

Apollo.io는 시장에서 가장 널리 사용되는 B2B 프로스펙팅 플랫폼 중 하나입니다: 2억 7,500만 개 이상의 연락처, 내장된 이메일 시퀀싱, 그리고 100만 명 이상의 사용자를 보유한 무료 플랜을 제공합니다. 이메일 전용 아웃바운드를 운영하는 소규모 SDR 팀에게 검색, 아웃리치, 추적을 하나의 인터페이스로 통합해 줍니다.
Bright Data는 다른 접근 방식을 취합니다. 정적 연락처 데이터베이스를 유지하는 대신, LinkedIn, Crunchbase, ZoomInfo, 6sense, PitchBook 등 10개 이상의 프리미엄 소스에서 B2B 데이터를 온디맨드로 수집하는 API 접근권을 제공합니다. 모든 레코드는 요청 시점에 스크래핑됩니다.
두 플랫폼을 데이터 품질, 신선도, API 기능, 커버리지, 가격 측면에서 비교했습니다. 아래는 그 결과입니다.
Quick Comparison
| 기능 | Bright Data | Apollo.io |
|---|---|---|
| 데이터 아키텍처 | 실시간 스크래핑 + 사전 집계된 다중 소스 데이터셋 | 주기적 갱신이 있는 독점 정적 데이터베이스 |
| 데이터 소스 | 10개 이상 (LinkedIn, Crunchbase, ZoomInfo, 6sense, PitchBook 등) | 기여자 네트워크 + 공개 크롤링 + 서드파티 벤더 |
| 총 레코드 수 | Company Data API 데이터셋 전반에 걸친 5억 개 이상의 기업 프로필; 온디맨드 LinkedIn 스크래핑 | 2억 7,500만 개 이상의 연락처, 3,500만 개 이상의 기업 |
| 데이터 신선도 | 실시간 (요청 시점에 수집) | 주기적 갱신 사이클 (레코드 우선순위에 따라 다름) |
| API 접근 | 모든 계정에서 완전한 REST API 제공 | 유료 플랜(Basic+)에서 API 데이터 보강; 테스트 결과 무료 플랜의 검색/보강 엔드포인트는 403 반환 |
| 데이터 전달 방식 | API, S3, Snowflake, Azure, Webhook을 통한 JSON, CSV, Parquet | CSV/JSON 내보내기; 지원 엔드포인트의 API 응답 |
| 가격 모델 | 레코드당 과금 (PAYG $1.5/1K) 또는 Scale 플랜 (월 $499, 384K 레코드 포함) | 사용자 시트당 + 크레딧 시스템 (사용자당 월 $0~$119) |
| 아웃리치 도구 | 없음 (데이터 인프라 전용) | 이메일 시퀀스, 다이얼러, 미팅 스케줄러, CRM |
| 최적 활용 대상 | 데이터 팀, AI 파이프라인, 대규모 보강, 다중 소스 인텔리전스 | 자체 완결형 아웃바운드 캠페인을 운영하는 SMB SDR 팀 |
The Freshness Problem with Static B2B Databases
B2B 연락처 데이터는 연간 약 22~30% 비율로 노후화됩니다. 사람들은 직장을 옮기고, 기업은 리브랜딩을 하며, 전화번호는 재할당됩니다. 미국 노동통계국은 2024년과 2025년 모두 총 이직률이 3.3%라고 보고했으며, 이는 직업 변경만으로도 매년 연락처 데이터베이스의 상당 부분이 outdated된다는 것을 의미합니다.
Apollo는 세 가지 채널을 통해 데이터베이스를 유지합니다: 이메일 및 캘린더 데이터를 동기화하는 200만 명 이상의 기여자 네트워크, 공개 웹 크롤링, 그리고 서드파티 데이터 벤더입니다. 시스템은 갱신 사이클에서 매월 약 2억 7,000만 개의 레코드를 처리합니다. ‘처리됨’이 ‘레코드별 검증’을 의미하지는 않습니다. 트래픽이 많은 연락처는 더 자주 갱신되고, 트래픽이 적은 레코드는 수개월간 업데이트되지 않을 수 있습니다.
이 문제는 공개 리뷰에서 일관되게 나타납니다:
- G2와 Capterra 리뷰어들은 데이터 정확도가 Apollo의 광고 수치보다 낮은 전반적으로 65~70% 수준이라고 보고합니다
- Apollo에서 내보낸 목록의 이메일 반송률은 독립 테스트에서 지역 및 산업에 따라 15~35%에 달합니다
- 6~12개월 전에 직책을 변경한 연락처의 직함 및 회사 정보는 종종 오래된 상태로 남아있습니다
- 미국 기반 테크 및 SaaS 연락처가 가장 강한 세그먼트로 80~88% 정확도를 보이며, 국제 데이터는 60~73%로 낮아집니다
- 전화번호는 8크레딧이 소모되며 이메일보다 정확도가 낮습니다. 이는 리뷰 플랫폼 전반에서 가장 많이 제기되는 불만 사항입니다
r/coldemail에 공유된 한 상세 테스트에서는 ‘검증됨’으로 표시된 연락처를 포함하여 Apollo에서 내보낸 500~1,000개 리드의 반송률이 32~38%에 달하는 것으로 나타났습니다.
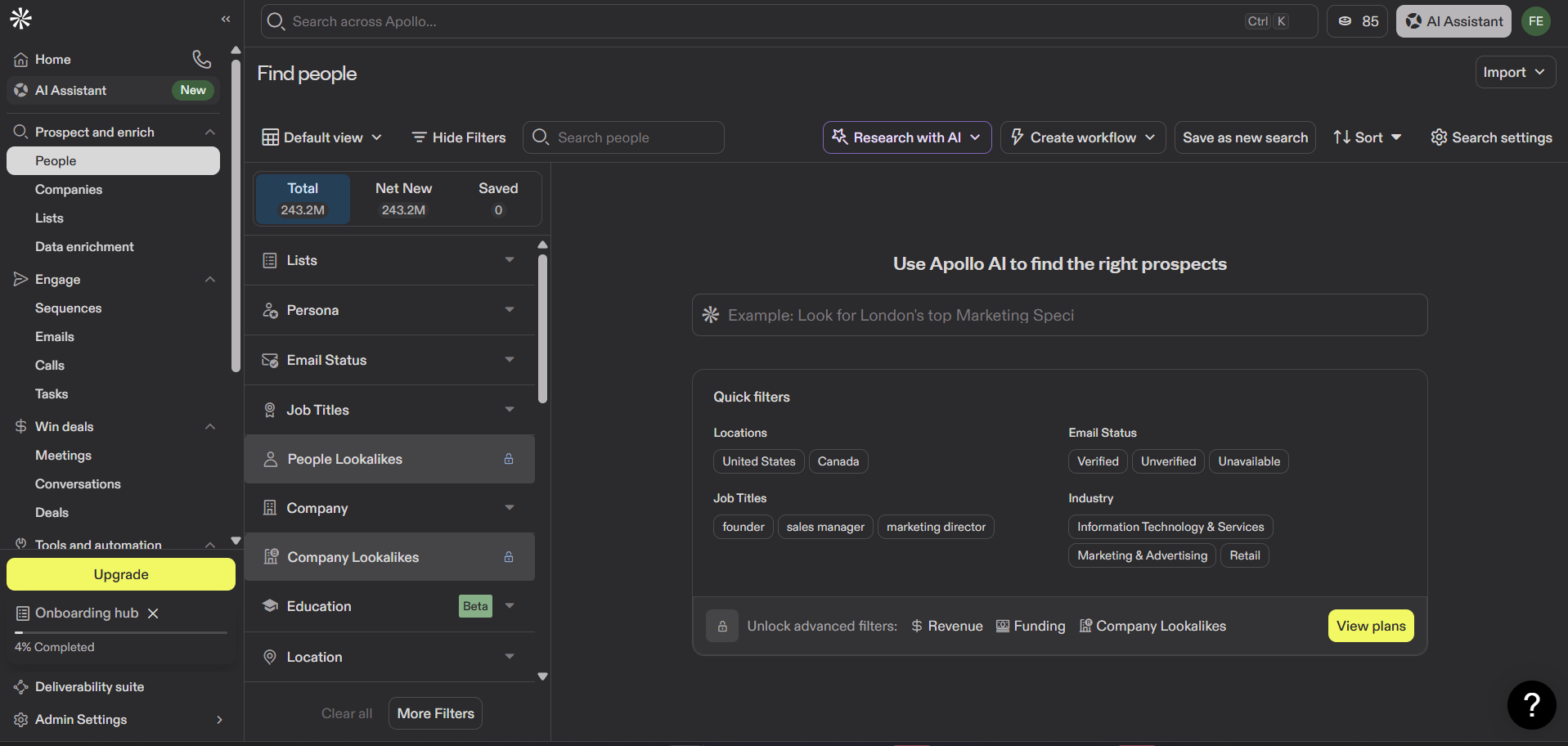
Apollo의 People 검색은 65개 이상의 필터 속성을 갖춘 2억 7,500만 개 이상의 연락처 검색 가능한 데이터베이스를 제공합니다.
Bright Data는 갱신 문제를 완전히 제거합니다. LinkedIn Profiles Scraper API를 호출하면, 데이터는 요청 시점에 실제 LinkedIn 페이지에서 수집됩니다. 캐시 레이어도 없고 갱신 사이클도 없습니다. 잠재 고객이 오늘 아침 LinkedIn 프로필을 업데이트했다면, API는 오후에 업데이트된 버전을 반환합니다.
이를 직접 테스트했습니다. Profiles API를 통해 Satya Nadella의 LinkedIn 프로필을 스크래핑한 결과, 7.2초 만에 응답이 반환되었으며 수집 타임스탬프는 2026-05-27T10:22:15.544Z로, 데이터가 캐시가 아닌 실시간으로 수집되었음을 확인했습니다.
Bright Data’s B2B Data Stack: Hands-On Walkthrough
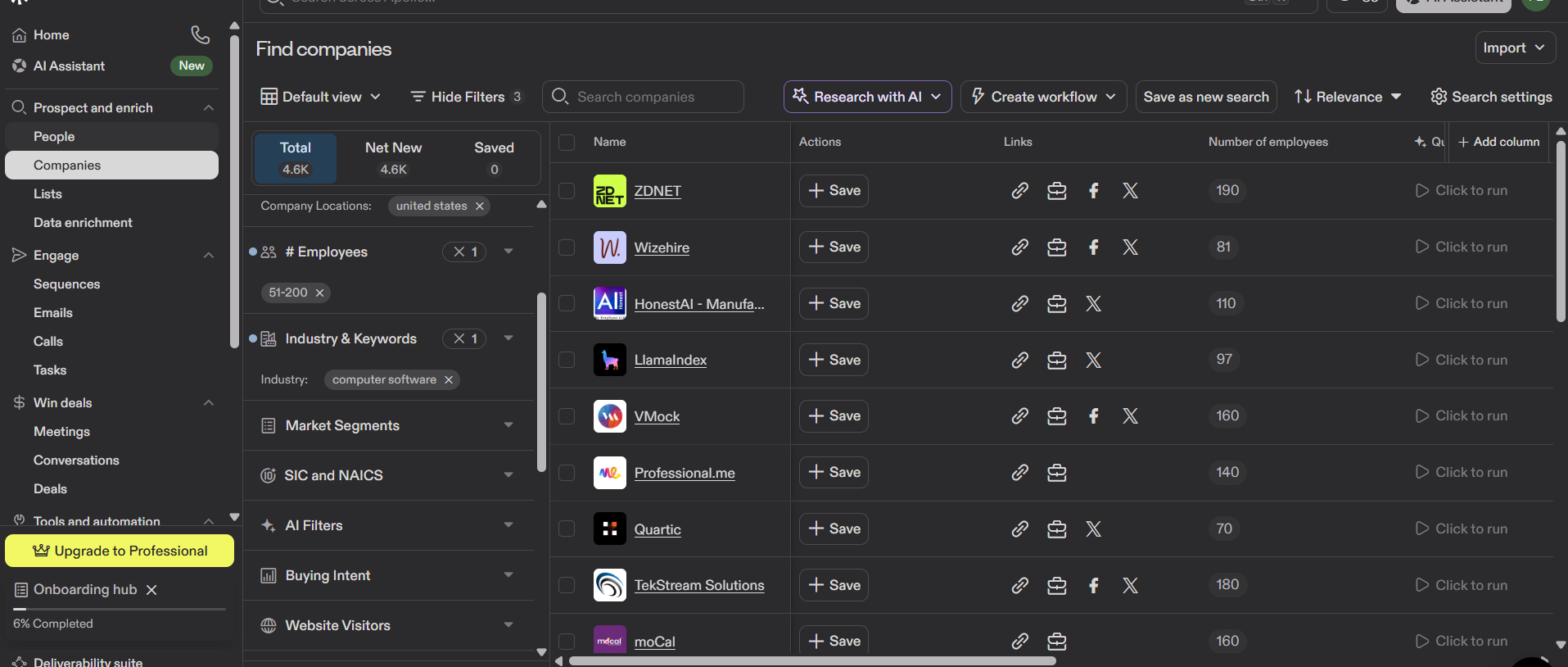
The Dataset Filter API: Large-Scale Company Search
Filter API는 Apollo의 기업 검색과 가장 직접적으로 동등한 기능입니다. 구조화된 필터를 정의하고 사전 집계된 기업 데이터셋을 쿼리합니다. Bright Data의 Company Data API는 집계된 모든 소스(LinkedIn, Crunchbase, ZoomInfo, 6sense, PitchBook 등)에 걸쳐 5억 개 이상의 기업 레코드를 제공합니다. 결과는 몇 분 내에 도착하며, 최종 출력의 레코드에 대해서만 비용을 지불합니다.
직원 수 51~200명의 미국 소프트웨어 기업을 찾기 위해 사용한 API 호출은 다음과 같습니다:
import requests
import time
# Step 1: Trigger a filtered snapshot
# Field names vary by dataset; use API Request Builder for your selected dataset.
response = requests.post(
"https://api.brightdata.com/datasets/filter",
headers={
"Authorization": "Bearer YOUR_API_TOKEN",
"Content-Type": "application/json"
},
json={
"dataset_id": "gd_l1vikfnt1wgvvqz95w",
"filter": {
"operator": "and",
"filters": [
{"name": "industries", "operator": "includes",
"value": "Software Development"},
{"name": "country_code", "operator": "=", "value": "US"},
{"name": "company_size", "operator": "=",
"value": "51-200 employees"}
]
},
"records_limit": 100
}
)
snapshot_id = response.json().get("snapshot_id")
# Step 2: Poll until ready, then download
download_url = (
f"https://api.brightdata.com/datasets/snapshots"
f"/{snapshot_id}/download?format=json"
)
# Poll download_url until HTTP 200, then parse the JSON response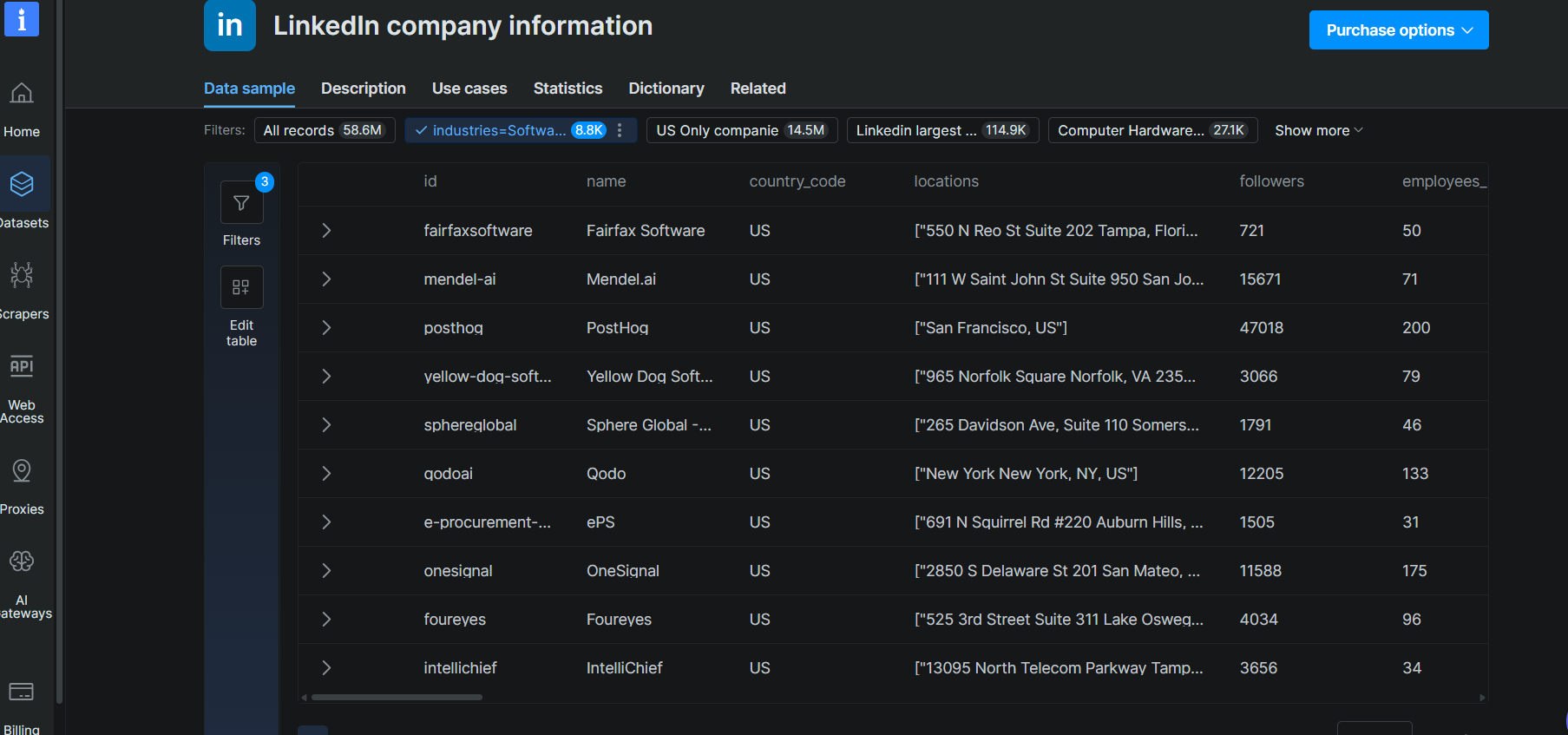
응답은 46.5초 만에 100개의 일치하는 기업을 반환했습니다. 각 레코드에는 기업명, 도메인, 산업 분류, 직원 수, 본사 위치, 설립 연도, LinkedIn URL, Crunchbase URL이 포함되었습니다. 기반 소스에서 데이터가 제공되는 경우 펀딩 필드도 포함될 수 있습니다.
샘플 레코드 (Leanpath):
{
"about": "Leanpath, a Certified B-Corp, is on a mission to make food waste prevention and measurement everyday practice in the world's kitchens...",
"company_id": "400488",
"company_size": "51-200 employees",
"country_code": "US",
"crunchbase_url": "https://www.crunchbase.com/organization/leanpath-inc",
"employees_in_linkedin": 78,
"followers": 6199,
"founded": 2004,
"funding": {
"last_round_date": "2025-03-04T00:00:00.000Z",
"last_round_raised": "US$ 750.0K",
"last_round_type": "Debt financing",
"rounds": 3
}
}다중 소스 아키텍처가 중요한 이유가 바로 여기에 있습니다. 기업의 LinkedIn 데이터에는 직원 수와 산업이 표시될 수 있습니다. Crunchbase는 펀딩 라운드, 투자자, 기업가치 데이터를 추가합니다. ZoomInfo는 테크노그래픽스와 매출 추정치를 제공합니다. Filter API는 이를 여러 제공업체에 걸쳐 교차 검증된 단일 레코드로 병합합니다. Apollo의 기업 검색은 하나의 독점 데이터베이스만 쿼리합니다.
LinkedIn Profiles Scraper API: Live Contact Data in 7 Seconds
연락처 수준의 데이터를 위해 Bright Data의 LinkedIn Profiles Scraper API를 테스트했습니다. 이 API는 LinkedIn 프로필 URL을 받아 실제 페이지를 스크래핑하고(CAPTCHA, 로그인 장벽, JS 렌더링 처리), 구조화된 JSON을 반환합니다.
import requests
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape",
params={
"dataset_id": "gd_l1viktl72bvl7bjuj0",
"format": "json"
},
headers={
"Authorization": "Bearer YOUR_API_TOKEN",
"Content-Type": "application/json"
},
json=[{"url": "https://www.linkedin.com/in/fimber-elemuwa/"}]
)
profile = response.json()이번에는 테스트로 Fimber Elemuwa의 프로필을 스크래핑했습니다. 응답은 7.2초 만에 반환되었으며 이름, 현재 직함, 현재 회사, 위치, 전체 경력 이력, 학력, 스킬, 참여 데이터가 포함되었습니다. 타임스탬프 필드는 2026-05-27T10:22:15.544Z로, 데이터가 실시간으로 수집되었음을 확인했습니다.
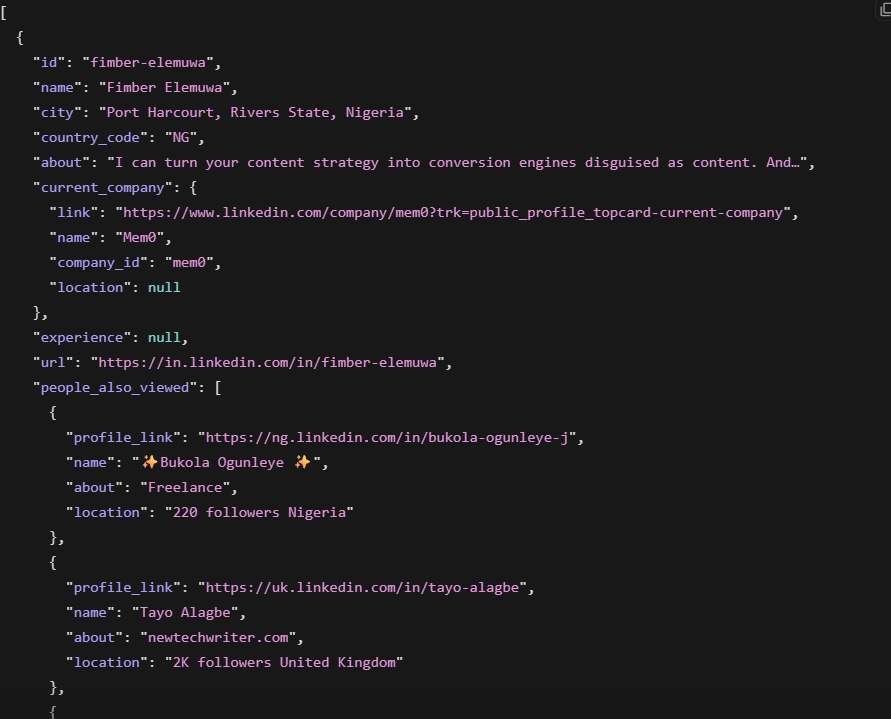
Apollo는 자체 일정에 따라 갱신된 이 프로필의 스냅샷을 저장합니다. Bright Data는 요청 시점에 LinkedIn에서 데이터를 수집합니다. 잘 알려진 CEO의 경우 두 소스가 일치할 가능성이 높습니다. 차이는 Apollo의 갱신 주기가 덜 빈번하고 오래된 데이터가 더 많은 소규모 기업의 중간급 연락처에서 나타납니다.
LinkedIn Companies Scraper API: Firmographic Data on Demand
Microsoft의 LinkedIn 기업 페이지를 가져와 Companies Scraper API도 테스트했습니다.
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape",
params={
"dataset_id": "gd_l1vikfnt1wgvvqz95w",
"format": "json"
},
headers={
"Authorization": "Bearer YOUR_API_TOKEN",
"Content-Type": "application/json"
},
json=[{"url": "https://www.linkedin.com/company/microsoft/"}]
)
company = response.json()응답은 12.3초 만에 반환되었으며 기업명, 직원 수(LinkedIn 기준 231,622명), 본사 위치, 산업, Crunchbase URL, 최근 기업 게시물이 포함되었습니다. 이 경우 펀딩 필드도 포함되었지만, 기업에 따라 제공 여부가 다를 수 있습니다.
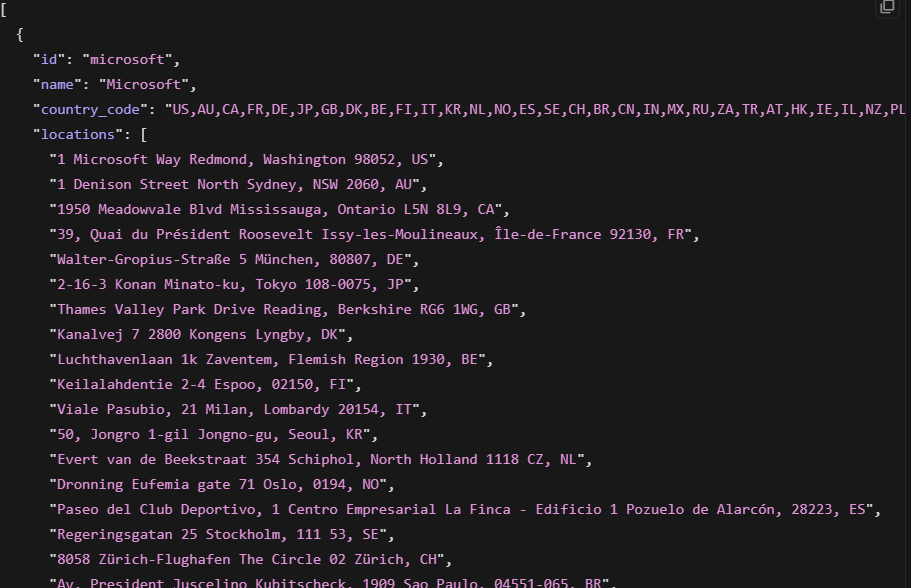
더 심층적인 펌모그래픽 데이터(금액 및 투자자가 포함된 전체 펀딩 라운드 이력, 매출 추정치, 테크노그래픽 프로필)를 위해서는 Company Data API의 다중 소스 집계 레이어가 LinkedIn 단독 스크래핑보다 더 완전한 그림을 제공합니다. 기업 스크래퍼는 빠른 단일 소스 조회에 적합하고, Filter API는 대규모의 풍부한 다중 소스 레코드에 적합합니다.
The Full Scraper API Suite
테스트한 두 API 외에도, Bright Data의 LinkedIn 스크래퍼 제품군에는 다음도 포함됩니다:
| API | 입력 | 주요 출력 |
|---|---|---|
| Jobs API | LinkedIn 채용공고 URL | 직함, 회사, 위치, 급여, 직무 설명, 요구사항, 게시 날짜 |
| Posts API | LinkedIn 게시물 URL | 작성자, 콘텐츠, 참여 지표, 날짜, 미디어 |
이는 채용 신호 감지(어떤 기업이 어떤 팀을 확장하는지)와 경쟁 인텔리전스(기업이 무엇에 대해 게시하는지 추적)에 유용합니다. URL을 제출하면 실시간 스크래핑을 통해 구조화된 JSON을 받습니다.
Building Automated Lead Gen Pipelines
이러한 API의 진정한 강점은 자동화된 워크플로에 연결할 때 나타납니다. Bright Data는 Streamlit 기반의 오픈소스 AI Lead Generator를 유지 관리하며, 이는 다음을 수행합니다:
- 자연어 쿼리를 받습니다 (“케냐의 핀테크 기업에서 마케팅 매니저 찾기”)
- OpenAI를 사용해 쿼리에서 구조화된 필터를 추출합니다
- Bright Data의 API를 호출해 LinkedIn에서 일치하는 리드를 수집합니다
- AI로 각 리드를 점수화하고 보강합니다
- 리드별 아웃리치 제안을 반환합니다
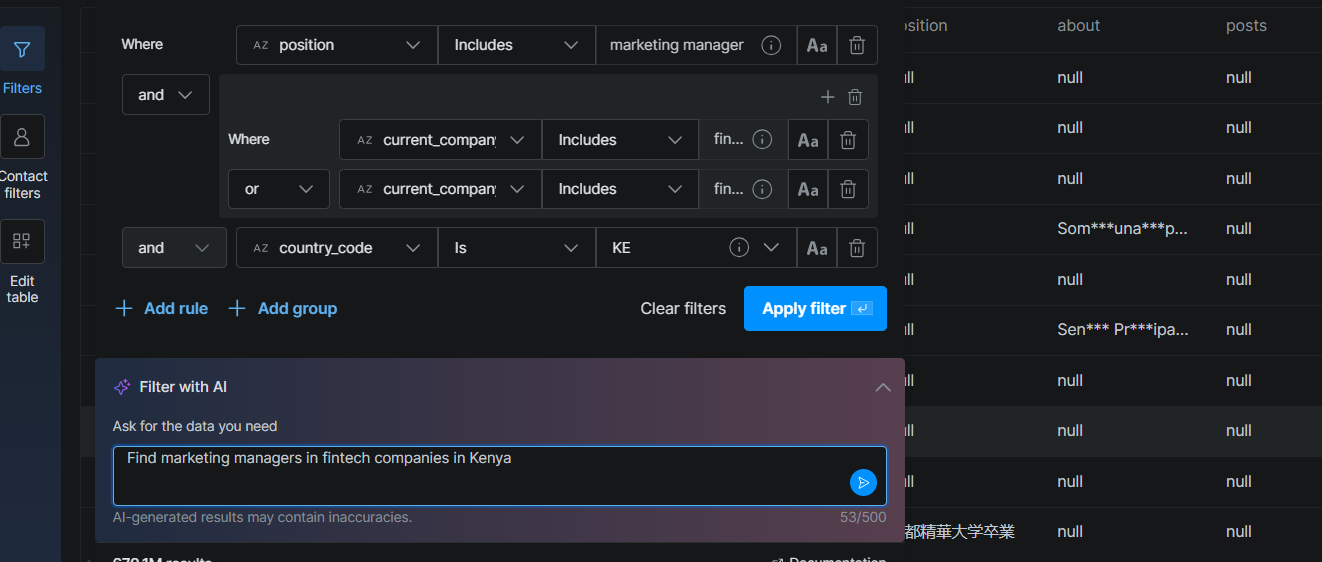
Apollo에도 AI 기능(이메일 작성, 리드 점수 제안)이 있지만, 이는 Apollo의 인터페이스 내에서만 작동합니다. 커스텀 파이프라인을 위한 조합 가능한 빌딩 블록이 아닙니다. LangChain, LlamaIndex, 또는 CrewAI로 에이전트 기반 워크플로를 구축하는 팀에게 Bright Data의 API는 데이터 검색 도구로 직접 통합됩니다.
Pricing: What You Actually Pay
Apollo
Apollo는 통합 크레딧 시스템을 사용합니다. 유료 플랜은 연간 전체 크레딧을 선불로 제공하고, 무료 플랜은 월별로 제공합니다. 가격 페이지에서 확인한 내용은 다음과 같습니다:
| 플랜 | 연간 결제 | 크레딧 | 제공 일정 |
|---|---|---|---|
| Free | $0 | 900/년 | 월별 (75/월) |
| Basic | $49/시트/월 | 30,000/년 | 선불 |
| Professional | $79/시트/월 | 48,000/년 | 선불 |
| Organization | $119/시트/월 (최소 3시트) | 72,000/년 | 선불 |
세 가지 유료 플랜 모두 CSV, CRM, API 데이터 보강을 포함합니다. 무료 플랜은 포함하지 않습니다. 테스트에서 people 검색 및 보강 API 엔드포인트(mixed_people/api_search, people/match, people/bulk_match)는 무료 플랜 계정에서 모두 403 오류를 반환했으며, 이는 무료 티어에 ‘API 데이터 보강’이 없다는 것과 일치합니다.
크레딧은 작업별로 소모됩니다: 이메일 공개는 1크레딧, 휴대폰 번호 공개는 더 많이 소모됩니다(계정 설정에 따라 8크레딧으로 보고됨). API를 통한 보강은 요청된 필드에 따라 다릅니다. 크레딧은 연간 계약 기간이 지나면 이월되지 않습니다. 적극적인 아웃바운드 팀은 보강 및 전화번호 공개가 늘어나면 기본 플랜 가격을 초과해 크레딧을 추가 구매하는 경우가 많습니다.
티어별 주요 기능: Basic은 CRM 통합, 고급 필터, 워터폴 보강, 미국 다이얼러를 추가합니다. Professional은 시퀀스의 A/Z 테스트, 자동화 워크플로, 통화 녹음(4,000분), 분석을 추가합니다. Organization은 맞춤형 보고서, SSO, 고급 보안, 자체 LLM API 키 사용 옵션을 추가합니다.
Bright Data
| 제품 | 가격 |
|---|---|
| LinkedIn Scraper APIs (PAYG) | $1.5/1K 레코드 (성공 시에만 과금) |
| LinkedIn Scraper APIs (Scale) | 월 $499 (384,000 레코드 포함; 추가 레코드 $1.3/1K) |
| Company Data API (Filter) | $2.50/1K 레코드부터 |
| 사전 구축 데이터셋 | 100K 레코드당 $250부터 |
| 무료 체험 | 1K 요청 (일회성), 1주일 이용 가능, 신용카드 불필요 |
시트당 요금 없음. 크레딧 시스템 없음. 플랜 티어별 기능 제한 없음. 무료 체험을 포함한 모든 계정에서 완전한 API 접근 가능. S3, Snowflake, Azure, Google Cloud 또는 Webhook으로의 데이터 전달이 포함됩니다.
Cost Comparison for a Real Workflow
월 10,000개의 LinkedIn 기업 프로필 수집:
Bright Data: PAYG 플랜에서 10,000 레코드, $1.5/1K = 월 $15. 계정 수준 타겟팅을 위한 Filter API 추가, $2.50/1K = 10K 필터링 레코드에 $25. 총계: 약 월 $40. 더 많은 볼륨(월 100K+ 레코드)에서는 384,000 레코드가 포함된 월 $499의 Scale 플랜으로 실효 요금이 $1.3/1K로 낮아집니다.
Apollo: API 접근이 가능한 가장 저렴한 플랜은 시트당 월 $49($588/년)의 Basic으로, 연간 30,000 크레딧이 선불로 제공됩니다. 이메일 공개당 1크레딧으로 30,000 크레딧은 이메일 전용 내보내기 30,000건을 커버하지만, 전화번호는 8크레딧이 소모되어 크레딧 풀이 훨씬 빨리 소진됩니다. Basic 플랜의 3인 팀은 시트 비용만 연간 $1,764를 지불하며, 연간 총 90,000 크레딧을 공유합니다.
월 100,000 레코드에서 격차는 더 벌어집니다. Bright Data의 PAYG 요금은 월 $150이며, Scale 플랜 월 $499로 384,000 레코드를 충분한 여유와 함께 커버합니다.
위의 Apollo 가격은 2026년 5월 기준 Apollo 가격 페이지에서 직접 가져왔습니다. 작업별 크레딧 비용(이메일 공개, 전화번호 공개, 보강)은 가격 페이지에 명시되어 있지 않으며 다를 수 있습니다. Bright Data 가격은 현재 공개된 요금을 반영합니다.
When to Use Which
Apollo 사용을 권장하는 경우: 검색, 시퀀싱, 추적을 하나의 플랫폼에서 원하는 소규모 SDR 팀(1~5명)인 경우. ICP가 Apollo의 데이터가 가장 강한 미국 기반 테크/SaaS에 집중되어 있고, 월별 프로스펙팅 볼륨이 플랜의 크레딧 한도 내에 있는 경우입니다.
Bright Data 사용을 권장하는 경우: 대규모의 신선한 데이터(월 10K+ 레코드)가 필요한 경우, ICP에 정적 데이터베이스의 공백이 알려진 국제 시장이나 소규모 기업이 포함된 경우, 자동화된 보강 또는 AI 기반 리드 생성 파이프라인을 구축하는 경우, 또는 사용 사례가 영업 아웃리치를 넘어 경쟁 인텔리전스, 투자 리서치, 시장 매핑까지 확장되는 경우입니다.
두 플랫폼 함께 사용이 가장 강력한 조합입니다. 이는 데이터 품질과 실행 효율성을 모두 원하는 성장 팀에게 권장되는 접근 방식입니다:
- Bright Data의 Company Data API를 사용해 10개 이상의 소스에서 펌모그래픽스, 펀딩 단계, 테크노그래픽스, 성장 신호로 필터링된 적격 계정 목록 구축
- Bright Data의 LinkedIn Profiles Scraper API를 사용해 해당 타겟 계정의 의사결정자를 위한 신선한 연락처 데이터 수집
- 발송 전 이메일 주소 검증을 위한 검증 도구(NeverBounce, ZeroBounce, 또는 Prospeo)
- Apollo(또는 다른 시퀀싱 도구)로 검증된 연락처를 불러와 아웃리치 캠페인 실행
이 설정은 각 플랫폼의 강점을 활용합니다: Bright Data는 데이터 레이어를 담당하고, 검증 도구는 이메일 정확도를 담당하며, Apollo는 실행 레이어를 담당합니다.
!bright-data-apollo-combined-stack
Final Thoughts
Apollo는 저렴하고 자체 완결형 워크플로가 필요한 SMB 영업 팀을 위한 유능한 아웃바운드 플랫폼입니다. 무료 티어, 내장된 시퀀싱, 짧은 설정 시간 덕분에 제로에서 첫 캠페인까지 가장 빠른 경로를 제공합니다.
한계는 데이터 신선도입니다. 공개 리뷰에서는 전반적인 정확도가 65~70%이며, 내보낸 목록의 반송률이 15~35%라고 일관되게 보고합니다. 수개월 전에 직책을 변경한 연락처의 직함도 종종 오래된 상태로 남아있습니다. 소규모, 미국 중심의 이메일 아웃리치에서는 이 정도가 허용될 수 있습니다. 대규모에서는 오래된 데이터의 누적 비용이 상당해집니다: 낭비된 크레딧, 손상된 발신자 평판, 이미 이직한 잠재 고객으로 인한 파이프라인 손실.
Bright Data의 Dataset Filter API와 LinkedIn Scraper APIs는 요청 시점에 소스에서 데이터를 수집하며, 집계된 기업 데이터 제품 전반에 걸쳐 팀 성장에 불이익을 주지 않는 레코드당 가격을 제공합니다. 실제 LinkedIn 프로필을 7.2초, 기업 페이지를 12.3초 만에 수집했으며, LinkedIn Companies 데이터셋에서 100개 기업을 1분 이내에 필터링했습니다.
아웃바운드 결과가 데이터 품질에 의해 제한되고 있거나, 기본적인 이메일 프로스펙팅 이상의 B2B 데이터가 필요하다면, Bright Data는 사용 사례에 맞는 정확한 인프라를 구축할 수 있게 해줍니다.




