이 튜토리얼에서는 다음을 확인하게 됩니다:
- Google Maps 스크레이퍼의 정의
- 이를 통해 추출 가능한 데이터
- 파이썬으로 Google Maps 스크래핑 스크립트 구축 방법
자, 시작해 보겠습니다!
구글 맵 스크레이퍼란 무엇인가요?
구글 맵 스크레이퍼는 구글 맵에서 데이터를 추출하기 위한 전문 도구입니다. 예를 들어파이썬 스크래핑 스크립트를 통해 맵 데이터 수집 과정을 자동화합니다. 이러한 스크레이퍼로 검색된 데이터는 일반적으로 시장 조사, 경쟁사 분석 등에 사용됩니다.
Google 지도에서 추출할 수 있는 데이터
Google 지도에서 스크래핑할 수 있는 정보는 다음과 같습니다:
- 사업체명: Google 지도에 등록된 사업체 또는 위치의 이름.
- 주소: 비즈니스 또는 위치의 실제 도로 주소.
- 전화번호: 비즈니스 연락처 전화번호.
- 웹사이트: 업체 웹사이트의 URL.
- 영업 시간: 업체의 개점 및 폐점 시간.
- 리뷰: 평점 및 상세한 피드백을 포함한 고객 리뷰.
- 평점: 사용자 피드백을 기반으로 한 평균 별점.
- 사진: 업체 또는 고객이 업로드한 이미지.
파이썬으로 Google Maps 스크래핑하는 단계별 안내
이 안내 섹션에서는 Google 지도를 스크랩하는 Python 스크립트를 만드는 방법을 배웁니다.
최종 목표는 “이탈리아 레스토랑” 페이지의 Google 지도 항목에 포함된 데이터를 추출하는 것입니다:
아래 단계를 따라하세요!
1단계: 프로젝트 설정
시작하기 전에 컴퓨터에 Python 3이 설치되어 있는지 확인해야 합니다. 설치되어 있지 않다면 다운로드하여 설치하고 설치 마법사를 따라 진행하세요.
그런 다음 다음 명령어를 사용하여 프로젝트 폴더를 생성하고, 해당 폴더로 이동한 후 가상 환경을 생성하세요:
mkdir google-maps-scraper
cd google-maps-scraper
python -m venv env
google-maps-scraper 디렉터리는 Python Google Maps 스크레이퍼의 프로젝트 폴더를 나타냅니다.
선호하는 Python IDE에서 프로젝트 폴더를 로드하세요. PyCharm Community Edition 이나 Python 확장 프로그램이 설치된 Visual Studio Code를 사용하면 됩니다.
프로젝트 폴더 내에서 scraper.py 파일을 생성하세요. 현재 프로젝트의 파일 구조는 다음과 같아야 합니다:
scraper.py는 현재 빈 Python 스크립트이지만 곧 스크래핑 로직이 포함될 것입니다.
IDE 터미널에서 가상 환경을 활성화하세요. Linux 또는 macOS에서는 다음 명령어를 실행합니다:
./env/bin/activate
Windows에서는 다음 명령을 실행하세요:
env/Scripts/activate
훌륭합니다! 이제 스크레이퍼를 위한 Python 환경이 준비되었습니다!
2단계: 스크래핑 라이브러리 선택
Google Maps는 상호작용이 매우 활발한 플랫폼으로, 정적 사이트인지 동적 사이트인지 판단하는 데 시간을 할애할 필요가 없습니다. 이러한 경우 스크래핑을 위한 최선의 접근 방식은 브라우저 자동화 도구를 사용하는 것입니다.
해당 기술에 익숙하지 않다면, 브라우저 자동화 도구를 사용하면 제어 가능한 브라우저 환경에서 웹 페이지를 렌더링하고 상호작용할 수 있습니다. 또한 유효한 Google Maps 검색 URL을 생성하는 것은 쉽지 않습니다. 이를 처리하는 가장 간단한 방법은 브라우저에서 직접 검색을 수행하는 것입니다.
파이썬용 최고의 브라우저 자동화 도구 중 하나인 셀레니움( Selenium)은 구글 맵스 스크래핑에 이상적인 선택입니다. 이 작업에 주로 사용될 라이브러리이므로 설치 준비를 하세요!
3단계: 스크래핑 라이브러리 설치 및 구성
활성화된 Python 가상 환경에서 다음 명령어로 selenium pip 패키지를 설치하세요:
pip install selenium
이 도구 사용법에 대한 자세한 내용은 Selenium을 활용한 웹 스크래핑 튜토리얼을 참고하세요.
scraper.py 파일에 Selenium을 임포트하고 헤드리스 모드에서 Chrome 인스턴스를 제어할 WebDriver 객체를 생성하세요:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# 헤드리스 모드로 Chrome 실행
options = Options()
options.add_argument("--headless") # 개발 중에는 주석 처리
# 지정된 옵션으로 Chrome 웹 드라이버 인스턴스 생성
driver = webdriver.Chrome(
service=Service(),
options=options
)
위 코드 조각은 프로그래밍 방식으로 Chrome 브라우저 창을 제어하기 위해 Chrome WebDriver 인스턴스를 초기화합니다. --headless 플래그는 Chrome을 헤드리스 모드로 시작하기 위한 것으로, 창을 로드하지 않고 백그라운드에서 실행합니다. 디버깅을 위해 이 줄을 주석 처리하면 스크립트의 동작을 실시간으로 확인할 수 있습니다.
Google 지도 스크래핑 스크립트의 마지막 줄에서 웹 드라이버를 종료하는 것을 잊지 마세요:
driver.quit()
훌륭합니다! 이제 Google Maps 페이지 스크래핑을 시작할 모든 준비가 완료되었습니다.
4단계: 대상 페이지에 연결하기
get() 메서드를 사용하여 Google 지도 홈페이지에 연결하세요:
driver.get("https://www.google.com/maps")
현재 scraper.py 파일에는 다음과 같은 내용이 포함됩니다:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# 헤드리스 모드로 Chrome 실행
options = Options()
options.add_argument("--headless") # 개발 중에는 주석 처리
# 지정된 옵션으로 Chrome 웹 드라이버 인스턴스 생성
driver = webdriver.Chrome(
service=Service(),
options=options)
# Google Maps 홈페이지 연결
driver.get("https://www.google.com/maps")
# 스크래핑 로직...
# 웹 브라우저 종료
driver.quit()
멋지네요, 이제 지도처럼 동적인 웹사이트를 스크래핑할 시간입니다!
단계 #5: GDPR 쿠키 대화상자 처리하기
참고: 유럽 연합(EU) 지역에 거주하지 않는 경우 이 단계를 건너뛸 수 있습니다.
가능하다면 마지막 줄 앞에 중단점을 추가하여 스크레이퍼.py 스크립트를 헤더드 모드로 실행하세요. 이렇게 하면 브라우저 창이 즉시 닫히지 않고 열려 있는 상태를 관찰할 수 있습니다. EU에 거주하는 경우 다음과 같은 메시지가 표시됩니다:
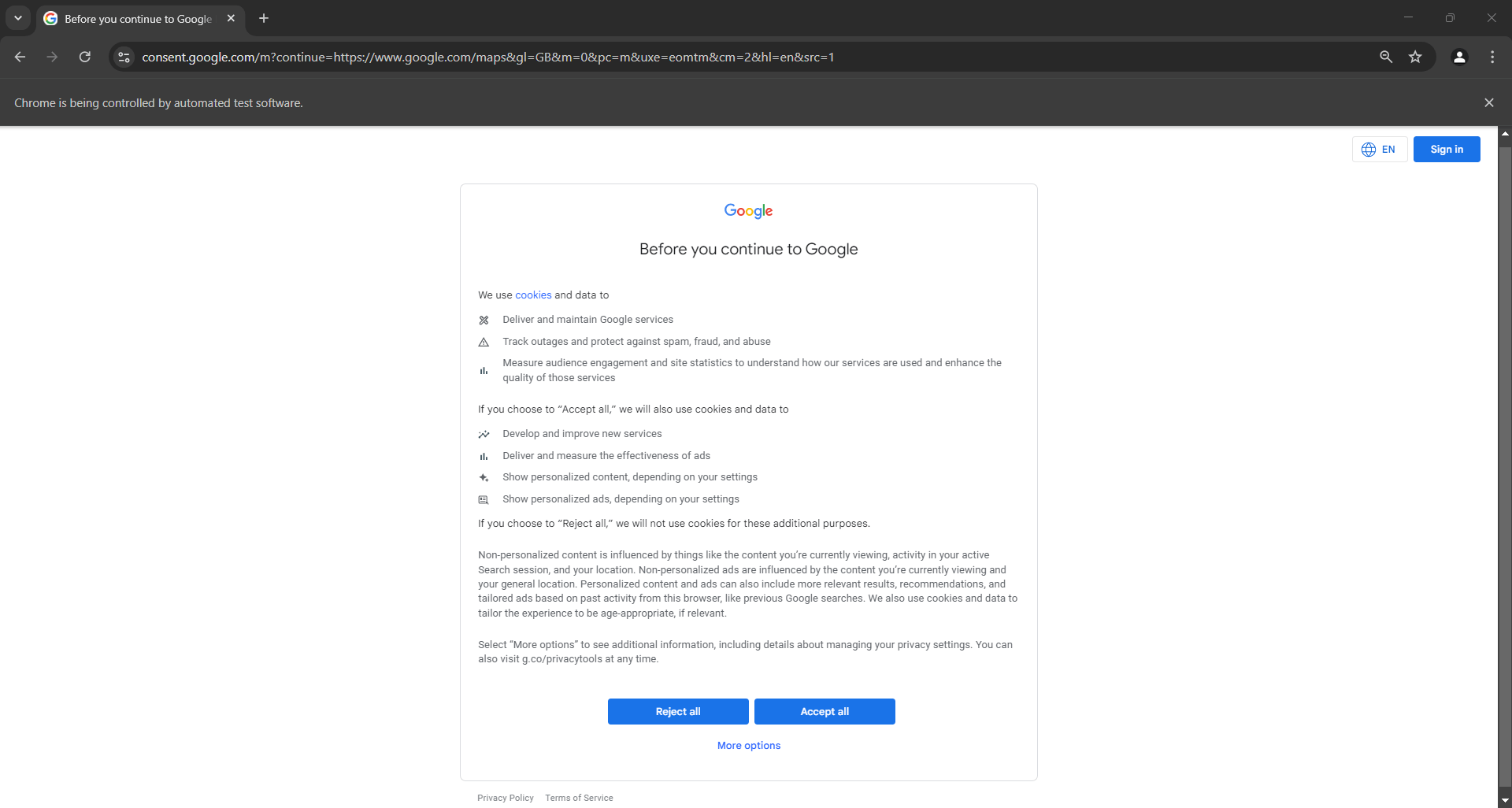
참고: “Chrome이 자동화된 테스트 소프트웨어에 의해 제어되고 있습니다.”라는 메시지는 Selenium이 Chrome을 성공적으로 제어하고 있음을 확인해 줍니다.
GDPR 요건으로 인해 Google은 EU 사용자에게 쿠키 정책 옵션을 표시해야 합니다. 해당되는 경우 페이지와 상호작용하려면 이 선택 사항을 처리해야 합니다. 해당되지 않는다면 6단계로 건너뛸 수 있습니다.
브라우저 주소창의 URL을 확인해 보시면 get()에서 지정한 페이지와 일치하지 않음을 알 수 있습니다. 이는 Google이 사용자를 리디렉션했기 때문입니다. “모두 수락” 버튼을 클릭하면 대상 페이지인 Google 지도 홈페이지로 돌아갑니다.
GDPR 옵션을 처리하려면 브라우저의 시크릿 모드에서 Google 지도 홈페이지를 열고 리디렉션을 기다리세요. “모두 수락” 버튼을 마우스 오른쪽 버튼으로 클릭하고 “검사” 옵션을 선택하세요:
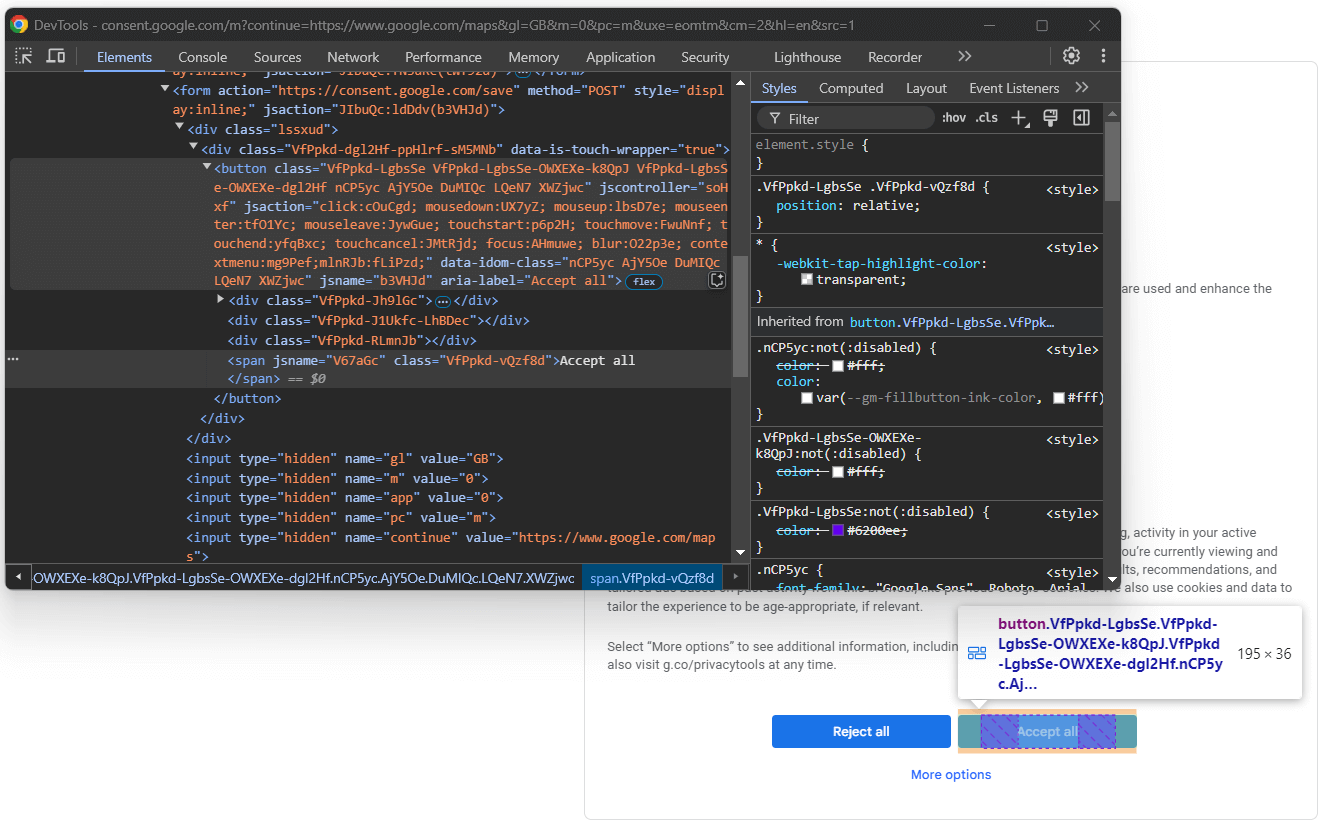
페이지의 HTML 요소 CSS 클래스가 무작위로 생성된 것처럼 보인다는 점을 눈치채셨을 것입니다. 이는 배포 시마다 업데이트될 가능성이 높아 웹 스크래핑에 신뢰할 수 없음을 의미합니다. 따라서 aria-label과 같이 보다 안정적인 속성을 타겟팅하는 데 집중해야 합니다:
accept_button = driver.find_element(By.CSS_SELECTOR, "[aria-label="Accept all"]")
find_element() 는 Selenium의 메서드로, 다양한 전략을 활용해 페이지 내 HTML 요소를 찾는 데 사용됩니다. 이 경우 CSS 선택자를 사용했습니다. 다양한 선택자 유형에 대해 자세히 알고 싶다면 XPath vs CSS 선택자 문서를 참고하세요.
scraper.py에 다음 임포트 문장을 추가하여 By를 반드시 임포트하세요:
from selenium.webdriver.common.by import By
다음 명령은 버튼을 클릭하는 것입니다:
accept_button.click()
선택적 Google 쿠키 페이지를 처리하기 위해 모든 요소가 어떻게 결합되는지 보여드립니다:
try:
# GDPR 쿠키 옵션 페이지에서 "Accept all" 버튼 선택
accept_button = driver.find_element(By.CSS_SELECTOR, "[aria-label="Accept all"]")
# 클릭
accept_button.click()
except NoSuchElementException:
print("GDPR 요구사항 없음")
click() 명령어는 “모두 수락” 버튼을 눌러 Google이 사용자를 지도 홈페이지로 리디렉션하도록 합니다. EU 지역에 있지 않은 경우 이 버튼이 페이지에 표시되지 않아 NoSuchElementException이 발생합니다. 스크립트는 예외를 포착하고 진행합니다. 이는 치명적인 오류가 아닌 잠재적 시나리오이기 때문입니다.
NoSuchElementException을 반드시 임포트하세요:
from selenium.common import NoSuchElementException
잘하셨습니다! 이제 Google Maps 스크래핑에 집중할 준비가 되었습니다.
6단계: 검색 양식 제출
현재 구글 맵 스크래퍼는 아래와 같은 페이지에 도달해야 합니다:
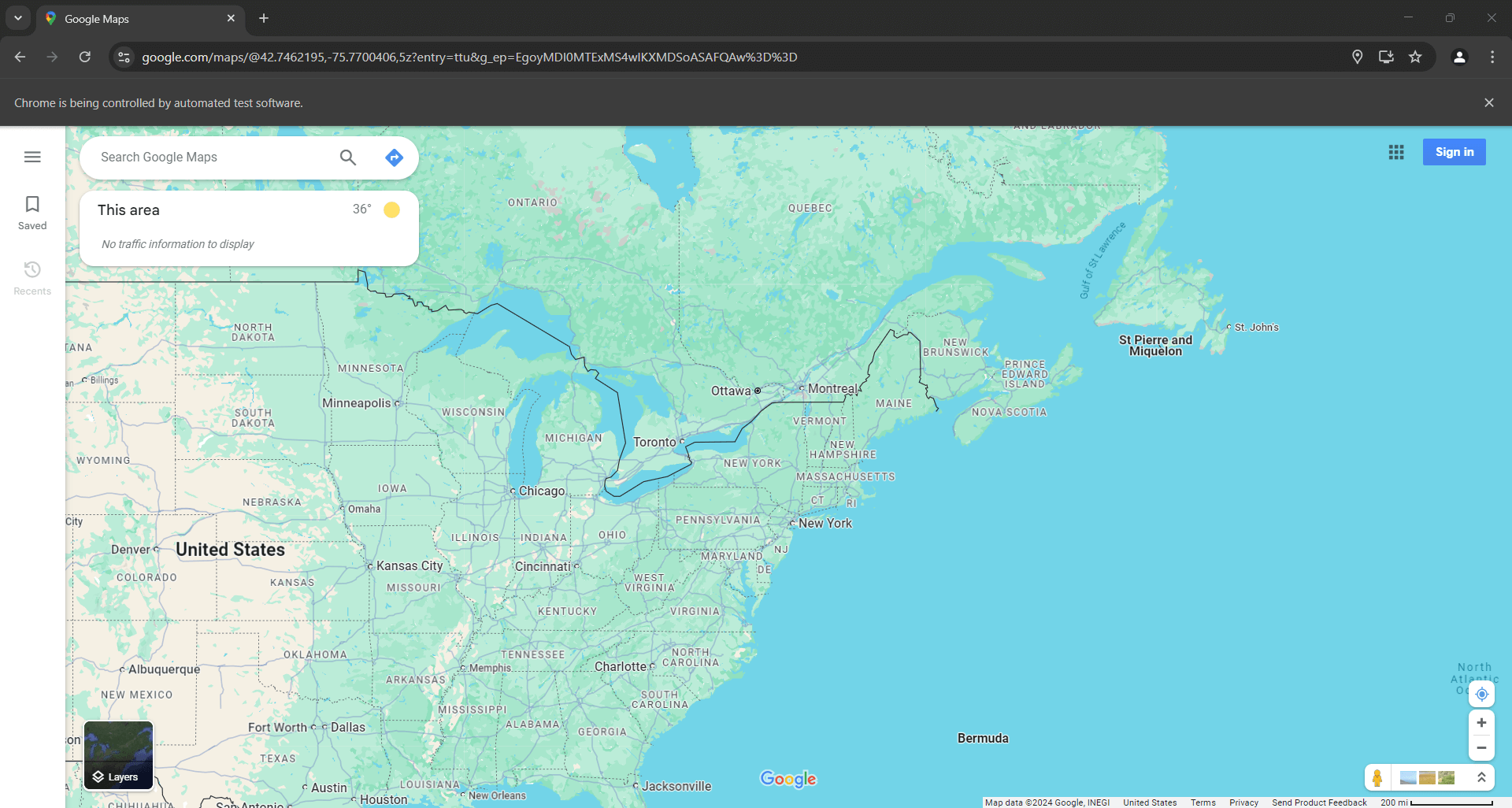
지도상의 위치는 사용자의 IP 위치에 따라 달라집니다. 본 예시에서는 뉴욕에 위치해 있습니다.
다음으로 “Google 지도 검색” 필드를 채우고 검색 양식을 제출해야 합니다. 이 요소를 찾으려면 브라우저에서 시크릿 모드로 Google 지도 홈페이지를 엽니다. 검색 입력 필드를 마우스 오른쪽 버튼으로 클릭하고 “검사” 옵션을 선택하세요:
search_input = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#searchboxinput"))
)
WebDriverWait는 페이지에서 지정된 조건이 충족될 때까지 스크립트를 일시 중지하는 Selenium의 특수 클래스입니다. 위 예시에서는 입력 HTML 요소가 나타날 때까지 최대 5초 동안 대기합니다. 이 대기 시간은 페이지가 완전히 로드되었는지 확인하는 역할을 하며, 5단계를 수행한 경우(리디렉션 때문에) 필수적입니다.
위 코드가 작동하도록 scraper.py에 다음 임포트 문장을 추가하세요:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
다음으로 `[send_keys()](https://www.selenium.dev/documentation/webdriver/actions_api/keyboard/#send-keys)` 메서드로 입력란을 채웁니다:
search_query = "이탈리안 레스토랑"
search_input.send_keys(search_query)
이 경우 “이탈리안 레스토랑”이 검색어이지만, 다른 어떤 용어로도 검색할 수 있습니다.
이제 양식을 제출하기만 하면 됩니다. 제출 버튼(돋보기 아이콘)을 확인하세요:
aria-label 속성을 대상으로 선택한 후 클릭합니다:
search_button = driver.find_element(By.CSS_SELECTOR, "button[aria-label="Search"]")
search_button.click()
놀랍습니다! 제어되는 브라우저가 이제 스크래핑할 데이터를 로드할 것입니다.
7단계: Google 지도 항목 선택
현재 스크립트는 다음과 같아야 합니다:
스크랩할 데이터는 왼쪽의 Google 지도 항목에 포함되어 있습니다. 이는 목록이므로 스크랩된 데이터를 담기에 가장 적합한 데이터 구조는 배열입니다. 배열을 초기화합니다:
items = []
이제 목표는 왼쪽의 Google Maps 항목을 선택하는 것입니다. 그중 하나를 살펴보세요:
다시 한번, CSS 클래스는 무작위로 생성된 것으로 보이며, 스크래핑에 신뢰할 수 없습니다. 대신 jsaction 속성을 대상으로 삼을 수 있습니다. 이 속성의 내용 일부도 무작위로 생성된 것으로 보이지만, 그 안에서 일관된 문자열, 특히 "mouseover:pane"에 집중하세요.
아래 XPath 선택기는 role="feed"인 부모 <div> 내부에 있는 모든 <div> 요소 중 jsaction 속성에 "mouseover:pane" 문자열이 포함된 요소를 선택하는 데 도움이 됩니다:
maps_items = WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located((By.XPATH, '//div[@role="feed"]//div[contains(@jsaction, "mouseover:pane")]'))
)
다시 말해, 왼쪽의 콘텐츠가 페이지에 동적으로 로드되기 때문에 WebDriverWait가 필요합니다.
각 요소를 반복 처리하며 Google Maps 스크래퍼를 준비하여 데이터를 추출합니다:
for maps_item in maps_items:
# 스크래핑 로직...
훌륭합니다! 다음 단계는 해당 요소들로부터 데이터를 추출하는 것입니다.
단계 #8: Google 지도 항목 스크래핑
단일 Google 지도 항목을 검사하고 내부 요소에 집중하세요:
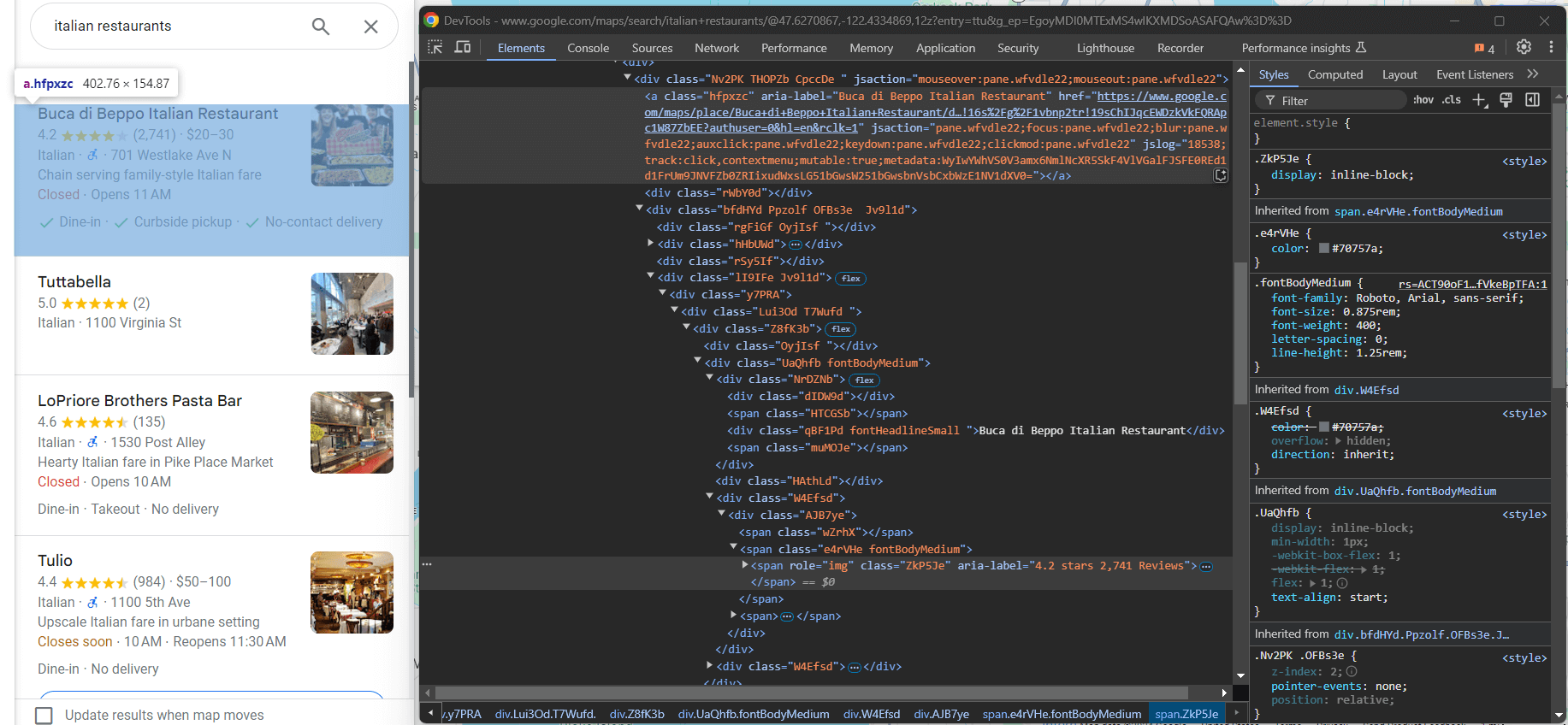
여기서 스크래핑할 수 있는 항목은 다음과 같습니다:
a[jsaction][jslog]요소에서 지도 항목의 링크div.fontHeadlineSmall요소에서 제목span[role="img"]에서 별점과 리뷰 수
아래 로직으로 이를 구현할 수 있습니다:
link_element = maps_item.find_element(By.CSS_SELECTOR, "a[jsaction][jslog]")
url = link_element.get_attribute("href")
title_element = maps_item.find_element(By.CSS_SELECTOR, "div.fontHeadlineSmall")
title = title_element.text
reviews_element = maps_item.find_element(By.CSS_SELECTOR, "span[role="img"]")
reviews_string = reviews_element.get_attribute("aria-label")
# 별점과 리뷰 수 추출을 위한 정규식 패턴 정의
reviews_string_pattern = r"(d+.d+) stars (d+[,]*d+) Reviews"
# re.match로 일치하는 그룹 찾기
reviews_string_match = re.match(reviews_string_pattern, reviews_string)
reviews_stars = None
reviews_count = None
# 일치하는 그룹이 발견되면 데이터를 추출
if reviews_string_match:
# 별점을 부동 소수점으로 변환
reviews_stars = float(reviews_string_match.group(1))
# 리뷰 수를 정수로 변환
reviews_count = int(reviews_string_match.group(2).replace(",", ""))
get_attribute() 함수는 지정된 HTML 속성 내부의 내용을 반환하는 반면 , .text는 노드 내부의 문자열 내용을 반환합니다.
“X.Y stars in Z reviews” 문자열에서 특정 데이터 필드를 추출하기 위해 정규 표현식을 사용한 점에 유의하세요. 웹 스크래핑을 위한 정규 표현식 사용에 관한 자세한 내용은 당사 문서를 참조하십시오.
Python 표준 라이브러리에서 re 패키지를 반드시 임포트하세요:
import re
Google Maps 항목을 계속 검사해 보겠습니다:
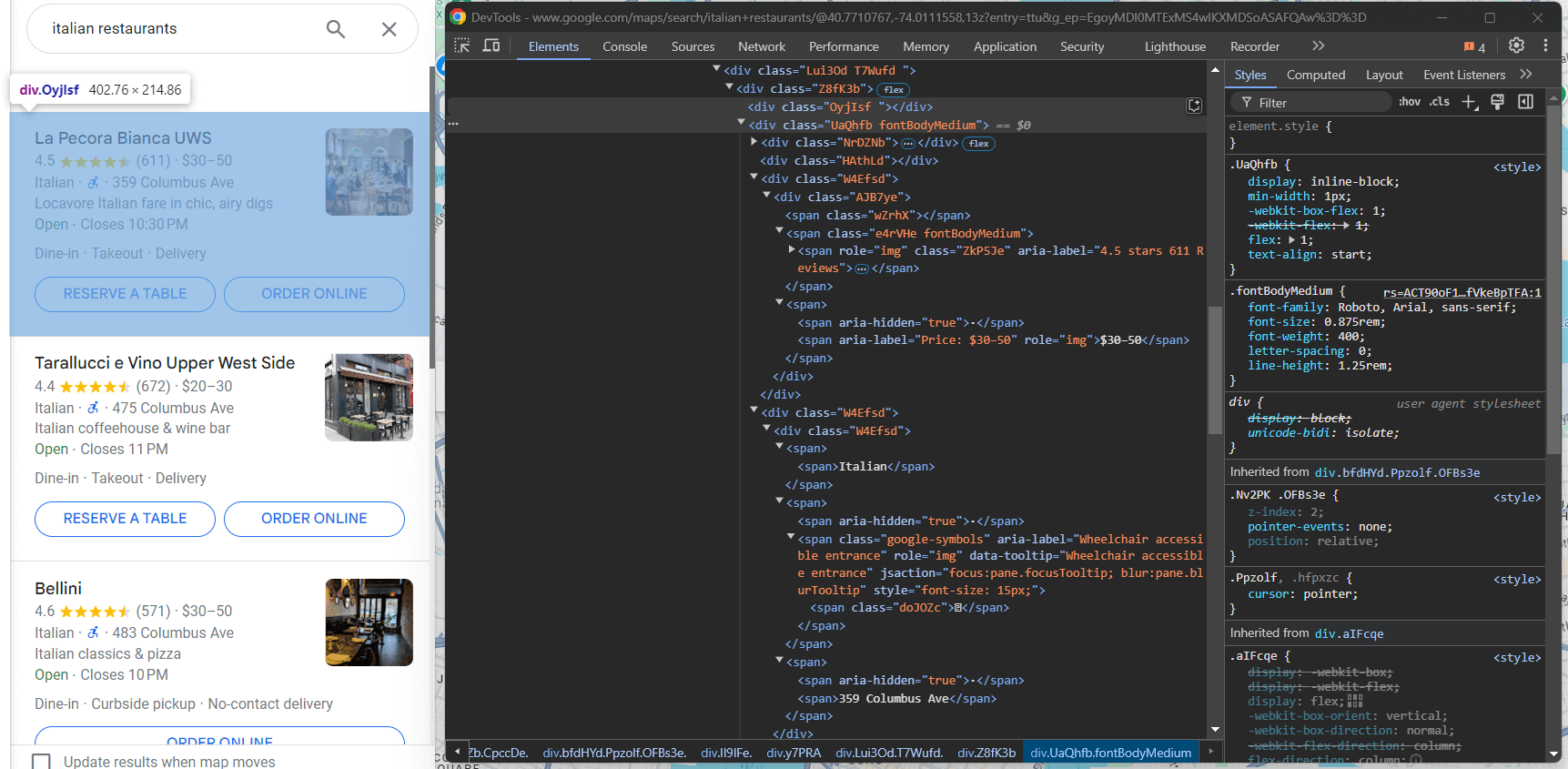
fondBodyMedium 클래스가 지정된 <div> 내부에서, 속성이 없거나 style 속성만 있는 <span> 노드에서 대부분의 정보를 얻을 수 있습니다. 선택적 가격 요소(pricing element)의 경우, aria-label 속성에 “Price”가 포함된 노드를 대상으로 선택할 수 있습니다:
info_div = maps_item.find_element(By.CSS_SELECTOR, ".fontBodyMedium")
# 가격 정보가 존재할 경우 추출
try:
price_element = info_div.find_element(By.XPATH, ".//*[@aria-label[contains(., 'Price')]]")
price = price_element.text
except NoSuchElementException:
price = None
info = []
# 속성이 없거나 @style 속성이 있는 모든 <span> 요소 선택
# 그리고 <span>의 하위 요소
span_elements = info_div.find_elements(By.XPATH, ".//span[not(@*) or @style][not(descendant::span)]")
for span_element in span_elements:
info.append(span_element.text.replace("⋅", "").strip())
# 중복 정보 및 빈 문자열 제거
info = list(filter(None, list(set(info))))
가격 요소는 선택 사항이므로 해당 로직을 try ... except 블록으로 감싸야 합니다. 이렇게 하면 가격 노드가 페이지에 없을 때 스크립트가 실패하지 않고 계속 실행됩니다. 5단계를 건너뛰었다면 NoSuchElementException에 대한 임포트를 추가하세요:
from selenium.common import NoSuchElementException
빈 문자열과 중복 정보 요소를 방지하려면 filter() 와 set()의 사용법을 참고하세요.
이제 이미지에 집중하세요:
다음과 같이 스크랩할 수 있습니다:
img_element = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "img[decoding="async"][aria-hidden="true"]")))
image = img_element.get_attribute("src")
이미지는 비동기식으로 로드되어 표시되기까지 시간이 걸릴 수 있으므로 WebDriverWait가 필수적임을 명심하세요.
마지막 단계는 하단 요소의 태그를 스크래핑하는 것입니다:
마지막 .fontBodyMedium 요소의 style 속성을 가진 <span> 노드에서 모두 가져올 수 있습니다:
tags_div = maps_item.find_elements(By.CSS_SELECTOR, ".fontBodyMedium")[-1]
tags = []
tag_elements = tags_div.find_elements(By.CSS_SELECTOR, "span[style]")
for tag_element in tag_elements:
tags.append(tag_element.text)
대단합니다! Python Google Maps 스크래핑 로직이 완성되었습니다.
단계 #9: 스크래핑된 데이터 수집
이제 여러 변수에 스크래핑된 데이터가 있습니다. 새 항목 객체를 생성하고 해당 데이터로 채웁니다:
item = {
"url": url,
"image": image,
"title": title,
"reviews": {
"stars": reviews_stars,
"count": reviews_count
},
"price": price,
"info": info,
"tags": tags
}
그런 다음 items 배열에 추가하세요:
items.append(item)
Google Maps 항목 노드에 대한 for 루프가 끝날 때쯤이면 items에는 모든 스크래핑 데이터가 포함되어 있을 것입니다. 이제 해당 정보를 CSV와 같은 사람이 읽을 수 있는 파일로 내보내기만 하면 됩니다.
10단계: CSV로 내보내기
파이썬 표준 라이브러리에서 csv 패키지를 임포트합니다:
import csv
다음으로, Google Maps 데이터를 평면 CSV 파일에 채우기 위해 csv를 사용합니다:
# 출력 CSV 파일 경로
output_file = "items.csv"
# 평면화 및 CSV로 내보내기
with open(output_file, mode="w", newline="", encoding="utf-8") as csv_file:
# CSV 필드 이름 정의
fieldnames = ["url", "image", "title", "reviews_stars", "reviews_count", "price", "info", "tags"]
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
# 헤더 작성
writer.writeheader()
# 각 항목을 작성하며 info와 tags를 평면화
for item in items:
writer.writerow({
"url": item["url"],
"image": item["image"],
"title": item["title"],
"reviews_stars": item["reviews"]["stars"],
"reviews_count": item["reviews"]["count"],
"price": item["price"],
"info": "; ".join(item["info"]),
"tags": "; ".join(item["tags"])
})
위의 코드 조각은 항목들을 items.csv라는 CSV 파일로 내보냅니다. 사용된 주요 함수는 다음과 같습니다:
open(): 텍스트 출력을 처리하기 위해 UTF-8 인코딩으로 지정된 파일을 쓰기 모드로 엽니다.csv.DictWriter(): 지정된 필드 이름을 사용하여 CSV 라이터 객체를 생성하며, 행을 사전(dictionary) 형태로 작성할 수 있게 합니다.writeheader(): 필드 이름을 기반으로 헤더 행을 CSV 파일에 기록합니다.writer.writerow(): 각 항목을 CSV의 행으로 작성합니다.
배열을 평평한 문자열로 변환하기 위해 join() 문자열 함수를 사용한 점에 유의하십시오. 이는 출력 CSV가 깔끔한 단일 레벨 파일로 생성되도록 보장합니다.
11단계: 모든 것을 통합하기
다음은 Python Google Maps 스크레이퍼의 최종 코드입니다:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
import csv
# 헤드리스 모드로 Chrome 실행
options = Options()
options.add_argument("--headless") # 개발 중에는 주석 처리
# 지정된 옵션으로 Chrome 웹 드라이버 인스턴스 생성
driver = webdriver.Chrome(
service=Service(),
options=options
)
# Google 지도 홈페이지에 접속
driver.get("https://www.google.com/maps")
# GDPR 옵션 처리
try:
# GDPR 쿠키 옵션 페이지에서 "모두 수락" 버튼 선택
accept_button = driver.find_element(By.CSS_SELECTOR, "[aria-label="Accept all"]")
# 클릭
accept_button.click()
except NoSuchElementException:
print("GDPR 요구사항 없음")
# 검색 입력란 선택 및 입력
search_input = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "#searchboxinput"))
)
search_query = "이탈리안 레스토랑"
search_input.send_keys(search_query)
# 검색 양식 제출
search_button = driver.find_element(By.CSS_SELECTOR, "button[aria-label="검색"]")
search_button.click()
# 스크랩된 데이터 저장 위치
items = []
# Google Maps 항목 선택
maps_items = WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located((By.XPATH, '//div[@role="feed"]//div[contains(@jsaction, "mouseover:pane")]'))
)
# Google 지도 항목을 반복 처리하며
# 스크래핑 로직 수행
for maps_item in maps_items:
link_element = maps_item.find_element(By.CSS_SELECTOR, "a[jsaction][jslog]")
url = link_element.get_attribute("href")
title_element = maps_item.find_element(By.CSS_SELECTOR, "div.fontHeadlineSmall")
title = title_element.text
reviews_element = maps_item.find_element(By.CSS_SELECTOR, "span[role="img"]")
reviews_string = reviews_element.get_attribute("aria-label")
# 별점과 리뷰 수 추출을 위한 정규식 패턴 정의
reviews_string_pattern = r"(d+.d+) stars (d+[,]*d+) Reviews"
# re.match로 일치하는 그룹 찾기
reviews_string_match = re.match(reviews_string_pattern, reviews_string)
reviews_stars = None
reviews_count = None
# 일치하는 패턴이 발견되면 데이터를 추출
if reviews_string_match:
# 별점을 부동소수점으로 변환
reviews_stars = float(reviews_string_match.group(1))
# 리뷰 수를 정수로 변환
reviews_count = int(reviews_string_match.group(2).replace(",", ""))
# 가장 많은 정보를 가진 Google Maps 항목 <div> 선택
# 그리고 그로부터 데이터 추출
info_div = maps_item.find_element(By.CSS_SELECTOR, ".fontBodyMedium")
# 가격이 존재할 경우 스크랩
try:
price_element = info_div.find_element(By.XPATH, ".//*[@aria-label[contains(., 'Price')]]")
price = price_element.text
except NoSuchElementException:
price = None
info = []
# 속성이 없거나 @style 속성이 있는 모든 <span> 요소 선택
# 그리고 <span>의 하위 요소
span_elements = info_div.find_elements(By.XPATH, ".//span[not(@*) or @style][not(descendant::span)]")
for span_element in span_elements:
info.append(span_element.text.replace("⋅", "").strip())
# 중복 정보 및 빈 문자열 제거
info = list(filter(None, list(set(info))))
img_element = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "img[decoding="async"][aria-hidden="true"]"))
)
image = img_element.get_attribute("src")
# <div> 태그 요소를 선택하고 데이터를 추출
tags_div = maps_item.find_elements(By.CSS_SELECTOR, ".fontBodyMedium")[-1]
tags = []
tag_elements = tags_div.find_elements(By.CSS_SELECTOR, "span[style]")
for tag_element in tag_elements:
tags.append(tag_element.text)
# 스크랩된 데이터로 새 항목 채우기
item = {
"url": url,
"image": image,
"title": title,
"reviews": {
"stars": reviews_stars,
"count": reviews_count
},
"price": price,
"info": info,
"tags": tags
}
# 스크랩된 데이터 목록에 추가
items.append(item)
# CSV 파일 경로 설정
output_file = "items.csv"
# 평탄화 후 CSV로 내보내기
with open(output_file, mode="w", newline="", encoding="utf-8") as csv_file:
# CSV 필드 이름 정의
fieldnames = ["url", "image", "title", "reviews_stars", "reviews_count", "price", "info", "tags"]
writer = csv.DictWriter(csv_file, fieldnames=fieldnames)
# 헤더 작성
writer.writeheader()
# 각 항목을 작성하며 info와 tags를 평면화
for item in items:
writer.writerow({
"url": item["url"],
"image": item["image"],
"title": item["title"],
"reviews_stars": item["reviews"]["stars"],
"reviews_count": item["reviews"]["count"],
"price": item["price"],
"info": "; ".join(item["info"]),
"tags": "; ".join(item["tags"])
})
# 웹 브라우저 닫기
driver.quit()
약 150줄의 코드로 Google Maps 스크래핑 스크립트를 완성했습니다!
scraper.py 파일을 실행하여 작동 여부를 확인하세요. Windows에서는 다음 명령어로 스크레이퍼를 실행합니다:
python scraper.py
Linux 또는 macOS에서는 다음과 같이 실행하세요:
python3 scraper.py
스크레이퍼 실행이 완료될 때까지 기다리면 프로젝트 루트 디렉터리에 items.csv 파일이 생성됩니다. 파일을 열어 추출된 데이터를 확인하세요. 다음과 같은 데이터가 포함되어 있을 것입니다:

축하합니다, 미션 완료!
결론
이 튜토리얼에서는 Google Maps 스크레이퍼가 무엇이며 Python으로 이를 구축하는 방법을 배웠습니다. 보셨듯이 Google Maps에서 데이터를 자동으로 가져오는 간단한 스크립트를 만드는 데는 Python 코드 몇 줄이면 충분합니다.
이 솔루션은 소규모 프로젝트에는 적합하지만 대규모 스크래핑에는 실용적이지 않습니다. Google은 CAPTCHA나 IP 차단 같은 고급 봇 방지 조치를 통해 접근을 차단할 수 있습니다. 또한 여러 페이지에 걸쳐 프로세스를 확장하면 인프라 비용이 증가합니다. 게다가 이 간단한 예시는 Google 지도 페이지에서 필요한 모든 복잡한 상호작용을 고려하지 않습니다.
그렇다면 Google Maps를 효율적이고 안정적으로 스크래핑하는 것이 불가능하다는 뜻일까요? 전혀 아닙니다! Bright Data의 Google Maps Scraper API와 같은 고급 솔루션만 있으면 됩니다.
Google Maps Scraper API는 주요 난제들을 모두 해결해 주는 Google Maps 데이터 추출용 엔드포인트를 제공합니다. 간단한 API 호출만으로 필요한 데이터를 JSON 또는 HTML 형식으로 얻을 수 있습니다. API 호출이 부담스럽다면, 바로 사용 가능한 Google Maps 데이터셋도 확인해 보세요.
스크레이퍼 API를 사용해 보거나 데이터셋을 살펴보려면 지금 바로 무료 Bright Data 계정을 생성하세요!