

인터넷에 직접 접속할 경우, 웹사이트는 사용자의 요청을 IP 주소로 쉽게 추적할 수 있습니다. 이러한 노출은 타겟팅 광고 및 온라인 추적으로 이어질 수 있으며, 잠재적으로 디지털 신원을 위협할 수 있습니다.
이때 프록시가 필요합니다. 프록시는 사용자의 컴퓨터와 인터넷 사이의 중개자 역할을 하여 디지털 신원을 보호합니다. 프록시 서버를 사용하면 해당 서버의 자체 IP 주소를 사용하여 웹사이트에 요청을 전송합니다.
웹 스크래핑과 관련해서는 프록시가 IP 차단 우회, 지역 제한 회피, 신원 보호에 도움이 될 수 있습니다. 이 글에서는 모든 웹 스크래핑 프로젝트를 위해 C#으로 프록시를 구현하는 방법을 배울 수 있습니다.
필수 조건
이 튜토리얼을 시작하기 전에 다음 사항을 준비하세요:
- Visual Studio 2022
- .NET 7 이상
- HtmlAgilityPack
이 문서의 예제는 별도의 .NET 콘솔 애플리케이션을 사용합니다. 직접 만들려면 다음 가이드 중 하나를 참조하세요:
시작하려면 WebScrapApp과 WebScrapBrightData라는 두 개의 콘솔 애플리케이션을 생성해야 합니다:
웹 스크래핑, 특히 HTML 콘텐츠를 다룰 때는 HtmlAgilityPack과 같은 특정 도구가 필요합니다. 이 라이브러리는 HTML 파싱 및 조작을 단순화하여 웹 페이지에서 데이터를 추출하기 쉽게 만듭니다.
두 프로젝트(즉, WebScrapApp 및 WebScrapBrightData) 모두에서 NuGet 폴더를 마우스 오른쪽 버튼으로 클릭한 다음 ‘NuGet 패키지 관리’를 선택하여 HtmlAgilityPack NuGet 패키지를 추가하세요. 팝업 창이 나타나면 “HtmlAgilityPack”을 검색하고 두 프로젝트 모두에 설치하세요:

다음 프로젝트를 실행하려면 명령 프롬프트에서 프로젝트 디렉터리로 이동한 후 ` cd 프로젝트경로 `를 입력하고 ` dotnet run`을 실행하세요. 또는 Visual Studio에서 F5 키를 눌러 프로젝트를 빌드하고 실행할 수도 있습니다. 두 방법 모두 애플리케이션을 컴파일하고 실행하여 결과를 표시합니다.
참고: Visual Studio 2022가 없는 경우 .NET 7을 지원하는 다른 IDE를 사용할 수 있습니다. 다만 본 가이드의 일부 단계가 다를 수 있음을 유의하십시오.
로컬 프록시 설정 방법
웹 스크래핑을 수행하려면 먼저 프록시 서버를 사용해야 합니다. 본 튜토리얼에서는 오픈소스 프록시인 mitmproxy를 사용합니다.
먼저 mitmproxy 다운로드 페이지로 이동하여 버전 10.1.6을 다운로드하고 운영 체제에 맞는 버전을 선택하세요. 추가 도움말은 공식 mitmproxy 설치 가이드를 참조하세요.
mitmproxy 설치가 완료되면 터미널을 열고 다음 명령어로 mitmproxy를 실행하세요:
mitmproxy
터미널에 다음과 같은 창이 표시됩니다:
프록시를 테스트하려면 다른 터미널이나 셸을 열고 다음 curl 요청을 실행하세요:
curl --proxy http://localhost:8080 "http://wttr.in/Dunedin?0"
출력 결과는 다음과 같아야 합니다:
날씨 정보: 더니든
흐림
.--. +11(9) °C
.-( ). ↙ 15 km/h
(___.__)__) 10 km
0.0 mm
mitmproxy 창에서는 로컬 프록시를 통해 호출이 가로채진 것을 확인할 수 있습니다:
C#을 이용한 웹 스크래핑
다음 섹션에서는 웹 스크래핑을 위한 C# 콘솔 애플리케이션 WebScrapApp을 설정합니다. 이 애플리케이션은 프록시 서버를 활용하며 효율성 향상을 위한 프록시 로테이션 기능을 포함합니다.
HttpClient 생성
ProxyHttpClient 클래스는 요청을 지정된 프록시 서버를 통해 라우팅하도록 HttpClient 인스턴스를 구성하기 위해 설계되었습니다.
WebScrapApp 프로젝트 아래에 ProxyHttpClient. cs라는 새 클래스 파일을 생성하고 다음 코드를 추가하세요:
namespace WebScrapApp
{
public class ProxyHttpClient
{
public static HttpClient CreateClient(string proxyUrl)
{
var httpClientHandler = new HttpClientHandler()
{
Proxy = new WebProxy(proxyUrl),
UseProxy = true
};
return new HttpClient(httpClientHandler);
}
}
}
프록시 로테이션 구현
프록시 로테이션을 구현하려면 WebScrapApp 솔루션 아래에 ProxyRotator.cs 클래스 파일을 생성하세요:
namespace WebScrapApp
{
public class ProxyRotator
{
private List<string> _validProxies = new List<string>();
private readonly Random _random = new();
public ProxyRotator(string[] proxies, bool isLocal)
{
if (isLocal)
{
_validProxies.Add("http://localhost:8080/");
}
else
{
_validProxies = ProxyChecker.GetWorkingProxies(proxies.ToList()).Result;
}
if (_validProxies.Count == 0)
throw new InvalidOperationException();
}
public HttpClient ScrapeDataWithRandomProxy(string url)
{
if (_validProxies.Count == 0)
throw new InvalidOperationException();
var proxyUrl = _validProxies[_random.Next(_validProxies.Count)];
return ProxyHttpClient.CreateClient(proxyUrl);
}
}
}
이 클래스는 프록시 목록을 관리하며, 각 웹 요청에 대해 프록시를 무작위로 선택하는 메서드를 제공합니다. 이 무작위 선택은 웹 스크래핑 중 탐지 위험과 잠재적인 IP 차단 가능성을 줄이는 핵심 요소입니다.
isLocal이 True로 설정되면 mitmproxy의 로컬 프록시를 사용합니다. False로 설정되면 프록시의 공인 IP를 사용합니다.
ProxyChecker 는 프록시 서버 목록을 검증하는 데 사용됩니다.
다음으로 ProxyChecker. cs라는 새 클래스 파일을 생성하고 다음 코드를 추가합니다:
using WebScrapApp;
namespace WebScrapApp
{
public class ProxyChecker
{
private static SemaphoreSlim consoleSemaphore = new SemaphoreSlim(1, 1);
private static int currentProxyNumber = 0;
public static async Task<List<string>> GetWorkingProxies(List<string> proxies)
{
var tasks = new List<Task<Tuple<string, bool>>>();
foreach (var proxyUrl in proxies)
{
tasks.Add(CheckProxy(proxyUrl, proxies.Count));
}
var results = await Task.WhenAll(tasks);
var workingProxies = new List<string>();
foreach (var result in results)
{
if (result.Item2)
{
workingProxies.Add(result.Item1);
}
}
return workingProxies;
}
private static async Task<Tuple<string, bool>> CheckProxy(string proxyUrl, int totalProxies)
{
var client = ProxyHttpClient.CreateClient(proxyUrl);
bool isWorking = await IsProxyWorking(client);
await consoleSemaphore.WaitAsync();
try
{
currentProxyNumber++;
Console.WriteLine($"Proxy: {currentProxyNumber} de {totalProxies}");
}
finally
{
consoleSemaphore.Release();
}
return new Tuple<string, bool>(proxyUrl, isWorking);
}
private static async Task<bool> IsProxyWorking(HttpClient client)
{
try
{
var testUrl = "http://www.google.com";
var response = await client.GetAsync(testUrl);
return response.IsSuccessStatusCode;
}
catch
{
return false;
}
}
}
}
이 코드는 프록시 서버 목록을 검증하기 위한 ProxyChecker를 정의합니다. 프록시 URL 목록과 함께 GetWorkingProxies 메서드를 사용하면, CheckProxy 메서드를 통해 각 프록시의 상태를 비동기적으로 확인하고 작동하는 프록시를 workingProxies 목록에 수집합니다. CheckProxy 내부에서는 프록시 URL로 HttpClient를 생성하고, http://www.google.com에 테스트 요청을 수행하며, 세마포어를 사용하여 안전하게 진행 상황을 기록합니다.
IsProxyWorking 메서드는 응답 상태 코드를 검사하여 프록시의 기능을 확인하고, 작동하는 프록시에 대해 true를 반환합니다. 이 클래스는 주어진 목록에서 작동하는 프록시를 식별하는 데 도움이 됩니다.
웹 데이터 스크래핑
데이터를 스크래핑하려면 WebScrapApp 솔루션 아래에 새로운 WebScraper.cs 클래스 파일을 생성하고 다음 코드를 추가하세요:
using HtmlAgilityPack;
namespace WebScrapApp
{
public class WebScraper
{
public static async Task ScrapeData(ProxyRotator proxyRotator, string url)
{
try
{
var client = proxyRotator.ScrapeDataWithRandomProxy(url);
// HttpClient를 사용하여 비동기 GET 요청 수행
var response = await client.GetAsync(url);
var content = await response.Content.ReadAsStringAsync();
// HTML 콘텐츠를 HtmlDocument에 로드
HtmlDocument doc = new();
doc.LoadHtml(content);
// XPath를 사용하여 <li>, <p>, 또는 <td>의 직접 자식인 모든 <a> 태그 찾기
var nodes = doc.DocumentNode.SelectNodes("//li/a[@href] | //p/a[@href] | //td/a[@href]");
if (nodes != null)
{
foreach (var node in nodes)
{
string hrefValue = node.GetAttributeValue("href", string.Empty);
string title = node.InnerText; // <a> 태그의 텍스트 콘텐츠(보통 제목)를 가져옴
// 위키백과 URL은 상대 경로이므로 절대 경로로 변환해야 함
Uri baseUri = new(url);
Uri fullUri = new(baseUri, hrefValue);
Console.WriteLine($"제목: {title}, 링크: {fullUri.AbsoluteUri}");
// 각 제목과 링크를 필요에 따라 처리할 수 있습니다
}
}
else
{
Console.WriteLine("페이지에서 기사 링크를 찾지 못했습니다.");
}
// 필요에 따라 다른 데이터 추출을 위한 추가 로직을 추가하세요
}
catch (Exception ex)
{
throw ex;
}
}
}
}
이 코드에서는 웹 스크래핑 기능을 캡슐화하는 WebScraper를 정의합니다. ScrapeData 메서드를 호출할 때 ProxyRotator 인스턴스와 대상 URL을 전달합니다. 이 메서드 내부에서는 HttpClient를 사용하여 URL에 대한 비동기 GET 요청을 수행하고, HTML 콘텐츠를 가져온 후 HtmlAgilityPack 라이브러리를 사용하여 파싱합니다. 그런 다음 XPath 쿼리를 활용하여 특정 HTML 요소에서 링크와 해당 제목을 찾아 추출합니다. 기사 링크가 발견되면 해당 제목과 절대 URL을 출력하고, 그렇지 않으면 링크가 발견되지 않았음을 알리는 메시지를 출력합니다.
프록시 로테이션 메커니즘을 구성하고 웹 스크래핑 기능을 구현한 후에는, 이러한 구성 요소들을 애플리케이션의 주요 진입점(일반적으로 Program.cs에 위치)에 원활하게 통합해야 합니다. 이 통합을 통해 애플리케이션은 로테이션 프록시를 활용하면서 웹 스크래핑 작업을 실행할 수 있으며, 특히 위키피디아 홈페이지에서 데이터를 스크래핑하는 데 중점을 둡니다:
namespace WebScrapApp {
public class Program
{
static async Task Main(string[] args)
{
string[] proxies = {
"http://162.223.89.84:80",
"http://203.80.189.33:8080",
"http://94.45.74.60:8080",
"http://162.248.225.8:80",
"http://167.71.5.83:3128"
};
var proxyRotator = new ProxyRotator(proxies, false);
string urlToScrape = "https://www.wikipedia.org/";
await WebScraper.ScrapeData(proxyRotator, urlToScrape);
}
}
}
이 코드에서 애플리케이션은 프록시 URL 목록을 초기화하고, ProxyRotator 인스턴스를 생성하며, 스크래핑 대상 URL(이 경우 https://www.wikipedia.org/)을 지정한 후 WebScraper.ScrapeData 메서드를 호출하여 웹 스크래핑 프로세스를 시작합니다.
애플리케이션은 proxies 배열에 지정된 무료 프록시 IP 목록을 사용하여 웹 스크래핑 요청을 라우팅함으로써 신뢰할 수 있는 소스를 숨기고 위키피디아 서버에 의해 차단될 위험을 최소화합니다. ScrapeData 메서드는 위키피디아 홈페이지를 스크래핑하여 기사 제목과 링크를 추출하고 콘솔에 표시하도록 설정됩니다. ProxyRotator 클래스는 이러한 프록시의 회전을 처리하여 스크래핑의 은밀성을 높입니다.
WebScrapApp 실행
WebScrapApp을 실행하려면 WebScrapApp 애플리케이션의 루트 디렉터리에서 새 터미널 또는 셸을 열고 다음 명령을 실행하세요:
dotnet build
dotnet run
출력 결과는 다음과 같아야 합니다:
…출력 생략…
제목: Latina, 링크: https://la.wikipedia.org/
제목: Latviešu, 링크: https://lv.wikipedia.org/
제목: Lietuvių, 링크: https://lt.wikipedia.org/
제목: Magyar, 링크: https://hu.wikipedia.org/
제목: Македонски, 링크: https://mk.wikipedia.org/
제목: Bahasa Melayu, 링크: https://ms.wikipedia.org/
제목: Bahaso Minangkabau, 링크: https://min.wikipedia.org/
제목: bokmål, 링크: https://no.wikipedia.org/
제목: nynorsk, 링크: https://nn.wikipedia.org/
제목: 우즈베크어 / Ўзбекча, 링크: https://uz.wikipedia.org/
제목: 카자흐어 / Qazaqşa / قازاقشا, 링크: https://kk.wikipedia.org/
제목: Română, 링크: https://ro.wikipedia.org/
제목: Simple English, 링크: https://simple.wikipedia.org/
제목: Slovenčina, 링크: https://sk.wikipedia.org/
제목: Slovenščina, 링크: https://sl.wikipedia.org/
제목: Српски / Srpski, 링크: https://sr.wikipedia.org/
제목: 세르보크로아트어, 링크: https://sh.wikipedia.org/
제목: 핀란드어, 링크: https://fi.wikipedia.org/
제목: 타밀어, 링크: https://ta.wikipedia.org/
…출력 생략…
WebScraper 클래스의 ScrapeData 메서드가 호출되면 위키백과에서 데이터를 추출하여 콘솔에 문서 제목과 해당 링크를 표시합니다. 이 코드는 공개적으로 이용 가능한 프록시를 사용하며, 애플리케이션을 실행할 때마다 나열된 IP 주소 중 하나를 프록시로 선택합니다.
mitmproxy의 로컬 프록시로 테스트하려면 Program 파일의 ProxyRotator 메서드를 다음과 같이 업데이트하십시오:
var proxyRotator = new ProxyRotator(proxies, true)
string urlToScrape = "http://toscrape.com/";
값을 true로 설정하면 로컬호스트 포트 8080에서 실행 중인 로컬 프록시 서버(즉, mitmproxy 서버)를 사용합니다.
컴퓨터에 인증서를 설정할 때 구성 과정을 단순화하려면 URL을 http://toscrape.com/로 변경하십시오.
mitmproxy 서버가 실행 중인지 확인한 후 동일한 명령어를 다시 실행하세요:
dotnet build
dotnet run
출력 결과는 다음과 같아야 합니다:
…출력 생략…
Title: fictional bookstore, Link: http://books.toscrape.com/
Title: books.toscrape.com, Link: http://books.toscrape.com/
Title: A website, Link: http://quotes.toscrape.com/
Title: Default, Link: http://quotes.toscrape.com/
제목: 스크롤, 링크: http://quotes.toscrape.com/scroll
제목: 자바스크립트, 링크: http://quotes.toscrape.com/js
제목: 지연, 링크: http://quotes.toscrape.com/js-delayed
제목: 테이블 전체, 링크: http://quotes.toscrape.com/tableful
제목: 로그인, 링크: http://quotes.toscrape.com/login
제목: 뷰스테이트, 링크: http://quotes.toscrape.com/search.aspx
제목: 랜덤, 링크: http://quotes.toscrape.com/random
…출력 생략…
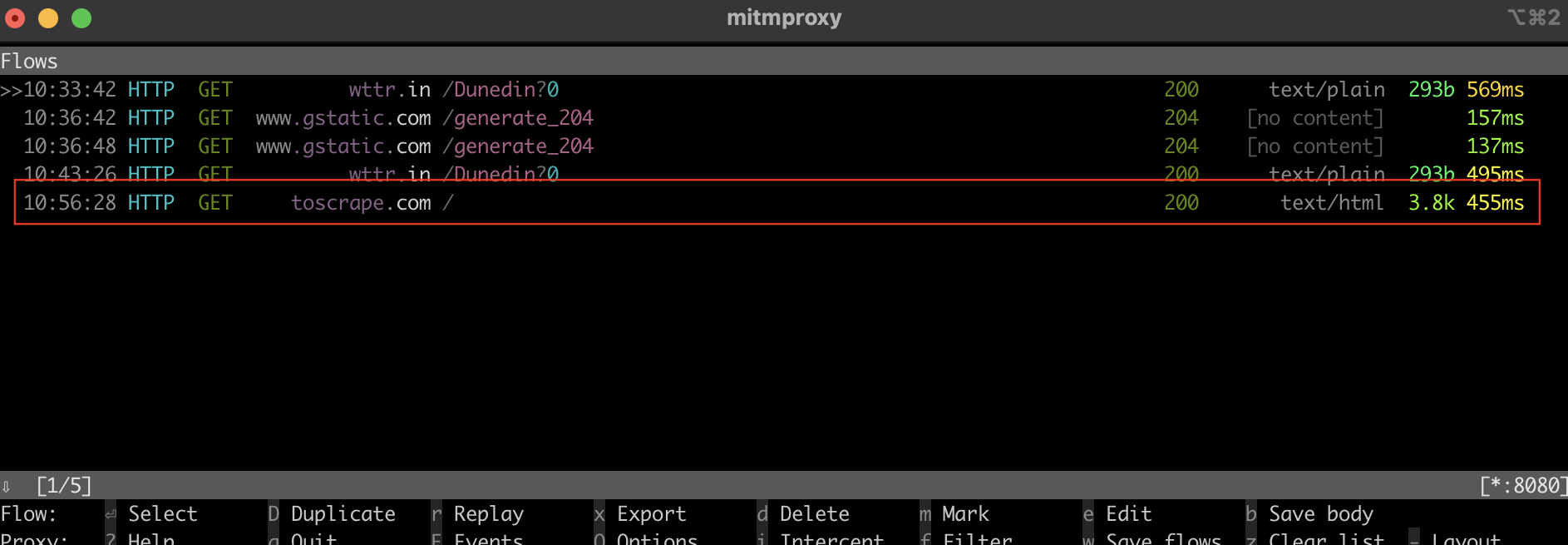
터미널이나 셸에서 mitmproxy 창을 확인하면 요청이 가로채진 것을 확인할 수 있습니다:
보시다시피, 로컬 프록시를 설정하거나 여러 프록시 간 전환하는 작업은 복잡하고 시간이 많이 소요될 수 있습니다. 다행히 Bright Data와 같은 도구가 도움이 될 수 있습니다. 다음 섹션에서는 Bright Data 프록시 서버를 사용하여 스크래핑 과정을 간소화하는 방법을 알아보겠습니다.
Bright Data 프록시
Bright Data는 195개 지역에 걸쳐 이용 가능한 프록시 서비스 네트워크를 제공합니다. 이 네트워크는 Bright Data 프록시 로테이션 기능을 통합하여 서버를 체계적으로 순환시켜 웹 스크래핑의 효율성과 보안을 강화합니다.
이 회전 프록시 시스템을 사용하면 웹 스크래핑 작업 중 흔히 발생하는 IP 차단 또는 접근 제한 위험을 줄일 수 있습니다. 각 요청마다 다른 프록시를 사용함으로써 스크래퍼의 신원을 숨기고, 웹사이트가 이를 탐지하여 접근을 제한하기 어렵게 만듭니다. 이 접근 방식은 데이터 수집의 신뢰성을 높여 익명성과 보안을 강화합니다.
Bright Data 플랫폼은 사용 편의성과 간편한 설정을 위해 설계되어, 다음 섹션에서 살펴볼 C# 웹 스크래핑 프로젝트에 완벽하게 부합합니다.
주거용 프록시 생성
프로젝트에서 Bright Data 프록시를 사용하려면 먼저 계정을 설정해야 합니다. Bright Data 웹사이트를 방문하여 무료 체험판에 가입하세요.
계정 설정이 완료되면 로그인한 후 왼쪽의 위치 아이콘을 클릭하여 ‘프록시 및 스크래핑 인프라’로 이동하세요. 그런 다음 ‘추가’를 클릭하고 ‘주거용 프록시’를 선택하세요:
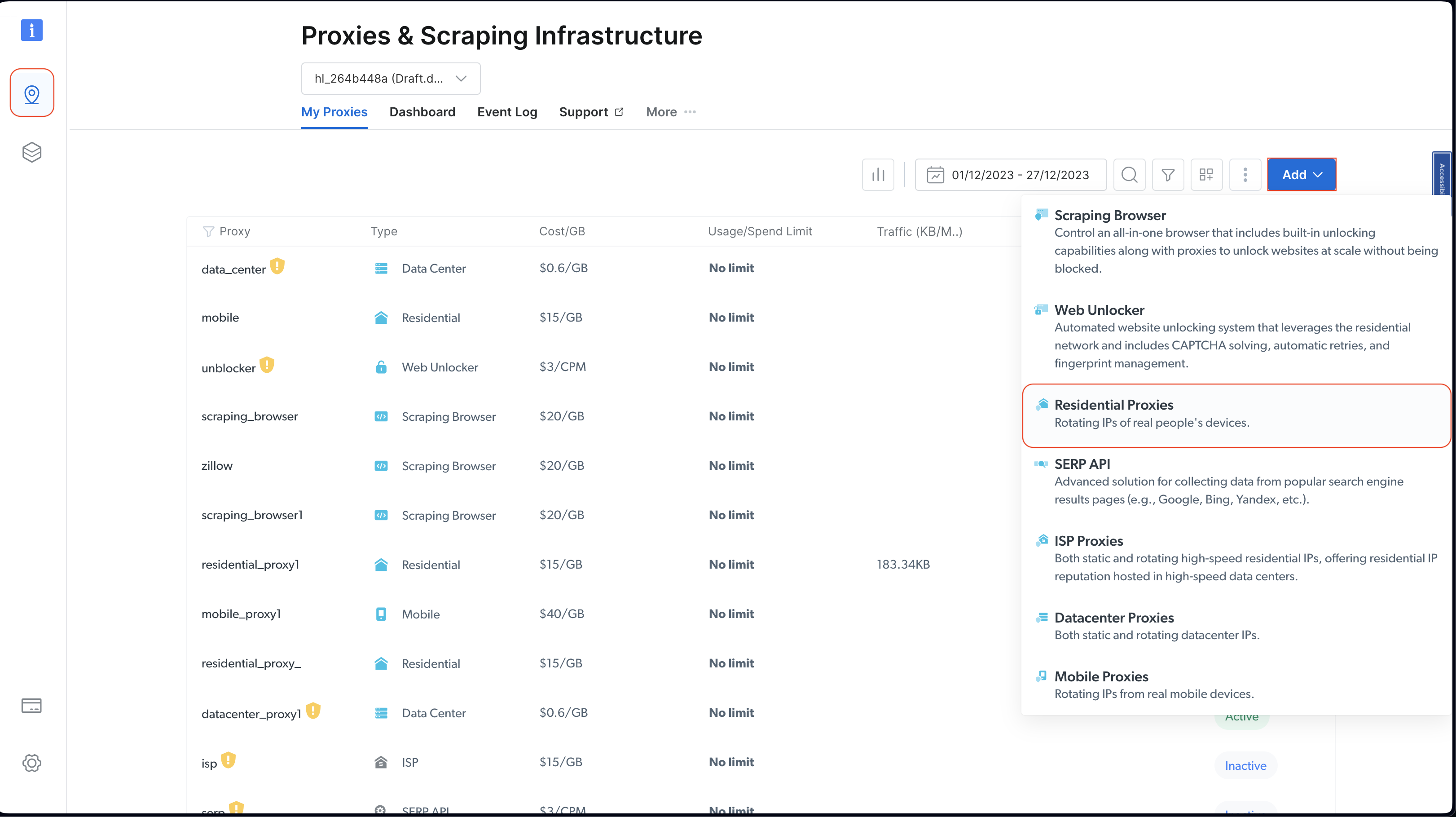
기본 이름을 유지한 상태로 다시 ‘추가’를 클릭하여 주거용 프록시를 생성하세요:
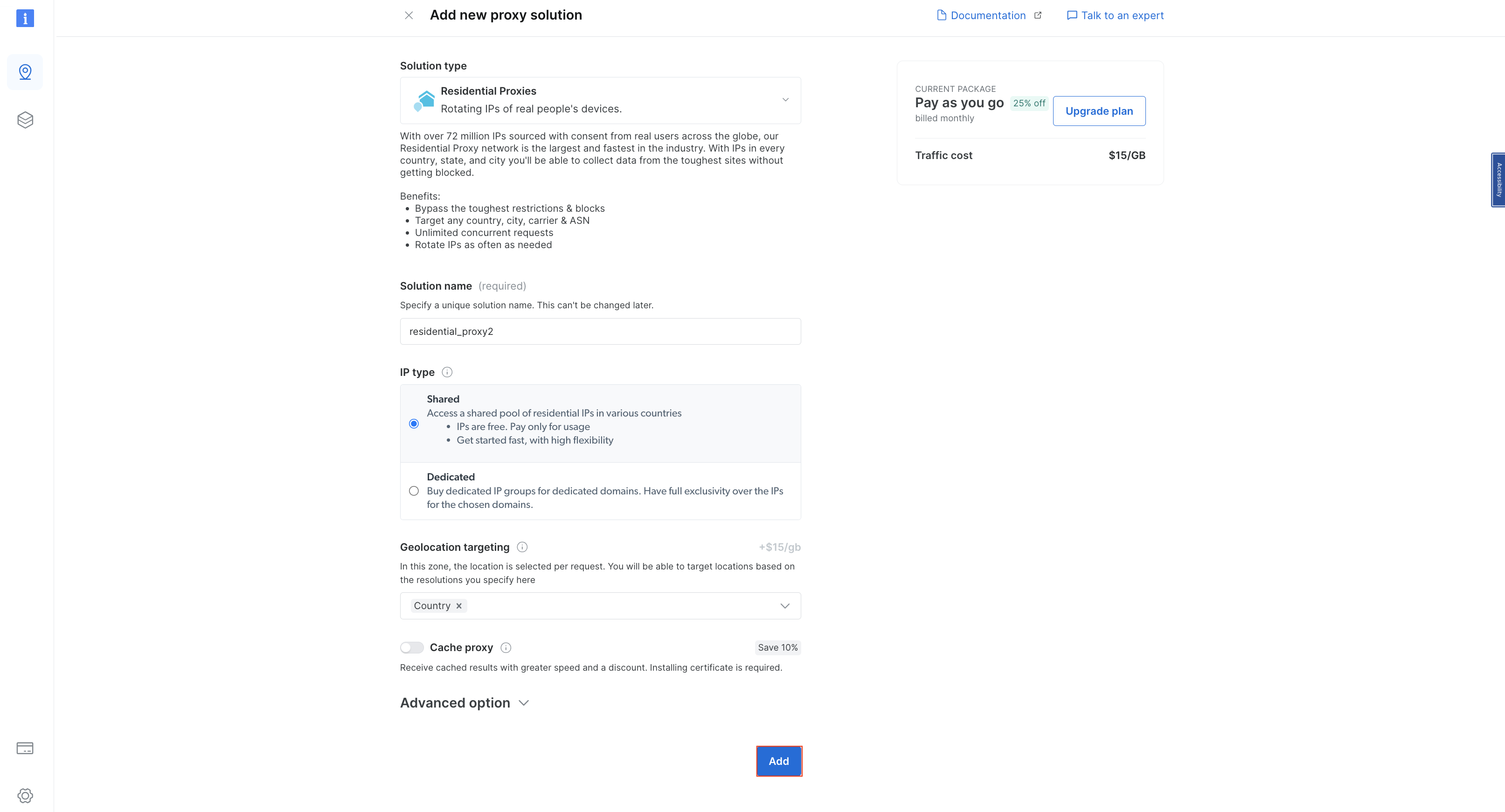
프록시가 생성되면 호스트, 포트, 사용자 이름, 비밀번호를 포함한 자격 증명이 표시됩니다. 나중에 필요하므로 이 자격 증명을 안전한 곳에 저장하세요:
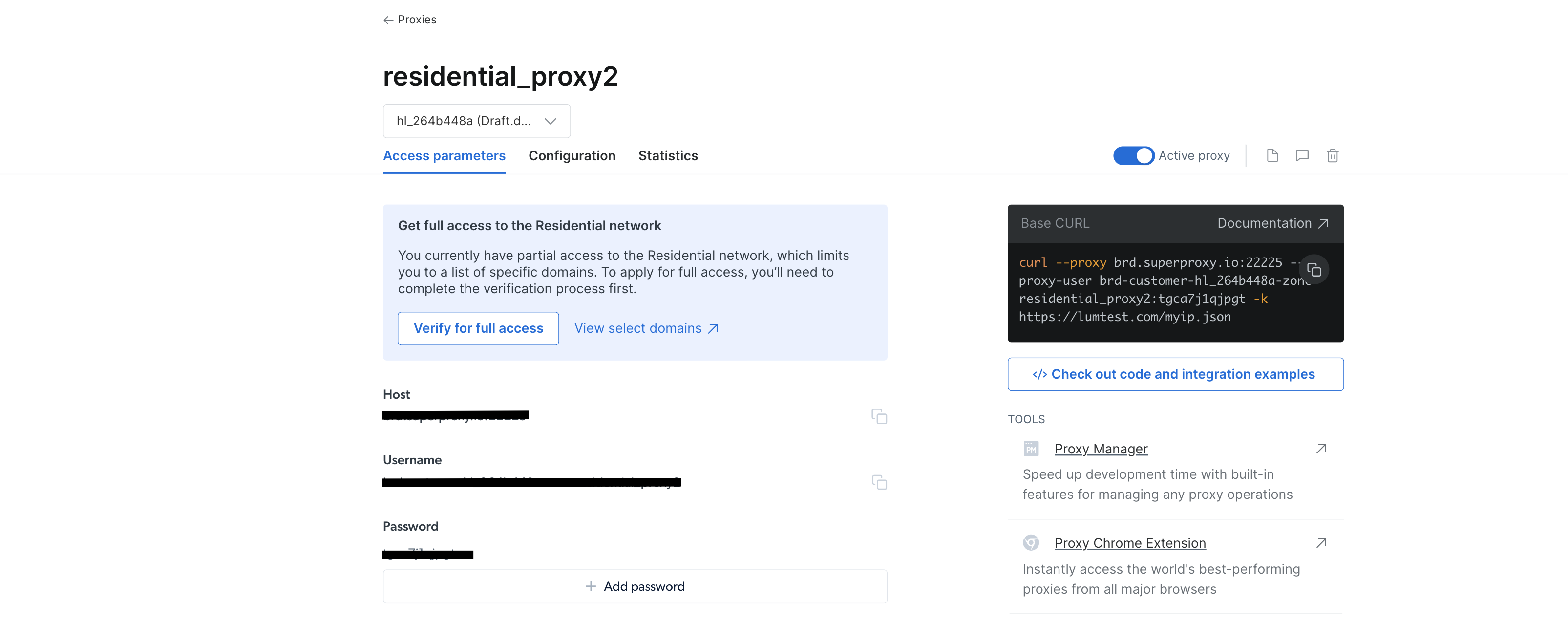
IDE 또는 터미널/셸에서 WebScrapingBrightData 프로젝트로 이동하세요. 그런 다음 BrightDataProxyConfigurator.cs 클래스 파일을 생성하고 다음 코드를 추가하세요:
using System.Net;
namespace WebScrapBrightData
{
public class BrightDataProxyConfigurator
{
public static HttpClient ConfigureHttpClient(string proxyHost, string proxyUsername, string proxyPassword)
{
var proxy = new WebProxy(proxyHost) {
Credentials = new NetworkCredential(proxyUsername, proxyPassword)
};
var httpClientHandler = new HttpClientHandler() {
Proxy = proxy,
UseProxy = true
};
var client = new HttpClient(httpClientHandler);
client.DefaultRequestHeaders.Add("User-Agent", "YourUserAgent");
client.DefaultRequestHeaders.Add("Accept", "application/json");
client.DefaultRequestHeaders.TryAddWithoutValidation("Proxy-Authorization", Convert.ToBase64String(System.Text.Encoding.UTF8.GetBytes($"{proxyUsername}:{proxyPassword}")));
return client;
}
}
}
이 코드에서는 BrightDataProxyConfigurator 클래스를 정의하며, 여기에는 ConfigureHttpClient 메서드가 포함됩니다. 호출 시 이 메서드는 프록시 서버를 사용하도록 설정된 HttpClient를 구성하여 반환합니다. 제공된 사용자 이름, 비밀번호, 호스트 및 포트를 사용하여 프록시 URL을 생성한 다음, 이 프록시로 HttpClientHandler를 구성함으로써 이를 달성합니다. 이 메서드는 궁극적으로 모든 요청을 지정된 프록시를 통해 라우팅하는 HttpClient 인스턴스를 반환합니다.
다음으로 WebScrapingBrightData 프로젝트 아래에 WebContentScraper.cs 클래스 파일을 생성하고 다음 코드를 추가합니다:
using HtmlAgilityPack;
namespace WebScrapBrightData
{
public class WebContentScraper
{
public static async Task ScrapeContent(string url, HttpClient client)
{
var response = await client.GetAsync(url);
var content = await response.Content.ReadAsStringAsync();
HtmlDocument doc = new();
doc.LoadHtml(content);
var nodes = doc.DocumentNode.SelectNodes("//li/a[@href] | //p/a[@href] | //td/a[@href]");
if (nodes != null)
{
foreach (var node in nodes)
{
string hrefValue = node.GetAttributeValue("href", string.Empty);
string title = node.InnerText;
Uri baseUri = new(url);
Uri fullUri = new(baseUri, hrefValue);
Console.WriteLine($"제목: {title}, 링크: {fullUri.AbsoluteUri}");
}
}
else
{
Console.WriteLine("페이지에서 기사 링크를 찾을 수 없습니다.");
}
}
}
}
이 코드는 정적 비동기 메서드 ScrapeContent를 가진 WebContentScraper 클래스를 정의합니다. 이 메서드는 URL과 HttpClient를 받아 웹 페이지의 콘텐츠를 가져오고, HTML로 파싱한 후 특정 HTML 요소(목록 항목, 단락, 테이블 셀)에서 링크를 추출합니다. 그런 다음 해당 링크의 제목과 절대 URI를 콘솔에 출력합니다.
프로그램 클래스
이제 위키백과를 다시 스크래핑하여 Bright Data가 접근성과 익명성을 어떻게 개선하는지 확인해 보세요.
다음 코드로 Program.cs 클래스 파일을 업데이트하세요:
namespace WebScrapBrightData
{
public class Program
{
public static async Task Main(string[] args)
{
// Bright Data 프록시 구성
string host = "your_brightdata_proxy_host";
string username = "your_brightdata_proxy_username";
string password = "your_brightdata_proxy_password";
var client = BrightDataProxyConfigurator.ConfigureHttpClient(host, username, password);
// 대상 URL에서 콘텐츠 스크래핑
string urlToScrape = "https://www.wikipedia.org/";
await WebContentScraper.ScrapeContent(urlToScrape, client);
}
}
}
참고: Bright Data 프록시 자격 증명을 이전에 저장한 것으로 반드시 교체하십시오.
다음으로 애플리케이션을 테스트하고 실행하려면 WebScrapBrightData 프로젝트의 루트 디렉터리에서 셸 또는 터미널을 열고 다음 명령을 실행하세요:
dotnet build
dotnet run
공개 프록시를 사용했을 때와 동일한 출력이 표시되어야 합니다:
…출력 생략…
Title: Latina, Link: https://la.wikipedia.org/
Title: Latviešu, Link: https://lv.wikipedia.org/
Title: Lietuvių, Link: https://lt.wikipedia.org/
Title: Magyar, Link: https://hu.wikipedia.org/
Title: Македонски, Link: https://mk.wikipedia.org/
Title: Bahasa Melayu, Link: https://ms.wikipedia.org/
Title: Bahaso Minangkabau, Link: https://min.wikipedia.org/
Title: bokmål, Link: https://no.wikipedia.org/
Title: nynorsk, Link: https://nn.wikipedia.org/
제목: 우즈베크어 / Ўзбекча, 링크: https://uz.wikipedia.org/
제목: 카자흐어 / Qazaqşa / قازاقشا, 링크: https://kk.wikipedia.org/
제목: Română, 링크: https://ro.wikipedia.org/
제목: Simple English, 링크: https://simple.wikipedia.org/
제목: Slovenčina, 링크: https://sk.wikipedia.org/
제목: Slovenščina, 링크: https://sl.wikipedia.org/
제목: Српски / Srpski, 링크: https://sr.wikipedia.org/
제목: 세르보크로아트어, 링크: https://sh.wikipedia.org/
제목: 핀란드어, 링크: https://fi.wikipedia.org/
제목: 타밀어, 링크: https://ta.wikipedia.org/
…출력 생략…
이 프로그램은 Bright Data 프록시를 사용하여 위키피디아 홈페이지를 스크래핑하고 추출된 제목과 링크를 콘솔에 표시합니다. 이는 C# 웹 스크래핑 프로젝트에 Bright Data 프록시를 통합하여 신중하고 강력한 데이터 추출을 수행하는 효과성과 용이성을 보여줍니다.
Bright Data 프록시 사용 효과를 시각화하려면 http://lumtest.com/myip.json로 GET 요청을 보내보세요. 이 웹사이트는 현재 접속 중인 클라이언트의 위치 및 기타 네트워크 관련 세부 정보를 반환합니다. 직접 시도하려면 새 브라우저 탭에서 링크를 열어보세요. 공개적으로 확인 가능한 네트워크 세부 정보가 표시될 것입니다.
Bright Data 프록시로 테스트하려면 WebContentScraper. cs의 코드를 다음과 같이 수정하세요:
using HtmlAgilityPack;
public class WebContentScraper
{
public static async Task ScrapeContent(string url, HttpClient client)
{
var response = await client.GetAsync(url);
var content = await response.Content.ReadAsStringAsync();
HtmlDocument doc = new();
doc.LoadHtml(content);
Console.Write(content);
}
}
그런 다음 Program.cs 파일에서 urlToScrape 변수를 업데이트하여 웹사이트를 스크래핑합니다:
string urlToScrape = "http://lumtest.com/myip.json";
이제 앱을 다시 실행해 보세요. 터미널에 다음과 같은 출력이 표시되어야 합니다:
{"ip":"79.221.123.68","country":"DE","asn":{"asnum":3320,"org_name":"Deutsche Telekom AG"},"geo":{"city":"Koenigs Wusterhausen","region":"BB","region_name":"Brandenburg","postal_code":"15711","latitude":52.3014,"longitude":13.633,"tz":"Europe/Berlin","lum_city":"koenigswusterhausen","lum_region":"bb"}}
이는 요청이 현재 Bright Data의 프록시 서버 중 하나를 통해 프록시되고 있음을 확인해 줍니다.
결론
이 글에서는 웹 스크래핑을 위해 C#으로 프록시 서버를 사용하는 방법을 배웠습니다.
로컬 프록시 서버가 일부 시나리오에서는 유용할 수 있지만, 웹 스크래핑 프로젝트에는 종종 한계가 있습니다. 다행히 프록시 서버가 도움이 될 수 있습니다. 광범위한 글로벌 네트워크와 주거용, ISP, 데이터센터, 모바일 프록시를 포함한 다양한 프록시 옵션을 통해 Bright Data는 높은 수준의 유연성과 안정성을 보장합니다. 특히 프록시 로테이션 기능은 대규모 스크래핑 작업에 매우 유용하며, 익명성을 유지하고 IP 차단 위험을 줄이는 데 도움이 됩니다.
웹 스크래핑 작업을 진행할 때, Bright Data 솔루션을 활용하여 웹 스크래핑 모범 사례를 준수하면서 효율적으로 데이터를 수집할 수 있는 강력하고 확장 가능한 방법을 고려해 보십시오.
이 튜토리얼의 모든 코드는 이 GitHub 저장소에서 확인할 수 있습니다.





