다시피, 스크립트는 데이터가 준비될 때까지 계속 폴링합니다. 프로세스가 완료되면 프로젝트 폴더에 news-data.json이라는 파일이 생성되며, 여기에는 구조화된 JSON 형식으로 스크랩된 기사 데이터가 포함됩니다.
2단계: 스크랩된 데이터 정리 및 준비
출력 데이터 파일을 열면 다음과 같은 뉴스 항목 배열을 확인할 수 있습니다:
[
{
"input": {
"url": "https://www.bbc.com/sport/football/articles/c807p94r41do",
"keyword": ""
},
"id": "c807p94r41do",
"url": "https://www.bbc.com/sport/football/articles/c807p94r41do",
"author": "BBC",
"headline": "맨시티 여자팀: 이번 시즌 WSL 팀에 무슨 일이 있었나?",
"topics": [
"축구",
"여자 축구"
],
"publication_date": "2026-04-13T19:35:45.288Z",
"content": "여자 챔피언스리그 진출이 확정된 가운데 ...",
"videos": [],
"images": [
// ...
],
"관련기사": [
// ...
],
"키워드": null,
"타임스탬프": "2026-04-15T13:14:27.754Z"
}
// ...
]이제 데이터를 확보했으니, 다음 단계는 이 파일을 가져와 내용을 정리하고 머신러닝 임베딩 생성을 위해 준비하는 것입니다.
이 경우 Bright Data가 대부분의 복잡한 작업을 대신 처리해 줍니다. 스크랩된 데이터는 파싱되고 구조화된 형식으로 반환되므로 HTML 데이터 파싱에 대해 걱정할 필요가 없습니다.
대신 다음과 같은 작업을 수행해야 합니다:
- 텍스트 콘텐츠 내 공백, 줄바꿈, 탭을 정규화합니다.
- 기사 제목과 본문 내용을 결합하여 임베딩 생성에 적합한 단일하고 깔끔한 텍스트 문자열을 형성합니다.
데이터 처리를 용이하게 하려면 Pandas 사용을 권장합니다. 설치 방법은 다음과 같습니다:
pip install pandas이전 단계에서 생성한 news-data.json 파일을 로드하고 데이터 처리 로직을 수행합니다:
import pandas as pd
import json
import re
# JSON 배열 로드
with open("news-data.json", "r") as f:
news_data = json.load(f)
# 임베딩 품질 향상을 위한 공백/줄바꿈/탭 정규화
def clean_text(text):
text = re.sub(r"s+", " ", text)
return text.strip()
# DataFrame 생성
df = pd.DataFrame(news_data)
# 임베딩 입력용으로 헤드라인과 정리된 콘텐츠 결합
df["text_for_embedding"] = df["headline"].map(clean_text) + ". " + df["content"].map(clean_text)
# ID가 문자열인지 확인
df["id"] = df["id"].astype(str)새로운 text_for_embedding 필드에는 통합되고 정리된 텍스트 콘텐츠가 포함되어 임베딩 생성에 바로 사용할 수 있습니다.
3단계: 임베딩 생성
SentenceTransformer를 사용하여 text_for_embedding 필드로부터 임베딩을 생성합니다:
from sentence_transformers import SentenceTransformer
# 2단계 ...
# 임베딩 생성을 위한 모델 초기화
model = SentenceTransformer("all-MiniLM-L6-v2")
# 임베딩 생성
texts = df["text_for_embedding"].tolist()
embeddings = model.encode(texts, show_progress_bar=True, batch_size=16)
# 결과 임베딩을 DataFrame에 저장
df["embedding"] = embeddings.tolist()show_progress_bar가 True로 설정되어 있으므로, sentence_transformers는 임베딩 생성 중 터미널에 진행률 표시줄을 표시합니다. 이 작업은 시간이 다소 소요될 수 있으므로 대규모 데이터셋 처리 시 특히 유용합니다.
생성된 벡터 임베딩은 1단계에서 생성된 원본 DataFrame의 embedding 열에 직접 저장됩니다.
4단계: 벡터 데이터베이스 선택 및 설정
이 예제에서 벡터 데이터베이스로 Milvus를 선택하는 것은 탁월한 선택입니다. Milvus는 무료이며 오픈 소스이고, 주요 사용 사례 중 하나로 시맨틱 검색을 지원하기 때문입니다.
로컬 머신에 Milvus를 설치하려면 공식 문서 페이지를 따르세요:
로컬에서 포트 19530으로 Milvus 인스턴스가 실행 중이어야 합니다.
다음으로 Python Milvus 클라이언트인 pymilvus를설치하세요:
pip install pymilvus참고: Milvus 서버 버전은 Python 클라이언트 버전과 일치해야 합니다. 호환되지 않는 버전은 연결 오류로 이어질 수 있습니다. 지원되는 버전 조합은 Milvus GitHub 릴리즈 페이지에서 확인할 수 있습니다. 본 문서 작성 시점 기준, 다음 조합이 작동합니다:
- Milvus 서버 버전:
2.5.9 pymilvus버전:2.5.6
5단계: 벡터 데이터베이스에 임베딩 로드하기
pymilvus를 사용하여 로컬 Milvus 서버에 연결하고, news_articles 컬렉션을 생성하며, 스키마와 인덱스를 정의한 후 임베딩으로 채웁니다:
from pymilvus import connections, utility, CollectionSchema, FieldSchema, DataType, Collection
# 4단계...
# Milvus에 연결
connections.connect("default", host="localhost", port="19530")
# "news_articles" 컬렉션이 이미 존재하면 삭제
if utility.has_collection("news_articles"):
utility.drop_collection("news_articles")
# 컬렉션 스키마 정의
fields = [
FieldSchema(name="id", dtype=DataType.VARCHAR, is_primary=True, max_length=64),
FieldSchema(name="url", dtype=DataType.VARCHAR, max_length=65535),
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=65535),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=384),
]
schema = CollectionSchema(fields, description="의미적 검색을 위한 뉴스 기사 임베딩")
collection = Collection(name="news_articles", schema=schema)
# 임베딩 필드에 인덱스 생성
index_params = {
"metric_type": "COSINE",
"index_type": "HNSW",
}
collection.create_index(field_name="embedding", index_params=index_params)
# 컬렉션을 처음 로드
collection.load()
# 삽입할 데이터 준비
ids = df["id"].tolist()
urls = df["url"].tolist()
texts = df["text_for_embedding"].tolist()
vectors = df["embedding"].tolist()
# Milvus 컬렉션에 데이터 삽입
collection.insert([ids, urls, texts, vectors])
collection.flush()이 코드 줄 이후로, 로컬 Milvus 서버의 news_articles 컬렉션에는 의미적 검색 쿼리를 지원할 준비가 된 임베딩 데이터가 포함됩니다.
6단계: 시맨틱 검색 수행
news_articles 컬렉션에 시맨틱 검색을 수행하는 함수를 정의합니다:
# 5단계...
def search_news(query: str, top_k=3, score_threshold=0.5):
query_embedding = model.encode([query])
search_params = {"metric_type": "COSINE"}
results = collection.search(
data=query_embedding,
anns_field="embedding",
param=search_params,
limit=top_k,
output_fields=["id", "url", "text"]
)
for hits in results:
for hit in hits:
if hit.score >= score_threshold:
print(f"점수: {hit.score:.4f}")
print(f"URL: {hit.fields["url"]}")
print(f"텍스트: {hit.fields["text"][:300]}...n")이 코드는 제공된 쿼리와 의미적으로 일치하는 상위 3개 결과를 검색하며, 유사도 점수가 0.5 이상인 결과만 반환합니다. 코사인 유사도를 사용하므로 점수는 -1 (완전히 반대)부터 1 (완벽한 일치)까지입니다.
이제“포뮬러 1에서 레드불 레이싱 팀의 미래”쿼리에 대해 의미적 검색을 수행할 수 있습니다:
search_news("Future of the Red Bull racing team in Formula 1")출력 결과는 다음과 같습니다:
점수: 0.5736
URL: https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo
텍스트: 맥스 페르스타펜: 레드불 고문 헬무트 마르코, 팀 내 세계 챔피언의 미래에 '큰 우려' 표명. 사우디 아라비아 그랑프리 개최지: 제다 일정: 4월 18-20일 레이스 시작: 일요일 18:00 BST 중계: 연습, 예선, 레이스 생방송 라디오 해설 온라인 및 BBC 5 Sports Extra; 생중계 텍스트...
점수: 0.5715
URL: https://www.bbc.com/sport/formula1/articles/czed4jk7eeeo
F1 엔진: V10 복귀인가 하이브리드인가 - 미래는 무엇인가?. 크리스천 호너의 전화가 울렸다. 버니 에클스톤이었다. 레드불 팀 감독은 전화를 받고 스피커폰으로 전환한 뒤, 모인 F1 팀장들 앞 테이블 위에 놓았다. "우리는 F1 위원회에 있습니다," 호너가 에클스톤에게 말했다....검색된 기사들을 읽어보면, 쿼리가 텍스트에 문자 그대로 존재하지 않음을 알 수 있습니다. 그럼에도 검색된 기사들은 분명히 포뮬러 1에서의 레드불의 미래에관한 내용입니다—이는 벡터 임베딩의 힘을 보여줍니다!
벡터 데이터베이스 성능 최적화
벡터 데이터베이스를 최대한 활용하려면 먼저 데이터를 의미 있는 컬렉션으로 구성하세요. 다음으로 데이터 샤딩 및 클러스터링 구현을 고려하고, 특정 쿼리 패턴에 최적화된 인덱싱 전략을 정의하세요.
이러한 최적화 작업 대부분은 벡터 데이터베이스 프로세스가 성숙된 후에 가장 효과적이라는 점을 명심하세요. 이는 어떤 데이터가 가장 자주 쿼리되는지 확실히 파악했을 때 발생합니다. 그때서야 실제 사용 패턴에 기반해 성능을 최적화해야 하며, 성급한 가정에 의존해서는 안 됩니다.
기타 일반적인 성능 문제로는 임베딩 드리프트, 벡터 차원 불일치, 오래되거나 중복된 데이터 등이 있습니다. 정기적인 재임베딩, 고차원 데이터에 대한 스키마 일관성 강제 적용, 자동화된 정리 작업 설정 등을 통해 해결하세요.
새로운 데이터가 시스템에 유입될 때 실시간 벡터 업데이트 또는 예약된 배치 삽입을 지원해야 합니다. 이 과정에서 검증되지 않은 데이터를 수집하면 잡음이 많은 임베딩과 신뢰할 수 없는 검색 결과가 발생할 수 있음을 유의하십시오.
마지막으로, 단일 노드 데이터베이스 최적화를 위해 인덱스 정밀도, 벡터 차원, 샤드 수 등의 매개변수 조정을 고려하십시오. 워크로드가 증가함에 따라 일반적으로 수직 확장보다 수평 확장이 선호됩니다. 따라서 여러 분산 노드(일반적으로 클라우드 기반)를 구축하게 될 수 있습니다.
벡터 데이터베이스의 미래 동향
현대 AI 시스템은 아직 비교적 새로운 분야이며 생태계가 빠르게 진화하고 있습니다. 벡터 데이터베이스가 AI 발전의 핵심 엔진 역할을 수행함에 따라, 이 기술 자체도 점점 더 복잡해지는 실제 애플리케이션을 지원하기 위해 지속적으로 적응하고 있습니다.
앞으로 벡터 데이터베이스의 미래를 형성할 흥미로운 트렌드는 다음과 같을 수 있습니다:
- 하이브리드 검색 통합: 벡터 검색을 기존 관계형 또는 NoSQL 시스템과 결합하여 구조화 및 비구조화 데이터 전반에 걸쳐 더 유연한 쿼리를 가능하게 합니다.
- 네이티브 다중 모드 지원: 텍스트, 이미지, 오디오, 비디오 등 다양한 출처의 임베딩을 통합 저장하고 쿼리할 수 있도록 합니다.
- 더 스마트한 인덱싱 및 튜닝: 자동 튜닝된 매개변수, 비용 효율적인 저장, SQL 데이터베이스 통합 등의 기능을 활용하여 확장성과 기업 적용 준비도를 개선합니다.
결론
이 가이드에서 배운 바와 같이, 벡터 데이터베이스는 머신러닝 데이터 저장소의 핵심 구성 요소입니다. 특히 벡터 데이터베이스의 정의, 작동 방식, 현재 업계에서 이용 가능한 주요 옵션, 그리고 현대 AI 데이터 인프라에서 차지하는 중추적 역할을 이해하셨을 것입니다.
또한 시맨틱 검색 사용 사례를 위해 원시 데이터에서 벡터 데이터베이스에 저장된 임베딩으로 전환하는 방법도 살펴보았습니다. 이는 포괄적이고 신뢰할 수 있으며 최신 데이터로 시작하는 것의 중요성을 강조했는데, 바로 여기에 Bright Data의 웹 스크래핑 솔루션이 활용됩니다.
벡터 데이터베이스 애플리케이션을 구동할 고품질 데이터를 확보하려면 Bright Data의 무료 체험을 시작하세요!




