이 블로그 포스트에서 다루는 내용:
- Amazon SageMaker가 무엇이며 머신러닝에 어떤 가치를 제공하는지.
- 피처 엔지니어링 성공을 위해 웹 데이터가 필수적인 이유.
- 피처 엔지니어링 및 기타 머신러닝 시나리오를 위한 고품질 웹 데이터를 어디서 확보할 수 있는지.
- 웹 데이터를 저장한 데이터셋을 사용하여 Amazon SageMaker에서 피처 엔지니어링을 수행하는 방법.
바로 시작해 봅시다!
Amazon SageMaker란 무엇인가?
Amazon SageMaker는 대규모로 머신러닝 모델과 AI 애플리케이션을 빌드, 학습 및 배포할 수 있도록 설계된 완전 관리형 서비스입니다. 분석과 AI를 위한 통합된 엔드투엔드 환경을 제공합니다.
Amazon S3 데이터 레이크, Redshift 데이터 웨어하우스, 서드파티 및 페더레이션 시스템 등 다양한 소스의 데이터에 접근할 수 있으며, 엔터프라이즈급 보안과 거버넌스를 보장합니다.
요약하자면, SageMaker는 ML 워크플로를 단순화하고 피처 엔지니어링부터 모델 배포까지 모델 개발을 가속화합니다. 주요 기능과 역량은 다음과 같습니다:
- SageMaker Unified Studio: 완전 관리형 인프라와 통합 도구를 사용하여 ML 및 생성형 AI 모델을 빌드, 학습, 배포하는 단일 개발 환경.
- 모델 개발 및 MLOps: 빠른 프로토타이핑, 학습, 모델 운영화를 위한 사전 빌드 템플릿, HyperPod, JumpStart 포함.
- 생성형 AI 지원: Amazon Bedrock으로 애플리케이션을 빌드 및 확장하고 Amazon Q Developer와 같은 내장 AI 어시스턴트를 활용.
- 데이터 처리 및 SQL 분석: Amazon Athena, EMR, Glue, Redshift의 오픈소스 프레임워크를 사용하여 데이터를 준비, 분석, 통합.
- 레이크하우스 아키텍처: 포괄적인 분석과 AI를 지원하기 위해 스토리지 시스템 전반의 사일로화된 데이터에 대한 접근을 통합.
웹 데이터를 활용한 피처 엔지니어링 소개
피처 엔지니어링은 원시 데이터를 머신러닝 모델이 더 효과적으로 활용할 수 있는 의미 있는 변수, 즉 “피처”로 변환하는 과정입니다. 모델에 가공되지 않은 데이터를 직접 입력하는 대신, 소스 데이터셋의 패턴을 더 잘 포착하는 파생 지표를 만드는 것이 핵심입니다.
예시로는 값 집계, 점수 정규화, 관련 변수 결합, 또는 다양한 필드 간의 관계를 강조하는 비율 생성 등이 있습니다. 훌륭한 피처 엔지니어링은 알고리즘 선택보다 모델 성능에 더 큰 영향을 미칠 수 있습니다. 잘 설계된 피처는 모델이 숨겨진 신호를 식별하는 데 도움을 주기 때문입니다.
웹 데이터는 실세계 활동을 대규모로 반영하기 때문에 피처 엔지니어링에 특히 유용합니다. 공개 웹사이트에는 기업, 제품, 채용, 리뷰, 가격, 사용자 행동에 관한 방대한 정보가 담겨 있습니다. 이러한 신호는 인기 지표, 시장 수요 지표, 감성 점수, 채용 트렌드 등의 피처로 변환될 수 있으며, 머신러닝 파이프라인의 성능을 크게 향상시킬 수 있습니다.
그러나 웹 데이터를 다루는 데는 여러 과제가 따릅니다. 데이터에 노이즈가 있거나 불완전하거나 일관성이 없을 수 있으며, 이는 입력 데이터의 품질에 크게 영향을 미칩니다. 또한 많은 웹사이트들이 안티봇 조치를 도입하고 있습니다.
따라서 머신러닝에 웹 스크래핑을 활용하는 것은 까다롭습니다. 수집된 데이터를 ML 파이프라인에 사용하기 전에 정제, 검증, 준비 과정이 필요합니다.
대용량 고품질 웹 데이터를 확보하는 방법
앞서 살펴봤듯이, 웹 데이터는 피처 엔지니어링에서 핵심적인 역할을 합니다. 동시에 엔터프라이즈 수준의 활용을 위해 안정적으로 데이터를 수집하는 것은 쉽지 않습니다. 웹 스크래핑 로드맵을 따르면 몇 페이지에서 데이터를 수집하는 것은 간단해 보일 수 있지만, 다수의 도메인이나 대형 사이트 전반에 걸쳐 일관되게 수행하는 것은 훨씬 복잡합니다.
웹사이트는 구조를 자주 변경하고, 속도 제한을 적용하며, 자동화된 요청을 차단하는 안티봇 보호를 배포합니다. 또한 데이터를 수집하더라도 고품질이고 완전하며 최신 상태를 유지하는 것이 어려울 수 있습니다.
이러한 이유로 많은 조직이 웹 데이터셋 기업과 Bright Data 같은 웹 데이터 제공업체에 의존합니다. 이러한 플랫폼은 스크래핑 인프라를 직접 구축하고 유지할 필요 없이 대량의 웹 데이터에 접근할 수 있게 해줍니다.
Bright Data는 215개 이상의 인기 웹 도메인에서 수백 개의 데이터셋을 제공하며, 총 170억 개 이상의 레코드를 보유하고 있습니다. 이 데이터셋은 지속적으로 업데이트되는 구조화된 웹 데이터로, ML 및 AI 애플리케이션에 최적화되어 있습니다. 데이터셋 마켓플레이스를 탐색해 보세요!
사전 수집된 데이터셋이 요구 사항을 충족하지 못하는 경우, Bright Data는 웹 스크래핑 API와 기타 데이터 수집 도구도 제공합니다. 이를 통해 스크래핑 문제를 직접 처리하지 않고도 웹사이트에서 원하는 시점에 최신 데이터를 수집할 수 있습니다.
Bright Data의 차별점은 데이터 수집 인프라에 있습니다. 195개국 이상에 걸쳐 1억 5천만 개 이상의 IP를 보유한 글로벌 프록시 네트워크를 기반으로 하며, 99.99%의 가동률과 99.95%의 성공률을 달성합니다. 이 기반은 신뢰할 수 있는 웹 데이터로 구동되는 데이터 기반 애플리케이션과 ML 파이프라인을 더 쉽게 구축할 수 있게 해줍니다.
Amazon SageMaker에서 웹 데이터 피처 엔지니어링 수행 방법
이 단계별 섹션에서는 Amazon SageMaker에서 피처 엔지니어링을 수행하는 과정을 안내합니다.
Bright Data의 Glassdoor 데이터셋으로 시작하여 Amazon S3에 업로드하고, SageMaker 노트북에 로드한 후 피처 엔지니어링을 적용하여 의미 있는 지표를 생성합니다. 피처가 준비되면, 이를 사용하여 높은 직원 만족도를 예측하는 머신러닝 모델을 학습시킵니다.
이것은 하나의 예시일 뿐이며, 다양한 다른 활용 사례가 가능합니다.
지침을 따라 진행하세요!
사전 준비 사항
이 가이드를 따르려면 다음이 필요합니다:
- AWS 계정 (무료 체험 포함).
- Bright Data 계정.
- AWS 계정에 정의된 S3 버킷.
- 특히 머신러닝 개발 및 데이터 과학 측면에서의 기본 Python 지식.
이후부터는 S3 버킷 이름이 bright-data-sagemaker라고 가정합니다:
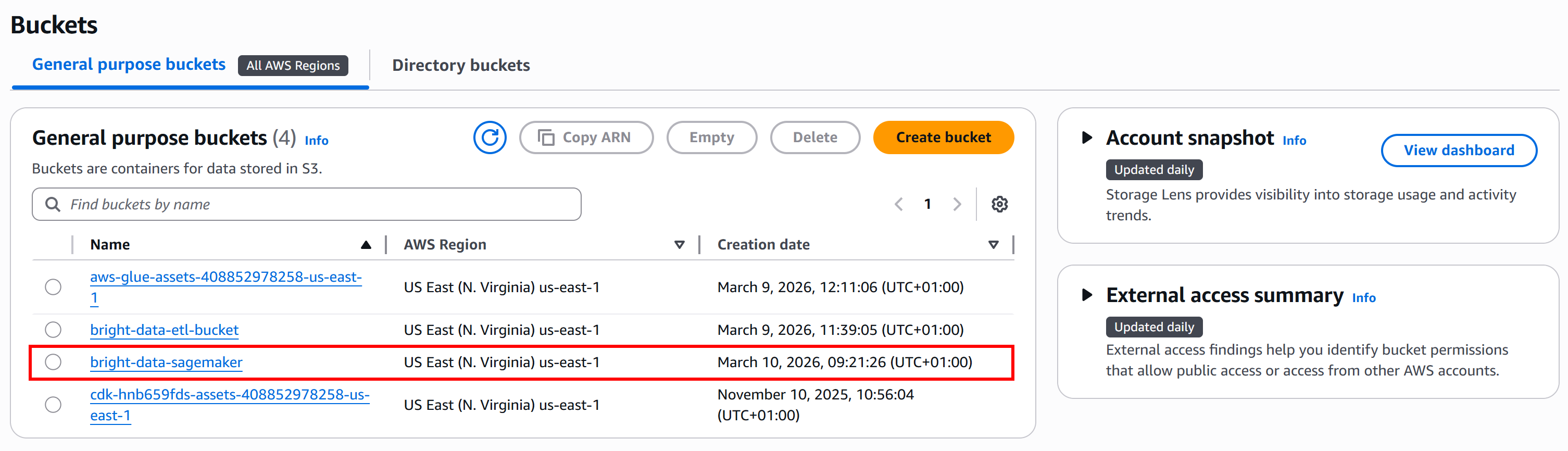
1단계: Bright Data에서 입력 데이터셋 가져오기
첫 번째 단계는 입력 웹 데이터를 확보하는 것입니다. 피처 엔지니어링에는 크고 고품질의 데이터셋으로 시작하는 것이 가장 좋습니다. 이 예시에서는 앞서 계획한 대로 Glassdoor 데이터셋에 초점을 맞춰 Bright Data의 방대한 데이터셋 컬렉션을 활용합니다.
대안: 새 데이터를 수집하려면 Bright Data 웹 스크래핑 API 중 하나를 사용하여 신선하고 구조화된 ML 준비 데이터셋을 수집할 수 있습니다. 이 API는 Amazon S3 계정으로 직접 데이터를 전송하는 전달 옵션을 제공하여 SageMaker와의 통합을 원활하게 합니다.
Bright Data 계정이 없다면 먼저 계정을 만드세요. 이미 계정이 있다면 로그인하세요.
Bright Data 제어판에서 “Web Datasets” 메뉴 옵션을 선택합니다. “Dataset marketplace” 탭으로 이동하여 사용 가능한 데이터셋을 탐색합니다:
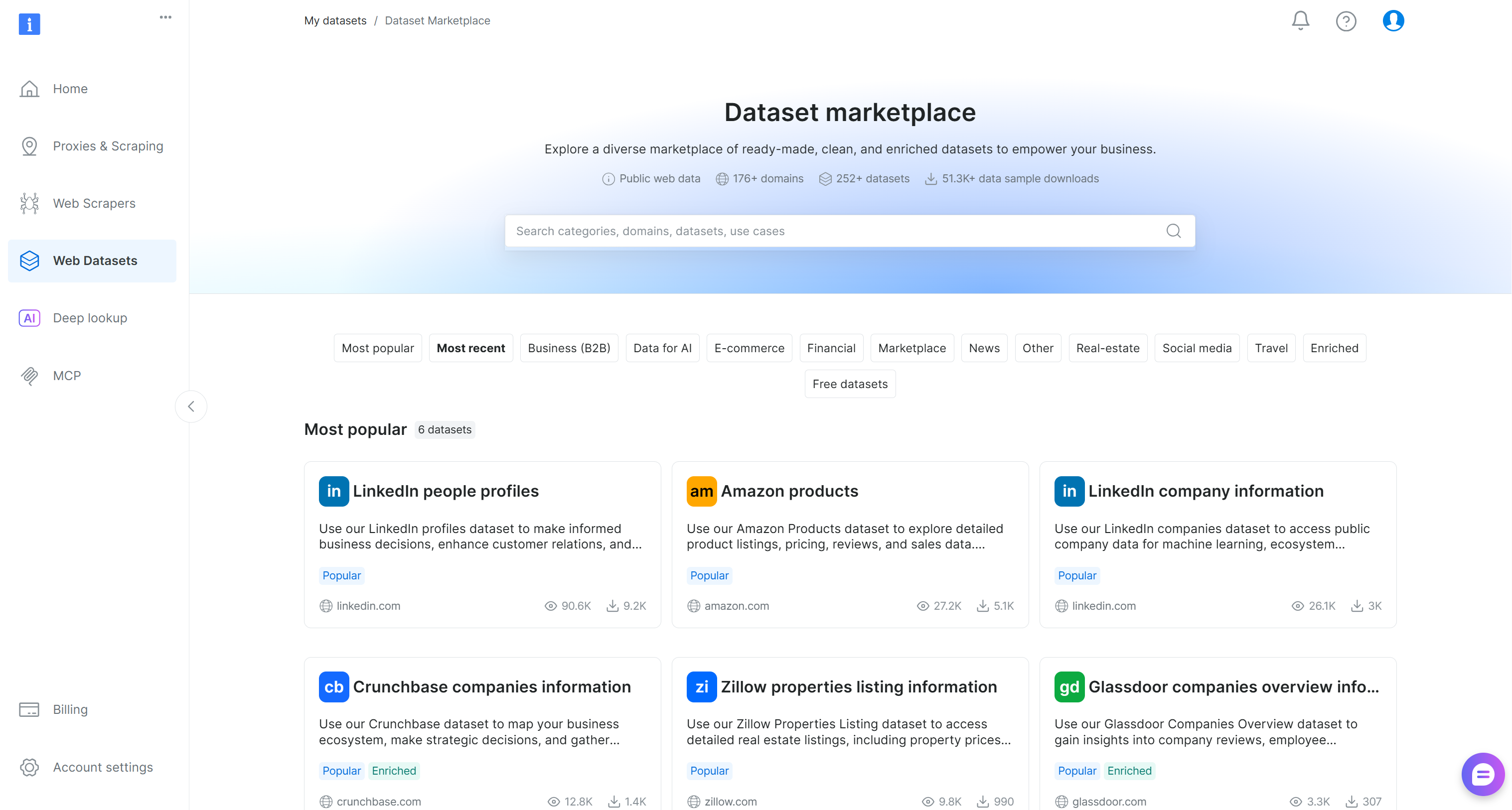
여기서 155개 이상의 도메인에서 수십억 개의 레코드를 포함한 200개 이상의 스크래핑된 데이터셋을 탐색할 수 있습니다.
이제 “Glassdoor companies overview information” 데이터셋을 찾아 해당 페이지를 열어봅니다:
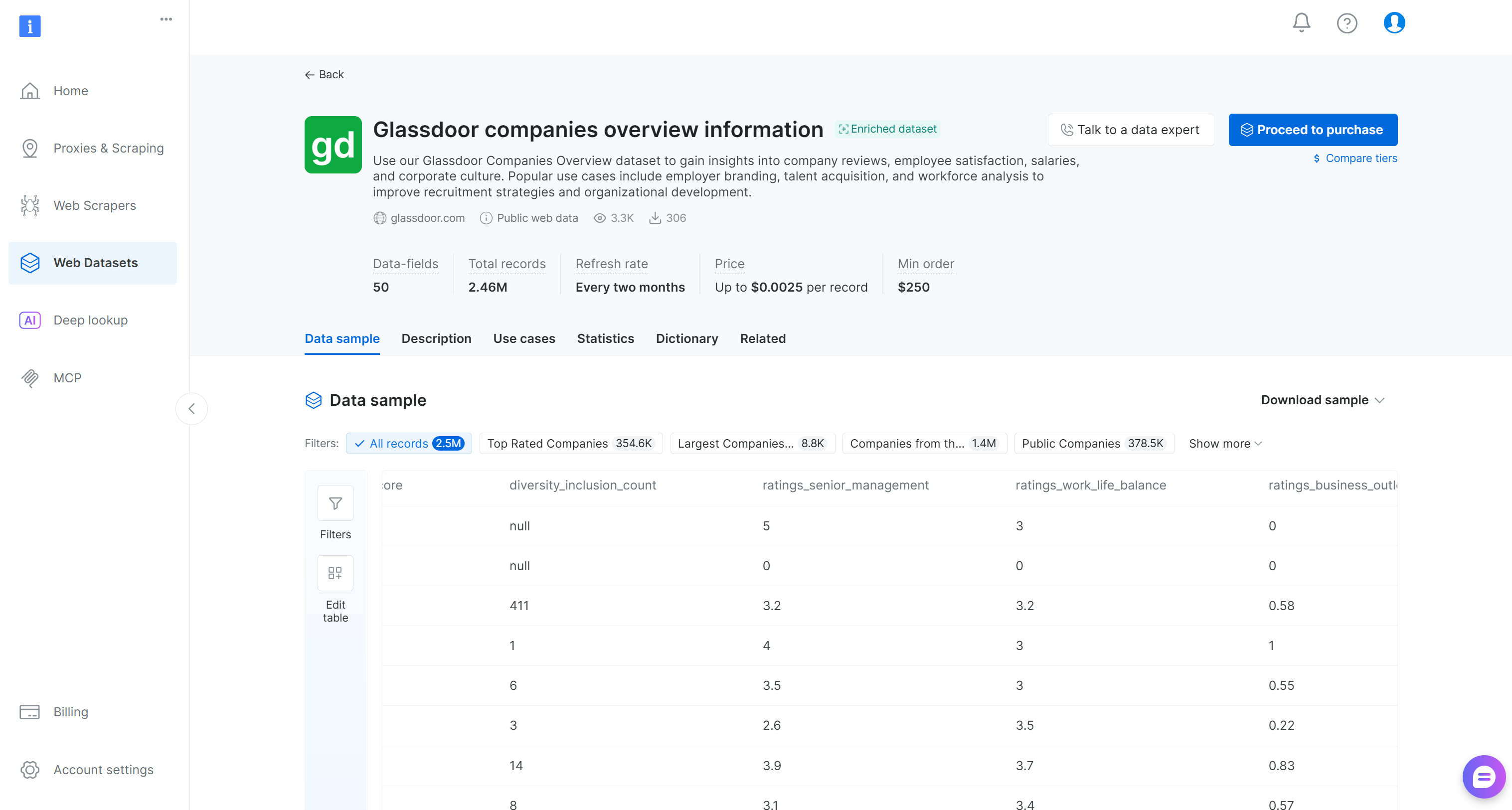
이 데이터셋에는 회사 리뷰, 직원 만족도 점수, 급여, 기업 문화 정보가 포함되어 있습니다. 주요 활용 사례로는 고용주 브랜딩, 인재 확보, 인력 분석 등이 있습니다. 50개의 데이터 필드와 함께 246만 개 이상의 항목을 포함합니다.
필터링된 서브셋을 구매하거나 무료 샘플을 다운로드할 수 있습니다. 프로덕션 환경에서는 입력 데이터셋이 클수록 피처 엔지니어링 결과가 더 신뢰할 수 있습니다.
이 튜토리얼은 단순한 예시이므로 무료 샘플을 사용합니다. 샘플을 받으려면 “Download sample” 드롭다운을 클릭하고 “Download as JSON” 옵션을 선택합니다:
Glassdoor companies overview information.json이라는 샘플 파일을 받게 됩니다. 이 파일에는 각각 50개의 필드를 가진 1,000개의 회사 레코드가 포함되어 있습니다.
파일 이름을 glassdoor-companies.json으로 변경하고 S3 버킷에 업로드할 준비를 합니다. 이 파일은 SageMaker 피처 엔지니어링 노트북의 입력으로 사용됩니다. 잘 하셨습니다!
2단계: S3 버킷에 웹 데이터 업로드
Amazon S3 버킷 페이지로 이동하여 “Upload” 버튼을 클릭하고 glassdoor-companies.json 파일을 추가합니다. 업로드가 완료되면 버킷에 다음과 같이 표시됩니다:

또는 다양한 Amazon S3 클라이언트 중 하나를 사용하여 파일을 업로드할 수 있습니다.
참고: Bright Data 웹 스크래핑 API를 사용하면 스크래핑된 데이터를 Amazon S3로 직접 전송할 수 있습니다.
훌륭합니다! 이제 Amazon SageMaker에서 피처 엔지니어링을 위한 입력 웹 데이터가 준비되었습니다.
3단계: Amazon SageMaker 시작하기
AWS 콘솔에 로그인하고 “SageMaker”를 검색합니다. 서비스를 선택하여 메인 페이지를 엽니다:
“Get started” 버튼을 클릭하여 Amazon SageMaker 사용을 시작합니다.
설정 페이지에서 자동 IAM 설정을 위해 “Auto-create a new role with admin permissions”이 선택되어 있는지 확인합니다. “Set up” 버튼을 눌러 계속 진행합니다:
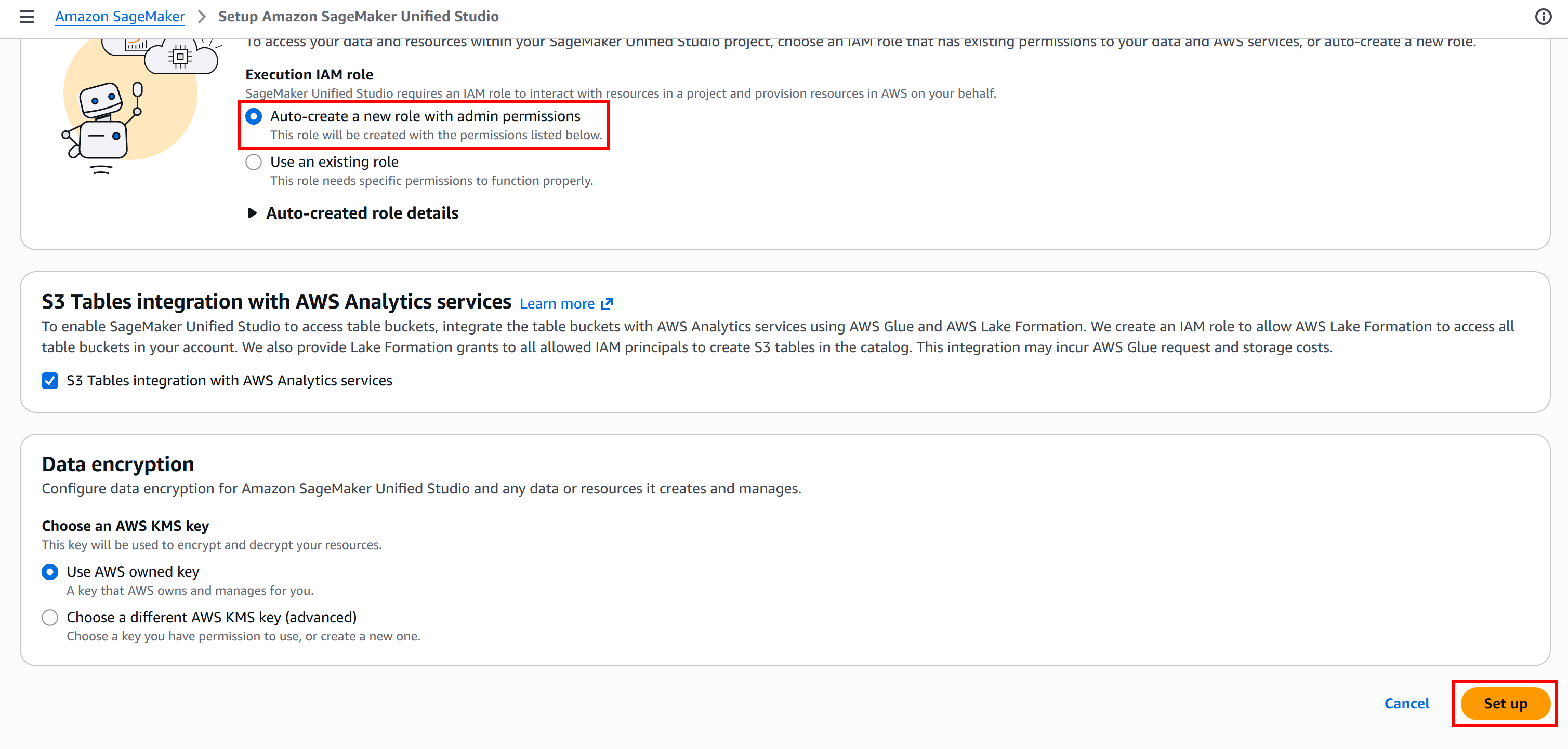
초기화 과정에는 몇 분이 걸릴 수 있으니 잠시 기다려 주세요. 진행 중에는 “Setting up Amazon SageMaker Unified Studio…” 메시지가 표시됩니다.
설정이 완료되면 다음 페이지가 나타납니다:
“Open”을 클릭하여 Amazon SageMaker Unified Studio를 실행합니다:
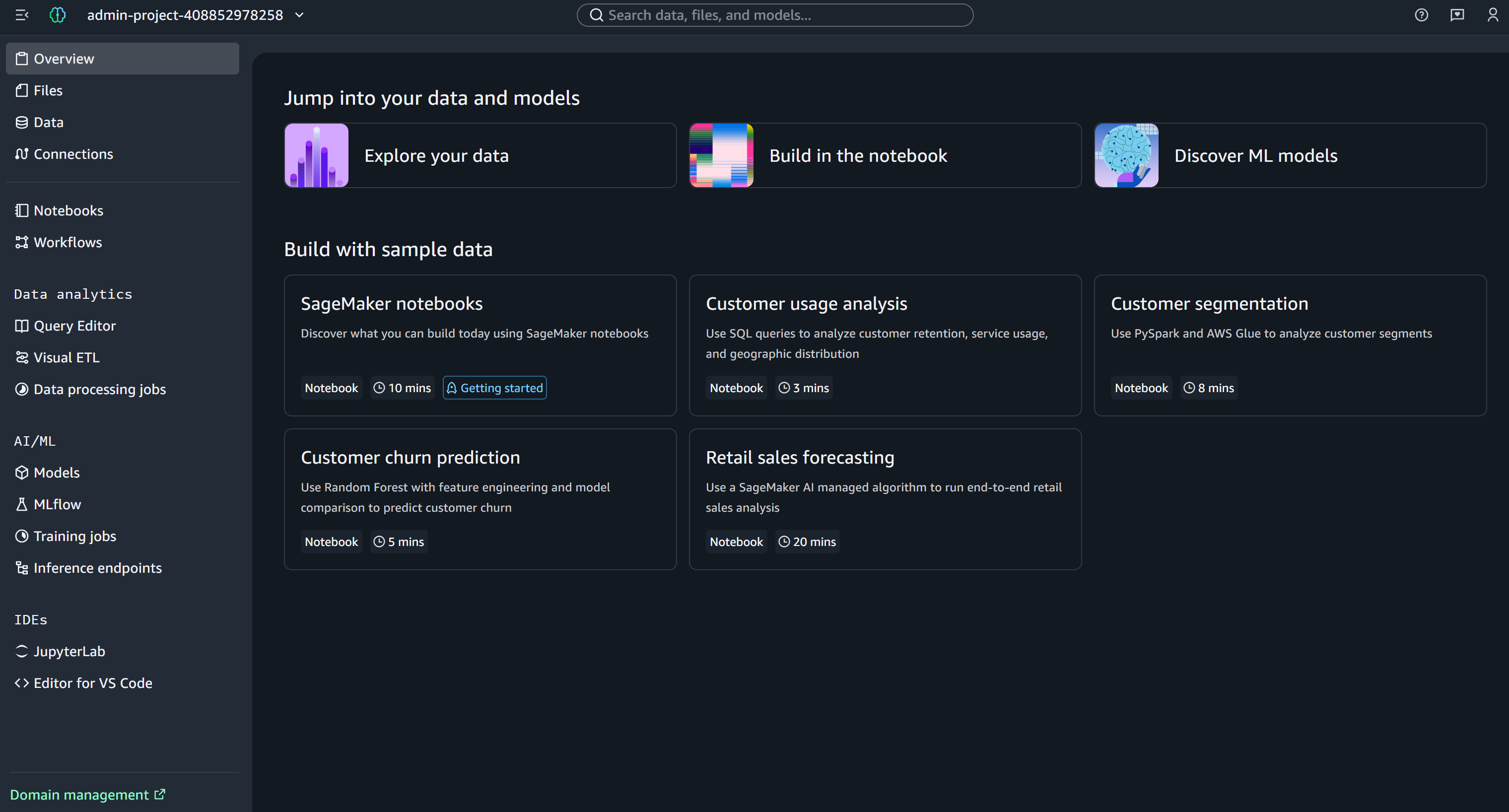
여기서 노트북 개발 및 실행을 포함한 SageMaker 환경을 탐색하고 관리할 수 있습니다. 멋지네요!
4단계: 새 노트북 만들기
Amazon SageMaker Unified Studio에서 “Build in the notebook” 버튼을 클릭하여 새 노트북을 만듭니다:

새로운 SageMaker 노트북은 다음과 같이 표시됩니다:
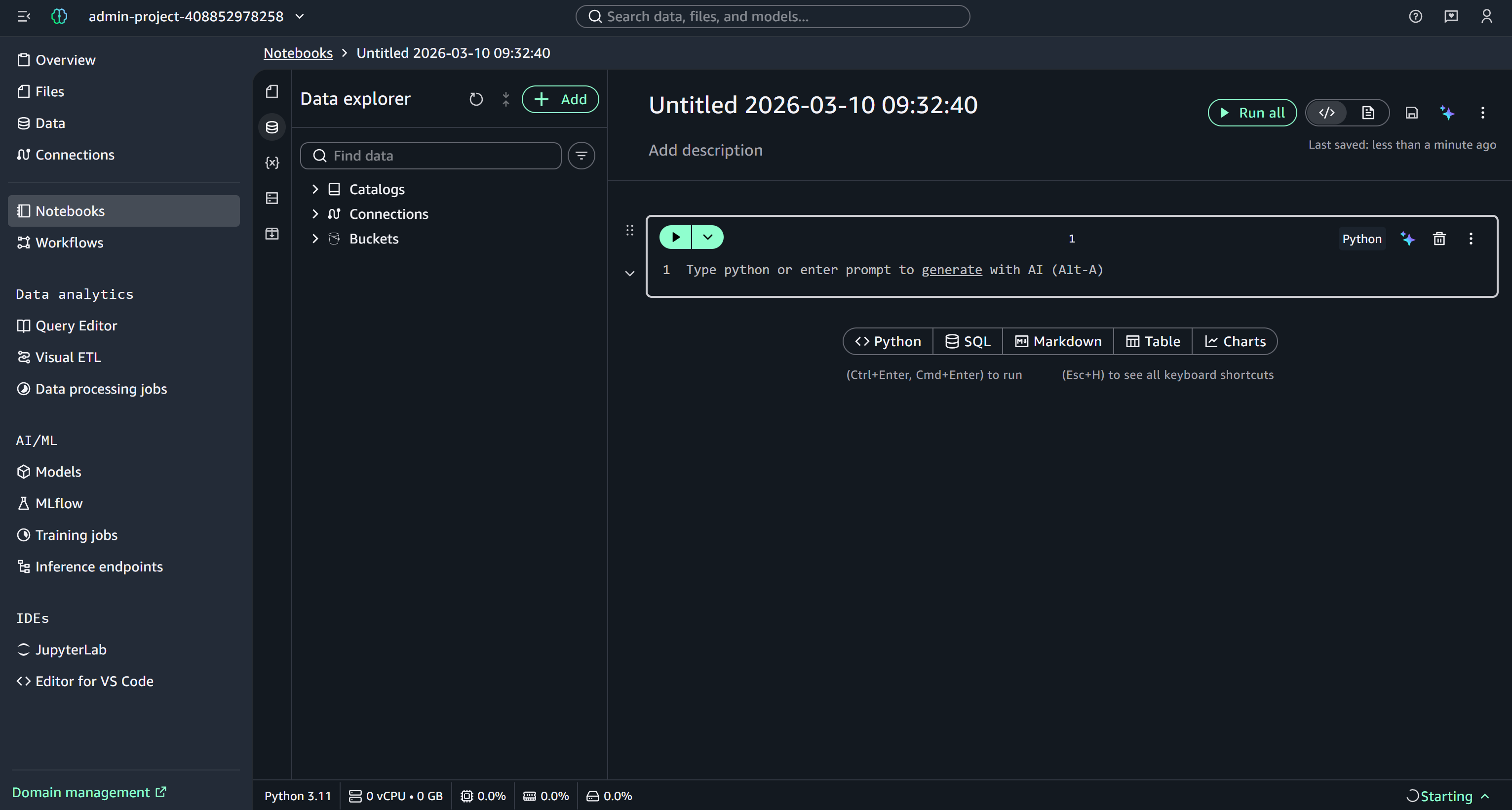
노트북에 “Company Data Feature Engineering”과 같이 설명적인 이름을 지정하는 것을 고려해 보세요.
Amazon SageMaker 노트북은 Jupyter Notebook을 실행하는 관리형 머신러닝 컴퓨팅 인스턴스입니다. 데이터 준비 및 처리, 학습 코드 작성 및 테스트, SageMaker 호스팅에 모델 배포, 모델 검증에 필요한 모든 것을 제공합니다.
훌륭합니다! 이제 SageMaker 피처 엔지니어링 로직을 구현하기 위한 모든 구성 요소가 준비되었습니다.
5단계: 입력 웹 데이터 로드
첫 번째 단계는 Bright Data의 입력 Glassdoor 웹 데이터를 SageMaker 노트북에 로드하는 것입니다.
왼쪽의 “Data Explorer” 패널에서 “Buckets” 드롭다운을 펼칩니다. S3 버킷을 찾아 glassdoor-companies.json 파일을 찾습니다. 파일 옆의 버거 메뉴를 클릭하고 “Read as dataframe” 옵션을 선택합니다:
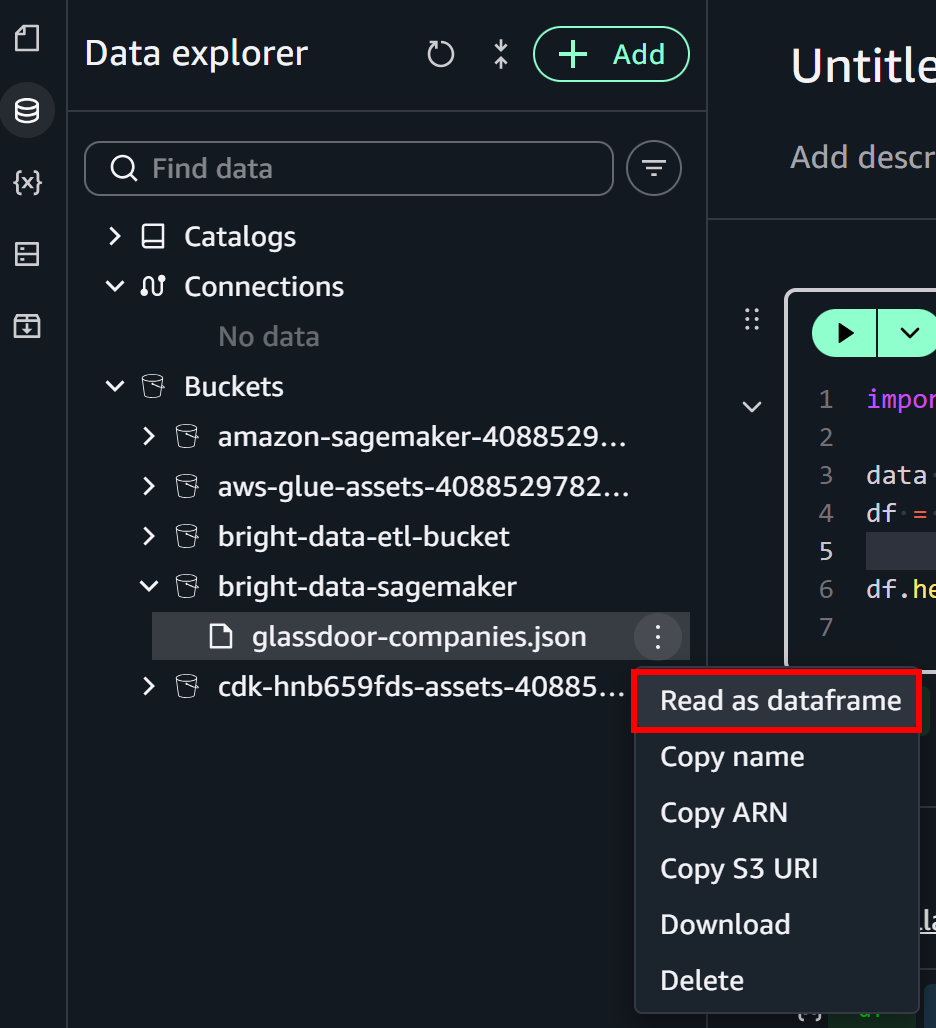
이렇게 하면 초기 노트북 셀에 S3에서 파일을 로드하는 로직이 자동으로 채워집니다:
import pandas as pd
data = pd.read_json("s3://bright-data-sagemaker/glassdoor-companies.json")참고: bright-data-sagemaker를 자신의 S3 버킷 이름으로 교체하세요.
첫 번째 셀의 데이터 가져오기 로직을 다음과 같이 완성합니다:
import pandas as pd
# S3 버킷에서 입력 데이터 로드
data = pd.read_json("s3://bright-data-sagemaker/glassdoor-companies.json")
# 구조화된 JSON 필드 정규화
df = pd.json_normalize(data.to_dict(orient="records"))
# 처음 10줄 출력
df.head(10)이 코드 스니펫은 Python에서 분석하기 위해 S3 버킷의 JSON 데이터셋을 로드하고 전처리합니다. pd.read_json()으로 파일을 읽은 다음, pd.json_normalize()로 중첩된 JSON 필드를 표 형식의 DataFrame으로 평탄화합니다. 마지막으로 df.head(10)은 처음 10개 행을 표시하여 구조화된 데이터를 빠르게 미리 볼 수 있게 합니다.
“▶” 버튼을 눌러 셀을 실행합니다. 다음과 같은 미리보기가 표시됩니다:
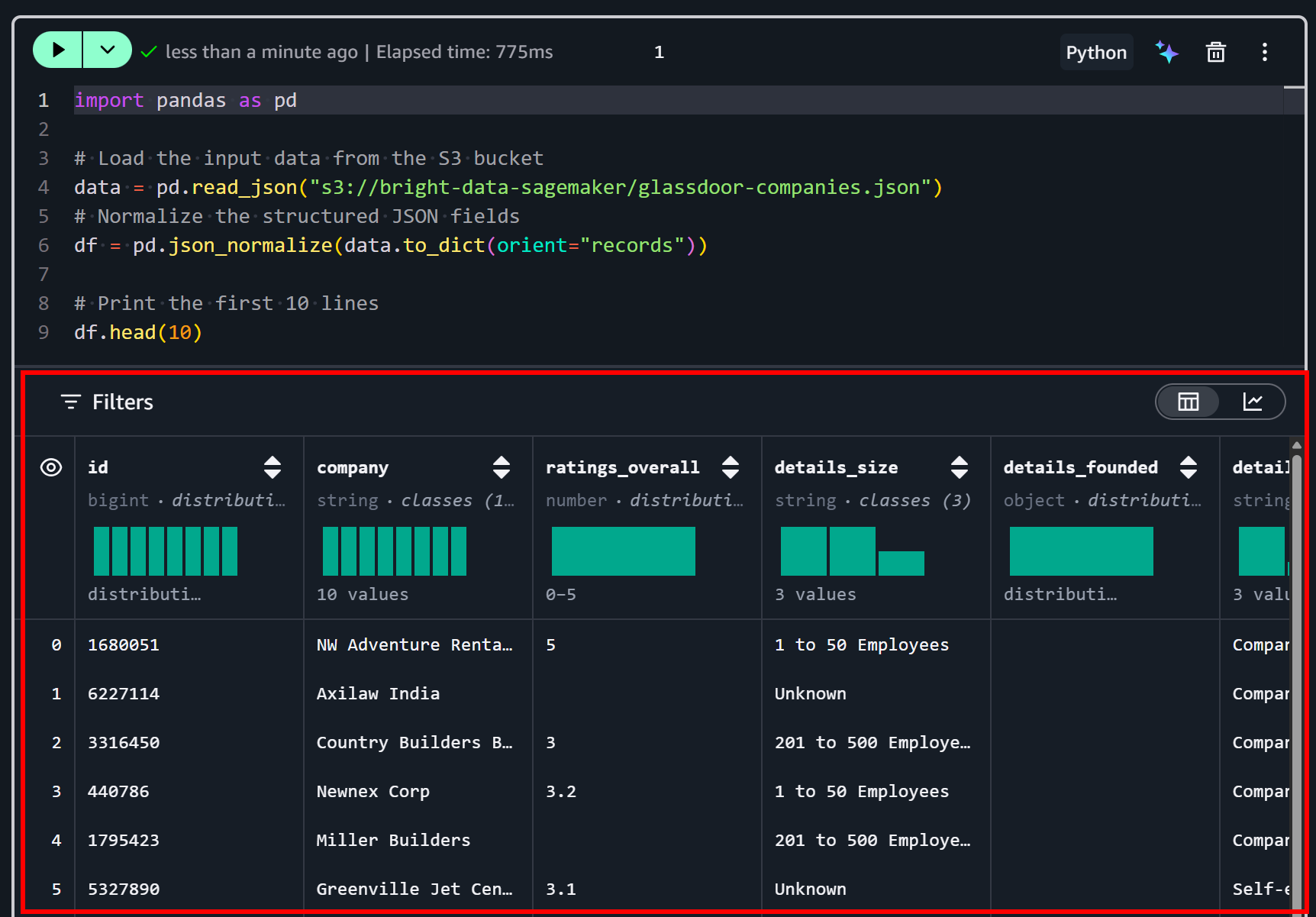
보시다시피 데이터셋이 올바르게 로드되었습니다. 이것은 Bright Data 데이터셋 페이지의 “Dictionary” 탭에 나열된 대로 50개의 데이터 필드를 포함합니다:
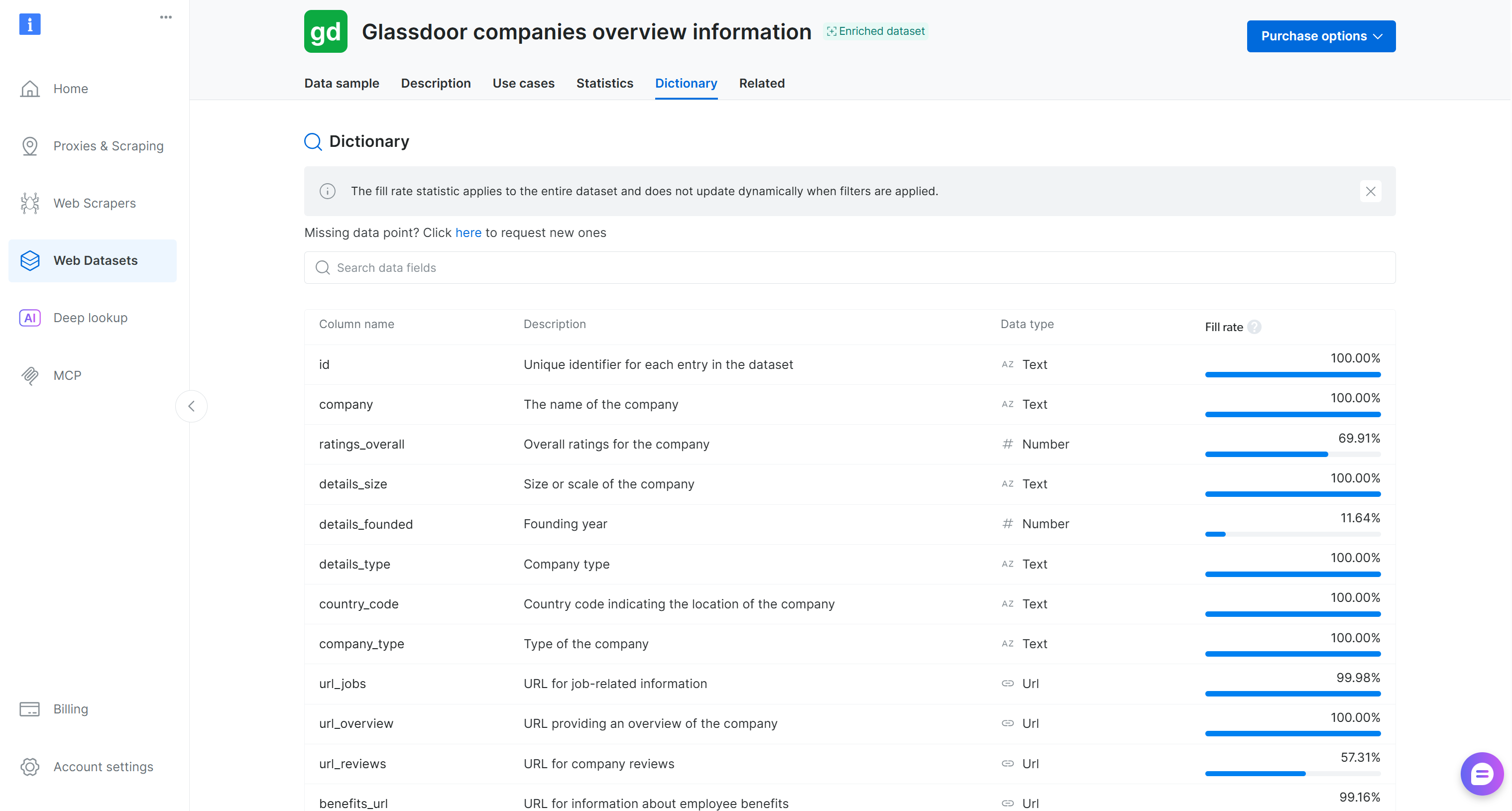
피처 엔지니어링을 위한 입력 웹 데이터가 준비되었습니다. 훌륭합니다!
6단계: 입력 데이터 전처리
데이터셋을 노트북으로 가져왔으니, 다음 단계는 피처 엔지니어링을 위해 데이터를 정제하고 준비하는 것입니다.
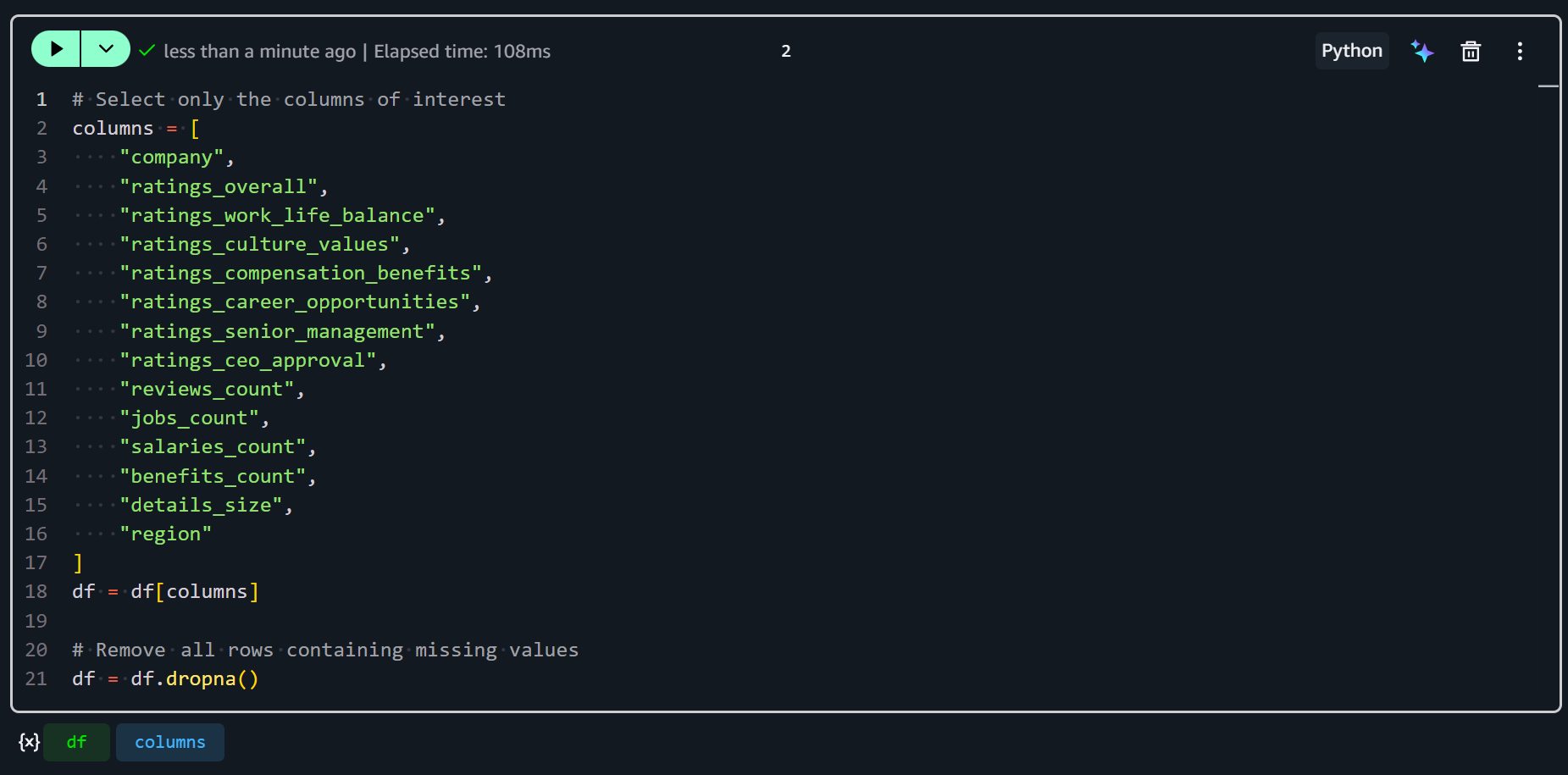
SageMaker 노트북에 새 셀을 추가하고 다음 코드를 입력합니다:
# 관심 있는 열만 선택
columns = [
"company",
"ratings_overall",
"ratings_work_life_balance",
"ratings_culture_values",
"ratings_compensation_benefits",
"ratings_career_opportunities",
"ratings_senior_management",
"ratings_ceo_approval",
"reviews_count",
"jobs_count",
"salaries_count",
"benefits_count",
"details_size",
"region"
]
df = df[columns]
# 누락된 값이 있는 모든 행 제거
df = df.dropna()이 스니펫은 관심 있는 열만 선택하여 데이터셋을 관련 지표와 식별자에 집중시킵니다. 그런 다음 df.dropna()를 사용하여 선택된 열에 누락된 값이 있는 행을 제거합니다. 이를 통해 피처 엔지니어링을 위한 데이터가 깨끗하고 일관성 있게 유지됩니다.
새 셀은 다음과 같이 표시됩니다:
좋습니다! 이제 입력 데이터셋이 SageMaker에서 피처 엔지니어링을 위한 준비가 되었습니다.
7단계: 피처 정의
이제 머신러닝에 사용할 피처를 정의할 시간입니다. 피처는 원시 데이터를 요약하거나 변환하여 기저 패턴을 더 잘 나타내는 의미 있는 지표로 만든 파생 열임을 기억하세요.
이 예시에서는 회사 문화, 보상, 인기도, 성장 활동을 포착하는 피처를 추가합니다.
먼저, culture_score 피처는 여러 관련 평점을 회사의 전반적인 문화 환경을 나타내는 단일 지표로 결합합니다:
df["culture_score"] = (
df["ratings_culture_values"] +
df["ratings_work_life_balance"] +
df["ratings_senior_management"]
) / 3세 가지 평점 열을 평균합니다:
ratings_culture_values: 회사가 명시된 가치를 얼마나 잘 구현하는지를 설명합니다.ratings_work_life_balance: 직원들의 워크라이프 밸런스 인식을 평가합니다.ratings_senior_management: 리더십과 경영진에 대한 인식을 추적합니다.
세 평점을 합산하여 3으로 나누면 정규화된 점수가 생성됩니다. 결과 점수는 원래 평점과 동일한 스케일을 유지하며 문화의 각 측면에 동일한 가중치를 부여합니다.
두 번째로, compensation_score 피처는 급여와 커리어 성장에 대한 직원 만족도의 결합된 시각을 나타냅니다:
df["compensation_score"] = (
df["ratings_compensation_benefits"] +
df["ratings_career_opportunities"]
) / 2다음이 포함됩니다:
ratings_compensation_benefits: 급여와 복리후생에 대한 직원 만족도를 표시합니다.ratings_career_opportunities: 커리어 발전 기회에 대한 직원 만족도를 추적합니다.
평균을 취함으로써 피처는 두 측면을 균등하게 균형을 맞추기 위해 다른 점수와 일관되게 스케일링됩니다.
세 번째로, review_popularity 피처는 Glassdoor에서 회사가 얼마나 자주 리뷰되는지를 측정합니다:
df["review_popularity"] = df["reviews_count"].apply(lambda x: x ** 0.5)리뷰 수에 제곱근 변환을 적용하여 구합니다. 왜 제곱근일까요? 리뷰 수는 종종 크게 치우쳐 있기 때문입니다(일부 회사는 수천 개의 리뷰를 가지고 있고, 많은 회사는 매우 적습니다). 제곱근을 취하면 극단적으로 높은 값의 영향을 줄이고 분산을 안정화하여 처리와 분석을 더 쉽게 만듭니다.
네 번째로, hiring_intensity 피처는 리뷰 활동 대비 회사가 얼마나 활발히 채용하는지를 추정합니다:
df["hiring_intensity"] = df["jobs_count"] / (df["reviews_count"] + 1)공개 채용 공고 수(jobs_count)를 리뷰 수 + 1로 나누어 계산합니다(리뷰가 없는 회사의 0으로 나누기 방지).
높은 값은 직원들이 리뷰를 남기는 것에 비해 활발히 채용하는 회사를 나타냅니다. 이는 성장 또는 확장 활동의 대리 지표가 될 수 있습니다.
모두 합치면 다음과 같습니다:
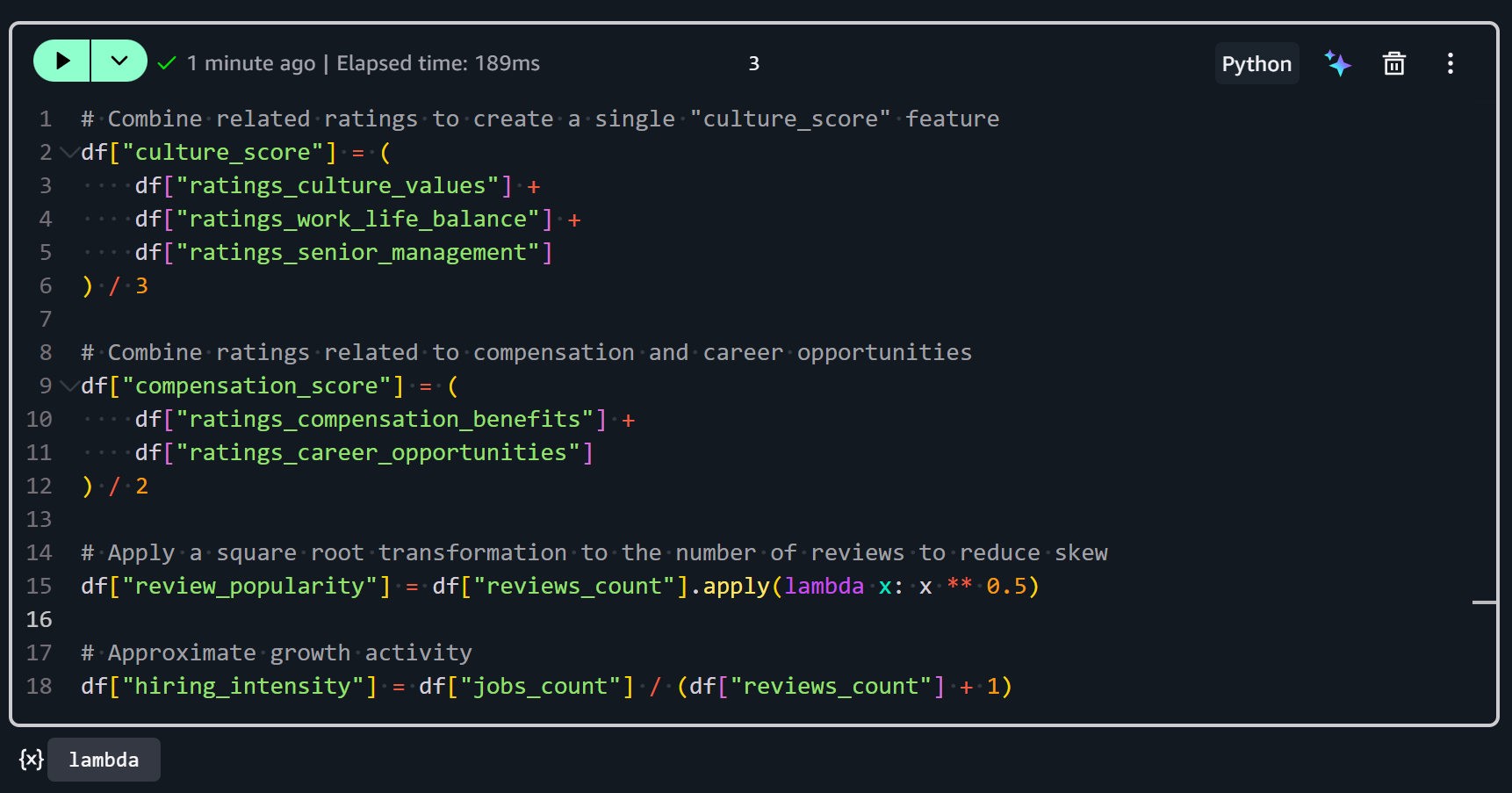
이러한 변환을 실행한 후, 데이터셋에는 원시 평점과 수치를 더 유익한 지표로 결합한 파생 피처가 포함됩니다. 훌륭합니다!
8단계: 타겟 변수 설정
피처가 정의되었으니, 다음 단계는 머신러닝 작업을 위한 타겟 변수를 설정하는 것입니다. 타겟 변수는 모델이 예측하려는 결과를 나타냅니다. 이 경우 회사의 직원 만족도가 높은지 여부를 예측합니다.
타겟을 설정하려면 노트북에 새 셀을 추가하고 다음 코드를 입력합니다:
# 타겟 변수 정의
df["high_satisfaction"] = (df["ratings_overall"] >= 4).astype(int)이는 전체 평점이 4 이상인 회사를 True(높은 만족도)로, 그 외는 False(낮은 만족도)로 표시하는 불리언 필드를 만듭니다.

많은 머신러닝 알고리즘은 숫자형 타겟 변수를 필요로 합니다. 만족도 평점을 이진 0/1 불리언 레이블로 변환하면 분류 작업을 위한 모델을 학습시킬 수 있습니다. 이를 통해 만든 피처를 기반으로 회사가 높은 직원 만족도를 가질 가능성이 있는지 예측할 수 있습니다. 다음 단계에서 이를 달성해 보세요!
9단계: 만족도 예측을 위한 ML 모델 학습
피처와 타겟 변수가 정의되었으니, 이제 높은 직원 만족도를 예측하는 머신러닝 모델을 학습시킬 수 있습니다.
선택된 ML 모델은 XGBoost로, 표 형식 데이터와 분류 작업에서 탁월한 성능을 발휘하는 그래디언트 부스팅 알고리즘입니다. 수치 및 파생 피처의 혼합을 기반으로 high_satisfaction 변수를 예측하는 데 적합합니다.
노트북에 새 셀을 추가하고 모델 학습 로직을 추가합니다:
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
# 예측에 사용할 피처 정의
features = [
"culture_score",
"compensation_score",
"ratings_ceo_approval",
"review_popularity",
"hiring_intensity"
]
# 입력 피처(X)와 타겟 변수(y) 분리
X = df[features]
y = df["high_satisfaction"]
# 데이터를 학습 세트와 테스트 세트로 분할
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 합리적인 하이퍼파라미터로 XGBoost 분류기 초기화
model = XGBClassifier(
n_estimators=500,
max_depth=5,
learning_rate=0.05,
eval_metric="logloss"
)
# 학습 데이터로 모델 학습
model.fit(X_train, y_train)위 스니펫은 높은 직원 만족도를 예측하기 위한 머신러닝 모델을 준비하고 학습시킵니다. 엔지니어링된 피처를 선택하고 데이터를 학습 세트와 테스트 세트로 분할합니다. 그런 다음 조정된 하이퍼파라미터로 XGBoost 분류기를 초기화합니다. 마지막으로 학습 데이터에 모델을 적합시킵니다.
셀을 실행하여 실제로 예측 모델을 학습시킵니다:
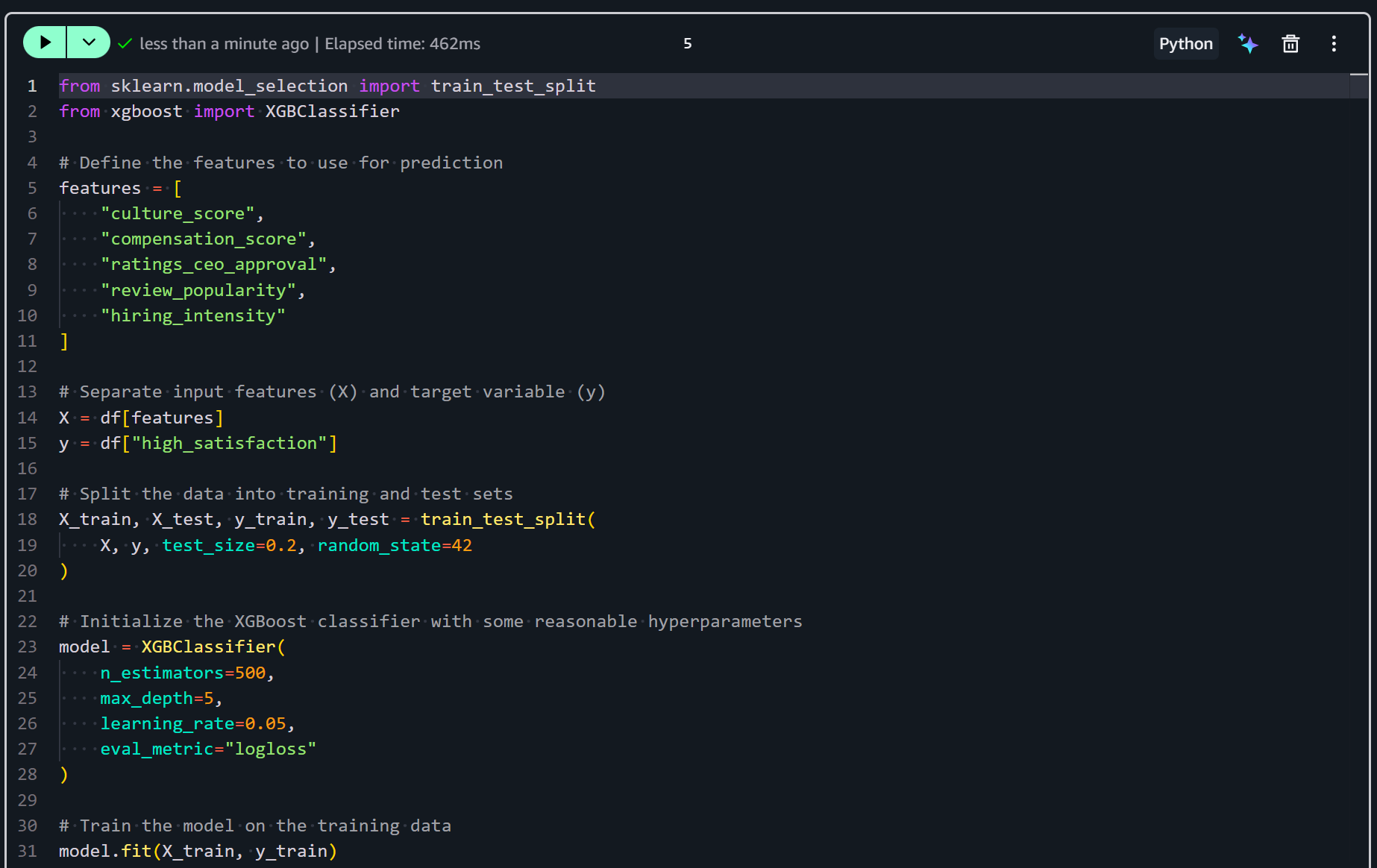
이 단계 후, XGBoost 분류기가 학습되어 평가 및 예측을 위한 준비가 됩니다. 다음 단계는 성능을 평가하는 것입니다!
10단계: 모델 성능 평가
마지막 단계는 모델이 미지의 데이터에서 얼마나 잘 수행하는지 평가하는 것입니다. 노트북에 새 셀을 추가하고 다음 코드를 입력합니다:
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix, roc_auc_score, accuracy_score
# 학습된 모델을 사용하여 테스트 세트에서 레이블 예측
pred = model.predict(X_test)
print(classification_report(y_test, pred))
# 혼동 행렬
cm = confusion_matrix(y_test, pred)
print("\nConfusion Matrix:\n", cm)
# ROC-AUC 점수
roc = roc_auc_score(y_test, model.predict_proba(X_test)[:,1])
print("\nROC-AUC:", roc)“Run All” 버튼을 눌러 모든 단계를 실행하고 지표를 계산합니다:

마지막 셀이 실행된 후 다음과 유사한 출력이 표시됩니다:
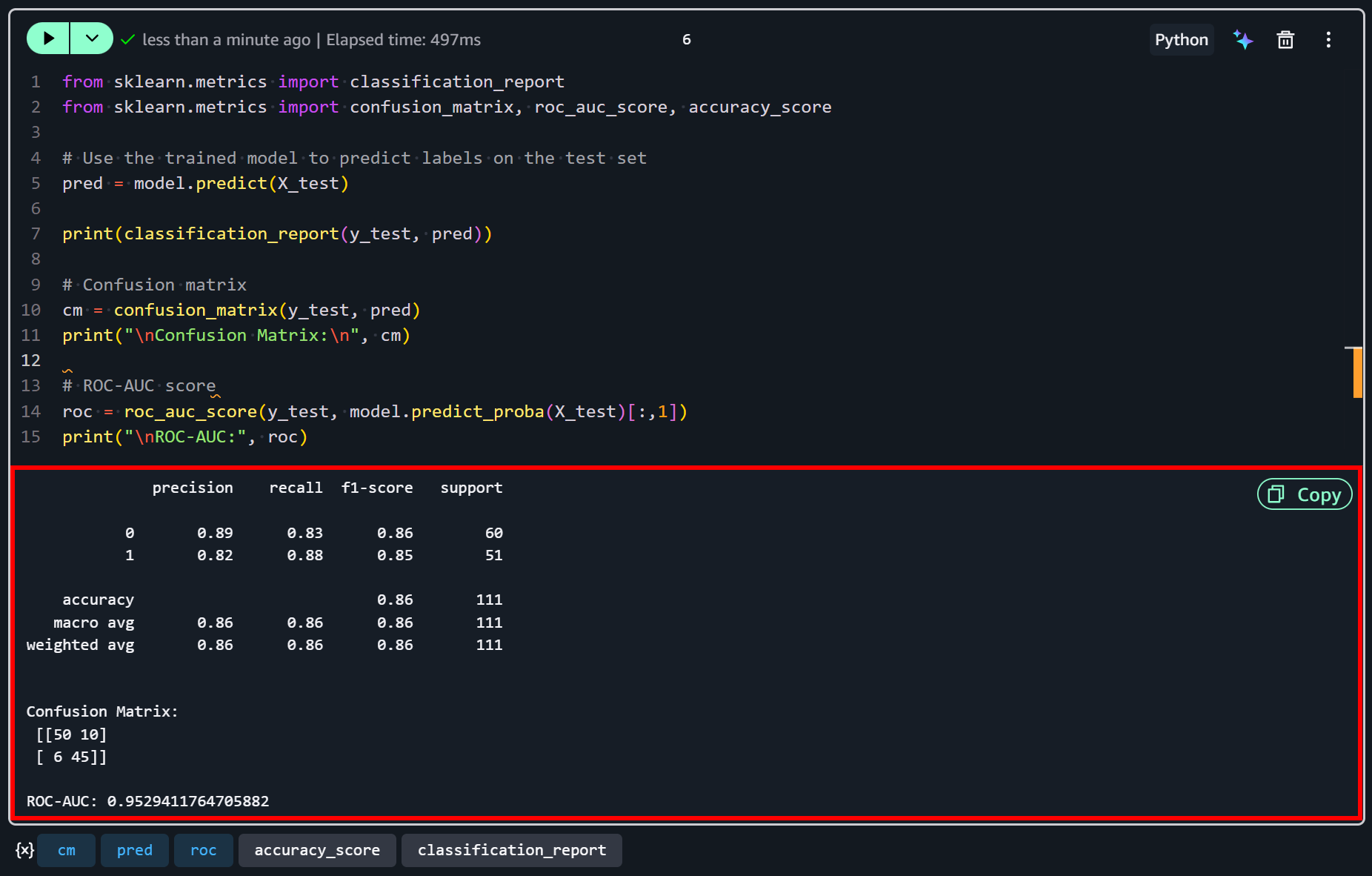
이 결과는 모델이 이 예시 데이터셋에서 합리적으로 잘 수행됨을 보여줍니다. 86%의 정확도와 0.95의 ROC-AUC로, 높은 만족도와 낮은 만족도 회사를 구별하는 강력한 능력을 보여줍니다.
두 클래스 모두 균형 잡힌 정밀도와 재현율을 보여주며, 이는 모델이 높은 만족도(1)와 낮은 만족도(0) 회사를 올바르게 식별하는 데 유사하게 효과적임을 의미합니다.
그러나 일부 오분류가 여전히 존재합니다… 혼동 행렬에서 볼 수 있듯이, 10개의 낮은 만족도 회사가 높은 만족도로 잘못 예측되었고, 6개의 높은 만족도 회사가 낮은 만족도로 잘못 예측되었습니다.
이는 모델이 데이터의 주요 패턴을 포착하지만 완벽하지 않으며, 추가 피처(또는 더 많은 데이터)로 더 개선될 수 있음을 나타냅니다.
완성입니다! Bright Data의 입력 웹 데이터셋 덕분에 Amazon SageMaker에서 피처 엔지니어링을 수행하고 예측 모델을 학습시킬 수 있었습니다. 이것은 Bright Data가 제공하는 다양한 구조화된 웹 데이터셋을 통해 탐색할 수 있는 많은 활용 사례 중 하나입니다.
다음 단계
피처 엔지니어링을 통해 파생된 필드를 사용하여 높은 직원 만족도를 예측하는 현재 모델은 괜찮은 결과를 달성합니다. 그러나 개선의 여지가 있습니다. 성능을 향상시키는 몇 가지 방법이 있습니다:
- 더 많은 파생 피처 생성: 기존 평점을 새로운 방식으로 결합합니다. 예를 들어,
ratings_senior_management와ratings_ceo_approval에서leadership_score를 계산하거나, 급여와 워크라이프 밸런스 간의 트레이드오프를 포착하는work_life_compensation_ratio를 만들 수 있습니다. 숨겨진 패턴을 드러낼 수 있는 비율, 차이 또는 피처 간의 상호작용을 탐색해 보세요. - 왜곡된 분포 변환:
reviews_count나jobs_count와 같은 피처는 종종 왜곡되어 있습니다. 이미 제곱근 변환을 적용했지만, 분산을 더 안정화하기 위해 로그 또는 Box-Cox 변환을 고려해 보세요. - 범주형 피처 통합: 현재
region과details_size는 숫자형이 아닙니다. 원-핫 인코딩이나 타겟 인코딩으로 인코딩하면 추가적인 예측 신호를 제공할 수 있습니다. - 여러 데이터 포인트 집계: 과거 리뷰나 채용 트렌드를 얻을 수 있다면, 시간에 따른
jobs_count평균 성장이나culture_score의 변화와 같은 피처를 생성하면 역동적인 회사 행동을 포착할 수 있습니다. - 피처 선택 및 중요도 분석: 학습 후 XGBoost 피처 중요도를 검사하여 어떤 피처가 예측에 가장 많이 기여하는지 파악합니다. 가장 예측력 있는 피처에서 영감을 얻어 새로운 피처를 엔지니어링할 수 있습니다.
- 외부 데이터 보강: 다른 Bright Data 데이터셋을 병합하여 더 풍부하고 맥락적인 피처를 만드는 것을 고려해 보세요.
결론
이 튜토리얼에서 Amazon SageMaker가 머신러닝 시나리오에 가져오는 가치를 확인했습니다. 특히 스크래핑된 데이터셋이 피처 엔지니어링의 훌륭한 소스인 이유와 예측 ML 모델 학습에 어떻게 적용될 수 있는지를 배웠습니다.
시연된 바와 같이, Bright Data는 수백 개의 도메인과 수십억 개의 웹 데이터 레코드를 포괄하는 풍부한 데이터셋 마켓플레이스를 제공합니다. 이 데이터셋은 웹 스크래핑을 통해 지속적으로 업데이트되어 머신러닝과 AI 워크플로를 지원하기에 이상적입니다. 중요하게도, 이 가이드에서 보여주듯 Amazon SageMaker와 원활하게 통합됩니다.
오늘 무료 Bright Data 계정을 만들고 웹 데이터 솔루션 탐색을 시작하세요!