

웹 스크래핑은 데이터 수집 기법으로, IP 차단, 지역 제한, 개인정보 보호 문제 등 다양한 장애물에 의해 종종 방해받습니다. 다행히 프록시 서버는 이러한 문제를 해결하는 데 도움이 됩니다. 프록시 서버는 사용자의 컴퓨터와 인터넷 사이의 중개자 역할을 하며, 자체 IP 주소로 요청을 처리합니다. 이 기능은 IP 관련 제한 및 차단을 회피하는 데 도움이 될 뿐만 아니라 지역적으로 제한된 콘텐츠에 대한 접근도 용이하게 합니다. 또한 프록시 서버는 웹 스크래핑 중 익명성을 유지하고 개인 정보를 보호하는 데 중요한 역할을 합니다.
프록시 서버를 활용하면 웹 스크래핑 작업의 성능과 안정성도 향상시킬 수 있습니다. 요청을 여러 서버에 분산함으로써 단일 서버에 과도한 부하가 걸리지 않도록 하여 프로세스를 최적화합니다.
이 튜토리얼에서는 웹 스크래핑 프로젝트를 위해 Node.js에서 프록시 서버를 사용하는 방법을 배웁니다.
필수 조건
이 튜토리얼을 시작하기 전에 JavaScript와 Node.js에 대한 기본적인 이해가 필요합니다. 컴퓨터에 Node.js 가 설치되어 있지 않다면 지금 설치해야 합니다.
또한 적합한 텍스트 편집기가 필요합니다. Sublime Text 등 여러 옵션이 있으며, 본 튜토리얼에서는 Visual Studio Code(VS Code)를 사용합니다. 사용자 친화적이며 코딩을 용이하게 하는 다양한 기능을 제공합니다.
시작하려면 web-scraping-proxy라는 새 디렉터리를 생성한 후 Node.js 프로젝트를 초기화하세요. 터미널 또는 셸을 열고 다음 명령어로 새 디렉터리로 이동합니다:
cd web-scraping-proxynnpm init -yn
다음으로 HTTP 요청 처리 및 HTML 파싱을 위한 Node.js 패키지를 설치해야 합니다.
프로젝트 디렉터리에 위치했는지 확인한 후 다음 명령어를 실행하세요:
npm install axios node-fetch playwright puppeteer http-proxy-agentnnpx playwright installn
Axios는 웹 콘텐츠를 가져오기 위한 HTTP 요청을 수행하는 데 사용됩니다. Playwright와 Puppeteer는 동적 웹사이트 스크래핑에 필수적인 브라우저 상호작용을 자동화합니다. Playwright는 다양한 브라우저를 지원하며, Puppeteer는 Chrome 또는 Chromium에 중점을 둡니다. http-proxy-agent 라이브러리는 HTTP 요청을 위한 프록시 에이전트를 생성하는 데 사용됩니다.
npx playwright install 명령어는 Playwright 라이브러리가 사용할 필수 드라이버를 설치하는 데 필요합니다.
이 단계들을 완료하면 Node.js로 웹 스크래핑의 세계에 뛰어들 준비가 된 것입니다.
웹 스크래핑을 위한 로컬 프록시 설정
웹 스크래핑의 중요한 첫 단계는 프록시 서버를 설정하는 것이며, 이 튜토리얼에서는 오픈 소스 도구인 mitmproxy를 사용합니다.
시작하려면 mitmproxy 다운로드 페이지로 이동하여 사용 중인 운영 체제에 맞는 버전 10.1.6을 다운로드하세요. 설치 중 도움이 필요하면 mitmproxy 설치 가이드가 유용한 자료입니다.
mitmproxy 설치가 완료되면 터미널에서 다음 명령어를 입력하여 실행하세요:
mitmproxyn
이 명령어는 터미널에 mitmproxy 인터페이스로 사용될 창을 엽니다:
프록시가 올바르게 설정되었는지 확인하려면 테스트를 실행해 보세요. 새 터미널 창을 열고 다음 명령어를 실행합니다:
curl u002du002dproxy http://localhost:8080 u0022http://wttr.in/Paris?0u0022n
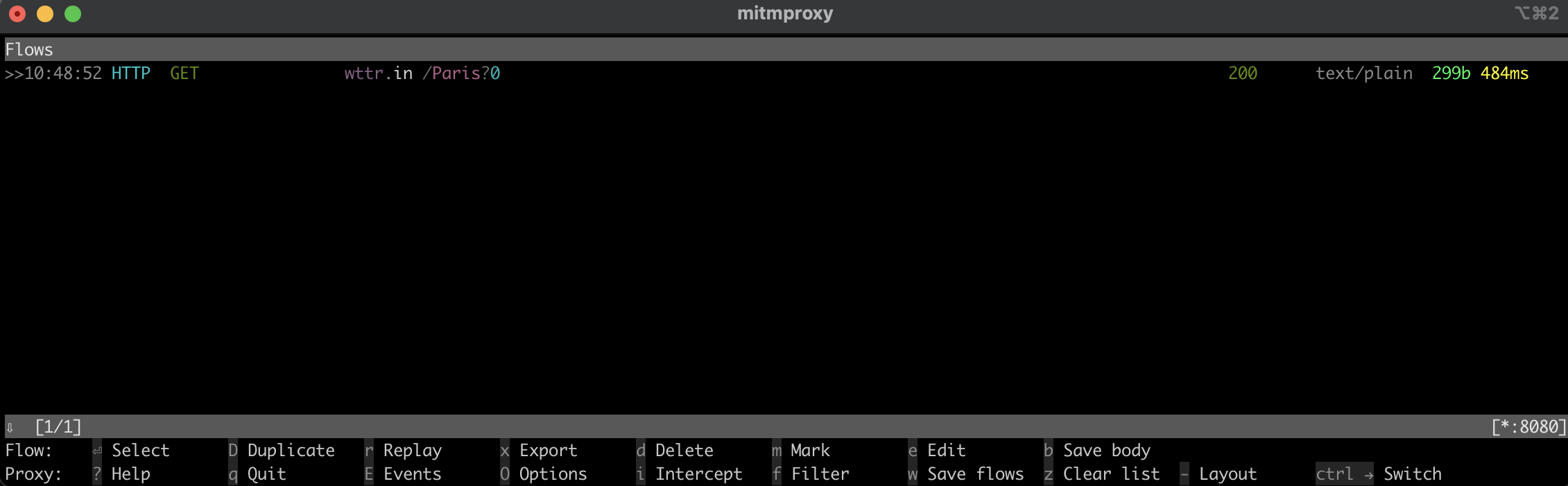
이 명령어는 파리의 날씨 정보를 가져옵니다. 출력 결과는 다음과 같아야 합니다:
Weather report: Parisnn Overcastn .u002du002d. -2(-6) °Cn .-( ). â 11 km/hn (___.__)__) 10 kmn 0.0 mmn
mitmproxy 창으로 돌아가면 요청이 캡처된 것을 확인할 수 있으며, 이는 로컬 프록시가 정상적으로 작동함을 의미합니다:
Node.js에서 웹 스크래핑을 위한 프록시 구현
이제 Node.js를 활용한 웹 스크래핑의 실용적인 측면으로 넘어가겠습니다. 이 섹션에서는 로컬 프록시 서버를 통해 요청을 전송하여 웹사이트를 스크래핑하는 스크립트를 작성할 것입니다.
Fetch 메서드를 사용한 웹사이트 스크래핑
프로젝트 루트 디렉터리에 fetchScraping.js라는 새 파일을 생성합니다. 이 파일에는 웹사이트(이 경우 https://toscrape.com/)의 콘텐츠를 스크래핑하는 코드가 포함됩니다.
fetchScraping.js에 다음 JavaScript 코드를 입력하세요. 이 스크립트는 fetch 메서드를 사용하여 프록시 서버를 통해 요청을 전송합니다:
const fetch = require(u0022node-fetchu0022);nconst HttpProxyAgent = require(u0022http-proxy-agentu0022);nnasync function fetchData(url) {n try {n const proxyAgent = new HttpProxyAgent.HttpProxyAgent(n u0022http://localhost:8080u0022n );n const response = await fetch(url, { agent: proxyAgent });n const data = await response.text();n console.log(data); // Outputs the fetched datan } catch (error) {n console.error(u0022Error fetching data:u0022, error);n }n}nnfetchData(u0022http://toscrape.com/u0022);n
이 코드 조각은 URL을 인수로 받아 로컬 프록시를 경유하여 fetch를 통해 해당 URL로 요청을 보내고 응답 데이터를 출력하는 비동기 함수 fetchData를 정의합니다.
웹 스크래핑 스크립트를 실행하려면 터미널 또는 셸을 열고 프로젝트의 루트 디렉터리( fetchScraping.js 파일이 위치한 곳)로 이동하세요. 다음 명령어로 스크립트를 실행합니다:
node fetchScraping.jsn
터미널에 다음과 같은 출력이 표시됩니다:
â¦output omittedâ¦n u003cdiv class=u0022rowu0022u003en u003cdiv class=u0022col-md-1u0022u003eu003c/divu003en u003cdiv class=u0022col-md-10u0022u003en u003ch2u003eBooksu003c/h2u003en u003cpu003eA u003ca href=u0022http://books.toscrape.comu0022u003efictional bookstoreu003c/au003e that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: u003ca href=u0022http://books.toscrape.comu0022u003ebooks.toscrape.comu003c/au003eu003c/pu003en u003cdiv class=u0022col-md-6u0022u003en u003ca href=u0022http://books.toscrape.comu0022u003eu003cimg src=u0022./img/books.pngu0022 class=u0022img-thumbnailu0022u003eu003c/au003en u003c/divu003en u003cdiv class=u0022col-md-6u0022u003en u003ctable class=u0022table table-hoveru0022u003en u003ctru003eu003cth colspan=u00222u0022u003eDetailsu003c/thu003eu003c/tru003en u003ctru003eu003ctdu003eAmount of items u003c/tdu003eu003ctdu003e1000u003c/tdu003eu003c/tru003en u003ctru003eu003ctdu003ePagination u003c/tdu003eu003ctdu003eu0026#10004;u003c/tdu003eu003c/tru003en u003ctru003eu003ctdu003eItems per page u003c/tdu003eu003ctdu003emax 20u003c/tdu003eu003c/tru003en u003ctru003eu003ctdu003eRequires JavaScript u003c/tdu003eu003ctdu003eu0026#10008;u003c/tdu003eu003c/tru003en u003c/tableu003en u003c/divu003en u003c/divu003en u003c/divu003enâ¦output omittedâ¦n
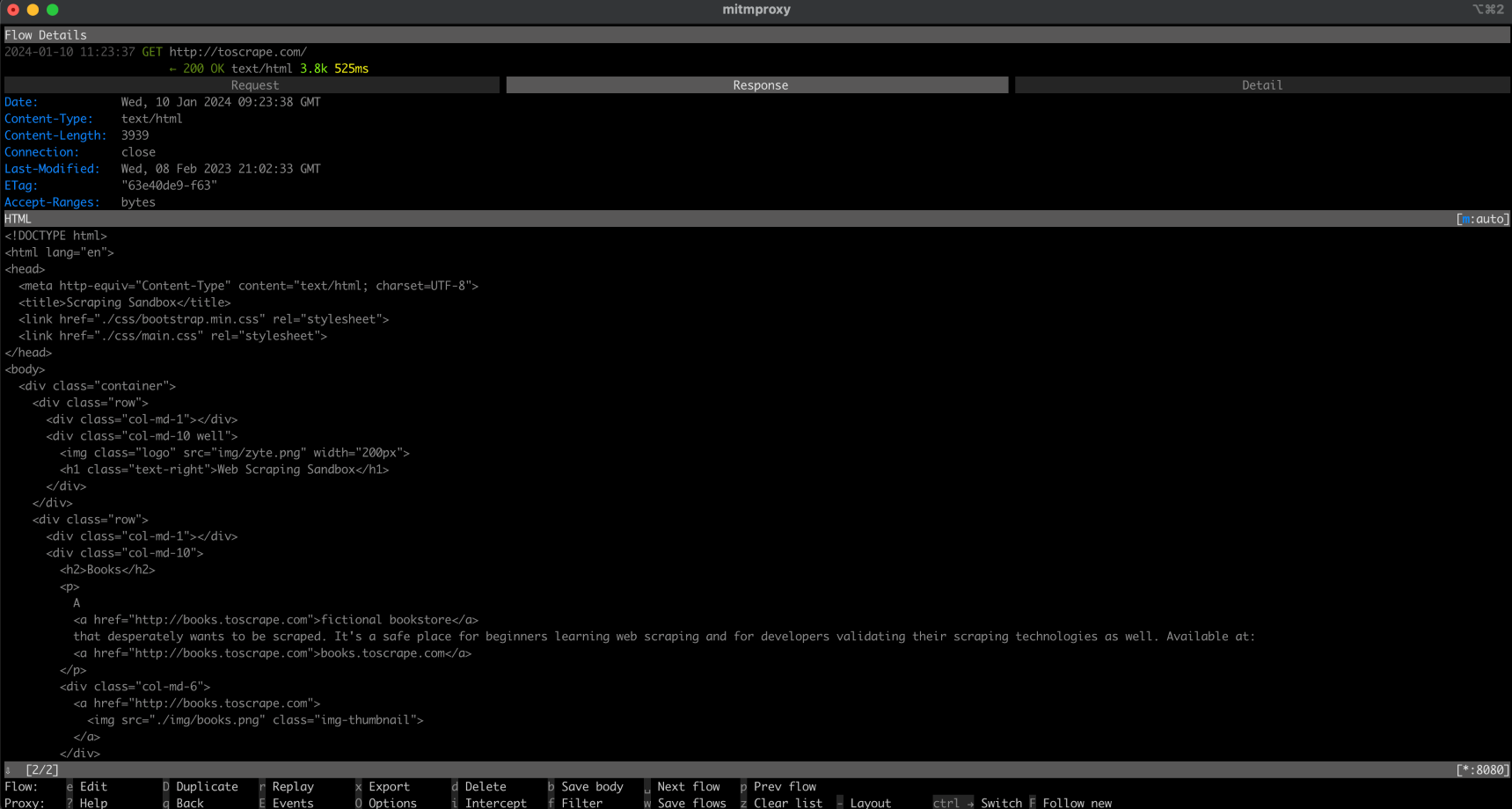
이 출력은 http://toscrape.com 웹 페이지의 HTML 콘텐츠입니다. 이 데이터가 성공적으로 표시되면 로컬 프록시를 경유하는 웹 스크래핑 스크립트가 정상적으로 작동함을 의미합니다.
이제 mitmproxy 창으로 돌아가면 요청이 로깅되는 것을 확인할 수 있습니다. 이는 요청이 로컬 프록시를 통과했음을 의미합니다:
Playwright를 사용한 웹사이트 스크래핑
Fetch에 비해 Playwright는 웹 페이지와 더 동적인 상호작용을 허용하는 고급 도구입니다. 사용하려면 프로젝트에 playwrightScraping.js라는 새 파일을 생성해야 합니다. 이 파일에 다음 JavaScript 코드를 입력하세요:
const { chromium } = require(u0022playwrightu0022);nn(async () =u003e {n const browser = await chromium.launch({n proxy: {n server: u0022http://localhost:8080u0022,n },n });n const page = await browser.newPage();n await page.goto(u0022http://toscrape.com/u0022);nn // Extract and log the entire HTML contentn const content = await page.content();n console.log(content);nn await browser.close();n})();n
이 코드는 Playwright를 사용하여 로컬 프록시 서버를 사용하도록 구성된 Chromium 브라우저 인스턴스를 실행합니다. 그런 다음 브라우저에서 새 페이지를 열고 http://toscrape.com로 이동한 후 페이지가 로드될 때까지 기다립니다. 필요한 데이터를 스크래핑한 후 브라우저를 닫습니다.
이 스크립트를 실행하려면 playwrightScraping.js 파일이 있는 디렉터리에 위치해 있는지 확인하세요. 터미널 또는 셸을 열고 다음 명령어로 스크립트를 실행합니다:
node playwrightScraping.jsn
스크립트를 실행하면 Playwright가 Chromium 브라우저를 시작하고 지정된 URL로 이동한 후 추가로 설정한 스크래핑 명령어를 실행합니다. 이 과정은 로컬 프록시 서버를 사용하므로 IP 주소 노출을 방지하고 잠재적 제한을 우회할 수 있습니다.
예상 출력은 이전과 유사해야 합니다:
â¦output omittedâ¦n u003cdiv class=u0022rowu0022u003en u003cdiv class=u0022col-md-1u0022u003eu003c/divu003en u003cdiv class=u0022col-md-10u0022u003en u003ch2u003eBooksu003c/h2u003en u003cpu003eA u003ca href=u0022http://books.toscrape.comu0022u003efictional bookstoreu003c/au003e that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: u003ca href=u0022http://books.toscrape.comu0022u003ebooks.toscrape.comu003c/au003eu003c/pu003en u003cdiv class=u0022col-md-6u0022u003en u003ca href=u0022http://books.toscrape.comu0022u003eu003cimg src=u0022./img/books.pngu0022 class=u0022img-thumbnailu0022u003eu003c/au003en u003c/divu003en u003cdiv class=u0022col-md-6u0022u003en u003ctable class=u0022table table-hoveru0022u003en u003ctru003eu003cth colspan=u00222u0022u003eDetailsu003c/thu003eu003c/tru003en u003ctru003eu003ctdu003eAmount of items u003c/tdu003eu003ctdu003e1000u003c/tdu003eu003c/tru003en u003ctru003eu003ctdu003ePagination u003c/tdu003eu003ctdu003eu0026#10004;u003c/tdu003eu003c/tru003en u003ctru003eu003ctdu003eItems per page u003c/tdu003eu003ctdu003emax 20u003c/tdu003eu003c/tru003en u003ctru003eu003ctdu003eRequires JavaScript u003c/tdu003eu003ctdu003eu0026#10008;u003c/tdu003eu003c/tru003en u003c/tableu003en u003c/divu003en u003c/divu003en u003c/divu003enâ¦output omittedâ¦n
이전과 마찬가지로 요청 내용이 mitmproxy 창에 기록되는 것을 확인할 수 있습니다.
Puppeteer를 사용한 웹사이트 스크래핑
이제 Puppeteer를 사용하여 웹사이트를 스크래핑합니다. Puppeteer는 헤드리스 Chrome 또는 Chromium 브라우저를 고도로 제어할 수 있는 강력한 도구입니다. 이 방법은 JavaScript 렌더링이 필요한 동적 웹사이트 스크래핑에 특히 유용합니다.
시작하려면 프로젝트에 puppeteerScraping.js라는 새 파일을 생성하세요. 이 파일에는 프록시 서버를 통해 요청을 보내 웹사이트를 스크래핑하는 Puppeteer 코드가 포함됩니다.
새로 생성한 puppeteerScraping.js 파일을 열고 다음 JavaScript 코드를 삽입하세요:
const puppeteer = require('puppeteer');nn (async () =u003e {n const browser = await puppeteer.launch({n args: ['u002du002dproxy-server=http://localhost:8080']n });n const page = await browser.newPage();n await page.goto('http://toscrape.com/');n const content = await page.content();n console.log(content); // Outputs the page HTMLn await browser.close();n })();n
이 코드에서는 Puppeteer를 초기화하여 헤드리스 브라우저를 실행하고, 로컬 프록시 서버를 사용하도록 지정합니다. 브라우저는 새 페이지를 열고 http://toscrape.com로 이동한 후 페이지의 HTML 콘텐츠를 가져옵니다. 콘텐츠가 콘솔에 기록되면 브라우저 세션이 종료됩니다.
스크립트를 실행하려면 터미널 또는 셸에서 puppeteerScraping.js 파일이 있는 폴더로 이동하세요. 다음 명령어로 스크립트를 실행합니다:
node puppeteerScraping.jsn
스크립트 실행 후, Puppeteer는 프록시 서버를 통해 http://toscrape.com/ URL을 엽니다. 터미널에 페이지의 HTML 콘텐츠가 출력되는 것을 확인할 수 있습니다. 이는 Puppeteer 스크립트가 로컬 프록시를 통해 웹 페이지를 올바르게 스크래핑하고 있음을 나타냅니다.
예상 출력은 이전과 유사해야 하며, mitmproxy 창에 요청 로그가 표시됩니다:
â¦output omittedâ¦n u003cdiv class=u0022rowu0022u003en u003cdiv class=u0022col-md-1u0022u003eu003c/divu003en u003cdiv class=u0022col-md-10u0022u003en u003ch2u003eBooksu003c/h2u003en u003cpu003eA u003ca href=u0022http://books.toscrape.comu0022u003efictional bookstoreu003c/au003e that desperately wants to be scraped. It's a safe place for beginners learning web scraping and for developers validating their scraping technologies as well. Available at: u003ca href=u0022http://books.toscrape.comu0022u003ebooks.toscrape.comu003c/au003eu003c/pu003en u003cdiv class=u0022col-md-6u0022u003en u003ca href=u0022http://books.toscrape.comu0022u003eu003cimg src=u0022./img/books.pngu0022 class=u0022img-thumbnailu0022u003eu003c/au003en u003c/divu003en u003cdiv class=u0022col-md-6u0022u003en u003ctable class=u0022table table-hoveru0022u003en u003ctru003eu003cth colspan=u00222u0022u003eDetailsu003c/thu003eu003c/tru003en u003ctru003eu003ctdu003eAmount of items u003c/tdu003eu003ctdu003e1000u003c/tdu003eu003c/tru003en u003ctru003eu003ctdu003ePagination u003c/tdu003eu003ctdu003eu0026#10004;u003c/tdu003eu003c/tru003en u003ctru003eu003ctdu003eItems per page u003c/tdu003eu003ctdu003emax 20u003c/tdu003eu003c/tru003en u003ctru003eu003ctdu003eRequires JavaScript u003c/tdu003eu003ctdu003eu0026#10008;u003c/tdu003eu003c/tru003en u003c/tableu003en u003c/divu003en u003c/divu003en u003c/divu003enâ¦output omittedâ¦n
더 나은 대안: Bright Data 프록시 서버
웹 스크래핑 기능을 향상시키고 싶다면 Bright Data 사용을 고려해 보세요. Bright Data 프록시 서버는 웹 요청 관리를 위한 고급 솔루션을 제공합니다.
Bright Data는 주거용, ISP, 데이터센터, 모바일 프록시 등 다양한 프록시 서버를 제공하여 서로 다른 지리적 위치에서 모든 웹사이트에 접근할 수 있게 합니다. 이를 통해 다양한 사용자 에이전트를 모방하고 익명성을 유지할 수 있습니다.
Bright Data는 또한 IP 로테이션 기능을 제공하여 다양한 프록시 간 자동 전환을 통해 IP 차단 방지를 실현함으로써 웹 스크래핑 활동의 효율성과 익명성을 강화합니다.
또한 Bright Data의 스크래핑 브라우저를 활용할 수 있습니다. 이 자동화 브라우저는 CAPTCHA, 쿠키, 브라우저 지문 인식과 같은 차단 기능을 해제하는 내장 기능을 갖추고 있습니다. Bright Data의 웹 언락커도 활용할 수 있습니다. 이 도구는 머신 러닝 알고리즘을 통해 대상 웹사이트의 모든 차단을 우회하여 차단당하지 않고 데이터를 수집할 수 있게 합니다.
Node.js 프로젝트에 Bright Data 프록시 구현하기
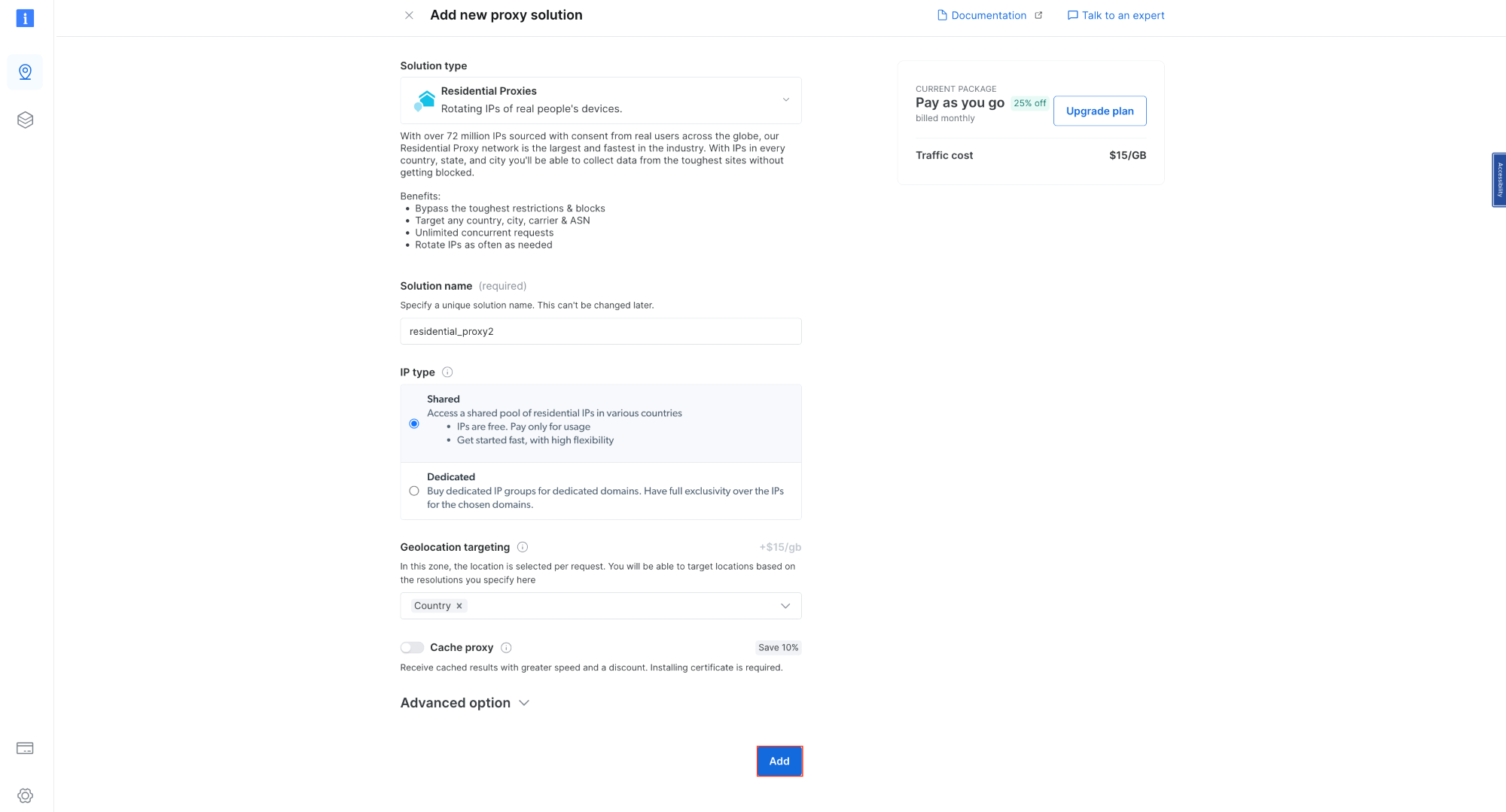
Bright Data 프록시를 Node.js 프로젝트에 통합하려면 무료 체험판에 가입해야 합니다. 계정이 활성화되면 로그인 후 ‘프록시 및 스크래핑 인프라’로 이동하여 ‘주거용 프록시’를 선택해 새 프록시를 추가하세요:
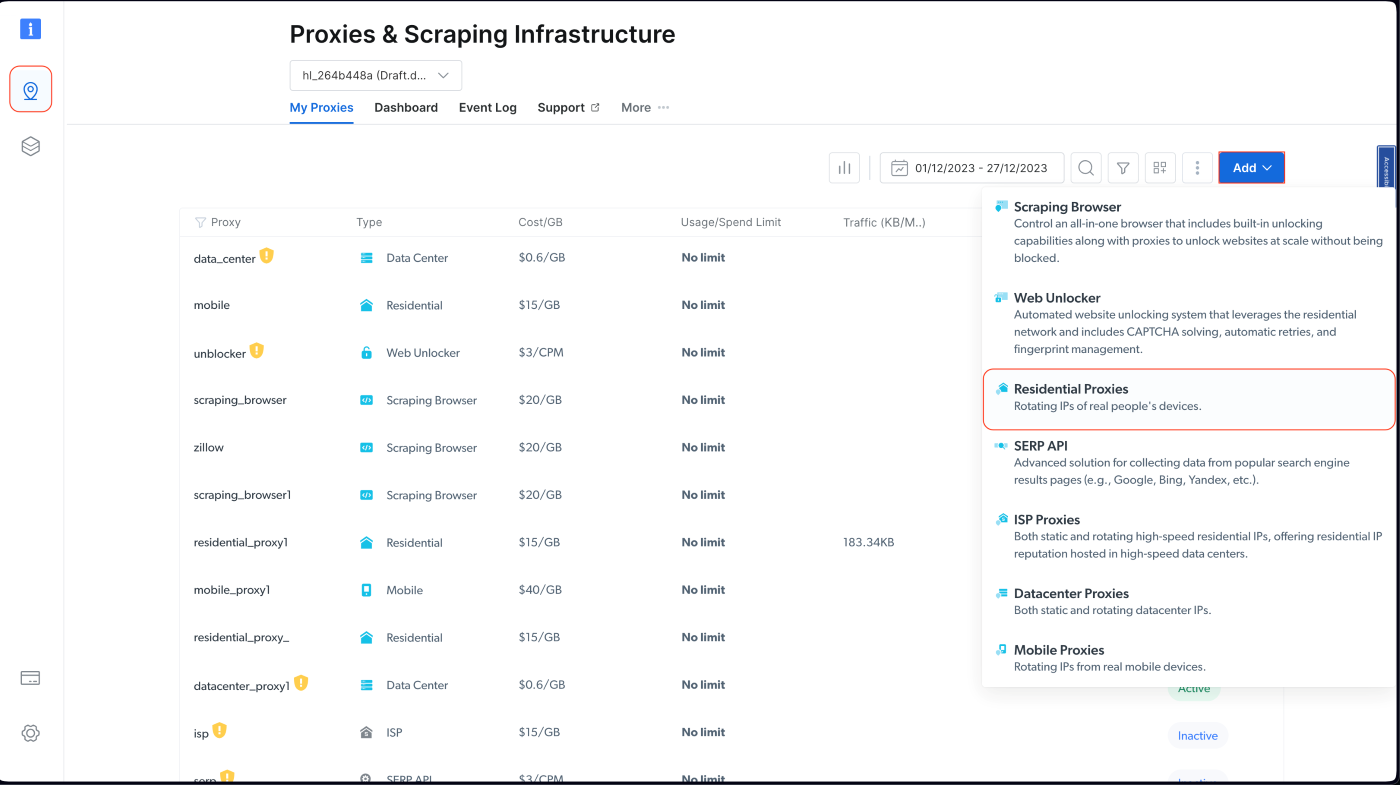
기본 설정을 유지한 채 주거용 프록시 생성을 완료하세요:
생성 후 호스트, 포트, 사용자 이름, 비밀번호를 포함한 프록시 자격 증명을 기록해 두세요. 다음 단계에서 필요합니다:
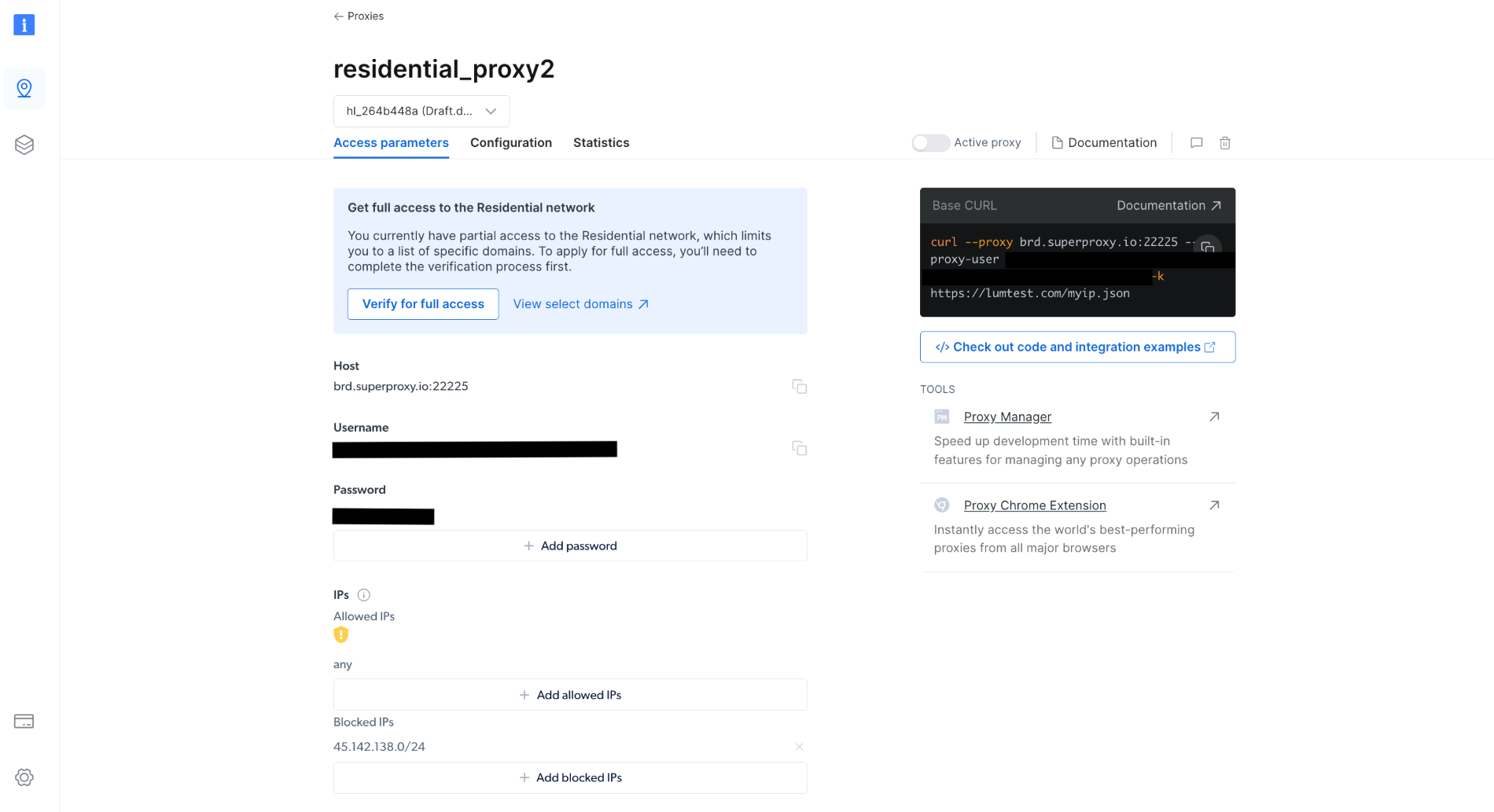
프로젝트에 scrapingWithBrightData.js 파일을 생성하고 다음 코드 조각을 추가하세요. 이때 점유자 텍스트를 Bright Data 프록시 자격 증명으로 반드시 교체해야 합니다:
const axios = require('axios');nn async function fetchDataWithBrightData(url) {n const proxyOptions = {n proxy: {n host: 'YOUR_BRIGHTDATA_PROXY_HOST',n port: YOUR_BRIGHTDATA_PROXY_PORT,n auth: {n username: 'YOUR_BRIGHTDATA_USERNAME',n password: 'YOUR_BRIGHTDATA_PASSWORD'n }n }n };n try {n const response = await axios.get(url, proxyOptions);n console.log(response.data); // Outputs the fetched datan } catch (error) {n console.error('Error:', error);n }n }nn fetchDataWithBrightData('http://lumtest.com/myip.json');n
이 스크립트는 axios가 HTTP 요청을 Bright Data 프록시를 통해 라우팅하도록 구성합니다. 이 프록시 설정을 사용하여 지정된 URL에서 데이터를 가져옵니다. 이 예시에서는 http://lumtest.com/myip.json을 대상으로 하여 Bright Data 구성에 따른 다양한 프록시 서버 소스를 확인할 수 있습니다.
스크립트를 실행하려면 터미널 또는 셸에서 scrapingWithBrightData.js 파일이 있는 폴더로 이동하세요. 그런 다음 다음 명령어로 스크립트를 실행합니다:
node scrapingWithBrightData.jsn
명령을 실행하면 콘솔에 IP 주소 위치가 출력됩니다. 이는 주로 Bright Data 프록시 서버와 관련된 정보입니다.
예상 출력 결과는 다음과 유사합니다:
{n ip: '108.53.191.230',n country: 'US',n asn: { asnum: 701, org_name: 'UUNET' },n geo: {n city: 'Jersey City',n region: 'NJ',n region_name: 'New Jersey',n postal_code: '07302',n latitude: 40.7182,n longitude: -74.0476,n tz: 'America/New_York',n lum_city: 'jerseycity',n lum_region: 'nj'n }n}n
이제 node scrapingWithBrightData.js로 스크립트를 다시 실행하면 Bright Data 프록시 서버가 다른 IP 주소 위치를 사용함을 확인할 수 있습니다. 이는 Bright Data가 스크래핑 스크립트 실행 시마다 다른 위치와 IP를 사용하므로 대상 웹사이트의 차단 또는 IP 차단 조치를 우회할 수 있음을 의미합니다.
출력 결과는 다음과 같습니다:
{n ip: '93.85.111.202',n country: 'BY',n asn: {n asnum: 6697,n org_name: 'Republican Unitary Telecommunication Enterprise Beltelecom'n },n geo: {n city: 'Orsha',n region: 'VI',n region_name: 'Vitebsk',n postal_code: '211030',n latitude: 54.5081,n longitude: 30.4172,n tz: 'Europe/Minsk',n lum_city: 'orsha',n lum_region: 'vi'n }n}n
Bright Data의 직관적인 인터페이스와 설정은 초보자도 강력한 프록시 관리 기능을 효과적으로 활용할 수 있게 합니다.
결론
이 글에서는 Node.js에서 프록시를 활용하는 방법을 알아보았습니다. Bright Data와 같은 적절한 프록시 관리 솔루션이 없다면 IP 차단이나 대상 웹사이트 접근 제한과 같은 문제에 직면할 수 있으며, 이는 스크래핑 작업을 방해할 수 있습니다. 또한 Bright Data 프록시를 사용하여 웹 스크래핑 작업을 향상시키는 것이 얼마나 쉬운지도 배웠습니다. 이러한 서버는 데이터 수집 과정에 견고성과 효율성을 더할 뿐만 아니라 다양한 스크래핑 시나리오에 필요한 유연성도 제공합니다.
이러한 기술을 실제 적용할 때는 웹사이트 이용 약관과 데이터 개인정보 보호법의 범위 내에서 운영해야 한다는 점을 기억하세요. 웹사이트가 정한 규칙을 존중하며 책임감 있게 스크래핑하는 것이 중요합니다. 특히 Bright Data 프록시가 제공하는 기능을 포함한 지금까지 습득한 지식으로, 성공적이고 윤리적인 웹 스크래핑을 수행할 준비가 잘 되어 있습니다. 즐거운 스크래핑 되세요!
이 튜토리얼의 모든 코드는 이 GitHub 저장소에서 확인할 수 있습니다.



