

TL;DR: 거래 및 투자를 위한 재무 분석 수행을 목적으로 주식 데이터를 추출하는 Yahoo Finance 스크레이퍼 구축 방법을 배워봅시다.
이 튜토리얼에서 다룰 내용:
- 웹에서 금융 데이터를 스크래핑해야 하는 이유?
- 금융 스크래핑 라이브러리 및 도구
- Selenium을 사용한 Yahoo Finance 주식 데이터 스크래핑
웹에서 금융 데이터를 스크래핑해야 하는 이유는?
웹에서금융 데이터를 스크래핑하면 다음과 같은 다양한 시나리오에서 유용한 통찰력을 얻을 수 있습니다:
- 자동화된 거래: 개발자는 주가 및 거래량과 같은 실시간 또는 과거 시장 데이터를 수집하여 자동화된 거래 전략을 구축할 수 있습니다.
- 기술적 분석: 과거 시장 데이터와 지표는 기술적 분석가에게 매우 중요합니다. 이를 통해 패턴과 추세를 식별하여 투자 의사 결정을 지원할 수 있습니다.
- 재무 모델링: 연구원과 애널리스트는 재무제표 및 경제 지표와 같은 관련 데이터를 수집하여 기업 성과 평가, 수익 예측, 투자 기회 평가를 위한 복잡한 모델을 구축할 수 있습니다.
- 시장 조사: 금융 데이터는 주식, 시장 지수, 상품에 대한 방대한 정보를 제공합니다. 이 데이터를 분석함으로써 연구자들은 시장 동향, 투자 심리, 산업 건전성을 이해하고 정보에 기반한 투자 결정을 내릴 수 있습니다.
시장 모니터링 측면에서 야후 파이낸스는 인기 있는 금융 웹사이트 중 하나입니다. 주식, 채권, 뮤추얼 펀드, 상품, 통화, 시장 지수에 대한 실시간 및 과거 데이터를 비롯해 투자자와 트레이더에게 다양한 정보와 도구를 제공합니다. 또한 뉴스 기사, 재무제표, 애널리스트 추정, 차트 및 기타 유용한 자료를 제공합니다.
야후 파이낸스를 스크래핑하면 재무 분석, 연구 및 의사 결정 과정을 지원하는 풍부한 정보에 접근할 수 있습니다.
금융 스크래핑 라이브러리 및 도구
파이썬은 구문, 사용 편의성, 풍부한 라이브러리 생태계 덕분에 스크래핑에 가장 적합한 언어 중 하나로 꼽힙니다. 파이썬을 활용한 웹 스크래핑 가이드를 확인해 보세요.
다양한 스크래핑 라이브러리 중 적합한 것을 선택하려면 브라우저에서 야후 파이낸스를 탐색해 보세요. 사이트의 대부분의 데이터가 실시간으로 업데이트되거나 상호작용 후 변경된다는 점을 확인할 수 있습니다. 이는 페이지 재로딩 없이 데이터를 동적으로 로드하고 업데이트하기 위해 AJAX를 많이 사용한다는 의미입니다. 즉, 자바스크립트를 실행할 수 있는 도구가 필요합니다.
셀레늄(Selenium) 은 파이썬으로 동적 웹사이트를 스크래핑할 수 있게 합니다. 이 라이브러리는 웹 브라우저에서 사이트를 렌더링하며, 데이터 렌더링이나 검색에 자바스크립트를 사용하는 경우에도 프로그래밍 방식으로 해당 작업을 수행합니다.
셀레늄 덕분에 파이썬으로 대상 사이트를 스크래핑할 수 있습니다. 방법을 알아봅시다!
셀레니움을 활용한 야후 파이낸스 주식 데이터 스크래핑
이 단계별 튜토리얼을 따라 야후 파이낸스 웹 스크래핑 파이썬 스크립트를 구축하는 방법을 알아보세요.
1단계: 설정
금융 데이터 스크래핑을 시작하기 전에 다음 필수 조건을 충족하세요:
- 컴퓨터에 설치된 Python 3+: 설치 프로그램을 다운로드하고 더블클릭한 후 설치 마법사를 따르세요.
- 원하는 Python IDE: PyCharm Community Edition 또는 Python 확장 기능이 설치된 Visual Studio Code를 사용하세요.
다음으로 아래 명령어를 사용하여 가상 환경이 포함된 Python 프로젝트를 설정하세요:
mkdir yahoo-finance-scraper
cd yahoo-finance-scraper
python -m venv env이렇게 하면 yahoo-finance-scraper 프로젝트 폴더가 생성됩니다. 해당 폴더 내에 아래와 같이 scraper.py 파일을 추가하세요:
print('Hello, World!')여기에는 Yahoo Finance 스크래핑 로직을 추가하게 됩니다. 현재는 “Hello, World!”만 출력하는 샘플 스크립트입니다.
실행하여 정상 작동하는지 확인합니다:
python scraper.py터미널에 다음과 같이 표시됩니다:
Hello, World!좋습니다. 이제 파이썬으로 만든 금융 스크래퍼 프로젝트가 완성되었습니다. 이제 프로젝트의 종속성만 추가하면 됩니다. 다음 터미널 명령어로 Selenium과 Webdriver Manager를 설치하세요:
pip install selenium webdriver-manager시간이 좀 걸릴 수 있으니 기다려 주세요.
웹드라이버 매니저는 꼭 필요한 것은 아닙니다. 하지만 Selenium에서 웹 드라이버 관리를 훨씬 쉽게 해주기 때문에 적극 권장합니다. 이를 통해 웹 드라이버를 수동으로 다운로드하고 구성하며 임포트할 필요가 없습니다.
scraper.py 업데이트
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
# Chrome 창을 제어할 웹 드라이버 인스턴스 초기화
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
# 스크래핑 로직...
# 브라우저를 닫고 리소스를 해제
driver.quit()이 스크립트는 단순히ChromeWebDriver 인스턴스를 생성합니다. 곧 데이터 추출 로직 구현에 이 드라이버를 사용할 것입니다.
2단계: 대상 웹 페이지에 연결
야후 파이낸스 주식 페이지의 URL은 다음과 같습니다:
https://finance.yahoo.com/quote/AMZN보시다시피, 이 URL은 티커 심볼에 따라 동적으로 변경됩니다. 티커 심볼이란 주식 시장에서 거래되는 주식을 고유하게 식별하기 위해 사용되는 문자열 약어입니다. 예를 들어, “AMZN”은 아마존 주식의 티커 심볼입니다.
명령줄 인자로 티커 심볼을 읽도록 스크립트를 수정해 보겠습니다.
import sys
# 명령줄 인수가 없는 경우
if len(sys.argv) <= 1:
print('티커 심볼 명령줄 인수가 누락되었습니다!')
sys.exit(2)
# 명령줄 인수에서 티커 읽기
ticker_symbol = sys.argv[1]
# 대상 페이지의 URL 생성
url = f'https://finance.yahoo.com/quote/{ticker_symbol}'sys는 명령줄 인자에 접근할 수 있게 해주는 Python 표준 라이브러리입니다. 인덱스 0의 인자는 스크립트 이름이라는 점을 잊지 마세요. 따라서 인덱스 1의 인자를 대상으로 삼아야 합니다.
CLI에서 티커를 읽은 후, 이를 f-string 에 사용해 스크래핑할 대상 URL을 생성합니다.
예를 들어, 테슬라 티커 “TSLA:”로 스크레이퍼를 실행한다고 가정하면
python scraper.py TSLA
url에는 다음이 포함됩니다:
https://finance.yahoo.com/quote/TSLACLI에서 티커 심볼을 입력하지 않으면 아래와 같은 오류로 프로그램이 실패합니다:
티커 심볼 CLI 인자 누락!Selenium에서 페이지를 열기 전에 모든 요소가 표시되도록 창 크기를 설정하는 것이 좋습니다:
driver.set_window_size(1920, 1080)이제 Selenium을 사용하여 대상 페이지에 다음과 같이 연결할 수 있습니다:
driver.get(url)get() 함수는 브라우저가 원하는 페이지를 방문하도록 지시합니다.
지금까지 작성한 Yahoo Finance 스크래핑 스크립트는 다음과 같습니다:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
import sys
# CLI 인수가 없는 경우
if len(sys.argv) <= 1:
print('티커 심볼 CLI 인수가 누락되었습니다!')
sys.exit(2)
# CLI 인자로 티커 읽기
ticker_symbol = sys.argv[1]
# 대상 페이지 URL 생성
url = f'https://finance.yahoo.com/quote/{ticker_symbol}'
# Chrome 창 제어용 웹 드라이버 인스턴스 초기화
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
# 제어 브라우저의 창 크기 설정
driver.set_window_size(1920, 1080)
# 대상 페이지 방문
driver.get(url)
# 스크래핑 로직...
# 브라우저 닫기 및 리소스 해제
driver.quit()실행하면 종료되기 직전 찰나 동안 이 창이 열립니다:
UI와 함께 브라우저를 시작하면 스크레이퍼가 웹 페이지에서 수행하는 작업을 모니터링하여 디버깅하는 데 유용합니다. 동시에 많은 리소스를 소모합니다. 이를 방지하려면 Chrome을 헤드리스 모드로 실행하도록 구성하세요:
from selenium.webdriver.chrome.options import Options
# ...
options = Options()
options.add_argument('--headless=new')
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options
)이제 제어되는 브라우저가 UI 없이 백그라운드에서 실행됩니다.
3단계: 대상 페이지 검사
효과적인 데이터 마이닝 전략을 수립하려면 먼저 대상 웹 페이지를 분석해야 합니다. 브라우저를 열고 Yahoo 주식 페이지를 방문하세요.
유럽에 거주하는 경우, 먼저 쿠키 수락을 요청하는 모달이 표시됩니다:
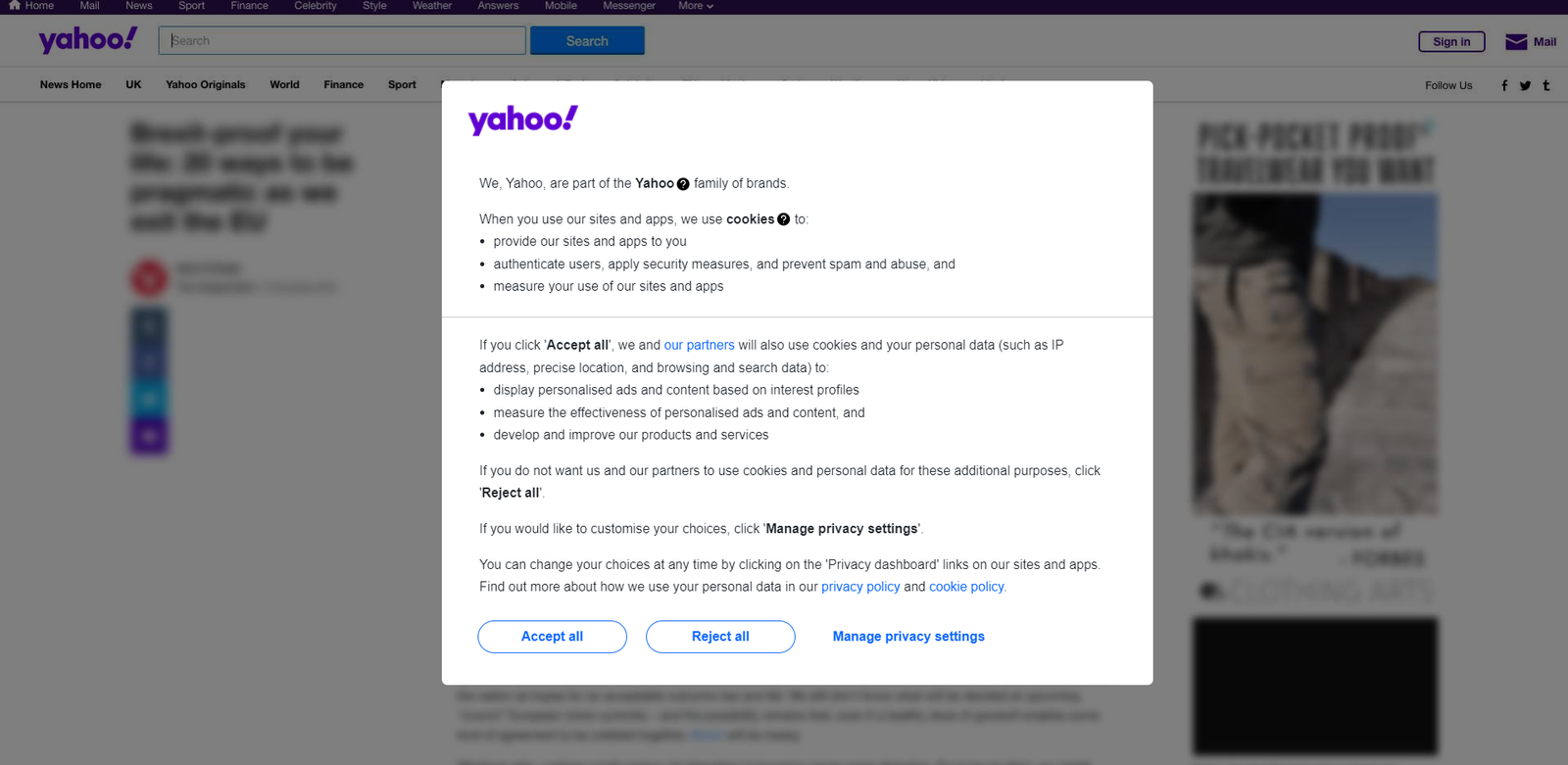
원하는 페이지를 계속 방문하려면 “모두 수락” 또는 “모두 거부”를 클릭하여 닫아야 합니다. 첫 번째 버튼을 마우스 오른쪽 버튼으로 클릭하고 “검사” 옵션을 선택하여 브라우저의 개발자 도구를 엽니다:
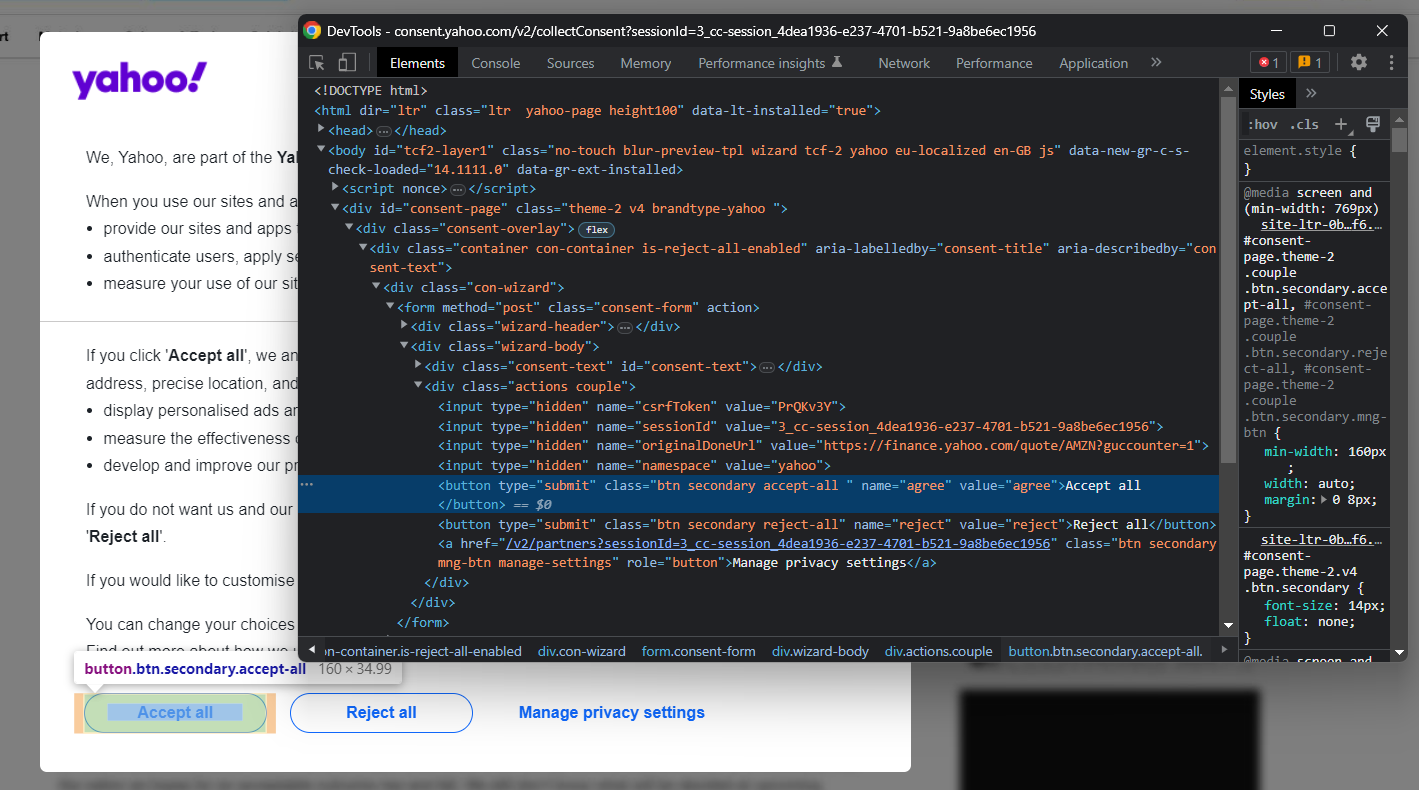
여기서 다음과 같은 CSS 선택자로 해당 버튼을 선택할 수 있음을 확인할 수 있습니다:
.consent-overlay .accept-allSelenium에서 동의 모달을 처리하려면 다음 코드를 사용하세요:
try:
# 동의 모달이 표시될 때까지 최대 3초 대기
consent_overlay = WebDriverWait(driver, 3).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.consent-overlay')))
# "모두 수락" 버튼 클릭
accept_all_button = consent_overlay.find_element(By.CSS_SELECTOR, '.accept-all')
accept_all_button.click()
except TimeoutException:
print('쿠키 동의 오버레이가 없습니다')WebDriverWait는 페이지에서 예상되는 조건이 발생할 때까지 대기할 수 있게 합니다. 지정된 시간 내에 아무 일도 발생하지 않으면 TimeoutException을 발생시킵니다. 쿠키 오버레이는 출구 IP가 유럽일 때만 표시되므로, try-catch 문으로 예외를 처리할 수 있습니다. 이렇게 하면 동의 모달이 없을 때도 스크립트가 계속 실행됩니다.
스크립트가 정상 작동하려면 다음 임포트를 추가해야 합니다:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import TimeoutException이제 개발자 도구에서 대상 사이트를 계속 검사하며 DOM 구조에 익숙해지세요.
4단계: 주식 데이터 추출
이전 단계에서 확인하셨듯이 가장 중요한 정보는 이 섹션에 있습니다:
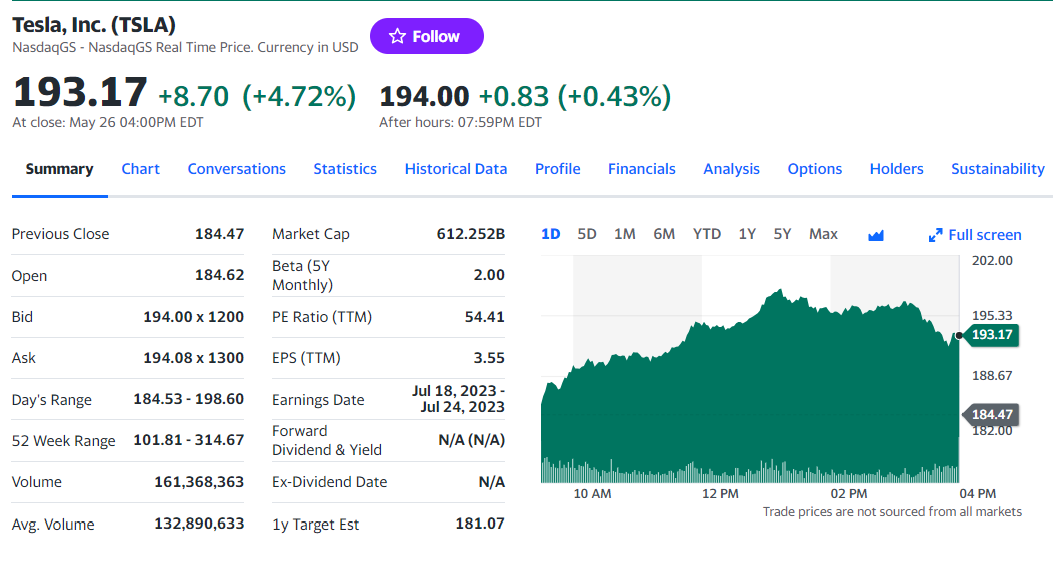
HTML 가격 표시기 요소를 검사하세요:
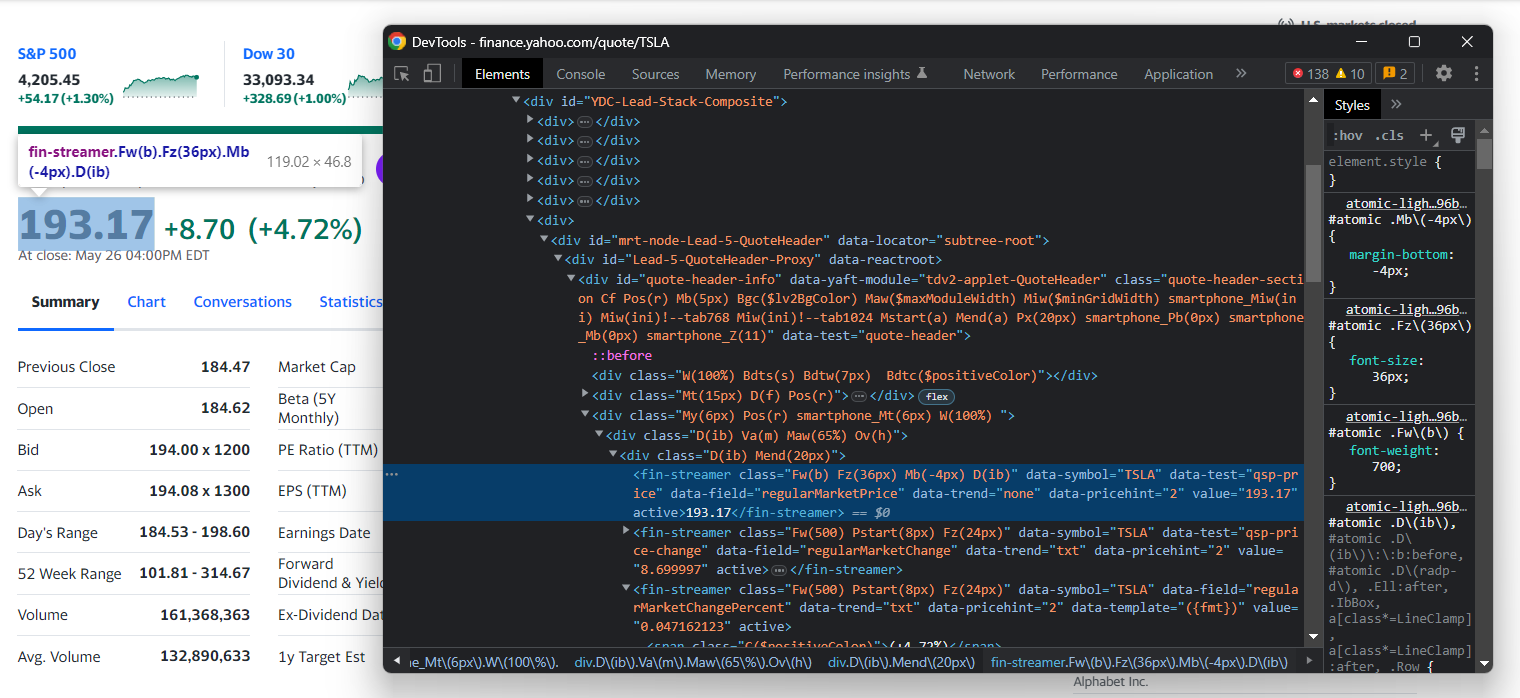
Yahoo Finance에서는 CSS 클래스가 적절한 선택자 정의에 유용하지 않습니다. 스타일링 프레임워크를 위한 특수 구문을 따르는 것으로 보입니다. 대신 다른 HTML 속성에 집중하세요. 예를 들어, 아래 CSS 선택자로 주가를 얻을 수 있습니다:
[data-symbol="TSLA"][data-field="regularMarketPrice"]비슷한 접근 방식으로 가격 표시기에서 모든 주식 데이터를 추출하려면 다음을 사용하세요:
regular_market_price = driver.find_element(
By.CSS_SELECTOR,
f'[data-symbol="{ticker_symbol}"][data-field="regularMarketPrice"]'
).text
regular_market_change = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketChange"]')
.text
regular_market_change_percent = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketChangePercent"]')
.text
.replace('(', '').replace(')', '')
post_market_price = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketPrice"]')
.text
post_market_change = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketChange"]')
.text
post_market_change_percent = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketChangePercent"]')
.text
.replace('(', '').replace(')', '')
특정 CSS 선택기 전략을 통해 HTML 요소를 선택한 후, text 필드를 사용하여 해당 콘텐츠를 추출할 수 있습니다. 백분율 필드에는 둥근 괄호가 포함되어 있으므로, replace()를 사용하여 이를 제거합니다.
주식 사전(dictionary)에 추가하고 출력하여 금융 데이터 스크래핑 과정이 예상대로 작동하는지 확인합니다:
# 사전 초기화
stock = {}
# 간결함을 위해 주가 스크래핑 로직 생략...
# 스크래핑된 데이터를 사전에 추가
stock['regular_market_price'] = regular_market_price
stock['regular_market_change'] = regular_market_change
stock['regular_market_change_percent'] = regular_market_change_percent
stock['post_market_price'] = post_market_price
stock['post_market_change'] = post_market_change
stock['post_market_change_percent'] = post_market_change_percent
print(stock)스크래핑하려는 증권에 대해 스크립트를 실행하면 다음과 같은 결과가 표시됩니다:
{'regular_market_price': '193.17', 'regular_market_change': '+8.70', 'regular_market_change_percent': '+4.72%', 'post_market_price': '194.00', 'post_market_change': '+0.83', 'post_market_change_percent': '+0.43%'}#quote-summary 테이블에서 다른 유용한 정보를 찾을 수 있습니다:
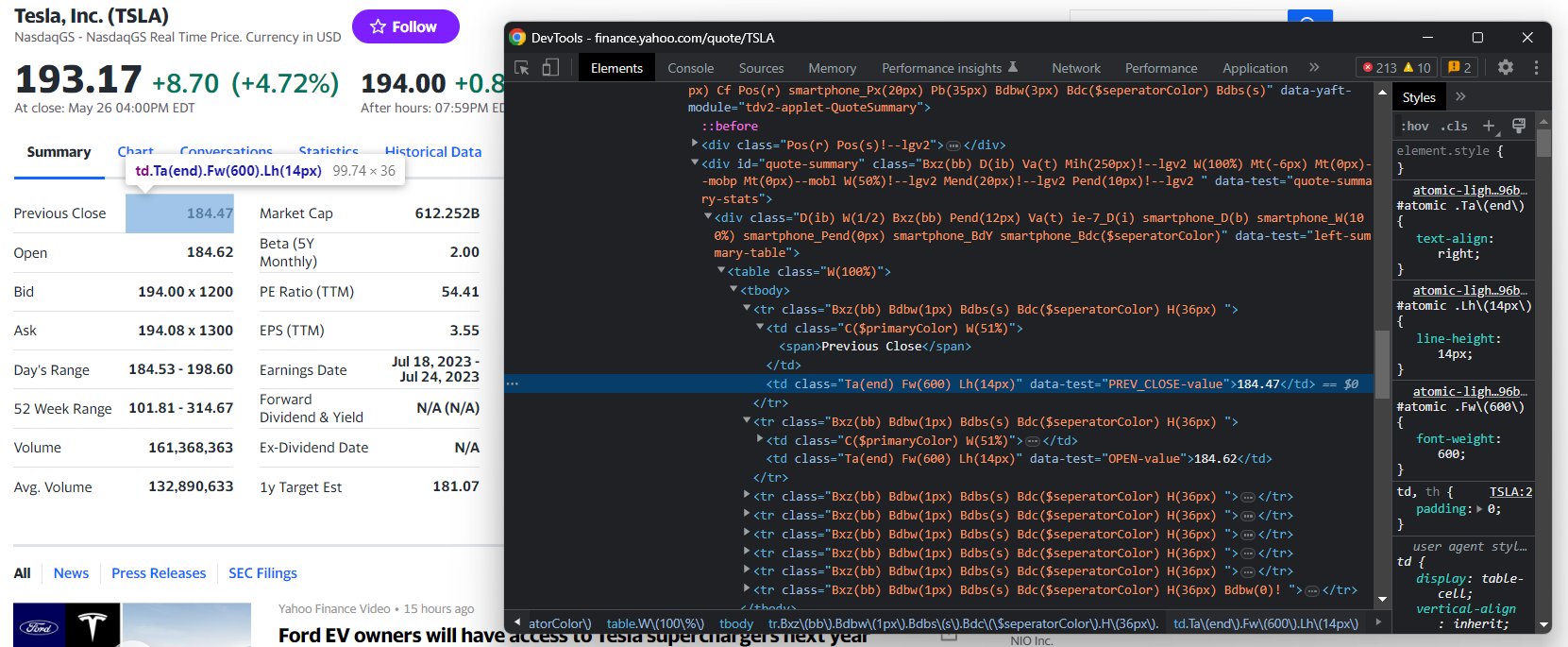
이 경우 아래 CSS 선택자처럼 data-test 속성을 통해 각 데이터 필드를 추출할 수 있습니다:
#quote-summary [data-test="PREV_CLOSE-value"]다음 코드로 모두 스크래핑하세요:
previous_close = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="PREV_CLOSE-value"]').text
open_value = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="OPEN-value"]').text
bid = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="BID-value"]').text
ask = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="ASK-value"]').text
days_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="DAYS_RANGE-value"]').text
week_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="FIFTY_TWO_WK_RANGE-value"]').text
volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="TD_VOLUME-value"]').text
avg_volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="AVERAGE_VOLUME_3MONTH-value"]').text
market_cap = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="MARKET_CAP-value"]').text
beta = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="BETA_5Y-value"]').text
pe_ratio = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="PE_RATIO-value"]').text
eps = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EPS_RATIO-value"]').text
earnings_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EARNINGS_DATE-value"]').text
dividend_yield = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="DIVIDEND_AND_YIELD-value"]').text
ex_dividend_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EX_DIVIDEND_DATE-value"]').text
year_target_est = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="ONE_YEAR_TARGET_PRICE-value"]').text그런 다음, 주가에 추가합니다:
stock['previous_close'] = previous_close
stock['open_value'] = open_value
stock['bid'] = bid
stock['ask'] = ask
stock['days_range'] = days_range
stock['week_range'] = week_range
stock['volume'] = volume
stock['avg_volume'] = avg_volume
stock['market_cap'] = market_cap
stock['beta'] = beta
stock['pe_ratio'] = pe_ratio
stock['eps'] = eps
stock['earnings_date'] = earnings_date
stock['dividend_yield'] = dividend_yield
stock['ex_dividend_date'] = ex_dividend_date
stock['year_target_est'] = year_target_est훌륭합니다! 방금 파이썬으로 금융 웹 스크래핑을 수행하셨습니다!
5단계: 여러 주식 스크래핑하기
다각화된 투자 포트폴리오는 하나 이상의 증권으로 구성됩니다. 모든 증권에 대한 데이터를 가져오려면 스크립트를 확장하여 여러 티커를 스크래핑해야 합니다.
먼저 스크래핑 로직을 함수로 캡슐화합니다:
def scrape_stock(driver, ticker_symbol):
url = f'https://finance.yahoo.com/quote/{ticker_symbol}'
driver.get(url)
# 동의 모달 처리...
# 티커 심볼로 주식 사전 초기화
stock = { 'ticker': ticker_symbol }
# 원하는 데이터 스크래핑 및 주식 사전 채우기...
return stock그런 다음 CLI 티커 인수를 반복하며 스크래핑 함수를 적용합니다:
if len(sys.argv) <= 1:
print('티커 심볼 CLI 인수가 누락되었습니다!')
sys.exit(2)
# 올바른 설정으로 Chrome 인스턴스 초기화
options = Options()
options.add_argument('--headless=new')
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options)
driver.set_window_size(1150, 1000)
# 스크랩된 모든 데이터를 포함하는 배열
stocks = []
# 모든 시장 증권 스크랩
for ticker_symbol in sys.argv[1:]:
stocks.append(scrape_stock(driver, ticker_symbol))for 루프가 끝날 때, Python 사전 목록 stocks에는 모든 주식 시장 데이터가 포함됩니다.
6단계: 수집한 데이터를 CSV로 내보내기
수집한 데이터를 CSV로 내보내는 데는 몇 줄의 코드만 필요합니다:
import csv
# ...
# 사전 필드 이름을 추출하여
# 출력 CSV 파일의 헤더로 사용
csv_header = stocks[0].keys()
# 스크랩한 데이터를 CSV로 내보내기
with open('stocks.csv', 'w', newline='') as output_file:
dict_writer = csv.DictWriter(output_file, csv_header)
dict_writer.writeheader()
dict_writer.writerows(stocks)이 코드 조각은 open()으로 stocks.csv 파일을 생성하고, 헤더 행으로 초기화한 후 데이터를 채웁니다. 특히 DictWriter.writerows() 는 각 딕셔너리를 CSV 레코드로 변환하여 출력 파일에 추가합니다.
csv는 Python 표준 라이브러리에서 제공되므로, 원하는 목표를 달성하기 위해 별도의 종속성을 설치할 필요조차 없습니다.
웹페이지에 포함된 원시 데이터에서 시작하여 CSV 파일에 저장된 반구조화된 데이터를 얻었습니다. 이제 전체 Yahoo Finance 스크래퍼를 살펴볼 차례입니다.
7단계: 모든 것을 통합하기
다음은 완성된 scraper.py 파일입니다:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import TimeoutException
import sys
import csv
def scrape_stock(driver, ticker_symbol):
# 대상 페이지 URL 생성
url = f'https://finance.yahoo.com/quote/{ticker_symbol}'
# 대상 페이지 방문
driver.get(url)
try:
# 동의 모달이 표시될 때까지 최대 3초 대기
consent_overlay = WebDriverWait(driver, 3).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.consent-overlay')))
# '모두 수락' 버튼 클릭
accept_all_button = consent_overlay.find_element(By.CSS_SELECTOR, '.accept-all')
accept_all_button.click()
except TimeoutException:
print('쿠키 동의 오버레이 미검출')
# 대상 페이지에서 수집된 데이터를 담을
# 사전 초기화
stock = { 'ticker': ticker_symbol }
# 가격 지표에서 주식 데이터 스크래핑
regular_market_price = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketPrice"]')
.text
regular_market_change = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketChange"]')
.text
regular_market_change_percent = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="regularMarketChangePercent"]')
.text
.replace('(', '').replace(')', '')
post_market_price = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketPrice"]')
.text
post_market_change = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketChange"]')
.text
post_market_change_percent = driver
.find_element(By.CSS_SELECTOR, f'[data-symbol="{ticker_symbol}"][data-field="postMarketChangePercent"]')
.text
.replace('(', '').replace(')', '')
stock['regular_market_price'] = regular_market_price
stock['regular_market_change'] = regular_market_change
stock['regular_market_change_percent'] = regular_market_change_percent
stock['post_market_price'] = post_market_price
stock['post_market_change'] = post_market_change
stock['post_market_change_percent'] = post_market_change_percent
# "Summary" 테이블에서 주식 데이터 스크래핑
previous_close = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="PREV_CLOSE-value"]').text
open_value = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="OPEN-value"]').text
bid = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="BID-value"]').text
ask = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="ASK-value"]').text
days_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="DAYS_RANGE-value"]').text
week_range = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="FIFTY_TWO_WK_RANGE-value"]').text
volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="TD_VOLUME-value"]').text
avg_volume = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="AVERAGE_VOLUME_3MONTH-value"]').text
market_cap = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="MARKET_CAP-value"]').text
beta = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="BETA_5Y-value"]').text
pe_ratio = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="PE_RATIO-value"]').text
eps = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EPS_RATIO-value"]').text
earnings_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EARNINGS_DATE-value"]').text
dividend_yield = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="DIVIDEND_AND_YIELD-value"]').text
ex_dividend_date = driver.find_element(By.CSS_SELECTOR, '#quote-summary [data-test="EX_DIVIDEND_DATE-value"]').text
year_target_est = driver.find_element(By.CSS_SELECTOR,
'#quote-summary [data-test="ONE_YEAR_TARGET_PRICE-value"]').text
stock['previous_close'] = previous_close
stock['open_value'] = open_value
stock['bid'] = bid
stock['ask'] = ask
stock['days_range'] = days_range
stock['week_range'] = week_range
stock['volume'] = volume
stock['avg_volume'] = avg_volume
stock['market_cap'] = market_cap
stock['beta'] = beta
stock['pe_ratio'] = pe_ratio
stock['eps'] = eps
stock['earnings_date'] = earnings_date
stock['dividend_yield'] = dividend_yield
stock['ex_dividend_date'] = ex_dividend_date
stock['year_target_est'] = year_target_est
return stock
# CLI 인수가 없는 경우
if len(sys.argv) <= 1:
print('티커 심볼 CLI 인수가 누락되었습니다!')
sys.exit(2)
options = Options()
options.add_argument('--headless=new')
# Chrome 창을 제어하기 위한 웹 드라이버 인스턴스 초기화
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()),
options=options)
# 제어되는 브라우저의 창 크기 설정
driver.set_window_size(1150, 1000)
# 스크래핑된 모든 데이터를 포함하는 배열
stocks = []
# 모든 시장 증권 스크래핑
for ticker_symbol in sys.argv[1:]:
stocks.append(scrape_stock(driver, ticker_symbol))
# 브라우저 닫기 및 리소스 해제
driver.quit()
# 사전 필드 이름 추출
# 출력 CSV 파일 헤더로 사용
csv_header = stocks[0].keys()
# 스크랩한 데이터를 CSV로 내보내기
with open('stocks.csv', 'w', newline='') as output_file:
dict_writer = csv.DictWriter(output_file, csv_header)
dict_writer.writeheader()
dict_writer.writerows(stocks)150줄 미만의 코드로 Yahoo Finance에서 데이터를 가져오는 완전한 웹 스크래퍼를 구축했습니다.
아래 예시처럼 대상 주식에 대해 실행하세요:
python scraper.py TSLA AMZN AAPL META NFLX GOOG스크래핑이 완료되면 프로젝트 루트 폴더에 stocks.csv 파일이 생성됩니다:

결론
이 튜토리얼을 통해 야후 파이낸스가 웹상 최고의 금융 포털 중 하나인 이유와 해당 사이트에서 데이터를 추출하는 방법을 이해하셨습니다. 특히 야후 파이낸스에서 주식 데이터를 가져올 수 있는 파이썬 스크레이퍼를 구축하는 방법을 살펴보았습니다. 여기서 보셨듯이 복잡하지 않으며 몇 줄의 코드만으로 가능합니다.
그러나 야후 파이낸스는 자바스크립트에 크게 의존하고 고급 데이터 보호 기술을 구현하는 동적 사이트입니다. 이러한 사이트에서 원활한 데이터 추출을 원하신다면 저희 야후 파이낸스 스크레이퍼 API 사용을 고려해 보세요. 이 API는 CAPTCHA 관리, 지문 인식 처리, 자동 재시도 수행 등 스크래핑의 복잡성을 처리하여 구조화된 금융 데이터를 손쉽게 얻을 수 있게 해줍니다. 데이터 수집 프로세스를 간소화하기 위해 지금 바로 저희 야후 파이낸스 스크레이퍼 API를 시작해 보세요.
웹 스크래핑 자체는 원치 않지만 금융 데이터에는 관심이 있으신가요? 야후 파이낸스 데이터셋을 활용하세요.
참고: 본 가이드는 작성 당시 당사 팀이 철저히 테스트했으나, 웹사이트는 코드와 구조를 자주 업데이트하므로 일부 단계가 예상대로 작동하지 않을 수 있습니다.






