
글로벌 금융 기관은 웹의 실시간 시장 데이터와 기밀 내부 분석 데이터를 결합해야 합니다. 해당 데이터는 민감한 고객 데이터를 위한 온프레미스 데이터 웨어하우스와 확장 가능한 분석을 위한 Azure Data Lake로 분할 저장됩니다. 본 가이드는 Bright Data의 API를 통해 양자를 연결하여 안전하고 거의 실시간에 가까운 통합을 구현하는 방법을 안내합니다.
배울 내용:
- 금융 기관이 하이브리드 데이터 설정이 필요한 이유
- Bright Data를 활용한 규정 준수 웹 데이터 수집 방법
- Azure Data Lake와 온프레미스 웨어하우스 간 안전한 양방향 동기화 설정 방법
- 종단 간 데이터 동기화 검증 방법
- 민감한 데이터 이동 없이 통합 분석 실행 방법
- GitHub에서 샘플 구성 및 스크립트를 찾을 수 있는 위치
하이브리드 데이터 통합이란 무엇이며 금융 분야에 필요한 이유
금융 기관은 GDPR, SOC 2, MiFID II, 바젤 III와 같은 엄격한 규제를 받으며 데이터 저장 위치를 통제합니다. 공개 웹 데이터는 실시간 시장 인텔리전스를 제공하지만, 기존 내부 데이터 세트는 장기적 모델링 및 규정 준수를 지원합니다. 기존 ETL 시스템은 이 두 가지를 안전하게 통합하는 경우가 거의 없습니다.
과제: 보안이나 규정 준수를 저해하지 않으면서 외부 시장 데이터와 내부 분석을 어떻게 결합할 것인가?
해결책: Bright Data는 API를 통해 구조화되고 규정 준수된 웹 데이터를 제공하며, Azure의 하이브리드 인프라스트럭처는 민감한 데이터를 온프레미스에 보관합니다.
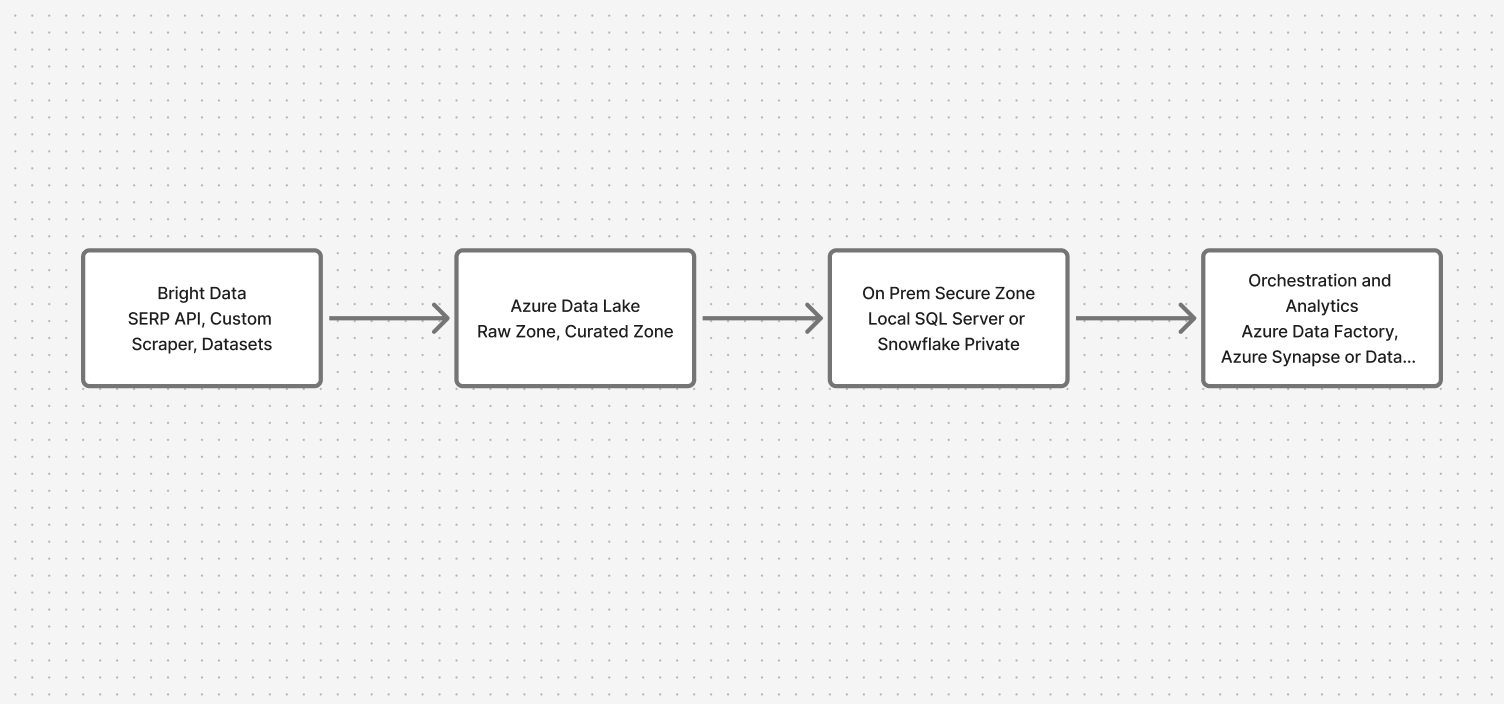
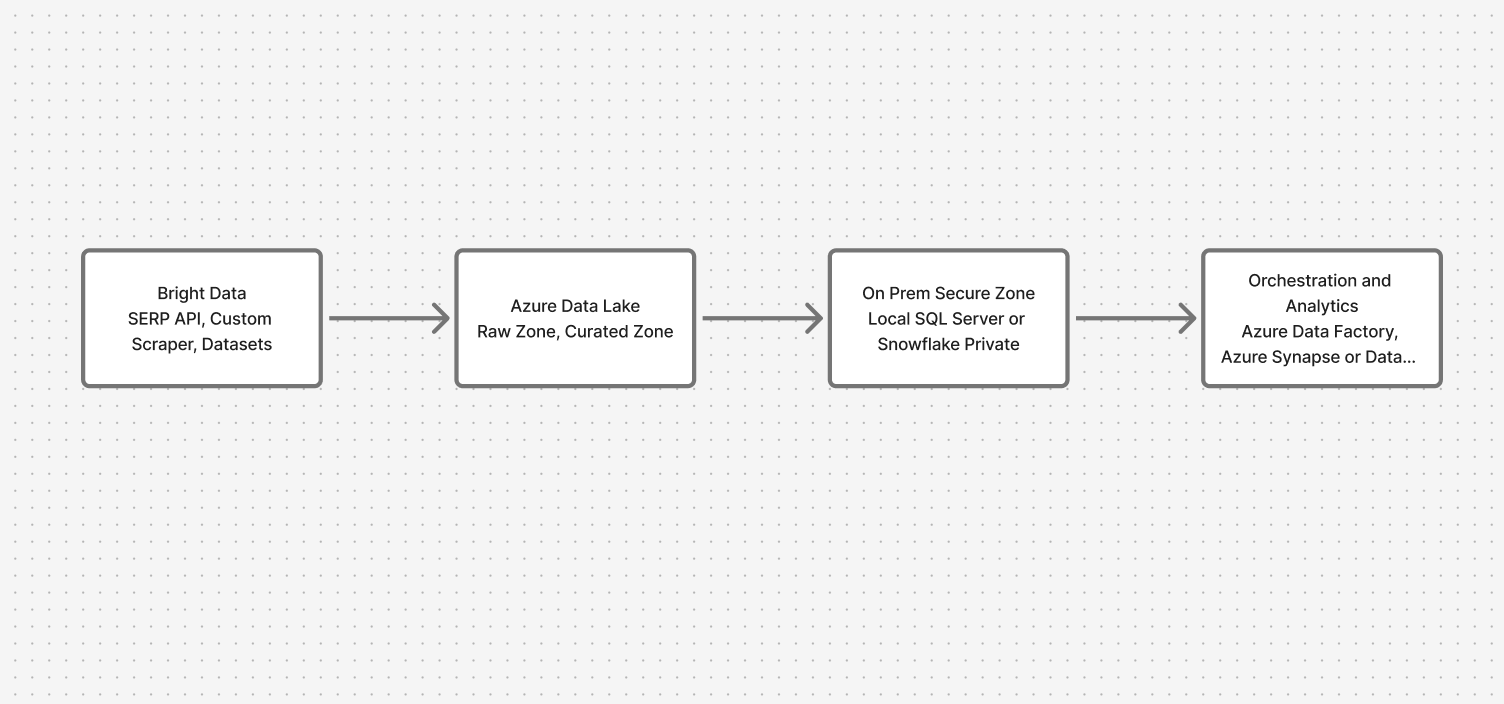
아키텍처 개요: 클라우드와 온프레미스의 안전한 연결
시스템은 네 가지 핵심 계층을 거칩니다:
- 데이터 수집: Bright Data API(SERP, 맞춤형 스크레이퍼, 데이터셋)
- 클라우드 랜딩 존: Azure Data Lake(원본 및 큐레이션 영역)
- 온프레미스 보안 영역: 로컬 SQL Server 또는 Snowflake
- 오케스트레이션 및 분석: 프라이빗 엔드포인트를 지원하는 Azure Data Factory, 연동 쿼리를 위한 Synapse/Databricks
이를 통해 웹 데이터는 유입되지만 민감한 데이터는 제자리에 유지됩니다.
필수 조건
시작하기 전에:
- API 접근 권한이 있는 활성 Bright Data 계정
- 데이터 레이크, 데이터 팩토리, 시냅스 또는 데이터브릭스가 포함된 Azure 구독
- 프라이빗 네트워크(ODBC 또는 JDBC)를 통해 접근 가능한 온프레미스 데이터베이스
- 보안 사설 링크(ExpressRoute, 사이트 간 VPN 또는 사설 엔드포인트)
- 샘플 저장소 복제를 위한 GitHub 계정
💡 팁: 모든 단계를 먼저 비생산 환경 작업 공간에서 실행하세요.
단계별 구현
1. Bright Data로 금융 웹 데이터 수집
Bright Data의 커스텀 스크레이퍼를 구성하여 주가, 규제 서류, 금융 뉴스를 추출합니다. 스크레이퍼는 분석 준비가 된 구조화된 JSON을 출력합니다.
데이터는 다음과 같습니다:
[
{
"symbol": "AAPL",
"price": 230.66,
"currency": "USD",
"timestamp": "2026-11-10T20:15:36Z",
"source": "https://finance.yahoo.com/quote/AAPL",
"sector": "Technology",
"scraped_at": "2026-11-10T20:16:10Z"
},
{
...
}
]
간편한 구성: scraper_config.yaml은 수집 대상과 주기를 정의합니다. 금융 사이트를 대상으로 특정 데이터 포인트를 추출하며, 시간별 수집과 웹훅 알림을 스케줄링합니다.
이 접근 방식은 수동 개입 없이 깨끗하고 구조화된 데이터를 확보할 수 있도록 합니다.
# scraper_config.yaml
name: financial_data_aggregator
description: >
실시간 주가, SEC 공시 자료, 금융 뉴스 헤드라인을 수집하여
하이브리드 클라우드 통합을 지원합니다.
targets:
- https://finance.yahoo.com/quote/AAPL
- https://finance.yahoo.com/quote/MSFT
- https://www.reuters.com/markets/
- https://www.sec.gov/edgar/search/
selectors:
- name: symbol
type: text
selector: "h1[data-testid='quote-header'] span"
- 이름: price
유형: 텍스트
선택자: "fin-streamer[data-field='regularMarketPrice']"
- 이름: headline
유형: 텍스트
선택자: "article h3 a"
- 이름: filing_type
유형: 텍스트
선택자: "td[class*='filetype']"
- 이름: filing_date
type: text
selector: "td[class*='filedate']"
- name: filing_url
type: link
selector: "td[class*='filedesc'] a"
pagination:
type: next-link
selector: "a[aria-label='Next']"
output:
format: json
file_name: financial_data.json
schedule:
frequency: hourly
timezone: UTC
webhook: "https://<your-webhook-endpoint>/brightdata/ingest"
notifications:
email_on_success: [email protected]
email_on_failure: [email protected]2. Azure Data Lake에 데이터를 안전하게 수집
이제 수집된 데이터를 Azure Function을 사용하여 Azure Data Lake로 라우팅합니다. 이 함수는 안전한 게이트웨이 역할을 수행합니다:
- Bright Data로부터 HTTPS POST를 통해 JSON 데이터 수신
- 관리형 ID를 사용하여 인증(비밀 관리 불필요)
- 추적을 용이하게 하기 위해 소스 및 타임스탬프별로 파일을 구성
- 규정 준수 추적을 위한 메타데이터 태그 추가
결과: 시장 데이터가 파티션화된 폴더에 저장되어 관리 및 쿼리가 용이해집니다.
azure_ingest.py
# azure_function_ingest.py
import azure.functions as func
import json
import os
from datetime import datetime
from azure.identity import ManagedIdentityCredential
from azure.storage.blob import BlobServiceClient, ContentSettings
# 환경 변수
STORAGE_ACCOUNT_URL = os.getenv("STORAGE_ACCOUNT_URL") # 예: "https://myaccount.blob.core.windows.net"
CONTAINER_NAME = os.getenv("CONTAINER_NAME", "brightdata-market")
# 관리형 ID로 Blob 클라이언트 초기화
credential = ManagedIdentityCredential()
blob_service_client = BlobServiceClient(account_url=STORAGE_ACCOUNT_URL, credential=credential)
def main(req: func.HttpRequest) -> func.HttpResponse:
try:
# Bright Data에서 수신된 JSON 파싱
payload = req.get_json()
source = detect_source(payload)
now = datetime.utcnow()
date_str = now.strftime("%Y-%m-%d")
# 대상 경로 준비
blob_path = f"raw/source={source}/date={date_str}/financial_data_{now.strftime('%H%M%S')}.json"
# JSON 파일 업로드
blob_client = blob_service_client.get_blob_client(container=CONTAINER_NAME, blob=blob_path)
data_bytes = json.dumps(payload, indent=2).encode("utf-8")
blob_client.upload_blob(
data_bytes,
overwrite=True,
content_settings=ContentSettings(content_type="application/json"),
metadata={
"classification": "public",
"data_category": "market_data",
"source": source,
"ingested_at": now.isoformat(),
},
)
return func.HttpResponse(
f"{source}의 데이터가 {blob_path}에 저장되었습니다.",
status_code=200
)
except Exception as ex:
return func.HttpResponse(str(ex), status_code=500)
def detect_source(payload: dict) -> str:
"""소스 이름을 식별하는 간단한 헬퍼 함수."""
# 배열의 첫 번째 요소에서 'source' 필드 검색
if isinstance(payload, list) and payload:
src_url = payload[0].get("source", "")
if "yahoo" in src_url:
return "finance_yahoo"
elif "reuters" in src_url:
return "reuters"
elif "sec" in src_url:
return "sec"
return "unknown"3. 민감하지 않은 하위 집합을 온프레미스로 동기화
모든 데이터가 환경 간 이동할 필요는 없습니다. Azure Data Factory를 스마트 필터로 활용하여 온프레미스 웨어하우스와 동기화해도 안전한 데이터 하위 집합만 신중하게 선별합니다.
실제 프로세스는 다음과 같습니다:
파이프라인은 데이터 레이크에 새로 도착한 파일을 스캔하는 것으로 시작합니다. 그런 다음 시장 가격 및 주식 심볼과 같은 공개적이고 민감하지 않은 데이터만 포함하도록 지능형 필터링을 적용합니다. 고객 정보나 독점 분석 데이터는 제외됩니다.
보안성과 신뢰성을 보장하는 요소:
프라이빗 엔드포인트는 Azure와 온프레미스 인프라 간 전용 터널을 생성하여 공용 인터넷을 완전히 우회합니다. 이를 통해 외부 위협에 대한 노출을 차단하면서 일관된 성능을 보장합니다.
워터마크 추적을 통한 증분 로딩은 시스템이 새로 추가되거나 변경된 레코드만 이동하도록 합니다. 자동 스키마 유효성 검사와 결합되어 중복을 방지하면서 두 환경을 완벽하게 동기화합니다.
이제 실제 파이프라인 코드로 어떻게 구현되는지 살펴보겠습니다:
{
"name": "Hybrid_Cloud_OnPrem_Sync",
"properties": {
"activities": [
{
"name": "Lookup_NewFiles",
"type": "Lookup",
"dependsOn": [],
"typeProperties": {
"source": {
"type": "JsonSource"
},
"dataset": {
"referenceName": "ADLS_NewFiles_Dataset",
"type": "DatasetReference"
},
"firstRowOnly": false
}
},
{
"name": "Get_Metadata",
"type": "GetMetadata",
"dependsOn": [
{
"activity": "Lookup_NewFiles",
"dependencyConditions": ["Succeeded"]
}
],
"typeProperties": {
"dataset": {
"referenceName": "ADLS_NewFiles_Dataset",
"type": "DatasetReference"
},
"fieldList": ["childItems", "size", "lastModified"]
}
},
{
"name": "Filter_PublicData",
"type": "Filter",
"dependsOn": [
{
"activity": "Get_Metadata",
"dependencyConditions": ["Succeeded"]
}
],
"typeProperties": {
"items": {
"value": "@activity('Lookup_NewFiles').output.value",
"type": "Expression"
},
"condition": "@equals(item().metadata.classification, 'public')"
}
},
{
"name": "Copy_To_OnPrem_SQL",
"type": "Copy",
"dependsOn": [
{
"activity": "Filter_PublicData",
"dependencyConditions": ["Succeeded"]
}
],
"typeProperties": {
"source": {
"type": "JsonSource",
"treatEmptyAsNull": true
},
"sink": {
"type": "SqlSink",
"preCopyScript": "IF OBJECT_ID('stg_market_data') IS NULL CREATE TABLE stg_market_data (symbol NVARCHAR(50), price FLOAT, currency NVARCHAR(10), timestamp DATETIME2, source NVARCHAR(500));"
}
},
"inputs": [
{
"referenceName": "ADLS_PublicData_Dataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "OnPrem_SQL_Dataset",
"type": "DatasetReference"
}
]
},
{
"name": "Log_Load_Status",
"type": "StoredProcedure",
"dependsOn": [
{
"activity": "Copy_To_OnPrem_SQL",
"dependencyConditions": ["Succeeded", "Failed"]
}
],
"typeProperties": {
"storedProcedureName": "usp_Log_HybridLoad",
"storedProcedureParameters": {
"load_source": {
"value": "BrightData",
"type": "String"
},
"status_msg": {
"value": "@activity('Copy_To_OnPrem_SQL').output",
"type": "Expression"
}
}
},
"linkedServiceName": {
"referenceName": "OnPrem_SQL_LinkedService",
"type": "LinkedServiceReference"
}
}
],
"annotations": ["HybridIntegrationDemo"]
}
}주요 구성 요소 분석:
- Lookup_NewFiles는 파이프라인의 검사 역할을 수행합니다. 먼저 데이터 레이크에 도착한 처리 대상 신규 데이터를 식별합니다. 이를 통해 시스템이 불필요하게 기존 파일을 재처리하는 것을 방지합니다.
- Get_Metadata는 해당 파일들을 면밀히 검사하여 크기, 수정 날짜, 구조를 확인합니다. 이 단계는 완전하고 유효한 파일로 작업한 후 다음 단계로 진행하도록 보장합니다.
- Filter_PublicData는 보안 마법이 일어나는 곳입니다. 이전에 임베드한 분류 메타데이터를 사용하여 민감한 데이터를 자동으로 필터링하여 공개 시장 정보만 파이프라인을 계속 통과하도록 보장합니다.
- Copy_To_OnPrem_SQL은 실제 전송을 처리하지만 스마트한 안전 장치를 갖추고 있습니다. preCopyScript는 대상 테이블이 올바른 스키마로 존재하는지 확인하며, 프라이빗 엔드포인트 연결은 모든 데이터를 보안 네트워크 내에 유지합니다.
- Log_Load_Status는 모든 동기화 작업이 온프레미스 데이터베이스에 기록되도록 하여 중요한 가시성을 제공합니다. 이는 규정 준수 팀이 요구하는 감사 추적을 생성하는 동시에 운영 담당자에게 파이프라인 상태를 즉시 확인할 수 있는 가시성을 제공합니다.
진정한 이점: 온프레미스 팀은 필요한 시장 상황과 실시간 인텔리전스를 확보하는 동시에, 민감한 고객 데이터와 독점 모델은 안전하게 제자리에 보관됩니다. 민첩성과 보안이 조화를 이루는 최적의 솔루션입니다.
4. 양방향 동기화 검증 활성화
신뢰할 수 있는 비즈니스 의사 결정을 위해서는 데이터 일관성이 필수적입니다. 클라우드 분석과 온프레미스 보고서가 동일한 수치를 보여준다는 확신이 필요합니다. 이를 보장하기 위해 지속적으로 실행되는 자동화된 데이터 검증 기능을 구축했습니다.
검증 프로세스는 다음과 같이 작동합니다:
- 행 수 비교는 초기 경보 시스템 역할을 합니다. 이 초기 검사는 전송 실패나 불완전한 데이터 로드 같은 주요 문제를 신속하게 식별합니다. 클라우드와 온프레미스 간 행 수가 일치하지 않으면 즉시 조사 필요 사항을 파악할 수 있습니다.
- 해시 체크섬은 데이터의 디지털 지문을 생성합니다. 수천 개의 레코드를 수동으로 비교하는 대신, 각 데이터 세트에 고유한 암호화 해시를 생성합니다. 단일 문자 변경만으로도 완전히 다른 해시가 생성됩니다. 이 방법을 통해 데이터 손상이나 부분 전송을 즉시 감지할 수 있습니다.
- 실시간에 가까운 동기화는 몇 분마다 검증이 실행됨을 의미합니다. 문제를 발견하기 위해 밤새 실행되는 배치 작업을 기다릴 필요가 없습니다. 시스템은 며칠이 아닌 몇 분 내에 문제를 포착하여 데이터를 최신 상태로 유지하고 신뢰성을 보장합니다.
- 자동화된 알림은 데이터 문제를 즉각적인 조치로 전환합니다. 시스템이 불일치를 감지하면 Slack, 이메일 또는 기존 모니터링 도구를 통해 알림을 전송합니다. 팀은 문제가 비즈니스 결정에 영향을 미치기 전에 해결할 수 있습니다.
실제 구현 예시는 다음과 같습니다:
def validate_sync():
# 시스템 간 레코드 수 비교
cloud_count = get_cloud_record_count()
onprem_count = get_onprem_record_count()
if cloud_count != onprem_count:
alert_team(f"레코드 수 불일치: 클라우드 {cloud_count} vs 온프레미스 {onprem_count}")
return False
# 데이터 무결성 검증을 위한 체크섬 생성
cloud_checksum = generate_data_checksum('cloud')
onprem_checksum = generate_data_checksum('onprem')
if cloud_checksum != onprem_checksum:
alert_team(f"데이터 무결성 실패: 체크섬 불일치")
return False
# 동기화 시점 확인
last_sync_time = get_last_sync_timestamp()
if is_sync_delayed(last_sync_time):
alert_team(f"동기화 지연 감지: 마지막 동기화 {last_sync_time}")
return False
return True5. 민감한 데이터 이동 없이 통합 분석 구축
여기서 가장 강력한 점은 민감한 정보를 이동하지 않고도 클라우드와 온프레미스 데이터를 사실상 결합할 수 있다는 것입니다.
쿼리 예시:
SELECT c.symbol,
c.stock_price,
o.risk_score
FROM adls.market_data c
JOIN external.onprem_portfolio o
ON c.symbol = o.ticker
WHERE o.client_tier = 'premium';Azure Synapse는 온프레미스 웨어하우스를 가리키는 외부 테이블을 생성하는 반면, Databricks는 역할 기반 접근 제어(RBAC)를 적용한 JDBC 연결을 사용합니다.
규정 준수 및 감사 추적 모범 사례
감사 및 법적 요구 사항을 충족하려면 데이터 추적 및 보안에 대한 체계적인 접근 방식이 필요합니다. 규정 준수 프레임워크 구축 방법은 다음과 같습니다:
- 완벽한 데이터 이동 로깅을 통해 모든 전송이 Azure Monitor 및 온프레미스 SIEM에 기록됩니다. 이를 통해 데이터가 언제, 어디로 이동했는지에 대한 불변의 기록이 생성되어 감사자에게 완전한 추적성을 제공합니다.
- 명확한 데이터 출처 추적은 Bright Data 소스 ID를 디지털 지문으로 활용합니다. 이러한 태그는 데이터의 전체 수명 주기 동안 유지되어 모든 분석을 원본 소스 수집까지 추적할 수 있게 합니다.
- Azure Purview를 통한 자동화된 계보 추적은 데이터가 파이프라인을 통해 어떻게 변환되는지 매핑합니다. 특정 보고서에 기여한 원시 피드와 적용된 변환 내용을 자동으로 문서화합니다.
- 중앙 집중식 액세스 제어는 Azure AD와 온프레미스 LDAP를 동기화합니다. 이를 통해 기존 보안 정책을 두 환경 모두에 적용하여 클라우드와 온프레미스 시스템 전반에 걸쳐 일관된 권한 관리를 보장합니다.
그 결과 자동화된 규정 준수 보고, 중앙 집중식 보안 관리, 팀의 업무 속도를 저하시키지 않으면서 데이터를 보호하는 프레임워크가 구현됩니다.
일반적인 과제 및 Bright Data의 해결 방안
| 과제 | Bright Data 기능 |
|---|---|
| IP 차단 또는 속도 제한 | 주거용 및 ISP 프록시 (1억 5천만 개 이상의 IP) |
| CAPTCHA 또는 로그인 장벽 | 자동화된 해결을 위한웹 언락커 |
| 자바스크립트 사용량이 많은 웹사이트 | 스크래핑 브라우저 (Playwright 기반 렌더링) |
| 빈번한 사이트 변경 | AI 자동 수정 기능이 포함된관리형 데이터 서비스 |
결론 및 향후 계획
금융 기관은 Bright Data의 API와 Azure의 하이브리드 인프라를 함께 사용하여 공개 데이터와 사설 데이터를 안전하게 통합할 수 있습니다.
그 결과 민첩성과 제어력을 모두 제공하는 규정 준수 시스템을 구축할 수 있습니다.
💡 완전한 관리형 데이터 액세스를 선호하는 경우 Bright Data의 관리형 데이터 서비스를 사용하여 스크래핑 및 전달을 종단 간 처리하십시오.





