Google Travel은 항공권, 휴가 패키지, 호텔 객실 등 다양한 여행 관련 카테고리에 대해 웹 전반에서 여행 정보 수집업체의 데이터를 수집합니다. 호텔 예약은 까다로운 작업이며, 가장 큰 어려움 중 하나는 광고 후원 목록과 검색 조건과 무관한 무작위 객실 정보의 혼란을 가려내는 것입니다.
스크래핑에 관심이 없다면, 저희가 미리 준비한 여행 데이터셋을 살펴보세요. 데이터셋을 사용하면 저희가 스크래핑을 대신해 드리므로 직접 할 필요가 없습니다. 스크래핑을 시작할 준비가 되셨다면 계속 읽어보세요!
필수 준비 사항
여행 데이터를 스크래핑하려면 Python과 Selenium, Requests, AIOHTTP 중 하나가 필요합니다. Selenium을 사용하면 Google Travel에서 직접 호텔 정보를 스크래핑할 수 있습니다. Requests와 AIOHTTP를 사용하면 Bright Data의 Booking.com API를 활용할 수 있습니다.
Selenium을 사용하시는 경우, 웹드라이버(webdriver)가 설치되어 있는지 확인해야 합니다. Selenium에 익숙하지 않으시다면, 이 가이드를 참고하여 빠르게 익혀보실 수 있습니다.
Selenium 설치
pip install selenium
Requests 설치
pip install requests
AIOHTTP 설치
pip install aiohttp
선택한 도구를 설치하면 준비가 완료됩니다.
Google Travel에서 추출할 내용
Google Travel을 수동으로 스크래핑하기로 선택한 경우, 스크래핑하려는 데이터에 대해 더 잘 이해해야 합니다. 우리의 모든 호텔 결과는 Google Travel의 사용자 정의 c-wiz 요소에 포함되어 있습니다.
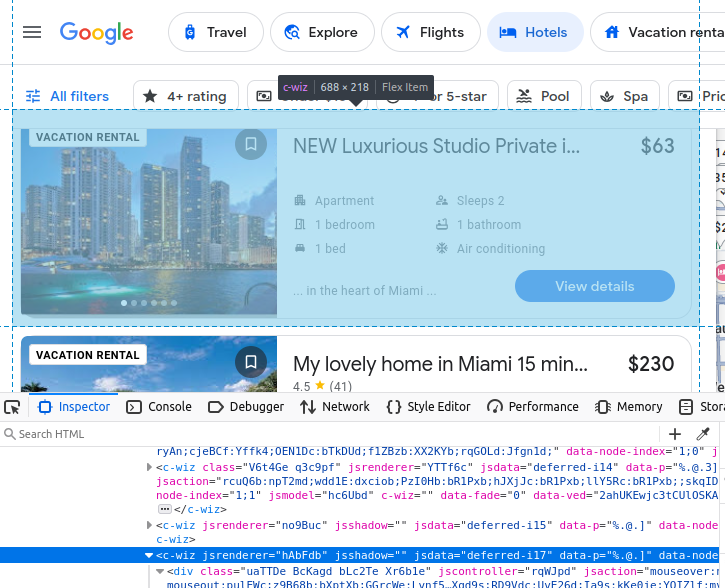
그러나 페이지에는 많은 c-wiz 요소가 있습니다. 각 호텔 카드에는 div와 이 c-wiz 요소에서 직접 하위 요소가 되는 a 요소가 포함되어 있습니다. 다음 요소의 하위 요소가 되는 모든 a 태그를 찾기 위해 CSS 선택기를 작성할 수 있습니다: c-wiz > div > a.
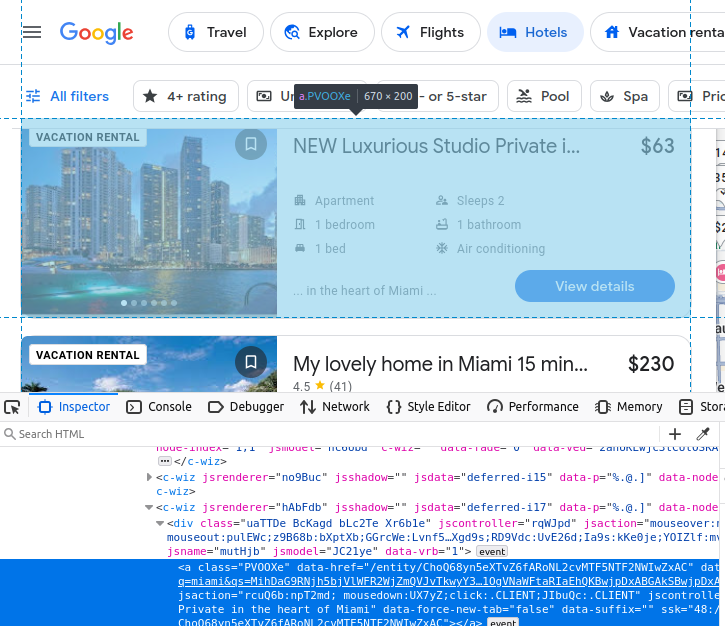
목록 이름은 h2 태그에 내장되어 있습니다.
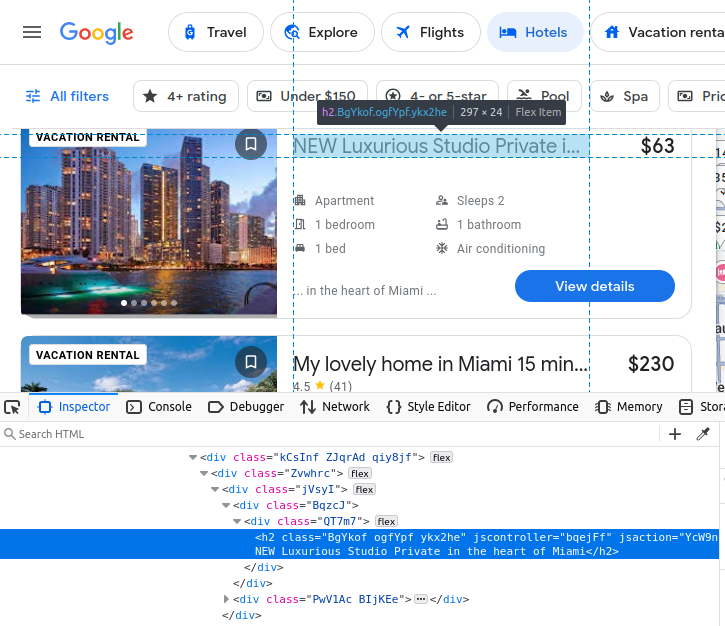
가격은 span에 포함되어 있습니다.
편의시설은 li (목록) 요소 내에 포함됩니다.
호텔 카드를 찾은 후, 위에서 언급한 모든 데이터를 추출할 수 있습니다.
Selenium으로 데이터 추출하기
Selenium으로 이 데이터를 추출하는 것은 무엇을 찾아야 하는지 알면 비교적 간단합니다. 그러나 Google Travel은 결과를 동적으로 로드하기 때문에 사전 설정된 대기 시간, 마우스 클릭, 사용자 정의 창으로 연결된 다소 섬세한 과정이 필요합니다. 사용자 정의 창이 없으면 결과가 제대로 로드되지 않습니다.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import json
from time import sleep
OPTIONS = webdriver.ChromeOptions()
OPTIONS.add_argument("--headless")
OPTIONS.add_argument("--window-size=1920,1080")
def scrape_hotels(location, pages=5):
driver = webdriver.Chrome(options=OPTIONS)
actions = ActionChains(driver)
url = f"https://www.google.com/travel/search?q={location}"
driver.get(url)
done = False
found_hotels = []
page = 1
result_number = 1
while page <= pages:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
sleep(5)
hotel_links = driver.find_elements(By.CSS_SELECTOR, "c-wiz > div > a")
print(f"-----------------PAGE {page}------------------")
print("FOUND ITEMS: ", len(hotel_links))
for hotel_link in hotel_links:
hotel_card = hotel_link.find_element(By.XPATH, "..")
try:
info = {}
info["url"] = hotel_link.get_attribute("href")
info["rating"] = 0.0
info["price"] = "n/a"
info["name"] = hotel_card.find_element(By.CSS_SELECTOR, "h2").text
price_holder = hotel_card.find_elements(By.CSS_SELECTOR, "span")
info["amenities"] = []
amenities_holders = hotel_card.find_elements(By.CSS_SELECTOR, "li")
for amenity in amenities_holders:
info["amenities"].append(amenity.text)
if "DEAL" in price_holder[0].text or "PRICE" in price_holder[0].text:
if price_holder[1].text[0] == "$":
info["price"] = price_holder[1].text
else:
info["price"] = price_holder[0].text
rating_holder = hotel_card.find_elements(By.CSS_SELECTOR, "span[role='img']")
if rating_holder:
info["rating"] = float(rating_holder[0].get_attribute("aria-label").split(" ")[0])
info["result_number"] = result_number
if info not in found_hotels:
found_hotels.append(info)
result_number+=1
except:
continue
print("Scraped Total:", len(found_hotels))
next_button = driver.find_elements(By.XPATH, "//span[text()='Next']")
if next_button:
print("다음 버튼 발견!")
sleep(1)
actions.move_to_element(next_button[0]).click().perform()
page+=1
sleep(5)
else:
done = True
driver.quit()
with open("scraped-hotels.json", "w") as file:
json.dump(found_hotels, file, indent=4)
if __name__ == "__main__":
PAGES = 2
scrape_hotels("miami", pages=PAGES)
- 먼저
ChromeOptions인스턴스를 생성합니다. 이를 통해--headless및--window-size=1920,1080인수를 추가합니다.- 사용자 정의 창 크기를 지정하지 않으면 결과가 제대로 로드되지 않아 동일한 결과를 반복적으로 스크래핑하게 됩니다.
- 브라우저를 실행할 때
options=OPTIONS키워드 인수를 사용합니다. 이로써 사용자 지정 옵션이 적용된 Chrome이 실행됩니다. ActionChains(driver)는ActionChains인스턴스를 제공합니다. 이 인스턴스는 스크립트 후반부에 커서를'다음'버튼으로 이동시킨 후 클릭하는 데 사용됩니다.- 실행 시간을 제어하기 위해
while루프를 사용합니다. 스크래핑이 완료되면 이 루프에서 나옵니다. hotel_links = driver.find_elements(By.CSS_SELECTOR, "c-wiz > div > a")는 페이지의 모든 호텔 링크를 제공합니다. xpath를 사용하여 상위 요소를 찾습니다:hotel_card = hotel_link.find_element(By.XPATH, "..").- 다음으로, 앞서 살펴본 개별 데이터 조각들을 추출합니다:
- url:
hotel_link.get_attribute("href") - name:
hotel_card.find_element(By.CSS_SELECTOR, "h2").text - 가격을 찾을 때 카드 내에
DEAL이나GREAT PRICE같은 추가 요소가 있는 경우가 있습니다. 항상 올바른 가격을 확보하기 위해span요소를 배열로 추출합니다. 배열에 이러한 단어가 포함되어 있다면 첫 번째 요소(price_holder[0].text) 대신 두 번째 요소(price_holder[1].text)를 사용합니다. - 평점을 찾을 때도
find_elements()메서드를 사용합니다. 평점이 존재하지 않으면 기본값으로n/a를부여합니다. hotel_card.find_elements(By.CSS_SELECTOR, "li")는 편의시설 홀더를 반환합니다. 각 홀더의text속성을 추출합니다.
- url:
- 원하는 모든 페이지를 스크래핑할 때까지 이 루프를 계속합니다. 데이터를 모두 수집하면
done을True로설정하고 루프를 종료합니다. - 브라우저를 닫고
json.dump()를사용하여 스크래핑한 모든 데이터를 JSON 파일로 저장합니다.
Google Travel에서 호텔 정보를 스크래핑할 때 차단 문제는 발생하지 않았으나, 모든 가능성은 열려 있습니다. 문제가 발생할 경우, 저희는 주거용 프록시와 프록시가 통합된 Scraping Browser를 제공하여 장애물을 극복할 수 있도록 지원합니다.
Selenium으로 이러한 결과를 스크래핑하는 것은 지루하고 섬세하지만, 완전히 가능합니다.
Bright Data의 Travel API로 데이터 추출하기
스크레이퍼에 의존하거나 셀렉터와 로케이터 처리에 하루 종일 시간을 할애하고 싶지 않을 때가 있습니다. 괜찮습니다! 저희는 다양한 유형의 여행 데이터를 제공합니다. Booking.com API를 사용해 호텔 데이터를 추출할 수도 있습니다. 여러분이 해야 할 일은 몇 번의 HTTP 요청만 보내는 것입니다. 나머지는 저희가 처리하므로 여러분은 본업에 집중하시면 됩니다.
요청
아래 코드는 Booking.com API를 설정합니다. API 키, 여행지, 체크인 날짜, 체크아웃 날짜만 입력하면 됩니다. 먼저 API에 요청을 보내 데이터를 생성합니다. 그런 다음 보고서가 준비될 때까지 10초마다 데이터를 반복적으로 확인합니다. 데이터를 수신하면 편리하게 JSON 파일로 저장합니다.
import requests
import json
import time
def get_bookings(api_key, location, dates):
url = "https://api.brightdata.com/datasets/v3/trigger"
#booking.com 데이터셋
dataset_id = "gd_m4bf7a917zfezv9d5"
endpoint = f"{url}?dataset_id={dataset_id}&include_errors=true"
auth_token = api_key
#
headers = {
"Authorization": f"Bearer {auth_token}",
"Content-Type": "application/json"
}
payload = [
{
"url": "https://www.booking.com",
"location": location,
"check_in": dates["check_in"],
"check_out": dates["check_out"],
"adults": 2,
"rooms": 1
}
]
response = requests.post(endpoint, headers=headers, json=payload)
if response.status_code == 200:
print("요청 성공. 응답:")
print(json.dumps(response.json(), indent=4))
return response.json()["snapshot_id"]
else:
print(f"오류: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file="snapshot-data.json"):
# 스냅샷 URL 생성
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"ID: {snapshot_id}에 대한 스냅샷 폴링 중...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("스냅샷 준비 완료. 다운로드 중...")
snapshot_data = response.json()
# 스냅샷을 새 json 파일에 기록
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"스냅샷을 {output_file}에 저장했습니다")
break
elif response.status_code == 202:
print("스냅샷이 아직 준비되지 않았습니다. 10초 후에 재시도 중...")
else:
print(f"오류: {response.status_code}")
print(response.text)
break
time.sleep(10)
if __name__ == "__main__":
API_KEY = "your-bright-data-api-key"
LOCATION = "Miami"
CHECK_IN = "2026-02-01T00:00:00.000Z"
CHECK_OUT = "2026-02-02T00:00:00.000Z"
DATES = {
"check_in": CHECK_IN,
"check_out": CHECK_OUT
}
snapshot_id = get_bookings(API_KEY, LOCATION, DATES)
poll_and_retrieve_snapshot(API_KEY, snapshot_id)
get_bookings()는API_KEY,LOCATION및DATES를입력으로 받습니다. 이후 데이터를 요청하여snapshot_id를 반환합니다.snapshot_id는 매우 중요합니다. 스냅샷을 가져오기 위해 필요합니다.스냅샷_id가생성된 후,poll_and_retrieve_snapshot()은10초마다 데이터 준비 상태를 확인합니다.- 데이터가 준비되면
json.dump()를사용하여 JSON 파일로 저장합니다.
코드를 실행하면 터미널에 다음과 유사한 내용이 표시됩니다.
Request successful. Response:
{
"snapshot_id": "s_m5moyblm1wikx4ntot"
}
Polling snapshot for ID: s_m5moyblm1wikx4ntot...
Snapshot is not ready yet. Retrying in 10 seconds...
스냅샷이 아직 준비되지 않았습니다. 10초 후에 재시도 중...
스냅샷이 아직 준비되지 않았습니다. 10초 후에 재시도 중...
스냅샷이 아직 준비되지 않았습니다. 10초 후에 재시도 중...
스냅샷 준비 완료. 다운로드 중...
스냅샷이 snapshot-data.json에 저장되었습니다.
그러면 다음과 같은 객체들로 가득 찬 JSON 파일을 받게 됩니다.
{
"input": {
"url": "https://www.booking.com",
"location": "Miami",
"check_in": "2026-02-01T00:00:00.000Z",
"check_out": "2026-02-02T00:00:00.000Z",
"adults": 2,
"rooms": 1
},
"url": "https://www.booking.com/hotel/us/ramada-plaze-by-wyndham-marco-polo-beach-resort.html?checkin=2025-02-01&checkout=2025-02-02&group_adults=2&no_rooms=1&group_children=",
"location": "Miami",
"check_in": "2026-02-01T00:00:00.000Z",
"check_out": "2026-02-02T00:00:00.000Z",
"adults": 2,
"children": null,
"rooms": 1,
"id": "55989",
"title": "윈덤 마르코 폴로 비치 리조트 라마다 플라자",
"address": "19201 콜린스 애비뉴",
"city": "써니 아일스 비치 (플로리다)",
"review_score": 6.2,
"review_count": "1788",
"image": "https://cf.bstatic.com/xdata/images/hotel/square600/414501733.webp?k=4c14cb1ec5373f40ee83d901f2dc9611bb0df76490f3673f94dfaae8a39988d8&o=",
"최종가격": 217,
"원가": 217,
"통화": "USD",
"tax_description": null,
"nb_livingrooms": 0,
"nb_kitchens": 0,
"nb_bedrooms": 0,
"nb_all_beds": 2,
"full_location": {
"description": "지도상의 직선 거리입니다. 실제 이동 거리는 다를 수 있습니다.",
"main_distance": "다운타운에서 11.4마일",
"display_location": "마이애미 비치",
"beach_distance": "해변가",
"nearby_beach_names": []
},
"no_prepayment": false,
"free_cancellation": true,
"property_sustainability": {
"is_sustainable": false,
"level_id": "L0",
"facilities": [
"436",
"490",
"492",
"496",
"506"
]
},
"timestamp": "2026-01-07T16:43:24.954Z"
},
AIOHTTP
AIOHTTP를 사용하면 이 과정을 상당히 빠르게 진행할 수 있습니다. 실제로 여러 데이터셋을 동시에 트리거하고, 폴링하고, 다운로드할 수 있습니다. 아래 코드는 위의 Requests 예제에서 다룬 개념을 기반으로 하지만, 강력한 aiohttp.ClientSession() 을 사용하여 비동기적으로 여러 요청을 수행합니다.
import aiohttp
import asyncio
import json
async def get_bookings(api_key, location, dates):
url = "https://api.brightdata.com/datasets/v3/trigger"
dataset_id = "gd_m4bf7a917zfezv9d5"
endpoint = f"{url}?dataset_id={dataset_id}&include_errors=true"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = [
{
"url": "https://www.booking.com",
"location": location,
"check_in": dates["check_in"],
"check_out": dates["check_out"],
"adults": 2,
"rooms": 1
}
]
async with aiohttp.ClientSession(headers=headers) as session:
async with session.post(endpoint, json=payload) as response:
if response.status == 200:
response_data = await response.json()
print(f"위치 {location}에 대한 요청 성공. 응답:")
print(json.dumps(response_data, indent=4))
return response_data["snapshot_id"]
else:
print(f"위치 {location} 에 대한 오류. 상태: {response.status}")
print(await response.text())
return None
async def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file):
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"ID: {snapshot_id} 스냅샷 폴링 중...")
async with aiohttp.ClientSession(headers=headers) as session:
while True:
async with session.get(snapshot_url) as response:
if response.status == 200:
print(f"{output_file}용 스냅샷 준비 완료. 다운로드 중...")
snapshot_data = await response.json()
# 스냅샷 데이터를 파일로 저장
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"{output_file}에 스냅샷 저장됨")
break
elif response.status == 202:
print(f"{output_file}에 대한 스냅샷이 아직 준비되지 않았습니다. 10초 후에 재시도 중...")
else:
print(f"{output_file}에 대한 스냅샷 폴링 중 오류 발생. 상태: {response.status}")
print(await response.text())
break
await asyncio.sleep(10)
async def process_location(api_key, location, dates):
snapshot_id = await get_bookings(api_key, location, dates)
if snapshot_id:
output_file = f"snapshot-{location.replace(' ', '_').lower()}.json"
await poll_and_retrieve_snapshot(api_key, snapshot_id, output_file)
async def main():
api_key = "your-bright-data-api-key"
locations = ["Miami", "Key West"]
dates = {
"check_in": "2026-02-01T00:00:00.000Z",
"check_out": "2026-02-02T00:00:00.000Z"
}
# 모든 위치를 병렬로 처리
tasks = [process_location(api_key, location, dates) for location in locations]
await asyncio.gather(*tasks)
if __name__ == "__main__":
asyncio.run(main())
get_bookings()와poll_and_retrieve_snapshot()모두 이제aiohttp.ClientSession객체를 사용하여 서버에 대한 비동기 요청을 생성합니다.process_location()은특정 위치의 모든 데이터를 처리하는 데 사용됩니다.main()은모든 위치에 대해process_location()을 동시에 호출할 수 있게 합니다.
AIOHTTP를 사용하면 여러 데이터 세트를 동시에 트리거, 폴링 및 다운로드할 수 있습니다. 이렇게 하면 다음 보고서를 생성하기 전에 한 보고서가 완료될 때까지 불필요하게 기다릴 필요가 없습니다.
출력 결과를 살펴보세요. 보시다시피 두 보고서를 모두 트리거합니다. 그런 다음 한 보고서를 다운로드하는 동안 다른 보고서를 계속 대기합니다. 대규모로 처리할 때 이 방법은 엄청난 시간을 절약해 줍니다.
위치: 마이애미 요청 성공. 응답:
{
"snapshot_id": "s_m5mtmtv62hwhlpyazw"
}
위치: 키웨스트 요청 성공. 응답:
{
"snapshot_id": "s_m5mtmtv72gkkgxvdid"
}
ID: s_m5mtmtv62hwhlpyazw에 대한 스냅샷 폴링 중...
ID: s_m5mtmtv72gkkgxvdid에 대한 스냅샷 폴링 중...
snapshot-miami.json에 대한 스냅샷이 아직 준비되지 않았습니다. 10초 후 재시도...
snapshot-key_west.json에 대한 스냅샷이 아직 준비되지 않았습니다. 10초 후에 재시도 중...
snapshot-key_west.json 스냅샷이 아직 준비되지 않았습니다. 10초 후에 재시도 중...
snapshot-miami.json 스냅샷이 아직 준비되지 않았습니다. 10초 후에 재시도 중...
snapshot-key_west.json 스냅샷이 아직 준비되지 않았습니다. 10초 후에 재시도 중...
snapshot-miami.json 스냅샷이 아직 준비되지 않았습니다. 10초 후 재시도 중...
snapshot-miami.json 스냅샷이 준비되었습니다. 다운로드 중...
snapshot-key_west.json 스냅샷이 아직 준비되지 않았습니다. 10초 후 재시도 중...
스냅샷이 snapshot-miami.json에 저장되었습니다.
snapshot-key_west.json 스냅샷이 아직 준비되지 않았습니다. 10초 후에 재시도 중...
snapshot-key_west.json 스냅샷이 아직 준비되지 않았습니다. 10초 후에 재시도 중...
snapshot-key_west.json 스냅샷이 아직 준비되지 않았습니다. 10초 후에 재시도 중...
snapshot-key_west.json 스냅샷이 준비되었습니다. 다운로드 중...
snapshot-key_west.json에 스냅샷 저장됨
Bright Data의 대체 솔루션
강력한 웹 스크레이퍼 API 외에도 Bright Data는 다양한 요구를 충족하도록 맞춤화된 즉시 사용 가능한 데이터 세트를 제공합니다. 가장 인기 있는 여행 데이터 세트는 다음과 같습니다:
Bright Data를 사용하면 완전 관리형 또는 자체 관리형 사용자 지정 데이터 세트 중에서 선택할 수 있으므로, 모든 공개 웹사이트에서 데이터를 추출하고 정확한 사양에 맞게 사용자 지정할 수 있습니다.
결론
웹 스크래핑을 통해 Google Travel에서 호텔 정보의 보물창고를 발견할 수 있습니다. Selenium을 활용한 DIY 방식을 선호하든, Booking.com API로 빠르고 편리한 결과를 원하든, 이 데이터를 수집하여 정말 가치 있는 통찰력을 얻을 수 있습니다. 과거 가격을 분석하든, 효율적으로 객실을 예약하든, 여러분의 기술 스택에 또 하나의 유용한 기술을 추가한 셈입니다!
지금 바로 가입하여 Bright Data 제품을 무료로 체험해 보세요.