

웹 스크래핑은 웹 페이지에서 데이터를 추출하는 데 사용할 수 있는 기술입니다. 대상 웹사이트가 API를 제공하지 않거나, API를 사용할 수 없거나, 원하는 정확한 데이터를 반환하지 않을 때 특히 유용합니다.
정규 표현식(Regex)은 텍스트에서 데이터를 추출하기 위한 강력한 문법 패턴으로, 웹 스크래핑에 흔히 사용됩니다. 정규 표현식은 텍스트에서 일치시킬 수 있는 패턴을 정의하며, 텍스트에서 정보를 찾아 추출하는 데 주로 활용됩니다. 따라서 웹 스크래핑에서 널리 사용됩니다.
이 글에서는웹 스크래핑을 위해 파이썬에서 정규 표현식을 사용하는 방법을 배웁니다. 글을 마치면 정적 및 동적 사이트를 스크래핑하는 방법을 알게 되며, 직면할 수 있는 몇 가지 한계에 대해서도 이해하게 될 것입니다.
정규 표현식(Regex)이란?
정규 표현식은 특정 패턴과 일치하는 토큰을 사용하여 정의됩니다. 모든 토큰을 상세히 설명하는 것은 본 글의 범위를 벗어납니다. 다만 자주 접하게 될 몇 가지 토큰을 아래 표에 정리했습니다:
| 토큰 | 일치하는 문자 |
|---|---|
| 특수 문자가 아닌 모든 문자 | 지정된 문자 |
^ |
문자열의 시작 |
$ |
문자열의 끝 |
. |
n을 제외한 모든 문자 |
* |
이전 요소가 0회 이상 반복됨 |
? |
이전 요소가 0번 또는 1번 나타남 |
+ |
이전 문자가 하나 이상 반복됨 |
{숫자} |
이전 요소의 정확한 개수 |
d |
어떤 숫자든 |
s |
어떤 공백 문자 |
w |
어떤 단어 문자 |
D |
d의 역수 |
S |
s의 역수 |
W |
w의 역수 |
정규 표현식에 대해 더 알아보고 직접 해보려면regexr.com을 방문하세요. 또한이 글에서는정규 표현식 성능을 최적화하는 중요한 팁을 공유합니다.
웹 스크래핑을 위한 Python에서 정규 표현식 사용하기
이 튜토리얼에서는 정규식을 사용하여 웹 페이지에서 데이터를 추출하는 간단한 Python 웹 스크레이퍼를 구축합니다.
시작하려면 프로젝트용 디렉터리를 생성하세요:
mkdir web_scraping_with_regex
cd web_scraping_with_regex
그런 다음 Python 가상 환경을 생성합니다:
python -m venv venv
활성화합니다:
source ./venv/bin/activate
웹 스크레이퍼를 작성하려면 두 개의 라이브러리를 설치해야 합니다:
- 웹 페이지 가져오기용
requests - HTML 콘텐츠 파싱 및 요소 찾기용
beautifulsoup4
라이브러리 설치 명령어 실행:
pip install beautifulsoup4 requests
참고: 웹사이트를 스크래핑하기 전에 반드시 해당 사이트의 이용 약관을 확인하여 스크래핑이 허용되는지 확인하세요. 금지된 사이트는 스크래핑해서는 안 됩니다.
전자상거래 사이트 스크래핑
이 섹션에서는 간단한모의 전자상거래 사이트를 스크래핑하는 웹 스크래퍼를 구축합니다. 첫 페이지를 스크래핑하여 책의 제목과 가격을 추출할 것입니다.
이를 위해 scraper.py 라는 파일을 생성하고 필요한 모듈을 임포트합니다:
import requests
from bs4 import BeautifulSoup
import re
참고:
re모듈은 정규 표현식(regex)을 처리하는 파이썬 내장 모듈입니다.
다음으로 대상 웹 페이지에 GET 요청을 보내 페이지의 HTML 콘텐츠를 가져옵니다:
page = requests.get('https://books.toscrape.com/')
이 데이터를 Beautiful Soup에 전달하면 웹 페이지의 HTML 구조를 파싱합니다:
soup = BeautifulSoup(page.content, 'html.parser')
HTML에서 요소가 어떻게 구성되어 있는지 파악하려면‘요소 검사’도구를 사용합니다. 브라우저에서웹 페이지를열고Ctrl + Shift + I를눌러검사기를 엽니다. 스크린샷에서 볼 수 있듯이, 상품은col-xs-6 col-sm-4 col-md-3 col-lg-3 클래스를 가진li요소 안에 저장되어 있습니다. 책 제목은title속성을 읽어a요소에서 찾을 수 있으며, 가격은price_color 클래스를 가진p요소 안에 저장되어 있습니다:
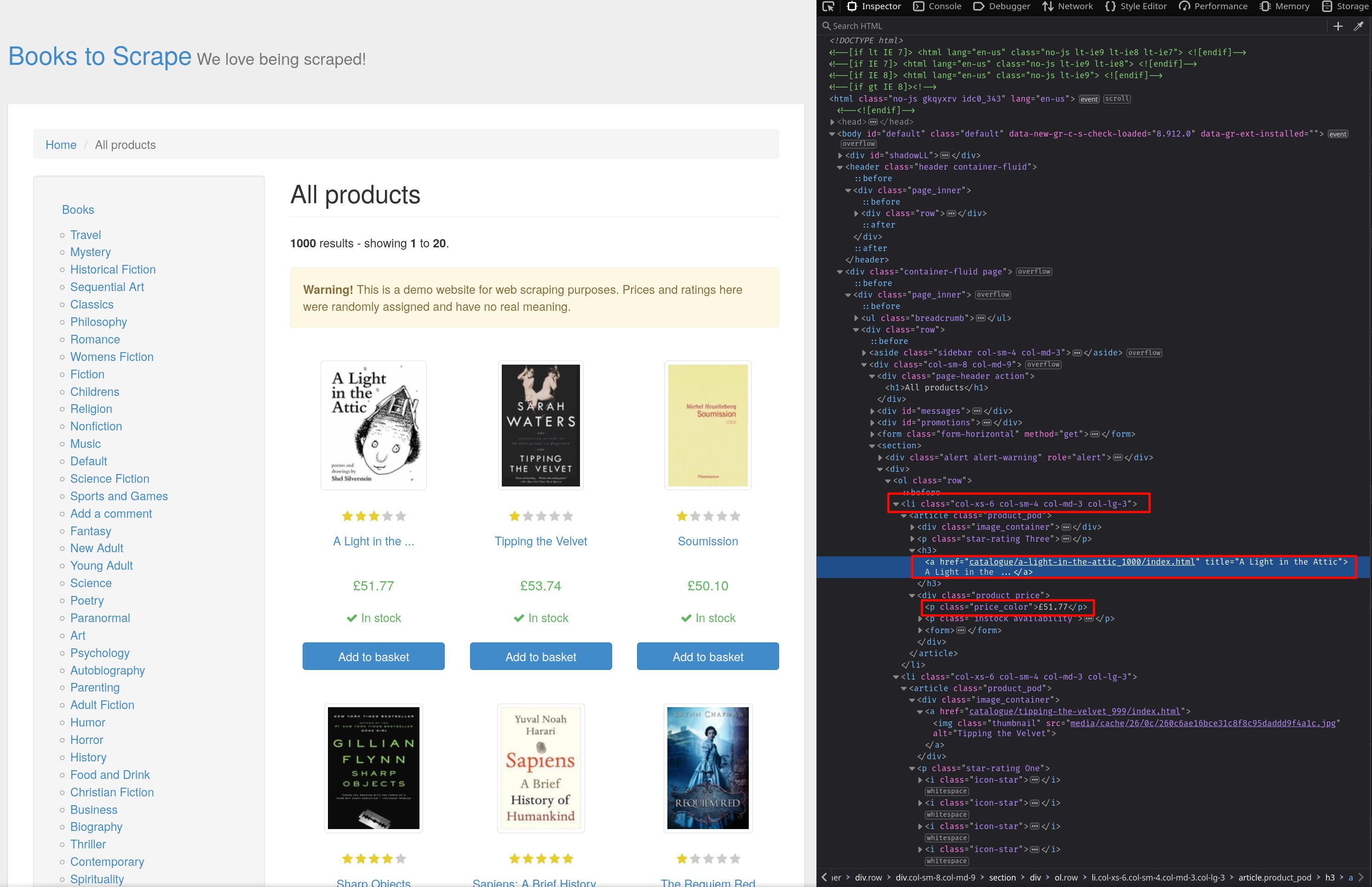
Beautiful Soup의 find_all 메서드를 사용하여 col-xs-6 col-sm-4 col-md-3 col-lg-3 클래스를 가진 모든 li 요소를 찾습니다:
books = soup.find_all("li", class_="col-xs-6 col-sm-4 col-md-3 col-lg-3")
content = str(books)
이제 content 변수는 li 요소의 HTML 텍스트를 포함하며, 정규식을 사용하여 제목과 가격을 추출할 수 있습니다.
첫 번째 단계는 텍스트의 제목과 가격을 일치시키는 정규식을 구성하는 것입니다. 이를 위해 다시 한 번 ‘요소 검사’를 사용해야 합니다.
책 제목은 a 요소의 title 속성에 저장되어 있으며, a 요소는 다음과 같은 형태입니다:
<a href="..." title="...">
제목 뒤에 있는 큰따옴표 안의 내용을 일치시키려면 고전적인 .*? 정규 표현식을 사용하세요. .는 단일 문자를 일치시키고, *는 앞의 요소(이 경우 .가 일치시키는 모든 것)가 0회 이상 반복되는 것을 일치시키며, ?는 앞의 요소(이 경우 .*가 일치시키는 모든 것)가 0회 또는 1회 반복되는 것을 일치시킵니다. 이들을 함께 사용하면 다음 완전한 표현식에서 큰따옴표 안의 내용을 일치시킬 수 있습니다:
<a href=".*?" title="(.*?)"
.*?를 둘러싼 괄호는캡처 그룹을 생성하기 위해 사용됩니다. 캡처 그룹은 패턴 일치에 대한 정보를 기억하며, 복잡한 표현식에서 이미 일치된 패턴을 식별하고 참조하는 데 사용됩니다. 그러나 이 경우 캡처 그룹은 일치된 텍스트를 추출하는 데 사용됩니다. 캡처 그룹이 없으면 텍스트는 여전히 일치되지만, 일치된 텍스트에 접근할 수 없습니다.
가격을 추출하려면 동일한 정규 표현식 (.*?)을 사용합니다. 가격은 price_color 클래스의 p 요소 내에 저장되므로, 완전한 정규 표현식은 <p class="price_color">(.*?)</p>입니다.
두 패턴을 정의합니다:
re_book_title = r'<a href=".*?" title="(.*?)"'
re_prices = r'<p class="price_color">(.*?)</p>'
참고:
.*뒤에?가 필요한 이유를 궁금해하신다면,이 Stack Overflow 답변에서?의 역할을 잘 설명하고 있습니다.
이제 re.findall() 을 사용하여 HTML 문자열에서 모든 정규 표현식 일치 항목을 찾을 수 있습니다:
titles = re.findall(re_book_title, content)
prices = re.findall(re_prices, content)
마지막으로 일치 항목을 반복 처리하여 결과를 출력합니다:
for i in zip(titles, prices):
print(f"{i[0]}: {i[1]}")
이 코드는 python scraper.py로 실행할 수 있습니다. 출력 결과는 다음과 같습니다:
A Light in the Attic: £51.77
Tipping the Velvet: £53.74
Soumission: £50.10
Sharp Objects: £47.82
Sapiens: A Brief History of Humankind: £54.23
The Requiem Red: £22.65
The Dirty Little Secrets of Getting Your Dream Job: £33.34
유명한 페미니스트 빅토리아 우드헐의 삶을 바탕으로 한 소설, 다가오는 여성: £17.93
보트 위의 소년들: 1936년 베를린 올림픽에서 금메달을 향한 아홉 미국인의 위대한 도전: £22.60
블랙 마리아: £52.15
굶주린 마음들 (삼각 무역 3부작, #1): £13.99
셰익스피어의 소네트: £20.66
나를 자유롭게 해줘: £17.46
스캇 필그림의 소중한 작은 인생 (스캇 필그림 #1): £52.29
찢어버리고 다시 시작해: £35.02
우리 밴드가 당신의 인생이 될 수 있다: 1981-1991년 미국 인디 언더그라운드의 현장: £57.25
올리오: £23.88
메사에리온: 최고의 공상과학 소설 1800-1849: £37.59
초보자를 위한 자유지상주의: £51.33
그저 히말라야일 뿐: £45.17
위키피디아 페이지 스크래핑
이제위키피디아 페이지를스크래핑하고 모든 링크에 대한 정보를 추출할 수 있는 스크래퍼를 만들어 보겠습니다.
wiki_scraper.py라는 새 파일을 생성하세요. 이전과 마찬가지로 라이브러리 임포트, GET 요청 수행, 콘텐츠 파싱 순으로 시작합니다:
import requests
from bs4 import BeautifulSoup
import re
page = requests.get('https://en.wikipedia.org/wiki/Web_scraping')
soup = BeautifulSoup(page.content, 'html.parser')
모든 링크를 찾으려면 find_all() 메서드를 사용합니다:
links = soup.find_all("a")
content = str(links)
링크 텍스트는 title 속성에 저장되며, 링크 URL은 href 속성에 저장됩니다. 동일한 정규 표현식 (.*?) 을 사용하여 정보를 추출할 수 있습니다. 전체 표현식은 다음과 같습니다:
<a href="(.*?)" title="(.*?)">.*?</a>
세 번째 .*? 는 캡처 그룹에 포함되지 않습니다. a 태그의 내용을 추출하는 것이 목적이 아니기 때문입니다.
이전과 마찬가지로 findall() 을 사용하여 모든 일치 항목을 찾고 결과를 출력합니다:
re_links = r'<a href="(.*?)" title="(.*?)">.*?</a>'
links = re.findall(re_links, content)
for i in links:
print(f"{i[0]} => {i[1]}")
python wiki_scraper.py로 실행하면 다음과 같은 출력이 나옵니다:
간결함을 위해 출력 생략
/wiki/Category:Web_scraping => Category:Web scraping
/wiki/Category:CS1_maint:_multiple_names:_authors_list => Category:CS1 maint: multiple names: authors list
/wiki/Category:CS1_Danish-language_sources_(da) => Category:CS1 Danish-language sources (da)
/wiki/Category:CS1_French-language_sources_(fr) => Category:CS1 French-language sources (fr)
/wiki/Category:Articles_with_short_description => Category:Articles with short description
/wiki/Category:Short_description_matches_Wikidata => Category:Short description matches Wikidata
/wiki/Category:Articles_needing_additional_references_from_April_2023 => Category:Articles needing additional references from April 2023
/wiki/Category:추가 참고 자료가 필요한 모든 문서 => 추가 참고 자료가 필요한 모든 문서
/wiki/Category:2015년 10월부터 지리적 범위가 제한된 문서 => 2015년 10월부터 지리적 범위가 제한된 문서
/wiki/Category:United_States-centric => Category:미국 중심
/wiki/Category:All_articles_with_unsourced_statements => Category:출처 미기재 진술이 있는 모든 문서
/wiki/Category:Articles_with_unsourced_statements_from_April_2023 => Category:2023년 4월 출처 미기재 진술이 있는 문서
동적 사이트 스크래핑
지금까지 스크래핑한 모든 웹 페이지는 정적 페이지였습니다. 동적 웹 페이지를 스크래핑하는 것은Selenium과 같은 브라우저 자동화 도구가 필요하므로 조금 더 어렵습니다. 다음은OpenWeatherMap홈페이지에서 런던의 현재 기온을 정규 표현식과 Selenium을 사용하여 스크래핑하는 예시입니다:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
driver = webdriver.Firefox()
driver.get("https://openweathermap.org/city/2643743")
elem = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.CSS_SELECTOR, ".current-temp")))
content = elem.get_attribute('innerHTML')
re_temp = r'<span .*?>(.*?)</span>'
temp = re.findall(re_temp, content)
print(repr(temp))
driver.close()
이 코드는 Selenium을 사용하여 Firefox 인스턴스를 실행하고 CSS 선택자를 통해 현재 온도가 표시된 요소를 선택합니다. 그런 다음 정규 표현식 <span .*?>(.*?)</span> 을 사용하여 온도를 추출합니다.
Selenium으로 동적 웹 페이지 스크래핑을 시작하는 데 도움이 되는 더 많은 정보를 원한다면이 튜토리얼을 확인해 보세요.
웹 스크래핑에 대한 정규 표현식의 한계
정규 표현식은 패턴 매칭과 텍스트 정보 추출에 강력한 도구입니다. 개발자들은 종종 정규 표현식을 배우고 웹 스크래핑에 사용하려 합니다. 그러나 정규 표현식 자체만으로는 웹 스크래핑에 적합하지 않습니다. 정규 표현식은 텍스트를 대상으로 하며 HTML 구조에 대한 개념이나 이해가 없습니다. 이는 결과가 HTML 코드가 작성된 방식에 크게 의존함을 의미합니다. 예를 들어, 위키피디아 예제에서 일부 링크가 올바르게 추출되지 않았다는 점을 눈치챘을 수 있습니다:

Python 코드를 수정하여 Beautiful Soup이 반환한 HTML 문자열을 출력하도록 print(content)를 추가하면 문제의 원인이 다음과 같이 보입니다:
<a href="#cite_ref-9">^</a>
여기서 title 속성이 누락되었지만, 정규 표현식에서는 <a href="(.*?)" title="(.*?)">.*?</a> 구조를 가정했습니다. 정규 표현식은 HTML 요소를 인식하지 못하기 때문에, .*? 패턴은 오류를 발생시키거나 일치를 중단하지 않고 무작정 문자를 일치시키다가 " title="(.*?)">.*?</a> 패턴을 완성할 수 있을 때까지 진행했습니다. 이로 인해 다음 몇 개의 a 태그까지 잡아먹게 되었으며, HTML 코드가 예상치 못한 방식으로 작성될 경우 정규 표현식 사용이 의도하지 않은 결과를 초래할 수 있음을 보여줍니다.
또한 HTML은 정규 언어가 아니므로, 정규 표현식만으로는 임의의 HTML 데이터를 파싱할 수 없습니다. 이스택 오버플로우 답변은정규 표현식으로 HTML을 파싱하려는 개발자들을 풍자한 내용으로 개발자들 사이에서 컬트적인 명성을 얻었습니다. 그러나 정규 표현식을 사용해 HTML 데이터를 파싱하고 스크래핑할 수 있는 몇 가지 상황은 존재합니다.
예를 들어, 알려진 제한된 HTML 코드 집합이 있고 코드 구조를 완전히 이해하고 있다면 정규 표현식을 사용할 수 있습니다. HTML 내 모든 a 태그가 href 및 title 속성을 가지며 고정된 패턴을 따르는 것을 알고 있다면, 정규 표현식을 사용해 정보를 추출할 수 있습니다. 그러나 더 나은 방법이자 견고한 해결책은 Beautiful Soup 같은 HTML 파서를 사용해 요소를 찾고 텍스트 데이터를 추출하는 것입니다.
텍스트 데이터를 추출한 후에는 정규 표현식을 사용하여 추가로 처리할 수 있습니다. 예를 들어, Beautiful Soup을 사용하여 href 및 title 속성을 추출한 다음 정규 표현식을 사용하여 영숫자가 아닌 문자를 포함하는 태그를 걸러내는 위키피디아 스크레이퍼의 수정된 버전은 다음과 같습니다:
import requests
from bs4 import BeautifulSoup
import re
page = requests.get('https://en.wikipedia.org/wiki/Web_scraping')
soup = BeautifulSoup(page.content, 'html.parser')
links = soup.find_all("a")
for link in links:
href = link.get('href')
title = link.get('title')
if title == None:
title = link.string
if title == None:
continue
pattern = r"[a-zA-Z0-9]"
if re.match(pattern, title):
print(f"{href} => {title}")
결론
정규 표현식은 텍스트 데이터에서 패턴을 찾는 강력한 도구입니다. 그 견고성 덕분에 웹 스크래핑에서 정보를 추출하는 데 자주 사용됩니다.
이 글에서는 정규 표현식이 무엇인지, 그리고 Beautiful Soup과 함께 전자상거래 웹사이트, 위키피디아, 동적 웹 페이지를 스크래핑하는 방법을 배웠습니다. 또한 정규 표현식의 한계점과 다른 도구와 함께 최적으로 활용하는 방법도 알아보았습니다.
정규 표현식을 최대한 활용하더라도 웹 스크래핑은 도전 과제가 많습니다. 반복적인 스크래핑은 스크래퍼의 IP 주소가 차단되는 원인이 될 수 있습니다. 또한 스크래퍼의 정상 작동을 방해하는 CAPTCHA에 직면할 수도 있습니다. Bright Data는IP 차단 우회 기능을 갖춘 강력한 프록시를 제공합니다. 전 세계 프록시 네트워크에는데이터 센터 프록시,주거용 프록시,ISP 프록시,모바일 프록시가 포함됩니다.Web Unlocker를 사용하면 봇 탐지를 우회하고 번거로움 없이 CAPTCHA를 해결할 수 있습니다. 지금 바로 무료 체험을 시작하세요!






