

이 블로그 글에서 여러분은 다음을 배우게 됩니다:
- 머신러닝을 통한 데이터 분석에 TensorFlow가 이상적인 도구인 이유.
- 비즈니스에 가치 있는 통찰력을 제공하는 고품질 데이터를 수집하기 위해 어떤 솔루션을 활용해야 하는지.
- Bright Data를 통해 수집한 아마존 제품 리뷰에 대한 감성 분석을 TensorFlow로 수행하는 방법.
자, 시작해 보겠습니다!
머신러닝을 활용한 텐서플로우 데이터 분석의 필요성
데이터는 통찰력을 제공하기 때문에 가치가 있습니다. 특히 기업은 데이터를 활용해 의사결정을 내리고 전략을 조정하며 결과를 최적화합니다. 고객 만족도 향상과 마케팅 전략의 전반적 성과 최적화가 대표적인 목표입니다.
데이터 분석에 있어 TensorFlow는 가장 인기 있는 오픈소스 라이브러리 중 하나입니다. 머신러닝 및 인공지능 시스템을 구동하며 다양한 작업을 지원합니다.
특히 이 글에서는 텐서플로우를 활용해 제품 리뷰에 대한 감성 분석을 수행할 것입니다. 동시에 동일한 기술은 고객 피드백 분석, 추천 시스템, 예측 모델링 등 다양한 다른 사용 사례에도 적용될 수 있습니다.
비즈니스 데이터 수집 방법
아무리 정교한 머신러닝이나 인공지능 파이프라인을 구축하더라도, 모든 데이터 분석가들은 “더 나은 알고리즘보다 더 많은 데이터가 중요하다“는 사실을 잘 알고 있습니다. 간단히 말해, 의미 있는 통찰력을 얻는 핵심은 데이터의 질과 양에 달려 있습니다.
그렇다면 양질의 데이터를 대량으로 확보하는 방법은 무엇일까요? 데이터 소싱은 어려울 수 있으며, Bright Data와 같은 신뢰할 수 있는 데이터 공급업체에 의존하는 것이 중요합니다.
Bright Data는 다음과 같은 다양한 데이터 솔루션을 제공합니다:
- 웹 스크레이퍼 API: 웹 스크래핑을 통해 수집된 수십 개의 인기 도메인에서 구조화된 웹 데이터에 대한 프로그래매틱 접근.
- 데이터셋 마켓플레이스: 100개 이상의 웹사이트에서 수집한 수십억 개의 항목으로 구성된 신선하고 즉시 사용 가능한 데이터셋.
- 관리형 데이터 수집 서비스: 개발이나 유지보수의 번거로움 없이 데이터와 인사이트를 얻을 수 있도록 지원하는 완전 관리형 엔터프라이즈급 데이터 수집 서비스입니다.
이 제품들은 연구자, 중소기업(SMB), 대기업을 대상으로 합니다. 구체적으로, 머신 러닝 워크플로우, AI 훈련, 에이전트 개발 및 기타 다양한 시나리오를 지원하기 위한 공개 웹 데이터 수집을 가능하게 합니다.
Bright Data를 통해 수집한 아마존 제품 리뷰에 대한 감성 분석 수행 방법
이 단계별 섹션에서는 TensorFlow를 사용하여 실제 데이터 분석 워크플로를 구축합니다. 제품 리뷰에 대한 감정 분석 수행이라는 실용적인 사용 사례를 다룰 것입니다.
여러 제품을 아마존에서 판매하는 기업이라고 가정해 보겠습니다. 고객 만족도를 높이기 위해 각 제품에 대한 사용자 리뷰를 주기적으로 모니터링하고 감정 분석을 수행하여 잘 작동하는 부분과 개선이 필요한 부분을 파악하는 프로세스가 필요합니다.
이 예시에서는 다음 아마존 제품을 중심으로 살펴보겠습니다:
참고: Bright Data 아마존 리뷰 스크레이퍼는 무제한 확장성을 통해 여러 상품의 리뷰를 스크래핑할 수 있으므로, 이 워크플로를 여러 아마존 상품으로 확장할 수 있습니다.
이 제품은 5점 만점에 걸쳐 상당히 균등하게 분포된 다수의 리뷰를 보유하고 있어 훌륭한 사례입니다: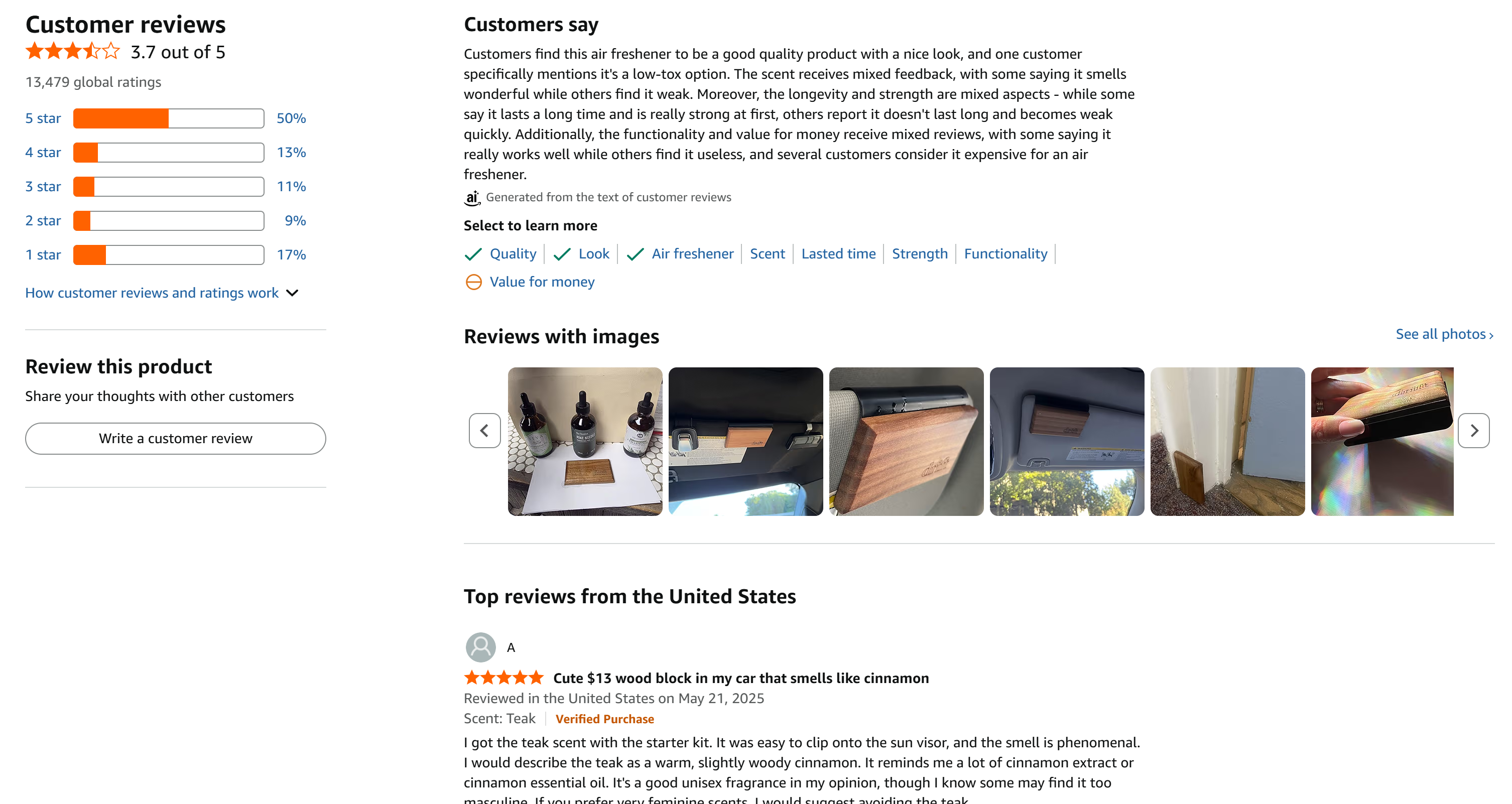
기업용 감성 분석 프로세스를 구축하려면 아래 지침을 따르십시오. 해당 상품의 리뷰는 Bright Data를 통해 수집된 후 Python 기반 TensorFlow의 머신러닝 워크플로로 분석됩니다.
필수 조건
이 튜토리얼을 따라하려면 다음을 준비하십시오:
- 로컬에 설치된Python 3.9 이상
- API 키가 설정된 Bright Data 계정.
아직 Bright Data 계정이 없더라도 걱정하지 마십시오. 다음 단계에서 설정 과정을 안내해 드리겠습니다.
감정 분석 TensorFlow 로직을 완전히 이해하려면 유니버설 센텐스 인코더(Universal Sentence Encoder) 모델, 벡터 임베딩 작동 방식, 그리고 딥 뉴럴 네트워크 레이어를 가진 Keras Sequential 모델의 작동 방식에 대한 이해가 매우 유용할 것입니다.
1단계: JupyterLab 프로젝트 설정
이 TensorFlow 머신러닝 프로세스에는 차트 및 데이터 시각화도 포함되므로 개발 환경으로 JupyterLab을 사용하는 것이 합리적입니다. 그러면 코드를 쉽게 프로덕션 준비가 된 ML 파이프라인으로 이전할 수 있습니다.
먼저 프로젝트 폴더를 생성합니다. 해당 폴더로 이동하세요:
mkdir tensorflow-brightdata-product-review-analysis
cd tensorflow-brightdata-product-review-analysis다음으로 폴더 내에서 가상 환경을 초기화합니다:
python -m venv .venv이제 가상 환경을 활성화할 차례입니다. macOS/Linux에서는 다음을 실행하세요:
source .venv/bin/activateWindows에서는 다음을 실행하세요:
.venvScriptsactivate활성화된 환경에서 jupyterlab 패키지를 통해 JupyterLab을 설치하세요:
pip install jupyterlab다음 명령어로 JupyterLab을 실행하세요:
jupyter labJupyterLab 인터페이스가 표시됩니다:
“Notebook” 섹션 아래의 “Python 3 (ipykernel)” 버튼을 클릭하여 새 노트북을 생성하세요:
노트북에 이름을 지정하고 저장하세요.
완료! 이제 TensorFlow를 사용한 머신러닝 데이터 분석 워크플로우 개발에 적합한 Python 환경이 설정되었습니다.
2단계: 라이브러리 설치
코드 블록을 추가하고 다음 명령어로 필요한 라이브러리를 설치하세요:
!pip install tensorflow tensorflow-hub scikit-learn pandas numpy matplotlib requests이 구현에 필요한 모든 라이브러리를 설치하려면 이 블록을 실행하세요:
tensorflow: 머신러닝 모델 구축 및 훈련을 위한 라이브러리.tensorflow-hub: 사전 훈련된 머신러닝 모델을 로드하기 위해 사용됩니다.scikit-learn: 데이터 전처리, 훈련-테스트 분할, 메트릭, 클래스 가중치 계산용.pandas: 표 형식 데이터 처리 및 집계 수행을 위해.numpy: 수치 계산 및 배열 처리를 위해.matplotlib: 차트 플로팅 및 결과 시각화용.requests: HTTP 요청을 수행하고 Bright Data Scraper API와 상호 작용하기 위해.
다음으로, 필요한 모든 라이브러리를 임포트하고 구성하기 위해 코드 블록을 추가합니다:
import time
import requests
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tensorflow_hub as hub
from tensorflow import keras
from keras.layers import Input, Dense, Dropout
from keras.models import Sequential
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.utils.class_weight import compute_class_weight
from IPython.display import display, HTML
plt.rcParams["figure.figsize"] = (10, 5)대단하네요! 이제 이후의 모든 코드 블록이 Bright Data 데이터 수집 및 TensorFlow 기반 분석 워크플로우를 구동할 준비가 되었습니다.
3단계: Bright Data 아마존 리뷰 스크레이퍼 시작하기
아마존 리뷰 데이터를 가져오는 코드를 작성하기 전에, Bright Data 계정을 설정하고 필요한 데이터 스크래핑 솔루션에 익숙해지는 시간을 가지세요.
이 튜토리얼에서는 Bright Data Amazon 리뷰 API를 사용합니다. 이 API를 사용하면 주어진 제품에 대한 최신 리뷰 데이터를 프로그래밍 방식으로 스크래핑할 수 있습니다. 이는 자신의 제품에 대한 리뷰를 모니터링하려는 경우에 이상적입니다.
또는 보다 일반적인 시나리오를 위해 Bright Data는 2,860만 개 이상의 리뷰가 포함된 즉시 사용 가능한 “Amazon Reviews”데이터셋도 제공합니다: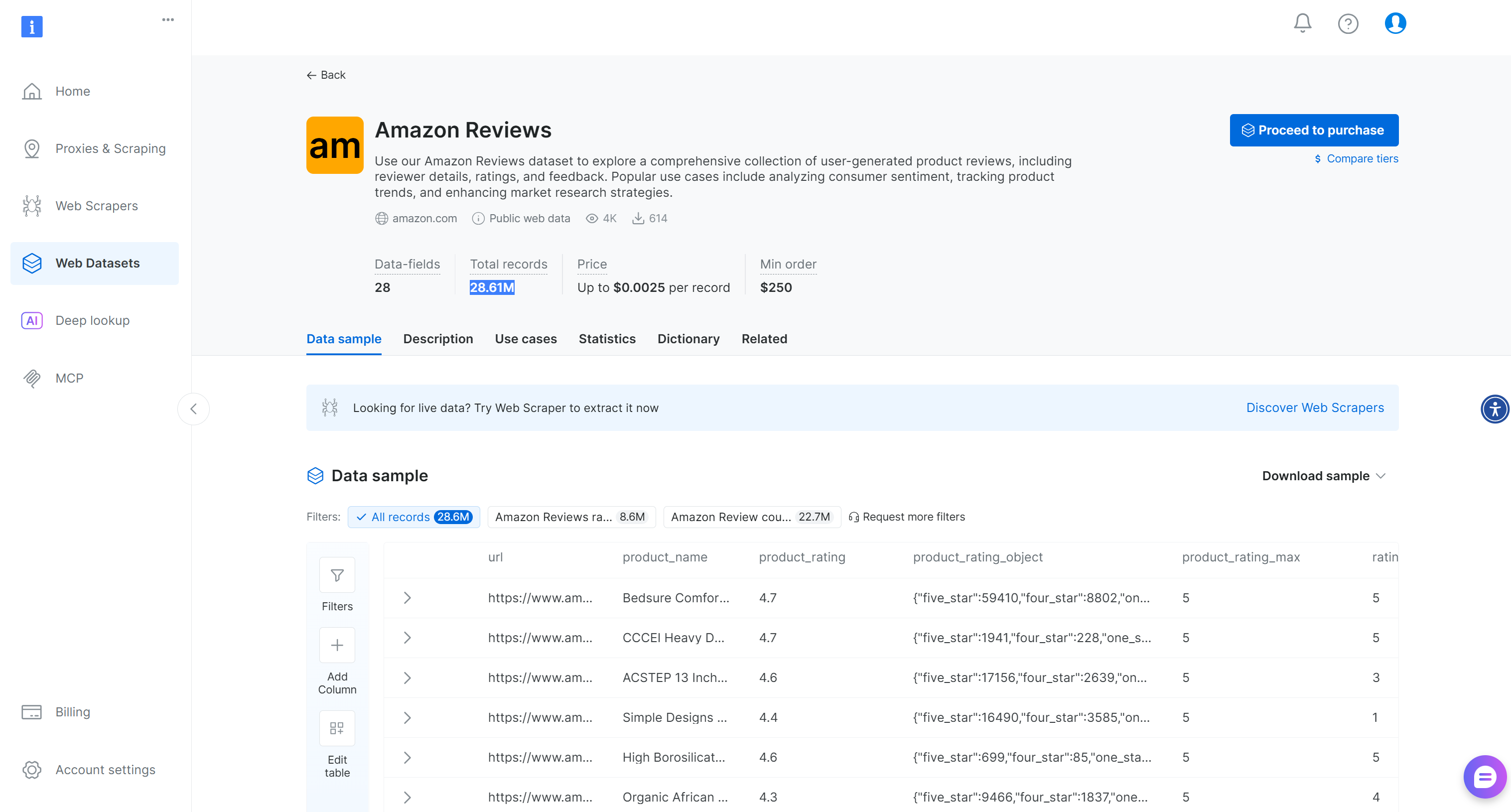
아직 Bright Data 계정이 없다면 새로 생성하세요. 기존 계정이라면 로그인 후 계정의 “웹 스크레이퍼 라이브러리” 페이지로 이동하세요:
“amazon”을 검색하고 “Amazon Reviews – collect by URL” 스크레이퍼를 선택하세요:
이 페이지에서 통합 준비 완료 코드를 생성하거나 코드 없이 웹 애플리케이션을 통해 스크레이퍼를 직접 테스트할 수 있습니다.
“스크레이퍼 API” 옵션을 선택하면 아래 페이지로 이동합니다:
여기서 지원되는 입력 매개변수와 출력 형식을 확인하세요. 특히 이 데이터셋은 Amazon 리뷰 목록을 반환하며 ID는 gd_le8e811kzy4ggddlq입니다.
API를 통해 이 스크레이퍼를 호출하려면 Bright Data API 키로 요청을 인증해야 합니다. 키가 없다면 공식 가이드를 따라 생성하세요. 곧 필요할 수 있으니 안전한 곳에 보관하십시오.
훌륭합니다! 이제 Bright Data의 Amazon 리뷰 스크레이퍼를 사용하여 분석을 위한 제품 리뷰 데이터를 가져올 준비가 되었습니다.
4단계: 아마존 제품 리뷰 데이터 가져오기
새 노트북 셀을 생성하고 다음 코드를 붙여넣으세요:
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # 본인의 Bright Data API 키로 대체
def trigger_snapshot(amazon_product_url):
# 지정된 아마존 제품 URL에 대해 Bright Data 웹 스크레이퍼 API 실행
url = "https://api.brightdata.com/datasets/v3/trigger"
params = {
"dataset_id": "gd_le8e811kzy4ggddlq", # "Amazon Reviews - collect by URL" 스크레이퍼 ID
"include_errors": "true",
}
# API 호출을 위한 입력 데이터 형식화
data = [{"url": amazon_product_url}]
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}", # 요청 인증
"Content-Type": "application/json",
}
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"요청 성공! 스냅샷 ID: {snapshot_id}")
return snapshot_id
else:
print(f"요청 실패! 상태 코드: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(snapshot_id, output_file, format="csv", polling_timeout=20):
# 스냅샷이 준비될 때까지 Bright Data Scraper API를 폴링한 후 저장
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format={format}"
headers = {"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}"}
print(f"ID: {snapshot_id} 스냅샷 폴링 중...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("스냅샷 준비 완료. 다운로드 중...")
snapshot_data = response.text
# 스냅샷을 파일로 기록
with open(output_file, "w", encoding="utf-8") as file:
file.write(snapshot_data)
print(f"스냅샷 저장됨: {output_file}")
return
elif response.status_code == 202:
print(f"스냅샷 아직 준비되지 않음. {polling_timeout} 초 후에 재시도 중...")
time.sleep(polling_timeout)
else:
print(f"요청 실패! 상태 코드: {response.status_code}")
print(response.text)
break
# 리뷰를 가져올 아마존 상품 URL
amazon_product_url = "https://www.amazon.com/Drift-Car-Air-Freshener-Eliminator/dp/B0C1HJV7BJ/"
# 스냅샷 트리거 및 리뷰 다운로드
snapshot_id = trigger_snapshot(amazon_product_url)
poll_and_retrieve_snapshot(snapshot_id, "product-reviews.csv")<YOUR_BRIGHT_DATA_API_KEY> 자리 표시자를 앞서 생성한 실제 Bright Data API 키로 대체하세요.
위 코드:
datasets/v3/trigger를사용하여 리뷰 스크래퍼를 트리거합니다. 이는 Bright Data 클라우드에서 Amazon 리뷰 스크래퍼를 사용한 스크래핑 작업을 시작합니다.datasets/v3/snapshot/{snapshot_id}를사용하여 생성된 데이터셋 스냅샷을 폴링하며, Bright Data가 리뷰 스크래핑을 완료할 때까지 대기합니다.- 최종 데이터를 CSV 형식으로 내보내며(
format="csv"지정), 로컬에product-reviews.csv로저장합니다.
이것이 바로 웹 스크레이퍼 API 워크플로우의 작동 방식입니다. 자세한 내용은 Bright Data 공식 문서를 참조하세요.
코드 블록을 실행하면 다음과 유사한 결과가 표시됩니다: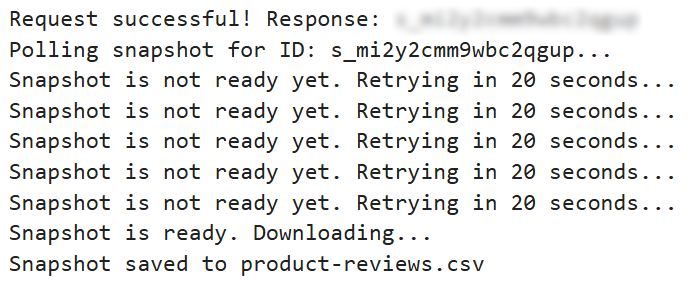
그러면 프로젝트 폴더에 product-reviews.csv 파일이 생성됩니다. 파일을 열면 구조화된 형식으로 스크래핑된 리뷰를 확인할 수 있습니다: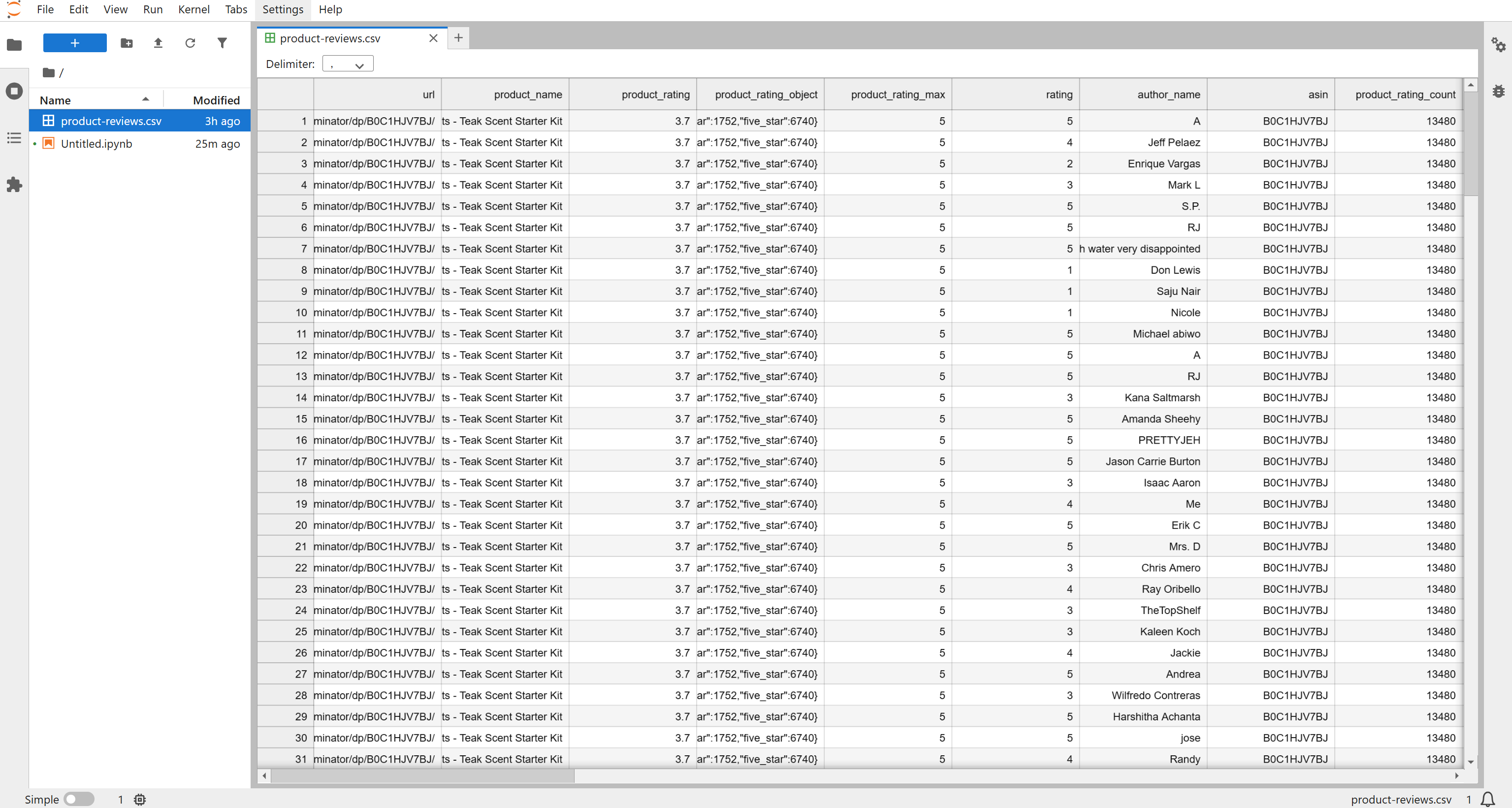
기본적으로 스크레이퍼는 최신 리뷰 약 200개를 반환하지만, 필요 시 API 입력을 조정하여 더 많은 데이터를 얻을 수 있습니다. 본 튜토리얼에서는 감정 분석 파이프라인을 완료하기에 196개의 리뷰로도 충분합니다.
좋아요! 이제 TensorFlow 분석을 위한 최신 아마존 제품 리뷰 데이터를 확보했습니다.
단계 #5: 스크랩된 데이터 탐색
product-reviews.csv 파일에서 스크랩된 데이터를 불러오는 것으로 시작합니다:
# Bright Data를 통해 생성된 CSV 파일에서 제품 리뷰 로드
df = pd.read_csv("product-reviews.csv")
# 리뷰 게시 날짜를 datetime 형식으로 변환
df["date"] = pd.to_datetime(df["review_posted_date"])
# 텍스트가 누락된 리뷰 삭제
df = df.dropna(subset=["review_text"])
# 게시일 기준 리뷰 정렬 (오름차순)
df = df.sort_values(by="date", ascending=True)
print(f"{len(df)}개의 리뷰를 로드했습니다.")이 셀을 실행하면 로드된 총 리뷰 수가 표시됩니다:
196개의 리뷰를 로드했습니다.다음으로 평점 분포를 분석합니다:
print(df["rating"].value_counts())다음과 유사한 결과가 표시됩니다:
rating
1 74
2 31
3 16
4 12
5 63위에서 볼 수 있듯이, 리뷰는 1~5점 범위에 걸쳐 상당히 고르게 분포되어 있습니다. 이 분포를 더 잘 시각화하려면 Matplotlib를 사용한 막대 차트를 활용하세요:
# 별점별(1~5점) 리뷰 수 계산
rating_counts = df["rating"].value_counts().sort_index()
# 바 차트로 별점 분포 플롯
colors = plt.cm.RdYlGn(np.linspace(0, 1, len(rating_counts)))
plt.bar(
rating_counts.index,
rating_counts.values,
color=colors,
edgecolor="black",
width=0.6,
align="center"
)
plt.title("평점 분포 (1–5점)"
plt.xlabel("별점")
plt.ylabel("개수")
plt.xticks(rating_counts.index)
plt.grid(axis="y", linestyle="--", alpha=0.5)
plt.show()아래와 유사한 차트가 표시됩니다: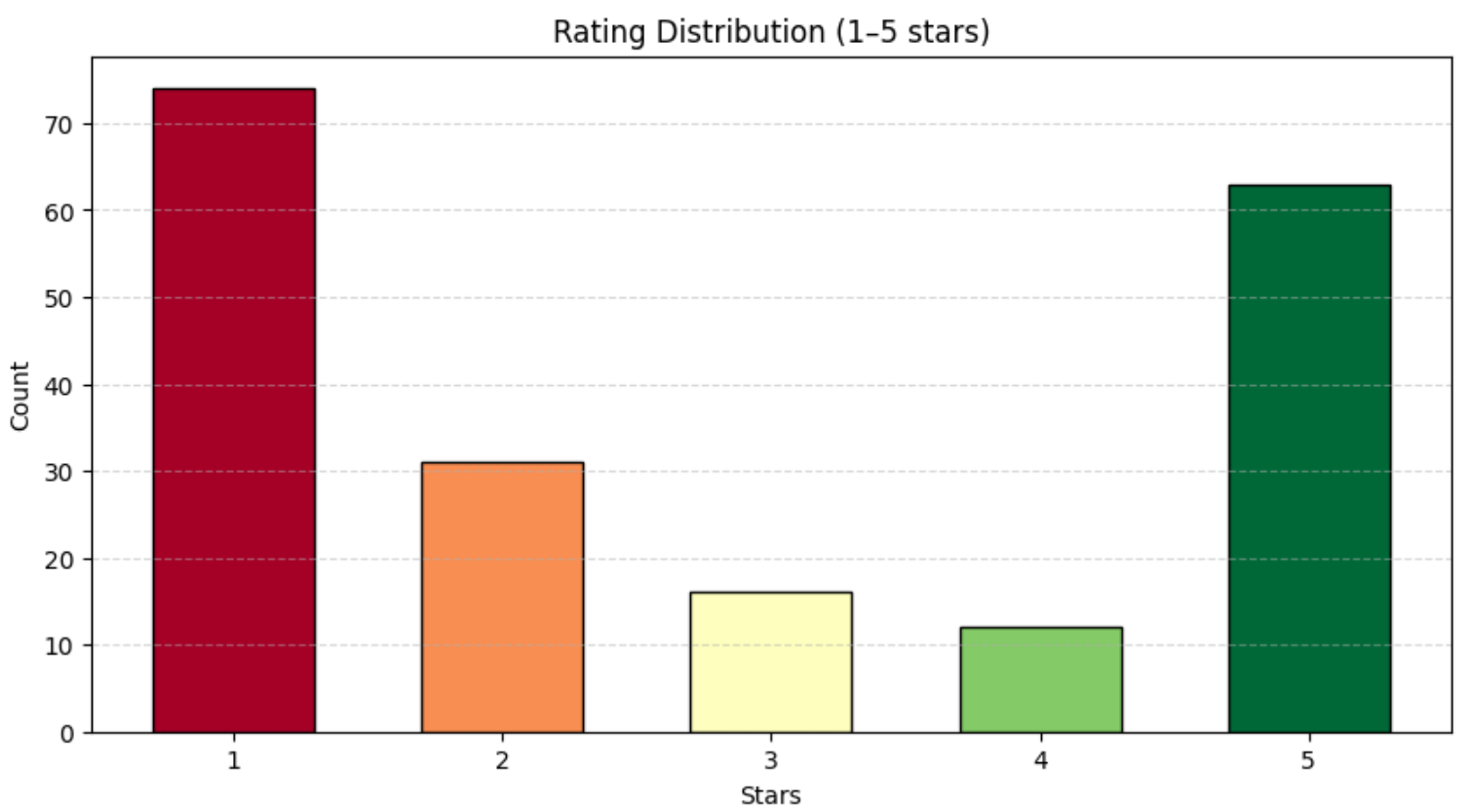
완벽합니다! 이제 방금 가져온 아마존 리뷰 데이터셋에 대한 명확하고 높은 수준의 이해를 갖게 되었습니다. 이 기초는 모델 훈련과 감정 분석으로 넘어가기 전에 필수적입니다.
6단계: 리뷰에 감정 분석 점수 할당하기
머신러닝을 적용하기 전에 3점 리뷰를 무시함으로써 감정 분류 작업을 단순화하는 것이 도움이 됩니다. 이는 해당 리뷰들이 일반적으로 중립적이며 긍정적 또는 부정적 감정을 명확히 표현하지 않기 때문입니다.
이를 포함하면 모델이 3개 클래스(긍정/중립/부정) 문제를 학습해야 하므로 더 많은 데이터와 복잡한 모델링이 필요합니다. 대신 다음과 같이 이진 감정 분류 작업으로 전환하겠습니다:
- 4–5점 리뷰는 “긍정적”(
1)으로; - 1–2성급 리뷰는 “부정적” (
0)으로 간주합니다.
이를 바탕으로 TensorFlow에서 감성 분석 로직을 다음과 같이 구현합니다:
# 이진 감정 분류 명확성을 위해 중립적 리뷰(rating=3) 제외
df = df[df["rating"] != 3]
# 평점에 감정 라벨 매핑: 1=긍정적(≥4), 0=부정적(<4)
df["sentiment_label"] = np.where(df["rating"] >= 4, 1, 0)
# 유니버설 센텐스 인코더 임베딩 로드
print("유니버설 센텐스 인코더 임베딩 로드 중...")
use = hub.load("https://tfhub.dev/google/universal-sentence-encoder/4")
X_emb = np.array(use(df["review_text"].tolist()).numpy(), dtype=np.float32) # 고정된 float32 형식
y = df["sentiment_label"].values
# 데이터셋을 훈련집합과 검증집합으로 분할
X_train, X_val, y_train, y_val = train_test_split(
X_emb, y, test_size=0.2, random_state=42, stratify=y
)
# 클래스 불균형 처리용 클래스 가중치 계산
classes = np.unique(y_train)
class_weights = compute_class_weight("balanced", classes=classes, y=y_train)
class_weights = dict(zip(classes, class_weights))
# 입력 레이어를 먼저 가진 간단한 Dense 분류기 구축
model = Sequential([
Input(shape=(X_emb.shape[1],)),
Dense(128, activation="relu"),
Dropout(0.3),
Dense(64, activation="relu"),
Dense(1, activation="sigmoid")
])
model.compile(optimizer="adam", loss="binary_crossentropy", metrics=["accuracy"])
# 모델 재구축 방지 위해 강제 생성
_ = model(X_emb[:1])
# 모델 훈련
history = model.fit(
X_train, y_train,
validation_data=(X_val, y_val),
epochs=20,
batch_size=16,
class_weight=class_weights,
verbose=1
)
# 검증 세트에 대해 예측하고 평가
y_pred = (model.predict(X_val, batch_size=32) > 0.5).astype(int)
print("nSentiment 모델 분류 보고서:")
print(classification_report(y_val, y_pred))
# 전체 데이터셋에 예측하고 감정 점수 저장
df["sentiment_score"] = model.predict(X_emb, batch_size=32).flatten()이 코드 블록은 각 리뷰를 의미 벡터로 변환하기 위해 유니버설 센텐스 인코더 ( Universal Sentence Encoder )에 의존합니다. 해당 모델에 익숙하지 않다면, 유니버설 센텐스 인코더는 분류, 의미적 유사도 등 자연어 처리 작업을 위해 텍스트를 512차원 임베딩 벡터 로 변환하는 Google의 모델입니다.
이러한 임베딩은 각 리뷰에 표현된 어조, 감정, 의도 등의 의미를 포착합니다. 그런 다음 Keras Sequential 모델은 완전 연결(Dense) 레이어를 사용하여 긍정적 감정과 부정적 감정을 구분하는 임베딩 내 패턴을 학습합니다. 출력은 확률 점수로, 다음과 같습니다:
- 값이
1.0에 가까울수록 긍정적 감정; 0.0에 가까운 값은 부정적 감정을 나타냅니다.
모델은 모든 리뷰에 이러한 점수 중 하나를 할당합니다. 검증 세트의 분류 보고서는 다음과 같습니다:
감정 모델 분류 보고서:
정밀도 재현율 F1 점수 지원
0 0.91 0.95 0.93 21
1 0.93 0.87 0.90 15
정확도 0.92 36
매크로 평균 0.92 0.91 0.91 36
가중 평균 0.92 0.92 0.92 36이는 다음을 보여줍니다:
- 모델은 검증되지 않은 검증 데이터에서 92%의 정확도를 달성합니다.
- 양성 및 음성 클래스 모두에서 정밀도와 재현율이 일관되게 우수합니다.
- 훈련 정확도와 검증 정확도가 근접하여 모델이 과적합되지 않았음을 나타냅니다.
머신러닝 훈련 과정을 더 잘 시각화하려면 아래와 같은 차트를 추가하는 것을 고려하십시오:
plt.plot(history.history["accuracy"], label="훈련 정확도")
plt.plot(history.history["val_accuracy"], label="검증 정확도")
plt.title("감정 모델 훈련 성능")
plt.xlabel("에포크")
plt.ylabel("정확도")
plt.legend()
plt.grid(True, linestyle="--", alpha=0.5)
plt.show()이 코드는 전체 훈련 이력을 표시합니다: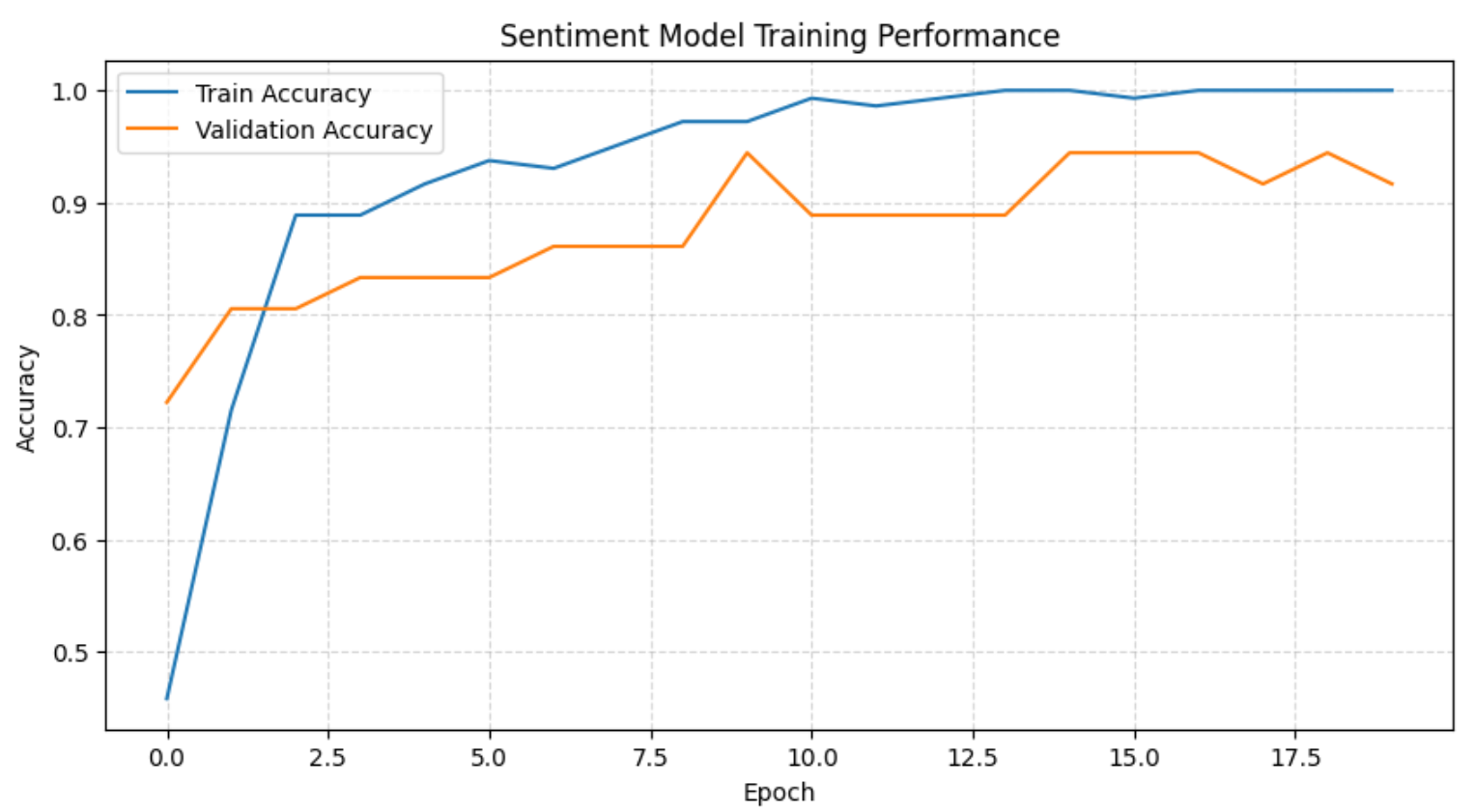
위 차트와 훈련 로그를 종합하면, 모델이 초기 몇 에포크 내에 감정의 경계를 빠르게 학습한 후 높은 검증 정확도로 안정화되는 것을 확인할 수 있습니다. 훈련이 진행됨에 따라 훈련 세트 정확도는 100%에 도달하는 반면, 검증 정확도는 지속적으로 높은 수준을 유지하여 데이터셋 규모를 고려할 때 경미하고 허용 가능한 수준의 과적합만 발생했음을 나타냅니다.
마지막으로 예측된 감정 확률 분포를 시각화합니다:
plt.hist(df["sentiment_score"], bins=20, edgecolor="black", color="skyblue")
plt.title("예측 감정 점수 분포")
plt.xlabel("감정 점수")
plt.ylabel("카운트")
plt.grid(axis="y", linestyle="--", alpha=0.5)
plt.show()결과는 다음과 같습니다: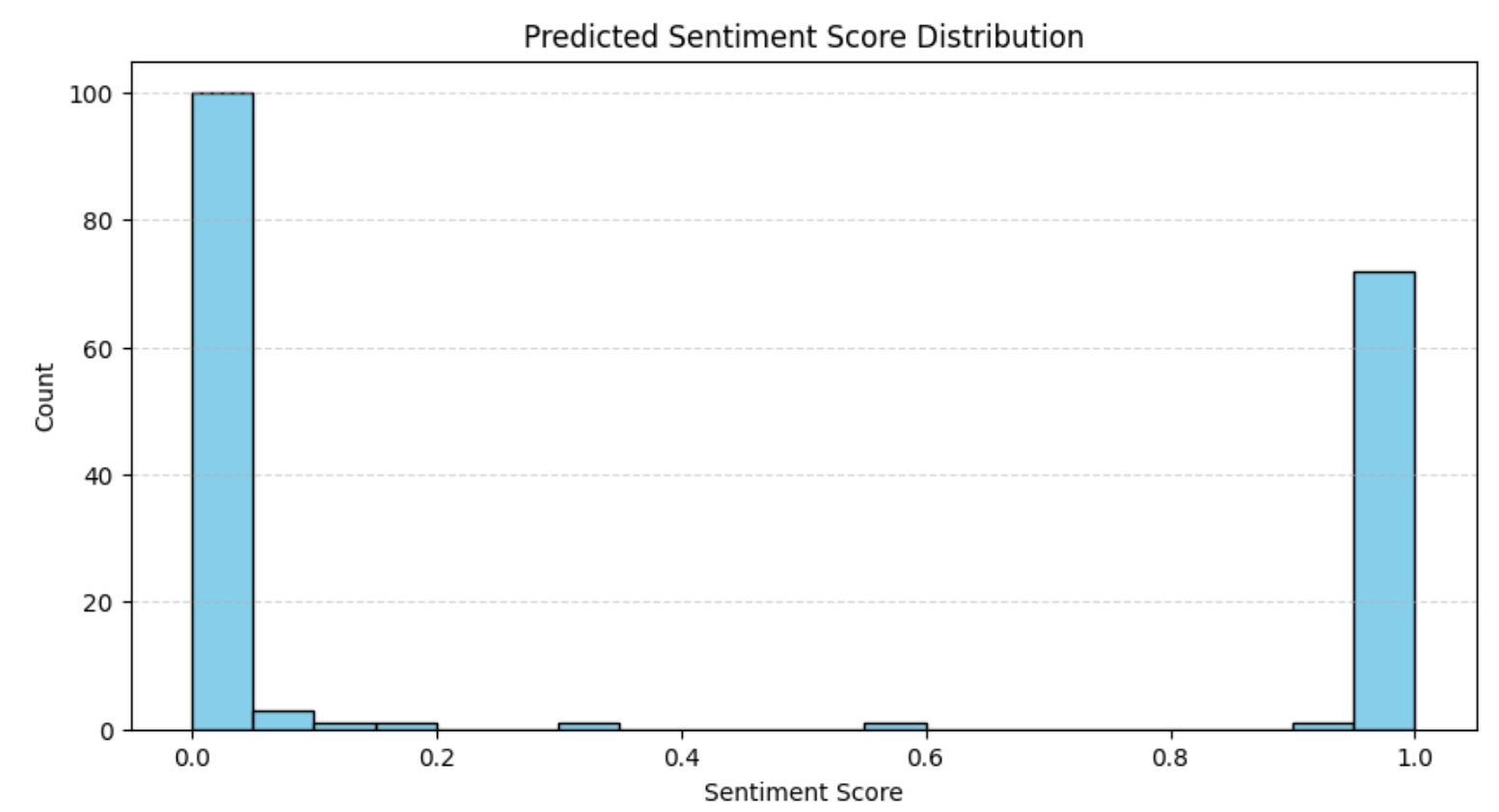
이 분포는 앞서 평점 분석에서 관찰한 내용과 일치합니다. 즉, 대부분의 리뷰는 매우 긍정적이거나 매우 부정적인 경향을 보입니다. 이러한 패턴은 양극화된 의견이 지배적인 전자상거래 플랫폼에서 흔히 나타납니다.
훌륭합니다! 감성 분석 완료.
7단계: 시간 경과에 따른 감정 분석 연구
이제 모든 리뷰에 감정 점수가 부여되었으므로, 지난 1년간 고객 감정이 어떻게 변화했는지 시각화해 보겠습니다. 일일 평균 감정에 7일 이동 평균 추세를 적용하여 일일 변동성을 완화합니다:
# 일일 평균 감정 준비
daily = df.groupby(df["date"].dt.date)["sentiment_score"].mean().reset_index()
daily["date"] = pd.to_datetime(daily["date"])
daily = daily.sort_values("date")
# 작년 데이터로 필터링
one_year_ago = daily["date"].max() - pd.DateOffset(years=1)
daily_last_year = daily[daily["date"] >= one_year_ago]
# 7일 이동 평균 추세 계산
trend = daily_last_year["sentiment_score"].rolling(window=7, min_periods=1).mean()
# 월별 x축 레이블 설정
monthly_labels = pd.date_range(
start=daily_last_year["date"].min(),
end=daily_last_year["date"].max(),
freq="MS" # 월 시작
)
# 일별 감정 점수와 이동 평균 추세선 플롯
plt.bar(daily_last_year["date"], daily_last_year["sentiment_score"], color="skyblue", label="일별 감정 점수")
plt.plot(daily_last_year["date"], trend, color="red", linewidth=2, label="7일 이동 평균 추세")
# x축 레이블 설정
plt.xticks(ticks=monthly_labels, labels=[d.strftime("%Y-%m") for d in monthly_labels], rotation=45)
plt.title("일별 평균 감정 점수 (지난해) + 추세")
plt.xlabel("날짜")
plt.ylabel("감정 점수")
plt.ylim(0,1)
plt.legend()
plt.grid(True, axis="y", linestyle="--", alpha=0.5)
plt.tight_layout()
plt.show()아래는 시간별 감정 변화를 나타낸 차트입니다: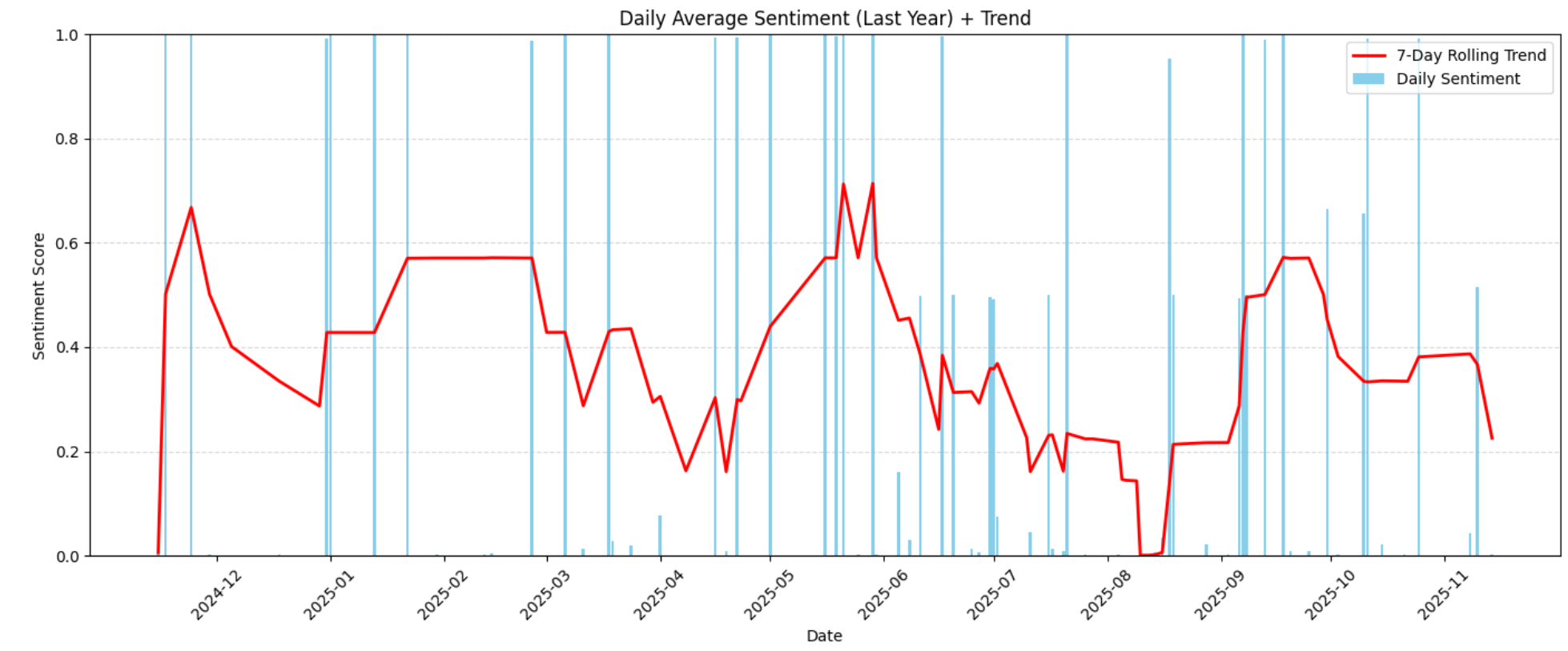
이 시각화는 연도별 감정의 증가 또는 감소 패턴을 강조합니다. 이러한 추세를 통해 고객 만족도가 개선되거나 하락한 시점, 그리고 외부 요인(제품 변경, 지연, 결함, 가격 업데이트)이 감정의 변화를 초래했는지 여부를 파악할 수 있습니다.
예를 들어, 차트에서 2026년 6월부터 2026년 8월 중순 사이에 감정이 급격히 하락하여 중간 긍정적 수준(약 0.6)에서 극도로 부정적 수준( 0.0 근처)으로 떨어진 것을 명확히 확인할 수 있습니다: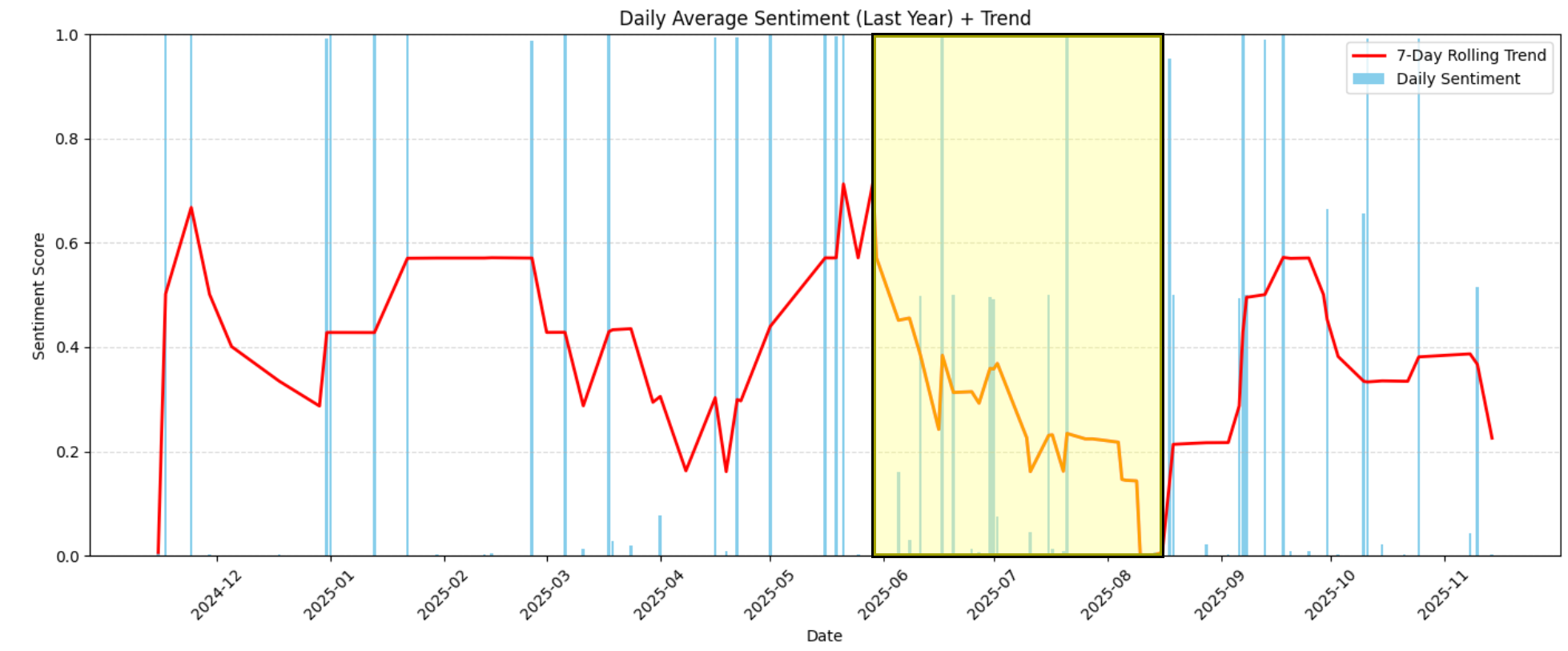
이 기간 동안 발생한 상황을 파악하려면 데이터셋을 해당 날짜로 제한하세요:
# 2026년 6월부터 2026년 8월 중순 사이 리뷰 필터링
start_date = pd.Timestamp("2026-06-01")
end_date = pd.Timestamp("2026-08-15")
df_filtered = df[(df["date"] >= start_date) & (df["date"] <= end_date)]
print(f"해당 기간 리뷰 수: {len(df_filtered)}")출력 결과에서 볼 수 있듯이, 해당 기간 동안 34개의 리뷰가 있습니다:
기간 내 리뷰 수: 34다음으로 평점별 감정이 어떻게 분포하는지 요약합니다:
rating_summary = df_filtered.groupby("rating")["sentiment_score"].agg(["count", "mean"]).reset_index()
rating_summary.rename(columns={"count":"num_reviews", "mean":"avg_sentiment"}, inplace=True)
print("n평점 요약:")
print(rating_summary)결과는 다음과 같습니다:
평점 요약:
평점 평점수 평균감정점수
0 1 16 0.004767
1 2 11 0.048928
2 4 2 0.998977
3 5 5 0.993221이는 34개 리뷰 중 27개가 1~2점이었으며, 해당 감정 점수가 0.0에 매우 근접함을 의미합니다.
평점과 감정 점수의 관계를 그래프로 표시합니다:
# 차트에 감정 대 평점 플롯
fig, ax1 = plt.subplots(figsize=(10,6))
ax1.bar(rating_summary["rating"], rating_summary["num_reviews"], color="skyblue", label="리뷰 수")
ax1.set_xlabel("평점")
ax1.set_ylabel("리뷰 수", color="skyblue")
ax1.tick_params(axis="y", labelcolor="skyblue")
ax2 = ax1.twinx()
ax2.plot(rating_summary["rating"], rating_summary["avg_sentiment"], color="red", marker="o", label="평균 감정")
ax2.set_ylabel("평균 감정 점수", color="red")
ax2.tick_params(axis="y", labelcolor="red")
ax2.set_ylim(0,1)
fig.suptitle("감정 분석 vs 평점 (2026-06-01 ~ 2026-08-15)")
fig.tight_layout()
plt.show()결과 차트는 다음과 같습니다: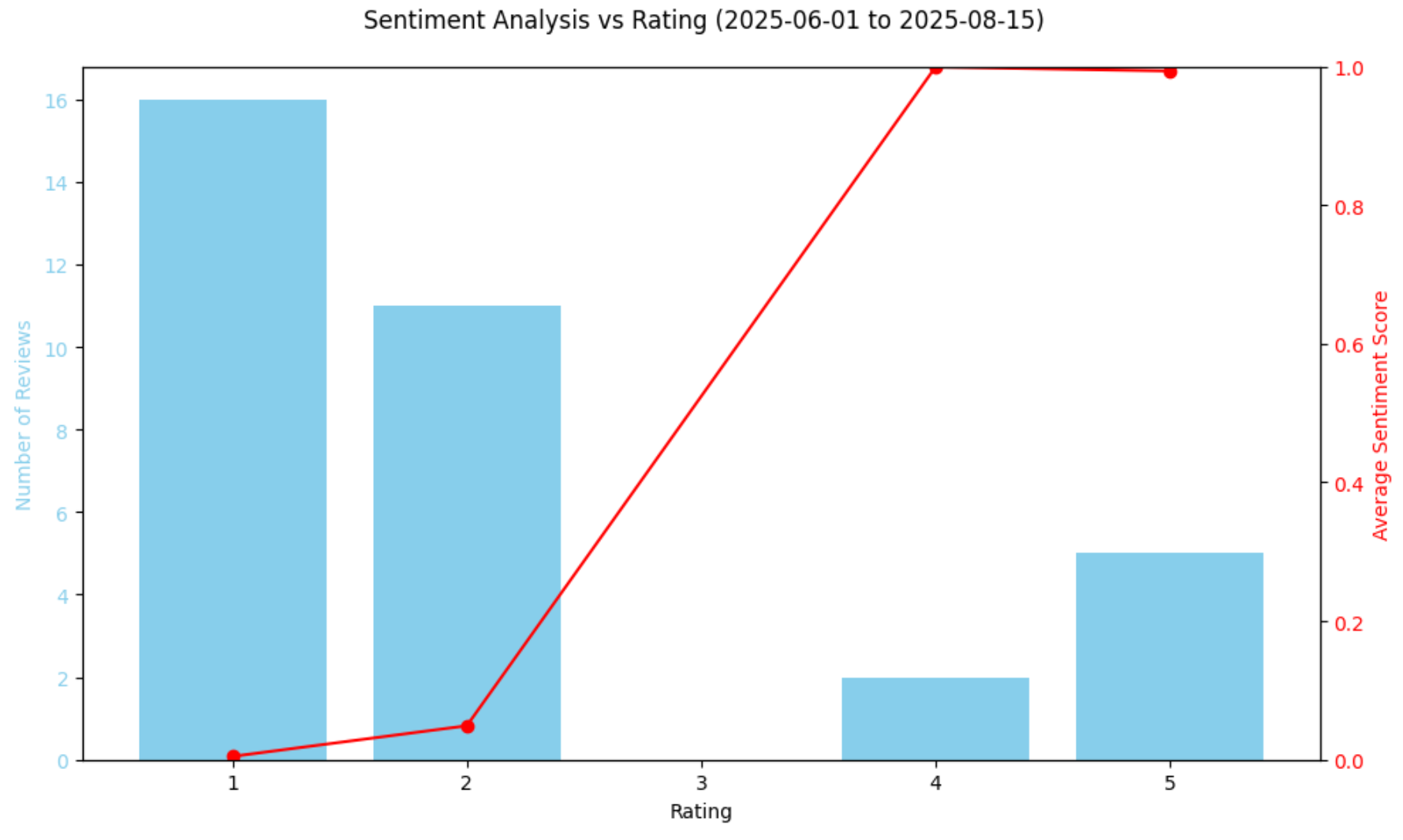
위 차트는 감정 점수의 급격한 하락을 확인시켜 주며, 해당 기간 대부분의 리뷰가 완전히 부정적이었습니다. 흥미롭게도 모델은 감정 분석 점수를 통해 4점 리뷰를 5점 리뷰보다 약간 더 긍정적으로 평가합니다. 이는 오류가 아닙니다. 별점만으로는 감정적 어조를 항상 반영하지 못하기 때문입니다. 일부 5점 리뷰에는 여전히 우려 사항이 포함될 수 있으며, 일부 4점 리뷰는 극도로 긍정적인 표현을 담고 있을 수 있습니다.
결국 별점은 고객의 감정을 빠르게 파악할 수 있게 해주지만, 리뷰 텍스트의 모든 미묘한 차이를 항상 포착하지는 못합니다. 모델이 예측한 감정 점수와 숫자별 평점을 비교하면 리뷰의 언어가 부여된 별점과 일치하는지 확인할 수 있습니다. 이는 높은 평점을 받은 리뷰에 부정적인 표현이 포함되거나 낮은 평점의 리뷰에 미묘한 긍정성이 드러나는 등의 이상 현상을 식별하는 데 도움이 됩니다.
점점 낮아지는 리뷰 점수에서 발견된 이 흥미로운 패턴을 계속 분석해 보겠습니다!
단계 #8: 관련 리뷰 읽기
2026년 6월부터 8월 중순까지 리뷰 점수가 하락한 원인을 진정으로 파악하기 위한 마지막 단계는 리뷰를 직접 확인하는 것입니다. 다음을 통해 이를 수행하세요:
# 관련 열 선택
df_table = df_filtered[["date", "review_text", "rating", "sentiment_score"]]
# HTML을 통해 노트북에 테이블 표시
display(HTML(df_table.to_html(index=False)))결과는 다음과 같은 HTML 테이블입니다:

이 기간 동안 대부분의 리뷰는 향이 빨리 사라지거나 충분히 강하지 않다는 불만을 제기하고 있습니다. 이는 해당 주 동안 출하된 제품의 잠재적 생산 문제를 시사합니다.
이러한 통찰력은 생산 공정을 조사하고 반복되는 문제를 해결하며, 불만족 고객에게 바우처나 할인 등의 해결책을 제공할 수 있는 기회를 제공하므로 매우 가치 있습니다.
참고: 이 리뷰 분석 프로세스는 LLM을 활용해 더욱 자동화할 수 있으며, 이를 통해 완전 자율적이고 즉시 가동 가능한 파이프라인을 구축할 수 있습니다.
자, 이제 완성되었습니다! Bright Data의 스크래핑 기능을 통해 아마존 제품 데이터를 수집했습니다. 이후 TensorFlow를 활용한 감정 분석을 수행하고, 트렌드를 연구하며 특정 기간 내 리뷰 감소의 원인을 규명했습니다.
결론
이 글에서는 Bright Data를 통해 아마존 제품 리뷰 데이터를 추출하고, Python 노트북에서 TensorFlow로 구축한 머신러닝 워크플로를 활용해 감정 분석 트렌드를 식별하는 방법을 살펴보았습니다.
본 프로젝트는 사용자 리뷰 모니터링 및 고객 만족도 향상을 모색하는 중소기업 또는 대기업의 요구를 충족합니다. Bright Data가 기업에 제공하는 데이터 서비스 없이는 이러한 분석이 불가능했을 것입니다.
이러한 솔루션에는 아마존, 링크드인, 야후 파이낸스 등 100개 이상의 도메인에서 과거 또는 최신 업데이트된 데이터를 수집할 수 있도록 지원하는 풍부한 데이터셋 마켓플레이스와 웹 스크레이퍼 API가 포함됩니다. 해당 데이터를 TensorFlow 또는 유사 기술에 입력하여 머신러닝을 통해 분석할 수 있습니다.
스크래퍼 API를 사용해 보거나 데이터셋을 탐색하려면 지금 바로 무료 Bright Data 계정을 생성하세요!






