
이 글에서는 다음 내용을 다룹니다:
- Apache Airflow와 Apache Spark가 무엇이며 어떤 기능을 제공하는지.
- Airflow와 Spark를 사용하여 Bright Data의 Web Unlocker API를 오케스트레이션하는 것이 리드 생성을 위한 강력한 전략인 이유.
- 구조화된 비즈니스 데이터를 대규모로 수집, 처리 및 저장하는 엔드투엔드 파이프라인을 구축하는 방법.
구체적인 도구와 구현 방법에 대해 자세히 알아보기 전에, 먼저 기초 개념을 정리하고 리드 생성 워크플로우 내에서 이들이 어떻게 연결되는지 살펴보겠습니다.
아파치 에어플로우란 무엇인가?
Apache Airflow는 데이터 파이프라인을 프로그래밍 방식으로 작성, 스케줄링 및 모니터링하기 위한 오픈 소스 워크플로우 오케스트레이션 플랫폼입니다. 원래 Airbnb에서 개발된 이 플랫폼은 데이터 엔지니어가 일반 Python을 사용하여 워크플로우를 DAG(방향성 비순환 그래프)로 정의할 수 있게 해 주며, 작업 종속성, 재시도, 스케줄링 및 알림에 대한 완전한 제어 기능을 제공합니다.
이 플랫폼의 주요 목표는 복잡하고 다단계인 데이터 파이프라인을 안정적으로 실행할 수 있도록 돕는 것입니다. 이는 풍부한 오퍼레이터 생태계(Bash, Python, HTTP, Spark, SQL 등 지원), 실행 모니터링을 위한 시각적 웹 UI, 내장된 재시도 및 알림 로직, 그리고 AWS, GCP, Azure와 같은 클라우드 플랫폼과의 네이티브 통합을 제공함으로써 달성됩니다.
워크플로 오케스트레이션에 대한 이해를 바탕으로, 이제 파이프라인의 데이터 처리 측면을 살펴보겠습니다.
Apache Spark는 대규모 데이터 처리를 위한 통합 분석 엔진입니다. 이 엔진은 머신 클러스터 전반에 걸쳐 메모리 내에서 방대한 데이터 세트를 처리할 수 있는 분산 컴퓨팅 프레임워크를 제공하여, 기존의 디스크 기반 처리 시스템보다 훨씬 빠른 속도를 자랑합니다.
Spark는 Python(PySpark), Scala, Java 및 R에서 사용할 수 있는 통합 API를 통해 배치 처리, 스트리밍, SQL 쿼리, 머신 러닝 및 그래프 계산을 지원합니다. 대량의 스크랩된 비즈니스 데이터를 정리, 중복 제거, 보강 및 변환하는 것과 같은 데이터 집약적인 워크로드의 경우, Spark는 업계 표준 도구입니다.
Apache Airflow 대 Apache Spark: 차이점은 무엇인가?
이 스택을 처음 접하는 분이라면, 두 기술이 종종 함께 등장하기 때문에 혼동하기 쉽습니다. 하지만 두 기술은 매우 다른 목적을 수행합니다:
- Apache Airflow는 오케스트레이터입니다. 이 도구는 태스크를 언제, 어떤 순서로 실행할지, 오류를 어떻게 처리할지, 전체 파이프라인을 어떻게 모니터링할지 결정합니다. 데이터 자체를 처리하지는 않습니다.
- 아파치 스파크는 데이터 처리 도구입니다. 원시 데이터나 반구조화 데이터를 가져와 다수의 코어나 머신에 걸친 분산 컴퓨팅을 통해 대규모로 변환합니다.
이 두 도구는 서로를 훌륭하게 보완합니다. Airflow는 적절한 시기와 순서에 따라 Spark 작업을 스케줄링하고 트리거하는 반면, Spark는 데이터 변환이라는 중책을 담당합니다. 이 튜토리얼에서는 Airflow가 전체 파이프라인을 종단 간(end-to-end)으로 어떻게 오케스트레이션하는지 살펴보겠습니다. Bright Data를 트리거하여 비즈니스 목록을 수집하고, 원시 결과를 Spark로 전달하여 정리 및 보강 작업을 수행한 후, 최종 리드를 데이터베이스에 기록하는 과정을 다룹니다.
왜 Bright Data를 Airflow + Spark 파이프라인에 통합해야 할까요?
Airflow는 파이프라인 작업으로 모든 REST API를 호출할 수 있는 SimpleHttpOperator 와 PythonOperator를 제공합니다. 즉, 변환 및 로딩 작업과 함께 DAG 내에서 웹 데이터 수집을 핵심 단계로 트리거할 수 있습니다.
하지만 대규모로 신뢰할 수 있고 구조화된 비즈니스 데이터를 파이프라인에 주입하려면, 별도의 스크래퍼 유지 관리 없이도 봇 방지 조치, 지역 타겟팅 및 구조화된 출력을 처리할 수 있는 소스가 필요합니다. 바로 여기에서 Bright Data의 Web Unlocker API가 빛을 발합니다.
Web Unlocker API를 사용하면 봇 방지, JavaScript 렌더링 요구 사항 또는 지리적 제한과 관계없이 모든 공개 웹 페이지에 액세스할 수 있습니다. 대상 URL을 포함한 POST 요청을 전송하면 Bright Data가 페이지 콘텐츠를 반환합니다. 브라우저 자동화 코드, 프록시 관리, CAPTCHA 처리가 필요 없습니다.
이 방식은 특히 다음 용도에 유용합니다:
- 디렉토리에서 주기적으로 최신 비즈니스 목록을 수집하여 CRM이나 아웃리치 도구로 전송하는 리드 생성 파이프라인.
- 경쟁 분석을 위해 지역이나 산업 전반에 걸쳐 비즈니스 데이터를 집계하는 시장 조사 워크플로우.
- 기존 리드 데이터베이스에 연락처 정보, 기업 규모 또는 산업 분류를 추가하는 데이터 보강 시스템.
- 기업 목록의 변경 사항을 모니터링하고 대상 기업이 프로필을 업데이트할 때 알림을 트리거하는 영업 인텔리전스 플랫폼.
Airflow의 스케줄링 및 오케스트레이션 기능을 Spark의 분산 데이터 처리 및 Bright Data의 웹 데이터 인프라와 결합하면, 자동으로 작동하는 프로덕션급 리드 생성 엔진을 구축할 수 있습니다.
Airflow, Spark 및 Bright Data를 사용하여 리드 생성 파이프라인 구축하는 방법
이 가이드 섹션에서는 다음 세 가지 주요 단계로 구성된 엔드투엔드 파이프라인을 구축하게 됩니다.
- 기업 목록 가져오기: Airflow 태스크가 Bright Data의 Web Unlocker API를 호출하여 3개 도시의 옐로우 페이지 검색 결과를 수집합니다.
- 수집된 데이터 검증: 두 번째 태스크가 저장된 결과를 읽어들이고 데이터가 성공적으로 수집되었는지 확인합니다.
- Spark를 이용한 처리: PySpark 작업이 원시 레코드를 정리하고 중복을 제거하며 점수를 매깁니다.
참고: 이는 가능한 여러 아키텍처 중 하나입니다. Spark 출력을 BigQuery나 Snowflake와 같은 데이터 웨어하우스에 저장하거나, API를 통해 CRM으로 직접 전송하거나, 자동 리드 스코어링을 위해 LLM 기반 보강 단계로 전달할 수도 있습니다.
Apache Airflow 및 Spark 내에서 Bright Data의 Web Unlocker API를 활용한 자동 리드 생성 파이프라인을 구축하려면 아래 지침을 따르세요!
필수 사항
이 가이드를 따라 하려면 다음이 필요합니다:
- 활성 Web Unlocker 존이 있는 Bright Data 계정. Bright Data 대시보드에 로그인하여 계정 설정( Account Settings)으로 이동한 후 API 토큰을 복사하세요. 토큰은 UUID 형식입니다. 또한 존 이름도 기록해 두세요.
- Docker Desktop (macOS 또는 Windows) 또는 네이티브 Python 환경(Ubuntu/Linux). 두 옵션에 대한 내용은 1단계를 참조하세요.
1단계: 프로젝트 설정
Docker Desktop을 설치하고 계속 진행하기 전에 실행 중인지 확인하십시오. Docker Desktop 설정에서 ‘리소스(Resources )’로 이동하여 최소 5GB의 메모리를 할당하십시오. Airflow의 멀티 컨테이너 스택에 필요합니다.
2단계: 프로젝트 구조 생성
작업 디렉터리와 Airflow에 필요한 폴더를 생성합니다:
mkdir airflow-lead-pipeline && cd airflow-lead-pipeline
mkdir dags spark_jobs logs plugins config프로젝트 구조는 다음과 같습니다:
airflow-lead-pipeline/
├── dags/
│ └── lead_generation_dag.py
├── spark_jobs/
│ └── process_leads.py
├── logs/
├── plugins/
├── config/
├── Dockerfile
└── docker-compose.yaml3단계: Docker Compose 설정
공식 Airflow Docker Compose 파일을 다운로드합니다:
curl -LfO 'https://airflow.apache.org/docs/apache-airflow/2.7.3/docker-compose.yaml'동일한 디렉터리에 Dockerfile을 생성합니다. 이 파일은 기본 Airflow 이미지를 확장하여 requests 라이브러리를 추가합니다:
FROM apache/airflow:2.7.3
RUN pip install requests pysparkdocker-compose.yaml 파일을 엽니다. 상단 부근에 있는 x-airflow-common 블록을 찾아 image: 줄 바로 아래에 build: .을 추가합니다:
x-airflow-common:
&airflow-common
image: ${AIRFLOW_IMAGE_NAME:-apache/airflow:2.7.3}
build: .또한, _PIP_ADDITIONAL_REQUIREMENTS 줄이 비어 있는지 확인하십시오. 종속성은 이 환경 변수가 아닌 Dockerfile에 지정해야 합니다:
_PIP_ADDITIONAL_REQUIREMENTS: ""마지막으로, 같은 블록의 volumes: 목록에 spark_jobs/에 대한 볼륨 마운트를 추가하십시오. 기본 파일은 dags/, logs/, plugins/, config/만 마운트하므로, 이 추가 사항이 없으면 워커 컨테이너가 Spark 작업 파일을 찾을 수 없습니다:
volumes:
- ${AIRFLOW_PROJ_DIR:-.}/spark_jobs:/opt/airflow/spark_jobs파일의 나머지 부분은 다운로드한 그대로 유지합니다. 기본 설정으로는 메시지 브로커로 Redis를, 메타데이터 데이터베이스로 PostgreSQL을 사용하는 CeleryExecutor가 제공되며, 프로젝트 폴더의 dags/, logs/, config/, plugins/ 폴더가 볼륨으로 마운트되고, 기본 자격 증명으로 사용자명 airflow 및 비밀번호 airflow가 설정되며, 첫 실행 시 데이터베이스를 마이그레이션하고 관리자 사용자를 생성하기 위해 한 번 실행되는 airflow-init 서비스가 포함됩니다.
사용자 정의 이미지를 빌드하고 모든 서비스를 시작합니다:
docker compose build
docker compose up -d약 60초 정도 기다린 후, 6개의 컨테이너가 모두 정상적으로 실행 중인지 확인합니다:
docker compose ps예상 출력:

브라우저에서 http://localhost:8080을 열고 사용자 이름 airflow, 비밀번호 airflow로 로그인합니다.
4단계: Airflow DAG 작성
dags/lead_generation_dag.py 파일을 생성합니다:
import json
import requests
from datetime import datetime, timedelta
from pathlib import Path
from airflow import DAG
from airflow.operators.python import PythonOperator
API_KEY = "your-brightdata-api-token-here"
ZONE = "web_unlocker1"
BASE_URL = "https://api.brightdata.com/request"
RAW_DATA_PATH = "/tmp/brightdata_raw/leads.json"
HEADERS = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
}
TARGETS = [
"https://www.yellowpages.com/search?search_terms=software+company&geo_location_terms=San+Francisco+CA",
"https://www.yellowpages.com/search?search_terms=marketing+agency&geo_location_terms=New+York+NY",
"https://www.yellowpages.com/search?search_terms=fintech+startup&geo_location_terms=Austin+TX",
]
default_args = {
"owner": "data-team",
"retries": 2,
"retry_delay": timedelta(minutes=5),
}
def fetch_business_listings(**context):
results = []
for url in TARGETS:
print(f"Fetching: {url}")
response = requests.post(
BASE_URL,
headers=HEADERS,
json={
"zone": ZONE,
"url": url,
"format": "raw",
"data_format": "markdown",
},
timeout=60,
)
response.raise_for_status()
results.append({
"url": url,
"content": response.text,
"status": response.status_code,
})
print(f"{url}에서 {len(response.text)} 바이트 가져옴")
Path(RAW_DATA_PATH).parent.mkdir(parents=True, exist_ok=True)
with open(RAW_DATA_PATH, "w") as f:
json.dump(results, f, indent=2)
print(f"{len(results)} 페이지를 {RAW_DATA_PATH}에 저장했습니다")
context["ti"].xcom_push(key="record_count", value=len(results))
def validate_output(**context):
count = context["ti"].xcom_pull(key="record_count", task_ids="fetch_listings")
with open(RAW_DATA_PATH) as f:
data = json.load(f)
print(f"검증 통과: {count} 페이지 수집됨")
for item in data:
print(f" URL: {item['url']} | 상태: {item['status']} | 크기: {len(item['content'])} 자")
with DAG(
dag_id="brightdata_lead_generation",
default_args=default_args,
description="Bright Data Web Unlocker를 사용하여 비즈니스 리드 수집",
schedule_interval="0 6 * * 1",
start_date=datetime(2026, 3, 12),
catchup=False,
tags=["lead-generation", "brightdata"],
) as dag:
fetch_listings = PythonOperator(
task_id="fetch_listings",
python_callable=fetch_business_listings,
)
validate_data = PythonOperator(
task_id="validate_data",
python_callable=validate_output,
)
fetch_listings >> validate_datayour-brightdata-api-token-here를 실제 API 토큰으로 교체하고, ZONE을 Web Unlocker의 존 이름에 맞게 업데이트하십시오.
각 부분의 역할을 자세히 살펴보겠습니다:
API_KEY및ZONE: Bright Data 자격 증명입니다. API 토큰은 계정 설정에서 확인할 수 있는 UUID 형식의 토큰이며, 존 비밀번호가 아닙니다.TARGETS: 샌프란시스코의 소프트웨어 기업, 뉴욕의 마케팅 대행사, 오스틴의 핀테크 스타트업을 다루는 세 개의 옐로우 페이지 검색 URL입니다.fetch_business_listings: 각 대상 URL을 순차적으로 처리하며 Web Unlocker API로 POST 요청을 전송합니다. Bright Data는 봇 방지 조치, 프록시 로테이션, 자바스크립트 렌더링을 처리하여 페이지 콘텐츠를 마크다운(Markdown) 형식으로 반환합니다. 결과는 디스크에 저장되며, 레코드 수는 다음 태스크에서 읽을 수 있도록 Airflow의 XCom 스토어로 전송됩니다.validate_output: 저장된 파일을 읽고 각 URL, HTTP 상태, 콘텐츠 크기를 기록합니다. 이는 후속 처리 전에 수행되는 가벼운 데이터 품질 검사 역할을 합니다.fetch_listings >> validate_data:>>연산자는 작업 간 종속성을 정의합니다. 검증은 데이터 가져오기가 성공한 후에만 실행됩니다.
중요: 반복 일정이 포함된 DAG를 처음 배포할 때는 항상
start_date를오늘 날짜로 설정하고catchup=False로설정하십시오.start_date를과거 날짜로 설정하고catchup=True로설정하면, Airflow는 해당 날짜 이후 놓친 모든 간격에 대해 백필(backfill) 실행을 대기열에 넣습니다. 10주 전부터 시작된 주간 일정의 경우, DAG의 일시 중지를 해제하는 순간 10개의 실행이 동시에 진행되어 워커 슬롯을 놓고 경쟁하게 됩니다.
5단계: PySpark 변환 작업 작성
spark_jobs/process_leads.py 파일을 생성합니다:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, trim, regexp_replace, when, lit
import sys
def main(input_path: str, output_path: str):
spark = SparkSession.builder
.appName("BrightData Lead Processing")
.config("spark.sql.adaptive.enabled", "true")
.getOrCreate()
raw_df = spark.read.option("multiLine", True).json(input_path)
cleaned_df = raw_df.select(
trim(col("name")).alias("company_name"),
trim(col("phone")).alias("phone"),
trim(col("website")).alias("website"),
trim(col("address")).alias("address"),
trim(col("city")).alias("city"),
trim(col("state")).alias("state"),
trim(col("category")).alias("industry"),
col("rating").cast("float").alias("rating"),
col("reviews_count").cast("integer").alias("reviews_count"),
)
.filter(col("company_name").isNotNull())
.filter(col("phone").isNotNull())
.dropDuplicates(["company_name", "phone"])
enriched_df = cleaned_df.withColumn(
"lead_score",
when(
(col("rating") >= 4.0) & (col("reviews_count") >= 50), lit("hot")
).when(
(col("rating") >= 3.0) & (col("reviews_count") >= 10), lit("warm")
).otherwise(lit("cold"))
).withColumn(
"website_clean",
regexp_replace(col("website"), "^https?://", "")
)
enriched_df.write.mode("overwrite").parquet(output_path)
print(f"{enriched_df.count()}개의 리드 처리 완료. 출력은 {output_path}에 기록됨")
spark.stop()
if __name__ == "__main__":
main(sys.argv[1], sys.argv[2])이 작업은 네 가지 작업을 수행합니다. 먼저 fetch_listings에서 생성한 원시 JSON 데이터를 디스크에서 불러옵니다. 공백을 정규화하고, 숫자 필드를 형변환하며, 이름이나 전화번호가 누락된 레코드를 제거하여 데이터를 정리합니다. 또한 회사명과 전화번호를 기준으로 레코드를 중복 제거하여 도시 간 중복 목록을 제거합니다. 마지막으로, 각 레코드에 lead_score 레이블을 부여합니다. 평점 4.0 이상이고 리뷰가 50개 이상인 업체는 'hot'으로, 평점 3.0 이상이고 리뷰가 10개 이상인 업체는 'warm'으로, 그 외의 모든 업체는 'cold'로 표시합니다.
6단계: 파이프라인 트리거 및 모니터링
dags/ 폴더에 DAG 파일을 저장하면 Airflow가 30초 이내에 자동으로 이를 인식합니다.
Docker 사용자는 DAG의 일시 중지를 해제하고 실행하십시오:
docker compose exec --user airflow airflow-scheduler airflow dags unpause brightdata_lead_generation
docker compose exec --user airflow airflow-scheduler airflow dags trigger brightdata_lead_generation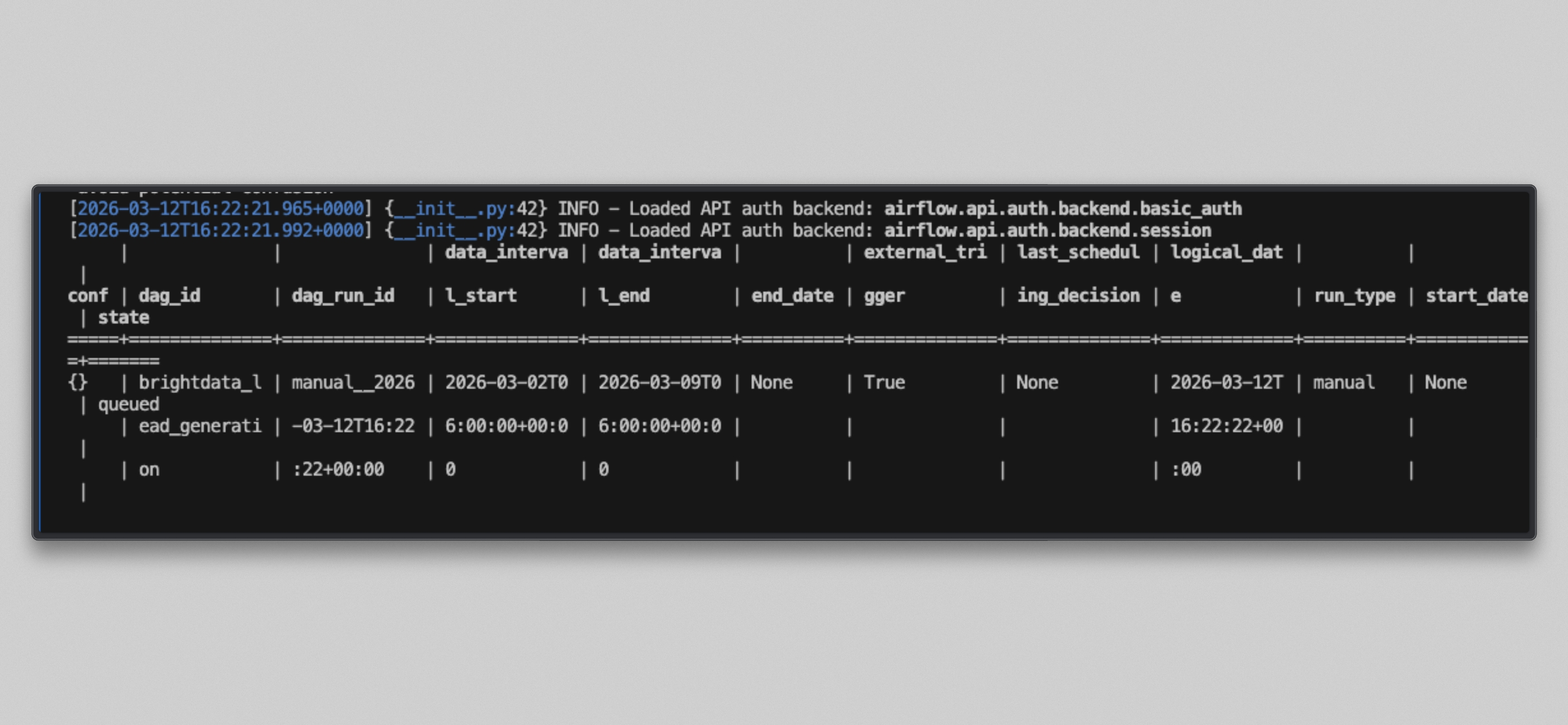
워커 로그를 확인하세요:
docker compose logs airflow-worker -f --tail=20태스크가 실행되면 다음과 같은 출력이 표시됩니다:
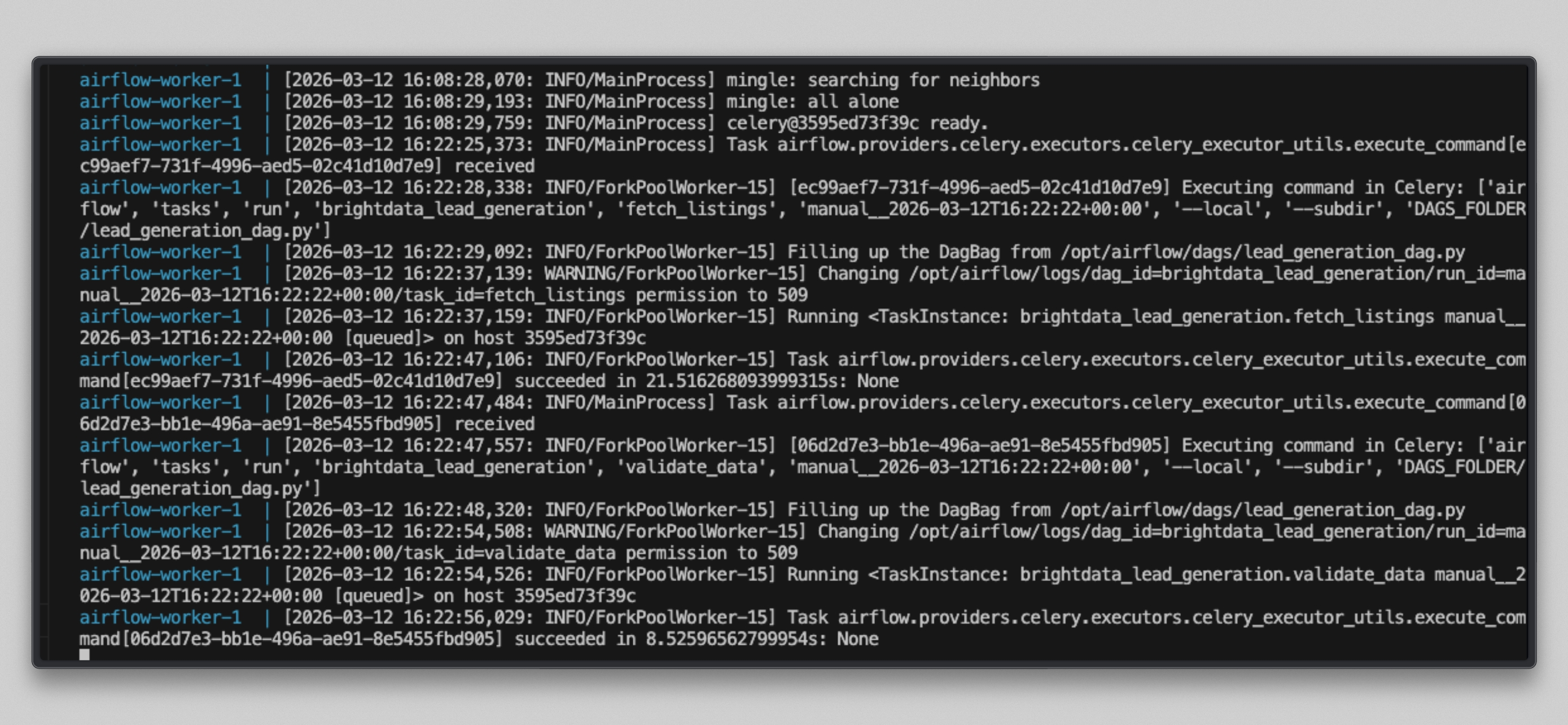
http://localhost:8080를 열고, brightdata_lead_generation DAG를 클릭한 후 그리드 보기로 전환하세요. 각 태스크 타일은 완료됨에 따라 녹색으로 변합니다. 아무 태스크 타일이나 클릭하고 ‘로그’를 선택하면, 가져온 각 URL과 Bright Data에서 반환한 문자 수를 포함한 실시간 출력을 확인할 수 있습니다.
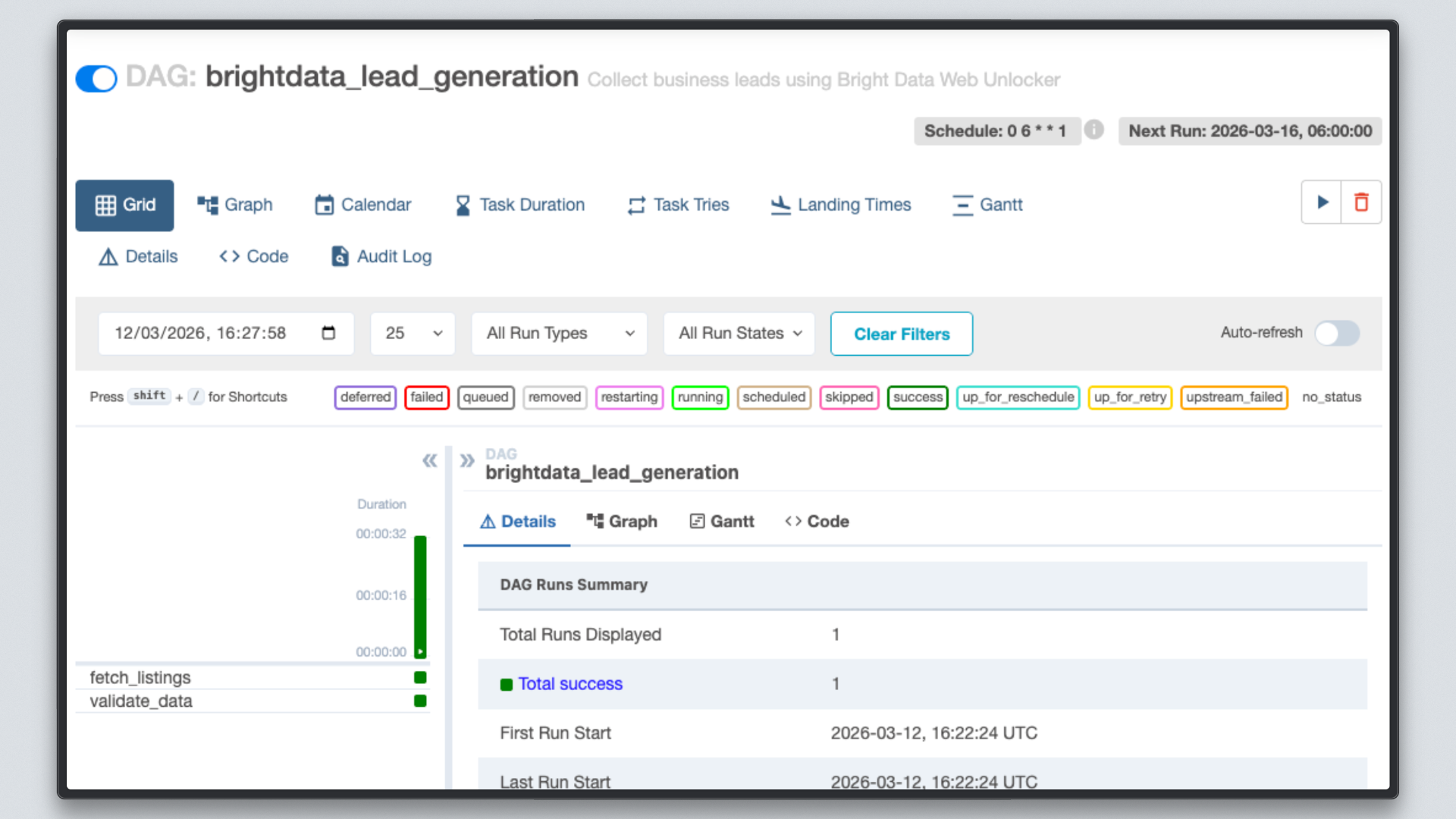
7단계: 결과 확인
두 태스크 모두 녹색으로 표시되면 출력 파일을 확인하세요.
Docker 사용자:
docker compose exec --user airflow airflow-worker cat /tmp/brightdata_raw/leads.jsonUbuntu 기본 사용자:
cat /tmp/brightdata_raw/leads.json대상 URL마다 하나씩, 총 세 개의 항목이 포함된 JSON 배열을 확인할 수 있습니다:
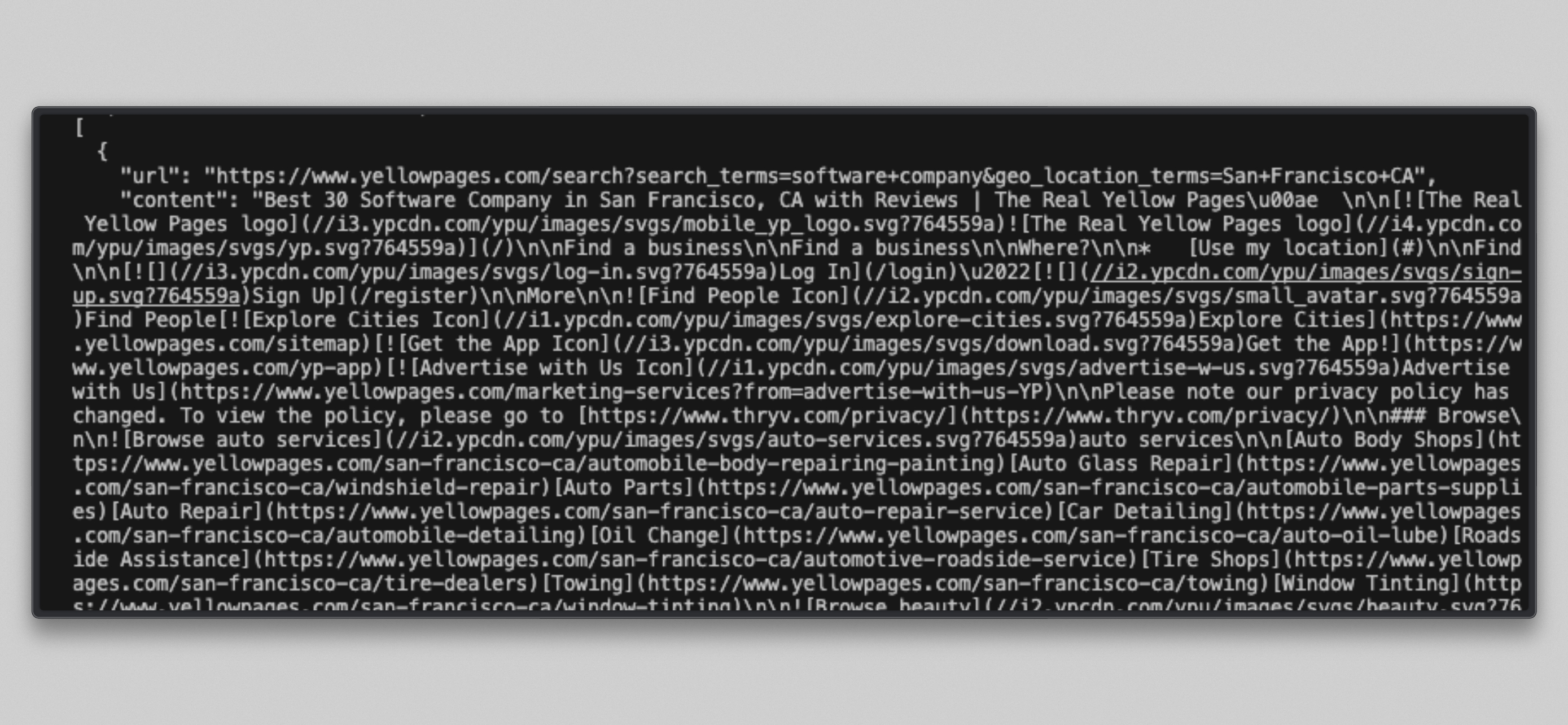
참고: Bright Data의 즉시 액세스 모드에서 사이트가 제한된 경우 일부 Yellow Pages URL은
bad_endpoint메시지를 반환할 수 있습니다. 이는 정상적인 현상입니다. Bright Data는 오류가 발생했을 때 조용히 실패하는 대신 응답에 오류를 명시적으로 표시합니다. 제한된 사이트에 대한 전체 액세스 권한이 필요한 경우 Bright Data 계정 관리자에게 문의하십시오.
마지막으로, 출력을 대상으로 Spark 작업을 실행합니다:
docker compose exec --user airflow airflow-worker python /opt/airflow/spark_jobs/process_leads.py
/tmp/brightdata_raw/leads.json
/tmp/brightdata_processed/leads이렇게 하면 정리되고 점수가 매겨진 Parquet 파일이 /tmp/brightdata_processed/leads에 작성되며, PostgreSQL이나 하류 시스템에 로드할 준비가 됩니다.
Web Unlocker API는 Yellow Pages에서 최신 실시간 콘텐츠를 제공했으며, 스크래핑이나 프록시 관리 코드를 단 한 줄도 작성하지 않고도 파이프라인이 이를 자동으로 정리, 점수화 및 저장했습니다. 봇 탐지 시스템과 속도 제한으로 인해 비즈니스 목록을 수동으로 수집하는 것은 매우 어려운 것으로 알려져 있습니다. Bright Data의 Web Unlocker를 사용하면 유지 관리해야 할 인프라 없이도 모든 지역의 공개 사이트에서 페이지 콘텐츠를 안정적으로 가져올 수 있습니다.
한 단계 더 나아가기
이 파이프라인은 작동 가능한 기반이므로 다양한 방향으로 확장할 수 있습니다:
- 중간 데이터 레이어에서 로컬 파일 시스템을 Amazon S3 또는 Google Cloud Storage로 교체하여 파이프라인이 분산된 워커 간에 작동하도록 합니다.
- Spark 처리와 데이터베이스 로드 사이에 LLM 보강 단계를 추가하여, OpenAI 또는 Anthropic API를 활용해 각 유망 리드에 대한 맞춤형 아웃리치 요약문을 생성할 수 있습니다.
- Airflow의 기존 프로바이더 오퍼레이터를 사용하여 로컬 출력을 Salesforce, HubSpot 또는 Pipedrive로의 직접 CRM 푸시로 교체합니다.
- Great Expectations 또는 Airflow의 SQLCheckOperator를 사용하여 데이터 커밋 전에 레코드 수와 필드 완성도를 검증하는 데이터 품질 검사 작업을 추가합니다.
AWS EMR, - Airflow 내의 Spark 연결 URL을 업데이트하여 AWS EMR, Google Dataproc 또는 Databricks로 Spark 작업을 확장하고, DAG 및 PySpark 코드는 그대로 유지합니다.
- Bright Data의 SERP API를 병렬 수집 작업으로 사용하여 각 리드에 최신 뉴스나 검색 노출 데이터를 보강하세요.
가능성은 사실상 무한합니다!
결론
이 기사에서는 Bright Data의 Web Unlocker API, Apache Airflow 및 Apache Spark를 결합하여 작동하는 리드 생성 파이프라인을 구축했습니다.
Airflow는 스케줄링, 재시도 로직, 종속성 관리 및 가시성을 처리합니다. Spark는 원시 비즈니스 데이터의 분산 정리, 중복 제거 및 스코어링을 처리합니다. Bright Data는 프록시 관리, 스크래퍼 코드 작성 또는 봇 방지 시스템과의 싸움 없이 웹에서 최신 페이지 콘텐츠를 수집하는 가장 어려운 부분을 해결해 줍니다.
노코드 자동화 도구와 달리, 이 스택을 사용하면 수집 매개변수, 변환 로직, 출력 스키마, 스케줄링 주기 등 파이프라인의 모든 계층을 완전히 제어할 수 있습니다. 또한 모든 최신 데이터 플랫폼에 자연스럽게 통합되며 데이터 양에 따라 확장됩니다.
더 풍부한 파이프라인을 구축하려면, 검색 데이터용 SERP API, 자바스크립트가 많은 페이지용 Web Unlocker, 일반적인 사용 사례를 위한 기성 데이터셋을 포함한 Bright Data의 전체 데이터 수집 도구 제품군을 살펴보세요.
지금 바로Bright Data 무료 계정에 가입하고, 파이프라인에 필요한 비즈니스 데이터 수집을 시작하세요.





