이 글에서는 다음을 다룹니다:
- 프론트엔드 자바스크립트를 활용한 웹 스크래핑
- 필수 조건
- Node.js용 웹 스크래핑 라이브러리
- 결론
프론트엔드 자바스크립트를 활용한 웹 스크래핑
웹 스크래핑에 있어 프론트엔드 자바스크립트는 제한적인 해결책입니다. 첫째, 자바스크립트 웹 스크래핑 스크립트를 브라우저 콘솔에서 직접 실행해야 하기 때문입니다. 이는 프로그래밍 방식으로 수행할 수 있는 작업이 아닙니다.
특히 콘솔에서 다음과 같이 페이지 데이터를 스크래핑할 수 있습니다:
둘째, 다른 웹 페이지의 데이터를 스크래핑하려면 AJAX를 통해 해당 페이지를 다운로드해야 합니다. 그러나 웹 브라우저가 AJAX에 동일 출처 정책(Same-Origin Policy)을 적용한다는 점을 잊지 마십시오. 따라서 프론트엔드 자바스크립트로는 동일 출처 내의 웹 페이지만 접근할 수 있습니다.
간단한 예시로 이 의미를 이해해 보겠습니다. brightdata.com의 페이지를 방문 중이라고 가정해 보죠. 그러면 프론트엔드 자바스크립트 웹 스크래핑 스크립트는 brightdata.com 도메인 하위의 웹 페이지만 다운로드할 수 있습니다.
이는 자바스크립트가 웹 크롤링에 적합하지 않다는 의미는 전혀 아닙니다. 실제로 Node.js를 사용하면 서버에서 자바스크립트를 실행하여 위에서 언급한 두 가지 제한을 피할 수 있습니다.
이제 Node.js로 자바스크립트 웹 스크레이퍼를 구축하는 방법을 알아보겠습니다.
필수 조건
Node.js 웹 스크래핑 앱 작업을 시작하기 전에 다음 필수 조건을 충족해야 합니다:
- Node.js 18+ 및 npm 8+: npm을 포함하는 Node.js 18+의 모든 LTS(장기 지원) 버전이 적합합니다. 본 튜토리얼은 작성 시점의 최신 LTS 버전인 Node.js 18.12와 npm 8.19를 기준으로 합니다.
- JavaScript를 지원하는 IDE: 본 튜토리얼에서는 IntelliJ IDEA 커뮤니티 에디션을 사용하지만, JavaScript 및 Node.js를 지원하는 다른 IDE도 가능합니다.
위 링크를 클릭하고 설치 마법사를 따라 필요한 모든 것을 설정하세요. 터미널에서 아래 명령어를 실행하여 Node.js가 올바르게 설치되었는지 확인할 수 있습니다:
node -v다음과 같은 결과가 표시되어야 합니다:
v18.12.1마찬가지로 npm이 올바르게 설치되었는지 다음 명령어로 확인하세요:
npm -v 다음과 같은 문자열이 반환되어야 합니다:
8.19.2위의 두 명령어는 각각 컴퓨터에서 전역적으로 사용 가능한 Node.js와 npm의 버전을 나타냅니다.
훌륭합니다! 이제 Node.js에서 JavaScript 웹 스크래핑을 수행하는 방법을 살펴볼 준비가 되었습니다!
Node.js용 최고의 JavaScript 웹 스크래핑 라이브러리
Node.js에서 웹 스크래핑을 위한 최고의 JavaScript 라이브러리를 살펴보겠습니다:
- Axios – JavaScript에서 HTTP 요청을 쉽게 수행할 수 있도록 도와주는 라이브러리입니다. Axios는 브라우저와 Node.js 모두에서 사용할 수 있으며, 가장 인기 있는 JavaScript HTTP 클라이언트 중 하나입니다.
- Cheerio – HTML 및 XML 문서를 탐색하기 위한 jQuery와 유사한 API를 제공하는 경량 라이브러리입니다. Cheerio를 사용해 HTML 문서를 파싱하고, HTML 요소를 선택하며, 해당 요소에서 데이터를 추출할 수 있습니다. 즉, Cheerio는 고급 웹 스크래핑 API를 제공합니다.
- Selenium – 웹 애플리케이션 자동화 테스트 구축에 활용할 수 있는 여러 프로그래밍 언어를 지원하는 라이브러리입니다. 웹 스크래핑 목적으로 헤드리스 브라우저 기능으로도 사용할 수 있습니다. 자세한 Selenium 웹 스크래핑 가이드를 참고하세요.
- Playwright – 마이크로소프트에서 개발한 웹 애플리케이션 자동화 테스트 스크립트 생성 도구입니다. 브라우저에 특정 작업을 수행하도록 지시하는 방법을 제공합니다. 따라서 헤드리스 브라우저 솔루션으로 웹 스크래핑에 Playwright를 사용할 수 있습니다.
- 퍼피티어 (Puppeteer ) – 구글이 개발한 웹 애플리케이션 테스트 자동화 도구입니다. 퍼피티어는 크롬 개발자 도구 프로토콜을 기반으로 구축되었습니다. 셀레늄 및 플레이라이트와 마찬가지로, 인간 사용자와 동일하게 브라우저와 프로그래밍 방식으로 상호작용할 수 있게 합니다. 셀레늄과 퍼피티어의 차이점에 대해 자세히 알아보세요.
Node.js에서 JavaScript 웹 스크레이퍼 구축하기
여기서는 웹사이트에서 데이터를 자동으로 추출할 수 있는 Node.js 기반 자바스크립트 웹 스크레이퍼 구축 방법을 배웁니다. 구체적으로 대상 웹페이지는 Bright Data 홈페이지입니다. Node.js 웹 스크래핑 프로세스의 목표는 페이지에서 관심 있는 HTML 요소를 선택하고, 해당 요소에서 데이터를 추출한 후 스크랩된 데이터를 더 유용한 형식으로 변환하는 것입니다.
작성 시점의 Bright Data 홈페이지 모습은 다음과 같습니다:
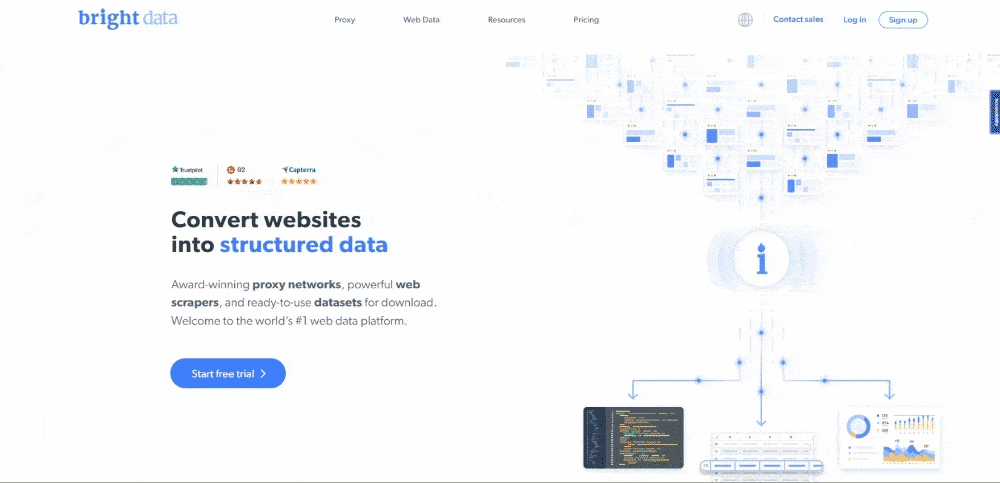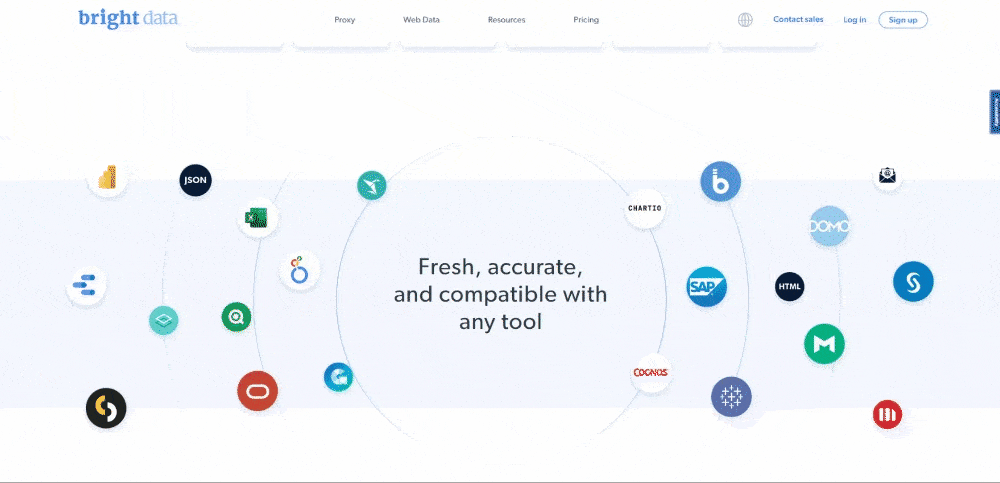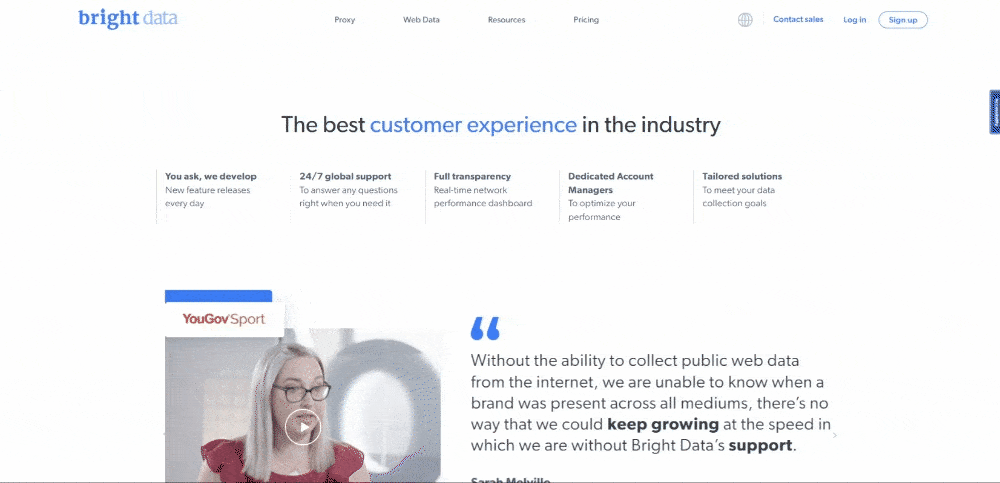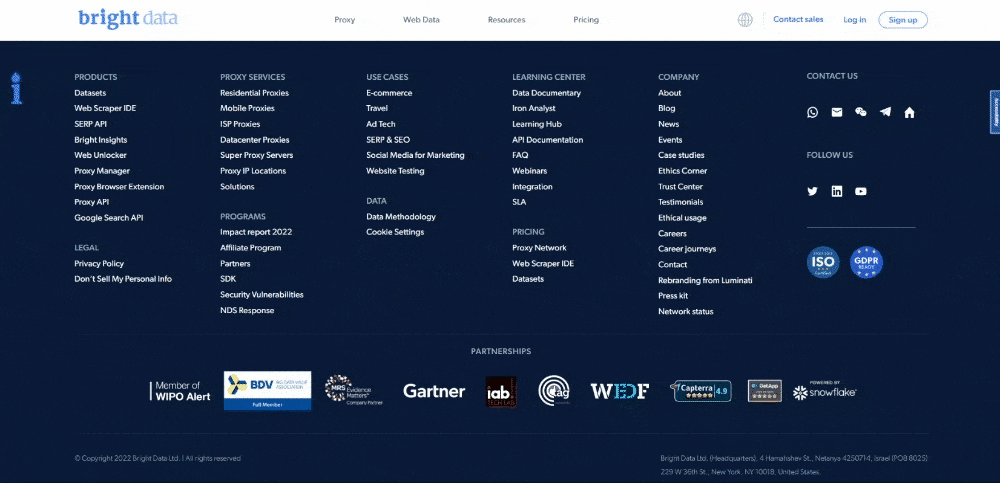
보시다시피 Bright Data 홈페이지에는 텍스트 설명부터 이미지까지 다양한 형식의 데이터와 정보가 풍부하게 포함되어 있습니다. 또한 유용한 링크도 다수 포함되어 있습니다. 이 모든 데이터를 추출하는 방법을 배워보겠습니다.
이제 단계별 튜토리얼을 통해 Node.js로 데이터를 스크래핑하는 방법을 살펴보겠습니다!
1단계: Node.js 프로젝트 설정
먼저 Node.js 웹 스크래핑 프로젝트를 담을 폴더를 생성합니다:
mkdir web-scraper-nodejs이제 빈 web-scraper-nodejs 디렉터리가 생성되었습니다. 프로젝트 폴더 이름은 원하는 대로 지정할 수 있습니다. 다음 명령어로 폴더로 이동하세요:
cd web-scraper-nodejs이제 다음 명령어로 npm 프로젝트를 초기화합니다:
npm init -y이 명령어는 새 npm 프로젝트를 설정해 줍니다. -y 플래그는 대화형 과정을 거치지 않고 기본 프로젝트를 초기화하기 위해 필수입니다. -y 플래그를 생략하면 터미널에서 몇 가지 질문을 받게 됩니다.
이제web-scraper-nodejs 폴더에는 다음과 같은 package.json 파일이 포함되어 있어야 합니다:
{rn u0022nameu0022: u0022web-scraper-nodejsu0022,rn u0022versionu0022: u00221.0.0u0022,rn u0022descriptionu0022: u0022u0022,rn u0022mainu0022: u0022index.jsu0022,rn u0022scriptsu0022: {rn u0022testu0022: u0022echo u0022Error: no test specifiedu0022 u0026u0026 exit 1u0022rn },rn u0022keywordsu0022: [],rn u0022authoru0022: u0022u0022,rn u0022licenseu0022: u0022ISCu0022rn}
이제 프로젝트 루트 폴더에 index.js 파일을 생성하고 아래와 같이 초기화하세요:
// index.js
console.log("Hello, World!")이 자바스크립트 파일에는 Node.js 웹 스크래핑 로직이 포함됩니다.
package.json 파일을 열고 scripts 섹션에 다음 스크립트를 추가하세요:
"start": "node index.js"이제 터미널에서 아래 명령어를 실행하여 Node.js 스크립트를 시작할 수 있습니다:
npm run start다음과 같은 결과가 반환됩니다:
Hello, World!이는 Node.js 애플리케이션이 정상적으로 작동함을 의미합니다. 이제 IDE에서 프로젝트를 열고 Node.js로 스크래핑 로직을 작성할 준비를 하세요!
IntelliJ IDEA 사용자라면 다음과 같은 화면을 볼 수 있습니다:
2단계: Axios와 Cheerio 설치
Node.js에서 웹 스크래퍼를 구현하는 데 필요한 종속성을 설치할 차례입니다. 어떤 JavaScript 웹 스크래핑 라이브러리를 채택해야 할지 파악하려면 대상 웹 페이지를 방문하고 빈 영역을 마우스 오른쪽 버튼으로 클릭한 후 “검사” 옵션을 선택하세요. 그러면 브라우저의 DevTools 창이 열립니다. 네트워크 탭에서 Fetch/XHR 섹션을 살펴보세요.
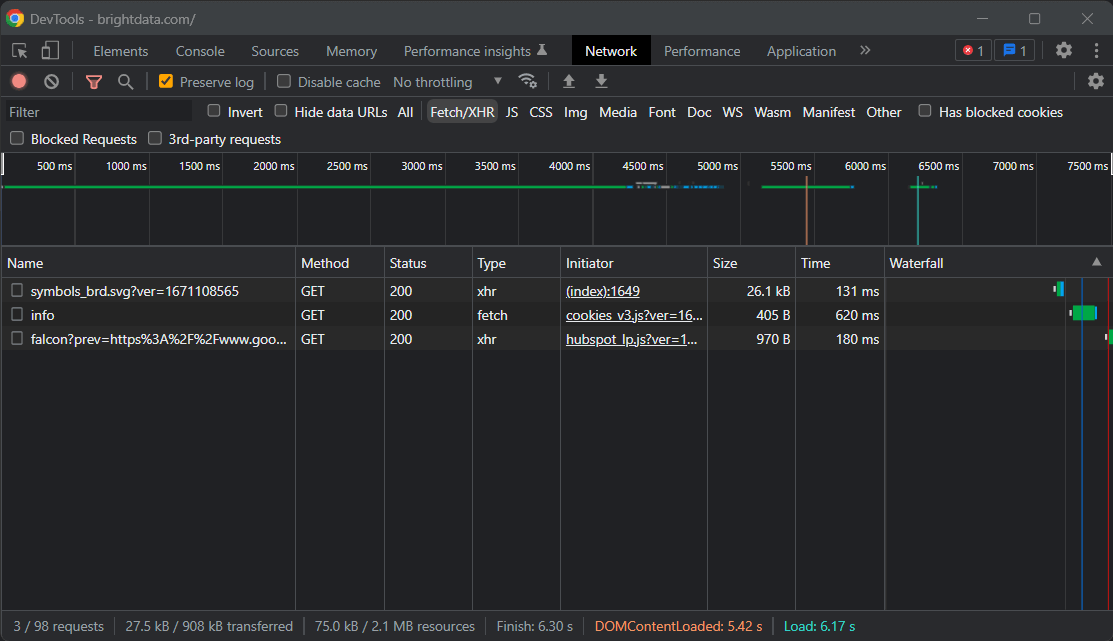
대상 페이지의 AJAX 요청에는 중요한 데이터가 표시되지 않습니다. 필요한 정보는 서버 측에서 렌더링되는 사이트의 전형적인 특징처럼 웹페이지의 소스 코드에 직접 포함되어 있습니다. 이는 페이지가 콘텐츠를 표시하거나 데이터를 가져오기 위해 자바스크립트가 필요하지 않음을 의미하므로, 스크래핑에 헤드리스 브라우저가 불필요합니다. 브라우저 사용으로 인한 추가 부하를 피하기 위해, 더 효율적이고 불필요한 복잡성을 피할 수 있는 Cheerio와 Axios를 함께 사용하는 것이 더 간단한 해결책입니다.
따라서 cheerio 와 axios 를 다음과 같이 설치하세요:
npm install cheerio axios그런 다음 index.js에 다음 두 줄의 코드를 추가하여 cheerio와 axios를 임포트하세요:
// index.js
const cheerio = require("cheerio")
const axios = require("axios")이제 Cheerio와 Axios를 사용해 웹 스크래핑을 수행하는 Node.js 스크립트를 작성해 보겠습니다!
3단계: 대상 웹사이트 다운로드
Axios를 사용하여 다음 코드 줄로 대상 웹사이트에 연결하세요:
// Axios에서 HTTP GET 요청을 수행하여
// 대상 웹 페이지를 다운로드합니다
const axiosResponse = await axios.request({
method: "GET",
url: "https://brightdata.com",
})Axios의 request() 메서드를 사용하면 모든 HTTP 요청을 실행할 수 있습니다. 구체적으로, 웹 페이지의 소스 코드를 다운로드하려면 해당 URL에 HTTP GET 요청을 수행해야 합니다. 일반적으로 Axios는 즉시 Promise를 반환합니다. await 키워드를 사용하면 Promise를 기다려 그 값을 동기적으로 얻을 수 있습니다.
request()가 실패하면 Error가 발생한다는 점에 유의하세요. 이는 URL이 유효하지 않거나 서버가 일시적으로 이용 불가능한 등 여러 이유로 발생할 수 있습니다. 또한, 많은 사이트가 스크래핑 방지 조치를 구현하고 있다는 점을 잊지 마세요. 가장 흔한 방법 중 하나는 유효한 User-Agent HTTP 헤더가 없는 요청을 차단하는 것입니다. 웹 스크래핑을 위한User-Agent에 대해 자세히 알아보세요.
기본적으로 Axios는 다음 User-Agent를 사용합니다:
axios <axios_version>이는 브라우저가 사용하는 User-Agent와 다릅니다. 따라서 스크래핑 방지 기술이 Node.js 웹 스크레이퍼를 탐지하여 차단할 수 있습니다.
request()에 전달되는 객체에 다음 속성을 추가하여 Axios에서 유효한 User-Agent 헤더를 설정하세요:
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}headers 속성을 사용하면 Axios에서 모든 HTTP 헤더를 설정할 수 있습니다.
이제 index.js 파일은 다음과 같아야 합니다:
// index.js
const cheerio = require("cheerio")
const axios = require("axios")
async function performScraping() {
// Axios에서 HTTP GET 요청을 수행하여
// 대상 웹 페이지를 다운로드합니다
const axiosResponse = await axios.request({
method: "GET",
url: "https://brightdata.com",
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}
})
}
performScraping()await는 async로 표시된 함수에서만 사용할 수 있다는 점에 유의하세요. 따라서 JavaScript 웹 스크래핑 로직은 async performScraping() 함수 안에 포함시켜야 합니다.
이제 대상 웹 페이지를 분석하여 웹 스크래핑 전략을 정의하는 데 시간을 할애해 보겠습니다.
4단계: HTML 페이지 검사
Bright Data 홈페이지를 살펴보면 Bright Data를 활용할 수 있는 산업 목록이 표시됩니다. 이 데이터는 스크래핑하기에 흥미로운 대상입니다.
해당 HTML 요소 중 하나를 마우스 오른쪽 버튼으로 클릭하고 “검사”를 선택하세요:
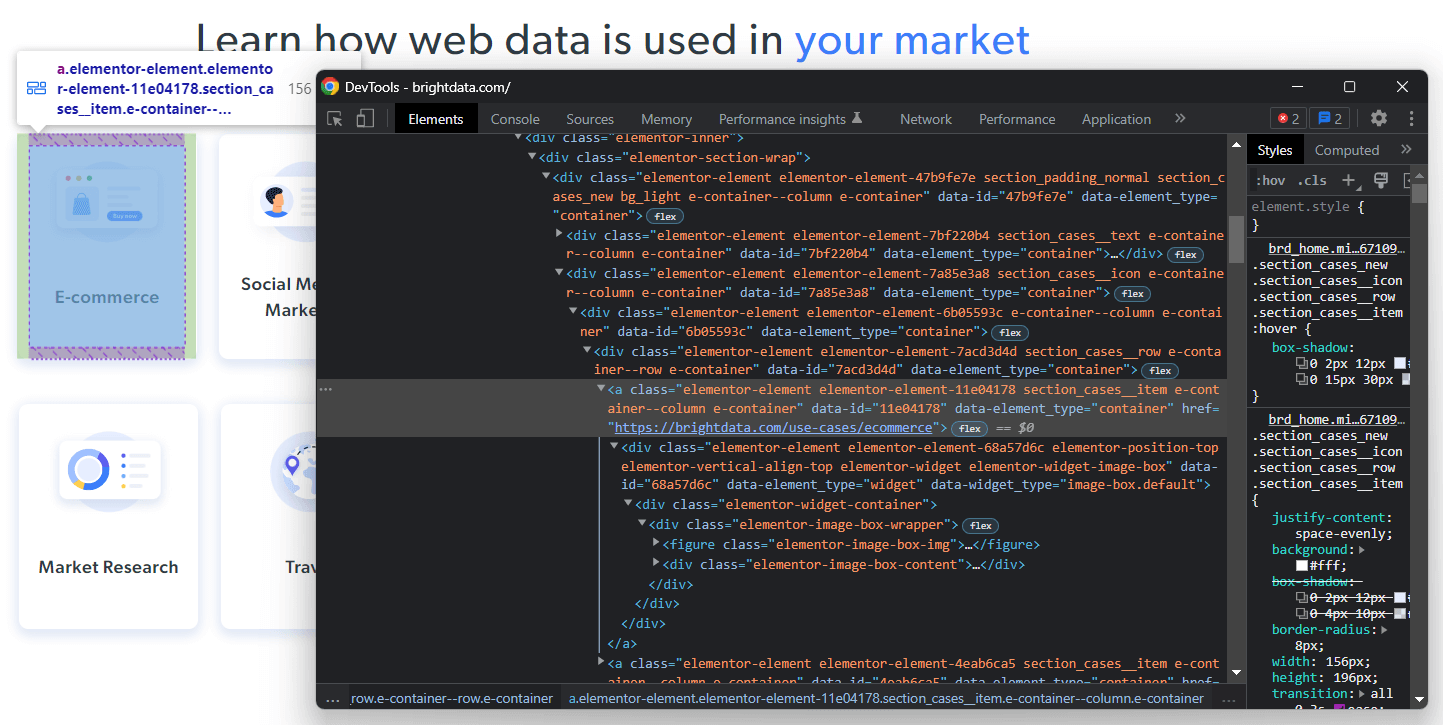
선택한 노드의 HTML 코드를 분석하면 해당 카드가 <a> HTML 요소임을 확인할 수 있습니다. 구체적으로 이 <a> 요소는 다음을 포함합니다:
- 산업 분야와 연관된 이미지를 포함하는
<figure>HTML 요소 - 산업 분야 이름을 포함하는
<div>HTML 요소
이제 해당 HTML 요소를 특징짓는 CSS 클래스를 확인하세요. 이를 활용하면 DOM에서 해당 HTML 요소를 선택하는 데 필요한 CSS 선택자를 정의할 수 있습니다. 세부적으로, .e-container 카드들은 .elementor-element-7a85e3a8 <div> 내에 포함되어 있음을 주목하세요. 그런 다음, 특정 카드를 대상으로 다음과 같은 CSS 선택자를 사용하여 모든 관련 데이터를 추출할 수 있습니다:
.elementor-image-box-img img.elementor-image-box-content .elementor-image-box-title
마찬가지로 동일한 논리를 적용하여 다음을 수행하는 데 필요한 CSS 선택자를 정의할 수 있습니다:
- Bright Data가 업계 선두주자인 이유를 추출하세요.
- Bright Data가 제공하는 고객 경험이 시장에서 최고인 이유를 선택합니다.
다시 말해, 대상 웹 페이지에는 세 가지 스크래핑 목표가 있습니다:
- Bright Data를 활용할 수 있는 산업 분야에 대한 데이터.
- Bright Data가 업계 선두주자인 이유에 대한 데이터.
- Bright Data가 업계 최고의 고객 경험을 제공하는 이유에 관한 데이터.
5단계: Cheerio로 HTML 요소 선택하기
Cheerio는 웹 페이지에서 HTML 요소를 선택하는 여러 방법을 제공합니다. 하지만 먼저 Cheerio를 초기화해야 합니다:
// Cheerio로 대상 웹 페이지의 HTML 소스 파싱
const $ = cheerio.load(axiosResponse.data)Cheerio의 load() 메서드는 문자열 형태의 HTML 콘텐츠를 받아들입니다. Axios 응답 객체는 HTTP 요청이 반환한 데이터를 data 속성에 포함하고 있다는 점에 유의하세요. 이 경우 data에는 서버가 반환한 웹 페이지의 HTML 소스 코드가 저장됩니다. 따라서 Cheerio를 초기화하려면 axiosResponse.data를 load() 에 전달합니다.
Cheerio는 jQuery와 기본적으로 동일한 구문을 공유하므로 Cheerio 변수를 $로 호출해야 합니다. 이렇게 하면 인터넷에서 jQuery 코드 조각을 복사할 수 있습니다.
Cheerio로 HTML 요소를 선택하려면 클래스를 사용하여 다음과 같이 작성합니다:
const htmlElement = $(".elementClass")마찬가지로 ID로 HTML 요소를 가져올 수 있습니다:
const htmlElement = $("#elementId")자세히 설명하자면, jQuery에서와 마찬가지로 $에 유효한 CSS 선택자를 전달하여 HTML 요소를 선택할 수 있습니다. find() 메서드를 사용하여 선택 논리를 연결할 수도 있습니다:
// 업계 카드 목록 가져오기
const industryCards = $(".elementor-element-7a85e3a8").find(".e-container")find()는 CSS 선택자로 필터링된 현재 HTML 요소의 하위 요소들에 접근할 수 있게 합니다. 이후 each() 메서드를 사용하여 Cheerio 노드 목록을 반복 처리할 수 있습니다:
// 산업 카드 목록 반복 처리
$(".elementor-element-7a85e3a8")
.find(".e-container")
.each((index, element) => {
// 스크래핑 로직...
})이제 Cheerio를 사용하여 관심 있는 HTML 요소에서 데이터를 추출하는 방법을 알아보겠습니다.
6단계: Cheerio로 대상 웹페이지에서 데이터 스크래핑하기
선행된 로직을 확장하여 선택된 HTML 요소에서 원하는 데이터를 추출하는 방법은 다음과 같습니다:
// 스크래핑된 데이터를 담을 데이터 구조 초기화
const industries = []
// "Learn how web data is used in your market" 섹션 스크래핑
$(".elementor-element-7a85e3a8")
.find(".e-container")
.each((index, element) => {
// 관심 데이터 추출
const pageUrl = $(element).attr("href")
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const name = $(element).find(".elementor-image-box-content .elementor-image-box-title").text()
// 관심 없는 데이터 필터링
if (name && pageUrl) {
// 추출된 데이터를 더 읽기 쉬운 객체로 변환
const industry = {
url: pageUrl,
image: image,
name: name
}
// 스크래핑된 데이터를 포함하는 객체를 industries 배열에 추가
industries.push(industry)
}
})이 웹 스크래핑 Node.js 스니펫은 Bright Data 홈페이지에서 모든 산업 카드(industry card)를 선택합니다. 그런 다음 모든 HTML 카드 요소를 반복 처리합니다. 각 카드에 대해 해당 카드와 연결된 웹 페이지의 URL, 이미지, 산업 이름을 스크래핑합니다. Cheerio의 attr() 및 text() 메서드를 통해 각각 HTML 속성값과 텍스트를 가져올 수 있습니다. 마지막으로 스크래핑된 데이터를 객체에 저장하고 industries 배열에 추가합니다.
each() 루프가 완료되면 industries에는 첫 번째 스크래핑 목표와 관련된 모든 관심 데이터가 포함됩니다. 이제 나머지 두 목표를 달성하는 방법도 살펴보겠습니다.
마찬가지로, Bright Data가 업계 선두주자인 이유를 뒷받침하는 데이터를 다음과 같이 스크래핑할 수 있습니다:
const marketLeaderReasons = []
// "Bright Data가
// 업계 최고의 리더인 이유" 섹션 스크래핑
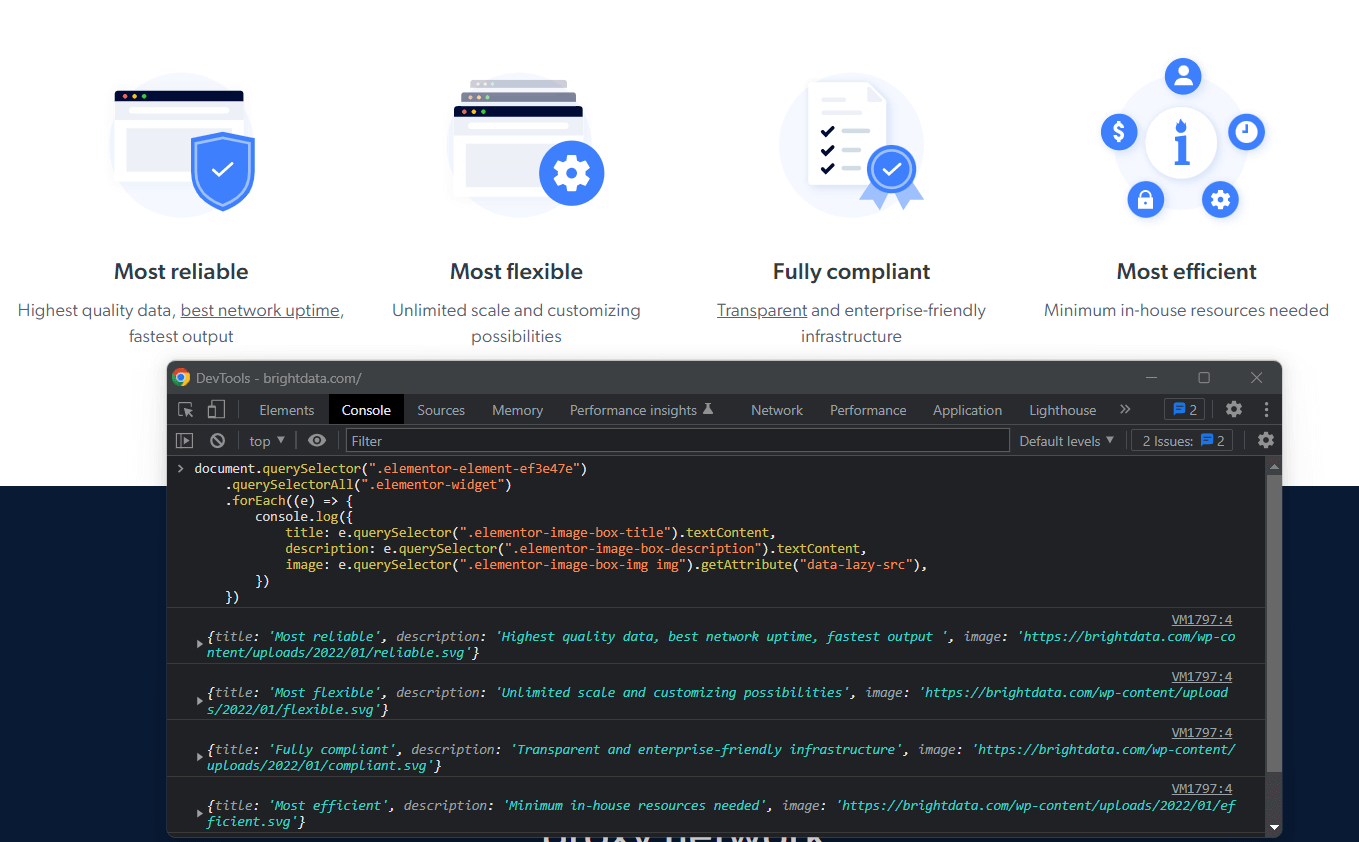
$(".elementor-element-ef3e47e")
.find(".elementor-widget")
.each((index, element) => {
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const title = $(element).find(".elementor-image-box-title").text()
const description = $(element).find(".elementor-image-box-description").text()
const marketLeaderReason = {
title: title,
image: image,
description: description,
}
marketLeaderReasons.push(marketLeaderReason)
})마지막으로, Bright Data가 우수한 고객 경험을 제공하는 이유에 대한 데이터를 다음과 같이 스크래핑할 수 있습니다:
const customerExperienceReasons = []
// "업계 최고의 고객 경험" 섹션 스크래핑
$(".elementor-element-288b23cd .elementor-text-editor")
.find("li")
.each((index, element) => {
const title = $(element).find("strong").text()
// 제목이 설명의 일부이므로, 설명만 추출하려면
// 제목을 제거해야 합니다
const description = $(element).text().replace(title, "").trim()
const customerExperienceReason = {
title: title,
description: description,
}
customerExperienceReasons.push(customerExperienceReason)
})축하합니다! 이제 Node.js 웹 스크래핑의 세 가지 목표를 모두 달성하는 방법을 배웠습니다!
현재 페이지에서 발견한 링크를 따라 다른 웹 페이지의 데이터도 스크래핑할 수 있다는 점을 기억하세요. 이것이 바로 웹 크롤링의 핵심입니다. 따라서 해당 페이지에서도 데이터를 추출할 수 있는 웹 스크래핑 로직을 정의할 수 있습니다.
industries, marketLeaderReasons, customerExperienceReasons는 스크래핑된 모든 데이터를 자바스크립트 객체에 저장합니다. 이를 더 유용한 형식으로 변환하는 방법을 알아봅시다.
7단계: 추출한 데이터를 JSON으로 변환하기
JSON은 자바스크립트 환경에서 가장 우수한 데이터 형식 중 하나입니다. JSON은 자바스크립트에서 파생되었으며 API가 데이터를 수신하거나 반환할 때 일반적으로 사용하는 형식이기 때문입니다. 따라서 자바스크립트 스크래핑 데이터를 JSON으로 변환해야 할 가능성이 높습니다. 아래 로직으로 쉽게 달성할 수 있습니다:
// 스크랩된 데이터를 일반 객체로 변환
const scrapedData = {
industries: industries,
marketLeader: marketLeaderReasons,
customerExperience: customerExperienceReasons,
}
// 스크랩된 데이터 객체를 JSON으로 변환
const scrapedDataJSON = JSON.stringify(scrapedData)먼저, 스크래핑된 모든 데이터를 포함하는 자바스크립트 객체를 생성해야 합니다. 그런 다음 JSON.stringify()를 사용하여 해당 자바스크립트 객체를 JSON으로 변환할 수 있습니다.
scrapedDataJSON에는 다음과 같은 JSON 데이터가 포함됩니다:
{
"산업 분야": [
{
"url": "https://brightdata.com/use-cases/ecommerce",
"image": "https://media.brightdata.com/2022/07/E_commerce.svg",
"name": "전자상거래"
},
// ...
{
"url": "https://brightdata.com/use-cases/data-for-good",
"image": "https://media.brightdata.com/2022/07/Data_for_Good_N.svg",
"name": "Data for Good"
}
],
"marketLeader": [
{
"title": "가장 신뢰할 수 있는",
"image": "https://media.brightdata.com/2022/01/reliable.svg",
"description": "최고 품질의 데이터, 최상의 네트워크 가동 시간, 가장 빠른 출력"
},
// ...
{
"title": "가장 효율적인",
"image": "https://media.brightdata.com/2022/01/efficient.svg",
"description": "최소한의 내부 자원 필요"
}
],
"customerExperience": [
{
"title": "요청하시면 개발해 드립니다",
"description": "매일 새로운 기능 출시"
},
// ...
{
"title": "맞춤형 솔루션",
"description": "데이터 수집 목표 달성을 위해"
}
]
}축하합니다! 웹사이트 연결부터 시작하여 이제 데이터를 스크래핑하고 JSON으로 변환할 수 있게 되었습니다. 이제 완성된 웹 스크래핑 Node.js 스크립트를 살펴볼 준비가 되었습니다.
모든 것을 합쳐보기
Node.js 웹 스크레이퍼는 다음과 같습니다:
// index.js
const cheerio = require("cheerio")
const axios = require("axios")
async function performScraping() {
// Axios를 통해 HTTP GET 요청을 수행하여
// 대상 웹 페이지를 다운로드합니다
const axiosResponse = await axios.request({
method: "GET",
url: "https://brightdata.com/",
headers: {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}
})
// Cheerio로 대상 웹 페이지의 HTML 소스 파싱
const $ = cheerio.load(axiosResponse.data)
// 스크래핑된 데이터를 담을 데이터 구조 초기화
const industries = []
const marketLeaderReasons = []
const customerExperienceReasons = []
// "Learn how web data is used in your market" 섹션 스크래핑
$(".elementor-element-7a85e3a8")
.find(".e-container")
.each((index, element) => {
// 관심 데이터 추출
const pageUrl = $(element).attr("href")
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const name = $(element).find(".elementor-image-box-content .elementor-image-box-title").text()
// 관심 없는 데이터 필터링
if (name && pageUrl) {
// 추출된 데이터를 더 읽기 쉬운 객체로 변환
const industry = {
url: pageUrl,
image: image,
name: name
}
// 스크랩된 데이터를 포함한 객체를 industries 배열에 추가
industries.push(industry)
}
})
// "Bright Data가 업계 최고의 리더인 이유" 섹션 스크래핑
$(".elementor-element-ef3e47e")
.find(".elementor-widget")
.each((index, element) => {
// 관심 데이터 추출
const image = $(element).find(".elementor-image-box-img img").attr("data-lazy-src")
const title = $(element).find(".elementor-image-box-title").text()
const description = $(element).find(".elementor-image-box-description").text()
// 추출된 데이터를 더 읽기 쉬운 객체로 변환
const marketLeaderReason = {
title: title,
image: image,
description: description,
}
// 스크랩된 데이터를 포함한 객체를 marketLeaderReasons 배열에 추가
marketLeaderReasons.push(marketLeaderReason)
})
// "업계 최고의 고객 경험" 섹션 스크래핑
$(".elementor-element-288b23cd .elementor-text-editor")
.find("li")
.each((index, element) => {
// 관심 데이터 추출
const title = $(element).find("strong").text()
// 제목이 텍스트의 일부이므로
// 설명만 추출하려면 제목을 제거해야 함
const description = $(element).text().replace(title, "").trim()
// 추출된 데이터를 더 읽기 쉬운 객체로 변환
const customerExperienceReason = {
title: title,
description: description,
}
// 스크랩된 데이터를 포함하는 객체를
// customerExperienceReasons 배열에 추가
customerExperienceReasons.push(customerExperienceReason)
})
// 스크랩된 데이터를 일반 객체로 변환
const scrapedData = {
industries: industries,
marketLeader: marketLeaderReasons,
customerExperience: customerExperienceReasons,
}
// 스크랩된 데이터 객체를 JSON으로 변환
const scrapedDataJSON = JSON.stringify(scrapedData)
// API 호출을 통해 scrapedDataJSON을 데이터베이스에 저장...
}
performScraping()여기서 볼 수 있듯이, Node.js로 100줄 미만의 코드로 웹 스크레이퍼를 구축할 수 있습니다. Cheerio와 Axios를 사용하면 HTML 웹 페이지를 다운로드하고, 파싱하며, 모든 데이터를 자동으로 추출할 수 있습니다. 그런 다음 스크랩된 데이터를 JSON으로 쉽게 변환할 수 있습니다. 이것이 바로 Node.js 웹 스크래핑의 핵심입니다.
Node.js에서 웹 스크레이퍼를 실행하려면 다음 명령어를 사용하세요:
npm run start자, 이제 Node.js에서 JavaScript 웹 스크래핑을 수행하는 방법을 배웠습니다!
결론
이 튜토리얼에서는 프론트엔드에서 JavaScript로 웹 스크래핑하는 것이 제한적인 해결책인 이유와 Node.js가 더 나은 선택인 이유를 살펴보았습니다. 또한 Node.js 웹 스크래핑 스크립트를 생성하는 데 필요한 요소와 JavaScript로 웹 데이터를 추출하는 방법을 살펴보았습니다. 구체적으로 실제 사례를 바탕으로 Cheerio와 Axios를 활용해 Node.js에서 JavaScript 웹 스크래핑 애플리케이션을 만드는 방법을 배웠습니다. 학습한 바와 같이 Node.js를 이용한 웹 스크래핑은 몇 줄의 코드만으로 가능합니다.
하지만 웹 스크래핑이 그렇게 쉽지 않을 수 있다는 점을 명심하세요. 그 이유는 해결해야 할 많은 도전 과제들이 존재하기 때문입니다. 구체적으로, 안티 스크래핑 및 안티 봇 솔루션이 점점 더 보편화되고 있습니다. 다행히 Bright Data에서 제공하는 차세대 고급 웹 스크래핑 도구로 이 모든 문제를 쉽게 피할 수 있습니다. 웹 스크래핑을 직접 다루고 싶지 않으신가요? 저희 데이터셋을 살펴보세요.
차단을 피하는 방법에 대해 자세히 알고 싶다면, 여러 프록시 서비스 중 하나에서 웹 프록시를 채택하거나 고급 웹 언락커 사용을 시작하세요.