이 튜토리얼에서는 다음을 배울 수 있습니다:
- Cloudflare란 무엇인가.
- WAF 메커니즘에 대한 심층 분석.
- 기술적 관점에서 본 클라우드플레어의 봇 방지 시스템 작동 방식.
- 표준 자동화 도구로 Cloudflare 보호 사이트를 공격할 때 발생하는 현상.
- Cloudflare 우회 방법의 고수준 접근법.
- Python으로 Cloudflare 인간 확인을 우회하는 방법.
- 클라우드플레어를 대규모로 우회하는 방법.
자, 시작해 보겠습니다!
Cloudflare란 무엇인가요?
Cloudflare는 웹에서 가장 큰 네트워크 중 하나를 운영하는 웹 인프라 및 보안 회사입니다. 웹사이트를 더 빠르고 안전하게 만들기 위해 설계된 포괄적인 서비스 제품군을 제공합니다.
핵심적으로 Cloudflare는 주로 CDN(콘텐츠 전송 네트워크)으로 기능하며, 글로벌 네트워크에 사이트 콘텐츠를 캐싱하여 로드 시간을 개선하고 지연 시간을 줄입니다. 또한 DDoS(분산 서비스 거부) 보호, WAF(웹 애플리케이션 방화벽), 봇 관리, DNS 서비스 등의 기능을 제공합니다.
Cloudflare 네트워크와 통합함으로써 사이트는 신속하게 강화된 보안과 최적화된 성능을 확보할 수 있습니다. 이로 인해 Cloudflare는 전 세계 수백만 웹사이트의 필수 솔루션으로 자리매김했습니다.
Cloudflare의 봇 방지 메커니즘 이해
Cloudflare가 널리 사용되는 이유 중 하나는 WAF(웹 애플리케이션 방화벽) 기능입니다. 글로벌 네트워크를 통해 제공되는 모든 웹 페이지에서 활성화할 수 있습니다. 구체적으로, 스크레이퍼, 원치 않는 크롤러 및 일반적인 봇에 대한 가장 효과적인 해결책 중 하나를 제공합니다.
더 구체적으로, Cloudflare WAF는 웹 애플리케이션 앞에 위치합니다. 서버에 도달하거나 웹 페이지에 접근하기 전에 공격이나 원치 않는 트래픽을 차단하기 위해 실시간으로 들어오는 요청을 검사하고 필터링합니다.
다중 계층 방어 전략의 일환으로, Cloudflare WAF는 독자적인 알고리즘을 사용하여 악성 봇을 탐지하고 차단합니다. 이 알고리즘은 다음과 같은 들어오는 트래픽의 여러 특성을 분석합니다:
- TLS 지문: HTTP 클라이언트 또는 브라우저가 TLS 핸드셰이크를 수행하는 방식을 검사합니다. 제안된 암호 모음, 협상 순서 및 기타 저수준 특성 등의 세부 정보를 살펴봅니다. 봇과 비표준 클라이언트는 종종 특이하고 브라우저와 유사하지 않은 TLS 서명을 가지고 있어 이를 통해 식별됩니다.
- HTTP 요청 세부 정보: HTTP 헤더, 쿠키, 사용자 에이전트 문자열 및 기타 측면을 검토합니다. 봇은 실제 브라우저와 다른 기본값 또는 의심스러운 구성을 재사용하는 경우가 많습니다.
- 자바스크립트 지문: 클라이언트 브라우저에서 자바스크립트를 실행하여 환경에 대한 상세 정보를 수집합니다. 여기에는 정확한 브라우저 버전, 운영 체제, 설치된 폰트 또는 확장 프로그램, 심지어 미묘한 하드웨어 특성까지 포함됩니다. 이러한 데이터 포인트는 실제 사용자와 자동화된 스크립트를 구분하는 데 도움이 되는 지문을 형성합니다.
- 행동 분석: 자동화된 트래픽의 가장 강력한 지표 중 하나는 비정상적인 행동입니다. Cloudflare는 빠른 요청, 마우스 움직임 부재, 동일한 클릭 경로, 유휴 시간 등의 패턴을 모니터링합니다. 머신 러닝을 활용하여 브라우징 행동이 인간과 봇 중 어느 쪽에 해당하는지 판단합니다. 이는 가장 복잡한 봇 방지 기술 중 하나입니다.
Cloudflare는 일반적으로 두 가지 방식의 인간 인증을 제공합니다:
- 항상 인간 인증 챌린지 표시
- 자동화된 인간 인증 도전 과제 (의심스러운 활동이 감지된 경우에만)
아래에서 두 가지 옵션을 모두 살펴보세요!
모드 #1: 항상 인간 인증 챌린지 표시
첫 번째 모드는 덜 일반적이지만 더 강력한 보호 기능을 제공합니다. 사이트에 처음 접속할 때마다 항상 인간 인증을 요구하는 방식입니다.
예를 들어, 현재 작성 시점 기준 StackOverflow가 이 방식으로 운영됩니다. 시크릿 모드(쿠키가 없는 새 세션 보장)로 접속해 보세요. 실제 인간 사용자라도 Cloudflare Turnstile이라는 CAPTCHA가 표시됩니다:
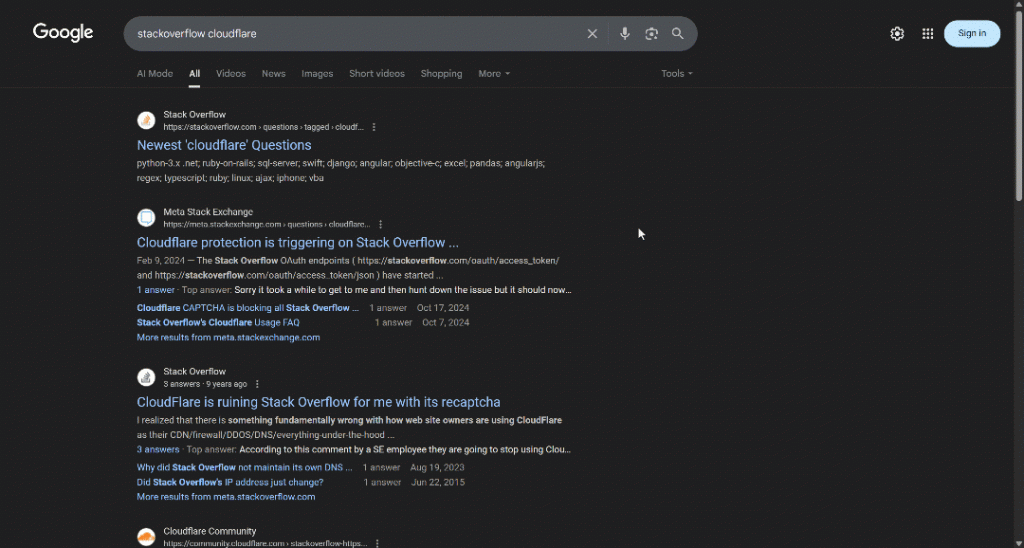
참고: 이 글을 읽는 시점에는 StackOverflow의 봇 방지 기능이 변경되었거나 다르게 작동할 수 있습니다.
이 경우 자동화 스크립트를 구축한다면, Turnstile CAPTCHA 상호작용을 인간과 유사한 방식으로 자동화하는 것만이 유일한 선택지입니다. 문제는 Turnstile이 백엔드 행동 분석 및 기타 독점적 검증을 기반으로 한다는 점입니다. 바로 이 덕분에 단 한 번의 클릭으로 사용자가 인간임을 확인할 수 있는 것입니다.
모드 #2: 자동화된 인간 인증 도전
이 모드에서는 Cloudflare가 요청이 봇에서 온 것으로 의심될 때만 도전을 발행합니다. 이는 브라우저에서 보이지 않게 실행되는 자바스크립트 도전을 제시하여 클라이언트가 정상적인 사용자처럼 행동하는지 확인하는 방식으로 이루어집니다:
일반 브라우저를 사용하는 인간이라면 이 과정은 매끄럽게 진행되며 대개 자동으로 완료됩니다. 통과하면 중단 없이 사이트 탐색을 계속할 수 있습니다. 일반 사용자에게 최소한의 방해만 주기 때문에, 이는 현재까지 가장 흔히 사용되는 Cloudflare 모드입니다.
그러나 자바스크립트 검증에 실패할 경우(클라이언트가 봇일 가능성이 높다고 Cloudflare가 판단할 때), 인간 인증을 위한 Turnstile CAPTCHA로 전환됩니다:
이제 이전 시나리오에서 보았던 화면으로 돌아갑니다. 이 모드에서는 인간과 유사한 지문을 제시하는 봇을 사용하면 초기 인증을 통과할 수 있어 Turnstile CAPTCHA를 완전히 피할 수도 있습니다. 하지만 CAPTCHA가 나타난다면 이를 처리할 방법이 필요합니다.
기술적 관점에서 본 Cloudflare의 상세 작동 방식
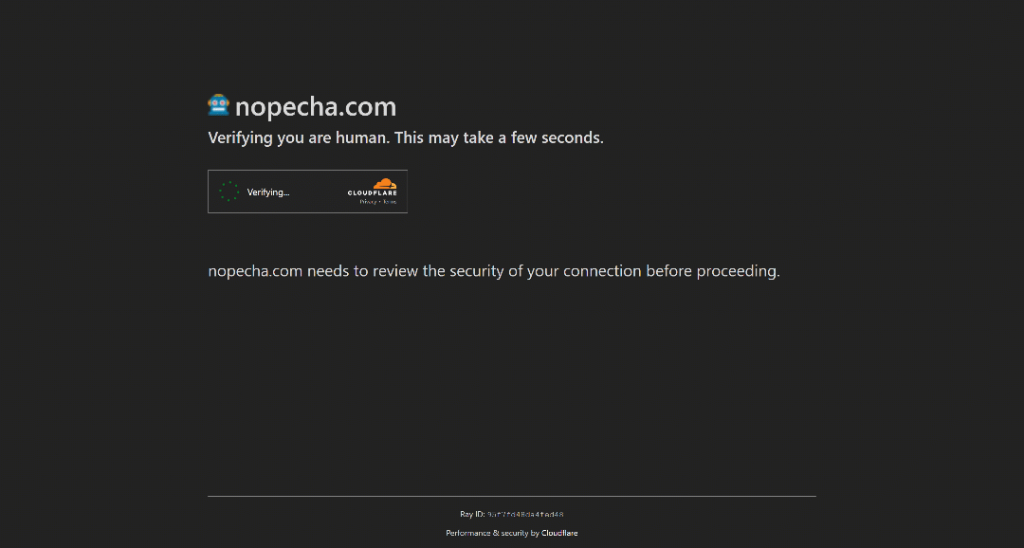
브라우저의 시크릿 모드에서 NopeCHA Cloudflare 테스트 페이지를 열어보세요. 이 페이지는 Cloudflare WAF로 보호되므로 자동화된 자바스크립트 기반 검증 프로세스가 즉시 시작됩니다.
백그라운드에서는 일련의 POST 요청이 Cloudflare 엔드포인트와 교환되며, 페이로드 내에 암호화된 데이터를 전송합니다:
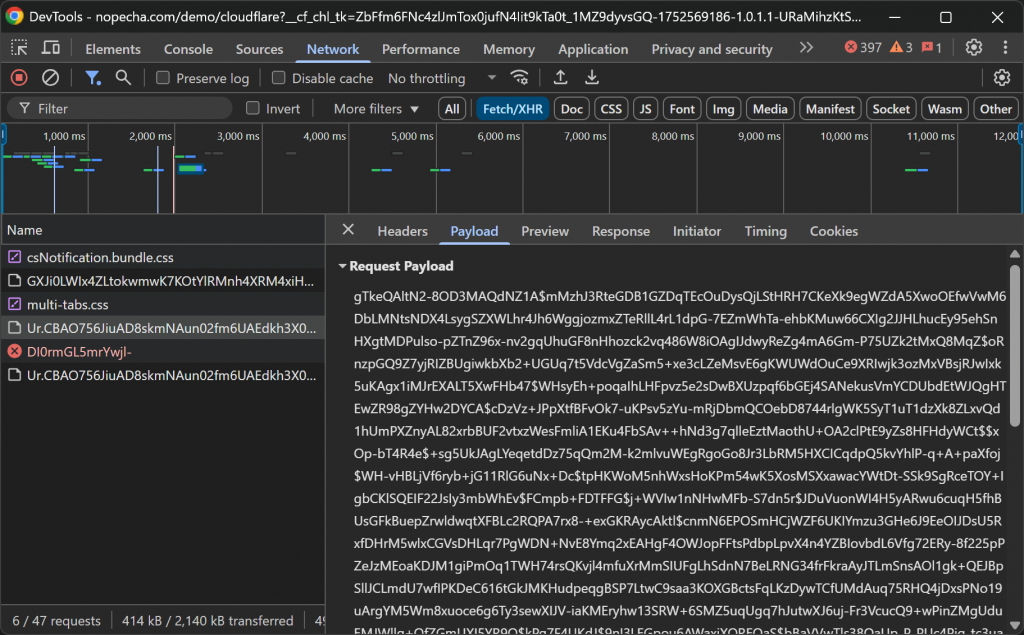
이 페이로드의 정확한 내용은 공개적으로 문서화되어 있지 않습니다. 그러나 Cloudflare의 알려진 탐지 전략을 고려할 때, 여러 유형의 브라우저 및 시스템 지문이 포함되어 있다고 가정하는 것이 합리적입니다.
사용자의 브라우저 및 하드웨어 구성이 정상적이라면 이 검증은 자동으로 통과됩니다. 그렇지 않은 경우 필요한 사용자 상호작용(예: 체크박스 클릭)을 수행하십시오.
검증이 성공하면 Cloudflare 서버는 특정 사용자 세션이 웹사이트 접근을 허용받았음을 나타내는 cf_clearance 쿠키를 발급합니다:
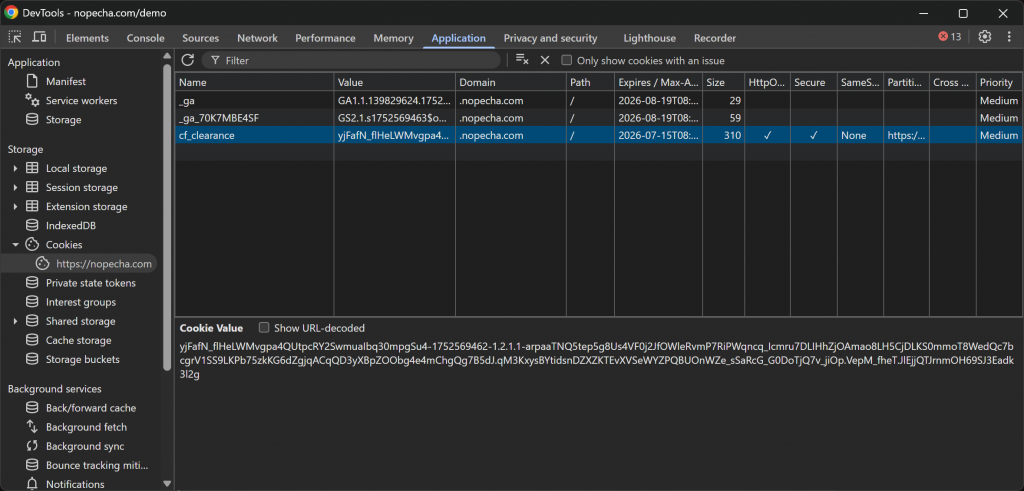
이 경우 쿠키는 15일간 유효합니다. 이는 이론적으로 자동화된 봇이 몇 주 동안 재사용하여 다시 검증 과정을 거치지 않고도 대상 사이트에 접근할 수 있음을 의미합니다.
Cloudflare로 보호된 사이트에 접속할 때 발생하는 현상
이제 자동화된 봇이 Cloudflare로 보호되는 페이지를 방문하려고 할 때 실제로 어떤 일이 발생하는지 살펴보겠습니다.
참고: 아래 샘플 스크립트는 Python으로 작성되지만, 선택한 프로그래밍 언어, HTTP 클라이언트 또는 브라우저 자동화 도구에 관계없이 동일한 원리가 적용됩니다.
이 데모에서는 ScrapingCourse의 Cloudflare 챌린지 페이지를 사용하겠습니다:
이 사이트는 Cloudflare 인증을 통과해야 합니다. 챌린지를 성공적으로 해결하면 다음과 같은 페이지가 표시됩니다:
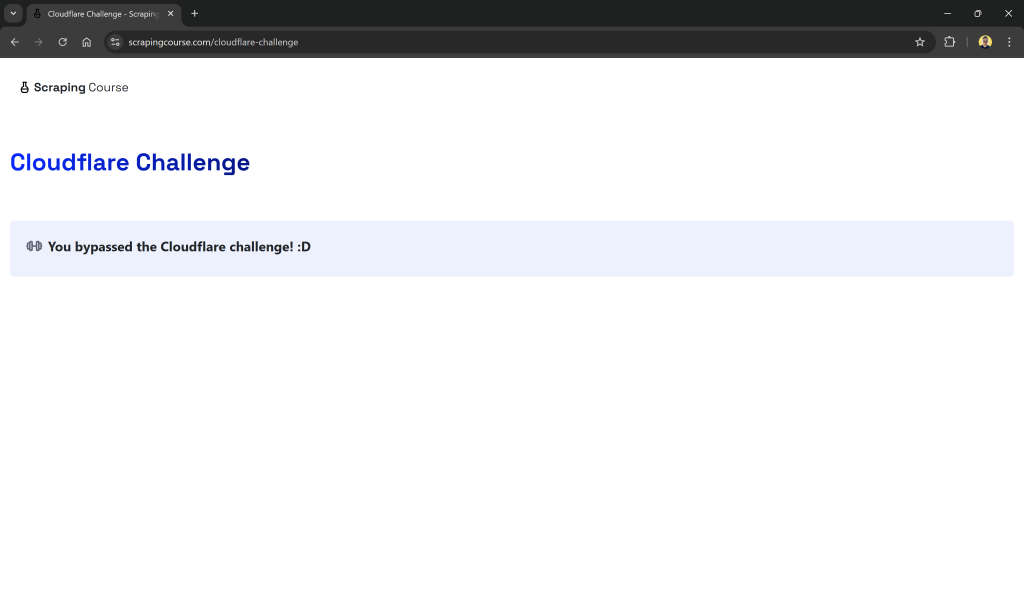
다음 예시에서는 특히 가져온 페이지 콘텐츠에 다음 문자열이 포함되는지 확인할 것입니다:
"You bypassed the Cloudflare challenge! :D"이를 통해 인증 절차가 성공적으로 완료되었음을 확인할 수 있습니다.
기본 테스트로, 위의 Cloudflare 보호 페이지를 두 가지 다른 접근 방식으로 방문했을 때 어떤 일이 발생하는지 살펴보겠습니다:
- Requests 같은 HTTP 클라이언트 사용
- Playwright와 같은 브라우저 자동화 도구 사용
Requests로 Cloudflare 보호 페이지 타겟팅
다음 명령어로 Requests가 Cloudflare의 인간 인증을 자동으로 우회하는지 확인합니다:
# pip install requests
import requests
# 대상 페이지에 연결
response = requests.get(
"https://www.scrapingcourse.com/cloudflare-challenge")
# HTTP 오류 상태 코드 발생 시 예외 발생
response.raise_for_status()
# 성공 페이지 수신 여부 확인
html = response.text
print("Cloudflare 우회 성공:", "Cloudflare 인증을 우회했습니다! :D" in html) 이 스크립트는 최종 print() 문까지 도달하지 못할 것입니다. 대신 다음과 같은 오류가 발생합니다:
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: https://www.scrapingcourse.com/cloudflare-challenge보시다시피, Cloudflare는 이 요청이 자동화된 스크립트에서 온 것으로 인식하고 403 Forbidden 응답으로 차단했습니다.
Playwright로 Cloudflare 보호 페이지 방문하기
이제 Playwright와 같은 브라우저 자동화 솔루션을 사용해 보겠습니다:
# pip install playwright
# python -m playwright install
from playwright.sync_api import sync_playwright
from playwright.sync_api import TimeoutError
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
# 대상 페이지로 이동
page.goto("https://www.scrapingcourse.com/cloudflare-challenge")
try:
# 페이지에 원하는 텍스트가 표시될 때까지 대기
page.locator("text=You bypassed the Cloudflare challenge! :D").wait_for()
challenge_bypassed = True
except TimeoutError:
challenge_bypassed = False
# 브라우저 닫기 및 리소스 해제
browser.close()
print("Cloudflare 우회 성공:", challenge_bypassed)이 스크립트는 Chromium 브라우저가 대상 페이지를 방문하도록 지시합니다. 그런 다음 로케이터를 사용하여 필요한 텍스트를 포함하는 요소가 페이지에 나타나는지 확인하고 자동으로 대기합니다(기본적으로 Playwright는 최대 30초까지 대기합니다).
필요한 설치 명령어를 실행하고 위 스크립트를 실행하세요. 다음과 같은 출력이 표시됩니다:
Cloudflare 우회 성공: False헤드리스 모드(headless=False)로 실행하면 스크립트가 Cloudflare 인증 페이지에서 멈추는 것을 확인할 수 있습니다. 이 페이지에는 Turnstile CAPTCHA가 표시되며 수동으로 해결될 때까지 대기합니다:

참고: Turnstile 체크박스를 자동으로 클릭하려고 시도하면 인증이 실패합니다. Cloudflare는 자동화된 행위인지 실제 인간 상호작용인지 감지할 만큼 지능적이기 때문입니다.
Cloudflare 우회를 위한 고수준 접근법
자동화 스크립트로 Cloudflare 보호를 우회하는 세 가지 방법을 살펴보세요.
방법 #1: Cloudflare 전체 우회
Cloudflare는 CDN 역할을 한다는 점을 잊지 마십시오. 즉, 사이트 콘텐츠를 캐싱하고 지리적으로 분산된 여러 서버에 배포합니다. 따라서 Cloudflare를 통해 배포되는 사이트는 일반적으로 CDN 네트워크 내 서버를 통해서만 접근 가능합니다.
이제 CDN 뒤에 있는 사이트 서버의 IP 주소를 알아낼 수 있다고 가정해 보세요. 그 결과 Cloudflare를 완전히 우회하면서 사이트와 상호작용할 수 있게 됩니다. 결국 Cloudflare는 자체 네트워크를 통과하는 요청만 평가할 수 있기 때문입니다.
SecurityTrails 같은 DNS 기록 조회 도구를 활용해 원본 서버 IP를 드러내는 과거 DNS 레코드를 확인하면 가능합니다. IP를 확보한 후에는 Cloudflare를 우회해 서버에 직접 요청을 전송할 수 있습니다.
문제는 해당 서버가 Cloudflare의 IP 범위에서만 요청을 수락하도록 추가 설정이 되어 있을 수 있다는 점입니다. 이 경우 차단 없이 사이트에 직접 연결하는 것은 거의 불가능합니다. 또한 원본 서버 IP를 성공적으로 찾는 것은 상당히 어렵고 가능성이 낮습니다.
접근법 #2: 클라우드플레어 솔버 활용
온라인에서 Cloudflare 우회를 위해 설계된 여러 무료 오픈소스 라이브러리를 찾을 수 있습니다. 가장 널리 사용되는 것들로는 다음과 같습니다:
- cloudscraper: Cloudflare의 봇 방지 도전을 처리하는 Python 모듈.
- Cfscrape: Cloudflare의 안티봇 페이지를 우회하는 경량 PHP 모듈.
- Humanoid: Cloudflare의 안티봇 자바스크립트 챌린지를 우회하는 Node.js 패키지.
당연히도, 이러한 프로젝트 대부분은 수년간 업데이트되지 않았습니다. 그 이유는 개발자들이 Cloudflare의 업데이트를 따라잡기 위한 지속적인 노력에 지쳐 포기했기 때문입니다. 따라서 이러한 도구들은 일반적으로 오래 작동하지 않습니다.
접근법 #3: Cloudflare 우회 기능이 있는 자동화 솔루션 사용
대부분의 경우 Cloudflare로 보호된 사이트를 스크래핑하는 최선의 해결책은 올인원 자동화 솔루션을 사용하는 것입니다. 효과적이기 위해서는 이러한 라이브러리나 온라인 서비스가 최소한 다음과 같은 기능을 제공해야 합니다:
- Cloudflare의 자바스크립트 챌린지를 제대로 실행할 수 있도록 자바스크립트 렌더링
- 실제 사용자를 모방하고 탐지를 피하기 위한 TLS, HTTP 헤더 및 브라우저 지문 위조 기능.
- 터널스타일 CAPTCHA 해결 기능: Cloudflare의 인간 인증이 나타날 때 처리할 수 있어야 합니다.
- 마우스 움직임을 B-스플라인 곡선으로 시뮬레이션하는 등 자연스러운 사용자 행동을 모방하는 인간형 상호작용.
또한 프리미엄 솔루션은 IP 주소를 순환하고 차단 위험을 줄이기 위한 통합 프록시 네트워크를 포함하는 경우가 많습니다.
다음 두 장에서는 오픈 소스 및 주로 프리미엄 솔루션이 실제로 작동하는 모습을 볼 수 있습니다!
파이썬으로 Cloudflare 인간 확인 우회하는 방법
클라우드플레어 우회를 주장하는 대부분의 오픈소스 솔루션은 제한된 기간 동안만 작동합니다. 이는 본질적으로 고양이와 쥐의 게임이며, 클라우드플레어 엔지니어가 코드를 쉽게 분석할 수 있는 오픈소스 특성 탓입니다.
따라서 한때 작동했던 많은 도구(예: Puppeteer Stealth)가 더 이상 목표를 달성하지 못하는 것은 놀라운 일이 아닙니다. 그럼에도 불구하고, 작성 시점 기준으로 Cloudflare의 보호 기능을 실제로 우회하는 두 가지 솔루션이 있습니다:
- Camoufox: 맞춤형 파이어폭스 빌드를 기반으로 한 오픈소스 안티디텍트 파이썬 브라우저로, 봇 탐지를 회피하고 웹 스크래핑을 가능하게 설계되었습니다.
- SeleniumBase: 고급 웹 자동화를 위한 오픈소스 전문급 Python 툴킷입니다.
ScrapingCourse의 Cloudflare 챌린지 페이지에서 두 도구의 성능을 비교해 보겠습니다!
Camoufox로 Cloudflare Turnstile 우회하기
먼저, Python 프로젝트에 Camoufox를 설치합니다:
pip install camoufox[geoip]그런 다음 필요한 추가 종속성을 가져옵니다:
python -m camoufox fetch자세한 내용은 공식 설치 가이드를 참조하세요.
Camoufox Python 라이브러리는 Playwright를 기반으로 구축되었으므로 API가 매우 유사합니다. 대상 사이트를 방문하고 Turnstile 챌린지가 나타날 때까지 기다린 후, 실제로 표시되면 다음 로직을 사용하여 처리하세요:
# pip install camoufox[geoip]
# python -m camoufox fetch
from camoufox.sync_api import Camoufox
from playwright.sync_api import TimeoutError
with Camoufox(
headless=False,
humanize=True,
window=(1280, 720) # Turnstile 체크박스가 (210, 290) 좌표에 위치하도록)
as browser:
page = browser.new_page()
# 대상 페이지 방문
page.goto("https://www.scrapingcourse.com/cloudflare-challenge")
# Cloudflare Turnstile이 나타나고 로드될 때까지 대기
page.wait_for_load_state(state="domcontentloaded")
page.wait_for_load_state("networkidle")
page.wait_for_timeout(5000) # 5초
# Turnstile 체크박스 클릭 (존재할 경우)
page.mouse.click(210, 290)
try:
# 원하는 텍스트가 나타날 때까지 대기
page.locator("text=You bypassed the Cloudflare challenge! :D").wait_for()
challenge_bypassed = True
except TimeoutError:
# 텍스트가 나타나지 않음
challenge_bypassed = False
# 브라우저 닫기 및 리소스 해제
browser.close()
print("Cloudflare 우회 성공:", challenge_bypassed)Turnstile 처리 로직은 다소 까다롭다는 점에 유의하세요. 이 로직은 Turnstile 체크박스가 1280×720 브라우저 창에서 대략 (210, 290) 좌표에 나타날 것이라는 가정에 기반합니다.
위 스크립트를 실행하면 다음과 같은 결과를 얻을 수 있습니다:
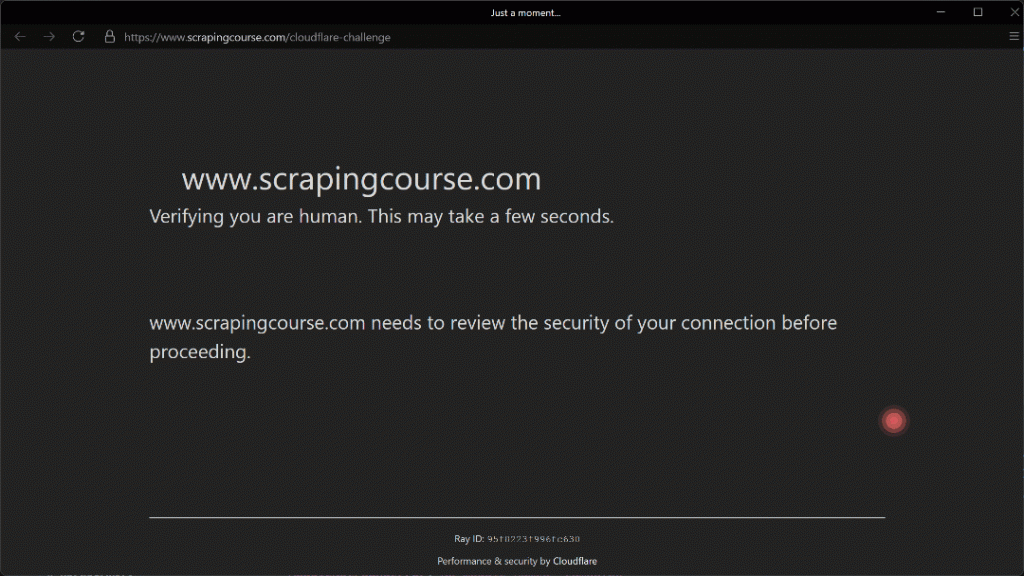
Humanize=True 매개변수 덕분에 (210, 290) 좌표 방향으로의 자동화된 마우스 움직임이 현실적으로 보입니다.
여기서 볼 수 있듯이 Camoufox는 체크박스를 성공적으로 클릭합니다. 결과적으로 터미널에는 다음과 같은 출력이 표시됩니다:
Cloudflare 우회 성공: True미션 완료!
SeleniumBase로 Cloudflare 우회하기
SeleniumBase 설치 방법:
pip install seleniumbase그런 다음 Cloudflare 처리를 위해 사용:
# pip install seleniumbase
from seleniumbase import Driver
from seleniumbase.common.exceptions import TextNotVisibleException
# 탐지되지 않는 크롬 드라이버 모드로 실행
driver = Driver(uc=True)
# 대상 페이지 방문
url = "https://www.scrapingcourse.com/cloudflare-challenge"
driver.uc_open_with_reconnect(url, 4)
# 턴스타일(존재할 경우) 클릭 후 페이지 재로드
driver.uc_gui_click_captcha()
try:
# 원하는 텍스트가 나타날 때까지 대기
driver.wait_for_text("You bypassed the Cloudflare challenge! :D", "main")
challenge_bypassed = True
except TextNotVisibleException:
# 텍스트가 표시되지 않음
challenge_bypassed = False
# 브라우저를 닫고 리소스를 해제
driver.quit()
print("Cloudflare 우회 성공:", challenge_bypassed) uc=True 모드(내부적으로 undetected-chromedriver 사용)에서는 SeleniumBase가 전용 uc_gui_click_captcha() 메서드를 활용해 Turnstile CAPTCHA를 처리할 수 있습니다(해당 CAPTCHA가 나타날 경우). 따라서 이번에는 커스텀 클릭 로직이 필요하지 않습니다.
스크립트를 실행하면 다음과 같은 결과를 확인할 수 있습니다:
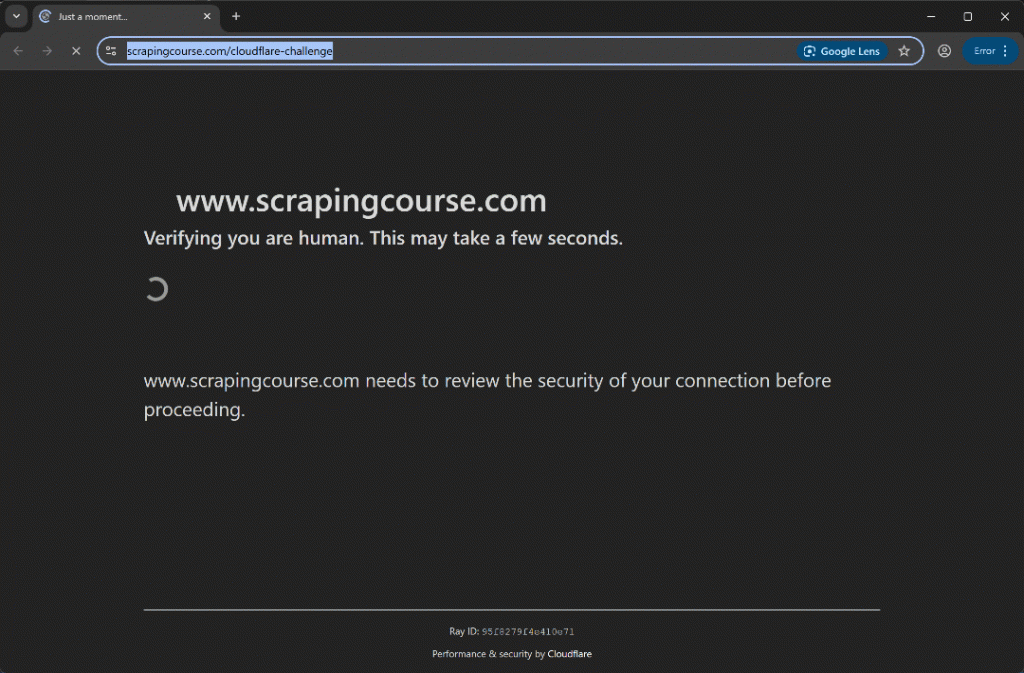
이번에는 자동화 스크립트가 Turnstile CAPTCHA를 트리거하지도 않은 채 초기 인증 단계를 우회합니다. 어느 쪽이든 uc_gui_click_captcha() 메서드가 이를 성공적으로 처리할 수 있었을 것입니다. 이는 UC 모드 덕분에 가능하며, 자세한 내용은 SeleniumBase 스크래핑 가이드에서 확인할 수 있습니다.
자, 이제 Cloudflare를 또다시 우회했습니다.
대규모로 Cloudflare 우회하는 방법
앞서 소개한 두 라이브러리는 간단한 자동화 스크립트에는 효과적이지만 세 가지 주요 단점이 있습니다:
- 효과적인 결과 비율을 높이려면 헤더 모드에서 브라우저를 실행해야 합니다. 이는 많은 시스템 자원을 소모하며 확장성을 어렵게 만듭니다.
- Cloudflare가 탐지 로직을 업데이트하면 일시적으로 작동이 중단될 수 있을 정도로 일관성이 부족합니다. 커뮤니티에서 유지 관리하는 솔루션인 만큼 업데이트가 적용되기까지 며칠에서 몇 주까지 걸릴 수 있습니다.
- 공식 지원이 없습니다. 온라인 자료와 커뮤니티 도움에 의존해야 합니다.
이러한 이유로 Cloudflare 우회 기능을 갖춘 오픈소스 라이브러리는 실제 운영 환경 프로젝트에 권장되지 않습니다. 더 확장 가능하고 일관된 결과, 그리고 전담 24/7 지원팀의지원을 받으려면 Bright Data와 같은 프리미엄 제품이 필요합니다.
특히 여기서는 다음 두 가지 솔루션에 집중하겠습니다:
- 웹 언락커(Web Unlocker): 모든 사이트에서 HTML을 추출하기 위한 모든 안티봇 우회 기능을 포함하는 올인원 스크래핑 엔드포인트입니다.
- 브라우저 API: 모든 자동화 워크플로우를 지원하도록 설계된 무한 확장형 클라우드 브라우저입니다. Puppeteer, Selenium, Playwright 및 기타 모든 브라우저 자동화 도구와 통합됩니다. 고급 지문 관리, 내장형 CAPTCHA 해결 기능, 자동 프록시 로테이션을 포함합니다.
자동화 스크립트에서 이 도구들을 통합하는 방법(모든 프로그래밍 언어를 지원함)을 Python으로 확인하세요!
Web Unlocker로 Cloudflare 우회하기
시작하기 전에 공식 가이드를 따라 Bright Data 계정에서 Web Unlocker를 무료로 설정하세요. 또한 Web Unlocker 엔드포인트에 대한 요청 인증을 위해 Bright Data API 키를 생성해야 합니다.
여기서는 Web Unlocker 영역의 이름을 web_unlocker라고 가정하겠습니다.
위 단계를 완료한 후, 본 문서에서 사용된 대상 페이지에 대해 Web Unlocker를 테스트해 보세요:
# pip install requests
import requests
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # 본인의 Bright Data API 키로 대체
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json"
}
data = {
"zone": "web_unlocker", # Web Unlocker 영역 이름으로 교체
"url": "https://www.scrapingcourse.com/cloudflare-challenge",
"format": "raw"
}
# Web Unlocker 엔드포인트에 요청 수행
response = requests.post(
"https://api.brightdata.com/request",
json=data,
headers=headers)
# 응답 수신 및 Cloudflare 우회 여부 확인
html = response.text
print("Cloudflare 우회 성공:", "Cloudflare 인증을 우회했습니다! :D" in html)Web Unlocker는 Cloudflare 인증 벽 뒤에 있는 페이지의 HTML 콘텐츠를 반환합니다. 특히 html 변수에는 다음과 같은 내용이 포함됩니다:
<!doctype html>
<html lang="en"><head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Cloudflare Challenge - ScrapingCourse.com</title>
<!-- 간결함을 위해 생략 ... -->
<main class="page-content py-4" id="main-content" data-testid="main-content" data-content="main">
<div class="container" id="content-container" data-testid="content-container" data-content="container">
<div class="cloudflareChallenge">
<h1 id="page-title" class="page-title text-4xl font-bold mb-2 text-left gradient-text highlight gradient-text leading-10" data-testid="page-title" data-content="title">
Cloudflare Challenge
</h1>
<div class="challenge-info bg-[#EDF1FD] rounded-md p-4 mb-8 mt-5" id="challenge-info" data-testid="challenge-info" data-content="challenge-info">
<div class="info-header flex items-center gap-2 pb-2" id="info-header" data-testid="info-header" data-content="info-header">
<img width="25" height="15" src="https://www.scrapingcourse.com/assets/images/challenge.svg" data-testid="challenge-image" data-content="challenge-image">
<h2 class="challenge-title text-xl font-bold" id="challenge-title" data-testid="challenge-title" data-content="challenge-title">
클라우드플레어 도전을 우회하셨습니다! 😀
</h2>
</div>
</div>
</div>
</div>
</main>
<!-- 생략 ... -->
</html>이것이 바로 Cloudflare 인간 인증 벽 뒤에 있는 페이지의 HTML 콘텐츠입니다. 따라서 스크립트의 출력이 다음과 같다는 것은 놀라운 일이 아닙니다:
Cloudflare 우회 성공: True성공한 요청에 대해서만 요금이 부과되며, 무료 체험판도 이용 가능합니다!
브라우저 API를 통한 Cloudflare 자동화
사전 준비 단계로 Bright Data 계정에 브라우저 API 제품을 설정하세요. 영역 페이지에서 Playwright CDP 연결 URL을 복사합니다:
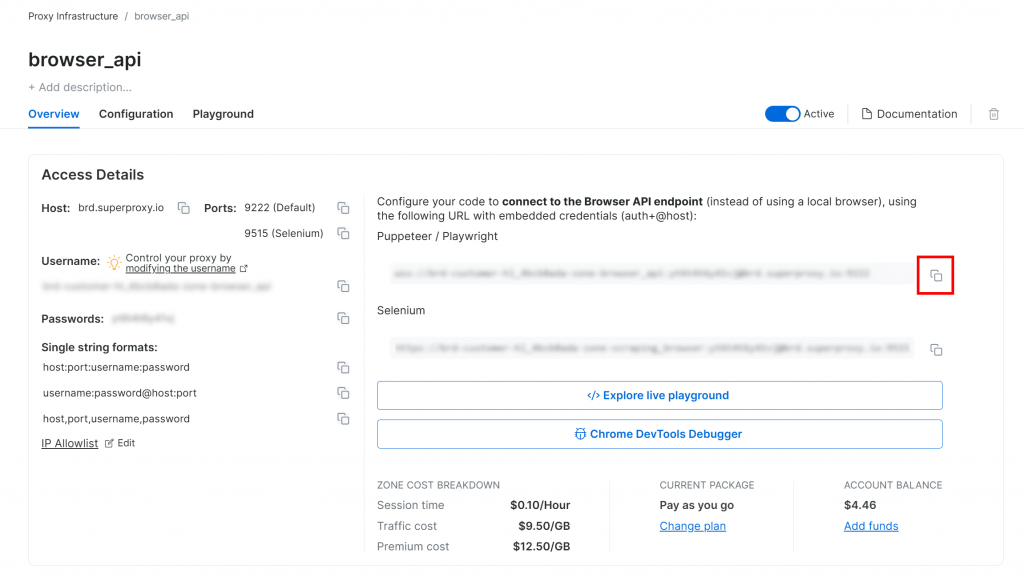
이 URL에는 인증 정보가 포함되어 있으며, 원격 CDP(Chrome DevTools Protocol)를 지원하는 모든 브라우저 자동화 솔루션이 Bright Data 브라우저 API에 연결하도록 지시할 수 있습니다. 즉, 자동화 도구는 Bright Data가 관리하는 원격 호스팅 브라우저 인스턴스에서 작동합니다. 이는 확장성과 브라우저 유지 관리가 자동으로 처리됨을 의미합니다.
앞서 보여드린 Playwright 스크립트를 확장하여 CDP URL을 통해 브라우저 API에 연결하세요:
# pip install playwright
# python install -m playwright install
from playwright.sync_api import sync_playwright
from playwright.sync_api import TimeoutError
BRIGHT_DATA_API_CDP_URL = "<YOUR_BRIGHT_DATA_API_CDP_URL>" # 브라우저 API Playwright CDP URL로 대체
with sync_playwright() as p:
# 원격 브라우저 API에 연결
browser = p.chromium.connect_over_cdp(BRIGHT_DATA_API_CDP_URL)
page = browser.new_page()
# 대상 페이지로 이동
page.goto("https://www.scrapingcourse.com/cloudflare-challenge")
try:
# 페이지에 원하는 텍스트가 표시될 때까지 대기
page.locator("text=You bypassed the Cloudflare challenge! :D").wait_for()
challenge_bypassed = True
except TimeoutError:
challenge_bypassed = False
# 브라우저를 닫고 리소스를 해제
browser.close()
print("Cloudflare 우회 성공:", challenge_bypassed)이번에는 브라우저 API의 고급 기능 덕분에 스크립트가 Cloudflare 인증을 성공적으로 우회할 것입니다. 터미널에 다음과 같은 출력이 표시됩니다:
Cloudflare 우회 성공: True잘하셨습니다! Cloudflare 우회는 더 이상 문제가 되지 않습니다.
결론
이 글에서는 Cloudflare의 작동 방식을 이해하고 자동화 워크플로우에서 이를 우회하는 실용적인 해결책을 살펴보았습니다. 여기서 보셨듯이 Cloudflare의 스크래핑 방지 조치를 우회하는 것은 어렵지만 분명히 가능합니다.
어떤 접근 방식을 선택하든 다음과 같은 전문적이고 빠르며 신뢰할 수 있는 솔루션으로 모든 것이 더 쉬워집니다:
- 웹 언락커(Web Unlocker): 속도 제한, 지문 인식 및 기타 봇 방지 제한을 자동으로 우회해 주는 엔드포인트입니다.
- 브라우저 API: 모든 웹 페이지와의 상호작용을 자동화할 수 있는 완전 호스팅형 브라우저입니다.
지금 무료로 가입하여 Bright Data의 솔루션 중 어떤 것이 귀하의 요구에 가장 적합한지 확인해 보세요!