

Google Flights는 항공권 가격, 일정, 항공사 정보 등 풍부한 데이터를 제공하는 널리 사용되는 항공권 예약 서비스입니다. 안타깝게도 Google은 이 데이터에 접근할 수 있는 공개 API를 제공하지 않습니다. 그러나 웹 스크래핑은 이 데이터를 추출하는 훌륭한 대안이 될 수 있습니다.
이 글에서는 Python을 사용해 강력한 Google Flights 스크래퍼를 구축하는 방법을 보여드리겠습니다. 모든 단계가 명확히 이해될 수 있도록 하나씩 살펴보겠습니다.
왜 Google Flights를 스크래핑할까요?
Google Flights 스크래핑은 다음과 같은 여러 이점을 제공합니다:
- 시간 경과에 따른 항공권 가격 추적
- 가격 추세 분석
- 항공권 예약 최적 시기 파악
- 다양한 날짜와 항공사 간 가격 비교
여행객에게는 최적의 거래를 찾아 비용을 절감하는 결과를 가져옵니다. 기업에게는 시장 분석, 경쟁사 정보 수집, 효과적인 가격 전략 수립에 도움이 됩니다.
Google Flights 스크레이퍼 구축
구축할 스크레이퍼는 출발 공항, 목적지, 여행 날짜, 티켓 유형(편도 또는 왕복) 등의 세부 정보를 입력할 수 있게 합니다. 왕복 항공권을 예약하는 경우 귀국 날짜도 제공해야 합니다. 스크레이퍼가 나머지를 처리합니다: 이용 가능한 모든 항공편을 불러오고, 데이터를 추출하며, 추가 분석을 위해 결과를 JSON 파일로 저장합니다.
파이썬으로 웹 스크래핑을 처음 접하신다면, 시작하기 위해 이 튜토리얼을 확인해 보세요.
1. Google Flights에서 어떤 데이터를 추출할 수 있나요?
Google Flights는 항공사명, 출발 및 도착 시간, 총 소요 시간, 경유 횟수, 항공권 가격, 환경 영향 데이터(예: CO2 배출량) 등 다양한 데이터를 제공합니다.
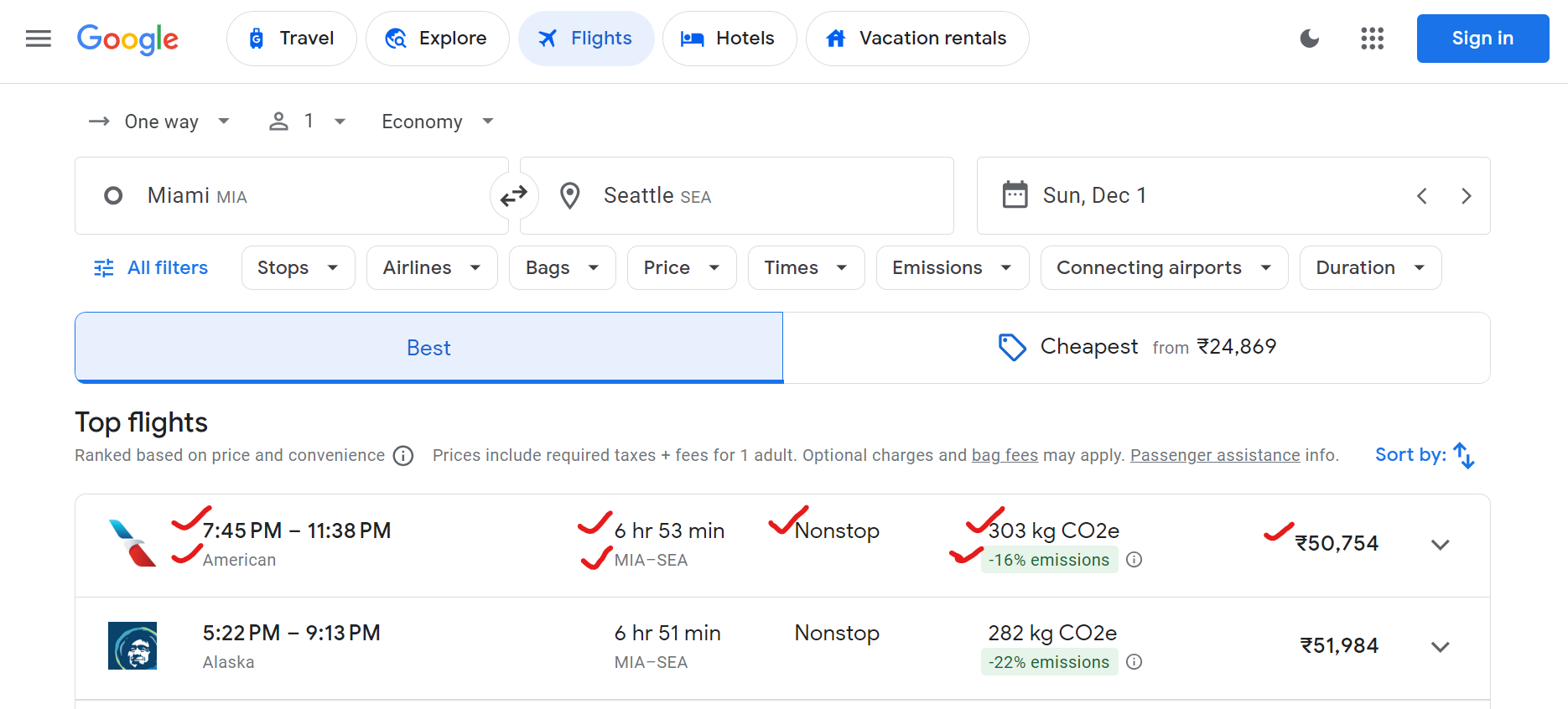
스크래핑 가능한 데이터 예시는 다음과 같습니다:
{
"airline": "Alaska",
"departure_time": "5:22 PM",
"arrival_time": "9:13 PM",
"duration": "6 hr 51 min",
"stops": "Nonstop",
"price": "₹51,984",
"co2_emissions": "282 kg CO2e",
"emissions_variation": "-22% emissions"
}
2. 환경 설정
먼저 스크레이퍼를 실행할 시스템을 설정합니다.
# 가상 환경 생성 (선택 사항)
python -m venv flight-scraper-env
# 가상 환경 활성화
# Windows:
.flight-scraper-envScriptsactivate
# macOS/Linux:
source flight-scraper-env/bin/activate
# 필수 패키지 설치
pip install playwright tenacity asyncio
# Playwright 브라우저 설치
playwright install chromium
Playwright는 Google Flights와 같은 동적 웹 페이지와의 상호작용 및 브라우저 자동화에 이상적입니다. 재시도 메커니즘 구현을 위해 Tenacity를 사용합니다.
Playwright를 처음 사용한다면 Playwright를 활용한 웹 스크래핑 가이드를 꼭 확인하세요.
3. 데이터 클래스 정의
Python의 dataclass를 사용하면 검색 매개변수와 항공편 데이터를 깔끔하게 구조화할 수 있습니다.
from dataclasses import dataclass
from typing import Optional
@dataclass
class SearchParameters:
departure: str
destination: str
departure_date: str
return_date: Optional[str] = None
ticket_type: str = "One way"
@dataclass
class FlightData:
airline: str
departure_time: str
arrival_time: str
duration: str
stops: str
price: str
co2_emissions: str
emissions_variation: str
여기서 SearchParameters 클래스는 출발지, 목적지, 날짜, 티켓 유형과 같은 항공편 검색 세부 정보를 저장하는 반면, FlightData 클래스는 항공사, 가격, CO2 배출량 및 기타 관련 세부 정보를 포함한 각 항공편에 대한 데이터를 저장합니다.
4. FlightScraper 클래스의 스크래퍼 로직
주요 스크래핑 로직은 FlightScraper 클래스에 캡슐화되어 있습니다. 자세한 내용은 다음과 같습니다:
4.1 CSS 선택자 정의
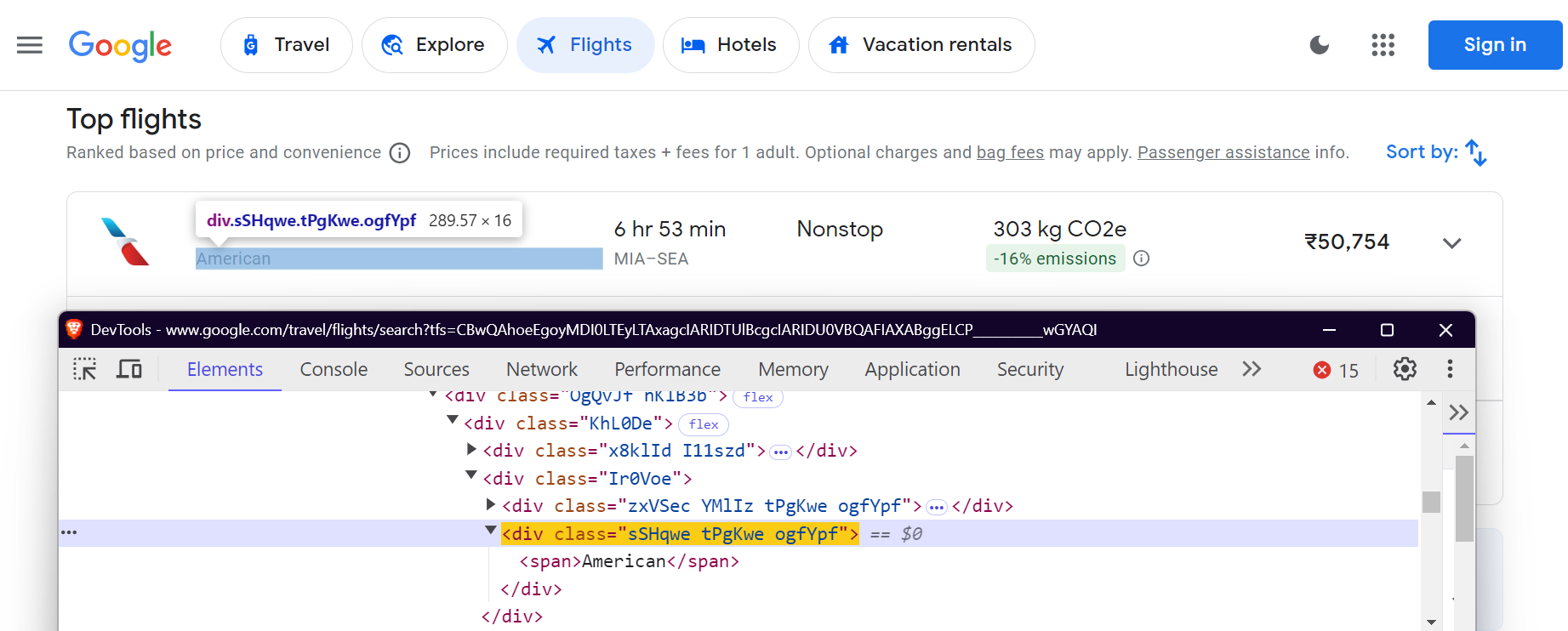
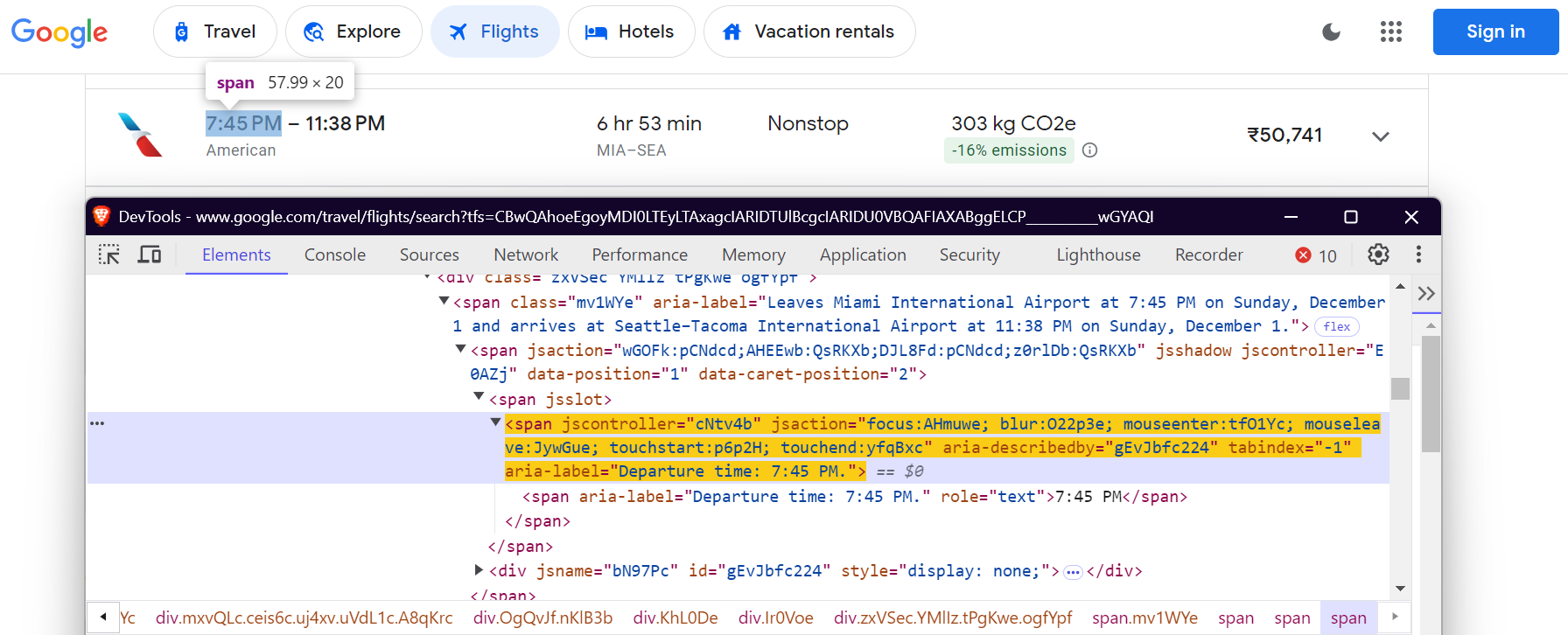
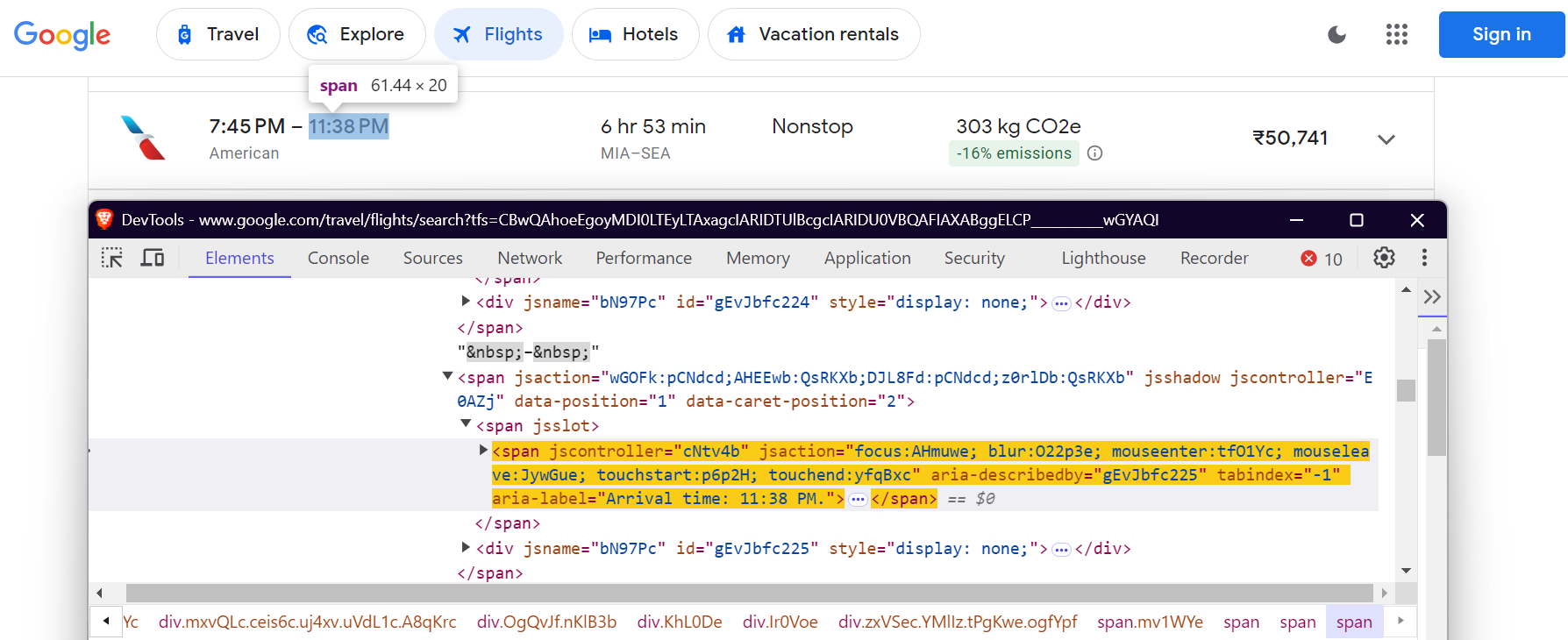
데이터 추출을 위해 Google Flights 페이지의 특정 요소를 찾아야 합니다. 이는 CSS 선택자를 사용하여 수행됩니다. FlightScraper 클래스에서 선택자가 정의된 방식은 다음과 같습니다:
class FlightScraper:
SELECTORS = {
"airline": "div.sSHqwe.tPgKwe.ogfYpf",
"departure_time": 'span[aria-label^="Departure time"]',
"arrival_time": 'span[aria-label^="Arrival time"]',
"duration": 'div[aria-label^="Total duration"]',
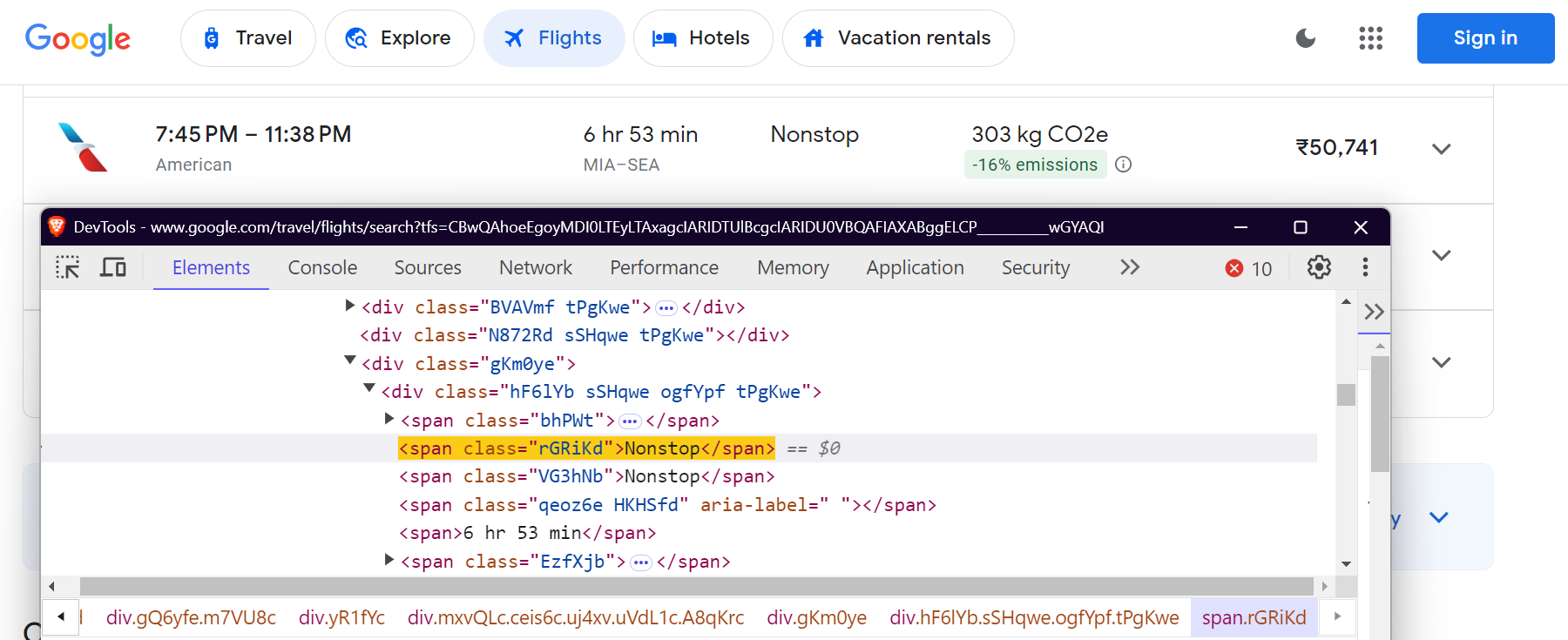
"stops": "div.hF6lYb span.rGRiKd",
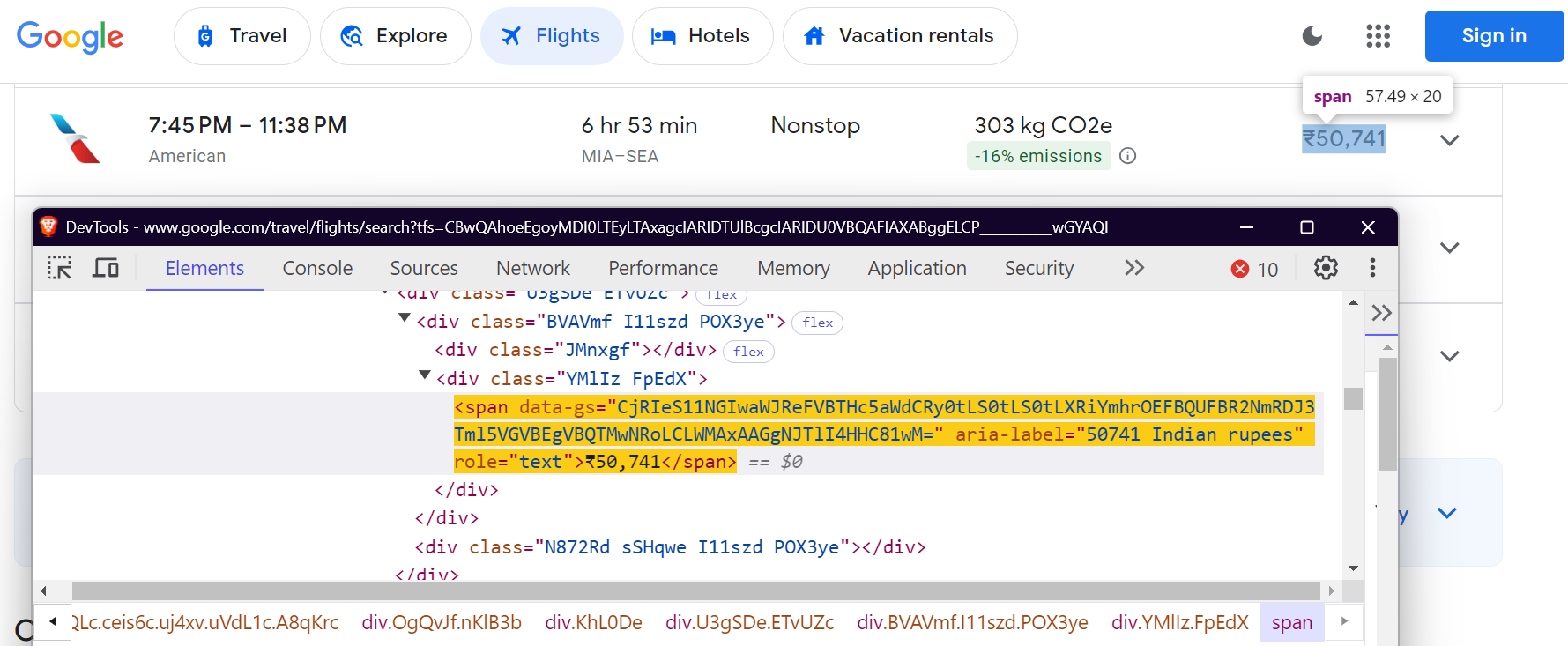
"price": "div.FpEdX span",
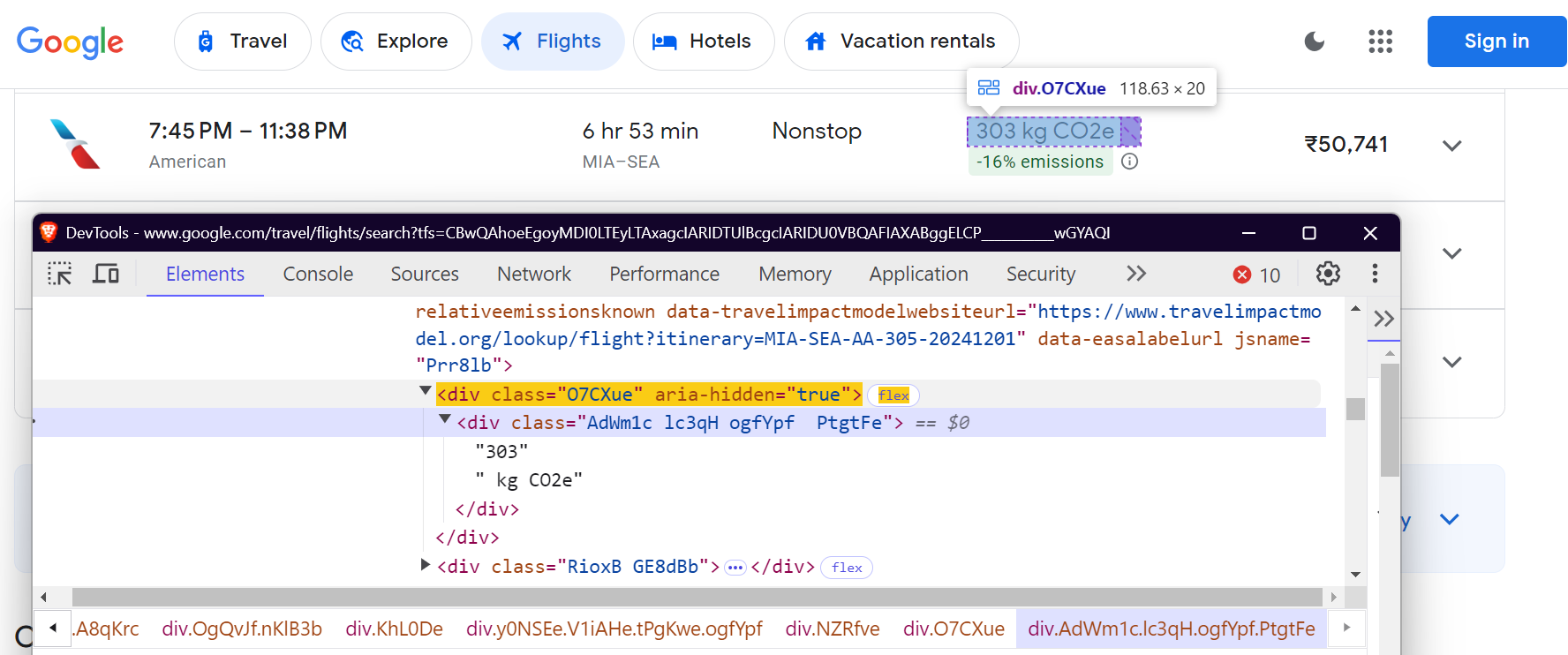
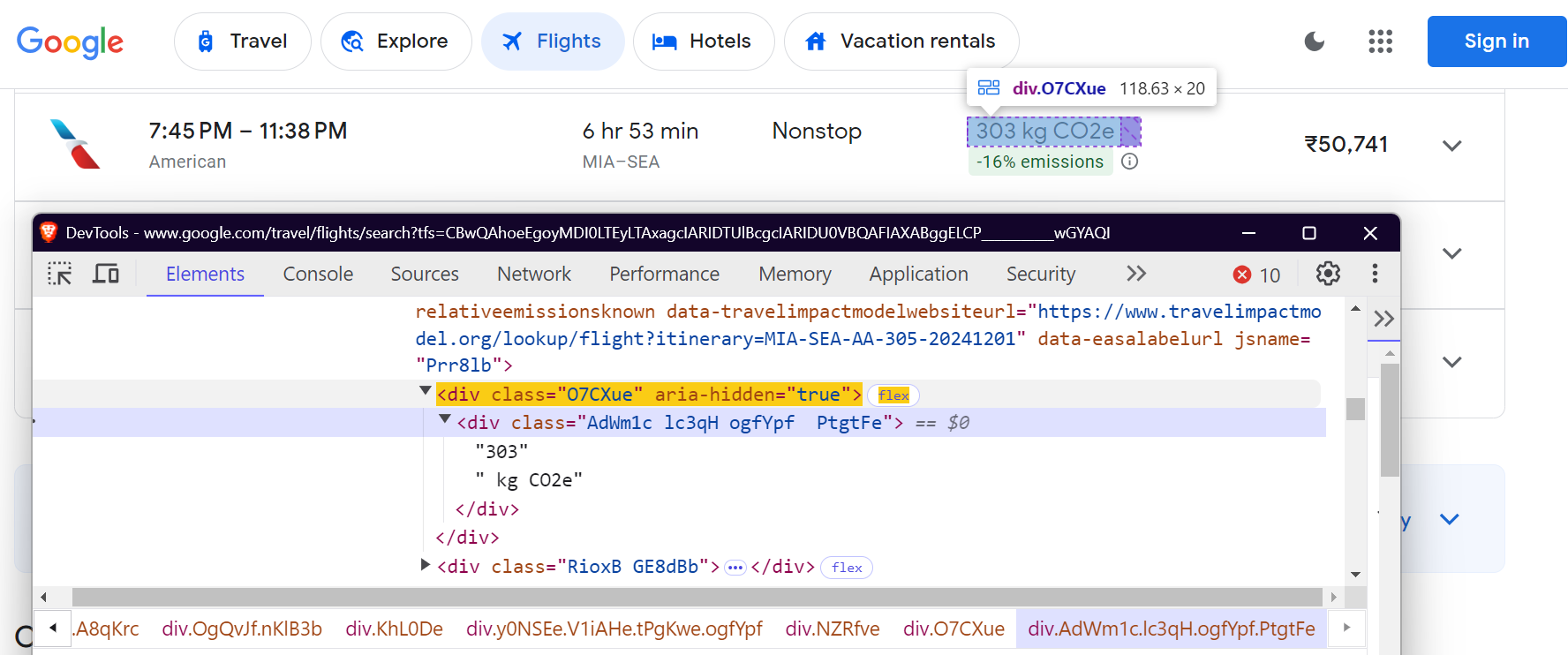
"co2_emissions": "div.O7CXue",
"emissions_variation": "div.N6PNV",
}
이 선택기는 항공사명, 비행 시간, 소요 시간, 경유지, 가격 및 배출량 데이터를 대상으로 합니다.
항공사명:
출발 시간:
도착 시간:
비행 소요 시간:
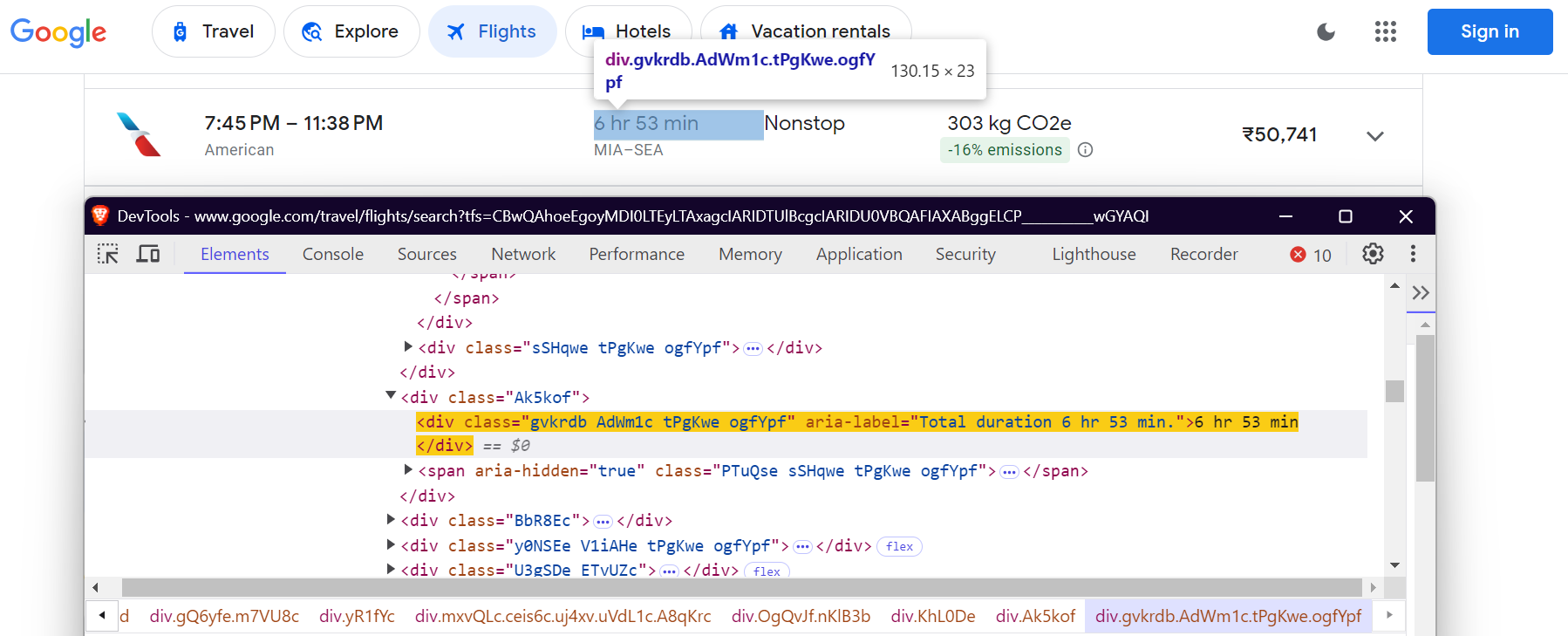
경유 횟수:
가격:
이산화탄소 배출량:
CO2 배출량 변동:
4.2 검색 양식 작성
_fill_search_form 메서드는 출발지, 목적지, 날짜 정보를 입력하여 검색 양식을 작성하는 과정을 시뮬레이션합니다:
async def _fill_search_form(self, page, params: SearchParameters) -> None:
# 먼저 티켓 유형을 선택합니다
ticket_type_div = page.locator("div.VfPpkd-TkwUic[jsname='oYxtQd']").first
await ticket_type_div.click()
await page.wait_for_selector("ul[aria-label='Select your ticket type.']")
await page.locator("li").filter(has_text=params.ticket_type).nth(0).click()
# 이제 출발지와 목적지를 입력해 보겠습니다
from_input = page.locator("input[aria-label='Where from?']")
await from_input.click()
await from_input.fill("")
await page.keyboard.type(params.departure)
# ... 나머지 양식 입력 코드
4.3 모든 결과 로드하기
Google Flights는 페이징을 사용하여 항공편을 로드합니다. 이용 가능한 모든 항공편을 로드하려면 “더 많은 항공편 보기” 버튼을 클릭해야 합니다:
async def _load_all_flights(self, page) -> None:
while True:
try:
more_button = await page.wait_for_selector(
'button[aria-label*="more flights"]', timeout=5000
)
if more_button:
await more_button.click()
await page.wait_for_timeout(2000)
else:
break
except:
break
4.4 항공편 데이터 추출
항공편이 로드되면 항공편 세부 정보를 스크래핑할 수 있습니다:
async def _extract_flight_data(self, page) -> List[FlightData]:
await page.wait_for_selector("li.pIav2d", timeout=30000)
await self._load_all_flights(page)
flights = await page.query_selector_all("li.pIav2d")
flights_data = []
for flight in flights:
flight_info = {}
for key, selector in self.SELECTORS.items():
element = await flight.query_selector(selector)
flight_info[key] = await self._extract_text(element)
flights_data.append(FlightData(**flight_info))
return flights_data
5. 재시도 메커니즘 추가
스크레이퍼의 안정성을 높이기 위해 tenacity 라이브러리를 사용한 재시도 로직을 추가합니다:
@retry(stop=stop_after_attempt(3), wait=wait_fixed(5))
async def search_flights(self, params: SearchParameters) -> List[FlightData]:
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
context = await browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) ..."
)
# ... 나머지 검색 구현
6. 스크래핑된 결과 저장
스크랩한 항공편 데이터를 향후 분석을 위해 JSON 파일로 저장합니다.
def save_results(self, flights: List[FlightData], params: SearchParameters) -> str:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = (
f"flight_results_{params.departure}_{params.destination}_{timestamp}.json"
)
output_data = {
"search_parameters": {
"departure": params.departure,
"destination": params.destination,
"departure_date": params.departure_date,
"return_date": params.return_date,
"search_timestamp": timestamp,
},
"flights": [vars(flight) for flight in flights],
}
filepath = os.path.join(self.results_dir, filename)
with open(filepath, "w", encoding="utf-8") as f:
json.dump(output_data, f, indent=2, ensure_ascii=False)
return filepath
7. 스크레이퍼 실행
Google Flights 스크레이퍼 실행 방법은 다음과 같습니다:
async def main():
scraper = FlightScraper()
params = SearchParameters(
departure="MIA",
destination="SEA",
departure_date="2024-12-01",
# return_date="2024-12-30",
ticket_type="One way",
)
try:
flights = await scraper.search_flights(params)
print(f"{len(flights)}편의 항공편을 성공적으로 찾았습니다")
except Exception as e:
print(f"항공편 검색 중 오류 발생: {str(e)}")
if __name__ == "__main__":
asyncio.run(main())
최종 결과
스크레이퍼 실행 후 항공편 데이터는 다음과 같은 JSON 파일로 저장됩니다:
{
"search_parameters": {
"departure": "MIA",
"destination": "SEA",
"departure_date": "2024-12-01",
"return_date": null,
"search_timestamp": "20241027_172017"
},
"flights": [
{
"airline": "American",
"departure_time": "7:45 PM",
"arrival_time": "11:38 PM",
"duration": "6시간 53분",
"stops": "직항",
"price": "₹50,755",
"co2_emissions": "303 kg CO2e",
"emissions_variation": "-16% 배출량"
},
{
"airline": "알래스카",
"departure_time": "오후 5:22",
"arrival_time": "오후 9:13",
"duration": "6시간 51분",
"stops": "직항",
"price": "₹51,984",
"co2_emissions": "282 kg CO2e",
"emissions_variation": "-22% 배출량"
},
{
"airline": "알래스카",
"departure_time": "오전 9:00",
"arrival_time": "오후 12:40",
"duration": "6시간 40분",
"stops": "직항",
"price": "₹62,917",
"co2_emissions": "325 kg CO2e",
"emissions_variation": "-10% 배출량"
}
]
}
전체 코드는 제 GitHub Gist에서 확인하실 수 있습니다.
Google Flights 데이터 스크래핑 확장 시 흔히 발생하는 문제점
Google Flights 데이터 스크래핑을 확장할 때 IP 차단 및 CAPTCHA와 같은 문제가 흔히 발생합니다. 예를 들어 스크래퍼를 사용하여 짧은 시간에 너무 많은 요청을 보내면 웹사이트에서 IP 주소를 차단할 수 있습니다. 이를 방지하려면 수동 IP 회전을 사용하거나 최고의 프록시 서비스 중 하나를 선택할 수 있습니다. 사용 사례에 가장 적합한 프록시 유형이 무엇인지 확실하지 않다면 웹 스크래핑에 가장 적합한 프록시에 대한 가이드를 확인하세요.
또 다른 문제는 CAPTCHA 처리입니다. 웹사이트는 봇 트래픽을 의심할 때 CAPTCHA를 사용해 스크레이퍼가 이를 해결할 때까지 차단합니다. 수동으로 처리하는 것은 시간 소모적이고 복잡합니다.
그렇다면 해결책은 무엇일까요? 다음에서 자세히 알아보겠습니다!
해결책: Bright Data 웹 스크래핑 도구
Bright Data는 웹 스크래핑 작업을 효율적으로 간소화하고 확장할 수 있도록 설계된 다양한 솔루션을 제공합니다. Bright Data가 이러한 일반적인 문제를 극복하는 데 어떻게 도움이 되는지 살펴보겠습니다.
1. 주거용 프록시
Bright Data의 주거용 프록시는 정교한 대상 웹사이트에 접근하고 스크래핑할 수 있는 능력을 제공합니다. 주거용 프록시를 사용하면 합법적인 주거용 연결을 통해 웹 스크래핑 요청을 라우팅할 수 있습니다. 귀하의 요청은 대상 웹사이트에 특정 지역 또는 지역의 실제 사용자로부터 온 것처럼 보입니다. 결과적으로, IP 기반 스크래핑 방지 조치로 보호되는 페이지에 접근하기 위한 효과적인 솔루션입니다.
2. 웹 언락커
Bright Data의 웹 언락커는 CAPTCHA나 접근 제한에 직면한 스크래핑 프로젝트에 완벽합니다. 수동으로 이러한 문제를 처리하는 대신, 웹 언락커가 자동으로 처리하며 변화하는 사이트 차단에 적응하여 높은 성공률(일반적으로 100%)을 보입니다. 사용자는 요청 하나만 보내면 나머지는 웹 언락커가 처리합니다.
3. 스크래핑 브라우저
Bright Data의 스크래핑 브라우저는 Puppeteer나 Playwright 같은 헤드리스 브라우저를 사용하는 개발자를 위한 또 다른 강력한 도구입니다. 기존 헤드리스 브라우저와 달리 스크래핑 브라우저는 CAPTCHA 해결, 브라우저 지문 인식, 재시도 등을 모두 자동으로 처리하므로 사이트 제한에 대한 걱정 없이 데이터 수집에 집중할 수 있습니다.
결론
이 글에서는 Python과 Playwright를 사용해 Google Flights 데이터를 스크래핑하는 방법을 살펴보았습니다. 수동 스크래핑도 효과적일 수 있지만, IP 차단이나 지속적인 스크립트 유지 관리 같은 문제가 종종 발생합니다. 데이터 수집 작업을 단순화하고 향상시키려면 Bright Data의 솔루션(레지던셜 프록시, Web Unlocker, Scraping Browser 등)을 활용해 보세요.
지금 바로 Bright Data 무료 체험판에 가입하세요!
또한Google 검색 결과 데이터,Google 트렌드,Google Scholar, Google Finance,Google Maps 등 다른 Google 서비스 스크래핑 가이드도 확인해 보세요.





