

Tableau는 데이터 시각화를 위한 선도적인 도구이지만, 한 가지 큰 한계가 있습니다. 자체적으로 웹사이트에서 실시간 데이터를 안정적으로 가져올 수 없다는 점입니다. 이전에 이 문제를 해결해 주었던 구형 웹 데이터 커넥터(WDC v2)는 2023년에 지원이 중단되었습니다. 마지막으로 호환되던 버전(Tableau 2022.4)도 이후 지원 종료되어, 분석가들은 더 이상 지원되는 솔루션을 사용할 수 없게 되었습니다.
이 가이드에서는 웹 스크래핑 및 실시간 데이터를 Tableau에 연결하는 6가지 방법을 비교합니다. 또한 Bright Data의 Web Scraper API를 사용하여 API-to-Tableau 파이프라인을 구축하는 단계별 튜토리얼도 포함되어 있습니다.
요약
Tableau는 기본적으로 웹사이트를 스크래핑할 수 없으며, 웹 데이터 커넥터(WDC v2)는 2023년에 지원이 중단되었습니다. 따라서 외부 데이터 파이프라인이 필요합니다.
- WDC v2는 더 이상 지원되지 않으며, WDC v3는 추출 전용이고 구축이 복잡합니다
- Google 스프레드시트, Excel, TabPy는 모두 대규모 환경에서 심각한 한계가 있습니다
- 직접 작성한 Python 스크립트는 초기에는 작동하지만 지속적인 유지 관리가 필요합니다
- 관리형 스크래핑 API는 프록시, CAPTCHA 및 데이터 파싱을 자동으로 처리합니다
이 가이드의 단계별 튜토리얼을 따라 Amazon → Bright Data → Tableau 파이프라인을 구축해 보세요.
Tableau에 외부 데이터 파이프라인이 필요한 이유
현대적인 데이터 스택에는 경쟁사 가격, 소셜 미디어 지표, 채용 공고, 부동산 매물 정보, 금융 피드 등 실시간 웹 데이터가 필요합니다. Tableau는 이러한 데이터를 수집하도록 설계되지 않았습니다.
주요 과제는 다음과 같습니다:
- 웹사이트는 끊임없이 변화합니다. 레이아웃이 바뀌고, 봇 방지 조치가 진화하며, 자바스크립트 렌더링 요구 사항이 증가합니다
- 확장성이 핵심입니다 – 매일 10,000개의 경쟁사 SKU를 모니터링하려면 단일 페이지 스크립트에서는 필요하지 않은 재시도 로직, 속도 제한 및 오류 처리가 필요합니다
- 규정준수는 필수입니다 – GDPR, CCPA 및 플랫폼 약관은 신중한 데이터 수집 관행을 요구합니다
- 인프라 비용이 높습니다 – 프록시 로테이션, CAPTCHA 해결, 재시도 로직, IP 관리는 지속적인 엔지니어링 과제입니다
다음 방법들은 이러한 격차를 해소합니다.
웹 스크래핑 및 실시간 데이터를 Tableau에 연결하는 6가지 방법
각 방법은 확장성, 유지 관리, 안정성 간의 균형을 서로 다르게 맞춥니다. 실행 가능성이 가장 낮은 방법부터 실제 운영에 가장 적합한 방법 순으로 나열했습니다.
방법 1: Tableau 웹 데이터 커넥터 v2(사용 중단됨)
이전 기능: WDC v2를 사용하면 웹 API에서 데이터를 직접 Tableau로 가져오는 JavaScript 기반 커넥터를 구축할 수 있었습니다.
더 이상 작동하지 않는 이유: Tableau 2023.1에서 사용 중단되었습니다. WDC v2 커넥터는 현재 모든 Tableau 버전에서 지원되지 않으며, 향후 릴리스에서 완전히 제거될 수 있습니다. WDC v3로 마이그레이션해야 하지만, v3는 근본적으로 다른 아키텍처를 채택하고 있습니다.
중대한 제한 사항: 지원이 종료되었습니다. 아직 WDC v2 커넥터를 사용 중이라면, 향후 Tableau 업데이트 시 작동이 중단될 수 있으므로 지금 바로 마이그레이션하십시오.
방법 2: 중간 계층으로 Google 스프레드시트 사용
작동 방식: 데이터를 Google 스프레드시트로 가져온 후(Apps Script, IMPORTXML, IMPORTDATA 또는 타사 도구를 통해), Tableau를 실시간 데이터 소스로 Google 스프레드시트에 연결합니다.
사용 이유: 무료이며 코딩이 필요 없고, Tableau는 Google 드라이브 커넥터를 통해 Google 스프레드시트에 연결할 수 있습니다.
주요 제한 사항:
- Google 스프레드시트는 1,000만 셀 제한이 있어 대규모 데이터 세트는 금방 이 한도에 도달합니다
- 웹사이트 구조 변경으로 인해
IMPORTXML및IMPORTDATA함수가 끊임없이 오류가 발생합니다 - 갱신 시점이 불확실합니다. Google은 예측할 수 없는 방식으로 수식 실행을 제한합니다
- JavaScript 렌더링이 지원되지 않아 최신 단일 페이지 애플리케이션(SPA)의 경우 빈 데이터가 반환됩니다(이 경우 스크래핑 브라우저가 필요합니다)
- Google 스프레드시트 API의 요청 제한으로 인해 예약된 새로고침 시 동기화 오류가 발생합니다
결론: 소규모 프로토타입에는 적합합니다. 규모가 커지면 작동하지 않습니다. 변경 빈도가 낮은 10,000행 미만의 데이터를 추적하는 개인용 대시보드에는 좋은 선택입니다.
방법 3: Excel + OneDrive / SharePoint
작동 방식: Excel의 Power Query 또는 “웹에서 데이터 가져오기” 기능을 사용하여 URL에서 데이터를 가져와 OneDrive에 저장합니다. 그런 다음 Tableau를 클라우드 호스팅된 Excel 파일에 연결합니다.
주요 제한 사항:
- 수동 새로고침 필요 – Power Query는 백그라운드에서 안정적으로 자동 새로고침을 수행하지 못함
- JavaScript 렌더링이 지원되지 않아 React, Angular 또는 SPA 기반 사이트를 처리할 수 없음
- 구문 분석 기능이 제한적입니다. 복잡한 HTML 구조로 인해 가져오기가 실패하는 경우가 많습니다
- OneDrive 동기화 충돌로 인해 데이터 무결성 문제가 발생합니다
- 프록시 로테이션 기능이 없어, 대규모 스크래핑 시 IP 차단 위험이 있음
결론: 정적 웹페이지에서 단일 보고서를 가져오는 용도로는 적합합니다. 데이터 파이프라인으로는 적합하지 않습니다.
방법 4: TabPy (Python + Tableau 확장 기능)
작동 원리: TabPy는 Tableau의 공식 Python 서버입니다. SCRIPT_REAL 및 SCRIPT_STR과 같은 함수를 사용하여 Tableau 계산 필드 내에서 Python 스크립트를 실행합니다. 이론적으로 웹 스크래핑 로직은 TabPy를 통해 Tableau 내부에서 직접 실행됩니다.
사용 이유: Python에는 방대한 스크래핑 라이브러리가 있으며, TabPy는 Tableau에서 공식적으로 지원됩니다.
주요 제한 사항:
- TabPy 서버가 실행 중이어야 함 – 유지 관리해야 할 추가 인프라필요
- Tableau 계산 필드 내에서의 스크래핑은 권장되지 않는 방식입니다. 속도가 느리고, 신뢰성이 낮으며, 대시보드 렌더링을 차단합니다
- 프록시 로테이션 기능이 없어, 트래픽이 많은 대상 사이트에서는 TabPy 서버의 IP가 즉시 차단됩니다
- CAPTCHA 해결, 재시도 로직, JavaScript 렌더링 기능이 없음
- 계산 필드에는 실행 시간 제한이 있어, 복잡한 스크래핑 작업은 시간 초과됩니다
- 오류가 불분명한 Tableau 오류 메시지로 표시되어 디버깅이 매우 어렵습니다
결론: TabPy는 Tableau 내에서 머신러닝 모델 실행 및 통계 계산에는 훌륭합니다. 웹 스크래핑에는 적합하지 않습니다.
방법 5: 직접 작성한 Python 스크립트(requests, Scrapy, Selenium)
작동 방식: requests, BeautifulSoup, Scrapy 또는 Selenium과 같은 라이브러리를 사용하여 사용자 지정 Python 스크립트를 작성합니다. 이를 일정(예: cron 또는 Airflow)에 따라 실행하고, CSV/JSON 파일을 출력한 다음 Tableau를 해당 파일에 연결합니다.
사용 이유: 유연성이 극대화됩니다. 모든 과정을 직접 제어할 수 있습니다.
주요 한계:
- 높은 유지 관리 부담 – 웹사이트는 레이아웃을 변경하고, 봇 방지 조치를 추가하며, HTML 구조를 변경합니다. 스크래퍼가 예고 없이 실패하면 대시보드에 오래된 데이터가 표시됩니다.
- 대규모 IP 차단 – 프록시 네트워크가 없으면 대상 사이트에서 몇 시간 내에 서버를 차단합니다
- CAPTCHA 해결 불가 – Cloudflare, reCAPTCHA, hCaptcha는 내장된 해결책 없이 스크레이퍼를 차단합니다( Web Unlocker와 같은 서비스는 이를 자동으로 처리합니다)
- 인프라 비용 – 서버, 프록시 구독, 모니터링 및 알림 시스템이 필요합니다
- 규정 준수 위험 – 적절한 인프라가 없으면 GDPR, CCPA 또는 플랫폼 이용 약관을 위반할 수 있습니다
- 확장성 부족 – 100개의 URL을 스크래핑하는 것과 10만 개를 스크래핑하는 것은 다릅니다. 한 가지 경우에 효과적인 아키텍처가 다른 경우에는 완전히 실패할 수 있습니다.
결론: DIY 방식은 초기에는 실행 가능하지만 장기적으로는 신뢰할 수 없습니다. 대부분의 팀이 여기서 시작하며, 처음에는 성공하는 경우도 많습니다. 하지만 시간이 지날수록 유지 관리에 드는 노력이 늘어납니다.
첫 달에는 잘 작동하지만, 몇 달이 지나면 대시보드를 구축하는 것보다 고장 난 셀렉터와 IP 차단 문제를 해결하는 데 더 많은 시간을 소비하게 됩니다. 소량의 데이터로 한두 개의 사이트만 스크래핑한다면, 직접 만든 스크립트만으로도 충분할 수 있습니다.
방법 6: Bright Data 웹 스크레이퍼 API (권장)
작동 방식: Bright Data의 웹 스크레이퍼 API는 프록시 로테이션, CAPTCHA 해결, 자바스크립트 렌더링, 봇 차단 우회, 구조화된 데이터 출력 등 데이터 수집 레이어 전체를 처리합니다. API를 통해 수집 작업을 실행하면 정제된 JSON/CSV 데이터를 받아 Tableau에 로드할 수 있습니다.
장점:
| 기능 | Bright Data | 직접 작성 스크립트 |
|---|---|---|
| 프록시 네트워크 | 195개국에 걸쳐 1억 5천만 개 이상의 IP | 직접 구매하기 (비쌈) |
| 기성 스크래퍼 | 주요 플랫폼용 120개 이상 | 처음부터 직접 구축 |
| CAPTCHA 해결 | 자동 | 포함되지 않음 |
| JavaScript 렌더링 | 내장 | Selenium/Playwright 필요 |
| 봇 우회 방지 | 자동 | 지속적인 수동 업데이트 필요 |
| 가동 시간 | 99.99% | 사용 중인 인프라에 따라 다름 |
| 규정 준수 | GDPR, CCPA, ISO 27001 | 고객의 책임 |
| 유지 관리 | 최소 – Bright Data에서 스크레이퍼 업데이트를 처리합니다 | 지속적 |
| 확장성 | 하루 수백만 페이지 | 사용자 서버 용량에 따라 제한됨 |
| 가격 | 1,000건당 $1.50부터 | 변동 (서버 + 프록시 + 유지보수) |
결론: 귀하는 Tableau 대시보드에 집중하고, Bright Data가 데이터 수집 인프라를 처리합니다.
단점: Bright Data는 유료 제3자 서비스입니다. 귀하는 해당 서비스의 인프라와 가격 정책에 의존하게 됩니다. 소량의 데이터를 한두 개의 사이트에서 가끔씩 수집하는 경우, 직접 작성한 스크립트(방법 5)를 사용하는 것이 비용이 더 저렴하고 완전한 제어권을 가질 수 있습니다.
어떤 Tableau 데이터 연결 방식을 선택해야 할까요?
이 표는 프로덕션 파이프라인에 가장 중요한 기능들을 기준으로 6가지 방법을 모두 비교합니다.
| 방법 | JS 렌더링 | 프록시 로테이션 | CAPTCHA 해결 | 자동 새로고침 | 확대/축소 | 유지보수 | 상태 |
|---|---|---|---|---|---|---|---|
| WDC v2 | 아니요 | 아니요 | 아니요 | 예 | 낮음 | 해당 없음 | 사용 중단됨 |
| Google 스프레드시트 | 아니요 | 아니요 | 아니요 | 신뢰할 수 없음 | 매우 낮음 | 낮음 | 셀 제한 |
| Excel + OneDrive | 없음 | 아니요 | 아니요 | 수동 | 매우 낮음 | 중간 | 수동 프로세스 |
| TabPy | 수동/DIY | 아니요 | 아니요 | 예 | 낮음 | 높음 | IP 차단 |
| 직접 만들기: 파이썬 | Selenium을 통해 | 직접 만들기 | 아니요 | cron을 통해 | 중간 | 매우 높음 | 대규모 환경에서 중단됨 |
| Bright Data API | 예 | 예 (1억 5천만 개 이상의 IP) | 예 | 예 | 높음 | 최소 | 실전 사용 가능 |
튜토리얼: 웹 스크래핑 API를 Tableau에 연결하기
이 튜토리얼에서는 Amazon Scraper API를 사용하여 실제 파이프라인을 구축합니다: Amazon 제품 가격 → Bright Data API → CSV → Tableau 대시보드. 이 튜토리얼은 팀이 웹 데이터를 Tableau에 연결하는 가장 일반적인 이유인 “경쟁사 가격 모니터링” 사용 사례를 다룹니다.
아키텍처
파이프라인은 다음과 같은 흐름을 따릅니다:
┌─────────────────┐ ┌──────────────────────┐ ┌─────────────┐ ┌─────────────┐
│ 사용자 스크립트 │────▶│ Bright Data 스크래퍼 │────▶ │ CSV/JSON │────▶│ Tableau │
│ (Python/cron) │ │ API │ │ 출력 │ │ 대시보드 │
└─────────────────┘ └──────────────────────┘ └─────────────┘ └─────────────┘
│ │ │
키워드/URL로 트리거 프록시 처리, 가격 시각화,
CAPTCHA, 렌더링 평점, 트렌드필수 사항
시작하기 전에 다음이 설치되어 있거나 사용 가능해야 합니다:
- Python 3.8 이상
- Bright Data 계정 (무료 체험 가능, 신용카드 불필요)
- Bright Data 대시보드에서 발급받은 API 토큰 (단계 0의 지침 참조)
- Tableau Desktop (14일 무료 체험), Tableau Cloud 또는 Tableau Public (무료, 대시보드는 공개됨)
이러한 도구가 준비되면, 먼저 Bright Data API 토큰을 생성하세요.
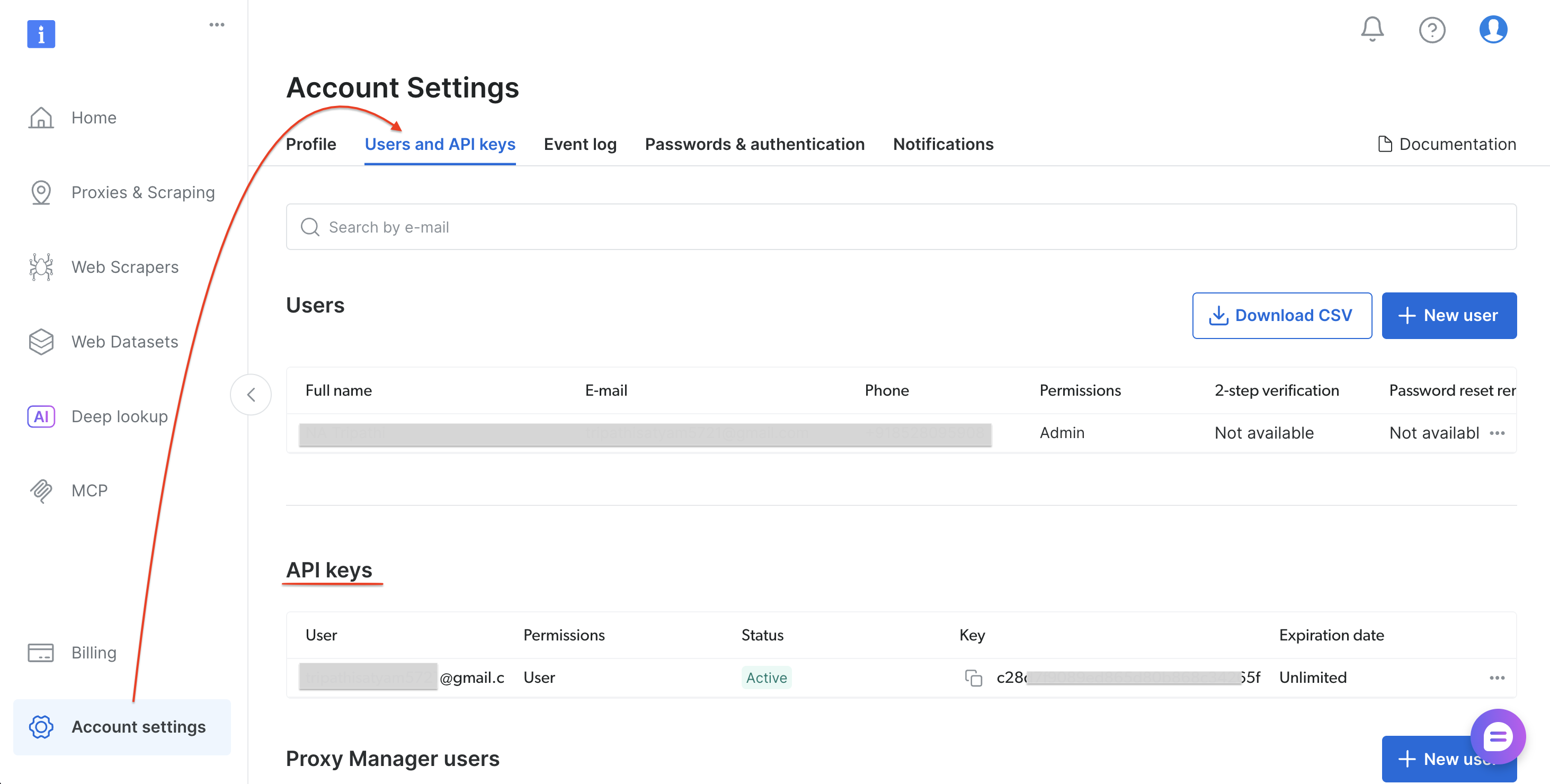
0단계: Bright Data API 토큰 받기
다음 단계를 따라 API 토큰을 생성하세요:
- brightdata.com/cp에서 가입하거나 로그인하세요
- 계정 설정 → 사용자 및 API 키로 이동
- “API 키 추가”를 선택하세요(API 키 섹션의 오른쪽 상단)
- 권한 및 만료 기간을 설정한 후 ‘저장’을 선택하세요
- 토큰을 복사하세요
API 토큰을 저장한 후, Python 종속성을 설치하세요.
1단계: 종속성 설치
필요한 Python 패키지를 설치합니다:
pip install requests pandasrequests와 pandas가 설치되었으면 파이프라인 스크립트를 생성합니다.
2단계: 파이프라인 스크립트
bright_data_to_tableau.py라는 파일을 생성합니다:
"""
Bright Data → Tableau 파이프라인
Bright Data의 Web Scraper API를 통해 Amazon 제품 데이터를 수집하고
Tableau에서 바로 사용할 수 있는 CSV 파일을 출력합니다.
사용법:
1. YOUR_API_TOKEN을 본인의 Bright Data API 토큰으로 교체하세요
2. 실행: python bright_data_to_tableau.py
3. Tableau Desktop에서 출력된 CSV 파일을 엽니다
"""
import requests
import time
import json
import sys
import pandas as pd
from datetime import datetime
# ─── 구성 ───────────────────────────────────────────────────────────
API_TOKEN = "YOUR_API_TOKEN" # Bright Data API 토큰으로 대체
DATASET_ID = "gd_lwdb4vjm1ehb499uxs" # Amazon 제품 검색 (키워드 기준)
OUTPUT_CSV = "amazon_products_tableau.csv"
POLL_INTERVAL = 10 # 상태 확인 간격 (초)
POLL_TIMEOUT = 300 # 최대 대기 시간 (초)
# ─── API 엔드포인트 ───────────────────────────────────────────────────────────
TRIGGER_URL = (
f"https://api.brightdata.com/datasets/v3/trigger"
f"?dataset_id={DATASET_ID}&include_errors=true"
)
SNAPSHOT_URL = "https://api.brightdata.com/datasets/v3/snapshot"
HEADERS = {
"Authorization": f"Bearer {API_TOKEN}",
"Content-Type": "application/json",
}
def trigger_collection(keyword: str) -> str:
"""Bright Data에서 데이터 수집 작업을 트리거합니다."""
payload = [{
"keyword": keyword,
"url": "https://www.amazon.com",
"pages_to_search": 1
}]
print(f"[1/3] 키워드 '{keyword}'에 대한 수집을 트리거 중...")
response = requests.post(TRIGGER_URL, headers=HEADERS, data=json.dumps(payload))
if response.status_code != 200:
print(f" ERROR {response.status_code}: {response.text}")
sys.exit(1)
result = response.json()
snapshot_id = result.get("snapshot_id")
print(f" 스냅샷 ID: {snapshot_id}")
return snapshot_id
def poll_snapshot(snapshot_id: str) -> list:
"""데이터가 준비될 때까지 스냅샷 엔드포인트를 폴링합니다."""
url = f"{SNAPSHOT_URL}/{snapshot_id}?format=json"
elapsed = 0
print(f"[2/3] 결과 대기 중...")
while elapsed < POLL_TIMEOUT:
response = requests.get(url, headers=HEADERS)
if response.status_code == 200:
data = response.json()
print(f" 준비 완료! {len(data)}개의 레코드를 수신했습니다.")
return data
elif response.status_code == 202:
print(f" 처리 중... ({elapsed}초 / {POLL_TIMEOUT}초)")
time.sleep(POLL_INTERVAL)
elapsed += POLL_INTERVAL
else:
print(f" 오류 {response.status_code}: {response.text}")
sys.exit(1)
print(f" 시간 초과: {POLL_TIMEOUT}초가 지나도 스냅샷이 준비되지 않았습니다.")
print(f" POLL_TIMEOUT 값을 늘려보거나 Bright Data 대시보드를 확인해 주세요.")
sys.exit(1)
def to_tableau_csv(data: list, output_path: str) -> pd.DataFrame:
"""원시 API 데이터를 정리된 Tableau 최적화 CSV로 변환합니다."""
df = pd.DataFrame(data)
# API 필드 이름 → Tableau 호환 이름 매핑
column_mapping = {
"title": "제품명",
"seller_name": "판매자",
"brand": "브랜드",
"initial_price": "원가",
"final_price": "현재 가격",
"currency": "통화",
"rating": "평점",
"reviews_count": "리뷰 수",
"availability": "재고 상태",
"url": "상품 URL",
"asin": "ASIN",
"categories": "카테고리",
"delivery": "배송 정보",
}
# 데이터에 존재하는 열만 유지
available = {k: v for k, v in column_mapping.items() if k in df.columns}
df = df.rename(columns=available)
df = df[list(available.values())]
# Tableau 필터링 및 추적을 위한 메타데이터 추가
df["Scrape Date"] = datetime.now().strftime("%Y-%m-%d")
df["Scrape Timestamp"] = datetime.now().isoformat()
df["Data Source"] = "Bright Data API"
df.to_csv(output_path, index=False)
print(f"[3/3] {len(df)} 행 저장됨 → {output_path}")
return df
def print_summary(df: pd.DataFrame):
"""스크랩된 데이터의 요약을 출력합니다."""
print(f"n{'─'*50}")
print(f" 요약")
print(f"{'─'*50}")
print(f" 총 상품 수 : {len(df)}")
if "Current Price" in df.columns:
prices = pd.to_numeric(df["Current Price"], errors="coerce")
print(f" 가격 범위 : ${prices.min():.2f} – ${prices.max():.2f}")
print(f" 평균 가격 : ${prices.mean():.2f}")
if "Brand" in df.columns:
print(f" 고유 브랜드 수 : {df['Brand'].nunique()}")
if "Rating" in df.columns:
ratings = pd.to_numeric(df["Rating"], errors="coerce")
print(f" 평균 평점 : {ratings.mean():.1f} / 5.0")
print(f"{'─'*50}n")
def run_pipeline(keyword: str):
"""전체 파이프라인 실행: 트리거 → 폴링 → CSV → 요약."""
print(f"n{'='*50}")
print(f" Bright Data → Tableau 파이프라인")
print(f" 키워드: '{keyword}'")
print(f"{'='*50}n")
snapshot_id = trigger_collection(keyword)
data = poll_snapshot(snapshot_id)
df = to_tableau_csv(data, OUTPUT_CSV)
print_summary(df)
return df
if __name__ == "__main__":
# 기본 키워드 — 이 값을 변경하거나 CLI 인수로 전달하세요
keyword = sys.argv[1] if len(sys.argv) > 1 else "wireless headphones"
run_pipeline(keyword)3단계: 스크립트 실행
파이프라인 스크립트 실행:
python bright_data_to_tableau.py예상 출력:
==================================================
Bright Data → Tableau 파이프라인
키워드: 'wireless headphones'
==================================================
[1/3] 키워드 'wireless headphones'에 대한 수집 트리거 중...
스냅샷 ID: sd_mmlan9p51yycmmkd7d
[2/3] 결과 대기 중...
처리 중... (0초 / 300초)
준비 완료! 43개 레코드 수신.
[3/3] 43개 행 저장 → amazon_products_tableau.csv
──────────────────────────────────────────────────
요약
──────────────────────────────────────────────────
총 상품 수 : 43
가격 범위 : $0.00 – $169.95
평균 가격 : $45.98
브랜드 수 : 4
평균 평점 : 4.4 / 5.0
──────────────────────────────────────────────────CSV 파일이 준비되었습니다. Tableau에서 파일을 열어 대시보드 구축을 시작하세요.
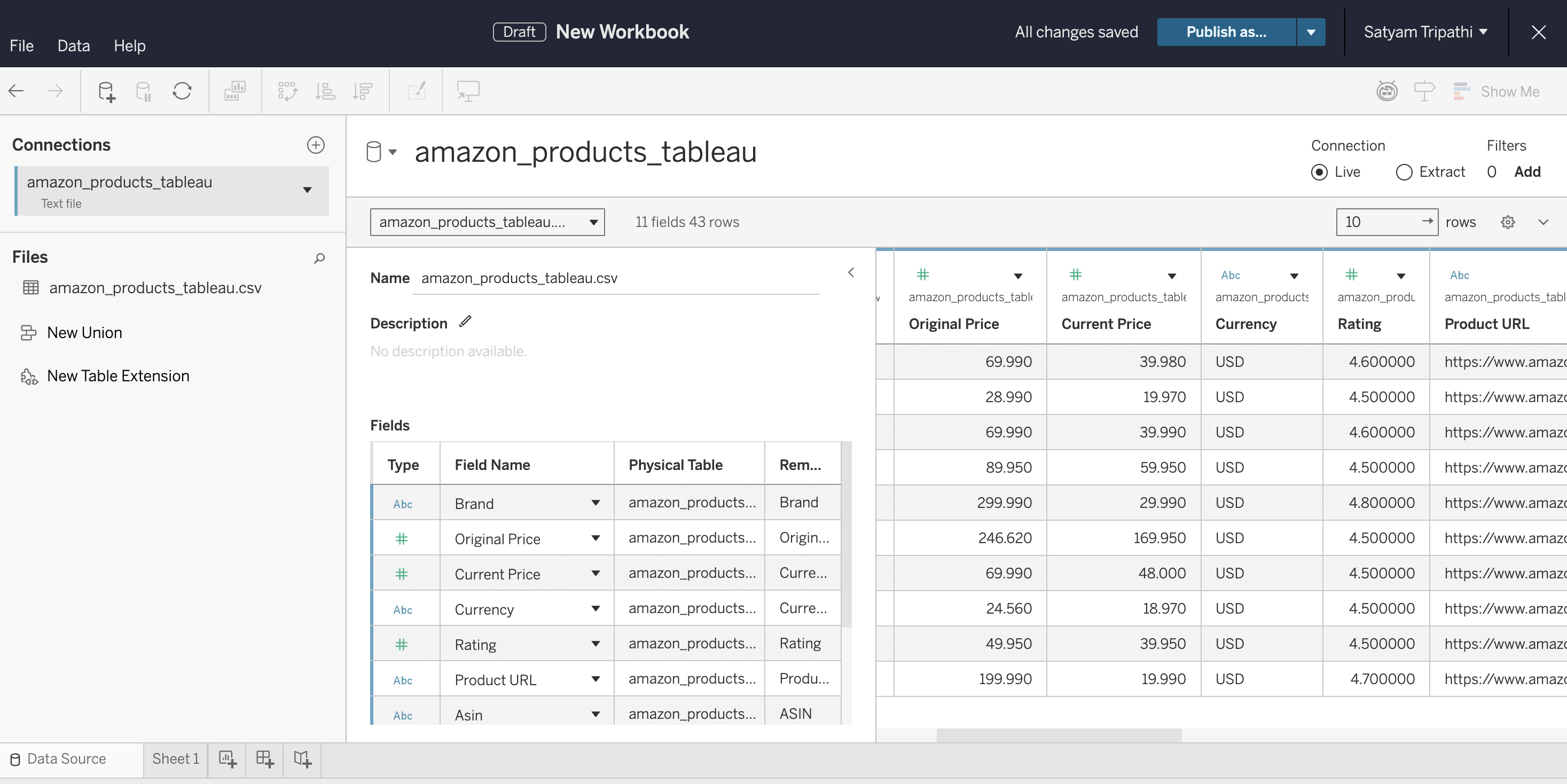
4단계: Tableau에 연결
CSV를 Tableau에 불러와 데이터 유형을 확인하세요:
- Tableau Desktop, Tableau Cloud 또는 Tableau Public을 엽니다
- CSV에 연결: Desktop에서는 연결 → 텍스트 파일을 선택합니다. Cloud에서는 새로 만들기 → 워크북 → 파일 탭을 선택하고 파일을 업로드합니다
'Current Price‘와'Rating'이‘String’이 아닌 ‘Number‘로 인식되는지 확인하십시오- 시트 1을 선택하여 구축을 시작합니다
권장 대시보드 뷰:
- 가격 분포 – 시장 위치를 파악하기 위한
현재 가격의히스토그램 - 가격 하락 분석 – 할인율을 파악하기 위한
원가대비현재 가격의나란히 배치된 막대 차트 - 평점 대 가격 – 고가치 제품을 찾기 위한 산점도
- 브랜드 비교 –
브랜드별제품 그룹화 막대 차트로 가격 및 평점 비교
5단계: 자동 새로고침 설정
대시보드를 실시간으로 유지하려면 cron (Linux/Mac) 또는 작업 스케줄러(Windows)를 사용하여 스크립트를 예약하십시오:
# 6시간마다 실행 — crontab -e
0 */6 * * * cd /path/to/project && python bright_data_to_tableau.py새로운 데이터를 표시하도록 Tableau 새로 고침:
- Tableau Desktop. cron 작업이 CSV를 업데이트한 후 F5 (Windows) 또는 Command+R (Mac) 을 눌러 다시 로드합니다. 또는 데이터 메뉴에서 데이터 원본을 선택하고 새로 고침을 선택합니다. Tableau Desktop은 파일 기반 원본을 자동으로 새로 고치지 않으므로 수동으로 새로 고치거나 워크북을 다시 열어야 합니다.
- Tableau Server. Tableau Desktop에서 서버(Server) → 워크북 게시(Publish Workbook)를 통해 게시합니다. 게시 대화 상자에서 추출 새로 고침 일정 (예: cron 작업과 일치하도록 6시간마다)을 설정합니다. Tableau Server는 해당 일정에 따라 추출을 자동으로 새로 고칩니다.
- Tableau Cloud. 브라우저를 통해 업로드된 CSV 파일은 자동 새로 고침이 불가능합니다. 새로 고침을 자동화하려면 cron 작업을 실행하는 컴퓨터에 Tableau Bridge를 설치하십시오. Bridge는 로컬 CSV를 Tableau Cloud에 연결하며 예약된 추출 새로 고침을 지원합니다. Bridge가 없는 경우, 파이프라인이 실행될 때마다 CSV를 수동으로 다시 업로드해야 합니다.
- Tableau Public. 파일 기반 소스에 대한 예약된 새로 고침은 지원하지 않습니다. CSV 기반 파이프라인의 경우, 데이터가 업데이트될 때마다 워크북을 다시 게시해야 합니다.
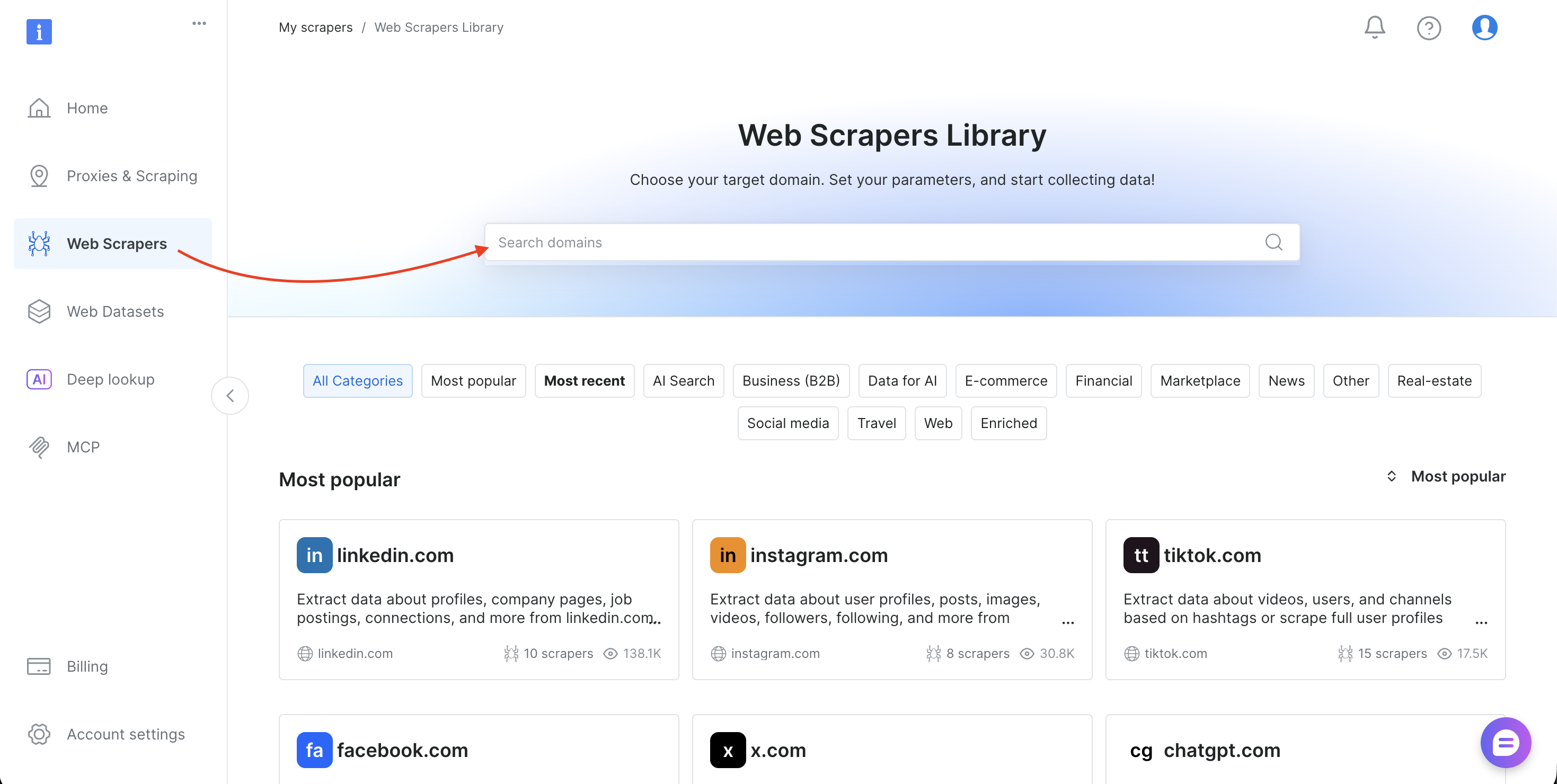
6단계: 스크래퍼 사용(데이터셋 ID 찾기)
이 튜토리얼에서는 Amazon Products Search 데이터셋(gd_lwdb4vjm1ehb499uxs)을 사용합니다. 다른 웹사이트를 스크래핑하려면 데이터셋 ID를 변경하십시오. ID를 찾는 방법은 다음과 같습니다:
- Bright Data 제어판에 로그인합니다
- 사이드바에서 ‘Web Scrapers’를 선택하여 웹 스크래퍼 라이브러리를 엽니다
- 대상 도메인(예: amazon.com, zillow.com, linkedin.com)을 검색하여 선택합니다
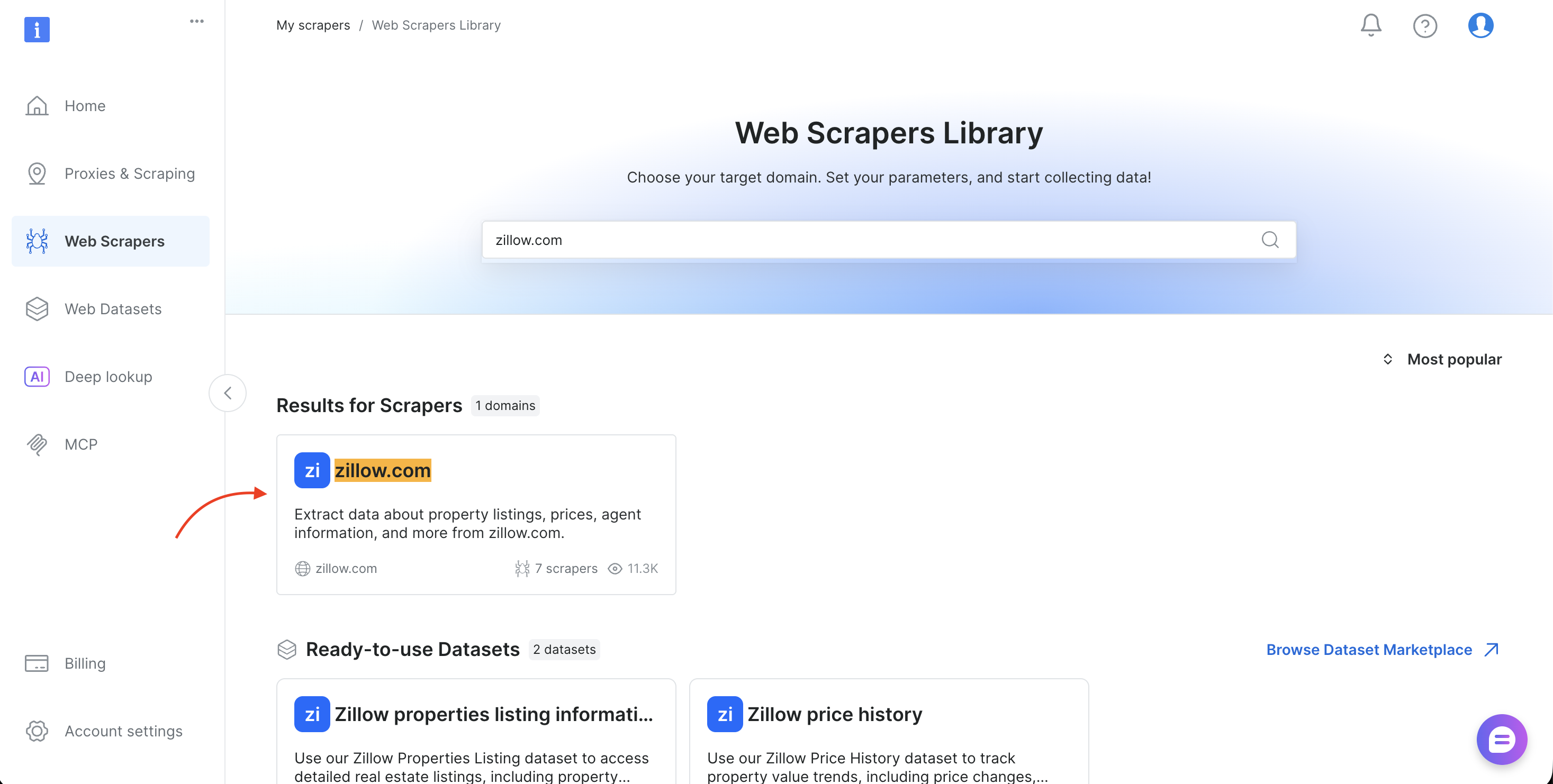
- 수집 방법(URL로 수집 또는 키워드로 검색)을 선택합니다
- 브라우저 주소 표시줄(예:
brightdata.com/cp/scrapers/gd_lfqkr8wm13ixtbd8f5) 또는 ‘코드 예제 ‘ 패널에서dataset_id를 복사합니다
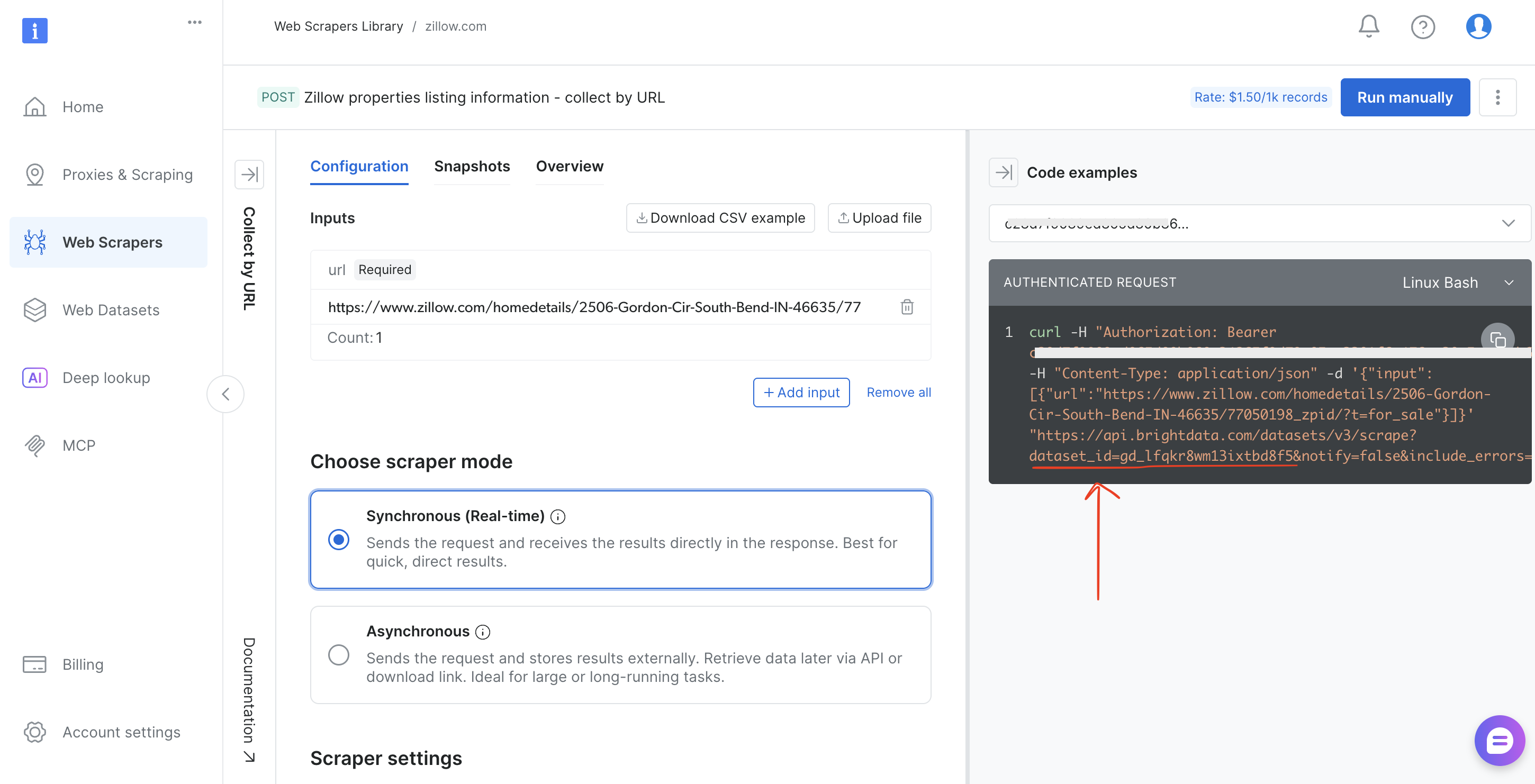
스크립트에서 DATASET_ID를 교체하고 페이로드를 조정하면, Bright Data의 120개 이상의 스크레이퍼 모두에서 동일한 파이프라인이 작동합니다.
실제 결과: 스크래핑된 데이터의 모습
다음 스크린샷은 파이프라인에서 출력된 원시 CSV 데이터로, Bright Data의 API가 “wireless headphones” 키워드에 대해 반환한 결과와 정확히 일치합니다:
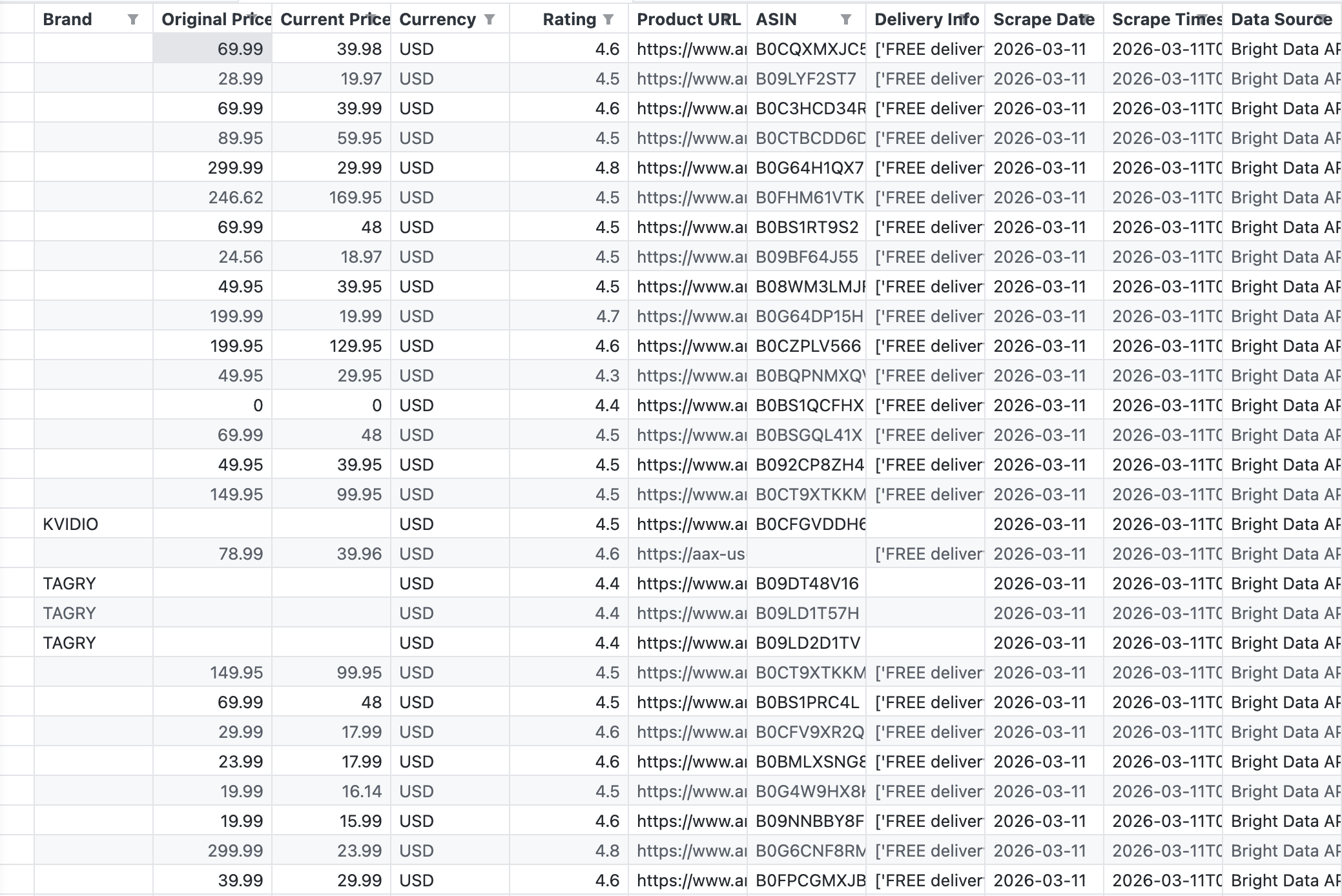
API는 브랜드, 원래 가격, 현재 가격, 평점, ASIN, 제품 URL, 배송 정보 등의 필드를 포함한 43개의 레코드를 반환했습니다.
API는 단 한 번의 호출로 43개의 제품을 반환했습니다. 데이터는 구조화되어 있으며 Tableau에서 바로 사용할 수 있습니다. HTML 파싱, 깨진 셀렉터, CAPTCHA 문제 등이 전혀 없습니다. Amazon 스크래핑 옵션에 대한 자세한 내용은 Amazon 제품 데이터 스크래핑 방법을 참조하십시오.
데이터 시각화: CSV에서 인사이트로
다음 네 가지 시각화는 파이프라인의 결과물을 보여줍니다. 각 뷰는 스크립트가 생성한 정확한 CSV 파일을 기반으로 구축되었습니다:
상품별 가격 분포
이 차트는 31개 상품(아마존 URL에서 이름을 파싱할 수 있는 상품)을 현재 가격 기준으로 최저가에서 최고가 순으로 정렬합니다:
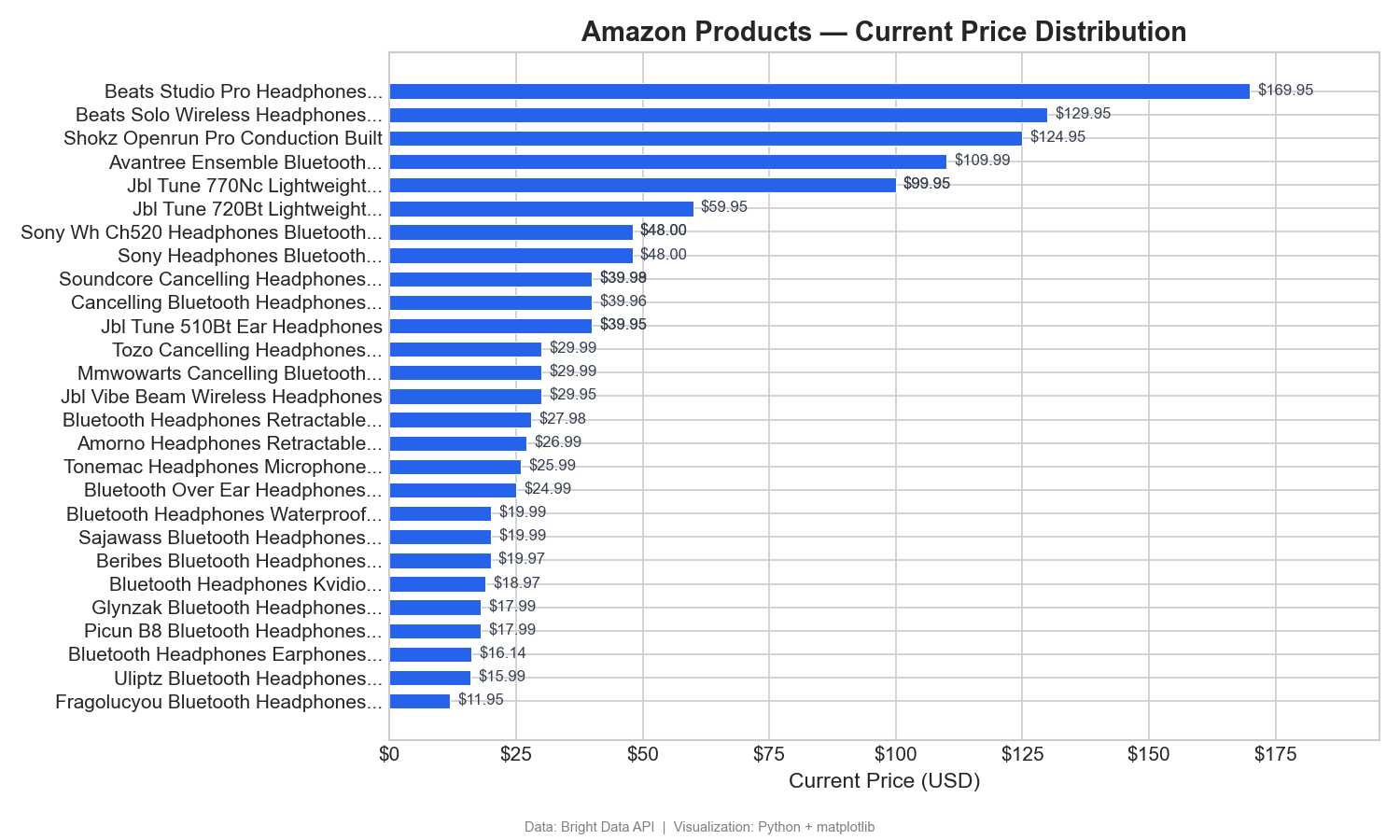
이 가로 막대 차트는 가격대를 명확하게 보여줍니다. Beats가 프리미엄 가격대($125–$170)를 주도하는 반면, 대부분의 무선 헤드폰은 $12–$60 범위에 집중되어 있습니다. Tableau에서는 '현재 가격'을 열로, '제품 이름'을 행으로 설정하여 정렬된 막대 차트로 이 그래프를 만들 수 있습니다.
가격 하락: 정가 대비 현재 가격
이 그룹화 막대 차트는 할인된 상위 10개 제품의 정가와 현재 가격을 비교합니다:
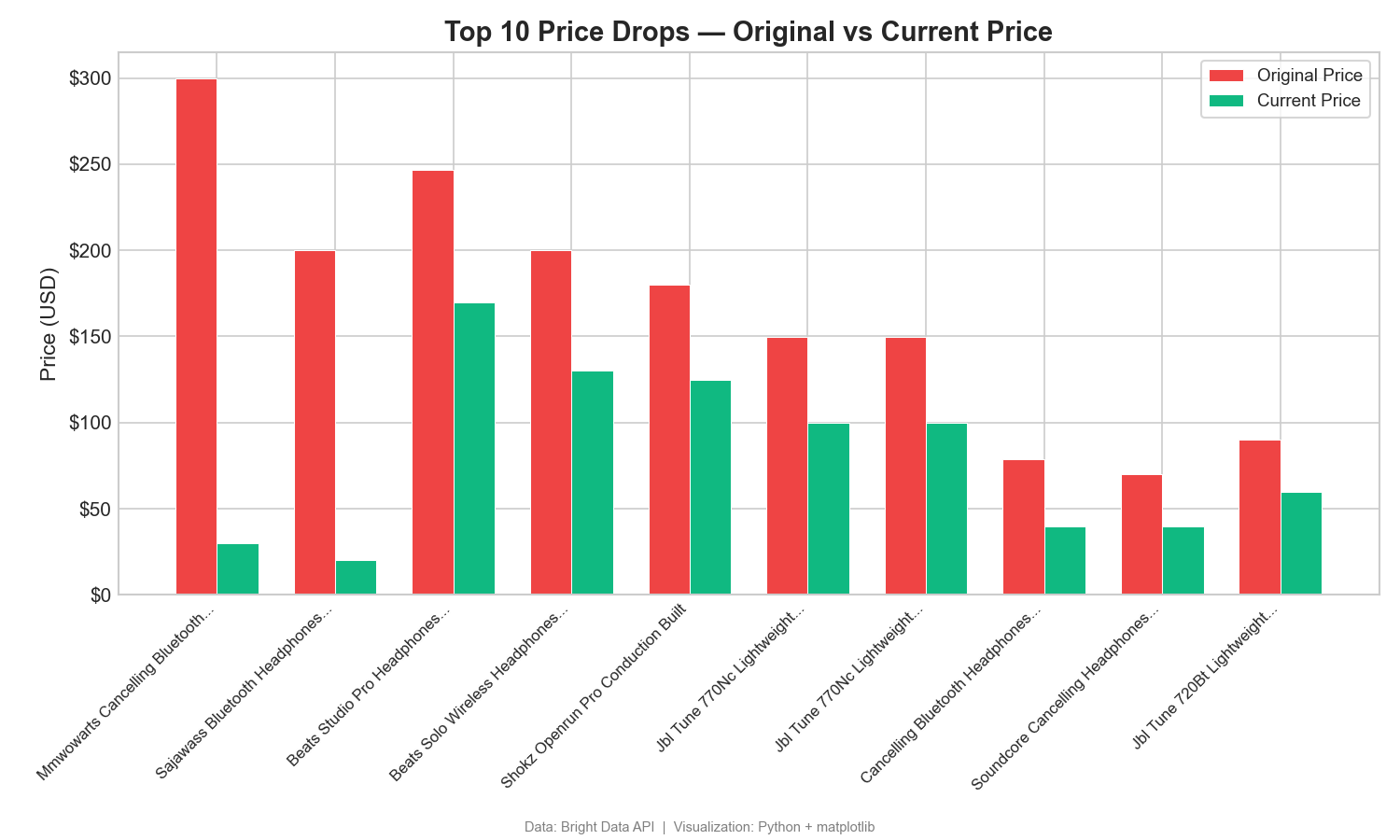
정가와 현재 가격 간의 차이는 큰 할인 폭을 보여줍니다. 한 제품은 정가($299.99)에서 $270이나 하락한 ($29.99) 것을 확인할 수 있습니다. 이와 같은 가격 차이는 프로모션 및 가격 책정 전략을 보여줍니다. Tableau에서는 측정값 이름을 색상으로 지정하여 나란히 배치된 막대 차트를 사용하세요.
평점 대 가격: 가치 파악
이 산점도는 고객 평점과 가격을 대비하여 가성비가 뛰어난 제품을 식별합니다:
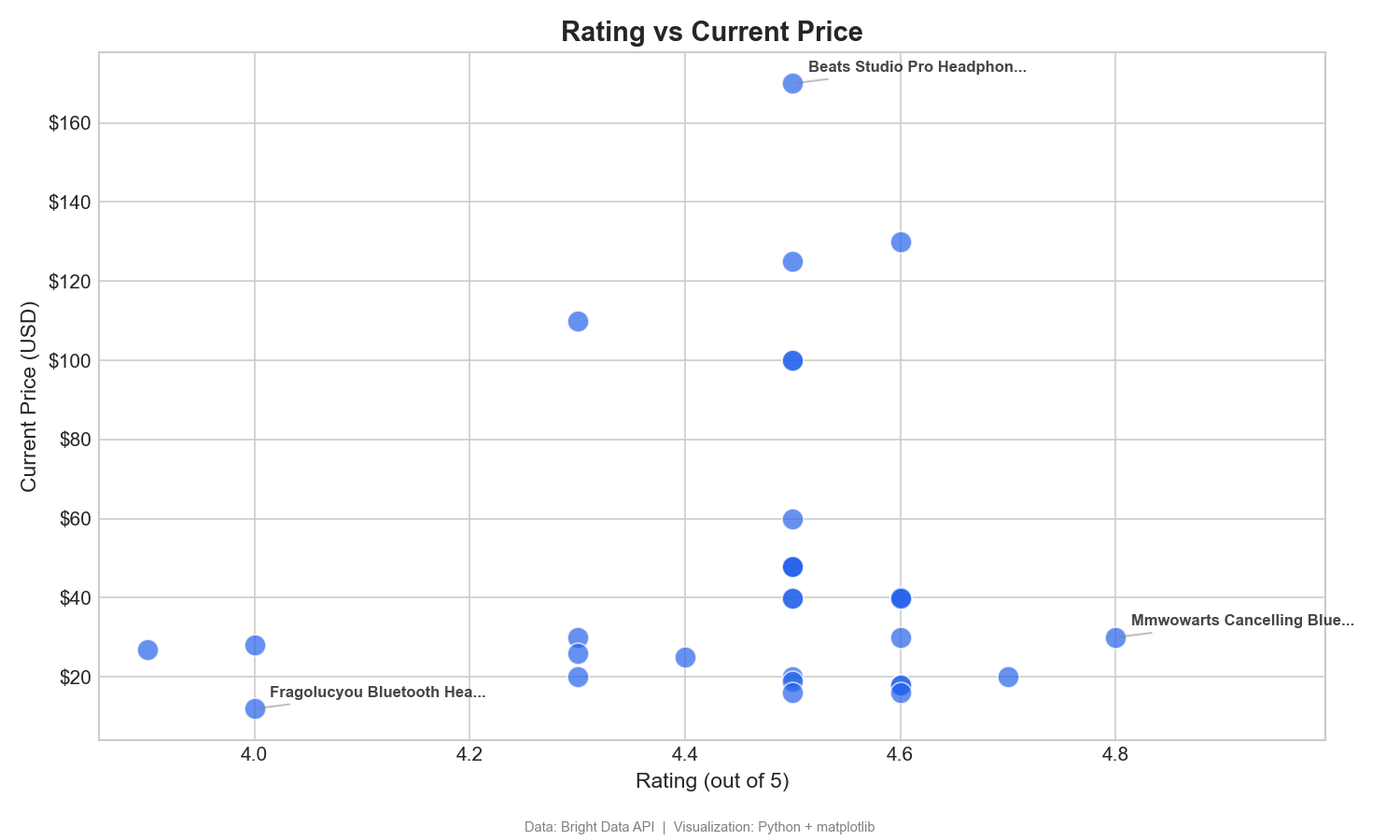
이 산점도는 높은 평점과 낮은 가격을 동시에 갖춘 고가치 제품(우하단 사분면)을 식별하는 데 도움이 됩니다. 29.99달러에 4.8점의 평점을 받은 MMWOWARTS 헤드폰이 대표적인 예입니다. Tableau에서 '평점'을 ‘열’로, '현재 가격'을 ‘행’으로, '제품 이름'을 ‘세부 정보’로 드래그합니다.
가격대별 시장 세분화
이 도넛 차트는 가격대별로 제품을 분류합니다:
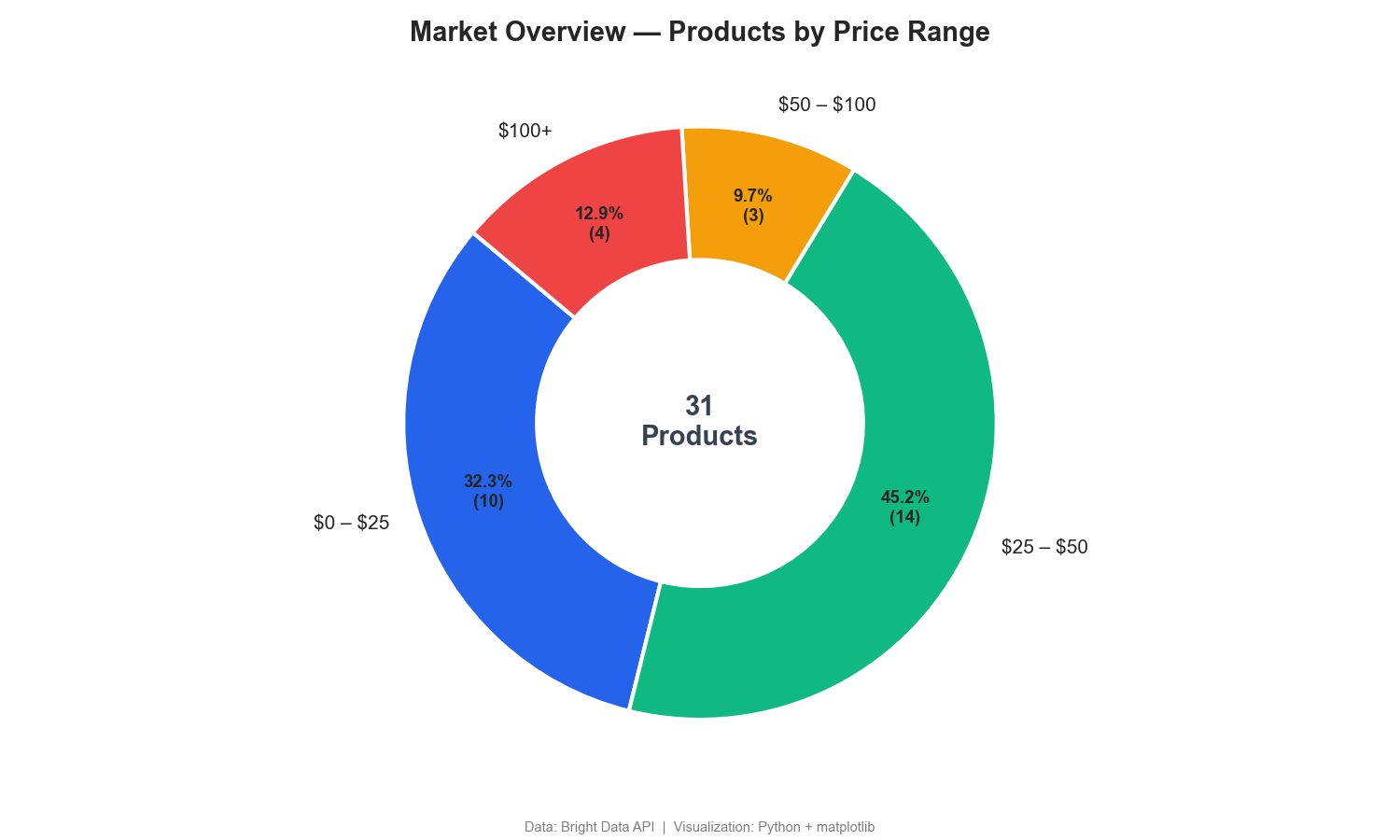
도넛 차트에 따르면 무선 헤드폰의 77%가 50달러 미만으로 판매되며, 100달러 이상의 프리미엄 세그먼트는 13%에 불과합니다. 경쟁사 가격 모니터링 대시보드에는 종종 이와 유사한 세분화가 포함됩니다.
보너스: Zillow를 활용한 부동산 파이프라인
동일한 파이프라인 패턴은 Bright Data의 120개 이상의 스크레이퍼 중 어느 것과도 호환됩니다. 다음 예시는 Zillow 스크레이퍼 API (GitHub 저장소)를 사용합니다. bright_data_to_tableau.py 파일의 두 변수만 업데이트하면 나머지 파이프라인은 변경 없이 실행됩니다:
# Amazon 데이터셋 ID를 Zillow 데이터셋 ID로 교체
DATASET_ID = "gd_lfqkr8wm13ixtbd8f5" # Zillow 부동산그런 다음 trigger_collection() 내의 페이로드를 키워드 대신 위치 URL을 사용하도록 업데이트합니다:
payload = [{
"url": "https://www.zillow.com/new-york-ny/"
}]스크립트를 동일한 방식으로 실행하세요. 폴링 및 CSV 내보내기 로직은 변경 없이 작동합니다.
Zillow 필드에는 부동산 주소, 가격, 침실 수, 욕실 수, 면적, 대지 면적, 건축 연도, 부동산 유형, 매물 상태 및 Zestimate가포함됩니다.
Tableau 대시보드 아이디어:
- 우편번호별 평방피트당 가격 히트맵
- 매물 가격 대 Zestimate 격차 분석
- 도시 또는 우편번호별 주택 유형 분포
- 리모델링 기회를 위한 건축 연도 대 가격 산점도
주요 이점: 패턴을 한 번 파악하면 어떤 데이터 소스에도 적용할 수 있습니다. Amazon, Zillow, LinkedIn 채용 정보 등 모두 동일한 Bright Data 인프라를 사용하여 Tableau 대시보드로 데이터를 전송합니다.
Tableau에서 실시간 웹 데이터를 활용하는 6가지 주요 사례
다음은 팀이 Tableau에 웹 데이터 파이프라인을 구축하는 가장 일반적인 이유입니다.
1. 경쟁사 가격 모니터링
아마존, 월마트, 타겟 또는 기타 전자상거래 플랫폼 전반에 걸쳐 경쟁사 가격을 추적하세요. 일일 가격 변동, 과거 추세, 시장 내 가격 포지셔닝을 보여주는 Tableau 대시보드를 구축하세요. 경쟁사가 귀사의 최저 가격 아래로 떨어질 때 알림을 설정하세요.
Bright Data의 120개 이상의 기성 스크레이퍼를 사용하여 여러 마켓플레이스에 걸쳐 수천 개의 SKU를 모니터링하세요. 별도의 맞춤형 스크레이퍼가 필요하지 않습니다.
Tableau 뷰: 가격 폭포형 차트, SKU별 시계열 추세, 경쟁사 가격 히트맵.
2. 소셜 미디어 브랜드 추적
인스타그램, 트위터/X, 틱톡, 링크드인에서 브랜드 언급, 참여 지표, 팔로워 수, 댓글 데이터를 수집하세요. 플랫폼 전반의 브랜드 가시성을 추적하고 시간 경과에 따른 캠페인 성과를 측정하는 대시보드를 구축하세요. 스크래핑 브라우저는 표준 HTTP 요청으로는 렌더링할 수 없는 자바스크립트 기반 소셜 플랫폼도 처리합니다.
Tableau 뷰: 참여율 추세, 시간 경과에 따른 언급량, 플랫폼 비교 막대 차트.
3. 채용 시장 분석
인디드( Indeed), 글래스도어(Glassdoor), 링크드인(LinkedIn,GitHub 저장소), 전문 구인 게시판의 채용 공고를 집계합니다. 산업 및 지역별 채용 동향, 급여 벤치마크, 필수 기술, 수요 변화를 분석합니다. HR 팀과 채용 담당자는 이러한 대시보드를 활용하여 보상 수준을 벤치마킹하고 경쟁사보다 먼저 인재 시장의 변화를 파악합니다.
Tableau 뷰: 채용 공고의 지리적 버블 맵, 급여 분포 히스토그램, 기술 수요 트리맵.
4. 부동산 대시보드
Zillow, Realtor.com, Redfin, Airbnb의 매물 목록, 가격 변동, 재고 수준 및 지역별 동향을 모니터링합니다. 부동산 투자자와 분석가는 Tableau에서 지리적 히트맵을 구축하여 저평가된 시장을 파악하고 도시별 임대 수익률 추세를 추적합니다.
Tableau 뷰: 우편번호 히트맵, 평방피트당 가격 산점도, 매물량 시계열.
5. 금융 데이터 피드
Yahoo Finance, Bloomberg 및 기타 금융 플랫폼에서 주가, 실적 보고서, 애널리스트 평가, 내부자 거래 데이터 및 금융 뉴스를 수집합니다. 퀀트 애널리스트와 포트폴리오 매니저는 자동 데이터 갱신 기능을 갖춘 금융 대시보드를 구축하여 포트폴리오 성과와 시장 신호를 추적합니다.
Tableau 뷰: 캔들스틱 스타일의 가격 차트, 실적 서프라이즈 막대 차트, 섹터 로테이션 대시보드.
6. 공급망 모니터링
전 세계 마켓플레이스에서 제품 재고 현황, 예상 배송 기간, 판매자 재고 수준 및 가격을 추적합니다. 운영 팀은 갑작스러운 품절이나 배송 시간 급증과 같은 공급 차질이 나머지 공급망에 영향을 미치기 전에 이를 감지하는 Tableau 대시보드를 구축합니다.
Tableau 뷰: 재고 현황 매트릭스, 배송 시간 추세선, 공급업체 리스크 스코어카드.
이러한 각 사용 사례는 모두 동일한 아키텍처를 따릅니다: Bright Data API → 구조화된 데이터 → Tableau 대시보드. 달라지는 것은 데이터셋 ID와 사용자가 구축하는 Tableau 시각화뿐입니다.
Bright Data API 파이프라인의 작동 방식
이 튜토리얼 스크립트는 트리거링과 폴링을 처리합니다. API 호출부터 Tableau 대시보드에 이르기까지 전체 파이프라인에서 발생하는 과정은 다음과 같습니다.
단계별 데이터 흐름
- 트리거. Python 스크립트가 Bright Data의
/trigger엔드포인트로 POST 요청을 전송합니다. 키워드(탐색용) 또는 URL 목록(표적 수집용) 중 하나를 포함해야 합니다. API는 즉시snapshot_id를반환합니다. - 수집. Bright Data의 인프라는 1억 5천만 개 이상의 레지덴셜 프록시를 통해 요청을 라우팅합니다. CAPTCHA 문제를 자동으로 처리하고, 필요한 경우 JavaScript를 렌더링하며, 실패한 요청을 재시도합니다.
- 파싱. Bright Data는 원시 HTML을 구조화된 데이터 필드로 파싱합니다. Amazon 제품의 경우 제목, 가격, 평점, 리뷰, 판매자 정보, 재고 현황 등이 포함될 수 있으나, 반환되는 정확한 필드는 데이터셋과 검색 유형에 따라 다릅니다.
- 스냅샷. 수집 및 파싱이 완료되면 Bright Data는 데이터를 스냅샷으로 저장합니다. 사용자의 스크립트는 상태가
202(처리 중)에서200(준비됨)으로 변경될 때까지/snapshot엔드포인트를 폴링합니다. - 전송. 스냅샷을 JSON 또는 CSV 형식으로 가져옵니다. 또는 Amazon S3, Google Cloud Storage, Azure Blob, Snowflake, SFTP 또는 웹훅으로 전송하도록 구성할 수 있습니다. 자동 전송 기능은 데이터를 데이터 웨어하우스에 저장하는 프로덕션 파이프라인에 유용합니다.
- 변환. 스크립트(또는 pandas와 같은 도구)를 사용하여 열 이름을 변경하고, 필드를 필터링하며, Tableau가 읽을 수 있도록 데이터 형식을 조정합니다. 이 단계에서 스크랩 날짜 및 데이터 소스와 같은 메타데이터 열을 추가합니다.
- 시각화. Tableau는 출력 파일을 읽거나(데이터를 데이터베이스에 로드한 경우 데이터베이스에 연결하여) 최신 데이터로 대시보드를 렌더링합니다.
파이프라인 확장
프로덕션 환경에서 사용할 경우 다음 개선 사항을 고려하십시오:
- 다중 키워드. 스크립트에서 키워드 또는 제품 카테고리 목록을 순차적으로 처리하여 포괄적인 데이터 세트를 구축하십시오.
- 데이터베이스 저장. CSV 대신 PostgreSQL 또는 MySQL에 데이터를 저장하십시오. Tableau는 두 데이터베이스 모두에 기본적으로 연결되며, 시간이 지남에 따라 축적된 과거 데이터를 통해 추세 분석을 수행할 수 있습니다.
- 오케스트레이션. Apache Airflow, Prefect 또는 cron 작업을 사용하여 비즈니스 요구 사항에 맞는 빈도(매시간, 매일, 매주)로 실행을 예약하십시오.
- 웹훅 전달. 결과가 준비되면 Bright Data가 서버로 결과를 POST하도록 구성하여 폴링을 완전히 생략하십시오.
프로덕션 체크리스트
파이프라인을 프로덕션 스케줄에 배포하기 전에 다음 운영 관련 사항을 처리하십시오:
- 오류 처리. 재시도 로직을 포함한 try/except 블록으로 API 호출을 감싸십시오. 실패 시 파일을 통해 또는 모니터링 서비스에 로그를 기록하여 오래된 데이터를 조기에 탐지할 수 있도록 하십시오.
- 데이터 중복 제거. 고유 키(예: ASIN + 스크랩 날짜)를 추가하고 Tableau로 로드하기 전에 중복을 제거하십시오. 중복 행은 집계 결과를 왜곡합니다.
- 스키마 검증. CSV에 기록하기 전에 API 응답에 예상된 필드가 포함되어 있는지 확인하십시오. 웹사이트 변경으로 인해 사전 경고 없이 데이터 구조가 변경될 수 있습니다.
- 모니터링 및 알림. 실행 실패, 빈 데이터 세트, 예상치 못한 행 수 감소에 대한 알림(이메일, Slack 또는 PagerDuty)을 설정하십시오.
- 데이터 백업. 각 CSV 스냅샷을 타임스탬프와 함께 보관하십시오. 잘못된 스크래핑으로 인해 작업 파일이 손상된 경우 이전 버전으로 롤백하십시오.
Tableau 파이프라인에 Bright Data를 선택해야 하는 이유
프로덕션용 Tableau 워크플로우에서는 다음 요소가 중요합니다:
- 유연한 전달. API, 웹훅, Amazon S3, Google Cloud, Azure 또는 SFTP를 통해 JSON, CSV 또는 NDJSON 형식으로 결과를 받아보세요. 데이터를 Tableau 데이터 웨어하우스에 로드하세요.
- 맞춤형 또는 기성 솔루션. Serverless Functions를 사용하여 맞춤형 스크레이퍼를 생성하거나, Scraper Studio를 통해 AI 기반 및 자동 생성 스크레이퍼를 만들거나, 코드를 작성하지 않고도 즉시 액세스할 수 있는 기성 데이터셋을 활용하세요.
- 비용 효율성. 종량제 요금제로 레코드 1,000건당 $1.50를 지불하며, 상위 요금제에서는 볼륨 할인을 통해 1,000건당 $0.75까지 낮아집니다.
실시간 웹 데이터 파이프라인 구축
사용 가능한 데이터와 필요한 데이터 간의 격차는 계속 커지고 있으며, 특히 해당 데이터가 API나 커넥터 없이 공개 웹에 존재하는 경우 더욱 그렇습니다.
WDC v2는 더 이상 사용되지 않으며 지원되지 않습니다. Google 스프레드시트는 셀 제한에 도달합니다. Excel은 수작업이 필요합니다. TabPy는 프록시 로테이션 기능이 부족합니다. 직접 작성한 스크립트는 대규모로 확장할 때 오류가 발생합니다.
Bright Data의 웹 스크레이퍼 API는 이러한 접근 방식에 부족한 인프라 계층을 제공합니다. 이 API에는 120개 이상의 기성 스크레이퍼, 195개국에 걸쳐 1억 5천만 개 이상의 프록시, 자동 CAPTCHA 해결 기능, Tableau가 기본적으로 지원하는 형식의 구조화된 데이터 출력이 포함되어 있습니다. 요금은 레코드 1,000건당 1.50달러부터 시작하며, 99.99%의 가동 시간을 보장하고 GDPR, CCPA 및 ISO 27001을 완벽하게 준수합니다.
데이터 수집 인프라를 구축하는 대신 대시보드 제작에 집중하세요.
자주 묻는 질문
Tableau WDC는 더 이상 지원되지 않나요?
예. Tableau의 Web Data Connector v2는 2023.1 릴리스에서 공식적으로 단종되었습니다. WDC v2를 지원하는 마지막 버전인 Tableau 2022.4는 지원이 종료되었습니다. WDC v2 커넥터는 현재 모든 Tableau 버전에서 지원되지 않으며, 향후 업데이트에서 제거될 수 있습니다.
Tableau WDC를 대체한 것은 무엇인가요?
Tableau는 WDC v3를 출시했으나, 이는 추출 전용이며 Tableau Bridge에서는 지원되지 않습니다. 실시간 웹 데이터의 경우, 스크래핑 API 파이프라인(Bright Data → CSV/JSON → Tableau)이 실용적인 대안입니다. 이 가이드의 튜토리얼에서는 해당 파이프라인을 구축합니다.
Tableau가 웹 스크래핑 API에 직접 연결할 수 있나요?
기본적으로는 아닙니다. Tableau는 데이터베이스, 파일 및 특정 클라우드 서비스에 연결합니다. 스크래핑 API를 사용하려면 API를 호출하고 데이터를 수신하는 Python 또는 Node.js 기반의 경량 스크립트가 필요합니다. 그런 다음 이 스크립트는 Tableau가 읽을 수 있는 형식(CSV, JSON 또는 데이터베이스 삽입)으로 데이터를 출력합니다.
Tableau 대시보드 데이터를 최신 상태로 유지하려면 어떻게 해야 하나요?
cron(Linux/Mac), 작업 스케줄러(Windows) 또는 Apache Airflow와 같은 워크플로 오케스트레이터를 사용하여 데이터 수집 스크립트를 예약하십시오. 이 스크립트는 Bright Data의 API에서 최신 데이터를 가져와 CSV 파일을 덮어씁니다. Tableau는 다음 새로 고침 주기에서 업데이트된 데이터를 로드합니다.
Tableau에 웹 데이터를 로드하는 데 비용은 얼마나 듭니까?
Bright Data의 웹 스크레이퍼 API는 종량제 기준으로 레코드 1,000건당 1.50달러부터 시작하며, 대량 할인 시 1,000건당 0.75달러까지 낮아집니다. 매일 5,000개의 제품을 추적하는 일반적인 경쟁사 모니터링 대시보드의 경우, 하루 약 7.50달러 또는 월 약 225달러가 소요됩니다.
Bright Data는 Tableau용으로 어떤 데이터 형식을 출력하나요?
Bright Data는 API를 통해 JSON, CSV 또는 NDJSON 형식으로 데이터를 제공합니다. Tableau의 경우 CSV가 가장 직접적인 옵션입니다. Tableau는 별도의 변환 과정 없이 이 파일을 기본적으로 읽을 수 있습니다. 또는 프로덕션 파이프라인을 위해 Amazon S3, Google Cloud Storage, Azure Blob, Snowflake, SFTP 또는 웹훅으로의 자동 전송을 구성할 수 있습니다.
Bright Data를 Tableau Public과 함께 사용할 수 있나요?
네. Bright Data는 Tableau Public이 기본적으로 읽을 수 있는 표준 CSV 파일을 출력합니다. 단, Tableau Public 측의 제한 사항으로, 파일 기반 소스에 대한 예약된 새로 고침 기능을 지원하지 않습니다. 데이터가 업데이트될 때마다 데이터 수집 스크립트를 다시 실행하고 워크북을 다시 게시해야 합니다.






