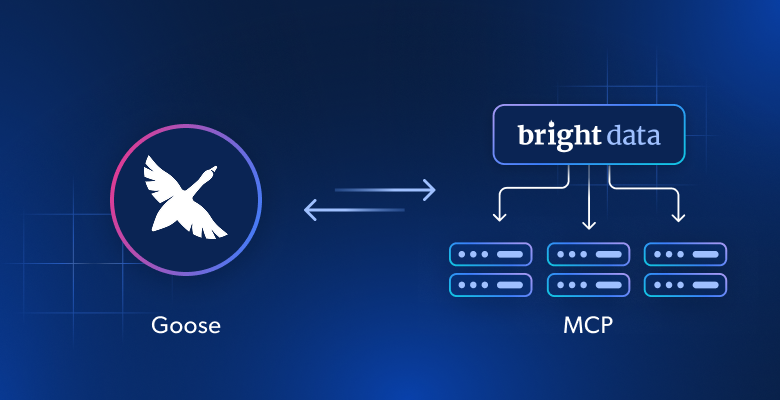
이 글에서 배울 내용:
- Oracle Generative AI 에이전트 서비스가 무엇인지, 그리고 어떤 기능을 제공하는지.
- 엔터프라이즈 AI 에이전트가 실시간 웹 데이터를 통한 맥락적 시장 인사이트에 접근해야 하는 이유, 그리고 Bright Data가 이를 가능하게 하는 방법.
- Bright Data 기반의 커스텀 도구를 사용하여 웹 접근 기능을 갖춘 Oracle Generative AI 에이전트를 구축하는 방법.
바로 시작해 봅시다!
Oracle Generative AI 에이전트 서비스란?
Oracle Generative AI 에이전트는 AI 에이전트를 구축하고 배포하기 위한 완전 관리형 OCI(Oracle Cloud Infrastructure) 서비스입니다. 이 에이전트는 자연어를 이해하고, 대화 맥락을 유지하며, 도구를 조율하고, 엔터프라이즈 데이터에 접근하며, 복잡한 워크플로를 자동화할 수 있습니다.
주요 활용 사례로는 고객 지원, 기술 문제 해결, 법률 및 금융 조사, 콘텐츠 생성, 교육 튜터링, 공급망 분석, 부동산 인사이트, 여행 지원 등이 있습니다.
주요 기능
Oracle Generative AI 에이전트가 제공하는 핵심 기능은 다음과 같습니다:
- 간편한 에이전트 설정: 인프라 관리 없이 가이드 기반의 완전 관리형 설정 프로세스를 통해 AI 에이전트를 생성하고 배포합니다.
- 멀티턴 대화: 여러 메시지에 걸쳐 맥락 인식 상호작용으로 자연스럽고 인간적인 대화를 지원합니다.
- 맥락 유지: 이전 대화 내용을 기억하여 개인화되고 일관성 있으며 관련성 높은 응답을 제공합니다.
- 커스텀 지침: 설정 가능한 지침을 통해 에이전트의 동작, 어조, 목표 및 라우팅 로직을 정의합니다.
- 내장 가드레일: 프롬프트 인젝션 공격 방어, 콘텐츠 조정, 민감한 PII 데이터 감지를 지원합니다.
- 휴먼 인더 루프 지원: 민감한 작업 및 비즈니스 중요 운영에 대한 사람의 검토 및 개입을 가능하게 합니다.
- 엔터프라이즈 확장성 및 보안: 엔터프라이즈급 신뢰성과 거버넌스를 갖춘 OCI의 안전하고 확장 가능한 인프라에서 실행됩니다.
- 내장 및 커스텀 도구: SQL, RAG, 에이전트 간 조율, 함수 호출, 커스텀 API 통합으로 에이전트를 확장합니다.
공식 문서에서 자세한 내용을 확인하세요.
엔터프라이즈 Oracle AI 에이전트에 웹 접근이 필요한 이유
비즈니스 준비 결정을 내리려면 엔터프라이즈 AI 에이전트가 외부 시장 데이터에 접근해야 합니다. 여기에는 현재 트렌드, 경쟁사 활동, 고객 감정, 속보, 규제 업데이트 등이 포함됩니다.
문제는 LLM이 기본적으로 실시간 웹에 연결되어 있지 않다는 점입니다. 따라서 두 가지 주요 한계에 직면합니다:
- 실시간 정보 접근 불가: LLM은 기본적으로 최신 웹 콘텐츠를 검색할 수 없습니다.
- 웹사이트 접근 제한: 많은 웹사이트가 자동화 시스템의 데이터 수집을 차단하는 안티봇 기술을 사용합니다.
이러한 제약은 AI 에이전트를 외부 도구 및 통합으로 확장함으로써 극복할 수 있습니다.
이것이 바로 Oracle Generative AI 에이전트가 다양한 도구 옵션을 지원하는 이유입니다. 특히 API 엔드포인트 호출 도구를 통해 Bright Data와 같은 외부 API 기반 서비스에 안전하게 연결할 수 있습니다.
솔루션으로서의 Bright Data
Bright Data는 선도적인 엔터프라이즈급 AI 지원 웹 데이터 플랫폼입니다. 포괄적인 제품군을 통해 공개 웹 데이터를 윤리적으로 대규모로 수집, 구조화, 분석할 수 있습니다.
제품군에는 다음이 포함됩니다:
- Unlocker API: CAPTCHA, 안티봇 시스템, 웹사이트 차단을 우회하여 모든 웹 페이지에서 데이터를 검색합니다.
- SERP API: Google, Bing, Yandex 및 기타 주요 검색 엔진의 구조화된 실시간 검색 결과를 제공합니다.
- Discover API: 추가 처리를 위해 준비된 실시간 웹에서 AI가 순위를 매긴 관련 URL 목록을 반환합니다.
- Crawl API: 대규모 웹사이트 크롤링 및 자동화된 데이터 추출을 지원합니다.
- 스크래퍼 API: 120개 이상의 인기 웹사이트 및 플랫폼에서 구조화된 데이터 추출을 제공합니다.
Bright Data가 돋보이는 이유는 195개국에 걸쳐 4억 개 이상의 주거용 IP 네트워크입니다. 이 인프라는 98.50%의 성공률과 SLA 보장 99.99% 가동 시간을 달성하면서 고도로 확장 가능하고 지리적으로 분산된 웹 데이터 수집을 가능하게 합니다. 또한 GDPR 및 CCPA를 포함한 모든 주요 개인정보 보호 및 보안 프레임워크를 준수합니다.
API 엔드포인트 호출 도구를 통해 Bright Data를 통합함으로써 Oracle Generative AI 에이전트는 웹을 검색하고, 최신 온라인 정보에 접근하고, 웹사이트에서 데이터를 검색하며, 실제 맥락을 응답에 통합할 수 있습니다. 이를 통해 더 정확하고 최신의 실행 가능한 결과를 얻을 수 있습니다.
Bright Data를 Oracle Generative AI 에이전트와 통합하기
이 단계별 섹션에서는 Bright Data와 통합된 Oracle Generative AI 에이전트를 구축하는 방법을 배웁니다. 구체적으로, Bright Data의 Web Unlocker API와 SERP API에 연결하기 위한 두 가지 커스텀 API 엔드포인트 호출 도구를 정의하는 방법을 살펴봅니다.
SERP API를 통해 에이전트가 새로운 소스를 발견하고, Web Unlocker API를 통해 해당 소스의 콘텐츠에 접근할 수 있습니다. 함께 사용하면 강력한 검색 및 추출 패턴을 구현할 수 있습니다. 이를 통해 에이전트가 실시간으로 검증 가능한 맥락적 웹 데이터를 기반으로 자율적으로 응답을 생성하고 더 사실적인 엔터프라이즈급 결과를 제공할 수 있습니다.
아래 지침을 따라하세요!
사전 요구 사항
이 섹션을 따라하려면 다음이 필요합니다:
- Oracle Cloud 계정 (무료 티어 계정으로 충분합니다).
- API 키가 구성된 Bright Data 계정. Bright Data API 키 설정을 위한 공식 가이드를 참조하세요.
1단계: VCN 설정
Oracle 계정에 로그인하고 “Virtual Cloud Networks”를 검색한 후 해당 서비스를 선택합니다:
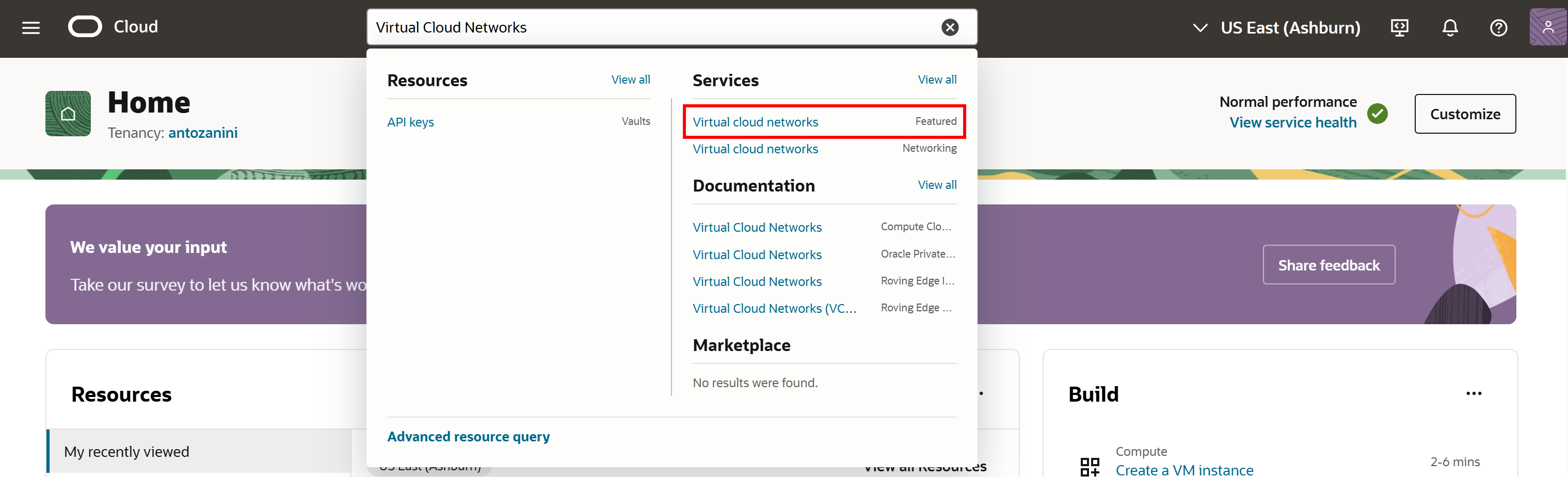
“Virtual Cloud Networks” 페이지에서 “Actions” 드롭다운을 열고 “Start VCN Wizard“를 선택합니다:
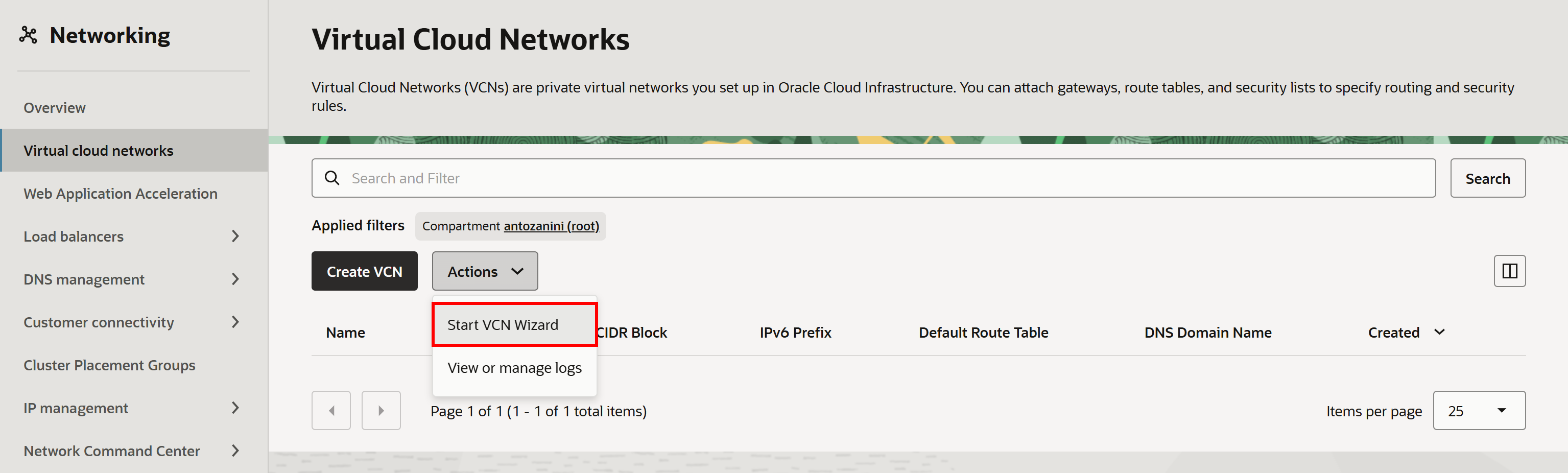
다음으로 “Create VCN with Internet Connectivity” 옵션을 선택하고 설정 마법사를 따릅니다:
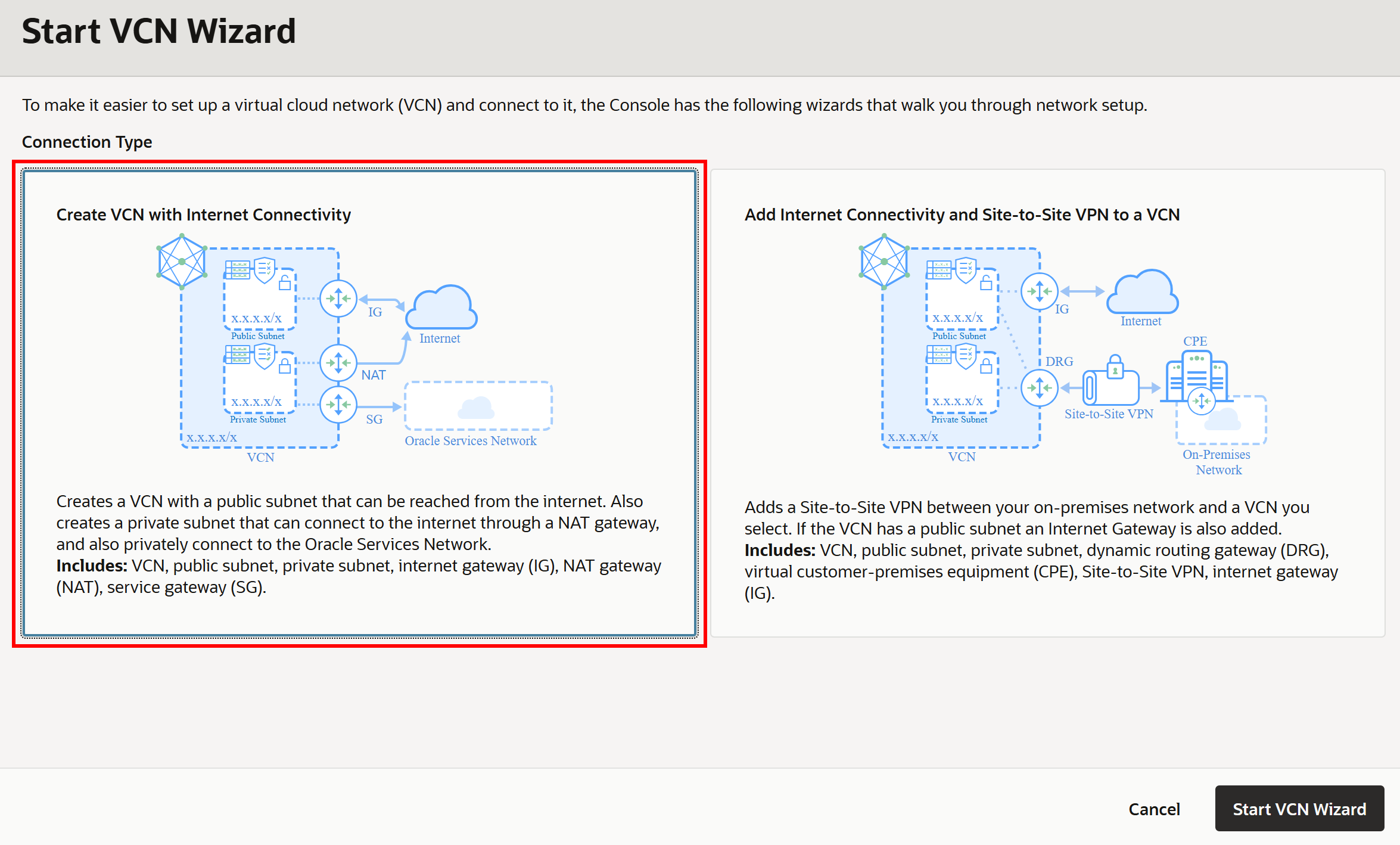
VCN에 이름(예: “ai”)을 지정하고 마법사를 계속 진행합니다. 기본 설정으로도 이 설정에 충분합니다.
참고: 서브넷에 “DNS Resolution” 기능이 활성화되어 있어야 합니다. 그렇지 않으면 커스텀 도구가 외부 엔드포인트를 호출할 수 없습니다. 그러나 OCI 네트워킹 마법사를 사용할 때 해당 기능이 기본적으로 활성화되어 있으므로 걱정할 필요가 없습니다.
VCN이 생성되면 다음과 같이 표시됩니다:
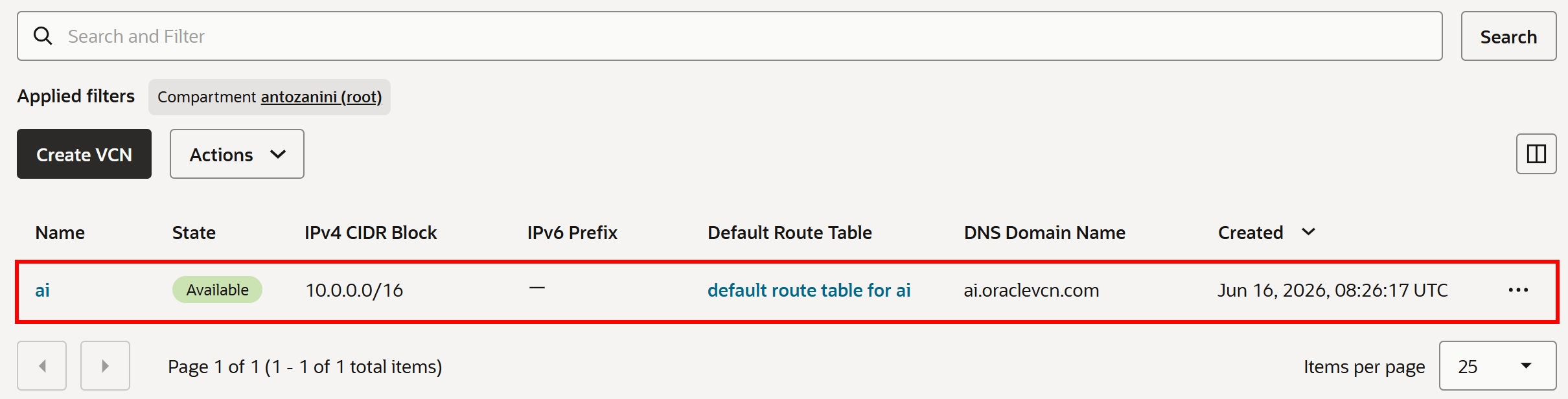
좋습니다! 이제 Bright Data 도구가 HTTP 트래픽을 라우팅하는 데 사용할 수 있는 서브넷이 있는 OCI Virtual Cloud Network(VCN)가 생겼습니다.
2단계: Oracle Vault에 Bright Data API 키 저장
먼저 공식 Oracle 가이드에 따라 Oracle Vault를 설정합니다(암호화 키 포함). 다음으로 Oracle 계정에서 “Secret Management”를 검색하고 서비스를 엽니다. “Create secret” 버튼을 클릭합니다:

“Create secret” 양식에서 시크릿에 이름(예: “bright-data-api-key-bearer”)을 지정하고, Oracle Vault와 암호화 키를 선택한 후 “Manual secret generation” 옵션을 선택합니다. 다음 형식으로 시크릿 값을 입력합니다:
Bearer <BRIGHT_DATA_API_KEY><BRIGHT_DATA_API_KEY> 플레이스홀더를 실제 Bright Data API 키로 교체하세요.
참고: API 키 앞의 “Bearer” 접두사가 필요합니다. 이는 표준 토큰 기반 형식으로 Bright Data API 인증을 위해 Authorization 헤더에 설정해야 합니다.
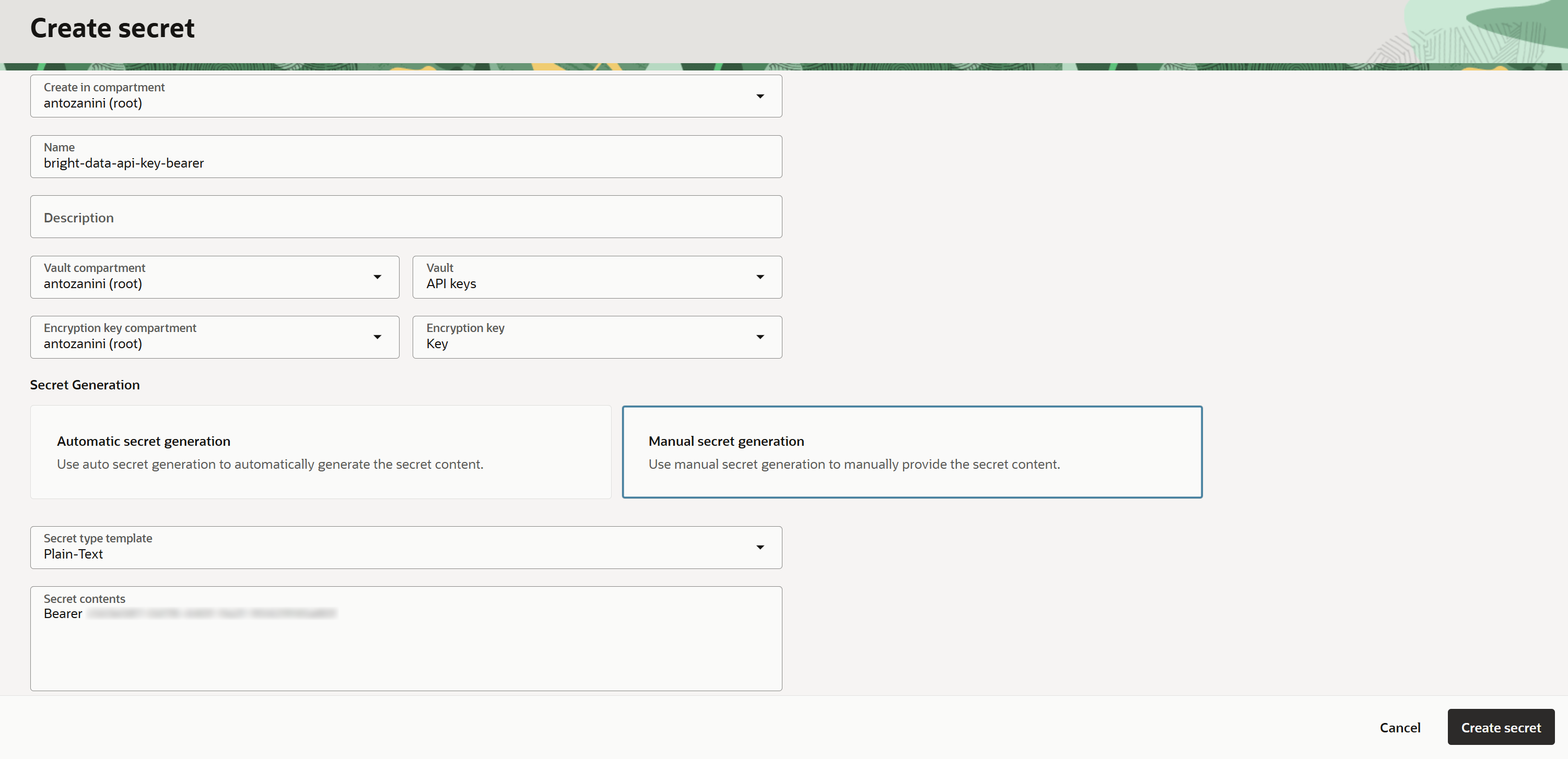
“Create secret”을 눌러 시크릿 생성을 완료합니다. 이제 “Secrets” 페이지에 시크릿이 나열된 것을 볼 수 있습니다:
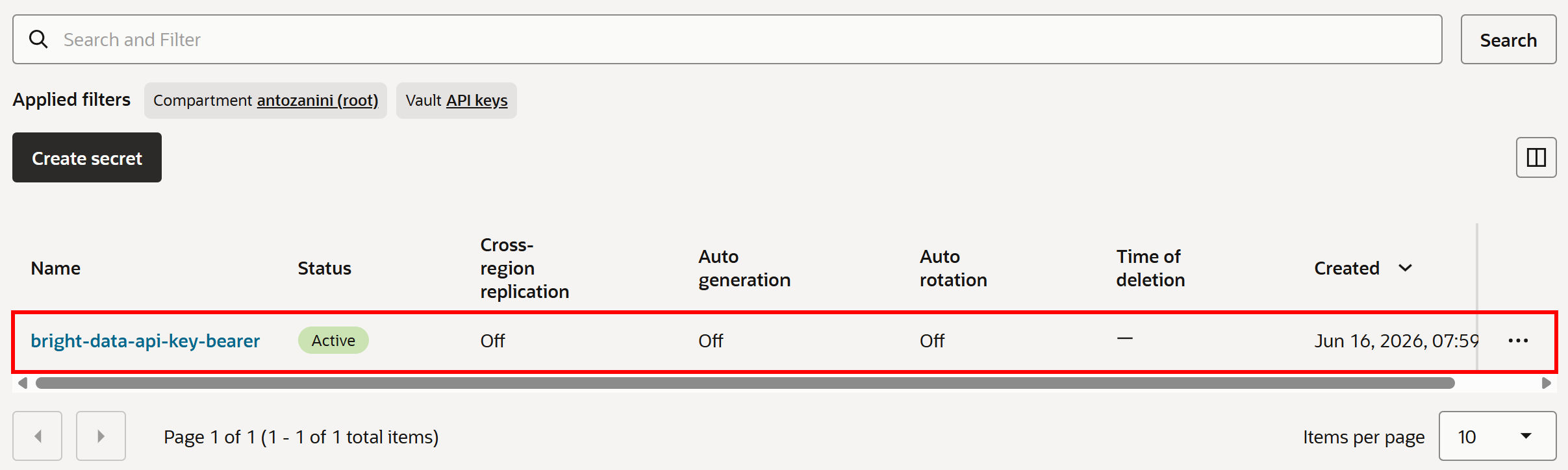
좋습니다! 이 시크릿은 커스텀 에이전트 도구가 Bright Data API에 요청할 때 인증에 사용됩니다.
3단계: 필요한 IAM 정책 추가
기본적으로 Oracle Generative AI 서비스는 Vault에 저장된 시크릿에 접근할 수 없습니다. 이를 활성화하려면 올바른 IAM 정책을 추가해야 합니다.
OCI 콘솔에서 “Policies”를 검색하고 해당 페이지를 엽니다. 그런 다음 “Create Policy”를 클릭합니다:
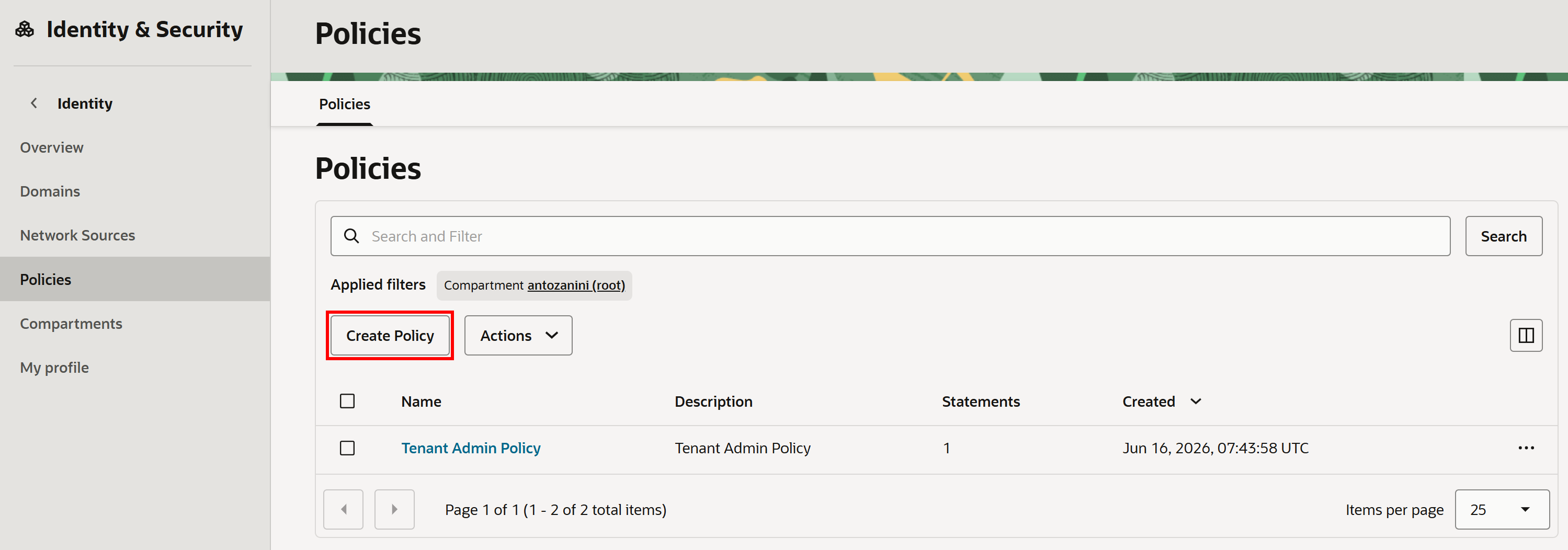
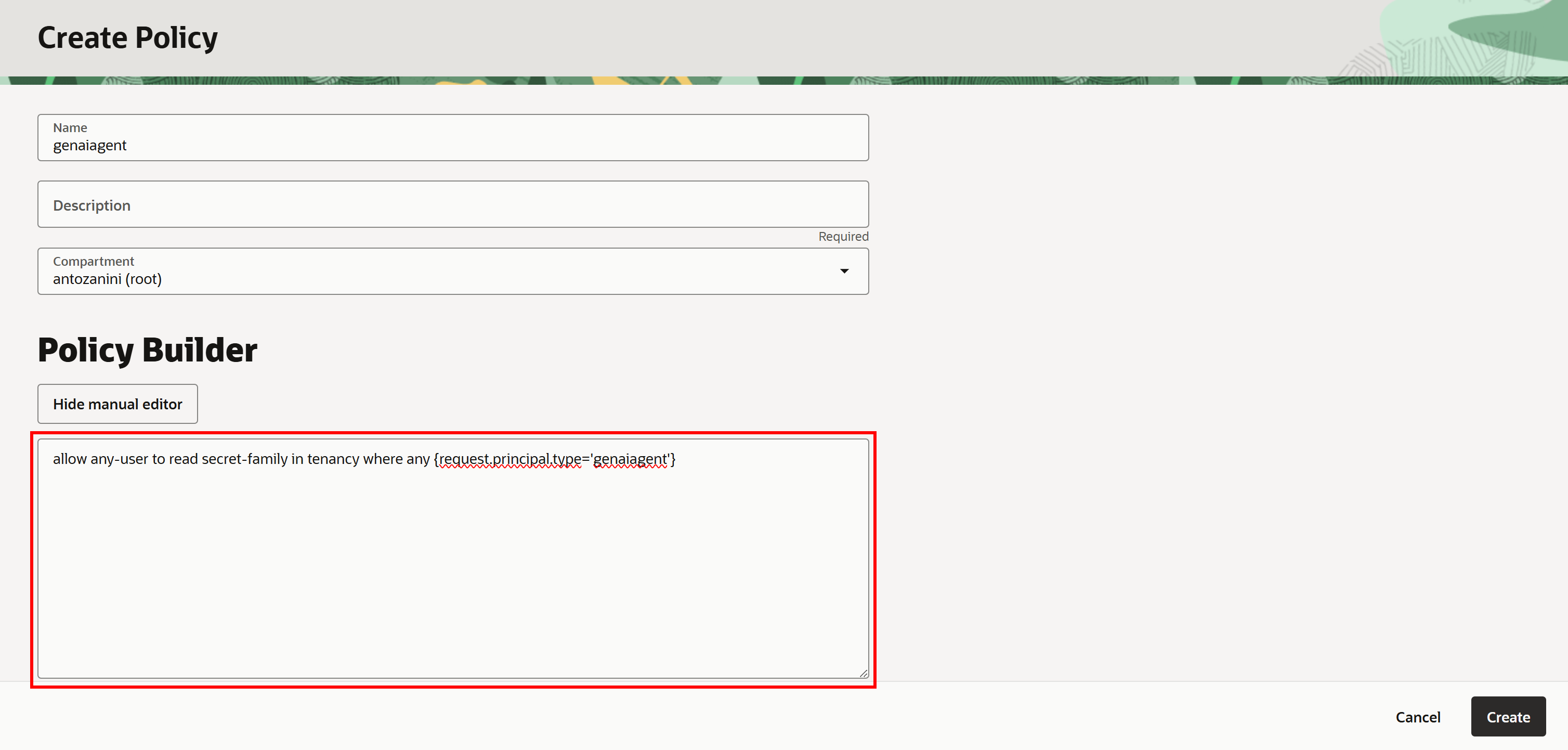
“Create Policy” 양식에서 정책에 이름(예: “genaiagent”)을 지정합니다. 그런 다음 “Show manual editor”를 클릭하고 다음 IAM 정책을 붙여넣습니다:
allow any-user to read secret-family in tenancy where any {request.principal.type='genaiagent'}이 정책은 모든 Generative AI 에이전트가 앞서 생성한 “bright-data-api-key-bearer” 시크릿을 포함하여 테넌시 전체의 OCI Vault 인스턴스에 저장된 시크릿을 읽을 수 있도록 허용합니다.
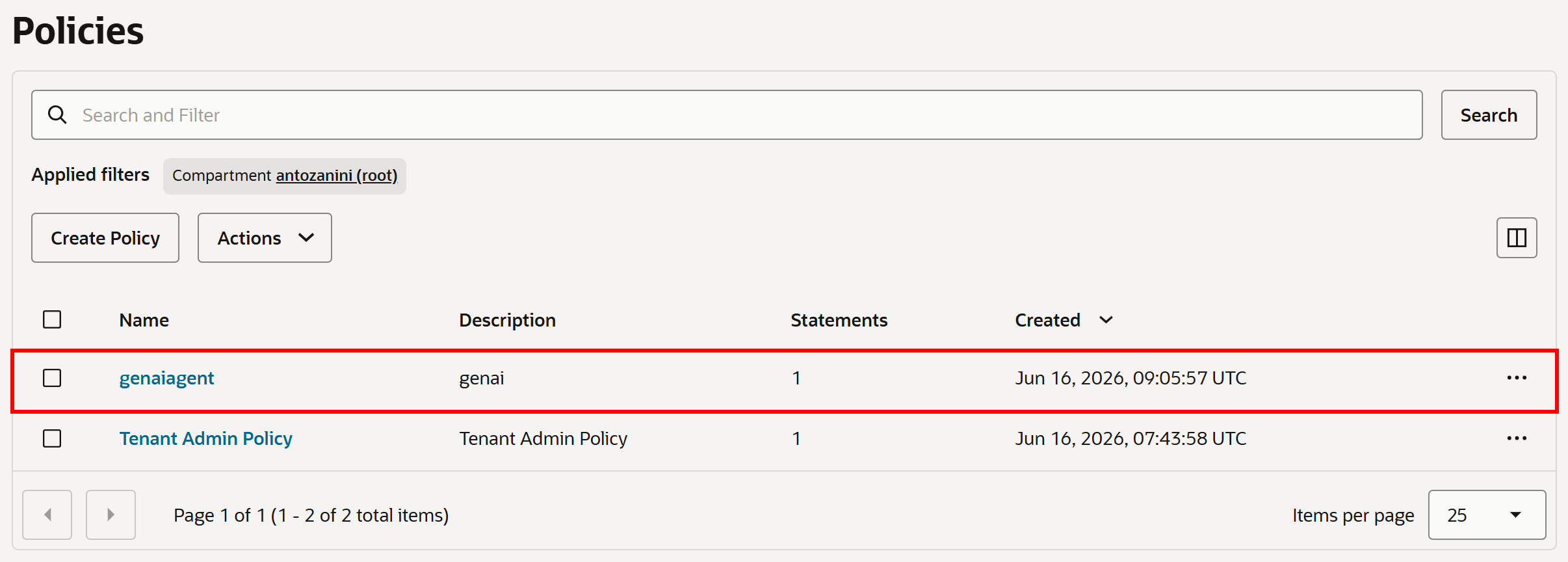
“Create”를 클릭하여 정책 생성을 확인합니다:
생성 후 정책이 “Policies” 페이지에 나타납니다:
또는 동일한 목표를 달성하기 위해 동적 그룹 설정을 위한 공식 가이드를 따를 수 있습니다.
잘 했습니다! 이제 커스텀 도구를 통해 Bright Data에 연결할 수 있는 Oracle Generative AI 에이전트를 구축하는 데 필요한 모든 구성 요소가 갖춰졌습니다.
4단계: 웹 접근 에이전트 초기화
“Agents”를 검색하고 “Generative AI Agents” 서비스의 해당 페이지를 엽니다:
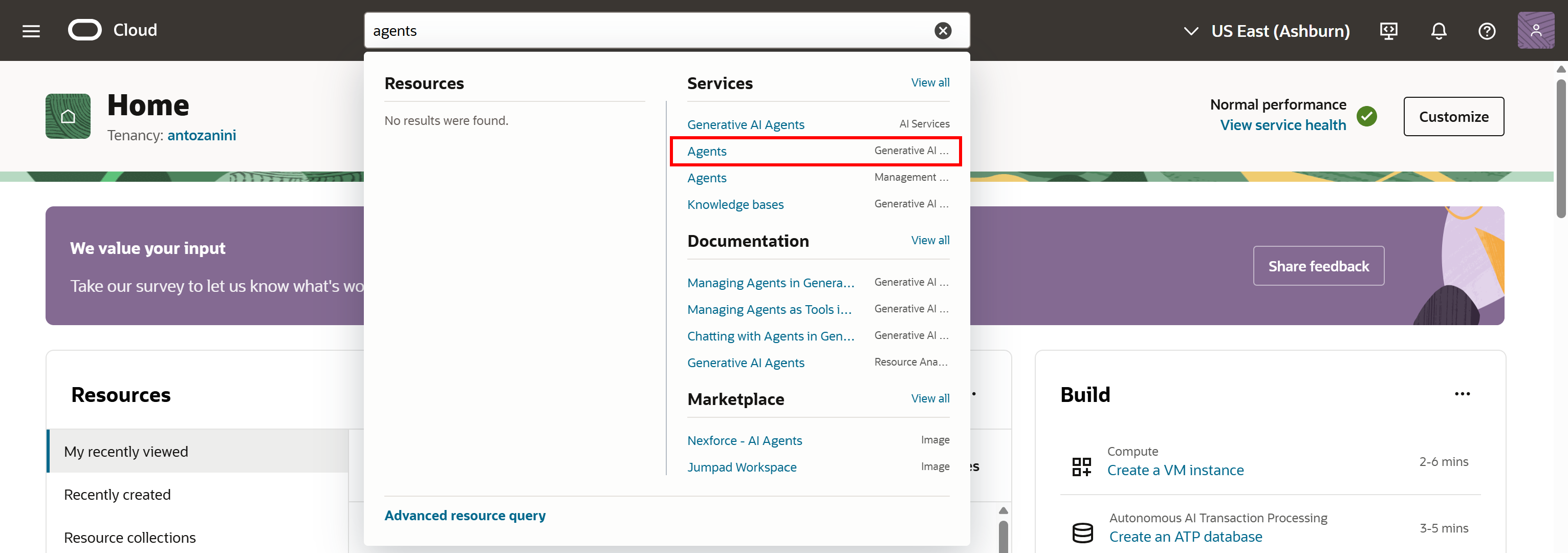
“Create agent” 버튼을 눌러 계속 진행합니다:

에이전트 생성 마법사가 실행됩니다. 양식을 다음과 같이 작성합니다:
- 이름:
Web Access AI Agent - 설명:
You are a web agent with web access powered by the Bright Data integration - 라우팅 지침:
When asked to search the web, retrieve online data, or scrape web pages, use the Bright Data tools
그런 다음 에이전트의 두뇌로 사용할 선호하는 LLM을 선택합니다. 이 경우 기본 Llama 3.3 70B 모델로 충분합니다.
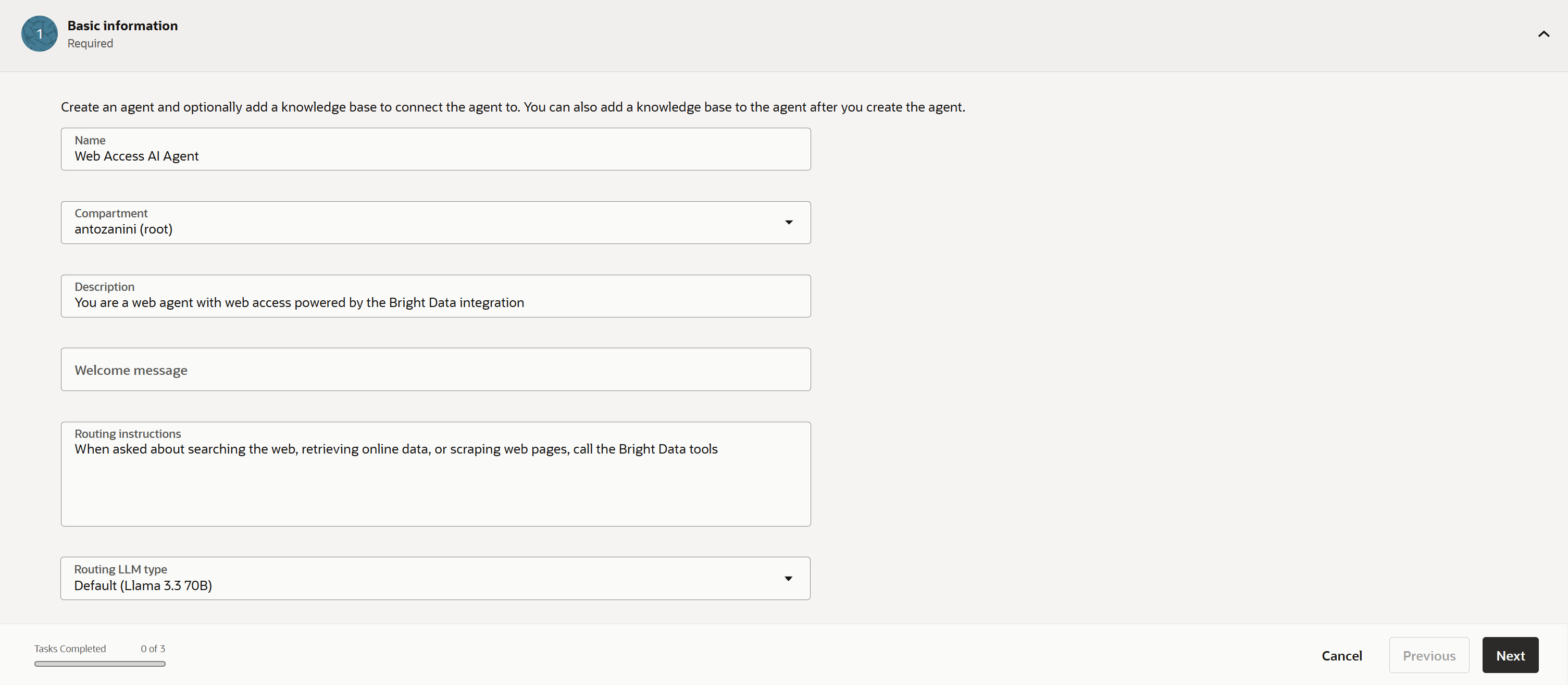
완벽합니다! “Next”를 클릭하여 마법사의 “Tools” 섹션으로 이동합니다. Bright Data 통합 도구를 정의하기 전에 먼저 시작해 봅시다.
5단계: Bright Data의 Unlocker API와 SERP API 시작하기
이제 Bright Data 계정에서 Unlocker API와 SERP API를 생성할 차례입니다. 빠른 설정을 위해 공식 문서 페이지를 참조하세요:
또는 아래 지침을 따르세요.
아직 계정이 없다면 Bright Data 계정을 생성하세요. 이미 계정이 있다면 로그인하여 제어판을 엽니다:
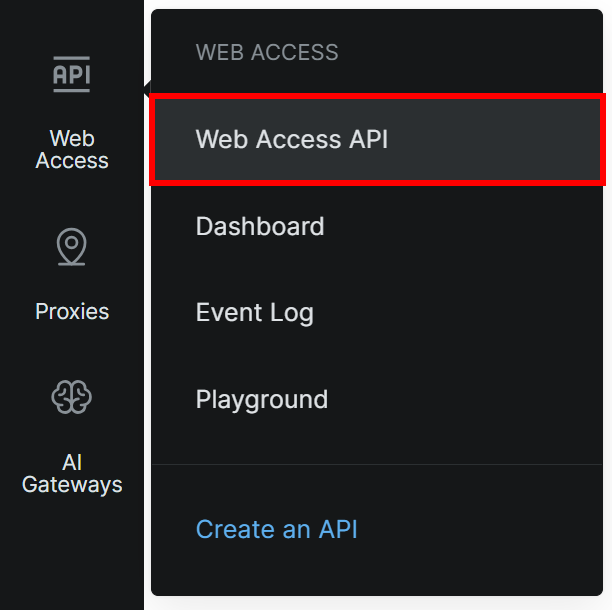
다음으로 왼쪽 메뉴에서 “Web Access > Web Access API”로 이동합니다:
“My APIs” 테이블에 이미 “Web Unlocker API”와 “SERP API” 항목이 보인다면 바로 시작할 수 있습니다:
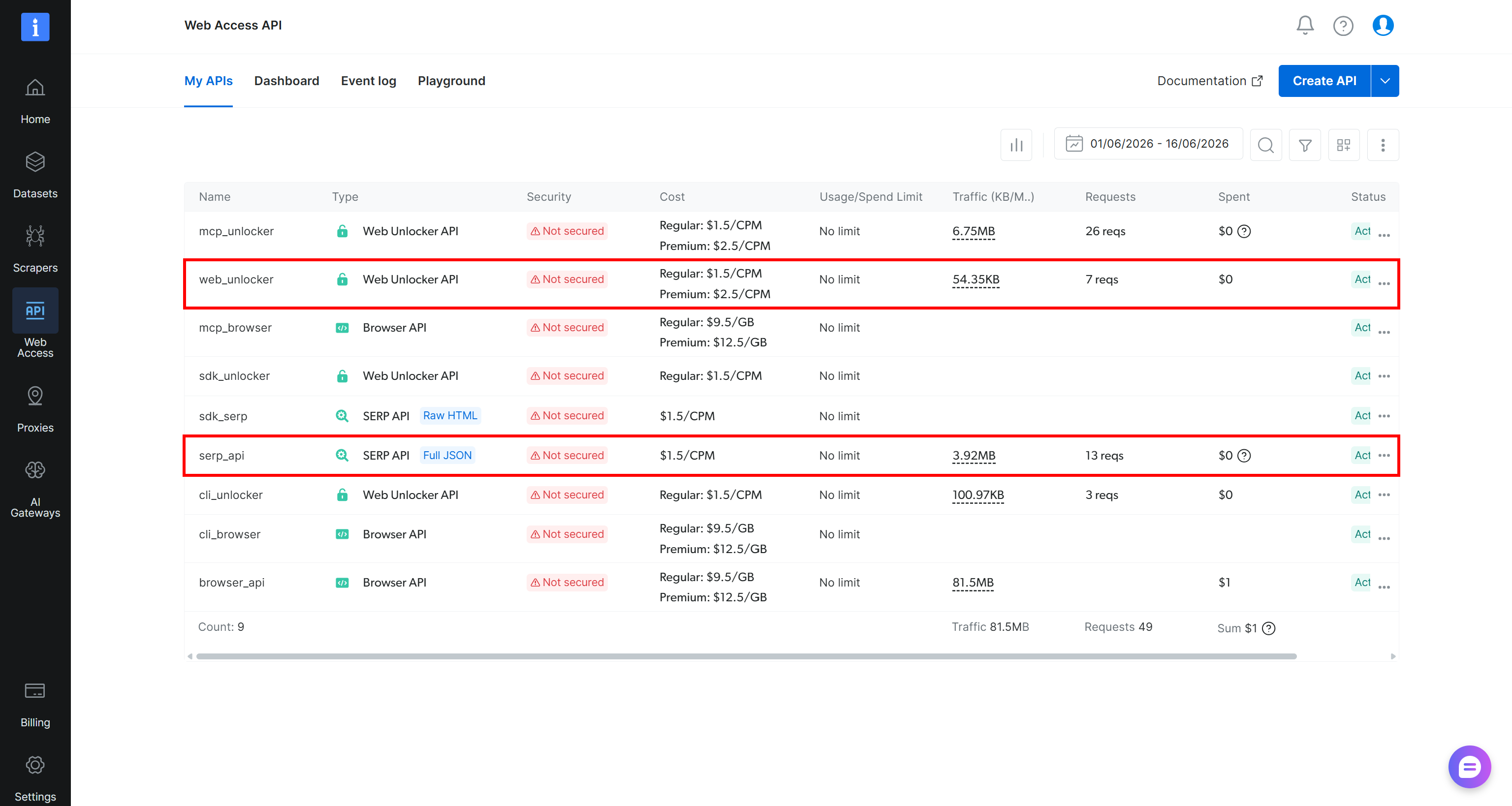
없다면 Create API 버튼의 드롭다운을 클릭하고 “Unlocker API”(또는 대신 생성하려면 “SERP API”)를 선택합니다:
Unlocker/SERP API 설정 마법사가 실행됩니다. API에 이름(예: unlocker_api/serp_api)을 지정하고 필요에 따라 API를 구성합니다:
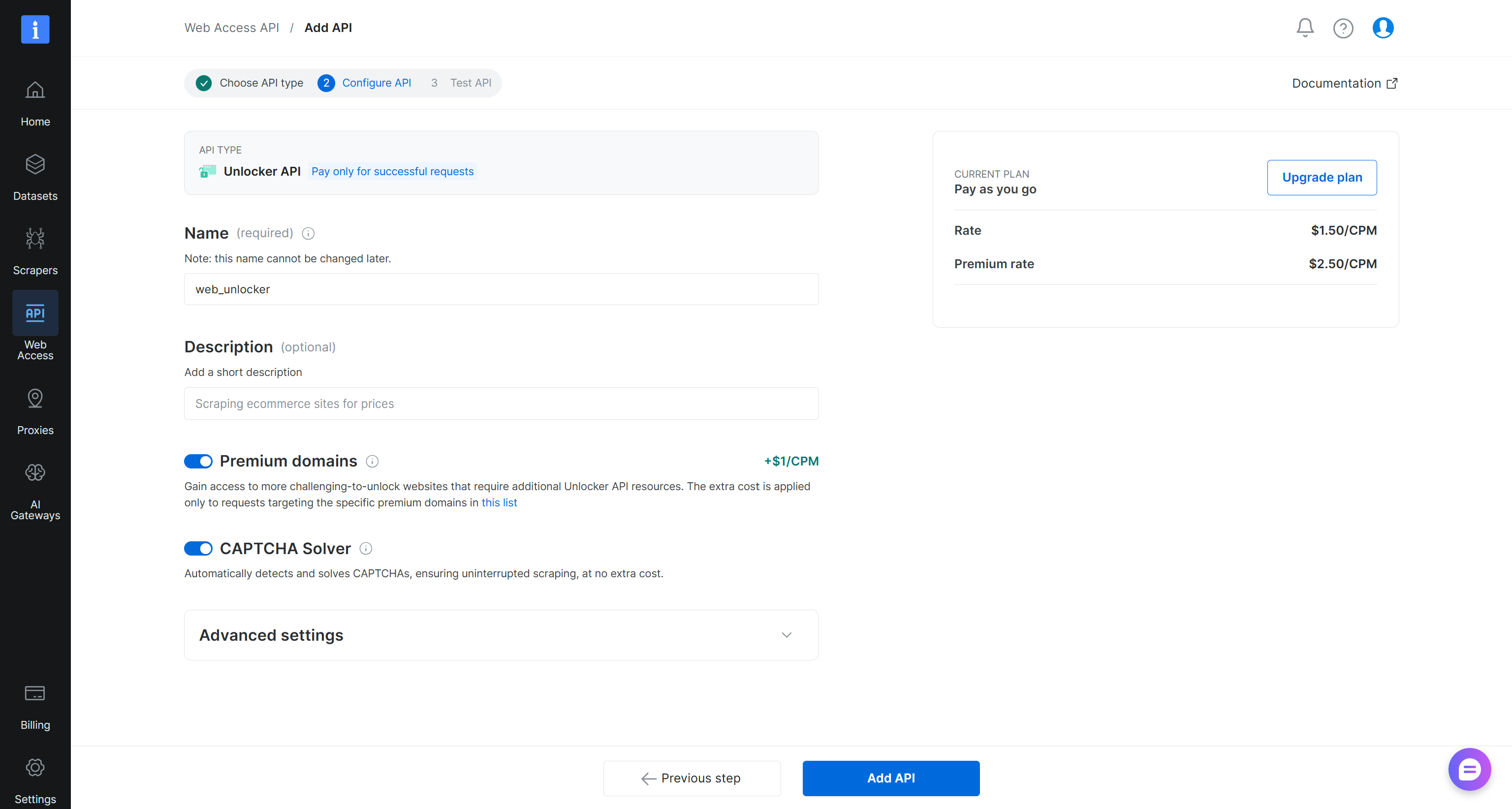
완료되면 “Add API”를 클릭합니다. 이후 다음 API 이름을 설정했다고 가정합니다:
- Bright Data Unlocker API의 경우
unlocker_api. - Bright Data SERP API의 경우
serp_api.
이제 이러한 API에 연결하는 커스텀 API 엔드포인트 호출 도구를 정의할 준비가 되었습니다. 훌륭합니다!
6단계: Web Unlocker API 통합을 위한 커스텀 도구 생성
Generative AI 에이전트 생성 마법사로 돌아갑니다. Tools 섹션에서 “Add tool”을 클릭합니다.
Unlocker API 통합을 위한 도구를 생성하려면 “Custom tool” 옵션을 선택합니다. 그런 다음 양식을 다음과 같이 작성합니다:
- 이름:
Web Unlocker API - 설명:
An automated web scraping tool that extracts content from web pages and bypasses anti-bot protections
“Tool configuration” 섹션에서 “API endpoint calling (agent execution)” 옵션을 선택합니다:
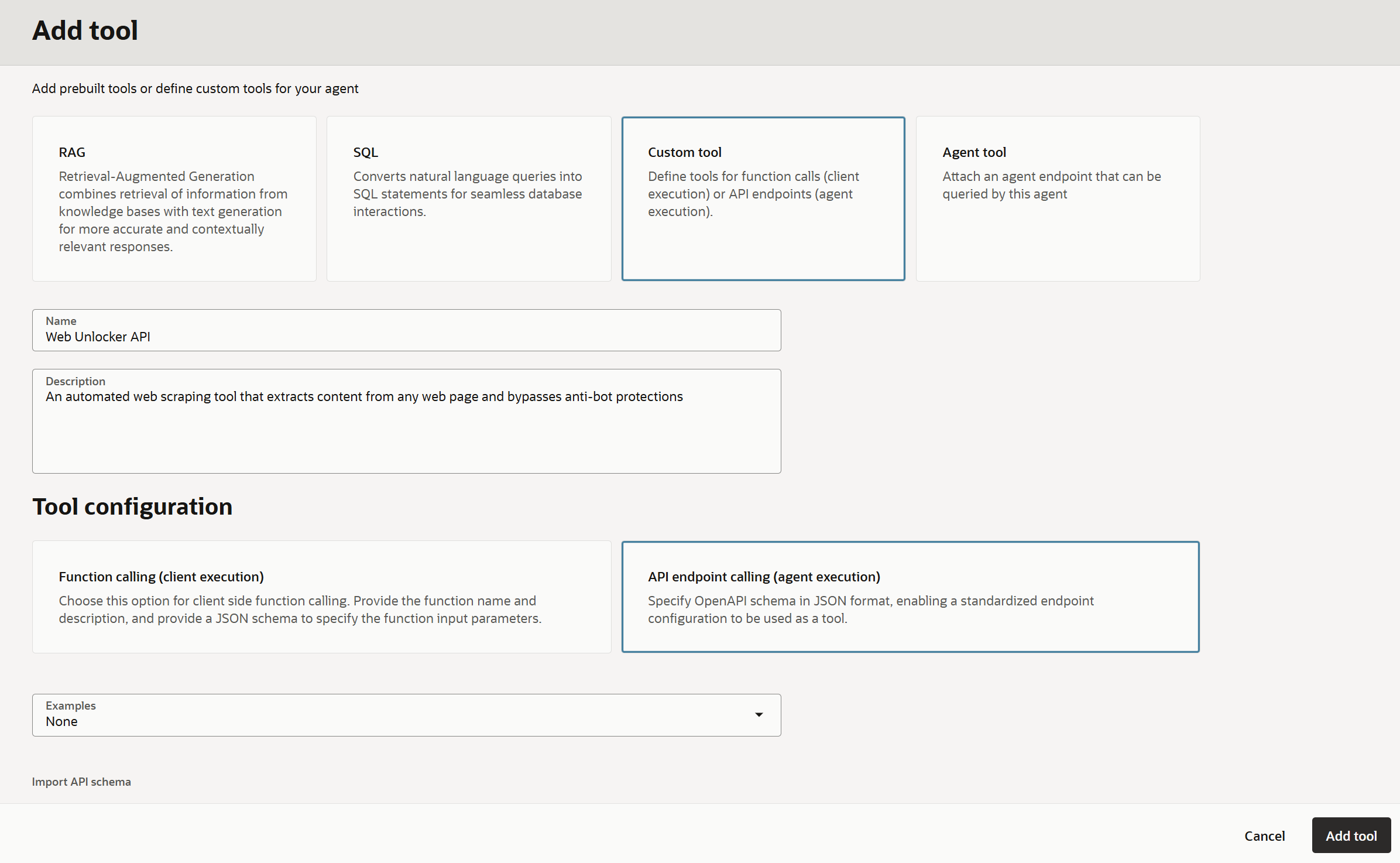
“Examples” 섹션에서 “None”을 선택하여 빈 캔버스로 시작한 후 다음 OpenAPI 명세를 붙여넣습니다:
{
"openapi": "3.0.4",
"info": {
"title": "Bright Data Web Unlocker API",
"version": "1.0.0",
"description": "Bright Data Unlocker API enables you to bypass anti-bot measures. It manages proxies and solves CAPTCHAs automatically for easier web data collection.\n\n\[Web Unlocker API documentation\](https://docs.brightdata.com/scraping-automation/web-unlocker/introduction)\n"
},
"servers": [
{
"url": "https://api.brightdata.com"
}
],
"paths": {
"/request": {
"post": {
"operationId": "sendWebUnlockerRequest",
"summary": "Send a Web Unlocker API request",
"description": "Submit a Web Unlocker API request using your Bright Data Web Unlocker API zone.\n\n\[Web Unlocker API `/request` documentation\](https://docs.brightdata.com/api-reference/rest-api/unlocker/unlock-website)\n",
"requestBody": {
"required": true,
"content": {
"application/json": {
"schema": {
"type": "object",
"required": ["zone", "url", "format"],
"properties": {
"zone": {
"type": "string",
"description": "Your Web Unlocker zone name.",
"default": "unlocker_api"
},
"url": {
"type": "string",
"description": "The target website URL to unlock and fetch.",
"example": "https://example.com/products"
},
"format": {
"type": "string",
"description": "Response format.\nAllowed values:\n- raw: Returns the response immediately in the body.\n- json: Returns the response as a structured JSON object.",
"default": "raw"
},
"method": {
"type": "string",
"description": "HTTP method used when fetching the target URL.",
"example": "GET"
},
"country": {
"type": "string",
"description": "Country code for proxy location (ISO 3166-1 alpha-2 format).",
"example": "us"
}
}
}
}
}
},
"responses": {
"200": {
"description": "Successful response containing search results."
},
"400": {
"description": "Invalid request (missing required fields or invalid parameters)."
},
"401": {
"description": "Unauthorized (invalid or missing Bright Data API key)."
}
}
}
}
}
}이는 Bright Data Web Unlocker OpenAPI 명세에 해당합니다. 자세한 내용은 “OpenAPI Specs: AI Integration with SERP & Unlocker APIs” 가이드를 참조하세요.
중요: zone 속성 아래의 "default": "unlocker_api" 필드를 확인하세요. 이는 AI 에이전트가 Bright Data Unlocker API를 호출하는 방법을 지시하기 때문에 필수적입니다. "unlocker_api"를 실제 Unlocker API 이름으로 교체하세요.
인증 방법을 구성하려면 양식을 다음과 같이 작성합니다:
- 인증 유형:
API key - 키 위치:
Header - 키 이름:
Authorization - 시크릿 값:
bright-data-api-key-bearer(또는 저장된 Bright Data API 키 시크릿의 이름) - VCN:
ai(또는 Oracle VCN의 이름) - 서브넷:
private-subnet-ai(중요: 프라이빗 서브넷을 선택하세요. 그렇지 않으면 모든 도구 호출이500오류로 실패합니다)
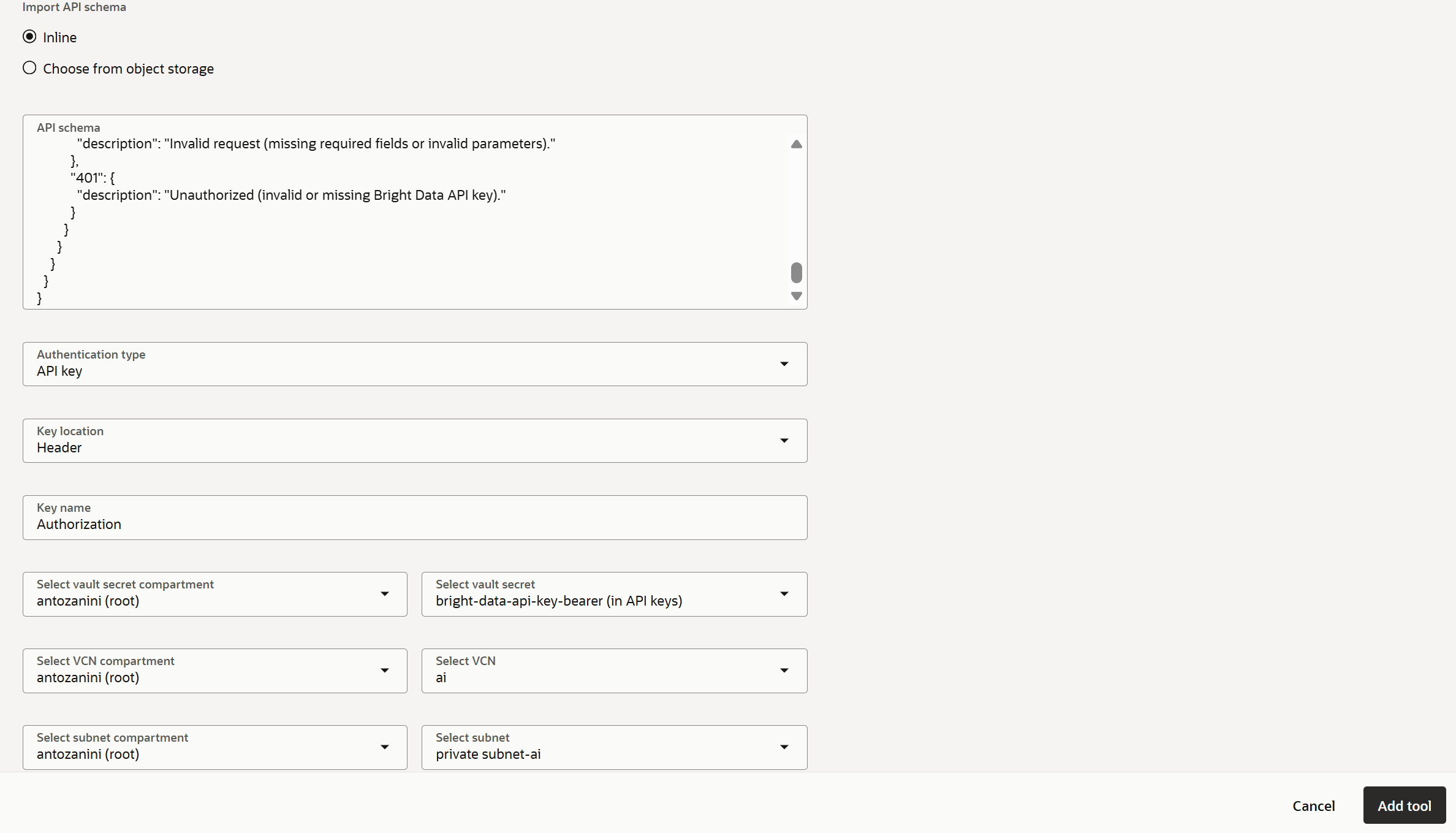
이렇게 하면 Bright Data에서 요구하는 인증 방법으로 커스텀 도구가 구성됩니다. 또한 Unlocker API에 대한 API 호출이 OCI VCN 프라이빗 서브넷을 통해 실행되도록 보장합니다.
마지막으로 “Add tool”을 클릭하여 설정을 완료합니다. Bright Data 기반의 웹 스크래핑 도구가 이제 에이전트에서 사용 가능합니다. 훌륭합니다!
7단계: SERP API 도구 생성
웹 콘텐츠를 자율적으로 발견하는 기능 없이 스크래핑 기능만 갖춘 에이전트는 제한적입니다. 바로 이때 Bright Data SERP API가 필요합니다!
“Add tool”을 다시 클릭하고 이전과 동일한 과정을 반복합니다. 이번에는 양식을 다음과 같이 작성합니다:
- 이름:
SERP API - 설명:
An endpoint that provides real users'search results at high volume across major search engines, including Google
다음으로 아래 명세를 붙여넣습니다:
{
"openapi": "3.0.4",
"info": {
"title": "Bright Data SERP API",
"version": "1.0.0",
"description": "Extract search engine results using Bright Data SERP API. Extract structured data from major search engines, including Google, Bing, Yandex, DuckDuckGo, and more. \nGet organic results, paid ads, local listings, shopping results, and other SERP features.\n\[SERP API documentation\](https://docs.brightdata.com/scraping-automation/serp-api/introduction)\n"
},
"servers": [
{
"url": "https://api.brightdata.com"
}
],
"paths": {
"/request": {
"post": {
"operationId": "sendSerpRequest",
"summary": "Send a SERP API request",
"description": "Submit a SERP API request using your Bright Data SERP API zone. \n\n\[SERP API `/request` documentation\](https://docs.brightdata.com/api-reference/rest-api/serp/scrape-serp)\n",
"requestBody": {
"required": true,
"content": {
"application/json": {
"schema": {
"type": "object",
"required": [
"zone",
"url",
"format"
],
"properties": {
"zone": {
"type": "string",
"description": "The name of your SERP API zone.",
"default": "serp_api"
},
"url": {
"type": "string",
"description": "The search engine URL to query (e.g., `https://www.google.com/search?q=<search_query>`).",
"example": "https://www.google.com/search?q=pizza&hl=en&gl=us"
},
"format": {
"type": "string",
"description": "Response format. \nAllowed values: \n- `raw`: Returns the response immediately in the body. \n- `json`: Returns the response as a structured JSON object. \n",
"default": "raw",
"enum": [
"raw",
"json"
]
},
"country": {
"type": "string",
"description": "Country code for proxy location (ISO 3166-1 alpha-2 format). \n",
"example": "us"
}
}
}
}
}
},
"responses": {
"200": {
"description": "Successful response containing search results."
},
"400": {
"description": "Invalid request (missing required fields or invalid parameters)."
},
"401": {
"description": "Unauthorized (invalid or missing Bright Data API key)."
}
}
}
}
}
}중요: 앞서 강조했듯이, zone 속성 아래의 default 필드가 SERP API 이름과 일치하는지 확인하세요.
이 도구를 추가하면 다음과 같이 표시됩니다:
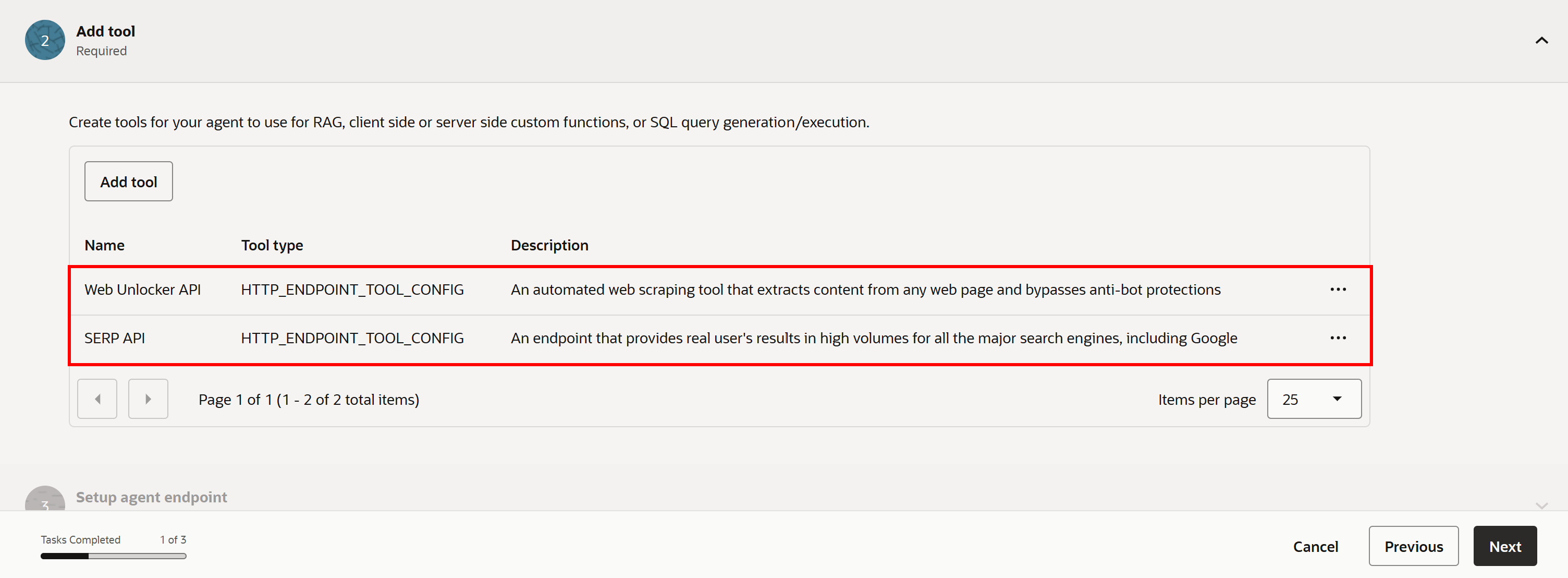
참고: 마찬가지로 다른 모든 API 기반 Bright Data 솔루션을 연결할 수 있습니다.
좋습니다! 이제 마지막 마무리 작업만 남았습니다.
8단계: 에이전트 생성 완료
“Next”를 클릭하여 에이전트 엔드포인트 설정으로 진행합니다. 에이전트를 테스트하려면 이 설정이 필요합니다. 그런 다음 모든 에이전트 정보를 검토하고 “Create agent”를 클릭한 후 Llama 3 라이선스 계약에 동의합니다.
“Agents” 페이지로 리디렉션되며 “Creating” 상태의 “Web Access AI Agent” 항목이 표시됩니다. 프로비저닝 프로세스는 몇 분 정도 걸릴 수 있으니 인내심을 가지세요.
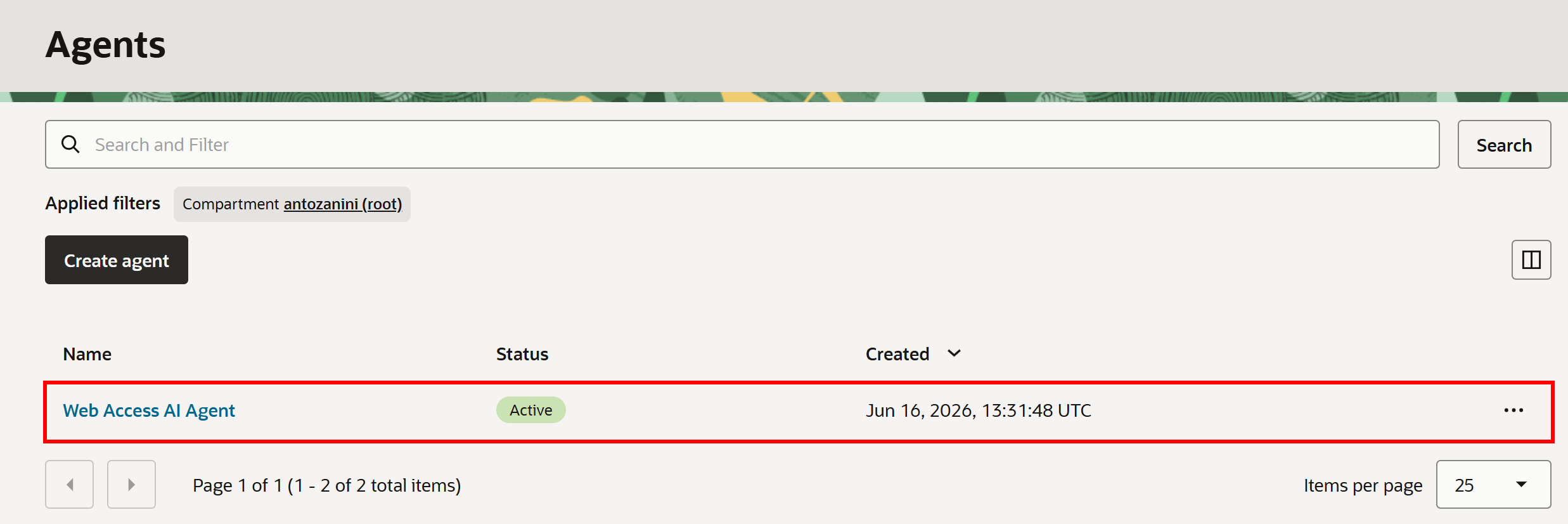
잠시 후 상태가 “Active”로 변경되면 Bright Data 통합이 포함된 Oracle Generative AI 에이전트가 준비된 것입니다!
8단계: 에이전트 테스트
에이전트 이름을 클릭하면 다음 페이지로 리디렉션됩니다:
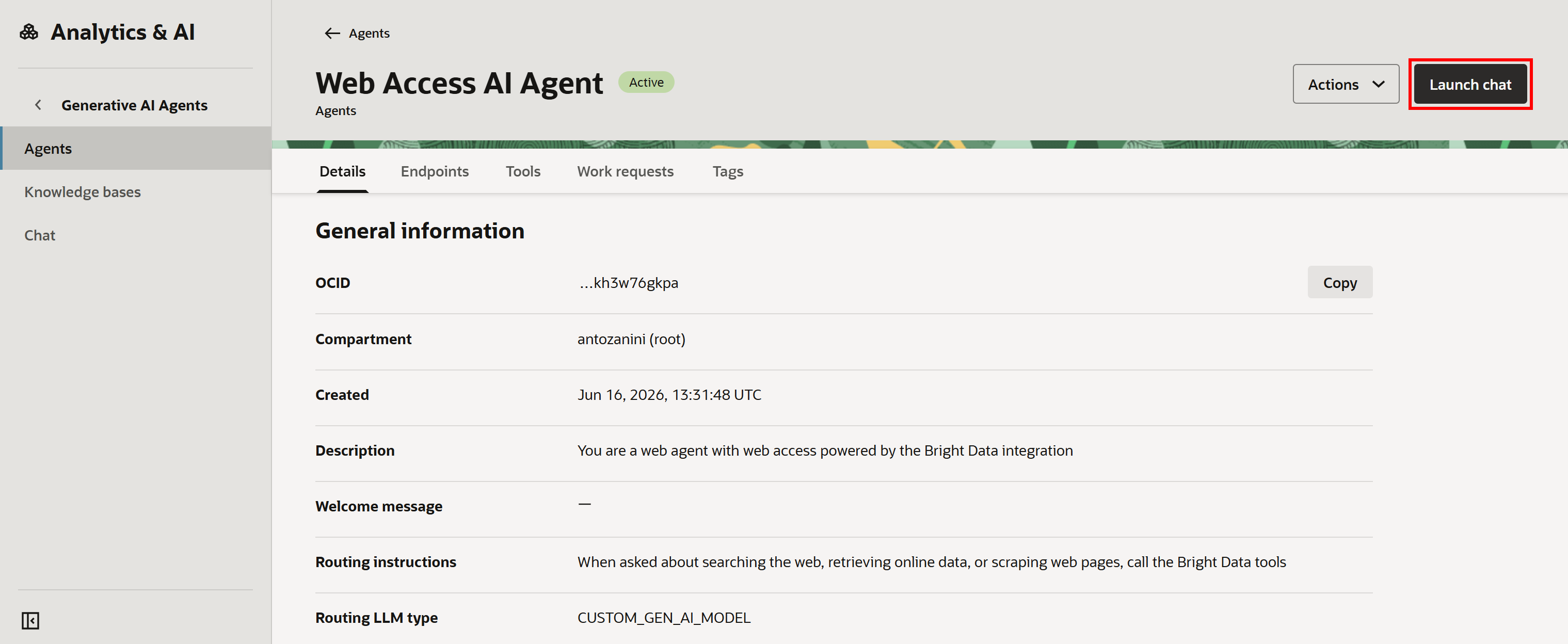
여기에서 “Launch chat”을 눌러 에이전트를 테스트할 수 있습니다.
AI 에이전트와 관련 엔드포인트가 선택되어 있는지 확인한 후 다음과 같은 프롬프트를 붙여넣습니다:
Search Google for the latest news about SpaceX stock, review the content from the 2,3 most relevant sources, and provide a report summarizing the most important information이는 Bright Data 통합이 웹 검색과 스크래핑 작업을 모두 처리할 수 있는지 확인하기 때문에 이상적인 테스트입니다.
“Chat” 페이지에서 프롬프트를 실행합니다. 다음과 같은 결과가 표시됩니다:
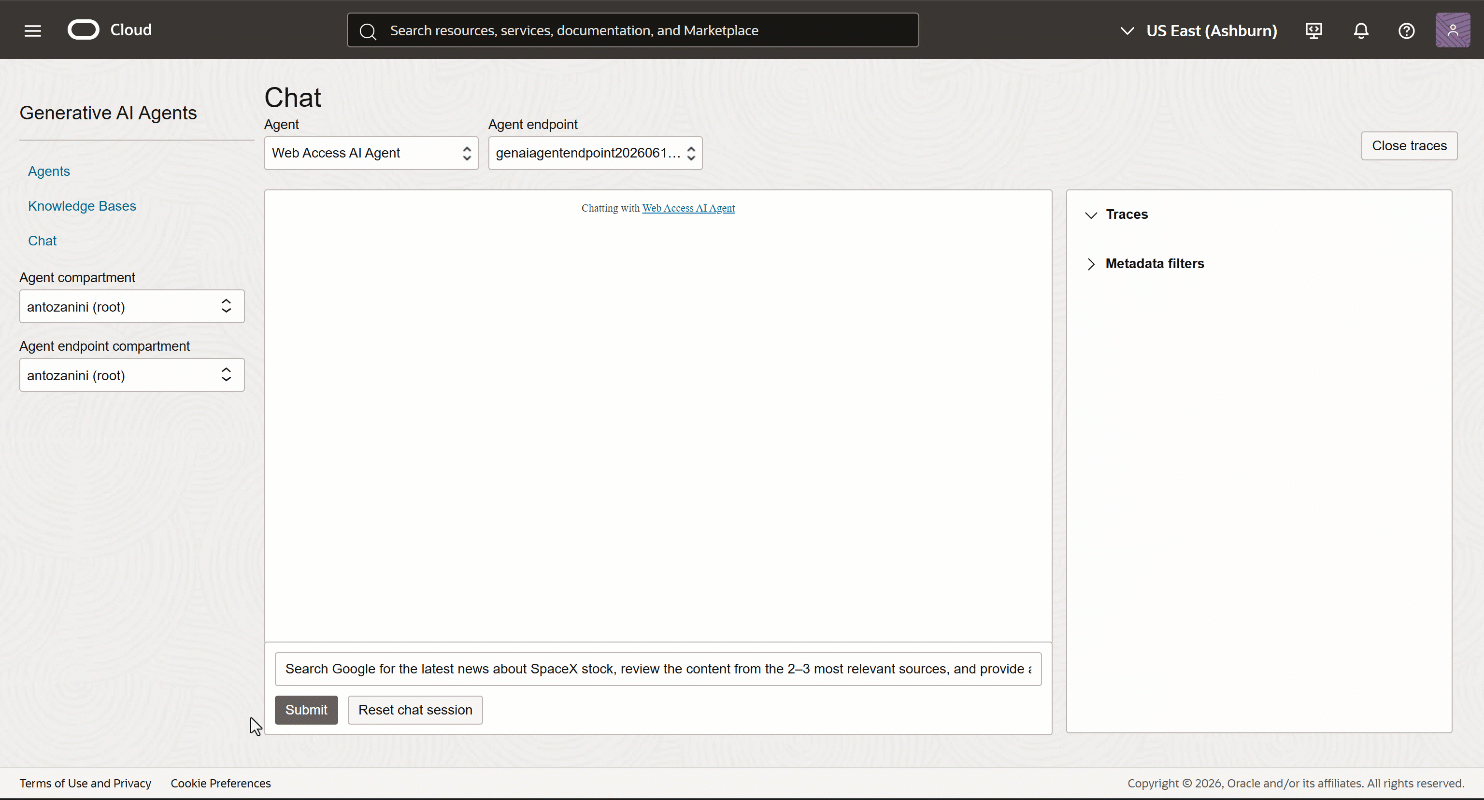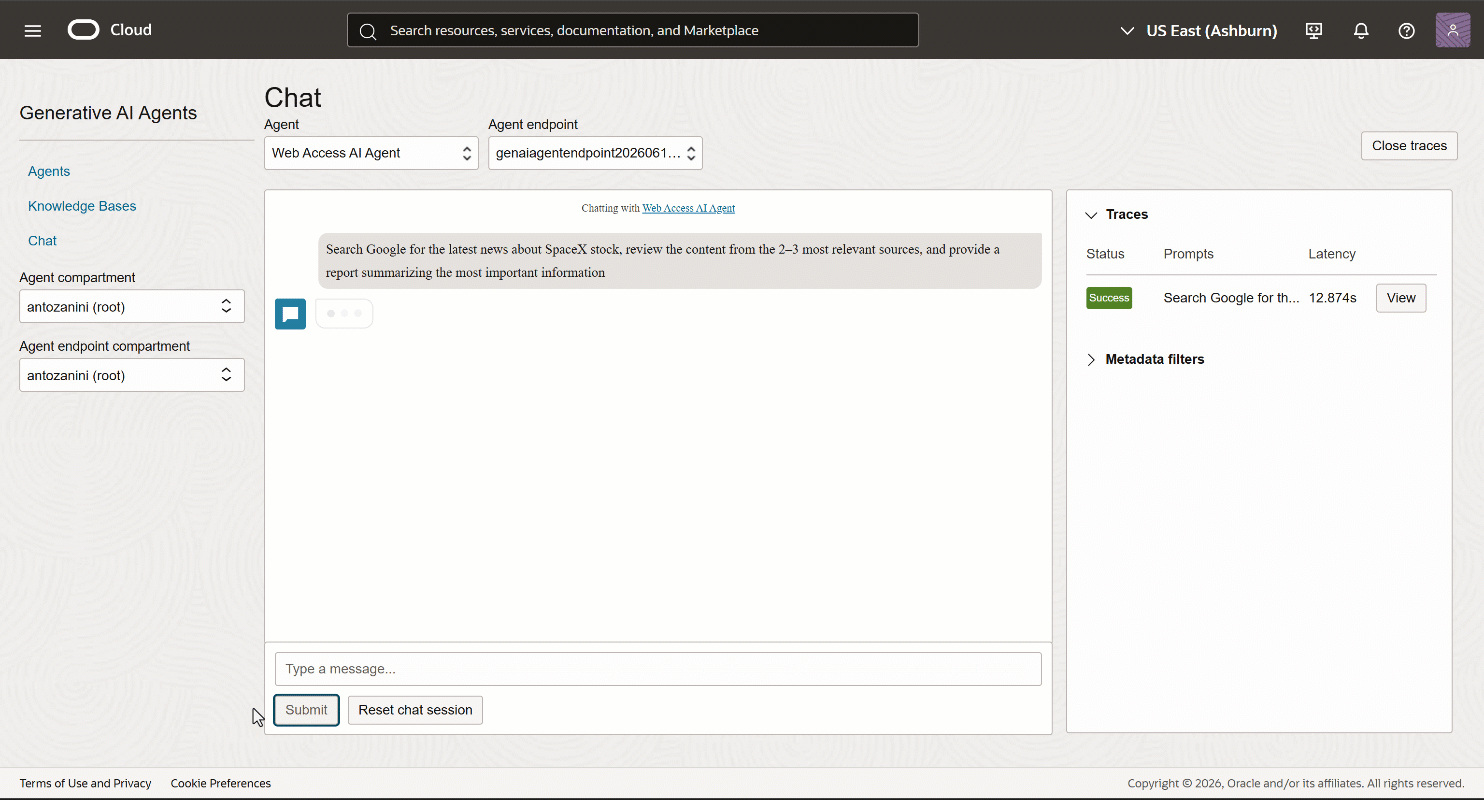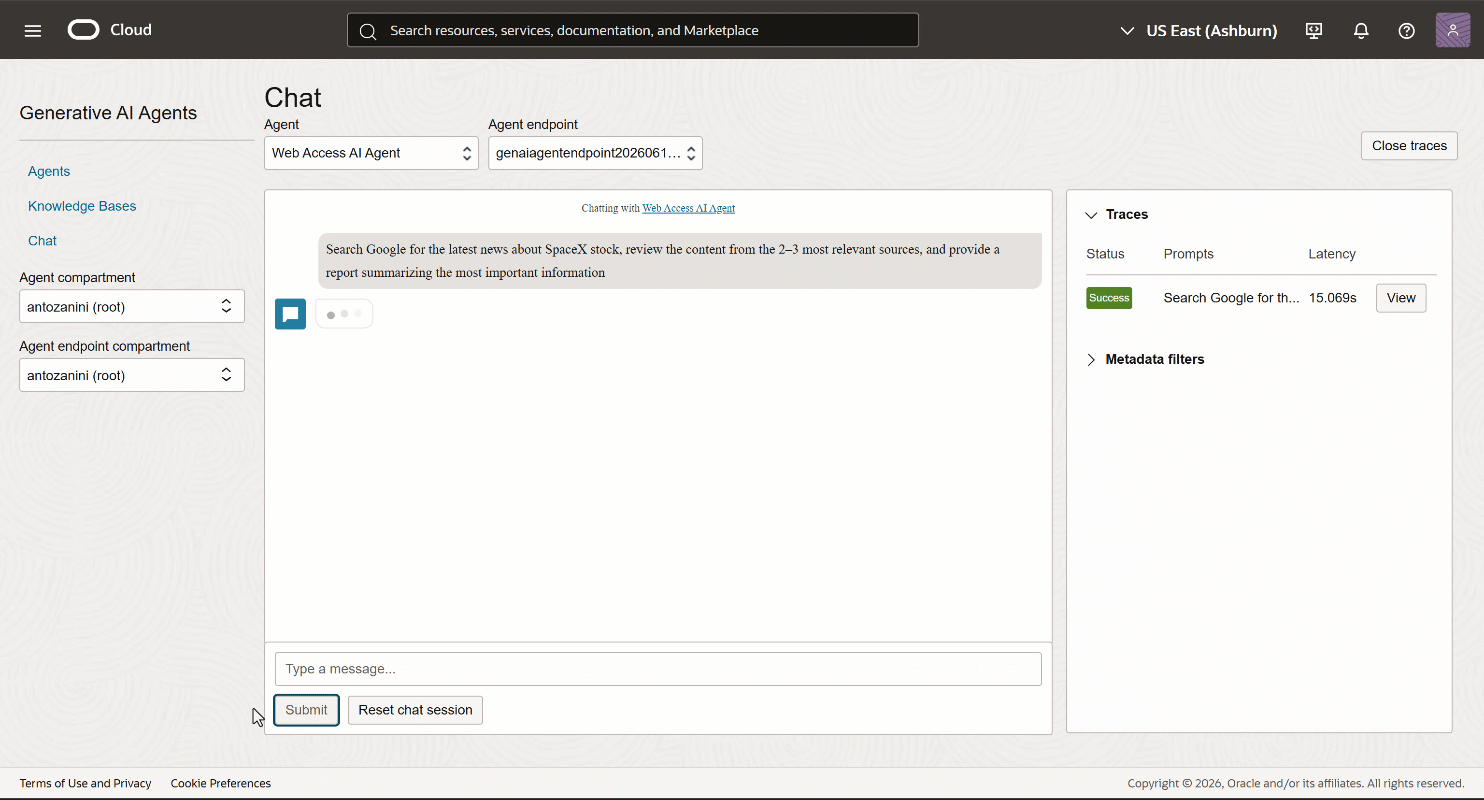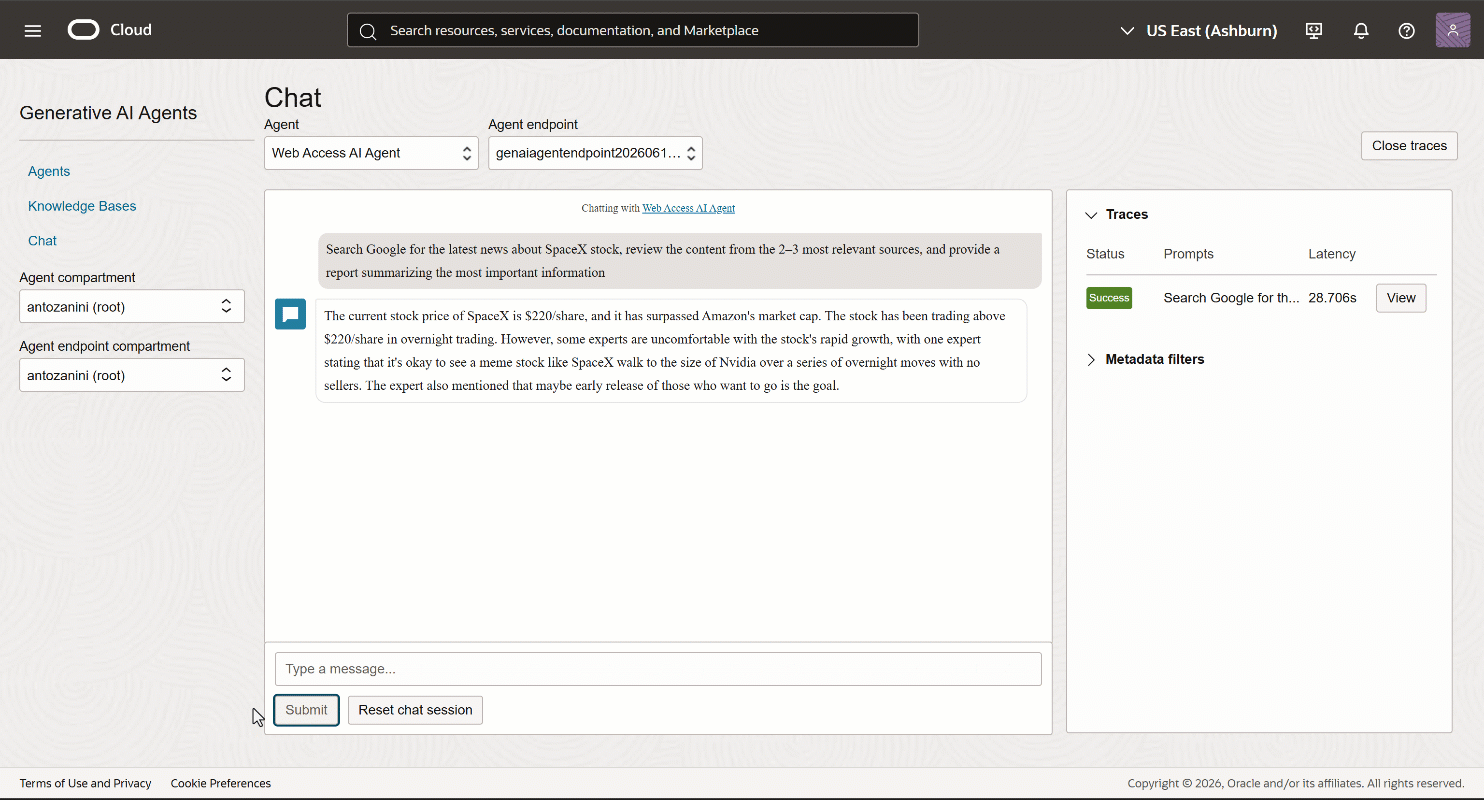
보시다시피 AI 에이전트가 SpaceX 주식에 대한 맥락적 정보를 반환했습니다. SpaceX가 불과 몇 시간 전에 상장되었기 때문에(이 글 작성 시점 기준) 매우 최신 정보입니다.
표준 LLM은 정적 데이터셋으로 훈련되기 때문에 이를 제공할 수 없습니다. Bright Data 도구가 호출되었음을 확인하려면(결과가 환각이 아님을 확인하기 위해) “Traces” 드롭다운을 확장하고 오른쪽의 “View” 버튼을 클릭합니다.
여기에서 에이전트의 계획 및 실행 단계를 검사할 수 있습니다. SpaceX 주식 뉴스에 대한 Google 검색을 위해 SERP API 도구를 호출했음을 볼 수 있습니다:
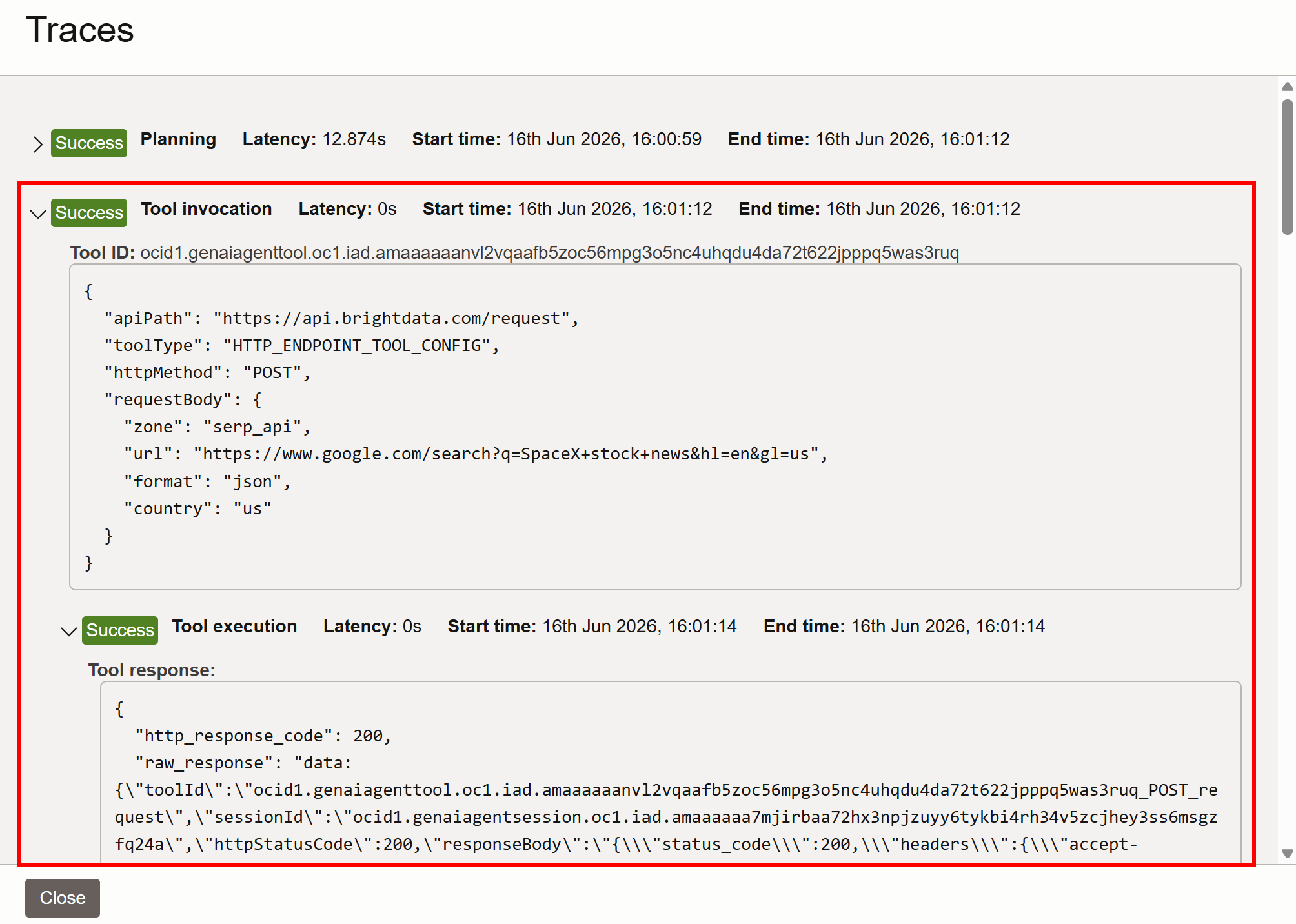
내부적으로 에이전트 도구는 Bright Data SERP API를 호출하며, 이 Google SERP의 JSON 버전을 반환합니다:
발견된 URL에서 에이전트는 가장 관련성 높은 소스를 선택하고, 스크래핑하여 검색된 모든 정보를 최종 맥락적 결과로 집계합니다.
완성입니다! 이 간단한 예시는 Bright Data가 제공하는 웹 검색 및 스크래핑 기능 덕분에 Oracle Generative AI 에이전트가 얼마나 근거 있고 정확한지를 보여줍니다. 이제 다양한 프롬프트를 시도하여 지원되는 모든 엔터프라이즈 활용 사례를 탐색해 보세요.
결론
이 튜토리얼에서는 Oracle Generative AI 에이전트 서비스가 무엇인지와 제공하는 기능에 대해 배웠습니다. 또한 AI 에이전트의 한계와 Bright Data API를 통해 엔터프라이즈 시나리오에서 이를 해결하는 방법도 살펴보았습니다.
Bright Data 엔드포인트를 호출하는 커스텀 도구를 갖춘 Oracle Generative AI 에이전트를 정의하는 과정을 안내받았습니다. 그 결과 마치 인간처럼 웹을 탐색하고 정보를 검색할 수 있는 AI 에이전트가 완성되었습니다.
이것은 Bright Data 통합으로 가능한 많은 활용 사례 중 하나에 불과합니다. 구현에 도움이 필요하거나 다른 가능한 시나리오를 탐색하고 싶다면 24/7 지원 팀에 문의하세요.
오늘 무료로 Bright Data 계정을 만들고 웹 데이터 솔루션을 탐색해 보세요!