

이 튜토리얼에서는 다음을 살펴봅니다:
- 전자상거래 스크래핑의 정의와 유용성
- 다양한 유형의 전자상거래 스크래퍼 도구
- 전자상거래 플랫폼에서 스크래핑할 수 있는 데이터
- 파이썬으로 전자상거래 스크래핑 스크립트 작성 방법
- 전자상거래 웹사이트 스크래핑의 어려움
자, 시작해 보겠습니다!
전자상거래 웹 스크래핑이란?
전자상거래 웹 스크래핑은 아마존, 월마트, 이베이 등과 같은 온라인 소매 플랫폼에서 데이터를 추출하는 과정입니다. 수동으로 데이터를 복사하여 수행할 수도 있지만, 일반적으로 자동화된 도구나 스크립트를 사용하여 수행됩니다.
전자상거래 사이트에서 추출한 데이터는 기업, 연구자, 개발자에게 다음과 같은 도움을 줄 수 있습니다:
- 제품 가격 변동 분석
- 리뷰 점수 추적
- 시장 동향 파악
- 경쟁사 연구
이러한 통찰력은 정보에 기반한 의사 결정과 전략적 계획 수립을 가능하게 합니다.
전자 상거래 데이터 스크래핑 도구는 일반적으로 전자 상거래 스크레이퍼라고 합니다.
전자상거래 스크레이퍼의 유형
다음은 가장 널리 사용되는 전자상거래 스크레이퍼 도구 유형 목록입니다:
- 사용자 지정 스크립트: Python이나 JavaScript와 같은 웹 스크래핑 프로그래밍 언어를 사용하여 특정 전자상거래 데이터를 추출하기 위해 맞춤 제작된 스크립트입니다.
- 노코드 스크레이퍼: 코딩 없이 데이터 추출이 가능한 사용자 친화적인 도구로, 비기술 사용자에게 이상적입니다. 최고의 노코드 스크레이퍼를 확인해 보세요.
- 웹 스크래핑 API: 구조화된 전자상거래 데이터를 프로그래밍 방식으로 제공하는 인터페이스로, 실시간 또는 대규모 추출을 지원하는 경우가 많습니다.
- 스크래핑 확장 프로그램: 전자상거래 웹 페이지를 탐색하면서 직접 데이터를 수집하는 것을 단순화하는 브라우저 기반 애드온입니다.
이 글에서는 맞춤형 전자상거래 웹 스크래핑 봇 구축에 특히 초점을 맞출 것입니다.
전자상거래 사이트에서 추출할 데이터
전자상거래 웹 스크레이퍼는 일반적으로 다음과 같은 데이터 수집을 지원합니다:
- 제품 세부 정보: 이름, 설명, 사양 및 이미지.
- 가격 정보: 현재 가격, 할인, 과거 가격 추이.
- 고객 리뷰: 평점, 리뷰 내용 및 고객 피드백.
- 카테고리 및 태그: 제품 분류 및 카테고리화.
- 판매자 정보: 판매자명, 평점, 연락처 정보.
- 배송 세부 정보: 비용, 배송 시간 및 배송 정책.
- 재고 현황: 재고 수준 및 품절 알림.
- 마케팅 데이터: 제품 목록, 가격 전략, 프로모션 및 시즌 할인.
이제 Python 전자상거래 스크레이퍼를 구축하는 방법을 알아보세요!
전자상거래 스크레이퍼 구축 방법
수동으로 전자상거래 스크레이퍼를 구축하려면 먼저 대상 사이트에 익숙해져야 합니다. 개발자 도구(DevTools)로 대상 페이지를 검사하여 다음을 수행하세요:
- 구성을 파악합니다
- 추출 가능한 데이터 파악
- 사용할 스크래핑 라이브러리 결정
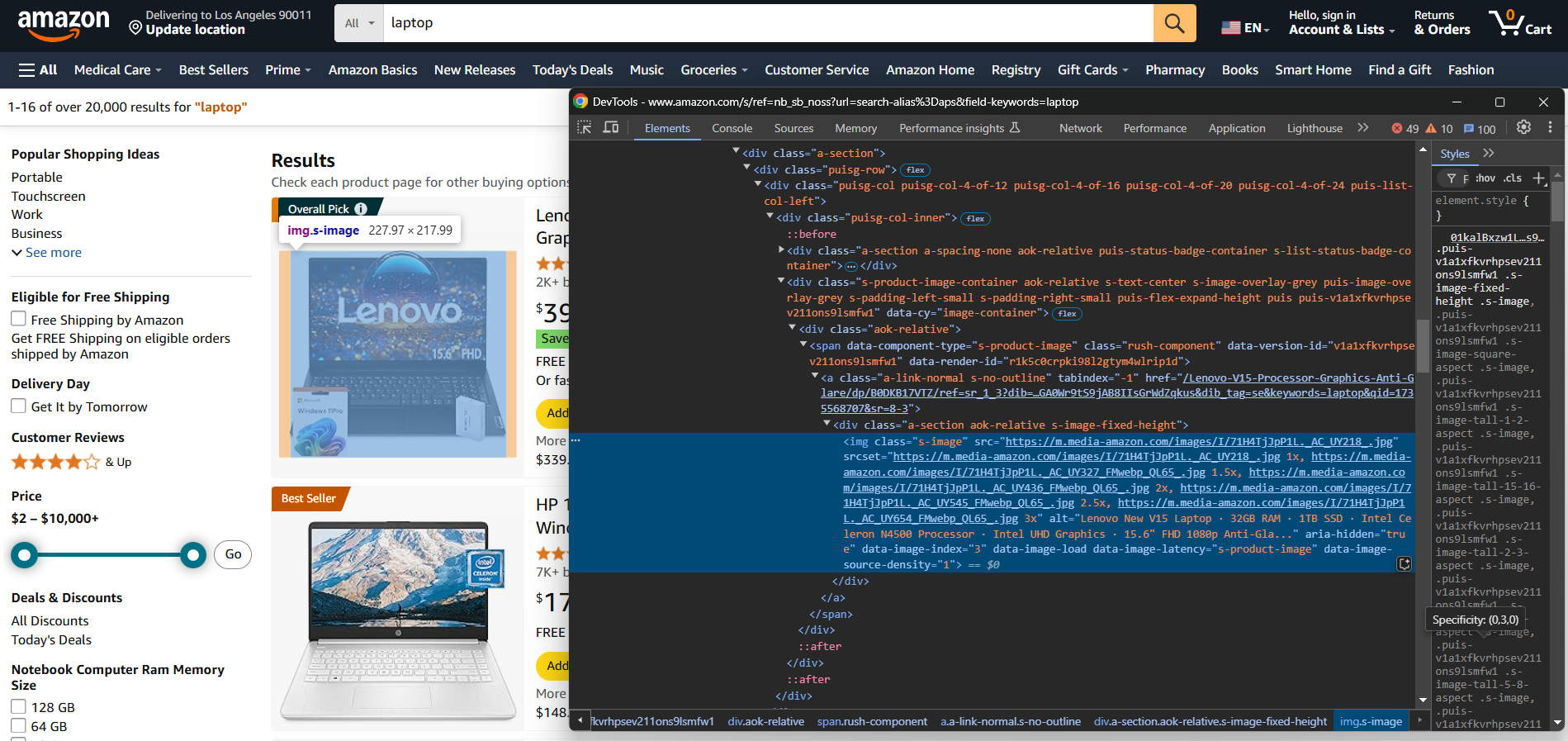
간단한 전자상거래 사이트의 경우 다음 두 Python 라이브러리로 충분합니다:
- Requests: HTTP 요청 전송용. 웹페이지의 원시 HTML 콘텐츠를 가져오는 데 도움이 됩니다.
- Beautiful Soup: HTML 및 XML 문서 파싱용. 페이지 HTML 구조 내 탐색 및 데이터 추출을 간소화합니다. Beautiful Soup 스크래핑 가이드에서 자세히 알아보세요.
두 라이브러리 모두 다음 명령어로 설치할 수 있습니다:
pip install requests beautifulsoup4
데이터를 동적으로 로드하거나 자바스크립트 렌더링에 크게 의존하는 전자상거래 플랫폼의 경우 Selenium과 같은 브라우저 자동화 도구가 필요합니다. 자세한 내용은 Selenium 스크래핑 튜토리얼을 참조하세요.
Selenium 설치 방법:
pip install selenium
다음으로 웹 스크래핑 프로세스는 다음과 같습니다:
- 대상 사이트에 연결: Requests 또는 Selenium을 사용하여 페이지의 HTML을 가져와 파싱합니다.
- 관심 요소 선택: HTML 구조에서 특정 요소(예: 제품 이미지, 가격, 설명)를 찾아 CSS 선택기 또는 XPath 표현식으로 선택합니다.
- 데이터 추출: 해당 HTML 요소에서 원하는 정보를 추출합니다.
- 데이터 정리: 추출된 데이터를 처리하여 불필요한 내용을 제거하거나 필요한 경우 재포맷합니다.
- 데이터 내보내기: 정리된 데이터를 JSON이나 CSV 등 선호하는 형식으로 저장합니다.
이 접근법의 장점으로는 데이터 추출 과정을 완전히 통제할 수 있고 특정 요구사항에 맞게 맞춤화할 수 있다는 점이 있습니다. 그러나 설계와 유지보수를 위한 기술적 전문성이 필요하며, 각 전자상거래 사이트마다 별도의 스크립트가 필요합니다.
다음 장에서는 아마존, 월마트, 이베이에서 데이터를 추출하기 위한 Python 전자상거래 스크래핑 스크립트 예시를 확인할 수 있습니다!
아마존 스크래핑
- 대상 페이지: 아마존의 “노트북” 검색 페이지
- 대상 페이지 URL: https://www.amazon.com/s?k=laptop&ref=nb_sb_noss
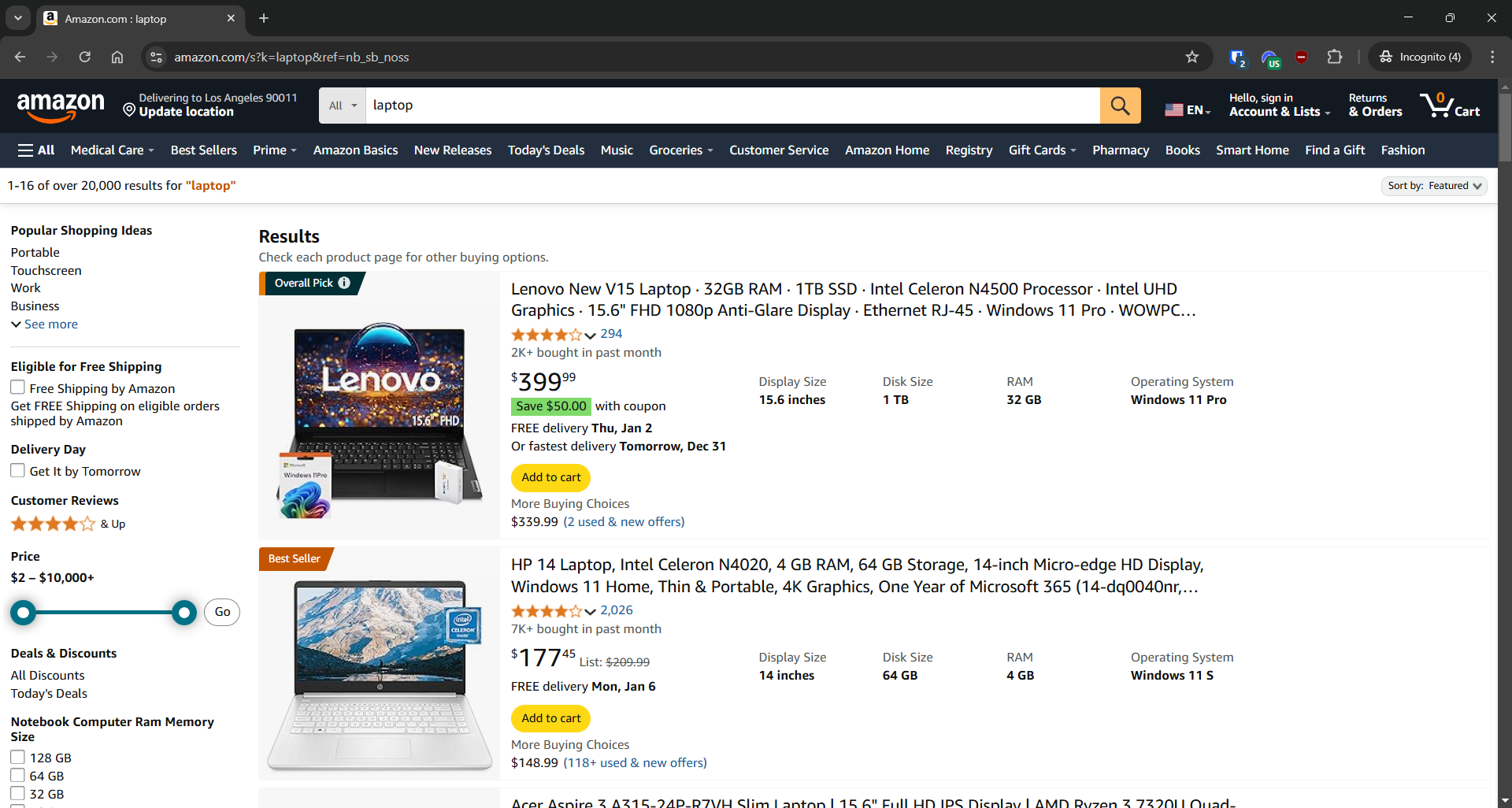
아마존은 브라우저에서 발생하지 않은 요청을 차단하도록 설계된 스크래핑 방지 조치를 시행합니다. 이러한 제한을 우회하려면 셀레늄(Selenium)과 같은 브라우저 자동화 도구를 사용해야 합니다:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
import json
# WebDriver 초기화
driver = webdriver.Chrome(service=Service())
# 브라우저에서 아마존 홈페이지 열기
driver.get("https://amazon.com/")
# 검색 양식 입력
search_input_element = driver.find_element(By.ID, "twotabsearchtextbox")
search_input_element.send_keys("laptop")
# 검색 버튼 위치 파악 및 클릭
search_button_element = driver.find_element(By.ID, "nav-search-submit-button")
search_button_element.click()
# 이제 대상 페이지에 있습니다
# 스크래핑된 데이터를 저장할 위치
products = []
# 페이지의 모든 제품 요소 선택
product_elements = driver.find_elements(By.CSS_SELECTOR, "[role="listitem"][data-asin]")
# 반복 처리
for product_element in product_elements:
# 스크래핑 로직
url_element = product_element.find_element(By.CSS_SELECTOR, ".a-link-normal")
url = url_element.get_attribute("href")
name_element = product_element.find_element(By.CSS_SELECTOR, "h2")
name = name_element.text
image_element = product_element.find_element(By.CSS_SELECTOR, "img[data-image-load]")
image = image_element.get_attribute("src")
# 스크랩한 데이터로 새 객체 생성
product = {
"url": url,
"name": name,
"image": image
}
# 스크랩된 제품 목록에 추가
products.append(product)
# 데이터를 JSON 파일로 내보내기
with open("products.json", "w", encoding="utf-8") as json_file:
json.dump(products, json_file, indent=4)
위 아마존 전자상거래 스크레이퍼를 실행하면, 아마존이 CAPTCHA를 표시하지 않을 경우 다음과 같은 결과가 생성됩니다:
[
{
"url": "https://www.amazon.com/A315-24P-R7VH-Display-Quad-Core-Processor-Graphics/dp/B0BS4BP8FB/ref=sr_1_3?crid=1W7R6D59KV9L1&dib=eyJ2IjoiMSJ9.iBCtzwnCm6CE8Bx8hKmQ8ez6PkzMg3asWNhAxvflBg3pKVi5IxQUSDpcaksihO-jEO1nyLGkdoGk_2hNyQ7EWOa6epS_hZHxqV7msqdtcEZv4irFZRnYHcP5YnEwKu17BjsYS_IPI1tFVDS65v_roSCu_IiBNfotAEHSx4zOwQ4u1CRKfvnLjIX4VlECydRjsKaAQ-mErT89tyBUCfEGjzKPPZxwHi3Y0MoieuPceL8.jIuIrqzxNYISYPLHifRJq289Vy9Z6hqT8vmMcUQw9HY&dib_tag=se&keywords=laptop&qid=1735572968&sprefix=l%2Caps%2C271&sr=8-3",
"name": "에이서 아스파이어 3 A315-24P-R7VH 슬림 노트북 | 15.6인치 풀 HD IPS 디스플레이 | AMD 라이젠 3 7320U 쿼드 코어 프로세서 | AMD 라데온 그래픽 | 8GB LPDDR5 | 128GB NVMe SSD | Wi-Fi 6 | Windows 11 Home in S Mode",
"image": "https://m.media-amazon.com/images/I/61gKkYQn6lL._AC_UY218_.jpg"
},
// 생략...
{
"url": "https://www.amazon.com/Lenovo-Newest-Flagship-Chromebook-HubxcelAccesory/dp/B0CBJ46QZX/ref=sr_1_8?crid=1W7R6D59KV9L1&dib=eyJ2IjoiMSJ9.iBCtzwnCm6CE8Bx8hKmQ8ez6PkzMg3asWNhAxvflBg3pKVi5IxQUSDpcaksihO-jEO1nyLGkdoGk_2hNyQ7EWOa6epS_hZHxqV7msqdtcEZv4irFZRnYHcP5YnEwKu17BjsYS_IPI1tFVDS65v_roSCu_IiBNfotAEHSx4zOwQ4u1CRKfvnLjIX4VlECydRjsKaAQ-mErT89tyBUCfEGjzKPPZxwHi3Y0MoieuPceL8.jIuIrqzxNYISYPLHifRJq289Vy9Z6hqT8vmMcUQw9HY&dib_tag=se&keywords=laptop&qid=1735572968&sprefix=l%2Caps%2C271&sr=8-8",
"name": "레노버 최신 플래그십 크롬북, 14인치 FHD 터치스크린 슬림 초경량 노트북, 8코어 미디어텍 컴패니오 520 프로세서, 4GB RAM, 64GB eMMC, WiFi 6, 크롬 OS+허브엑셀액세서리, 어비스 블루",
"image": "https://m.media-amazon.com/images/I/61KlKRdsQ7L._AC_UY218_.jpg"
}
]
참고: 셀레니움을 통해 요청을 수행하더라도 아마존이 여전히 CAPTCHA를 표시하고 요청을 차단할 수 있습니다. 이 경우 대안으로 SeleniumBase를 확인해 보세요. 그렇지 않으면 확실한 해결책을 제시할 예정이니 계속해서 글을 읽어보시기 바랍니다.
종합적인 안내를 원하시면 아마존 웹 스크래핑에 관한 상세한 튜토리얼을 참고하세요.
월마트 스크래핑
- 대상 페이지: 월마트의 “키보드” 검색 페이지
- 대상 페이지 URL: https://www.walmart.com/search?q=keyboard
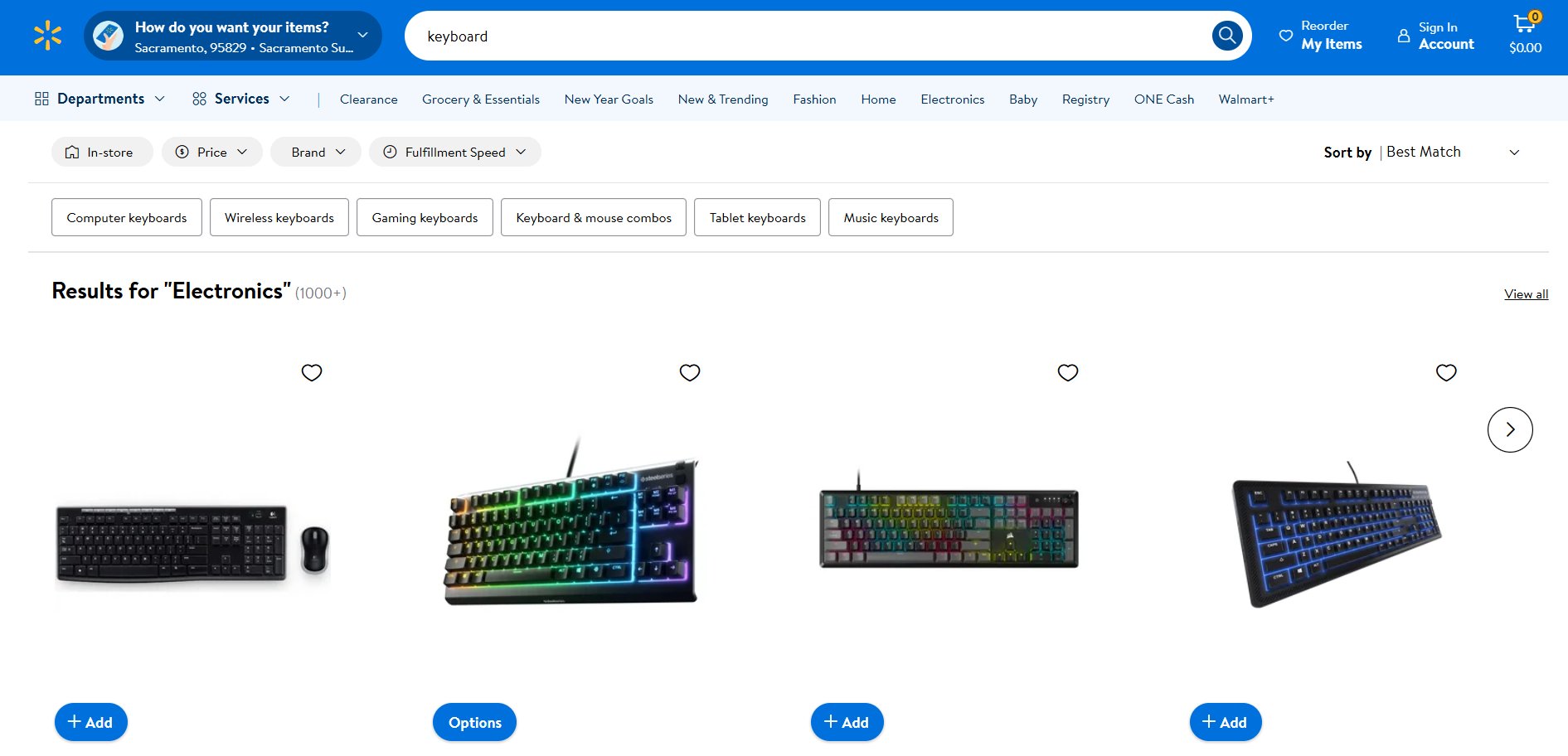
아마존과 마찬가지로 월마트도 자동화된 HTTP 클라이언트에서 오는 요청을 차단하기 위해 안티봇 솔루션을 사용합니다. 따라서 아래와 같이 셀레니움으로 스크래핑할 수 있습니다:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
import json
# WebDriver 초기화
driver = webdriver.Chrome(service=Service())
# 대상 페이지로 이동
driver.get("https://www.walmart.com/search?q=keyboard")
# 스크랩된 데이터 저장 위치
products = []
# 페이지의 모든 제품 요소 선택
product_elements = driver.find_elements(By.CSS_SELECTOR, ".carousel-4[data-testid="carousel-container"] li")
# 반복 처리
for product_element in product_elements:
# 스크래핑 로직
url_element = product_element.find_element(By.CSS_SELECTOR, "a")
url = url_element.get_attribute("href")
name_element = product_element.find_element(By.CSS_SELECTOR, "h3")
name = name_element.get_attribute("innerText")
image_element = product_element.find_element(By.CSS_SELECTOR, "img[data-testid="productTileImage"]")
image = image_element.get_attribute("src")
# 스크랩한 데이터로 새 객체 생성
product = {
"url": url,
"name": name,
"image": image
}
# 스크랩된 제품 목록에 추가
products.append(product)
# 데이터를 JSON 파일로 내보내기
with open("products.json", "w", encoding="utf-8") as json_file:
json.dump(products, json_file, indent=4)
월마트 전자상거래 스크래퍼를 실행하면 다음과 같은 결과를 얻을 수 있습니다:
[
{
"url": "https://www.walmart.com/sp/track?bt=1&eventST=click&plmt=sp-search-middle~desktop~Results%20for%20%22Electronics%22&pos=1&tax=3944_1089430_132959_1008621_7197407&rdf=1&rd=https%3A%2F%2Fwww.walmart.com%2Fip%2FLogitech-920-004536-Mk270-키보드-마우스-USB-무선-콤보-블랙%2F28540111%3FclassType%3DREGULAR%26adsRedirect%3Dtrue&adUid=094fb4ae-62f3-4954-ae99-b2938550d72c&mloc=sp-search-middle&pltfm=desktop&pgId=keyboard&pt=search&spQs=sAX_0l4wzWXzBji34bVpmheXU7_ETXGbDXcA9LhcshG_YbqBx24VWzt7yesHivpt1lpckuNhxQqbLidA-d8L4agqx_YPQVlj2EfM_TnEyfsSWiTEkvBaqgkaMzy6bgIZ4eC8t9-qqz7qtb7uXMz3cH92UCf5EEgQlfKwnxJ-SAF1EW1ouCjC10Ur3hELs3143xQPjxNUSUoN8FIF12fxJmTlSlTe4makoj1s2NoubYTqnlJLs3pohowJCRFT76Vl&storeId=3081&couponState=na&bkt=ace1_default%7Cace2_default%7Cace3_default%7Ccoldstart_off%7Csearch_default&classType=REGULAR",
"name": "로지텍 무선 콤보 MK270",
"image": "https://i5.walmartimages.com/seo/Logitech-920-004536-Mk270-Keyboard-Mouse-USB-Wireless-Combo-Black_99591453-341e-4c5b-937e-b2ab9b321519.3860011d84a23ccd0732e46474590b15.jpeg?odnHeight=784&odnWidth=580&odnBg=FFFFFF"
},
{
"url": "https://www.walmart.com/sp/track?bt=1&eventST=click&plmt=sp-search-middle~desktop~Results%20for%20%22Electronics%22&pos=2&tax=3944_1089430_132959_1008621_7197407&rdf=1&rd=https%3A%2F%2Fwww.walmart.com%2Fip%2FSteelSeries-Apex-3-TKL-RGB-게이밍-키보드-텐키리스-방수-방진-PC-및-USB-A%2F996783321%3FclassType%3DVARIANT%26adsRedirect%3Dtrue&adUid=094fb4ae-62f3-4954-ae99-b2938550d72c&mloc=sp-search-middle&pltfm=desktop&pgId=keyboard&pt=search&spQs=Dp3ons-xIcmPw9Ze7UUZuW3PD9Dto_vYCLjglme5vSy5Ze1p4NXg3uzApRy4mgfB-dGDchsq6FDoaZeMy6Dmeagqx_YPQVlj2EfM_TnEyfv_0r9GA9WwEd1cWbcx63Diahe72Zw6lw8suSf-OFKKH6UaiJl_8Qtpar-x0VhgrMsbqG7gDKh5DkQZql3HeMLncWSwburhSEjvpT1dXlDoWKxUrZwxZhOMry-uCqhuSb7Y6B-xZGrNPjYyel0nw11Z&storeId=3081&couponState=na&bkt=ace1_default%7Cace2_default%7Cace3_default%7Ccoldstart_off%7Csearch_default&classType=VARIANT",
"name": "SteelSeries Apex 3 TKL RGB 게이밍 키보드 - 텐키리스 - 방수 및 방진 - PC 및 USB-A",
"image": "https://i5.walmartimages.com/seo/SteelSeries-Apex-3-TKL-RGB-Gaming-Keyboard-Tenkeyless-Water-Dust-Resistant-PC-and-USB-A_876430c2-eed8-404a-aa55-1c66193daf8e.8c617e57ba48bc49d003f917f85cb535.jpeg?odnHeight=784&odnWidth=580&odnBg=FFFFFF"
},
// 간결함을 위해 생략...
{
"url": "https://www.walmart.com/ip/DEP-06-Portable-Digital-Piano-with-X-Stand/7598762909?classType=REGULAR",
"name": "도너 휴대용 디지털 피아노 88키 신스 액션 키보드 (X 스탠드, 페달, 자동 반주 기능 포함), 초보자용, 128 음색, 83 리듬, USB/MIDI/Melodics 지원, 무선 연결",
"image": "https://i5.walmartimages.com/seo/DEP-06-Portable-Digital-Piano-with-X-Stand_1175fc1e-c191-4c71-9e9a-7e4a13274487.6673e0430c23d122744cfb63ccc8c155.jpeg?odnHeight=784&odnWidth=580&odnBg=FFFFFF"
}
]
자세한 안내는 월마트 웹 스크래핑 관련 글을 참고하세요.
eBay 스크래핑
- 대상 페이지: eBay의 “마우스” 검색 페이지
- 대상 페이지 URL: https://www.ebay.com/sch/i.html?_from=R40&_trksid=m570.l1313&_nkw=mouse&_sacat=0
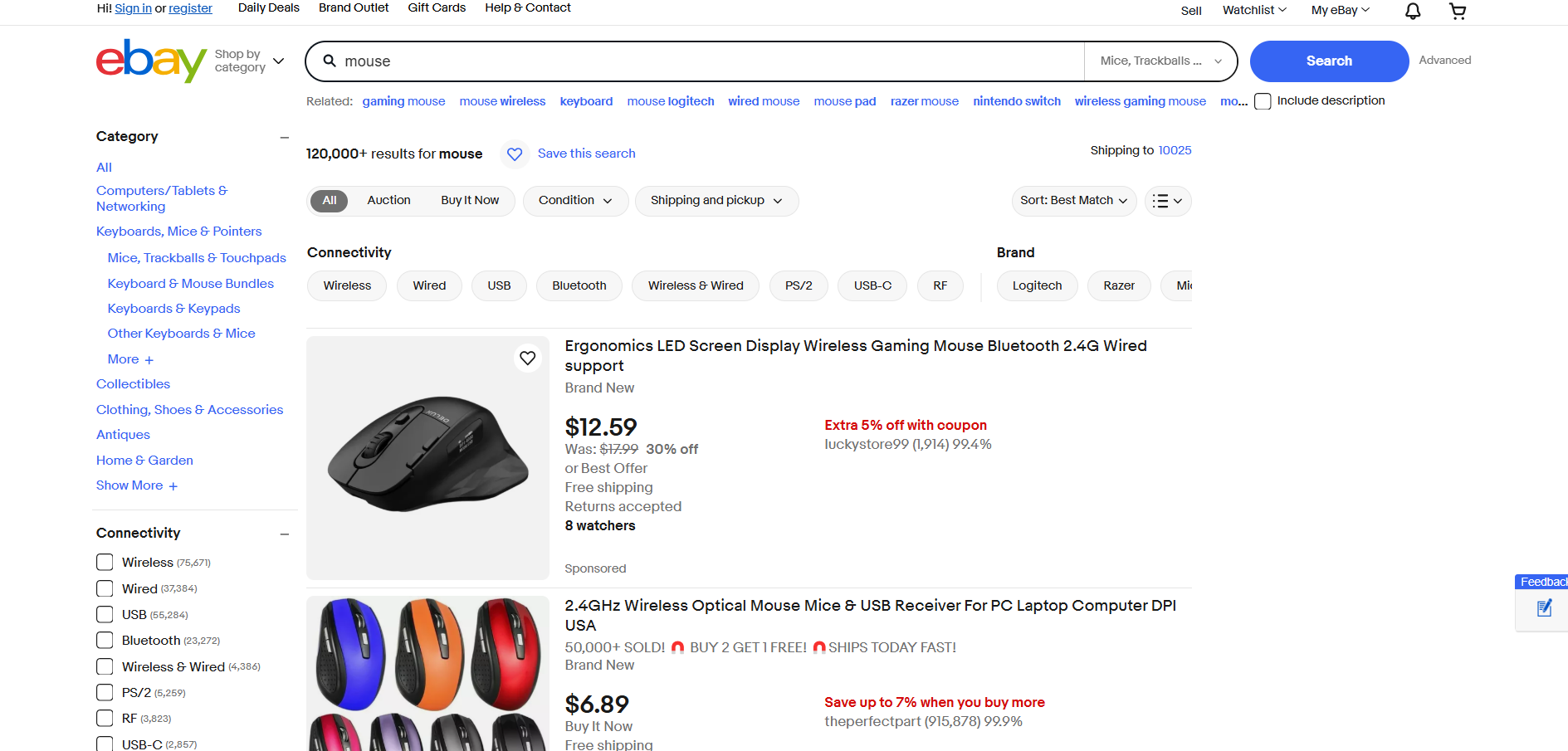
eBay는 제품 렌더링이나 데이터 동적 로딩에 자바스크립트를 사용하지 않습니다. 따라서 다음과 같이 Requests와 Beautiful Soup을 사용해 스크래핑할 수 있습니다:
import requests
from bs4 import BeautifulSoup
import json
# 대상 페이지
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=m570.l1313&_nkw=mouse&_sacat=0"
# eBay 검색 페이지에 GET 요청 전송
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
# BeautifulSoup로 페이지 콘텐츠 파싱
soup = BeautifulSoup(response.text, "html.parser")
# 스크랩된 데이터 저장 위치
products = []
# 페이지의 모든 제품 요소 선택
product_elements = soup.select("li.s-item")
# 반복 처리
for product_element in product_elements:
# 스크래핑 로직
url_element = product_element.select("a[data-interactions]")[0]
url = url_element["href"]
name_element = product_element.select("[role="heading"]")[0]
name = name_element.text
image_element = product_element.select("img")[0]
image = image_element["src"]
# 스크랩된 데이터로 새 객체 생성
product = {
"url": url,
"name": name,
"image": image
}
# 스크랩된 제품 목록에 추가
products.append(product)(product)
# 데이터를 JSON 파일로 내보내기
with open("products.json", "w", encoding="utf-8") as json_file:
json.dump(products, json_file, indent=4)eBay 전자상거래 웹 스크래핑 스크립트를 실행하면 다음과 같은 결과가 생성됩니다:
[
{
"url": "https://www.ebay.com/itm/193168148815?_skw=mouse&itmmeta=01JGC679WKT327K11R9YCGMQAN&hash=item2cf9b8094f:g:8F4AAOSw3B1drMr-&itmprp=enc%3AAQAJAAAAwHoV3kP08IDx%2BKZ9MfhVJKlr8NKoodwElhyHbl4CwcBMRqdGJme95%2F3tIll4uI7QYBk4%2BUBpwVvwiXdAl2%2BcILZ9axc%2BdHSZStWWMxWVyq4JdZ6r52PrRP2aS1jUoFoJ11vL4KyH2S8R5ha71xBtDFcGA2%2BtzhTzcR7J25kxuxbyd%2Frd4YnKbTPKwhn2Q0TP8qL30BJKcj4FnJYP0zhgO4WOGgOCHQhM21%2BanVk%2Fl0eg1H8mqCU91mkgKAt8KghFmw%3D%3D%7Ctkp%3ABlBMULSenYaDZQ",
"name": "2.4GHz 무선 광학 마우스 마우스 & USB 수신기 PC 노트북 컴퓨터 DPI 미국",
"image": "https://i.ebayimg.com/images/g/8F4AAOSw3B1drMr-/s-l500.webp"
},
{
"url": "https://www.ebay.com/itm/356159975164?_skw=mouse&itmmeta=01JGC679WKE9V782ZXT15SEPHP&hash=item52ecc9eefc:g:0ikAAOSwHStnD33Q&itmprp=enc%3AAQAJAAAAwHoV3kP08IDx%2BKZ9MfhVJKlZ7pO0lYrvftkZhnT7ja625fcsjcktK0eaub2HNzEgsmo3b2VehoA4tffYdt0xiTXwHb%2BzYU4NBZ5onBh68cyKWhhMJowbRvnCwuwy2IQIRlkeijpbRtJNJPuaaiDZdV0eabGGkps8433kCR6fcX1xEodUxujoeYUjp0VP81OWcl%2BbBGd70%2Fq45HC3SXg4k%2FlK0%2FqR80yJYexSEfzUq7%2BN3Sa6Y01uCo5XPWFLHzRoSw%3D%3D%7Ctkp%3ABlBMULSenYaDZQ",
"name": "인체공학 LED 화면 디스플레이 무선 게이밍 마우스 블루투스 2.4G 유선 지원",
"image": "https://i.ebayimg.com/images/g/0ikAAOSwHStnD33Q/s-l500.webp"
},
// 생략...
{
"url": "https://www.ebay.com/itm/116250548048?_skw=mouse&itmmeta=01JGC679WN076MJ17QJ9P4FA5J&hash=item1b11129750:g:gr8AAOSwsSFmkXG3&itmprp=enc%3AAQAJAAAAwHoV3kP08IDx%2BKZ9MfhVJKkArX38iC0VVXTpfv4BzqCegsh22yxmsDAwZAmd4RxM9JlEMfuVRoYGVZFVCeurJYwAjWd2YK3%2BNs6m5rQHZXISyWtev1lEvfVVKP4Rd5QeC2KzLgqXOvp1lWiK5b31kfujkmKjF%2BEaR1kplulwrgUvzMO%2F78F%2BFukgIAoL8dE4nRD9jo%2BieiAgIpLBUcs8AmCy5vk65gt1JGonUOncRksGYciF%2FJg6arB9%2FVOYYq7N8A%3D%3D%7Ctkp%3ABlBMULyenYaDZQ",
"name": "레이저 x 산리오 쿠로미 데스애더 게이밍 마우스 및 마우스 패드 콤보",
"image": "https://i.ebayimg.com/images/g/gr8AAOSwsSFmkXG3/s-l500.webp"
}
]
대단하네요! 방금 Python 전자상거래 데이터 스크래핑 스크립트의 몇 가지 예시를 보셨습니다!
전자상거래 웹 스크래핑의 과제와 극복 방법
위 예시에서는 몇몇 전자상거래 사이트에서 제품명, URL, 이미지 URL과 같은 기본 정보를 추출하는 데 집중했습니다. 이러한 단순성으로 인해 전자상거래 스크래핑이 직관적으로 보일 수 있지만, 실제로는 여러 이유로 훨씬 더 복잡합니다:
- 동적 페이지 구조: 전자상거래 플랫폼은 페이지 디자인을 자주 업데이트하므로 스크립트를 지속적으로 유지 관리해야 합니다.
- 다양한 상품 페이지: 상품마다 표시되는 데이터 세트가 다르고 완전히 다른 레이아웃을 사용할 수 있습니다.
- 동적 가격: 일시적인 특가, 할인 또는 지역별 제안으로 인해 정확한 가격 데이터를 스크래핑하는 것이 어려울 수 있습니다.
또한 아마존과 같은 주요 전자상거래 사이트는 CAPTCHA와 같은 고급 스크래핑 방지 조치를 사용합니다:
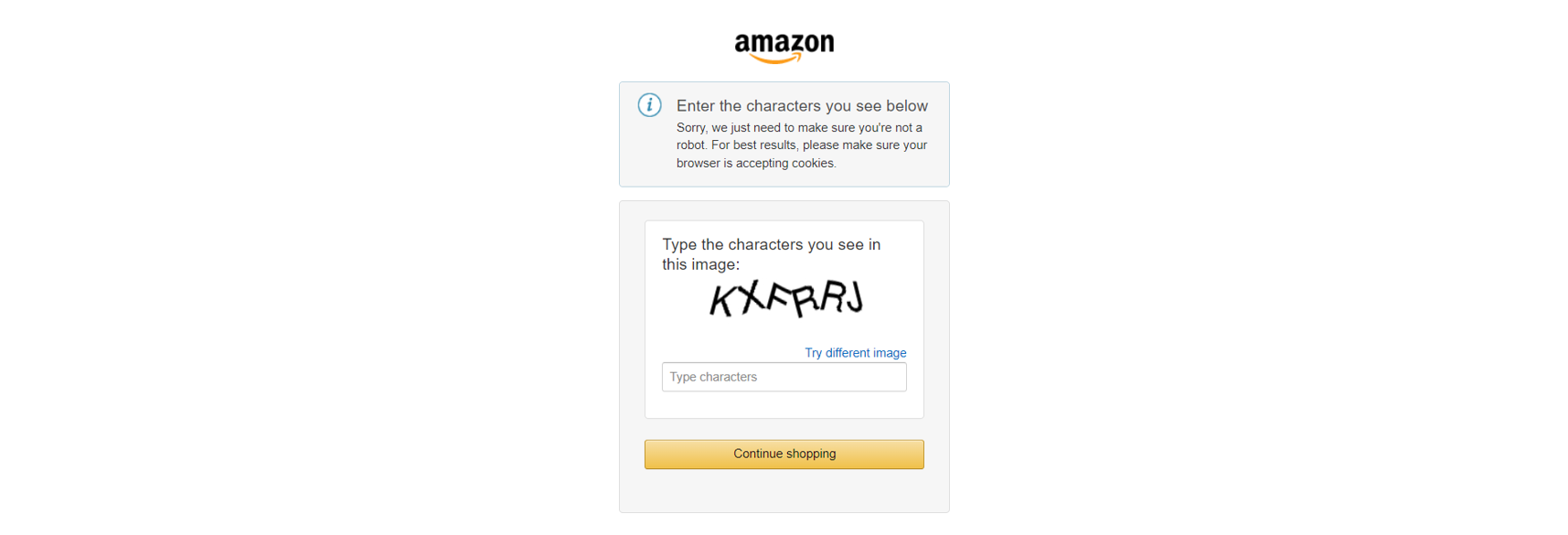
또는 유사하게 자바스크립트 기반의 방어 체계:

이러한 장애물을 극복하려면:
- 고급 스크래핑 기술 습득: Python으로 CAPTCHA 우회하는 가이드를 참고하고, 실용적인 팁을 위한 심층 스크래핑 튜토리얼을 살펴보세요.
- 고급 자동화 도구 활용: Playwright Stealth와 같은 강력한 도구를 사용하여 봇 방지 메커니즘이 적용된 사이트를 스크래핑하세요.
그러나 가장 효율적인 해결책은 전용 전자상거래 스크레이퍼 API를 사용하는 것입니다.
Bright Data의 eCommerce Scraper API는 Amazon, Target, Walmart, Lazada, Shein, Shopee 등 전자상거래 플랫폼에서 데이터를 추출하는 신뢰할 수 있는 솔루션입니다. 주요 이점은 다음과 같습니다:
- 제품 제목, 판매자 이름, 브랜드, 설명, 리뷰, 초기 가격, 통화, 재고 상태, 카테고리 등 구조화된 세부 정보를 추출합니다.
- 서버 관리, 프록시 설정, 웹사이트 차단 회피에 대한 우려를 없앨 수 있습니다.
- CAPTCHA나 자바스크립트 관련 문제로 인한 중단을 방지합니다.
오늘 바로 전자상거래 스크래핑 프로세스를 간소화하세요!
결론
이 글에서는 전자상거래 스크레이퍼가 무엇이며, 전자상거래 웹 페이지에서 어떤 유형의 데이터를 추출할 수 있는지 알아보았습니다. 아무리 정교한 전자상거래 웹 스크래핑 스크립트를 사용하더라도 대부분의 사이트는 자동화된 활동을 감지하여 차단할 수 있습니다.
해결책은 다양한 플랫폼에서 전자상거래 데이터를 안정적으로 검색하도록 특별히 설계된 강력한 전자상거래 스크레이퍼 API입니다. 이러한 API는 다음과 같은 구조화되고 포괄적인 데이터를 제공합니다:
- Amazon 스크레이퍼 API: 아마존을 스크레이핑하여 제목, 판매자 이름, 브랜드, 설명, 리뷰, 초기 가격, 통화, 재고 상태, 카테고리, ASIN, 판매자 수 등 다양한 데이터를 수집합니다.
- eBay 스크레이퍼 API: ASIN, 판매자명, 판매자 ID, URL, 이미지 URL, 브랜드, 제품 개요, 설명, 사이즈, 색상, 최종 가격 등의 데이터를 수집합니다.
- 월마트 스크레이퍼 API: URL, SKU, 가격, 이미지 URL, 관련 페이지, 배송 및 픽업 가능 여부, 브랜드, 카테고리, 제품 ID 및 설명 등의 데이터를 수집합니다.
- Target 스크레이퍼 API: URL, 제품 ID, 제목, 설명, 평점, 리뷰 수, 가격, 할인, 통화, 이미지, 판매자 이름, 오퍼, 배송 정책 등의 데이터를 수집합니다.
- Lazada 스크레이퍼 API: URL, 제목, 평점, 리뷰, 초기 및 최종 가격, 통화, 이미지, 판매자 이름, 제품 설명, SKU, 색상, 프로모션, 브랜드 등의 데이터를 스크레이핑합니다.
- Shein 스크레이퍼 API: 제품명, 설명, 가격, 통화, 색상, 재고, 사이즈, 리뷰 수, 메인 이미지, 국가 코드, 도메인 등의 데이터를 검색합니다.
- Shopee 스크레이퍼 API: URL, ID, 제목, 평점, 리뷰, 가격, 통화, 재고, 즐겨찾기, 이미지, 상점 URL, 평점, 가입 날짜, 팔로워, 판매, 브랜드 등의 데이터를 스크레이핑합니다.
특정 상품 데이터 스크래핑을 원하신다면 웹 스크래퍼 API를 고려해 보세요. 스크래퍼 구축이 부담스럽다면 즉시 사용 가능한 전자상거래 데이터셋을 살펴보세요.
스크레이퍼 API를 사용해 보거나 데이터셋을 살펴보려면 지금 바로 Bright Data 무료 계정을 생성하세요.






