이 가이드에서는 다음을 배울 수 있습니다:
- SeleniumBase란 무엇이며 웹 스크래핑에 유용한 이유
- 기본 Selenium과 비교 시 장점
- SeleniumBase가 제공하는 기능과 장점
- 간단한 스크레이퍼 구축 방법
- 더 복잡한 사용 사례에 활용하는 방법
자, 시작해 보겠습니다!
SeleniumBase란 무엇인가요?
SeleniumBase는 브라우저 자동화를 위한 Python 프레임워크입니다. Selenium/WebDriver API를 기반으로 구축되어 웹 자동화를 위한 전문가 수준의 툴킷을 제공합니다. 테스트부터 스크래핑까지 다양한 작업을 지원합니다.
SeleniumBase는 웹 페이지 테스트, 워크플로 자동화, 웹 기반 작업 확장을 위한 올인원 라이브러리입니다. CAPTCHA 우회, 봇 탐지 회피, 생산성 향상 도구 등 고급 기능을 갖추고 있습니다.
SeleniumBase vs Selenium: 기능 및 API 비교
SeleniumBase의 필요성을 더 잘 이해하려면, 그 기반이 되는 도구인 기본 Selenium 버전과 직접 비교해 보는 것이 합리적입니다.
간단한 Selenium 대 SeleniumBase 비교를 위해 아래 요약표를 참고하세요:
| 기능 | 셀레니움베이스 | Selenium |
|---|---|---|
| 내장 테스트 실행기 | pytest, pynose, behave와 통합 |
테스트 통합을 위한 수동 설정 필요 |
| 드라이버 관리 | 브라우저 버전에 맞는 브라우저 드라이버를 자동으로 다운로드 | 수동 드라이버 다운로드 및 구성이 필요함 |
| 웹 자동화 로직 | 여러 단계를 단일 메서드 호출로 통합 | 유사한 기능을 구현하기 위해 여러 줄의 코드 필요 |
| 선택기 처리 | CSS 또는 XPath 선택자를 자동으로 감지 | 메서드 호출 시 선택기 유형을 명시적으로 정의해야 함 |
| 타임아웃 처리 | 실패를 방지하기 위해 기본 타임아웃 적용 | 명시적으로 타임아웃이 설정되지 않은 경우 메서드가 즉시 실패 |
| 오류 출력 | 디버깅을 용이하게 하기 위해 깔끔하고 읽기 쉬운 오류 메시지를 제공합니다 | 자세하지만 해석하기 어려운 오류 로그 생성 |
| 대시보드 및 보고서 | 내장된 대시보드, 보고서 및 실패 스크린샷 포함 | 내장형 대시보드 또는 보고 기능 없음 |
| 데스크톱 GUI 애플리케이션 | 테스트 실행을 위한 시각적 도구 제공 | 테스트 실행을 위한 데스크톱 GUI 도구가 없음 |
| 테스트 레코더 | 수동 브라우저 동작에서 스크립트를 생성하기 위한 내장 테스트 레코더 | 수동 스크립트 작성이 필요함 |
| 테스트 케이스 관리 | 테스트를 구성하고 프레임워크 내에서 직접 단계를 문서화하기 위한 CasePlans 제공 | 내장형 테스트 케이스 관리 도구 없음 |
| 데이터 앱 지원 | Python에서 JavaScript를 생성하여 데이터 앱을 만드는 ChartMaker 포함 | 데이터 앱 구축을 위한 추가 도구 없음 |
이제 차이점을 살펴볼 시간입니다!
내장 테스트 실행기
SeleniumBase는 pytest, pynose, behave와 같은 널리 사용되는 테스트 실행기와 통합됩니다. 이러한 도구는 체계적인 구조, 원활한 테스트 검색, 실행, 테스트 상태 추적(예: 통과, 실패 또는 건너뛰기) 및 브라우저 선택과 같은 설정을 사용자 지정하기 위한 명령줄 옵션을 제공합니다.
일반적인 Selenium을 사용하면 옵션 파서를 수동으로 구현하거나 명령줄에서 테스트를 구성하기 위해 타사 도구에 의존해야 합니다.
향상된 드라이버 관리
기본적으로 SeleniumBase는 브라우저의 주요 버전과 호환되는 드라이버 버전을 다운로드합니다. pytest 명령어에서 --driver-version=VER 옵션을 사용하여 이를 재정의할 수 있습니다. 예시:
pytest my_script.py --driver-version=114
반면 Selenium은 사용자가 직접 적절한 드라이버를 다운로드하고 구성해야 합니다. 이 경우 브라우저 버전과의 호환성을 보장하는 것은 사용자의 책임입니다.
다중 작업 메서드
SeleniumBase는 웹 자동화를 간소화하기 위해 여러 단계를 단일 메서드로 결합합니다. 예를 들어, driver.type(selector, text) 메서드는 다음을 수행합니다:
- 요소가 표시될 때까지 대기
- 요소가 상호작용 가능해질 때까지 대기
- 기존 텍스트를 지움
- 제공된 텍스트 입력
- 텍스트가
"n"으로 끝날 경우 제출
원시 Selenium으로 동일한 로직을 구현하려면 몇 줄의 코드가 필요합니다.
간소화된 선택자 처리
SeleniumBase는 CSS 선택자와 XPath 표현식을 자동으로 구분합니다. 따라서 By.CSS_SELECTOR나 By.XPATH로 선택자 유형을 명시적으로 지정할 필요가 없습니다. 다만 원하는 경우 유형을 직접 지정할 수도 있습니다.
SeleniumBase 사용 예시:
driver.click("button.submit") # CSS 선택자로 자동 감지
driver.click("//button[@class='submit']") # XPath로 자동 감지
기본 Selenium의 동등한 코드는 다음과 같습니다:
driver.find_element(By.CSS_SELECTOR, "button.submit").click()
driver.find_element(By.XPATH, "//button[@class='submit']").click()
기본 및 사용자 정의 타임아웃 값
SeleniumBase는 메서드에 기본적으로 10초의 타임아웃을 자동 적용하여 요소가 로드될 시간을 보장합니다. 이는 원시 Selenium에서 흔히 발생하는 즉각적인 실패를 방지합니다.
아래 예시처럼 메서드 호출 시 직접 사용자 정의 타임아웃 값을 설정할 수도 있습니다:
driver.click("button", timeout=20)
동일한 기능을 구현하는 Selenium 코드는 훨씬 더 장황하고 복잡합니다:
WebDriverWait(driver, 20).until(EC.element_to_be_clickable((By.CSS_SELECTOR, "button"))).click()
명확한 오류 출력
SeleniumBase는 스크립트 실패 시 깔끔하고 읽기 쉬운 오류 메시지를 제공합니다. 반면 원시 Selenium은 종종 장황하고 해석하기 어려운 오류 로그를 생성하여 디버깅에 추가 노력이 필요합니다.
대시보드, 보고서 및 스크린샷
SeleniumBase는 테스트 실행을 위한 대시보드 및 보고서 생성 기능을 포함합니다. 또한 디버깅을 용이하게 하기 위해 실패 시점의 스크린샷을 ./latest_logs/ 폴더에 저장합니다. 기본 Selenium은 이러한 기능을 기본적으로 제공하지 않습니다.
추가 기능
Selenium과 비교하여 SeleniumBase에는 다음이 포함됩니다:
- 테스트를 시각적으로 실행할 수 있는 데스크톱 GUI 애플리케이션:
pytest용 SeleniumBase Commander,behave용 SeleniumBase Behave GUI 등. - 수동 브라우저 동작을 기반으로 테스트 스크립트를 생성하는 내장형 레코더/테스트 생성기. 복잡한 워크플로우에 대한 테스트 작성에 필요한 노력을 크게 줄여줍니다.
- 테스트를 구성하고 프레임워크 내에서 직접 단계 설명을 문서화하는 테스트 케이스 관리 소프트웨어인 CasePlans.
- Python에서 JavaScript 코드를 생성하여 데이터 앱을 구축하는 ChartMaker 같은 도구. 이는 표준 테스트 자동화를 넘어서는 다목적 솔루션으로 만듭니다.
SeleniumBase: 기능, 메서드 및 CLI 옵션
SeleniumBase의 기능과 API를 살펴보고 특별한 점을 확인하세요.
기능
다음은 SeleniumBase의 주요 기능 목록입니다:
- Python으로 브라우저 테스트를 즉시 생성하는 레코더 모드 포함.
- 동일한 테스트 내에서 여러 브라우저, 탭, iframe 및 프록시를 지원합니다.
- 마크다운 기술을 활용한 테스트 케이스 관리 소프트웨어를 제공합니다.
- 스마트 대기 메커니즘으로 신뢰성을 자동으로 향상시키고 불안정한 테스트를 줄입니다.
- 테스트 발견 및 실행을 위해
pytest,unittest,nose,behave와 호환됩니다. - 대시보드, 보고서 및 스크린샷을 위한 고급 로깅 도구를 포함합니다.
- 브라우저 인터페이스를 숨기는 헤드리스 모드에서 테스트를 실행할 수 있습니다.
- 병렬 브라우저에서 멀티스레드 테스트 실행 지원.
- Chromium의 모바일 기기 에뮬레이터를 사용하여 테스트를 실행할 수 있습니다.
- 인증된 프록시 서버를 통한 테스트 실행을 지원합니다.
- 테스트를 위해 브라우저의 사용자 에이전트 문자열을 사용자 정의합니다.
- Selenium 자동화를 차단하는 웹사이트의 탐지를 방지합니다.
- 브라우저 네트워크 요청을 검사하기 위해 selenium-wire와 통합됩니다.
- 테스트 실행 옵션을 사용자 정의할 수 있는 유연한 명령줄 인터페이스.
- 테스트 설정을 관리하기 위한 글로벌 구성 파일.
- GitHub Actions, Google Cloud, Azure, S3 및 Docker와의 통합을 지원합니다.
- Python에서 JavaScript 실행 지원.
- CSS 선택자에서
::shadow를사용하여 섀도우 DOM 요소와 상호작용할 수 있습니다.
전체 목록은문서를 참조하십시오. SeleniumBase를 프록시와 함께 사용하는 방법에 대한 블로그를 꼭 읽어보시기 바랍니다.
메소드
다음은 가장 유용한 SeleniumBase 메서드 목록입니다:
driver.open(url): 브라우저 창을 지정된 URL로 이동합니다.driver.go_back(): 이전 URL로 돌아갑니다.driver.type(selector, text): 선택기로 식별된 필드를 지정된 텍스트로 업데이트합니다.driver.click(selector): 셀렉터로 식별된 요소를 클릭합니다.driver.click_link(link_text): 지정된 텍스트를 포함하는 링크를 클릭합니다.driver.select_option_by_text(dropdown_selector, option): 드롭다운 메뉴에서 보이는 텍스트로 옵션을 선택합니다.driver.hover_and_click(hover_selector, click_selector): 요소에 마우스를 올린 상태에서 다른 요소를 클릭합니다.driver.drag_and_drop(drag_selector, drop_selector): 요소를 드래그하여 다른 요소에 드롭합니다.driver.get_text(selector): 지정된 요소의 텍스트를 가져옵니다.driver.get_attribute(selector, attribute): 요소의 지정된 속성을 가져옵니다.driver.get_current_url(): 현재 페이지의 URL을 가져옵니다.driver.get_page_source(): 현재 페이지의 HTML 소스를 가져옵니다.driver.get_title(): 현재 페이지의 제목을 가져옵니다.driver.switch_to_frame(frame): 지정된 iframe 컨테이너로 전환합니다.driver.switch_to_default_content(): iframe 컨테이너를 종료하고 메인 문서로 돌아갑니다.driver.open_new_window(): 동일한 세션에서 새 브라우저 창을 엽니다.driver.switch_to_window(window): 지정된 브라우저 창으로 전환합니다.driver.switch_to_default_window(): 원래 브라우저 창으로 돌아갑니다.driver.get_new_driver(OPTIONS): 지정된 옵션으로 새 드라이버 세션을 엽니다.driver.switch_to_driver(driver): 지정된 브라우저 드라이버로 전환합니다.driver.switch_to_default_driver(): 원래 브라우저 드라이버로 돌아갑니다.driver.wait_for_element(selector): 지정된 요소가 표시될 때까지 기다립니다.driver.is_element_visible(selector): 지정된 요소가 보이는지 확인합니다.driver.is_text_visible(text, selector): 지정된 텍스트가 요소 내에서 보이는지 확인합니다.driver.sleep(seconds): 지정된 시간 동안 실행을 일시 중지합니다.driver.save_screenshot(name): 지정된 이름으로.png형식의 스크린샷을 저장합니다.driver.assert_element(selector): 지정된 요소가 보이는지 확인합니다.driver.assert_text(text, selector): 지정된 텍스트가 요소에 존재하는지 확인합니다.driver.assert_exact_text(text, selector): 지정된 텍스트가 요소 내에서 정확히 일치하는지 확인합니다.driver.assert_title(title): 현재 페이지 제목이 지정된 제목과 일치하는지 확인합니다.driver.assert_downloaded_file(file): 지정된 파일이 다운로드되었는지 확인합니다.driver.assert_no_404_errors(): 페이지에 끊어진 링크가 없는지 확인합니다.driver.assert_no_js_errors(): 페이지에 자바스크립트 오류가 없는지 확인합니다.
전체 목록을 보려면 문서를 참조하십시오.
CLI 옵션
SeleniumBase는 pytest를 다음과 같은 명령줄 옵션으로 확장합니다:
--browser=BROWSER: 웹 브라우저 설정 (기본값: “chrome”).--chrome:--browser=chrome의단축키입니다.--edge:--browser=edge의 단축 명령어.--firefox:--browser=firefox의 단축 명령어.--safari:--browser=safari의단축 명령어.--settings-file=FILE: 기본 SeleniumBase 설정을 재정의합니다.--env=ENV: 테스트 환경 설정,driver.env를통해 접근 가능.--account=STR: 계정 설정,driver.account를통해 접근 가능.--data=STRING: 추가 테스트 데이터,driver.data를통해 접근 가능.--var1=STRING: 추가 테스트 데이터,driver.var1을통해 접근 가능.--var2=STRING: 추가 테스트 데이터,driver.var2를통해 접근 가능.--var3=STRING: 추가 테스트 데이터,driver.var3를통해 접근 가능.--variables=DICT: 추가 테스트 데이터,driver.variables를통해 접근 가능.--proxy=서버:포트: 프록시 서버에 연결합니다.--proxy=사용자명:비밀번호@서버:포트: 인증된 프록시 서버 사용.--proxy-bypass-list=STRING: 우회할 호스트 (예: “*.foo.com”).--proxy-pac-url=URL: PAC URL을 통해 연결합니다.--proxy-pac-url=사용자명:비밀번호@URL: PAC URL을 통한 인증된 프록시.--proxy-driver: 드라이버 다운로드에 프록시 사용.--multi-proxy: 멀티스레딩에서 여러 인증된 프록시 허용.--agent=문자열: 브라우저의 User-Agent 문자열 수정.--mobile: 모바일 기기 에뮬레이터 활성화.--metrics=STRING: 모바일 메트릭 설정 (예: “CSSWidth,CSSHeight,PixelRatio”).--chromium-arg="ARG=N,ARG2": 크로미움 인수를 설정합니다.--firefox-arg="ARG=N,ARG2": Firefox 인수를 설정합니다.--firefox-pref=SET: Firefox 환경 설정 지정.--extension-zip=ZIP: Chrome 확장 프로그램.zip/.crx파일을 로드합니다.--extension-dir=DIR: Chrome 확장 프로그램 디렉터리를 로드합니다.--disable-features="F1,F2": 기능을 비활성화합니다.--binary-location=PATH: Chromium 바이너리 경로를 설정합니다.--driver-version=버전: 드라이버 버전 설정.--headless: 기본 헤드리스 모드.--headless1: Chrome의 구형 헤드리스 모드 사용.--headless2: Chrome의 새로운 헤드리스 모드 사용.--headed: Linux에서 GUI 모드 활성화.--xvfb: Linux에서 Xvfb로 테스트 실행.--locale=LOCALE_CODE: 브라우저의 언어 로케일을 설정합니다.--reuse-session: 모든 테스트에 브라우저 세션을 재사용합니다.--reuse-class-session: 클래스 테스트에 세션 재사용.--crumbs: 재사용 세션 간 쿠키 삭제.--disable-cookies: 쿠키를 비활성화합니다.--disable-js: 자바스크립트를 비활성화합니다.--disable-csp: 콘텐츠 보안 정책(CSP)을 비활성화합니다.--disable-ws: 웹 보안을 비활성화합니다.--enable-ws: 웹 보안을 활성화합니다.--log-cdp: Chrome 개발자 도구 프로토콜(CDP) 이벤트를 기록합니다.--remote-debug: Chrome 원격 디버거와 동기화합니다.--visual-baseline: 레이아웃 테스트용 시각적 기준선 설정.--timeout-multiplier=MULTIPLIER: 기본 시간 초과 값을 곱합니다.
명령줄 옵션 정의 전체 목록은 문서를 참조하십시오.
웹 스크래핑을 위한 SeleniumBase 사용: 단계별 가이드
다음 단계별 튜토리얼을 따라 Quotes to Scrape 샌드박스에서 데이터를 추출하는 SeleniumBase 스크레이퍼를 구축하는 방법을 배워보세요:
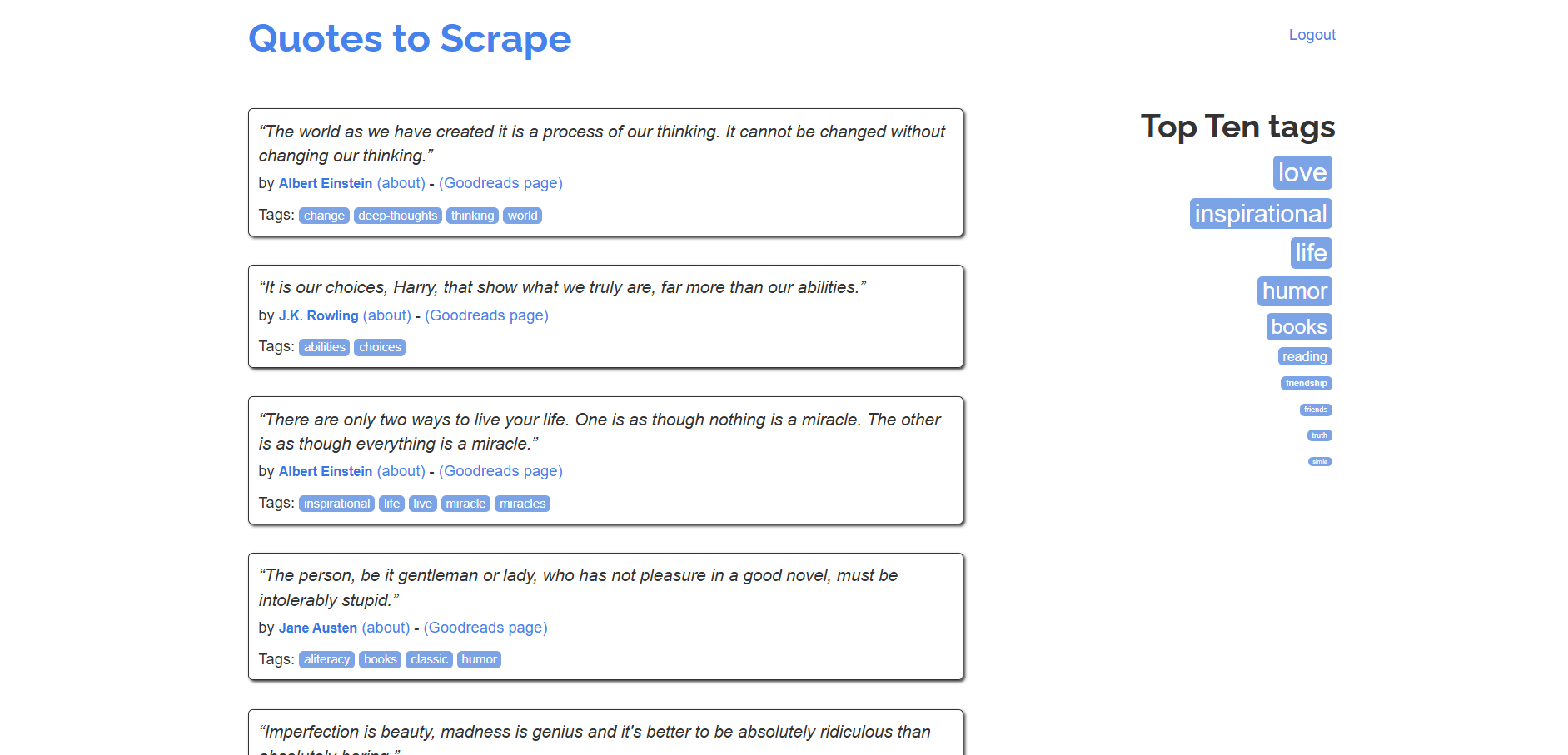
기본 Selenium을 사용하는 유사한 튜토리얼은 Selenium을 활용한 웹 스크래핑 가이드를 참조하세요.
1단계: 프로젝트 초기화
시작하기 전에 컴퓨터에 Python 3이 설치되어 있는지 확인하세요. 설치되어 있지 않다면 다운로드하여 설치하십시오.
터미널을 열고 아래 명령어를 실행하여 프로젝트 디렉터리를 생성하세요:
mkdir seleniumbase-scraper
seleniumbase-scraper 디렉터리에 SeleniumBase 스크레이퍼가 포함됩니다.
해당 디렉터리로 이동하여 가상 환경을 초기화하세요:
cd seleniumbase-scraper
python -m venv env
다음으로 선호하는 Python IDE에서 프로젝트 폴더를 로드하세요. Python 확장 프로그램이 설치된 Visual Studio Code 나 PyCharm Community Edition을 사용하면 됩니다.
프로젝트 디렉터리에 scraper.py 파일을 생성합니다. 현재 디렉터리 구조는 다음과 같아야 합니다:

scraper.py에는 곧 스크래핑 로직이 포함될 것입니다.
IDE 터미널에서 가상 환경을 활성화하세요. Linux 또는 macOS에서는 아래 명령어로 수행합니다:
./env/bin/activate
Windows에서는 동등하게 다음을 실행하세요:
env/Scripts/activate
활성화된 환경에서 SeleniumBase를 설치하려면 다음 명령어를 실행하세요:
pip install seleniumbase
완벽합니다! SeleniumBase 웹 스크래핑을 위한 Python 환경이 준비되었습니다.
2단계: SeleniumBase 테스트 설정
SeleniumBase는 테스트 구축을 위한 pytest 구문을 지원하지만, 웹 스크래핑 봇은 테스트 스크립트가 아닙니다. SB 구문을 사용하면 SeleniumBase의 모든 pytest 명령줄 확장 옵션을 활용할 수 있습니다:
from seleniumbase import SB
with SB() as sb:
pass
# 스크래핑 로직...
이제 다음과 같이 테스트를 실행할 수 있습니다:
python3 scraper.py
참고: Windows에서는 python3을 python으로 대체하십시오.
헤드리스 모드로 실행하려면 다음을 실행하세요:
python3 scraper.py --headless
여러 명령줄 옵션을 조합하여 사용할 수 있습니다.
3단계: 대상 페이지에 연결하기
open() 메서드를 사용하여 제어되는 브라우저가 대상 페이지를 방문하도록 지시하세요:
sb.open("https://quotes.toscrape.com/")
헤드드 모드에서 스크래핑 테스트 스크립트를 실행하면, 다음과 같은 화면이 순간적으로 표시됩니다:
일반 Selenium과 달리 드라이버를 수동으로 종료할 필요가 없습니다. SeleniumBase가 이를 자동으로 처리합니다.
단계 #4: 인용문 요소 선택
브라우저에서 시크릿 모드로 대상 페이지를 열고 인용문 요소를 검사하세요:
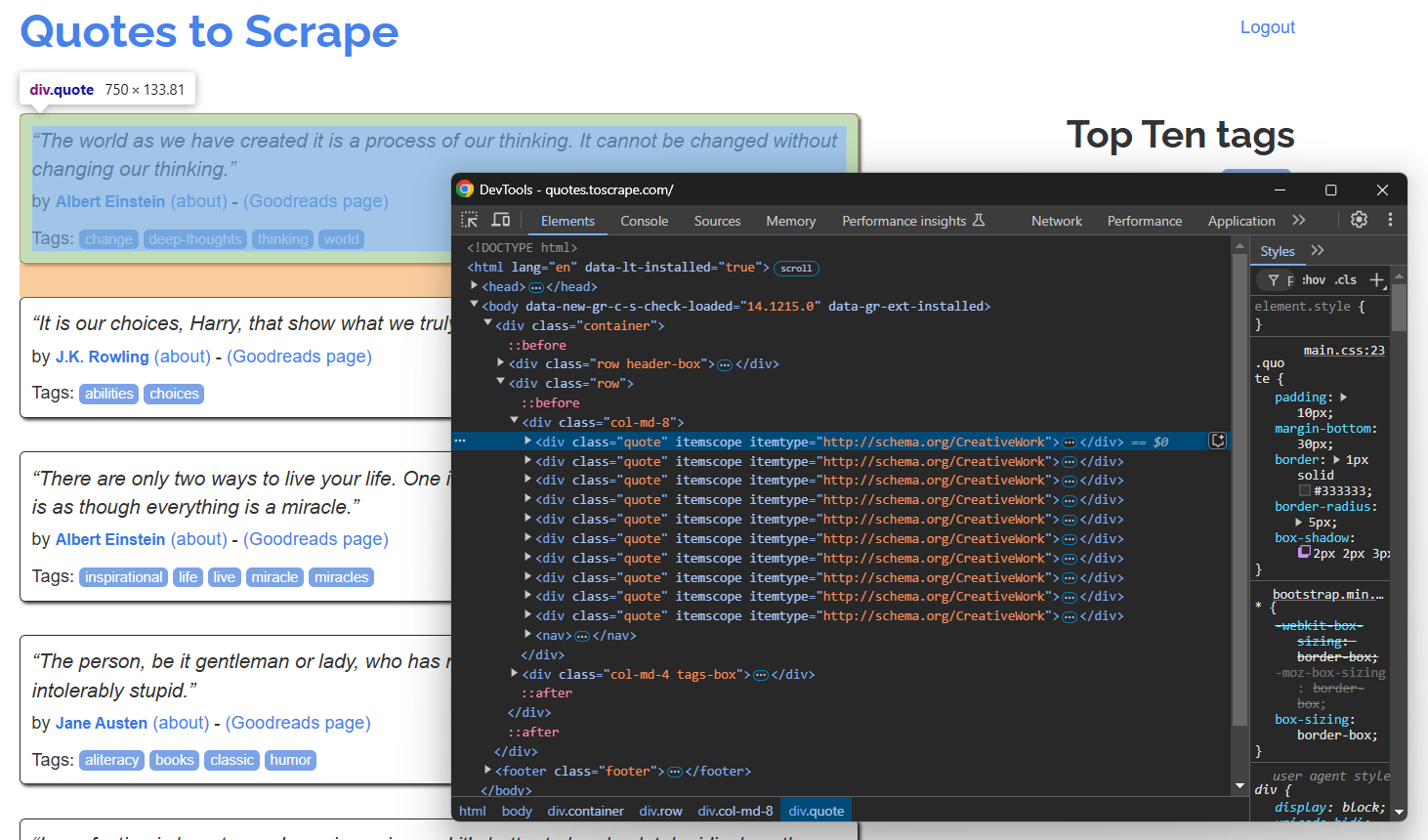
페이지에 여러 인용문이 있으므로 스크래핑된 데이터를 저장할 quotes 배열을 생성합니다:
quotes = []
위 개발자 도구(DevTools) 섹션에서 모든 인용문은 .quote CSS 선택자로 선택할 수 있음을 확인할 수 있습니다. find_elements() 를 사용하여 모두 선택하세요:
quote_elements = sb.find_elements(".quote")
다음으로, 각 요소를 반복 처리하여 각 인용문 요소에서 데이터를 스크랩할 준비를 합니다. 스크랩된 데이터를 배열에 추가합니다:
for quote_element in quote_elements:
# 스크래핑 로직...
좋습니다! 이제 고수준 스크래핑 로직이 준비되었습니다.
단계 #5: 인용문 데이터 스크래핑
단일 인용문 요소를 살펴봅니다:
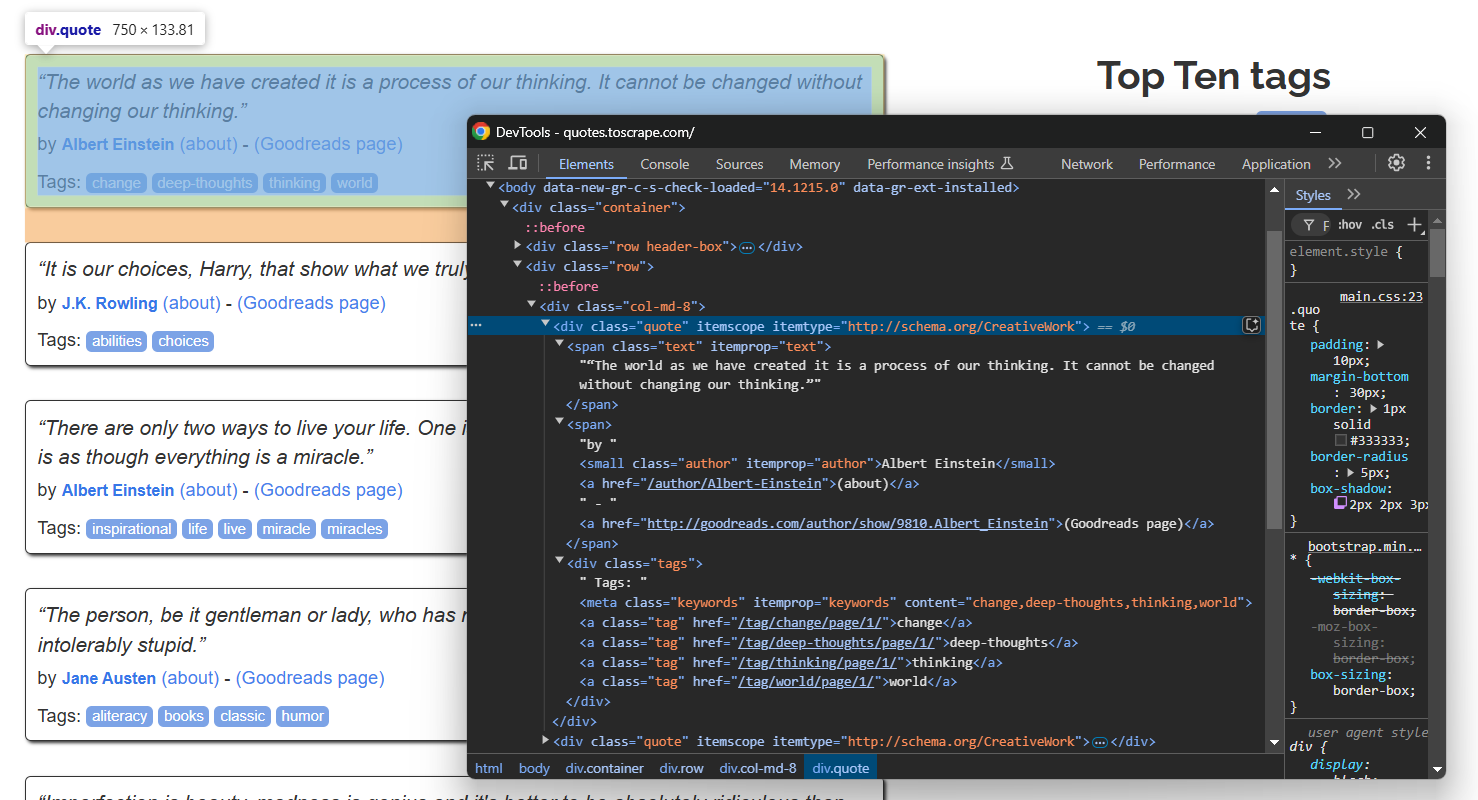
다음 항목을 스크랩할 수 있습니다:
.text속성의 인용문 텍스트.author속성의 인용문 작성자.tag속성의 명언 태그
각 노드를 선택하고 text 속성으로 데이터를 추출합니다:
text_element = quote_element.find_element(By.CSS_SELECTOR, ".text")
text = text_element.text.replace("“", "").replace("”", "")
author_element = quote_element.find_element(By.CSS_SELECTOR, ".author")
author = author_element.text
tags = []
tag_elements = quote_element.find_elements(By.CSS_SELECTOR, ".tag")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)
find_elements() 는 기본 Selenium WebElement 객체를 반환합니다. 따라서 내부 요소를 선택하려면 Selenium의 기본 메서드를 사용해야 합니다. 이 때문에 로케이터로 By.CSS_SELECTOR를 지정해야 합니다.
스크립트 시작 부분에서 By를 반드시 임포트하세요:
from selenium.webdriver.common.by import By
태그를 스크래핑하려면 루프가 필요한 점에 유의하세요. 단일 따옴표 하나에 하나 이상의 태그가 포함될 수 있기 때문입니다. 또한 텍스트를 둘러싼 특수한 큰따옴표를 제거하기 위해 replace() 메서드를 사용하는 점도 확인하세요.
6단계: 인용문 배열 채우기
스크랩한 데이터로 새 quotes 객체를 생성하고 quotes에 추가합니다:
quote = {
"text": text,
"author": author,
"tags": tags
}
quotes.append(quote)
대단합니다! SeleniumBase 스크래핑 로직이 완성되었습니다.
7단계: 크롤링 로직 구현
대상 사이트에는 여러 페이지가 포함되어 있음을 기억하세요. 다음 페이지로 이동하려면 하단의 “다음 →” 버튼을 클릭하세요:
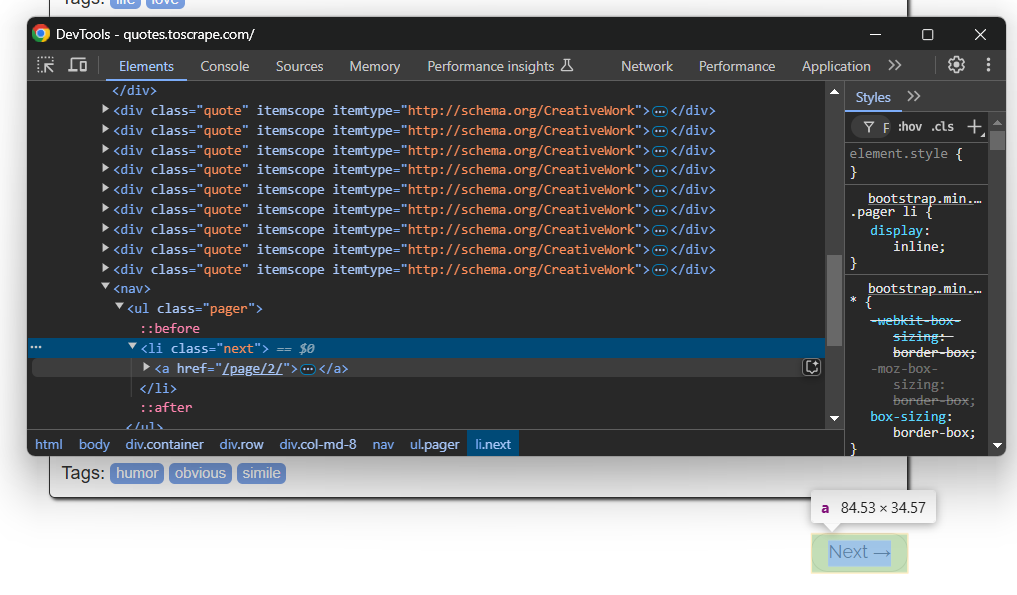
마지막 페이지에서는 이 버튼이 표시되지 않습니다.
웹 크롤링을 구현하고 모든 페이지를 스크래핑하려면, “다음 →” 버튼을 클릭하는 스크래핑 로직을 루프에 감싸고 버튼이 더 이상 존재하지 않을 때 중지하도록 합니다:
while sb.is_element_present(".next"):
# 스크래핑 로직...
# 다음 페이지로 이동
sb.click(".next a")
버튼 존재 여부를 확인하기 위해 SeleniumBase의 특수 메서드 `is_element_present() `를 사용한 점에 유의하세요.
완벽합니다! 이제 SeleniumBase 스크레이퍼가 사이트 전체를 탐색할 것입니다.
단계 #8: 스크랩된 데이터 내보내기
스크랩한 데이터를 따옴표로 묶어 다음과 같이 CSV 파일로 내보냅니다:
with open("quotes.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["text", "author", "tags"])
writer.writeheader()
# CSV 기록을 위해 인용문 객체를 평면화
for quote in quotes:
writer.writerow({
"text": quote["text"],
"author": quote["author"],
"tags": ";".join(quote["tags"])
})
Python 표준 라이브러리에서 csv를 반드시 임포트하세요:
import csv
9단계: 모든 것을 합치기
이제 script.py 파일에 다음 코드가 포함되어야 합니다:
from seleniumbase import SB
from selenium.webdriver.common.by import By
import csv
with SB() as sb:
# 대상 페이지에 연결
sb.open("https://quotes.toscrape.com/")
# 스크랩된 데이터 저장 위치
quotes = []
# 모든 인용문 페이지 반복
while sb.is_element_present(".next"):
# 페이지의 모든 인용문 요소 선택
quote_elements = sb.find_elements(".quote")
# 각 인용문 요소 반복 및 데이터 추출
for quote_element in quote_elements:
# 데이터 추출 로직
text_element = quote_element.find_element(By.CSS_SELECTOR, ".text")
text = text_element.text.replace("“", "").replace("”", "")
author_element = quote_element.find_element(By.CSS_SELECTOR, ".author")
author = author_element.text
tags = []
tag_elements = quote_element.find_elements(By.CSS_SELECTOR, ".tag")
for tag_element in tag_elements:
tag = tag_element.text
tags.append(tag)
# 수집한 데이터로 새 인용문 객체 생성
quote = {
"text": text,
"author": author,
"tags": tags
}
# 수집된 인용문 목록에 추가
quotes.append(quote)
# 다음 페이지로 이동
sb.click(".next a")
# 스크랩한 데이터를 CSV로 내보내기
with open("quotes.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=["text", "author", "tags"])
writer.writeheader()
# CSV 기록을 위해 인용문 객체를 평면화
for quote in quotes:
writer.writerow({
"text": quote["text"],
"author": quote["author"],
"tags": ";".join(quote["tags"])
})
헤드리스 모드에서 SeleniumBase 스크레이퍼를 실행하려면 다음을 사용하세요:
python3 script.py --headless
몇 초 후 프로젝트 폴더에 quotes.csv 파일이 생성됩니다.
열어보면 다음과 같습니다:
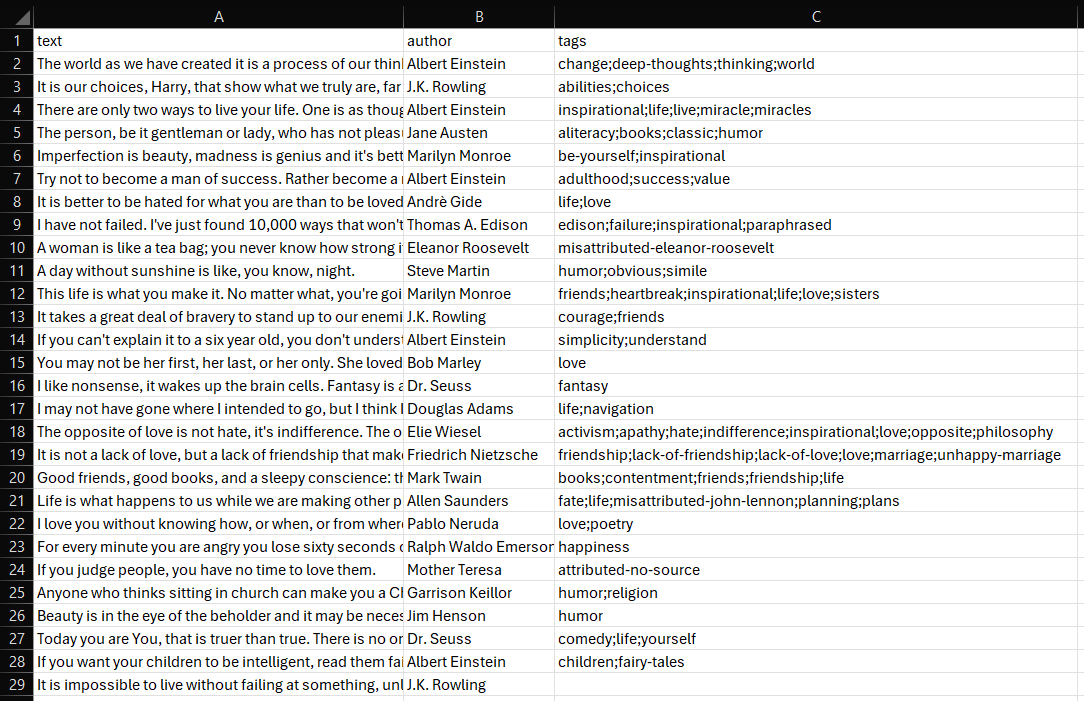
자, 이제 SeleniumBase 웹 스크래핑 스크립트가 완벽하게 작동합니다.
고급 SeleniumBase 스크래핑 활용 사례
이제 SeleniumBase의 기본을 익혔으니, 좀 더 복잡한 시나리오를 탐구할 준비가 되었습니다.
양식 작성 및 제출 자동화
참고: Bright Data는 로그인 뒤의 콘텐츠를 스크래핑하지 않습니다.
SeleniumBase를 사용하면 실제 사용자와 동일하게 페이지의 요소와 상호작용할 수 있습니다. 예를 들어, 아래와 같은 로그인 양식과 상호작용해야 한다고 가정해 보겠습니다:
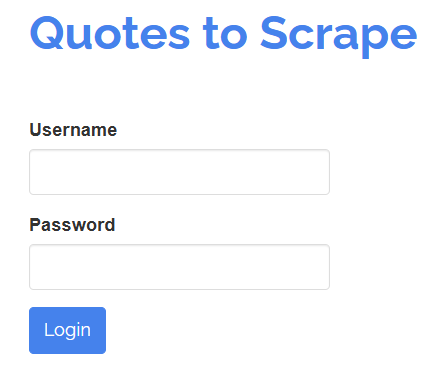
목표는 “사용자 이름”과 “비밀번호” 필드를 작성한 후 “로그인” 버튼을 클릭하여 양식을 제출하는 것입니다. SeleniumBase 테스트를 통해 다음과 같이 구현할 수 있습니다:
# login.py
from seleniumbase import BaseCase
BaseCase.main(__name__, __file__)
class LoginTest(BaseCase):
def test_submit_login_form(self):
# 대상 페이지 방문
self.open("https://quotes.toscrape.com/login")
# 양식 작성
self.type("#username", "test")
self.type("#password", "test")
# 양식 제출
self.click("input[type="submit"]")
# 올바른 페이지 확인
self.assert_text("Top Ten tags")
이 예제는 테스트를 구축하기에 매우 적합하므로 BaseCase 클래스의 사용법을 참고하세요. 이를 통해 pytest 테스트를 생성할 수 있습니다.
다음 명령어로 테스트를 실행하세요:
pytest login.py
브라우저가 열리고 로그인 페이지가 로드된 후, 양식이 작성되고 제출되며, 마지막으로 지정된 텍스트가 페이지에 표시되는지 확인하는 과정을 볼 수 있습니다.
터미널 출력은 다음과 유사하게 표시됩니다:
login.py . [100%]
======================================== 1 passed in 11.20s =========================================
간단한 봇 방지 기술 우회하기
많은 사이트는 봇이 데이터에 접근하는 것을 막기 위해 고급 스크래핑 방지 조치를 구현합니다. 이러한 기술에는 CAPTCHA 챌린지, 속도 제한, 브라우저 지문 인식 등이 포함됩니다. 차단당하지 않고 웹사이트를 효과적으로 스크래핑하려면 이러한 보호 기능을 우회해야 합니다.
SeleniumBase는 UC 모드(Undetected-Chromedriver Mode)라는 특수 기능을 제공하여 스크래핑 봇이 실제 사용자처럼 보이도록 돕습니다. 이를 통해 봇 차단 서비스의 탐지를 회피할 수 있으며, 그렇지 않으면 스크래핑 봇이 직접 차단되거나 CAPTCHA가 트리거될 수 있습니다.
UC 모드는 undetected-chromedriver를 기반으로 구축되었으며 다음과 같은 여러 업데이트, 수정 및 개선 사항을 포함합니다:
- 탐지를 피하기 위한 자동 사용자 에이전트 로테이션.
- 필요에 따른 크로미움 인자 자동 구성.
- CAPTCHA 우회를 위한 특수
uc_*()메서드.
이제 SeleniumBase에서 UC 모드를 사용하여 안티봇 도전을 우회하는 방법을 살펴보겠습니다.
이 데모에서는 Scraping Course 사이트의 안티봇 페이지에 접근하는 방법을 보여드리겠습니다:
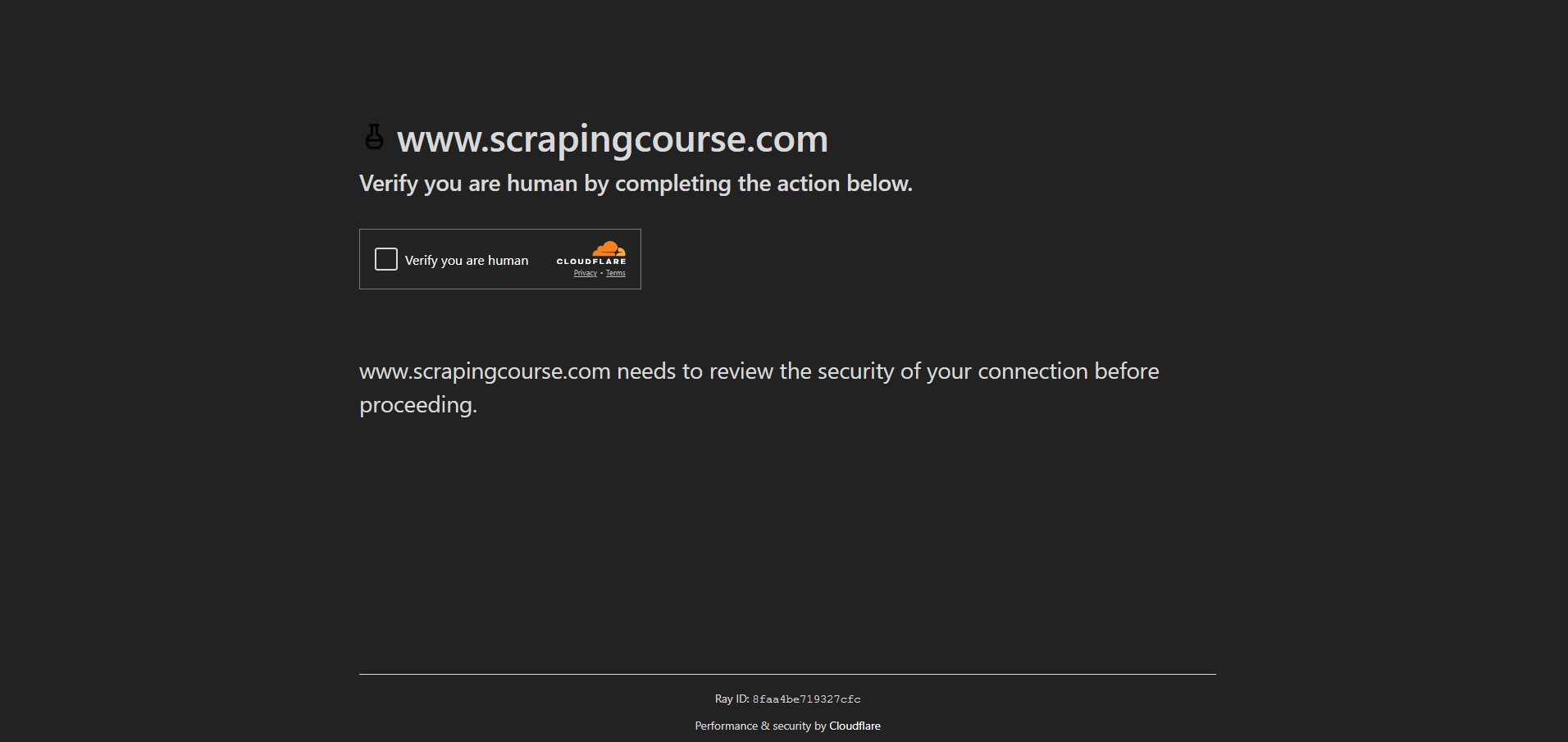
반봇 조치를 우회하고 CAPTCHA를 처리하려면 UC 모드를 활성화하고 uc_open_with_reconnect() 및 uc_gui_click_captcha() 메서드를 사용하세요:
from seleniumbase import SB
with SB(uc=True) as sb:
# 안티봇 조치가 적용된 대상 페이지
url = "https://www.scrapingcourse.com/antibot-challenge"
# 초기 탐지를 피하기 위해 4초 재연결 시간으로 UC 모드 사용 시 URL 열기
sb.uc_open_with_reconnect(url, reconnect_time=4)
# CAPTCHA 우회 시도
sb.uc_gui_click_captcha()
# 페이지 스크린샷 캡처
sb.save_screenshot("screenshot.png")
이제 스크립트를 실행하고 예상대로 작동하는지 확인하세요. uc_gui_click_captcha() 는 PyAutoGUI가 필요하므로 SeleniumBase가 첫 실행 시 자동으로 설치합니다:
PyAutoGUI 필요! 설치 중...
브라우저가 자동으로 마우스를 움직여 “인간임을 확인하세요” 체크박스를 클릭하는 것을 확인할 수 있습니다. 프로젝트 폴더 내 screenshot.png 파일에는 다음과 같이 표시됩니다:
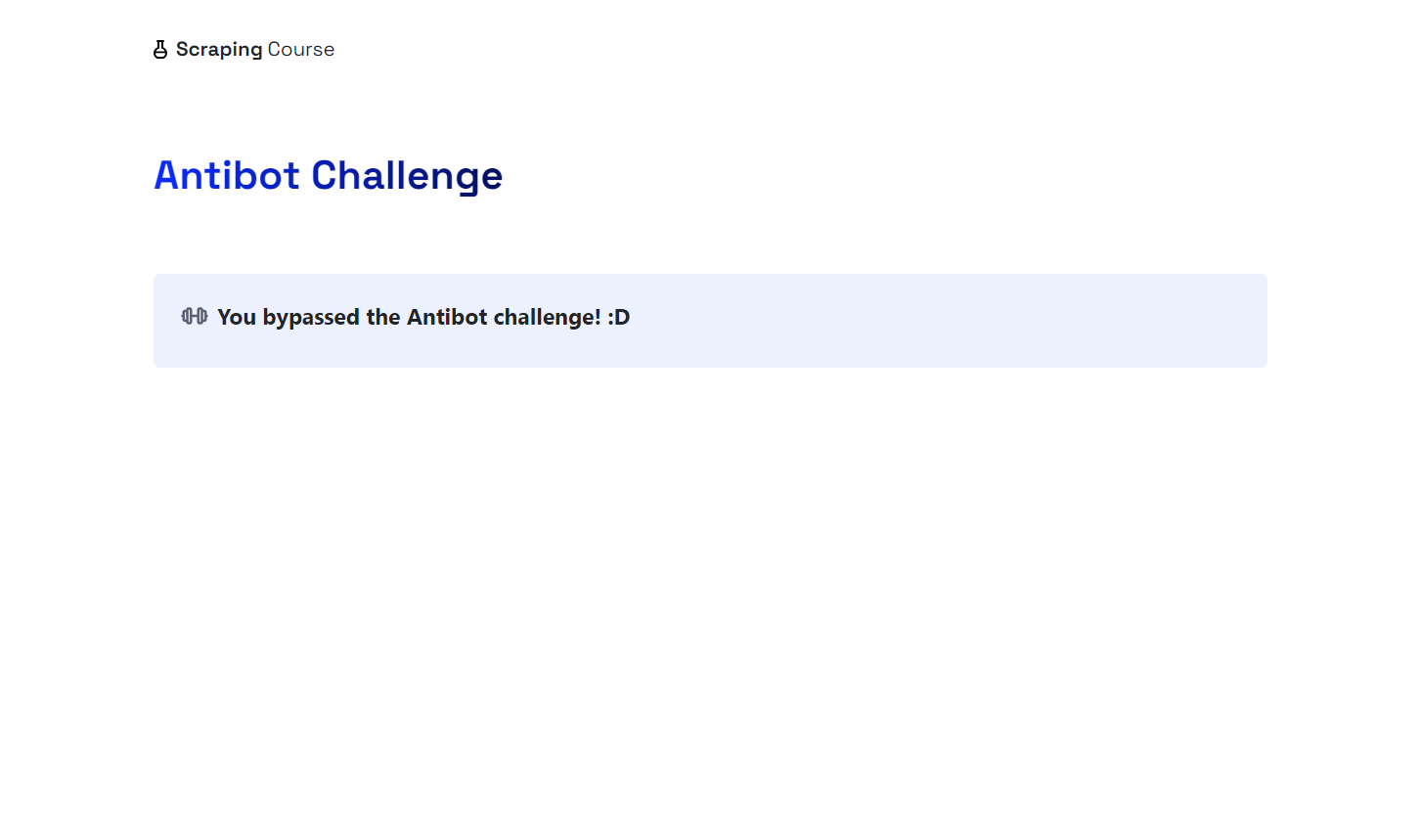
와! Cloudflare가 우회되었습니다.
복잡한 안티봇 기술 우회
봇 방지 솔루션은 점점 정교해지고 있으며, UC 모드가 항상 효과적인 것은 아닙니다. 이에 SeleniumBase는 특별한 CDP 모드(Chrome DevTools Protocol Mode)도 제공합니다.
CDP 모드는 UC 모드 내에서 작동하며 CDP-Driver를 통해 브라우저를 제어함으로써 봇이 더 인간처럼 보이도록 합니다. 일반 UC 모드는 드라이버가 브라우저에서 분리되면 WebDriver 작업을 수행할 수 없지만, CDP-Driver는 여전히 브라우저와 상호작용할 수 있어 이 한계를 극복합니다.
CDP 모드는 python-cdp, trio-cdp, nodriver를 기반으로 구축되었습니다. 아래 예시와 같이 실제 사이트의 고급 안티봇 솔루션을 우회하도록 설계되었습니다:
from seleniumbase import SB
with SB(uc=True, test=True) as sb:
# 고급 안티봇 조치가 적용된 대상 페이지
url = "https://gitlab.com/users/sign_in"
# CDP 모드로 페이지 방문
sb.activate_cdp_mode(url)
# CAPTCHA 처리
sb.uc_gui_click_captcha()
# 페이지 재로드 및 드라이버 제어권 회복을 위해 2초 대기
sb.sleep(2)
# 페이지 스크린샷 캡처
sb.save_screenshot("screenshot.png")
결과는 다음과 같습니다:
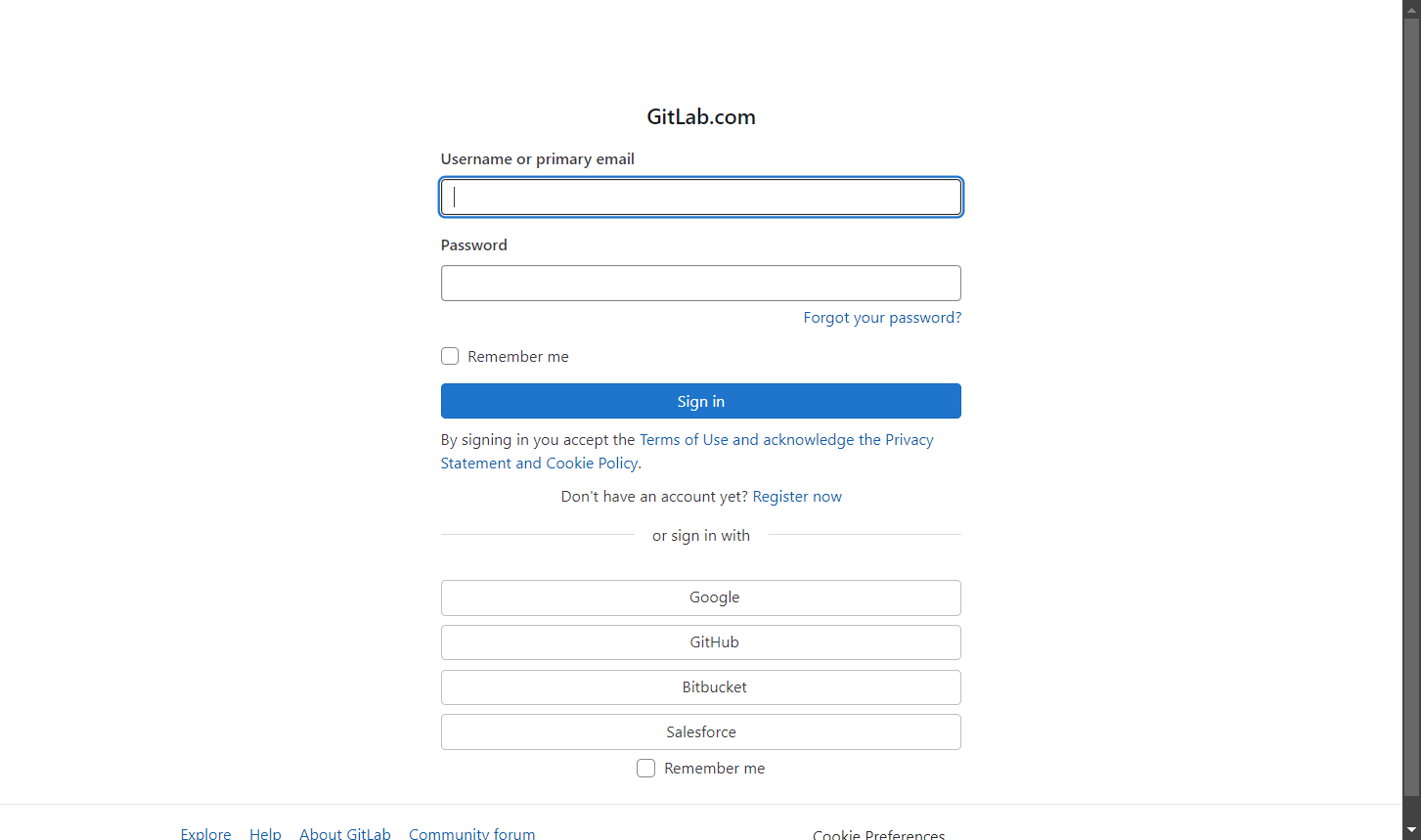
자, 이제 SeleniumBase 스크래핑 마스터가 되셨습니다.
결론
이 글에서는 SeleniumBase의 기능과 메서드, 그리고 웹 스크래핑에 활용하는 방법을 배웠습니다. 기본 시나리오부터 시작하여 더 복잡한 사용 사례까지 살펴보았습니다.
UC 모드와 CDP 모드는 특정 봇 방지 조치를 우회하는 데 효과적이지만 완벽하지는 않습니다.
너무 많은 요청을 보내거나 여러 단계의 복잡한 CAPTCHA를 요구하는 경우 웹사이트에서 IP를 차단할 수 있습니다. 더 효과적인 해결책은 Selenium과 같은 웹 브라우저 자동화 도구를 Bright Data의 Scraping Browser와 같은 스크래핑 전용, 클라우드 기반, 고도로 확장 가능한 브라우저와 함께 사용하는 것입니다.
Scraping Browser는 Playwright, Puppeteer, Selenium 등과 연동되는 브라우저입니다. 요청마다 자동으로 출구 IP를 회전시키며, 브라우저 지문 인식, 재시도, CAPTCHA 해결 등 다양한 기능을 처리할 수 있습니다. 차단되는 일은 잊고 스크래핑 작업을 간소화하세요.
지금 가입하여 무료 체험을 시작하세요!