

이 단계별 튜토리얼을 따라 Indeed의 채용 공고 데이터를 자동으로 수집하는 웹 스크래핑 Python 스크립트를 구축하는 방법을 배워보세요.
이 가이드에서는 다음을 다룹니다:
- 웹에서 채용 정보를 스크래핑해야 하는 이유는?
- 인디드 스크래핑을 위한 라이브러리 및 도구
- Selenium을 이용한 Indeed 채용 정보 스크래핑
웹에서 채용 공고 데이터를 스크래핑해야 하는 이유는 무엇인가요?
웹에서 채용 정보를 스크래핑하는 것은 다음과 같은 여러 이유로 유용합니다:
- 시장 조사: 기업과 취업 시장 분석가가 업계 동향에 대한 정보를 수집할 수 있게 합니다. 예를 들어, 수요가 높은 기술이나 일자리 증가를 경험하는 지역을 파악하는 것이 포함됩니다. 또한 경쟁사의 채용 활동을 모니터링할 수 있게 합니다.
- 구직 및 매칭 효율화: 구직자가 여러 출처의 채용 공고를 검색하여 자신의 자격과 선호도에 맞는 직위를 찾을 수 있도록 지원합니다.
- 채용 및 인사 관리 최적화: 채용 절차를 지원하고 시장 급여 동향 및 지원자가 원하는 복리후생을 파악하는 데 도움을 줍니다.
따라서 구인 데이터는 고용주와 구직자 모두에게 유용합니다.
구인 목록 스크래퍼와 관련하여 강조해야 할 핵심 사항이 하나 있습니다. 대상 플랫폼은 공개되어야 합니다. 즉, 로그인하지 않은 사용자도 구직 검색을 수행할 수 있어야 합니다. 로그인 장벽 아래에서 데이터를 스크래핑하면 법적 문제로 곤란을 겪을 수 있기 때문입니다.
이는 LinkedIn을 제외해야 함을 의미합니다. 그렇다면 어떤 채용 플랫폼이 남을까요? 바로 주요 온라인 채용 플랫폼 중 하나인 Indeed입니다!
인디드 스크래핑을 위한 라이브러리와 도구
파이썬은 구문, 사용 편의성, 풍부한 라이브러리 생태계 덕분에 스크래핑에 가장 적합한 언어 중 하나로 꼽힙니다. 그럼 시작해 보죠. 파이썬을 활용한 웹 스크래핑 가이드를 확인해 보세요.
이제 다양한 스크래핑 라이브러리 중 적합한 것을 선택해야 합니다. 정보에 기반한 결정을 내리기 위해 브라우저에서 인디드를 탐색해 보세요. 사이트의 대부분의 데이터가 상호작용 후에 불러온다는 점을 알 수 있을 것입니다. 이는 사이트가 페이지 재로딩 없이 동적으로 콘텐츠를 로드하고 업데이트하기 위해 AJAX를 많이 사용한다는 의미입니다. 이러한 사이트에서 웹 스크래핑을 하려면 자바스크립트를 실행할 수 있는 도구가 필요합니다. 그 도구가 바로 셀레늄입니다!
셀레늄은 파이썬으로 동적 웹사이트를 스크래핑할 수 있게 합니다. 제어 가능한 웹 브라우저에서 사이트를 렌더링하며 사용자의 지시에 따라 작업을 수행합니다. 셀레늄 덕분에 대상 사이트가 렌더링이나 데이터 검색에 자바스크립트를 사용하더라도 데이터를 추출할 수 있습니다.
인디드(Indeed) 같은 웹사이트에서 채용 공고를 스크래핑하는 방법을 배워보세요!
셀레니움으로 인디드에서 채용 공고 데이터 스크래핑하기
이 단계별 튜토리얼을 따라 Indeed 웹 스크래핑 Python 스크립트를 구축하는 방법을 확인하세요.
1단계: 프로젝트 설정
웹 스크래핑 작업을 시작하기 전에 다음 필수 조건을 충족하는지 확인하세요:
- 컴퓨터에 Python 3 이상 설치: 설치 프로그램을 다운로드하고 더블 클릭한 후 설치 마법사를 따라 진행하세요.
- 원하는 Python IDE: PyCharm Community Edition 또는 Python 확장 프로그램이 설치된 Visual Studio Code가 두 가지 훌륭한 선택지입니다.
이제 Python 프로젝트를 설정하는 데 필요한 모든 것이 준비되었습니다!
터미널을 열고 다음 명령어를 실행하여:
- indeed-scraper 폴더 생성
- 해당 폴더로 이동
- Python 가상 환경으로 초기화하기
mkdir indeed-scraper
cd indeed-scraper
python -m venv envLinux 또는 macOS에서는 아래 명령어로 환경을 활성화하세요:
./env/bin/activate
Windows에서는 다음을 실행하세요:
envScriptsactivate.ps1
다음으로, 프로젝트 폴더에 아래 줄이 포함된 scraper.py 파일을 생성합니다:
print("Hello, World!")
현재는 “Hello, World!”만 출력되지만, 곧 인디드 스크래핑 로직이 포함될 예정입니다.
다음 명령어로 실행하여 정상 작동하는지 확인하세요:
python scraper.py
모든 것이 계획대로 진행되었다면 터미널에 다음과 같은 메시지가 출력됩니다:
Hello, World!
스크립트가 작동한다는 것을 확인했으니, Python IDE에서 프로젝트 폴더를 열어 보세요.
잘하셨습니다! 이제 Python 코드를 작성할 준비를 하세요!
2단계: 스크래핑 라이브러리 설치
앞서 언급했듯이, Selenium은 Indeed에서 웹 스크래핑으로 채용 공고를 수집할 때 유용한 도구입니다. 활성화된 Python 가상 환경에서 아래 명령어를 실행하여 프로젝트의 종속성에 추가하세요:
pip install selenium
시간이 좀 걸릴 수 있으니 기다려 주세요.
이 튜토리얼은 자동 드라이버 감지 기능을 갖춘 Selenium 4.11.2 버전을 기준으로 합니다. PC에 이전 버전의 Selenium이 설치되어 있다면 다음 명령어로 업데이트하세요:
pip install selenium -U
이제 scraper.py 파일을 비워주세요. 그런 다음 패키지를 임포트하고 Selenium 스크레이퍼를 초기화합니다:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 제어 가능한 Chrome 인스턴스 설정
# 헤드리스 모드에서 실행
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=service,
options=options
)
# 스크래핑 로직...
# 브라우저 종료 및 리소스 해제
driver.quit()
이 스크립트는 WebDriver 인스턴스를 생성하여 Chrome 인스턴스를 프로그래밍 방식으로 제어합니다. 브라우저는 백그라운드에서 헤드리스 모드(GUI 없이)로 실행됩니다. 이는 프로덕션 환경에서 흔히 사용되는 설정입니다. 대신 웹 스크래핑 작업 스크립트가 페이지에서 실행하는 작업을 따라가려면 해당 옵션을 주석 처리하세요. 이는 개발 시 유용합니다.
Python IDE에서 오류가 발생하지 않는지 확인하세요. 사용되지 않는 임포트 때문에 발생하는 경고는 무시해도 됩니다. 이제 GitHub에서 저장소 데이터를 추출하기 위해 라이브러리를 사용할 예정입니다!
완벽합니다! 이제 웹 스크래핑을 위한 Indeed Python 스크레이퍼를 구축할 시간입니다.
3단계: 대상 웹 페이지 연결
인디드(Indeed)를 열고 관심 있는 일자리를 검색하세요. 본 가이드에서는 뉴욕 지역 소프트웨어 엔지니어 원격 채용 공고를 스크래핑하는 방법을 보여드립니다. 다른 인디드 일자리 검색도 동일하게 적용 가능하며 스크래핑 로직은 동일합니다.
현재 작성 시점 기준 대상 페이지의 브라우저 화면은 다음과 같습니다:
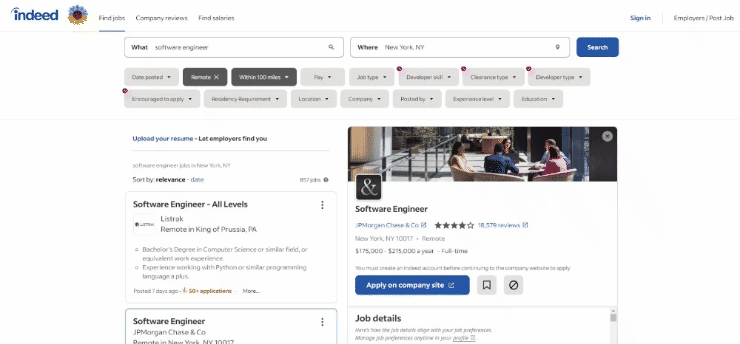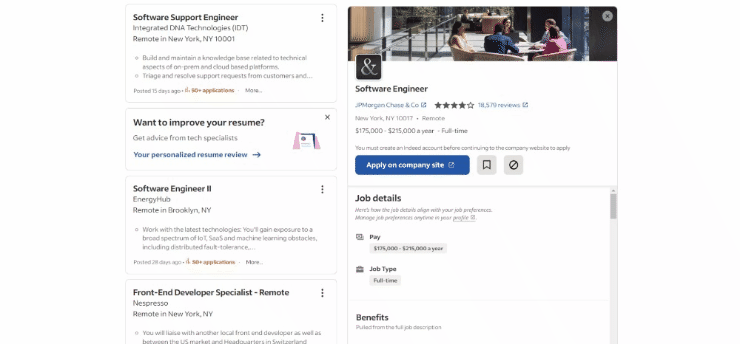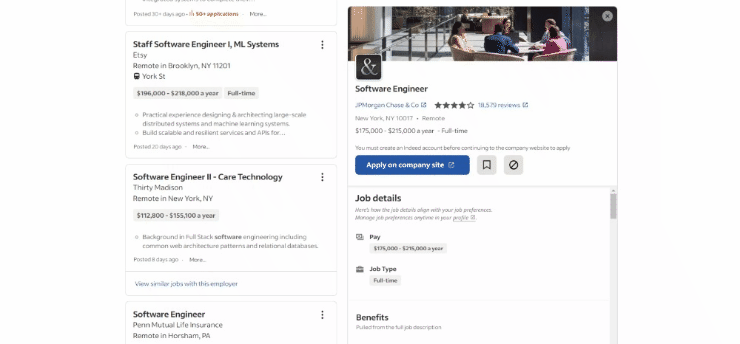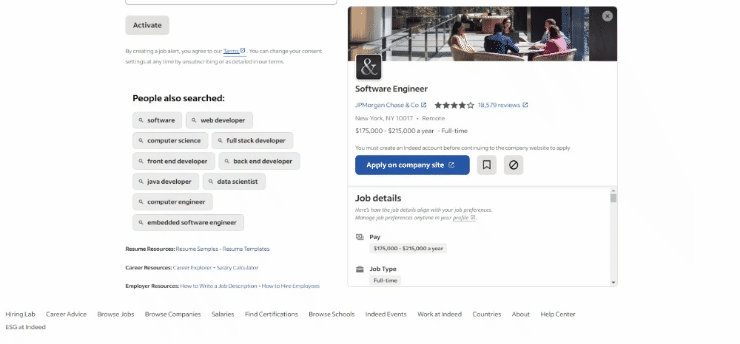
특히, 대상 페이지의 URL은 다음과 같습니다:
https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100
보시다시피, 이는 일부 쿼리 매개변수에 따라 변경되는 동적 URL입니다.
Selenium을 사용하여 대상 페이지에 다음과 같이 연결할 수 있습니다:
driver.get("https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100")
get() 함수는 브라우저가 매개변수로 전달된 URL로 지정된 페이지를 방문하도록 지시합니다.
페이지 열기 후 모든 요소가 표시되도록 창 크기를 설정해야 합니다:
driver.set_window_size(1920, 1080)
지금까지 작성한 Indeed 스크래핑 스크립트는 다음과 같습니다:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 제어 가능한 Chrome 인스턴스 설정
# 헤드리스 모드에서 실행
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=service,
options=options
)
# 페이지가 반응형 모드로 렌더링되지 않도록
# 창 크기를 설정
driver.set_window_size(1920, 1080)
# 브라우저에서 대상 페이지 열기
driver.get("https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100")
# 스크래핑 로직...
# 브라우저 닫기 및 리소스 해제
driver.quit()
헤드리스 모드 활성화 옵션을 주석 처리하고 스크립트를 실행하세요. 창이 닫히기 직전 아주 짧은 순간 아래와 같은 창이 열립니다:
“Chrome이 자동화된 소프트웨어로 제어되고 있습니다”라는 경고 문구를 확인하세요. 이는 Selenium이 정상적으로 작동함을 보장합니다.
4단계: 페이지 구조 파악하기
스크래핑을 시작하기 전에 수행해야 할 또 다른 중요한 단계가 있습니다. 사이트에서 데이터를 스크래핑하려면 HTML 요소를 선택하고 해당 요소에서 데이터를 추출해야 합니다. DOM에서 원하는 노드를 찾는 방법이 항상 쉬운 것은 아닙니다. 효과적인 선택 전략을 정의하는 방법을 이해하기 위해 페이지 구조를 분석하는 데 시간을 할애해야 하는 이유가 바로 여기에 있습니다.
브라우저를 열고 인디드(Indeed) 구직 검색 페이지를 방문하세요. 아무 요소나 마우스 오른쪽 버튼으로 클릭하고 “검사” 옵션을 선택하여 브라우저의 개발자 도구(DevTools)를 엽니다:
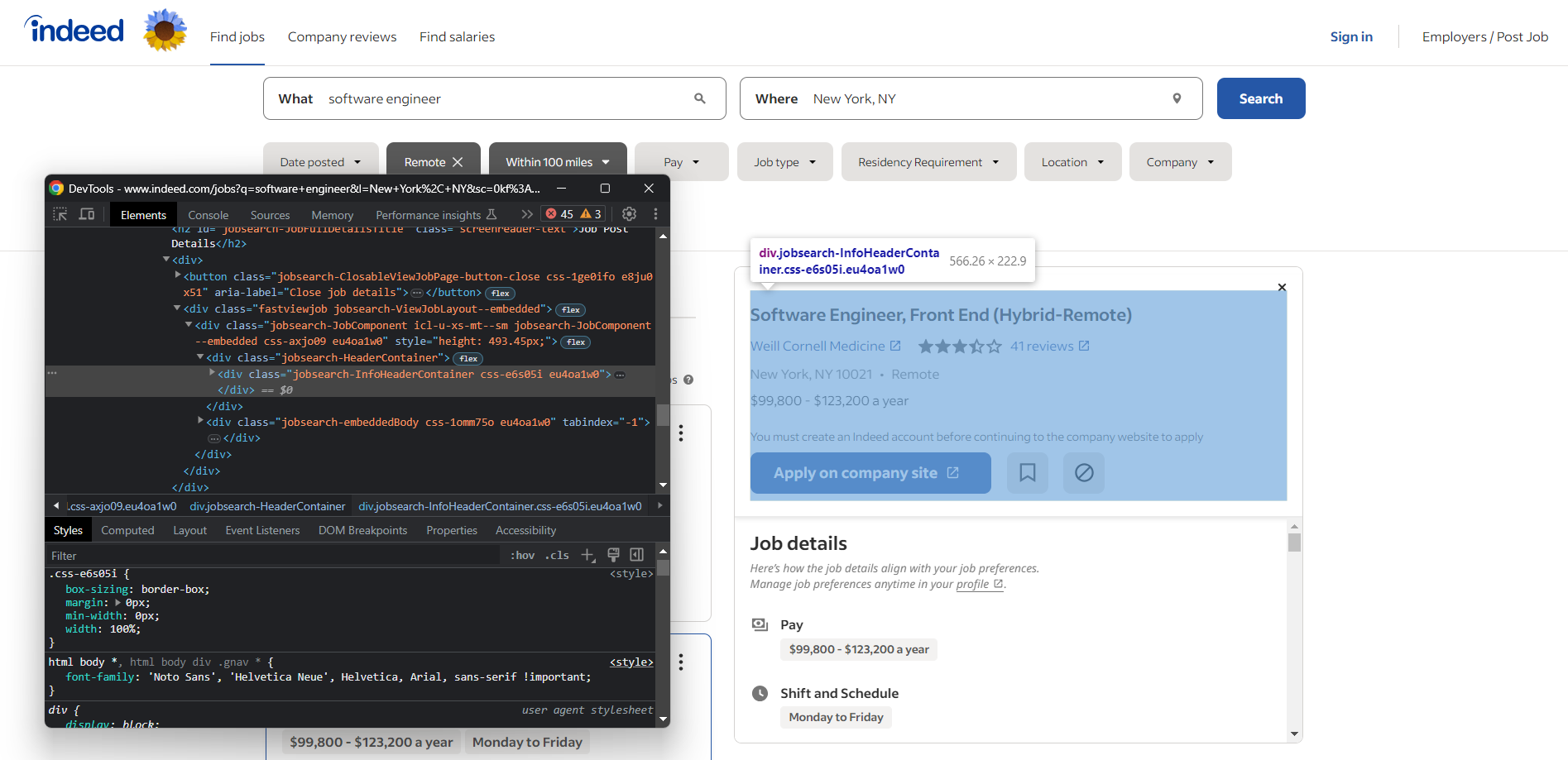
여기서 흥미로운 데이터를 포함하는 대부분의 요소가 다음과 같은 CSS 클래스를 가지고 있음을 확인할 수 있습니다:
css-j45z4f,css-1m4cuuf, …e37uo190,eu4oa1w0, …job_f27ade40cc1a3686,job_1a53a17f1faeae92, …
이러한 클래스는 컴파일 시점에 무작위로 생성된 것으로 보이기 때문에 스크래핑에 의존해서는 안 됩니다. 대신 다음과 같은 클래스를 기반으로 선택 로직을 구성해야 합니다:
jobsearch-JobInfoHeader-titledatecardOutline
또는 다음과 같은 ID를 사용하십시오:
companyRatingsapplyButtonLinkContainerjobDetailsSection
또한 일부 노드에는 고유한 HTML 속성이 있습니다:
data-company-namedata-testid
이는 인디드에서 웹 스크래핑 작업을 수행할 때 유용한 정보입니다. 페이지와 상호작용하며 반응 방식과 표시되는 데이터를 연구하세요. 서로 다른 채용 공고마다 다른 정보 속성을 가지고 있음을 알게 될 것입니다.
다음 단계로 넘어가기 전에 목표 사이트를 계속 검사하고 DOM 구조에 익숙해지세요.
5단계: 채용 정보 추출 시작
단일 인디드 검색 페이지에는 여러 채용 공고가 포함됩니다. 따라서 페이지에서 스크래핑한 채용 정보를 추적하기 위해 배열이 필요합니다:
jobs = []이전 단계에서 확인했듯이, 채용 공고는 .cardOutline 카드에 표시됩니다:
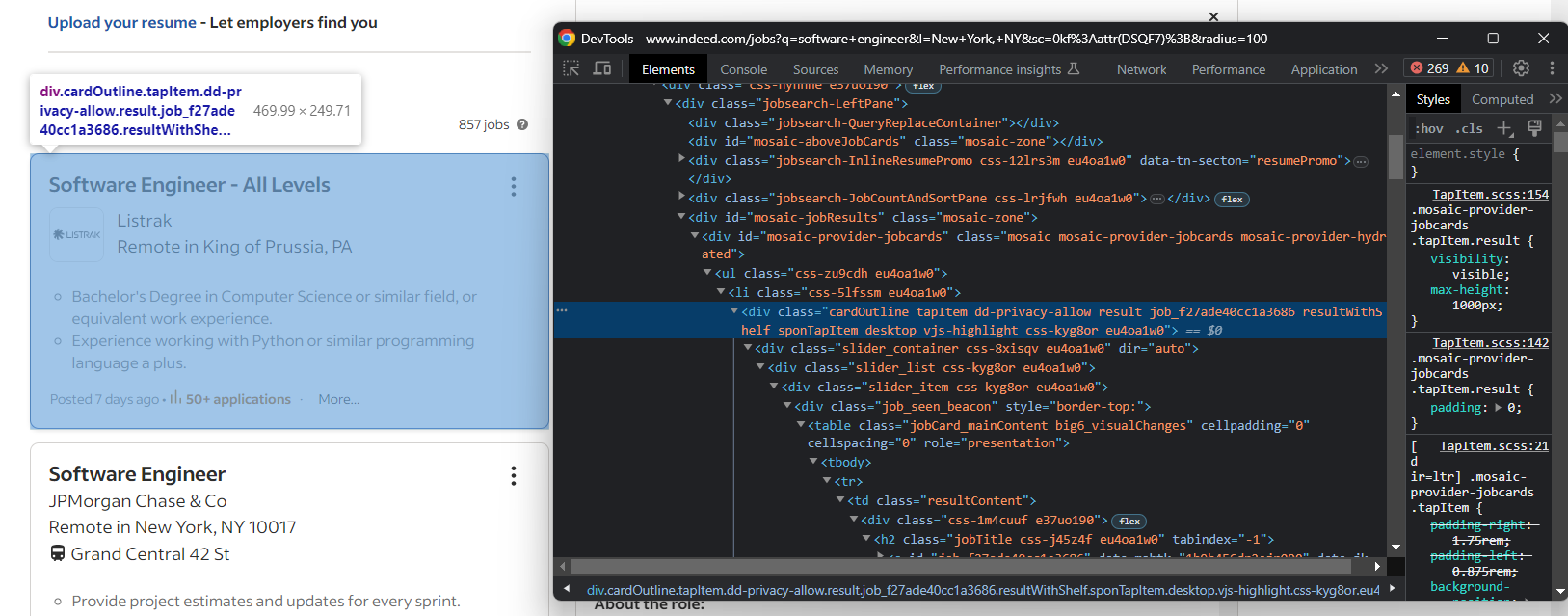
다음 코드로 모두 선택하세요:
job_cards = driver.find_elements(By.CSS_SELECTOR, ".cardOutline")
Selenium의 find_elements() 메서드는 웹 페이지에서 웹 요소를 찾을 수 있게 해줍니다. 마찬가지로, 선택 쿼리와 일치하는 첫 번째 노드를 가져오는 find_element() 메서드도 있습니다.
By.CSS_SELECTOR는 드라이버에게 CSS 선택기 전략을 사용하도록 지시합니다. Selenium은 또한 다음을 지원합니다:
By.ID: HTMLid속성으로 요소를 검색합니다By.TAG_NAME: HTML 태그를 기반으로 요소를 검색합니다By.XPATH: XPath 표현식을 통해 요소를 검색합니다
By를 다음에서 임포트하세요:
from selenium.webdriver.common.by import By
작업 카드 목록을 반복 처리하고 작업 세부 정보를 저장할 Python 사전 초기화:
for job_card in job_cards:
# 스크랩된 작업 데이터를 저장할 사전 초기화
job = {}
# 작업 데이터 추출 로직...
구인 공고에는 여러 속성이 있을 수 있습니다. 필수 속성은 일부에 불과하므로, 기본값을 가진 변수 목록을 즉시 초기화합니다:
posted_at = None
applications = None
title = None
company_name = None
company_rating = None
company_reviews = None
location = None
location_type = None
apply_link = None
pay = None
job_type = None
benefits = None
description = None
이제 페이지 구조를 파악하셨으니, 일부 세부 정보는 개요 탭의 채용 카드에 표시되고, 다른 정보는 상호작용 시 나타나는 상세 정보 탭에 있다는 점을 아실 겁니다.
예를 들어, 생성 날짜와 지원자 수는 요약 탭에 있습니다:
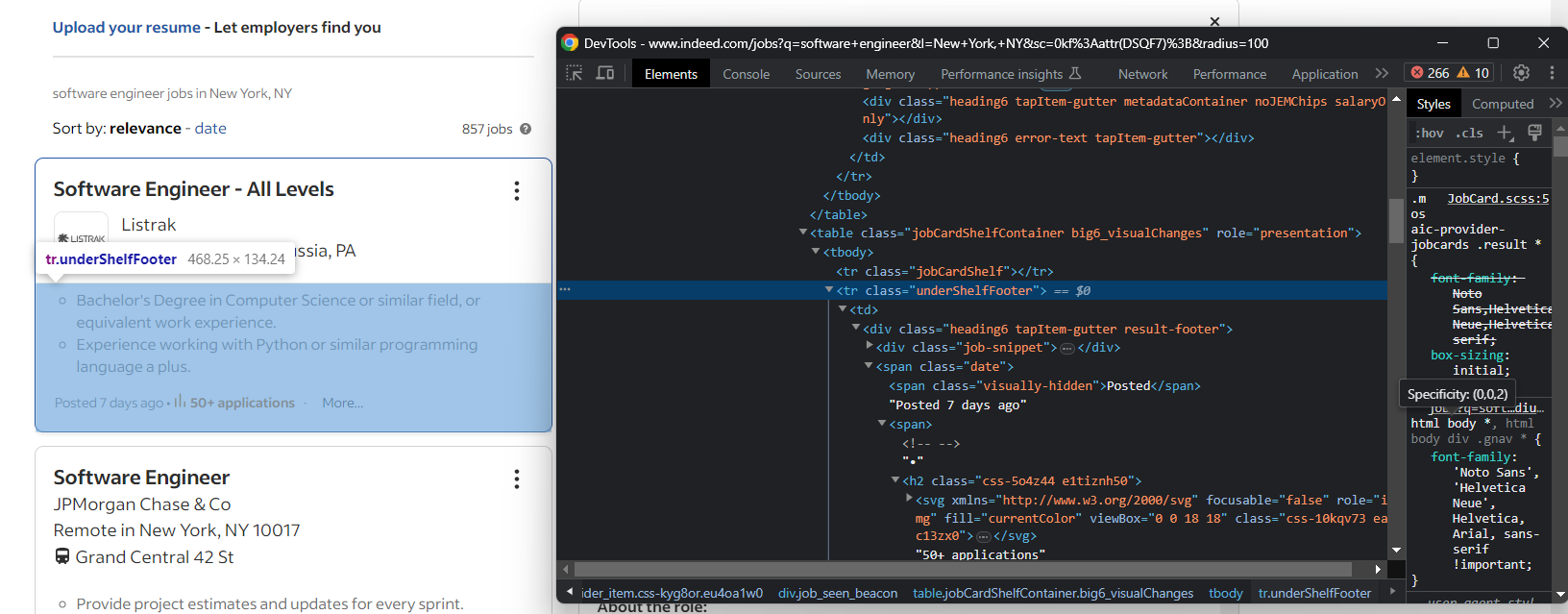
다음 코드로 둘 다 추출하세요:
try:
date_element = job_card.find_element(By.CSS_SELECTOR, ".date")
date_element_text = date_element.text
posted_at_text = date_element_text
if "•" in date_element_text:
date_element_text_array = date_element_text.split("•")
posted_at_text = date_element_text_array[0]
applications = date_element_text_array[1]
.replace("applications", "")
.replace("in progress", "")
.strip()
posted_at = posted_at_text
.replace("Posted", "")
.replace("Employer", "")
.replace("Active", "")
.strip()
except NoSuchElementException:
pass
이 코드 조각은 인디드에서 채용 공고를 웹 스크래핑하는 데 핵심적인 패턴을 보여줍니다. 대부분의 정보 요소가 선택 사항이므로 다음 오류로부터 보호해야 합니다:
selenium.common.exceptions.NoSuchElementException: Message: no such element
Selenium은 현재 페이지에 존재하지 않는 HTML 요소를 선택하려고 할 때 이 예외를 발생시킵니다.
예외를 다음과 같이 임포트하세요:
from selenium.common import NoSuchElementException
try ... catch 구문을 사용하면 대상 요소가 DOM에 존재하지 않을 경우 스크립트가 오류 없이 계속 실행됩니다.
또한 일부 작업 정보는 다음과 같은 문자열에 포함됩니다:
<info_1> • <info_2>
<info_2> 가 누락된 경우 문자열 형식은 다음과 같습니다:
<info_1>
따라서 "•" 문자의 유무에 따라 데이터 추출 로직을 변경해야 합니다.
HTML 요소가 주어지면 text 속성을 통해 해당 텍스트 콘텐츠에 접근할 수 있습니다. 수집된 문자열을 정리하기 위해 Python의 replace() 메서드를 사용하세요.
6단계: 인디드(Indeed)의 스크래핑 방지 조치 대응
Indeed는 봇이 데이터에 접근하는 것을 방지하기 위해 몇 가지 기술과 기법을 채택하고 있습니다. 예를 들어, 채용 공고 카드와 상호작용할 때 가끔씩 다음과 같은 모달 창을 열곤 합니다:
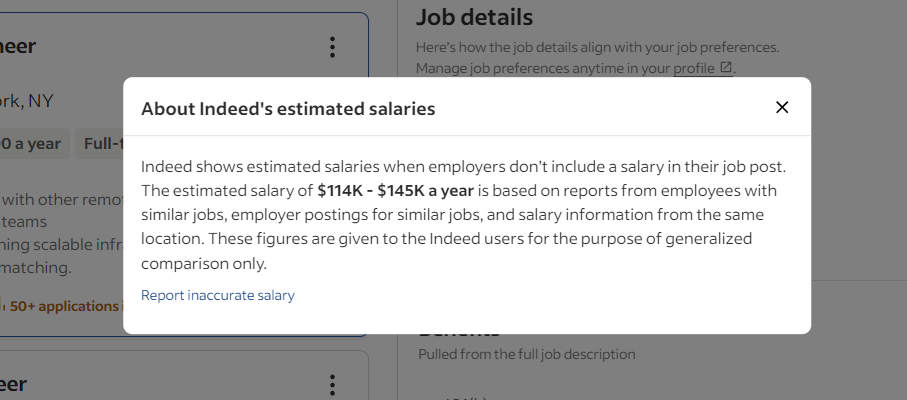
이 팝업은 상호작용을 차단합니다. 제대로 처리하지 않으면 Selenium Indeed 스크립트가 중단됩니다. 개발자 도구(DevTools)에서 이를 검사하고 닫기 버튼에 주목하세요:
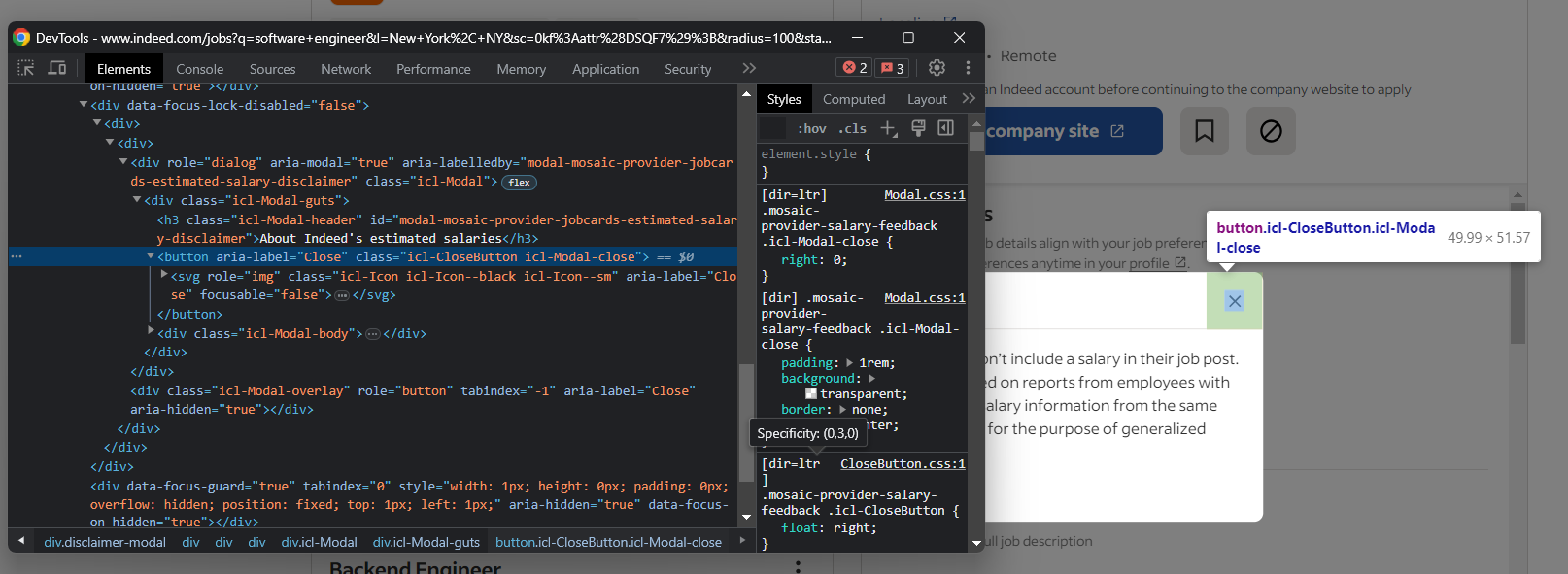
Selenium에서 이 모달을 닫으려면 다음을 사용하세요:
try:
dialog_element = driver.find_element(By.CSS_SELECTOR, "[role=dialog]")
close_button = dialog_element.find_element(By.CSS_SELECTOR, ".icl-CloseButton")
close_button.click()
except NoSuchElementException:
pass
Selenium의 click() 메서드를 사용하면 제어 중인 브라우저에서 선택한 요소를 클릭할 수 있습니다.
훌륭합니다! 이렇게 하면 팝업이 닫히고 상호작용을 계속할 수 있습니다.
진지하게 고려해야 할 또 다른 데이터 보호 기술은 Cloudflare입니다. 페이지와 지나치게 상호작용하고 너무 많은 요청을 생성하면 Indeed는 다음과 같은 봇 방지 화면을 표시합니다:
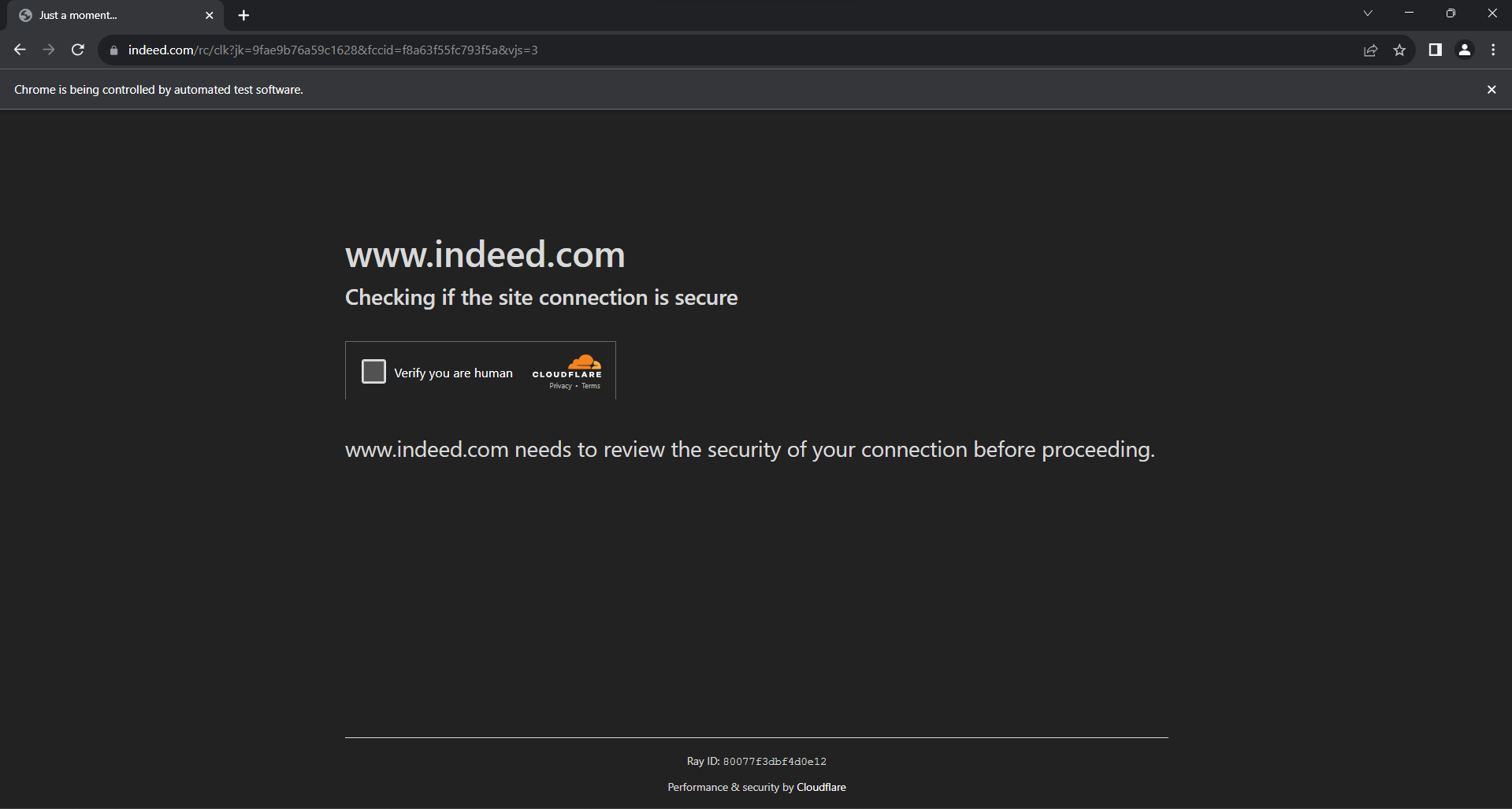
Selenium으로 Cloudflare CAPTCHA를 해결하는 것은 프리미엄 제품이 필요한 매우 까다로운 작업입니다. 결국 Indeed 스크래핑은 쉽지 않습니다. 다행히 스크립트에 무작위 지연을 도입하면 이를 피할 수 있습니다.
for 루프의 마지막 작업은 반드시 다음과 같아야 합니다:
time.sleep(random.uniform(1, 5))
이렇게 하면 스크립트가 1초에서 5초 사이의 무작위 시간 동안 멈춥니다.
파이썬 표준 라이브러리에서 필요한 패키지를 다음과 같이 임포트하세요:
import random
import time
잘하셨습니다! 이제 자동화된 스크립트가 인디드(Indeed)에서 스크래핑하는 것을 막을 수 있는 것은 아무것도 없습니다.
7단계: 채용 공고 상세 카드 열기
개요 채용 카드(outline job card)를 클릭하면 Indeed는 AJAX 호출을 수행하여 실시간으로 세부 정보를 가져옵니다. 이 데이터를 기다리는 동안 페이지에는 애니메이션 플레이스홀더가 표시됩니다:
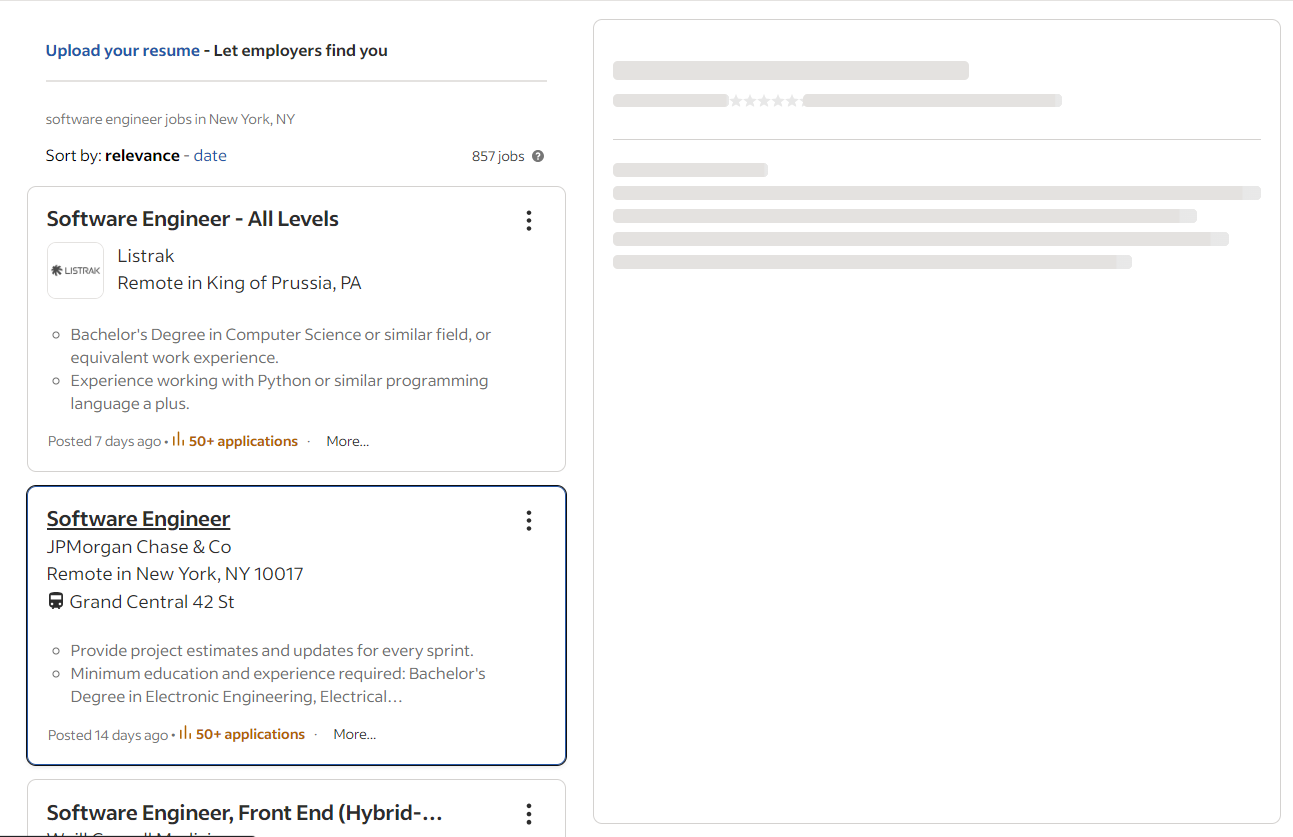
아래 요소가 페이지에 표시되면 상세 정보 섹션이 로드된 것을 확인할 수 있습니다:
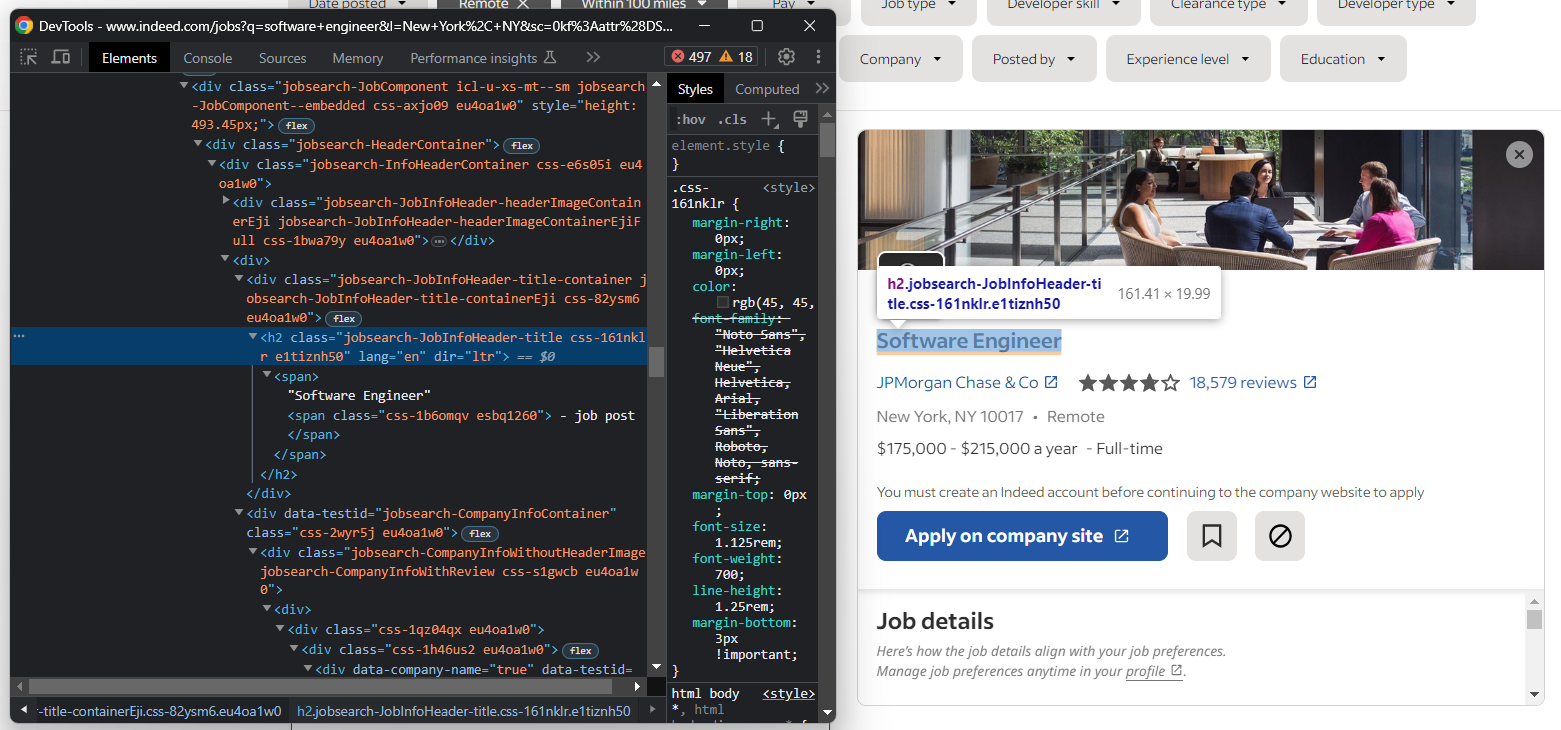
따라서 Selenium에서 채용 공고 상세 데이터에 접근하려면 다음을 수행해야 합니다:
- 클릭 작업을 수행하세요
- 관심 데이터가 페이지에 포함될 때까지 대기
이를 달성하는 방법은 다음과 같습니다:
job_card.click()
try:
title_element = WebDriverWait(driver, 5)
.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".jobsearch-JobInfoHeader-title")))
title = title_element.text.replace("n- job post", "")
except NoSuchElementException:
continue
Selenium의 WebDriverWait 객체는 특정 조건이 발생할 때까지 대기할 수 있게 합니다. 이 경우 스크립트는 .jobsearch-JobInfoHeader-title이 페이지에 표시될 때까지 최대 5초 동안 대기합니다. 이후에는 TimeoutException을 발생시킵니다.
위 코드 조각은 채용 공고의 제목도 함께 가져온다는 점에 유의하십시오.
WebDriverWait 및 EC 임포트:
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
이제부터 주목할 요소는 이 세부 정보 열입니다:
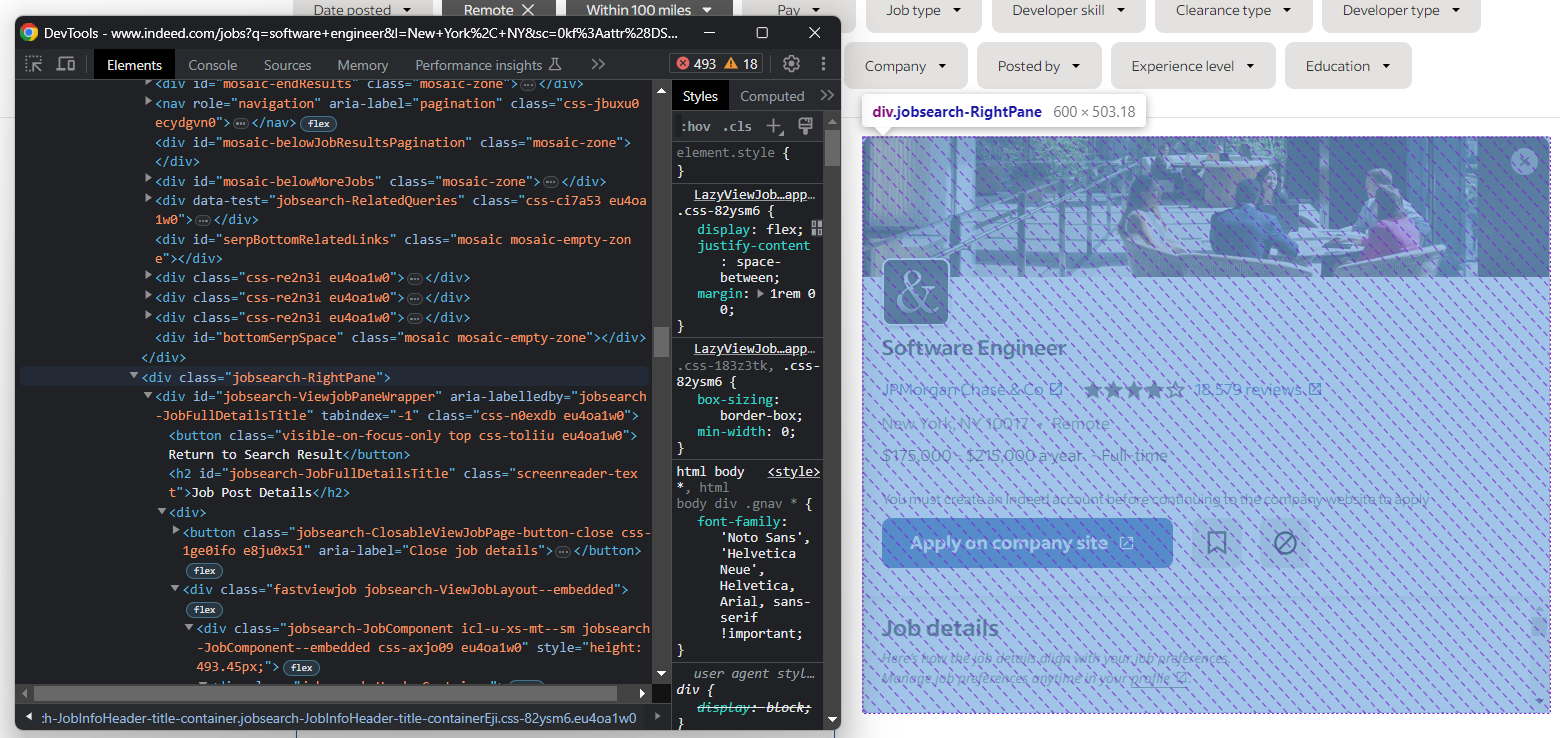
다음으로 선택합니다:
job_details_element = driver.find_element(By.CSS_SELECTOR, ".jobsearch-RightPane")
훌륭합니다! 이제 채용 정보를 스크래핑할 준비가 모두 완료되었습니다!
8단계: 채용 정보 세부사항 추출
4단계에서 정의한 변수에 채용 정보를 채울 시간입니다.
채용 공고의 회사명을 가져옵니다:
try:
company_link_element = job_details_element.find_element(By.CSS_SELECTOR, "div[data-company-name='true'] a")
company_name = company_link_element.text
except NoSuchElementException:
pass
그런 다음 회사의 사용자 평점과 리뷰 수 정보를 추출합니다:
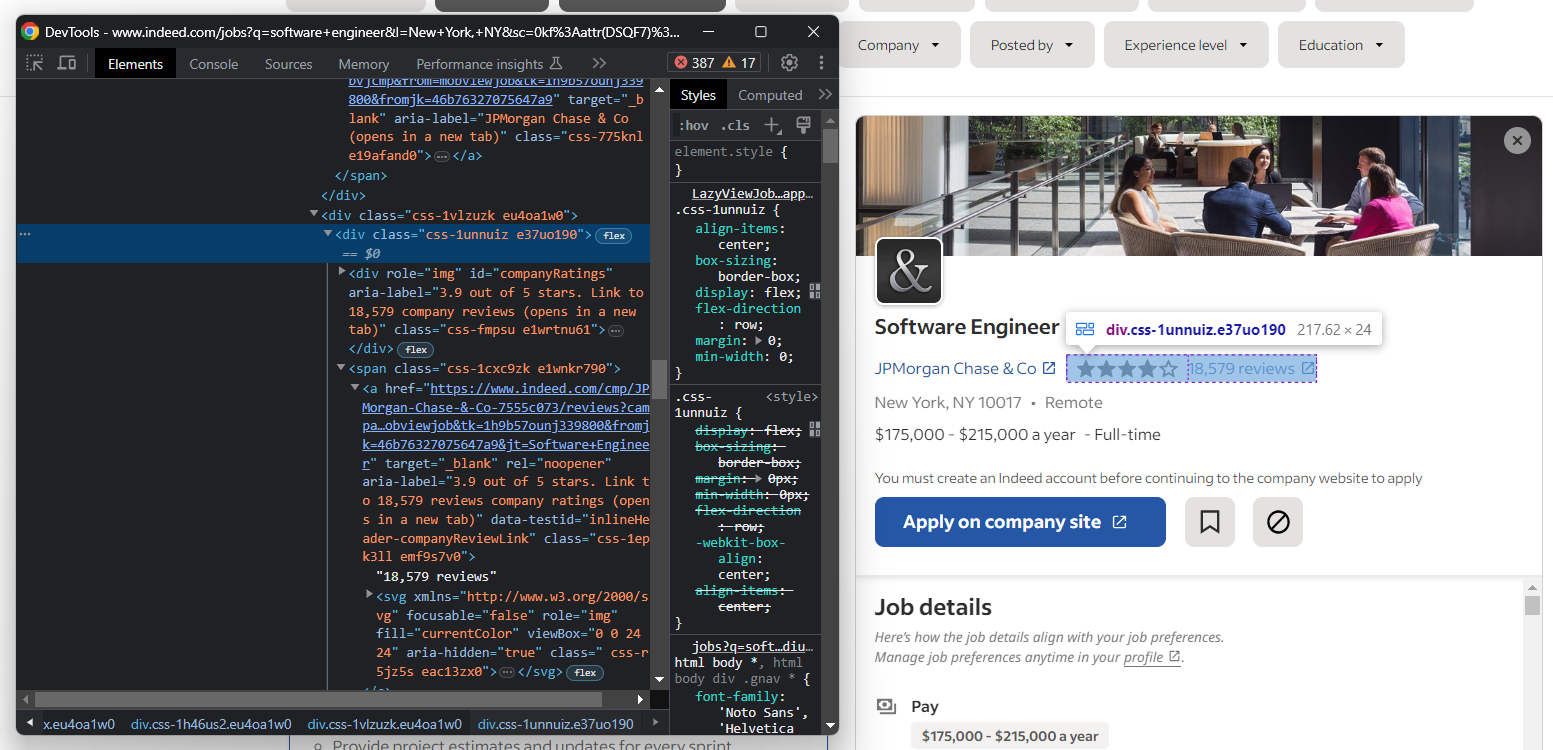
보시다시피, 리뷰 수를 저장하는 요소에 접근하는 쉬운 방법은 없습니다.
try:
company_rating_element = job_details_element.find_element(By.ID, "companyRatings")
company_rating = company_rating_element.get_attribute("aria-label").split("out")[0].strip()
company_reviews_element = job_details_element.find_element(By.CSS_SELECTOR, "[data-testid='inlineHeader-companyReviewLink']")
company_reviews = company_reviews_element.text.replace(" reviews", "")
except NoSuchElementException:
pass
다음으로 회사 위치에 집중하세요:
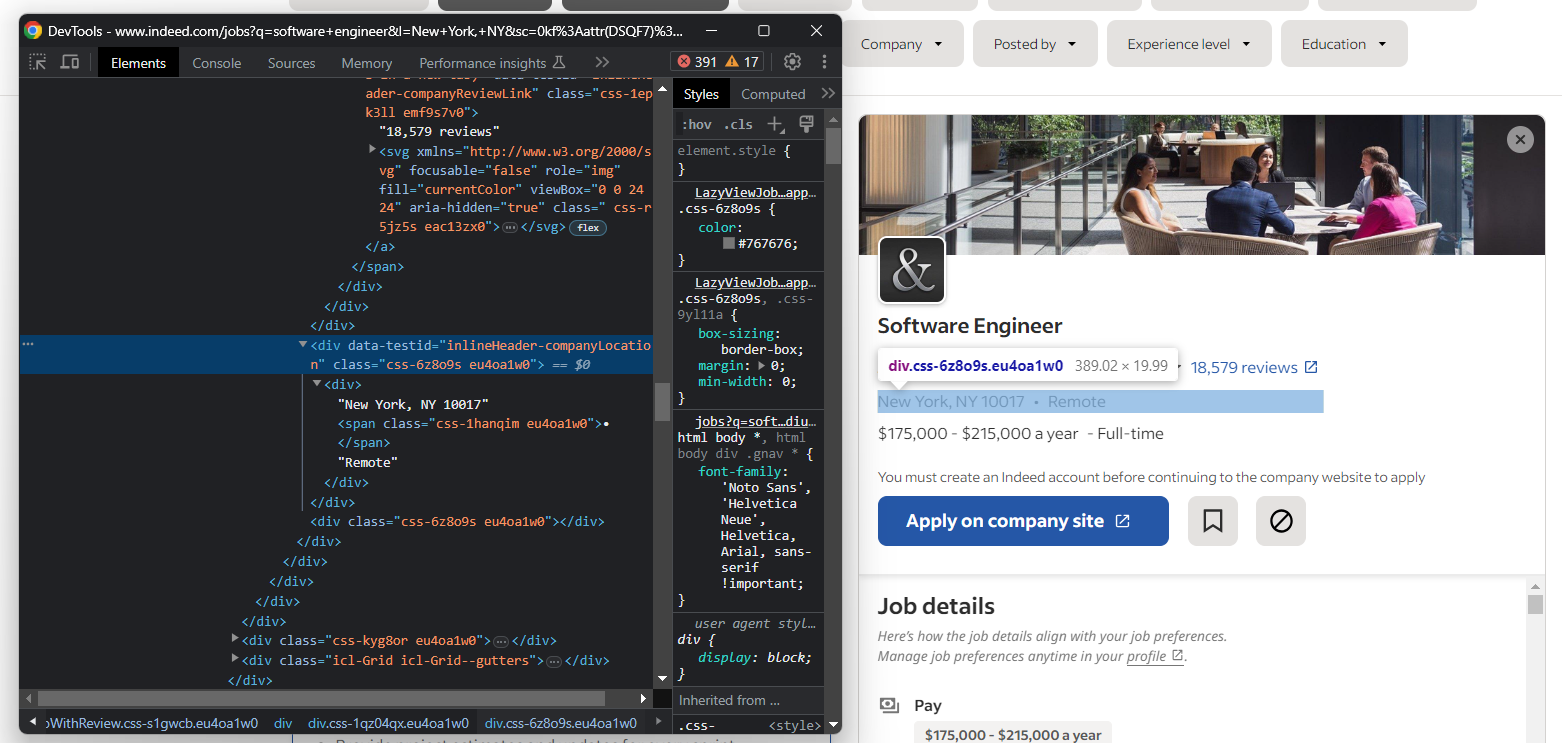
다시, 4단계에서 언급한 "``•``" 패턴을 적용해야 합니다:
try:
company_location_element = job_details_element.find_element(By.CSS_SELECTOR,
"[data-testid='inlineHeader-companyLocation']")
company_location_element_text = company_location_element.text
location = company_location_element_text
if "•" in company_location_element_text:
company_location_element_text_array = company_location_element_text.split("•")
location = company_location_element_text_array[0]
location_type = company_location_element_text_array[1]
except NoSuchElementException:
pass
빠르게 지원하고 싶을 수 있으니, 인디드(Indeed)의 “회사 사이트에서 지원하기” 버튼도 확인해 보세요:
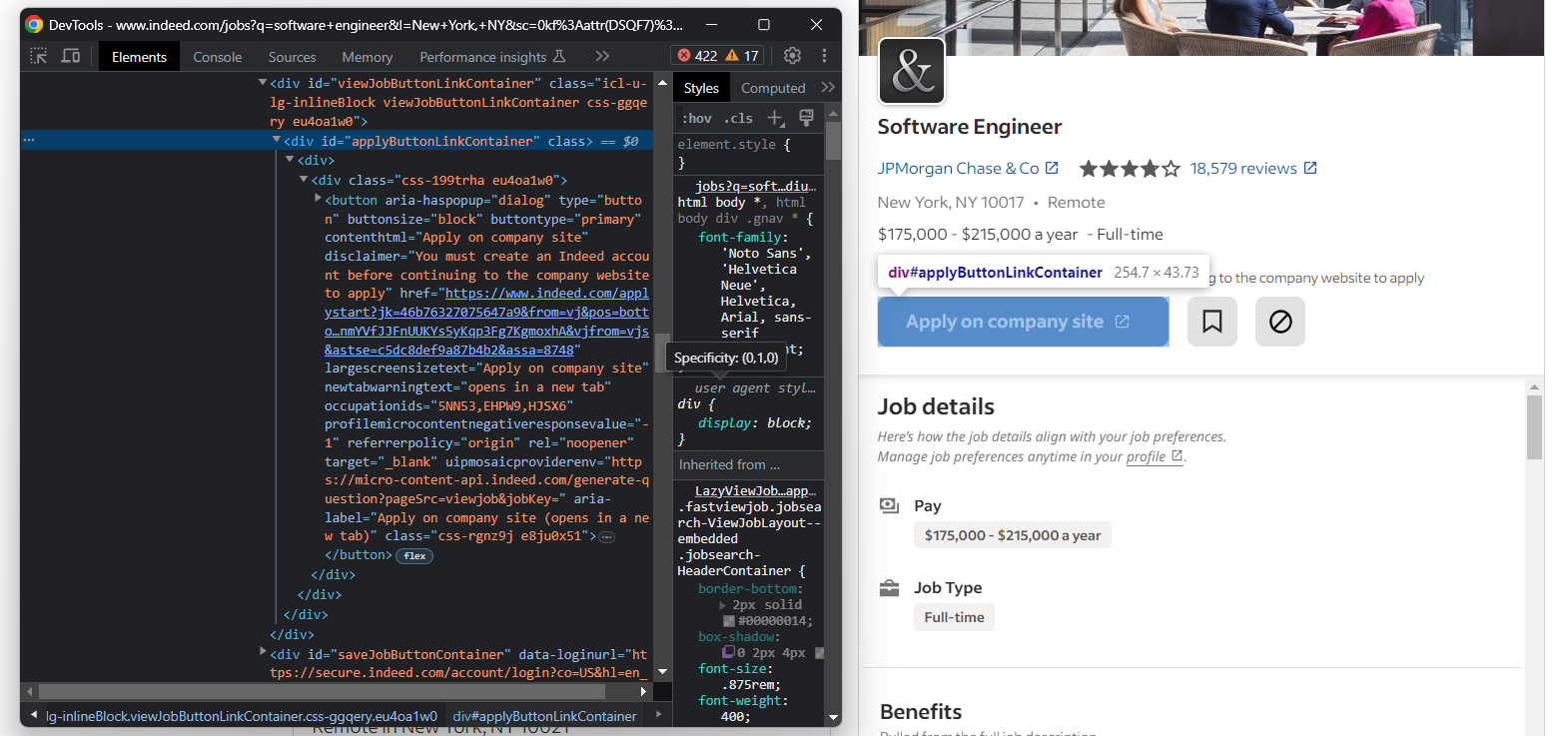
버튼의 대상 URL을 다음과 같이 가져옵니다:
try:
apply_link_element = job_details_element.find_element(By.CSS_SELECTOR, "#applyButtonLinkContainer button")
apply_link = apply_link_element.get_attribute("href")
except NoSuchElementException:
pass
Selenium의 get_attribute() 는 지정된 HTML 속성의 값을 반환합니다.
이제 까다로운 부분이 시작됩니다.
“Job details” 섹션을 살펴보면 급여와 직무 유형 요소를 쉽게 선택할 방법이 없다는 것을 알 수 있습니다:
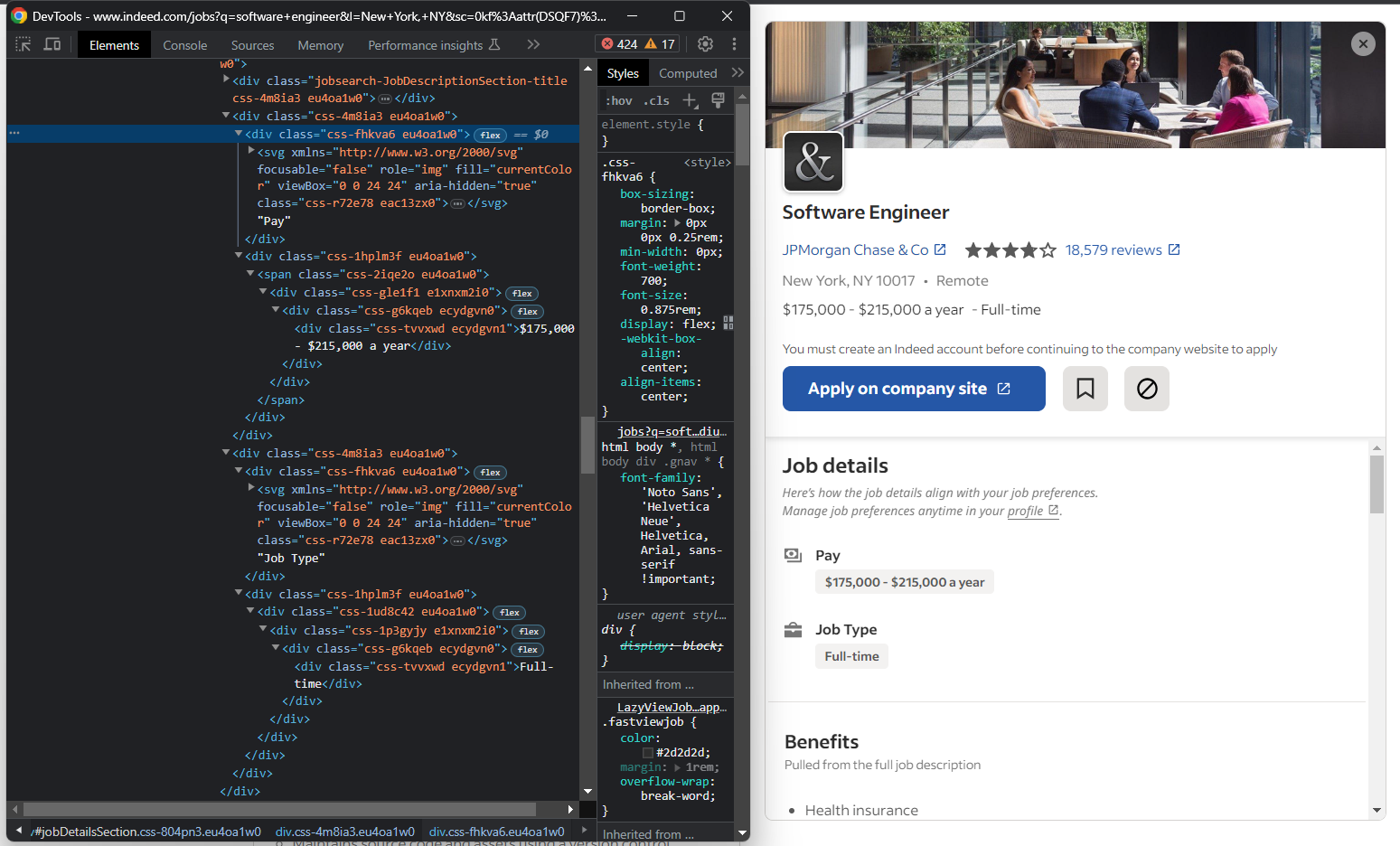
다음과 같은 방법이 있습니다:
- “Job details”
<div>내부의 모든<div>를 가져옵니다. - 이들을 반복 처리합니다
- 현재
<div>의 텍스트에 “급여” 또는 “직종”이 포함되어 있다면, 바로 다음 형제 요소를 가져옵니다 - 관심 있는 데이터를 추출합니다
다시 말해, 아래와 같은 로직을 구현해야 합니다:
for div in job_details_element.find_elements(By.CSS_SELECTOR, "#jobDetailsSection div"):
if div.text == "Pay":
pay_element = div.find_element(By.XPATH, "following-sibling::*")
pay = pay_element.text
elif div.text == "Job Type":
job_type_element = div.find_element(By.XPATH, "following-sibling::*")
job_type = job_type_element.text
Selenium은 노드의 형제 요소에 접근하기 위한 유틸리티 메서드를 제공하지 않습니다. 대신 following-sibling::* Xpath 표현식을 사용할 수 있습니다.
이제 직무 혜택에 집중하세요. 일반적으로 하나 이상 존재합니다:
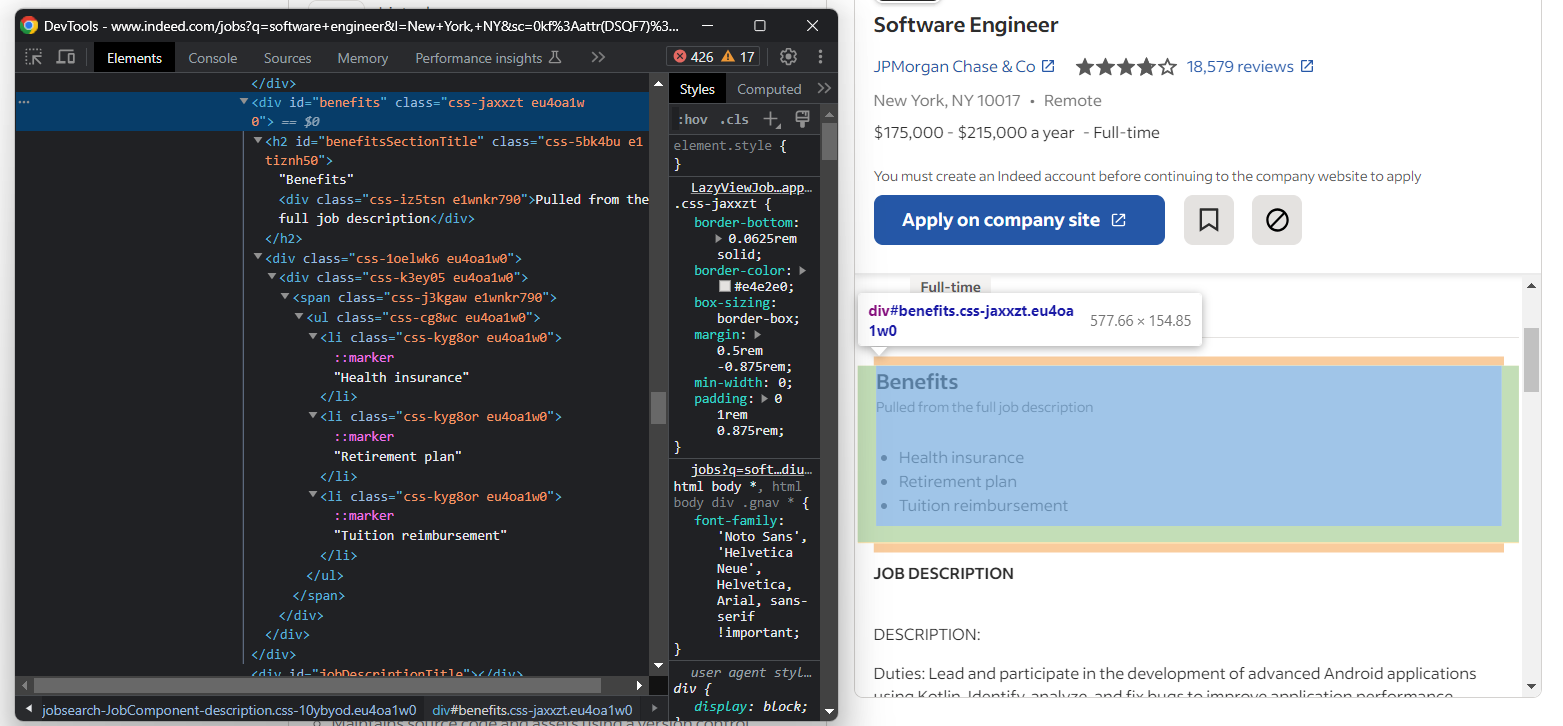
모든 혜택을 가져오려면 리스트를 초기화하고 다음으로 채워야 합니다:
try:
benefits_element = job_details_element.find_element(By.ID, "benefits")
benefits = []
for benefit_element in benefits_element.find_elements(By.TAG_NAME, "li"):
benefit = benefit_element.text
benefits.append(benefit)
except NoSuchElementException:
pass
마지막으로 원본 직무 설명을 가져옵니다:
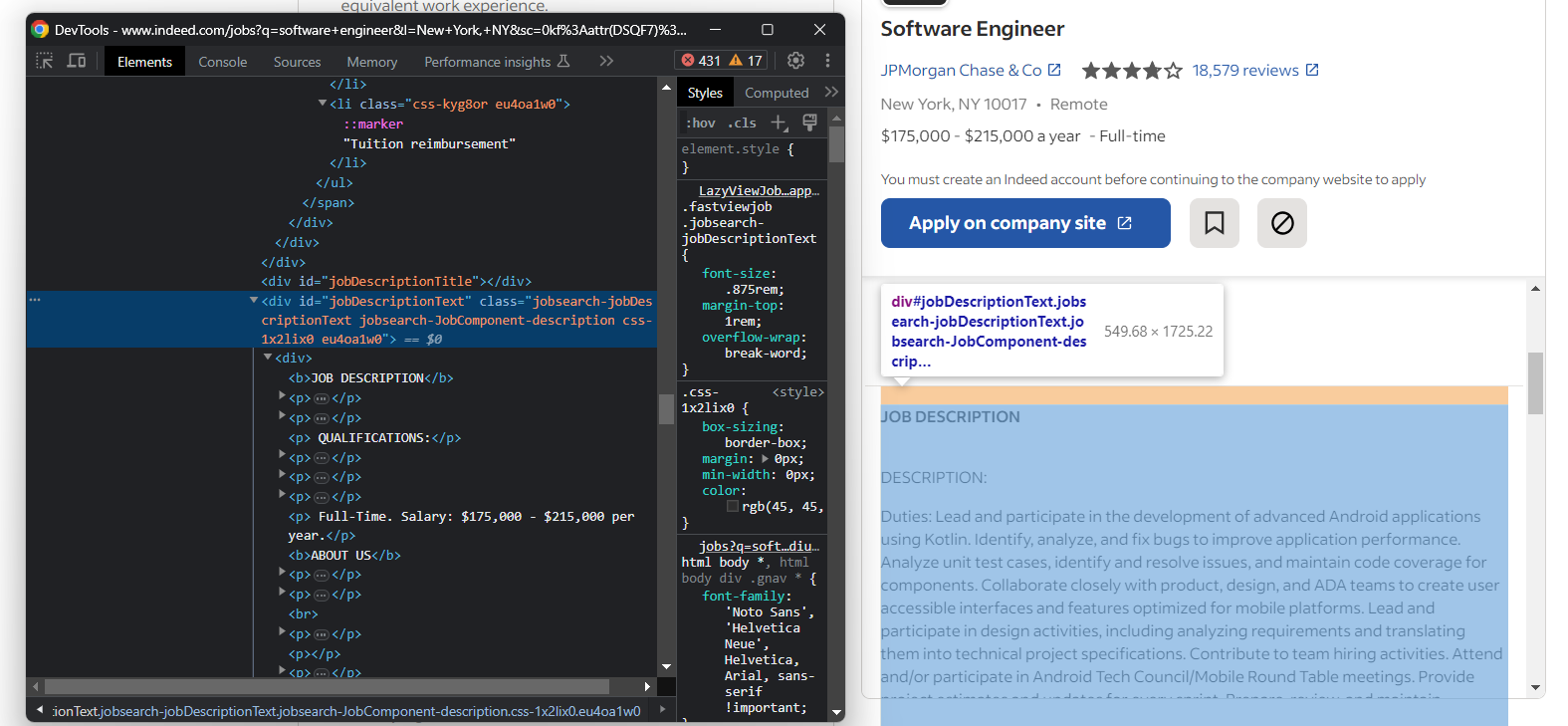
설명 텍스트를 추출합니다:
try:
description_element = job_details_element.find_element(By.ID, "jobDescriptionText")
description = description_element.text
except NoSuchElementException:
pass
직무 사전(dictionary)을 채우고 jobs 목록에 추가합니다:
job["posted_at"] = posted_at
job["applications"] = applications
job["title"] = title
job["company_name"] = company_name
job["company_rating"] = company_rating
job["company_reviews"] = company_reviews
job["location"] = location
job["location_type"] = location_type
job["apply_link"] = apply_link
job["pay"] = pay
job["job_type"] = job_type
job["benefits"] = benefits
job["description"] = description
jobs.append(job)
스크립트가 예상대로 작동하는지 확인하기 위해 로그 지시문을 추가할 수도 있습니다:
print(job)
스크립트 실행:
python scraper.py
다음과 유사한 출력이 생성됩니다:
{'posted_at': '17 days ago', 'applications': '50+', 'title': 'Software Support Engineer', 'company_name': 'Integrated DNA Technologies (IDT)', 'company_rating': '3.5', 'company_reviews': '95', 'location': 'New York, NY 10001', 'location_type': 'Remote', 'apply_link': 'https://www.indeed.com/applystart?jk=c00120130a9c933b&from=vj&pos=bottom&mvj=0&jobsearchTk=1h9fpft0fj3t3800&spon=0&sjdu=YmZE5d5THV8u75cuc0H6Y26AwfY51UOGmh3Z9h4OvXiYhWlsa56nLum9aT96NeA9XAwdulcUk0atwlDdDDqlBQ&vjfrom=tp-semfirstjob&astse=bcf3778ad128bc26&assa=2447', 'pay': '연봉 $80,000 - $100,000', 'job_type': '정규직', 'benefits': ['401(k)', '401(k) 매칭', '치과 보험', '건강 보험', '유급 육아 휴직', '유급 휴가', '육아 휴직', '안과 보험'], 'description': "통합 DNA 기술(IDT)은 맞춤형 올리고뉴클레오타이드 및 독점 기술 분야의 선도적 제조업체입니다(생략됨...)"}
자, 이제 웹사이트에서 채용 공고를 스크래핑하는 방법을 배웠습니다.
9단계: 여러 채용 공고 페이지 스크래핑하기
Indeed에서 일반적인 구직 검색을 하면 수십 개의 결과가 페이지별로 나열됩니다. 각 페이지를 스크래핑하는 방법을 보셨죠!
먼저 페이지를 검사하여 인디드의 동작 방식을 확인하세요. 구체적으로, 다음 페이지가 있을 때 다음과 같은 요소를 표시합니다.
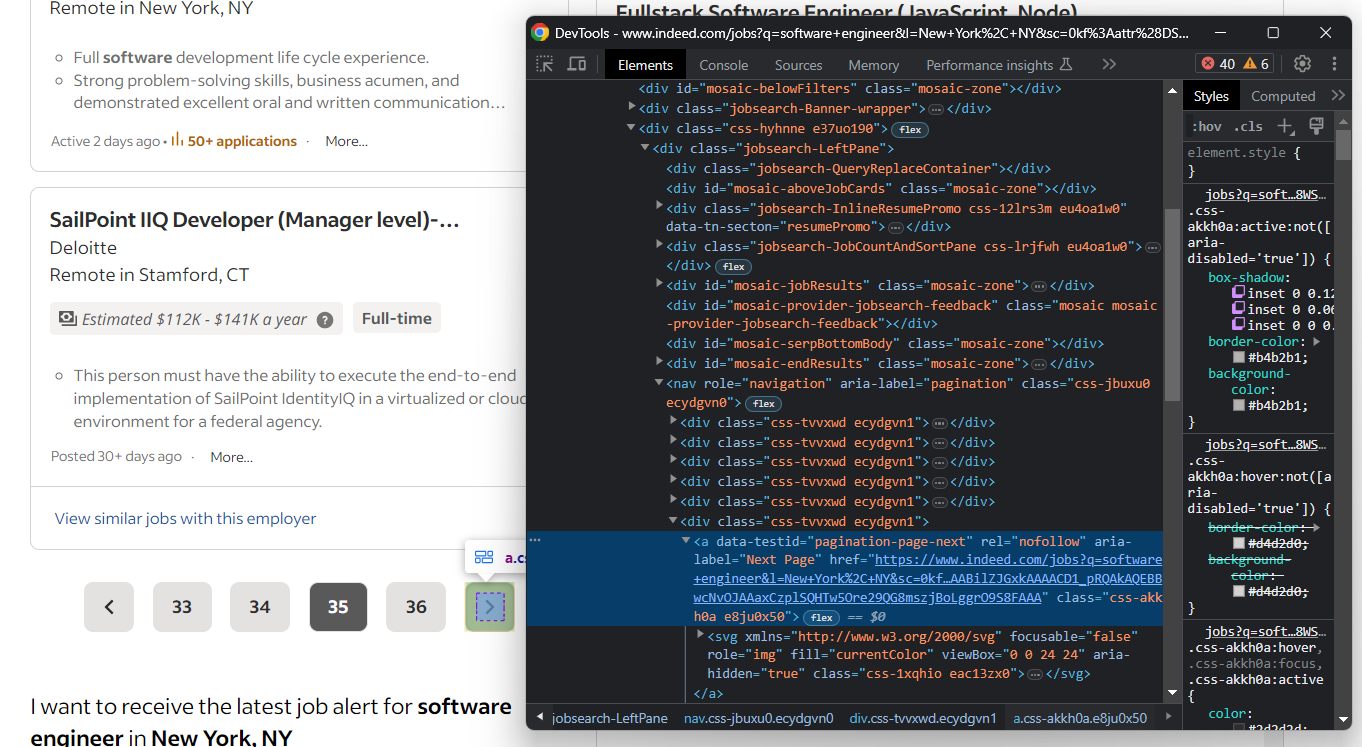
반대로, 다음 페이지 요소가 없는 경우:
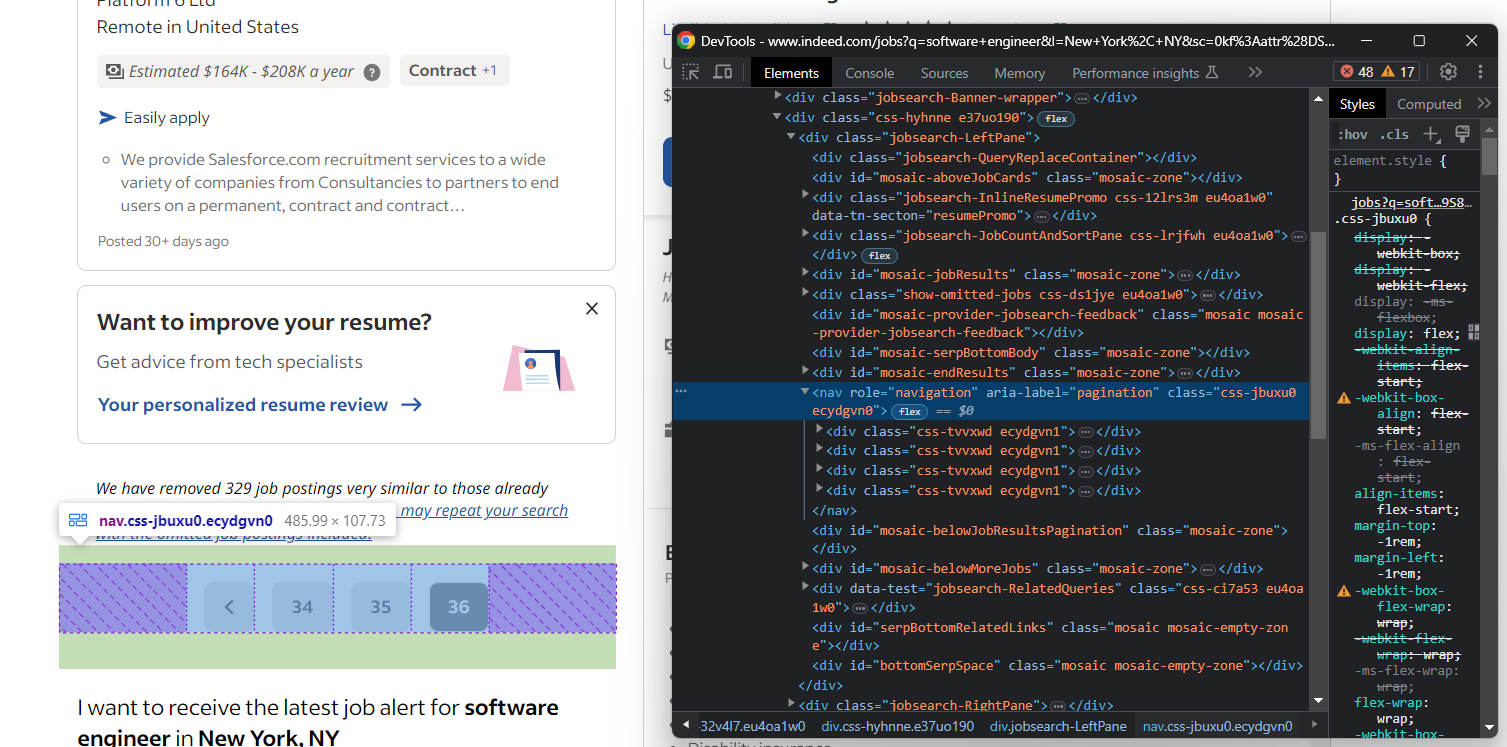
인디드는 수백 개의 채용 공고가 포함된 목록을 반환할 수 있다는 점을 명심하세요. 스크립트가 무한정 실행되는 것을 원치 않는다면, 스크랩하는 페이지 수에 제한을 추가하는 것을 고려하세요.
Selenium을 사용해 Indeed에서 웹 크롤링을 구현하는 방법:
pages_scraped = 0
pages_to_scrape = 5
while pages_scraped < pages_to_scrape:
job_cards = driver.find_elements(By.CSS_SELECTOR, ".cardOutline")
for job_card in job_cards:
# 스크래핑 로직...
pages_scraped += 1
# 마지막 페이지가 아니면 다음 페이지로 이동
# 그렇지 않으면 while 루프 종료
try:
next_page_element = driver.find_element(By.CSS_SELECTOR, "a[data-testid=pagination-page-next]")
next_page_element.click()
except NoSuchElementException:
break
이제 인디드 스크레이퍼는 마지막 페이지에 도달하거나 5페이지를 모두 처리할 때까지 계속 반복합니다.
10단계: 스크랩한 데이터를 JSON으로 내보내기
현재 스크래핑된 데이터는 Python 사전 목록에 저장되어 있습니다. 공유 및 읽기 편의를 위해 JSON으로 내보내세요.
먼저 출력 객체를 생성합니다:
output = {
"date": datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
"jobs": jobs
}
날짜 속성은 필수입니다. 채용 공고 게시일이 “<X>일 전” 형식으로 표시되기 때문입니다. 데이터 수집 날짜에 대한 맥락이 없으면 이해하기 어렵습니다.
datetime을 반드시 임포트하세요:
from datetime import datetime
다음과 같이 내보내세요:
import json
# 스크래핑 로직...
with open("jobs.json", "w") as file:
json.dump(output, file, indent=4)
위 코드 조각은 open() 으로 jobs.json 출력 파일을 초기화하고 json.dump()를 통해 JSON 데이터로 채웁니다. Python에서 데이터를 JSON으로 파싱 및 직렬화하는 방법에 대해 자세히 알아보려면 저희 글을 참고하세요 .
json 패키지는 Python 표준 라이브러리에 포함되어 있으므로, 추가 의존성을 설치할 필요 없이 바로 사용할 수 있습니다.
와! 웹페이지에 포함된 원시 작업 데이터에서 시작하여 이제 반구조화된 JSON 데이터를 얻었습니다. 이제 전체 웹 스크래핑 Indeed Python 스크립트를 살펴볼 준비가 되었습니다.
11단계: 모든 것을 통합하기
다음은 완성된 scraper.py 파일입니다:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import random
import time
from datetime import datetime
import json
# 제어 가능한 Chrome 인스턴스 설정
# 헤드리스 모드에서
service = Service()
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
driver = webdriver.Chrome(
service=service,
options=options
)
# 브라우저에서 대상 페이지 열기
driver.get("https://www.indeed.com/jobs?q=software+engineer&l=New+York%2C+NY&sc=0kf%3Aattr%28DSQF7%29%3B&radius=100")
# 페이지가 반응형 모드로 렌더링되지 않도록
# 창 크기를 설정
driver.set_window_size(1920, 1080)
# 페이지에서 스크랩한 채용 공고를 저장할
# 데이터 구조
jobs = []
pages_scraped = 0
pages_to_scrape = 3
while pages_scraped < pages_to_scrape:
# 페이지에서 채용 공고 카드 선택
job_cards = driver.find_elements(By.CSS_SELECTOR, ".cardOutline")
for job_card in job_cards:
# 스크랩된 채용 데이터 저장용 사전 초기화
job = {}
# 스크랩할 채용 정보 속성 초기화
posted_at = None
applications = None
title = None
company_name = None
company_rating = None
company_reviews = None
location = None
location_type = None
apply_link = None
pay = None
job_type = None
benefits = None
description = None
# 개요 카드에서 일반 채용 정보 가져오기
try:
date_element = job_card.find_element(By.CSS_SELECTOR, ".date")
date_element_text = date_element.text
posted_at_text = date_element_text
if "•" in date_element_text:
date_element_text_array = date_element_text.split("•")
posted_at_text = date_element_text_array[0]
applications = date_element_text_array[1]
.replace("applications", "")
.replace("진행 중", "")
.strip()
posted_at = posted_at_text
.replace("게시됨", "")
.replace("고용주", "")
.replace("활성", "")
.strip()
except NoSuchElementException:
pass
# 스크래핑 방지 모달 닫기
try:
dialog_element = driver.find_element(By.CSS_SELECTOR, "[role=dialog]")
close_button = dialog_element.find_element(By.CSS_SELECTOR, ".icl-CloseButton")
close_button.click()
except NoSuchElementException:
pass
# 채용 정보 카드 로드
job_card.click()
# 클릭 후 채용 정보 섹션 로드 대기
try:
title_element = WebDriverWait(driver, 5)
.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".jobsearch-JobInfoHeader-title")))
title = title_element.text.replace("n- job post", "")
except NoSuchElementException:
continue
# 채용 정보 추출
job_details_element = driver.find_element(By.CSS_SELECTOR, ".jobsearch-RightPane")
try:
company_link_element = job_details_element.find_element(By.CSS_SELECTOR, "div[data-company-name='true'] a")
company_name = company_link_element.text
except NoSuchElementException:
pass
try:
company_rating_element = job_details_element.find_element(By.ID, "companyRatings")
company_rating = company_rating_element.get_attribute("aria-label").split("out")[0].strip()
company_reviews_element = job_details_element.find_element(By.CSS_SELECTOR, "[data-testid='inlineHeader-companyReviewLink']")
회사_리뷰 = 회사_리뷰_요소.text.replace(" 리뷰", "")
except NoSuchElementException:
pass
try:
회사_위치_요소 = job_details_element.find_element(By.CSS_SELECTOR,
"[data-testid='inlineHeader-companyLocation']")
회사_위치_요소_텍스트 = 회사_위치_요소.text
위치 = 회사_위치_요소_텍스트
if "•" in 회사_위치_요소_텍스트:
회사_위치_요소_텍스트_배열 = 회사_위치_요소_텍스트.split("•")
위치 = 회사_위치_요소_텍스트_배열[0]
location_type = company_location_element_text_array[1]
except NoSuchElementException:
pass
try:
apply_link_element = job_details_element.find_element(By.CSS_SELECTOR, "#applyButtonLinkContainer button")
apply_link = apply_link_element.get_attribute("href")
except NoSuchElementException:
pass
for div in job_details_element.find_elements(By.CSS_SELECTOR, "#jobDetailsSection div"):
if div.text == "Pay":
pay_element = div.find_element(By.XPATH, "following-sibling::*")
pay = pay_element.text
elif div.text == "Job Type":
job_type_element = div.find_element(By.XPATH, "following-sibling::*")
job_type = job_type_element.text
try:
benefits_element = job_details_element.find_element(By.ID, "benefits")
benefits = []
for benefit_element in benefits_element.find_elements(By.TAG_NAME, "li"):
benefit = benefit_element.text
benefits.append(benefit)
except NoSuchElementException:
pass
try:
description_element = job_details_element.find_element(By.ID, "jobDescriptionText")
description = description_element.text
except NoSuchElementException:
pass
# 추출한 데이터 저장
job["posted_at"] = posted_at
job["applications"] = applications
job["title"] = title
job["company_name"] = company_name
job["company_rating"] = company_rating
job["company_reviews"] = company_reviews
job["location"] = location
job["location_type"] = location_type
job["apply_link"] = apply_link
job["pay"] = pay
job["job_type"] = job_type
job["benefits"] = benefits
job["description"] = description
jobs.append(job)
# 속도 제한 차단 방지 위해 1~5초 무작위 대기
time.sleep(random.uniform(1, 5))
# 스크래핑 카운터 증가
pages_scraped += 1
# 마지막 페이지가 아니면 다음 페이지로 이동
# 마지막 페이지가 아니면 while 루프 종료
try:
next_page_element = driver.find_element(By.CSS_SELECTOR, "a[data-testid=pagination-page-next]")
next_page_element.click()
except NoSuchElementException:
break
# 브라우저 종료 및 리소스 해제
driver.quit()
# 출력 객체 생성
output = {
"date": datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
"jobs": jobs
}
# JSON으로 내보내기
with open("jobs.json", "w") as file:
json.dump(output, file, indent=4)
200줄 미만의 코드로 Indeed에서 채용 정보를 스크래핑하는 완전한 웹 스크레이퍼를 구축했습니다.
실행 명령어:
python scraper.py
스크립트가 완료될 때까지 몇 분간 기다리세요
스크래핑이 완료되면 프로젝트 루트 폴더에 jobs.json 파일이 생성됩니다. 파일을 열면 다음과 같은 내용을 확인할 수 있습니다:
{
"date": "2023-09-02 19:56:44",
"jobs": [
{
"posted_at": "7 days ago",
"applications": "50+",
"title": "Software Engineer - All Levels",
"company_name": "Listrak",
"company_rating": "3",
"company_reviews": "5",
"location": "King of Prussia, PA",
"location_type": "Remote",
"apply_link": "https://www.indeed.com/applystart?jk=f27ade40cc1a3686&from=vj&pos=bottom&mvj=0&jobsearchTk=1h9bge7mbhdj0800&spon=0&sjdu=YmZE5d5THV8u75cuc0H6Y26AwfY51UOGmh3Z9h4OvXgPYWebWpM-4nO05Ssl8I8z-BhdrQogdzP3xc9-PmOQTQ&vjfrom=vjs&astse=16430083478063d1&assa=2381",
"pay": null,
"job_type": null,
"benefits": [
"헬스장 회원권",
"유급 휴가"
],
"description": "Listrak 소개:n당사는 이메일, 문자 메시지 마케팅, 신원 확인, 행동 기반 트리거 및 크로스 채널 오케스트레이션을 위해 1,000개 이상의 선도적인 소매업체 및 브랜드가 신뢰하는 통합 디지털 마케팅 플랫폼을 제공하는 SaaS 기업입니다. 본사는 (간결함을 위해 생략...)에 위치해 있습니다."
},
// 간결함을 위해 생략...
{
"posted_at": "9일 전",
"applications": null,
"title": "프론트엔드 소프트웨어 엔지니어 (하이브리드-원격 근무)",
"company_name": "웨일 코넬 의과대학",
"company_rating": "3.4",
"회사_리뷰": "41",
"위치": "뉴욕, NY 10021",
"location_type": "Remote",
"apply_link": "https://www.indeed.com/applystart?jk=1a53a17f1faeae92&from=vj&pos=bottom&mvj=0&jobsearchTk=1h9bge7mbhdj0800&spon=0&sjdu=YmZE5d5THV8u75cuc0H6Y26AwfY51UOGmh3Z9h4OvXgZADiLYj9Y4htcvtDy_iaWMIfcMu539kP3i1FMxIq2rA&vjfrom=vjs&astse=90a9325429efdf13&assa=4615",
"pay": "$99,800 - $123,200 a year",
"job_type": null,
"benefits": null,
"description": "Title: 소프트웨어 엔지니어, 프론트엔드 (하이브리드-원격 근무)nTitle: 프론트엔드 소프트웨어 엔지니어 (하이브리드-원격 근무)n근무지: 어퍼 이스트 사이드n소속 부서: Olivier Elemento Labn근무일: 월요일-금요일n면제 상태: 면제n연봉 범위: $99,800.00 - $123,200.00n기타 (생략...)"
}
}
축하합니다! 방금 Python으로 Indeed 스크래핑하는 법을 배웠습니다!
결론
이 튜토리얼을 통해 인디드가 웹상 최고의 구직 포털 중 하나인 이유와 데이터 추출 방법을 이해하셨습니다. 특히, 인디드에서 채용 공고 데이터를 가져올 수 있는 파이썬 스크레이퍼를 구축하는 방법을 살펴보았습니다.
여기서 보셨듯이 Indeed 스크래핑은 쉬운 작업이 아닙니다. 해당 사이트는 스크립트를 차단할 수 있는 교묘한 안티 스크래핑 보호 기능을 갖추고 있습니다. 이러한 사이트를 다룰 때는 CAPTCHA, 지문 인식, 자동 재시도 등을 자동으로 처리할 수 있는 제어 가능한 브라우저가 필요합니다. 바로 이것이 저희의 새로운 Scraping Browser 솔루션이 제공하는 핵심 기능입니다!
웹 스크래핑은 원치 않지만 채용 데이터에는 관심이 있으신가요? 인디드 데이터셋과 채용 공고 데이터셋을 살펴보세요. 지금 등록하고 무료 체험을 시작하세요.
참고: 본 가이드는 작성 당시 저희 팀이 철저히 테스트했으나, 웹사이트는 코드와 구조를 자주 업데이트하므로 일부 단계가 예상대로 작동하지 않을 수 있습니다.




