

대부분의 데이터 팀이 실패하는 이유는 데이터를 수집하지 못해서가 아닙니다. 원시 데이터가 지저분하고 중복되며 일관성이 없는 상태로 도착하는데, 이를 분석가와 모델이 신뢰할 수 있는 형태로 변환하는 체계적인 방법이 없기 때문입니다. 메달리온 아키텍처는 대부분의 현대적인 데이터 플랫폼이 이 문제를 해결하기 위해 사용하는 패턴으로, 데이터를 브론즈, 실버, 골드라는 세 개의 점진적으로 정제된 레이어를 통해 이동시킵니다.
이 가이드는 데이터 엔지니어가 이해해야 하는 방식으로 패턴을 설명합니다. 각 레이어의 동작 방식, 데이터가 레이어 간에 물리적으로 이동하는 방법, 그리고 외부에서 수집된 웹 데이터가 원시 브론즈 입력으로 어떻게 활용되는지를 다룹니다.
이 글의 내용:
- 메달리온 아키텍처란 무엇이며 Databricks가 왜 이를 대중화했는가
- 브론즈, 실버, 골드 레이어가 각각 하는 일과 이를 사용하는 주체
- 테이블 형식, ACID 트랜잭션, 변경 데이터 캡처를 통해 데이터가 레이어 간에 이동하는 방법
- 외부 및 웹 데이터가 브론즈 소스로 패턴에 진입하는 위치
- 모범 사례, 일반적인 함정, 그리고 패턴이 효과를 발휘하는 사용 사례
메달리온 아키텍처란 무엇인가?
메달리온 아키텍처는 레이크하우스 내에서 데이터를 조직하는 설계 패턴으로, 데이터가 브론즈에서 실버, 골드로 흐르면서 각 단계마다 구조와 품질이 향상됩니다. 이름은 메달의 은유를 차용한 것으로, 데이터는 가치가 낮은 원시 브론즈로 진입하여 더 가치 있는 실버, 그리고 골드로 정제됩니다. 모든 레코드가 소비에 적합해지기 전에 여러 단계를 거치기 때문에 멀티홉 아키텍처라고도 불립니다.
이 패턴은 Databricks가 레이크하우스 패러다임과 2019년 오픈 소스로 공개된 Delta Lake 테이블 형식과 함께 대중화했습니다. 레이크하우스는 데이터 레이크의 저렴한 스토리지 비용과 ACID 트랜잭션 및 스키마 적용과 같은 데이터 웨어하우스의 안정성 기능을 결합합니다. 메달리온 아키텍처는 레이크하우스에 명확한 신뢰 흐름을 부여하는 조직 원칙입니다. 현재는 크로스 플랫폼 관례가 되어 Databricks, Microsoft Fabric, Snowflake 문서에서 동일한 브론즈, 실버, 골드 언어를 볼 수 있습니다.
핵심 개념은 단순합니다. 하나의 불투명한 단계에서 데이터를 정제하는 대신, 영구적인 원시 복사본을 유지하면서 각 단계가 명확한 계약을 가진 단계적으로 정제합니다. 이 분리가 패턴을 오래 지속되게 만드는 요소이며, 이하 모든 내용의 기반이 됩니다.
데이터 팀이 이를 채택하는 이유
메달리온 아키텍처는 여러 문제를 동시에 해결하기 때문에 그 자리를 차지하고 있습니다.
점진적이고 검사 가능한 데이터 품질. 품질은 이해하기 어려운 단일 변환이 아닌 단계적으로 개선됩니다. 각 단계는 정의된 역할이 있어서 문제가 발생했을 때 어느 레이어를 검사해야 하는지 알 수 있습니다.
원시 데이터에서 재처리. 브론즈 레이어는 영구적인 역사 아카이브이므로 소스 시스템으로 돌아가지 않고도 언제든지 실버 및 골드 테이블을 재구성할 수 있습니다. 변환에 버그가 있거나 비즈니스 로직이 변경되면 더 이상 사용 불가능할 수 있는 데이터를 다시 수집하는 대신 브론즈에서 재실행합니다.
계보 및 감사 가능성. 브론즈는 원본 페이로드를 보존하여 법의학적 기록을 제공합니다. 규정 준수 및 감사 팀은 대시보드의 모든 숫자를 해당 숫자가 출처인 정확한 원시 레코드까지 추적할 수 있습니다.
소비자 간 관심사 분리. 서로 다른 레이어는 서로 다른 대상을 위해 제공됩니다. 데이터 엔지니어와 운영 팀은 브론즈와 실버에서 작업합니다. 분석가와 데이터 과학자는 실버에서 작업합니다. 비즈니스 분석가, 임원, 애플리케이션은 골드를 소비합니다.
다중 소비자 서빙. 단일한 정제된 실버 엔티티가 많은 골드 테이블을 공급할 수 있으므로, 재무, 운영, 마케팅 각각 동일한 신뢰할 수 있는 소스에서 자체 소비 준비 뷰를 구축할 수 있습니다.
이것이 패턴이 ELT 마인드셋과 자연스럽게 짝을 이루는 이유이기도 합니다. 모든 것을 변환한 후 로드하는 대신 원시 데이터를 먼저 로드한 다음 플랫폼 내부에서 변환합니다. 더 넓은 수집 흐름에 대한 복습이 필요하다면, ETL 파이프라인 설명과 데이터 파이프라인 아키텍처 개요 모두 메달리온 모델에 깔끔하게 매핑됩니다.
세 레이어의 상세 설명
흐름은 개념적으로 선형입니다: 원시 데이터가 브론즈에 도착하고, 실버로 정제되며, 골드에서 소비를 위한 형태로 가공됩니다.
flowchart LR
S["External and web sources"] --> B["Bronze: raw, as-is, append-only"]
B --> SI["Silver: cleaned, conformed, deduplicated"]
SI --> G["Gold: aggregated, business-level"]
G --> C["BI, dashboards, ML, applications"]데이터는 브론즈에서 실버, 골드로 이동하면서 점진적으로 정제됩니다.
브론즈 레이어: 원시 및 불변
브론즈는 외부 소스 시스템에서 도착하는 모든 데이터의 착륙 지점입니다. 브론즈 테이블은 로드 타임스탬프와 행을 작성한 프로세스 같은 세부 정보를 기록하는 몇 가지 추가 메타데이터 열과 함께 소스의 형태를 있는 그대로 반영합니다. 여기서의 우선순위는 캡처 속도, 소스의 내구성 있는 역사 아카이브, 명확한 계보, 그리고 원점 시스템을 다시 읽지 않고도 나중에 재처리할 수 있는 옵션입니다.
브론즈에는 몇 가지 정의적 속성이 있습니다. 원래 형식의 원시 상태의 데이터를 포함합니다. 증분적으로 추가되어 시간이 지남에 따라 성장합니다. 도착한 그대로의 데이터 충실도를 보존하는 단일 진실의 원천 역할을 합니다. 직접적인 분석가 접근보다는 다운스트림 처리를 위해 설계되었습니다.
핵심 구현 세부 사항: 브론즈에서는 일반적으로 타입을 적용하지 않습니다. Databricks는 업스트림의 예상치 못한 스키마 변경으로부터 보호하기 위해 대부분의 필드를 문자열, VARIANT, 또는 바이너리로 저장할 것을 권장합니다. 사실상 브론즈는 읽기 시 스키마입니다. 먼저 캡처하고 나중에 해석하는 방식으로, 소스 스키마가 제어 범위 밖에 있을 때 원하는 바로 그것입니다. 브론즈 소스는 Amazon S3, Google Cloud Storage, Azure Data Lake Storage 같은 클라우드 객체 스토리지, Kafka 및 Kinesis 같은 메시지 버스, 연합 시스템 등 스트리밍과 배치 입력의 어떤 조합이든 될 수 있습니다.
실버 레이어: 정제 및 표준화
실버는 브론즈 레코드가 매칭, 병합, 표준화, 정제되는 곳으로, 비즈니스에 핵심 엔티티, 개념, 트랜잭션에 대한 단일하고 일관된 뷰를 제공하기에 충분합니다. 마스터 고객 레코드, 중복 제거된 트랜잭션, 상호 참조 테이블을 생각해보세요. 많은 소스의 데이터를 하나의 일관된 형태로 조정함으로써 실버는 셀프 서비스 분석, 임시 보고, 고급 분석, 머신 러닝을 지원하는 레이어가 됩니다.
여기서 일반적으로 발생하는 작업은 구체적입니다: 스키마 적용, null 및 누락 값 처리, 중복 제거, 순서 없는 및 늦게 도착하는 레코드 해결, 데이터 품질 검사, 스키마 진화, 타입 캐스팅, 조인. 이 단계에서 실제 데이터 모델링을 시작하며, 종종 더 정규화된 쓰기 성능이 좋은 구조를 사용합니다. 이 단계에서 데이터 품질 메트릭을 추적하는 것이 신뢰할 수 있는 실버 레이어와 브론즈의 화려한 복사본을 구분하는 것입니다.
확고한 모범 사례 하나: 수집에서 직접 실버에 쓰지 마세요. 브론즈를 건너뛰고 실버에 직접 쓰면 스키마 변경 및 손상된 소스 레코드로 인한 실패가 발생하고 재실행 능력을 잃게 됩니다. 실버는 항상 각 레코드의 검증된 비집계 표현을 최소 하나 이상 포함해야 하므로, 원시 브론즈까지 내려가지 않고도 상세한 분석이 가능합니다.
골드 레이어: 비즈니스 준비 완료
골드는 소비 준비가 된 프로젝트별 데이터를 보유합니다. 여기의 모델은 더 비정규화되어 있고 적은 조인으로 빠른 읽기에 최적화되어 있으며, 최종 변환과 비즈니스 규칙이 여기에 위치합니다. 고객 및 재고 분석, 세분화, 영업 보고 등 프레젠테이션 레이어 작업의 본거지입니다. 실제로 이 레이어에서 Kimball 스타일의 스타 스키마나 Inmon 스타일의 데이터 마트를 종종 볼 수 있습니다.
골드는 대시보드, 머신 러닝, 애플리케이션을 구동하는 고도로 정제된 뷰를 나타냅니다. 데이터는 종종 특정 기간이나 지역으로 크게 집계되고 필터링됩니다. 단일 비즈니스 도메인이 하나의 형태에 맞는 경우가 드물기 때문에, 많은 팀이 동일한 실버 기반에서 파생된 재무, 운영, HR 등의 별도 뷰와 같이 여러 골드 테이블을 구축합니다.
아래 표는 세 레이어의 차이점을 요약합니다.
| 레이어 | 데이터 상태 | 일반적인 작업 | 주요 소비자 |
|---|---|---|---|
| 브론즈 | 원시, 있는 그대로, 추가 전용 | 수집, 메타데이터 캡처, 이력 보존 | 데이터 엔지니어, 감사 및 컴플라이언스 팀 |
| 실버 | 정제, 표준화, 중복 제거 | 유효성 검사, 중복 제거, 스키마 적용, 조인 | 데이터 엔지니어, 분석가, 데이터 과학자 |
| 골드 | 집계, 비즈니스 수준 | 최종 집계, 비즈니스 규칙, 스타 스키마 | BI 개발자, 임원, 애플리케이션, ML |
데이터가 레이어를 통해 이동하는 방법
메달리온 아키텍처는 논리적 패턴이지만 특정 물리적 메커니즘에 기반합니다. 전체 그림은 이렇습니다: 많은 소스가 브론즈를 공급하고, 데이터는 레이크하우스 내에서 실버와 골드를 통해 정제되며, 많은 소비자가 골드에서 읽습니다.
flowchart LR
subgraph SRC["Sources"]
WEB["Web data via Bright Data"]
DB["Databases and apps"]
MB["Message buses: Kafka, Kinesis"]
end
subgraph LH["Lakehouse: Delta, Iceberg, or Hudi on Parquet"]
BRONZE["Bronze: raw, append-only"] --> SILVER["Silver: cleaned, conformed"] --> GOLD["Gold: business aggregates"]
end
subgraph CON["Consumers"]
BI["BI and dashboards"]
ML["ML and AI"]
APP["Applications"]
end
WEB --> BRONZE
DB --> BRONZE
MB --> BRONZE
GOLD --> BI
GOLD --> ML
GOLD --> APP참조 메달리온 스택: 많은 소스가 브론즈에 도착하고, 실버와 골드를 통해 정제되며, 많은 소비자에게 제공됩니다.
테이블 및 파일 형식. 레이어는 일반적으로 클라우드 객체 스토리지의 Parquet 파일 위에 있는 오픈 테이블 형식으로 구축됩니다. Delta Lake는 Databricks와 Microsoft Fabric의 기본 형식으로, 내부적으로 데이터를 Parquet으로 저장하지만 일반 Parquet을 넘어서는 안정성과 성능을 제공하는 트랜잭션 로그와 통계를 추가합니다. Apache Iceberg는 다중 엔진 상호 운용성이 중요할 때 동등하게 유능한 대안이며, Apache Hudi는 업서트가 많은 변경 데이터 캡처 수집에 강력하게 적합합니다. 세 가지 모두 패턴이 의존하는 ACID 보장을 제공합니다.
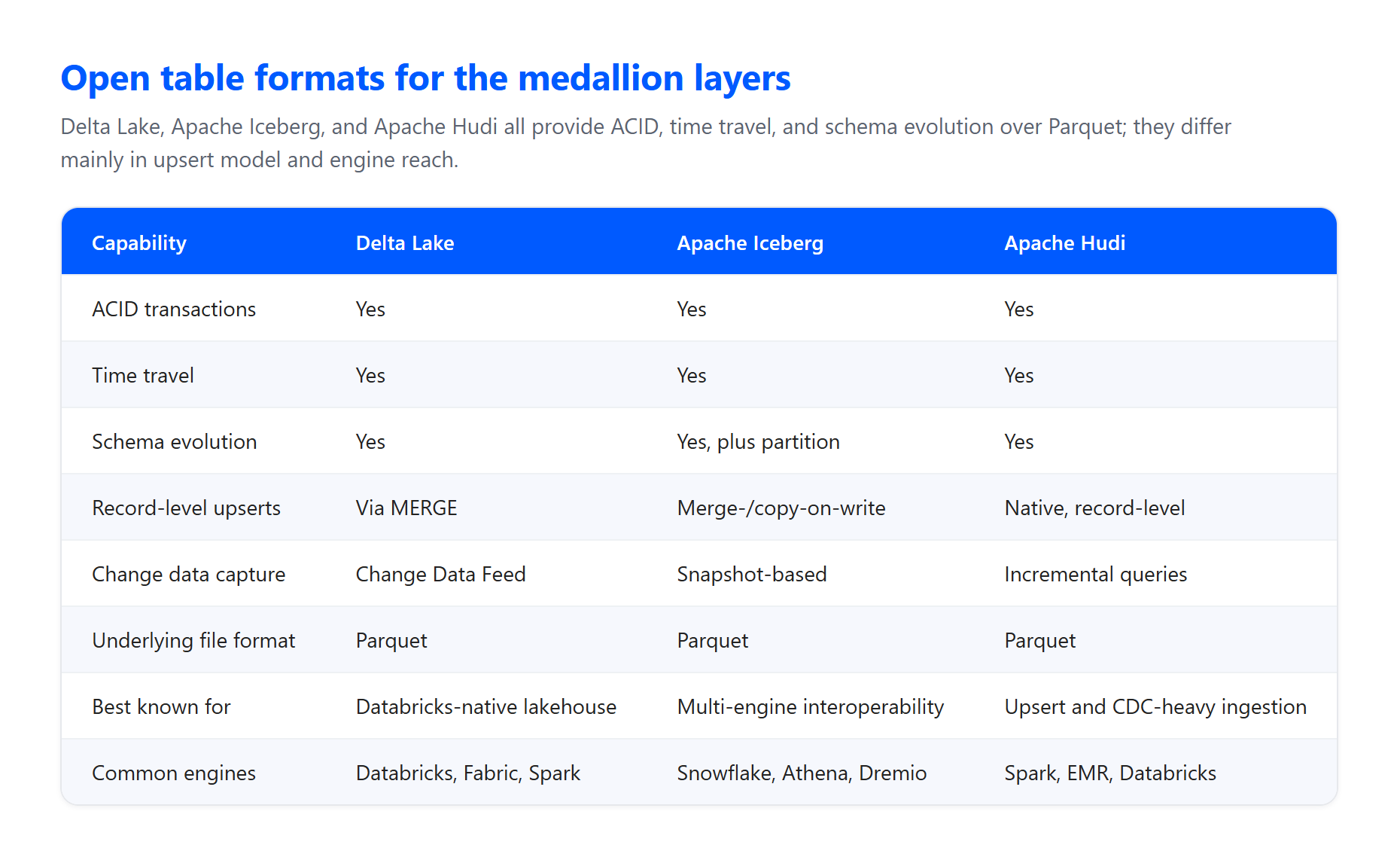
ACID 트랜잭션. 아키텍처는 데이터가 유효성 검사와 변환을 통과할 때 원자성, 일관성, 격리성, 내구성을 보장합니다. 이것이 실패한 작업이 테이블을 절반만 쓰고 손상된 상태로 남기는 것을 방지하는 것으로, 많은 파이프라인이 동시에 읽고 쓸 때 매우 중요합니다.
증분 로드 및 변경 데이터 캡처. 모든 실행에서 모든 것을 재처리하는 경우는 드뭅니다. Delta Lake의 변경 데이터 피드를 사용하면 다운스트림 레이어가 변경된 것만 소비할 수 있습니다. 예를 들어 실버 테이블에서 피드를 활성화하고 이를 사용하여 매 실행마다 전체 새로 고침 없이 골드 집계를 증분 업데이트할 수 있습니다. 브론즈에서의 증분 수집은 비용과 지연 시간의 트레이드오프입니다: 연속 스트리밍은 가장 낮은 지연 시간과 가장 높은 비용을 가지고, 트리거된 증분 로드는 비용이 적지만 지연 시간이 추가되며, 전체 배치 로드는 가장 높은 지연 시간을 가집니다.
멱등성. 브론즈 수집은 멱등적이어야 하므로 로드를 다시 실행해도 중복이 생성되거나 데이터가 손실되지 않습니다. 추가 전용 설계와 실버에서의 중복 제거가 안전한 재실행을 가능하게 합니다.
오케스트레이션, 배치, 스트리밍. Apache Spark 같은 도구는 배치와 구조화된 스트리밍 모드 모두에서 브론즈-실버 및 실버-골드 변환을 처리합니다. Spark Declarative Pipelines, Microsoft Fabric 구체화된 레이크 뷰, Snowflake 태스크 같은 선언적 프레임워크는 레이어 간 데이터 이동의 보일러플레이트를 줄입니다. Apache Airflow 같은 오케스트레이터가 실행을 조율합니다. 이 오케스트레이션 패턴의 실제 예시는 이 Airflow 및 Spark 파이프라인 안내에서 볼 수 있으며, 스트리밍 변형은 Spark Structured Streaming 가이드에서 확인할 수 있습니다.
메달리온 어휘가 보편적이지 않다는 점을 언급할 가치가 있습니다. 인기 있는 변환 프레임워크인 dbt는 프로젝트를 스테이징, 중간, 마트 레이어로 구조화합니다. 관심사는 브론즈, 실버, 골드에 밀접하게 매핑되지만 이름이 다르므로 문서를 읽을 때 두 어휘가 서로 교환 가능하다고 가정하지 마세요.
웹 데이터가 진입하는 곳: 브론즈 레이어
대부분의 아키텍처 다이어그램이 간략히 넘어가는 부분이 있습니다: 외부 데이터는 실제로 어디서 오며 어떻게 사용 가능한 상태로 브론즈에 도착하는가?
브론즈 레이어는 모든 외부 소스 시스템의 착륙 지점으로 정의되며, Databricks는 S3, GCS, ADLS 같은 클라우드 객체 스토리지를 유효한 브론즈 소스로 명시적으로 나열합니다. 이것이 외부에서 수집된 웹 데이터가 적합한 지점입니다. 경쟁사 가격, 제품 카탈로그, 공개 회사 기록, 검색 결과, 리뷰 데이터는 모두 원래 형태로 브론즈에 속하는 원시 입력으로, 실버 레이어가 해결할 수 있도록 특이점과 불일치가 보존됩니다.
바로 이 지점에서 Bright Data가 운영됩니다. Bright Data는 공개 웹 데이터를 대규모로 수집하여 원시 구조화된 파일로 전달하는 웹 데이터 플랫폼으로, 자연스러운 브론즈 레이어 소스가 됩니다. 정렬이 직접적입니다: Bright Data가 전달하는 대상은 레이크하우스 플랫폼이 브론즈 입력으로 처리하는 동일한 클라우드 객체 스토어입니다.
flowchart LR
W["Public web: sites, SERPs, marketplaces"] --> BD["Bright Data ingestion: Web Scraper API, Datasets, Data Firehose"]
BD -->|"JSON, NDJSON, CSV, Parquet"| L["Cloud storage: S3, GCS, Azure, or Snowflake"]
L --> BR["Bronze layer: raw, preserved as source of truth"]
BR --> SV["Silver: clean and conform"]
SV --> GD["Gold: serve analytics and ML"]Bright Data가 전달한 외부 웹 데이터는 클라우드 스토리지에 브론즈 레이어로 도착한 다음 실버와 골드를 통해 흐릅니다.
배치, 온디맨드, 연속 스트림 중 무엇이 필요한지에 따라 브론즈를 공급하는 여러 방법이 있습니다:
- 웹 스크레이퍼 API는 437개 이상의 사전 구축된 스크레이퍼로 모든 사이트를 구조화된 데이터 엔드포인트로 변환하여 JSON, NDJSON, CSV 형식으로 데이터를 반환합니다. 신선한 브론즈 레코드를 위한 온디맨드 트리거입니다.
- 즉시 사용 가능한 데이터셋은 수백 개의 인기 도메인에서 사전 수집된 데이터를 즉시 다운로드하거나 일정에 따라 새로 고침할 수 있게 제공합니다. 이것이 브론즈로의 배치 경로입니다.
- Data Firehose는 Amazon S3, 웹훅, 또는 스트림으로 직접 웹 레코드의 연속적인 실시간 스트림을 전달하여 스트리밍 브론즈 수집 패턴에 적합합니다.
- SERP API는 경쟁 인텔리전스 및 생성 엔진 모니터링 파이프라인을 위한 일반적인 브론즈 입력인 구조화된 검색 엔진 결과를 제공합니다.
- 스크레이핑 브라우저는 JavaScript가 많은 사이트를 처리하여 정적 수집으로는 놓칠 수 있는 렌더링된 페이지 데이터를 제공합니다.
- 목적별 피드의 경우 회사 데이터 API와 큐레이션된 AI 및 LLM 데이터셋이 파이프라인에 바로 투입할 수 있는 수직 데이터를 전달하며, 웹 아카이브 API는 시계열 브론즈 테이블을 위한 역사적 스냅샷을 제공합니다.
전달 방식이 이를 깔끔하게 만드는 것입니다. Bright Data 데이터셋은 JSON, NDJSON, CSV, XLSX, 그리고 중요하게도 레이크하우스 테이블이 기본적으로 사용하는 컬럼형 형식인 Parquet으로 내보낼 수 있습니다. 전달 대상에는 Amazon S3, Google Cloud Storage, Microsoft Azure Blob Storage, Snowflake, Google Cloud Pub/Sub, SFTP, 웹훅, 직접 API 다운로드가 포함됩니다. 실제로 이는 예약된 데이터셋이 반복적인 주기로 Parquet 형식으로 S3 브론즈 버킷에 도착할 수 있으며 글루 코드를 작성할 필요가 없음을 의미합니다. 노코드 스크레이퍼 스튜디오는 이를 더욱 확장하여 스크레이퍼를 시각적으로 구축하고 출력을 S3, GCS, Azure, BigQuery, Snowflake로 직접 로드할 수 있게 합니다.
두 가지 원칙이 이를 메달리온 패턴에 충실하게 유지합니다. 첫째, 원시 페이로드를 보존하세요. 아직 사용하지 않는 필드를 포함하여 제공자의 출력을 브론즈에 전달된 그대로 도착시켜 전체 법의학적 기록을 유지하세요. 둘째, 브론즈가 아닌 실버에서 정규화하세요. 날짜 형식, 통화, 필드 매핑, 교차 소스 중복 제거는 모두 외부 제공자가 데이터를 어떻게 구조화했는지에 관계없이 실버 단계에 속합니다. 배치와 온디맨드 경로 중 결정하고 있다면, 데이터셋 대 웹 스크레이핑 API 비교가 유용한 출발점이며, 구조화 데이터 대 비구조화 데이터 입문서도 참고할 수 있습니다.
신뢰성은 여기서 어느 곳보다 중요합니다. 조용히 실패하는 브론즈 소스는 그 위의 모든 레이어를 오염시키기 때문입니다. Bright Data는 11개 제공자의 독립 벤치마크에서 98.44%의 평균 성공률을 보고하며, 4억 개 이상의 IP를 가진 윤리적으로 소싱된 주거용 프록시 네트워크와 99.99% 가동 시간 목표로 뒷받침됩니다. 거버넌스 요구 사항이 있는 팀을 위해 Bright Data는 GDPR, CCPA, SOC 2 Type II, ISO 27001 준수를 유지하고 공개적으로 사용 가능한 데이터만 수집하는데, 이는 브론즈 레이어의 감사 추적이 캡처하려는 종류의 출처입니다.
실제 예시: 원시 스크레이프에서 골드 테이블까지
이론은 실행할 수 있을 때 더 신뢰하기 쉽습니다. 아래는 소규모의 실제 웹 제품 데이터 샘플에 대한 최소한의 메달리온 파이프라인입니다: 세 카테고리에 걸쳐 실제 Amazon US 및 UK 검색 결과에서 수집된 12개 목록입니다. 코드는 의도적으로 단순하게 유지하여 도구가 아닌 패턴이 두드러지도록 했습니다.
브론즈. 수집된 그대로 행을 도착시킵니다. 가격은 여전히 문자열이고, 통화는 혼합되어 있으며, 아무것도 정제되거나 삭제되지 않습니다.
import pandas as pd
# Bronze: raw scraped rows, landed as-is with ingestion metadata
bronze = pd.DataFrame(scraped_rows)
bronze["_ingested_at"] = "2026-06-23T00:00:00Z"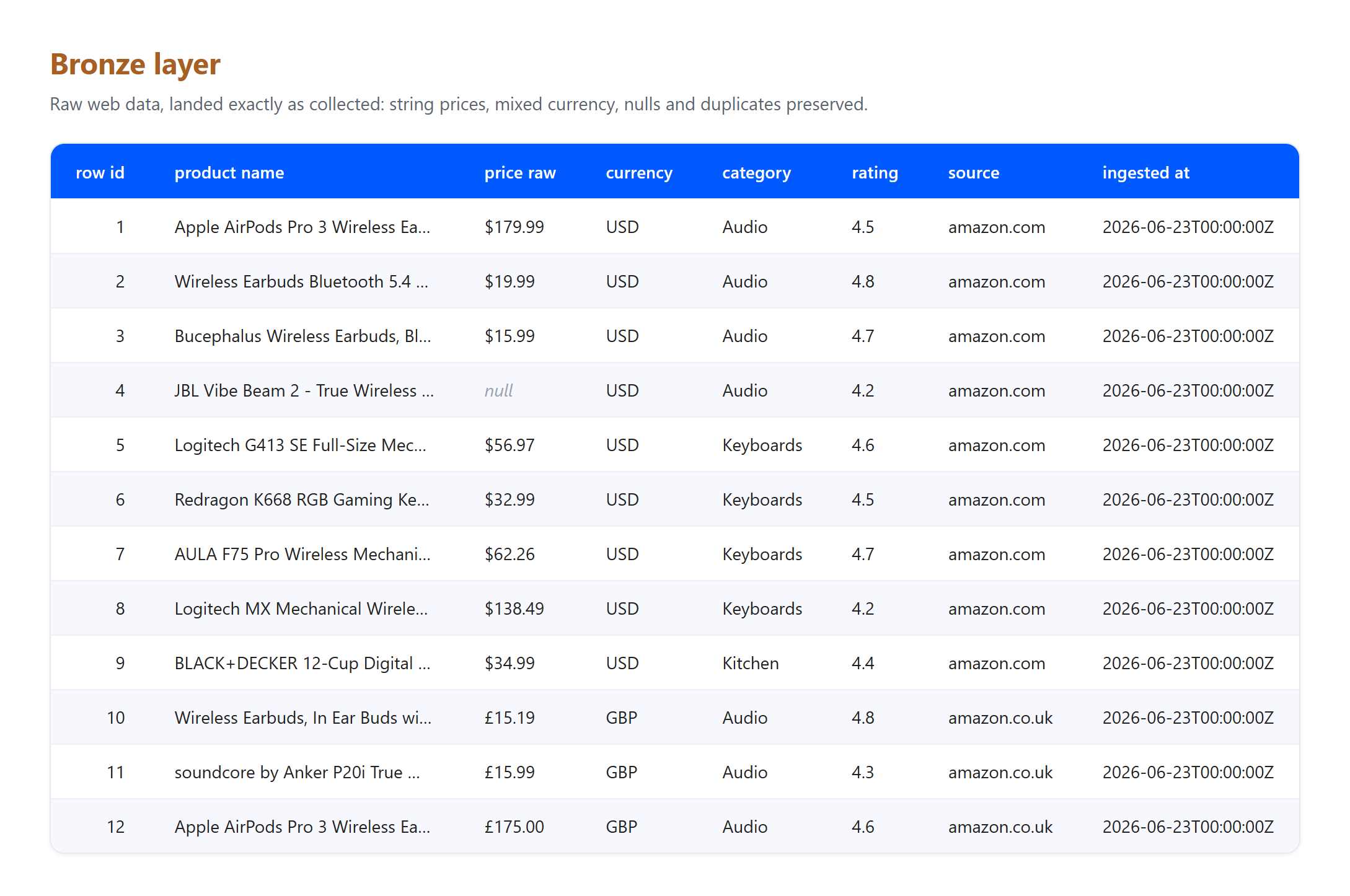
실버. 가격을 숫자로 파싱하고, 모든 것을 USD로 정규화하고, 제목의 HTML 엔티티를 디코딩하고, 사용 가능한 가격이 없는 행을 삭제하고, 두 번 이상 캡처된 동일한 제품을 중복 제거합니다.
import html, re
def to_usd(price_raw, gbp_rate=1.27): # 1.27 is an illustrative fixed rate
if not price_raw:
return None # no price, the row cannot be trusted
is_gbp = "£" in price_raw
value = float(re.sub(r"[^0-9.]", "", price_raw.replace(",", "")))
return round(value * gbp_rate, 2) if is_gbp else round(value, 2)
silver = bronze.copy()
silver["price_usd"] = silver["price_raw"].map(to_usd)
silver["rating"] = silver["rating"].astype(float) # text rating to number
silver["product_name"] = silver["product_name"].map(html.unescape) # & becomes &
silver = silver[silver["price_usd"].notna()] # drop unpriced rows
silver = silver.sort_values("price_usd").drop_duplicates("product_name") # dedup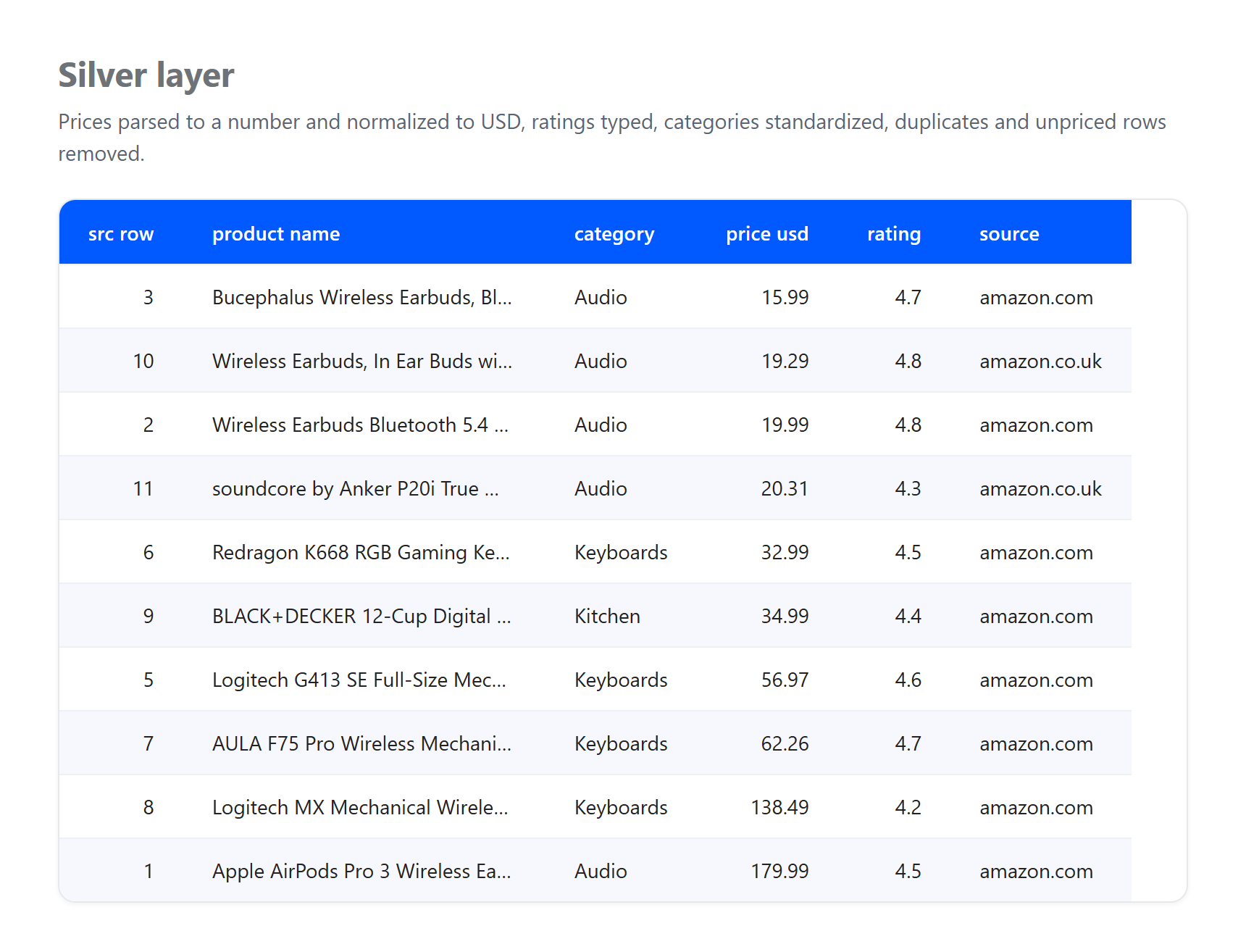
골드. 정제된 레코드를 대시보드나 모델이 실제로 쿼리하는 비즈니스 뷰로 집계합니다.
gold = (
silver.groupby("category")
.agg(
products=("product_name", "count"),
avg_price_usd=("price_usd", "mean"),
min_price_usd=("price_usd", "min"),
max_price_usd=("price_usd", "max"),
avg_rating=("rating", "mean"),
)
.round(2)
.reset_index()
)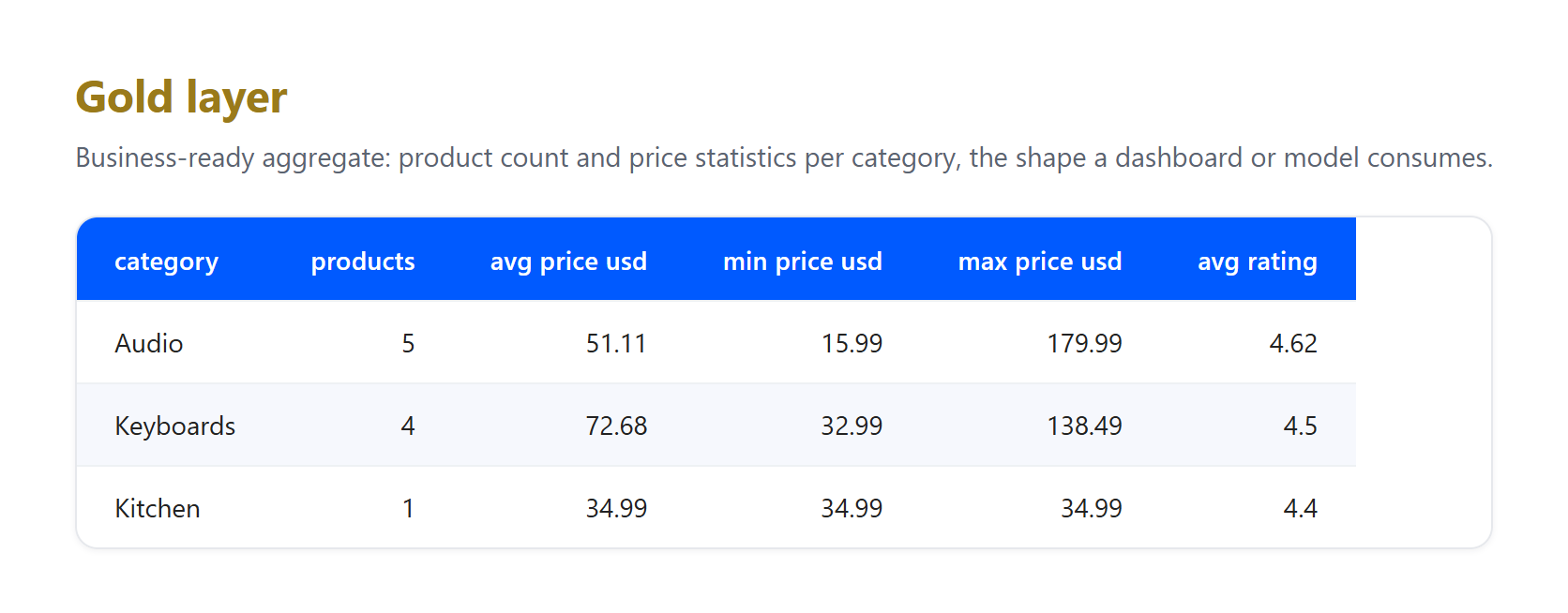
레이어가 흡수한 것에 주목하세요. 이것이 실제 파이프라인이 직면해야 하는 것이기 때문입니다. 이것은 2026년 6월 23일에 수집된 소규모 실제 샘플이며, GBP에서 USD 수치는 라이브 변환이 아닌 예시적인 고정 환율입니다. 세 가지 진짜 아티팩트가 브론즈에 도착하여 실버에서 해결되었습니다: 하나의 목록이 가격 없이 도착하여 삭제되었고, 동일한 Apple AirPods Pro 3 제품이 US와 UK 페이지 모두에서 캡처되어 단일 레코드로 중복 제거되었으며, &와 같은 원시 HTML 엔티티를 포함한 제목이 일반 텍스트로 디코딩되었습니다. 이러한 정제 작업은 브론즈에 속하지 않으며, 브론즈의 유일한 역할은 도착한 것을 보존하는 것입니다. 이 역할 분리가 패턴의 핵심입니다.
레이크하우스 도구 생태계
메달리온 패턴은 익숙한 도구 세트에서 구현됩니다. 이 도구들은 서로 교환할 수 없지만, 작동하는 아키텍처는 일반적으로 여러 도구를 결합합니다.
- Databricks는 레이크하우스 패러다임과 메달리온 아키텍처를 모두 만든 상업용 레이크하우스 플랫폼으로, 기본 Delta Lake 지원과 선언적 파이프라인 도구를 갖추고 있습니다.
- Delta Lake는 Parquet 위에 ACID 트랜잭션, 스키마 적용, 시간 여행, 변경 데이터 캡처를 추가하는 오픈 소스 테이블 형식입니다.
- Apache Spark는 배치 또는 스트리밍으로 브론즈-실버 및 실버-골드 변환을 실행하는 분산 컴퓨팅 엔진입니다.
- Apache Iceberg는 여러 엔진이 동일한 테이블을 읽어야 할 때 선호되는 오픈 테이블 형식입니다.
- Apache Hudi는 강력한 레코드 수준 업서트 및 증분 풀 지원을 갖춘 오픈 테이블 형식으로, 변경이 많은 브론즈 레이어에서 일반적으로 사용됩니다.
- Snowflake는 골드 레이어를 위한 관리형 Iceberg 테이블을 포함하여 패턴을 기본적으로 지원합니다.
- dbt는 많은 팀이 실버와 골드 레이어를 구축하는 데 사용하는 SQL 우선 변환 프레임워크입니다.
- Microsoft Fabric은 Delta Lake를 표준으로 하여 OneLake에서 메달리온 아키텍처를 기본적으로 구현합니다.
플랫폼이 Snowflake 또는 Google Cloud인 경우, Bright Data와 Snowflake Cortex 통합 가이드와 Vertex AI 및 SERP API 워크플로우에서 브론즈 핸드오프를 맥락에서 확인할 수 있습니다.
모범 사례
몇 가지 관례가 깔끔한 구현과 취약한 구현을 구분합니다.
- 수집에서 실버에 직접 쓰지 마세요. 항상 원시 데이터를 먼저 브론즈에 도착시켜 스키마 변경과 손상된 레코드가 정제된 테이블을 깨뜨리지 않도록 하세요.
- 브론즈를 느슨하게 타입화하세요. 업스트림 스키마 드리프트가 데이터를 삭제하지 않도록 대부분의 필드를 문자열, VARIANT, 또는 바이너리로 저장하세요.
- 가능한 경우 브론즈를 스트림으로 읽으세요. 추가 전용 소스의 경우 스트리밍 읽기가 지연 시간을 낮게 유지합니다. 소규모 데이터셋에는 배치 읽기를 사용하세요.
- 실버에 항상 비집계 레코드를 유지하세요. 집계는 골드에 속하므로 실버는 많은 소비자에게 재사용 가능하게 유지됩니다.
- 골드를 실시간으로 강제하지 마세요. 골드는 자주 쿼리되는 배치 새로 고침 집계에 최적화되어 있습니다. 낮은 지연 시간 워크로드에 맞게 개조하면 취약하고 비용이 많이 드는 파이프라인이 생성되는 경향이 있습니다.
- 레이어별로 테이블에 이름을 붙이세요. catalog.bronze.table, catalog.silver.table, catalog.gold.table과 같은 네임스페이스는 어떤 테이블의 신뢰 수준도 한눈에 전달합니다.
일반적인 함정과 비판
패턴은 견고하지만, 잘못 사용되는 경우가 많아 실패 모드가 잘 문서화되어 있습니다.
브론즈 건너뛰기. 외부 데이터가 이미 깨끗해 보일 때 유혹적이지만, 브론즈를 건너뛰면 감사 추적과 재처리 능력이 제거됩니다. 뒤에 원시 레코드가 없으면 실버 레이어의 의미론이 조용히 변합니다.
실버를 골드처럼 취급하기. 팀이 실버에서 직접 비즈니스 KPI와 무거운 집계를 구축하면 서로 다른 팀이 메트릭을 다르게 정의하고 단일 권위 있는 버전이 없게 됩니다. 집계는 골드에 유지하세요.
원시 브론즈를 프로덕션 데이터처럼 읽기. 브론즈는 검증되지 않았고 종종 지저분합니다. 대시보드를 브론즈에 연결하면 중복 카운트와 일관성 없는 결과가 발생합니다. 브론즈는 역사적 기록이지 분석을 위한 진실의 원천이 아닙니다.
레이어 간 얽힘. 파이프라인이 레이어 간에 책임을 누출할 때, 예를 들어 원시 이벤트를 골드로 직접 수집할 때, 단일 스키마 변경이 전체 스택에 걸쳐 연쇄적으로 발생할 수 있습니다.
패턴을 엄격하게 적용하는 것에 대한 정당한 비판도 있습니다. 한 분석에서 지적했듯이, 모든 소스에 엄격한 3레이어 구조를 적용하면 특정 데이터셋이 광범위한 정제가 필요하지 않을 때 비효율성이 발생하며, 순차적 레이어링은 실시간 사용 사례가 허용하지 않을 수 있는 지연 시간을 추가합니다. 실무자 커뮤니티는 일부 설계에서 사전 브론즈 착륙 지점이나 골드 위의 플래티넘 레이어와 같은 추가 레이어를 제안하여 이에 대응했습니다.
이 모든 것을 건강하게 읽는 방법은 메달리온 아키텍처가 명령이 아닌 유연한 프레임워크라는 것입니다. Databricks 자체는 메달리온 아키텍처를 따르는 것이 권장 모범 사례이지 요구 사항이 아니라고 명시하며, Delta Lake 프로젝트는 이를 선택적이고 유연한 프레임워크로 설명합니다. 쿼리 패턴과 소비자에 맞는 레이어 수와 이름을 사용하세요.
일반적인 사용 사례
패턴은 원시 입력이 지저분하고 많은 소비자가 신뢰할 수 있는 출력을 필요로 하는 곳에서 가장 명확하게 효과를 발휘합니다.
- 경쟁 가격 및 이커머스 인텔리전스. 많은 소매업체에서 수집된 제품 및 가격 데이터가 있는 그대로 브론즈에 도착하고, 실버에서 정규화 및 중복 제거되며, 골드 가격 추적 및 품목 대시보드를 공급합니다.
- AI 및 머신 러닝 훈련 데이터. 웹 규모의 텍스트와 구조화된 데이터가 브론즈에 원시로 도착하고, 실버에서 정제 및 중복 제거되며, 골드에서 모델 준비 피처로 가공됩니다. 실용적인 단계는 머신 러닝을 위한 웹 스크레이핑 가이드에서, 더 넓은 전략은 AI 데이터 플라이휠 글에서 다룹니다.
- 시장 및 대안 데이터 연구. 많은 소스의 외부 신호가 실버에서 단일 연구 뷰로 표준화된 다음 골드 지표로 집계됩니다.
- 검색 및 SERP 모니터링. 연속적인 검색 결과 스트림이 브론즈로 흐르고, 실버에서 구조화되며, 골드 가시성 및 점유율 메트릭으로 롤업됩니다.
- 기업 정보 및 고객 강화. 회사 데이터 피드가 실버 레이어에서 내부 레코드를 강화하여 영업 및 마케팅을 위한 골드 테이블을 생성합니다.
이러한 파이프라인의 엔지니어링 배관에 대해서는 AWS Glue ETL, AWS Step Functions, Kubeflow 파이프라인, Mage AI 파이프라인, Tableau에 라이브 웹 데이터 연결 안내서 각각이 실제 브론즈-서빙 경로를 보여줍니다. 추출 단계 자체의 기본 사항은 데이터 추출 입문서에서 다룹니다.
결론
메달리온 아키텍처는 팀에게 원시 데이터를 신뢰할 수 있는 데이터로 변환하기 위한 공유 언어를 제공하기 때문에 지속됩니다. 한 번에 하나의 규율 있는 단계씩입니다. 브론즈는 진실을 보존하고, 실버는 일관성을 만들며, 골드는 유용하게 만듭니다. 패턴은 이를 공급하는 원시 데이터만큼만 잘 작동하므로, 신뢰할 수 있고 잘 구조화된 브론즈 소스는 세부 사항이 아닌 기반입니다.
외부 및 웹 데이터의 경우, 그 기반이 Bright Data가 적합한 곳입니다: 레이크하우스가 이미 브론즈로 처리하는 클라우드 스토리지로 직접 JSON, CSV, Parquet으로 전달되는 프로덕션급 수집입니다. 신뢰할 수 있는 웹 데이터로 브론즈 레이어를 공급할 준비가 되셨나요? 무료 체험을 시작하고 원시 웹 데이터가 파이프라인으로 얼마나 빠르게 흐를 수 있는지 확인해보세요.
자주 묻는 질문
Q: 메달리온 아키텍처란 간단히 말하면 무엇인가요?
레이크하우스에서 세 개의 레이어를 통해 이동하면서 데이터가 더 깨끗하고 유용해지도록 조직하는 방법입니다. 원시 데이터는 브론즈 레이어에 도착하고, 실버 레이어에서 정제 및 표준화되며, 골드 레이어에서 비즈니스 준비 테이블로 집계됩니다. 각 레이어는 명확한 역할이 있어 데이터 품질을 관리하고 감사하기 더 쉽게 만듭니다.
Q: 브론즈, 실버, 골드 레이어의 차이점은 무엇인가요?
브론즈는 도착한 그대로의 원시 데이터를 추가 전용으로 변환 없이 영구적인 진실의 원천으로 보유합니다. 실버는 중복 제거, 스키마 적용, 조인이 적용된 정제 및 표준화된 데이터를 보유하여 데이터가 신뢰할 수 있고 일관성이 있습니다. 골드는 특정 보고, 대시보드, 머신 러닝, 애플리케이션을 위해 모델링된 집계된 비즈니스 수준 데이터를 보유합니다.
Q: 메달리온 아키텍처는 ETL과 같은 건가요?
아니요, 하지만 관련이 있습니다. ETL은 데이터를 추출, 변환, 로드하는 것을 설명합니다. 메달리온 아키텍처는 이러한 변환이 어디서 발생하는지를 조직하는 레이어링 패턴입니다. 레이크하우스에서는 일반적으로 ELT 스타일을 따르며, 원시 데이터가 먼저 브론즈에 로드된 다음 플랫폼 내부에서 실버와 골드로 단계적으로 변환됩니다.
Q: 세 레이어가 항상 필요한가요?
아니요. Databricks는 메달리온 아키텍처를 권장 모범 사례로 설명하지 요구 사항이 아닙니다. 깨끗하게 도착하는 일부 데이터셋은 광범위한 실버 단계가 필요하지 않을 수 있으며, 일부 실시간 사용 사례는 의도적으로 흐름의 일부를 우회합니다. 레이어 수와 이름은 쿼리 패턴과 소비자에 맞아야 합니다. 주요 주의 사항은 브론즈를 건너뛰면 원시 감사 추적과 재처리 능력이 제거된다는 것입니다.
Q: 메달리온 테이블에 어떤 파일 형식을 사용해야 하나요?
대부분의 구현은 Delta Lake, Apache Iceberg, Apache Hudi와 같은 오픈 테이블 형식을 사용하며, 모두 클라우드 객체 스토리지의 Parquet 파일 위에 있습니다. 이러한 형식은 패턴이 의존하는 ACID 트랜잭션, 스키마 적용, 시간 여행을 추가합니다. Delta Lake는 Databricks와 Microsoft Fabric의 기본 형식이며, Iceberg는 여러 엔진이 동일한 테이블을 읽을 때 일반적입니다.
Q: 외부 또는 웹 데이터는 메달리온 아키텍처에 어떻게 맞나요?
외부 및 웹 데이터는 브론즈 레이어 입력입니다. 예를 들어 제품, 가격, 검색, 회사 데이터 등 원시 수집 데이터를 브론즈에 원래 형태로 도착시킨 다음 실버에서 정규화 및 중복 제거합니다. 레이크하우스 플랫폼이 S3, GCS, Azure 같은 클라우드 객체 스토리지를 유효한 브론즈 소스로 처리하기 때문에, Bright Data 같은 제공자가 웹 데이터를 JSON, CSV, Parquet으로 해당 스토어에 직접 전달할 수 있으며, 이것이 브론즈 레이어가 됩니다.
Q: 메달리온 아키텍처는 Databricks에 종속되어 있나요?
Databricks는 레이크하우스 패러다임과 Delta Lake와 함께 이 용어를 대중화했지만, 패턴은 Databricks에만 국한되지 않습니다. 동일한 브론즈, 실버, 골드 언어가 Microsoft Fabric과 Snowflake 문서에서도 사용되며, 기본 오픈 테이블 형식은 많은 엔진에서 실행됩니다. 패턴은 단일 벤더의 제품이 아닌 일반적인 관례입니다.





