

이 가이드에서 배우게 될 내용:
- 머신 러닝이란 무엇인가?
- 웹 스크래핑이 머신 러닝에 유용한 이유
- 머신 러닝을 위한 스크래핑 수행 방법
- 스크래핑된 데이터에 머신 러닝을 적용하는 방법
- 스크래핑된 데이터로 머신러닝 모델을 훈련하는 과정의 세부 사항
- 머신 러닝을 위한 데이터 스크래핑 시 ETL 설정 방법
자, 시작해 보겠습니다!
머신 러닝이란 무엇인가?
머신 러닝(ML)은 데이터로부터 학습할 수 있는 시스템을 구축하는 데 초점을 맞춘 인공 지능(AI)의 하위 분야입니다. 특히 머신 러닝을 소프트웨어 및 컴퓨팅 시스템에 적용함으로써 발생하는 큰 혁신은 컴퓨터가 ML 문제를 해결하기 위해 명시적으로 프로그래밍될 필요가 없다는 점입니다. 머신 러닝 시스템이 데이터로부터 학습하기 때문입니다.
기계는 어떻게 데이터로부터 학습할 수 있을까요? 기계 학습을 응용 수학 그 이상으로 생각할 필요는 없습니다. 실제로 ML 모델은 노출된 데이터의 근본적인 패턴을 식별하여 새로운 입력 데이터에 노출되었을 때 출력에 대한 예측을 가능하게 합니다.
웹 스크래핑이 머신 러닝에 유용한 이유
머신 러닝 시스템은 물론, 더 일반적으로는 모든 AI 시스템이 모델을 훈련시키기 위해데이터를 필요로 합니다. 바로 여기서 웹 스크래핑이 데이터 전문가들에게 기회가 됩니다.
웹 스크래핑이 머신 러닝에 중요한 이유는 다음과 같습니다:
- 대규모 데이터 수집: 머신러닝 모델, 특히 딥러닝 모델은 효과적인 훈련을 위해 방대한 양의 데이터가 필요합니다. 웹 스크래핑은 다른 곳에서는 구하기 어려운 대규모 데이터셋을 수집할 수 있게 합니다.
- 다양하고 풍부한 데이터 소스: 이미 머신러닝 모델 훈련용 데이터를 보유하고 있다면, 웹은 방대한 양의 데이터를 호스팅하므로 웹 스크래핑은 데이터셋을 확장할 수 있는 기회입니다.
- 최신 정보 확보: 보유한 데이터가 최신 동향을 반영하지 못할 때가 있는데, 웹 스크래핑이 이를 해결해 줍니다. 특히 최신 정보에 의존하는 모델(예: 주가 예측, 뉴스 감정 분석 등)의 경우 웹 스크래핑을 통해 실시간 데이터 피드를 제공할 수 있습니다.
- 모델 성능 향상: 작업 중인 모델이나 프로젝트에 따라 보유한 데이터가 단순히 부족할 수 있습니다. 따라서 웹 스크래핑을 통해 웹에서 데이터를 수집하는 것은 모델 성능을 향상시키고 검증하기 위한 목적으로 더 많은 데이터를 확보하는 방법입니다.
- 시장 분석: 리뷰, 댓글, 평점을 스크래핑하면 소비자 심리를 이해하는 데 도움이 되며, 이는 기업에 가치 있는 정보입니다. 또한 새롭게 부상하는 주제에 대한 데이터를 수집하고 시장 동향이나 여론을 예측하는 데 기여할 수 있습니다.
필수 조건
이 튜토리얼에서는 머신러닝을 위한 파이썬 웹 스크래핑 수행 방법을 배웁니다.
아래 파이썬 프로젝트를 재현하려면 시스템이 다음 필수 조건을 충족해야 합니다:
- Python 3.6 이상: 3.6보다 높은 버전의 Python이면 됩니다. 특히, 3.4보다 높은 버전의 Python에는 이미 설치되어 있는
pip를통해 종속성을 설치할 것입니다. - Jupyter Notebook 6.x: 머신러닝으로 데이터를 분석하고 예측을 수행하기 위해 Jupyter Notebook을 사용할 것입니다. 6.x보다 높은 버전이면 됩니다.
- 통합 개발 환경(IDE): VS CODE 또는 원하는 다른 Python IDE를 사용하면 됩니다.
머신러닝을 위한 스크래핑 수행 방법
이 단계별 섹션에서는 머신 러닝으로 추가 분석할 데이터를 수집하는 웹 스크래핑 프로젝트를 만드는 방법을 배웁니다.
구체적으로, 야후 파이낸스에서 NVIDIA 주가를 스크래핑하는 방법을 살펴보겠습니다. 그런 다음 해당 데이터를 머신 러닝에 활용할 것입니다.
1단계: 환경 설정
먼저, 예를 들어 scraping_project라는이름의 저장소를 생성하고, 그 안에 data, notebooks, scripts와 같은 하위 폴더를 다음과 같이 만듭니다:
scraping_project/
├── data/
│ └── ...
├── notebooks/
│ └── analysis.ipynb
├── scripts/
│ └── data_retrieval.py
└── venv/
여기서:
data_retrieval.py에는스크래핑 로직이 포함됩니다.analysis.ipynb에는머신러닝 로직이 포함됩니다.data/ 폴더에는머신러닝을 통해 분석할 스크래핑된 데이터가 포함됩니다.
venv/ 폴더에는 가상 환경이 포함됩니다. 다음과 같이 생성할 수 있습니다:
python3 -m venv venv
활성화하려면 Windows에서 다음을 실행하세요:
venvScriptsactivate
macOS/Linux에서는 다음 명령을 실행하세요:
source venv/bin/activate
이제 필요한 모든 라이브러리를 설치할 수 있습니다:
pip install selenium requests pandas matplotlib scikit-learn tensorflow notebook
단계 #2: 대상 페이지 정의
NVIDIA의 과거 데이터를 얻으려면 다음 URL로 이동해야 합니다:
https://finance.yahoo.com/quote/NVDA/history/
그러나 해당 페이지에는 데이터 표시 방식을 정의할 수 있는 필터가 제공됩니다:

머신러닝에 충분한 데이터를 수집하려면 5년 단위로 필터링할 수 있습니다. 편의를 위해 이미 5년 단위로 필터링된 다음 URL을 사용할 수 있습니다:
https://finance.yahoo.com/quote/NVDA/history/?frequency=1d&period1=1574082848&period2=1731931014
이 페이지에서 다음 테이블을 대상으로 데이터를 추출해야 합니다:
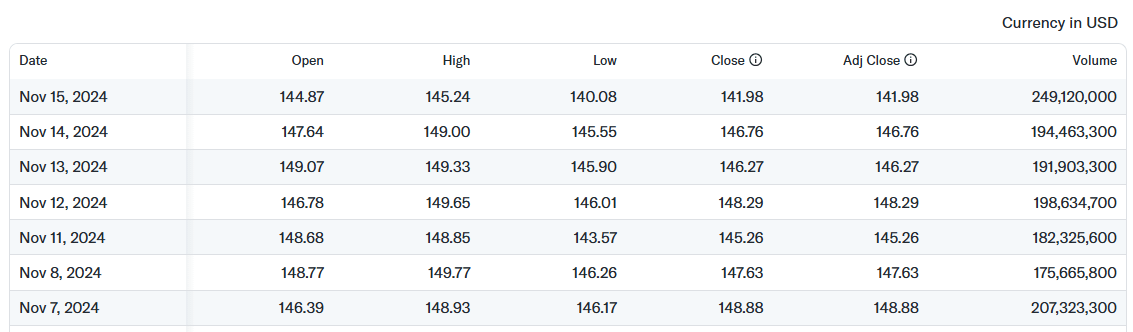
테이블을 정의하는 CSS 선택자는 .table이므로 data_retrieval.py 파일에 다음과 같은 코드를 작성할 수 있습니다:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
import pandas as pd
import os
# 셀레니움 구성
driver = webdriver.Chrome(service=Service())
# 대상 URL
url = "https://finance.yahoo.com/quote/NVDA/history/?frequency=1d&period1=1574082848&period2=1731931014"
driver.get(url)
# 테이블 로드 대기
try:
WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, ".table"))
)
except NoSuchElementException:
print("테이블을 찾을 수 없습니다. HTML 구조를 확인하세요.")
driver.quit()
exit()
# 테이블을 찾아 행을 추출
table = driver.find_element(By.CSS_SELECTOR, ".table")
rows = table.find_elements(By.TAG_NAME, "tr")
지금까지 이 코드는 다음과 같은 작업을 수행합니다:
- Selenium Chrome 드라이버 인스턴스 설정
- 대상 URL을 정의하고 Selenium이 해당 URL을 방문하도록 지시
- 테이블 로드 대기: 대상 테이블이 자바스크립트로 로드되므로 웹 드라이버가 테이블 로드 완료를 확인하기 위해 20초 대기
- 전용 CSS 선택자를 사용하여 전체 테이블을 가로챕니다
3단계: 데이터를 추출하여 CSV 파일로 저장
이 시점에서 다음 작업을 수행할 수 있습니다:
- 테이블에서 헤더 추출 (CSV 파일에 그대로 추가됨)
- 테이블의 모든 데이터를 가져옵니다
- 데이터를 Numpy 데이터 프레임으로 변환
다음 코드로 수행할 수 있습니다:
# 테이블 첫 번째 행에서 헤더 추출
headers = [header.text for header in rows[0].find_elements(By.TAG_NAME, "th")]
# 후속 행에서 데이터 추출
data = []
for row in rows[1:]:
cols = [col.text for col in row.find_elements(By.TAG_NAME, "td")]
if cols:
data.append(cols)
# 데이터를 pandas DataFrame으로 변환
df = pd.DataFrame(data, columns=headers)
단계 #4: CSV 파일을 data/ 폴더에 저장
생성된 폴더 구조를 보면 data_retrieval.py 파일이 scripts/ 폴더에 있음을 기억해야 합니다. 반면 CSV 파일은 data/ 폴더에 저장해야 하므로 코드에서 이를 고려해야 합니다:
# CSV 파일 저장 경로 결정
current_dir = os.path.dirname(os.path.abspath(__file__))
# "data/" 디렉터리로 이동
data_dir = os.path.join(current_dir, "../data")
# 디렉터리가 존재하는지 확인
os.makedirs(data_dir, exist_ok=True)
# CSV 파일의 전체 경로
csv_path = os.path.join(data_dir, "nvda_stock_data.csv")
# DataFrame을 CSV 파일에 저장
df.to_csv(csv_path, index=False)
print(f"역사적 주식 데이터가 {csv_path}에 저장됨")
# WebDriver 종료
driver.quit()
이 코드는 os.path.dirname() 메서드를 사용하여 (절대) 현재 경로를 결정하고, os.path.join() 메서드로 data/ 폴더로 이동하며, os.makedirs(data_dir, exist_ok=True) 메서드로 해당 폴더가 존재하는지 확인한 후, Pandas 라이브러리의 df.to_csv() 메서드로 데이터를 CSV 파일에 저장하고, 마지막으로 드라이버를 종료합니다.
단계 #5: 모든 것 통합하기
다음은 data_retrieval.py 파일의 전체 코드입니다:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
import pandas as pd
import os
# 셀레니움 구성
driver = webdriver.Chrome(service=Service())
# 대상 URL
url = "https://finance.yahoo.com/quote/NVDA/history/?frequency=1d&period1=1574082848&period2=1731931014"
driver.get(url)
# 테이블 로드 대기
try:
WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "table.table.yf-j5d1ld.noDl"))
)
except NoSuchElementException:
print("테이블을 찾을 수 없습니다. HTML 구조를 확인하세요.")
driver.quit()
exit()
# 테이블 위치 확인 및 행 추출
table = driver.find_element(By.CSS_SELECTOR, ".table")
rows = table.find_elements(By.TAG_NAME, "tr")
# 테이블 첫 번째 행에서 헤더 추출
headers = [header.text for header in rows[0].find_elements(By.TAG_NAME, "th")]
# 후속 행에서 데이터 추출
data = []
for row in rows[1:]:
cols = [col.text for col in row.find_elements(By.TAG_NAME, "td")]
if cols:
data.append(cols)
# 데이터를 pandas DataFrame으로 변환
df = pd.DataFrame(data, columns=headers)
# CSV 파일 저장 경로 결정
current_dir = os.path.dirname(os.path.abspath(__file__))
# "data/" 디렉터리로 이동
data_dir = os.path.join(current_dir, "../data")
# 디렉터리가 존재하는지 확인
os.makedirs(data_dir, exist_ok=True)
# CSV 파일의 전체 경로
csv_path = os.path.join(data_dir, "nvda_stock_data.csv")
# DataFrame을 CSV 파일에 저장
df.to_csv(csv_path, index=False)
print(f"역사적 주식 데이터가 {csv_path}에 저장됨")
# WebDriver 종료
driver.quit()
몇 줄의 코드로 NVIDIA 주식의 5년간 과거 데이터를 가져와 CSV 파일에 저장했습니다.
Windows에서 위 스크립트를 실행하려면:
python data_retrieval.py
또는 동등하게, Linux/macOS에서는:
python3 data_retrieval.py
스크랩된 데이터의 출력 형식은 다음과 같습니다:
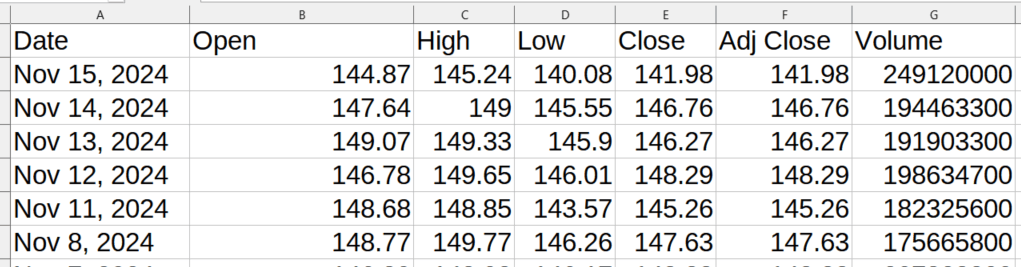
스크랩된 데이터에 머신 러닝 적용하기
이제 데이터가 CSV 파일에 저장되었으므로 머신 러닝을 사용하여 예측을 수행할 수 있습니다.
다음 단계에서 이를 수행하는 방법을 살펴보겠습니다.
1단계: 새로운 Jupyter Notebook 파일 생성
새 Jupyter Notebook 파일을 생성하려면 메인 폴더에서 notebooks/ 폴더로 이동하세요:
cd notebooks
그런 다음 다음과 같이 Jupyter Notebook을 엽니다:
jupyter notebook
브라우저가 열리면, New > Python3 (ipykernel) 을 클릭하여 새 Jupyter Notebook 파일을 생성합니다:
예를 들어, 파일을 analysis.ipynb로 이름을 변경하세요.
단계 #2: CSV 파일 열기 및 데이터 프레임 머리 부분 표시
이제 데이터가 포함된 CSV 파일을 열고 데이터 프레임의 헤더를 표시할 수 있습니다:
import pandas as pd
# CSV 파일 경로
csv_path = "../data/nvda_stock_data.csv"
# CSV 파일 열기
df = pd.read_csv(csv_path)
# 헤더 표시
df.head()
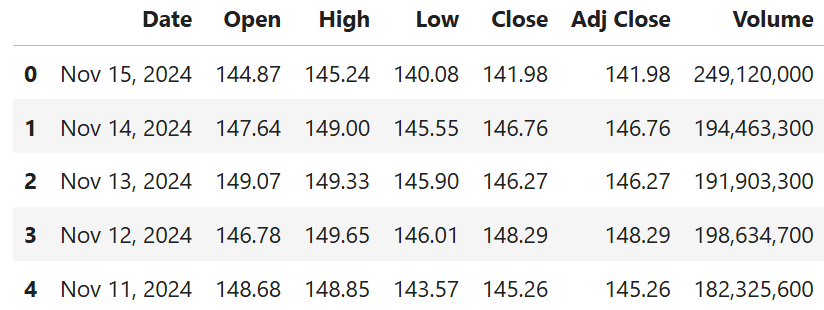
이 코드는 csv_path = "../data/nvda_stock_data.csv"로 data/ 폴더로 이동합니다. 그런 다음 pd.read_csv() 메서드로 CSV를 데이터 프레임으로 열고, df.head() 메서드로 데이터 프레임의 머리 부분(첫 5행)을 표시합니다.
예상 결과는 다음과 같습니다:
단계 #3: **조정 종가( Adj Close )**의 시간별 추세 시각화
데이터 프레임이 올바르게 로드되었으므로 조정 종가를 나타내는 조정 종가( Adj Close ) 값의 추세를 시각화할 수 있습니다:
import matplotlib.pyplot as plt
# "Date" 열이 날짜/시간 형식인지 확인
df["Date"] = pd.to_datetime(df["Date"])
# 날짜별로 데이터 정렬 (아직 정렬되지 않은 경우)
df = df.sort_values(by="Date")
# 시간별 "조정 종가" 값 플롯
plt.figure(figsize=(10, 6))
plt.plot(df["Date"], df["Adj Close"], label="조정 종가", linewidth=2)
# 플롯 커스터마이징
plt.title("NVDA 주식 조정 종가 시계열", fontsize=16) # 제목 설정
plt.xlabel("날짜", fontsize=12) # x축 레이블 설정
plt.ylabel("조정 종가 (USD)", fontsize=12) # y축 레이블 설정
plt.grid(True, linestyle="--", alpha=0.6) # 선 스타일 정의
plt.legend(fontsize=12) # 범례 표시
plt.tight_layout()
# 플롯 표시
plt.show()
이 코드 조각은 다음을 수행합니다:
df["Date"]는 데이터 프레임의Date열에 접근하며,pd.to_datetime()메서드를 통해 날짜가 날짜 형식으로 변환되도록 합니다.df.sort_values()는Date열의 날짜를 정렬합니다. 이는 데이터가 시간순으로 표시되도록 보장합니다.plt.figure()는 플롯의 크기를 설정하고plt.plot()은 플롯을 표시합니다# 플롯 커스터마이징주석 아래의 코드 줄은 제목, 축 레이블 제공 및 범례 표시를 통해 플롯을 커스터마이징하는 데 유용합니다.plt.show()메서드는 실제로 플롯을 표시하도록 허용하는 메서드입니다.
예상 결과는 다음과 같습니다:
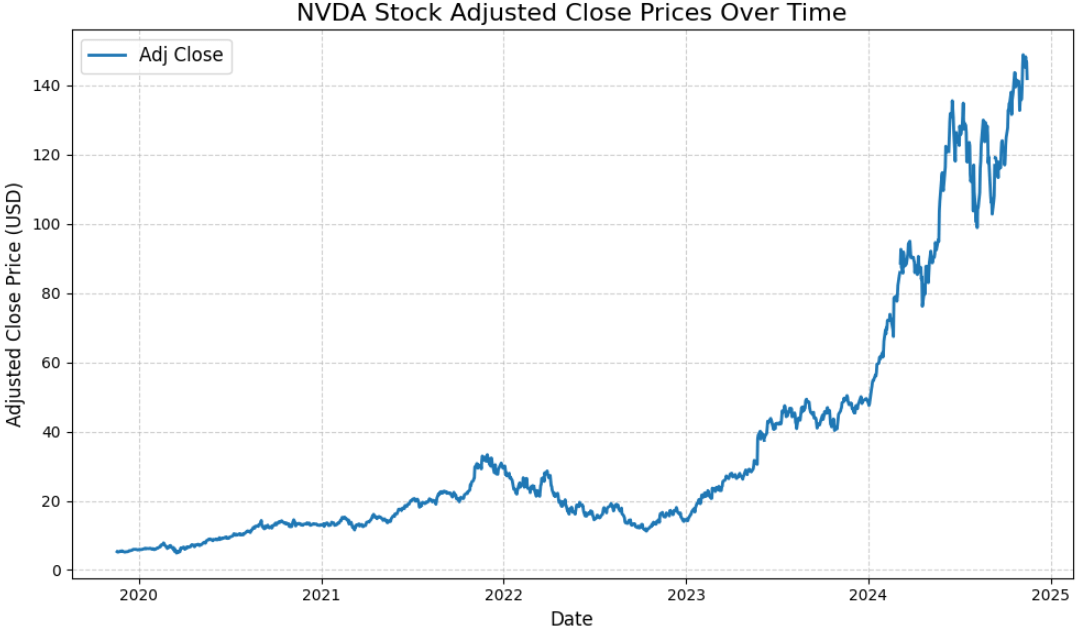
이 플롯은 NVIDIA 주식의 조정 종가 값이 시간에 따른 실제 추세를 보여줍니다. 훈련할 머신러닝 모델은 이를 최대한 정확하게 예측해야 합니다.
단계 #3: 머신러닝을 위한 데이터 준비
머신러닝을 위한 데이터 준비 시간입니다!
먼저 데이터 정리 및 준비를 수행할 수 있습니다:
from sklearn.preprocessing import MinMaxScaler
# 데이터 유형 변환
df["Volume"] = pd.to_numeric(df["Volume"].str.replace(",", ""), errors="coerce")
df["Open"] = pd.to_numeric(df["Open"].str.replace(",", ""), errors="coerce")
# 누락된 값 처리
df = df.infer_objects().interpolate()
# 대상 변수("조정 종가") 선택 및 데이터 스케일링
scaler = MinMaxScaler(feature_range=(0, 1)) # 데이터를 0과 1 사이로 스케일링
data = scaler.fit_transform(df[["조정 종가"]])
이 코드는 다음을 수행합니다:
to_numeric()메서드로 거래량(Volume) 및시가(Open) 값 변환interpolate()메서드를 사용하여 보간법으로 누락된 값을 처리합니다MinMaxScaler()로 데이터 스케일링 수행fit_transform()메서드로 대상 변수Adj Close를선택 및 변환(스케일링)
4단계: 훈련 및 테스트 세트 생성
이 튜토리얼에 사용된 모델은 LSTM(Long Short-Term Memory)으로, RNN(Recurrent Neural Network)의 일종입니다. 따라서 데이터 학습을 위한 단계 시퀀스를 생성합니다:
import numpy as np
# 예측을 위한 60개 시간 단계 시퀀스 생성
sequence_length = 60
X, y = [], []
for i in range(sequence_length, len(data)):
X.append(data[i - sequence_length:i, 0]) # 최근 60일 데이터
y.append(data[i, 0]) # 목표값
X, y = np.array(X), np.array(y)
# 훈련 세트와 테스트 세트로 분할
split_index = int(len(X) * 0.8) # 80% 훈련, 20% 테스트
X_train, X_test = X[:split_index], X[split_index:]
y_train, y_test = y[:split_index], y[split_index:]
이 코드는:
- 60개의 시간 단계 시퀀스를 생성합니다.
X는특징량 배열,y는목표값 배열입니다. - 초기 데이터프레임을 다음과 같이 분할합니다: 80%는 훈련 세트, 20%는 테스트 세트가 됨
단계 #5: 모델 훈련
이제 훈련 데이터로 RNN을 훈련시킬 수 있습니다:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM
# LSTM용 X 재구성 [샘플, 시간 단계, 특징]
X_train = X_train.reshape((X_train.shape[0], X_train.shape[1], 1))
X_test = X_test.reshape((X_test.shape[0], X_test.shape[1], 1))
# 시퀀셜 신경망 구축
model = Sequential()
model.add(LSTM(32, activation="relu", return_sequences=False))
model.add(Dense(1))
model.compile(loss="mean_squared_error", optimizer="adam")
# 모델 훈련
history = model.fit(X_train, y_train, epochs=20, batch_size=32, validation_data=(X_test, y_test), verbose=1)
이 코드는 다음을 수행합니다:
reshape()메서드를 사용하여 훈련 세트와 테스트 세트 모두에 대해 LSTM 신경망에 사용할 수 있도록 특징 배열을 재구성합니다.- LSTM 신경망의 매개변수를 설정하여 구축합니다
fit()메서드를 사용하여 LSTM을 훈련 세트에 맞춥니다
이제 모델이 훈련 세트에 학습되었으며 예측을 수행할 준비가 되었습니다.
6단계: 예측 수행 및 모델 성능 평가
이제 모델이 조정 종가(Adj Close) 값을 예측할 준비가 되었으며, 다음과 같이 성능을 평가할 수 있습니다:
from sklearn.metrics import mean_squared_error, r2_score
# 예측 수행
y_pred = model.predict(X_test)
# 비교를 위해 예측값과 실제값의 스케일 역변환
y_test = scaler.inverse_transform(y_test.reshape(-1, 1))
y_pred = scaler.inverse_transform(y_pred)
# 모델 평가
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# 결과 출력
print("nLSTM 신경망 결과:")
print(f"평균 제곱 오차: {mse:.2f}")
print(f"R 제곱 점수: {r2:.2f}")
이 코드는 다음을 수행합니다:
- 수평축의 값을 반전시켜 데이터를 시간순으로 표시할 수 있도록 합니다. 이는
inverse_transform()메서드로 수행됩니다. - 평균 제곱 오차 (MSE)와 R^2 점수를 사용하여 모델을 평가합니다.
ML 모델의 확률적 특성으로 인해 발생할 수 있는 통계적 오차를 고려할 때, 예상되는 결과는 다음과 같습니다:

상당히 우수한 값으로, 선택한 모델이 주어진 특징을 바탕으로 조정 종가를예측하는 데 적합함을 나타냅니다.
7단계: 플롯을 통한 실제값과 예측값 비교
머신러닝에서는 이전 단계에서 수행한 것과 같은 분석적 결과 비교만으로는 충분하지 않은 경우가 있습니다. 선택한 모델이 적합한지 확률을 높이기 위한 일반적인 해결책은 플롯을 추가로 생성하는 것입니다.
예를 들어, 조정 종가의 실제 값과 LSTM 모델이 예측한 값을 비교하는 플롯을 생성하는 것이 일반적인 해결책입니다:
# 결과 시각화
test_results = pd.DataFrame({
"Date": df["Date"].iloc[len(df) - len(y_test):], # 테스트 세트 날짜
"Actual": y_test.flatten(),
"Predicted": y_pred.flatten()
})
# 플롯 설정
plt.figure(figsize=(12, 6))
plt.plot(test_results["Date"], test_results["Actual"], label="조정 종가 실제값", color="blue", linewidth=2)
plt.plot(test_results["Date"], test_results["Predicted"], label="예측 조정 종가", color="orange", linestyle="--", linewidth=2)
plt.title("실제 vs 예측 조정 종가 (LSTM)", fontsize=16)
plt.xlabel("날짜", fontsize=12)
plt.ylabel("조정 종가 (USD)", fontsize=12)
plt.legend()
plt.grid(alpha=0.6)
plt.tight_layout()
plt.show()
이 코드는:
- 테스트 세트 수준에서 실제값과 예측값의 비교를 설정하므로, 실제값은 테스트 세트의 형상에 맞게 트리밍되어야 합니다. 이는
iloc()및flatten()메서드를 사용하여 수행됩니다. - 플롯을 생성하고, 축에 레이블을 추가하며, 제목을 설정하고, 시각화를 개선하기 위한 기타 설정을 관리합니다.
예상 결과는 다음과 같습니다:
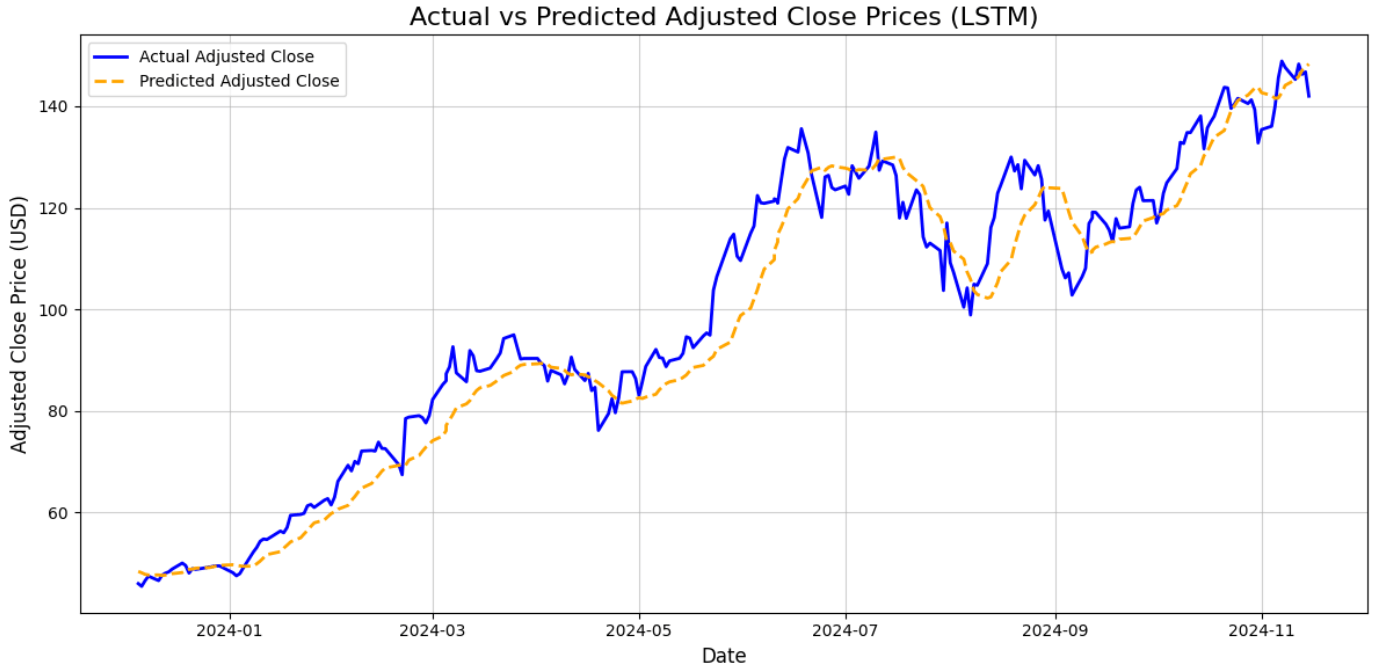
플롯에서 볼 수 있듯이, LSTM 신경망이 예측한 값(노란색 점선)은 실제 값(파란색 실선)을 상당히 잘 예측합니다. 분석 결과가 양호했기에 이는 기대에 부합하는 결과였지만, 플롯을 통해 결과가 실제로 양호함을 시각적으로 확인할 수 있습니다.
단계 #8: 모든 것 통합하기
분석.ipynb 노트북의 전체 코드는 다음과 같습니다:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, r2_score
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM
# CSV 파일 경로
csv_path = "../data/nvda_stock_data.csv"
# CSV를 데이터프레임으로 열기
df = pd.read_csv(csv_path)
# "Date" 열을 datetime 형식으로 변환
df["Date"] = pd.to_datetime(df["Date"])
# 날짜별로 정렬
df = df.sort_values(by="Date")
# 데이터 유형 변환
df["Volume"] = pd.to_numeric(df["Volume"].str.replace(",", ""), errors="coerce")
df["Open"] = pd.to_numeric(df["Open"].str.replace(",", ""), errors="coerce")
# 누락값 처리
df = df.infer_objects().interpolate()
# 목표 변수("Adj Close") 선택 및 데이터 스케일링
scaler = MinMaxScaler(feature_range=(0, 1)) # 데이터를 0과 1 사이로 스케일링
data = scaler.fit_transform(df[["Adj Close"]])
# LSTM을 위한 데이터 준비
# 예측을 위한 60시간 시퀀스 생성
sequence_length = 60
X, y = [], []
for i in range(sequence_length, len(data)):
X.append(data[i - sequence_length:i, 0]) # 최근 60일 데이터
y.append(data[i, 0]) # 목표값
X, y = np.array(X), np.array(y)
# 훈련 세트와 테스트 세트로 분할
split_index = int(len(X) * 0.8) # 80% 훈련, 20% 테스트
X_train, X_test = X[:split_index], X[split_index:]
y_train, y_test = y[:split_index], y[split_index:]
# LSTM용 X 재구성 [샘플, 시간 단계, 특징]
X_train = X_train.reshape((X_train.shape[0], X_train.shape[1], 1))
X_test = X_test.reshape((X_test.shape[0], X_test.shape[1], 1))
# 순차적 신경망 구축
model = Sequential()
model.add(LSTM(32, activation="relu", return_sequences=False))
model.add(Dense(1))
model.compile(loss="mean_squared_error", optimizer="adam")
# 모델 훈련
history = model.fit(X_train, y_train, epochs=20, batch_size=32, validation_data=(X_test, y_test), verbose=1)
# 예측 수행
y_pred = model.predict(X_test)
# 예측값과 실제값 비교를 위한 역 스케일링
y_test = scaler.inverse_transform(y_test.reshape(-1, 1))
y_pred = scaler.inverse_transform(y_pred)
# 모델 평가
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# 결과 출력
print("nLSTM 신경망 결과:")
print(f"평균 제곱 오차: {mse:.2f}")
print(f"R-제곱 점수: {r2:.2f}")
# 결과 시각화
test_results = pd.DataFrame({
"Date": df["Date"].iloc[len(df) - len(y_test):], # 테스트 세트 날짜
"Actual": y_test.flatten(),
"Predicted": y_pred.flatten()
})
# 플롯 설정
plt.figure(figsize=(12, 6))
plt.plot(test_results["Date"], test_results["Actual"], label="조정 종가(실제값)", color="blue", linewidth=2)
plt.plot(test_results["Date"], test_results["Predicted"], label="예측 조정 종가", color="orange", linestyle="--", linewidth=2)
plt.title("실제 vs 예측 조정 종가 (LSTM)", fontsize=16)
plt.xlabel("날짜", fontsize=12)
plt.ylabel("조정 종가 (USD)", fontsize=12)
plt.legend()
plt.grid(alpha=0.6)
plt.tight_layout()
plt.show()
이 전체 코드는 데이터 프레임 열 때 표시되는 헤더 부분을 생략하고 조정 종가의 실제 값만 플로팅하여 바로 목표에 도달합니다.
이러한 단계들은 본 단락 초반에 예비 데이터 분석의 일환으로 보고되었으며, 실제로 머신러닝 모델을 훈련하기 전에 데이터로 무엇을 수행하는지 이해하는 데 유용합니다.
참고: 코드는 단계별로 제시되었으나, 머신러닝의 확률적 특성을 고려할 때 LSTM 모델을 제대로 훈련하고 검증하려면 전체 코드를 한 번에 실행하는 것이 좋습니다. 그렇지 않으면 최종 플롯 결과가 크게 달라질 수 있습니다.
스크랩된 데이터로 ML 모델을 훈련하는 과정에 대한 참고 사항
간결함을 위해 본 문서의 단계별 가이드는 LSTM 신경망 적용 단계로 바로 넘어갑니다.
실제 ML 모델 작업에서는 이와 다릅니다. 따라서 ML 모델이 필요한 문제를 해결할 때는 다음 과정을 따릅니다:
- 사전 데이터 분석: 보유한 데이터를 이해하고, NaN 값 제거를 통한 데이터 정제, 중복 처리, 데이터 관련 수학적 문제 해결을 수행하는 가장 중요한 단계입니다.
- ML 모델 훈련: 머릿속에 떠오른 첫 번째 모델이 ML로 해결하려는 문제에 최적일지 알 수 없습니다. 일반적인 해결책은 소위 ‘스팟 체크(spot-check) ‘를 수행하는 것으로, 이는 다음과 같습니다:
- 훈련 데이터셋에서 3~4개의 머신러닝 모델을 훈련시키고, 해당 모델들의 성능을 평가합니다.
- 훈련 세트에서 가장 우수한 성능을 보이는 2~3개의 머신러닝 모델을 선별하고, 해당 모델의 하이퍼파라미터를 조정합니다.
- 최적화된 하이퍼파라미터를 적용한 최상위 모델들의 성능을 테스트 세트에서 비교합니다.
- 테스트 세트에서 가장 우수한 성능을 보이는 모델을 선택합니다.
- 배포: 가장 우수한 성능을 보인 모델이 실제 운영 환경에 배포됩니다.
머신러닝을 위한 데이터 스크래핑 시 ETL 설정
이 글의 시작 부분에서, 우리는 웹 스크래핑이 머신 러닝에 유용한 이유를 정의했습니다. 그러나 웹 스크래핑을 통해 검색된 데이터가 CSV 파일에 저장된다는 사실에 의존하는 개발된 프로젝트에서 불일치를 눈치챘을 수도 있습니다.
이는 머신 러닝에서 흔히 행해지는 관행이지만, 목표 값의 미래 값을 예측할 수 있는 최상의 모델을 찾는 것이 목적인 ML 프로젝트의 시작 단계에서 이를 수행하는 것이 더 낫다는 점을 고려해야 합니다.
최적의 모델을 찾은 후에는 웹에서 새 데이터를 가져와 정리하고 데이터베이스에 로드하는 ETL(추출, 변환, 로드) 파이프라인을 구축하는 것이 일반적인 후속 작업입니다.
프로세스는 다음과 같을 수 있습니다:
- 추출(Extract): 웹 스크래핑을 포함한 다양한 소스에서 데이터를 수집합니다.
- 변환(Transform): 수집된 데이터는 정제 및 준비 과정을 거칩니다.
- 로드(Load): 추출 및 변환된 데이터는 처리되어 데이터베이스나 데이터 웨어하우스에 저장됩니다.
데이터 저장 후, 후속 단계에서는 머신러닝 워크플로와의 통합을 제공합니다. 이 워크플로는 새로운 데이터로 모델을 재훈련하고 재검증하는 등의 작업을 수행합니다.
결론
본 문서에서는 웹 스크래핑을 통한 데이터 수집 방법과 머신러닝 목적의 활용 방안을 제시했습니다. 또한 머신러닝에서 웹 스크래핑의 중요성을 설명하고, 모델 훈련 및 ETL 구조화 과정을 논의했습니다.
제안된 프로젝트는 단순하지만, 특히 웹에서 지속적으로 데이터를 추출하여 머신러닝 모델을 개선하기 위한 ETL 구조화 과정과 같은 기반 프로세스들은 추가 분석이 필요한 복잡성을 내포하고 있음을 이해할 수 있습니다.
실제 환경에서 야후 파이낸스를 스크래핑하는 것은 여기서 보여준 것보다 훨씬 복잡할 수 있습니다. 해당 사이트는 일부 안티 스크래핑 기술을 사용하므로 추가적인 주의가 필요합니다. 전문적이고 모든 기능을 갖춘 올인원 솔루션을 원하신다면 Bright Data의 야후 파이낸스 스크레이퍼를 확인해 보세요!
스크래핑이 전문 분야가 아니더라도 머신러닝 프로젝트에 필요한 데이터가 필요하다면, AI 및 머신러닝 요구사항에 맞춤화된 효율적인 데이터 수집 솔루션을 살펴보세요.
지금 바로 무료 Bright Data 계정을 생성하여 스크레이퍼 API를 사용해 보거나 당사의 데이터셋을 살펴보세요.





