

Rust 웹 스크래핑 완전 가이드
이 가이드에서 배우게 될 내용:
- – Rust가 웹 스크래핑에 적합한 언어인지 여부
- 최고의 Rust 웹 스크래핑 라이브러리는 무엇인지.
- Rust로 웹 스크레이퍼 구축 방법
- 스크래핑 작업을 윤리적이고 존중하는 방식으로 유지하는 방법
자, 시작해 보겠습니다!
Rust는 웹 스크래핑에 적합한 언어인가?
Rust는 보안, 성능, 동시성에 중점을 둔 정적 타입 프로그래밍 언어로 알려져 있습니다. 최근 몇 년간 높은 효율성으로 인기를 얻었습니다. 이는 웹 스크래핑을 포함한 다양한 애플리케이션에 탁월한 선택이 됩니다.
Rust는 온라인 데이터 스크래핑 작업에 유용한 기능을 제공합니다. 특히 강력한 동시성 모델은 여러 웹 요청의 동시 실행을 용이하게 합니다. 이 특성 덕분에 다양한 웹사이트에서 대량의 데이터를 효율적으로 추출하는 데 능숙한 다목적 언어로 자리매김했습니다.
또한 Rust 생태계에는 HTTP 클라이언트 및 HTML 파싱 라이브러리가 포함되어 있어 웹 페이지 검색과 데이터 추출 과정을 간소화합니다. 가장 우수한 라이브러리 몇 가지를 살펴보겠습니다!
최고의 Rust 웹 스크래핑 라이브러리
가장 인기 있고 널리 채택된 Rust 웹 스크래핑 라이브러리로는 다음과 같습니다:
- reqwest: Rust용 강력한 HTTP 클라이언트로, 원활한 웹 요청 및 상호작용을 가능하게 합니다.
- scraper: Rust 기반의 유연한 HTML 파싱 라이브러리로, HTML 문서에서 데이터를 효율적으로 추출할 수 있습니다.
- rust-headless-chrome: Rust를 사용한 헤드리스 Chrome 브라우저 자동화를 제공하여 동적 웹 스크래핑을 위한 강력한 솔루션을 제공합니다.
- thirtyfour: Selenium용 Rust 바인딩으로, 웹 브라우저와의 상호작용을 통해 자동화된 테스트 및 웹 스크래핑을 가능하게 합니다.
필수 조건
아래 지침을 따라 Rust 코드를 작성할 준비를 하세요.
환경 설정
시작하기 전에 컴퓨터에 Rust가 설치되어 있어야 합니다. 이미 설치되어 있는지 확인하려면 터미널을 열고 다음 명령어를 입력하세요:
rustc --version결과가 아래와 유사하다면 준비 완료입니다:
rustc 1.75.0 (82e1608df 2023-12-21)다음 명령어로 Rust를 최신 버전으로 업데이트하세요:
rustup update해당 명령어가 오류로 반환된다면 Rust를 설치해야 합니다. 공식 웹사이트에서 설치 프로그램을 다운로드하고 실행한 후 마법사를 따라 설치하세요. 이로 인해 다음이 설정됩니다:
- rustup: Rust 프로그래밍 언어용 설치 프로그램 및 버전 관리 도구로, 다양한 툴체인 설치 및 관리를 용이하게 합니다.
- cargo: Rust의 공식 패키지 관리자이자 빌드 도구입니다. 의존성 관리 및 Rust 프로젝트 빌드 과정을 간소화합니다.
열려 있는 모든 터미널 창을 닫고 이 섹션 시작 부분의 명령어를 다시 실행하세요. 이번에는 원하는 결과를 얻을 수 있습니다.
훌륭합니다! 이제 Rust 환경이 준비되었습니다!
Rust 프로젝트 생성하기
simple_rust_web_scraper라는 새 Rust 프로젝트를 생성한다고 가정해 보겠습니다. 터미널을 열고 다음 cargo new 명령어를 실행하세요:
cargo new simple_rust_web_scraper모든 것이 정상적으로 진행되면 다음과 같은 메시지를 받게 됩니다:
바이너리(애플리케이션) `simple_rust_web_scraper` 패키지 생성됨이 명령어는 simple_rust_web_scraper 폴더를 생성합니다. 폴더를 열어보면 다음 내용이 포함되어 있음을 확인할 수 있습니다:
- Cargo.toml: 프로젝트의 종속성을 지정하는 매니페스트 파일입니다.
- src/: Rust 파일을 저장할 폴더입니다. 기본적으로 샘플 main.rs 파일이 생성됩니다.
Rust IDE에서 simple_rust_web_scraper를 엽니다. 예를 들어 Rust 확장 프로그램 이 설치된 Visual Studio Code가 적합합니다:
src/ 폴더 내부로 이동하여 main.rs 파일을 열면 다음과 같은 코드가 표시됩니다:
fn main() {
println!("Hello, world!");
}이는 터미널에 “Hello, world!”를 출력하는 단순한 Rust 스크립트에 불과합니다. 특히 main() 함수는 모든 Rust 애플리케이션의 진입점을 나타내며, 여기에 스크래핑 로직을 작성하게 됩니다.
대단하네요! 이제 새로 만든 Rust 프로젝트가 제대로 작동하는지 확인하기만 하면 됩니다!
IDE의 터미널을 열고 다음 명령어를 실행하여 Rust 애플리케이션을 컴파일하세요:
cargo build프로젝트 루트 폴더에 바이너리 파일을 저장하는 target/ 폴더가 생성됩니다.
컴파일된 바이너리 실행 파일을 다음과 같이 실행하세요:
cargo run그러면 터미널에 다음과 같이 출력됩니다:
Finished dev [unoptimized + debuginfo] target(s) in 0.05s
Running `targetdebugsimple_rust_web_scraper.exe`
Hello, world!처음 두 줄은 로그 정보이므로 무시해도 됩니다. 마지막 줄에 집중하여 프로젝트가 예상대로 “Hello, World!” 메시지를 생성했는지 확인하세요.
완벽합니다! 이제 Rust 프로젝트가 생성되었습니다. 이제 Rust로 웹 스크래핑 로직을 작성할 차례입니다!
Rust로 웹 스크레이퍼 구축하기
이 단계별 튜토리얼 섹션에서는 Rust로 웹 스크래핑을 수행하는 방법을 배웁니다. 구체적으로, Scrape This Site Country 샌드박스에서 데이터를 자동으로 수집하는 Rust 웹 스크래퍼를 구축할 것입니다. 대상 페이지의 모습은 다음과 같습니다:
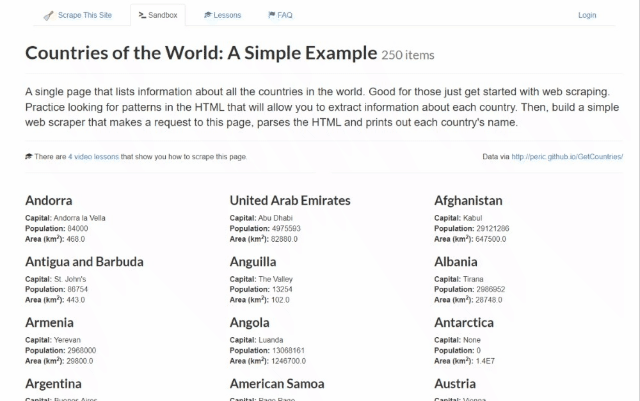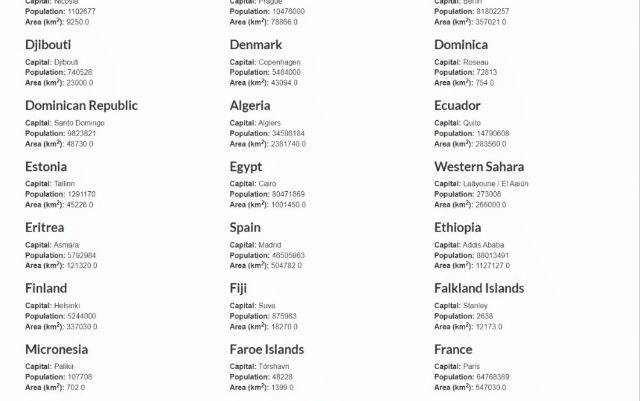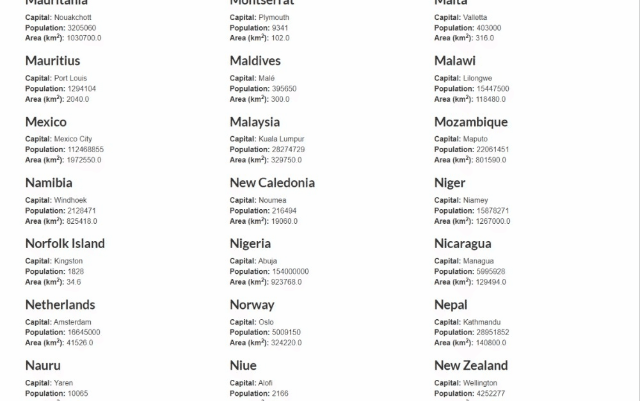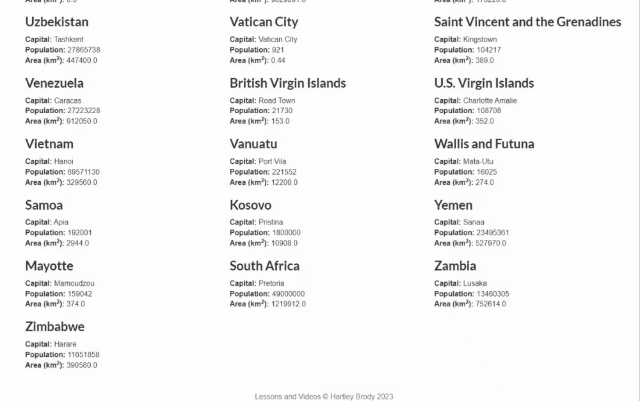
보시다시피, 전 세계 모든 국가 목록과 각 국가에 대한 흥미로운 정보가 포함되어 있습니다.
Rust 웹 스크래핑 스크립트가 수행할 작업은 다음과 같습니다:
- 대상 페이지에 연결하여 HTML을 파싱합니다.
- 페이지에서 국가 HTML 요소를 선택합니다.
- 해당 요소에서 데이터를 추출하여 Rust 데이터 구조에 저장합니다.
- 수집된 데이터를 CSV와 같은 사람이 읽을 수 있는 형식으로 변환합니다.
아래 단계를 따라 스크래핑 목표를 달성하세요!
1단계: 대상 사이트 분석
Rust로 웹 스크래핑을 수행하려면 일부 라이브러리를 설치해야 하지만, 특정 시나리오에 가장 적합한 라이브러리는 무엇일까요? 이에 대한 답을 찾으려면 대상 사이트가 정적 콘텐츠 페이지인지 동적 콘텐츠 페이지인지 파악해야 합니다. 따라서 브라우저에서 사이트를 방문하세요.
대상 페이지로 이동한 후 빈 영역을 마우스 오른쪽 버튼으로 클릭하고 “검사” 옵션을 선택하여 개발자 도구를 엽니다. “네트워크” 탭으로 이동한 후 페이지를 다시 로드하세요. “Fetch/XHR” 섹션에 표시되는 내용을 집중적으로 살펴보세요:
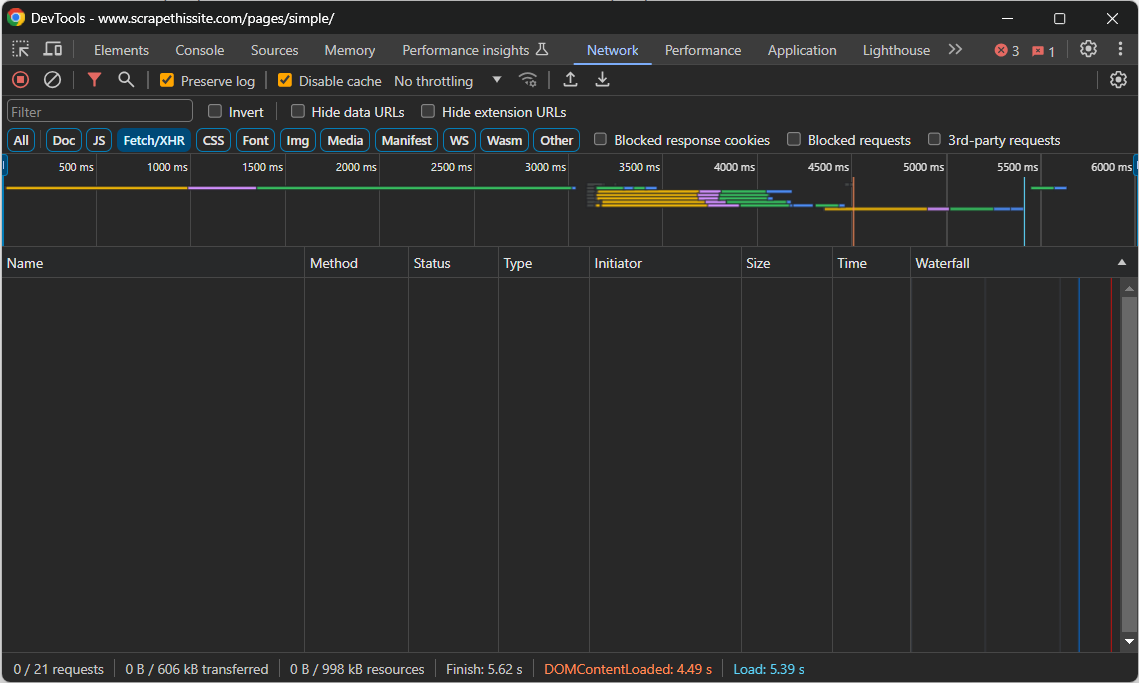
페이지가 로딩 및 렌더링되는 동안 해당 섹션은 비어 있을 것입니다. 이는 웹 페이지가 AJAX 요청을 전혀 수행하지 않음을 의미합니다. 즉, 클라이언트 측에서 JavaScript를 통해 동적으로 데이터를 가져오지 않는다는 뜻입니다. 따라서 HTML 문서에 필요한 모든 데이터가 이미 포함된 정적 콘텐츠 페이지입니다.
추가 확인을 위해 마우스 오른쪽 버튼을 클릭하고 “페이지 소스 보기” 옵션을 선택하세요:
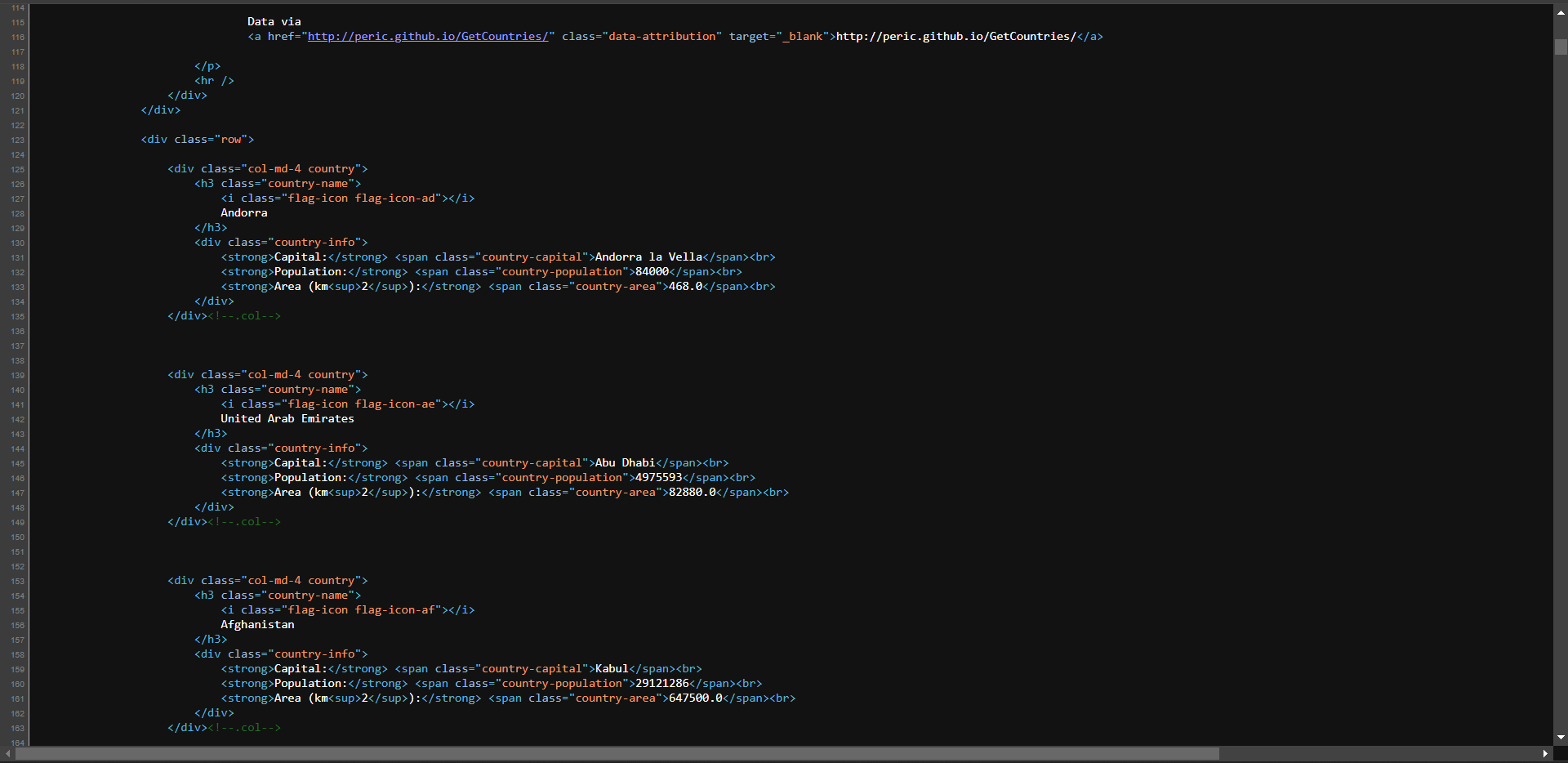
코드를 살펴보면 페이지의 모든 데이터가 서버에서 반환된 HTML에 내장되어 있음을 확인할 수 있습니다.
여러 페이지로 구성된 사이트에서는 관심 있는 모든 페이지에서 이 절차를 반복하세요.
대상 페이지들이 자바스크립트를 사용하지 않으므로 rust-headless-chrome 같은 브라우저 자동화 라이브러리가 필요하지 않습니다. 사용해도 되지만, 크롬 실행에는 시간과 자원이 소모되므로 성능 오버헤드만 발생하고 실질적 이점은 없습니다.
대신 HTTP 클라이언트 라이브러리를 활용해 페이지와 연관된 HTML 문서를 가져오고, HTML 파서 라이브러리로 데이터를 추출해야 합니다. 따라서 reqwest와 scraper가 필요한 두 가지 Rust 웹 스크래핑 라이브러리입니다!
2단계: 스크래핑 라이브러리 설치
이제 reqwest와 scraper를 설치할 차례입니다.
프로젝트 루트 폴더에서 터미널을 열거나 IDE의 터미널을 사용하세요. 다음 명령어를 실행하여 reqwest와 scraper를 프로젝트 의존성에 추가합니다:
cargo add scraper reqwest --features "reqwest/blocking"참고: reqwest/blocking 기능은 reqwest가 현재 스레드를 차단하는 동기식 HTTP 호출을 수행할 수 있게 합니다. 자세한 내용은 문서를 참조하세요.
cargo add 명령어는 Cargo.toml 파일을 다음과 같이 업데이트합니다:
[dependencies]
reqwest = { version = "0.11.23", features = ["blocking"] }
scraper = "0.18.1"
또한 두 라이브러리와 모든 종속성을 설치합니다.
완벽합니다! 이제 Rust로 웹 스크래핑을 수행하는 데 필요한 모든 것을 갖추셨습니다!
3단계: 대상 페이지에 연결하기
reqwest::blocking의 get() 메서드를 사용하여 지정된 URL로 GET 요청을 보내고 관련 HTML 문서를 다운로드합니다:
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;이 명령어는 동기식이라는 점을 유의하세요. 따라서 서버가 응답할 때까지 스크립트 실행이 중단됩니다.
응답을 받으면 다음 코드로 대상 페이지의 HTML 코드에 접근할 수 있습니다:
let html = response.text()?;다음 두 줄을 min.rs의 main() 함수에 작성하세요:
fn main() -> Result<(), Box<dyn std::error::Error>> {
// 대상 페이지에 연결
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// 원시 HTML 추출 및 출력
let html = response.text()?;
println!("{html}");
Ok(())
}Result<(), Box<dyn std::error::Error>>가 무엇인지 궁금하다면, 잔여값(Residuals)을 사용할 예정이기 때문입니다. 마지막에 있는 println() 함수도 살펴보세요. 이 함수는 가져온 HTML을 로그로 출력합니다.
스크립트를 실행하면 터미널에 다음과 같이 출력됩니다:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Countries of the World: A Simple Example | Scrape This Site | A public sandbox for learning web scraping</title>
<!-- 생략... -->잘하셨습니다! 바로 대상 페이지의 HTML입니다!
4단계: HTML 문서 파싱
이제 원하는 페이지의 소스 HTML이 문자열 변수에 저장되었습니다. 스크레이퍼의 parse_document() 함수에 전달하여 파싱하세요:
let document = scraper::Html::parse_document(&html);반환된 문서 객체는 Rust를 사용한 웹 스크래핑 수행에 필요한 DOM 탐색 API를 제공합니다.
지금까지 작성한 main.rs 파일은 다음과 같아야 합니다:
fn main() -> Result<(), Box<dyn std::error::Error>> {
// 대상 페이지에 연결
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// 원시 HTML 추출 및 출력
let html = response.text()?;
// HTML 문서 파싱
let document = scraper::Html::parse_document(&html);
Ok(())
}이제 데이터 파싱 로직을 작성할 준비가 되었습니다. 하지만 먼저 대상 페이지의 구조를 연구해야 합니다!
단계 #5: 페이지 검사
웹 스크래핑은 페이지에서 HTML 노드를 선택하고 데이터를 추출하는 작업입니다. CSS 선택자는 HTML 노드를 선택하는 가장 널리 쓰이는 방법 중 하나입니다. 웹 개발자라면 이미 익숙할 것입니다. 그렇지 않다면 문서를 살펴보세요.
효과적인 CSS 선택자를 정의하는 유일한 방법은 대상 페이지의 HTML을 검사하는 것입니다. 따라서 브라우저에서 Scrape This Site Country 샌드박스를 열고, 국가 요소(country element)를 마우스 오른쪽 버튼으로 클릭한 후 “검사:”를 선택하세요.
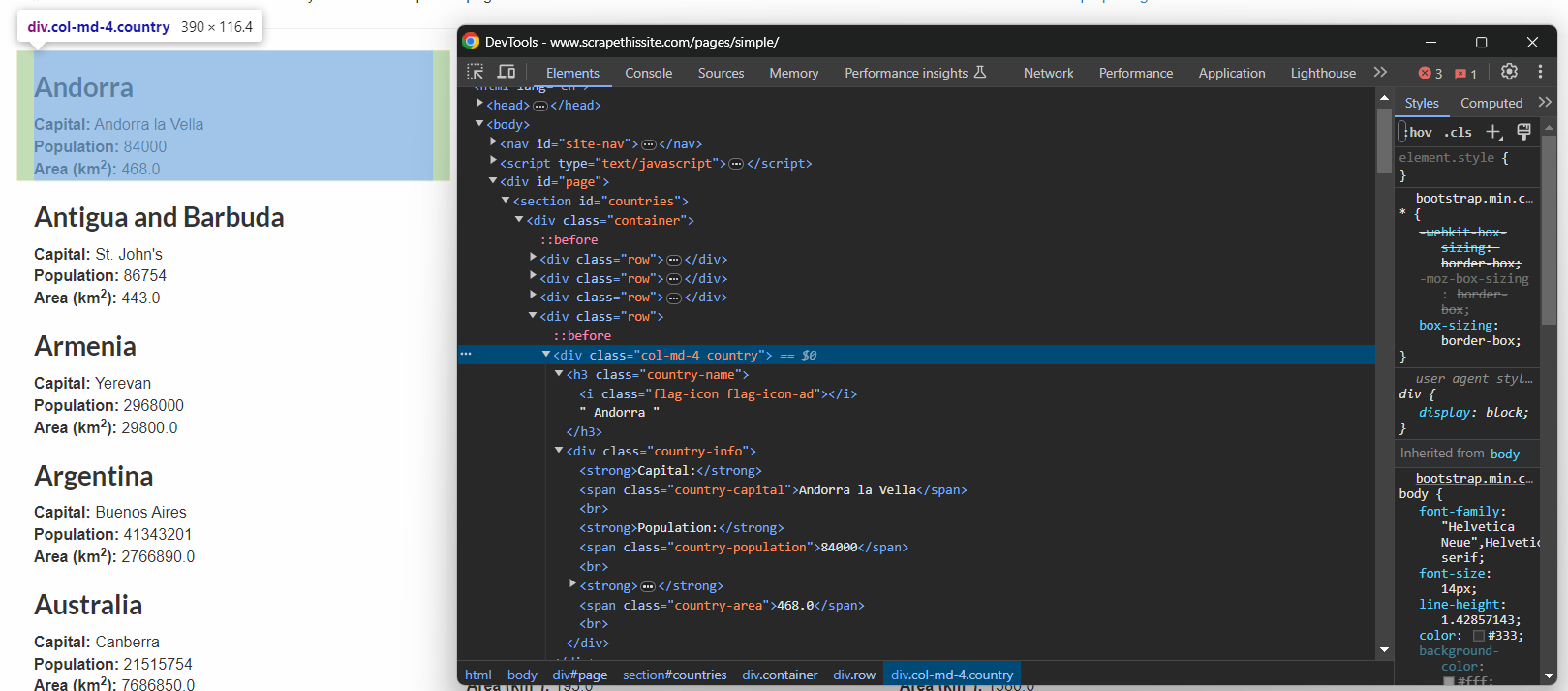
여기서 각 국가 정보 상자가 .country HTML 노드임을 확인할 수 있으며, 이 노드에는 다음이 포함됩니다:
- .country-name 요소 내의 국가명.
- 수도 이름이 .country-capital 요소에 포함됩니다.
- 인구 정보는 .country-population 요소입니다.
- .country-area 요소에 포함된 국가 면적(km²).
위 단락에는 원하는 HTML 노드를 선택하는 데 필요한 모든 CSS 선택자가 포함되어 있습니다. 페이지의 모든 요소에 적용하기 전에 국가 정보 상자에서 선택자를 테스트하세요!
6단계: 단일 요소에서 데이터 가져오기
scraper::Selector의 parse() 함수는 CSS 선택자를 나타내는 문자열을 받아 선택자 객체를 반환합니다. 아래와 같이 사용하세요:
let html_country_info_box_selector = scraper::Selector::parse(".country")?;그런 다음 이 선택자를 document가 제공하는 select() 메서드에 전달할 수 있습니다:
let html_country_info_box_element = document
.select(&html_country_info_box_selector)
.next()
.ok_or("Country info box element not found!")?;이 코드는 페이지에 CSS 선택자를 적용하여 선택된 HTML 요소를 반환합니다. select()는 항상 이터레이터를 반환하므로 첫 번째 국가 정보 상자 노드를 얻으려면 .next() 호출이 필요합니다.
select()가 반환하는 객체는 select() 함수도 노출합니다. 이 경우 현재 노드의 자식 요소 내에서만 노드를 검색합니다. 따라서 전체 Rust 웹 스크래핑 로직은 다음과 같이 구현할 수 있습니다:
let country_name_selector = scraper::Selector::parse(".country-name")?;
let name = html_country_info_box_element
.select(&country_name_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("국가 이름이 발견되지 않음")?;
let country_capital_selector = scraper::Selector::parse(".country-capital")?;
let capital = html_country_info_box_element
.select(&country_capital_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("국가 수도 찾지 못함")?;
let country_population_selector = scraper::Selector::parse(".country-population")?;
let population = html_country_info_box_element
.select(&country_population_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("국가 인구 정보 미검출")?;
let country_area_selector = scraper::Selector::parse(".country-area")?;
let area = html_country_info_box_element
.select(&country_area_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country area not found")?;text() 메서드를 사용하면 선택된 HTML 노드에 포함된 텍스트에 접근할 수 있습니다. 다른 데이터 추출 방식은 문서를 참고하세요. 추출된 텍스트에 불필요한 공백이 포함될 수 있으므로 trim()으로 제거하세요.
스크래핑된 데이터를 출력하여 스크래핑 로직이 예상대로 작동하는지 확인하세요:
println!("국가명: {name}");
println!("국가 수도: {capital}");
println!("국가 인구: {population}");
println!("국가 면적: {area}");
다음과 같은 결과가 출력됩니다:
Country name: Andorra
Country capital: Andorra la Vella
Country population: 84000
Country area: 468.0네! 방금 Rust로 웹 스크래핑을 수행하셨습니다!
7단계: 페이지의 모든 요소 스크래핑하기
이번에는 위에서 본 코드를 확장하여 페이지의 모든 국가 정보 박스 노드를 순회하도록 할 것입니다.
먼저 수집된 데이터를 저장할 사용자 정의 데이터 구조를 정의해야 합니다. 이를 위해 main.rs 파일 상단에 다음 줄을 추가하세요:
struct Country {
name: String,
capital: String,
population: String,
area: String,
}둘째, main()에서 Country 객체의 Vec 인스턴스를 생성합니다:
let mut countries: Vec<Country> = Vec::new();이 벡터에는 스크랩한 모든 데이터가 포함됩니다.
다음으로, 모든 국가 정보 상자를 가져오기 위해 .next() 호출을 제거하고, 이를 반복 처리하여 countries에 채웁니다:
// 스크랩된 데이터 저장 위치
let mut countries: Vec<Country> = Vec::new();
// 국가 정보 박스 HTML 요소 선택
let html_country_info_box_selector = scraper::Selector::parse(".country")?;
let html_country_info_box_elements = document.select(&html_country_info_box_selector);
// 국가 HTML 요소 반복
// 모든 요소 스크래핑
for html_country_info_box_element in html_country_info_box_elements {
// 단일 국가 정보 박스 HTML 요소 스크래핑 로직...
// 새 Country 객체를 생성하고 벡터에 추가
let country = Country {
name,
capital,
population,
area,
};
countries.push(country);
}스크래핑된 모든 국가를 출력하려면 다음을 사용하세요:
// 결과 기록
for country in countries {
println!("국가명: {}", country.name);
println!("국가 수도: {}", country.capital);
println!("국가 인구: {}", country.population);
println!("국가 면적: {}", country.area);
println!();
}
새로운 main.rs Rust 웹 스크래핑 파일에는 다음이 포함됩니다:
// 스크래핑 데이터를 저장할 사용자 정의 구조체
struct Country {
name: String,
capital: String,
population: String,
area: String,
}
fn main() -> Result<(), Box<dyn std::error::Error>> {
// 대상 페이지에 연결
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// 원본 HTML 추출 및 출력
let html = response.text()?;
// HTML 문서 파싱
let document = scraper::Html::parse_document(&html);
// 스크랩된 데이터 저장 위치
let mut countries: Vec<Country> = Vec::new();
// 국가 정보 박스 HTML 요소 선택
let html_country_info_box_selector = scraper::Selector::parse(".country")?;
let html_country_info_box_elements = document.select(&html_country_info_box_selector);
// 국가 HTML 요소 반복
// 모두 스크래핑
for html_country_info_box_element in html_country_info_box_elements {
// 단일 국가 정보 박스 HTML 요소에 대한 스크래핑 로직
let country_name_selector = scraper::Selector::parse(".country-name")?;
let name = html_country_info_box_element
.select(&country_name_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("국가 이름이 발견되지 않았습니다")?;
let country_capital_selector = scraper::Selector::parse(".country-capital")?;
let capital = html_country_info_box_element
.select(&country_capital_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("국가 수도 미검출")?;
let country_population_selector = scraper::Selector::parse(".country-population")?;
let population = html_country_info_box_element
.select(&country_population_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("국가 인구 정보 미검출")?;
let country_area_selector = scraper::Selector::parse(".country-area")?;
let area = html_country_info_box_element
.select(&country_area_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("국가 면적 정보 미검출")?;
// 새 Country 객체 생성 후 벡터에 추가
let country = Country {
name,
capital,
population,
area,
};
countries.push(country);
}
// 결과 출력
for country in countries {
println!("국가명: {}", country.name);
println!("국가 수도: {}", country.capital);
println!("국가 인구: {}", country.population);
println!("국가 면적: {}", country.area);
println!();
}
Ok(())
}
실행하면 다음과 같은 출력이 생성됩니다:
국가 이름: 안도라
국가 수도: 안도라 라 벨라
국가 인구: 84000
국가 면적: 468.0
# 간결함을 위해 생략...
국가 이름: 짐바브웨
국가 수도: 하라레
국가 인구: 11651858
국가 면적: 390580.0미션 완료! 대상 페이지에서 모든 국가 정보를 스크래핑했습니다!
단계 #8: 추출된 데이터를 CSV로 내보내기
수집된 데이터는 현재 Rust 벡터에 저장되어 있습니다. 다른 사람과 공유하려면 이 형식이 가장 적합하지 않습니다. 따라서 CSV와 같이 탐색하기 쉬운 형식으로 내보내야 합니다.
CSV 파일로 데이터를 내보내려면 csv 라이브러리를 사용해야 합니다. 다음 명령어로 설치하세요:
cargo add csv다음 명령어로 CSV 내보내기 파일을 생성할 수 있습니다:
// 출력 CSV 파일 초기화
let mut writer = csv::Writer::from_path("countries.csv")?;
// CSV 헤더 작성
writer.write_record(&["name", "capital", "population", "area"])?;
// 각 국가 정보로 파일 채우기
for country in countries {
writer.write_record(&[
country.name,
country.capital,
country.population,
country.area,
])?;
}이 코드 조각은 CSV 파일을 생성하고, 헤더 행으로 초기화한 후, 최종적으로 countries 벡터를 반복하여 데이터를 채웁니다.
9단계: 모든 것을 합치기
웹 스크래핑 Rust 스크립트의 완성된 코드는 다음과 같습니다:
// 스크래핑 데이터를 저장할 커스텀 구조체
pub struct Country {
name: String,
capital: String,
population: String,
area: String,
}
fn main() -> Result<(), Box<dyn std::error::Error>> {
// 대상 페이지에 연결
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// 원본 HTML 추출 및 출력
let html = response.text()?;
// HTML 문서 파싱
let document = scraper::Html::parse_document(&html);
// 추출된 데이터 저장 위치
let mut countries: Vec<Country> = Vec::new();
// 국가 정보 박스 HTML 요소 선택
let html_country_info_box_selector = scraper::Selector::parse(".country")?;
let html_country_info_box_elements = document.select(&html_country_info_box_selector);
// 국가 HTML 요소 반복 처리
// 모든 요소 스크래핑
for html_country_info_box_element in html_country_info_box_elements {
// 단일 국가 정보 박스 HTML 요소에 대한 스크래핑 로직
let country_name_selector = scraper::Selector::parse(".country-name")?;
let name = html_country_info_box_element
.select(&country_name_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country name not found")?;
let country_capital_selector = scraper::Selector::parse(".country-capital")?;
let capital = html_country_info_box_element
.select(&country_capital_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("국가 수도 찾지 못함")?;
let country_population_selector = scraper::Selector::parse(".country-population")?;
let population = html_country_info_box_element
.select(&country_population_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("국가 인구 정보 미검출")?;
let country_area_selector = scraper::Selector::parse(".country-area")?;
let area = html_country_info_box_element
.select(&country_area_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("국가 면적 정보 미검출")?;
// 새 Country 객체 생성 및 벡터에 추가
let country = Country {
name,
capital,
population,
area,
};
countries.push(country);
}
// 출력 CSV 파일 초기화
let mut writer = csv::Writer::from_path("countries.csv")?;
// CSV 헤더 작성
writer.write_record(&["name", "capital", "population", "area"])?;
// 각 국가 정보를 파일로 작성
for country in countries {
writer.write_record(&[
country.name,
country.capital,
country.population,
country.area,
])?;
}
Ok(())
}믿을 수 있나요? 100줄 미만의 코드로 Rust 데이터 스크레이퍼를 만들 수 있습니다.
아래 명령어로 애플리케이션을 컴파일하세요:
cargo build그런 다음 실행하세요:
cargo run스크립트가 종료되면 프로젝트 루트 폴더에 countries.csv 파일이 생성됩니다. 파일을 열면 다음과 같은 데이터를 확인할 수 있습니다:
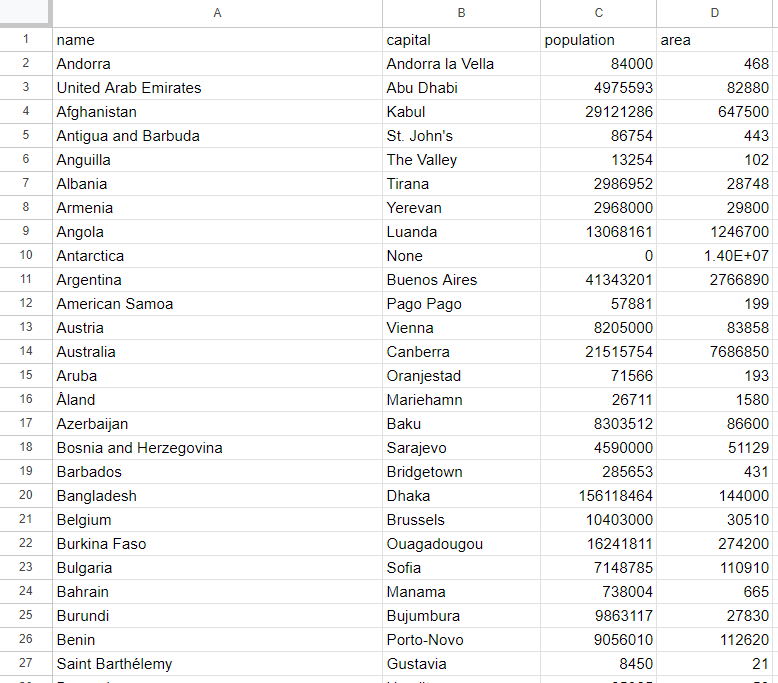
자, 이제 Rust 웹 스크래핑의 기본을 알게 되었습니다!
웹 스크래핑 작업을 윤리적이고 존중하는 방식으로 수행하세요
인터넷에서 데이터를 자동으로 수집하는 것은 유용한 정보를 얻는 효과적인 방법입니다. 그러나 이 과정에서 대상 사이트에 피해를 주어서는 안 됩니다. 따라서 적절한 예방 조치를 취하며 접근해야 합니다.
책임감 있는 웹 스크래핑을 위해 다음 팁을 고려하세요:
- robots.txt 파일 준수: 모든 사이트에는 자동 크롤러가 페이지에 접근하는 방식을 규정하는 robots.txt 파일이 있습니다. 윤리적인 스크래핑 관행을 유지하려면 해당 지침을 반드시 따라야 합니다. 자세한 내용은 웹 스크래핑용 robots.txt 가이드에서 확인하세요.
- 요청 빈도 제한: 짧은 시간에 너무 많은 요청을하면 서버 과부하가 발생하여 모든 사용자의 사이트 성능에 영향을 미칩니다. 이는 속도 제한 조치로 이어져 차단될 수도 있습니다. 따라서 대상 서버에 과부하가 걸리지 않도록 요청 간에 무작위 지연을 추가하세요.
- 사이트 이용 약관을 확인하고 준수하세요: 웹사이트 스크래핑 전 해당사이트의 이용 약관을 검토하고 준수하십시오. 여기에는 저작권, 지적 재산권 정보 및 데이터 사용 방법과 시기에 대한 지침이 포함될 수 있습니다.
- 공개적으로 접근 가능한 정보만 스크래핑하세요: 로그인 자격 증명이나 기타 인증 방식으로 보호되지 않고 사이트에서 공개적으로 접근 가능한 데이터 추출에집중하세요 . 적절한 허가 없이 사적 또는 민감한 데이터를 스크래핑하는 것은 비윤리적이며 법적 결과를 초래할 수 있습니다.
- 신뢰할 수 있고 최신 스크래핑 도구 사용: 평판이 좋은 공급자를선택하고 , 잘 관리되며 정기적으로 업데이트되는 라이브러리와 도구를 선택하십시오. 그래야만 최신 윤리적 스크래핑 원칙과 모범 사례에 부합함을 보장할 수 있습니다. 의문이 있다면, 최고의 웹 스크래핑 서비스 선택 방법에 관한 당사 글을 참고하십시오.
결론
이 튜토리얼에서는 Rust가 웹 스크래핑에 적합한 이유와 이를 수행하기 위해 사용해야 할 라이브러리를 살펴보았습니다. 실제 사이트에서 데이터를 추출할 수 있는 Rust 웹 스크래퍼를 구축하기 위해 reqwest와 scraper를 사용하는 방법을 배웠습니다. 단 몇 줄의 코드만으로 가능합니다!
하지만 웹 스크래핑이 항상 이렇게 쉽지만은 않다는 점을 명심하세요. 그 이유는 반스크래핑 및 반봇 솔루션이 점점 더 보편화되고 있기 때문입니다. 이러한 기술들은 여러분의 스크립트가 자동화된 스크래퍼임을 감지하고 차단할 수 있어, 스크래핑 작업에 심각한 장애물이 될 수 있습니다.
Bright Data가 제공하는 차세대 고급 웹 스크래핑 도구로 이러한 골칫거리를 피하세요. 차단되는 것을 피하는 방법에 대해 더 알고 싶다면, 여러 프록시 서비스 중 하나에서 웹 프록시를 채택하거나 고급 Web Unlocker 사용을 시작하세요.
웹 스크래핑을 직접 다루고 싶지 않으신가요? 당사의 데이터셋을 살펴보세요.
어떤 제품을 선택해야 할지 모르시나요? 지금 가입하여 비즈니스에 적합한 솔루션을 찾아보세요.





