
이 글에서 배울 내용:
- goose가 무엇이며 어떤 점이 특별한지.
- Bright Data의 Web MCP를 goose에 통합하면 AI 에이전트가 훨씬 강력해지는 이유.
- Web MCP를 goose Desktop에 연결하는 방법.
- Bright Data의 Web MCP를 goose CLI에 통합하는 방법.
시작해 봅시다!
goose란 무엇인가?
goose는 복잡한 소프트웨어 개발 작업을 처음부터 끝까지 자동화하기 위해 만들어진 오픈소스 확장형 AI 에이전트입니다.
기존 코드 어시스턴트와 달리, goose는 단순히 코드 조각을 제안하는 데 그치지 않습니다. 전체 프로젝트를 구축하고, 코드를 작성 및 실행하며, 오류를 디버깅하고, 워크플로를 조율하며, 외부 API와 자율적으로 상호작용할 수 있습니다.
goose의 특별한 점은 대부분의 LLM과 호환되고, 성능 및 비용 최적화를 위한 멀티 모델 구성을 지원하며, MCP 서버와의 스킬 및 통합을 지원한다는 것입니다. 프로토타입 제작, 코드 개선, 복잡한 엔지니어링 파이프라인 관리 등 어떤 작업이든 생산성을 높이는 것이 목표입니다.
이 솔루션은 데스크톱 애플리케이션과 CLI 도구 모두로 제공됩니다. 작성 시점 기준으로 GitHub에서 25.8k 스타를 기록하고 있습니다:
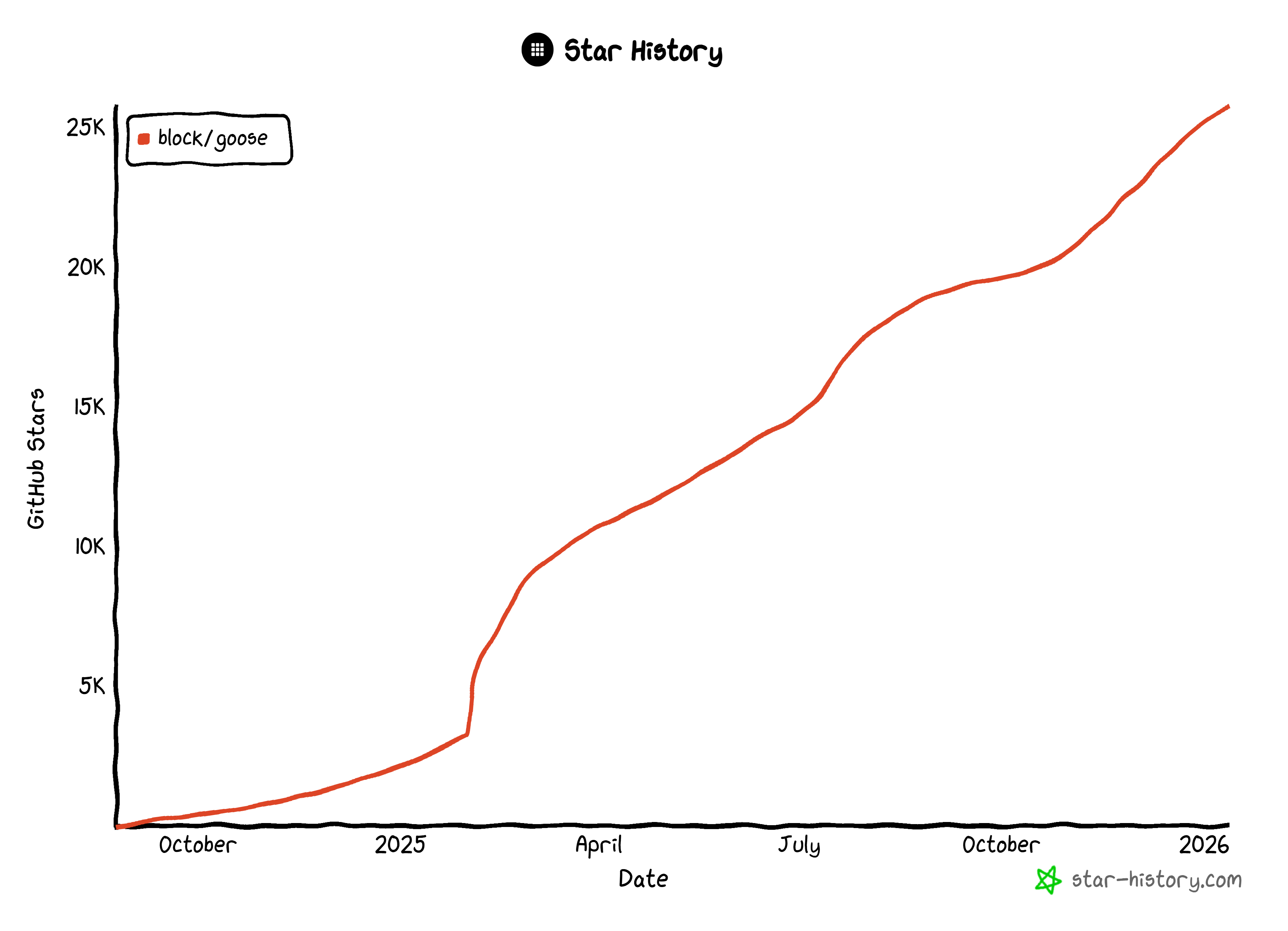
GitHub 스타의 꾸준한 성장은 강력한 커뮤니티 지지와 광범위한 채택의 증거입니다.
goose AI 에이전트를 웹 지원 기능으로 확장해야 하는 이유
goose에 통합된 LLM이 아무리 뛰어나도, 모든 언어 모델이 공유하는 핵심 한계인 정적 지식 문제를 피할 수 없습니다.
LLM은 학습된 데이터를 기반으로만 답변을 생성할 수 있습니다. 문제는 LLM 학습 데이터가 과거의 정적인 스냅샷을 나타낸다는 점입니다. 빠르게 변화하는 기술 환경에서 그 정보는 금방 낡아버릴 수 있습니다. 결과적으로 AI 모델은 구식 개발 방식을 제안할 수 있습니다.
goose는 확장을 통해 서드파티 제공업체와의 연결을 지원함으로써 이 한계를 극복합니다. 이러한 확장은 외부 데이터 및 리소스에 접근하고, 새로운 기능을 추가하는 등의 용도로 사용될 수 있습니다. goose 확장을 정의하는 가장 쉬운 방법 중 하나는 MCP를 통하는 것입니다.
예를 들어, goose를 Bright Data의 Web MCP와 통합하면 기반 AI 에이전트가 최신 튜토리얼, 문서, 가이드에 실시간으로 접근할 수 있게 됩니다. 이는 Web MCP가 자동화된 웹 데이터 수집, 구조화된 데이터 추출, 웹 인터랙션을 위한 60개 이상의 AI 지원 도구를 제공하기 때문에 가능합니다.
무료 티어에서도 다음 두 가지 강력한 도구(및 배치 버전)에 접근할 수 있습니다:
| 도구 | 설명 |
|---|---|
search_engine |
Google, Bing 또는 Yandex 결과를 JSON 또는 Markdown 형식으로 검색합니다. |
scrape_as_markdown |
안티봇 조치를 우회하여 모든 웹페이지를 깔끔한 Markdown으로 스크래핑합니다. |
하지만 Web MCP의 진가는 [Pro 모드](https://github.com/brightdata/brightdata-mcp?tab=readme-ov-file#-pricing, modes)에서 발휘됩니다. Pro 모드는 Amazon, LinkedIn, YouTube, TikTok, Zillow, Google Maps 같은 플랫폼에서 구조화된 데이터를 추출하고 자동화된 브라우저 작업을 수행하기 위한 프리미엄 도구를 제공합니다.
Bright Data Web MCP + goose 통합을 통해 AI 에이전트는 다음을 수행할 수 있습니다:
- 정확한 정보를 위해 웹을 검색합니다.
- 최신 튜토리얼이나 문서 페이지를 가져와 학습합니다.
- 테스트, 모킹 또는 분석을 위해 실시간으로 실제 웹사이트를 스크래핑합니다.
- 훨씬 더 많은 작업을 수행합니다…
goose Desktop과 Bright Data의 Web MCP 통합하기
이 가이드 섹션에서는 goose 기반 AI 에이전트에서 Web MCP 기능을 활용하는 방법을 배웁니다. 이 설정은 어떤 AI 제공업체를 구성하든 관계없이 향상된 웹 데이터 지원 AI 경험을 제공합니다.
아래 지침을 따라 진행하세요!
사전 요구 사항
이 튜토리얼 섹션을 따라가려면 다음을 갖추고 있는지 확인하세요:
- Web MCP 서버를 로컬에서 실행하기 위해 머신에 Node.js가 설치되어 있어야 합니다(최신 LTS 버전 권장).
- goose가 지원하는 다양한 AI 제공업체 중 하나의 API 키(이 경우 OpenAI를 사용합니다).
- API 키가 설정된 Bright Data 계정.
MCP 프로토콜 작동 방식과 Web MCP 서버가 노출하는 도구에 대한 기본적인 이해도 도움이 됩니다.
참고: Node.js가 공식 설치 프로그램을 통해 기본 시스템 경로에 설치되어 있는지 확인하세요(nvm이나 유사한 방법은 사용하지 마세요). 그렇지 않으면 goose에서 커스텀 MCP 서버에 연결할 때 다음과 같은 오류가 발생할 수 있습니다:
Failed to add extension: process quit before initialization: stderr =Bright Data 계정 설정은 나중에 별도 단계에서 다루므로 지금 당장 걱정하지 않아도 됩니다.
1단계: goose Desktop 설치 및 구성
먼저 운영 체제에 맞는 goose Desktop 설치 프로그램을 다운로드합니다. 설치 후 애플리케이션을 실행하면 다음 화면이 표시됩니다:
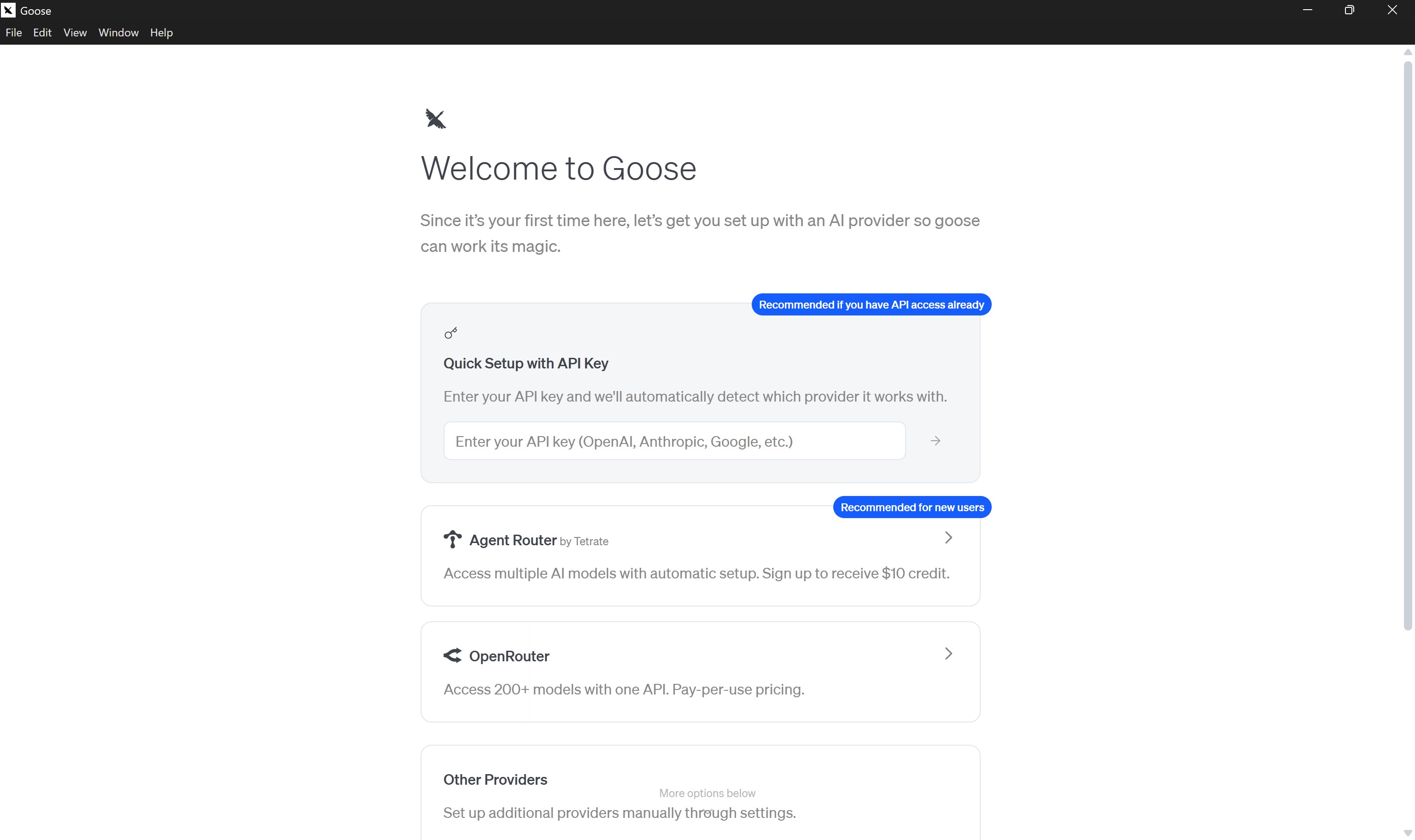
“API 키로 빠른 설정” 섹션에 원하는 AI 제공업체의 API 키를 붙여넣습니다. 이 경우 OpenAI API 키를 사용합니다:
오른쪽 화살표(“→”) 버튼을 누르면 “모델 선택” 모달이 나타납니다:
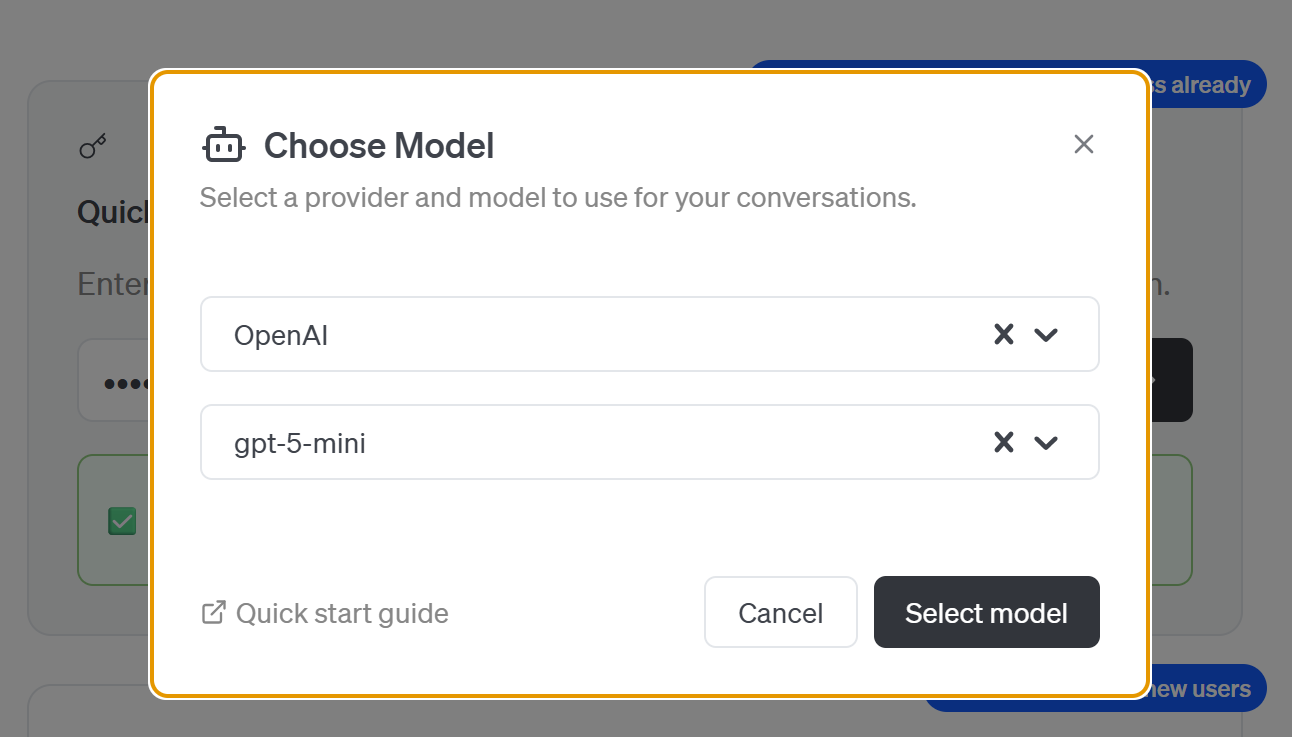
여기서 모델 제공업체와 특정 모델을 선택해야 합니다. OpenAI API 키를 구성했으므로 제공업체는 자동으로 “OpenAI”로 설정됩니다. 그런 다음 “gpt-5-mini“와 같은 모델을 선택합니다.
“모델 선택” 버튼을 클릭하여 확인하면 goose 홈 화면으로 이동합니다:
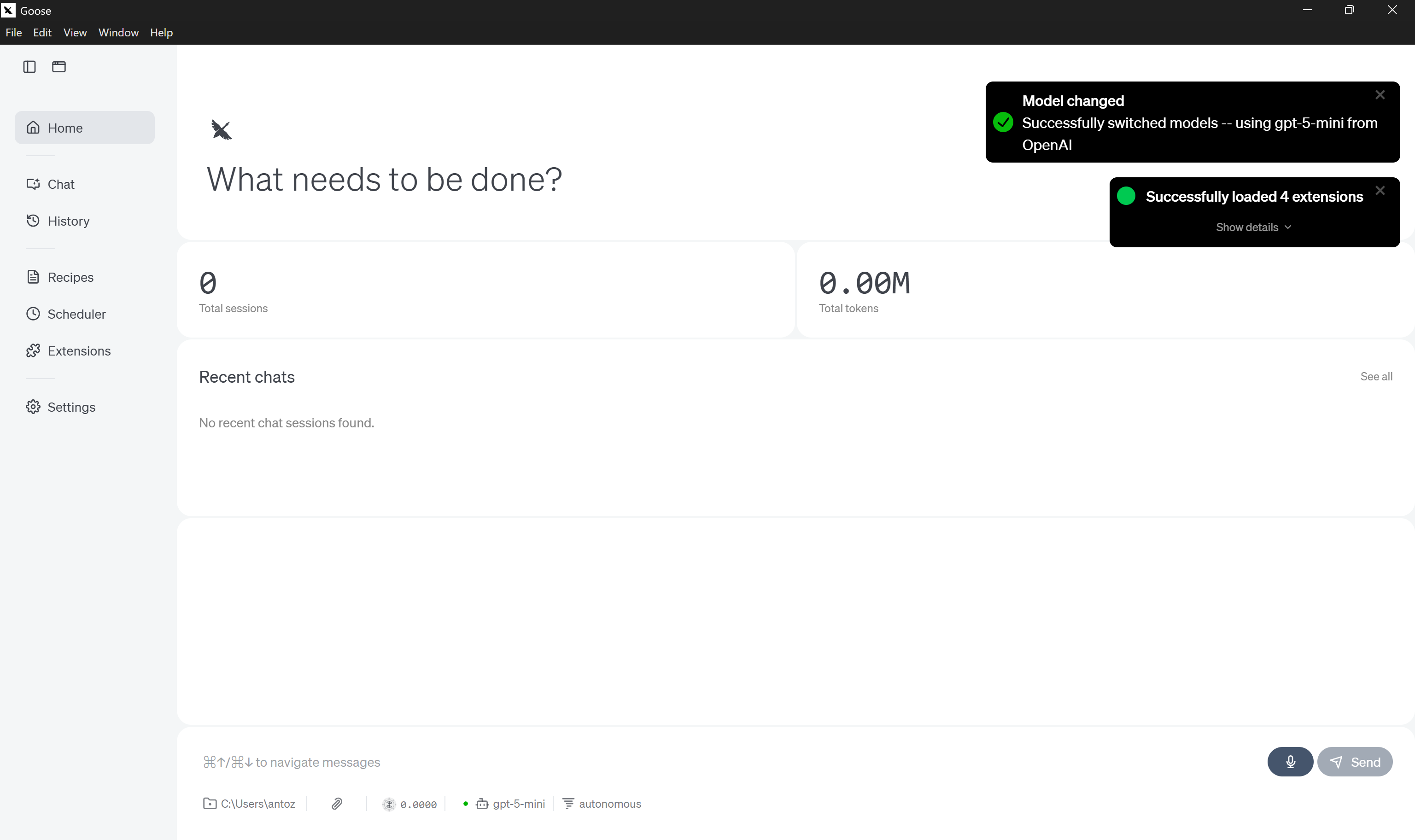
모델이 성공적으로 업데이트되었음을 확인하는 모델 변경 알림을 확인하세요.
참고: Windows에서 보안 문제를 방지하려면 다운로드한 goose 폴더에서 다음 명령을 실행하여 모든 파일의 차단을 해제하세요:
Get-ChildItem -Path "<YOUR_GOOSE_PATH>" -Recurse | Unblock-File예를 들어, <YOUR_GOOSE_PATH>는 C:\Users\<YOUR_USERNAME>\Downloads\goose-win32-x64일 수 있습니다. 그런 다음 애플리케이션을 재시작하세요.
잘 하셨습니다! 이제 완전히 구성된 goose 애플리케이션을 사용할 준비가 되었습니다.
2단계: Bright Data Web MCP 시작하기
goose Desktop을 Bright Data의 Web MCP에 연결하기 전에, 로컬 머신에서 MCP 서버를 실행할 수 있는지 확인하세요.
먼저 Bright Data 계정이 필요합니다. 이미 계정이 있다면 로그인하세요. 빠른 설정을 위해 대시보드의 “MCP” 섹션에 있는 지침을 따르세요:
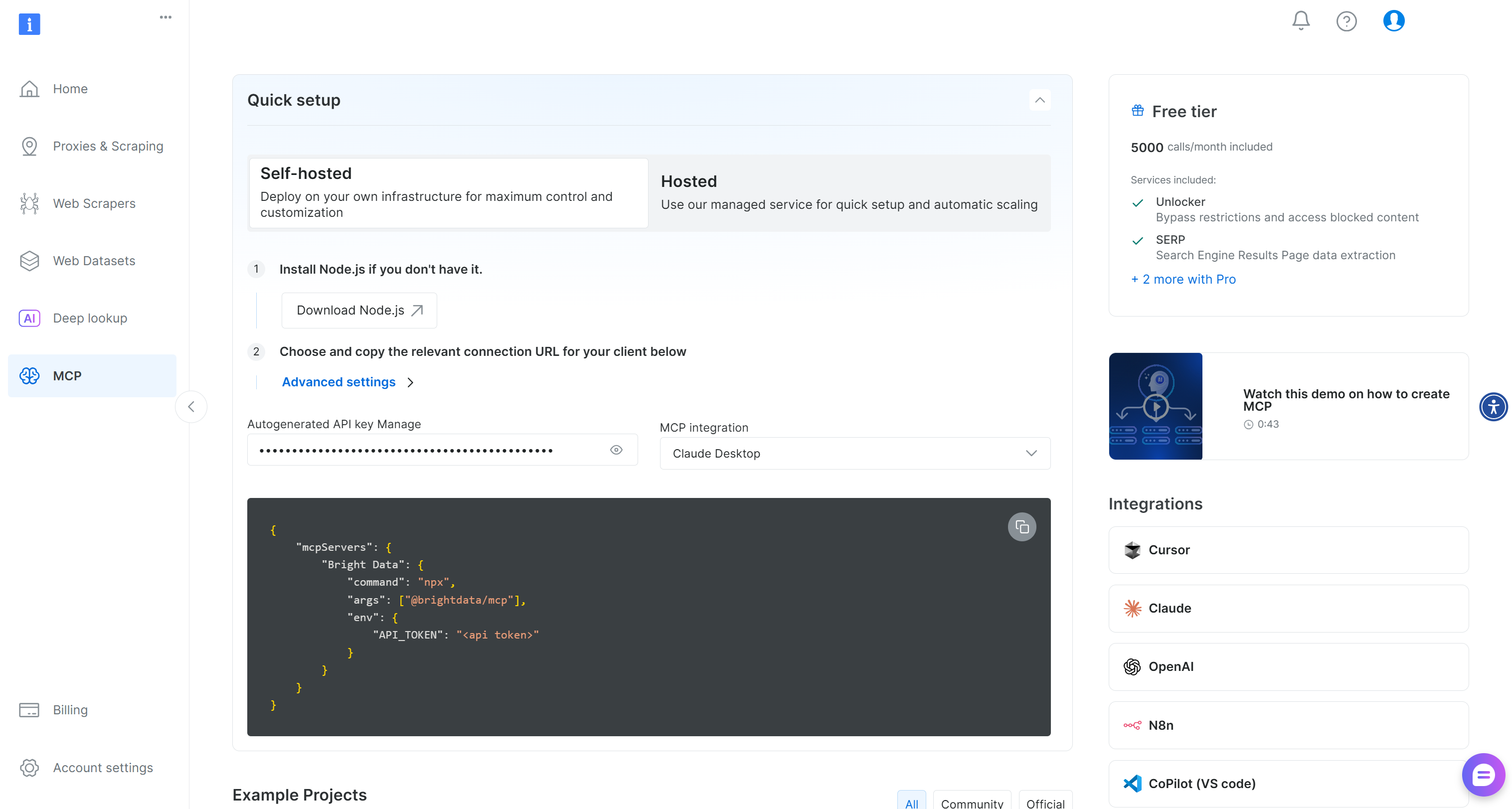
추가 안내가 필요하면 아래 지침을 참조하세요.
먼저 Bright Data API 키를 생성하세요. 곧 로컬 Web MCP 인스턴스를 Bright Data 계정으로 인증하는 데 사용할 것이므로 안전한 곳에 보관하세요.
그런 다음 @brightdata/mcp 패키지를 통해 Web MCP를 머신에 전역으로 설치하세요:
npm install -g @brightdata/mcp다음 명령을 실행하여 MCP 서버가 로컬에서 실행되는지 확인하세요:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcp또는 PowerShell에서 동일하게:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcp<YOUR_BRIGHT_DATA_API> 자리 표시자를 실제 Bright Data API 토큰으로 교체하세요. 두 (동일한) 명령은 필수 환경 변수인 API_TOKEN을 설정하고 Web MCP 서버를 로컬에서 실행합니다.
성공하면 다음과 유사한 출력이 표시됩니다:

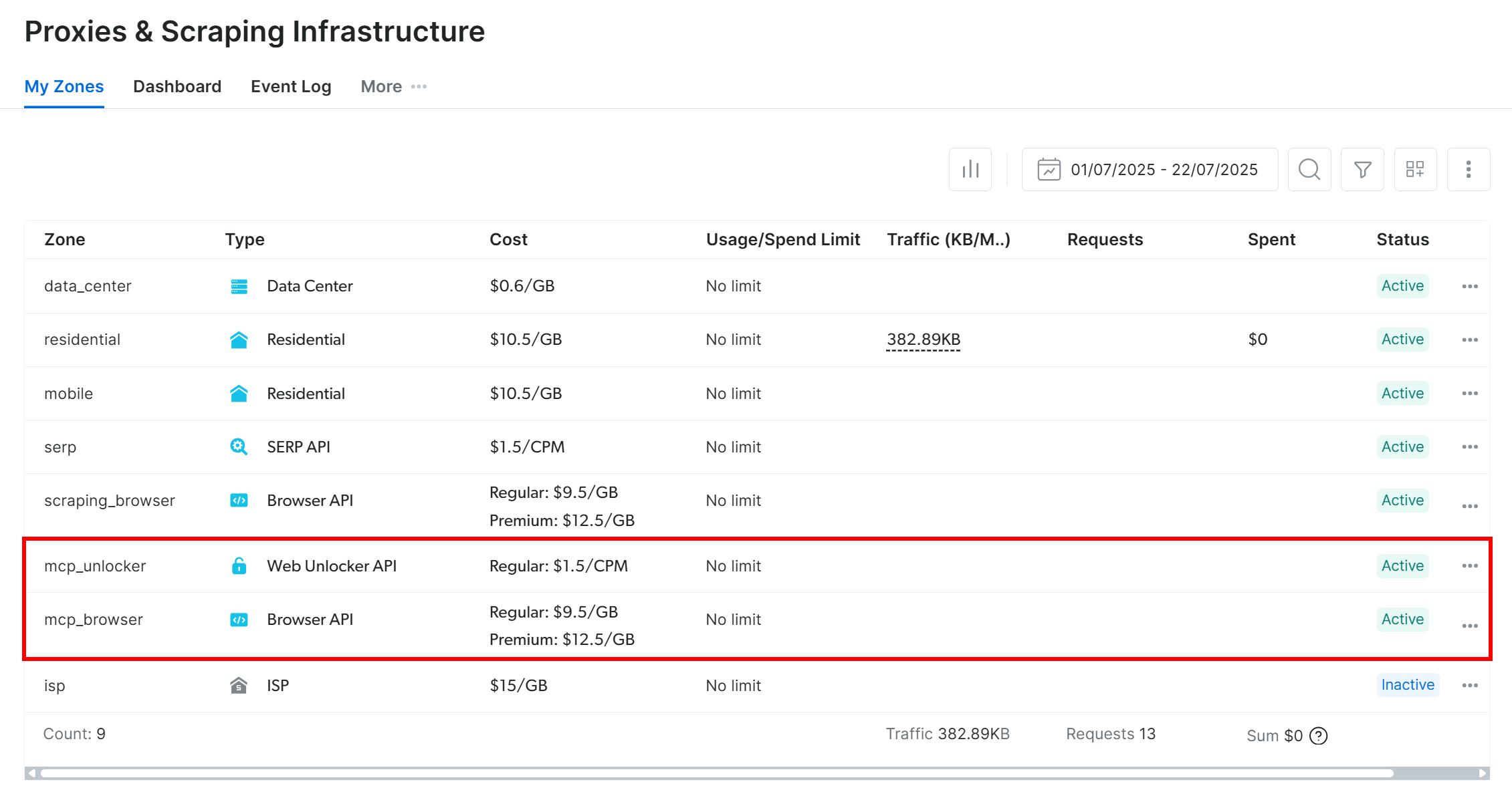
기본적으로 처음 실행 시 Web MCP는 Bright Data 계정에 두 개의 존을 생성합니다:
mcp_unlocker: Web Unlocker용 존.mcp_browser: Browser API용 존.
이 두 존이 Web MCP에서 사용 가능한 60개 이상의 도구를 지원합니다.
존이 생성되었는지 확인하려면 Bright Data 대시보드의 “프록시 및 스크래핑 인프라” 페이지로 이동하세요. 테이블에 두 존이 모두 나열되어 있어야 합니다:
Web MCP 무료 티어에서는 search_engine과 scrape_as_markdown 도구(및 배치 버전)만 사용할 수 있습니다.
모든 도구를 잠금 해제하려면 PRO_MODE="true" 환경 변수를 설정하여 Pro 모드를 활성화하세요:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcp또는 Windows에서:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpPro 모드는 60개 이상의 모든 도구를 잠금 해제하지만, 무료 티어에는 포함되지 않으며 [추가 요금이 발생](https://github.com/brightdata/brightdata-mcp?tab=readme-ov-file#-pricing, modes)합니다.
좋습니다! 이제 Web MCP 서버가 머신에서 작동하는지 확인했습니다. 다음으로 goose가 서버를 로컬에서 시작하고 연결하도록 구성할 것이므로 프로세스를 종료하세요.
3단계: Web MCP를 goose 확장으로 구성하기
goose Desktop에서 외부 MCP 서버에 연결하는 공식 방법은 커스텀 확장으로 추가하는 것입니다.
이를 위해 왼쪽 메뉴에서 “확장”을 클릭하세요:
다음으로 “커스텀 확장 추가” 버튼을 선택하세요:
“커스텀 확장 추가” 모달을 아래와 같이 입력하세요:
- 확장 이름: “Bright Data”
- 설명: “공개 웹 데이터에 대한 실시간 신뢰할 수 있는 접근으로 AI 모델과 에이전트를 강화하세요.”
- 명령:
npx -y @brightdata/mcp - 타임아웃:
300. - 환경 변수:
– API_TOKEN: <YOUR_BRIGHT_DATA_API_KEY> (실제 Bright Data API 키 값으로 교체하세요)
– PRO_MODE: true (선택 사항; Pro 모드를 활성화하려는 경우에만 설정하세요)
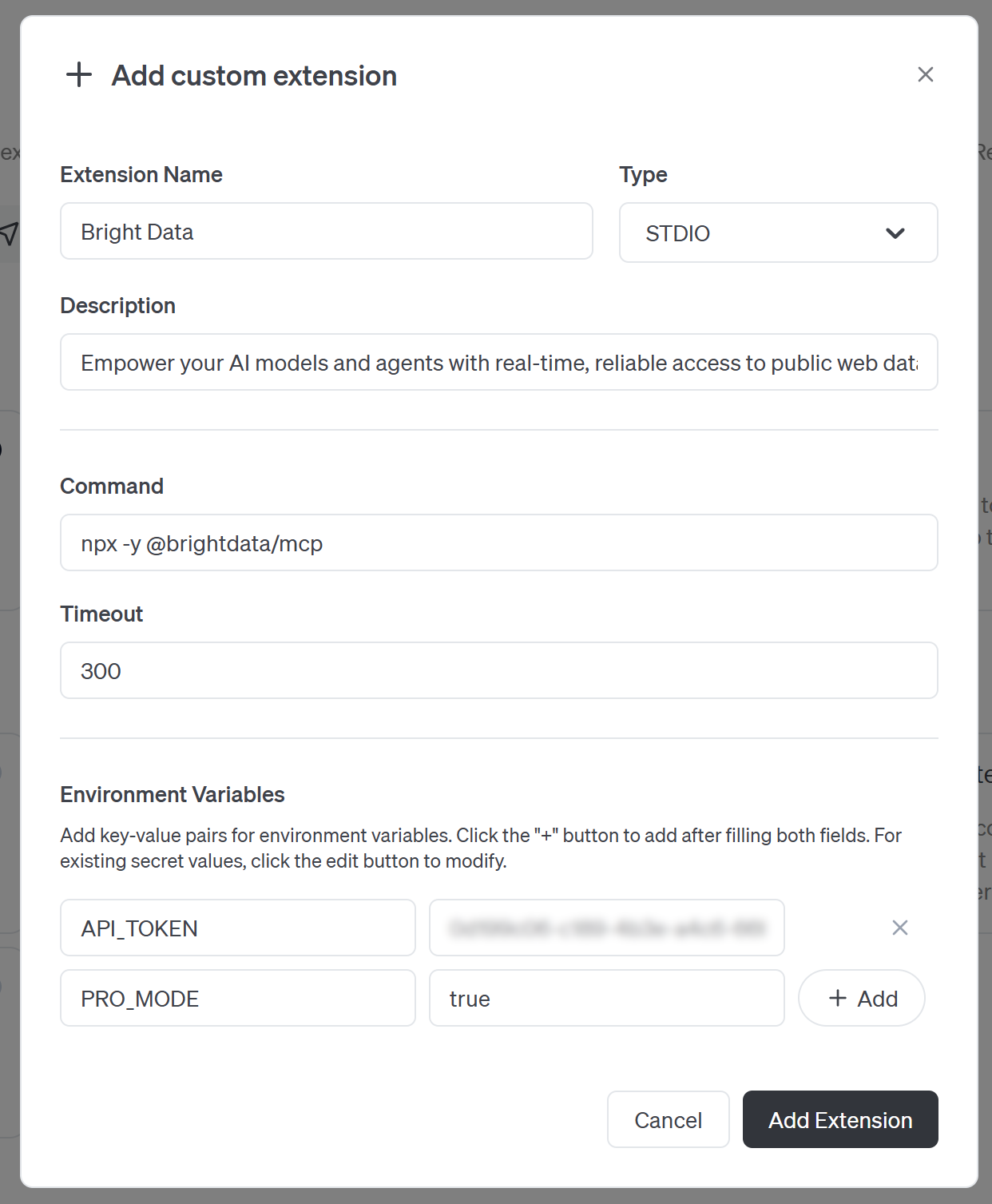
다음으로 “확장 추가” 버튼을 눌러 계속하세요.
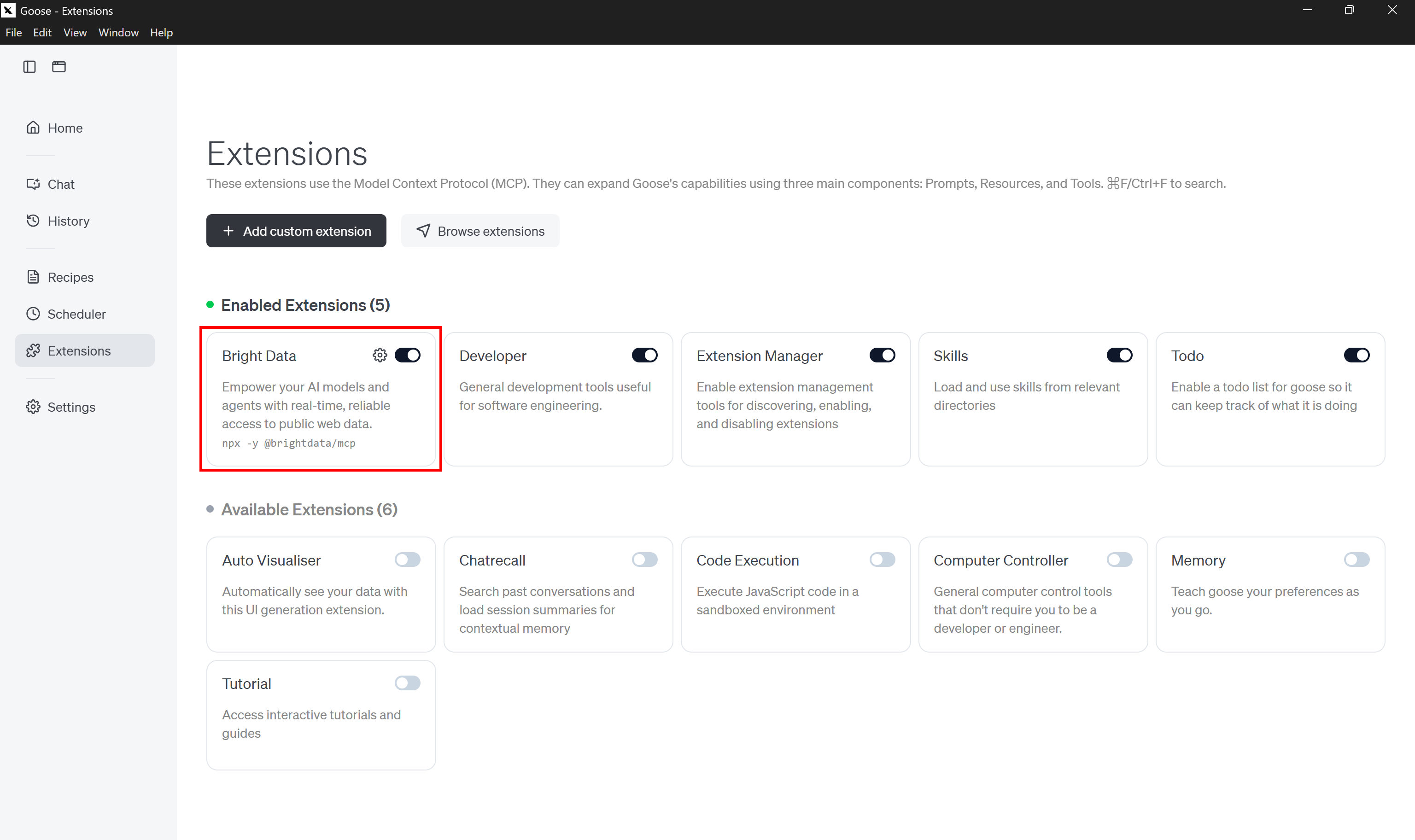
“Bright Data” 확장이 추가되고 기본적으로 활성화됩니다. 시작되지 않은 경우 확장을 직접 토글하여 활성화하세요.
이 방법은 본질적으로 앞서 Web MCP 서버를 로컬에서 시작하는 데 사용한 것과 동일한 명령을 실행하도록 goose에 지시하는 것입니다. goose는 해당 명령을 실행하고 로컬 서버에 자동으로 연결하여 에이전트가 도구에 접근할 수 있게 합니다.
참고: 마찬가지로, 서버를 로컬에서 실행하는 대신 Streamable HTTP를 통한 원격 Bright Data Web MCP에 연결할 수도 있습니다. 이 옵션은 엔터프라이즈급 사용 사례에 더 적합합니다.
훌륭합니다! 이제 goose가 Bright Data의 Web MCP에 연결할 수 있게 되었습니다.
4단계: Web MCP 연결 확인
현재 goose는 연결된 도구를 직접 나열하는 방법을 제공하지 않습니다. 그러나 모든 것이 작동하는지 확인하는 간단한 방법이 있습니다.
goose 홈 페이지로 이동하여 하단 채팅 섹션의 “autonomous” 레이블을 클릭하세요:
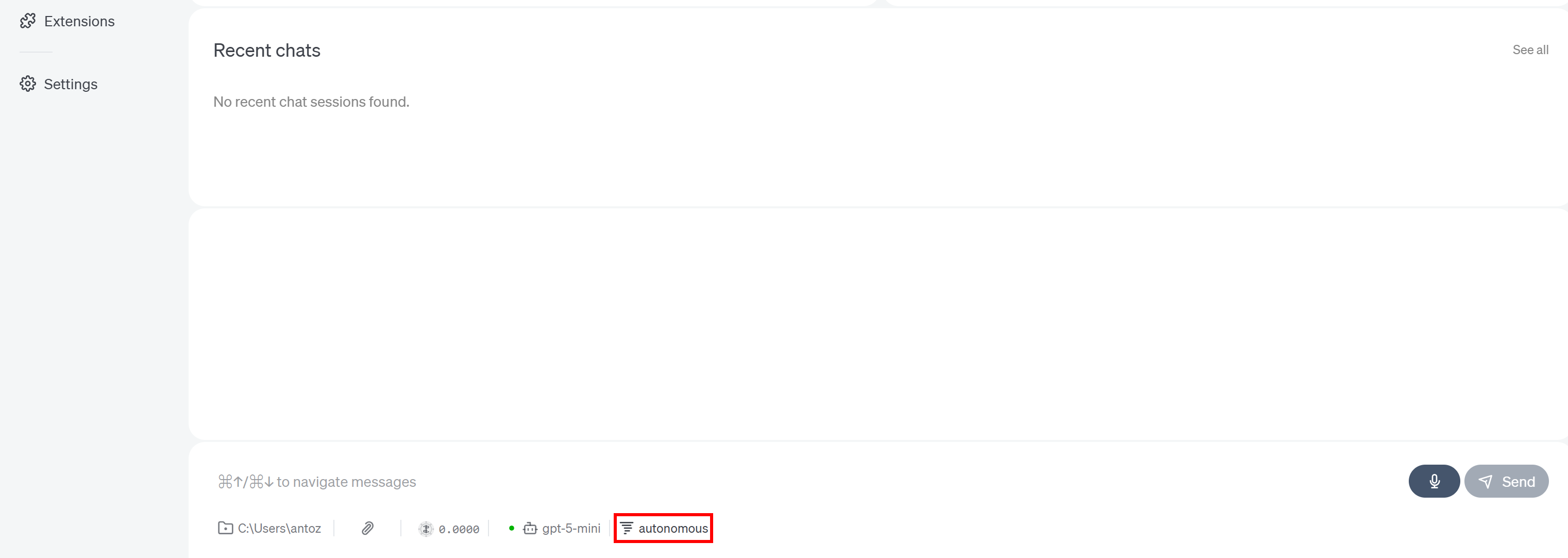
이 설정은 확장이 노출하는 도구를 사용할 때 AI 에이전트의 동작 방식을 제어합니다. 기본적으로 “Autonomous”로 설정되어 있으며, 이는 goose가 승인 없이 확장을 사용하고, 파일을 수정하며, 파일을 삭제할 수 있음을 의미합니다.
“Manual” 항목의 기어 아이콘을 누르세요:
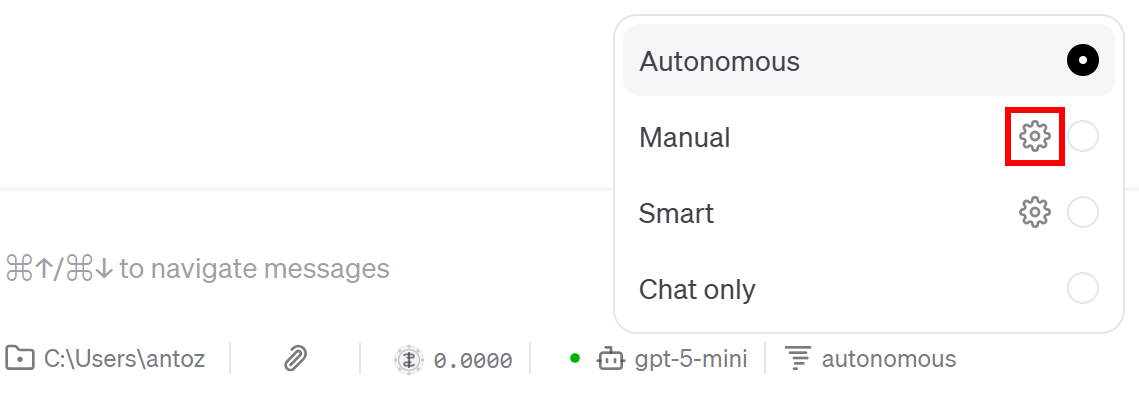
“권한 규칙” 모달에서 활성화된 확장 목록이 표시됩니다. “bright-data”를 선택하세요:
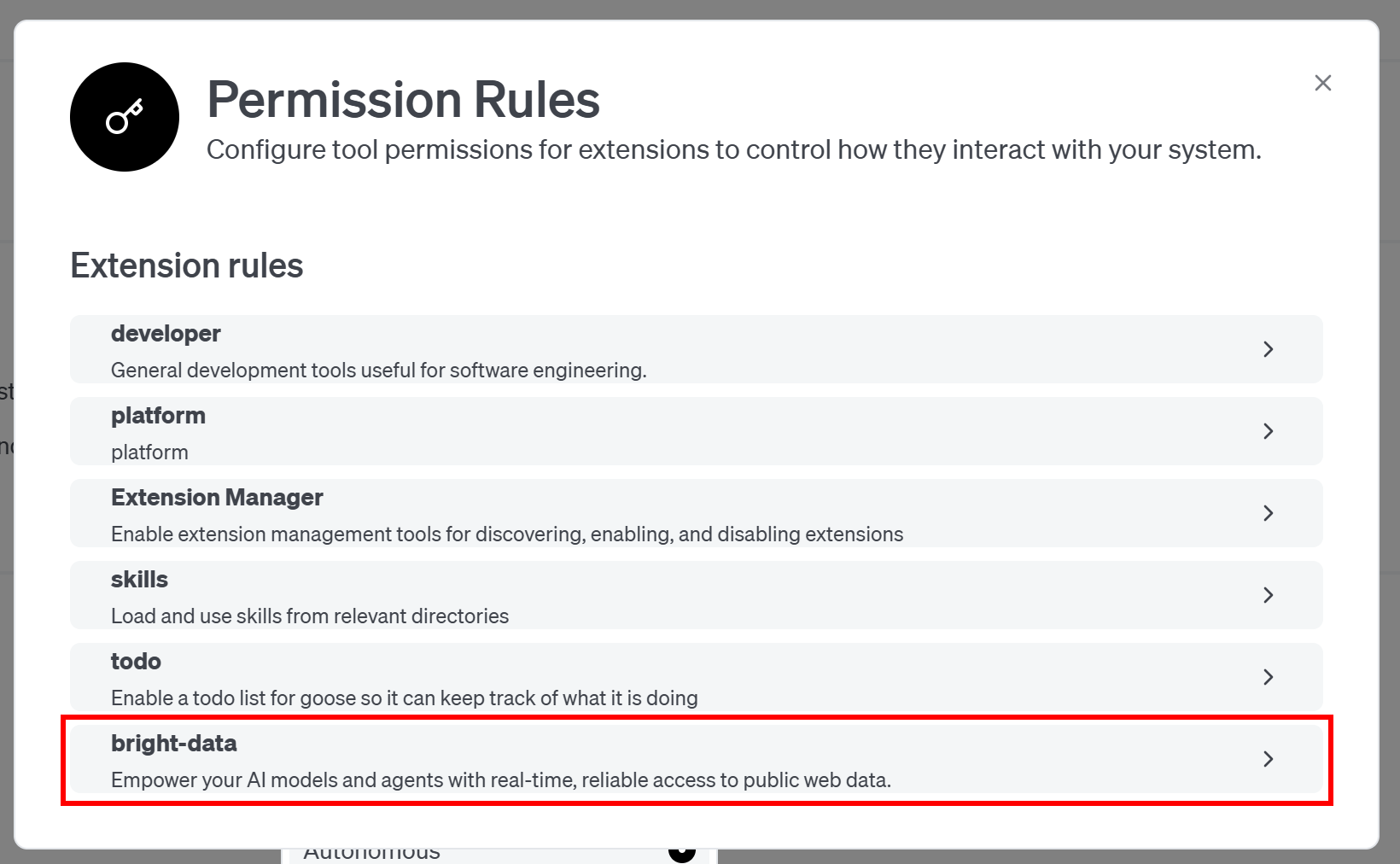
이제 goose가 Web MCP 서버가 노출하는 모든 도구를 나열합니다(각 도구에 대한 권한을 개별적으로 구성할 수 있습니다):
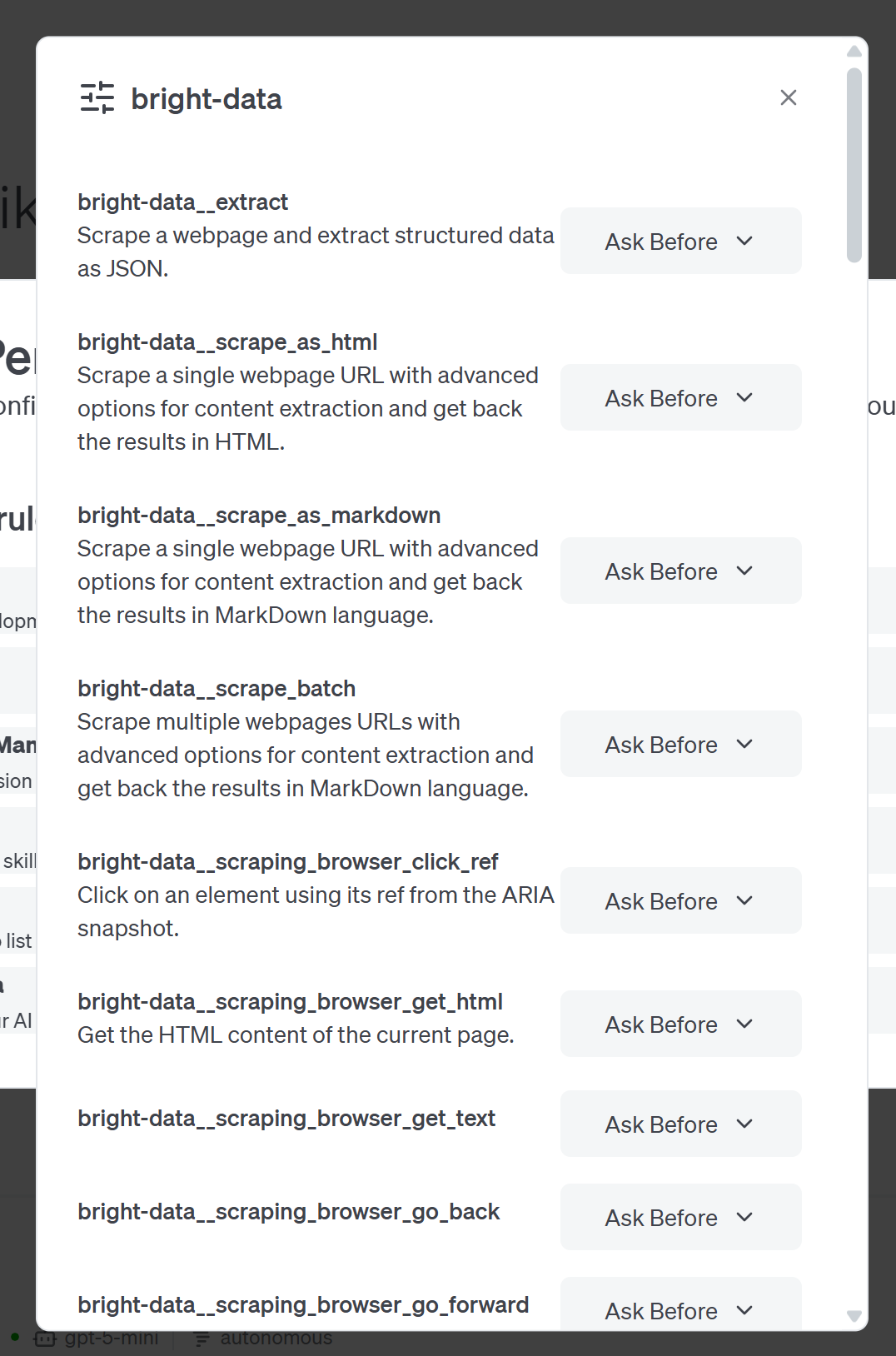
이 예시에서는 Web MCP 서버가 Pro 모드로 구성되었기 때문에 60개 이상의 도구가 목록에 포함됩니다. 일반 모드로 실행 중인 경우 네 가지 무료 도구(search_engine과 scrape_as_markdown, 그리고 배치 버전)만 사용할 수 있습니다.
여기서 사용하려는 도구에 대한 권한을 세밀하게 구성하거나 Autonomous 모드로 계속 진행할 수 있습니다.
훌륭합니다! goose가 Bright Data Web MCP에 성공적으로 연결되었습니다.
5단계: 통합 테스트
통합이 작동하는지 확인하기 위해, 최신 문서 정보가 필요한 실제 프로젝트를 만들고자 한다고 가정해 봅시다. 이는 LLM만으로는 갖출 수 없는 정보입니다.
더 높은 정확도를 위해 AI 에이전트에게 유사한 프로젝트의 GitHub 페이지에 접근하고, 파일을 탐색하며, 그로부터 학습하여 필요한 결과를 생성하도록 지시할 수 있습니다. 예를 들어, Node.js에서 Bright Data의 SERP API 통합 시작하기를 위해 다음과 같은 프롬프트를 테스트해 보세요:
Given the following GitHub project: "https://github.com/luminati-io/bright-data-serp-api-nodejs-project", access it and identify the main GitHub file URLs. Extract structured information from these GitHub file URLs and use it to generate a simple Node.js project that automates integration with the SERP API through a dedicated function.일반적으로 LLM은 모든 세부 정보를 알지 못하여 환각을 일으킬 수 있습니다. 하지만 공식 GitHub 정보에 의존함으로써 출력이 훨씬 더 정확해집니다.
특히 AI 에이전트는 Web MCP 도구를 사용하여 대상 프로젝트에서 정보를 읽고, 전문 GitHub 도구를 사용하여 저장소 파일에서 구조화된 데이터를 추출해야 합니다.
goose에서 프롬프트를 실행하세요:
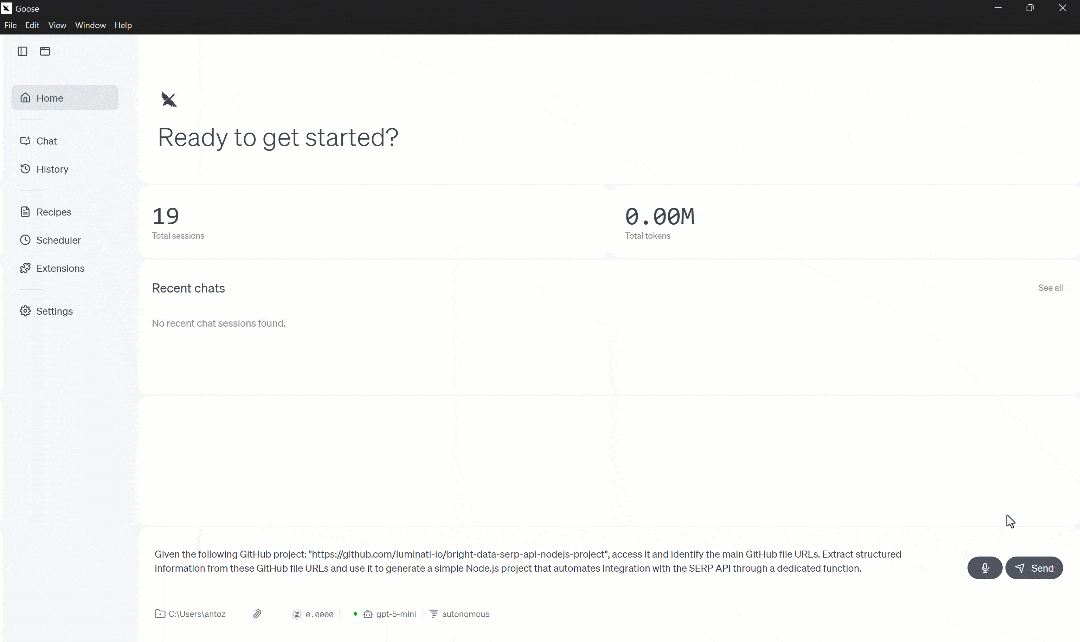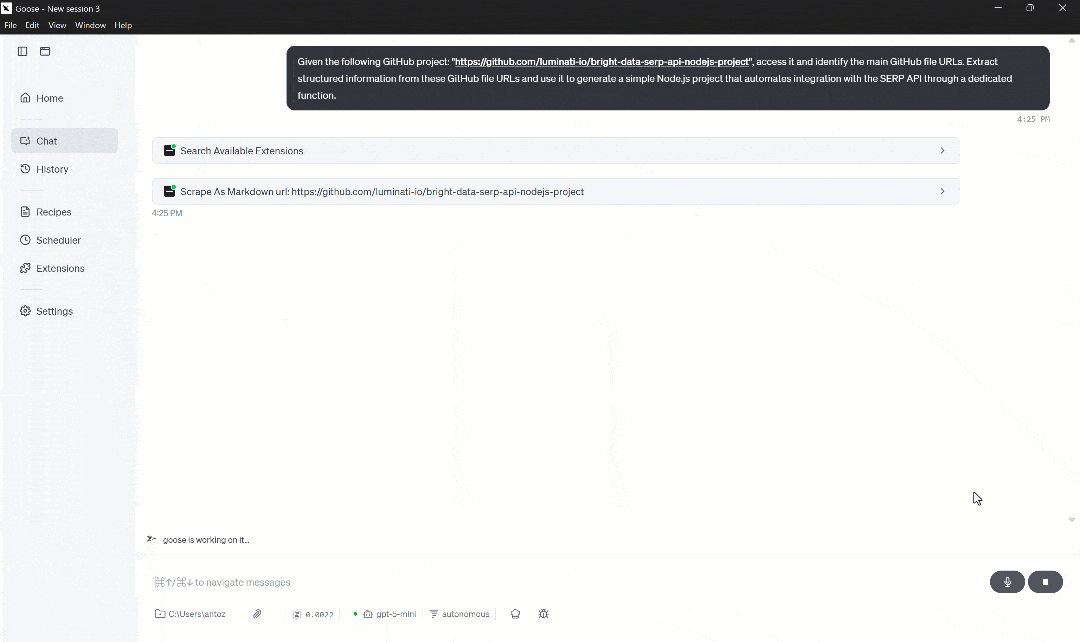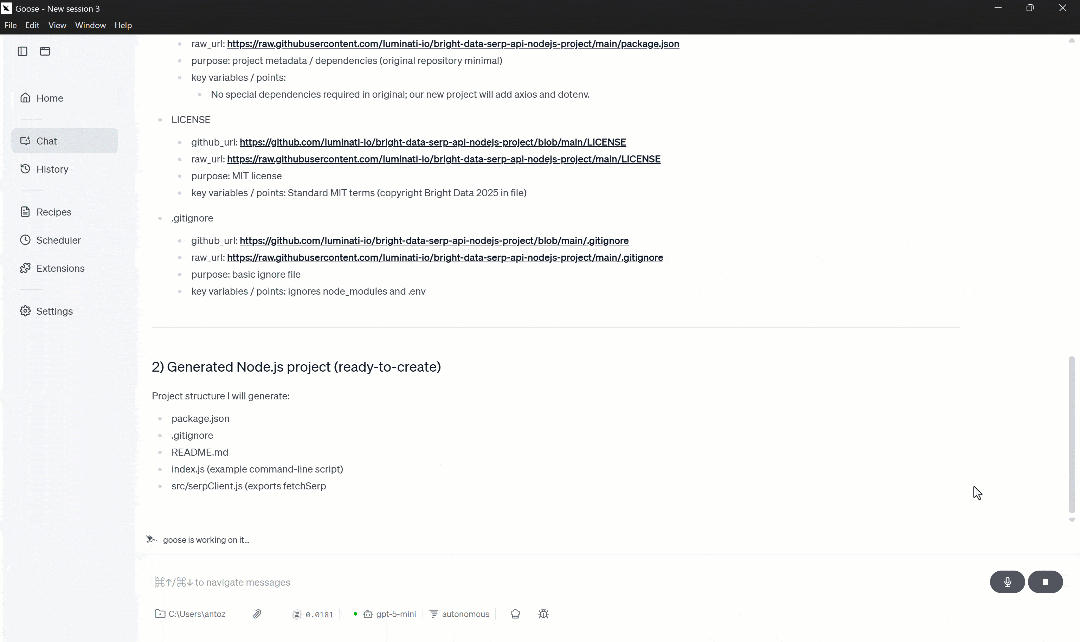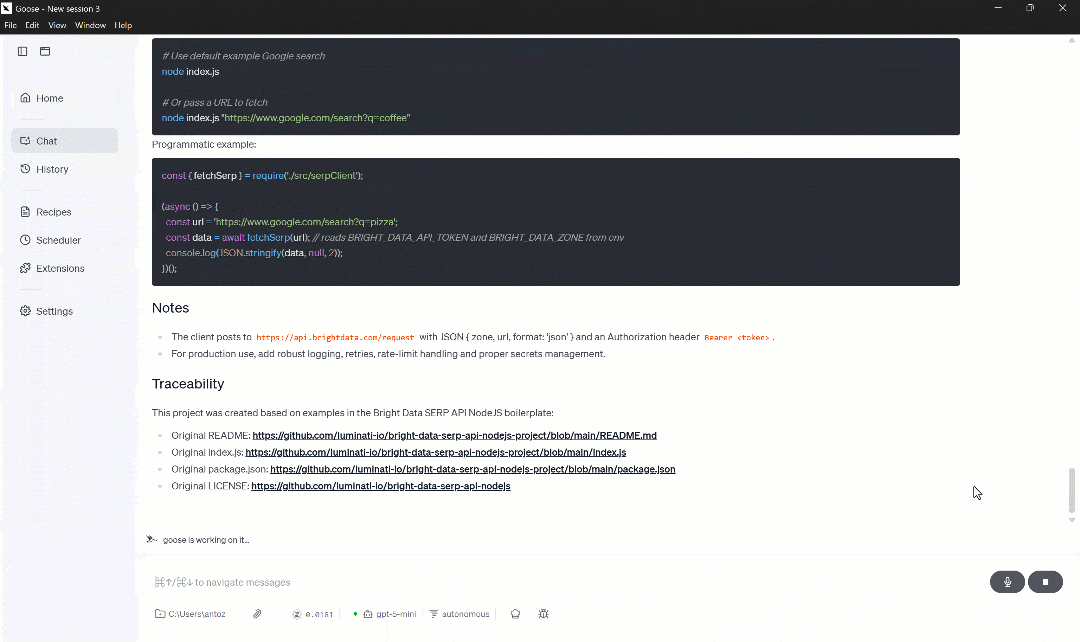
보시다시피, 에이전트는 “Scrape As Markdown” 도구를 호출하여 공식 저장소 페이지를 먼저 읽고 LLM에 최적화된 Markdown 형식(이는 AI 에이전트 수집에 이상적인 형식)으로 반환합니다.
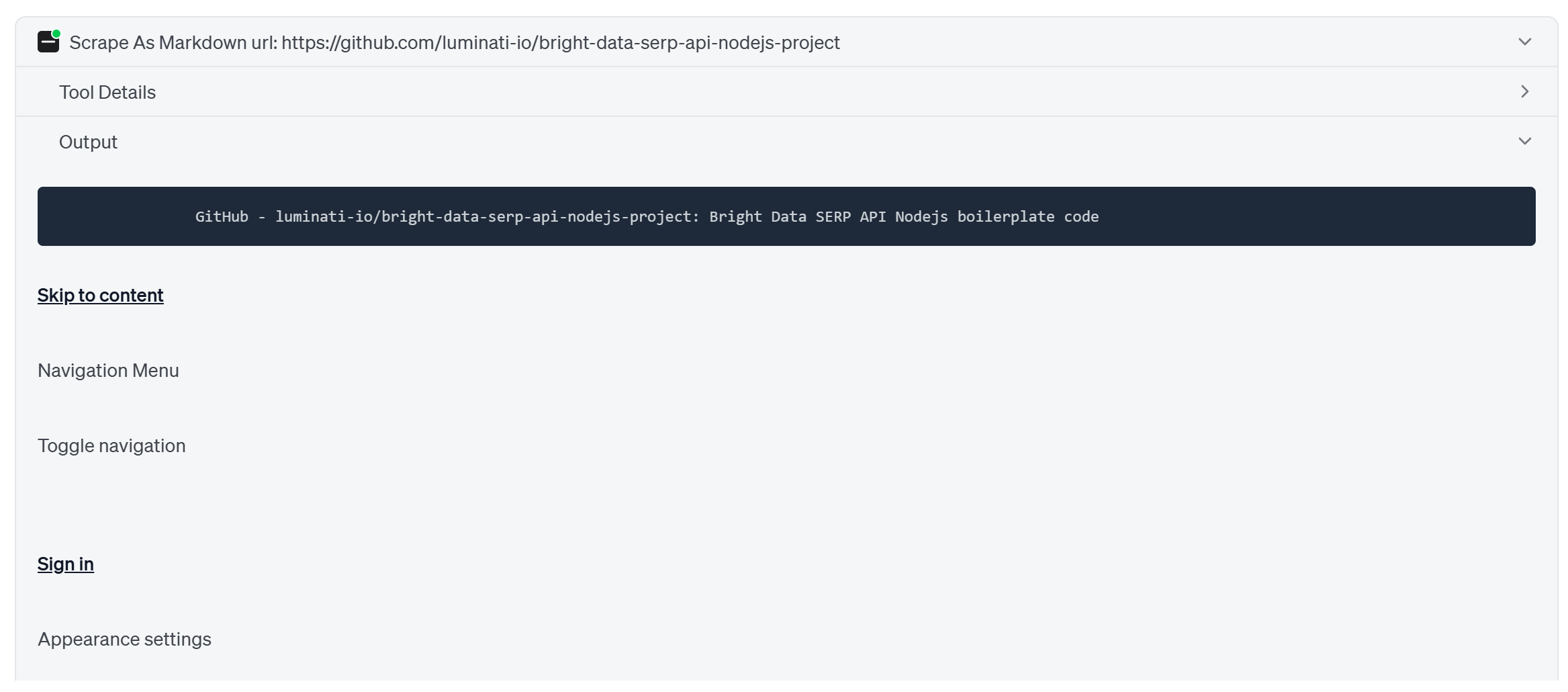
거기서 가장 중요한 파일 링크를 발견하고 Web MCP의 프리미엄 “Web Data GitHub Repository File” 도구를 통해 접근합니다. 이 도구는 주어진 GitHub URL에서 구조화된 JSON 데이터를 스크래핑합니다:
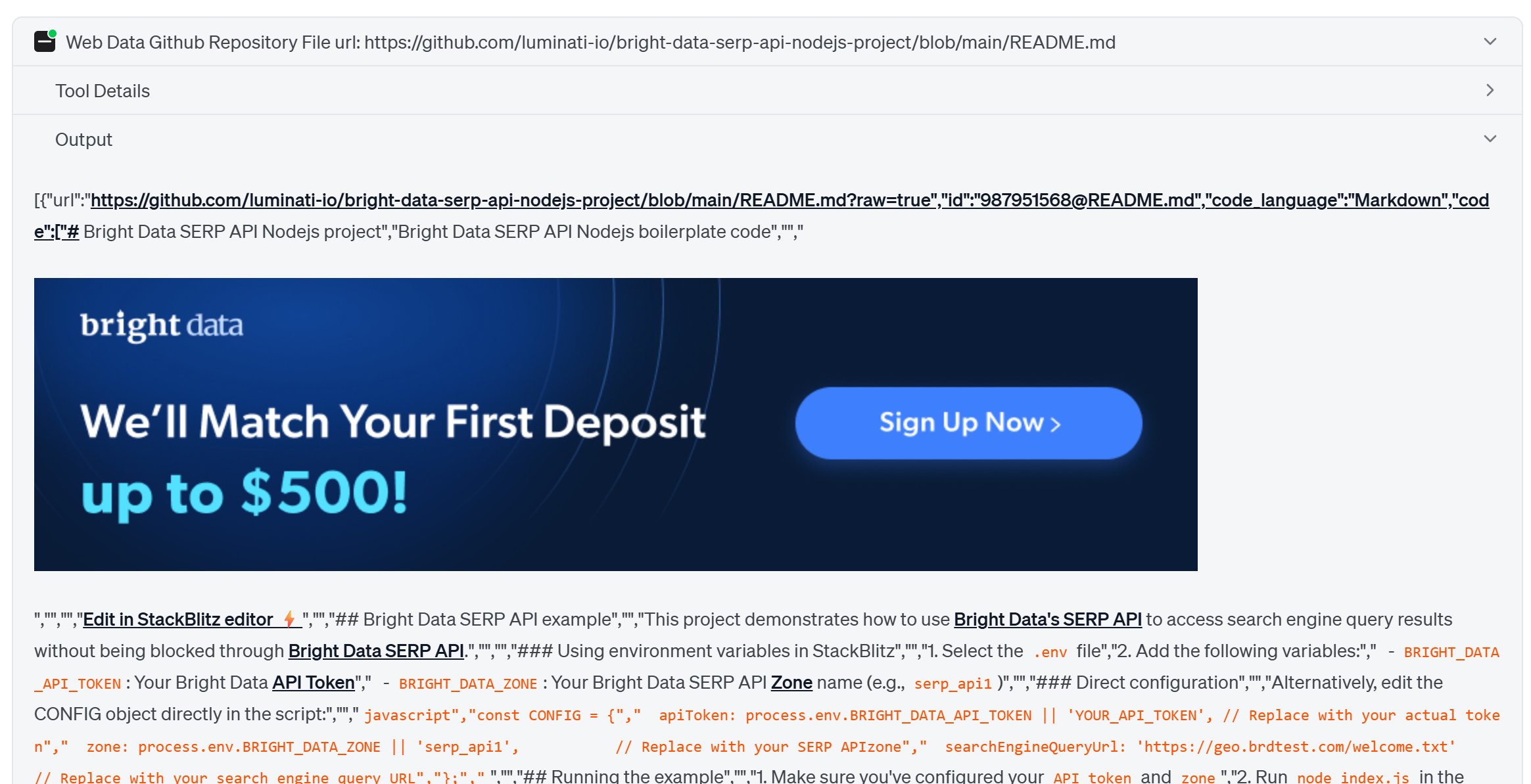
마지막으로 에이전트는 검색된 데이터로부터 학습하여 원하는 프로젝트 설정을 위한 매우 상세하고 맥락적인 지침을 잘 주석 처리된 코드와 함께 생성합니다.
완성! 이제 goose AI 에이전트는 Bright Data Web MCP 연결 덕분에 고품질 결과를 위해 필요한 모든 도구에 접근할 수 있어 그 어느 때보다 강력해졌습니다.
goose CLI에서 Bright Data Web MCP 연결하기: 단계별 튜토리얼
이 가이드 섹션에서는 CLI를 통해 goose에 Bright Data Web MCP를 통합하는 과정을 안내합니다.
1단계: goose CLI 설치 및 구성
먼저 운영 체제에 맞는 goose CLI 설치 공식 지침을 따르세요. 설치 중 goose configure 명령이 자동으로 실행됩니다:
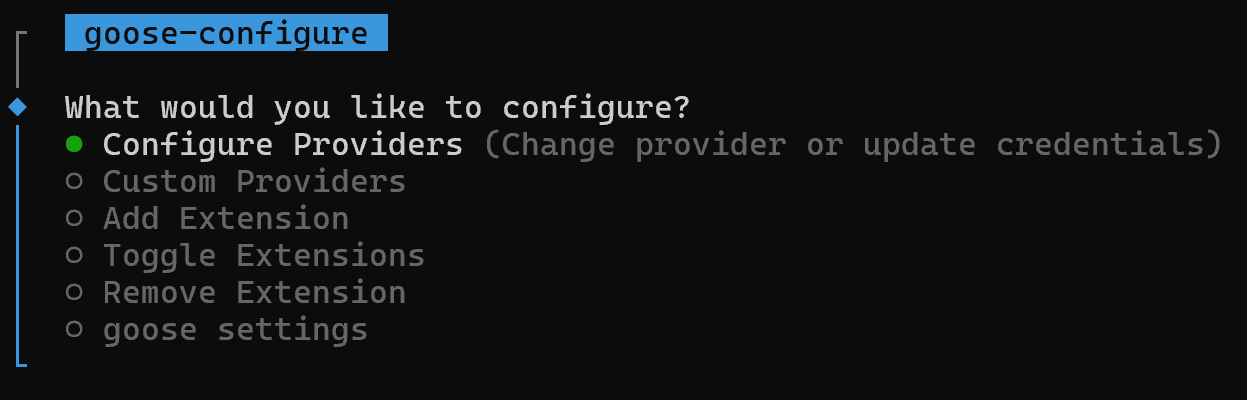
이 인터페이스를 통해 goose 설정을 구성할 수 있습니다.
이제 “제공업체 구성” 옵션에서 Enter를 누르고 지침에 따라 AI 제공업체 API 키를 설정하고 사용할 모델을 선택하세요(이 경우 gpt-5-mini):
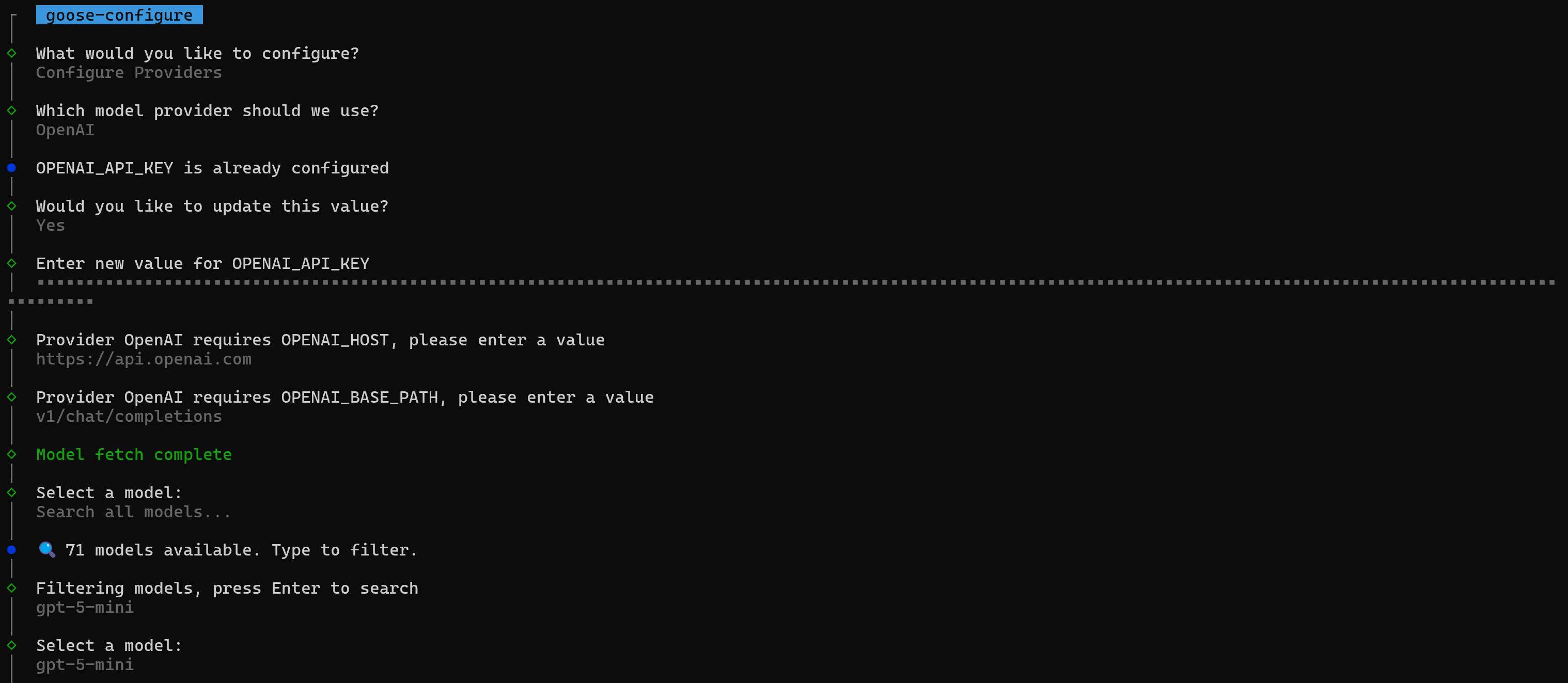
프로세스가 끝나면 Windows에서 다음과 유사한 출력이 표시됩니다:
C:\Users\<YOUR_USERNAME>\AppData\Roaming\Block\goose\config\config.yaml
goose CLI installation completed successfully!
goose is installed at: C:\Users\<YOUR_USERNAME>\.local\bin\goose.exe이는 goose 주요 구성 파일이 필요한 정보로 올바르게 업데이트되었음을 확인합니다. 이후에는 안내 설정을 위해 goose configure 명령을 다시 실행하거나 구성 파일을 직접 편집할 수 있습니다.
goose 구성 파일의 위치:
- macOS/Linux:
~/.config/goose/config.yaml - Windows:
%APPDATA%\Block\goose\config\config.yaml
좋습니다! 이제 goose CLI가 정상적으로 설치되었습니다.
2단계: Bright Data 확장 구성
goose configure를 다시 실행하되, 이번에는 “확장 추가” 옵션을 선택하세요:
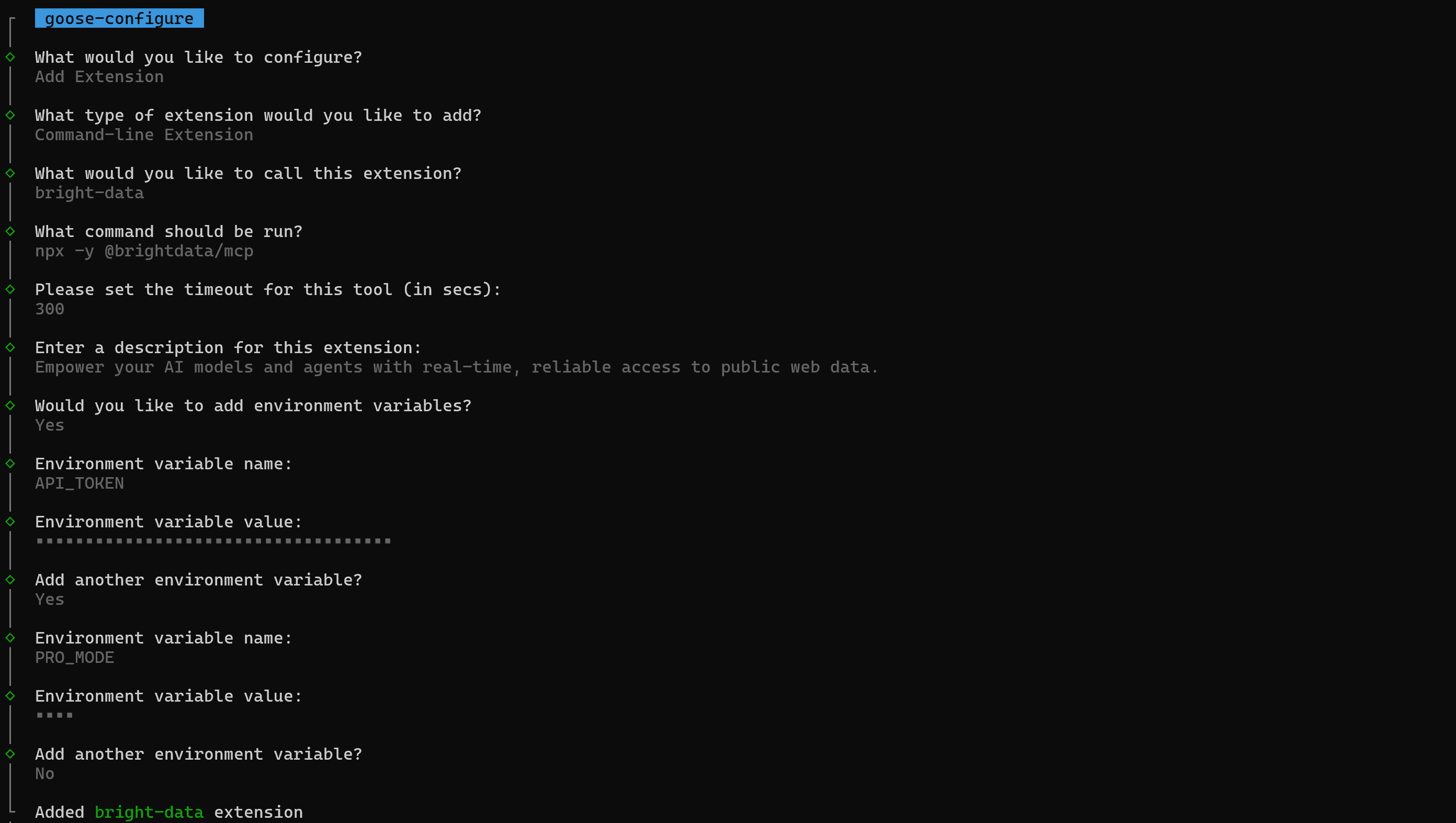
다시 말하지만, 커스텀 확장을 정의하는 것이 goose에서 커스텀 MCP 서버를 통합하는 공식 지원 방법입니다. 다음 정보로 질문에 답하세요:
- 확장 이름: “bright-data”
- 설명: “공개 웹 데이터에 대한 실시간 신뢰할 수 있는 접근으로 AI 모델과 에이전트를 강화하세요.”
- 명령:
npx -y @brightdata/mcp - 타임아웃:
300. - 환경 변수:
– API_TOKEN: <YOUR_BRIGHT_DATA_API_KEY> (실제 Bright Data API 키 값으로 교체하세요)
– PRO_MODE: true (선택 사항; Pro 모드를 활성화하려는 경우에만 설정하세요)
goose 구성 파일을 열면 새로 추가된 확장을 확인할 수 있습니다:
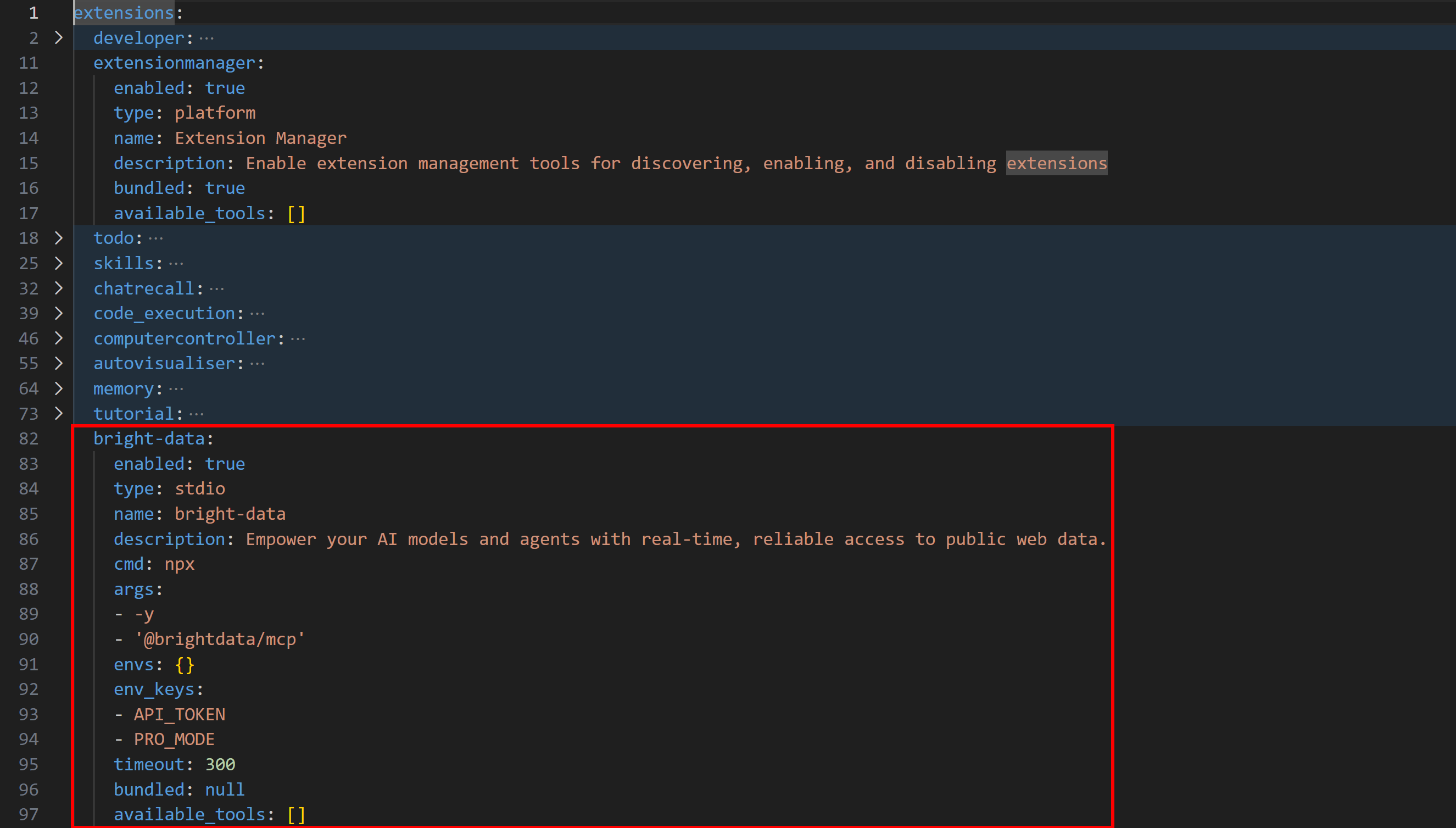
확장이 기본적으로 추가되고 활성화되어야 합니다. 그렇지 않은 경우 goose configure를 실행하고 “확장 토글”을 선택하여 수동으로 활성화하세요.
완벽합니다! Bright Data MCP가 이제 goose CLI에 완전히 통합되었습니다.
3단계: 통합 테스트
통합이 작동하는지 확인하려면 다음 명령으로 goose CLI를 실행하세요:
goose session이렇게 하면 구성된 확장에 연결된 기반 AI 에이전트와 대화할 수 있는 goose 세션이 시작됩니다. 다음과 같은 간단한 프롬프트를 시도해 보세요:
Retrieve and present the main stats from the "https://github.com/block/goose" repository 이는 외부 페이지 방문이 필요하기 때문에 일반 AI 모델이 단독으로 처리할 수 없는 작업입니다. Bright Data Web MCP 도구가 연결되면 이러한 작업을 쉽게 수행할 수 있습니다.
출력은 다음과 같이 표시됩니다:
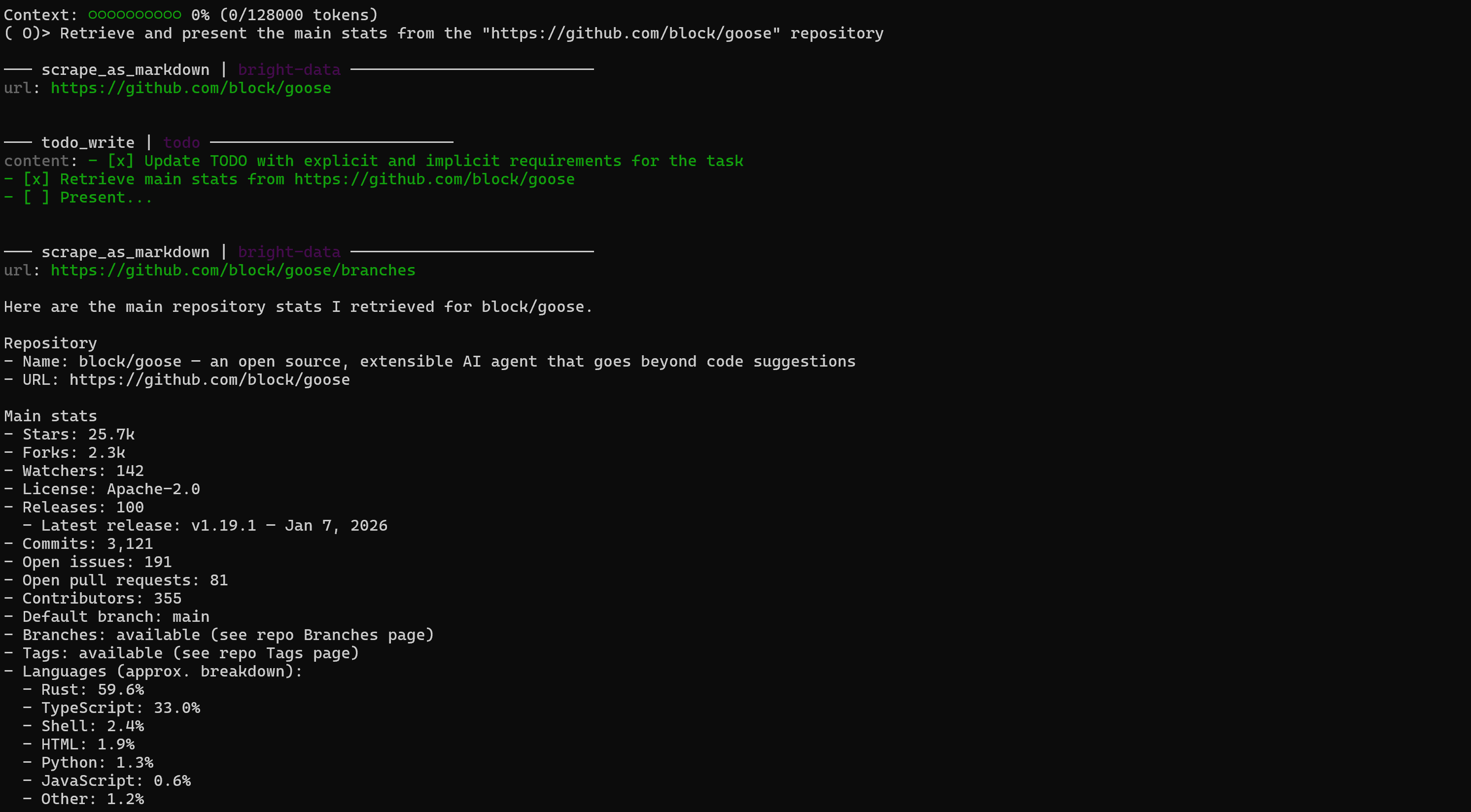
AI 에이전트가 scrape_as_markdown 도구를 활용하여 라이브 URL과 저장소 페이지에서 정보를 검색한 것을 확인하세요. 응답은 대상 GitHub 페이지에서 사용 가능한 정보와 정확히 일치합니다:
임무 완료! 이제 웹 탐색, 인터랙션, 데이터 검색을 위한 Bright Data Web MCP 기능으로 확장된 goose 기반 CLI AI 에이전트를 갖게 되었습니다.
결론
이 블로그 포스트에서는 Desktop 또는 CLI 애플리케이션을 통해 goose에서 MCP 통합을 활용하는 방법을 배웠습니다. 특히 Bright Data의 Web MCP에 연결하는 확장을 통해 goose AI 에이전트를 확장하는 방법을 살펴보았습니다.
이 설정은 goose AI 에이전트에 웹 검색, 구조화된 데이터 추출, 실시간 웹 데이터 검색, 자동화된 웹 인터랙션과 같은 강력한 기능을 제공합니다. 더욱 고급 워크플로를 구축하려면 Bright Data의 AI 생태계에서 제공하는 전체 서비스 범위를 탐색해 보세요.
지금 Bright Data 계정에 가입하고 AI 지원 웹 데이터 도구로 실험을 시작하세요!



