
이 블로그 글에서 배울 내용:
- Kubeflow Pipelines에 전용 웹 데이터 수집 구성 요소를 포함해야 하는 이유.
- 특정 TikTok 감정 분석 파이프라인에 이 접근법을 적용한 사례.
- 특정 스크래핑 솔루션을 통해 TikTok 댓글 데이터 피드에 연결하여 해당 파이프라인을 구현하는 방법.
자, 시작해 보겠습니다!
구조화된 웹 스크래핑 데이터가 Kubeflow Pipelines에 유익한 이유
현대적인 머신러닝 및 AI 워크플로는 고품질 데이터에 크게 의존합니다. 반면, 기존 파이프라인은 정적 데이터셋이나 사전 처리된 파일을 주로 사용합니다. 그러나 이러한 소스는 빠르게 구식이 되어 모델이 오래된 정보로 훈련되게 합니다.
이때 구조화된 웹 스크래핑 데이터가 해결책이 됩니다! 웹에서 실시간 컨텍스트 데이터를 수집함으로써 파이프라인은 최신 트렌드, 사용자 행동, 새롭게 등장하는 콘텐츠와 지속적으로 연동될 수 있습니다.
모듈화, 재현성, 확장성을 갖춘 머신러닝 워크플로우를 위해 설계된 Kubeflow Pipelines는 웹 데이터 수집 구성 요소를 통합함으로써 막대한 이점을 얻습니다. 이러한 구성 요소는 자동으로 수집, 필터링 및 후속 처리될 수 있는 최신 구조화된 피드를 제공합니다.
파이프라인에 웹 데이터 수집 구성 요소를 포함하면 모델 정확도 향상에 확실히 도움이 됩니다. 따라서 전용 웹 데이터 수집 구성 요소(또는 다양한 소스를 위한 여러 구성 요소)를 추가하는 것은 전략적으로 의미가 있습니다. 이를 통해 파이프라인이 지속적으로 적응하고 재훈련하며 거의 실시간으로 인사이트를 생성할 수 있어, 모든 AI 기반 프로젝트의 견고한 기반을 마련합니다.
TikTok 감정 분석을 위한 Kubeflow 파이프라인 소개
웹 데이터 수집 구성 요소가 Kubeflow 파이프라인을 어떻게 향상시키는지 이해하기 위해 실제 사례를 살펴보겠습니다. TikTok 게시물 집합을 가져와 그 콘텐츠의 감정을 분석하는 데이터 분석 워크플로를 구축한다고 가정해 보세요.
두 가지 구성 요소로 파이프라인을 설계할 수 있습니다:
- TikTok 댓글 데이터 구성 요소: 웹 스크래핑을 통해 TikTok 게시물에서 구조화된 댓글 데이터를 수집합니다.
- 데이터 분석 구성 요소: 해당 댓글에 감정 분석 결과 (
긍정적,부정적,중립적)를 추가합니다.
문제는 TikTok(또는 다른 많은 인기 플랫폼) 스크래핑이 악명 높을 정도로 어렵다는 점입니다. CAPTCHA, 자바스크립트 차단, IP 차단, 속도 제한 같은 반스크래핑 조치들 때문입니다. 이 과정을 확장하면 스로틀링과 차단으로 데이터 수집이 쉽게 중단될 수 있어 복잡성만 가중됩니다.
이러한 문제를 피하려면 Bright Data와 같은 최상급 웹 데이터 서비스로 웹 데이터 수집 구성 요소를 강화하는 것이 합리적입니다. Bright Data는 195개국에 걸쳐 1억 5천만 개의 프록시 IP를 보유한 고도로 확장 가능한 인프라, 99.95%의 성공률, 99.99%의 가동 시간을 바탕으로 대규모의 안정적인 스크래핑을 가능하게 합니다.
구체적으로, TikTok 게시물에서 구조화된 데이터 수집을 간소화하도록 설계된 웹 스크래핑 API인 TikTok Scraper를 활용할 것입니다. 이는 인기 도메인에서 데이터를 추출하기 위해 제공되는 수많은 웹 스크래핑 API 중 하나입니다. 마찬가지로, Filter Dataset API를 사용하여 Bright Data 데이터셋에서 필터링된 데이터를 가져와 즉시 사용 가능한 데이터로 ML/AI 파이프라인을 구동할 수 있습니다.
동적 웹 스크래핑 데이터 컴포넌트를 활용한 Kubeflow 파이프라인 구축 방법
이 가이드 섹션에서는 앞서 소개한 TikTok 감정 분석용 Kubeflow 파이프라인 구축 방법을 살펴보겠습니다.
아래 단계를 따르세요!
필수 구성 요소
이 튜토리얼을 따라하려면 다음이 필요합니다:
- Docker가 설치되어 실행 중인 환경.
- 로컬에 설치된 Python 3.10 이상.
- API 키가 올바르게 설정된 Bright Data 계정 (지금 바로 설정할 필요는 없습니다. 전용 하위 섹션에서 안내해 드립니다).
Kubeflow Pipelines의 작동 방식에 대한 기본적인 이해도 아래 지침을 이해하는 데 도움이 됩니다.
아래 예제를 실행하기 위한 권장 운영체제는 Linux, macOS 또는 WSL(Windows Subsystem for Linux)입니다.
1단계: 프로젝트 설정
터미널을 열고 Kubeflow Pipelines 프로젝트용 새 디렉터리를 생성하세요:
mkdir kfp-bright-data-pipeline프로젝트 디렉터리로 이동하여 그 안에 Python 가상 환경을 생성합니다:
cd kfp-bright-data-pipeline
python -m venv .venv다음으로 선호하는 Python IDE에서 프로젝트 폴더를 엽니다. Python 확장 프로그램이 설치된 Visual Studio Code 또는 PyCharm Community Edition을 권장합니다.
프로젝트 디렉토리 루트에 tiktok_sentiment_analysis_kfp_pipeline.py라는 새 파일을 생성하세요. 구조는 다음과 같아야 합니다:
kfp-bright-data-pipeline/
├── .venv/
└── tiktok_sentiment_analysis_kfp_pipeline.py # <-----------IDE 터미널에서 가상 환경을 활성화하세요. Linux 또는 macOS에서는 다음 명령을 실행합니다:
source venv/bin/activateWindows에서는 다음과 같이 실행하세요:
venv/Scripts/activate가상 환경이 활성화된 상태에서 필요한 종속성을 설치합니다:
pip install kfp필요한 라이브러리는 kfp뿐이며, 이를 통해 이동 가능하고 확장 가능한 머신 러닝 파이프라인을 구축하고 컴파일할 수 있습니다.
마지막으로 tiktok_sentiment_analysis_kfp_pipeline.py 파일을 열고 필요한 모듈을 임포트하세요:
from kfp import dsl, compiler
from kfp.dsl import Input, Output, Dataset이것으로 끝입니다! 이제 Kubeflow 파이프라인을 구축할 수 있는 Python 개발 환경이 준비되었습니다.
2단계: Bright Data 시작하기
파이프라인의 첫 번째 구성 요소는 Bright Data의 웹 스크래핑 API를 사용하여 실시간 웹 데이터를 가져옵니다. 이를 구현하기 전에 Bright Data 계정을 적절히 구성해야 합니다.
웹 스크래핑 API를 사용할 예정이므로 공식 문서를 잠시 살펴보는 것이 좋습니다. 간단히 말해, 이 API는 인기 웹사이트에서 구조화된 데이터 피드를 제공하며, ML/AI 워크플로우(또는 기타 지원되는 사용 사례)에서 바로 활용할 수 있습니다.
계정이 없다면 새로 생성하세요. 기존 계정이 있다면 로그인 후 사용자 대시보드를 엽니다. 대시보드에서 “웹 스크레이퍼” 섹션으로 이동하세요: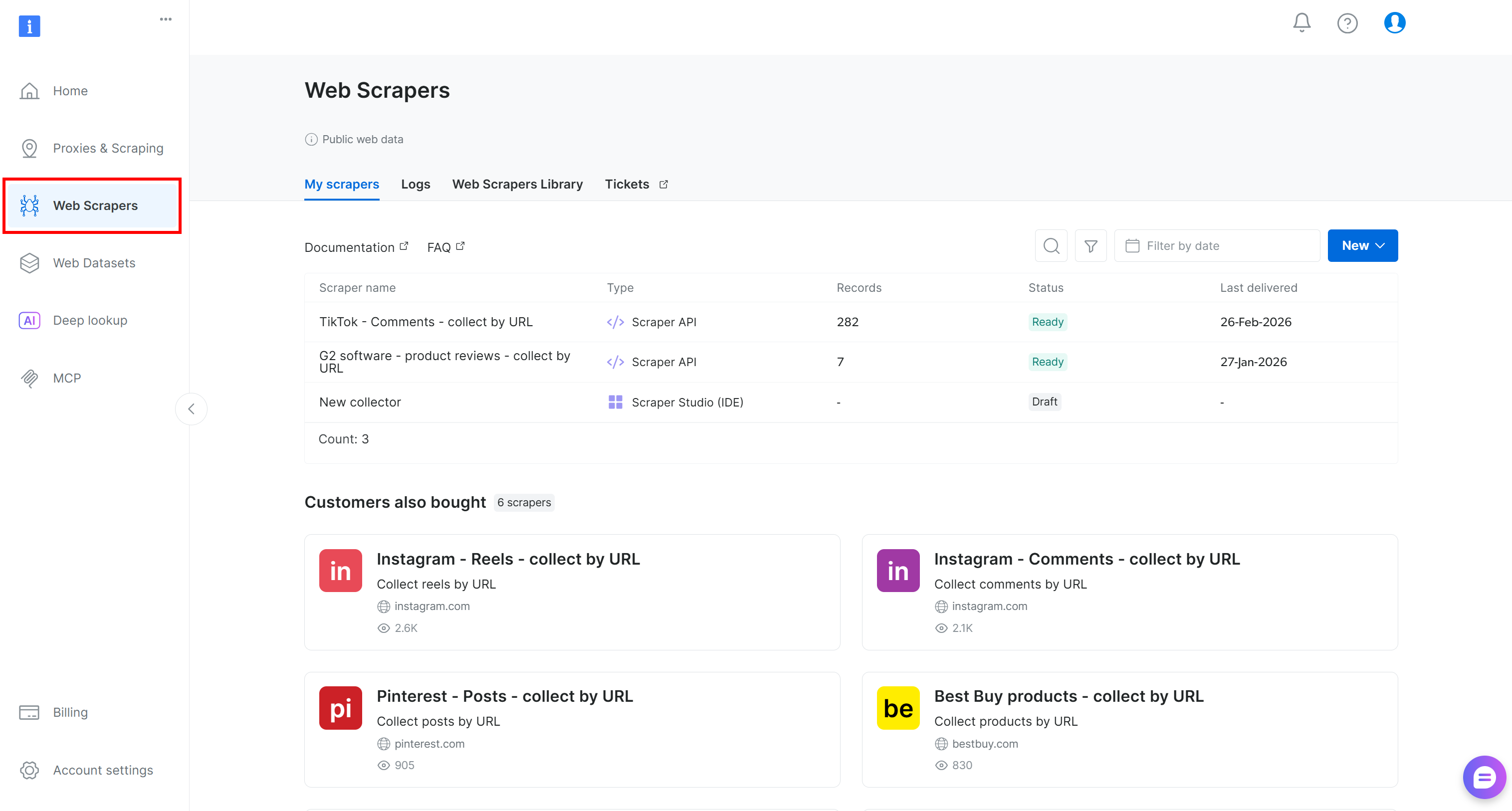
“웹 스크레이퍼 라이브러리” 탭으로 이동하세요. 인터넷에서 가장 인기 있는 플랫폼들을 위한 120개 이상의 사전 제작된 스크레이퍼를 찾을 수 있습니다.
이 튜토리얼에서는 TikTok 게시물의 실시간 댓글 데이터를 추출하여 감정 분석을 수행하는 것이 목표이므로 “tiktok.com”을 검색하세요.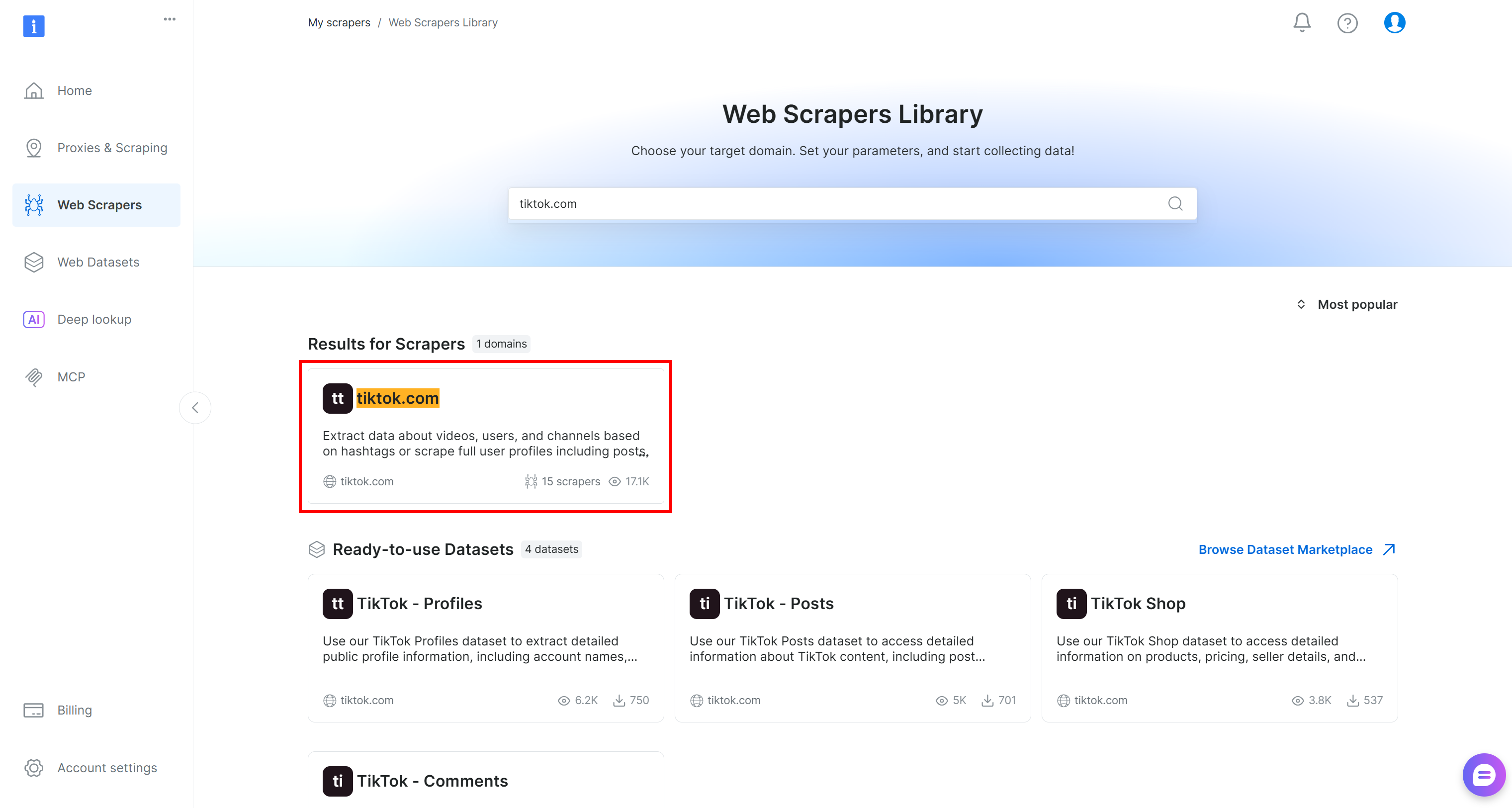
TikTok 스크레이퍼 페이지 내에서 사용 가능한 스크래핑 엔드포인트를 살펴보세요.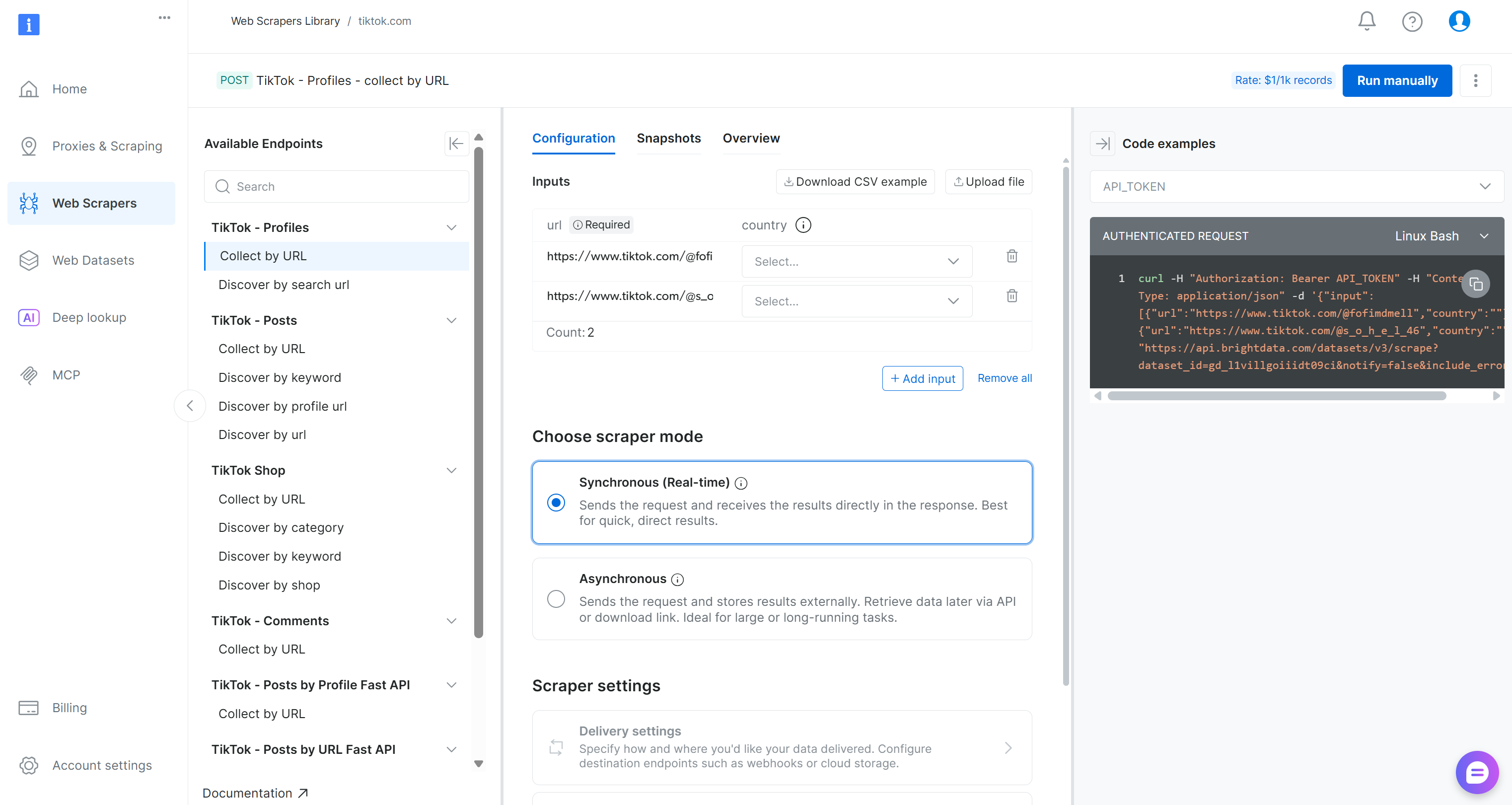
여기서 입력 매개변수를 구성하고, 요청/응답 형식을 확인하며, 예시 API 호출을 검토하는 등 다양한 작업을 수행할 수 있습니다.
이 파이프라인을 위해 “TikTok – Comments” 드롭다운 메뉴에서 “Collect by URL” 스크레이퍼를 찾으세요: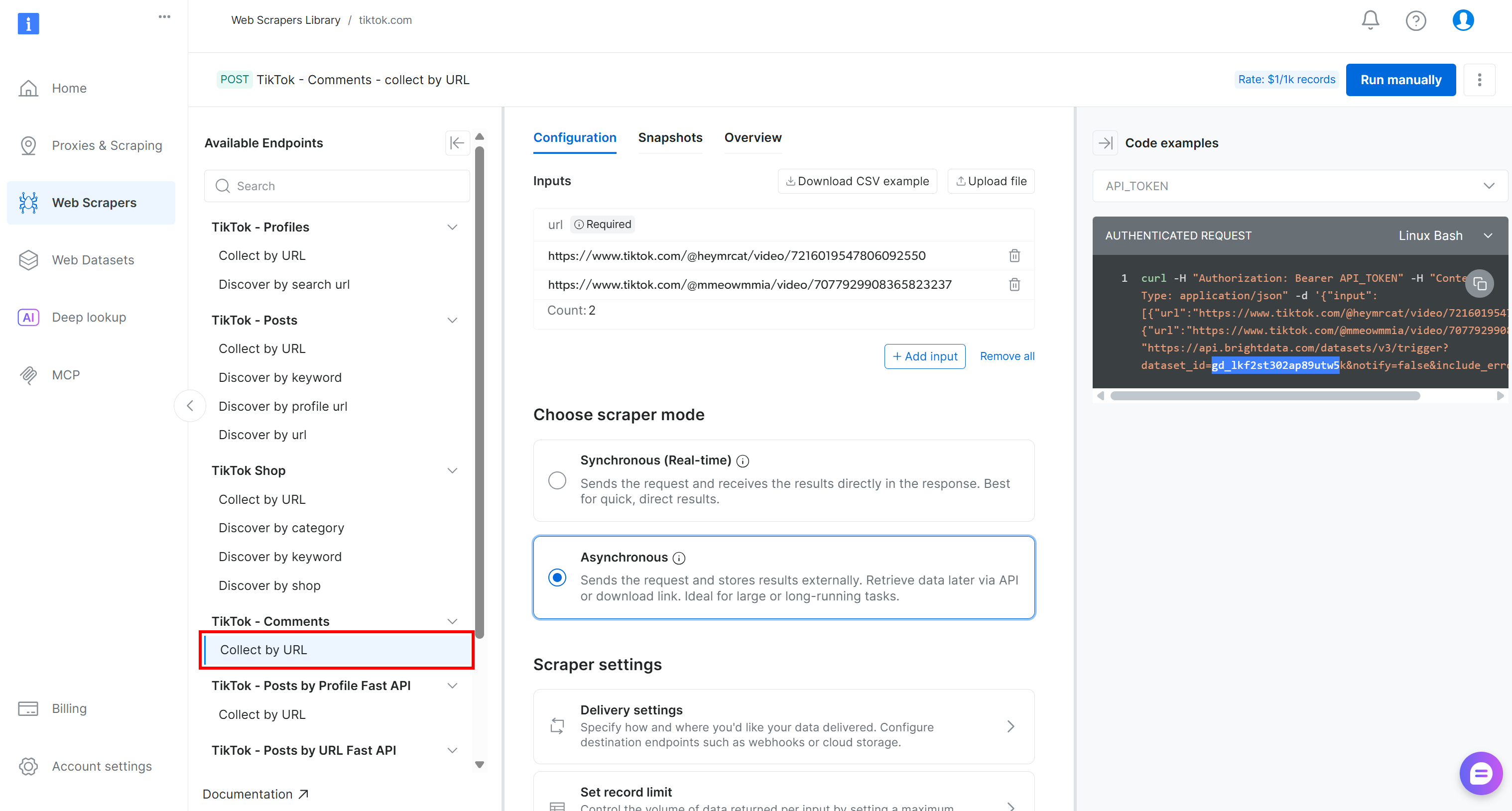
이것이 Kubeflow 파이프라인의 데이터 수집 구성 요소에서 사용할 Bright Data 기반 엔드포인트입니다.
해당 데이터셋 ID를 기록해 두세요:
gd_lkf2st302ap89utw5k이 ID는 TikTok 댓글 데이터 수집을 위한 특정 웹 스크래핑 API를 호출하는 데 필요합니다.
또한 오른쪽 스니펫에서 볼 수 있듯이, Bright Data API는 웹 스크래핑 API 호출 시 API_TOKEN을 사용하여 인증합니다. 이 값은 Bright Data API 키로 대체해야 하며, 이는 API 요청 인증을 위한 권장 방법입니다.
문서에 설명된 대로 API 키를 검색하여 안전한 장소에 보관하세요. 다음 단계에서 사용하게 됩니다!
단계 #3: 웹 데이터 수집 컴포넌트 정의
TikTok 스크래핑을 위한 Bright Data 웹 스크래핑 API와 통합하여 웹 데이터 수집용 Kubeflow 파이프라인 컴포넌트를 구현하세요:
@dsl.component(
base_image="python:3.10",
packages_to_install=["requests"])
def collect_tiktok_comments(post_urls: list, output_dataset: Output[Dataset]):
import requests, time, json, os
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # 본인의 Bright Data API 키로 대체
# "TikTok – Comments → Collect by URL" Bright Data 웹 스크래핑 API ID
TIKTOK_DATASET_ID = "gd_lkf2st302ap89utw5k"
# Bright Data에 대한 모든 요청에 공통으로 적용되는 HTTP 헤더
headers = {"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}", "Content-Type": "application/json"}
# 입력된 TikTok 게시물에 대해 Bright Data 웹 스크래핑 API 실행
trigger = requests.post(
f"https://api.brightdata.com/datasets/v3/trigger?dataset_id={TIKTOK_DATASET_ID}",
headers=headers,
json={"input": [{"url": u} for u in post_urls]},
)
trigger.raise_for_status()
# 데이터 스냅샷 ID 가져오기
snapshot_id = trigger.json()["snapshot_id"]
# 관심 데이터가 포함된 스냅샷이 생성되었는지 확인하기 위해
# 스냅샷 엔드포인트를 폴링
scraped_data = []
status = "running"
while status in ["running", "building", "starting"]:
progress = requests.get(f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json", headers=headers)
progress.raise_for_status()
# JSON 응답 데이터 접근
response_data = progress.json()
# 응답에 상태 정보가 포함되지 않았다면, 이는 스크랩된 데이터가 포함되었음을 의미함
if isinstance(response_data, dict) and "status" in response_data:
# 현재 스냅샷 상태 추출
status = progress.json()["status"]
# 다음 확인까지 5초 대기
time.sleep(5)
else:
scraped_data = response_data
break
# 스크랩된 데이터셋 저장
with open(output_dataset.path, "w", encoding="utf-8") as f:
json.dump(scraped_data, f, ensure_ascii=False, indent=2)참고: <YOUR_BRIGHT_DATA_API_KEY> 자리 표시자를 앞서 획득한 Bright Data API 키로 반드시 교체하세요. 실제 운영 환경 파이프라인에서는 구성 요소에 비밀 키를 하드코딩하지 마십시오. 대신 문서에 설명된 대로 안전하게 관리하세요.
Kubeflow Pipelines에서 컴포넌트는 특정 작업을 수행하는 독립적인 단위( dsl.component 어노테이션으로 정의)입니다. 이 경우 컴포넌트는 Bright Data에서 웹 데이터를 가져옵니다. 각 컴포넌트는 Docker 컨테이너에 패키징됩니다.
이 컴포넌트의 기본 이미지는 Python 3.10 환경입니다. 이후 Bright Data API 엔드포인트에 HTTP 요청을 수행하기 위해 requests 라이브러리가 포함됩니다. 배포 시 컴포넌트가 빌드되면 Python 3.10 이미지가 자동으로 풀링되고 requests가 설치됩니다.
Bright Data는 웹 스크래핑 API를 통해 동기식 및 비동기식 데이터 전달을 모두 지원합니다. 동기식 방법은 빠른 데이터 검색에 이상적이며, 비동기식 방법은 더 큰 데이터 세트에 적합합니다. 프로덕션 환경용 파이프라인의 경우 일반적으로 비동기식 접근 방식을 사용하는 것이 권장됩니다.
비동기 방식에서는 데이터 요청 시 즉시 제공되지 않을 수 있습니다. 대신 Bright Data는 요청된 데이터의 스냅샷을 생성하는데, 이 과정은 몇 초 이상 소요될 수 있습니다. 따라서 스냅샷이 준비되었는지 반복적으로 확인하는 폴링 메커니즘이 필요합니다.
이러한 맥락에서 웹 데이터 컴포넌트 코드의 작동 방식을 단계별로 설명하면 다음과 같습니다:
- 데이터 요청 전송: 컴포넌트가 Bright Data에 API 호출을 보내 요청한 데이터의 스냅샷 생성을 시작합니다.
- 스냅샷 엔드포인트 폴링: 컴포넌트는 스냅샷 엔드포인트를 반복적으로 호출하여 상태를 확인합니다. 응답에 “running”
상태필드가 포함되어 있다면 스냅샷이 아직 준비 중임을 의미합니다.상태필드가 없다면 스냅샷이 준비 완료되었으며 스크랩된 데이터를 포함하고 있음을 의미합니다. - 데이터 가져오기: 스냅샷이 준비되면 컴포넌트는 API 응답에서 데이터를 추출하여 파이프라인의 다운스트림 컴포넌트가 사용할 수 있도록 합니다.
대단합니다! 웹 데이터 수집용 Kubeflow 파이프라인 컴포넌트가 완성되었습니다.
4단계: 감정 분석 컴포넌트 구축
스크랩된 TikTok 데이터는 다음과 같은 구조의 JSON 배열로 가져옵니다: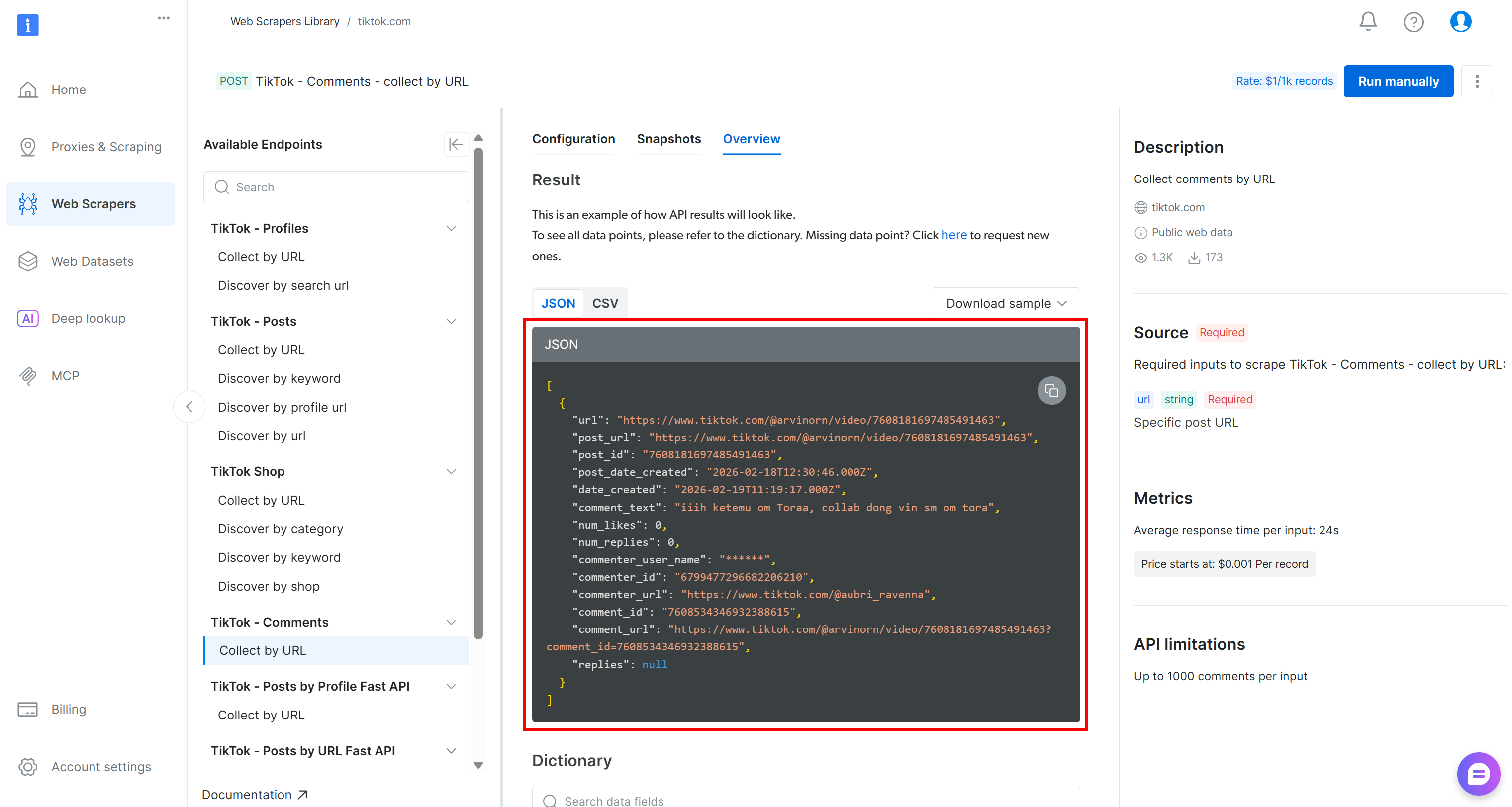
해당 데이터에 대한 감성 분석을 수행하려면 comment_text 필드를 VADER 감성 분석 도구와 같은 감성 분석 도구에 전달할 수 있습니다. VADER는 소셜 미디어에서 표현된 감정을 포착하기 위해 특별히 설계된 어휘 및 규칙 기반 도구입니다. 물론 AI 기반 모델을 포함한 다른 감성 분석 방법도 사용할 수 있습니다.
VADER는 자연어 처리 분야에서 가장 널리 사용되는 Python 도구 키트 중 하나인 NLTK에 포함되어 있습니다. 일반적인 작업 흐름은 다음과 같습니다:
- 이전 구성 요소에서 스크랩한 TikTok 댓글인 입력 JSON 배열을 읽습니다.
pandas를사용하여 데이터 필터링 및 선택을 간소화합니다.- 텍스트 데이터를
nltk를통해 VADER 감정 분석기에 전달합니다. - 분석 결과를 저장하여 후속 구성 요소에서 사용합니다.
이 모든 것을 종합하면 감성 분석 구성 요소는 다음과 같이 구현할 수 있습니다:
@dsl.component(
base_image="python:3.10",
packages_to_install=["pandas", "nltk"])
def sentiment_analysis(input_dataset: Input[Dataset], sentiment_output: Output[Dataset]):
import pandas as pd
from nltk.sentiment import SentimentIntensityAnalyzer
import nltk
# VADER 감정 어휘집 다운로드 (NLTK 감정 점수 산출에 사용)
nltk.download("vader_lexicon")
# TikTok 댓글이 포함된 입력 데이터셋 로드
df = pd.read_json(input_dataset.path)
# 감정 분석기 초기화
sia = SentimentIntensityAnalyzer()
# 각 댓글에 감정 분석을 적용하여 긍정, 부정, 중립으로 분류
df["sentiment"] = df["comment_text"].apply(lambda t: (
sia.polarity_scores(str(t))["compound"] >= 0.05 then "positive",
"negative" if sia.polarity_scores(str(t))["compound"] <= -0.05 else "neutral"
))
# 결과를 다운스트림 컴포넌트를 위한 출력 데이터셋에 저장
df.to_json(sentiment_output.path, orient="records")좋아요! 파이프라인의 두 주요 구성 요소(즉, 웹 데이터 수집 및 감정 분석)가 이제 완전히 구현되었습니다.
단계 #5: Kubeflow 파이프라인 완성
이제 두 구성 요소가 준비되었으므로 dsl.pipeline으로 주석 처리된 함수를 사용하여 단일 Kubeflow 파이프라인으로 구성할 수 있습니다:
@dsl.pipeline(name="TikTok Sentiment Pipeline")
def tiktok_sentiment_pipeline():
# 댓글을 수집할 TikTok 게시물 URL 목록
tiktok_post_urls = [
"https://www.tiktok.com/@nike/video/7600211777267272991",
"https://www.tiktok.com/@nike/video/7556252854294482189"
# Bright Data 웹 스크래핑 컴포넌트를 사용해 TikTok 댓글 수집
collect_task = collect_tiktok_comments(post_urls=tiktok_post_urls)
# 수집된 댓글에 대한 감성 분석 수행
sentiment_task = sentiment_analysis(
input_dataset=collect_task.outputs["output_dataset"]
)이 파이프라인은 먼저 동일한 프로필(@nike)의 두 대상 동영상에 대해 TikTok 댓글 수집 컴포넌트를 실행합니다. 구체적으로, 두 소스 TikTok 동영상은 신발 출시를 소개한다는 점에서 선정되었습니다. 이 동영상들에 대한 감정 분석은 출시와 관련해 관객의 생각을 파악하는 데 비즈니스적으로 중요합니다.
Bright Data 웹 스크래핑 API를 통해 생성된 데이터셋은 이후 하류 감정 분석 구성 요소로 전달됩니다. 감정 분석 단계는 스크래핑된 댓글을 처리하여 감정 라벨(긍정, 부정, 중립)이 포함된 새로운 데이터셋을 생성합니다. 이 출력은 보고나 시각화와 같은 추가 하류 구성 요소에서 활용될 수 있습니다.
훌륭합니다! Kubeflow 파이프라인이 이제 완전히 정의되었습니다.
6단계: 파이프라인 컴파일
마지막 단계는 파이프라인을 Kubeflow YAML 파이프라인 파일로 컴파일하는 것입니다:
if __name__ == "__main__":
compiler.Compiler().compile(
pipeline_func=tiktok_sentiment_pipeline,
package_path="tiktok_sentiment_analysis_kfp_pipeline.yaml"
)tiktok_sentiment_analysis_kfp_pipeline.py 스크립트를 실행하면 이 코드가 tiktok_sentiment_analysis_kfp_pipeline.yaml이라는 파일을 생성합니다. 이 YAML 파일에는 Kubeflow 배포에 필요한 전체 파이프라인 사양이 포함됩니다. 미션 완료!
7단계: 최종 코드
아래는 tiktok_sentiment_analysis_kfp_pipeline.py 파일에 포함되어야 할 완전한 Kubeflow 파이프라인입니다:
# tiktok_sentiment_analysis_kfp_pipeline.py
# pip install kfp
from kfp import dsl, compiler
from kfp.dsl import Input, Output, Dataset
@dsl.component(
base_image="python:3.10",
packages_to_install=["requests"])
def collect_tiktok_comments(post_urls: list, output_dataset: Output[Dataset]):
import requests, time, json, os
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # 본인의 Bright Data API 키로 대체
# "TikTok – Comments → Collect by URL" Bright Data 웹 스크래핑 API ID
TIKTOK_DATASET_ID = "gd_lkf2st302ap89utw5k"
# Bright Data에 대한 모든 요청에 공통으로 적용되는 HTTP 헤더
headers = {"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}", "Content-Type": "application/json"}
# 입력된 TikTok 게시물에 대해 Bright Data 웹 스크래핑 API 실행
trigger = requests.post(
f"https://api.brightdata.com/datasets/v3/trigger?dataset_id={TIKTOK_DATASET_ID}",
headers=headers,
json={"input": [{"url": u} for u in post_urls]},
)
trigger.raise_for_status()
# 데이터 스냅샷 ID 가져오기
snapshot_id = trigger.json()["snapshot_id"]
# 관심 데이터가 포함된 스냅샷이 생성되었는지 확인하기 위해
# 스냅샷 엔드포인트를 폴링
scraped_data = []
status = "running"
while status in ["running", "building", "starting"]:
progress = requests.get(f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json", headers=headers)
progress.raise_for_status()
# JSON 응답 데이터 접근
response_data = progress.json()
# 응답에 상태 정보가 포함되지 않았다면, 이는 스크랩된 데이터가 포함되었음을 의미함
if isinstance(response_data, dict) and "status" in response_data:
# 현재 스냅샷 상태 추출
status = progress.json()["status"]
# 다음 확인까지 5초 대기
time.sleep(5)
else:
scraped_data = response_data
break
# 스크랩된 데이터셋 저장
with open(output_dataset.path, "w", encoding="utf-8") as f:
json.dump(scraped_data, f, ensure_ascii=False, indent=2)
@dsl.component(
base_image="python:3.10",
packages_to_install=["pandas", "nltk"])
def sentiment_analysis(input_dataset: Input[Dataset], sentiment_output: Output[Dataset]):
import pandas as pd
from nltk.sentiment import SentimentIntensityAnalyzer
import nltk
# VADER 감정 어휘집 다운로드 (NLTK 감정 점수 산출에 사용)
nltk.download("vader_lexicon")
# TikTok 댓글이 포함된 입력 데이터셋 로드
df = pd.read_json(input_dataset.path)
# 감정 분석기 초기화
sia = SentimentIntensityAnalyzer()
# 각 댓글에 감정 분석 적용 및 긍정, 부정, 중립 분류
df["sentiment"] = df["comment_text"].apply(lambda t: (
sia.polarity_scores(str(t))["compound"] >= 0.05 then "positive",
"negative" if sia.polarity_scores(str(t))["compound"] <= -0.05 else "neutral"
))
# 결과를 다운스트림 컴포넌트를 위한 출력 데이터셋에 저장
df.to_json(sentiment_output.path, orient="records")
@dsl.pipeline(name="TikTok Sentiment Pipeline")
def tiktok_sentiment_pipeline():
# 댓글을 스크래핑할 TikTok 게시물 URL 목록
tiktok_post_urls = [
"https://www.tiktok.com/@nike/video/7600211777267272991",
"https://www.tiktok.com/@nike/video/7556252854294482189"
]
# Bright Data 웹 스크래핑 컴포넌트를 사용해 TikTok 댓글 수집
collect_task = collect_tiktok_comments(post_urls=tiktok_post_urls)
# 수집된 댓글에 대한 감성 분석 수행
sentiment_task = sentiment_analysis(
input_dataset=collect_task.outputs["output_dataset"]
)
if __name__ == "__main__":
compiler.Compiler().compile(
pipeline_func=tiktok_sentiment_pipeline,
package_path="tiktok_sentiment_analysis_kfp_pipeline.yaml"
)위의 스크립트를 다음 명령어로 실행합니다:
python3 tiktok_sentiment_analysis_kfp_pipeline.py명령 실행 후 아래와 같은 tiktok_sentiment_analysis_kfp_pipeline.yaml 파일이 생성됩니다: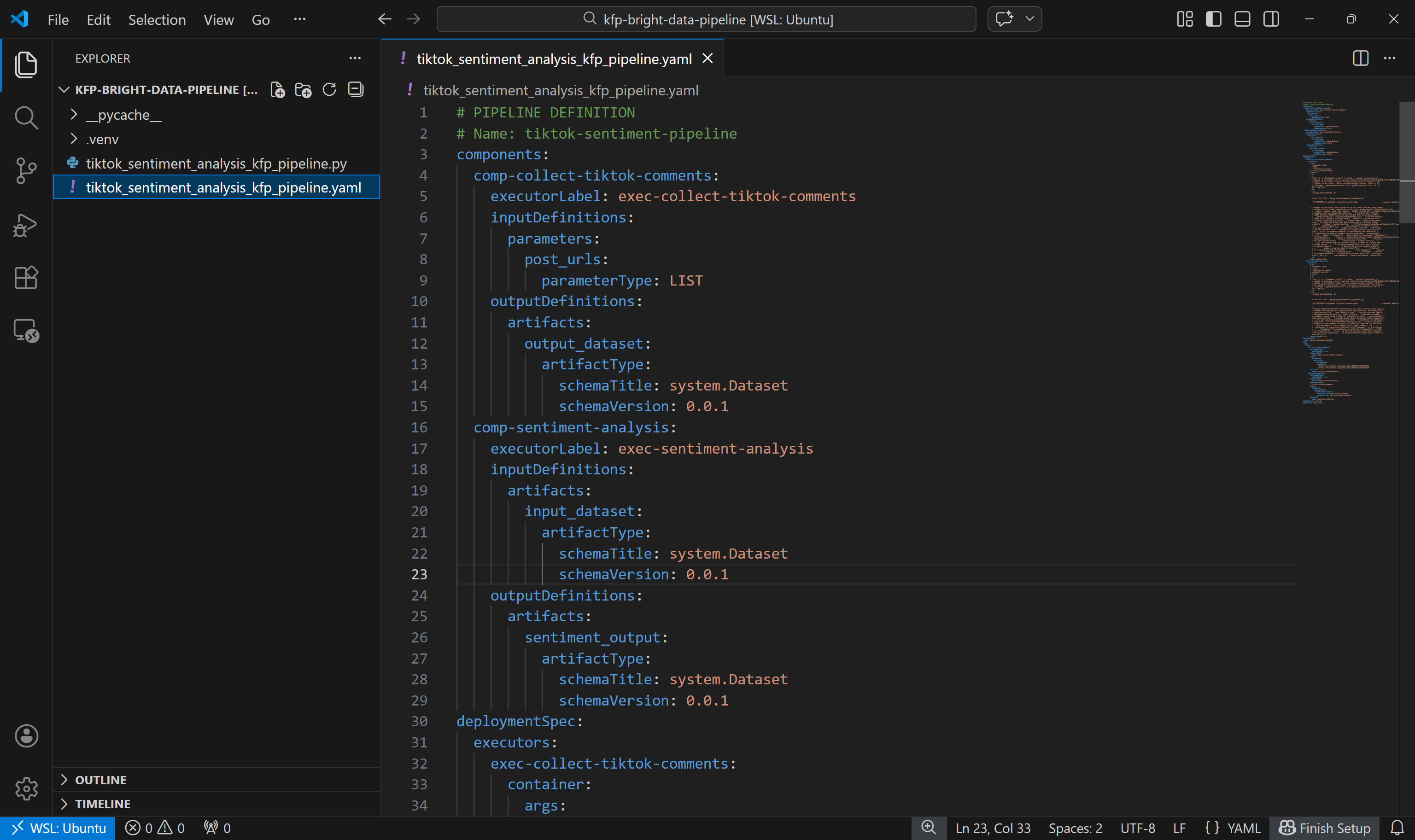
이제 Kubeflow에 배포하여 테스트하거나 Docker를 사용하여 로컬에서 실행할 수 있습니다. 본 가이드에서는 두 번째 방법에 집중하겠습니다.
8단계: 로컬에서 Kubeflow 파이프라인 테스트하기
Kubeflow 파이프라인을 로컬에서 실행하려면 DockerRunner 클래스를 사용할 수 있습니다. 이를 위해서는 Docker가 설치되어 실행 중이어야 합니다.
DockerRunner는 각 파이프라인 작업을 별도의 Docker 컨테이너 내에서 실행합니다. 즉, 실제 Kubeflow 환경에서 파이프라인이 실행되는 방식을 시뮬레이션합니다.
가상 환경을 활성화한 상태에서 필요한 docker 라이브러리를 설치하세요:
pip install docker 다음으로 프로젝트 폴더에 run_pipeline_local.py 파일을 추가합니다:
kfp-bright-data-pipeline/
├── .venv/
├── run_pipeline_local.py # <-----------
├── tiktok_sentiment_analysis_kfp_pipeline.py
└── tiktok_sentiment_analysis_kfp_pipeline.yaml다음과 같이 내용을 채우세요:
# run_pipeline_local.py
# pip install docker
from kfp import local
from tiktok_sentiment_analysis_kfp_pipeline import tiktok_sentiment_pipeline
# 로컬 Docker 러너 초기화
local.init(runner=local.DockerRunner())
# 파이프라인을 Python 함수 호출로 실행
pipeline_task = tiktok_sentiment_pipeline()이 스크립트는 tiktok_sentiment_analysis_kfp_pipeline.py에서 tiktok_sentiment_pipeline() 함수를 임포트하여 로컬 Docker 러너를 통해 실행합니다. 각 구성 요소는 자체 컨테이너에서 실행됩니다.
파이프라인 테스트를 위해 Docker가 실행 중인지 확인하십시오. 그런 다음 다음 명령을 실행하십시오:
python3 run_pipeline_local.py실행 로그에는 아래 예시와 유사한 성공 메시지가 표시되어야 합니다:
파이프라인 출력은 ./local_outputs 폴더에 저장됩니다. 결과를 살펴볼 시간입니다!
9단계: 파이프라인 결과 살펴보기
파이프라인 실행 후 ./local_outputs 폴더를 엽니다. 내부에는 현재 실행에 대한 하위 폴더가 생성되며, 생성된 모든 아티팩트가 포함되어 있습니다.
먼저 collect-tiktok-comments 구성 요소가 생성한 출력 데이터셋을 살펴보세요: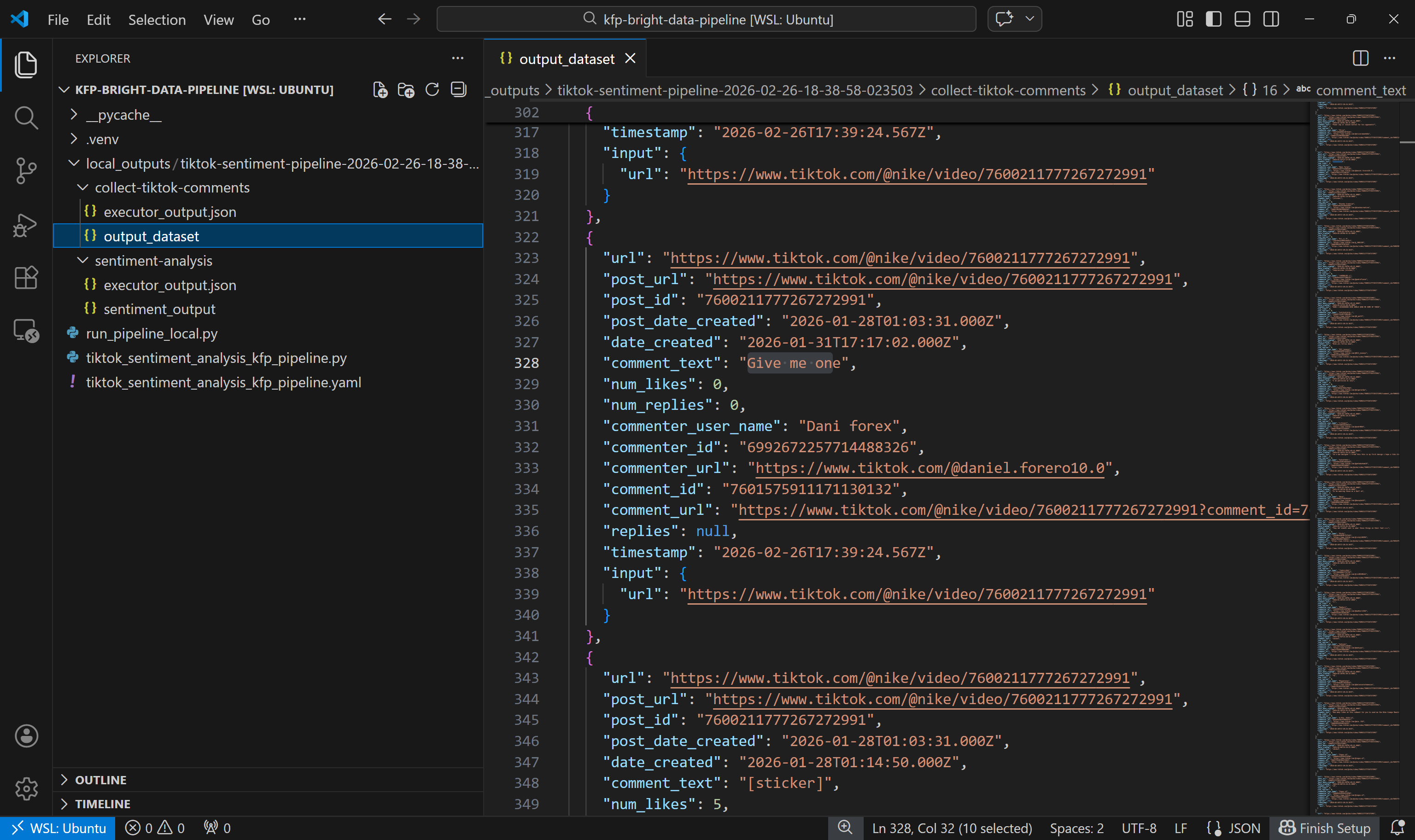
이 데이터셋에는 예상대로 Bright Data를 통해 TikTok 스크레이퍼가 반환한 두 지정 게시물의 댓글이 포함되어 있습니다.
다음으로 감정 분석 출력 데이터셋을 살펴봅니다: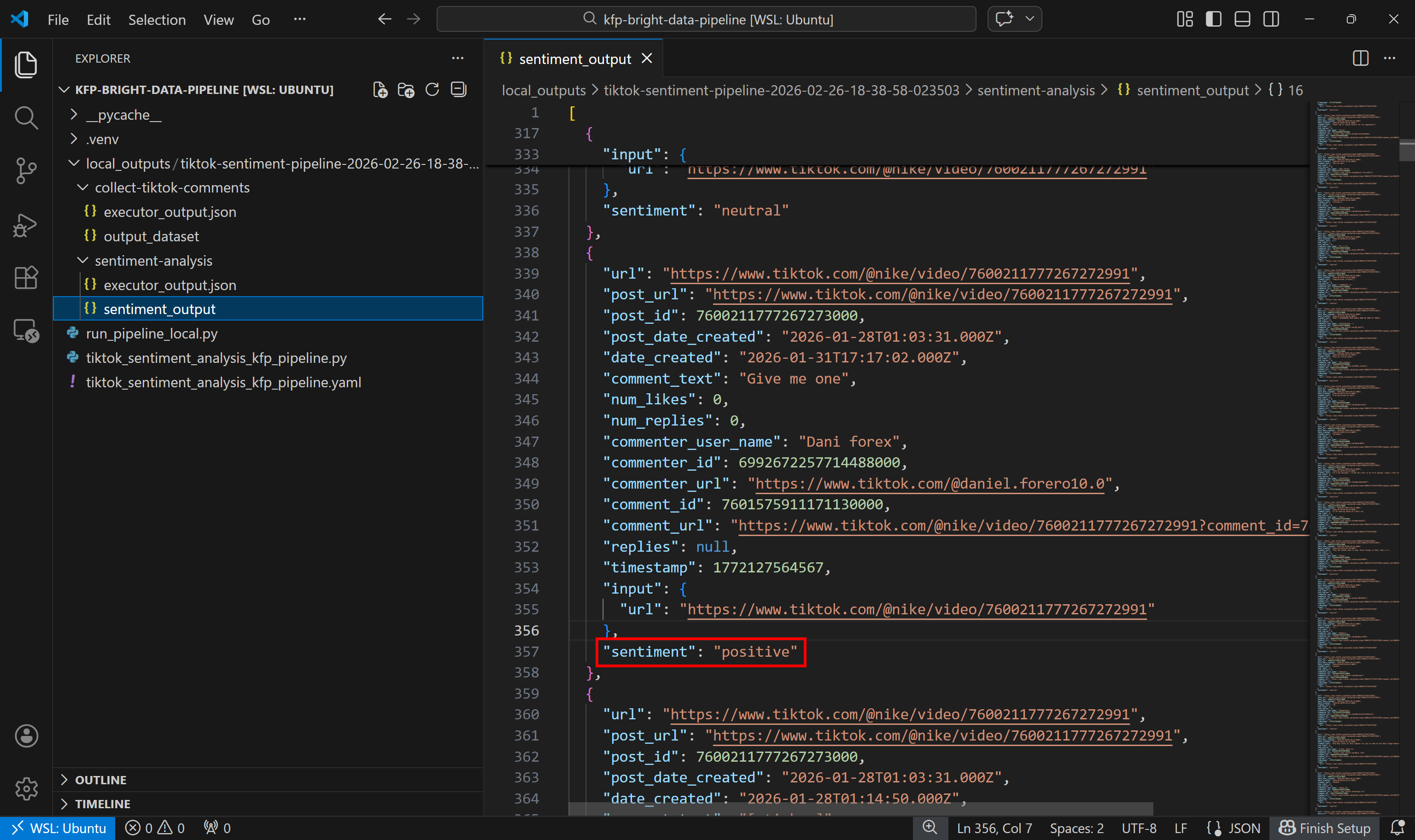
각 댓글이 감정 분석 컴포넌트에 의해 긍정적, 부정적, 중립적으로 라벨링된 방식을 확인하세요.
자, 이제 Bright Data를 사용하여 최신 웹 데이터를 가져온 후 분석하는 Kubeflow 파이프라인 구축 방법을 살펴보았습니다.
결론
이 튜토리얼에서는 웹 스크래핑을 통해 최신 데이터를 수집하는 것이 Kubeflow 파이프라인에 왜 유익한지 이해하셨습니다. 특히 파이프라인 내에 웹에서 최신, 맥락적, 구조화된 데이터를 수집하기 위한 전용 구성 요소를 갖는 것의 중요성을 확인하셨습니다.
Bright Data는 파이프라인을 위한 구조화된 데이터 피드 역할을 하는 다양한 웹 스크래핑 API를 통해 이를 지원합니다. 시연에서 보셨듯이, Bright Data의 스크래핑 API 덕분에 Kubeflow 파이프라인에 웹 데이터 수집 구성 요소를 구축하는 것은 매우 간단합니다!
무료 Bright Data 계정을 생성하고 오늘 바로 웹 데이터 솔루션을 탐색해 보세요!




